Javascript高级
ECMAScript 6+
1.let const var 区别
三者区别
(1)块级作用域: 块作用域由 { }包括,let 和 const 具有块级作用域,var 不存在块级作用域。块级作用域解决了 ES5 中的两个问题:
- 内层变量可能覆盖外层变量
- 用来计数的循环变量泄露为全局变量
(2)变量提升: var 存在变量提升,let 和 const 不存在变量提升,即在变量只能在声明之后使用,否在会报错。
(3)给全局添加属性: 浏览器的全局对象是 window,Node 的全局对象是 global。var 声明的变量为全局变量,并且会将该变量添加为全局对象的属性,但是 let 和 const 不会。
(4)重复声明: var 声明变量时,可以重复声明变量,后声明的同名变量会覆盖之前声明的遍历。const 和 let 不允许重复声明变量。
(5)暂时性死区: 在使用 let、const 命令声明变量之前,该变量都是不可用的。这在语法上,称为暂时性死区。使用 var 声明的变量不存在暂时性死区。
(6)初始值设置: 在变量声明时,var 和 let 可以不用设置初始值。而 const 声明变量必须设置初始值。
(7)指针指向: let 和 const 都是 ES6 新增的用于创建变量的语法。 let 创建的变量是可以更改指针指向(可以重新赋值)。但 const 声明的变量是不允许改变指针的指向。变量的值是栈中存放的内存地址,访问时会自动寻址找到堆中存放的对象
| 区别 | var | let | const |
|---|---|---|---|
| 是否有块级作用域 | × | ✔️ | ✔️ |
| 是否存在变量提升 | ✔️ | × | × |
| 是否添加全局属性 | ✔️ | × | × |
| 能否重复声明变量 | ✔️ | × | × |
| 是否存在暂时性死区 | × | ✔️ | ✔️ |
| 是否必须设置初始值 | × | × | ✔️ |
| 能否改变指针指向 | ✔️ | ✔️ | × |
变量声明特点
不使用 var let const
说明: 1.使用 var 声明变量,在方法内部是局部变量,在方法外部是全局变量 2.没有使用 var 声明的变量,在方法内部或外部都是全局变量,但如果是在方 法内部声明,在方法外部使用之前需要先调用方法,告知系统声明了全局变量后方可在方法外部使用。
在函数作用域内 加 var 定义的变量是局部变量,不加 var 定义的就成了全局变量 在 function 内部,加 var 的是局部变量,不加 var 的则是全局变量; 在 function 外部,不管有没有使用 var 声明变量,都是全局变量,在 function 外部,var 关键字一般可以省略,但是为了书写规范和维护方便以及可读性好,不建议省略 var 关键字
var 声明
var 声明的变量可以不初始化赋值,输出是 undefined,不会报错;
var 声明的变量可以修改,存在变量提升(大多数语言都有块级作用域,但 JS 使用 var 声明变量时,以 function 划分作用域,大括号“{}”去无法限值 var 的作用域);
var 声明的变量作用域是全局的或者是函数级的;
var 声明的变量在 window 上;
var 定义的变量可以修改,如果不初始化会输出 undefined,不会报错; var 声明的变量在 window 上,用 let 或者 const 去声明变量,这个变量不会被放到 window 上; 很多语言中都有块级作用域,但 JS 没有,它使用 var 声明变量,以 function 来划分作用域,大括号“{}” 却限定不了 var 的作用域,因此用 var 声明的变量具有变量提升的效果; var 声明的变量作用域是全局的或者是函数级的; var 可以重复声明:var 语句多次声明一个变量不仅是合法的,而且也不会造成任何错误;如果重复使用的一个声明有一个初始值,那么它担当的不过是一个赋值语句的角色;如果重复使用的一个声明没有一个初始值,那么它不会对原来存在的变量有任何的影响;
let 声明
需要”javascript 严格模式”:'use strict'; let 不能重复声明 不会预处理, 不存在变量提升 let 声明的变量作用域是在块级域中,函数内部使用 let 定义后,对函数外部无影响(块级作用域) 可以在声明变量时为变量赋值,默认值为 undefined,也可以稍后在脚本中给变量赋值,在生命前无法使用(暂时死区)
const 声明
const 定义的变量不可以修改,而且必须初始化 该变量是个全局变量,或者是模块内的全局变量;可以在全局作用域或者函数内声明常量,但是必须初始化常量 如果一个变量只有在声明时才被赋值一次,永远不会在其它的代码行里被重新赋值,那么应该使用 const,但是该变量的初始值有可能在未来会被调整(常变量) 创建一个只读常量,在不同浏览器上表现为不可修改;建议声明后不修改;拥有块级作用域 const 代表一个值的常量索引 ,也就是说,变量名字在内存中的指针不能够改变,但是指向这个变量的值可能 改变 const 定义的变量不可修改,一般在 require 一个模块的时候用或者定义一些全局常量 常量不能和它所在作用域内其它变量或者函数拥有相同名称
function 声明
function 命令用于定义(声明)一个函数:
function sum() {
var sum++
return sum;
}
声明了一个名为 sum 的新变量,并为其分配了一个函数定义 {}之间的内容被分配给了 sum 函数声明后不会立即执行,需要调用的时候才执行; 对支持 ES5 和 ES6 浏览器环境在块作用域内有一定区别,所以应避免在块级作用域内声明函数。
es5 实现 let 和 const
let
在 es6 出现以前我们一般使用无限接近闭包的形式或者立即执行函数的形式来定义不会被污染的变量。
(function () {
var a = 1;
console.log(a);
})();
console.log(a);
const
const 声明一个只读的常量。一旦声明,常量的值就不能改变。
有什么方法是可以限制一个值不能发生改变的呢?
需要用到 Object.defineProperty ,通过属性描述符来定义
writable:当前对象元素的值是否可修改。
由于 ES5 环境没有 block 的概念,所以是无法百分百实现 const,只能是挂载到某个对象下,要么是全局的 window,要么就是自定义一个 object 来当容器
var __const = function __const(data, value) {
window.data = value; // 把要定义的data挂载到window下,并赋值value
Object.defineProperty(window, data, {
// 利用Object.defineProperty的能力劫持当前对象,并修改其属性描述符
enumerable: false,
configurable: false,
get: function () {
return value;
},
set: function (data) {
if (data !== value) {
// 当要对当前属性进行赋值时,则抛出错误!
throw new TypeError("Assignment to constant variable.");
} else {
return value;
}
},
});
};
__const("a", 10);
console.log(a);
delete a;
console.log(a);
for (let item in window) {
// 因为const定义的属性在global下也是不存在的,所以用到了enumerable: false来模拟这一功能
if (item === "a") {
// 因为不可枚举,所以不执行
console.log(window[item]);
}
}
a = 20; // 报错
还可以使用 es5 的 Object.freeze()
var f = Object.freeze({ name: "admin" });
f.name = "hello"; // 严格模式下是会报错的
f.name; // 打印出admin ,值没有被改变
const 实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址不得改动。
对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。
但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指向实际数据的指针,const 只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。
因此,将一个对象声明为常量必须非常小心
2.作用域和作用域链
作用域
概念:作用域是在程序运行时代码中的某些特定部分中变量、函数和对象的可访问性。
从使用方面来解释,作用域就是变量的使用范围,也就是在代码的哪些部分可以访问这个变量,哪些部分无法访问到这个变量,换句话说就是这个变量在程序的哪些区域可见。
function Fun() {
var inVariable = "内部变量";
}
Fun();
console.log(inVariable); // Uncaught ReferenceError: inVariable is not defined
//inVariable是在Fun函数内部被定义的,属于局部变量,在外部无法访问,于是会报错
从存储上来解释的话,作用域本质上是一个对象, 作用域中的变量可以理解为是该对象的成员
总结:作用域就是代码的执行环境,全局作用域就是全局执行环境,局部作用域就是函数的执行环境,它们都是栈内存
作用域分类
作用域又分为全局作用域和局部作用域。在 ES6 之前,局部作用域只包含了函数作用域,ES6 的到来为我们提供了 ‘块级作用域’(由一对花括号包裹),可以通过新增命令 let 和 const 来实现;而对于全局作用域这里有一个小细节需要注意一下:
- 在 Web 浏览器中,全局作用域被认为是
window对象,因此所有全局变量和函数都是作为window对象的属性和方法创建的。- 在 Node 环境中,全局作用域是
global对象。
全局作用域很好理解,现在我们再来解释一下局部作用域吧,先来看看函数作用域,所谓函数作用域,顾名思义就是由函数定义产生出来的作用域
function fun1() {
var variable = "abc";
}
function fun2() {
var variable = "cba";
}
fun1();
fun2();
//这里有两个函数,他们分别都有一个同名变量variable,在严格模式下,程序不会报错,
//这是因为这两个同名变量位于不同的函数内,也就是位于不同的作用域中,所以他们不会产生冲突。
最外层函数 和在最外层函数外面定义的变量拥有全局作用域
var outVariable = "我是最外层变量"; //最外层变量
function outFun() {
//最外层函数
var inVariable = "内层变量";
function innerFun() {
//内层函数
console.log(inVariable);
}
innerFun();
}
console.log(outVariable); //我是最外层变量
outFun(); //内层变量
console.log(inVariable); //inVariable is not defined
innerFun(); //innerFun is not defined
- 所有末定义直接赋值的变量自动声明为拥有全局作用域
function outFun2() {
variable = "未定义直接赋值的变量";
var inVariable2 = "内层变量2";
}
outFun2(); //要先执行这个函数,否则根本不知道里面是啥
console.log(variable); //未定义直接赋值的变量
console.log(inVariable2); //inVariable2 is not defined
- 所有 window 对象的属性拥有全局作用域
一般情况下,window 对象的内置属性都拥有全局作用域,例如 window.name、window.location、window.top 等等。
let 声明的语法与 var 的语法一致。基本上可以用 let 来代替 var 进行变量声明,但会将变量的作用域限制在当前代码块中 (注意:块级作用域并不影响 var 声明的变量)。 但是使用 let 时有几点需要注意:
- 声明变量不会提升到代码块顶部,即不存在变量提升
- 禁止重复声明同一变量
- for 循环语句中()内部,即圆括号之内会建立一个隐藏的作用域,该作用域不属于 for 后边的{}中,并且只有 for 后边的{}产生的块作用域能够访问这个隐藏的作用域,这就使循环中 绑定块作用域有了妙用
ES5 和 ES6 版本的代码,ES5:
if(true) {
var a = 1
}
for(var i = 0; i < 10; i++) {
...
}
console.log(a) // 1
console.log(i) // 9
ES6:
for (let i = 0; i < 10; i++) {
console.log(i); //0,1,2,3,4,5,6,7,8,9
}
console.log(i); // Uncaught ReferenceError: i is not defined
if (true) {
let i = 9;
}
console.log(i); // Uncaught ReferenceError: i is not defined
作用域链(scope chain)
概念:多个作用域对象连续引用形成的链式结构。
使用方面解释:当在 Javascript 中使用一个变量的时候,首先 Javascript 引擎会尝试在当前作用域下去寻找该变量,如果没找到,再到它的上层作用域寻找,以此类推直到找到该变量或是已经到了全局作用域,如果在全局作用域里仍然找不到该变量,它就会直接报错。
存储方面解释:作用域链在 JS 内部中是以数组的形式存储的,数组的第一个索引对应的是函数本身的执行期上下文,也就是当前执行的代码所在环境的变量对象,下一个索引对应的空间存储的是该对象的外部执行环境,依次类推,一直到全局执行环境
var a = 100;
function fun() {
var b = 200;
console.log(a); //100
// fun函数局部作用域中没有变量a,于是从它的上一级,也就是全局作用域中找,
//在全局中a被赋值为100,于是输出100
console.log(b); //200 fun函数局部作用域中有变量b,并且它被赋值为了200,输出200
}
fun();
var a = 10;
function fun() {
console.log(a);
}
function show(f) {
var a = 20(function () {
f(); //10,而不是20; 函数的作用域是在函数定义的时候就被决定了,与函数在哪里被调用无关
})();
}
show(fun);
由于变量的查找是沿着作用域链来实现的,所以也称作用域链为变量查找的机制。是不是很好理解,这里再来补充一点作用域的作用
- 作用域最为重要的一点是安全。变量只能在特定的区域内才能被访问,外部环境不能访问内部环境的任何变量和函数,即可以向上搜索,但不可以向下搜索, 有了作用域我们就可以避免在程序其它位置意外对某个变量做出修改导致程序发生事故。
- 作用域能够减轻命名的压力。我们可以在不同的作用域内定义相同的变量名,并且这些变量名不会产生冲突。
作用域中取值,这里强调的是“创建”,而不是“调用”,切记切记——其实这就是所谓的"静态作用域"
var a = 10
function fn() {
var b = 20
function bar() {
console.log(a + b) //30
}
return bar
}
var x = fn(),
//b = 200
x() //bar()
fn()返回的是 bar 函数,赋值给 x。执行 x(),即执行 bar 函数代码。取 b 的值时,直接在 fn 作用域取出。取 a 的值时,试图在 fn 作用域取,但是取不到,只能转向创建 fn 的那个作用域中去查找,结果找到了,所以最后的结果是 30
var a = 10;
function fn() {
var b = 20;
function bar() {
console.log(a + b); //30
}
bar();
}
fn();
变量提升和暂时性死区
在当前上下文代码自上而下执行之前,会把所有带 var/function 关键字的进行提前的声明或者定义
- 带 var 是只声明
- 带 function 是声明+定义(赋值)都完成了
typeof 检测一个未被声明的变量不会报错,结果是undefined
1.var 声明的变量在词法分析阶段(执行上下文创建阶段)就会完成创建和初始化(undefined),因此在代码执行阶段,就可以在声明前使用 2.let 声明的变量在词法分析阶段(执行上下文创建阶段)会完成创建但不会初始化,如果在其定义之前使用,就是使用了未被初始化的变量,会报怎么样的错误我上面也已经贴出来了并进行了翻译。
3.箭头函数特性
1.箭头函数没有单独的 this
对于一般函数:
- 如果该函数是一个构造函数,this 指针指向一个新的对象
- 在严格模式下的函数调用下,this 指向
undefined - 如果该函数是一个对象的方法,则它的 this 指针指向这个对象
箭头函数不会创建自己的 this,它只会从自己的作用域链的上一层继承 this
对象不是作用域
所以对象内的箭头函数作用域是外部
而正常函数 this 会指向这个对象
var obj = {
i: 10,
b: () => console.log(this.i, this),
c: function () {
console.log(this.i, this);
},
};
obj.b();
// undefined, Window{...}
obj.c();
// 10, Object {...}
构造函数的 this
function Person() {
this.age = 0;
setInterval(() => {
this.age++; // |this| 正确地指向 p 实例
}, 1000);
}
var p = new Person();
function Person() {
this.age = 0;
}
Person.prototype.func=()=>{
console.log(this.age)
}
var p = new Person();
p.func()//undefined
2.通过 call 或 apply 调用
由于 箭头函数没有自己的 this 指针,通过 call() 或 apply() 方法调用一个函数时,只能传递参数(不能绑定 this),他们的第一个参数会被忽略
3.不绑定 arguments
箭头函数无法使用 arguments,而普通函数可以使用 arguments。如果要使用类似于 arguments 获取参数,可以使用 rest 参数代替
4.箭头函数不能作为构造器,和 new 一起使用会抛出错误
var Foo = () => {};
var foo = new Foo(); // TypeError: Foo is not a constructor
5.箭头函数没有 prototype 属性
var Foo = () => {};
console.log(Foo.prototype); // undefined
6.箭头函数不能当做 Generator 函数,不能使用 yield 关键字
7.省略写法
当箭头函数的函数体只有一个 return 语句时,可以省略 return 关键字和方法体的花括号
在一个简写体中,只需要一个表达式,并附加一个隐式的返回值。在块体中,必须使用明确的return语句。
var func = x => x * x;
// 简写函数 省略 return
var func = (x, y) => { return x + y; };
//常规编写 明确的返回值
记住用params => {object:literal}这种简单的语法返回对象字面量是行不通的。
var func = () => { foo: 1 };
// Calling func() returns undefined!
var func = () => { foo: function() {} };
// SyntaxError: function statement requires a name
这是因为花括号({} )里面的代码被解析为一系列语句(即 foo 被认为是一个标签,而非对象字面量的组成部分)。
所以,记得用圆括号把对象字面量包起来:
var func = () => ({ foo: 1 });
4.模板语法和字符串处理
ES6 提出了“模板语法”的概念。在 ES6 以前,拼接字符串是很麻烦的事情:
var name = "css";
var career = "coder";
var hobby = ["coding", "writing"];
var finalString =
"my name is " +
name +
", I work as a " +
career +
", I love " +
hobby[0] +
" and " +
hobby[1];
仅仅几个变量,写了这么多加号,还要时刻小心里面的空格和标点符号有没有跟错地方。但是有了模板字符串,拼接难度直线下降:
var name = "css";
var career = "coder";
var hobby = ["coding", "writing"];
var finalString = `my name is ${name}, I work as a ${career} I love ${hobby[0]} and ${hobby[1]}`;
字符串不仅更容易拼了,也更易读了,代码整体的质量都变高了。这就是模板字符串的第一个优势——允许用${}的方式嵌入变量。但这还不是问题的关键,模板字符串的关键优势有两个:
- 在模板字符串中,空格、缩进、换行都会被保留
- 模板字符串完全支持“运算”式的表达式,可以在${}里完成一些计算
基于第一点,可以在模板字符串里无障碍地直接写 html 代码:
let list = `
<ul>
<li>列表项1</li>
<li>列表项2</li>
</ul>
`;
console.log(message); // 正确输出,不存在报错
基于第二点,可以把一些简单的计算和调用丢进 ${} 来做:
function add(a, b) {
const finalString = `${a} + ${b} = ${a + b}`;
console.log(finalString);
}
add(1, 2); // 输出 '1 + 2 = 3'
除了模板语法外, ES6 中还新增了一系列的字符串方法用于提升开发效率:
(1)存在性判定:在过去,当判断一个字符/字符串是否在某字符串中时,只能用 indexOf > -1 来做。现在 ES6 提供了三个方法:includes、startsWith、endsWith,它们都会返回一个布尔值来告诉你是否存在。
- includes:判断字符串与子串的包含关系:
const son = "haha";
const father = "xixi haha hehe";
father.includes(son); // true
- startsWith:判断字符串是否以某个/某串字符开头:
const father = "xixi haha hehe";
father.startsWith("haha"); // false
father.startsWith("xixi"); // true
- endsWith:判断字符串是否以某个/某串字符结尾:
const father = "xixi haha hehe";
father.endsWith("hehe"); // true
(2)自动重复:可以使用 repeat 方法来使同一个字符串输出多次(被连续复制多次):
const sourceCode = "repeat for 3 times;";
const repeated = sourceCode.repeat(3);
console.log(repeated); // repeat for 3 times;repeat for 3 times;repeat for 3 times;
5.解构赋值的应用场景
1、数组解构赋值
模式匹配:只要等号两边的模式(结构和格式)相同,左边的变量就会被赋予对应的值
let [a,b,c] = [1,2,3];
let [foo, [[bar], baz]] = [1, [[2], 3]]
省略解构赋值
let [, , a, , b] = [1, 2, 3, 4, 5];
console.log(a, b); //3,5
let [, , third] = ["foo", "bar", "baz"];
third; // "baz"
let [x, , y] = [1, 2, 3];
x; // 1
y; // 3
let [head, ...tail] = [1, 2, 3, 4];
head; // 1
tail; // [2, 3, 4]
2、对象的解构赋值
对象的属性没有次序,变量必须与属性同名,才能取到正确的值
解构赋值
let { bar, foo } = { foo: "aaa", bar: "bbb" };
foo; // "aaa"
bar; // "bbb"
解构赋值的别名
如果使用别名,则不允许再使用原有的解构出来的属性名,对象的解构赋值的内部机制,是先找到同名属性,然后再赋给对应的变量。真正被赋值的是后者,而不是前者
let p = { foo: "aaa", bar: "bbb" };
let { foo: baz } = p;
console.log(baz, foo); // 'aaa', error: foo is not defined
foo 是匹配的模式,baz 才是变量。真正被赋值的是变量 baz,而不是模式 foo
些情况下,我们解构出来的值并不存在,解构出来的值为 undefined,所以需要设定一个默认值
let obj = {
name: "123",
};
let { name, age = 18 } = obj;
console.log(name, age); //"123",18
解构赋值的嵌套赋值
let obj = {
p: ["Hello", { y: "World" }],
};
let {
p,
p: [x, { y }],
} = obj;
console.log(p, x, y); // ["Hello", {…}], "Hello", "World"
3、字符串解构赋值
字符串也可以解构赋值。这是因为此时,字符串被转换成了一个类似数组的对象
const [a, b, c, d, e] = "hello";
a; // "h"
b; // "e"
c; // "l"
d; // "l"
e; // "o"
类似数组的对象都有一个 length 属性,因此还可以对这个属性解构赋值。
let { length: len } = "hello";
console.log(len); //5
4、布尔值和数值的解构赋值
布尔值和数值的解构,会先转为对象,然后对其包装对象的解构,取的是包装对象的属性。
let { toString: s } = 123;
s === Number.prototype.toString; // true
let { toString: s } = true;
s === Boolean.prototype.toString; // true
5、函数参数的解构赋值
function move({ x = 0, y = 0 } = {}) {
return x + y;
}
move({ x: 3, y: 8 }); // 11
move({ x: 3 }); // 3
move({}); // 0
move(); // 0
- 解构成对象,只要等号右边的值不是对象或数组,就先将其转为对象。由于 undefined 和 null 无法转为对象,所以对它们进行解构赋值,都会报错。
- 解构成数组,等号右边必须为可迭代对象。
6、解构赋值使用场景
浅拷贝
let colors = ["red", "green", "blue"];
let [...allColors] = colors;
console.log(allColors); // "[red,green,blue]"
交换变量
let x = 1;
let y = 2;
[x, y] = [y, x];
遍历 Map 结构
var map = new Map();
map.set("first", "hello");
map.set("second", "world");
for (let [key, value] of map) {
console.log(key + " is " + value);
}
// 获取键名
for (let [key] of map) {
// ...
}
// 获取键值
for (let [, value] of map) {
// ...
}
函数参数
解构赋值可以方便地将一组参数与变量名对应起来
// 参数是一组有次序的值
function f([x, y, z]) { ... }
f([1, 2, 3]);
提取 JSON 数据
let jsonData = {
id: 42,
status: "OK",
data: [867, 5309],
};
let { id, status, data: number } = jsonData;
console.log(id, status, number); // 42 "OK" [867, 5309];
输入模块的指定方法
const { SourceMapConsumer, SourceNode } = require("source-map");
6.剩余参数和扩展运算符使用场景
在 ES6 中。 三个点(...) 有 2 个含义。分别表示 扩展运算符 和 剩余运算符。
扩展运算
数组展开
function test(a, b, c) {
console.log(a);
console.log(b);
console.log(c);
}
var arr = [1, 2, 3];
test(...arr);
// 打印结果
// 1
// 2
// 3
将一个数组插入到另一个数据中
var arr1 = [1, 2, 3];
var arr2 = [...arr1, 4, 5, 6];
console.log(arr2);
// 打印结果
// [1, 2, 3, 4, 5, 6]
字符串转数据
var str = "test";
var arr3 = [...str];
console.log(arr3);
// 打印结果
// ["t", "e", "s", "t"]
剩余运算符
当函数参数个数不确定时,用 rest 运算符
function rest1(...arr) {
for (let item of arr) {
console.log(item);
}
}
rest1(1, 2, 3);
// 打印结果
// 1
// 2
// 3
当函数参数个数不确定时的第二种情况
function rest2(item, ...arr) {
console.log(item);
console.log(arr);
}
rest2(1, 2, 3, 4, 5);
// 打印结果
// 1
// [2, 3, 4, 5]
解构使用
var [a, ...temp] = [1, 2, 3, 4];
console.log(a);
console.log(temp);
// 打印结果
// 1
// [2, 3, 4]
7.proxy 和 reflect
Proxy
Proxy用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于一种“元编程”(meta programming),即对编程语言进行编程。可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。
- 将
Proxy对象,设置到object.proxy属性,从而可以在object对象上调用。
const object = { proxy: new Proxy(target, handler) };
- 使用
Proxy对象
const proxy = new Proxy(
{},
{
get: function (target, propKey) {
return "detanx";
},
}
);
obj.name; // 'detanx'
Proxy 拦截操作
Proxy 支持的拦截操作一览,一共 13 种
get(target, propKey, receiver):拦截对象属性的读取,比如proxy.foo和proxy['foo']。set(target, propKey, value, receiver):拦截对象属性的设置,比如proxy.foo = v或proxy['foo'] = v,返回一个布尔值。has(target, propKey):拦截propKey in proxy的操作,返回一个布尔值。deleteProperty(target, propKey):拦截delete proxy[propKey]的操作,返回一个布尔值。ownKeys(target):拦截Object.getOwnPropertyNames(proxy)、Object.getOwnPropertySymbols(proxy)、Object.keys(proxy)、for...in循环,返回一个数组。该方法返回目标对象所有自身的属性的属性名,而Object.keys()的返回结果仅包括目标对象自身的可遍历属性。getOwnPropertyDescriptor(target, propKey):拦截Object.getOwnPropertyDescriptor(proxy, propKey),返回属性的描述对象。defineProperty(target, propKey, propDesc):拦截Object.defineProperty(proxy, propKey, propDesc)、Object.defineProperties(proxy, propDescs),返回一个布尔值。preventExtensions(target):拦截Object.preventExtensions(proxy),返回一个布尔值。getPrototypeOf(target):拦截Object.getPrototypeOf(proxy),返回一个对象。isExtensible(target):拦截Object.isExtensible(proxy),返回一个布尔值。setPrototypeOf(target, proto):拦截Object.setPrototypeOf(proxy, proto),返回一个布尔值。如果目标对象是函数,那么还有两种额外操作可以拦截。apply(target, object, args):拦截Proxy实例作为函数调用的操作,比如proxy(...args)、proxy.call(object, ...args)、proxy.apply(...)。construct(target, args):拦截Proxy实例作为构造函数调用的操作,比如new proxy(...args)。
get()
- 拦截某个属性的读取操作,可以接受三个参数,依次为目标对象、属性名和
Proxy实例本身(严格地说,是操作行为所针对的对象),其中最后一个参数可选。
const proxy = new Proxy({}, {
get(target, propertyKey [, receiver]) {
return target[propertyKey];
}
});
- 如果一个属性不可配置(
configurable)且不可写(writable),则Proxy不能修改该属性,否则通过Proxy对象访问该属性会报错。
const target = Object.defineProperties(
{},
{
foo: {
value: 123,
writable: false,
configurable: false,
},
}
);
const handler = {
get(target, propKey) {
return "abc";
},
};
const proxy = new Proxy(target, handler);
proxy.foo;
// TypeError: Invariant check failed
set()
set方法用来拦截某个属性的赋值操作,可以接受四个参数,依次为目标对象、属性名、属性值和Proxy实例本身,其中最后一个参数可选。
let prxyo = new Proxy({}, {
set(target, propertyKey, value [, receiver]) {
return target[propertyKey];
}
});
- 如果目标对象自身的某个属性,不可配置(
configurable)且不可写(writable),那么set方法将不起作用。
const obj = {};
Object.defineProperty(obj, "foo", {
value: "bar",
writable: false,
});
const handler = {
set: function (obj, prop, value, receiver) {
obj[prop] = "baz";
},
};
const proxy = new Proxy(obj, handler);
proxy.foo = "baz";
proxy.foo; // "bar"
vue3 使用 Proxy 替换 defineProperty
Object.definePropertyObject.defineProperty无法监控到数组下标的变化,导致直接通过数组的下标给数组设置值,不能实时响应。经过 vue 内部处理后可以使用以下几种方法来监听数组push()、pop()、shift()、unshift()、splice()、sort()、reverse(),由于只针对了以上八种方法进行了hack处理,所以其他数组的属性也是检测不到的,还是具有一定的局限性。Object.defineProperty只能劫持对象的属性,因此我们需要对每个对象的每个属性进行遍历。
Proxy
- 可以劫持整个对象,并返回一个新对象。
- 有
13种劫持操作。
Proxy 存在的问题
在 JS 中任何函数本质上都是通过某个对象来调用的,比如obj.fun,默认情况下fun中的this就是对象obj。当然了,我们其实一直在享受这种特殊机制所带来的便利,但如果将这种机制发挥在代理对象中,可能会出现不符合我们预期的情况,最典型的问题莫过于在源对象中是否依赖于this作为标识
const origin = {
name: "鲨鱼辣椒",
say() {
// 两次的this并不相同
return this;
},
};
const handler = {};
const proxy = new Proxy(origin, handler);
console.log(origin.say()); // {name: '鲨鱼辣椒', say: ƒ}
console.log(proxy.say()); // Proxy {name: '鲨鱼辣椒', say: ƒ}
还有一个特殊的例子就是Date类型了。根据 ECMAScript 规范,Date 类型方法的执行依赖于this上的内部槽位[[ NumberDate ]],但代理对象毫无疑问是不存在这个槽位的,所以在使用代理对象访问Date类上的方法时会抛出TypeError
const origin = new Date();
const handler = {};
const proxy = new Proxy(origin, handler);
console.log(proxy.getDate()); // TypeError
Reflect
- 将
Object对象的一些明显属于语言内部的方法(比如Object.defineProperty),放到Reflect对象上。 - 修改某些
Object方法的返回结果,让其变得更合理。比如,Object.defineProperty(obj, name, desc)在无法定义属性时,会抛出一个错误,通常我们需要使用try catch去捕获这个错误,而Reflect.defineProperty(obj, name, desc)则会返回false。
// 老写法
try {
Object.defineProperty(target, property, attributes);
// success
} catch (e) {
// failure
}
// 新写法
if (Reflect.defineProperty(target, property, attributes)) {
// success
} else {
// failure
}
3.让Object操作都变成函数行为。某些Object操作是命令式,比如name in obj和delete obj[name],而Reflect.has(obj, name)和Reflect.deleteProperty(obj, name)让它们变成了函数行为。
// 老写法
"assign" in Object; // true
// 新写法
Reflect.has(Object, "assign"); // true
4.Reflect对象的方法与Proxy对象的方法一一对应,只要是Proxy对象的方法,就能在Reflect对象上找到对应的方法。每一个Proxy对象的拦截操作(get、delete、has、...),内部都调用对应的Reflect方法。
Reflect 常用方法
get
接收两个参数
- 要访问的对象
- 访问的属性
const obj = { name: "鲨鱼辣椒" };
console.log(Reflect.get(obj, "name")); // 鲨鱼辣椒
set
该方法的返回值为true或false,true代表本次操作成功,false代表失败;操作成功是指对于那些可写且可配置的属性。要注意的是,当操作失败时,在严格模式下会抛出TypeError。该方法接收三个参数
- 要添加新属性的对象
- 要添加新属性
- 描述属性
const obj = { name: "鲨鱼辣椒" };
Object.defineProperty(obj, "age", {
value: 25,
writable: false,
configurable: false,
});
console.log(obj.age); // 25
console.log(Reflect.set(obj, "age", 26)); // false
console.log(obj.age); // 25
has
检查一个对象中是否包含(继承)某个属性,相当于in操作符。接收两个参数
- 要检查的对象
- 要检查的属性
返回一个布尔值,代表是否检测到了当前属性
const origin = { age: 25 };
const obj = { name: "鲨鱼辣椒" };
obj.__proto__ = origin;
console.log("age" in obj); // true
console.log(Reflect.has(obj, "age")); // true
defineProperty
用法基本同Reflect.set一致
const obj = { name: "鲨鱼辣椒" };
Object.defineProperty(obj, "age", {
value: 25,
writable: false,
configurable: false,
});
console.log(obj.age); // 25
console.log(
Reflect.defineProperty(obj, "age", {
get() {
return;
},
})
); // false
console.log(obj.age); // 25
deleteProperty
相当于 delete property,该方法接收两个参数
- 要删除属性的对象
- 要删除的属性
返回一个布尔值,代表是否删除成功,删除成功是指对于那些可写且可配置的属性
const obj = { name: "鲨鱼辣椒" };
Object.defineProperty(obj, "age", {
value: 25,
writable: false,
configurable: false,
});
console.log(Reflect.deleteProperty(obj, "name")); // true
console.log(Reflect.deleteProperty(obj, "age")); // false
ownKeys
接收一个对象作为参数,并将该对象中自有属性、符号值、不可枚举属性作为数组返回,该数组中的每个成员都是字符串或符号值
类似于 Object.getOwnPropertyNames 和 Object.getOwnPropertySymbols
const origin = { bigName: "SYLJ" };
const obj = {
name: "鲨鱼辣椒",
[Symbol.for("age")]: 25,
};
obj.__proto__ = origin;
Object.defineProperty(obj, "gender", {
value: "男",
writable: false,
configurable: false,
enumerable: false,
});
console.log(Reflect.ownKeys(obj)); // ['name', 'gender', Symbol(age)]
属性排序
一般来说,当我们列举对象中的键(属性名)时,其顺序由于不同引擎的实现所以总是飘忽不定的,有可能这一次列举时 A 属性在 B 属性前面,而又有可能在下一次列举时 B 属性跑到了 A 属性的前面。为了避免这种尴尬的情况,我们可以使用Reflect.ownkeys来列举对象中的属性,这个方法会遵循以下顺序
- 按照数字上升排序
- 按照创建顺序列举字符串属性名
- 按照创建顺序列举符号属性名
const obj = {
1: "我的键是整数1",
one: "我的键是字符串1",
[Symbol.for("s1")]: "我的键是符号值1",
};
obj.two = "我的键是字符串2";
obj[Symbol.for("s2")] = "我的键是符号值2";
obj[2] = "我的键是整数2";
console.log(Reflect.ownKeys(obj)); // ['1', '2', 'one', 'two', Symbol(s1), Symbol(s2)]
8.Set Map 数组有什么特性和区别
Set
Set 本身是一个构造函数,用来生成 Set 数据结构。Set 函数可以接受一个数组(或者具有 iterable 接口的其他数据结构)作为参数,用来初始化。Set 对象允许你存储任何类型的值,无论是原始值或者是对象引用。它类似于数组,但是成员的值都是唯一的,没有重复的值。
const s = new Set()[(2, 3, 5, 4, 5, 2, 2)].forEach((x) => s.add(x));
for (let i of s) {
console.log(i);
}
// 2 3 5 4
Set 中的特殊值:
Set 对象存储的值总是唯一的,所以需要判断两个值是否恒等。有几个特殊值需要特殊对待:
- +0 与 -0 在存储判断唯一性的时候是恒等的,所以不重复
undefined与undefined是恒等的,所以不重复NaN与NaN是不恒等的,但是在Set中认为NaN与NaN相等,所有只能存在一个,不重复。
Set 的属性:
size:返回集合所包含元素的数量
const items = new Set([1, 2, 3, 4, 5, 5, 5, 5]);
items.size; // 5
Set 实例对象的方法
add(value):添加某个值,返回Set结构本身(可以链式调用)。delete(value):删除某个值,删除成功返回true,否则返回false。has(value):返回一个布尔值,表示该值是否为Set的成员。clear():清除所有成员,没有返回值。
s.add(1).add(2).add(2);
// 注意2被加入了两次
s.size; // 2
s.has(1); // true
s.has(2); // true
s.has(3); // false
s.delete(2);
s.has(2); // false
遍历方法
keys():返回键名的遍历器。values():返回键值的遍历器。entries():返回键值对的遍历器。forEach():使用回调函数遍历每个成员。
由于 Set 结构没有键名,只有键值(或者说键名和键值是同一个值),所以 keys 方法和 values 方法的行为完全一致。
let set = new Set(["red", "green", "blue"]);
for (let item of set.keys()) {
console.log(item);
}
// red
// green
// blue
for (let item of set.values()) {
console.log(item);
}
// red
// green
// blue
for (let item of set.entries()) {
console.log(item);
}
// ["red", "red"]
// ["green", "green"]
// ["blue", "blue"]
Set 的应用
1、Array.from 方法可以将 Set 结构转为数组。
const items = new Set([1, 2, 3, 4, 5]);
const array = Array.from(items);
2、数组去重
// 去除数组的重复成员
[...new Set(array)];
Array.from(new Set(array));
3、数组的 map 和 filter 方法也可以间接用于 Set
let set = new Set([1, 2, 3]);
set = new Set([...set].map((x) => x * 2));
// 返回Set结构:{2, 4, 6}
let set = new Set([1, 2, 3, 4, 5]);
set = new Set([...set].filter((x) => x % 2 == 0));
// 返回Set结构:{2, 4}
4、实现并集 (Union)、交集 (Intersect) 和差集
let a = new Set([1, 2, 3]);
let b = new Set([4, 3, 2]);
// 并集
let union = new Set([...a, ...b]);
// Set {1, 2, 3, 4}
// 交集
let intersect = new Set([...a].filter((x) => b.has(x)));
// set {2, 3}
// 差集
let difference = new Set([...a].filter((x) => !b.has(x)));
// Set {1}
实现 Set
function Set(arr = []) {
let items = {};
this.size = 0;
// has方法
this.has = function (val) {
return items.hasOwnProperty(val);
};
// add方法
this.add = function (val) {
// 如果没有存在items里面就可以直接写入
if (!this.has(val)) {
items[val] = val;
this.size++;
return true;
}
return false;
};
arr.forEach((val, i) => {
this.add(val);
});
// delete方法
this.delete = function (val) {
if (this.has(val)) {
delete items[val]; // 将items对象上的属性删掉
this.size--;
return true;
}
return false;
};
// clear方法
this.clear = function () {
items = {};
this.size = 0;
};
// keys方法
this.keys = function () {
return Object.keys(items);
};
// values方法
this.values = function () {
return Object.values(items);
};
// forEach方法
this.forEach = function (fn, context = this) {
for (let i = 0; i < this.size; i++) {
let item = Object.keys(items)[i];
fn.call(context, item, item, items);
}
};
// 并集
this.union = function (other) {
let union = new Set();
let values = this.values();
for (let i = 0; i < values.length; i++) {
union.add(values[i]);
}
values = other.values(); // 将values重新赋值为新的集合
for (let i = 0; i < values.length; i++) {
union.add(values[i]);
}
return union;
};
// 交集
this.intersect = function (other) {
let intersect = new Set();
let values = this.values();
for (let i = 0; i < values.length; i++) {
if (other.has(values[i])) {
intersect.add(values[i]);
}
}
return intersect;
};
// 差集
this.difference = function (other) {
let difference = new Set();
let values = this.values();
for (let i = 0; i < values.length; i++) {
if (!other.has(values[i])) {
difference.add(values[i]);
}
}
return difference;
};
// 子集
this.subset = function (other) {
if (this.size > other.size) {
return false;
} else {
let values = this.values();
for (let i = 0; i < values.length; i++) {
console.log(values[i]);
console.log(other.values());
if (!other.has(values[i])) {
return false;
}
}
return true;
}
};
}
module.exports = Set;
测试
const Set = require("./Set.js");
let set = new Set([2, 1, 3]);
console.log(set.keys()); // [ '1', '2', '3' ]
console.log(set.values()); // [ 1, 2, 3 ]
console.log(set.size); // 3
set.delete(1);
console.log(set.values()); // [ 2, 3 ]
set.clear();
console.log(set.size); // 0
// 并集
let a = [1, 2, 3];
let b = new Set([4, 3, 2]);
let union = new Set(a).union(b).values();
console.log(union); // [ 1, 2, 3, 4 ]
// 交集
let c = new Set([4, 3, 2]);
let intersect = new Set([1, 2, 3]).intersect(c).values();
console.log(intersect); // [ 2, 3 ]
// 差集
let d = new Set([4, 3, 2]);
let difference = new Set([1, 2, 3]).difference(d).values();
// [1,2,3]和[4,3,2]的差集是1
console.log(difference); // [ 1 ]
Map
Map 中存储的是 key-value 形式的键值对, 其中的 key 和 value 可以是任何类型的, 即对象也可以作为 key。 Map 的出现,就是让各种类型的值都可以当作键。Map 提供的是 “值-值”的对应。
Map 和 Object 的区别
Object对象有原型, 也就是说他有默认的key值在对象上面, 除非我们使用Object.create(null)创建一个没有原型的对象;- 在
Object对象中, 只能把String和Symbol作为key值, 但是在Map中,key值可以是任何基本类型(String,Number,Boolean,undefined,NaN….),或者对象(Map,Set,Object,Function,Symbol,null….); - 通过
Map中的size属性, 可以很方便地获取到Map长度, 要获取Object的长度, 你只能手动计算
Map 的属性
- size: 返回集合所包含元素的数量
const map = new Map();
map.set("foo", ture);
map.set("bar", false);
map.size; // 2
Map 对象的方法
set(key, val): 向Map中添加新元素get(key): 通过键值查找特定的数值并返回has(key): 判断Map对象中是否有Key所对应的值,有返回true,否则返回falsedelete(key): 通过键值从Map中移除对应的数据clear(): 将这个Map中的所有元素删除
const m = new Map();
const o = { p: "Hello World" };
m.set(o, "content");
m.get(o); // "content"
m.has(o); // true
m.delete(o); // true
m.has(o); // false
遍历方法
keys():返回键名的遍历器values():返回键值的遍历器entries():返回键值对的遍历器forEach():使用回调函数遍历每个成员
const map = new Map([
["a", 1],
["b", 2],
]);
for (let key of map.keys()) {
console.log(key);
}
// "a"
// "b"
for (let value of map.values()) {
console.log(value);
}
// 1
// 2
for (let item of map.entries()) {
console.log(item);
}
// ["a", 1]
// ["b", 2]
// 或者
for (let [key, value] of map.entries()) {
console.log(key, value);
}
// "a" 1
// "b" 2
// for...of...遍历map等同于使用map.entries()
for (let [key, value] of map) {
console.log(key, value);
}
// "a" 1
// "b" 2
数据类型转化
Map 转为数组
let map = new Map();
let arr = [...map];
数组转为 Map
Map: map = new Map(arr);
Map 转为对象
let obj = {};
for (let [k, v] of map) {
obj[k] = v;
}
对象转为 Map
for( let k of Object.keys(obj)){
map.set(k,obj[k])
}
Map 的应用
通过 Map 来改造,将我们需要显示的 label 和 value 存到我们的 Map 后渲染到页面,这样减少了大量的 html 代码
<template>
<div id="app">
<div class="info-item" v-for="[label, value] in infoMap" :key="value">
<span>{{label}}</span>
<span>{{value}}</span>
</div>
</div>
</template>
data: () => ({
info: {},
infoMap: {}
}),
mounted () {
this.info = {
name: 'jack',
sex: '男',
age: '28',
phone: '13888888888',
address: '广东省广州市',
duty: '总经理'
}
const mapKeys = ['姓名', '性别', '年龄', '电话', '家庭地址', '身份']
const result = new Map()
let i = 0
for (const key in this.info) {
result.set(mapKeys[i], this.info[key])
i++
}
this.infoMap = result
}
对象属性原理
V8 中的快速属性
对象大多数时候表现为 Dictionary:以字符串为 key,任意 object 为值。但是...往下看
命名属性: 如:{a:'foo',b:'bar'}
- 存储结构可以是数组也可以是 HashMap
- 具有额外的辅助信息(存储在描述符数组中)
数组索引属性(元素): 如:数组['foo','bar']有两个数组索引属性:0,值为'foo'; 1,值为'bar'。
- 存储结构通常为简单的数组结构。但某些情况下也会切换到 Hash 结构以节省内存。
- 可以使用键来推断它们在属性数组中的位置
数组索引属性和命名属性存储在两个单独的数据结构中:

隐藏类和描述符数组
每个 JS 对象都有一个隐藏类与之关联。 隐藏类存储有对象结构信息(属性数和对对象原型的引用),以及从属性名称到属性的索引映射。 隐藏类是动态创建的,并随着对象的变化而动态更新。

在 V8 中,位于堆内存并由 GC 管理的所有 JS 对象的第一个字段都指向隐藏类。 隐藏类存储中包含属性的数量,和一个指向描述符数组的指针。 在这个描述符数组中包含有命名属性的信息,例如命名属性的名称和存储属性值的位置。
注意:具有相同结构的 JS 对象(相同顺序和相同命名的属性),他们的隐藏类会指向同一个,以此达到复用的目的。对于不同结构的 JS 对象将使用不同的 HiddenClass。

每次添加新属性时,都会更改对象的 HiddenClass。V8 维护了一个把 HiddenClasses 链接在一起的转换树。按相同属性添加顺序将得到一样的隐藏类。

如果我们创建一个添加了不同属性的新对象('d'),则会创建一个单独的隐藏类分支。

结论: 具有相同结构的对象(相同属性的相同顺序)具有相同的 HiddenClass 默认情况下,每个添加的新命名属性都会导致创建一个新的 HiddenClass。 添加数组索引属性不会创建新的 HiddenClasses。
三种不同的命名属性
- 内嵌属性与普通属性:
- V8 支持对象内属性,存储在对象本身,可以直接访问,速度最快。
- 内嵌属性的数量由对象的初始大小预先确定。
- 如果添加的属性多于对象中的空间,则它们将存储在隐藏类链上,由隐藏类指向的一个属性数组。

- (普通属性中的)快属性与慢属性:
- 直接存储在属性数组(如上图中的 Properties 结构)中的属性为'快属性'。可通过属性数组中的索引访问,若要从属性名称获取属性数组中的实际位置,必须查看 HiddenClass 上的描述符数组才能知道(如上)。
- 慢属性使用 HashMap 作为属性存储,所有属性元信息不再存储在 HiddenClass 上的描述符数组中,而是直接存储在属性 Hash 中(没有缓存,所以叫慢属性)。

注意:过多的添加或删除属性,会从快属性模式切换为慢属性模式。
结论: 三种不同的命名属性类型:in-object,fast 和 slow(dictionary)。 内嵌属性直接存储在对象本身上,并提供最快的访问。 快速属性存在于属性存储中,所有元信息都存储在 HiddenClass 上的描述符数组中。 慢属性存在于自包含的属性字典中,不再通过 HiddenClass 共享元信息。 慢属性提供有效的属性删除和添加,但访问速度比其他两种类型慢。
数组索引属性
- 连续和有缺口的数组索引属性: 如果删除索引元素,或者例如没有定义它,则会在连续存储中出现漏洞。一个简单的例子是[1,,3],其中第二个项是一个缺口。
const o = ["a", "b", "c"];
console.log(o[1]); // Prints "b".
delete o[1]; // Introduces a hole in the elements store.
console.log(o[1]); // Prints "undefined"; property 1 does not exist.
o.\_\_proto\_\_ = {1: "B"}; // Define property 1 on the prototype.
console.log(o[0]); // Prints "a".
console.log(o[1]); // Prints "B".
console.log(o[2]); // Prints "c".
console.log(o[3]); // Prints undefined

当有缺口的时候会在该位置打上 the_hole 标记表示不存在的属性,可以大大提高数组操作效率。
- 快速数组索引属性或 Hash 数组索引属性: 快速数组索引属性是简单的 VM 内部数组,其中属性索引映射到数组索引属性存储中的索引。但是,该结构对于较大的数组但占用元素较少的情况相当浪费内存,这种情况会使用 HashMap 来节省内存,但代价是访问速度稍慢。
const sparseArray = [];
sparseArray [9999] ='foo'; //创建一个包含字典元素的数组。
注意:只要使用自定义描述符定义索引属性,V8 就会转向慢数组索引属性:
const array = [];
Object.defineProperty(array, 0, {value: "fixed", configurable: false});
console.log(array[0]); // Prints "fixed".
array[0] = "other value"; // Cannot override index 0.
console.log(array[0]); // Still prints "fixed".
9.weakMap 和 weakSet 特点,什么是弱引用
weakSet
WeakSet 结构与 Set 类似,也是不重复的值的集合。
- 成员都是数组和类似数组的对象,若调用
add()方法时传入了非数组和类似数组的对象的参数,就会抛出错误。
const b = [1, 2, [1, 2]];
new WeakSet(b); // Uncaught TypeError: Invalid value used in weak set
- 成员都是弱引用,可以被垃圾回收机制回收,可以用来保存 DOM 节点,不容易造成内存泄漏。
WeakSet不可迭代,因此不能被用在for-of等循环中。WeakSet没有size属性。
WeakMap
WeakMap 结构与 Map 结构类似,也是用于生成键值对的集合。
- 只接受对象作为键名(
null除外),不接受其他类型的值作为键名 - 键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的
- 不能遍历,方法有
get、set、has、delete
弱引用
WeakSet 中的对象都是弱引用,即垃圾回收机制不考虑 WeakSet 对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于 WeakSet 之中
- 弱引用:垃圾回收机制有一套自己的回收算法,我们都知道一个函数执行完成后该函数在调用栈中创建的执行上下文会被销毁,这里说的销毁,其实指的就是执行上下文中环境变量、词法变量中的数据存储所占据的内存空间被垃圾回收机制所回收,那么
垃圾回收机制不考虑 WeakSet 对该对象的引用是不是就意味着垃圾回收机制不会回收 WeakSet 对象里面的数据所占据的内存呢?不!不是的!代码是最好的解释
let obj = { name: "kirara" };
let ws = new WeakSet();
ws.add(obj);
obj = null;
console.log(ws); //WeakSet{}
用 ws 中存放一个对象,然后再将该对象置为 null,(一个变量被置为 null,就意味着这个变量的内存可以被回收了)只要 WeakSet 结构中的对象不再需要被引用,那么 WeakSet 就直接为空了,就意味着 WeakSet 中的数据所占据的内存被释放了
let obj = { name: "kirara" };
let s = new Set();
s.add(obj);
obj = null;
console.log(s);
//value.name='kirara'
WeakSet 中 - 垃圾回收机制会自动回收该对象所占用的内存
应用场景: 储存 DOM 节点,而不用担心这些节点从文档移除时,会引发内存泄漏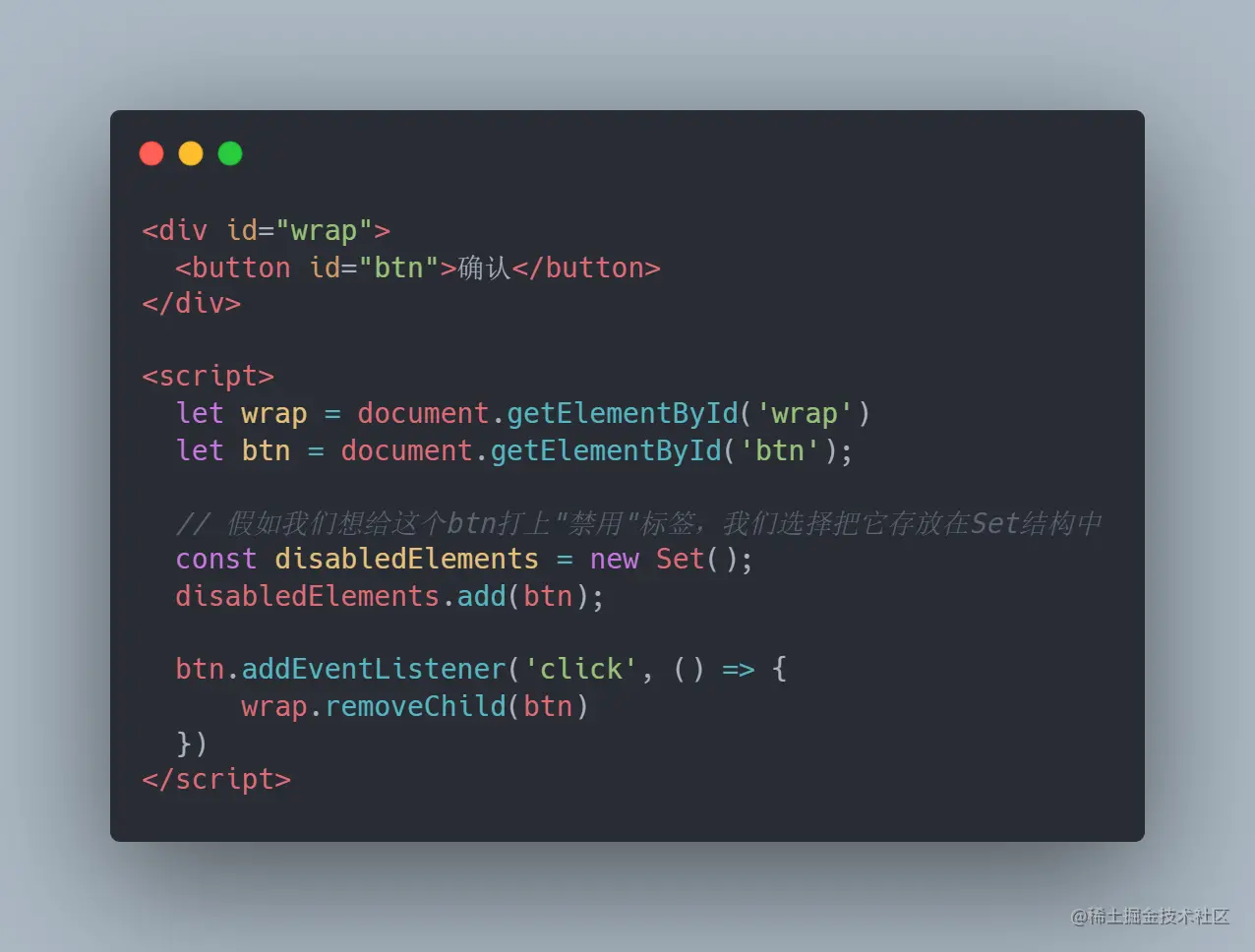
假设我们需要给记录页面上的禁用标签,那么一个 Set 对象存放就可以了,这样写功能上没有问题,但如果写成这样,当点击事件发生后,button 的 dom 被移除,那么整份 js 中 disabledElements 这个对象因为是强引用,其中的值依然存在于内存中的,那么内存泄漏就造成了,于是我们可以换成 WeakSet 来存放
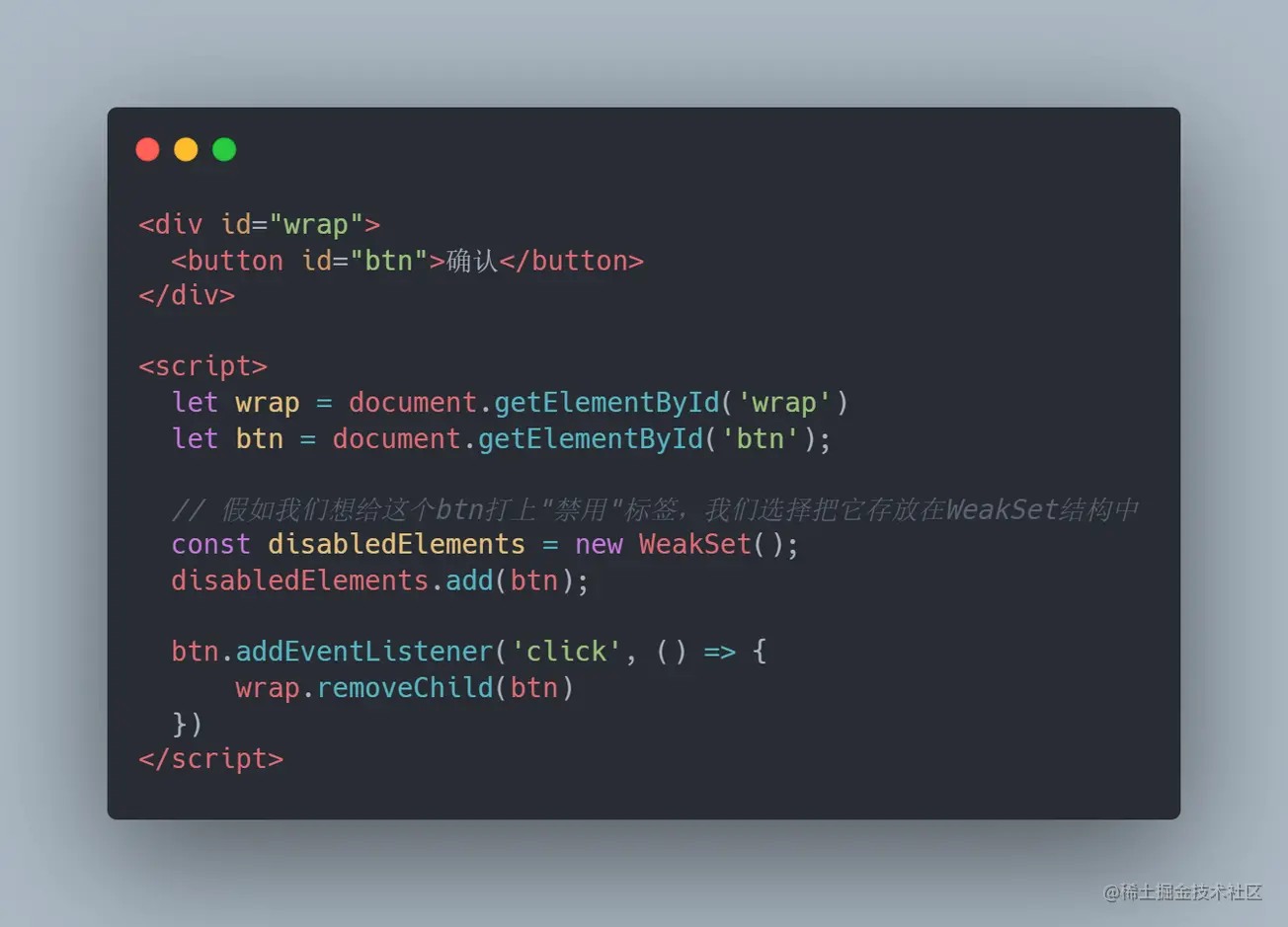 效果是一样的,这里当 button 被移除,disabledElements 中的内容会因为是弱引用而直接变成空,也就是 disabledElements 被垃圾回收掉了其中的内存,避免了一个小小的内存泄漏的产生
效果是一样的,这里当 button 被移除,disabledElements 中的内容会因为是弱引用而直接变成空,也就是 disabledElements 被垃圾回收掉了其中的内存,避免了一个小小的内存泄漏的产生
10.迭代器和生成器
迭代器
迭代器是一种特殊的对象,它具有一些专门为迭代过程设计的专有接口,所有的迭代器对象都有一个 next()方法,每次调用都返回一个结果对象。
结果对象有两个属性:一个是 value,表示下一个将要返回的值;另一个是 done,它是一个布尔值,当没有更多可返回的数据时返回 true。
迭代器还会保存一个内部指针,用来指向当前集合中值的位置,每一次调用 next()方法,都会返回下一个可用的值。
如果在最后一个值返回后在调用 next()方法,那么返回对象中属性 done 的值为 true,属性 value 则包含迭代器最终返回的值,这个返回值不是数据集的一部分,它与函数的返回值类似,是函数调用过程中最后一次给调用者传递信息的方法,如果没有相关数据则返回 undefined。
Generator是一个生成器函数,调用这个函数它并不会立马执行这个函数,而是生成一个遍历器(或者迭代器)对象(Iterator),必须调用这个遍历器对象的next方法才会执行,而且它并不是一次性全部执行完,如果执行过程中遇到了yield关键字函数会暂停,等调用下一个next方法才会恢复执行。
- 定义:为各种不同的数据结构提供统一的访问机制
- 原理:创建一个指针指向首个成员,按照次序使用
next()指向下一个成员,直接到结束位置(数据结构只要部署Iterator接口就可完成遍历操作) - 作用
- 为各种数据结构提供一个统一的简便的访问接口
- 使得数据结构成员能够按某种次序排列
- ES6 创造了新的遍历命令
for-of,Iterator接口主要供for-of消费
- 形式:
for-of(自动去寻找 Iterator 接口) - 数据结构
- 集合:
Array、Object、Set、Map - 原生具备接口的数据结构:
String、Array、Set、Map、TypedArray、Arguments、NodeList
- 集合:
- 部署:默认部署在
Symbol.iterator(具备此属性被认为可遍历的iterable) - 遍历器对象
- next():下一步操作,返回
{ done, value }(必须部署) - return():
for-of提前退出调用,返回{ done: true } - throw():不使用,配合
Generator函数使用
- next():下一步操作,返回
ForOf 循环
定义:调用
Iterator接口产生遍历器对象(for-of内部调用数据结构的Symbol.iterator())遍历字符串:
for-in获取索引,for-of获取值(可识别 32 位 UTF-16 字符)遍历数组:
for-in获取索引,for-of获取值遍历对象:
for-in获取键,for-of需自行部署遍历 Set:
for-of获取值=>for (const v of set)遍历 Map:
for-of获取键值对=>for (const [k, v] of map)遍历类数组:
包含length的对象、Arguments对象、NodeList对象(无Iterator接口的类数组可用Array.from()转换)计算生成数据结构:
Array、Set、Map
- keys():返回遍历器对象,遍历所有的键
- values():返回遍历器对象,遍历所有的值
- entries():返回遍历器对象,遍历所有的键值对
与 for-in 区别
- 有着同
for-in一样的简洁语法,但没有for-in那些缺点、 - 不同于
forEach(),它可与break、continue和return配合使用 - 提供遍历所有数据结构的统一操作接口
- 有着同
应用场景
- 改写具有
Iterator接口的数据结构的Symbol.iterator - 解构赋值:对 Set 进行结构
- 扩展运算符:将部署
Iterator接口的数据结构转为数组 - yield:`yield`后跟一个可遍历的数据结构,会调用其遍历器接口
- 接受数组作为参数的函数:
for-of、Array.from()、new Set()、new WeakSet()、new Map()、new WeakMap()、Promise.all()、Promise.race()
生成器
定义:封装多个内部状态的异步编程解决方案
形式:调用Generator函数(该函数不执行)返回指向内部状态的指针对象(不是运行结果)
声明:function* Func() {}
方法
- next():使指针移向下一个状态,返回
{ done, value }(入参会被当作上一个yield命令表达式的返回值) - return():返回指定值且终结遍历
Generator函数,返回{ done: true, value: 入参 } - throw():在
Generator函数体外抛出错误,在Generator函数体内捕获错误,返回自定义的new Errow()
yield 命令:声明内部状态的值(return声明结束返回的值)
- 遇到
yield命令就暂停执行后面的操作,并将其后表达式的值作为返回对象的value - 下次调用
next()时,再继续往下执行直到遇到下一个yield命令 - 没有再遇到
yield命令就一直运行到Generator函数结束,直到遇到return语句为止并将其后表达式的值作为返回对象的value Generator函数没有return语句则返回对象的value为undefined
yield*命令:在一个Generator函数里执行另一个Generator函数(后随具有Iterator接口的数据结构)
遍历:通过for-of自动调用next()
方法异同
- 相同点:
next()、throw()、return()本质上是同一件事,作用都是让函数恢复执行且使用不同的语句替换yield命令 - 不同点
- next():将
yield命令替换成一个值 - return():将
yield命令替换成一个return语句 - throw():将
yield命令替换成一个throw语句
- next():将
应用场景
- 异步操作同步化表达
- 控制流管理
- 为对象部署 Iterator 接口:把
Generator函数赋值给对象的Symbol.iterator,从而使该对象具有Iterator接口 - 作为具有 Iterator 接口的数据结构
重点难点
- 每次调用
next(),指针就从函数头部或上次停下的位置开始执行,直到遇到下一个yield命令或return语句为止 - 函数内部可不用
yield命令,但会变成单纯的暂缓执行函数(还是需要next()触发) yield命令是暂停执行的标记,next()是恢复执行的操作yield命令用在另一个表达式中必须放在圆括号里yield命令用作函数参数或放在赋值表达式的右边,可不加圆括号yield命令本身没有返回值,可认为是返回undefinedyield命令表达式为惰性求值,等next()执行到此才求值- 函数调用后生成遍历器对象,此对象的
Symbol.iterator是此对象本身 - 在函数运行的不同阶段,通过
next()从外部向内部注入不同的值,从而调整函数行为 - 首个
next()用来启动遍历器对象,后续才可传递参数 - 想首次调用
next()时就能输入值,可在函数外面再包一层 - 一旦
next()返回对象的done为true,for-of遍历会中止且不包含该返回对象 - 函数内部部署
try-finally且正在执行try,那么return()会导致立刻进入finally,执行完finally以后整个函数才会结束 - 函数内部没有部署
try-catch,throw()抛错将被外部try-catch捕获 throw()抛错要被内部捕获,前提是必须至少执行过一次next()throw()被捕获以后,会附带执行下一条yield命令- 函数还未开始执行,这时
throw()抛错只可能抛出在函数外部
生成器是一种返回迭代器的函数,通过 function 关键字后的星号(*)来表示,函数中会用到新的关键字 yield。星号可以紧挨着 function 关键字,也可以在中间添加一个空格,比如这样:
function* createIterator() {
yield 1;
yield 2;
yield 3;
}
let iterator = createIterator();
// 生成器的调用方式与普通函数一样,只不过返回的是一个迭代器console.log(iterator.next().value);
// console.log(iterator.next().value);
// console.log(iterator.next().value); // 3
使用 yield 关键字可以返回任何值或表达式,所以可以通过生成器函数批量地给迭代器添加元素。例如,可以在循环中使用 yield 关键字
function* createIterator(items) {
for (let i = 0; i < items.length; i++) {
yield items[i];
}
}
let iterator = createIterator([1, 2, 3]);
// 生成器的调用方式与普通函数一样,只不过返回的是一个迭代器console.log(iterator.next());
// {value: 1, done: false}console.log(iterator.next());
// {value: 2, done: false}console.log(iterator.next());
// {value: 3, done: false}console.log(iterator.next());
// {value: undefined, done: true}// 之后所有的调用都会返回相同的内容
console.log(iterator.next());
// {value: undefined, done: true}
可迭代对象具有 Symbol.iterator 属性,是一种与迭代器密切相关的对象。Symbol.iterator 通过指定的函数可以返回一个作用于附属对象的迭代器。在 ECMAScript6 中,所有的集合对象(数组,Set 集合和 Map 集合)和字符串都是可迭代对象,这些对象中都有默认的迭代器。ECMAScript 中新加入的特性 for-of 循环需要用到可迭代对象的这些功能。
11.class
基础理论
定义:对一类具有共同特征的事物的抽象(构造函数语法糖)
原理:类本身指向构造函数,所有方法定义在
prototype上,可看作构造函数的另一种写法(Class === Class.prototype.constructor)方法和关键字
- constructor():构造函数,
new命令生成实例时自动调用 - extends:继承父类
- super:新建父类的
this - static:定义静态属性方法
- get:取值函数,拦截属性的取值行为
- set:存值函数,拦截属性的存值行为
- constructor():构造函数,
属性
- **proto**:
构造函数的继承(总是指向父类) - **proto.proto**:子类的原型的原型,即父类的原型(总是指向父类的
__proto__) - prototype.proto****:
属性方法的继承(总是指向父类的prototype)
- **proto**:
静态属性:定义类完成后赋值属性,该属性
不会被实例继承,只能通过类来调用静态方法:使用
static定义方法,该方法不会被实例继承,只能通过类来调用(方法中的this指向类,而不是实例)继承
实质
- ES5 实质:先创造子类实例的
this,再将父类的属性方法添加到this上(Parent.apply(this)) - ES6 实质:先将父类实例的属性方法加到
this上(调用super()),再用子类构造函数修改this
- ES5 实质:先创造子类实例的
super
- 作为函数调用:只能在构造函数中调用
super(),内部this指向继承的当前子类(super()调用后才可在构造函数中使用this) - 作为对象调用:在
普通方法中指向父类的原型对象,在静态方法中指向父类
- 作为函数调用:只能在构造函数中调用
显示定义:使用
constructor() { super(); }定义继承父类,没有书写则显示定义子类继承父类:子类使用父类的属性方法时,必须在构造函数中调用 super(),否则得不到父类的 this
- 父类静态属性方法可被子类继承
- 子类继承父类后,可从
super上调用父类静态属性方法
实例:类相当于实例的原型
,所有在类中定义的属性方法都会被实例继承
- 显式指定属性方法:使用
this指定到自身上(使用Class.hasOwnProperty()可检测到) - 隐式指定属性方法:直接声明定义在对象原型上(使用
Class.__proto__.hasOwnProperty()可检测到)
- 显式指定属性方法:使用
表达式
- 类表达式:
const Class = class {} - name 属性:返回紧跟
class后的类名 - 属性表达式:
[prop] - Generator 方法:
* mothod() {} - Async 方法:
async mothod() {}
- 类表达式:
this 指向:解构实例属性或方法时会报错
- 绑定 this:
this.mothod = this.mothod.bind(this) - 箭头函数:
this.mothod = () => this.mothod()
- 绑定 this:
属性定义位置
- 定义在构造函数中并使用
this指向 - 定义在
类最顶层
- 定义在构造函数中并使用
new.target:确定构造函数是如何调用
原生构造函数
- String()
- Number()
- Boolean()
- Array()
- Object()
- Function()
- Date()
- RegExp()
- Error()
重点难点
- 在实例上调用方法,实质是调用原型上的方法
Object.assign()可方便地一次向类添加多个方法(Object.assign(Class.prototype, { ... }))- 类内部所有定义的方法是不可枚举的(
non-enumerable) - 构造函数默认返回实例对象(
this),可指定返回另一个对象 - 取值函数和存值函数设置在属性的
Descriptor对象上 - 类不存在变量提升
- 利用
new.target === Class写出不能独立使用必须继承后才能使用的类 - 子类继承父类后,
this指向子类实例,通过super对某个属性赋值,赋值的属性会变成子类实例的属性 - 使用
super时,必须显式指定是作为函数还是作为对象使用 extends不仅可继承类还可继承原生的构造函数
私有属性方法
const name = Symbol("name");
const print = Symbol("print");
class Person {
constructor(age) {
this[name] = "Bruce";
this.age = age;
}
[print]() {
console.log(`${this[name]} is ${this.age} years old`);
}
}
继承混合类
function CopyProperties(target, source) {
for (const key of Reflect.ownKeys(source)) {
if (key !== "constructor" && key !== "prototype" && key !== "name") {
const desc = Object.getOwnPropertyDescriptor(source, key);
Object.defineProperty(target, key, desc);
}
}
}
function MixClass(...mixins) {
class Mix {
constructor() {
for (const mixin of mixins) {
CopyProperties(this, new mixin());
}
}
}
for (const mixin of mixins) {
CopyProperties(Mix, mixin);
CopyProperties(Mix.prototype, mixin.prototype);
}
return Mix;
}
class Student extends MixClass(Person, Kid) {}
class 使用
下面我们来看看如何使用class关键字声明一个类。
class Animal {}
// or
const Animal = class {};
而在ES6之前,我们都是通过以下这样子的方式来模拟出类的。
function Animal() {}
类的构造函数
每一个类都可以有一个自己的构造函数,这个名称是固定的constructor,当我们通过new调用一个类时,这个类就会调用自己的constructor方法(构造函数)。
- 它用于创建对象时给类传递一些参数
- 每一个类只能有一个构造函数,否则报错
通过new调用一个类时,会调用构造函数,执行如下操作过程:
- 在内存中开辟一块新的空间用于创建新的对象
- 这个对象内部的
__proto__属性会被赋值为该类的prototype属性 - 构造函数内的 this,指向创建出来的新对象
- 执行构造函数的内部代码
- 如果函数没有返回对象,则返回
this
class Animal {
// 类的构造方法
// 用于接收函数
constructor(name) {
this.name = name;
}
}
var a = new Animal("ABC");
console.log(a); // Animal { name: 'ABC' }
上面这个例子中,我们在class中定义的constructor,这个就是构造方法,而this代表的是实例对象。
这个class,你可以把它看作构造函数的另外一种写法,因为它和它的构造函数的相等的,即是类本身指向构造函数。
console.log(Animal === Animal.prototype.constructor); // true
其实,在类上的所有方法都会放在prototype属性上。
类中的属性
实例属性
实例的属性必须定义在类的方法里,就如上面的例子,我们在构造函数中定义name这个属性。
class Animal {
constructor(name, height, weight) {
this.name = name;
this.height = height;
this.weight = weight;
}
}
静态属性
当我们把一个属性赋值给类本身,而不是赋值给它prototype,这样子的属性被称之为静态属性(static)。
静态属性直接通过类来访问,无需在实例中访问。
class Foo {
static name = "_island";
}
console.log(Foo.name);
私有属性
私有属性只能在类中读取、写入,不能通过外部引用私有字段。
class Animal {
#age;
constructor(name, age) {
this.name = name;
this.#age = age;
}
}
var a = new Animal("_island", 18);
console.log(a); // Animal { name: '_island' }
console.log(a.name); // _island
console.log(a.age); // undefined
console.log(a.#age); // Private field '#age' must be declared in an enclosing class
我们通过getOwnPropertyDescriptors方法获取到它的属性,同样也是获取不到。
console.log(Object.getOwnPropertyDescriptors(a))
{
name: {
value: '_island',
writable: true,
enumerable: true,
configurable: true
}
}
私有字段仅能在字段声明中预先定义。
公共和私有字段声明是 JavaScript 标准委员会TC39提出的实验性功能(第 3 阶段)。浏览器中的支持是有限的,但是可以通过Babel等系统构建后使用此功能。
类中的方法
实例方法
在ES6之前,我们定义类中的方法是类中的原型上进行定义的,防止类中的方法重复在多个对象上。
function Animal() {}
Animal.prototype.eating = function () {
console.log(this.name + " eating");
};
在ES6中,定义类中的方法更加简洁,直接在类中定义即可,这样子的写法即优雅可读性也强。
class Animal {
eating() {
console.log(this.name + " eating");
}
}
静态方法
静态方法与上面提到的静态属性是一样的,在方法前面使用static关键字进行声明,之后调用这个方法时不需要通过类的实例来调用,可以直接通过类名来调用它。
class Animal {
static createName(name) {
return name;
}
}
var a2 = Animal.createName("_island");
console.log(a2); // _island
私有方法
在面向对象中,私有方法是一个常见需求,但是在 ES6 中没有提供,我们可以通过某个方法来实现它。
class Foo {
__getBloodType() {
return "O";
}
}
需要注意的是,通过下划线开头通常我们会局限它是一个私有方法,但是在类的外部还是可以正常调用到这个方法的
类的继承
extends关键字用于扩展子类,创建一个类作为另外一个类的一个子类。
它会将父类中的属性和方法一起继承到子类的,减少子类中重复的业务代码。
这对比之前在ES5中修改原型链实现继承的方法的可读性要强很多,而且写法很简洁。
extends 的使用
class Animal {}
// dog 继承 Animal 类
class dog extends Animal {}
继承类的属性和方法
下面这个例子,我们定义了dog这个类,通过extends关键字继承了Animal类的属性和方法。
在子类的constructor方法中,我们使用了super关键字,在子类中它是必须存在的,否则新建实例时会抛出异常。这是因为子类的 this 对象是继承自父类的 this 对象,如果不调用super方法,子类就得不到this对象。
class Animal {
constructor(name) {
this.name = name;
}
eating() {
console.log(this.name + " eating");
}
}
// dog 继承 Animal 类
class dog extends Animal {
constructor(name, legs) {
super(name);
this.legs = legs;
}
speaking() {
console.log(this.name + " speaking");
}
}
var d = new dog("tom", 4);
d.eating(); // tom eating
d.speaking(); // tom speaking
console.log(d.name); // tom
Super
super关键字用于访问和调用一个对象的父对象上的函数。
super指的是超级、顶级、父类的意思
在子类的构造函数中使用this或者返回默认对象之前,必须先通过super调用父类的构造函数。
下面这段代码,子类的constructor方法中先调用了super方法,它代表了父类的构造函数,也就是说我们把参数传递进去之后,其实它是调用了父类的构造函数。
class Animal{
constructor(name)
}
class dog{
constructor(name,type,weight){
super(name)
this.type=type
this.weight=weight
}
}
下面这段代码使用 super 调用父类的方法
class Animal {
constructor(name) {
this.name = name;
}
eating() {
console.log(this.name + " eating");
}
}
// dog 继承 Animal 类
class dog extends Animal {
constructor(name, legs) {
super(name);
this.legs = legs;
}
speaking() {
super.eating();
console.log(this.name + " speaking");
}
}
var d = new dog("tom", 4);
d.speaking(); // tom eating tom speaking
Getter 和 Setter
在类内部也可以使用get和set关键字,对应某个属性设置存值和取值函数,拦截属性的存取行为。
class Animal {
constructor() {
this._age = 3;
}
get age() {
return this._age;
}
set age(val) {
this._age = val;
}
}
var a = new Animal();
console.log(a.age); // 3
a.age = 4;
console.log(a.age); //4
关于 class 扩展
严格模式
在类和模块的内部,默认是严格模式,所以不需要使用use strict指定运行模式。只要你的代码写在类或模块之中,就只有严格模式可用。
name 属性
ES6中的类只是ES5构造函数的一层包装,所以函数的许多属性都被class继承了,包括name属性。
class Animal {}
console.log(Animal.name); // Animal
变量提升
class不存在变量提升,这与我们在ES5中实现类的不同的,function关键字会存在变量提升。
new Foo(); // ReferenceError
class Foo {}
实现原理
12.JS Object 的底层实现
1. V8 的代码结构
v8 的源码位于src/v8/src/,代码层级相对比较简单,但是实现比较复杂,为了能看懂,需要找到一个切入点,通过打断点、加 log 等方式确定这个切入点是对的,如果这个点并不是关键的点,进行到某一步的时候就断了,那么由这个点出发尝试去找其它的点。不断验证,最后找到一个最关键的地方,由这个地方由浅入深地扩展到其它地方,最后形成一个体系。
以下,先说明 JS Object 的类图。
2. JS Object 类图
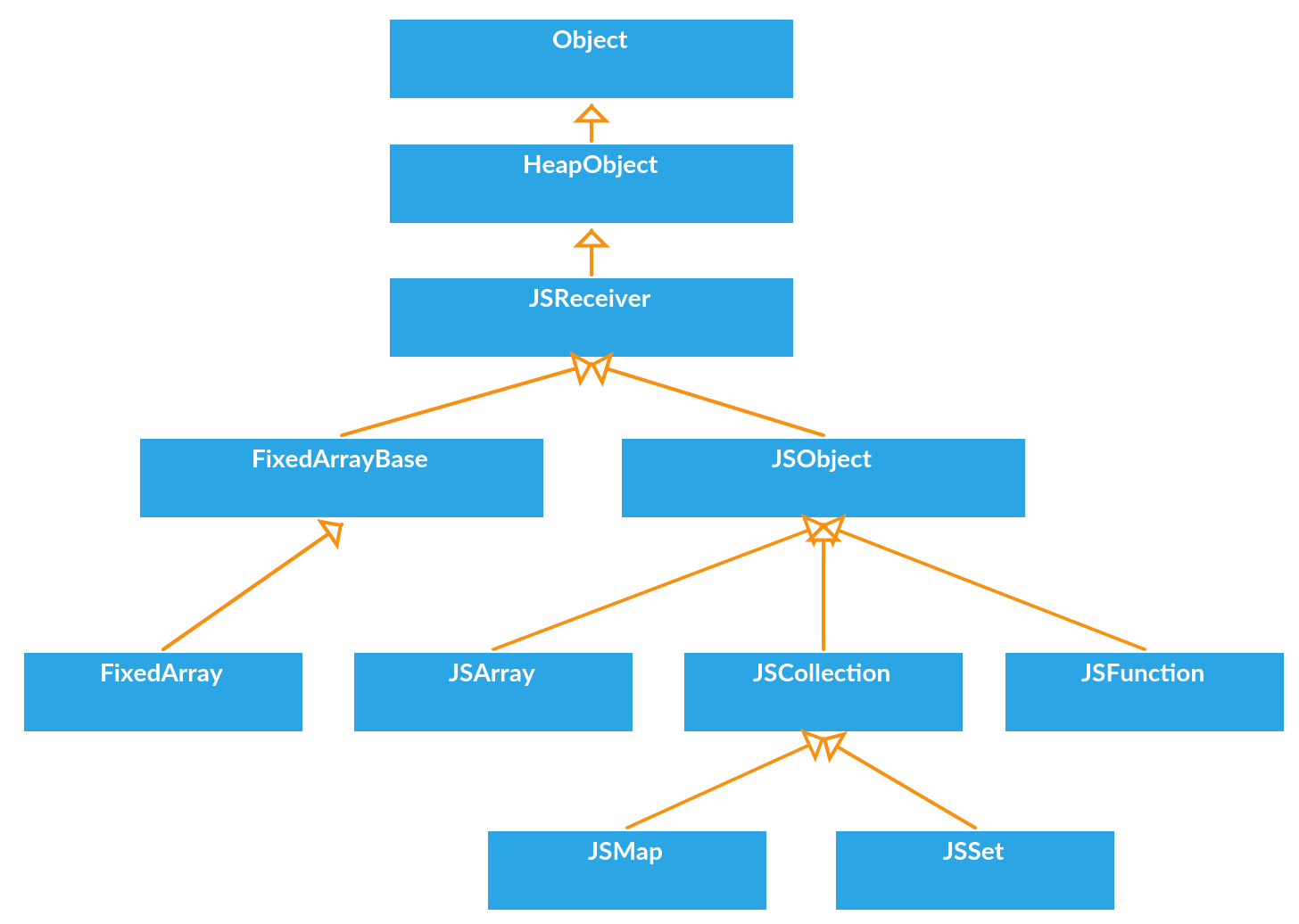
V8 里面所有的数据类型的根父类都是 Object,Object 派生 HeapObject,提供存储基本功能,往下的 JSReceiver 用于原型查找,再往下的 JSObject 就是 JS 里面的 Object,Array/Function/Date 等继承于 JSObject。左边的 FixedArray 是实际存储数据的地方。
3. 创建 JSObject
在创建一个 JSObject 之前,会先把读到的 Object 的文本属性序列化成 constant_properties,如下的 data:
var data = {
name: "yin",
age: 18,
"-school-": "high school",
};
会被序列成:
../../v8/src/runtime/http://runtime-literals.cc 72 constant_properties: 0xdf9ed2aed19: [FixedArray] – length: 6 [0]: 0x1b5ec69833d1 <String[4]: name> [1]: 0xdf9ed2aec51 <String3: yin> [2]: 0xdf9ed2aec71 <String3: age>
[4]: 0xdf9ed2aec91 <String[8]: -school-> [5]: 0xdf9ed2aecb1 <String[11]: high school>
它是一个 FixedArray,一共有 6 个元素,由于 data 总共是有 3 个属性,每个属性有一个 key 和一个 value,所以 Array 就有 6 个。第一个元素是第一个 key,第二个元素是第一个 value,第三个元素是第二个 key,第四个元素是第二个 key,依次类推。Object 提供了一个 Print()的函数,把它用来打印对象的信息非常有帮助。上面的输出有两种类型的数据,一种是 String 类型,第二种是整型类型的。
FixedArray 是 V8 实现的一个类似于数组的类,它表示一段连续的内存,上面的 FixedArray 的 length = 6,那么它占的内存大小将是:
length * kPointerSize
因为它存的都是对象的指针(或者直接是整型数据类型,如上面的 18),在 64 位的操作系统上,一个指针为 8 个字节,它的大小将是 48 个字节。它记录了一个初始的内存开始地址,使用元素 index 乘以指针大小作为偏移,加上开始地址,就可以取到相应 index 的元素,这和数组是一样的道理。只是 V8 自己封装了一个,方便添加一些自定义的函数。
FixedArray 主要用于表示数据的存储位置,在它上面还有一个 Map,这个 Map 用于表示数据的结构。这里的 Map 并不是哈希的意思,更接近于地图的意义,用来操作 FixedArray 表示的这段内存。V8 根据 constant_properties 的 length,去开辟相应大小空间的 Map:
Handle<Map> map = ComputeObjectLiteralMap(context, constant_properties,
&is_result_from_cache);
把这个申请后的 Map 打印出来:
> ../../v8/src/heap/[http://heap.cc](http://heap.cc/) 3472 map is
> 0x21528af9cb39: [Map]
> – type: JS_OBJECT_TYPE
> – **instance size: 48**
> – inobject properties: 3
> – back pointer: 0x3e2ca8902311 <undefined>
> – instance descriptors (own) #0: 0x3e2ca8902231 <FixedArray[0]>
从第 4 行加粗字体可以看到,它的大小确实和我们算的一样。并且它还有一个叫做 descriptors 表示它的数据结构。descriptor 记录了每个 key-value 对,以及它们在 FixedArray 里面的 index. 后续对 properties 的操作基本上通过 descriptor 进行。
有了这个 map 的对象之后,用它来创建一个 JSObect:
Handle<JSObject> boilerplate =
isolate->factory()->NewJSObjectFromMap(map, pretenure_flag);
重新开辟一段内存,把 map 的内容拷过去。
由于 map 只是一段相应大小的内存空间,它的内容是空的,所以接下来要设置它的 properties:
for (int index = 0; index < length; index += 2) {
Handle<Object> key(constant_properties->get(index + 0));
Handle<Object> value(constant_properties->get(index + 1));
Handle<String> name = Handle<String>::cast(key);
JSObject::SetOwnPropertyIgnoreAttributes(boilerplate, name,
value, NONE);
}
通过上面的代码,把 properties 设置到 map 的 FixedArray 里面,并且可以通过 index 用 descriptors 迅速地取出 key-value。由于这个过程比较复杂,细节不展开讨论。
在设置 properties 的同时,会初始化一个 searchCache,这个 cache 支持哈希查找某个属性。
4. 字符串哈希查找
在设置 cache 的时候,会先进行查找是否已存在相同的属性名,如果已经有了就把它的 value 值覆盖掉,否则把它添加到 cache 里面:
int DescriptorArray::SearchWithCache(Isolate* isolate, Name* name, Map* map) {
DescriptorLookupCache* cache = isolate->descriptor_lookup_cache();
//找到它的index
int number = cache->Lookup(map, name);
//如果没有的话
if (number == DescriptorLookupCache::kAbsent) {
//通过遍历找到它的index
number = Search(name, number_of_own_descriptors);
//更新cache
cache->Update(map, name, number);
}
return number;
}
如上代码的注释,我们先来看一下这个 Search 函数是怎么进行的:
template <SearchMode search_mode, typename T>
int Search(T* array, Name* name, int valid_entries, int* out_insertion_index) {
// Fast case: do linear search for small arrays.
const int kMaxElementsForLinearSearch = 8;
if (valid_entries <= kMaxElementsForLinearSearch) {
return LinearSearch<search_mode>(array, name, valid_entries,
out_insertion_index);
}
// Slow case: perform binary search.
return BinarySearch<search_mode>(array, name, valid_entries,
out_insertion_index);
}
如果属性少于等于 8 个时,则直接线性查找即依次遍历,否则进行二分查找,在线性查找里面判断是否相等,是用的内存地址比较:
for (int number = 0; number < valid_entries; number++) {
if (array->GetKey(number) == name) return number;
}
因为 name 都是用的上面第三点设置 Map 的时候传进来的 name,因此初始化的时候相同的 name 都指向同一个对象。所以可以直接用内存地址进行比较,得到 FixedArray 的索引 number。然后用 key 和 number 去 update cache:
cache->Update(map, name, number);
重点在于这个 update cache。这个 cache 的数据结构是这样的:
static const int kLength = 64;
struct Key {
Map* source;
Name* name;
};
Key keys_[kLength];
int results_[kLength];
它有一个数组 keys的成员变量存放 key,这个数组的大小是 64,数组的索引用哈希算出来,不同的 key 有不同的哈希,这个哈希就是它在数组里面的索引。它还有一个 results,存放上面线性查找出来的 number,这个 number 就是内存里面的偏移,有了这个偏移就可以很快地定位到它的内容,所以放到 results 里面.
关键在于这个哈希是怎么算的。来看一下 update 的函数:
void DescriptorLookupCache::Update(Map* source, Name* name, int result) {
int index = Hash(source, name);
Key& key = keys_[index];
key.source = source;
key.name = name;
results_[index] = result;
}
先计算哈希索引 index,然后把数据存到 results和 keys这两个数组的 index 位置。这个 Hash 函数是这样的:
int DescriptorLookupCache::Hash(Object* source, Name* name) {
// Uses only lower 32 bits if pointers are larger.
uint32_t source_hash =
static_cast<uint32_t>(reinterpret_cast<uintptr_t>(source)) >>
kPointerSizeLog2;
uint32_t name_hash = name->hash_field();
return (source_hash ^ name_hash) % kLength;
}
先计算 map 和 key 的 hash,map 的 hash 即 source_hash 是用 map 的地址的低 32 位,为了统一不同指针大小的区别,而计算 key 的 hash 即 name_hash,最核心的代码应该是以下几行:
uint32_t StringHasher::AddCharacterCore(uint32_t running_hash, uint16_t c) {
running_hash += c;
running_hash += (running_hash << 10);
running_hash ^= (running_hash >> 6);
return running_hash;
}
依次循环 name 的每个字符串做一些位运算,结果累计给 running_hash.
source_hash 是用 map 的内存地址,因为这个地址是唯一的,而 name_hash 是用的字符串的内容,只要字符串一样,那么它的 hash 值就一定一样,这样保证了同一个 object,它的同个 key 值的索引值就一定一样。source_hash 和 name_hash 最后异或一下,模以 kLength = 64 得到它在数组里面的索引。
这里自然而然会有一个问题,通过这样的计算不能够保证不同的 name 计算出来的哈希值一定不一样,好的哈希算法只能让结果尽可能随机,但是无法做到一定不重复,所以这里也有同样的问题。
先来看一下,它是怎么查找的:
int DescriptorLookupCache::Lookup(Map* source, Name* name) {
int index = Hash(source, name);
Key& key = keys_[index];
if ((key.source == source) && (key.name == name)) return results_[index];
return kAbsent;
}
先用同样的哈希算法,算出同样的 index,取出 key 里面的 map 和 name,和存储的 map 和 name 进行比较,如果相同则说明找到了,否则的话返回不存在-1 的标志。一旦不存在了又会执行上面的 update cache,先调 Search 找到它的偏移 index 作为 result,如果 index 存在重新 update cache。所以上面的问题就可以得到解答了,重复的哈希索引覆盖了第一个,导致查找第一个的时候没找找到,所以又去重新 update,把那个索引值的数组元素又改成了第一个的。因此,如果两个重复的元素如果循环轮流访问的话,就会造成不断地查找 index,不断地更新搜索 cache。但是这种情况还是比较少的。
如何保证传进来的具有相同字符串的 name 和原始的 name 是同一个对象,从而才能使它们的内存地址一样?一个办法是维护一个 Name 的数据池,据有相同字符串的 name 只能存在一个。
上面的那个 data 它的三个 name 的 index 在笔者电脑上实验计算结果为:
#name hash index = 62
#age hash index = 32 #-school- hash index = 51
有一个比较奇怪的地方是重复实验,它们的哈希值都是一样的。并且具有相同属性且顺序也相同的 object,它们的 map 地址就是一样的。
如果一个元素的属性值超过 64 个呢?那也是同样的处理,后面设置的会覆盖前面设置的。学过哈希的都知道,当元素的个数大于容器容量的一半时,重复的概率将会大大增加。所以一个 object 的属性的比较优的最大大小为 32。一旦超过 32,在一个:
for (var key in obj) {
obj[key]; //do sth.
}
for 循环里面,这种查找的开销将会很大。但是考虑到属性个数并不多。
那为什么它要把长度设置成 64 呢,如果改大了,不就可以减少重复率?但是这样会造成更多的内存消耗,即使一个 Object 只有一个属性,它也会初始化一个这么大的数组,对于这种属性比较少的 object 来说就很浪费。所以取 64,应该是一个比较适中的值。
同时另一方面,经常使用的那几个属性还是能够很快通过哈希计算定位到它的内容。并且这种场景还是很常见的,如获取数组元素的 lengh.
这种 cache 查找只支持属性个数小于等于 128 的,如果属性个数大于 128 个,将不采用 cache 存储和查找的方式。而是直接使用一个 hashtable
5. 字符串哈希表查找
如下的判断:
const int kMapCacheSize = 128;
// We do not cache maps for too many properties or when running builtin code.
if (number_of_properties > kMapCacheSize) {
*is_result_from_cache = false;
Handle<Map> map = Map::Create(isolate(), number_of_properties);
return map;
}
如果属性个数大于 128 时,将按照属性的个数消耗的空间创建和扩展 map 存储,不再创建 cache。同时这个 map 就会被标记为 dictionary_map,即哈希表。
往这个哈希表插入一个元素前,会先检查表的容量是否足够,不够进行扩容,在 EnsureCapacity 的函数里面:
int capacity = table->Capacity();
int nof = table->NumberOfElements() + n;
if (table->HasSufficientCapacityToAdd(n)) return table;
Handle<Derived> new_table = HashTable::New(
nof * 2,
USE_DEFAULT_MINIMUM_CAPACITY);
table->Rehash(new_table, key);
第二行获取到当前表元素个数加上需要插入的元素的个数得到新表的总元素个数;第 7 行再乘以 2,得到新表的容量,最后再 rehash,重新计算每个元素的哈希值,更新哈希表。
插入一个元素的关键是计算它的哈希,这里计算哈希的方式和上面的一样,都是调的 name->hash_field 函数,不一样的是它不再是覆盖存储,因为上面已经进行扩容了,可以保证空间一定足够。如果哈希值冲突了,那么将一直找到下一个存放它的地方,如下面的 FindInsertionEntry 函数:
template<typename Derived, typename Shape, typename Key>
uint32_t HashTable<Derived, Shape, Key>::FindInsertionEntry(uint32_t hash) {
uint32_t capacity = Capacity();
uint32_t entry = FirstProbe(hash, capacity);
uint32_t count = 1;
// EnsureCapacity will guarantee the hash table is never full.
Isolate* isolate = GetIsolate();
while (true) {
Object* element = KeyAt(entry);
if (!IsKey(isolate, element)) break;
entry = NextProbe(entry, count++, capacity);
}
return entry;
}
在上面代码第 10 行找到一个非 key 元素后,停止循环,返回这个位置。
在所有属性插入完成之后,查找的过程类似于上面的插入,如下面 FindEntry 的函数:
// Find entry for key otherwise return kNotFound.
template <typename Derived, typename Shape>
int NameDictionaryBase<Derived, Shape>::FindEntry(Handle<Name> key) {
// EnsureCapacity will guarantee the hash table is never full.
uint32_t capacity = this->Capacity();
uint32_t entry = Derived::FirstProbe(key->Hash(), capacity);
uint32_t count = 1;
while (true) {
Object* element = this->KeyAt(entry);
if (element->IsUndefined(isolate)) break; // Empty entry.
if (*key == element) return entry;
entry = Derived::NextProbe(entry, count++, capacity);
}
return Derived::kNotFound;
}
在 while 循环里,要么找到一个 undefined 的元素,返回无结果的标志,要么命中元素,返回 FixedArray 的索引 index,然后通过这个数组 index 就可以很快地取出数据:
property_details_ = dictionary->DetailsAt(entry);
当哈希值冲突时,如何找到下一个插入位置,在哈希算法里面也是一个很重要的部分,因为需要定位到下一个空的元素,才能进行插入,如果定位到的下一个元素又是非空的,又得继续找下一个。源码里面是这样进行的:
inline static uint32_t FirstProbe(uint32_t hash, uint32_t size) {
return hash & (size - 1);
}
inline static uint32_t NextProbe(
uint32_t last, uint32_t number, uint32_t size) {
return (last + number) & (size - 1);
}
所以当属性个数不超过 128 个时,是用 searchCache,大于 128 时,采用哈希表。源码里面查找的判断是这样的:
if (!map->is_dictionary_map()) {
DescriptorArray* descriptors = map->instance_descriptors();
int number = descriptors->SearchWithCache(isolate_, *name_, map);
//...
} else {
NameDictionary* dict = holder->property_dictionary();
int number = dict->FindEntry(name_);
//...
}
如果是一个字典,则执行 else 里面的逻辑,否则执行 if 里面的逻辑按 searchCache 查找。
这里自然而然会有一个问题,为什么在不大于 128 个属性的时候要专门搞一个 searchCache 呢,是因为 searchCache 比哈希表快么,快在哪里?我想这两者的区别在于 searchCache 不会冲突,每次都是直接定位,而 hashTable 如果冲突了需要不断地找下一个元素,增加了比较次数。当属性比较少,并且有几个属性经常被用到的时候,searchCache 应该会有明显的优势。
上面已经介绍了两种字符串的查找方式,当属性是数字的时候有另外两种查找方式。
6. 数字索引哈希查找
假设 data 变成:
var data = {
name: "yin",
age: 18,
"-school-": "high school",
1: "Monday",
2: "Thuesday",
"3": "Wednesday"
};
把生成的 data Object 打印出来是这样的:
> ../../v8/src/runtime/[http://runtime-literals.cc](http://runtime-literals.cc/) 105 boilerplate obj:
> 0x3930221af3a9: [JS_OBJECT_TYPE] > \- map = 0x6712e19cc41 [FastProperties] > \- prototype = 0x27d71d20f19
> \- elements = 0x2e1e1a56b579 <FixedArray[19]> [FAST_HOLEY_ELEMENTS] > \- properties = 0x2c2a4d782241 <FixedArray[0]> {
> \#name: 0x3930221aec51 <String[3]: yin> (data field at offset 0)
> \#age: 18 (data field at offset 1)
> \#-school-: 0x3930221aecb1 <String[11]: high school> (data field at offset 2)
> }
> \- elements = {
> 0: 0x2c2a4d782351 <the hole>
> 1: 0x3930221aecf9 <String[6]: Monday>
> 2: 0x3930221aed39 <String[8]: Thuesday>
> 3: 0x3930221aed79 <String[9]: Wednesday>
> 4-18: 0x2c2a4d782351 <the hole>
> }
那些 key 为数字的存放在 elements 的数据结构里面。上面的 elements 它是一个有序数组,它的 key 值直接作为它的 index。如果 data 改成:
var data = {
1: "Monday",
2: "Thuesday",
3: "Wednesday",
7: "Sunday",
};
那么 elements 是这样的:
> \- elements = {
> 0: 0x1e74f5702351 <the hole>
> 1: 0x1745ec52ec71 <String[6]: Monday>
> 2: 0x1745ec52ecb1 <String[8]: Thuesday>
> 3: 0x1745ec52ecf1 <String[9]: Wednesday>
> 4-6: 0x1e74f5702351 <the hole>
> 7: 0x1745ec52ed39 <String[6]: Sunday>
> 8-18: 0x1e74f5702351 <the hole>
> }
初始化大小仍然是 19 个元素,空的索引用 hole 元素填充。这种就跟数组一样,可直接根据索引定位到元素,代价是空间的消耗比较大,可以来看一下,当空间不足时,它是怎么扩容的:
if (index < capacity) {
*new_capacity = capacity;
return false;
}
*new_capacity = JSObject::NewElementsCapacity(index + 1);
由于第一个属性是 1: Monday,所以上面的 index = 1,执行最后一行计算新容量的元素:
// Computes the new capacity when expanding the elements of a JSObject.
static uint32_t NewElementsCapacity(uint32_t old_capacity) {
// (old_capacity + 50%) + 16
return old_capacity + (old_capacity >> 1) + 16;
}
可以看到,这是用老的空间的一半加上 16,上面的计算结果为 19,如果本来是 2M 大小,刚好不够再增加一个元素就成了 3M,一个多余的元素就增加了 1M 的空间。它的好处是不用频繁地开避内存。
这种用数组表示的属性在源码里面叫 FastElements,而用哈希表的叫做 SlowElements。什么时候会变成 slowElements?当 hole 太多的时候,例如给 data 增加一个 key 为 2000 的属性:
data["2000"] = "day";
data 就会转成慢元素,因为 3 之后就是 2000,hole 太多就被转换了,如下面的 ShouldConvertToSlowElements 函数:
static bool ShouldConvertToSlowElements(JSObject* object, uint32_t capacity,
uint32_t index,
uint32_t* new_capacity) {
if (index < capacity) {
return false;
}
//JSObject::kMaxGap = 1024
if (index - capacity >= JSObject::kMaxGap) return true;
*new_capacity = JSObject::NewElementsCapacity(index + 1);
// If the fast-case backing storage takes up roughly three times as
// much space (in machine words) as a dictionary backing storage
// would, the object should have slow elements.
int used_elements = object->GetFastElementsUsage();
int dictionary_size = SeededNumberDictionary::ComputeCapacity(used_elements) *
SeededNumberDictionary::kEntrySize;
return 3 * static_cast<uint32_t>(dictionary_size) <= *new_capacity;
}
如果当前的 index 比容量 capacity 大了 1024,就转成慢元素,或者是如上面的代码注释,如果快元素占的空间为慢元素的 3 倍之多时,也会被转成慢元素。
转成慢元素之后,它就和字符串的哈希表一样了,不一样的是,它计算哈希的方式不一样,字符串的需要一个个字符串循环计算计算 hash,而数字的 key,不需要循环,如下计算(第二个参数是随机化种子 seed):
inline uint32_t ComputeIntegerHash(uint32_t key, uint32_t seed) {
uint32_t hash = key;
hash = hash ^ seed;
hash = ~hash + (hash << 15); // hash = (hash << 15) - hash - 1;
hash = hash ^ (hash >> 12);
hash = hash + (hash << 2);
hash = hash ^ (hash >> 4);
hash = hash * 2057; // hash = (hash + (hash << 3)) + (hash << 11);
hash = hash ^ (hash >> 16);
return hash & 0x3fffffff;
}
然后再来简单看一下 ES6 的 Map 的实现
7. ES6 Map 的实现
这里有一个比较有趣的事情,就是 V8 的 Map 的核心逻辑是用 JS 实现的,具体文件是在v8/src/js/collection.js,用 JS 来实现 JS,比写 C++要高效多了,但是执行效率可能就没有直接写 C++的高,可以来看一下 set 函数的实现:
function MapSet(key, value) {
//添加一个log
%LOG("MapSet", key);
var table = %_JSCollectionGetTable(this);
var numBuckets = ORDERED_HASH_TABLE_BUCKET_COUNT(table);
var hash = GetHash(key);
var entry = MapFindEntry(table, numBuckets, key, hash);
if (entry !== NOT_FOUND) return ...//return代码省略
//如果个数大于capacity的二分之一,则执行%MapGrow(this)代码略
FIXED_ARRAY_SET(table, index, key);
FIXED_ARRAY_SET(table, index + 1, value);
}
第三行添加一个 log 函数,确认确实是执行这里的代码。%开头的 LOG,表示它是一个 C++的函数,这个代码写在 runtime.h 和http://runtime.cc里面。这些 JS 代码最后会被组装成 native code。在 V8 里,除了 Map/Set 之外,很多 ES6 新加的功能,都是用的 JS 实现的,如数组新加的很多函数。
8. Object 和 ES 6 Map 的速度比较
Object 和 ES 6 的 map 主要都是用的哈希,那么它们运行效率比较起来怎么样呢?
如以下代码,初始化一个 map 和一个 object:
var map = new Map(),
obj = {};
var size = 100000;
for(var i = 0; i < size; i++){
map.set('key' + i , i);
obj['key' + i] = i;
}
再准备一个 keys 数组,用来存储查找的 key,如下,分成三种情况分别测验:1. keys 都能查到;2. 只有一半的 keys 能找到;3. 全部的 keys 都查找不到:
var keys = [];
for (var i = 0; i < 100; i++) {
//1. keys都找得到
keys.push("key" + parseInt(Math.random() * size));
//2. 约一半的keys找不到
//keys.push('key' + parseInt(Math.random() * size * 2));
//3. 全部的keys都找不到
//keys.push('key' + parseInt(Math.random() * size) + size);
}
然后进行查找,重复多次,并打印时间:
var count = 100000;
console.time("map time");
for (var i = 0; i < count; i++) {
for (var j = 0; j < keys.length; j++) {
let x = map.get(keys[j]);
}
}
console.timeEnd("map time");
console.time("obj time");
for (var i = 0; i < count; i++) {
for (var j = 0; j < keys.length; j++) {
let x = obj[keys[j]];
}
}
console.timeEnd("obj time");
最后的结果如下:

可以看到,当查找的 keys 找不到时,object 更加地消耗时间(在实际的使用中,一半找得到一半找不到的情况应该会比较多一点)。这很可能是因为 object 里面每个 key 需要实例化一个全局唯一的 name,如果 name 已经存在了,那么它已经实例化好了,包括它的哈希值计算已经缓存起来了,如果未知的 name 越多,那么需要实例化的 name 也就越多,而 map 不存在这种情况,每次都是重新计算哈希。另一方面还可能和它们的哈希算法有关。
综上,Object 存储和查找一个属性时,可通过以下方式:
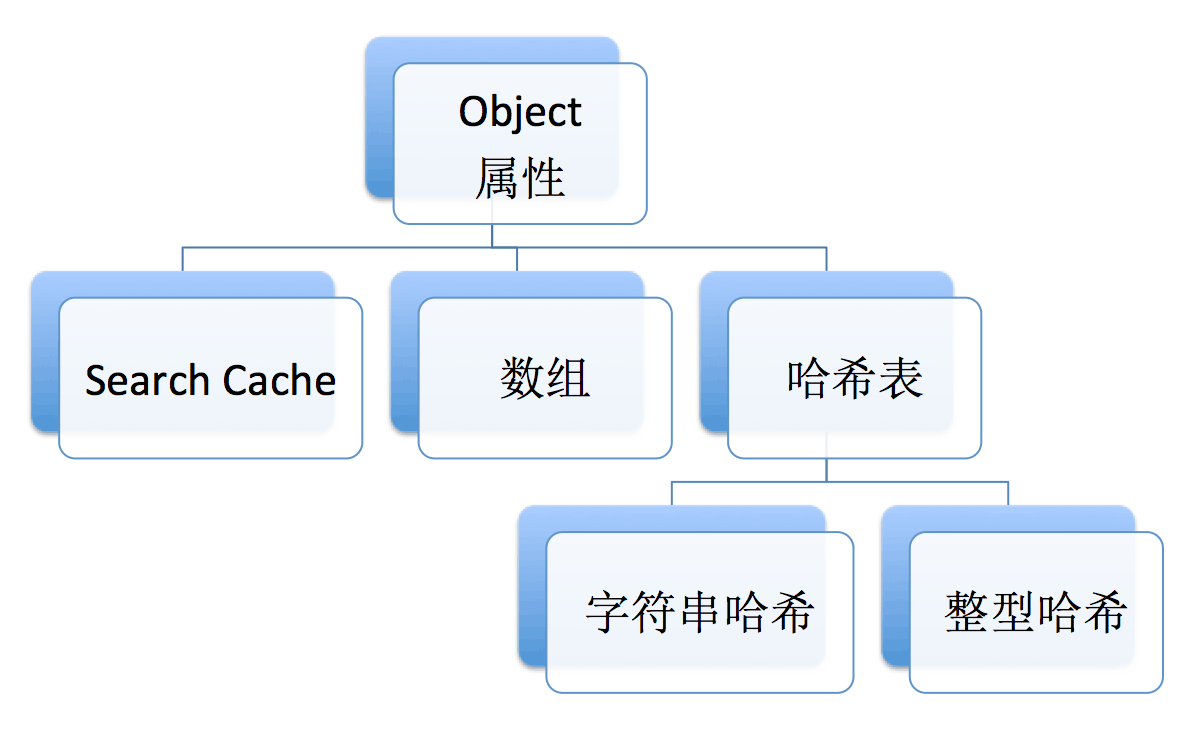
属性不超过 128 个,使用 Search Cache,当属性是较为连续的数字时,使用数组,此种方式最快。其它情况使用哈希表,并且数字和字符串的哈希不一样。
可以把 Object 当成哈希 map 使用,但是在效率上可能会比不上 ES6 的 Map,并且还有 Object 原型查找的问题。
原型和原型链
1.原型链
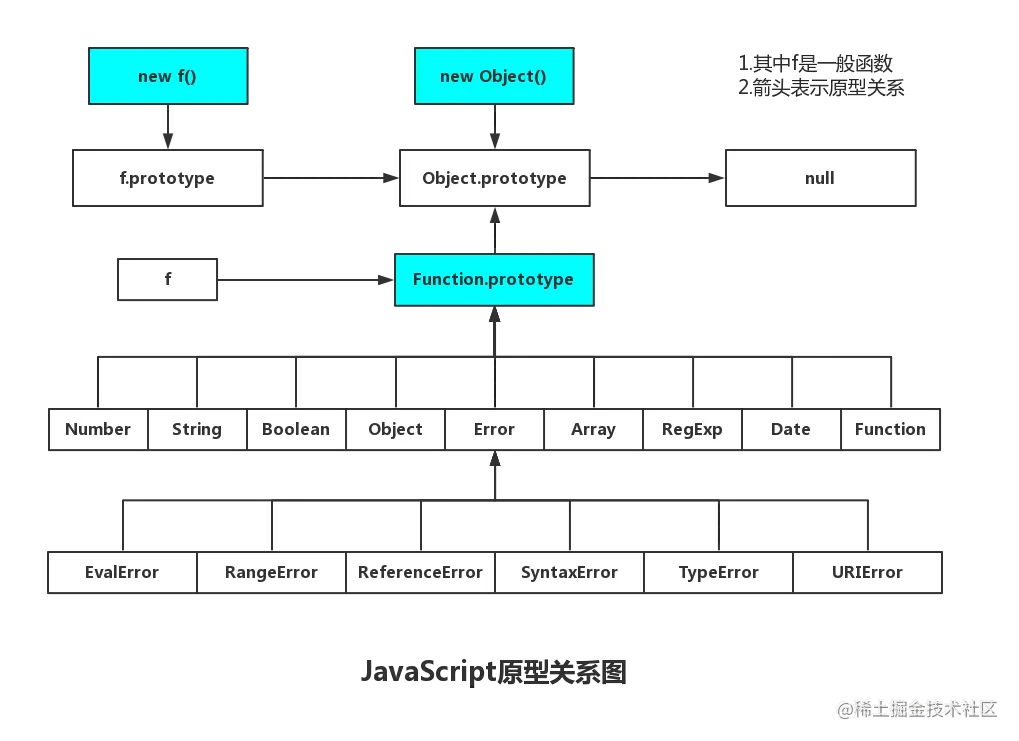
在 JavaScript 中是使用构造函数来新建一个对象的,每一个构造函数的内部都有一个 prototype 属性,它的属性值是一个对象,这个对象包含了可以由该构造函数的所有实例共享的属性和方法。
当使用构造函数新建一个对象后,在这个新建对象的内部将包含一个指针,这个指针指向构造函数的 prototype 属性对应的值,即原型对象,在 ES5 中这个指针被称为对象的原型。一般来说不应该能够获取到这个值的,但是现在浏览器中都实现了 proto 属性来访问这个属性,但是最好不要使用这个属性,因为它不是规范中规定的。ES5 中新增了一个 Object.getPrototypeOf() 方法,可以通过这个方法来获取对象的原型。
当访问一个对象的属性时,如果这个对象内部不存在这个属性,那么它就会去它的原型对象里找这个属性,这个原型对象又会有自己的原型,于是就这样一直找下去,也就是原型链的概念。原型链的尽头一般来说都是 Object.prototype ,这就是新建的对象为什么能够使用 toString() 等方法的原因
JavaScript 对象是通过引用来传递的,创建的每个新对象实体中并没有一份属于自己的原型副本。当修改原型时,与之相关的对象也会继承这一改变
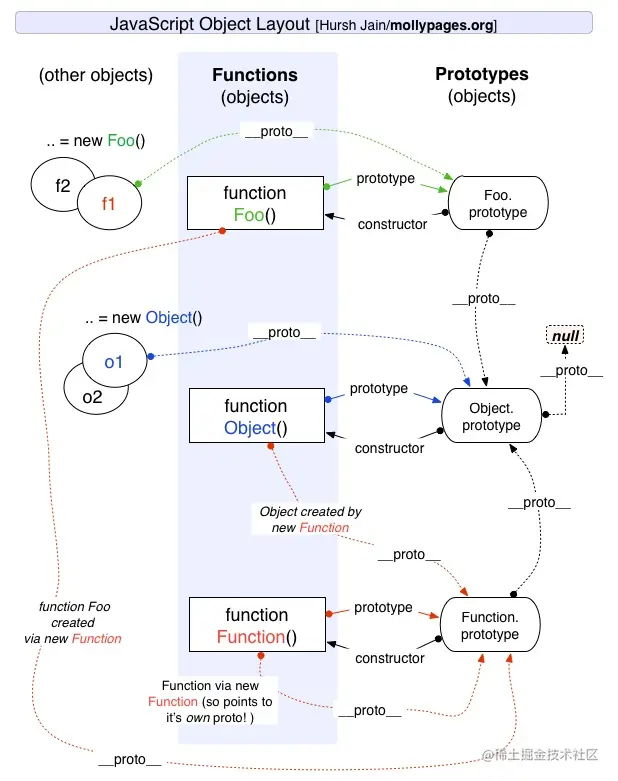
function Person() {}
// 说明:name,age,job这些本不应该放在原型上,只是为了说明属性查找机制
Person.prototype.name = "Nicholas";
Person.prototype.age = 29;
Person.prototype.job = "Software Engineer";
Person.prototype.sayName = function () {
console.log(this.name);
};
let person1 = new Person();
let person2 = new Person();
// 声明之后,构造函数就有了一个与之关联的原型对象
console.log(Object.prototype.toString.call(Person.prototype)); // [object Object]
console.log(Person.prototype); // {constructor: ƒ}
// 构造函数有一个 prototype 属性引用其原型对象,而这个原型对象也有一个constructor 属性,引用这个构造函数
// 换句话说,两者循环引用
console.log(Person.prototype.constructor === Person); // true
// 构造函数、原型对象和实例是 3 个完全不同的对象
console.log(person1 !== Person); // true
console.log(person1 !== Person.prototype); // true
console.log(Person.prototype !== Person); // true
// 实例通过__proto__链接到原型对象,它实际上指向隐藏特性[[Prototype]]
// 构造函数通过 prototype 属性链接到原型对象,实例与构造函数没有直接联系,与原型对象有直接联系,后面将会画图再次说明这个问题
console.log(person1.__proto__ === Person.prototype); // true
conosle.log(person1.__proto__.constructor === Person); // true
// 同一个构造函数创建的两个实例,共享同一个原型对象
console.log(person1.__proto__ === person2.__proto__); // true
// Object.getPrototypeOf(),返回参数的内部特性[[Prototype]]的值 ,用于获取原型对象,兼容性更好
console.log(Object.getPrototypeOf(person1) == Person.prototype); // true
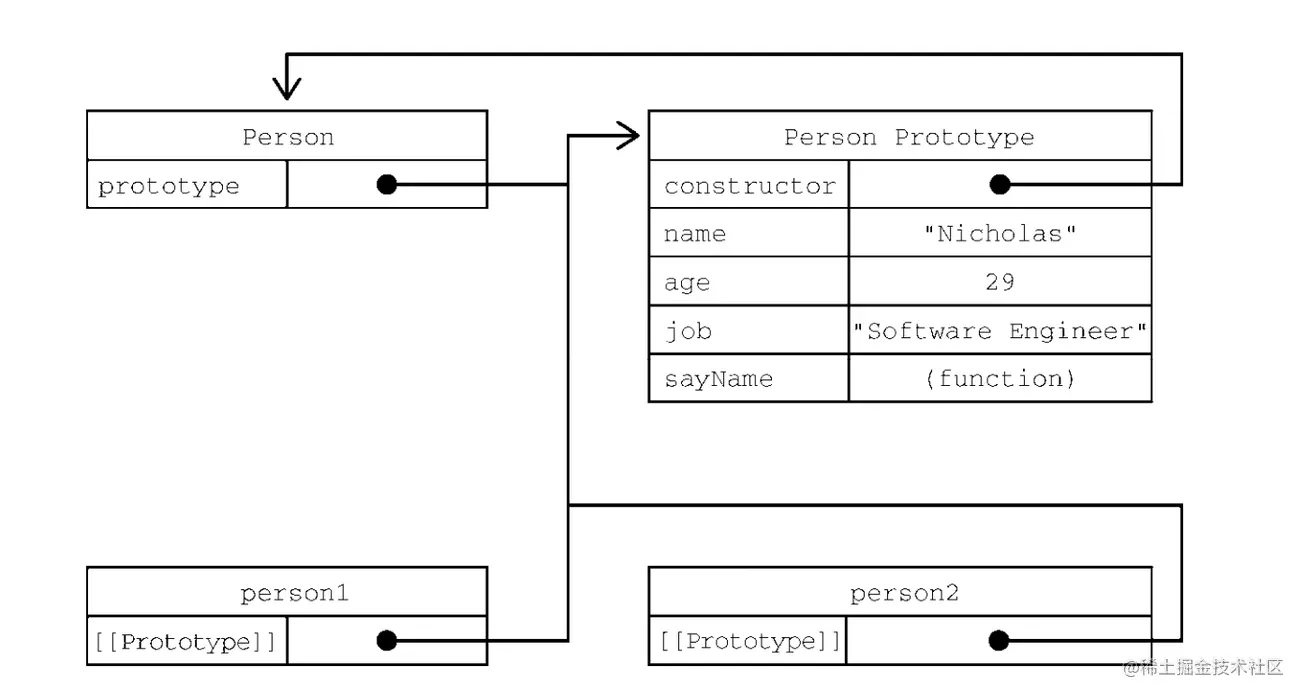
2.原型修改、重写
function Person(name) {
this.name = name;
}
// 修改原型
Person.prototype.getName = function () {};
var p = new Person("hello");
console.log(p.__proto__ === Person.prototype); // true
console.log(p.__proto__ === p.constructor.prototype); // true
// 重写原型
Person.prototype = {
getName: function () {},
};
var p = new Person("hello");
console.log(p.__proto__ === Person.prototype); // true
console.log(p.__proto__ === p.constructor.prototype); // false
以看到修改原型的时候 p 的构造函数不是指向 Person 了,因为直接给 Person 的原型对象直接用对象赋值时,它的构造函数指向的了根构造函数 Object,所以这时候p.constructor === Object ,而不是p.constructor === Person。要想成立,就要用 constructor 指回来:
Person.prototype = {
getName: function () {},
};
var p = new Person("hello");
p.constructor = Person;
console.log(p.__proto__ === Person.prototype); // true
console.log(p.__proto__ === p.constructor.prototype); // true
3.原型链指向
p.__proto__; // Person.prototype
Person.prototype.__proto__; // Object.prototype
p.__proto__.__proto__; //Object.prototype
p.__proto__.constructor.prototype.__proto__; // Object.prototype
Person.prototype.constructor.prototype.__proto__; // Object.prototype
p1.__proto__.constructor; // Person
Person.prototype.constructor; // Person
4.原型链终点
由于Object是构造函数,原型链终点是Object.prototype.__proto__,而Object.prototype.__proto__=== null // true,所以,原型链的终点是null。原型链上的所有原型都是对象,所有的对象最终都是由Object构造的,而Object.prototype的下一级是Object.prototype.__proto__
5.Object 和 Function 的关系
原型链的底层实现顺序结论
首先:js 中先创建的是 Object.prototype 这个原型对象。
然后:在这个原型对象的基础之上创建了 Function.prototype 这个原型对象。
其次:通过这个原型对象创建出来 Function 这个函数。
最后: 又通过 Function 这个函数创建出来之后,Object()这个对象。
1.一切对象都最终继承自 Object 对象,Object 对象直接继承自根源对象 null
(1)一切对象的原型链最终都是.... → Object.prototype → null。例如定义一个 num 变量var num = 1,则 num 的原型链为x → Number.prototype → Object.prototype → null; 定义一个函数对象 fnfunction fn() {},则 fn 的原型链为fn → Function.prototype → Object.prototype → null;等等...
(2)一切对象都包含有 Object 的原型方法,Object 的原型方法包括了 toString、valueOf、hasOwnProperty 等等,在 js 中不管是普通对象,还是函数对象都拥有这些方法,下面列出了几个例子,大家可以自行去举例验证:
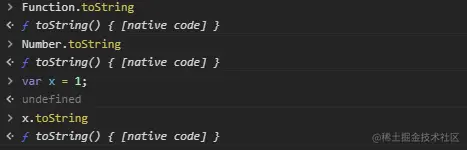
2.一切函数对象(包括 Object 对象)都直接继承自 Function 对象
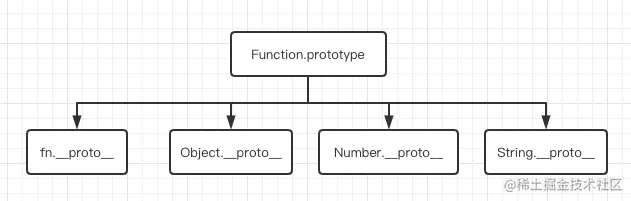

函数对象包括了 Function、Object、Array、String、Number,还有正则对象 RegExp、Date 对象等等,它们在 js 中的构造源码都是function xxx() {[native code]);,Function 其实不仅让我们用于构造函数,它也充当了函数对象的构造器,甚至它也是自己的构造器。
从原型链可以佐证:
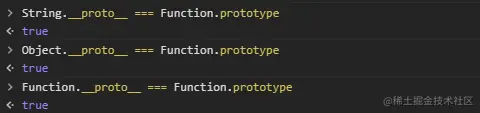
js 中对象.__proto__ === 构造器.prototype,由此可以见得它们之间的关系。
(1)一切对象都继承自 Object 对象是因为一切对象的原型链最终都是.... → Object.prototype → null,包括 Function 对象,只是 Function 的原型链稍微绕了一点,Function 的原型链为Function → Function.prototype → Object.prototype → null,它与其它对象的特别之处就在于它的构造器为自己,即直接继承了自己,最终继承于 Object,上面的原型链可以在浏览器验证:
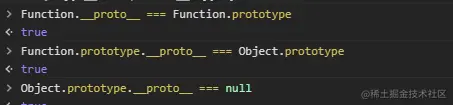
(2)Object 继承自 Function,Object 的原型链为Object → Function.prototype → Object.prototype → null,原型链又绕回来了,并且跟第一点没有冲突。可以说 Object 和 Function 是互相继承的关系
3.Object 对象直接继承自 Function 对象
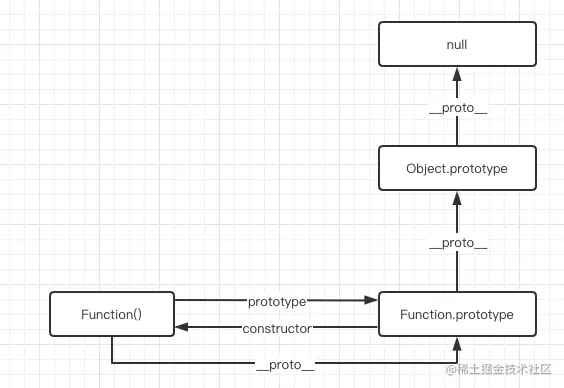
4.Function 对象直接继承自己,最终继承自 Object 对象
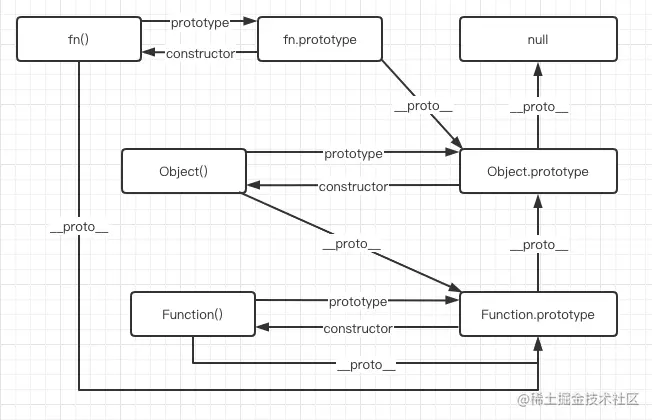
普通对象直接继承了 Object.prototype,而函数对象在中间还继承了 Function.prototype
除了 Object 的原型对象(Object.prototype)的__proto__指向 null 其他内置函数对象的原型对象和自定义构造函数的__proto__都指向 Object.prototype 因为原型对象本身是普通对象
Object.__proto__ === Function.prototype;
Object.prototype.__proto__ === null;
Function.__proto__ === Function.prototype;
Function.prototype.__proto__ === Object.prototype;
6.获得对象原型链上的属性
使用hasOwnProperty()方法来判断属性是否属于原型链的属性:
function iterate(obj) {
var res = [];
for (var key in obj) {
if (obj.hasOwnProperty(key)) res.push(key + ": " + obj[key]);
}
return res;
}
7.instanceof 使用和问题
instanceof 主要的作用就是判断一个实例是否属于某种类型
let person = function () {};
let nicole = new person();
nicole instanceof person; // true
当然,instanceof 也可以判断一个实例是否是其父类型或者祖先类型的实例。
let person = function () {};
let programmer = function () {};
programmer.prototype = new person();
let nicole = new programmer();
nicole instanceof person; // true
nicole instanceof programmer; // true
实现原理
function new_instance_of(leftVaule, rightVaule) {
let rightProto = rightVaule.prototype; // 取右表达式的 prototype 值
leftVaule = leftVaule.__proto__; // 取左表达式的__proto__值
while (true) {
if (leftVaule === null) {
return false;
}
if (leftVaule === rightProto) {
return true;
}
leftVaule = leftVaule.__proto__;
}
}
看几个特殊的例子
function Foo() {}
Object instanceof Object; // true
Function instanceof Function; // true
Function instanceof Object; // true
Foo instanceof Foo; // false
Foo instanceof Object; // true
Foo instanceof Function; // true
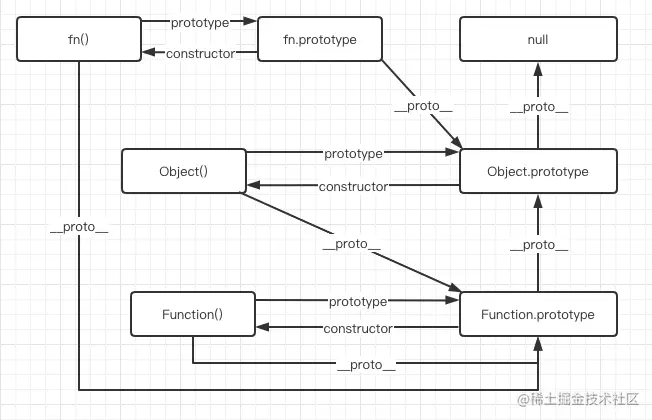
Object instanceof Object由图可知,Object 的
prototype属性是Object.prototype, 而由于 Object 本身是一个函数,由 Function 所创建,所以Object.__proto__的值是Function.prototype,而Function.prototype的__proto__属性是Object.prototype,所以我们可以判断出,Object instanceof Object的结果是 true 。用代码简单的表示一下leftValue = Object.__proto__ = Function.prototype;
rightValue = Object.prototype;
// 第一次判断
leftValue != rightValue;
leftValue = Function.prototype.__proto__ = Object.prototype;
// 第二次判断
leftValue === rightValue;
// 返回 trueFunction instanceof Function和Function instanceof Object的运行过程与Object instanceof Object类似,故不再详说。Foo instanceof FooFoo 函数的
prototype属性是Foo.prototype,而 Foo 的__proto__属性是Function.prototype,由图可知,Foo 的原型链上并没有Foo.prototype,因此Foo instanceof Foo也就返回 false 。我们用代码简单的表示一下
(leftValue = Foo), (rightValue = Foo);
leftValue = Foo.__proto = Function.prototype;
rightValue = Foo.prototype;
// 第一次判断
leftValue != rightValue;
leftValue = Function.prototype.__proto__ = Object.prototype;
// 第二次判断
leftValue != rightValue;
leftValue = Object.prototype = null;
// 第三次判断
leftValue === null;
// 返回 falseFoo instanceof Object(leftValue = Foo), (rightValue = Object);
leftValue = Foo.__proto__ = Function.prototype;
rightValue = Object.prototype;
// 第一次判断
leftValue != rightValue;
leftValue = Function.prototype.__proto__ = Object.prototype;
// 第二次判断
leftValue === rightValue;
// 返回 trueFoo instanceof Function(leftValue = Foo), (rightValue = Function);
leftValue = Foo.__proto__ = Function.prototype;
rightValue = Function.prototype;
// 第一次判断
leftValue === rightValue;
// 返回 true
对象创建和对象继承
1.继承对象方法
类的基础
ES6 的class可以看作只是一个语法糖,它的绝大部分功能,ES5 都可以做到,新的class写法只是让对象原型的写法更加清晰、更像面向对象编程的语法而已
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
toString() {
return "(" + this.x + ", " + this.y + ")";
}
}
上面代码定义了一个“类”,可以看到里面有一个constructor()方法,这就是构造方法,而this关键字则代表实例对象。这种新的 Class 写法,本质上与本章开头的 ES5 的构造函数Point是一致的。
Point类除了构造方法,还定义了一个toString()方法。注意,定义toString()方法的时候,前面不需要加上function这个关键字,直接把函数定义放进去了就可以了。另外,方法与方法之间不需要逗号分隔,加了会报错。
ES6 的类,完全可以看作构造函数的另一种写法。
class Point {
// ...
}
typeof Point; // "function"
Point === Point.prototype.constructor; // true
上面代码表明,类的数据类型就是函数,类本身就指向构造函数。
使用的时候,也是直接对类使用new命令,跟构造函数的用法完全一致。
class Bar {
doStuff() {
console.log("stuff");
}
}
const b = new Bar();
b.doStuff(); // "stuff"
构造函数的prototype属性,在 ES6 的“类”上面继续存在。事实上,类的所有方法都定义在类的prototype属性上面。
class Point {
constructor() {
// ...
}
toString() {
// ...
}
toValue() {
// ...
}
}
// 等同于
Point.prototype = {
constructor() {},
toString() {},
toValue() {},
};
上面代码中,constructor()、toString()、toValue()这三个方法,其实都是定义在Point.prototype上面。
因此,在类的实例上面调用方法,其实就是调用原型上的方法。
class B {}
const b = new B();
b.constructor === B.prototype.constructor; // true
上面代码中,b是B类的实例,它的constructor()方法就是B类原型的constructor()方法。
由于类的方法都定义在prototype对象上面,所以类的新方法可以添加在prototype对象上面。Object.assign()方法可以很方便地一次向类添加多个方法。
class Point {
constructor() {
// ...
}
}
Object.assign(Point.prototype, {
toString() {},
toValue() {},
});
prototype对象的constructor()属性,直接指向“类”的本身,这与 ES5 的行为是一致的。
Point.prototype.constructor === Point; // true
另外,类的内部所有定义的方法,都是不可枚举的(non-enumerable)。
class Point {
constructor(x, y) {
// ...
}
toString() {
// ...
}
}
Object.keys(Point.prototype);
// []
Object.getOwnPropertyNames(Point.prototype);
// ["constructor","toString"]
上面代码中,toString()方法是Point类内部定义的方法,它是不可枚举的。这一点与 ES5 的行为不一致。
var Point = function (x, y) {
// ...
};
Point.prototype.toString = function () {
// ...
};
Object.keys(Point.prototype)
// ["toString"]
Object.getOwnPropertyNames(Point.prototype)
// ["constructor","toString"]
上面代码采用 ES5 的写法,toString()方法就是可枚举的。
constructor 方法
constructor()方法是类的默认方法,通过new命令生成对象实例时,自动调用该方法。一个类必须有constructor()方法,如果没有显式定义,一个空的constructor()方法会被默认添加。
class Point {}
// 等同于
class Point {
constructor() {}
}
上面代码中,定义了一个空的类Point,JavaScript 引擎会自动为它添加一个空的constructor()方法。
constructor()方法默认返回实例对象(即this),完全可以指定返回另外一个对象。
class Foo {
constructor() {
return Object.create(null);
}
}
new Foo() instanceof Foo;
// false
上面代码中,constructor()函数返回一个全新的对象,结果导致实例对象不是Foo类的实例。
类必须使用new调用,否则会报错。这是它跟普通构造函数的一个主要区别,后者不用new也可以执行。
class Foo {
constructor() {
return Object.create(null);
}
}
Foo();
// TypeError: Class constructor Foo cannot be invoked without 'new'
毫无疑问的,class 机制还是在 prototype 的基础之上进行封装的 ——contructor 执行构造函数相关赋值 ——使用 Object.defineProperty()方法 将方法添加的构造函数的原型上或构造函数上 ——使用 Object.create() 和 Object.setPrototypeOf 实现类之间的继承 子类原型proto指向父类原型 子类构造函数proto指向父类构造函数 ——通过变更子类的 this 作用域实现 super()
一、原型链继承
将父类的实例作为子类的原型
function Parent() {
this.isShow = true;
this.info = {
name: "yhd",
age: 18,
};
}
Parent.prototype.getInfo = function () {
console.log(this.info);
console.log(this.isShow); // true
};
function Child() {}
Child.prototype = new Parent();
let Child1 = new Child();
Child1.info.gender = "男";
Child1.getInfo(); // {name: "yhd", age: 18, gender: "男"}
let child2 = new Child();
child2.getInfo(); // {name: "yhd", age: 18, gender: "男"}
child2.isShow = false;
console.log(child2.isShow); // false
优点:
1、父类方法可以复用
缺点:
- 父类的所有
引用属性(info)会被所有子类共享,更改一个子类的引用属性,其他子类也会受影响- 子类型实例不能给父类型构造函数传参
二、构造函数继承
在子类构造函数中调用父类构造函数,可以在子类构造函数中使用
call()和apply()方法
function Parent() {
this.info = {
name: "yhd",
age: 19,
};
}
function Child() {
Parent.call(this);
}
let child1 = new Child();
child1.info.gender = "男";
console.log(child1.info); // {name: "yhd", age: 19, gender: "男"};
let child2 = new Child();
console.log(child2.info); // {name: "yhd", age: 19}
通过使用call()或apply()方法,Parent构造函数在为Child的实例创建的新对象的上下文执行了,就相当于新的Child实例对象上运行了Parent()函数中的所有初始化代码,结果就是每个实例都有自己的info属性。
1、传递参数
相比于原型链继承,盗用构造函数的一个优点在于可以在子类构造函数中像父类构造函数传递参数。
function Parent(name) {
this.info = { name: name };
}
function Child(name) {
//继承自Parent,并传参
Parent.call(this, name);
//实例属性
this.age = 18;
}
let child1 = new Child("yhd");
console.log(child1.info.name); // "yhd"
console.log(child1.age); // 18
let child2 = new Child("wxb");
console.log(child2.info.name); // "wxb"
console.log(child2.age); // 18
在上面例子中,Parent构造函数接收一个name参数,并将他赋值给一个属性,在Child构造函数中调用Parent构造函数时传入这个参数, 实际上会在Child实例上定义name属性。为确保Parent构造函数不会覆盖Child定义的属性,可以在调用父类构造函数之后再给子类实例添加额外的属性
优点:
- 可以在子类构造函数中向父类传参数
- 父类的引用属性不会被共享
缺点:
- 子类不能访问父类原型上定义的方法(即不能访问 Parent.prototype 上定义的方法),因此所有方法属性都写在构造函数中,每次创建实例都会初始化
三、组合继承
组合继承综合了
原型链继承和构造函数继承,将两者的优点结合了起来,基本的思路就是使用原型链继承原型上的属性和方法,而通过构造函数继承实例属性,这样既可以把方法定义在原型上以实现重用,又可以让每个实例都有自己的属性
function Parent(name) {
this.name = name;
this.colors = ["red", "blue", "yellow"];
}
Parent.prototype.sayName = function () {
console.log(this.name);
};
function Child(name, age) {
// 继承父类属性
Parent.call(this, name);
this.age = age;
}
// 继承父类方法
Child.prototype = new Parent();
Child.prototype.sayAge = function () {
console.log(this.age);
};
let child1 = new Child("yhd", 19);
child1.colors.push("pink");
console.log(child1.colors); // ["red", "blue", "yellow", "pink"]
child1.sayAge(); // 19
child1.sayName(); // "yhd"
let child2 = new Child("wxb", 30);
console.log(child2.colors); // ["red", "blue", "yellow"]
child2.sayAge(); // 30
child2.sayName(); // "wxb"
上面例子中,Parent构造函数定义了name,colors两个属性,接着又在他的原型上添加了个sayName()方法。Child构造函数内部调用了Parent构造函数,同时传入了name参数,同时Child.prototype也被赋值为Parent实例,然后又在他的原型上添加了个sayAge()方法。这样就可以创建 child1,child2两个实例,让这两个实例都有自己的属性,包括colors,同时还共享了父类的sayName方法
优点:
- 父类的方法可以复用
- 可以在 Child 构造函数中向 Parent 构造函数中传参
- 父类构造函数中的引用属性不会被共享
四、原型式继承
对参数对象的一种浅复制
function objectCopy(obj) {
function Fun() {}
Fun.prototype = obj;
return new Fun();
}
let person = {
name: "yhd",
age: 18,
friends: ["jack", "tom", "rose"],
sayName: function () {
console.log(this.name);
},
};
let person1 = objectCopy(person);
person1.name = "wxb";
person1.friends.push("lily");
person1.sayName(); // wxb
let person2 = objectCopy(person);
person2.name = "gsr";
person2.friends.push("kobe");
person2.sayName(); // "gsr"
console.log(person.friends); // ["jack", "tom", "rose", "lily", "kobe"]
优点:
- 父类方法可复用
缺点:
- 父类的引用会被所有子类所共享
- 子类实例不能向父类传参
ES5 的 Object.create()方法在只有第一个参数时,与这里的 objectCopy()方法效果相同
五、寄生式继承
使用原型式继承对一个目标对象进行浅复制,增强这个浅复制的能力
function objectCopy(obj) {
function Fun() {}
Fun.prototype = obj;
return new Fun();
}
function createAnother(original) {
let clone = objectCopy(original);
clone.getName = function () {
console.log(this.name);
};
return clone;
}
let person = {
name: "yhd",
friends: ["rose", "tom", "jack"],
};
let person1 = createAnother(person);
person1.friends.push("lily");
console.log(person1.friends);
person1.getName(); // yhd
let person2 = createAnother(person);
console.log(person2.friends); // ["rose", "tom", "jack", "lily"]
六、寄生式组合继承
function objectCopy(obj) {
function Fun() {}
Fun.prototype = obj;
return new Fun();
}
function inheritPrototype(child, parent) {
let prototype = objectCopy(parent.prototype); // 创建对象
prototype.constructor = child; // 增强对象
Child.prototype = prototype; // 赋值对象
}
function Parent(name) {
this.name = name;
this.friends = ["rose", "lily", "tom"];
}
Parent.prototype.sayName = function () {
console.log(this.name);
};
function Child(name, age) {
Parent.call(this, name);
this.age = age;
}
inheritPrototype(Child, Parent);
Child.prototype.sayAge = function () {
console.log(this.age);
};
let child1 = new Child("yhd", 23);
child1.sayAge(); // 23
child1.sayName(); // yhd
child1.friends.push("jack");
console.log(child1.friends); // ["rose", "lily", "tom", "jack"]
let child2 = new Child("yl", 22);
child2.sayAge(); // 22
child2.sayName(); // yl
console.log(child2.friends); // ["rose", "lily", "tom"]
优点:
- 只调用一次父类构造函数
- Child 可以向 Parent 传参
- 父类方法可以复用
- 父类的引用属性不会被共享
寄生式组合继承可以算是引用类型继承的最佳模式
2.创建对象方法
首先解释几个概念:
- 对象 下面例子中所有的 Person 函数
- 实例/对象实例 通过
new Person()orPerson()返回的对象,如var person1 = new Person()中的 person1- 原型对象
Person.prototype
工厂模式
function Person() {
var o = new Object();
o.name = "hanmeimei";
o.say = function () {
alert(this.name);
};
return o;
}
var person1 = Person();
优点:完成了返回一个对象的要求。
缺点:
- 无法通过 constructor 识别对象,以为都是来自 Object,无法得知来自 Person
- 每次通过 Person 创建对象的时候,所有的 say 方法都是一样的,但是却存储了多次,浪费资源。
构造函数模式
function Person() {
this.name = "hanmeimei";
this.say = function () {
alert(this.name);
};
}
var person1 = new Person();
优点:
- 通过 constructor 或者 instanceof 可以识别对象实例的类别
- 可以通过 new 关键字来创建对象实例,更像 OO 语言中创建对象实例
缺点:
- 多个实例的 say 方法都是实现一样的效果,但是却存储了很多次(两个对象实例的 say 方法是不同的,因为存放的地址不同)
注意:
- 构造函数模式隐试的在最后返回
return this所以在缺少 new 的情况下,会将属性和方法添加给全局对象,浏览器端就会添加给 window 对象。 - 也可以根据
return this的特性调用 call 或者 apply 指定 this。这一点在后面的继承有很大帮助。
原型模式
function Person() {}
Person.prototype.name = "hanmeimei";
Person.prototype.say = function () {
alert(this.name);
};
Person.prototype.friends = ["lilei"];
var person1 = new Person();
优点:
say 方法是共享的了,所有的实例的 say 方法都指向同一个。
可以动态的添加原型对象的方法和属性,并直接反映在对象实例上。
var person1 = new Person();
Person.prototype.showFriends = function () {
console.log(this.friends);
};
person1.showFriends(); //['lilei']
缺点:
出现引用的情况下会出现问题具体见下面代码:
var person1 = new Person();
var person2 = new Person();
person1.friends.push('xiaoming');
console.log(person2.friends) //['lilei', 'xiaoming']因为 js 对引用类型的赋值都是将地址存储在变量中,所以 person1 和 person2 的 friends 属性指向的是同一块存储区域。
第一次调用 say 方法或者 name 属性的时候会搜索两次,第一次是在实例上寻找 say 方法,没有找到就去原型对象(Person.prototype)上找 say 方法,找到后就会在实力上添加这些方法 or 属性。
所有的方法都是共享的,没有办法创建实例自己的属性和方法,也没有办法像构造函数那样传递参数。
注意:
优点 ② 中存在一个问题就是直接通过对象字面量给
Person.prototype进行赋值的时候会导致constructor改变,所以需要手动设置,其次就是通过对象字面量给Person.prototype进行赋值,会无法作用在之前创建的对象实例上var person1 = new Person();
Person.prototype = {
name: "hanmeimei2",
setName: function (name) {
this.name = name;
},
};
person1.setName(); //Uncaught TypeError: person1.set is not a function(…)这是因为对象实例和对象原型直接是通过一个指针链接的,这个指针是一个内部属性[[Prototype]],可以通过
__proto__访问。我们通过对象字面量修改了 Person.prototype 指向的地址,然而对象实例的__proto__,并没有跟着一起更新,所以这就导致,实例还访问着原来的Person.prototype,所以建议不要通过这种方式去改变Person.prototype属性
构造函数和原型组合模式
function Person(name) {
this.name = name;
this.friends = ["lilei"];
}
Person.prototype.say = function () {
console.log(this.name);
};
var person1 = new Person("hanmeimei");
person1.say(); //hanmeimei
优点:
- 解决了原型模式对于引用对象的缺点
- 解决了原型模式没有办法传递参数的缺点
- 解决了构造函数模式不能共享方法的缺点
缺点:
- 和原型模式中注意 ① 一样
动态原型模式
function Person(name) {
this.name = name
if(typeof this.say != 'function') {
Person.prototype.say = function(
alert(this.name)
}
}
优点:
- 可以在初次调用构造函数的时候就完成原型对象的修改
- 修改能体现在所有的实例中
缺点:红宝书都说这个方案完美了。。。。
注意:
- 只用检查一个在执行后应该存在的方法或者属性就行了
- 不能用对象字面量修改原型对象
寄生构造函数模式
function Person(name) {
var o = new Object();
o.name = name;
o.say = function () {
alert(this.name);
};
return o;
}
var peron1 = new Person("hanmeimei");
优点:
- 和工厂模式基本一样,除了多了个 new 操作符
缺点:
- 和工厂模式一样,不能区分实例的类别
稳妥构造模式
function Person(name) {
var o = new Object();
o.say = function () {
alert(name);
};
}
var person1 = new Person("hanmeimei");
person1.name; // undefined
person1.say(); //hanmeimei
优点:
- 安全,那么好像成为了私有变量,只能通过 say 方法去访问
缺点:
- 不能区分实例的类别
异步编程
1.promise 的出现解决了什么问题
Promise 是异步编程的一种解决方案: 从语法上讲,promise 是一个对象,从它可以获取异步操作的消息;从本意上讲,它是承诺,承诺它过一段时间会给你一个结果。 promise 有三种状态:pending(等待态),fulfiled(成功态),rejected(失败态);状态一旦改变,就不会再变。创造 promise 实例后,它会立即执行。
一个异步请求套着一个异步请求,一个异步请求依赖于另一个的执行结果,使用回调的方式相互嵌套
缺点
- 嵌套函数存在耦合性,一旦有所改动,就会牵一发而动全身
- 嵌套函数一多,就很难处理错误
当然,回调函数还存在着别的几个缺点,比如不能使用 try catch 捕获错误,不能直接 return。
从表面上看,Promise 只是能够简化层层回调的写法,而实质上 Promise 的精髓是“状态”,用维护状态、传递状态的方式来使得回调函数能够及时调用,它比传递 callback 函数要简单、灵活的多
通过 Promise 这种方式很好的解决了回调地狱问题,使得异步过程同步化,让代码的整体逻辑与大脑的思维逻辑一致,减少出错率。
promise 和 async await 区别
- 首先说说两者的概念
- Promise Promise 是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大,简单地说,Promise 好比容器,里面存放着一些未来才会执行完毕(异步)的事件的结果,而这些结果一旦生成是无法改变的
- async await async await 也是异步编程的一种解决方案,他遵循的是 Generator 函数的语法糖,他拥有内置执行器,不需要额外的调用直接会自动执行并输出结果,它返回的是一个 Promise 对象。
- 两者的区别
- Promise 的出现解决了传统 callback 函数导致的“地域回调”问题,但它的语法导致了它向纵向发展行成了一个回调链,遇到复杂的业务场景,这样的语法显然也是不美观的。而 async await 代码看起来会简洁些,使得异步代码看起来像同步代码,await 的本质是可以提供等同于”同步效果“的等待异步返回能力的语法糖,只有这一句代码执行完,才会执行下一句。
- async await 与 Promise 一样,是非阻塞的。
- async await 是基于 Promise 实现的,可以说是改良版的 Promise,它不能用于普通的回调函数。
简单来看,这两者除了语法糖不一样外,他们解决的问题、达到的效果是大同小异的,我们可以在不同的应用场景,根据自己的喜好来选择使用
使用 async 函数可以让代码简洁很多,不需要像 Promise 一样需要 then,不需要写匿名函数处理 Promise 的 resolve 的值,也不需要定义多余的 data 变量,还避免了嵌套代码。
async/await 让 try/catch 可以同时处理同步和异步的错误。比如,try/catch 不能处理 JSON.parse 的错误,因为它在 Promise 中,我们需要使用.catch,这样的错误会显得代码非常的冗余
2.promise 的方法和注意的问题
方法
- Promise.resolve(value)
类方法,该方法返回一个以 value 值解析后的 Promise 对象 1、如果这个值是个 thenable(即带有 then 方法),返回的 Promise 对象会“跟随”这个 thenable 的对象,采用它的最终状态(指 resolved/rejected/pending/settled) 2、如果传入的 value 本身就是 Promise 对象,则该对象作为 Promise.resolve 方法的返回值返回。 3、其他情况以该值为成功状态返回一个 Promise 对象。
- Promise.reject
类方法,且与 resolve 唯一的不同是,返回的 promise 对象的状态为 rejected。
- Promise.prototype.then
实例方法,为 Promise 注册回调函数,函数形式:fn(vlaue){},value 是上一个任务的返回结果,then 中的函数一定要 return 一个结果或者一个新的 Promise 对象,才可以让之后的 then 回调接收。
console.log(Promise.resolve().then())
then 内部默认 return Promise.resolve(undefined);
- Promise.prototype.catch
实例方法,捕获异常,函数形式:fn(err){}, err 是 catch 注册 之前的回调抛出的异常信息。
- Promise.prototype.finally()
实例方法 在 promise 结束时,无论结果是 fulfilled 或者是 rejected,都会执行指定的回调函数。这为在
Promise是否成功完成后都需要执行的代码提供了一种方式。这避免了同样的语句需要在
then()和catch()中各写一次的情况
- Promise.race
类方法,多个 Promise 任务同时执行,返回最先执行结束的 Promise 任务的结果,不管这个 Promise 结果是成功还是失败。 。
- Promise.all
类方法,多个 Promise 任务同时执行。 如果全部成功执行,则以数组的方式返回所有 Promise 任务的执行结果。 如果有一个 Promise 任务 rejected,则只返回 rejected 任务的结果。
- Promise.allSettled
类方法
返回一个在所有给定的 promise 都已经
fulfilled或rejected后的 promise,并带有一个对象数组,每个对象表示对应的 promise 结果。当您有多个彼此不依赖的异步任务成功完成时,或者您总是想知道每个
promise的结果时,通常使用它
- Promise.any
类方法,Promise.any()接收一个 Promise 可迭代对象,只要其中的一个
promise成功,就返回那个已经成功的promise。如果可迭代对象中没有一个promise成功(即所有的promises都失败/拒绝),就返回一个失败的 promise
注意的问题
Promise的状态一经改变就不能再改变。.then和.catch都会返回一个新的Promise。catch不管被连接到哪里,都能捕获上层未捕捉过的错误。- 在
Promise中,返回任意一个非promise的值都会被包裹成promise对象,例如return 2会被包装为return Promise.resolve(2)。 Promise的.then或者.catch可以被调用多次, 但如果Promise内部的状态一经改变,并且有了一个值,那么后续每次调用.then或者.catch的时候都会直接拿到该值。.then或者.catch中return一个error对象并不会抛出错误,所以不会被后续的.catch捕获。返回任意一个非promise的值都会被包裹成promise对象
抛出错误可以选择
return Promise.reject(new Error("error!!!"));
// or
throw new Error("error!!!");
.then或.catch返回的值不能是 promise 本身,否则会造成死循环。.then或者.catch的参数期望是函数,传入非函数则会发生值透传。.then方法是能接收两个参数的,第一个是处理成功的函数,第二个是处理失败的函数,再某些时候你可以认为catch是.then第二个参数的简便写法。.finally方法也是返回一个Promise,他在Promise结束的时候,无论结果为resolved还是rejected,都会执行里面的回调函数。
链式调用原理
function Promise(fn) {
this.cbs = [];
const resolve = (value) => {
setTimeout(() => {
this.data = value;
this.cbs.forEach((cb) => cb(value));
});
};
fn(resolve);
}
Promise.prototype.then = function (onResolved) {
return new Promise((resolve) => {
this.cbs.push(() => {
const res = onResolved(this.data);
if (res instanceof Promise) {
res.then(resolve);
} else {
resolve(res);
}
});
});
};
案例
new Promise((resolve) => {
setTimeout(() => {
resolve(1);
}, 500);
})
.then((res) => {
console.log(res);
return new Promise((resolve) => {
setTimeout(() => {
resolve(2);
}, 500);
});
})
.then(console.log);
//500ms 后输出 1
//500ms 后输出 2
构造函数
首先来实现 Promise 构造函数
function Promise(fn) {
// Promise resolve时的回调函数集
this.cbs = [];
// 传递给Promise处理函数的resolve
// 这里直接往实例上挂个data
// 然后把onResolvedCallback数组里的函数依次执行一遍就可以
const resolve = (value) => {
// 注意promise的then函数需要异步执行
setTimeout(() => {
this.data = value;
this.cbs.forEach((cb) => cb(value));
});
};
// 执行用户传入的函数
// 并且把resolve方法交给用户执行
fn(resolve);
}
好,写到这里先回过头来看案例
const fn = (resolve) => {
setTimeout(() => {
resolve(1);
}, 500);
};
new Promise(fn);
分开来看,fn 就是用户传的函数,这个函数内部调用了 resolve 函数后,就会把 promise 实例上的 cbs 全部执行一遍。
到此为止我们还不知道 cbs 这个数组里的函数是从哪里来的
最重要的 then 实现,链式调用全靠它:
Promise.prototype.then = function (onResolved) {
// 这里叫做promise2
return new Promise((resolve) => {
this.cbs.push(() => {
const res = onResolved(this.data);
if (res instanceof Promise) {
// resolve的权力被交给了user promise
res.then(resolve);
} else {
// 如果是普通值 就直接resolve
// 依次执行cbs里的函数 并且把值传递给cbs
resolve(res);
}
});
});
};
再回到案例里
const fn = (resolve) => {
setTimeout(() => {
resolve(1);
}, 500);
};
const promise1 = new Promise(fn);
promise1.then((res) => {
console.log(res);
// user promise
return new Promise((resolve) => {
setTimeout(() => {
resolve(2);
}, 500);
});
});
注意这里的命名:
- 我们把
new Promise返回的实例叫做promise1 - 在
Promise.prototype.then的实现中,我们构造了一个新的 promise 返回,叫它promise2 - 在用户调用
then方法的时候,用户手动构造了一个 promise 并且返回,用来做异步的操作,叫它user promise
那么在 then 的实现中,内部的 this 其实就指向promise1
而promise2的传入的fn 函数执行了一个 this.cbs.push(),其实是往 promise1 的cbs数组中 push 了一个函数,等待后续执行。
Promise.prototype.then = function (onResolved) {
// 这里叫做promise2
return new Promise((resolve) => {
// 这里的this其实是promise1
this.cbs.push(() => {});
});
};
那么重点看这个 push 的函数,注意,这个函数在 promise1 被 resolve 了以后才会执行。
// promise2
return new Promise((resolve) => {
this.cbs.push(() => {
// onResolved就对应then传入的函数
const res = onResolved(this.data);
// 例子中的情况 用户自己返回了一个user promise
if (res instanceof Promise) {
// user promise的情况
// 用户会自己决定何时resolve promise2
// 只有promise2被resolve以后
// then下面的链式调用函数才会继续执行
res.then(resolve);
} else {
resolve(res);
}
});
});
如果用户传入给 then 的 onResolved 方法返回的是个 user promise,那么这个user promise里用户会自己去在合适的时机 resolve promise2,那么进而这里的 res.then(resolve) 中的 resolve 就会被执行:
if (res instanceof Promise) {
res.then(resolve);
}
结合下面这个例子来看:
new Promise((resolve) => {
setTimeout(() => {
// resolve1
resolve(1);
}, 500);
})
// then1
.then((res) => {
console.log(res);
// user promise
return new Promise((resolve) => {
setTimeout(() => {
// resolve2
resolve(2);
}, 500);
});
})
// then2
.then(console.log);
then1这一整块其实返回的是 promise2,那么 then2 其实本质上是 promise2.then(console.log),
也就是说 then2注册的回调函数,其实进入了promise2的 cbs 回调数组里,又因为我们刚刚知道,resolve2 调用了之后,user promise 会被 resolve,进而触发 promise2 被 resolve,进而 promise2 里的 cbs 数组被依次触发。
这样就实现了用户自己写的 resolve2 执行完毕后,then2 里的逻辑才会继续执行,也就是异步链式调用。
3.async 和 await 特点和用法
特点
async 函数是 Generator 函数的语法糖。使用 关键字 async 来表示,在函数内部使用 await 来表示异步。相较于 Generator,async 函数的改进在于下面四点:
- 内置执行器。
Generator函数的执行必须依靠执行器,而async函数自带执行器,调用方式跟普通函数的调用一样 - 更好的语义。
async和await相较于*和yield更加语义化 - 更广的适用性。
co模块约定,yield命令后面只能是 Thunk 函数或 Promise 对象。而async函数的await命令后面则可以是 Promise 或者 原始类型的值(Number,string,boolean,但这时等同于同步操作) - 返回值是 Promise。
async函数返回值是 Promise 对象,比 Generator 函数返回的 Iterator 对象方便,可以直接使用then()方法进行调用
async 函数,就是 Generator 函数的语法糖。
它有以下几个特点:
- 建立在 promise 之上。所以,不能把它和回调函数搭配使用。但它会声明一个异步函数,并隐式地返回一个 Promise。因此可以直接 return 变量,无需使用 Promise.resolve 进行转换。
- 和 promise 一样,是非阻塞的。但不用写 then 及其回调函数,这减少代码行数,也避免了代码嵌套。而且,所有异步调用,可以写在同一个代码块中,无需定义多余的中间变量。
- 它的最大价值在于,可以使异步代码,在形式上,更接近于同步代码。
- 它总是与 await 一起使用的。并且,await 只能在 async 函数体内。
- await 是个运算符,用于组成表达式,它会阻塞后面
await意思是 async wait(异步等待)。这个关键字只能在使用async定义的函数里面使用。任何async函数都会默认返回promise,并且这个promise解析的值都将会是这个函数的返回值,而async函数必须等到内部所有的 await 命令的 Promise 对象执行完,才会发生状态改变。
必须等所有await 函数执行完毕后,才会告诉promise我成功了还是失败了,执行then或者catch
很多人以为
await会一直等待之后的表达式执行完之后才会继续执行后面的代码,实际上await是一个让出线程的标志。await后面的函数会先执行一遍(比如 await Fn()的 Fn ,并非是下一行代码),然后就会跳出整个async函数来执行后面 js 栈的代码。等本轮事件循环执行完了之后又会跳回到async函数中等待 await 后面表达式的返回值,如果返回值为非promise则继续执行async函数后面的代码,否则将返回的promise放入Promise队列(Promise 的 Job Queue)
async 做了什么
带 async 关键字的函数,它使得函数的返回值必是 promise 对象 如果 async 关键字函数返回的不是 promise,会自动用 Promise.resolve() 包装 如果 async 关键字函数显式的返回 promise,以你返回的 promise 为准
async 函数一定会返回一个 promise 对象。如果一个 async 函数的返回值看起来不是 promise,那么它将会被隐式地包装在一个 promise 中
async function fn1() {
return 123;
}
function fn2() {
return 123;
}
console.log(fn1()); // Promise {<resolved>: 123}
console.log(fn2()); // 123
用 Promise.resolve() 包装
async function fn1() {
return 123; //不返回 则是undefined
}
let promise = fn1();
promise.then((res) => {
console.log(res);
});
//123
async function fn1() {
throw new Error("error6666");
}
let promise = fn1();
promise.catch((err) => {
console.log("999", err);
});
//999 Error: error6666
以返回的 promise 为准
async function fn1() {
return new Promise((resolve, reject) => {
resolve(123);
});
}
let promise = fn1();
promise.then((res) => {
console.log(res);
});
//123
async 函数中 return 值如何接受
通过 promise.then-cb 形参获取
async function foo() {
console.log(222222);
return 123;
}
let res = foo();
res.then((data) => {
console.log(data); //123
});
第二种接受函数返回值的方式是 await
(async function () {
console.log("async run");
//第二种接受函数返回值的方式是 await
let res = await foo();
console.log(res);
})();
async function foo() {
console.log("foo run");
return 123;
}
//res作用:接受 async foo函数返回值 是promise
let res = foo();
promiseValue
[[PromiseValue]]是个内部变量,外部无法得到,只能在 then 中获取。
[promiseValue]哪些能赋值
- async 函数的 return
- new promise 中 resolve 实参
- then 中 return (catch finally 中的 return)
- promise.reslove()实参 promise.reject()实参
await 等的是右侧 [表达式] 的结果
await 关键字的作用 就是获取 Promise 中返回的内容, 获取的是 Promise 函数中 resolve 或者 reject 的值(await 作用是获取 promise.[[promiseValue]]的值)
关于 await 的注意点
- await 必须写在 async 中
- await 后是一个 promise 实例对象
async function async1() {
await async2()
console.log( 'async1 end' )
}
async function async2() {
console.log( 'async2' )
}
async1()
console.log( 'script start' )
async2
script start
async1 end
也就是遇到 await 后,阻塞的是 await 当前行之后的代码
let b=await async2() b 拿到的是 async2 的返回的 promise 的 resolve 的值
await 需要等待结果 然后跳出函数 执行外面的代码 然后 resolve 之后再去执行 await 后面的代码
async queryTextbookRes() {
//正常的请求过程就相当于new Promise后面
const data= await new Promise((resolve)=>{
setTimeout(()=>{
let result = []
resolve(result)
},2000)
})
return data
}
async queryTextbookRes() {
return await new Promise((resolve)=>{
setTimeout(()=>{
let result = []
resolve(result)
},2000)
})
}
async queryTextbookRes() {
return new Promise((resolve)=>{
setTimeout(()=>{
let result = []
resolve(result)
},2000)
})
}
this.queryTextbookRes().then((res) => {
resolveres(res);
});
await 实际上相当于过一段时间 resolve(value) 返回 value
await 接受普通值 会直接返回
await 接受 new Promise 或者 promise 对象 会返回 resoLve 的值
也 await 可以接受一个函数 函数返回的是一个 promise
- 当 await 接收的值非 Promise 对象时,它会将返回值包装成 Promise.then(返回值)将值和恢复执行的消息一起添加到消息队列中;
- 如果是 Promise 对象,先添加到消息队列,等待可用值;等有可用值后再把恢复执行的消息添加到消息队列;有两个添加到消息队列的操作。
(async () => {
console.log(1);
setTimeout(() => {
console.log(2);
});
await new Promise((resolve, reject) => {
console.log(3);
resolve();
}).then(() => {
console.log(4);
});
console.log(5);
})();
//1 3 4 5 2
这个 4 在 5 之前就很好得说明了 await 会阻塞后面的代码
await 等到之后,做了什么事情
右侧表达式的结果,就是 await 要等的东西 等待的就是 async 的返回值 等到之后,对 await 来说,分 2 种情况
- 不是 promise 对象
- 是 promise 对象
如果不是 promise,await 会阻塞后面的代码,先执行 async 外面的同步代码,同步代码执行完,再回到 async 内部,把这个非 promise 的东西,作为 await 表达式的结果
如果它等到的是一个 promise 对象,await 也会暂停 async 后面的代码,先执行 async 外面的同步代码,等着 Promise 对象 fulfilled,然后把 resolve 的参数作为 await 表达式的运算结果
async function async1() {
console.log("async1 start");
await async2();
console.log("async1 end");
}
async function async2() {
console.log("async2");
}
console.log("script start");
setTimeout(function () {
console.log("setTimeout");
}, 0);
async1();
new Promise(function (resolve) {
console.log("promise1");
resolve();
}).then(function () {
console.log("promise2");
});
console.log("script end");
执行顺序:
同步代码 console.log( ‘script start’ ) 将 setTimeout 放入宏任务队列 执行 async1() 函数 console.log( ‘async1 start’ ) 分析下 await async2() 先得到 await 右侧表达式的结果. 执行 async2() ,打印同步代码
console.log( ‘async2’ ),并且 return Promise.resolve(undefined); await 后,中断 async 函数,先执行 async 外的同步代码 被阻塞后,执行 async 之外的代码 执行 new Promise(), console.log( ‘promise1’ ) promise.then(),发现这个是微任务,所以暂时不打印,只是推入当前宏任务的微任务队列中。 打印同步代码 console.log( ‘script end’ ) 执行完同步代码后,执行 await Promise.resolve(undefined) 了,类似于 Promise.resolve(undefined) .then((undefined) => { }) 微任务队列,先进先出原则:
Promise.resolve(undefined),语句结束后,后面的代码不再被阻塞,所以打印 console.log( ‘async1 end’ )
然后 console.log( ‘promise2’ )
宏任务队列,console.log(‘setTimeout’)
4.async/await 原理和捕获异常
JavaScript 中的 thunk 函数(译为转换程序)是把带有回调函数的多参数函数转换成只接收回调函数的单参数版本
Generator是一个生成器函数,调用这个函数它并不会立马执行这个函数,而是生成一个遍历器(或者迭代器)对象(Iterator),必须调用这个遍历器对象的next方法才会执行,而且它并不是一次性全部执行完,如果执行过程中遇到了yield关键字函数会暂停,等调用下一个next方法才会恢复执行。
每次执行 generator 函数 thunk 函数的真正作用是统一多参数函数的调用方式,在 next 调用时把控制权交还给 generator,使 generator 函数可以使用递归方式自启动流程,也就是能够跳出再回来的函数,就是生成器函数,生成器有两个特性:1. yield 跳出执行 2. next 继续执行
自动执行器,如果一个 Generator 函数没有执行完,则递归调用需要启动器让生成器函数执行,如果自己写启动器比较麻烦,可以利用 co 函数, co 函数库 是一个 generator 函数的自启动执行器,使用条件是 generator 函数的 yield 命令后面,只能是 thunk 函数或 Promise 对象,co 函数执行完返回一个 Promise 对象 vv 一句话,async、await 是 co 库的官方实现。也可以看作自带启动器的 generator 函数的语法糖。不同的是,async、await 只支持 Promise 和原始类型的值,不支持 thunk 函数。
async 函数返回的是一个Promise对象,如果函数中有返回值。则通过Promise.resole()封装成Promise对象,当然我们就可以使用then()就可以取出这个值。async只能配套和await使用,单独使用就会报错。
async function foo() {
let bar = await test();
}
await 后面接受一个Promise 对象。当Promise对象状态变化的时候,得到返回值。async函数完全可以看作多个异步操作,封装成的一个Promise对象,而await就是内部then命令的语法糖,用同步的书写方式实现异步代码。
// 返回一个生成器驱动函数
function generatorToAsync(genFn) {
// 驱动函数的主体
return function () {
const gen = genFn.apply(this, arguments); // gen有可能传参
// async会返回一个Promise
return new Promise((resolve, reject) => {
// 构建递归函数
function go(key, arg) {
// 执行生成器
let res;
try {
res = gen[key](arg);
} catch (error) {
// 生成器执行出错了
return reject(error);
}
const { value, done } = res;
// 执行完,退出(边界条件)
if (done) return resolve(value);
// 未执行完,继续递归
// Promise.resolve(value)用于实现await解析后面Promise的值
return Promise.resolve(value).then(
(val) => go("next", val),
// await后面Promise执行出错了
(err) => go("throw", err)
);
}
go("next");
});
};
}
const asyncFn = generatorToAsync(gen);
asyncFn().then((res) => console.log(res));
如果await后面的异步操作出错,那么等同于 async 函数返回的 Promise 对象被reject。
防止出错的方法就是我们将其放在try/catch代码块中。并且能够捕获异常。
async function fn() {
try {
let a = await Promise.reject("error");
} catch (error) {
console.log(error);
}
}
实现
- 返回的是一个新的函数 先调用 generator 函数 生成迭代器 对应 var gen = testG()
- 返回一个 promise 因为外部是用.then 的方式 或者 await 的方式去使用这个函数的返回值的
- 内部定义一个 step 函数 用来一步一步的跨过 yield 的阻碍,key 有 next 和 throw 两种取值,分别对应了 gen 的 next 和 throw 方法
- arg 参数则是用来把 promise resolve 出来的值交给下一个 yield
- 在 try catch 中 如果报错了 就把 promise 给 reject 掉 外部通过.catch 可以获取到错误
- gen.next() 得到的结果是一个 { value, done } 的结构
- 如果已经完成了 就直接 resolve 这个 promise 这个 done 是在最后一次调用 next 后才会为 true
- 除了最后结束的时候外,每次调用 gen.next(), 其实是返回 { value: Promise, done: false } 的结构
function asyncToGenerator(generatorFunc) {
// 返回的是一个新的函数
return function () {
// 先调用generator函数 生成迭代器
// 对应 var gen = testG()
const gen = generatorFunc.apply(this, arguments);
// 返回一个promise 因为外部是用.then的方式 或者await的方式去使用这个函数的返回值的
// var test = asyncToGenerator(testG)
// test().then(res => console.log(res))
return new Promise((resolve, reject) => {
// 内部定义一个step函数 用来一步一步的跨过yield的阻碍
// key有next和throw两种取值,分别对应了gen的next和throw方法
// arg参数则是用来把promise resolve出来的值交给下一个yield
function step(key, arg) {
let generatorResult;
// 这个方法需要包裹在try catch中
// 如果报错了 就把promise给reject掉 外部通过.catch可以获取到错误
try {
generatorResult = gen[key](arg);
} catch (error) {
return reject(error);
}
// gen.next() 得到的结果是一个 { value, done } 的结构
const { value, done } = generatorResult;
if (done) {
// 如果已经完成了 就直接resolve这个promise
// 这个done是在最后一次调用next后才会为true
// 以本文的例子来说 此时的结果是 { done: true, value: 'success' }
// 这个value也就是generator函数最后的返回值
return resolve(value);
} else {
// 除了最后结束的时候外,每次调用gen.next()
// 其实是返回 { value: Promise, done: false } 的结构,
// 这里要注意的是Promise.resolve可以接受一个promise为参数
// 并且这个promise参数被resolve的时候,这个then才会被调用
return Promise.resolve(
// 这个value对应的是yield后面的promise
value
).then(
// value这个promise被resove的时候,就会执行next
// 并且只要done不是true的时候 就会递归的往下解开promise
// 对应gen.next().value.then(value => {
// gen.next(value).value.then(value2 => {
// gen.next()
//
// // 此时done为true了 整个promise被resolve了
// // 最外部的test().then(res => console.log(res))的then就开始执行了
// })
// })
function onResolve(val) {
step("next", val);
},
// 如果promise被reject了 就再次进入step函数
// 不同的是,这次的try catch中调用的是gen.throw(err)
// 那么自然就被catch到 然后把promise给reject掉啦
function onReject(err) {
step("throw", err);
}
);
}
}
step("next");
});
};
}
5.promisify 实现
在实际的项目需求中,经常会遇到函数需要链式调用的情况
而在 ES6 之前,基本采用的是 callback 回调的形式,
在 ES6 提供了原生 Promise 对象后,可以自己构造一个 Promise 对象来实现需求
function promisify(fn) {
console.log(fn, "fn"); // 保存的是原始函数(add)
return function (...args) {
console.log(...args, "...args"); // 2 6 保存的是调用时的参数
返回promise对象;
return new Promise(function (resolve, reject) {
// 将callback放到参数末尾,并执行callback函数
args.push(function (err, ...arg) {
console.log(...args, "12"); // 2 6 callback,
if (err) {
reject(err);
return;
}
resolve(...arg);
});
fn.apply(null, args);
});
};
}
// 示例
let add = (a, b, callback) => {
let result = a + b;
if (typeof result === "number") {
callback(null, result);
} else {
callback("请输入正确数字");
}
};
const addCall = promisify(add);
addCall(2, 6).then((res) => {
console.log(res);
});
保存原始函数,将 callback 函数添加到参数末尾进行执行,将结果通过 promise 对象返回
function promisify(original) {
function fn(...args) {
return new Promise((resolve, reject) => {
args.push((err, ...values) => {
if (err) {
return reject(err);
}
resolve(values);
});
Reflect.apply(original, this, args);
});
}
return fn;
}
let add = (a, b, callback) => {
let result = a + b;
if (typeof result === "number") {
callback(null, result);
} else {
callback("请输入正确数字");
}
};
const addCall = promisify(add);
async function load() {
try {
const res = await addCall(2, 6);
console.log(res);
} catch (err) {
console.log(err);
}
}
load();
6.异步和同步的理解
单线程
单线程指的是,JavaScript 只在一个线程上运行。也就是说,JavaScript 同时只能执行一个任务,其他任务都必须在后面排队等待。
JavaScript 之所以采用单线程,而不是多线程,跟历史有关系。JavaScript 从诞生起就是单线程,原因是不想让浏览器变得太复杂,因为多线程需要共享资源、且有可能修改彼此的运行结果,对于一种网页脚本语言来说,这就太复杂了。
单线程的好处:
- 实现起来比较简单
- 执行环境相对单纯
单线程的坏处:
- 坏处是只要有一个任务耗时很长,后面的任务都必须排队等着,会拖延整个程序的执行
如果排队是因为计算量大,CPU 忙不过来,倒也算了,但是很多时候 CPU 是闲着的,因为 IO 操作(输入输出)很慢(比如 Ajax 操作从网络读取数据),不得不等着结果出来,再往下执行。JavaScript 语言的设计者意识到,这时 CPU 完全可以不管 IO 操作,挂起处于等待中的任务,先运行排在后面的任务。等到 IO 操作返回了结果,再回过头,把挂起的任务继续执行下去。这种机制就是 JavaScript 内部采用的 “事件循环”机制(Event Loop)。
单线程虽然对 JavaScript 构成了很大的限制,但也因此使它具备了其他语言不具备的优势。如果用得好,JavaScript 程序是不会出现堵塞的,这就是为什么 Node 可以用很少的资源,应付大流量访问的原因。
为了利用多核 CPU 的计算能力,HTML5 提出 Web Worker 标准,允许 JavaScript 脚本创建多个线程,但是子线程完全受主线程控制,且不得操作 DOM。所以,这个新标准并没有改变 JavaScript 单线程的本质。
同步
同步行为对应内存中顺序执行的处理器指令。每条指令都会严格按照它们出现的顺序来执行,而每条指令执行后也能立即获得存储在系统本地(如寄存器或系统内存)的信息。这样的执行流程容易分析程序在执行到代码任意位置时的状态(比如变量的值)。
同步操作的例子可以是执行一次简单的数学计算:
let xhs = 3;
xhs = xhs + 4;
在程序执行的每一步,都可以推断出程序的状态。这是因为后面的指令总是在前面的指令完成后才会执行。等到最后一条指定执行完毕,存储在 xhs 的值就立即可以使用。
首先,操作系统会在栈内存上分配一个存储浮点数值的空间,然后针对这个值做一次数学计算,再把计算结果写回之前分配的内存中。所有这些指令都是在单个线程中按顺序执行的。在低级指令的层面,有充足的工具可以确定系统状态。
异步
异步行为类似于系统中断,即当前进程外部的实体可以触发代码执行。异步操作经常是必要的,因为强制进程等待一个长时间的操作通常是不可行的(同步操作则必须要等)。如果代码要访问一些高延迟的资源,比如向远程服务器发送请求并等待响应,那么就会出现长时间的等待。
异步操作的例子可以是在定时回调中执行一次简单的数学计算:
let xhs = 3;
setTimeout(() => (xhs = xhs + 4), 1000);
这段程序最终与同步代码执行的任务一样,都是把两个数加在一起,但这一次执行线程不知道 xhs 值何时会改变,因为这取决于回调何时从消息队列出列并执行。
异步代码不容易推断。虽然这个例子对应的低级代码最终跟前面的例子没什么区别,但第二个指令块(加操作及赋值操作)是由系统计时器触发的,这会生成一个入队执行的中断。到底什么时候会触发这个中断,这对 JavaScript 运行时来说是一个黑盒,因此实际上无法预知(尽管可以保证这发生在当前线程的同步代码执行之后,否则回调都没有机会出列被执行)。无论如何,在排定回调以后基本没办法知道系统状态何时变化。
为了让后续代码能够使用 xhs ,异步执行的函数需要在更新 xhs 的值以后通知其他代码。如果程序不需要这个值,那么就只管继续执行,不必等待这个结果了。
任务队列和事件循环
JavaScript 运行时,除了一个正在运行的主线程,引擎还提供一个任务队列(task queue),里面是各种需要当前程序处理的异步任务。(实际上,根据异步任务的类型,存在多个任务队列。为了方便理解,这里假设只存在一个队列。)
首先,主线程会去执行所有的同步任务。等到同步任务全部执行完,就会去看任务队列里面的异步任务。如果满足条件,那么异步任务就重新进入主线程开始执行,这时它就变成同步任务了。等到执行完,下一个异步任务再进入主线程开始执行。一旦任务队列清空,程序就结束执行。
异步任务的写法通常是回调函数。一旦异步任务重新进入主线程,就会执行对应的回调函数。如果一个异步任务没有回调函数,就不会进入任务队列,也就是说,不会重新进入主线程,因为没有用回调函数指定下一步的操作。
JavaScript 引擎怎么知道异步任务有没有结果,能不能进入主线程呢?答案就是引擎在不停地检查,一遍又一遍,只要同步任务执行完了,引擎就会去检查那些挂起来的异步任务,是不是可以进入主线程了。这种循环检查的机制,就叫做事件循环(Event Loop)。
7.并发和并行的理解
- 并发是宏观概念,我分别有任务 A 和任务 B,在一段时间内通过任务间的切换完成了这两个任务,这种情况就可以称之为并发。
- 并行是微观概念,假设 CPU 中存在两个核心,那么我就可以同时完成任务 A、B。同时完成多个任务的情况就可以称之为并行。
多核 CPU 可以同时执行多个进程。 扩展了说,单核 CPU 就可以“同时”执行多个进程。
并发 当有多个线程在操作时,如果系统只有一个 CPU,则它根本不可能真正同时进行一个以上的线程,它只能把 CPU 运行时间划分成若干个时间段,再将时间 段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状。.这种方式我们称之为并发(Concurrent)。
并行 当系统有一个以上 CPU 时,则线程的操作有可能非并发。当一个 CPU 执行一个线程时,另一个 CPU 可以执行另一个线程,两个线程互不抢占 CPU 资源,可以同时进行,这种方式我们称之为并行(Parallel)。
区别 并发和并行是即相似又有区别的两个概念,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。在多道程序环境下,并发性是指在一段时间内宏观上有多个程序在同时运行,但在单处理机系统中,每一时刻却仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。倘若在计算机系统中有多个处理机,则这些可以并发执行的程序便可被分配到多个处理机上,实现并行执行,即利用每个处理机来处理一个可并发执行的程序,这样,多个程序便可以同时执行。所以微观上说,多核 CPU 可以同时执行多个进程,进程数与 CPU 核数相当。但宏观上说,由于 CPU 会分时间片执行多个进程,所以实际执行进程个数会远多于 CPU 核数。
8.setTimeOut 和 setInterval 有什么区别
异步编程当然少不了定时器了,常见的定时器函数有 setTimeout、setInterval、requestAnimationFrame。最常用的是setTimeout,很多人认为 setTimeout 是延时多久,那就应该是多久后执行。
其实这个观点是错误的,因为 JS 是单线程执行的,如果前面的代码影响了性能,就会导致 setTimeout 不会按期执行。当然了,可以通过代码去修正 setTimeout,从而使定时器相对准确:
setInterval,其实这个函数作用和 setTimeout 基本一致,只是该函数是每隔一段时间执行一次回调函数。
通常来说不建议使用 setInterval。第一,它和 setTimeout 一样,不能保证在预期的时间执行任务。第二,它存在执行累积的问题
考虑极端情况,假如定时器里面的代码需要进行大量的计算(耗费时间较长),或者是 DOM 操作。这样一来,花的时间就比较长,有可能前一次代码还没有执行完,后一次代码就被添加到队列了。也会到时定时器变得不准确,甚至出现同一时间执行两次的情况。
有循环定时器的需求,其实完全可以通过 requestAnimationFrame 来实现
9.promise 错误捕获
try catch
try catch 只能捕获当前上下文中的错误,也就是只能捕获同步任务的情况,如下场景:
try {
throw "程序执行遇到了一些错误";
} catch (e) {
console.log(e);
}
// 控制台会输出:程序执行遇到了一些错误
这很好,错误被捕获了,我们可以在程序中进程错误的处理;
但是对于异步的任务,trycatch 就显得无能为力,不能正确捕获错误:
try {
setTimeout(() => {
throw "程序执行遇到了一些错误";
});
} catch (e) {
console.log(e);
}
// 控制台输出:Uncaught 程序执行遇到了一些错误;
又或者这样:
try {
Promise.reject("程序执行遇到了一些错误");
} catch (e) {
console.log(e);
}
// 控制台输出:Uncaught (in promise) 程序执行遇到了一些错误
上面的代码都无法正常捕获到错误,因为:trycatch 永远捕获的是同步的错误
什么是同步的错误?
当在一个事件循环内,同一个任务队列中出现的错误,对于这个任务所在的上下文而言,就是同步错误。
setTimeout和Promise被称为任务源,来自不同的任务源注册的回调函数会被放入不同的任务队列中。
- setTimeout 中的任务会被放入宏任务
- Promise 中的任务会被放入微任务
- 拓展:setTimeout 是宿主浏览器发起的任务,一般会被放入宏任务
- 而 Promise 是由 JS 引擎发起的任务,会被放入微任务
第一次事件循环中,JS 引擎会把整个 script 代码当成一个宏任务执行,执行完成之后,再检测本次循环中是否存在微任务,存在的话就依次从微任务的任务队列中读取执行完所有的微任务,再读取宏任务的任务队列中的任务执行,再执行所有的微任务,如此循环。
JS 的执行顺序就是每次事件循环中的宏任务-微任务的不断切换。
再看setTimeout中抛出的错误,这个错误已经不在trycatch所在的事件循环中了,所以这是一个异步错误,无法被trycatch捕获到。
同理,Promise.reject()此处虽然是同步执行的,但是此处 reject 的内容却在另一个微任务循环中,对于trycatch来讲也不是同步的,所以这两个错误都无法被捕获。
promise.reject
要理解 Promise.reject 首先要了解它的返回值,Promise.reject 返回的是一个 Promise 对象,请注意:是Promise对象。
Promise 对象在任何时候都是一个合法的对象,它不是错误也不是异常,所以在任何实现,直接对 Promise.reject 或者一个返回 Promise 对象的调用直接try catch是没有意义的,一个正常的对象永远不可能触发 catch 捕获。
function getData() {
Promise.reject("遇到了一些错误");
}
function click() {
try {
getData();
} catch (e) {
console.log(e);
}
}
click(); // 我们模拟业务场景中的click事件
// 控制台输出: Uncaught (in promise) 遇到了一些错误
Promise 已经通过 reject 抛出了错误,为什么try catch捕获不到呢?
首先,需要知道,对于一个函数的错误是否可以被捕获到,可以尝试将函数调用的返回值替换到函数调用出,看看是否为一个错误
上面 getDate()调用会被替换为undefined;
对于一个没有明确 return 的函数调用,其返回值永远是undefined的,所以代码如下:
function click() {
try {
undefined;
} catch (e) {
console.log(e);
}
}
这个代码会正常执行,不会走到 catch 中
可能会有另一种思路,就是将Promise.reject返回出去,那么代码就变成:
function getData() {
return Promise.reject("遇到了一些错误");
}
function click() {
try {
getData();
} catch (e) {
console.log(e);
}
}
click();
Promise.reject 返回的是一个 Promise 对象,它是对象,不是错误。所以在try catch中完成 getData()调用后这里会出现一个 Promise 对象,这个对象是一个再正常不过的对象,不会被 catch 捕获,所以这个try catch依然是无效的。
于是,又出现一种思路:再调用处使用 Promise 的 catch 方法进行捕获,于是代码变成:
function getData() {
return Promise.reject("遇到了一些错误");
}
function click() {
try {
getData().catch(console.log);
} catch (e) {
console.log(e);
}
}
click();
这是可行的,reject 的错误可以被捕获,但这不是try catch的功劳,而是 Promise 的内部消化,所以这里的try catch依然没有意义。
解决 Promise 异常捕获
Promise 异常是最常见的异步异常,其内部的错误基本都是被包装成了 Promise 对象后进行传递,所以解决 Promise 异步捕获整体思路有两个:
- 使用 Promise 的 catch 方法内部消化;
- 使用 async 和 await 将异步错误转同步错误再由 try catch 捕获
Promise.catch
对于 Promise.reject 中抛出的错误,或者 Promise 构造器中抛出的错误,亦或者 then 中出现的错误,无论是运行时还是通过 throw 主动抛出的,原则上都可以被 catch 捕获。
如下:
function getData() {
Promise.reject("这里发生了错误").catch(console.log);
}
function click() {
getData();
}
click();
亦或者在调用处捕获,但这需要被调用的函数能返回 Promise 对象;
function getData() {
return Promise.reject("程序发生了一些错误");
}
function click() {
getData().catch(console.log);
}
click();
上面两个方案都可行,事实上建议在业务逻辑允许的情况下,将 Promise 都返回出去,以便能向上传递,同时配合unhandledrejection进行兜底
async await 异步转同步
使用 async 和 await 可以将一个异步函数调用在语义上变成同步执行的效果,这样我们就可以使用 try catch 去统一处理。
例如:
function getData() {
return Promise.reject("程序发生错误");
}
async function click() {
try {
await getData();
} catch (e) {
console.log(e);
}
}
click();
需要注意的是,如果 getData 方法没有写 return, 那么就无法将 Promise 对象向上传递,那么调用出的 await 等到的就是一个展开的 undefined, 依旧不能进行错误处理。
注意事项
一个函数如果内部处理了 Promise 异步对象,那么原则上其处理结果应该也是一个 Promise 对象,对于需要进行错误捕获的场景,Promise 对象应该始终通过 return 向上传递
兜底方案
一般情况下,同步错误如果没有进行捕获,那么这个错误所在的事件循环将终止,所以在开发阶段没有捕获的错误,使用一种方法进行兜底是很有必要的。
对于同步错误,可以定义window.onerror进行兜底处理,或者使用window.addEventListener('error', errHandler)来定义兜底函数。
对于 Promise 异常,则可以同步使用window.onunhandledrejection或者window.addEventListener('unhandledrejection', errHandler)来定义兜底函数。
then 方法中的第二个参数和 Promise.catch 方法的区别
Promise 中的 then 的第二个参数和 catch 有什么区别?
reject 是用来抛出错误的,属于 Promise 的方法
catch 是用来处理异常的,属于 Promise 实例的方法
区别
主要区别就是,如果在 then 的第一个函数中抛出了异常,后面的 catch 能捕获到,但是 then 的第二个参数却捕获不到
then 的第二个参数和 catch 捕获信息的时候会遵循就近原则,如果是 promise 内部报错,reject 抛出错误后,then 的第二个参数和 catch 方法都存在的情况下,只有 then 的第二个参数能捕获到,如果 then 的第二个参数不存在,则 catch 方法会被捕获到。
new Promise((resolve, reject) => {
setTimeout(() => {
resolve(1);
}, 1000);
})
.then((res) => {
console.log(res);
return new Promise((resolve, reject) => {
reject("第一个then方法报错了");
});
})
.then((res) => {
console.log(res);
return new Promise((resolve, reject) => {
reject("第二个then方法报错了");
});
})
.catch((err) => {
console.log(err);
});
//1
//第一个then方法报错了
10.promise 的中断
Promise 有个缺点就是一旦创建就无法取消,所以本质上 Promise 是无法被终止的,但我们在开发过程中可能会遇到下面两个需求:
中断调用链
就是在某个 then/catch 执行之后,不想让后续的链式调用继续执行了,即:
somePromise
.then(() => {})
.then(() => {
// 终止 Promise 链,让下面的 then、catch 和 finally 都不执行
})
.then(() => console.log("then"))
.catch(() => console.log("catch"))
.finally(() => console.log("finally"));
答案就是在 then/catch 的最后一行返回一个永远 pending 的 promise 即可:
return new Promise((resolve, reject) => {})
这样的话后面所有的 then、catch 和 finally 都不会执行了。
中断 Promise
注意这里是中断而不是终止,因为 Promise 无法终止,这个中断的意思是:在合适的时候,把 pending 状态的 promise 给 reject 掉。例如一个常见的应用场景就是希望给网络请求设置超时时间,一旦超时就就中断,我们这里用定时器模拟一个网络请求,随机 3 秒之内返回:
const request = new Promise((resolve, reject) => {
setTimeout(() => {
resolve("收到服务端数据");
}, Math.random() * 3000);
});
如果认为超过 2 秒就是网络超时,可以对该 promise 写一个包装函数 timeoutWrapper:
function timeoutWrapper(p, timeout = 2000) {
const wait = new Promise((resolve, reject) => {
setTimeout(() => {
reject("请求超时");
}, timeout);
});
return Promise.race([p, wait]);
}
于是就可以像下面这样用了:
const req = timeoutWrapper(request);
req.then((res) => console.log(res)).catch((e) => console.log(e));
不过这种方式并不灵活,因为终止 promise 的原因可能有很多,例如当用户点击某个按钮或者出现其他事件时手动终止。所以应该写一个包装函数,提供 abort 方法,让使用者自己决定何时终止:
function abortWrapper(p1) {
let abort;
let p2 = new Promise((resolve, reject) => (abort = reject));
let p = Promise.race([p1, p2]);
p.abort = abort;
return p;
}
使用方法如下:
const req = abortWrapper(request);
req.then((res) => console.log(res)).catch((e) => console.log(e));
setTimeout(() => req.abort("用户手动终止请求"), 2000); // 这里可以是用户主动点击
最后,再次强调一下,虽然 promise 被中断了,但是 promise 并没有终止,网络请求依然可能返回,只不过那时我们已经不关心请求结果了。
11.AbortController
如何优雅地中断 Promise?来试试 AbortController 吧!
执行上下文和闭包
1.执行上下文有哪些
当 JS 引擎解析到可执行代码片段(通常是函数调用阶段)的时候,就会先做一些执行前的准备工作,这个 “准备工作”,就叫做 "执行上下文(execution context 简称 EC)" 或者也可以叫做执行环境。
执行上下文 为我们的可执行代码块提供了执行前的必要准备工作,例如变量对象的定义、作用域链的扩展、提供调用者的对象引用等信息。
javascript 中有三种执行上下文类型,分别是:
- 全局执行上下文——这是默认或者说是最基础的执行上下文,一个程序中只会存在一个全局上下文,它在整个
javascript脚本的生命周期内都会存在于执行堆栈的最底部不会被栈弹出销毁。全局上下文会生成一个全局对象(以浏览器环境为例,这个全局对象是window),并且将this值绑定到这个全局对象上。 - 函数执行上下文——每当一个函数被调用时,都会创建一个新的函数执行上下文(不管这个函数是不是被重复调用的)
- Eval 函数执行上下文—— 执行在
eval函数内部的代码也会有它属于自己的执行上下文.。
ES3 执行上下文的内容
执行上下文是一个抽象的概念,我们可以将它理解为一个 object ,一个执行上下文里包括以下内容:
- 变量对象
- 活动对象
- 作用域链
- 调用者信息
变量对象(variable object 简称 VO)
每个执行环境文都有一个表示变量的对象——变量对象,全局执行环境的变量对象始终存在,而函数这样局部环境的变量,只会在函数执行的过程中存在,在函数被调用时且在具体的函数代码运行之前,JS 引擎会用当前函数的参数列表(arguments)初始化一个 “变量对象” 并将当前执行上下文与之关联 ,函数代码块中声明的 变量 和 函数 将作为属性添加到这个变量对象上。
有一点需要注意,只有函数声明(function declaration)会被加入到变量对象中,而函数表达式(function expression)会被忽略。
全局执行上下文和函数执行上下文中的变量对象还略有不同,它们之间的差别简单来说:
- 全局上下文中的变量对象就是全局对象,以浏览器环境来说,就是
window对象。 - 函数执行上下文中的变量对象内部定义的属性,是不能被直接访问的,只有当函数被调用时,变量对象(
VO)被激活为活动对象(AO)时,我们才能访问到其中的属性和方法。
活动对象(activation object 简称 AO)
函数进入执行阶段时,原本不能访问的变量对象被激活成为一个活动对象,自此,我们可以访问到其中的各种属性。
其实变量对象和活动对象是一个东西,只不过处于不同的状态和阶段而已。
作用域链(scope chain)
作用域 规定了如何查找变量,也就是确定当前执行代码对变量的访问权限。当查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就叫做 作用域链。
函数的作用域在函数创建时就已经确定了。当函数创建时,会有一个名为 [[scope]] 的内部属性保存所有父变量对象到其中。当函数执行时,会创建一个执行环境,然后通过复制函数的 [[scope]] 属性中的对象构建起执行环境的作用域链,然后,变量对象 VO 被激活生成 AO 并添加到作用域链的前端,完整作用域链创建完成:Scope = [AO].concat([[Scope]])
ES3 执行上下文的生命周期
执行上下文的生命周期有三个阶段,分别是:
- 创建阶段
- 执行阶段
- 销毁阶段
创建阶段
函数执行上下文的创建阶段,发生在函数调用时且在执行函数体内的具体代码之前,在创建阶段,JS 引擎会做如下操作:
用当前函数的参数列表(
arguments)初始化一个 “变量对象” 并将当前执行上下文与之关联 ,函数代码块中声明的 变量 和 函数 将作为属性添加到这个变量对象上。在这一阶段,会进行变量和函数的初始化声明,变量统一定义为undefined需要等到赋值时才会有确值,而函数则会直接定义。有没有发现这段加粗的描述非常熟悉?没错,这个操作就是 变量声明提升(变量和函数声明都会提升,但是函数提升更靠前)。
构建作用域链(前面已经说过构建细节)
确定
this的值
执行阶段
执行阶段中,JS 代码开始逐条执行,在这个阶段,JS 引擎开始对定义的变量赋值、开始顺着作用域链访问变量、如果内部有函数调用就创建一个新的执行上下文压入执行栈并把控制权交出……
销毁阶段
一般来讲当函数执行完成后,当前执行上下文(局部环境)会被弹出执行上下文栈并且销毁,控制权被重新交给执行栈上一层的执行上下文。
注意这只是一般情况,闭包的情况又有所不同。
闭包的定义:有权访问另一个函数内部变量的函数。简单说来,如果一个函数被作为另一个函数的返回值,并在外部被引用,那么这个函数就被称为闭包。
function funcFactory() {
var a = 1;
return function () {
alert(a);
};
}
// 闭包
var sayA = funcFactory();
sayA();
当闭包的父包裹函数执行完成后,父函数本身执行环境的作用域链会被销毁,但是由于闭包的作用域链仍然在引用父函数的变量对象,导致了父函数的变量对象会一直驻存于内存,无法销毁,除非闭包的引用被销毁,闭包不再引用父函数的变量对象,这块内存才能被释放掉。过度使用闭包会造成 内存泄露 的问题,这块等到闭包章节再做详细分析。
ES3 执行上下文总结
对于 ES3 中的执行上下文,我们可以用下面这个列表来概括程序执行的整个过程:
函数被调用
在执行具体的函数代码之前,创建了执行上下文
进入执行上下文的创建阶段:
初始化作用域链
创建
arguments object检查上下文中的参数,初始化名称和值并创建引用副本扫描上下文找到所有函数声明:
- 对于每个找到的函数,用它们的原生函数名,在变量对象中创建一个属性,该属性里存放的是一个指向实际内存地址的指针
- 如果函数名称已经存在了,属性的引用指针将会被覆盖
扫描上下文找到所有 var 的变量声明:
- 对于每个找到的变量声明,用它们的原生变量名,在变量对象中创建一个属性,并且使用
undefined来初始化 - 如果变量名作为属性在变量对象中已存在,则不做任何处理并接着扫描
- 对于每个找到的变量声明,用它们的原生变量名,在变量对象中创建一个属性,并且使用
确定
this值
进入执行上下文的执行阶段:
- 在上下文中运行/解释函数代码,并在代码逐行执行时分配变量值。
ES5 中的执行上下文
ES5 规范又对 ES3 中执行上下文的部分概念做了调整,最主要的调整,就是去除了 ES3 中变量对象和活动对象,以 词法环境组件( LexicalEnvironment component) 和 变量环境组件( VariableEnvironment component) 替代。所以 ES5 的执行上下文概念上表示大概如下:
ExecutionContext = {
ThisBinding = <this value>,
LexicalEnvironment = { ... },
VariableEnvironment = { ... },
}
对于 ES5 中的执行上下文,我们可以用下面这个列表来概括程序执行的整个过程:
程序启动,全局上下文被创建
创建全局上下文的词法环境
创建 对象环境记录器 ,它用来定义出现在 全局上下文 中的变量和函数的关系(负责处理
let和const定义的变量)创建 外部环境引用,值为
null创建全局上下文的变量环境
创建 对象环境记录器,它持有 变量声明语句 在执行上下文中创建的绑定关系(负责处理
var定义的变量,初始值为undefined造成声明提升)创建 外部环境引用,值为
null确定
this值为全局对象(以浏览器为例,就是window)
函数被调用,函数上下文被创建
创建函数上下文的词法环境
创建 声明式环境记录器 ,存储变量、函数和参数,它包含了一个传递给函数的
arguments对象(此对象存储索引和参数的映射)和传递给函数的参数的 length。(负责处理let和const定义的变量)创建 外部环境引用,值为全局对象,或者为父级词法环境(作用域)
创建函数上下文的变量环境
创建 声明式环境记录器 ,存储变量、函数和参数,它包含了一个传递给函数的
arguments对象(此对象存储索引和参数的映射)和传递给函数的参数的 length。(负责处理var定义的变量,初始值为undefined造成声明提升)创建 外部环境引用,值为全局对象,或者为父级词法环境(作用域)
确定
this值
进入函数执行上下文的执行阶段:
- 在上下文中运行/解释函数代码,并在代码逐行执行时分配变量值。
关于 ES5 中执行上下文的变更,个人感觉就是变了个概念,本质和 ES3 差别并不大。至于变更的目的,应该是为了 ES6 中的 let 和 const 服务的。
2.Js 预编译
案例
var global = 100;
function fn() {
console.log(global);
}
fn();
面试官问你这个问题就是看你知不知道 JS 代码在运行时都发生了什么? 这个时候,很多小伙伴是不是已经开始想声明提升的问题了。用声明提升去思考代码也就是这样的顺序
var global; //变量声明提升
function fn() {
//函数声明提升
console.log(global);
}
global = 100; //变量赋值
fn(); //函数执行
看到这,很多小伙伴肯定会说不过如此。那么保持这个想法,看下面的代码
function fn(a) {
console.log(a); // function() {}
var a = 123;
console.log(a); // 123
function a() {}
console.log(a); // 123
var b = function () {};
console.log(b); // function() {}
function d() {}
var d = a;
console.log(d); // 123
}
fn(1);
请问:这段代码是怎么的运行顺序?开始声明提升?现在,大家应该就知道我要说什么,通过声明提升、作用域去思考一段代码的运行顺序,如果代码简单还好说,一旦代码的声明操作、赋值操作一大堆,就会浪费大把的时间,而且出错率极高。
函数体内
先以上面的代码为例,在一个函数体内的代码运行。其实 JS 运行可以分为编译阶段和执行阶段。那么这两个阶段分别发生了什么呢?
上述代码中
- 编译阶段
- 先创建一个 AO(activation object)对象
- 然后去找形参和变量声明,将形参和变量声明作为 AO 对象的属性名,值为 undefined
- 再者,将实参和形参统一
- 最后,找函数声明,将函数名作为 AO 对象的属性名,值赋予函数体
带着这些,我们再来看这段代码
function fn(a) { //二、形参是a,值为undefined
console.log(a); // function() {}
var a = 123; //二、a变量声明,AO里已经有了,覆盖后还是一样的
console.log(a); // 123
function a() {}// 四、a 申明为一个函数
console.log(a); // 123
var b = function() {} //二、变量b声明,值为undefined
console.log(b); // function() {}
function d() {} // 四、d声明为一个函数
var d = a //二、变量d声明,值为undefined
console.log(d); // 123
}
//第一步在这、函数在执行前进行编译,创建AO对象
AO:{
//第二步,开始找形参和变量声明,并写入AO
a:undefined 1 function (){}
b:undefined
d:undefined function(){}
//第三步,就相当于把实参传给形参,所以a的值现在就变成了1
//第四步,找函数声明,写入AO
}
fn(1)
到最后编译阶段结束,AO 对象中的属性和值是:
AO:{
a:function(){}
b:undefined
d:function(){}
}
现在,我们来通过看 AO 对象中,属性对应的值来执行整个函数。
- 从 fn(1)开始执行函数
- 第一个 log 要 a,去 AO 中找 a,是 function(){}。然后 a 被赋值为 123,AO 对象中的 a 随之更新
- 第二个 log 又要 a,去 AO 中找 a,现在输出的就是 123 了。然后变量 b 被赋值为一个函数,AO 中也随之更新
- 第三个 log 要 b,去 AO 中找 b,输出的就是 function(){},然后 a 的值被赋给了 d,AO 中 a 的值是 123,所以 d 也变成 123,AO 中随之更新
- 第四个 log 要 d,不就是 123 嘛 到这,这段代码就执行完了,不妨回过去看看,嗯?就这么简单?为了证明我不是在耍流氓,大家可以去跑一跑,对照一下。
看到这,聪明的朋友们马上会有疑问,这不过是函数体内的,那在全局上又是怎么样的。我只能说:更简单,接着看。。。
在全局下
在函数体中,整个编译阶段我总结成四部曲。在全局下,三步足以,多一步算我输。
- 第一步、创建一个 GO(global object)对象
- 第二步、找变量声明,将变量声明作为 GO 的属性名,值为 undefined
- 第三步、找全局里的函数声明,将函数名作为 GO 对象的属性名,值赋予函数体 三步,结束了,老规矩,拿代码来说话:
GO:{
fn:function(){}
}
global = 100
function fn() {
console.log(global); // undefined
global = 200
console.log(global); // 200
var global = 300
}
AO:{
global:undefined
}
fn()
- 编译阶段 来,三步走起!
- 第一步、创建一个 GO 对象
- 第二步、找变量声明,并没有,全局中只有一个赋值语句和函数声明
- 第三步、找函数声明,所以 GO 对象中编译阶段只有 fn 编译到这,全局就编译完了,接下来就是函数体内的编译了
- 第一步、创建一个 AO 对象
- 第二步、找形参和变量声明,这里没有形参,变量 global 声明,值为 undefined。写入 AO
- 第三步、传参,实参形参都没有
- 第四步、找函数声明,也没有 到这,整个编译就结束了,可以开始执行了。
- 执行阶段
- 先执行赋值语句,因为 global 在全局中没有定义,这里会强制声明一个 global 并赋值 100,写入 GO 中
- 然后到 fn()执行函数体。
- 第一个 log 要 global,先去自己的 AO 找,找到了,值为 undefined。所以输出 undefined
- 进行赋值,将 AO 中的 global 值更新为 200
- 第二个 log 还要 global,这里已经变成 200 了,所以输出 200
- 最后 AO 中 global 被赋值为 300 看到这里,再回想一下,是不是感觉很通透了。下面稍微总结下上面说的方法
总结
- 函数体内的编译四步曲,发生在函数执行之前
- 创建 AO 对象 (activation object)
- 找形参和变量声明,将形参和变量声明作为 AO 对象的属性名,值为 undefined
- 将实参和形参统一
- 在函数体里找函数声明,将函数名作为 AO 对象的属性名,值赋予函数体
- 全局下的编译三步曲,发生在代码最前面
- 创建 GO 对象
- 找变量声明,将变量声明作为 GO 对象的属性名,值赋予 undefined
- 找全局里的函数声明,将函数名作为 GO 对象的属性名,值赋予函数体
例题:
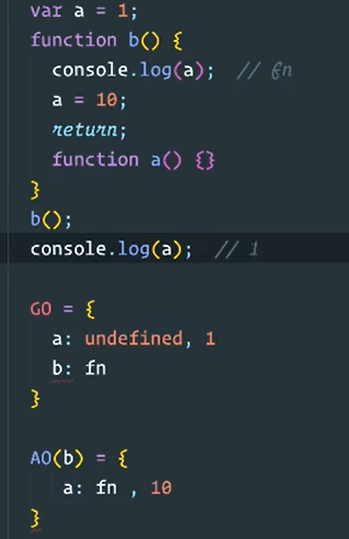
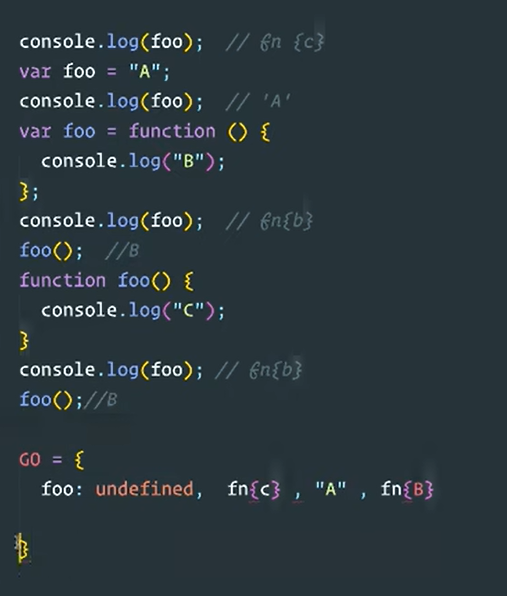
var foo=1;
function bar(a){
var a1=a;
var a=foo;
function a(){
console.log(a) //1
}
a1();
}
bar(3)
GO ={
foo: undefined, 1
bar: fn
}
AO ={
a1: undefined, fn
a: undefined, 3, fn, 1
}
3.什么是闭包
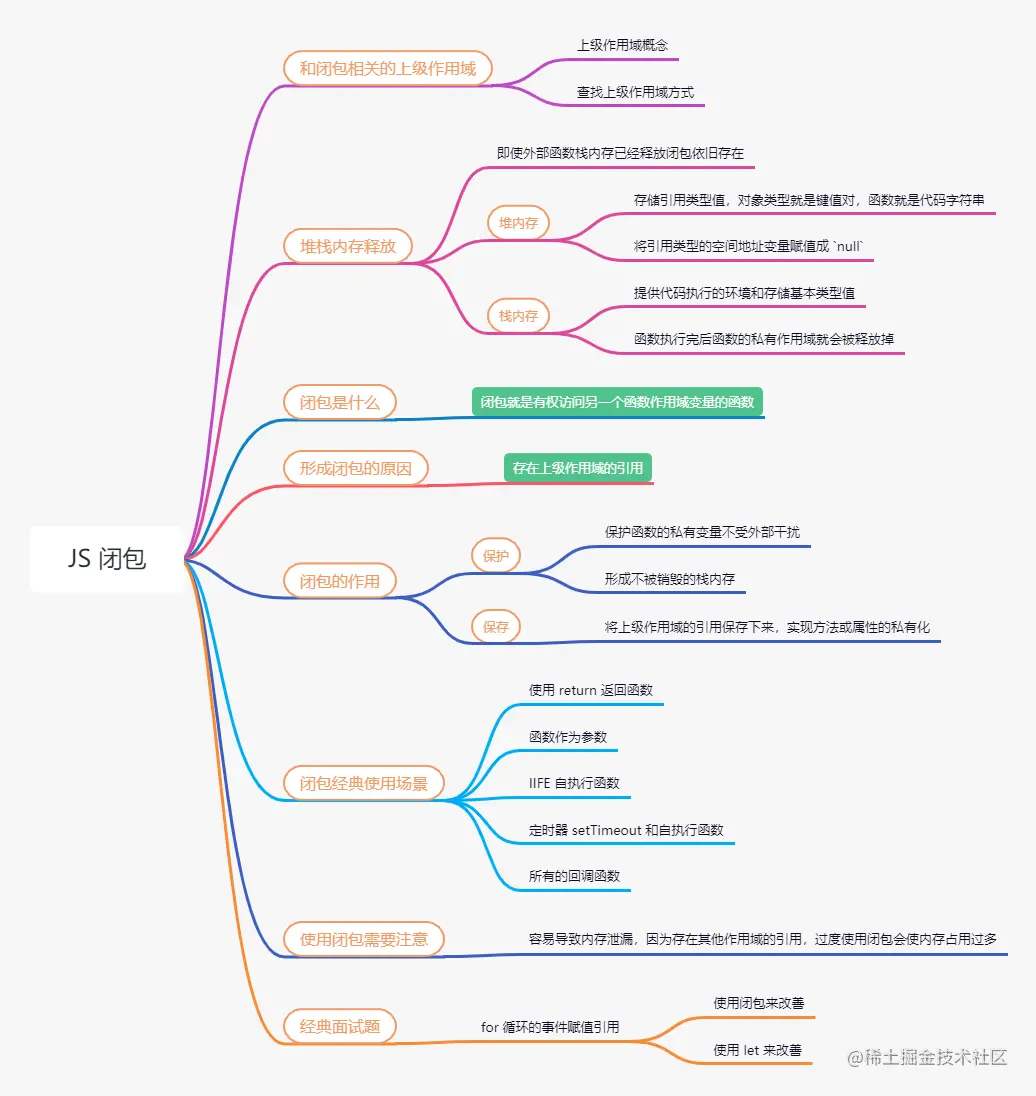
闭包是一个函数在创建时允许该自身函数访问并操作该自身函数以外的变量时所创建的作用域。
1.「函数」和「函数内部能访问到的变量」的总和,就是一个闭包
2.函数和对其词法环境的引用捆绑在一起,这样的组合就是闭包
内部函数总是可以访问其所在的外部函数中声明的变量和参数,即使在其外部函数被返回(寿命终结)了之后
本质就是上级作用域内变量的生命周期,因为被下级作用域内引用,而没有被释放。就导致上级作用域内的变量,等到下级作用域执行完以后才正常得到释放
4.闭包的应用场景
- 闭包的好处:
- 变量长期驻扎在内存中
- 避免污染全局变量
- 私有成员的存在
- 闭包的坏处:
- 增大内存的使用量
- 容易造成内存泄漏
闭包经典使用场景
如果创建全局变量的话,它很容易就会被污染,同名变量,或者被一些函数修改等。为了避免它被篡改,又想让它长时间保存,让他变得形似一个全局变量,可以随时去用,我们就会在这个时候,使用闭包
return回一个函数
var n = 10;
function fn() {
var n = 20;
function f() {
n++;
console.log(n);
}
return f;
}
var x = fn();
x(); // 21
复制代码;
这里的 return
f,f()就是一个闭包,存在上级作用域的引用。
- 函数作为参数
var a = '林一一'
function foo(){
var a = 'foo'
function fo(){
console.log(a)
}
return fo
}
function f(p){
var a = 'f'
p()
}
f(foo())
/* 输出
* foo
/
使用 return
fo返回回来,fo()就是闭包,f(foo())执行的参数就是函数fo,因为fo() 中的 a的上级作用域就是函数foo(),所以输出就是foo
- IIFE(自执行函数)
var n = '林一一';
(function p(){
console.log(n)
})()
/* 输出
* 林一一
/
同样也是产生了闭包
p(),存在window下的引用n。
- 循环赋值
for (var i = 0; i < 10; i++) {
(function (j) {
setTimeout(function () {
console.log(j);
}, 1000);
})(i);
}
因为存在闭包的原因上面能依次输出 1~10,闭包形成了 10 个互不干扰的私有作用域。将外层的自执行函数去掉后就不存在外部作用域的引用了,输出的结果就是连续的 10。为什么会连续输出 10,因为 JS 是单线程的遇到异步的代码不会先执行(会入栈),等到同步的代码执行完
i++到 10 时,异步代码才开始执行此时的i=10输出的都是 10。
- 使用回调函数就是在使用闭包
window.name = "林一一";
setTimeout(function timeHandler() {
console.log(window.name);
}, 100);
- 节流防抖
// 节流
function throttle(fn, timeout) {
let timer = null;
return function (...arg) {
if (timer) return;
timer = setTimeout(() => {
fn.apply(this, arg);
timer = null;
}, timeout);
};
}
// 防抖
function debounce(fn, timeout) {
let timer = null;
return function (...arg) {
clearTimeout(timer);
timer = setTimeout(() => {
fn.apply(this, arg);
}, timeout);
};
}
- 柯里化实现
function curry(fn, len = fn.length) {
return _curry(fn, len);
}
function _curry(fn, len, ...arg) {
return function (...params) {
let _arg = [...arg, ...params];
if (_arg.length >= len) {
return fn.apply(this, _arg);
} else {
return _curry.call(this, fn, len, ..._arg);
}
};
}
let fn = curry(function (a, b, c, d, e) {
console.log(a + b + c + d + e);
});
fn(1, 2, 3, 4, 5); // 15
fn(1, 2)(3, 4, 5);
fn(1, 2)(3)(4)(5);
fn(1)(2)(3)(4)(5);
5.闭包内存泄露问题
内存泄漏定义:应用程序不再需要占用的时候,由于某些原因,内存没有被操作系统或可用内存池回收。
内存泄漏的例子:
意外的全局变量
在函数内未声明的变量就赋值,这样会在全局对象创建一个新的变量。
function bar() {
say = "hehe";
}
即 ==
function bar() {
window.say = "hehe";
};或者是使用 this 创建了全局的变量
function foo() {
this.name = "hehe";
}
foo();
被遗忘的计时器或回调函数
- 使用计时器 setInterval()未清除,在老版本的 IE6 是无法处理循环引用的,会造成内存泄漏。
脱离 DOM 的引用的
怎么解决
手动释放
代码实现
var arr = [1, 2, 3];
arr = null;使用弱引用(weakset 和 weakmap)
优点:WeakMap 里面对 element 的引用就是弱引用,不会被计入垃圾回收机制的。也就是说一旦消除对该节点的引用,它的占用内存就会被垃圾回收机制释放。WeakMap 保存的这个键值对,也会自动消失。
代码实现
const vm = new WeakMap();
const element = document.getElementById("example");
vm.set(element, "something");
vm.get(element);
6.从 JS 引擎 V8 的角度看待闭包
原理分析
闭包的设计目的是为了存储私有变量,延长变量的生命周期,只有特定的接口才能访问该私有变量,可以防止防止全局变量命名冲突。 闭包常见例子:
function fn() {
var a = 1;
function foo1() {
console.log(a++);
}
return foo1;
}
var foo2 = fn();
foo2();
foo2();
这个闭包包括了 javascript 的三个特性: 1、父元素嵌套了子元素 2、子元素里引用了父元素里的变量 3、函数是一等公民,可以作为返回值返回给变量
现在看看 V8 引擎是如何实现这个闭包这个技术的
1、创建全局上下文,函数 fn 被创建,V8 将函数声明转换为函数对象,保存作用域链到[[scope]]属性中,将代码转换成字符串保存到 code 属性中
fn.[[scope]]={
globalContext.VO;
}
2、创建函数执行上下文,fn 函数执行上下文被压入执行上下文栈顶端
ECStack = [fnContext, globalContext];
3、进行预解析,赋值函数对象中的[[scope]]属性值创建作用域链
fnContext = {
Scope: fn.[[scope]],
}
4、用 arguement 创建活动对象,随后初始化活动对象,加入形参,变量提升,函数提升
fnContext = {
AO: {
arguments: {
length: 0,
},
a: undefined,
},
Scope: [AO, [[Scope]]],
};
此时如果碰到了函数,V8 不会直接跳过,而是会快速地解析内部代码,判断是否使用了外部变量,如果使用了,那么会复制一份保存到堆内存中其名为 closure(闭包),并将 closure 保存到子函数的[[scope]]属性中,该赋值操作会在父函数执行上下文销毁之前进行。在这个例子中,foo1 使用了 fn 中的变量,会将其保存到[[scope]]中,可以在 foo1 的 prototype 中看到。
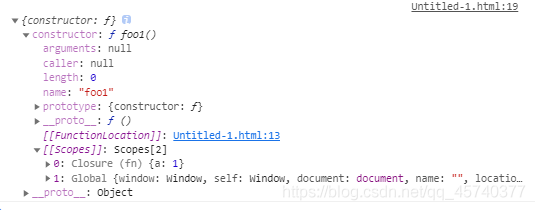 5、执行函数中的代码,并修改 AO 中属性的值
5、执行函数中的代码,并修改 AO 中属性的值
fnContext = {
AO: {
arguments: {
length: 0,
},
a: 1,
},
Scope: [AO, [[Scope]]],
};
6、最后返回了 foo1 的指针给全局变量foo2,函数上下文从执行上下文栈中弹出
ECStack = [globalContext];
为什么闭包对象没有被垃圾回收清除
根据垃圾回收规则,没有被引用的对象会被回收,而 fn 函数最后把闭包函数对象的指针返回给了全局变量 foo2,虽然 foo1 的父元素执行上下文最后出栈,foo1 中指向闭包函数对象的指针也被销毁,但是全局变量依然保存了,导致闭包函数对象一直保留在内存中,而 Closure 对象一直保存在[[scope]]中,所以不会被清除,下次再次调用 foo2 时可以直接从堆内存中取出 a。
为什么返回给全局变量可以叠加,不返回就不行?
function fn() {
var a = 1;
function foo1() {
console.log(a++);
}
return foo1;
}
var foo2 = fn();
foo2();
foo2();

function fn() {
var a = 1;
function foo1() {
console.log(a++);
}
return foo1;
}
fn()();
fn()();

如果返回给全局变量可以实现叠加器的效果,因为每次调用的都是指向同一个对象 而如果不返回,那么闭包函数对象的生命周期到父函数执行上下文销毁就结束了,会被回收,那么对象中的闭包对象也就不复存在了,再次调用的话,就是重新分配内存空间。
柯里化函数里的闭包
function sum(a) {
return function (b) {
return function (c) {
return a + b + c;
};
};
}
var sum1 = sum(1)(2)(3);
执行结果为
 看看 function© 这个匿名闭包函数的[[scope]]
看看 function© 这个匿名闭包函数的[[scope]]
function sum(a) {
return function (b) {
return function (c) {
return a + b + c;
};
};
}
var sum1 = sum(1)(2);
console.log(sum1.prototype);
 保存了两个闭包函数对象,分别存储了变量 a 和 b
保存了两个闭包函数对象,分别存储了变量 a 和 b
this
1.call apply bind 区别
它们的作用一模一样,区别仅在于传入参数的形式的不同。
- apply 接受两个参数,第一个参数指定了函数体内 this 对象的指向,第二个参数为一个带下标的集合,这个集合可以为数组,也可以为类数组,apply 方法把这个集合中的元素作为参数传递给被调用的函数。
- call 传入的参数数量不固定,跟 apply 相同的是,第一个参数也是代表函数体内的 this 指向,从第二个参数开始往后,每个参数被依次传入函数。
使用 apply
var a = {
name: "Cherry",
func1: function () {
console.log(this.name);
},
func2: function () {
setTimeout(
function () {
this.func1();
}.apply(a),
100
);
},
};
a.func2(); // Cherry
使用 call
var a = {
name: "Cherry",
func1: function () {
console.log(this.name);
},
func2: function () {
setTimeout(
function () {
this.func1();
}.call(a),
100
);
},
};
a.func2(); // Cherry
使用 bind
var a = {
name: "Cherry",
func1: function () {
console.log(this.name);
},
func2: function () {
setTimeout(
function () {
this.func1();
}.bind(a)(),
100
);
},
};
a.func2(); // Cherry
刚刚我们已经介绍了 apply、call、bind 都是可以改变 this 的指向的,但是这三个函数稍有不同。
在 MDN 中定义 apply 如下;
apply() 方法调用一个函数, 其具有一个指定的 this 值,以及作为一个数组(或类似数组的对象)提供的参数
语法:
fun.apply(thisArg, [argsArray])
- thisArg:在 fun 函数运行时指定的 this 值。需要注意的是,指定的 this 值并不一定是该函数执行时真正的 this 值,如果这个函数处于非严格模式下,则指定为 null 或 undefined 时会自动指向全局对象(浏览器中就是 window 对象),同时值为原始值(数字,字符串,布尔值)的 this 会指向该原始值的自动包装对象。
- argsArray:一个数组或者类数组对象,其中的数组元素将作为单独的参数传给 fun 函数。如果该参数的值为 null 或 undefined,则表示不需要传入任何参数。从 ECMAScript 5 开始可以使用类数组对象。浏览器兼容性请参阅本文底部内容。
apply 和 call 的区别
其实 apply 和 call 基本类似,他们的区别只是传入的参数不同。
call 的语法为:
fun.call(thisArg[, arg1[, arg2[, ...]]])复制代码
所以 apply 和 call 的区别是 call 方法接受的是若干个参数列表,而 apply 接收的是一个包含多个参数的数组。
var a = {
name: "Cherry",
fn: function (a, b) {
console.log(a + b);
},
};
var b = a.fn;
b.apply(a, [1, 2]); // 3
var a = {
name: "Cherry",
fn: function (a, b) {
console.log(a + b);
},
};
var b = a.fn;
b.call(a, 1, 2); // 3
var a = {
name: "Cherry",
fn: function (a, b) {
console.log(a + b);
},
};
var b = a.fn;
b.bind(a, 1, 2);
我们会发现并没有输出,这是为什么呢,我们来看一下 MDN 上的文档说明:
bind()方法创建一个新的函数, 当被调用时,将其 this 关键字设置为提供的值,在调用新函数时,在任何提供之前提供一个给定的参数序列。
所以我们可以看出,bind 是创建一个新的函数,我们必须要手动去调用:
var a = {
name: "Cherry",
fn: function (a, b) {
console.log(a + b);
},
};
var b = a.fn;
b.bind(a, 1, 2)(); // 3
2.this 解决了什么问题
this 是执行上下文中的一个属性,它指向最后一次调用这个方法的对象。在实际开发中,this 的指向可以通过四种调用模式来判断。
- 第一种是函数调用模式,当一个函数不是一个对象的属性时,直接作为函数来调用时,this 指向全局对象。
- 第二种是方法调用模式,如果一个函数作为一个对象的方法来调用时,this 指向这个对象。
- 第三种是构造器调用模式,如果一个函数用 new 调用时,函数执行前会新创建一个对象,this 指向这个新创建的对象。
- 第四种是 apply 、 call 和 bind 调用模式,这三个方法都可以显示的指定调用函数的 this 指向。其中 apply 方法接收两个参数:一个是 this 绑定的对象,一个是参数数组。call 方法接收的参数,第一个是 this 绑定的对象,后面的其余参数是传入函数执行的参数。也就是说,在使用 call() 方法时,传递给函数的参数必须逐个列举出来。bind 方法通过传入一个对象,返回一个 this 绑定了传入对象的新函数。这个函数的 this 指向除了使用 new 时会被改变,其他情况下都不会改变。
这四种方式,使用构造器调用模式的优先级最高,然后是 apply、call 和 bind 调用模式,然后是方法调用模式,然后是函数调用模式。
3.this 指向绑定规则
- 默认绑定
- 隐式绑定
- 硬绑定
- new 绑定
默认绑定
默认绑定,在不能应用其它绑定规则时使用的默认规则,通常是独立函数调用。
function sayHi() {
console.log("Hello,", this.name);
}
var name = "YvetteLau";
sayHi();
在调用 Hi()时,应用了默认绑定,this 指向全局对象(非严格模式下),严格模式下,this 指向 undefined,undefined 上没有 this 对象,会抛出错误。
上面的代码,如果在浏览器环境中运行,那么结果就是 Hello,YvetteLau
但是如果在 node 环境中运行,结果就是 Hello,undefined.这是因为 node 中 name 并不是挂在全局对象上的。
隐式绑定
函数的调用是在某个对象上触发的,即调用位置上存在上下文对象。典型的形式为 XXX.fun().我们来看一段代码:
function sayHi() {
console.log("Hello,", this.name);
}
var person = {
name: "YvetteLau",
sayHi: sayHi,
};
var name = "Wiliam";
person.sayHi();
打印的结果是 Hello,YvetteLau.
sayHi 函数声明在外部,严格来说并不属于 person,但是在调用 sayHi 时,调用位置会使用 person 的上下文来引用函数,隐式绑定会把函数调用中的 this(即此例 sayHi 函数中的 this)绑定到这个上下文对象(即此例中的 person)
注意这种 是在某处进行调用运行 类似于 setTimeout 的回调 上面是一种引用 这个是一种执行
var length = 10;
function fn() {
console.log("this", this); //window
console.log(this.length); //10
}
var obj = {
length: 5,
methods: function () {
fn();
},
};
obj.methods();
在 obj 调用 methods 方法后,而后调用 fn,其中的 this 具体是值 window 对象,所以答案为 10 ;js 中的函数,跟声明的位置有关,跟在哪里调用无关。fn 本来就是全局作用域,跟在哪里调用无关
需要注意的是:对象属性链中只有最后一层会影响到调用位置。
function sayHi() {
console.log("Hello,", this.name);
}
var person2 = {
name: "Christina",
sayHi: sayHi,
};
var person1 = {
name: "YvetteLau",
friend: person2,
};
person1.friend.sayHi();
结果是:Hello, Christina.
因为只有最后一层会确定 this 指向的是什么,不管有多少层,在判断 this 的时候,我们只关注最后一层,即此处的 friend。
隐式绑定有一个大陷阱,绑定很容易丢失(或者说容易给我们造成误导,我们以为 this 指向的是什么,但是实际上并非如此).
function sayHi() {
console.log("Hello,", this.name);
}
var person = {
name: "YvetteLau",
sayHi: sayHi,
};
var name = "Wiliam";
var Hi = person.sayHi;
Hi();
结果是: Hello,Wiliam.
这是为什么呢,Hi 直接指向了 sayHi 的引用,在调用的时候,跟 person 没有半毛钱的关系,针对此类问题,我建议大家只需牢牢记住这个格式:XXX.fn();fn()前如果什么都没有,那么肯定不是隐式绑定。
除了上面这种丢失之外,隐式绑定的丢失是发生在回调函数中(事件回调也是其中一种),我们来看下面一个例子:
function sayHi() {
console.log("Hello,", this.name);
}
var person1 = {
name: "YvetteLau",
sayHi: function () {
setTimeout(function () {
console.log("Hello,", this.name);
});
},
};
var person2 = {
name: "Christina",
sayHi: sayHi,
};
var name = "Wiliam";
person1.sayHi();
setTimeout(person2.sayHi, 100);
setTimeout(function () {
person2.sayHi();
}, 200);
结果为:
Hello, Wiliam;
Hello, Wiliam;
Hello, Christina;
第一条输出很容易理解,setTimeout 的回调函数中,this 使用的是默认绑定,非严格模式下,执行的是全局对象
第二条输出是不是有点迷惑了?说好 XXX.fun()的时候,fun 中的 this 指向的是 XXX 呢,为什么这次却不是这样了!Why?
其实这里我们可以这样理解: setTimeout(fn,delay){ fn(); },相当于是将 person2.sayHi 赋值给了一个变量,最后执行了变量,这个时候,sayHi 中的 this 显然和 person2 就没有关系了。
第三条虽然也是在 setTimeout 的回调中,但是我们可以看出,这是执行的是 person2.sayHi()使用的是隐式绑定,因此这是 this 指向的是 person2,跟当前的作用域没有任何关系。
显式绑定
显式绑定比较好理解,就是通过 call,apply,bind 的方式,显式的指定 this 所指向的对象。
call,apply 和 bind 的第一个参数,就是对应函数的 this 所指向的对象。call 和 apply 的作用一样,只是传参方式不同。call 和 apply 都会执行对应的函数,而 bind 方法不会。
function sayHi() {
console.log("Hello,", this.name);
}
var person = {
name: "YvetteLau",
sayHi: sayHi,
};
var name = "Wiliam";
var Hi = person.sayHi;
Hi.call(person); //Hi.apply(person)
输出的结果为: Hello, YvetteLau. 因为使用硬绑定明确将 this 绑定在了 person 上。
那么,使用了硬绑定,是不是意味着不会出现隐式绑定所遇到的绑定丢失呢?显然不是这样的,不信,继续往下看。
function sayHi() {
console.log("Hello,", this.name);
}
var person = {
name: "YvetteLau",
sayHi: sayHi,
};
var name = "Wiliam";
var Hi = function (fn) {
fn();
};
Hi.call(person, person.sayHi);
输出的结果是 Hello, Wiliam. 原因很简单,Hi.call(person, person.sayHi)的确是将 this 绑定到 Hi 中的 this 了。但是在执行 fn 的时候,相当于直接调用了 sayHi 方法(记住: person.sayHi 已经被赋值给 fn 了,隐式绑定也丢了),没有指定 this 的值,对应的是默认绑定。
现在,我们希望绑定不会丢失,要怎么做?很简单,调用 fn 的时候,也给它硬绑定。
function sayHi() {
console.log("Hello,", this.name);
}
var person = {
name: "YvetteLau",
sayHi: sayHi,
};
var name = "Wiliam";
var Hi = function (fn) {
fn.call(this);
};
Hi.call(person, person.sayHi);
此时,输出的结果为: Hello, YvetteLau,因为 person 被绑定到 Hi 函数中的 this 上,fn 又将这个对象绑定给了 sayHi 的函数。这时,sayHi 中的 this 指向的就是 person 对象。
至此,革命已经快胜利了,我们来看最后一种绑定规则: new 绑定。
new 绑定
javaScript 和C++不一样,并没有类,在 javaScript 中,构造函数只是使用 new 操作符时被调用的函数,这些函数和普通的函数并没有什么不同,它不属于某个类,也不可能实例化出一个类。任何一个函数都可以使用 new 来调用,因此其实并不存在构造函数,而只有对于函数的“构造调用”。
使用 new 来调用函数,会自动执行下面的操作:
- 创建一个空对象,构造函数中的 this 指向这个空对象
- 这个新对象被执行 [[原型]] 连接
- 执行构造函数方法,属性和方法被添加到 this 引用的对象中
- 如果构造函数中没有返回其它对象,那么返回 this,即创建的这个的新对象,否则,返回构造函数中返回的对象。
function _new() {
let target = {}; //创建的新对象
//第一个参数是构造函数
let [constructor, ...args] = [...arguments];
//执行[[原型]]连接;target 是 constructor 的实例
target.__proto__ = constructor.prototype;
//执行构造函数,将属性或方法添加到创建的空对象上
let result = constructor.apply(target, args);
if (result && (typeof result == "object" || typeof result == "function")) {
//如果构造函数执行的结构返回的是一个对象,那么返回这个对象
return result;
}
//如果构造函数返回的不是一个对象,返回创建的新对象
return target;
}
因此,我们使用 new 来调用函数的时候,就会新对象绑定到这个函数的 this 上。
function sayHi(name) {
this.name = name;
}
var Hi = new sayHi("Yevtte");
console.log("Hello,", Hi.name);
输出结果为 Hello, Yevtte, 原因是因为在 var Hi = new sayHi('Yevtte');这一步,会将 sayHi 中的 this 绑定到 Hi 对象上。
绑定优先级
我们知道了 this 有四种绑定规则,但是如果同时应用了多种规则,怎么办?
显然,我们需要了解哪一种绑定方式的优先级更高,这四种绑定的优先级为:
new 绑定 > 显式绑定 > 隐式绑定 > 默认绑定
绑定例外
凡事都有例外,this 的规则也是这样。
如果我们将 null 或者是 undefined 作为 this 的绑定对象传入 call、apply 或者是 bind,这些值在调用时会被忽略,实际应用的是默认绑定规则。
var foo = {
name: "Selina",
};
var name = "Chirs";
function bar() {
console.log(this.name);
}
bar.call(null); //Chirs
输出的结果是 Chirs,因为这时实际应用的是默认绑定规则。
箭头函数
箭头函数是 ES6 中新增的,它和普通函数有一些区别,箭头函数没有自己的 this,它的 this 继承于外层代码库中的 this。箭头函数在使用时,需要注意以下几点:
(1)函数体内的 this 对象,继承的是外层代码块的 this。
(2)不可以当作构造函数,也就是说,不可以使用 new 命令,否则会抛出一个错误。
(3)不可以使用 arguments 对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
(4)不可以使用 yield 命令,因此箭头函数不能用作 Generator 函数。
(5)箭头函数没有自己的 this,所以不能用 call()、apply()、bind()这些方法去改变 this 的指向.
OK,我们来看看箭头函数的 this 是什么?
var obj = {
hi: function () {
console.log(this);
return () => {
console.log(this);
};
},
sayHi: function () {
return function () {
console.log(this);
return () => {
console.log(this);
};
};
},
say: () => {
console.log(this);
},
};
let hi = obj.hi(); //输出obj对象
hi(); //输出obj对象
let sayHi = obj.sayHi();
let fun1 = sayHi(); //输出window
fun1(); //输出window
obj.say(); //输出window
那么这是为什么呢?如果大家说箭头函数中的 this 是定义时所在的对象,这样的结果显示不是大家预期的,按照这个定义,say 中的 this 应该是 obj 才对。
我们来分析一下上面的执行结果:
- obj.hi(); 对应了 this 的隐式绑定规则,this 绑定在 obj 上,所以输出 obj,很好理解。
- hi(); 这一步执行的就是箭头函数,箭头函数继承上一个代码库的 this,刚刚我们得出上一层的 this 是 obj,显然这里的 this 就是 obj.
- 执行 sayHi();这一步也很好理解,我们前面说过这种隐式绑定丢失的情况,这个时候 this 执行的是默认绑定,this 指向的是全局对象 window.
- fun1(); 这一步执行的是箭头函数,如果按照之前的理解,this 指向的是箭头函数定义时所在的对象,那么这儿显然是说不通。OK,按照箭头函数的 this 是继承于外层代码库的 this 就很好理解了。外层代码库我们刚刚分析了,this 指向的是 window,因此这儿的输出结果是 window.
- obj.say(); 执行的是箭头函数,当前的代码块 obj 中是不存在 this 的,只能往上找,就找到了全局的 this,指向的是 window.
箭头函数的 this 是静态的?
依旧是前面的代码。我们来看看箭头函数中的 this 真的是静态的吗?
var obj = {
hi: function () {
console.log(this);
return () => {
console.log(this);
};
},
sayHi: function () {
return function () {
console.log(this);
return () => {
console.log(this);
};
};
},
say: () => {
console.log(this);
},
};
let sayHi = obj.sayHi();
let fun1 = sayHi(); //输出window
fun1(); //输出window
let fun2 = sayHi.bind(obj)(); //输出obj
fun2(); //输出obj
var obj = {
say: () => {
console.log(this);
var say1 = () => {
console.log(this);
};
say1();
},
};
obj.say(); //window window
可以看出,fun1 和 fun2 对应的是同样的箭头函数,但是 this 的输出结果是不一样的。
牢牢记住一点: 箭头函数没有自己的 this,箭头函数中的 this 继承于外层代码中的 this.
垃圾回收和内存泄露
1.垃圾回收机制
定义:
- 找到内存空间中的垃圾。
- 回收垃圾,让程序员能再次利用这部分的空间。
常用的垃圾回收算法
引用计数法
定义:跟踪记录每个值被引用的次数。
优点:
- 可即刻回收:当被引用数值为 0,对象马上会把自己作为空闲空间连到空闲链表上。也就是说,在变成垃圾的时候就立刻被回收。
- 因为是即使回收,那么程序不会暂停去单独使用很长一段时间的 GC,那么最大暂停时间很短。
- 不用去遍历堆里面的所有活动对象和非活动对象。
缺点:
- 计数器需要占很大的位置:因为不能预估被引用的上限,打个比方,可能出现 32 位即 2 的 32 次方个对象同时引用一个对象,那么计时器就需要 32 位。
- 最大的劣势是无法解决循环引用无法回收的问题,这就是 IE 之前出现的问题。
代码示例
var a = new Object();
var b = a;
a = null;
b = null;
标记清除法(在 V8 引擎使用最多的)
- 定义:
- 标记阶段:把所有活动对象做上标记
- 清除阶段:把没有标记(也就是说非活动对象)销毁
- 优点:
- 实现简单,打标记用一位二进制就可以表示
- 解决了循环引用的问题
- 缺点:
- 造成碎片化(有点类似磁盘的碎片化)
- 再分配时遍历次数多,如果一直没有找到合适的内存块大小,那么会遍历空闲链表(保存堆中所有空闲地址空间的地址形成的链表)一直遍历到尾端。
- 定义:
复制算法
- 将一块内存空间分为两部分,分别为 From 空间和 To 空间。在这两个空间中,必定有一个空间是使用的,另一个空间是空闲的。新分配的对象会被放入 From 空间中,当 From 空间被占满的时,新生代 GC 就会启动了。算法就检查 From 空间中存活的对象复制到 To 空间中,如果有失活的对象就会销毁,当赋值完成后将 From,空间和 To 空间互换,这样 GC 就结束了。
垃圾回收的方式
浏览器通常使用的垃圾回收方法有两种:标记清除,引用计数。 1)标记清除
- 标记清除是浏览器常见的垃圾回收方式,当变量进入执行环境时,就标记这个变量“进入环境”,被标记为“进入环境”的变量是不能被回收的,因为他们正在被使用。当变量离开环境时,就会被标记为“离开环境”,被标记为“离开环境”的变量会被内存释放。
- 垃圾收集器在运行的时候会给存储在内存中的所有变量都加上标记。然后,它会去掉环境中的变量以及被环境中的变量引用的标记。而在此之后再被加上标记的变量将被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。最后。垃圾收集器完成内存清除工作,销毁那些带标记的值,并回收他们所占用的内存空间。
2)引用计数
- 另外一种垃圾回收机制就是引用计数,这个用的相对较少。引用计数就是跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型赋值给该变量时,则这个值的引用次数就是 1。相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数就减 1。当这个引用次数变为 0 时,说明这个变量已经没有价值,因此,在在机回收期下次再运行时,这个变量所占有的内存空间就会被释放出来。
- 这种方法会引起循环引用的问题:例如:
obj1和obj2通过属性进行相互引用,两个对象的引用次数都是 2。当使用循环计数时,由于函数执行完后,两个对象都离开作用域,函数执行结束,obj1和obj2还将会继续存在,因此它们的引用次数永远不会是 0,就会引起循环引用。
function fun() {
let obj1 = {};
let obj2 = {};
obj1.a = obj2; // obj1 引用 obj2
obj2.a = obj1; // obj2 引用 obj1
}
这种情况下,就要手动释放变量占用的内存:
obj1.a = null;
obj2.a = null;
减少 JavaScript 中垃圾回收
对象优化
最大限度复用对象,不用尽可能设置为 null,尽快被垃圾回收掉。
var obj = {};
for (var i = 0; i < 10; i++) {
// var obj = {}; // 这样每次都会创建一个对象
obj.age = 19;
obj.name = "hehe";
console.log(obj);
}
数组 Array 优化
将[]赋值给一个数组对象,是清空数组的捷径,但是这样又创建一个新的空对象,并且将原来的数组对象变成了一片小内存垃圾。
var arr = [1, 2, 3];
arr = [];将数组长度赋值为 0,也能达到清空数组的目的,并且同时能实现数组重用,减少内存垃圾的产生。
var arr = [1, 2, 3];
arr.length = 0;
方法 function 优化
例如在游戏的主循环中,setTimout 或 requestAnimationFrame 来调用一个成员方法是很常见的。每次调用都返回一个新的方法对象,这就导致了大量的方法对象垃圾。为了解决这个方法,可以将作为返回值的方法保存起来。
function say() {
console.log("hehe");
}
setTimeout(
(function (self) {
return function () {
self.say();
};
})(this),
16
);
// 优化
this.sayFunc = (function (self) {
return function () {
self.say();
};
})(this);
setTimout(this.sayFunc, 16);
虽然浏览器可以进行垃圾自动回收,但是当代码比较复杂时,垃圾回收所带来的代价比较大,所以应该尽量减少垃圾回收。
- 对数组进行优化: 在清空一个数组时,最简单的方法就是给其赋值为[ ],但是与此同时会创建一个新的空对象,可以将数组的长度设置为 0,以此来达到清空数组的目的。
- 对
object进行优化: 对象尽量复用,对于不再使用的对象,就将其设置为 null,尽快被回收。 - 对函数进行优化: 在循环中的函数表达式,如果可以复用,尽量放在函数的外面。
2.详解垃圾回收机制
GC 即 Garbage Collection ,程序工作过程中会产生很多 垃圾,这些垃圾是程序不用的内存或者是之前用过了,以后不会再用的内存空间,而 GC 就是负责回收垃圾的,因为他工作在引擎内部,所以对于我们前端来说,GC 过程是相对比较无感的,这一套引擎执行而对我们又相对无感的操作也就是常说的 垃圾回收机制 了
当然也不是所有语言都有 GC,一般的高级语言里面会自带 GC,比如 Java、Python、JavaScript 等,也有无 GC 的语言,比如 C、C++ 等,那这种就需要我们程序员手动管理内存了,相对比较麻烦
垃圾产生&为何回收
我们知道写代码时创建一个基本类型、对象、函数……都是需要占用内存的,但是我们并不关注这些,因为这是引擎为我们分配的,我们不需要显式手动的去分配内存
但是,你有没有想过,当我们不再需要某个东西时会发生什么?JavaScript 引擎又是如何发现并清理它的呢?
我们举个简单的例子
let test = {
name: "isboyjc",
};
test = [1, 2, 3, 4, 5];
如上所示,我们假设它是一个完整的程序代码
我们知道 JavaScript 的引用数据类型是保存在堆内存中的,然后在栈内存中保存一个对堆内存中实际对象的引用,所以,JavaScript 中对引用数据类型的操作都是操作对象的引用而不是实际的对象。可以简单理解为,栈内存中保存了一个地址,这个地址和堆内存中的实际值是相关的
那上面代码首先我们声明了一个变量 test,它引用了对象 {name: 'isboyjc'},接着我们把这个变量重新赋值了一个数组对象,也就变成了该变量引用了一个数组,那么之前的对象引用关系就没有了,如下图
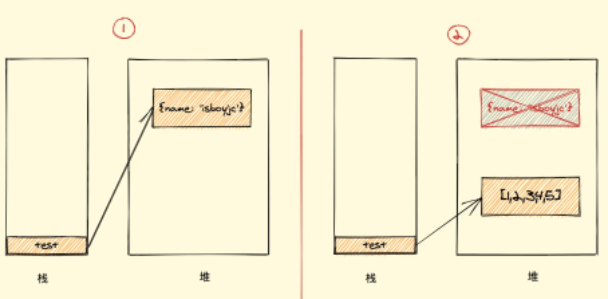
没有了引用关系,也就是无用的对象,这个时候假如任由它搁置,一个两个还好,多了的话内存也会受不了,所以就需要被清理(回收)
用官方一点的话说,程序的运行需要内存,只要程序提出要求,操作系统或者运行时就必须提供内存,那么对于持续运行的服务进程,必须要及时释放内存,否则,内存占用越来越高,轻则影响系统性能,重则就会导致进程崩溃
垃圾回收策略
在 JavaScript 内存管理中有一个概念叫做 可达性,就是那些以某种方式可访问或者说可用的值,它们被保证存储在内存中,反之不可访问则需回收
至于如何回收,其实就是怎样发现这些不可达的对象(垃圾)它并给予清理的问题, JavaScript 垃圾回收机制的原理说白了也就是定期找出那些不再用到的内存(变量),然后释放其内存
你可能还会好奇为什么不是实时的找出无用内存并释放呢?其实很简单,实时开销太大了
我们都可以 Get 到这之中的重点,那就是怎样找出所谓的垃圾?
这个流程就涉及到了一些算法策略,有很多种方式,我们简单介绍两个最常见的
- 标记清除算法
- 引用计数算法
标记清除算法
策略
标记清除(Mark-Sweep),目前在 JavaScript引擎 里这种算法是最常用的,到目前为止的大多数浏览器的 JavaScript引擎 都在采用标记清除算法,只是各大浏览器厂商还对此算法进行了优化加工,且不同浏览器的 JavaScript引擎 在运行垃圾回收的频率上有所差异
就像它的名字一样,此算法分为 标记 和 清除 两个阶段,标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁
你可能会疑惑怎么给变量加标记?其实有很多种办法,比如当变量进入执行环境时,反转某一位(通过一个二进制字符来表示标记),又或者可以维护进入环境变量和离开环境变量这样两个列表,可以自由的把变量从一个列表转移到另一个列表,当前还有很多其他办法。其实,怎样标记对我们来说并不重要,重要的是其策略
引擎在执行 GC(使用标记清除算法)时,需要从出发点去遍历内存中所有的对象去打标记,而这个出发点有很多,我们称之为一组 根 对象,而所谓的根对象,其实在浏览器环境中包括又不止于 全局Window对象、文档DOM树 等
整个标记清除算法大致过程就像下面这样
- 垃圾收集器在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为 0
- 然后从各个根对象开始遍历,把不是垃圾的节点改成 1
- 清理所有标记为 0 的垃圾,销毁并回收它们所占用的内存空间
- 最后,把所有内存中对象标记修改为 0,等待下一轮垃圾回收
优点
标记清除算法的优点只有一个,那就是实现比较简单,打标记也无非打与不打两种情况,这使得一位二进制位(0 和 1)就可以为其标记,非常简单
缺点
标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了 内存碎片(如下图),并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这就牵扯出了内存分配的问题
假设我们新建对象分配内存时需要大小为 size,由于空闲内存是间断的、不连续的,则需要对空闲内存列表进行一次单向遍历找出大于等于 size 的块才能为其分配(如下图)
那如何找到合适的块呢?我们可以采取下面三种分配策略
First-fit,找到大于等于size的块立即返回Best-fit,遍历整个空闲列表,返回大于等于size的最小分块Worst-fit,遍历整个空闲列表,找到最大的分块,然后切成两部分,一部分size大小,并将该部分返回
这三种策略里面 Worst-fit 的空间利用率看起来是最合理,但实际上切分之后会造成更多的小块,形成内存碎片,所以不推荐使用,对于 First-fit 和 Best-fit 来说,考虑到分配的速度和效率 First-fit 是更为明智的选择
综上所述,标记清除算法或者说策略就有两个很明显的缺点
- 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块
- 分配速度慢,因为即便是使用
First-fit策略,其操作仍是一个O(n)的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢
PS:标记清除算法的缺点补充
归根结底,标记清除算法的缺点在于清除之后剩余的对象位置不变而导致的空闲内存不连续,所以只要解决这一点,两个缺点都可以完美解决了
而 标记整理(Mark-Compact)算法 就可以有效地解决,它的标记阶段和标记清除算法没有什么不同,只是标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存(如下图)
引用计数算法
策略
引用计数(Reference Counting),这其实是早先的一种垃圾回收算法,它把 对象是否不再需要 简化定义为 对象有没有其他对象引用到它,如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收,目前很少使用这种算法了,因为它的问题很多,不过我们还是需要了解一下
它的策略是跟踪记录每个变量值被使用的次数
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1
- 如果同一个值又被赋给另一个变量,那么引用数加 1
- 如果该变量的值被其他的值覆盖了,则引用次数减 1
- 当这个值的引用次数变为 0 的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运行的时候清理掉引用次数为 0 的值占用的内存
如下例
let a = new Object() // 此对象的引用计数为 1(a引用)
let b = a // 此对象的引用计数是 2(a,b引用)
a = null // 此对象的引用计数为 1(b引用)
b = null // 此对象的引用计数为 0(无引用)
... // GC 回收此对象
这种方式是不是很简单?确实很简单,不过在引用计数这种算法出现没多久,就遇到了一个很严重的问题——循环引用,即对象 A 有一个指针指向对象 B,而对象 B 也引用了对象 A ,如下面这个例子
function test() {
let A = new Object();
let B = new Object();
A.b = B;
B.a = A;
}
如上所示,对象 A 和 B 通过各自的属性相互引用着,按照上文的引用计数策略,它们的引用数量都是 2,但是,在函数 test 执行完成之后,对象 A 和 B 是要被清理的,但使用引用计数则不会被清理,因为它们的引用数量不会变成 0,假如此函数在程序中被多次调用,那么就会造成大量的内存不会被释放
我们再用标记清除的角度看一下,当函数结束后,两个对象都不在作用域中,A 和 B 都会被当作非活动对象来清除掉,相比之下,引用计数则不会释放,也就会造成大量无用内存占用,这也是后来放弃引用计数,使用标记清除的原因之一
在 IE8 以及更早版本的 IE 中,
BOM和DOM对象并非是原生JavaScript对象,它是由C++实现的组件对象模型对象(COM,Component Object Model),而COM对象使用 引用计数算法来实现垃圾回收,所以即使浏览器使用的是标记清除算法,只要涉及到COM对象的循环引用,就还是无法被回收掉,就比如两个互相引用的DOM对象等等,而想要解决循环引用,需要将引用地址置为null来切断变量与之前引用值的关系,如下// COM对象
let ele = document.getElementById("xxx");
let obj = new Object();
// 造成循环引用
obj.ele = ele;
ele.obj = obj;
// 切断引用关系
obj.ele = null;
ele.obj = null;不过在 IE9 及以后的
BOM与DOM对象都改成了JavaScript对象,也就避免了上面的问题此处参考 JavaScript 高级程序设计 第四版 4.3.2 小节
优点
引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为 0 时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾
而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS 脚本)运行过程中线程就必须要暂停去执行一段时间的 GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以了
缺点
引用计数的缺点想必大家也都很明朗了,首先它需要一个计数器,而此计数器需要占很大的位置,因为我们也不知道被引用数量的上限,还有就是无法解决循环引用无法回收的问题,这也是最严重的
V8 对 GC 的优化
我们在上面也说过,现在大多数浏览器都是基于标记清除算法,V8 亦是,当然 V8 肯定也对其进行了一些优化加工处理,那接下来我们主要就来看 V8 中对垃圾回收机制的优化
分代式垃圾回收
试想一下,我们上面所说的垃圾清理算法在每次垃圾回收时都要检查内存中所有的对象,这样的话对于一些大、老、存活时间长的对象来说同新、小、存活时间短的对象一个频率的检查很不好,因为前者需要时间长并且不需要频繁进行清理,后者恰好相反,怎么优化这点呢???分代式就来了
新老生代
V8 的垃圾回收策略主要基于分代式垃圾回收机制,V8 中将堆内存分为新生代和老生代两区域,采用不同的垃圾回收器也就是不同的策略管理垃圾回收
新生代的对象为存活时间较短的对象,简单来说就是新产生的对象,通常只支持 1~8M 的容量,而老生代的对象为存活事件较长或常驻内存的对象,简单来说就是经历过新生代垃圾回收后还存活下来的对象,容量通常比较大
V8 整个堆内存的大小就等于新生代加上老生代的内存(如下图)
对于新老两块内存区域的垃圾回收,V8 采用了两个垃圾回收器来管控,我们暂且将管理新生代的垃圾回收器叫做新生代垃圾回收器,同样的,我们称管理老生代的垃圾回收器叫做老生代垃圾回收器好了
新生代垃圾回收
新生代对象是通过一个名为 Scavenge 的算法进行垃圾回收,在 Scavenge算法 的具体实现中,主要采用了一种复制式的方法即 Cheney算法 ,我们细细道来
Cheney算法 中将堆内存一分为二,一个是处于使用状态的空间我们暂且称之为 使用区,一个是处于闲置状态的空间我们称之为 空闲区,如下图所示
新加入的对象都会存放到使用区,当使用区快被写满时,就需要执行一次垃圾清理操作
当开始进行垃圾回收时,新生代垃圾回收器会对使用区中的活动对象做标记,标记完成之后将使用区的活动对象复制进空闲区并进行排序,随后进入垃圾清理阶段,即将非活动对象占用的空间清理掉。最后进行角色互换,把原来的使用区变成空闲区,把原来的空闲区变成使用区
当一个对象经过多次复制后依然存活,它将会被认为是生命周期较长的对象,随后会被移动到老生代中,采用老生代的垃圾回收策略进行管理
另外还有一种情况,如果复制一个对象到空闲区时,空闲区空间占用超过了 25%,那么这个对象会被直接晋升到老生代空间中,设置为 25% 的比例的原因是,当完成 Scavenge 回收后,空闲区将翻转成使用区,继续进行对象内存的分配,若占比过大,将会影响后续内存分配
老生代垃圾回收
相比于新生代,老生代的垃圾回收就比较容易理解了,上面我们说过,对于大多数占用空间大、存活时间长的对象会被分配到老生代里,因为老生代中的对象通常比较大,如果再如新生代一般分区然后复制来复制去就会非常耗时,从而导致回收执行效率不高,所以老生代垃圾回收器来管理其垃圾回收执行,它的整个流程就采用的就是上文所说的标记清除算法了
首先是标记阶段,从一组根元素开始,递归遍历这组根元素,遍历过程中能到达的元素称为活动对象,没有到达的元素就可以判断为非活动对象
清除阶段老生代垃圾回收器会直接将非活动对象,也就是数据清理掉
前面我们也提过,标记清除算法在清除后会产生大量不连续的内存碎片,过多的碎片会导致大对象无法分配到足够的连续内存,而 V8 中就采用了我们上文中说的标记整理算法来解决这一问题来优化空间
为什么需要分代式?
正如小标题,为什么需要分代式?这个机制有什么优点又解决了什么问题呢?
其实,它并不能说是解决了什么问题,可以说是一个优化点吧
分代式机制把一些新、小、存活时间短的对象作为新生代,采用一小块内存频率较高的快速清理,而一些大、老、存活时间长的对象作为老生代,使其很少接受检查,新老生代的回收机制及频率是不同的,可以说此机制的出现很大程度提高了垃圾回收机制的效率
并行回收(Parallel)
在介绍并行之前,我们先要了解一个概念 全停顿(Stop-The-World),我们都知道 JavaScript 是一门单线程的语言,它是运行在主线程上的,那在进行垃圾回收时就会阻塞 JavaScript 脚本的执行,需等待垃圾回收完毕后再恢复脚本执行,我们把这种行为叫做 全停顿
比如一次 GC 需要 60ms ,那我们的应用逻辑就得暂停 60ms ,假如一次 GC 的时间过长,对用户来说就可能造成页面卡顿等问题
既然存在执行一次 GC 比较耗时的情况,考虑到一个人盖房子难,那两个人、十个人...呢?切换到程序这边,那我们可不可以引入多个辅助线程来同时处理,这样是不是就会加速垃圾回收的执行速度呢?因此 V8 团队引入了并行回收机制
所谓并行,也就是同时的意思,它指的是垃圾回收器在主线程上执行的过程中,开启多个辅助线程,同时执行同样的回收工作
简单来说,使用并行回收,假如本来是主线程一个人干活,它一个人需要 3 秒,现在叫上了 2 个辅助线程和主线程一块干活,那三个人一块干一个人干 1 秒就完事了,但是由于多人协同办公,所以需要加上一部分多人协同(同步开销)的时间我们算 0.5 秒好了,也就是说,采用并行策略后,本来要 3 秒的活现在 1.5 秒就可以干完了
不过虽然 1.5 秒就可以干完了,时间也大大缩小了,但是这 1.5 秒内,主线程还是需要让出来的,也正是因为主线程还是需要让出来,这个过程内存是静态的,不需要考虑内存中对象的引用关系改变,只需要考虑协同,实现起来也很简单
新生代对象空间就采用并行策略,在执行垃圾回收的过程中,会启动了多个线程来负责新生代中的垃圾清理操作,这些线程同时将对象空间中的数据移动到空闲区域,这个过程中由于数据地址会发生改变,所以还需要同步更新引用这些对象的指针,此即并行回收
增量标记与懒性清理
我们上面所说的并行策略虽然可以增加垃圾回收的效率,对于新生代垃圾回收器能够有很好的优化,但是其实它还是一种全停顿式的垃圾回收方式,对于老生代来说,它的内部存放的都是一些比较大的对象,对于这些大的对象 GC 时哪怕我们使用并行策略依然可能会消耗大量时间
所以为了减少全停顿的时间,在 2011 年,V8 对老生代的标记进行了优化,从全停顿标记切换到增量标记
什么是增量
增量就是将一次 GC 标记的过程,分成了很多小步,每执行完一小步就让应用逻辑执行一会儿,这样交替多次后完成一轮 GC 标记(如下图)
试想一下,将一次完整的 GC 标记分次执行,那在每一小次 GC 标记执行完之后如何暂停下来去执行任务程序,而后又怎么恢复呢?那假如我们在一次完整的 GC 标记分块暂停后,执行任务程序时内存中标记好的对象引用关系被修改了又怎么办呢?
可以看出增量的实现要比并行复杂一点,V8 对这两个问题对应的解决方案分别是三色标记法与写屏障
三色标记法(暂停与恢复)
我们知道老生代是采用标记清理算法,而上文的标记清理中我们说过,也就是在没有采用增量算法之前,单纯使用黑色和白色来标记数据就可以了,其标记流程即在执行一次完整的 GC 标记前,垃圾回收器会将所有的数据置为白色,然后垃圾回收器在会从一组跟对象出发,将所有能访问到的数据标记为黑色,遍历结束之后,标记为黑色的数据对象就是活动对象,剩余的白色数据对象也就是待清理的垃圾对象
如果采用非黑即白的标记策略,那在垃圾回收器执行了一段增量回收后,暂停后启用主线程去执行了应用程序中的一段 JavaScript 代码,随后当垃圾回收器再次被启动,这时候内存中黑白色都有,我们无法得知下一步走到哪里了
为了解决这个问题,V8 团队采用了一种特殊方式: 三色标记法
三色标记法即使用每个对象的两个标记位和一个标记工作表来实现标记,两个标记位编码三种颜色:白、灰、黑
- 白色指的是未被标记的对象
- 灰色指自身被标记,成员变量(该对象的引用对象)未被标记
- 黑色指自身和成员变量皆被标记
如上图所示,我们用最简单的表达方式来解释这一过程,最初所有的对象都是白色,意味着回收器没有标记它们,从一组根对象开始,先将这组根对象标记为灰色并推入到标记工作表中,当回收器从标记工作表中弹出对象并访问它的引用对象时,将其自身由灰色转变成黑色,并将自身的下一个引用对象转为灰色
就这样一直往下走,直到没有可标记灰色的对象时,也就是无可达(无引用到)的对象了,那么剩下的所有白色对象都是无法到达的,即等待回收(如上图中的 C、E 将要等待回收)
采用三色标记法后我们在恢复执行时就好办多了,可以直接通过当前内存中有没有灰色节点来判断整个标记是否完成,如没有灰色节点,直接进入清理阶段,如还有灰色标记,恢复时直接从灰色的节点开始继续执行就可以
三色标记法的 mark 操作可以渐进执行的而不需每次都扫描整个内存空间,可以很好的配合增量回收进行暂停恢复的一些操作,从而减少 全停顿 的时间
写屏障(增量中修改引用)
一次完整的 GC 标记分块暂停后,执行任务程序时内存中标记好的对象引用关系被修改了,增量中修改引用,可能不太好理解,我们举个例子(如图)
假如我们有 A、B、C 三个对象依次引用,在第一次增量分段中全部标记为黑色(活动对象),而后暂停开始执行应用程序也就是 JavaScript 脚本,在脚本中我们将对象 B 的指向由对象 C 改为了对象 D ,接着恢复执行下一次增量分段
这时其实对象 C 已经无引用关系了,但是目前它是黑色(代表活动对象)此一整轮 GC 是不会清理 C 的,不过我们可以不考虑这个,因为就算此轮不清理等下一轮 GC 也会清理,这对我们程序运行并没有太大影响
我们再看新的对象 D 是初始的白色,按照我们上面所说,已经没有灰色对象了,也就是全部标记完毕接下来要进行清理了,新修改的白色对象 D 将在次轮 GC 的清理阶段被回收,还有引用关系就被回收,后面我们程序里可能还会用到对象 D 呢,这肯定是不对的
为了解决这个问题,V8 增量回收使用 写屏障 (Write-barrier) 机制,即一旦有黑色对象引用白色对象,该机制会强制将引用的白色对象改为灰色,从而保证下一次增量 GC 标记阶段可以正确标记,这个机制也被称作 强三色不变性
那在我们上图的例子中,将对象 B 的指向由对象 C 改为对象 D 后,白色对象 D 会被强制改为灰色
懒性清理
增量标记其实只是对活动对象和非活动对象进行标记,对于真正的清理释放内存 V8 采用的是惰性清理(Lazy Sweeping)
增量标记完成后,惰性清理就开始了。当增量标记完成后,假如当前的可用内存足以让我们快速的执行代码,其实我们是没必要立即清理内存的,可以将清理过程稍微延迟一下,让 JavaScript 脚本代码先执行,也无需一次性清理完所有非活动对象内存,可以按需逐一进行清理直到所有的非活动对象内存都清理完毕,后面再接着执行增量标记
增量标记与惰性清理的优缺?
增量标记与惰性清理的出现,使得主线程的停顿时间大大减少了,让用户与浏览器交互的过程变得更加流畅。但是由于每个小的增量标记之间执行了 JavaScript 代码,堆中的对象指针可能发生了变化,需要使用写屏障技术来记录这些引用关系的变化,所以增量标记缺点也很明显:
首先是并没有减少主线程的总暂停的时间,甚至会略微增加,其次由于写屏障机制的成本,增量标记可能会降低应用程序的吞吐量(吞吐量是啥总不用说了吧)
并发回收(Concurrent)
前面我们说并行回收依然会阻塞主线程,增量标记同样有增加了总暂停时间、降低应用程序吞吐量两个缺点,那么怎么才能在不阻塞主线程的情况下执行垃圾回收并且与增量相比更高效呢?
这就要说到并发回收了,它指的是主线程在执行 JavaScript 的过程中,辅助线程能够在后台完成执行垃圾回收的操作,辅助线程在执行垃圾回收的时候,主线程也可以自由执行而不会被挂起(如下图)
辅助线程在执行垃圾回收的时候,主线程也可以自由执行而不会被挂起,这是并发的优点,但同样也是并发回收实现的难点,因为它需要考虑主线程在执行 JavaScript 时,堆中的对象引用关系随时都有可能发生变化,这时辅助线程之前做的一些标记或者正在进行的标记就会要有所改变,所以它需要额外实现一些读写锁机制来控制这一点,这里我们不再细说
再说 V8 中 GC 优化
V8 的垃圾回收策略主要基于分代式垃圾回收机制,这我们说过,关于新生代垃圾回收器,我们说使用并行回收可以很好的增加垃圾回收的效率,那老生代垃圾回收器用的哪个策略呢?我上面说了并行回收、增量标记与惰性清理、并发回收这几种回收方式来提高效率、优化体验,看着一个比一个好,那老生代垃圾回收器到底用的哪个策略?难道是并发??内心独白:” 好像。。貌似。。并发回收效率最高 “
其实,这三种方式各有优缺点,所以在老生代垃圾回收器中这几种策略都是融合使用的
老生代主要使用并发标记,主线程在开始执行 JavaScript 时,辅助线程也同时执行标记操作(标记操作全都由辅助线程完成)
标记完成之后,再执行并行清理操作(主线程在执行清理操作时,多个辅助线程也同时执行清理操作)
同时,清理的任务会采用增量的方式分批在各个 JavaScript 任务之间执行
3.JS 内存的使用
JavaScript,会在创建变量(对象,字符串等)时分配内存,并且在不再使用它们时“自动”释放内存,这个自动释放内存的过程称为垃圾回收。
因为自动垃圾回收机制的存在,让大多 Javascript 开发者感觉他们可以不关心内存管理,所以会在一些情况下导致内存泄漏。
内存生命周期
JS 环境中分配的内存有如下声明周期:
- 内存分配:当我们申明变量、函数、对象的时候,系统会自动为他们分配内存
- 内存使用:即读写内存,也就是使用变量、函数等
- 内存回收:使用完毕,由垃圾回收机制自动回收不再使用的内存
JS 的内存分配
为了不让程序员费心分配内存,JavaScript 在定义变量时就完成了内存分配。
var n = 123; // 给数值变量分配内存
var s = "azerty"; // 给字符串分配内存
var o = {
a: 1,
b: null,
}; // 给对象及其包含的值分配内存
// 给数组及其包含的值分配内存(就像对象一样)
var a = [1, null, "abra"];
function f(a) {
return a + 2;
} // 给函数(可调用的对象)分配内存
// 函数表达式也能分配一个对象
someElement.addEventListener(
"click",
function () {
someElement.style.backgroundColor = "blue";
},
false
);
有些函数调用结果是分配对象内存:
var d = new Date(); // 分配一个 Date 对象
var e = document.createElement("div"); // 分配一个 DOM 元素
有些方法分配新变量或者新对象:
var s = "azerty";
var s2 = s.substr(0, 3); // s2 是一个新的字符串
// 因为字符串是不变量,
// JavaScript 可能决定不分配内存,
// 只是存储了 [0-3] 的范围。
var a = ["ouais ouais", "nan nan"];
var a2 = ["generation", "nan nan"];
var a3 = a.concat(a2);
// 新数组有四个元素,是 a 连接 a2 的结果
JS 的内存使用
使用值的过程实际上是对分配内存进行读取与写入的操作。
读取与写入可能是写入一个变量或者一个对象的属性值,甚至传递函数的参数。
var a = 10; // 分配内存
console.log(a); // 对内存的使用
JS 的内存回收
JS 有自动垃圾回收机制,那么这个自动垃圾回收机制的原理是什么呢?
其实很简单,就是找出那些不再继续使用的值,然后释放其占用的内存。
大多数内存管理的问题都在这个阶段。
在这里最艰难的任务是找到不再需要使用的变量。
不再需要使用的变量也就是生命周期结束的变量,是局部变量,局部变量只在函数的执行过程中存在,
当函数运行结束,没有其他引用(闭包),那么该变量会被标记回收。
全局变量的生命周期直至浏览器卸载页面才会结束,也就是说全局变量不会被当成垃圾回收。
因为自动垃圾回收机制的存在,开发人员可以不关心也不注意内存释放的有关问题,但对无用内存的释放这件事是客观存在的。
不幸的是,即使不考虑垃圾回收对性能的影响,目前最新的垃圾回收算法,也无法智能回收所有的极端情况。
4.内存泄露原因和案例
什么是内存泄漏
程序的运行需要内存。只要程序提出要求,操作系统或运行时(runtime)就必须提供内存。对于持续运行的服务进程(daemon),必须及时释放不再用到的内存。否则,内存占用越来越高,轻则影响系统性能,重则导致进程崩溃。
本质上讲,内存泄漏就是由于疏忽或错误造成程序未能释放那些不再使用的内存,照成内存的浪费。
简单地说就是申请了一块内存空间,使用完毕后没有释放掉。它的一般表现方式是程序运行时间越长,占用内存越多,最终用尽全部内存,整个系统崩溃。由程序申请的一块内存,且没有任何一个指针指向它,那么这块内存就泄露了。
经验法则是,如果连续 5 次垃圾回收之后,内存占用一次比一次大,就有内存泄漏。
这就要求实时查看内存的占用情况。
造成内存的泄漏情况
以下四种情况会造成内存的泄漏:
- 意外的全局变量: 由于使用未声明的变量,而意外的创建了一个全局变量,而使这个变量一直留在内存中无法被回收。
- 被遗忘的计时器或回调函数: 设置了 setInterval 定时器,而忘记取消它,如果循环函数有对外部变量的引用的话,那么这个变量会被一直留在内存中,而无法被回收。
- 脱离 DOM 的引用: 获取一个 DOM 元素的引用,而后面这个元素被删除,由于一直保留了对这个元素的引用,所以它也无法被回收。
- 闭包: 不合理的使用闭包,从而导致某些变量一直被留在内存当中。
常见的内存泄露案例:
1.意外的全局变量
function foo() {
bar1 = "some text"; // 没有声明变量 实际上是全局变量 => window.bar1
this.bar2 = "some text"; // 全局变量 => window.bar2
}
foo();
在这个例子中,意外的创建了两个全局变量 bar1 和 bar2
2.被遗忘的定时器和回调函数
在很多库中, 如果使用了观察者模式, 都会提供回调方法, 来调用一些回调函数。
要记得回收这些回调函数。举一个 setInterval 的例子:
var serverData = loadData();
setInterval(function () {
var renderer = document.getElementById("renderer");
if (renderer) {
renderer.innerHTML = JSON.stringify(serverData);
}
}, 5000); // 每 5 秒调用一次
如果后续 renderer 元素被移除,整个定时器实际上没有任何作用。
但如果你没有回收定时器,整个定时器依然有效, 不但定时器无法被内存回收,
定时器函数中的依赖也无法回收。在这个案例中的 serverData 也无法被回收。
3.闭包
在 JS 开发中,我们会经常用到闭包,一个内部函数,有权访问包含其的外部函数中的变量。
下面这种情况下,闭包也会造成内存泄露:
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing)
// 对于 'originalThing'的引用
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join("*"),
someMethod: function () {
console.log("message");
},
};
};
setInterval(replaceThing, 1000);
这段代码,每次调用 replaceThing 时,theThing 获得了包含一个巨大的数组和一个对于新闭包 someMethod 的对象。
同时 unused 是一个引用了 originalThing 的闭包。
这个范例的关键在于,闭包之间是共享作用域的,尽管 unused 可能一直没有被调用,但是 someMethod 可能会被调用,就会导致无法对其内存进行回收。
当这段代码被反复执行时,内存会持续增长。
4.DOM 引用
很多时候, 我们对 Dom 的操作, 会把 Dom 的引用保存在一个数组或者 Map 中。
var elements = {
image: document.getElementById("image"),
};
function doStuff() {
elements.image.src = "http://example.com/image_name.png";
}
function removeImage() {
document.body.removeChild(document.getElementById("image"));
// 这个时候我们对于 #image 仍然有一个引用, Image 元素, 仍然无法被内存回收.
}
上述案例中,即使我们对于 image 元素进行了移除,但是仍然有对 image 元素的引用,依然无法对齐进行内存回收。
另外需要注意的一个点是,对于一个 Dom 树的叶子节点的引用。
举个例子: 如果我们引用了一个表格中的 td 元素,一旦在 Dom 中删除了整个表格,我们直观的觉得内存回收应该回收除了被引用的 td 外的其他元素。
但是事实上,这个 td 元素是整个表格的一个子元素,并保留对于其父元素的引用。
这就会导致对于整个表格,都无法进行内存回收。所以我们要小心处理对于 Dom 元素的引用。
如何避免内存泄漏
记住一个原则:不用的东西,及时归还。
- 减少不必要的全局变量,使用严格模式避免意外创建全局变量。
- 在你使用完数据后,及时解除引用(闭包中的变量,dom 引用,定时器清除)。
- 组织好你的逻辑,避免死循环等造成浏览器卡顿,崩溃的问题。
5.内存泄露检测手段
什么是内存泄漏
javaScript 会在创建变量时分配内存并且在不适用变量时会自动的释放内存,这个释放内存的过程极为垃圾回收,程序运行需要内存,只要程序提出要求操作系统或者运行时就必须提供内存,对于持续运行的服务进行必须及时释放不在用到内存,否则内存占用越来越高,进一步导致系统的性能,有时会导致进程崩溃
内存泄漏的识别
如果连续几次垃圾回收之后内存占用一次比一次大,证明就有内存泄漏 需要实时查看内存的占比情况
怎么在 chrome 浏览器中查看内存占用情况
1:观察 chrome 浏览器,打开开发者模式,选择 Memory
2:在顶部勾选 Memory
3:点击坐上角的 record
4:在页面上进行各种操作,模拟用户的使用情况
5:一段时间后,点击对话框的 stop 按钮,面板上就会显示这段时间的内存占用情况
6:观察几分钟查看这个蓝色波动是否有逐渐消失
有消失证明没有泄漏
没有消失证明页面有内存泄漏
怎么判断当前是否存在内存泄漏
注:查看查看 JS Heap size 和 DOM Nodes 的数量
1:多次快照之后,比较每次快照中内存的占用情况,如果呈上升趋势那么可以可能存在内存泄漏
2:某次快照之后,当前内存占用的趋势图,如果走势不平稳呈上升趋势,可能存在内存泄漏
3:如果内存占用处于平稳趋势,证明没有内存泄漏
6.nodejs 内存管理
我们发现,在 nodejs 中使用内存时会有一定的限制,只能使用部分内存(64 位系统下约为 1.4 GB,32 位系统下约为 0.7 GB),在这样的限制下,我们不能在内存中操作大文件对象,比如不能把一个 2 GB 大小的文件读入内存中进行字符串处理,即使机器的物理内存有 32 GB。在 nodejs 单进程的情况下,机器的内存没法得到充分的利用
这个问题的原因主要是 nodejs 基于 V8 构建,V8 的内存分配机制。虽然在平时开发过程中,触达这个界限的时候比较少,但是如果不小心触发了,会导致进程的退出。
所以,下面会从几个方面,一起看看 V8 为什么会有这样的内存限制,知道原因之后,可以更好的避免这个问题:
V8 的对象分配
我们知道,在 V8 中所有对象都是存储在堆中,通过堆进行内存分配的,我们可以通过 nodejs 的 API 查看目前的内存使用情况

那么 V8 为什么要做这样的内存限制呢?
从表层原因上说,是因为 V8 最初是为浏览器设计的,浏览器环境下,这个内存限制绰绰有余了
内存限制主要原因是 v8 的垃圾回收制度。1.5GB 内存做一次小的回收需要 50MS,做一次非增量性回收需要 1S 以上,并且这会使 JS 线程暂停。因此限制内存。
从深层原因上看,是因为 V8 垃圾回收机制的限制,按照官方的说法来说,以回收 1.5 GB 堆内存为例,V8 做一次小的垃圾回收需要 50ms 以上,做一次非增量的垃圾回收甚至需要 1s 以上。而这些垃圾回收的时间,是 JavaScript 单线程暂停执行的时间,如果垃圾回收的时间过长,应用的响应速度和性能都会直线下降,所以限制内存使用是一个比较好的选择。
这个限制也是可以打开的,在 V8 启动时,可以有下面两个方式调整内存的大小
node --max-old-space-size=1700 test.js // 单位为MB
node --max-new-space-size=1024 test.js // 单位为KB
node.js 内存泄露检测
在服务器环境中使用 Node 提供的 process.memoryUsage 方法查看内存情况
console.log(process.memoryUsage());
// {
// rss: 27709440,
// heapTotal: 5685248,
// heapUsed: 3449392,
// external: 8772
// }
process.memoryUsage 返回一个对象,包含了 Node 进程的内存占用信息。
该对象包含四个字段,单位是字节,含义如下:
- rss(resident set size):所有内存占用,包括指令区和堆栈。
- heapTotal:"堆"占用的内存,包括用到的和没用到的。
- heapUsed:用到的堆的部分。
- external: V8 引擎内部的 C++ 对象占用的内存。
判断内存泄漏,以 heapUsed 字段为准。