Javascript基础
数据类型
1.数据类型有哪几种
JavaScript 共有八种数据类型,分别是 undefined、null、Boolean、Number、String、Object、Symbol、BigInt。
其中 Symbol 和 BigInt 是 ES6 中新增的数据类型:
- Symbol 代表创建后独一无二且不可变的数据类型,它主要是为了解决可能出现的全局变量冲突的问题。
- BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数,使用 BigInt 可以安全地存储和操作大整数,即使这个数已经超出了 Number 能够表示的安全整数范围。
这些数据可以分为原始数据类型和引用数据类型:
- 栈:原始数据类型(Undefined、Null、Boolean、Number、String)
- 堆:引用数据类型(对象、数组和函数)
两种类型的区别在于存储位置的不同:
- 原始数据类型直接存储在栈(stack)中的简单数据段,占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储;
- 引用数据类型存储在堆(heap)中的对象,占据空间大、大小不固定。如果存储在栈中,将会影响程序运行的性能;引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
堆和栈的概念存在于数据结构和操作系统内存中,在数据结构中:
- 在数据结构中,栈中数据的存取方式为先进后出。
- 堆是一个优先队列,是按优先级来进行排序的,优先级可以按照大小来规定。
在操作系统中,内存被分为栈区和堆区:
- 栈区内存由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆区内存一般由开发着分配释放,若开发者不释放,程序结束时可能由垃圾回收机制回收。
undefined
undefined 的字面意思就是:未定义的值 。这个值的语义是,希望表示一个变量最原始的状态,而非人为操作的结果 。 这种原始状态会在以下 4 种场景中出现:
1、声明一个变量,但是没有赋值
var foo;
console.log(foo); // undefined
访问 foo,返回了 undefined,表示这个变量自从声明了以后,就从来没有使用过,也没有定义过任何有效的值。
2、访问对象上不存在的属性或者未定义的变量
console.log(Object.foo); // undefined
console.log(typeof demo); // undefined
访问 Object 对象上的 foo 属性,返回 undefined , 表示 Object 上不存在或者没有定义名为 foo 的属性;对未声明的变量执行 typeof 操作符返回了 undefined 值。
3、函数定义了形参,但没有传递实参
//函数定义了形参 a
function fn(a) {
console.log(a); // undefined
}
fn(); //未传递实参
函数 fn 定义了形参 a,但 fn 被调用时没有传递参数,因此,fn 运行时的参数 a 就是一个原始的、未被赋值的变量。
4、使用 void 对表达式求值
void 0; // undefined
void false; // undefined
void []; // undefined
void null; // undefined
void function fn() {}; // undefined
ECMAScript 明确规定 void 操作符 对任何表达式求值都返回 undefined ,这和函数执行操作后没有返回值的作用是一样的,JavaScript 中的函数都有返回值,当没有 return 操作时,就默认返回一个原始的状态值,这个值就是 undefined,表明函数的返回值未被定义。
因此,undefined 一般都来自于某个表达式最原始的状态值,不是人为操作的结果。当然,你也可以手动给一个变量赋值 undefined,但这样做没有意义,因为一个变量不赋值就是 undefined
null
null 的字面意思是空值。这个值的语义是,希望表示一个对象被人为的重置为空对象,而非一个变量最原始的状态。在内存里的表示就是,栈中的变量没有指向堆中的内存对象。
1、一般在以下两种情况下我们会将变量赋值为 null
- 如果定义的变量在将来用于保存对象,那么最好将该变量初始化为 null,而不是其他值。换句话说,只要意在保存对象的变量还没有真正保存对象,就应该明确地让该变量保存 null 值,这样有助于进一步区分 null 和 undefined。
- 当一个数据不再需要使用时,我们最好通过将其值设置为 null 来释放其引用,这个做法叫做解除引用。不过解除一个值的引用并不意味着自动回收改值所占用的内存。解除引用的真正作用是让值脱离执行环境,以便垃圾收集器在下次运行时将其回收。解除引用还有助于消除有可能出现的循环引用的情况。这一做法适用于大多数全局变量和全局对象的属性,局部变量会在它们离开执行环境时(函数执行完时)自动被解除引用。
2、特殊的 typeof null
当我们使用 typeof 操作符检测 null 值,我们理所应当地认为应该返"Null"类型呀,但是事实返回的类型却是"object"。
var data = null;
console.log(typeof data); // "object"
是不是很奇怪?其实我们可以从两方面来理解这个结果:
- 一方面从逻辑角度来看,null 值表示一个空对象指针,它代表的其实就是一个空对象,所以使用 typeof 操作符检测时返回"object"也是可以理解的。
- 另一方面,其实在 JavaScript 最初的实现中,JavaScript 中的值是由一个表示类型的标签和实际数据值表示的(对象的类型标签是 0)。由于 null 代表的是空指针(大多数平台下值为 0x00),因此,null 的类型标签也成为了 0,typeof null 就错误的返回了"object"。在 ES6 中,当时曾经有提案为历史平凡, 将 type null 的值纠正为 null, 但最后提案被拒了,所以还是保持"object"类型。
严格相等运算符===可以正确区分undefined和null:
let nothing = undefined;
let missingObject = null;
nothing === missingObject; // => false
boolean
BooLean 类型 的值有两个: true 和 false 表示某个事物是真还是假
显示转换
就是我们不需要解析器帮我处理,我们来控制转换为 Boolean 类型,有两种方式:
在进行转换的时候我们可以看出对于引用类型的值都会转为true,基本类型 Number 中0、NaN 以及''、null、undefined会被转换为false
/* 第一种方式是 使用逻辑非来转换(!!) */
!!0; //=> false
!!""; //=> false
!!null; //=> false
!!undefined; //=> false
!![]; //=> true
!!{}; //=> true
!!1; //=> true
!!"2"; //=> true
!!NaN; //=> false
!![2022]; //=> true
!!{ year: 2022 }; //=> true
/* 第二种方式是 使用Boolean转换 */
Boolean(0); //=> false
Boolean(""); //=> false
Boolean(null); //=> false
Boolean(undefined); //=> false
Boolean([]); //=> true
Boolean({}); //=> true
Boolean(1); //=> true
Boolean("2"); //=> true
Boolean(NaN); //=> false
Boolean([2022]); //=> true
Boolean({ year: 2022 }); //=> true
隐式转换
隐式转换涉及到三种转换:
ToPrimitive、ToString、ToNumber
- 转换为数字类型(ToNumber)
Number(null); //=> 0
Number(undefined); //=> NaN
Number(""); //=> 0
Number("1"); //=> 1
Number("0a"); //=> NaN
Number(true); //=> 1
Number(false); //=> 0
Number([]); //=> 0
Number([1]); //=> 1
Number({}); //=> NaN
2.转换为字符串类型(ToString)
String(null) //=> 'null'
String(undefined) //=> 'undefined'
String(true) //=> 'true'
String(false) //=> 'false'
String(1) //=> '1'
String([]) //=> ''
String([null]) //=> ''
String([undefined]) //=> ''
String([a,a,a]) //=> 'a,a,a'
String({}) //=> '[object Objecr]'
3.转换为原始值(ToPrimitive(转换的值,可选参数 Numbei|String))
如果 ToPrimitive 的第二个参数标记为 Number
首先会判断要转换的值是不是原始值,是就返回,不是就会调用这个对象的 valueOf ,如果 valueOf 返回的是原始值,就返回这个原始值,不是就会调用这个对象的 toString ,如果 toString 返回的是原始值,就返回这个原始值,不是就会TypeError异常如果 ToPrimitive 的第二个参数标记为 String首先会判断要转换的值是不是原始值,是就返回,不是就会调用这个对象的 toString ,如果 toString 返回的是原始值,就返回这个原始值,不是就会调用这个对象的 valueOf ,如果 valueOf 返回的是原始值,就返回这个原始值,不是就会TypeError异常如果 ToPrimitive 的第二个参数没有作为标记 该对象为 Date 类型,第二个参数被设置为 String,否则设置为 Number
== 运算符隐式转换
NaN不等于任何其它类型布尔类型参与比较,布尔类型的值会被转换为数字类型String与Number比较,String转化为Numbernull与undefined进行比较结果为 truenull,undefined与其它任何类型进行比较结果都为 false引用类型与值类型比较,引用类型先转换为原始值( ToPrimitive )引用类型与引用类型,直接判断是否指向同一对象
经典题目
定义一个变量 a , 使 a == 1 && a == 2 && a == 3 表达式为 true
let a = {
x:1,
valueOf(){
return a.x++
}
}
a == 1 && a == 2 && a == 3 => true
表达式执行,从左到右执行 a == 1 时 a 会转化为原始值(ToPrimitive(a, Number)) 找到自己构造函数原型上的 valueOf ,我们 a 创建了一个 valueOf 方法,根据原型链查找机制使用的是我们定义的valueOf , 执行 a.valueOf 返回结果时 1 所以 a == 1` `第二次执行 a == 2 , 因为我们 valueOf return a.x++ 先赋值后自增 第一次执行完a.x的之久发生改变 a == 2 成立,依次往后比较...
number
/* 自变量创建(推荐) */
ler Num = 123
/* 构造函数创 */
let Num = new Number(123)
NaN
(Not a Number)是一个特殊的值,代表不是一个有效的数字,但是他是一个数字类型, NaN 与所有值都不相等,也包括它自己,如果想要判断是否是 Number 类型,可以使用 isNaN, isNaN 是判断是否是 NaN (无效数字)
typeof NaN; //=> 'number'
NaN == NaN; //=> 'false'
isNaN(NaN); //=> 'true'
isNaN(123); //=> 'false'
!isNaN(123); //=> 'true'
常用函数
判断是否为整数
Number.isInteger(0) //=> true
Number.isInteger(1) //=> true
Number.isInteger(1.1) //=> false
方法用来检测传入的参数是否是一个有穷数。
Number.isFinite()
指定小数位数,进行四舍五入 toFixed
const num = 1.1
num.toFixed(2) //=>1.10
常用属性
Number.EPSILON
Number.EPSILON 属性表示 1 与Number可表示的大于 1 的最小的浮点数之间的差值。
x = 0.2;
y = 0.3;
z = 0.1;
equal = Math.abs(x - y + z) < Number.EPSILON;
Number.MAX_SAFE_INTEGER
Number.MAX_SAFE_INTEGER 常量表示在 JavaScript 中最大的安全整数(maxinum safe integer)(2^53 - 1)。
MAX_SAFE_INTEGER 是一个值为 9007199254740991 的常量。因为 Javascript 的数字存储使用了 IEEE 754 中规定的双精度浮点数数据类型,而这一数据类型能够安全存储 -(2^53 - 1) 到 2^53 - 1 之间的数值(包含边界值)
Number.MAX_SAFE_INTEGER; // 9007199254740991
Math.pow(2, 53) - 1; // 9007199254740991
Number.MAX_VALUE
Number.MAX_VALUE 属性表示在 JavaScript 里所能表示的最大数值。
MAX_VALUE 属性值接近于 1.79E+308。
大于 MAX_VALUE 的值代表 "Infinity"。
因为 MAX_VALUE 是 Number 对象的一个静态属性,所以你应该直接使用Number.MAX_VALUE ,而不是作为一个创建的 Number 实例的属性。
Number.MIN_SAFE_INTEGER
Number.MIN_SAFE_INTEGER 代表在 JavaScript 中最小的安全的 integer 型数字 (-(2^53 - 1))。
MIN_SAFE_INTEGER 的值是-9007199254740991.
Number.MIN_VALUE
Number.MIN_VALUE 属性表示在 JavaScript 中所能表示的最小的正值。
MIN_VALUE 属性是 JavaScript 里最接近 0 的正值,而不是最小的负值。
MIN_VALUE 的值约为 5e-324。小于 MIN_VALUE ("underflow values") 的值将会转换为 0。
因为 MIN_VALUE 是 Number 的一个静态属性,因此应该直接使用: Number.MIN_VALUE, 而不是作为一个创建的 Number 实例的属性。
Number.NEGATIVE_INFINITY
Number.NEGATIVE_INFINITY 属性表示负无穷大。
Number.POSITIVE_INFINITY
Number.POSITIVE_INFINITY 属性表示正无穷大。
类型转换
Number: undefined 和 NaN 和 {}, 会被转化为 NaN
Number(null); //=> 0
Number(undefined); //=> NaN
Number([]); //=> 0
Number({}); //=> NaN
Number(true); //=> 1
Number(""); //=> 0
浮点精度
计算机以二进制处理数值类型, 都会有精度误差问题;
const num = 0.1 + 0.2;
console.log(num); //=> 0.30000000000000004
/* 可以用toFixed处理 */
num.tofixed(2); //=> 0.3
/* 还可以计算的数字乘以 10 的 n 次幂,换算成计算机能够精确识别的整数,然后再除以 10 的 n 次幂 */
function func(s, n) {
const m = Math.pow(10, 2);
return (s * m + n * m) / m;
}
func(0.1, 0.2); //=> 0.3
Math
Math 对象提供多种算数值类型和函数
/* 取最小与最大值 */
Math.min(1, 2, 3) //=> 1
Math.max(1, 2, 3) //=> 3
/* 向上取整 */
Math.ceil(1.1) //=> 2
/* 向下取整 */
Math.floor(1.1) //=> 1
/* 四舍五入 */
Math.round(1.1) //=> 1
Math.round(1.5) //=> 2
/* 随机数 */
Math.random() //=> 随机生成大于等于0,小于1的f浮点数
Math.random() * 10 //=> 随机生成大于等于0,小于10的浮点数
Math.floor(Math.random() * 10) //=> 随机生成大于等于0,小于10的整数
Math.ceil(Math.random() * 10) //=> 随机生成等于0,小于等于10的整数
symbol
symbol 做对象属性 不可枚举 不能被对象直接访问
使用Object.getOwnPropertyNames() 获取所有属性,无论是否是可枚举
创建 symbol
ES6 新增了Symbol作为原始数据类型,和其他原始数据类型,像 number、boolean、null、undefined、string,symbol 类型没有文字形式。
创建一个 symbol,我们要使用全局函数Symbol()
let s = Symbol("foo");
Symbol() 函数每次调用会创建一个新的唯一值
console.log(Symbol() === Symbol()); // false
Symbol() 函数接受一个可选参数作为描述,这样使 Symbol 更具有语义性
下面创建两个 symbol 分别为: firstName and lastName.
let firstName = Symbol("first name");
let lastName = Symbol("last name");
当我们使用 console.log()去打印 symbol 的时候会隐式调用 symbol 的 toString()方法
console.log(firstName); // Symbol(first name)
console.log(lastName); // Symbol(last name)
由于 symbol 为原始值,我们可以使用typeof去检查它的类型,同样 ES6 拓展了 typeof 关键字,在遇到 symbol 类型时会返回 symbol
console.log(typeof firstName);
// symbol
由于是原始类型,也不能使用 new 去创建
let s = new Symbol(); // error
共享 symbol
要创建一个共享的 symbol,要使用Symbol.for()函数,而不是Symbol()。
Symbol.for() 也接受一个可选参数作为描述
let ssn = Symbol.for("ssn");
Symbol.for() 会首先在全局中查找是否有已经创建的ssn的 symbol,如果有就会返回已经创建的 symbol,如果没有就会创建一个新的 symbol。
接下来,我们创建一个相同的 symbol,然后看看不是同一个 symbol
let nz = Symbol.for("ssn");
console.log(ssn === nz); // true
因为上面已经创建ssn的 symbol,所以 nz 变量的 symbol 和上面创建的将是同一个。
如果想要获取 symbol 的键,使用 Symbol.keyFor()方法
console.log(Symbol.keyFor(nz)); // 'ssn'
注意,如果 symbol 是通过Symbol()创建的,使用Symbol.keyFor()会返回 undefined
let systemID = Symbol("sys");
console.log(Symbol.keyFor(systemID)); // undefined
Symbol.toStringTag
这是一个内置 symbol,它通常作为对象的属性键使用,对应的属性值应该为字符串类型,这个字符串用来表示该对象的自定义类型标签
我们通常利用 Object.prototype.toString()来返回数据类型,比如:
console.log(Object.prototype.toString.call("foo")); // "[object String]"
console.log(Object.prototype.toString.call([1, 2])); // "[object Array]"
console.log(Object.prototype.toString.call(3)); // "[object Number]"
console.log(Object.prototype.toString.call(true)); // "[object Boolean]"
console.log(Object.prototype.toString.call(undefined)); // "[object Undefined]"
console.log(Object.prototype.toString.call(null)); // "[object Null]"
那么这些返回值[object Xxx]是怎么来的?其实就是 Object.prototype.toString()方法会去读取 Symbol.toStringTag 标签并把它包含在自己的返回值里。
let myObj = {};
Object.defineProperty(myObj, Symbol.toStringTag, { value: "Yuhua" });
console.log(Object.prototype.toString.call(myObj)); //[object Yuhua]
上面的例子第二行就通过 Object.defineProperty 改写了 myObj 的 Symbol.toStringTag,将值改为 Yuhua,所以,原本 myObj 的类型[object Object]变成了[object Yuhua]
结论: 通过重定义数据的 Symbol.toStringTag 可以改写 Object.prototype.toString.call()返回的数据类型。也就是说,可以使得数据类型自定义
Symbol 应用
使用 Symbol 作唯一值
我们在代码中经常会用字符串或者数字去表示一些状态,也经常会面临缺乏语义性或者重复定义的问题,这时使用 Symbol 是最好的选择,每次新创建的 Symbol 都是唯一的,不会产生重复,而且我们可以给 Symbol 传入相应的描述。
看下面的例子,我们使用 Symbol 来表达订单的几种状态,而不是字符串和数字
let statuses = {
OPEN: Symbol("已下单"),
IN_PROGRESS: Symbol("配送中"),
COMPLETED: Symbol("订单完成"),
CANCELED: Symbol("订单取消"),
};
// 完成订单
task.setStatus(statuses.COMPLETED);
使用 symbol 作为对象属性
使用Symbol作为属性名称
let statuses = {
OPEN: Symbol("已下单"),
IN_PROGRESS: Symbol("配送中"),
COMPLETED: Symbol("订单完成"),
CANCELED: Symbol("订单取消"),
};
let status = Symbol("status");
let task = {
[status]: statuses.OPEN,
description: "学习 ES6 Symbol",
};
console.log(task);
使用Object.keys()获取对象的所有可枚举属性
console.log(Object.keys(task));
// ["description"]
使用Object.getOwnPropertyNames() 获取所有属性,无论是否是可枚举
console.log(Object.getOwnPropertyNames(task));
// ["description"]
那么要获取对象中的 Symbol 属性,需要使用 ES6 新增的Object.getOwnPropertySymbols()方法
console.log(Object.getOwnPropertySymbols(task));
//[Symbol(status)]
Symbol.iterator
Symbol.iterator 指定函数是否会返回对象的迭代器。
具有 Symbol.iterator 属性的对象称为可迭代对象。
在 ES6 中,Array、Set、Map 和 string 都是可迭代对象。
ES6 提供了 for...of 循环,它可以用在可迭代对象上。
var numbers = [1, 2, 3];
for (let num of numbers) {
console.log(num);
}
// 1
// 2
// 3
JavaScript 引擎首先调用numbers数组的 Symbol.iterator 方法来获取迭代器对象,然后它调用 iterator.next() 方法并将迭代器对象的 value 属性复制到num变量中,3 次迭代后,对象的done 属性为true,循环推出
我们可以通过Symbol.iterator来获取数组的迭代器对象。
var iterator = numbers[Symbol.iterator]();
console.log(iterator.next()); // Object {value: 1, done: false}
console.log(iterator.next()); // Object {value: 2, done: false}
console.log(iterator.next()); // Object {value: 3, done: false}
console.log(iterator.next()); // Object {value: undefined, done: true}
默认情况下,一个自己定义的集合是不可以迭代的,但是我们可以用 Symbol.iterator 使其可迭代
class List {
constructor() {
this.elements = [];
}
add(element) {
this.elements.push(element);
return this;
}
*[Symbol.iterator]() {
for (let element of this.elements) {
yield element;
}
}
}
let chars = new List();
chars.add("A").add("B").add("C");
// 使用Symbol.iterator实现了迭代
for (let c of chars) {
console.log(c);
}
// A
// B
// C
bigint
JS 整数是怎么表示的
通过 Number 类型来表示,遵循 IEEE754 标准,通过 64 位来表示一个数字,(1 + 11 + 52),最大安全数字是 Math.pow(2, 53) - 1,对于 16 位十进制。(符号位 + 指数位 + 小数部分有效位)
Math.pow(2, 53) ,53 为有效数字,会发生截断,等于 JS 能支持的最大数字
什么是 BigInt?
BigInt是一种新的数据类型,用于当整数值大于 Number 数据类型支持的范围时。这种数据类型允许我们安全地对大整数执行算术操作,表示高分辨率的时间戳,使用大整数 id,等等,而不需要使用库。
为什么需要 BigInt?
在 JS 中,所有的数字都以双精度 64 位浮点格式表示,那这会带来什么问题呢?
这导致 JS 中的 Number 无法精确表示非常大的整数,它会将非常大的整数四舍五入,确切地说,JS 中的
Number类型只能安全地表示-9007199254740991(-(2^53-1))和9007199254740991((2^53-1)),任何超出此范围的整数值都可能失去精度。
console.log(999999999999999); //=>10000000000000000
同时也会有一定的安全性问题:
9007199254740992 === 9007199254740993;
// → true 居然是true!
如何创建并使用 BigInt?
要创建BigInt,只需要在数字末尾追加n即可
console.log( 9007199254740995n ); // → 9007199254740995n
console.log( 9007199254740995 ); // → 9007199254740996
另一种创建BigInt的方法是用BigInt()构造函数
BigInt("9007199254740995"); // → 9007199254740995n
简单使用如下:
10n + 20n; // → 30n
10n - 20n; // → -10n
+10n; // → TypeError: Cannot convert a BigInt value to a number
-10n; // → -10n
10n * 20n; // → 200n
20n / 10n; // → 2n
23n % 10n; // → 3n
10n ** 3n; // → 1000n
const x = 10n;
++x; // → 11n
--x; // → 9n
console.log(typeof x); //"bigint"
值得警惕的点
BigInt不支持一元加号运算符, 这可能是某些程序可能依赖于 + 始终生成Number的不变量,或者抛出异常。另外,更改+的行为也会破坏asm.js代码。
因为隐式类型转换可能丢失信息,所以不允许在bigint和 Number 之间进行混合操作。当混合使用大整数和浮点数时,结果值可能无法由BigInt或Number精确表示。
10 + 10n; // → TypeError
不能将
BigInt传递给Web api和内置的 JS 函数,这些函数需要一个 Number 类型的数字。尝试这样做会报 TypeError 错误。
Math.max(2n, 4n, 6n); // → TypeError
当
Boolean类型与BigInt类型相遇时,BigInt的处理方式与Number类似,换句话说,只要不是0n,BigInt就被视为truthy的值。
if(0n){//条件判断为false
}
if(3n){//条件为true
}
- 元素都为 BigInt 的数组可以进行 sort。
BigInt可以正常地进行位运算,如|、&、<<、>>和^
2.数据类型检测有哪几种方法
(1)typeof
console.log(typeof 2); // number
console.log(typeof true); // boolean
console.log(typeof "str"); // string
console.log(typeof function () {}); // function
console.log(typeof []); // object
console.log(typeof {}); // object
console.log(typeof undefined); // undefined
console.log(typeof null); // object
其中数组、对象、null都会被判断为 object,其他判断都正确。
typeof null 的结果是 Object。
在 JavaScript 第一个版本中,所有值都存储在 32 位的单元中,每个单元包含一个小的 类型标签(1-3 bits) 以及当前要存储值的真实数据。类型标签存储在每个单元的低位中,共有五种数据类型:
如果最低位是 1,则类型标签标志位的长度只有一位;如果最低位是 0,则类型标签标志位的长度占三位,为存储其他四种数据类型提供了额外两个 bit 的长度。
有两种特殊数据类型:
undefined的值是 (-2)^30(一个超出整数范围的数字);null的值是机器码 NULL 指针(null 指针的值全是 0)
那也就是说null 的类型标签也是 000,和 Object 的类型标签一样,所以会被判定为 Object。
(2)instanceof
instanceof可以正确判断对象的类型,其内部运行机制是判断在其原型链中能否找到该类型的原型。
console.log(2 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log("str" instanceof String); // false
console.log([] instanceof Array); // true
console.log(function () {} instanceof Function); // true
console.log({} instanceof Object); // true
可以看到,instanceof只能正确判断引用数据类型,而不能判断基本数据类型。instanceof 运算符可以用来测试一个对象在其原型链中是否存在一个构造函数的 prototype 属性。
instanceof 运算符用于判断构造函数的 prototype 属性是否出现在对象的原型链中的任何位置。
function myInstanceof(left, right) {
// 获取对象的原型
let proto = Object.getPrototypeOf(left);
// 获取构造函数的 prototype 对象
let prototype = right.prototype;
// 判断构造函数的 prototype 对象是否在对象的原型链上
while (true) {
if (!proto) return false;
if (proto === prototype) return true;
// 如果没有找到,就继续从其原型上找,Object.getPrototypeOf方法用来获取指定对象的原型
proto = Object.getPrototypeOf(proto);
}
}
(3)constructor
console.log((2).constructor === Number); // true
console.log(true.constructor === Boolean); // true
console.log("str".constructor === String); // true
console.log([].constructor === Array); // true
console.log(function () {}.constructor === Function); // true
console.log({}.constructor === Object); // true
constructor有两个作用,一是判断数据的类型,二是对象实例通过 constrcutor 对象访问它的构造函数。需要注意,如果创建一个对象来改变它的原型,constructor就不能用来判断数据类型了:
function Fn() {}
Fn.prototype = new Array();
var f = new Fn();
console.log(f.constructor === Fn); // false
console.log(f.constructor === Array); // true
(4)Object.prototype.toString.call()
Object.prototype.toString.call() 使用 Object 对象的原型方法 toString 来判断数据类型:
var a = Object.prototype.toString;
console.log(a.call(2)); // [object Number]
console.log(a.call(true)); //[object Boolean]
console.log(a.call("str")); //[object String]
console.log(a.call([])); //[object Array]
console.log(a.call(function () {})); //[object Function]
console.log(a.call({})); //[object Object]
console.log(a.call(undefined)); //[object Undefined]
console.log(a.call(null)); //[object Null]
同样是检测对象 obj 调用 toString 方法,obj.toString()的结果和Object.prototype.toString.call(obj)的结果不一样,这是为什么?
这是因为 toString 是 Object 的原型方法,而 Array、function 等类型作为 Object 的实例,都重写了 toString 方法。不同的对象类型调用 toString 方法时,根据原型链的知识,调用的是对应的重写之后的 toString 方法(function 类型返回内容为函数体的字符串,Array 类型返回元素组成的字符串…),而不会去调用 Object 上原型 toString 方法(返回对象的具体类型),所以采用 obj.toString()不能得到其对象类型,只能将 obj 转换为字符串类型;因此,在想要得到对象的具体类型时,应该调用 Object 原型上的 toString 方法。
function getDataType(data) {
var getType = Object.prototype.toString;
var myType = getType.call(data); //调用call方法判断类型,结果返回形如[object Function]
var typeName = myType.slice(8, -1); // [object Function],即取除了“[object ”的字符串。 ]"
var copyInfo = ""; //复制后的数据
//console.log(data+" is "+myType);
switch (typeName) {
case "Number":
copyInfo = data - 0;
break;
case "String":
copyInfo = "'" + data + "'";
break;
case "Function":
copyInfo = data;
break;
case "Null":
copyInfo = null;
break;
case "Undefined":
copyInfo = "Undefined";
break;
case "Array":
copyInfo = []; //先将copyInfo变为空数组
for (var i = 0; i < data.length; i++) {
copyInfo[i] = data[i]; //将data数组数据逐个写入copyInfo
}
break;
case "Object":
copyInfo = {}; //先将copyInfo变为空对象
for (var x in data) {
copyInfo[x] = data[x];
}
break;
case "Boolean":
copyInfo = data;
break;
default:
copyInfo = data;
break;
}
return copyInfo;
}
3.判断数组方法有哪些
- 通过
Object.prototype.toString.call()做判断
Object.prototype.toString.call(obj).slice(8, -1) === "Array";
- 通过原型链做判断
obj.__proto__ === Array.prototype;
- 通过 ES6 的
Array.isArray()做判断
Array.isArrray(obj);
- 通过
instanceof做判断
obj instanceof Array;
- 通过
Array.prototype.isPrototypeOf
Array.prototype.isPrototypeOf(obj);
4.null 和 undefined 区别
首先 Undefined 和 Null 都是基本数据类型,这两个基本数据类型分别都只有一个值,就是 undefined 和 null。
undefined 代表的含义是未定义,null 代表的含义是空对象。一般变量声明了但还没有定义的时候会返回 undefined,null 主要用于赋值给一些可能会返回对象的变量,作为初始化。
undefined 在 JavaScript 中不是一个保留字,这意味着可以使用 undefined 来作为一个变量名,但是这样的做法是非常危险的,它会影响对 undefined 值的判断。我们可以通过一些方法获得安全的 undefined 值,比如说 void 0。
当对这两种类型使用 typeof 进行判断时,Null 类型化会返回 “object”,这是一个历史遗留的问题。当使用双等号对两种类型的值进行比较时会返回 true,使用三个等号时会返回 false。
5.0.1+0.2!==0.3 为什么,怎么解决
在开发过程中遇到类似这样的问题:
let n1 = 0.1,
n2 = 0.2;
console.log(n1 + n2); // 0.30000000000000004
这里得到的不是想要的结果,要想等于 0.3,就要把它进行转化:
(n1 + n2).toFixed(2); // 注意,toFixed为四舍五入
toFixed(num) 方法可把 Number 四舍五入为指定小数位数的数字。
计算机是通过二进制的方式存储数据的,所以计算机计算 0.1+0.2 的时候,实际上是计算的两个数的二进制的和。
在 JavaScript 中只有一种数字类型:Number,它的实现遵循 IEEE 754 标准,使用64 位固定长度来表示,也就是标准的 double 双精度浮点数。在二进制科学表示法中,双精度浮点数的小数部分最多只能保留 52 位,再加上前面的 1,其实就是保留 53 位有效数字,剩余的需要舍去,遵从“0 舍 1 入”的原则
双精度数是保存: 
- 第一部分(蓝色):用来存储符号位(sign),用来区分正负数,0 表示正数,占用 1 位
- 第二部分(绿色):用来存储指数(exponent),占用 11 位
- 第三部分(红色):用来存储小数(fraction),占用 52 位
对于 0.1,它的二进制为:
0.00011001100110011001100110011001100110011001100110011001 10011...
转为科学计数法(科学计数法的结果就是浮点数):
(1.1001100110011001100110011001100110011001100110011001 * 2) ^ -4;
可以看出 0.1 的符号位为 0,指数位为-4,小数位为:
1001100110011001100110011001100110011001100110011001;
IEEE 标准规定了一个偏移量,对于指数部分,每次都加这个偏移量进行保存,这样即使指数是负数,那么加上这个偏移量也就是正数了。由于 JavaScript 的数字是双精度数,这里就以双精度数为例,它的指数部分为 11 位,能表示的范围就是 0~2047,IEEE 固定双精度数的偏移量为 1023
- 当指数位不全是 0 也不全是 1 时(规格化的数值),IEEE 规定,阶码计算公式为 e-Bias。 此时 e 最小值是 1,则 1-1023= -1022,e 最大值是 2046,则 2046-1023=1023,可以看到,这种情况下取值范围是
-1022~1013。 - 当指数位全部是 0 的时候(非规格化的数值),IEEE 规定,阶码的计算公式为 1-Bias,即 1-1023= -1022。
- 当指数位全部是 1 的时候(特殊值),IEEE 规定这个浮点数可用来表示 3 个特殊值,分别是正无穷,负无穷,NaN。 具体的,小数位不为 0 的时候表示 NaN;小数位为 0 时,当符号位 s=0 时表示正无穷,s=1 时候表示负无穷。
对于上面的 0.1 的指数位为-4,-4+1023 = 1019 转化为二进制就是:1111111011.
所以,0.1 表示为:
0 1111111011 1001100110011001100110011001100110011001100110011001
实现 0.1+0.2=0.3,一个直接的解决方法就是设置一个误差范围,通常称为“机器精度”。对 JavaScript 来说,这个值通常为 2-52,在 ES6 中,提供了Number.EPSILON属性,而它的值就是 2^-52,只要判断0.1+0.2-0.3是否小于Number.EPSILON,如果小于,就可以判断为 0.1+0.2 ===0.3
function numberepsilon(arg1, arg2) {
return Math.abs(arg1 - arg2) < Number.EPSILON;
}
console.log(numberepsilon(0.1 + 0.2, 0.3)); // true
6.类型转换规则
首先我们要知道,在
JS中类型转换只有三种情况,分别是:
- 转换为布尔值
- 转换为数字
- 转换为字符串
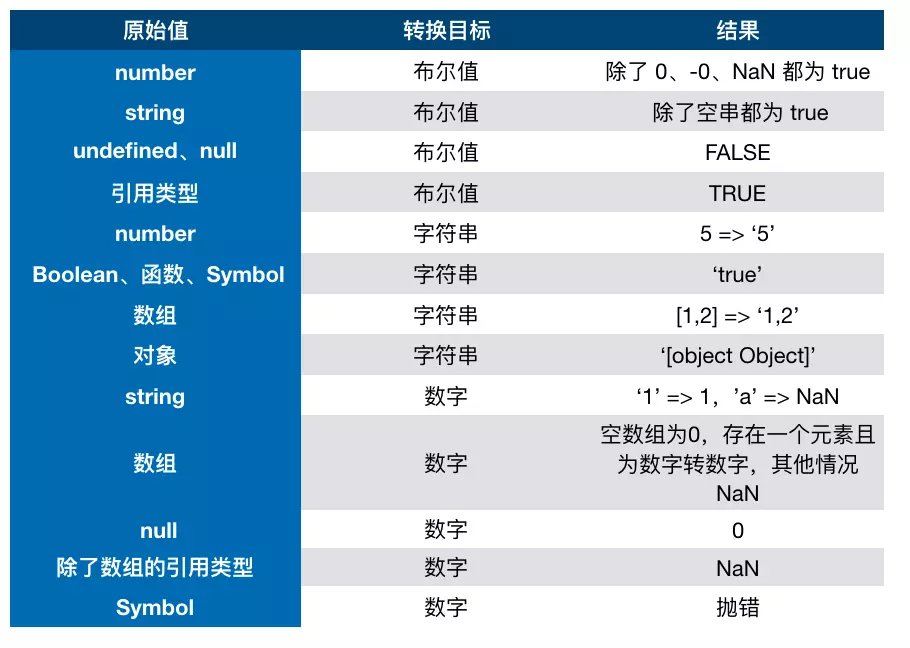
== 运算符隐式转换
NaN不等于任何其它类型Boolean参与比较,Boolean的值会被转换为NumberString与Number比较,String转化为Numbernull与undefined进行比较结果为 truenull,undefined与其它任何类型进行比较结果都为 false引用类型与值类型比较,引用类型先转换为原始值( ToPrimitive )引用类型与引用类型,直接判断是否指向同一对象
[] == ![]结果是什么?
==中,左右两边都需要转换为数字然后进行比较[]转换为数字为0![]首先是转换为布尔值,由于[]作为一个引用类型转换为布尔值为true- 因此
![]为false,进而在转换成数字,变为0 0 == 0, 结果为true
转 Boolean
在条件判断时,除了
undefined,null,false,NaN,'',0,-0,其他所有值都转为true,包括所有对象
对象转原始类型
对象在转换类型的时候,会调用内置的
[[ToPrimitive]]函数,对于该函数来说,算法逻辑一般来说如下
- 如果已经是原始类型了,那就不需要转换了
- 调用
x.valueOf(),如果转换为基础类型,就返回转换的值 - 调用
x.toString(),如果转换为基础类型,就返回转换的值 - 如果都没有返回原始类型,就会报错
当然你也可以重写
Symbol.toPrimitive,该方法在转原始类型时调用优先级最高。
let a = {
valueOf() {
return 0;
},
toString() {
return "1";
},
[Symbol.toPrimitive]() {
return 2;
},
};
1 + a; // => 3
四则运算符
它有以下几个特点:
- 运算中其中一方为字符串,那么就会把另一方也转换为字符串
- 如果一方不是字符串或者数字,那么会将它转换为数字或者字符串
1 + "1"; // '11'
true + true; // 2
4 + [1, 2, 3]; // "41,2,3"
- 对于第一行代码来说,触发特点一,所以将数字
1转换为字符串,得到结果'11' - 对于第二行代码来说,触发特点二,所以将
true转为数字1 - 对于第三行代码来说,触发特点二,所以将数组通过
toString转为字符串1,2,3,得到结果41,2,3 - 那么对于除了加法的运算符来说,只要其中一方是数字,那么另一方就会被转为数字
4 * "3"; // 12
4 * []; // 0
4 * [1, 2]; // NaN
比较运算符
- 如果是对象,就通过
toPrimitive转换对象 - 如果是字符串,就通过
unicode字符索引来比较
let a = {
valueOf() {
return 0;
},
toString() {
return "1";
},
};
a > -1; // true
在以上代码中,因为
a是对象,所以会通过valueOf转换为原始类型再比较值
7.“==”和“===”的区别
两者都是判断等式两边是否相等,最大的区别就是==会进行类型的转换之后再判断两者是否相等,而=====不会进行数据类型的转换,先判断两边的数据类型是否相等,如果数据类型相等的话才会进行接下来的判断,再进行等式两边值得判断,可以理解为只有等式两边是全等(数据类型相同,值相同)的时候结果才会是 true,否则全为 false。
==判断等式两边是否相等的情况:
(1)null、undefined 和不同类型比较,都是 false(null 和 undefined 结果为 true)
(2)NaN 和任何数据进行比较,都是 false(包括 NaN 和 NaN 相比较也为 false)
(3)布尔值是转换为数字 1 或 0 再和其他数据进行比较
拓展: 不同数据转换成布尔值的结果:
console.log(Boolean("")); //false
console.log(Boolean({})); //true
console.log(Boolean([])); //true
console.log(Boolean(null)); //false
console.log(Boolean(undefined)); //false
console.log(Boolean(NaN)); //false
console.log(Boolean(Object)); //true
(4)数字和其他简单数据类型进行比较时,会尝试将其他数据类型转换成数值型再进行比较
其他数据类型默认转数字使用的是 Number()
console.log("" == false); //true
console.log(parseInt("")); //NaN
console.log(Number("")); //0
console.log("" == 0); //true
(5)对象和其他简单数据类型进行比较的时候,会尝试使用对象的 valueOf()和 toString()方法将对象转换为原始值进行比较:
① 对象.toString()返回值只有[ object Object ]
let obj = {
name: "leon",
age: 18,
};
console.log(obj.toString()); //[object Object]
console.log(obj.valueOf()); //{name: 'leon', age: 18}
let obj = {};
console.log(obj.toString()); //[object Object]
console.log(obj.valueOf()); //{}
② 数组 [ ].toString()返回值是空 其他数组.toString()返回值是字符 ,一个成员一个字符逗号分隔
let arr1 = [1, 2, 3];
console.log(arr1.toString()); //1,2,3
console.log(arr1.valueOf()); //[1, 2, 3]
let arr = [];
console.log(arr.toString()); //空
console.log(arr.valueOf()); //[]
③ 其他的对象 function reg 返回字符串
function fn() {
console.log("你是最棒的!");
}
console.log(fn.toString());
console.log(fn.valueOf());
let reg = /^[^_$]\w{5,}@(163|126|qq|sina)\.(com|cn|net)$/;
console.log(reg.toString());
console.log(reg.valueOf());
(6)两者同为引用类型时,必须是指向同一个引用地址才相等,否则不相等
[]==[] //false []===[] //false
(7)-0 == +0 结果为:true
全等比较(===)不转换数据类型,数据类型和内容必须完全一致才是相等
全等比较(===)两边是否相等的情况:
(1)类型不同,一定不相等
(2)两个同为数值,并且相等,则相等;若其中一个为 NaN,一定不相等
(3)两个都为字符串,每个位置的字符都一样,则相等
(4)两个同为 true,或是 false,则相等
(5)两个值都引用同一个对象或函数,则相等,否则不相等(引用类型地址空间可能不一样)
(6)两个值都为 null,或 undefined,则相等
(7)两者同为引用类型时,必须是指向同一个引用地址才相等,否则不相等(5 的补充)
(8)-0 === +0 结果为:true
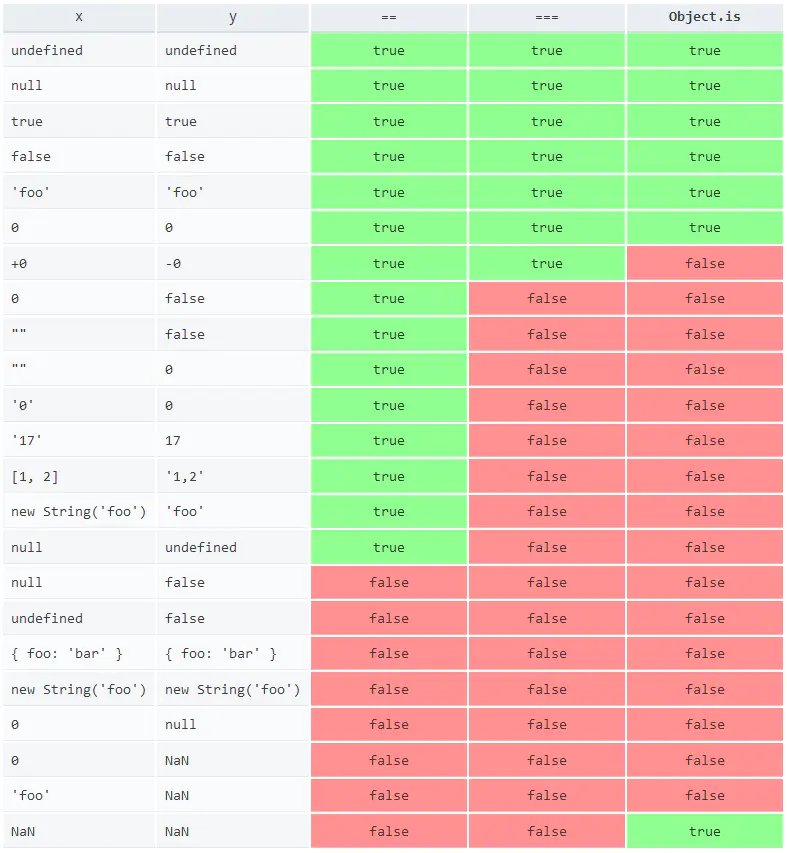
8.Object.is(),==,===三者的区别
- == :等于,两边值类型不同的时候,先进行类型转换,再比较;
- === :严格等于,只有当类型和值都相等时,才相等;
- Object.is() :与 === 的作用基本一样,但有些许不同。
== 和 === 的区别
== 和 === 的最大区别就是前者不限定类型而后者限定类型。如下例,如果想要实现严格相等(===),两者类型必须相同。
1 == "1"; // true
1 === "1"; // false
0 == false; // true
0 === false; // false
对于严格相等,有以下规则,如果 x === y,那么: a、如果 x 的类型和 y 的类型不一样,返回 false; b、如果 x 的类型是数字,那么: (1):如果 x 是 NaN,返回 false; (2):如果 y 是 NaN,返回 false; (3):如果 x 和 y 是同一个数字值,返回 true; (4):如果 x 是+0,y 是-0,返回 true; (5):如果 x 是-0,y 是+0,返回 true; (6):其余返回 false。 c、如果 x 和 y 的类型都为 undefined 或者 null,返回 true; d、如果 x 和 y 的类型都为字符串类型,那么如果 x 和 y 是完全相同的字符编码序列,返回 true,否则返回 false; e、如果 x 和 y 的类型都为布尔类型,那么如果 x 和 y 同为 true 或者 false,返回 true,否则返回 false; f、如果 x 和 y 是同一个对象值,返回 true,否则返回 false。
=== 和 Object.is() 的区别
Object.is() 的行为与 === 基本一致,但有两处不同: a、+0 不等于 -0; b、NaN 等于自身。
+0 === -0; // true
Object.is(+0, -0); // false
NaN === NaN; // false
Object.is(NaN, NaN); // true
三者详细对比如下如图所示:
9.JavaScript 梗图详解
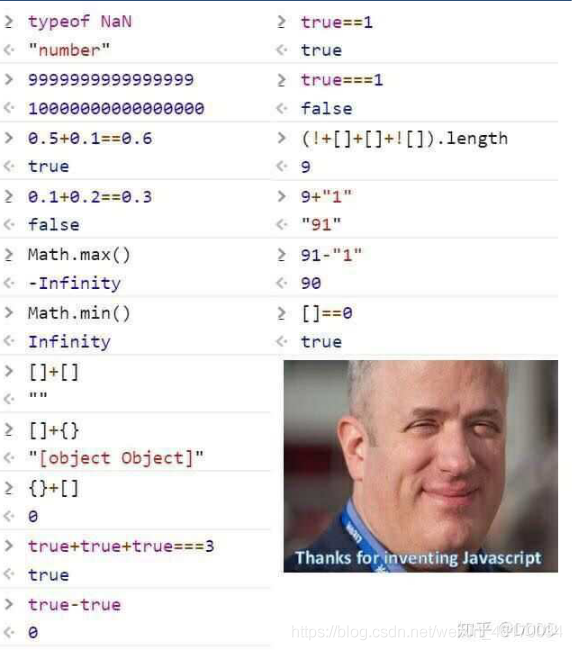
1.typeof NaN === "number"
NaN 同 Number.NaN 一样,都是表示 Not A Number。从 Number.NaN 可以推测 NaN 是数字类型。
但实际上 NaN 不是 JavaScript 创造的。IEEE 754 中将 NaN 定义为一种“特殊”的数字。
2.9999999999999999 === 10000000000000000
- JavaScript 对于数据储存使用的是 IEEE754 标准里的 双精度存储数字 (64 位)
- IEEE754 标准里面有符号位 1 位,指数位 11 位,有效数 52 位,这样就导致在十进制和二进制转化的时候会出现问题
JavaScript 中所有算数都是 IEEE 754 定义的双精度浮点数(链接),其可以表示的最大整数和浮点数分别在 JavaScript 中定义为 Number.MAX_SAFE_INTEGER(9007199254740991, 2^53-1) 和 Number.MAX_VALUE。
超出 9007199254740991 后,双精度浮点数只能表示偶数了,而且在不同范围内,步进还不相同。例如在 2^53 到 2^54,步进为 2。
> Number.MAX_SAFE_INTEGER
< 9007199254740991
> Number.MAX_SAFE_INTEGER + 1
< 9007199254740992
> Number.MAX_SAFE_INTEGER + 2
< 9007199254740992
> Number.MAX_SAFE_INTEGER + 3
< 9007199254740994
> Number.MAX_SAFE_INTEGER + 4
< 9007199254740996
> Number.MAX_SAFE_INTEGER + 5
< 9007199254740996
所以双精度浮点数无法表示 9999999999999999,只能将 9999999999999999 近似为 10000000000000000。
- 0.1 + 0.2 != 0.3
同样是浮点数的问题。双精度浮点数除了不能准确表示 9999999999999999 之类的整数,也不能准确表示 0.1 之类的小数。
就此我们也可以推知我们不发生大数精度的问题最大存储的数字大小 2^53 = 9007199254740992,大于这个数都有可能发生大数精度问题
小数的加减法,往往都是“随缘”算法。将 0.1 到 0.5 的几个小数打印为二进制:
> (0.1).toString(2)
< "0.0001100110011001100110011001100110011001100110011001101"
> (0.2).toString(2)
< "0.001100110011001100110011001100110011001100110011001101"
> (0.3).toString(2)
< "0.010011001100110011001100110011001100110011001100110011"
> (0.4).toString(2)
< "0.01100110011001100110011001100110011001100110011001101"
> (0.5).toString(2)
< "0.1"
除了 0.5,其余几个在二进制下都是无限不循环小数,在浮点数表示法中都会损失精度。
3.Math.max() === -Infinity
这个其实不算是坑,只是粗略看起来有点惊人,以为 max 容易理解为 max value。可以将 Math.max 理解为有一个隐参数 -Infinity 的函数,-Infinity 决定了返回值的下限。
4.加号问题
JavaScript 中加号有三个用途,一元运算符、二元运算符的算数加法和字符串拼接。无论是什么用途,都要求运算的值为原始类型,或可被转换成原始类型的对象。
依据提示,对象可转化为 string 或 number。提示分为 string 和 number 和 default,其中 default 会以 number 进行处理。在两元运算中,运算值既可以是 string 也可以是 number,所以转换的提示为 default。具体的转换还依赖于对象的 toString 和 valueOf 方法。详细的算法可以可以在这里找到。
// 1. 两个空数组相加等于一个空字符串
[] + [] = ""
// 2. 数组加对象等于 "[object Object]"
[] + {} = "[object Object]"
// 3. 对象加数组等于 0
{} + [] = 0
// 4. 三个 true 相加和 3 全等
true + true + true === 3
// 5. !+[]+[]+![]
(!+[]+[]+![]).length = 9
// 6. 数字加字符串
9 + "1" = "91"
一些例子:
> ({ valueOf() { return 1 }}) + 1
< 2
> ({ toString() { return '2' }}) + 1
< "21"
> ({ valueOf() { return 1 }}) + ({ valueOf() { return 2 } })
< 3
> ({ toString() { return '2' }, valueOf() { return 1 } }) + 1
< 2
> ({ toString() { return '2' }, valueOf() { return 1 } }) + '1'
< "11"
所以 []+[] → ""+"" → ""; []+{} → "" + "[object Object]" → "[object Object]"。
当加号的左右的运算值都为原始类型时,并且其中一个为 string,则应用字符串拼接算法,否则应用算数加法。运算过程中还可能发生原始类型之间的隐式转换。
所以 true+true+true → 1+1+1 → 3; !+[]+[]+![] → (!+[])+[]+(![]) → (!0)+[]+(![]) → true+""+false → "truefalse"。
这里比较费解的是,为何 {}+[] 等于 0?原因是这里的 {} 会识别为空语句块,从而 + 用为一元运算符,其含义是将运算值转换为 number。所以 {}+[] → +[] → +"" → 0。
{}识别为空对象还是空语句块,有一个**大体**的规则:若语句(statement)以{ 开头,则识别为语句块,否则识别为对象。当然生成中应当避免这类有歧义的写法,况且{}在各个 JavaScript 引擎中也有些差异,例如 {}+{}在 Firefox 下可能输出NaN,而在 Safari 下可能输出为 "[object Object][object object]"
js 里的减号默认是转化为 Number 类型然后计算的
// 1.
true - true = 0
// 2.
91 - "1" = 90
5.相等问题
JavaScript 提供了 == 和 === 两个比较运算符。前者会将运算值转化为相同类型后再应用 === 的算法,后者等价于 C Java 等编程语言中的 ==,是严格地相等。
所以 == 甚至可以进行对象和原始类型的比较:
> 1 == { valueOf() { return 1 } }
< true
> 1 == { toString() { return '1' } }
< true
> [] == 0
< true
值得一提的是,JavaScript 中还存在其他的比较算法 SameValue 和 SameValueZero。前者可通过 Object.is 来直接使用,后者可以通过 Array.prototype.includes 的方法来间接使用。
具体的例子如下:
> NaN == NaN
< false
> NaN === NaN
< false
> Object.is(NaN, NaN)
< true
> [NaN].includes(NaN)
< true
> Object.is(0, -0)
< false
> [0].includes(-0)
< true
Object.is()判断两个值是否相同。 如果下列任何一项成立,则两个值相同:
两个值都是 undefined 两个值都是 null 两个值都是 true 或者都是 false 两个值是由相同个数的字符按照相同的顺序组成的字符串 两个值指向同一个对象 两个值都是数字并且 都是正零 +0 都是负零 -0 都是 NaN 都是除零和 NaN 外的其它同一个数字
Js 基础
1.内置对象有哪些
JS 中对象分为 3 类:
- 自定义对象:属于 ECMAScript
- 内置对象:属于 ECMAScript,
Math、Date、Array、String。 - 浏览器对象:JS 独有的,JS API 学习
Math 对象
Math 不是构造函数,不需要 new 来调用,直接使用里面的属性和方法。
Math 常用内置属性和方法
| 属性/方法 | 描述 |
|---|---|
| Math.PI | 圆周率 |
| Math.floor() | 向下取整 |
| Math.ceil() | 向上取整 |
| Math.round() | 四舍五入,其他数字都是四舍五入,只有 5 是往大了取 -1.1→-1 -1.5→-1 |
| Math.abs() | 绝对值 |
| Math.max()/Math.min() | 求最大和最小值 |
| Math.random() | 返回一个随机小数[0,1) |
日期对象
Date()对象是一个构造函数,必须使用 new 来调用创建我们的日期对象,即为需要实例化后才能使用。
如果没有输入任何参数,则 Date 的构造器会依据系统设置的当前时间来创建一个 Date 对象。
| Date Creation | Output |
|---|---|
new Date() | Current date and time |
new Date(timestamp) | Creates date based on milliseconds since Epoch time |
new Date(date string) | Creates date based on date string |
new Date(year, month, day, hours, minutes, seconds, milliseconds) | Creates date based on specified date and time |
日期格式化
| 方法名 | 说明 |
|---|---|
| getFullyear() | 获取当年 |
| getMonth() | 获取当月 0~11 要+1 |
| getDate() | 获取当前日期 |
| getDay() | 获取星期几 周日 0~周六 6 需要+1 |
| getHours() | 获取当前小时 |
| getMinutes() | 获取当前分钟 |
| getSeconds | 获取当前秒钟 |
| getMilliseconds() | 获取当前毫秒 |
| getTime() | 获取时间戳 |
字符串对象
字符串里面的值不可变,虽然看上去可以改变内容,但其实是地址变了,内存中新开辟了一个内存空间。
var str = 'abc';
str = 'hello';
//当重新给 str 赋值的时候,常量'abc'不会被修改,依然在内存中。
//由于字符串不可变,在大量拼接字符串的时候会有效率问题:
var str = '';
for(var i = 0; i < 100000 ;i++){
str += i;
}
console.log(str);//这个结果需要花费大量时间来显示,因为需要不断开辟新的空间
//所以不要大量地对字符串重新赋值或者拼接字符串
常用方法
字符串所有方法,都不会修改字符串本身,操作完成会返回一个新的字符串。
| 方法名 | 说明 |
|---|---|
| indexOf('要查找的字符',[开始的位置]) | 返回指定内容在元字符串中的位置,如果找不到就返回-1 |
| lastIndexOf() | 从后往前找,只找第一个匹配的 |
| 方法名 | 说明 |
|---|---|
| charAt(index) | 返回指定位置的字符 |
| charCodeAt(index) | 获取指定位置处的 ASCll 码 |
| str[index] | 获取指定位置处的字符 HTML5, IE8+支持 和 charAt()等效 |
| 方法名 | 说明 |
|---|---|
| replace('被替换的字符','替换为的字符') | 只会替换第一个字符 |
| split('分隔符') | 字符转换为数组 |
正则对象
RegExp 对象表示正则表达式,它是对字符串执行模式匹配的强大工具
直接量语法
/pattern/attributes
创建 RegExp 对象的语法:
new RegExp(pattern, attributes);
参数 pattern 是一个字符串,指定了正则表达式的模式或其他正则表达式。
参数 attributes 是一个可选的字符串,包含属性 "g"、"i" 和 "m",分别用于指定全局匹配、区分大小写的匹配和多行匹配。ECMAScript 标准化之前,不支持 m 属性。如果 pattern 是正则表达式,而不是字符串,则必须省略该参数
返回值一个新的 RegExp 对象,具有指定的模式和标志。如果参数 pattern 是正则表达式而不是字符串,那么 RegExp() 构造函数将用与指定的 RegExp 相同的模式和标志创建一个新的 RegExp 对象。
如果不用 new 运算符,而将 RegExp() 作为函数调用,那么它的行为与用 new 运算符调用时一样,只是当 pattern 是正则表达式时,它只返回 pattern,而不再创建一个新的 RegExp 对象
RegExp 对象方法
| 方法 | 描述 |
|---|---|
| compile | 编译正则表达式。 |
| exec | 检索字符串中指定的值。返回找到的值,并确定其位置。 ans=reg.exec(str) ans[0]为匹配的全部字符串 ans[1]...ans[n]为分组捕获的字符 |
| test | 检索字符串中指定的值。返回 true 或 false。 reg.test(str) |
支持正则表达式的 String 对象的方法
| 方法 | 描述 |
|---|---|
| search | 检索与正则表达式相匹配的值。 |
| match | 找到一个或多个正则表达式的匹配。 |
| replace | 替换与正则表达式匹配的子串。 |
| split | 把字符串分割为字符串数组。 |
基本包装类型(基本类型的包装对象)
三个简单的数据类型:String、Number、Boolean。基本包装类型就是把简单的数据类型包装成复杂数据类型,这样基本数据类型就有了属性和方法。
实际使用中,调用方法,不需要使用new Number/String/Boolean,使用基础类型的时候,js 会自动帮我们包装成对应的对象:
内置方法
- toString()方法返回一个表示该对象的字符串。
- valueOf()方法返回指定对象的原始值。
var str = new String("123");
console.log(str.valueOf()); //123
var num = new Number(123);
console.log(num.valueOf()); //123
var date = new Date();
console.log(date.valueOf()); //1526990889729
var bool = new Boolean("123");
console.log(bool.valueOf()); //true
var obj = new Object({
valueOf: () => {
return 1;
},
});
console.log(obj.valueOf()); //1
valueOf() 和 toString()在特定的场合下会自行调用
2.js 全局变量和全局函数
全局变量
Infinity 代表正的无穷大的数值。 NaN 指示某个值是不是数字值。 undefined 指示未定义的值。
全局函数
decodeURI()
解码某个编码的 URI。
decodeURIComponent()
解码一个编码的 URI 组件。
encodeURI()
把字符串编码为 URI。
encodeURIComponent()
把字符串编码为 URI 组件。
escape()
对字符串进行编码。
unescape()
对由 escape() 编码的字符串进行解码
eval()
计算 JavaScript 字符串,并把它作为脚本代码来执行。
isFinite()
检查某个值是否为有穷大的数。
isNaN()
检查某个值是否是数字。isNaN()的缺点就在于 null、空格以及空串会被按照 0 来处理
Number()
把对象的值转换为数字。如果对象的值无法转换为数字,那么 Number() 函数返回 NaN
var test1 = new Boolean(true); //1
var test2 = new Boolean(false); //
var test3 = new Date(); //1660652058234
var test4 = new String("999"); //999
var test5 = new String("999 888"); //NaN
parseFloat()
解析一个字符串并返回一个浮点数。
parseInt()
解析一个字符串并返回一个整数。
String()
把对象的值转换为字符串。
String() 函数返回与字符串对象的 toString()方法值一样
var test1 = new Boolean(1);
var test2 = new Boolean(0);
var test3 = new Boolean(true);
var test4 = new Boolean(false);
var test5 = new Date();
var test6 = new String("999 888");
var test7 = 12345;
Number 与 parseInt
Number("123") //123 字符串
Number("") //0 字符串
Number(true) //1 布尔
Number(null) //0 对象
Number(1.1) //1.1 浮点数
Number("123abc") //NaN
parseInt("123") //123 字符串
parseInt(""); //NaN 字符串
parseInt(true) //NaN Boolean
parseInt(null) //NaN 对象
parseInt(1.1) //1 浮点数
parseInt("123abc")
在进行数值转换的过程中 (1)Number 有较为复杂的转换规则
如果是 boolean 值,true 和 false 将分别转换为十进制数值
如果是数字值,只是简单的传入与返回
如果是 null, 返回 0
如果是 undefined ,返回 NaN
如果是字符串,遵循下列原则:
1.只包含数字,八进制的数值将会被忽略前面的0,直接显示为十进制 如:“011” 应为 ‘9’但只能转换为‘11’;
2.浮点数可以转换为对应的浮点数值
3.如果是十六进制会转换为十进制值
4.如果字符串为空转换为0
5.其他转为NaN
(2) parseInt()在转换字符是更看其是否符合数值模式。它会忽略字符串前面的空格,知道找到第一个非空格字符。它是逐个解析字符的
e.g:parseInt("1234aaa")输出为“1234” 如果第一个字符是数字字符,会继续解析第二个字符,直到解析完所有的后续字符或者遇到了一个非数字字符。
parseInt()同样不具有解析八进制的能力,所以可以给 parseInt()加入第二个参数
e.g:parseInt("AF",16); //175 后面还可以为2,8,10,16,默认情况下为10
接收两个参数 parseInt(string,radix)
string:字母(大小写均可)、数组、特殊字符(不可放在开头,特殊字符及特殊字符后面的内容不做解析)的任意字符串,如 '2'、'2w'、'2!'
radix:解析字符串的基数,基数规则如下:
1) 区间范围介于 2~36 之间,否则返回 NaN
2 ) 当参数为 0,parseInt() 会根据十进制来解析;
3 ) 如果忽略该参数,默认的基数规则:
3.for in 和 for of 有什么区别
它们两者都可以用于遍历,不过for in遍历的是数组的索引(index),而for of遍历的是数组元素值(value)
for in
for in更适合遍历对象,当然也可以遍历数组,但是存在一些问题
index索引为字符串型数字,不能直接进行几何运算
var arr = [1, 2, 3];
for (let index in arr) {
let res = index + 1;
console.log(res);
}
//01 11 21
使用for in会遍历数组所有的可枚举属性,包括原型,如果不想遍历原型方法和属性的话,可以在循环内部判断一下,使用hasOwnProperty()方法可以判断某属性是不是该对象的实例属性
hasOwnProperty() 方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键)。
for of
for of遍历的是数组元素值,而且for of遍历的只是数组内的元素,不包括原型属性和索引
for of适用遍历数/数组对象/字符串/map/set等拥有迭代器对象(iterator)的集合,但是不能遍历对象,因为没有迭代器对象,但如果想遍历对象的属性,你可以用for in循环(这也是它的本职工作)或用内建的Object.keys()方法
var myObject = {
a: 1,
b: 2,
c: 3,
};
for (var key of Object.keys(myObject)) {
console.log(key + ": " + myObject[key]);
}
//a:1 b:2 c:3
实现 for of 遍历对象
for-of 在 object 对象上暂时没有实现,但是我们可以通过 Symbol.iterator 给对象添加这个塑性,我们就可以使用 for-of 了
var p={
name:'kevin',
age:2,
sex:'male'
}
Object.defineProperty(p,Symbol.iterator,{
enumberable:false,
configurable:false,
writable:false,
value:function(){
var _this=this;
var nowIndex=-1;
var key=Object.keys(_this);
return {
next:function(){
nowIndex++;
return {
value:_this[key[nowIndex]],
done:(nowIndex+1>key.length)
}
}
}
}
})
}
//这样的话就可以直接通过for-of来遍历对象了
for(var i of p){
console.log(i)
}
//kevin,2,male
其实 for-of 的原理最终也是通过调用 p[Symbol.iterator]()这个函数,这个迭代器函数返回一个 next 函数,for 循环会不断调用 next 那么知道原理之后,我们可以自己来调用 iterator.next 来实现循环
var students = {};
students[Symbol.iterator] = function () {
let index = 1;
return {
next() {
return { done: index > 100, value: index++ };
},
};
};
var iterator = students[Symbol.iterator]();
var s = iterator.next();
while (!s.done) {
console.log(s.value);
s = iterator.next();
}
上例中使用 iterator.next 和 while 结合实现了 for 循环。 除了使用 iterator 之外,我们还可以使用 yield 语法来实现循环,yield 相对简单一些,只要通过 yield 语句把值返回即可:
let students = {
[Symbol.iterator]: function* () {
for (var i = 0; i <= 100; i++) {
yield i;
}
},
};
for (var s of students) {
console.log(s);
}
//这个yield其实最后返回的就是iterator函数
总结
for in 遍历的是数组的索引(即键名),而 for of 遍历的是数组元素值
for in 总是得到对象的 key 或数组、字符串的下标
for of 总是得到对象的 value 或数组、字符串的值
4.什么是 DOM?
DOM
DOM, (Document Object Model, 文档对象模型)是文档内容(HTML 或 XML)在编程语言上的抽象模型,它建模了文档的内容和结构,并提供给编程语言一套完整的操纵文档的 API
站在浏览器方面的看法:DOM 是根据文档建模出来的一个树形模型,即是 DOM 树
DOM 的分层节点一般被称作是 DOM 树,树中的所有节点都可以通过脚本语言例如 JS 进行访问,所有 HTMlL 元素节点都可以被创建、添加或者删除。
在 DOM 分层节点中,页面就是用分层节点图表示的。
- 整个文档是一个文档节点,就想是树的根一样。
- 每个 HTML 元素都是元素节点。
- HTML 元素内的文本就是文本节点。
- 每个 HTML 属性时属性节点。
当咱们访问一个 web 页面时,浏览器会解析每个 HTML 元素,创建了 HTML 文档的虚拟结构,并将其保存在内存中。接着,HTML 页面被转换成树状结构,每个 HTML 元素成为一个叶子节点,连接到父分支
结构的顶部有一个document,也称为根元素,它包含另一个元素:html, 每个HTML元素都来自Element
dom 节点类型
- Document 节点,整个文档是一个文档节点;
- Element 节点,每个 HTML 标签是一个元素节点;
- Attribute 节点,每一个 HTML 属性是一个属性节点;
- Text 节点,包含在 HTML 元素中的文本是文本节点
document 和 window 之间的区别
简单来说,document是window的一个对象属性。window 对象表示浏览器中打开的窗口。如果文档包含框架(frame 或 iframe 标签),浏览器会为 HTML 文档创建一个 window 对象,并为每个框架创建一个额外的 window 对象。所有的全局函数和对象都属于 window 对象的属性和方法。
window 指窗体。document指页面。document是window的一个子对象。
用户不能改变 document.location(因为这是当前显示文档的位置)。但是,可以改变window.location (用其它文档取代当前文档)window.location本身也是一个对象,而document.location不是对象。
document接口有许多实用方法,比如querySelector(),它是用于查找给定页面内HTML元素的方法:
document.querySelector("h1");
window表示当前的浏览器,下面代码与上面等价:
window.document.querySelector("h1");
当然,更常见的是用第一种方式。
window 是一个全局对象,可以从浏览器中运行的任何 JS 代码直接访问。 window暴露了很多属性和方法,如:
window.alert("Hello world"); // Shows an alert
window.setTimeout(callback, 3000); // Delay execution
window.fetch(someUrl); // make XHR requests
window.open(); // Opens a new tab
window.location; // Browser location
window.history; // Browser history
window.navigator; // The actual user agent
window.document; // The current page
因为这些属性和方法也是全局的,所以也可以这样访问它们
alert("Hello world"); // Shows an alert
setTimeout(callback, 3000); // Delay execution
fetch(someUrl); // make XHR requests
open(); // Opens a new tab
location; // Browser location
history; // Browser history
navigator; // The actual user agent
document; // The current page
DOM 常用方法
获取节点
// 通过id号来获取元素,返回一个元素对象
document.getElementById(idName);
// 通过name属性获取id号,返回元素对象数组
document.getElementsByName(name);
// 通过class来获取元素,返回元素对象数组
document.getElementsByClassName(className);
// 通过标签名获取元素,返回元素对象数组
document.getElementsByTagName(tagName);
获取/设置元素的属性值:
// 括号传入属性名,返回对应属性的属性值
element.getAttribute(attributeName);
// 传入属性名及设置的值
element.setAttribute(attributeName, attributeValue);
创建节点 Node
// 创建一个html元素,这里以创建h3元素为例
document.createElement("h3");
// 创建一个文本节点;
document.createTextNode(String);
// 创建一个属性节点,这里以创建class属性为例
document.createAttribute("class");
增添节点
// 往element内部最后面添加一个节点,参数是节点类型
element.appendChild(Node);
// 在element内部的中在existingNode前面插入newNode
elelment.insertBefore(newNode, existingNode);
删除节点
//删除当前节点下指定的子节点,删除成功返回该被删除的节点,否则返回null
element.removeChild(Node);
DOM 操作
每个节点都拥有包含着关于节点某些信息的属性。这些属性是:
- nodeName(节点名称)
- nodeValue(节点值)
- nodeType(节点类型)
DOM 中的每个 HTML 元素也是一个节点,可以像这样查找节点:
document.querySelector("h1").nodeType;
上面会返回1,它是Element类型的节点的标识符,还可以检查节点名称:
document.querySelector("h1").nodeName;
上面的示例返回大写的节点名。但是需要理解的最重要的概念是,咱们主要使用 DOM 中的两种类型的节点:
- 元素节点
- 文本节点
创建元素节点,可以通过 createElement方法:
var heading = document.createElement("h1");
创建文本节点,可能通过 createTextNode 方法:
var text = document.createTextNode("Hello world");
接着将两个节点组合在一起,然后添加到 body 上:
var heading = document.createElement("h1");
var text = document.createTextNoe("Hello world");
heading.appendChild(text);
document.body.appendChild(heading);
DOM0、DOM1、DOM2、DOM3 事件模型区别
DOM0
DOM0 事件就是直接通过 onclick 绑定到 html 上的事件
DOM0 级事件具有极好的跨浏览器优势,会以最快的速度绑定。 为某一个元素的同一个行为绑定不同的方法在行内会分别执行。 为某一个元素的同一个行为绑定不同的方法在 script 标签中后面的方法会覆盖前面的方法。
<div id="box">点我</div>
<script>
// 某一个元素的同一个行为绑定不同的方法在script标签中后面的方法会覆盖前面的方法
var box = document.getElementById('box');
box.onclick = fun1;
box.onclick = fun2;
function fun1() {
console.log('方法1');
}
function fun2() {
console.log('方法2');
}
// 执行方法2;方法2覆盖方法1,所有方法1不执行
</script>
<div id="box">点我</div>
<script>
// 某一个元素的同一个行为绑定不同的方法在script标签中后面的方法会覆盖前面的方法
var box = document.getElementById('box');
box.onclick = fun1;
box.onclick = fun2;
function fun1() {
console.log('方法1');
}
function fun2() {
console.log('方法2');
}
// 执行方法2;方法2覆盖方法1,所有方法1不执行
</script>
删除 DOM 0 事件处理程序,只要将对应事件属性设为 null 即可。
box.onclick = null;
DOM1
主要定义的是 HTML 和 XML 文档的底层结构。DOM2 和 DOM3 级别则在这个结构的基础上引入了更多的交互能力,也支持了更高级的 XML 特性
DOM1 一般只有设计规范没有具体实现,所以一般跳过。
DOM2
DOM2 级事件是通过 addEventListener 绑定的事件,IE 下的 DOM2 事件通过 attachEvent 绑定;可以给某一个元素的同一个行为绑定不同的方法在行内会分别执行。
<div id="box">点我</div>
<script>
var box = document.getElementById('box');
box.addEventListener('click', fun1,false);
box.addEventListener('click', fun2,false);
function fun1() {
console.log('方法1');
}
function fun2() {
console.log('方法2');
}
// 执行方法1 // 执行方法2
</script>
删除 DOM 2 事件处理程序,通过 removeEventListener
box.removeEventListener("click", fun2, false);
DOM2 级事件处理添加进去的事件,我们可以控制事件的冒泡或是捕获过程。当 addEventListener 方法的第三个参数为 true 时,表示只进行事件捕获,不执行事件冒泡,再捕获的过程中,触发途径标签的对应事件函数。当第三个参数为 false,表示执行事件冒泡的过程(默认情况)
DOM3
DOM3 级事件在 DOM2 级事件的基础上添加了更多的事件类型,全部类型如下:
事件类型 说明 举例 UI 事件 当用户与页面上的元素交互时触发 load、scroll 焦点事件 当元素获得或失去焦点时触发 blur、focus 鼠标事件 当用户通过鼠标在页面执行操作时触发 dbclick、mouseup 滚轮事件 当使用鼠标滚轮或类似设备时触发 mousewheel 文本事件 当在文档中输入文本时触发 textInput 键盘事件 当用户通过键盘在页面上执行操作时触发 keydown、keypress 合成事件 当为 IME(输入法编辑器)输入字符时触发 compositionstart 变动事件 当底层 DOM 结构发生变化时触发 DOMsubtreeModified 同时 DOM3 级事件也允许开发人员自定义一些事件。
事件对象
event 写在侦听函数小括号中,当形参来看 也可以自己命名,如 event、evt、e 如事件侦听方法:div.addEventListener(‘click’,function(event){ console.log(event) }) ie 6/7/8 显示事件对象必须:consloe.log(window.event)
如果考虑事件对象的兼容性,可以:event = event || window.event
事件对象属性
.target与this的区别:
事件对象名.target : 指向的是我们点击的那个对象,谁点击了这个事件
this : 指向绑定的事件
e.type :返回事件类型
e.preventDefault(); : 阻止默认行为
e.stopPropagation(); 阻止冒泡 //有兼容性问题
window.event.cancelBubble = true; 阻止冒泡 //适用于ie678
事件委托
原理:不再给每个子节点单独设置事件监听器,而是事件监听器设置在父节点上,然后利用冒泡原理影响每个子节点。
键盘事件
keyup 键盘弹起
keydown 键盘按下
keypress 键盘按下,但是识别不了功能键,区分字母大小写
执行顺序2-3-1
属性:keyCode :返回ASCII码值
原生 Js 事件绑定的几种方式
在 Js 中,有三种常用的绑定事件的方法:
在 Dom 元素中直接绑定
<button onclick="handleClick">Click Me</button>
在 JS 代码中绑定
document.getElementById("demo").onclick = function () {
/* 函数体 */
};
绑定事件监听函数
绑定事件的另一种方法是用 addEventListener()或者 attachEvent()来绑定事件监听函数
elementObject.addEventListener(eventName, handle, useCapture);
这里的事件名称没有"on"前缀,handle 事件句柄函数,useCapture,布尔值,是否使用捕获类型,一般为 false,即为冒泡
elementObject.attachEvent(eventName, handle) 这里的事件名称有"on"前缀。
addEventListener()是标准的绑定事件监听函数的方法,是 W3C 所支持的,Chrome、FireFox、Opera、Safari、IE9.0 及其以上版本都支持的;但是,IE8.0 及其以下版本不支持该方法,它使用 attachEvent()来兼容。
function addEvent(obj, type, handle) {
try {
// Chrome、FireFox、Opera、Safari、IE9.0及其以上版本
obj.addEventListener(type, handle, false);
} catch (e) {
try {
// IE8.0及其以下版本
obj.attachEvent("on" + type, handle);
} catch (e) {
obj["on" + type] = handle;
}
}
}
MutationObserver
MutationObserver 接口提供了监视对 DOM 树所做更改的能力。它被设计为旧的 Mutation Events 功能的替代品,该功能是 DOM3 Events 规范的一部分。
浏览器中 DOM 节点的属性,文本,插入,移除等结构的变动我们之前主要是通过监听Mutation Events事件来执行
1.Mutation 事件列表
DOMAttrModified(节点属性变更)DOMAttributeNameChanged(节点属性属性节点名字改变)DOMCharacterDataModified(节点中的文本节点改变)DOMElementNameChanged(节点移除)DOMNodeInserted(节点子节点插入)DOMNodeRemoved(节点子节点移除)DOMNodeInsertedIntoDocument(节点插入文档)DOMSubtreeModified(节点子节点修改)
2.Mutation 简单的用法如下
document.getElementById("list").addEventListener(
"DOMSubtreeModified",
function () {
console.log("列表中子元素被修改");
},
false
);
3.Mutation Events 遇到的问题
- 浏览器兼容性问题
- IE9 不支持
Mutation Events - Webkit 内核不支持
DOMAttrModified特性, DOMElementNameChanged和DOMAttributeNameChanged在 Firefox 上不被支持。
- IE9 不支持
- 性能问题
Mutation Events是同步执行的,它的每次调用,都需要从事件队列中取出事件,执行,然后事件队列中移除,期间需要移动队列元素。如果事件触发的较为频繁的话,每一次都需要执行上面的这些步骤,那么浏览器会被拖慢。Mutation Events本身是事件,所以捕获是采用的是事件冒泡的形式,如果冒泡捕获期间又触发了其他的MutationEvents的话,很有可能就会导致阻塞 Javascript 线程,甚至导致浏览器崩溃。
4.Mutation Observer 的使用
Mutation Observer 是在 DOM4 中定义的,用于替代 mutation events 的新 API,它的不同于 events 的是,所有监听操作以及相应处理都是在其他脚本执行完成之后异步执行的,并且是所以变动触发之后,将变得记录在数组中,统一进行回调的,也就是说,当你使用observer监听多个 DOM 变化时,并且这若干个 DOM 发生了变化,那么observer会将变化记录到变化数组中,等待一起都结束了,然后一次性的从变化数组中执行其对应的回调函数。
- 构造函数(
MutationObserver) 用来实例化一个Mutation观察者对象,其中的参数是一个回调函数,它是会在指定的 DOM 节点发送变化后,执行的函数,并且会被传入两个参数。一个是变化记录数组(MutationRecord),另一个是观察者对象本身。
/*
*观察者实例
*/
var observer = null;
/*
*观察者回调
*records:变化记录数组
*instance:观察者对象本身
*/
const callback = (records, instance) => {
console.log(records);
console.log(instance);
records.map((record) => {
console.log("Mutation Type: " + record.type);
console.log("Mutation Change Attribute: " + record.attributeName);
console.log("Previous attribute value: " + record.oldValue);
});
};
if (
window.MutationObserver ||
window.WebKitMutationObserver ||
window.MozMutationObserver
) {
observer = new MutationObserver(callback);
}
- 观察者(
observe) 在观察者对象上,注册需要观察的 DOM 节点,以及相应的参数
//观察者配置项
var options = {
childList: true, //观察目标节点的子节点的新增和删除
subtree: true, //观察目标节点的所有后代节点
attributes: true, //观察目标节点的属性节点
attributeOldValue: true, //在attributes属性已经设为true的前提下, 将发生变化的属性节点之前的属性值记录下来
attributeFilter: [], //一个属性名数组(不需要指定命名空间),只有该数组中包含的属性名发生变化时才会被观察到,其他名称的属性发生变化后会被忽略想要设置那些删选参数的话
characterData: true, //如果目标节点为characterData节点(一种抽象接口,具体可以为文本节点,注释节点,以及处理指令节点)时,也要观察该节点的文本内容是否发生变化
characterDataOldValue: true, //在characterData属性已经设为true的前提下,将发生变化characterData节点之前的文本内容记录下来(记录到下面MutationRecord对象的oldValue属性中)
};
//待观察的DOM节点
var element = document.getElementById("text");
//执行观察
observer.observe(element, options);
- 停止观察(
disconnect) 在观察者对象上停止的节点的变化监听,直到重新调用observe方法
// 随后,你还可以停止观察
observer.disconnect();
- 清除变动记录(
takeRecords) 用来清除变动记录,即不再处理未处理的变动。该方法返回变动记录的数组
// 返回变动记录的数组,同时清除变动记录,即不再处理未处理的变动。
var changes = observer.takeRecords();
5.应用场景
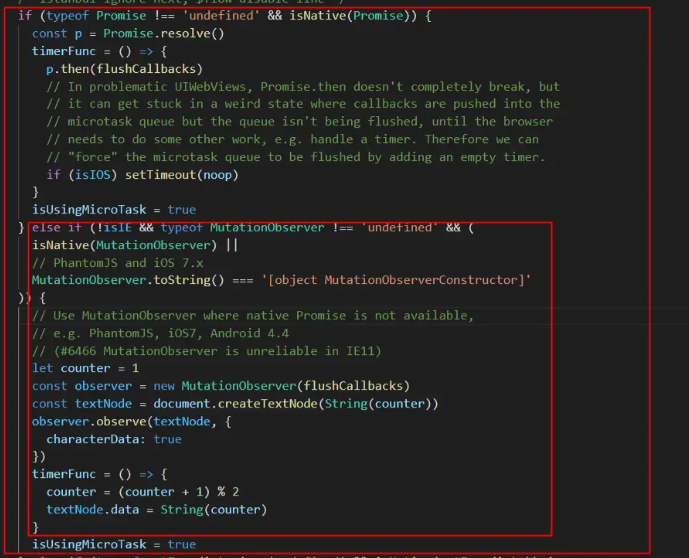
vue.$nextTrick
vue中的$nextTrick理解为 DOM 的下次更新后执行的回调,接受 2 个参数(回调函数和执行回调函数的上下文环境),如果没有提供回调函数,那么将返回promise对象。查看 vue 源码后发现在浏览器不支持porimise的情况,会首选MutationObserver进行微任务执行来实现 DOM 的异步更新
vue优先级是Promise 、 MutationObserver、 setTimeout。 当Promise不兼容时选择MutationObserver,从功能和性能角度来说两者基本一致,只是实现略有麻烦,要新建一个节点随便动一下。 setTimeout最后为了兼容备选使用,原因如下。
原因: MutationObserver与Promise属于微任务,setTimeout属于宏任务; 在浏览器执行机制里,每当宏任务执行结束都会进行重新渲染,微任务则在当前宏任务中执行,可以最快的得到最新的更新,如果有对应的 DOM 操作(回想一下上一篇),在宏任务结束时会一并完成。 但如果使用setTimeout宏任务,更新内容需要等待队列中前面的全部宏任务执行完毕,并且,如果其中更新内容中有 DOM 操作,浏览器会渲染两次。
5.什么是 BOM?
BOM
浏览器对象模型(BOM,Browser Object Model),是使用 JavaScript 开发 Web 应用程序的核心。
是实现 Web 开发与浏览器之间互相操作的基础。
BOM 主要包含五个基础对象:
1. window:表示浏览器实例
2. location:加载文档的信息和常用导航功能实例
3. navigator:客户端标识和信息的对象实例
4. screen:客户端显示器信息
5. history:当前窗口建立以来的导航历史记录
window 对象
BOM 的核心对象,有两个身份:ES 中的全局作用域和浏览器窗口的 JavaScript 接口。
global 全局作用域
在全局作用于下,所有使用 var 声明的变量和函数都会成为 window 对象的属性和方法。并且浏览器 API 和 多数构造函数 都会以 window 对象的属性。不同浏览器 window 对象的属性可能不同。
窗口关系
window 对象的 top 属性始终指向最外层的窗口,及浏览器窗口本身。
window 对象的 parent 属性始终指向当前窗口的父窗口,如果当前窗口就是最外层窗口,则 top等于parent
window 对象的 self 属性始终指向自身。
窗口属性
包含窗口位置、大小、像素比等。
window.screenLeft; // 窗口相对于屏幕左侧的距离, number (单位 px)
window.screenTop; // 窗口相对于屏幕顶部的距离, number (单位 px)
window.moveTo(x, y); // 移动到 (x, y) 坐标对应的新位置
window.moveBy(x, y); // 相对当前位置在两个方向上分别移动 x/y 个像素的距离
浏览器窗口大小不好确认,但是可以用 document.documentElement.clientWidth 和 document.documentElement.clientHeight 来确认可视窗口的大小。
移动浏览器中
document.documentElement.clientWidth和document.documentElement.clientHeight返回的通常是实际渲染的页面的大小,而可视窗口可能只能显示一部分内容。
调整窗口大小可以使用 resizeTo() 和 resizeBy() 两个方法。
// 缩放到 100×100
window.resizeTo(100, 100);
// 缩放到 200×150
window.resizeBy(100, 50);
// 缩放到 300×300
window.resizeTo(300, 300);
视口位置
浏览器窗口尺寸通常无法满足完整显示整个页面,为此用户可以通过滚动在有限的视口中查看文档。
度量文档相对于视口滚动距离的属性有两对,返回相等的值:window.pageXoffset/window.scrollX 和 window.pageYoffset/window.scrollY。
可以使用 scroll() 、scrollTo() 和 scrollBy() 方法滚动页面。
// 相对于当前视口向下滚动 100 像素
window.scrollBy(0, 100);
// 相对于当前视口向右滚动 40 像素
window.scrollBy(40, 0);
// 滚动到页面左上角
window.scrollTo(0, 0);
这几个方法也都接收一个 ScrollToOptions 字典,除了提供偏移值,还可以通过 behavior 属性告诉浏览器是否平滑滚动。
// 正常滚动
window.scrollTo({
left: 100,
top: 100,
behavior: "auto",
});
// 平滑滚动
window.scrollTo({
left: 100,
top: 100,
behavior: "smooth",
});
导航与跳转
window.open() 方法可以用于导航到指定 URL,也可以用于打开新浏览器窗口。这个方法接收 4 个参数:要加载的 URL、目标窗口、特性字符串和表示新窗口在浏览器历史记录中是否替代当前加载页面的布尔值。
定时器
setTimeout() 超时任务:等待一段时间之后再执行内部的代码,会返回一个超时 ID
setInterval() 定时任务:每隔一段时间执行一次内部的代码,会返回一个定时 ID
clearTimeout() 清除指定/所有超时任务。
clearInterval() 清除指定/所有定时任务。
`setTimeout() 和 setInterval() 都接收两个参数:要执行的代码(函数)和等待 / 间隔时间(毫秒)。
所有超时任务都会在全局作用域中的一个匿名函数中执行,因此函数中所有的 this 指向都是
window(严格模式下是undefined) 。如果定义setTimeout的时候传入的是一个箭头函数,则会保留原来的 this 指向。
setTimeout 可以不记录超时 ID,因为它会在满足条件(执行定义时传入的函数时)自动停止,再次定义时会重新定义一个超时任务。
let num = 0;
let max = 10;
let incrementNumber = function () {
num++;
// 如果还没有达到最大值,再设置一个超时任务
if (num < max) {
setTimeout(incrementNumber, 500);
} else {
alert("Done");
}
};
setTimeout(incrementNumber, 500);
setInterval() 会在被销毁之前一直按照定义的间隔时间一直执行,而不会在意定义时传入的函数的执行状态。
如果
setInterval()定义时传入的函数时一个异步请求Promise,则异步请求后的回调函数执行顺序可能不会按照预想顺序执行。所以这种情况推荐使用超时任务setTimeout()而非setInterval()。
加载触发事件
document.ready 和 onload 的区别
JavaScript 文档加载完成事件 页面加载完成有两种事件
ready:表示文档结构已经加载完成(不包含图片等除了文字媒体文件)
load:指示页面包含图片等文件在内的所有元素都加载完成。
history 对象
浏览器导航历史记录及相关操作的对象。
导航
history 对象提供了三个方法和一个属性来查看和操作历史记录(当前窗口)。
// 跳转到最近的 xxx 页面
history.go("xxx");
ry.back();
// 前进一页
history.forward();
go() 方法会接收一个字符串或者整数参数,传入整数时,正整数表示前进多少页,负整数表示后退多少页;传入字符串时,会匹配含有该字符串的最近的一条历史记录对应的网址,如果没有找到则不会发生变化。
history 提供一个 length 属性,可以用来查看当前窗口的历史记录数量。
历史状态管理
hashchange事件:页面 URL 的散列变化时被触发history.pushState()方法:接收 3 个参数:一个 state 对象、一个新状态的标题和一个(可选的)相对 URLpopstate事件(在window对象上):后退时触发history.state属性:当前的历史记录状态history.replaceState()方法:接收与pushState()一样的前两个参数来更新状态
location 对象
location 是最有用的 BOM 对象之一,提供了当前窗口中加载文档的信息,以及通常的导航功能。
它既是
window的属性,也是document的属性。即window.location和document.location指向同一个对象。
| 属性 | 值 | 说明 |
|---|---|---|
location.hash | "#contents" | URL 散列值(井号后跟零或多个字符)可为空 |
location.host | "www.wrox.com:80" | 服务器名及端口号 |
location.hostname | "www.wrox.com" | 服务器名 |
location.href | "www.wrox.com:80/WileyCDA/?q…" | 完整 URL 字符串 |
location.pathname | "/WileyCDA/" | URL 中的路径和(或)文件名 |
location.port | "80" | 请求端口号 |
location.protocol | "http:" | 页面使用的协议 |
location.search | "?q=javascript" | 查询字符串,以问号开头 |
location.username | "foouser" | 域名前指定的用户名 |
location.password | "barpassword" | 域名前指定的密码 |
location.haoriginsh | "www.wrox.com" | 源地址,只读 |
修改浏览器地址可以通过四种方式来修改:
location.assign()location.replace()location.href = newLocationwindow.location = newLocation
其中 location.href 和 window.location 都会在内部显式调用 location.assign() 方法,并且向浏览器历史记录中增加一条记录。点击浏览器 "后退" 按钮可以回到上页。
而 location.replace() 可以直接修改地址重载页面,而不会向历史记录中插入数据,也无法返回上页。
另外 location 还提供了一个 reload() 方法,用来重载当前页面
navigator 对象
客服端标识浏览器的标准,主要用来记录和检测浏览器与设备的主要信息,也可以让脚本注册和查询自己的一些活动(插件)。
| 属性 | 说明 |
|---|---|
appCodeName | 返回浏览器的代码名 |
appName | 返回浏览器的名称 |
appVersion | 返回浏览器的平台和版本信息 |
cookieEnabled | 返回指明浏览器中是否启用 cookie 的布尔值 |
platform | 返回运行浏览器的操作系统平台 |
userAgent | 返回由客户机发送服务器的 user-agent 头部的值 |
screen 对象
单纯的保存客服端能力的对象。包含以下属性:
| 属性 | 说明 |
|---|---|
availHeight | 屏幕像素高度减去系统组件高度,只读 |
availLeft | 没有被系统组件占用的屏幕的最左侧像素,只读 |
| availTop | 没有被系统组件占用的屏幕的最顶端像素,只读 |
| availWidth | 屏幕像素宽度减去系统组件宽度,只读 |
| colorDepth | 表示屏幕颜色的位数,只读 |
| height | 屏幕像素高度 |
| left | 当前屏幕左边的像素距离 |
| pixelDepth | 屏幕的位深,只读 |
| top | 当前屏幕顶端的像素距离 |
| width | 屏幕像素宽度 |
| orientation | 返回 Screen Orientation API 中屏幕的朝向 |
6.什么是事件捕获 委托(代理) 冒泡
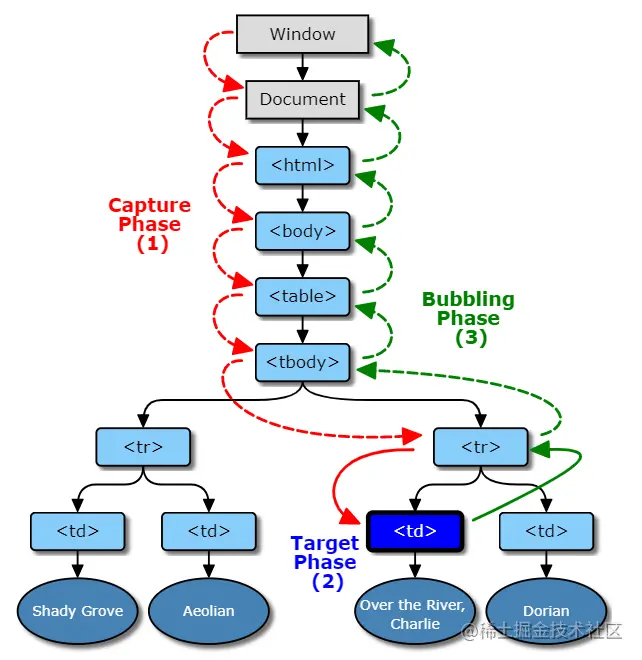
特点
元素事件响应在 DOM 树中是从顶层的 Window 开始“流向”目标元素,然后又从目标元素“流向”顶层的 Window
通常,我们将这种事件流向分为三个阶段:捕获阶段,目标阶段,冒泡阶段。
捕获阶段是指事件响应从最外层的 Window 开始,逐级向内层前进,直到具体事件目标元素。在捕获阶段,不会处理响应元素注册的冒泡事件。
目标阶段指触发事件的最底层的元素,如上图中的。
冒泡阶段与捕获阶段相反,事件的响应是从最底层开始一层一层往外传递到最外层的 Window。
DOM 事件流的三个阶段是先捕获阶段,然后是目标阶段,最后才是冒泡阶段。
事件代理就是利用事件冒泡或事件捕获的机制把一系列的内层元素事件绑定到外层元素
通过事件代理,我们可以将多个事件监听器减少为一个,这样就减少代码的重复编写了
使用案例
实际操作中,我们可以通过 element.addEventListener() 设置一个元素的事件模型为冒泡事件或者捕获事件。 先来看一下 addEventListener 函数的语法:
element.addEventListener(type, listener, useCapture);
- type 监听事件类型的字符串
- listener 事件监听回调函数,即事件触发后要处理的函数
- useCapture 默认值 false,表示事件冒泡;设为 true 时,表示事件捕获
事件冒泡由内到外,事件捕获由外到内
我们将上述的代码 a,b,c 三个元素都注册捕获和冒泡事件,并以元素 c 作为触发事件的主体,即事件流中的目标阶段。
<div id="a" style="width: 100%; height: 300px;background-color: antiquewhite;">
a
<div id="b" style="width: 100%; height: 200px;background-color: burlywood;">
b
<div id="c" style="width: 100%; height: 100px;background-color: cornflowerblue;">
c
</div>
</div>
</div>
<script>
var a = document.getElementById('a')
var b = document.getElementById('b')
var c = document.getElementById('c')
a.addEventListener('click', () => {console.log("冒泡a")})
b.addEventListener('click', () => {console.log('冒泡b')})
c.addEventListener('click', () => {console.log("冒泡c")})
a.addEventListener('click', () => {console.log("捕获a")}, true)
b.addEventListener('click', () => {console.log('捕获b')}, true)
c.addEventListener('click', () => {console.log("捕获c")}, true)
</script>
捕获a
捕获b
捕获c
冒泡c
冒泡b
冒泡a
a,b,c 三个元素都是先注册冒泡事件再注册捕获事件,从执行结果可以看到,a,b,c 两个元素的事件响应都是先捕获后冒泡的
对于非目标元素,如果我们要先执行冒泡事件再执行捕获事件,我们可以在注册监听器时通过暂缓执行捕获事件,等冒泡事件执行完之后,在执行捕获事件。
对于上述的列表元素,我们希望将用户点击了哪个 item 打印出来
<ul id="item-list">
<li>item1</li>
<li>item2</li>
<li>item3</li>
<li>item4</li>
</ul>;
var items = document.getElementById("item-list");
//事件捕获实现事件代理
items.addEventListener(
"click",
(e) => {
console.log("捕获:click ", e.target.innerHTML);
},
true
);
//事件冒泡实现事件代理
items.addEventListener(
"click",
(e) => {
console.log("冒泡:click ", e.target.innerHTML);
},
false
);
阻止冒泡方法
<!DOCTYPE html>
<html lang="en" onclick="handleClickHtml()">
<head>
<title>以这个html结构例举</title>
</head>
<body onclick="handleClickBody()">
<div onclick="handleClickDiv()">
<button id="btn1" onclick="handleClickBtn1(event)">
我是一个btn1按钮preventDefault取消默认行为
</button>
<button id="btn2" onclick="handleClickBtn2(event)">
我是一个btn2按钮stopPropagation取消后续事件捕获和事件冒泡
</button>
<button id="btn3" onclick="handleClickBtn3(event)">
我是一个btn3按钮return false
</button>
<button id="btn4">我是一个btn4按钮函数式写法</button>
</div>
</body>
<script>
function handleClickBtn1(e) {
console.log(e);
console.log("点击htn1");
e.preventDefault();
}
function handleClickBtn2(e) {
console.log(e);
console.log("点击htn2");
e.stopPropagation();
}
function handleClickBtn3(e) {
console.log(e);
console.log("点击htn3");
return false;
}
var btn4 = document.getElementById("btn4");
btn4.onclick = function (e) {
console.log(e);
console.log("点击htn4");
return false;
};
function handleClickDiv() {
console.log("点击div");
}
function handleClickBody() {
console.log("点击body");
}
function handleClickHtml() {
console.log("点击html");
}
</script>
</html>
<!-- 事件冒泡的: 如果在div中发生点击事件:那么click事件就在经过的结点上依次触发,button < div < body < html < document < window -->
处理事件冒泡的方法
1.使用 preventDefault();
<button
onClick={(e) => {
e.preventDefault();
}}
>
取消
</button>
使用 e.preventDefault()
用于取消事件的默认行为,如果 a 标签的默认事件是 href 跳转,加了就不会跳转了
2.使用 stopPropapation();
<button
onClick={(e) => {
e.stopPropagation();
}}
>
取消
</button>
使用 e.stopPropagation() 用于取消所有后续事件捕获和事件冒泡
3.直接使用 return false
<button onClick={(e) => { return false ;}}>取消</button>
据说是使用这个就会直接调用 preventDefault 和 stopPropapation,TM 的我自己使用这个居然没得一点效果,离谱,该冒的泡是一个都不会少啊
事件流总共 3 个阶段:事件捕获,到达目标,事件冒泡 事件捕获是从外层到里层到 body 这一层就结束,到达目标即触发事件的节点的过程一般是指 body 里的那一层,事件冒泡是从里层到外层
不发生冒泡的事件
当一个元素上的事件被触发的时候 比如鼠标点击了一个按钮 那么同样的事件将会在那个元素的所有祖先元素中被触发 这 一过程被称为事件冒泡 这个事件将会从原始元素开始一直被触发 直到 DOM 树的最上层 想是气泡冒泡一样 因而得名
Html5 的媒体事件(media Event):
play 不冒泡 ✖
mute 不冒泡 ✖
indexedDB 中的一系列事件:
abort 冒泡 ✔
blocked 不冒泡 ✖
close 不冒泡 ✖
complete 不冒泡 ✖
success 不冒泡 ✖
upgradeneeded 不冒泡 ✖
versionchange 不冒泡 ✖
表单验证合法性事件:
invalid 不冒泡 ✖
监听 Node 节点插入移除事件:
DOMNodeInsertedIntoDocument 不冒泡 ✖
DOMNodeRemovedFromDocument 不冒泡 ✖
Mouse 鼠标事件:
click 冒泡 ✔
dblclick 冒泡 ✔
mousedown 冒泡 ✔
mouseenter 不冒泡 ✖
mouseleave 不冒泡 ✖
mousemove 冒泡 ✔
mouseout 冒泡 ✔
mouseover 冒泡 ✔
mouseup 冒泡 ✔
Focus 聚焦事件:
blur 不冒泡 ✖ 因为失去焦点本身就是针对这个元素的
focus 不冒泡 ✖ 因为获取焦点本身就是针对这个元素的
focusin 冒泡 ✔
focusout 冒泡 ✔
UI 事件:
load 异步 不冒泡 ✖
unload 不冒泡 ✖
abort 不冒泡 ✖
error 异步 不冒泡 ✖
select 冒泡 ✔
总结
DOM 事件流有 3 个阶段:捕获阶段,目标阶段,冒泡阶段;三个阶段的顺序为:捕获阶段——目标阶段——冒泡阶段;
对于非目标阶段的元素,事件响应执行顺序遵循先捕获后冒泡的原则;通过暂缓执行捕获事件,可以达到先冒泡后捕获的效果;
对于目标元素,事件响应执行顺序根据的事件的执行顺序执行;
事件捕获是从顶层的 Window 逐层向内执行,事件冒泡则相反;
事件委托(事件代理)是根据事件冒泡或事件捕获的机制来实现的。
Window 对象是直接面向用户的,那么用户触发一个事件,如点击事件,肯定是用 window 对象开始的,所以自然就是先捕获后冒泡
7.数组方法

数组特点
ECMAScript 数组跟其他语言的数组一样,都是一组有序的数据,但跟其他语言不同的是,数组中每个槽位可以存储任意类型的数据。除此之外,ECMAScript 数组的长度也是动态的,会随着数据的增删而改变。
数组是被等分为许多小块的连续内存段,每个小块都和一个整数关联,可以通过这个整数快速访问对应的小块。除此之外,数组拥有一个 length 属性,该属性表示的并不是数组元素的数量,而是指数组元素的最高序号加 1
JS 数组有两种表现形式,fast 和 slow
fast :
快速的后备存储结构是 FixedArray ,并且数组长度 <= elements.length();
FixedArray 是 V8 实现的一个类似于数组的类,它表示一段固定长度的连续的内存。
slow :
缓慢的后备存储结构是一个以数字为键的 HashTable 。
HashTable
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
源码注释中的 fast 和 slow,对应的是快数组和慢数组
快数组是一种线性的存储方式。新创建的空数组,默认的存储方式是快数组,快数组长度是可变的,可以根据元素的增加和删除来动态调整存储空间大小,内部是通过扩容和收缩机制实现
慢数组是一种哈希表的内存形式。不用开辟大块连续的存储空间,节省了内存,但是由于需要维护这样一个 HashTable,其效率会比快数组低
数组创建
数组的创建方式有以下两种。
(1)字面量
最常用的创建数组的方式就是数组字面量,数组元素的类型可以是任意的,如下:
let colors = ["red", [1, 2, 3], true];
(2)构造函数
使用构造函数创建数组的形式如下:
let array = new Array(10); // [undefined × 10] new可省略
(3)ES6 构造器
鉴于数组的常用性,ES6 专门扩展了数组构造器 Array ,新增了 2 个方法:Array.of 和 Array.from。Array.of 用得比较少,Array.from 具有很强的灵活性。
1)Array.of
Array.of 用于将参数依次转化为数组项,然后返回这个新数组。它基本上与 Array 构造器功能一致,唯一的区别就在单个数字参数的处理上。
比如,在下面的代码中,可以看到:当参数为 2 个时,返回的结果是一致的;当参数是一个时,Array.of 会把参数变成数组里的一项,而构造器则会生成长度和第一个参数相同的空数组:
Array.of 用于将参数依次转化为数组项,然后返回这个新数组。它基本上与 Array 构造器功能一致,唯一的区别就在单个数字参数的处理上。
比如,在下面的代码中,可以看到:当参数为 2 个时,返回的结果是一致的;当参数是一个时,Array.of 会把参数变成数组里的一项,而构造器则会生成长度和第一个参数相同的空数组:
Array.of(8.0); // [8]
Array(8.0); // [empty × 8]
Array.of(8.0, 5); // [8, 5]
Array(8.0, 5); // [8, 5]
Array.of("8"); // ["8"]
Array("8"); // ["8"]
2)Array.from
Array.from 的设计初衷是快速基于其他对象创建新数组,准确来说就是从一个类似数组的可迭代对象中创建一个新的数组实例。其实,只要一个对象有迭代器,Array.from 就能把它变成一个数组(注意:该方法会返回一个的数组,不会改变原对象)。
从语法上看,Array.from 有 3 个参数:
- 类似数组的对象,必选;
- 加工函数,新生成的数组会经过该函数的加工再返回;
- this 作用域,表示加工函数执行时 this 的值。
这三个参数里面第一个参数是必选的,后两个参数都是可选的:
var obj = { 0: "a", 1: "b", 2: "c", length: 3 };
Array.from(
obj,
function (value, index) {
console.log(value, index, this, arguments.length);
return value.repeat(3); //必须指定返回值,否则返回 undefined
},
obj
);
结果如图:

以上结果表明,通过 Array.from 这个方法可以自定义加工函数的处理方式,从而返回想要得到的值;如果不确定返回值,则会返回 undefined,最终生成的是一个包含若干个 undefined 元素的空数组。
实际上,如果这里不指定 this,加工函数就可以是一个箭头函数。上述代码可以简写为以下形式。
Array.from(obj, (value) => value.repeat(3));
// 控制台打印 (3) ["aaa", "bbb", "ccc"]
除了上述 obj 对象以外,拥有迭代器的对象还包括 String、Set、Map 等,Array.from 都可以进行处理:
// String
Array.from("abc"); // ["a", "b", "c"]
// Set
Array.from(new Set(["abc", "def"])); // ["abc", "def"]
// Map
Array.from(
new Map([
[1, "ab"],
[2, "de"],
])
); // [[1, 'ab'], [2, 'de']]
数组索引
在数组中,我们可以通过使用数组的索引来获取数组的值:
let colors = new Array("red", "blue", "green");
console.log(array[1]); // blue
如果指定的索引值小于数组的元素数,就会返回存储在相应位置的元素,也可以通过这种方式来设置一个数组元素的值。如果设置的索引值大于数组的长度,那么就会将数组长度扩充至该索引值加一。
数组长度 length 的独特之处在于,他不是只读的。通过 length 属性,可以在数组末尾增加删除元素:
let colors = new Array("red", "blue", "green");
colors.length = 2;
console.log(colors[2]); // undefined
colors.length = 4;
console.log(colors[3]); // undefined
数组长度始终比数组最后一个值的索引大 1,这是因为索引值都是从 0 开始的
数组改变
改变原数组的方法:fill()、pop()、push()、shift()、splice()、unshift()、reverse()、sort();
不改变原数组的方法:concat()、every()、filter()、find()、findIndex()、forEach()、indexOf()、join()、lastIndexOf()、map()、reduce()、reduceRight()、slice()、some()。
1.复制和填充方法
(1)fill()
使用 fill()方法可以向一个已有数组中插入全部或部分相同的值,开始索引用于指定开始填充的位置,它是可选的。如果不提供结束索引,则一直填充到数组末尾。如果是负值,则将从负值加上数组的长度而得到的值开始。该方法的语法如下:
array.fill(value, start, end);
其参数如下:
- value:必需。填充的值;
- start:可选。开始填充位置;
- end:可选。停止填充位置 (默认为 array.length)。
(2)copyWithin()
copyWithin()方法会按照指定范围来浅复制数组中的部分内容,然后将它插入到指定索引开始的位置,开始与结束索引的计算方法和 fill 方法一样。该方法的语法如下:
array.copyWithin(target, start, end);
其参数如下:
- target:必需。复制到指定目标索引位置;
- start:可选。元素复制的起始位置;
- end:可选。停止复制的索引位置 (默认为 array.length)。如果为负值,表示倒数。
2.转化方法
(1)toString()
toString()方法返回的是由数组中每个值的等效字符串拼接而成的一个逗号分隔的字符串,也就是说,对数组的每个值都会调用 toString()方法,以得到最终的字符串:
let colors = ["red", "blue", "green"];
console.log(colors.toString()); // red,blue,green
(2)valueOf()
valueOf()方法返回的是数组本身,如下面代码:
let colors = ["red", "blue", "green"];
console.log(colors.valueOf()); // ["red", "blue", "green"]
(3)toLocaleString()
toLocaleString()方法可能会返回和 toString()方法相同的结果,但也不一定。在调用 toLocaleString()方法时会得到一个逗号分隔的数组值的字符串,它与 toString()方法的区别是,为了得到最终的字符串,会调用每个值的 toLocaleString()方法,而不是 toString()方法,看下面的例子:
let array = [{ name: "zz" }, 123, "abc", new Date()];
let str = array.toLocaleString();
console.log(str); // [object Object],123,abc,2016/1/5 下午1:06:23
//可以进行千分位格式转换
let num = 12345678;
console.log(num.toLocaleString()); // 12,345,678
需要注意,如果数组中的某一项是 null 或者 undefined,则在调用上述三个方法后,返回的结果中会以空字符串来表示。
(4)join()
join() 方法用于把数组中的所有元素放入一个字符串。元素是通过指定的分隔符进行分隔的。其使用语法如下:
arrayObject.join(separator);
其中参数 separator 是可选的,用来指定要使用的分隔符。如果省略该参数,则使用逗号作为分隔符。
该方法返回一个字符串。该字符串是通过把 arrayObject 的每个元素转换为字符串,然后把这些字符串连接起来,在两个元素之间插入 separator 字符串而生成的。
使用示例如下:
let array = ["one", "two", "three", "four", "five"];
console.log(array.join()); // one,two,three,four,five
console.log(array.join("-")); // one-two-three-four-five
3.栈方法
(1)push()
!!!注意:push 的返回值是数组加入元素之后的长度
push()方法可以接收任意数量的参数,并将它们添加了数组末尾,并返回数组新的长度。该方法会改变原数组。 其语法形式如下:
arrayObject.push(newelement1,newelement2,....,newelementX)
使用示例如下:
let array = ["football", "basketball", "badminton"];
let i = array.push("golfball");
console.log(array); // ["football", "basketball", "badminton", "golfball"]
console.log(i); // 4
(2)pop()
pop() 方法用于删除并返回数组的最后一个元素。它没有参数。该方法会改变原数组。 其语法形式如下:
arrayObject.pop();
使用示例如下:
let array = ["cat", "dog", "cow", "chicken", "mouse"];
let item = array.pop();
console.log(array); // ["cat", "dog", "cow", "chicken"]
console.log(item); // mouse
4.队列方法
(1)shift()
shift()方法会删除数组的第一项,并返回它,然后数组长度减一,该方法会改变原数组。 语法形式如下:
arrayObject.shift();
使用示例如下:
let array = [1, 2, 3, 4, 5];
let item = array.shift();
console.log(array); // [2,3,4,5]
console.log(item); // 1
注意:如果数组是空的,那么 shift() 方法将不进行任何操作,返回 undefined 值。
(2)unshift()
unshift()方法可向数组的开头添加一个或更多元素,并返回新的长度。该方法会改变原数组。 其语法形式如下:
arrayObject.unshift(newelement1,newelement2,....,newelementX)
使用示例如下:
let array = ["red", "green", "blue"];
let length = array.unshift("yellow");
console.log(array); // ["yellow", "red", "green", "blue"]
console.log(length); // 4
5.排序方法
(1)sort()
sort()方法是我们常用给的数组排序方法,该方法会在原数组上进行排序,会改变原数组,其使用语法如下:
arrayObject.sort(sortby);
其中参数 sortby 是可选参数,用来规定排序顺序,它是一个比较函数,用来判断哪个值应该排在前面。默认情况下,sort()方法会按照升序重新排列数组元素。为此,sort()方法会在每一个元素上调用 String 转型函数,然后比较字符串来决定顺序,即使数组的元素都是数值,也会将数组元素先转化为字符串在进行比较、排序。这就造成了排序不准确的情况,如下代码:
元素按照转换为的字符串的各个字符的 Unicode 位点进行排序。是Unicode 位点由小到大 升序排列
let array = [5, 4, 3, 2, 1];
let array2 = array.sort();
console.log(array2); // [1, 2, 3, 4, 5]
let array = [0, 1, 5, 10, 15];
let array2 = array.sort();
console.log(array2); // [0, 1, 10, 15, 5]
可以看到,上面第二段代码就出现了问题,虽然 5 是小于 10 的,但是字符串 10 在 5 的前面,所以 10 还是会排在 5 前面,因此可知,在很多情况下,不添加参数是不行的。
对于 sort()方法的参数,它是一个比较函数,它接收两个参数,
如果第一个参数应该排在第二个参数前面,就返回-1;
如果两个参数相等,就返回 0;
如果第一个参数应该排在第二个参数后面,就返回 1。
如果指定了 compareFunction,那么数组会按照调用该函数的返回值进行排序,即 a 和 b 是两个将要被比较的元素:
- 如果 compareFunction(a, b) 小于 0, 那么 a 会排在 b 的前面
- 如果 compareFunction(a, b) 大于 0, 那么 a 会排在 b 的后面
- 如果 compareFunction(a, b) 等于 0, 那么 a 和 b 的相对位置不变
一个比较函数的形式可以如下:
function compareFn(a, b) {
if (在某些排序规则中,a 小于 b) {
return -1;
}
if (在这一排序规则下,a 大于 b) {
return 1;
}
// a 一定等于 b
return 0;
}
let array = [0, 1, 5, 10, 15];
let array2 = array.sort(compare);
console.log(array2) // [0, 1, 5, 10, 15]
let array1 = [0, 1, 5, 10, 15];
array1.sort((a, b) => a - b);
console.log(array1); //[0, 1, 5, 10, 15]
let array2 = [0, 1, 5, 10, 15];
array2.sort((a, b) => b - a);
console.log(array2); // [15, 10, 5, 1, 0]
let array3 = [15, 10, 5, 1, 0];
array3.sort((a, b) => a - b);
console.log(array3); //[0, 1, 5, 10, 15]
let array4 = [15, 10, 5, 1, 0];
array4.sort((a, b) => b - a);
console.log(array4); // [15, 10, 5, 1, 0]
更清晰的验证(chrome 下)
var arr1 = [1, 2, 3, 4, 5, 6];
arr1.sort((a, b) => {
console.log(a, b); //2 1
console.log(a - b); //1
return a - b; //a会排在b的后面
});
var arr2 = [6, 5, 4, 3, 2, 1];
arr2.sort((a, b) => {
console.log(a, b); //5 6
console.log(a - b); //-1
return a - b; //a会排在b的前面
});
var arr3 = [1, 2, 3, 4, 5, 6];
arr3.sort((a, b) => {
console.log(b, a); //1 2
console.log(b - a); //-1
return b - a; //a会排在b的前面
});
console.log(arr3); //[ 6, 5, 4, 3, 2, 1 ]
var arr4 = [6, 5, 4, 3, 2, 1];
arr4.sort((a, b) => {
console.log(b, a); //6 5
console.log(b - a); //1
return b - a; //a会排在b的后面
});
console.log(arr4); //[ 6, 5, 4, 3, 2, 1 ]
对二维数组进行排序 数值相等序号小的在前面
var dp = [
[10, 2],
[2, 2],
[8, 2],
[1, 2],
[3, 4],
[4, 5],
[5, 6],
[3, 2],
];
dp.sort((b, a) => {
return a[1] - b[1];
});
dp.sort((b, a) => {
if (b[1] == a[1]) {
if (a[0] > b[0]) return -1;
}
});
console.log(dp);
//[ [ 5, 6 ], [ 4, 5 ],[3, 4], [1, 2],[2, 2], [3, 2],[8, 2], [10, 2]]
使用箭头函数来定义:
let array = [0, 1, 5, 10, 15];
let array2 = array.sort((a, b) => a - b); // 正序排序
console.log(array2); // [0, 1, 5, 10, 15]
let array3 = array.sort((a, b) => b - a); // 倒序排序
console.log(array3); // [15, 10, 5, 1, 0]
(2)reverse()
reverse() 方法用于颠倒数组中元素的顺序。该方法会改变原来的数组,而不会创建新的数组。其使用语法如下:
arrayObject.reverse();
使用示例如下:
let array = [1, 2, 3, 4, 5];
let array2 = array.reverse();
console.log(array); // [5,4,3,2,1]
console.log(array2 === array); // true
6.操作方法
对于数组,还有很多操作方法,下面我们就来看看常用的 concat()、slice()、splice()方法。
(1)concat()
concat() 方法用于连接两个或多个数组。该方法不会改变现有的数组,而仅仅会返回被连接数组的一个副本。其适用语法如下:
arrayObject.concat(arrayX,arrayX,......,arrayX)
其中参数 arrayX 是必需的。该参数可以是具体的值,也可以是数组对象。可以是任意多个。
使用示例如下:
let array = [1, 2, 3];
let array2 = array.concat(4, [5, 6], [7, 8, 9]);
console.log(array2); // [1, 2, 3, 4, 5, 6, 7, 8, 9]
console.log(array); // [1, 2, 3], 可见原数组并未被修改
该方法还可以用于数组扁平化
(2)slice()
slice() 方法可从已有的数组中返回选定的元素。返回一个新的数组,包含从 start 到 end (不包括该元素)的数组元素。方法并不会修改数组,而是返回一个子数组。其使用语法如下:
arrayObject.slice(start, end);
其参数如下:
- start:必需。规定从何处开始选取。如果是负数,那么它规定从数组尾部开始算起的位置。也就是说,-1 指最后一个元素,-2 指倒数第二个元素,以此类推;
- end:可选。规定从何处结束选取。该参数是数组片断结束处的数组下标。如果没有指定该参数,那么切分的数组包含从 start 到数组结束的所有元素。如果这个参数是负数,那么它规定的是从数组尾部开始算起的元素。
使用示例如下:
let array = ["one", "two", "three", "four", "five"];
console.log(array.slice(0)); // ["one", "two", "three","four", "five"]
console.log(array.slice(2, 3)); // ["three"]
(3)splice()
splice()方法可能是数组中的最强大的方法之一了,使用它的形式有很多种,它会向/从数组中添加/删除项目,然后返回被删除的项目。该方法会改变原始数组。其使用语法如下:
arrayObject.splice(index, howmany, item1,.....,itemX)
其参数如下:
- index:必需。整数,规定添加/删除项目的位置,使用负数可从数组结尾处规定位置。
- howmany:必需。要删除的项目数量。如果设置为 0,则不会删除项目。
- item1, ..., itemX:可选。向数组添加的新项目。
从上面参数可知,splice 主要有三种使用形式:
- 删除: 需要给 splice()传递两个参数,即要删除的第一个元素的位置和要删除的元素的数量;
- 插入: 需要给 splice()传递至少三个参数,即开始位置、0(要删除的元素数量)、要插入的元素。
- 替换: splice()方法可以在删除元素的同事在指定位置插入新的元素。同样需要传入至少三个参数,即开始位置、要删除的元素数量、要插入的元素。要插入的元素数量是任意的,不一定和删除的元素数量相等。
使用示例如下:
let array = ["one", "two", "three", "four", "five"];
console.log(array.splice(1, 2)); // 删除:["two", "three"]
let array = ["one", "two", "three", "four", "five"];
console.log(array.splice(2, 0, 996)); // 插入:[]
let array = ["one", "two", "three", "four", "five"];
console.log(array.splice(2, 1, 996)); // 替换:["three"]
7.归并方法
ECMAScript 为数组提供了两个归并方法:reduce()和 reduceRight()。下面就分别来看看这两个方法。
(1)reduce()
reduce() 方法对数组中的每个元素执行一个 reducer 函数(升序执行),将其结果汇总为单个返回值。其使用语法如下:
arr.reduce(callback, [initialValue]);
reduce 为数组中的每一个元素依次执行回调函数,不包括数组中被删除或从未被赋值的元素,接受四个参数:初始值(或者上一次回调函数的返回值),当前元素值,当前索引,调用 reduce 的数组。 (1) callback (执行数组中每个值的函数,包含四个参数)
- previousValue (上一次调用回调返回的值,或者是提供的初始值(initialValue))
- currentValue (数组中当前被处理的元素)
- index (当前元素在数组中的索引)
- array (调用 reduce 的数组)
initialValue (作为第一次调用 callback 的第一个参数。)
let arr = [1, 2, 3, 4];
let sum = arr.reduce((prev, cur, index, arr) => {
console.log(prev, cur, index);
return prev + cur;
});
console.log(arr, sum);
输出结果如下:
1 2 1
3 3 2
6 4 3
[1, 2, 3, 4] 10
再来加一个初始值看看:
let arr = [1, 2, 3, 4];
let sum = arr.reduce((prev, cur, index, arr) => {
console.log(prev, cur, index);
return prev + cur;
}, 5);
console.log(arr, sum);
输出结果如下:
5 1 0
6 2 1
8 3 2
11 4 3
[1, 2, 3, 4] 15
通过上面例子,可以得出结论:如果没有提供 initialValue,reduce 会从索引 1 的地方开始执行 callback 方法,跳过第一个索引。如果提供 initialValue,从索引 0 开始。
注意,该方法如果添加初始值,就会改变原数组,将这个初始值放在数组的最后一位。
使用 reduce 求和
arr = [1,2,3,4,5,6,7,8,9,10],求和
let arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
arr.reduce((prev, cur) => {
return prev + cur;
}, 0);
arr = [1,2,3,[[4,5],6],7,8,9],求和
let arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
arr.flat(Infinity).reduce((prev, cur) => {
return prev + cur;
}, 0);
arr = [{a:1, b:3}, {a:2, b:3, c:4}, {a:3}],求和
let arr = [{ a: 9, b: 3, c: 4 }, { a: 1, b: 3 }, { a: 3 }];
arr.reduce((prev, cur) => {
return prev + cur["a"];
}, 0);
(2)reduceRight()
该方法和的上面的reduce()用法几乎一致,只是该方法是对数组进行倒序查找的。而reduce()方法是正序执行的。
let arr = [1, 2, 3, 4];
let sum = arr.reduceRight((prev, cur, index, arr) => {
console.log(prev, cur, index);
return prev + cur;
}, 5);
console.log(arr, sum);
输出结果如下:
5 4 3
9 3 2
12 2 1
14 1 0
[1, 2, 3, 4] 15
8.搜索和位置方法
ECMAScript 提供了两类搜索数组的方法:按照严格相等搜索和按照断言函数搜索。
(1)严格相等
ECMAScript 通过了 3 个严格相等的搜索方法:indexOf()、lastIndexOf()、includes()。这些方法都接收两个参数:要查找的元素和可选的其实搜索位置。lastIndexOf()方法会从数组结尾元素开始向前搜索,其他两个方法则会从数组开始元素向后进行搜索。indexOf()和 lastIndexOf()返回的是查找元素在数组中的索引值,如果没有找到,则返回-1。includes()方法会返回布尔值,表示是否找到至少一个与指定元素匹配的项。在比较第一个参数和数组的每一项时,会使用全等(===)比较,也就是说两项必须严格相等。
使用示例如下:
let arr = [1, 2, 3, 4, 5];
console.log(arr.indexOf(2)); // 1
console.log(arr.lastIndexOf(3)); // 2
console.log(arr.includes(4)); // true
(2)断言函数
ECMAScript 也允许按照定义的断言函数搜索数组,每个索引都会调用这个函数,断言函数的返回值决定了相应索引的元素是否被认为匹配。使用断言函数的方法有两个,分别是 find()和 findIndex()方法。这两个方法对于空数组,函数是不会执行的。并且没有改变数组的原始值。他们的都有三个参数:元素、索引、元素所属的数组对象,其中元素是数组中当前搜索的元素,索引是当前元素的索引,而数组是当前正在搜索的数组。
这两个方法都从数组的开始进行搜索,find()返回的是第一个匹配的元素,如果没有符合条件的元素返回 undefined;findIndex()返回的是第一个匹配的元素的索引,如果没有符合条件的元素返回 -1。
使用示例如下:
let arr = [1, 2, 3, 4, 5];
arr.find((item) => item > 2); // 结果: 3
arr.findIndex((item) => item > 2); // 结果: 2
9.迭代器方法
在 ES6 中,Array 的原型上暴露了 3 个用于检索数组内容的方法:keys()、values()、entries()。keys()方法返回数组索引的迭代器,values()方法返回数组元素的迭代器,entries()方法返回索引值对的迭代器。
使用示例如下(因为这些方法返回的都是迭代器,所以可以将他们的内容通过Array.from 直接转化为数组实例):
let array = ["one", "two", "three", "four", "five"];
console.log(Array.from(array.keys())); // [0, 1, 2, 3, 4]
console.log(Array.from(array.values())); // ["one", "two", "three", "four", "five"]
console.log(Array.from(array.entries())); // [[0, "one"], [1, "two"], [2, "three"], [3, "four"], [4, "five"]]
10.迭代方法
ECMAScript 为数组定义了 5 个迭代方法,分别是 every()、filter()、forEach()、map()、some()。这些方法都不会改变原数组。这五个方法都接收两个参数:以每一项为参数运行的函数和可选的作为函数运行上下文的作用域对象(影响函数中的 this 值)。传给每个方法的函数接收三个参数,分别是当前元素、当前元素的索引值、当前元素所属的数对象。
(1)forEach()
forEach 方法用于调用数组的每个元素,并将元素传递给回调函数。该方法没有返回值,使用示例如下:
let arr = [1, 2, 3, 4, 5];
arr.forEach((item, index, arr) => {
console.log(index + ":" + item);
});
该方法还可以有第二个参数,用来绑定回调函数内部 this 变量(回调函数不能是箭头函数,因为箭头函数没有 this):
let arr = [1, 2, 3, 4, 5];
let arr1 = [9, 8, 7, 6, 5];
arr.forEach(function (item, index, arr) {
console.log(this[index]); // 9 8 7 6 5
}, arr1);
(2)map()
map() 方法会返回一个新数组,数组中的元素为原始数组元素调用函数处理后的值。该方法按照原始数组元素顺序依次处理元素。该方法不会对空数组进行检测,它会返回一个新数组,不会改变原始数组。使用示例如下:
let arr = [1, 2, 3];
arr.map((item) => {
return item + 1;
});
// 结果: [2, 3, 4]
第二个参数用来绑定参数函数内部的 this 变量:
var arr = ["a", "b", "c"];
[1, 2].map(function (e) {
return this[e];
}, arr);
// 结果: ['b', 'c']
该方法可以进行链式调用:
let arr = [1, 2, 3];
arr.map((item) => item + 1).map((item) => item + 1);
// 结果: [3, 4, 5]
forEach 和 map 区别如下:
- forEach()方法:会针对每一个元素执行提供的函数,对数据的操作会改变原数组,该方法没有返回值;
- map()方法:不会改变原数组的值,返回一个新数组,新数组中的值为原数组调用函数处理之后的值;
(3)filter()
filter()方法用于过滤数组,满足条件的元素会被返回。它的参数是一个回调函数,所有数组元素依次执行该函数,返回结果为 true 的元素会被返回。该方法会返回一个新的数组,不会改变原数组。
let arr = [1, 2, 3, 4, 5];
arr.filter((item) => item > 2);
// 结果:[3, 4, 5]
可以使用filter()方法来移除数组中的 undefined、null、NAN 等值
let arr = [1, undefined, 2, null, 3, false, "", 4, 0];
arr.filter(Boolean);
// 结果:[1, 2, 3, 4]
(4)every()
该方法会对数组中的每一项进行遍历,只有所有元素都符合条件时,才返回 true,否则就返回 false。
let arr = [1, 2, 3, 4, 5];
arr.every((item) => item > 0);
// 结果: true
(5)some()
该方法会对数组中的每一项进行遍历,只要有一个元素符合条件,就返回 true,否则就返回 false。
let arr = [1, 2, 3, 4, 5];
arr.some((item) => item > 4);
// 结果: true
11.其他方法
除了上述方法,遍历数组的方法还有 for...in 和 for...of。下面就来简单看一下。
(1)for…in
for…in 主要用于对数组或者对象的属性进行循环操作。循环中的代码每执行一次,就会对对象的属性进行一次操作。其使用语法如下:
for (var item in object) {
执行的代码块;
}
其中两个参数:
- item:必须。指定的变量可以是数组元素,也可以是对象的属性。
- object:必须。指定迭代的的对象。
使用示例如下:
const arr = [1, 2, 3];
for (var i in arr) {
console.log("键名:", i);
console.log("键值:", arr[i]);
}
输出结果如下:
键名: 0
键值: 1
键名: 1
键值: 2
键名: 2
键值: 3
需要注意,该方法不仅会遍历当前的对象所有的可枚举属性,还会遍历其原型链上的属性。 除此之外,该方法遍历数组时候,遍历出来的是数组的索引值,遍历对象的时候,遍历出来的是键值名。
(2)for...of
for...of 语句创建一个循环来迭代可迭代的对象。在 ES6 中引入的 for...of 循环,以替代 for...in 和 forEach() ,并支持新的迭代协议。for...of 允许遍历 Arrays(数组), Strings(字符串), Maps(映射), Sets(集合)等可迭代的数据结构等。
语法:
for (var item of iterable) {
执行的代码块;
}
其中两个参数:
- item:每个迭代的属性值被分配给该变量。
- iterable:一个具有可枚举属性并且可以迭代的对象。
该方法允许获取对象的键值:
var arr = ["a", "b", "c", "d"];
for (let a in arr) {
console.log(a); // 0 1 2 3
}
for (let a of arr) {
console.log(a); // a b c d
}
该方法只会遍历当前对象的属性,不会遍历其原型链上的属性。
注意:
- for...of 适用遍历 数组/ 类数组/字符串/map/set 等拥有迭代器对象的集合;
- 它可以正确响应 break、continue 和 return 语句;
- for...of 循环不支持遍历普通对象,因为没有迭代器对象。如果想要遍历一个对象的属性,可以用
for-in循环。
总结,for…of 和 for…in 的区别如下:
- for…of 遍历获取的是对象的键值,for…in 获取的是对象的键名;
- for… in 会遍历对象的整个原型链,性能非常差不推荐使用,而 for … of 只遍历当前对象不会遍历原型链;
- 对于数组的遍历,for…in 会返回数组中所有可枚举的属性(包括原型链上可枚举的属性),for…of 只返回数组的下标对应的属性值;
(3)flat()
在 ES2019 中,flat()方法用于创建并返回一个新数组,这个新数组包含与它调用 flat()的数组相同的元素,只不过其中任何本身也是数组的元素会被打平填充到返回的数组中:
[1, [2, 3]]
.flat() // [1, 2, 3]
[(1, [2, [3, 4]])].flat(); // [1, 2, [3, 4]]
在不传参数时,flat()默认只会打平一级嵌套,如果想要打平更多的层级,就需要传给 flat()一个数值参数,这个参数表示要打平的层级数:
[1, [2, [3, 4]]].flat(2); // [1, 2, 3, 4]
8.字符串方法
1. 获取字符串长度
JavaScript 中的字符串有一个 length 属性,该属性可以用来获取字符串的长度:
const str = "hello";
str.length; // 输出结果:5
2. 获取字符串指定位置的值
charAt()和 charCodeAt()方法都可以通过索引来获取指定位置的值:
- charAt() 方法获取到的是指定位置的字符;
- charCodeAt()方法获取的是指定位置字符的 Unicode 值。
(1)charAt()
charAt() 方法可以返回指定位置的字符。其语法如下:
string.charAt(index);
index 表示字符在字符串中的索引值:
const str = "hello";
str.charAt(1); // 输出结果:e
我们知道,字符串也可以通过索引值来直接获取对应字符,那它和 charAt()有什么区别呢?来看例子:
const str = "hello";
str.charAt(1); // 输出结果:e
str[1]; // 输出结果:e
str.charAt(5); // 输出结果:''
str[5]; // 输出结果:undefined
可以看到,当 index 的取值不在 str 的长度范围内时,str[index]会返回 undefined,而 charAt(index)会返回空字符串;除此之外,str[index]不兼容 ie6-ie8,charAt(index)可以兼容。
(2)charCodeAt()
ASCII 编码 0->48 A->65 a->97
charCodeAt():该方法会返回指定索引位置字符的 Unicode 值 ,返回值是 0 - 65535 之间的整数,表示给定索引处的 UTF-16 代码单元,如果指定位置没有字符,将返回 NaN:
let str = "abcdefg";
console.log(str.charCodeAt(1)); // "b" --> 98
通过这个方法,可以获取字符串中指定 Unicode 编码值范围的字符。比如,数字 0 ~ 9 的 Unicode 编码范围是: 48 ~ 57,可以通过这个方法来筛选字符串中的数字,当然如果你更熟悉正则表达式,会更方便
3. 检索字符串是否包含特定序列
这 5 个方法都可以用来检索一个字符串中是否包含特定的序列。其中前两个方法得到的指定元素的索引值,并且只会返回第一次匹配到的值的位置。后三个方法返回的是布尔值,表示是否匹配到指定的值。
注意:这 5 个方法都对大小写敏感!
(1)indexOf()
indexOf():查找某个字符,有则返回第一次匹配到的位置,否则返回-1,其语法如下:
string.indexOf(searchvalue, fromindex);
该方法有两个参数:
- searchvalue:必需,规定需检索的字符串值;
- fromindex:可选的整数参数,规定在字符串中开始检索的位置。它的合法取值是 0 到 string.length - 1。如省略该,则从字符串的首字符开始检索。
let str = "abcdefgabc";
console.log(str.indexOf("a")); // 输出结果:0
console.log(str.indexOf("z")); // 输出结果:-1
console.log(str.indexOf("c", 4)); // 输出结果:9
(2)lastIndexOf()
lastIndexOf():查找某个字符,有则返回最后一次匹配到的位置,否则返回-1
let str = "abcabc";
console.log(str.lastIndexOf("a")); // 输出结果:3
console.log(str.lastIndexOf("z")); // 输出结果:-1
该方法和 indexOf()类似,只是查找的顺序不一样,indexOf()是正序查找,lastIndexOf()是逆序查找。
(3)includes()
includes():该方法用于判断字符串是否包含指定的子字符串。如果找到匹配的字符串则返回 true,否则返回 false。该方法的语法如下:
string.includes(searchvalue, start);
该方法有两个参数:
- searchvalue:必需,要查找的字符串;
- start:可选,设置从那个位置开始查找,默认为 0。
let str = "Hello world!";
str.includes("o"); // 输出结果:true
str.includes("z"); // 输出结果:false
str.includes("e", 2); // 输出结果:false
(4)startsWith()
startsWith():该方法用于检测字符串是否以指定的子字符串开始。如果是以指定的子字符串开头返回 true,否则 false。其语法和上面的 includes()方法一样。
let str = "Hello world!";
str.startsWith("Hello"); // 输出结果:true
str.startsWith("Helle"); // 输出结果:false
str.startsWith("wo", 6); // 输出结果:true
(5)endsWith()
endsWith():该方法用来判断当前字符串是否是以指定的子字符串结尾。如果传入的子字符串在搜索字符串的末尾则返回 true,否则将返回 false。其语法如下:
string.endsWith(searchvalue, length);
该方法有两个参数:
- searchvalue:必需,要搜索的子字符串;
- length: 设置字符串的长度,默认值为原始字符串长度 string.length。
let str = "Hello world!";
str.endsWith("!"); // 输出结果:true
str.endsWith("llo"); // 输出结果:false
str.endsWith("llo", 5); // 输出结果:true
可以看到,当第二个参数设置为 5 时,就会从字符串的前 5 个字符中进行检索,所以会返回 true
4. 连接多个字符串
concat() 方法用于连接两个或多个字符串。该方法不会改变原有字符串,会返回连接两个或多个字符串的新字符串。其语法如下:
string.concat(string1, string2, ..., stringX)
其中参数 string1, string2, ..., stringX 是必须的,他们将被连接为一个字符串的一个或多个字符串对象。
let str = "abc";
console.log(str.concat("efg")); //输出结果:"abcefg"
console.log(str.concat("efg", "hijk")); //输出结果:"abcefghijk"
虽然 concat()方法是专门用来拼接字符串的,但是在开发中使用最多的还是加操作符+,因为其更加简单。
5. 字符串分割成数组
split() 方法用于把一个字符串分割成字符串数组。该方法不会改变原始字符串。其语法如下:
string.split(separator, limit);
该方法有两个参数:
- separator:必需。字符串或正则表达式,从该参数指定的地方分割 string。
- limit:可选。该参数可指定返回的数组的最大长度。如果设置了该参数,返回的子串不会多于这个参数指定的数组。如果没有设置该参数,整个字符串都会被分割,不考虑它的长度。
let str = "abcdef";
str.split("c"); // 输出结果:["ab", "def"]
str.split("", 4); // 输出结果:['a', 'b', 'c', 'd']
如果把空字符串用作 separator,那么字符串中的每个字符之间都会被分割。
str.split(""); // 输出结果:["a", "b", "c", "d", "e", "f"]
其实在将字符串分割成数组时,可以同时拆分多个分割符,使用正则表达式即可实现:
const list = "apples,bananas;cherries";
const fruits = list.split(/[,;]/);
console.log(fruits); // 输出结果:["apples", "bananas", "cherries"]
6. 截取字符串
substr()、substring()和 slice() 方法都可以用来截取字符串。
(1) slice()
slice() 方法用于提取字符串的某个部分,并以新的字符串返回被提取的部分。其语法如下:
string.slice(start, end);
该方法有两个参数:
- start:必须。 要截取的片断的起始下标,第一个字符位置为 0。如果为负数,则从尾部开始截取。
- end:可选。 要截取的片段结尾的下标。若未指定此参数,则要提取的子串包括 start 到原字符串结尾的字符串。如果该参数是负数,那么它规定的是从字符串的尾部开始算起的位置。
上面说了,如果 start 是负数,则该参数规定的是从字符串的尾部开始算起的位置。也就是说,-1 指字符串的最后一个字符,-2 指倒数第二个字符,以此类推:
let str = "abcdefg";
str.slice(1, 6); // 输出结果:"bcdef"
str.slice(1); // 输出结果:"bcdefg"
str.slice(); // 输出结果:"abcdefg"
str.slice(-2); // 输出结果:"fg"
str.slice(6, 1); // 输出结果:""
注意,该方法返回的子串包括开始处的字符,但不包括结束处的字符。
(2) substr()
substr() 方法用于在字符串中抽取从开始下标开始的指定数目的字符。其语法如下:
string.substr(start, length);
该方法有两个参数:
- start 必需。要抽取的子串的起始下标。必须是数值。如果是负数,那么该参数声明从字符串的尾部开始算起的位置。也就是说,-1 指字符串中最后一个字符,-2 指倒数第二个字符,以此类推。
- length:可选。子串中的字符数。必须是数值。如果省略了该参数,那么返回从 stringObject 的开始位置到结尾的字串。
let str = "abcdefg";
str.substr(1, 6); // 输出结果:"bcdefg"
str.substr(1); // 输出结果:"bcdefg" 相当于截取[1,str.length-1]
str.substr(); // 输出结果:"abcdefg" 相当于截取[0,str.length-1]
str.substr(-1); // 输出结果:"g"
(3) substring()
substring() 方法用于提取字符串中介于两个指定下标之间的字符。其语法如下:
string.substring(from, to);
该方法有两个参数:
- from:必需。一个非负的整数,规定要提取的子串的第一个字符在 string 中的位置。
- to:可选。一个非负的整数,比要提取的子串的最后一个字符在 string 中的位置多 1。如果省略该参数,那么返回的子串会一直到字符串的结尾。
注意: 如果参数 from 和 to 相等,那么该方法返回的就是一个空串(即长度为 0 的字符串)。如果 from 比 to 大,那么该方法在提取子串之前会先交换这两个参数。并且该方法不接受负的参数,如果参数是个负数,就会返回这个字符串。
let str = "abcdefg";
str.substring(1, 6); // 输出结果:"bcdef" [1,6)
str.substring(1); // 输出结果:"bcdefg" [1,str.length-1]
str.substring(); // 输出结果:"abcdefg" [0,str.length-1]
str.substring(6, 1); // 输出结果 "bcdef" [1,6)
str.substring(-1); // 输出结果:"abcdefg"
注意,该方法返回的子串包括开始处的字符,但不包括结束处的字符。
7. 字符串大小写转换
toLowerCase() 和 toUpperCase()方法可以用于字符串的大小写转换。
(1)toLowerCase()
toLowerCase():该方法用于把字符串转换为小写。
let str = "adABDndj";
str.toLowerCase(); // 输出结果:"adabdndj"
(2)toUpperCase()
toUpperCase():该方法用于把字符串转换为大写。
let str = "adABDndj";
str.toUpperCase(); // 输出结果:"ADABDNDJ"
我们可以用这个方法来将字符串中第一个字母变成大写:
let word = "apple";
word = word[0].toUpperCase() + word.substr(1);
console.log(word); // 输出结果:"Apple"
8. 字符串模式匹配
replace()、match()和 search()方法可以用来匹配或者替换字符。
(1)replace()
replace():该方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。其语法如下:
string.replace(searchvalue, newvalue);
该方法有两个参数:
- searchvalue:必需。规定子字符串或要替换的模式的 RegExp 对象。如果该值是一个字符串,则将它作为要检索的直接量文本模式,而不是首先被转换为 RegExp 对象。
- newvalue:必需。一个字符串值。规定了替换文本或生成替换文本的函数。
let str = "abcdef";
str.replace("c", "z"); // 输出结果:abzdef
执行一个全局替换, 忽略大小写:
let str = "Mr Blue has a blue house and a blue car";
str.replace(/blue/gi, "red"); // 输出结果:'Mr red has a red house and a red car'
注意: 如果 regexp 具有全局标志 g,那么 replace() 方法将替换所有匹配的子串。否则,它只替换第一个匹配子串。
var str = "hello world";
var str1 = str.replace(/o/g, function (match, pos, orginText) {
console.log(pos);
return "a";
});
console.log(str1); //hella warld
上面的代码,第一行定义了字符串变量,并初始化。第二行调用了字符串的 replace 方法,第一个参数是模式匹配,第二个参数是一个函数。函数拥有三个参数:第一个参数是匹配到的字符串,第二个参数是匹配的位置,第三个参数是原字符串。在函数里面可以对字符串进行操作。使用函数作为第二个参数,可以做一些复杂的替换,比如当匹配多个字符时候,可以对不同的字符做不同的替换。
(2)match()
match():该方法用于在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。该方法类似 indexOf() 和 lastIndexOf(),但是它返回指定的值,而不是字符串的位置。其语法如下:
string.match(regexp);
该方法的参数 regexp 是必需的,规定要匹配的模式的 RegExp 对象。如果该参数不是 RegExp 对象,则需要首先把它传递给 RegExp 构造函数,将其转换为 RegExp 对象。
注意: 该方法返回存放匹配结果的数组。该数组的内容依赖于 regexp 是否具有全局标志 g。
let str = "abcdef";
console.log(str.match("c")); // ["c", index: 2, input: "abcdef", groups: undefined]
(3)search()
search()方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。其语法如下:
string.search(searchvalue);
该方法的参数 regex 可以是需要在 string 中检索的子串,也可以是需要检索的 RegExp 对象。
注意: 要执行忽略大小写的检索,请追加标志 i。该方法不执行全局匹配,它将忽略标志 g,也就是只会返回第一次匹配成功的结果。如果没有找到任何匹配的子串,则返回 -1。
返回值: 返回 str 中第一个与 regexp 相匹配的子串的起始位置。
let str = "abcdef";
str.search(/bcd/); // 输出结果:1
9. 移除字符串收尾空白符
trim()、trimStart()和 trimEnd()这三个方法可以用于移除字符串首尾的头尾空白符,空白符包括:空格、制表符 tab、换行符等其他空白符等。
(1)trim()
trim() 方法用于移除字符串首尾空白符,该方法不会改变原始字符串:
let str = " abcdef ";
str.trim(); // 输出结果:"abcdef"
注意,该方法不适用于 null、undefined、Number 类型。
(2)trimStart()
trimStart() 方法的的行为与trim()一致,不过会返回一个从原始字符串的开头删除了空白的新字符串,不会修改原始字符串:
const s = " abc ";
s.trimStart(); // "abc "
(3)trimEnd()
trimEnd() 方法的的行为与trim()一致,不过会返回一个从原始字符串的结尾删除了空白的新字符串,不会修改原始字符串:
const s = " abc ";
s.trimEnd(); // " abc"
10. 获取字符串本身
valueOf()和 toString()方法都会返回字符串本身的值,感觉用处不大。
(1)valueOf()
valueOf():返回某个字符串对象的原始值,该方法通常由 JavaScript 自动进行调用,而不是显式地处于代码中。
let str = "abcdef";
console.log(str.valueOf()); // "abcdef"
(2)toString()
toString():返回字符串对象本身
let str = "abcdef";
console.log(str.toString()); // "abcdef"
11. 重复一个字符串
repeat() 方法返回一个新字符串,表示将原字符串重复 n 次:
"x".repeat(3); // 输出结果:"xxx"
"hello".repeat(2); // 输出结果:"hellohello"
"na".repeat(0); // 输出结果:""
如果参数是小数,会向下取整:
"na".repeat(2.9); // 输出结果:"nana"
如果参数是负数或者 Infinity,会报错:
"na".repeat(Infinity); // RangeError
"na".repeat(-1); // RangeError
如果参数是 0 到-1 之间的小数,则等同于 0,这是因为会先进行取整运算。0 到-1 之间的小数,取整以后等于-0,repeat 视同为 0。
"na".repeat(-0.9); // 输出结果:""
如果参数是 NaN,就等同于 0:
"na".repeat(NaN); // 输出结果:""
如果 repeat 的参数是字符串,则会先转换成数字。
"na".repeat("na"); // 输出结果:""
"na".repeat("3"); // 输出结果:"nanana"
12. 补齐字符串长度
padStart()和 padEnd()方法用于补齐字符串的长度。如果某个字符串不够指定长度,会在头部或尾部补全。
(1)padStart()
padStart()用于头部补全。该方法有两个参数,其中第一个参数是一个数字,表示字符串补齐之后的长度;第二个参数是用来补全的字符串。
如果原字符串的长度,等于或大于指定的最小长度,则返回原字符串:
"x".padStart(1, "ab"); // 'x'
如果用来补全的字符串与原字符串,两者的长度之和超过了指定的最小长度,则会截去超出位数的补全字符串:
"x".padStart(5, "ab"); // 'ababx'
"x".padStart(4, "ab"); // 'abax'
如果省略第二个参数,默认使用空格补全长度:
"x".padStart(4); // ' x'
padStart()的常见用途是为数值补全指定位数,笔者最近做的一个需求就是将返回的页数补齐为三位,比如第 1 页就显示为 001,就可以使用该方法来操作:
"1".padStart(3, "0"); // 输出结果: '001'
"15".padStart(3, "0"); // 输出结果: '015'
(2)padEnd()
padEnd()用于尾部补全。该方法也是接收两个参数,第一个参数是字符串补全生效的最大长度,第二个参数是用来补全的字符串:
"x".padEnd(5, "ab"); // 'xabab'
"x".padEnd(4, "ab"); // 'xaba'
13. 字符串转为数字
parseInt()和 parseFloat()方法都用于将字符串转为数字。
(1)parseInt()
parseInt() 方法用于可解析一个字符串,并返回一个整数。其语法如下:
parseInt(string, radix);
该方法有两个参数:
- string:必需。要被解析的字符串。
- radix:可选。表示要解析的数字的基数。该值介于 2 ~ 36 之间。
当参数 radix 的值为 0,或没有设置该参数时,parseInt() 会根据 string 来判断数字的基数。
parseInt("10"); // 输出结果:10
parseInt("17", 8); // 输出结果:15 (8+7)
parseInt("010"); // 输出结果:10 或 8
当参数 radix 的值以 “0x” 或 “0X” 开头,将以 16 为基数:
parseInt("0x10"); // 输出结果:16
如果该参数小于 2 或者大于 36,则 parseInt() 将返回 NaN:
parseInt("50", 1); // 输出结果:NaN
parseInt("50", 40); // 输出结果:NaN
只有字符串中的第一个数字会被返回,当遇到第一个不是数字的字符为止:
parseInt("40 4years"); // 输出结果:40
如果字符串的第一个字符不能被转换为数字,就会返回 NaN:
parseInt("new100"); // 输出结果:NaN
字符串开头和结尾的空格是允许的:
parseInt(" 60 "); // 输出结果: 60
(2)parseFloat()
parseFloat() 方法可解析一个字符串,并返回一个浮点数。该方法指定字符串中的首个字符是否是数字。如果是,则对字符串进行解析,直到到达数字的末端为止,然后以数字返回该数字,而不是作为字符串。其语法如下:
parseFloat(string);
parseFloat 将它的字符串参数解析成为浮点数并返回。如果在解析过程中遇到了正负号(+ 或 -)、数字 (0-9)、小数点,或者科学记数法中的指数(e 或 E)以外的字符,则它会忽略该字符以及之后的所有字符,返回当前已经解析到的浮点数。同时参数字符串首位的空白符会被忽略。
parseFloat("10.00"); // 输出结果:10.00
parseFloat("10.01"); // 输出结果:10.01
parseFloat("-10.01"); // 输出结果:-10.01
parseFloat("40.5 years"); // 输出结果:40.5
如果参数字符串的第一个字符不能被解析成为数字,则 parseFloat 返回 NaN。
parseFloat("new40.5"); // 输出结果:NaN
14. 编码生成字符
fromCharCode() 可接受一个指定的 Unicode 值,然后返回一个字符串
ASCII 编码 0->48 A->65 a->97
生成字符返回
str=String.fromCharCode(64 + parseInt(m))
生成生成 A~Z 字母
getEN () {
const arr = []
for (let i = 65; i < 91; i++) {
arr.push(String.fromCharCode(i))
}
return arr
}
9.类数组是什么,怎么转数组 ,arguments 的应用
JavaScript 中一直存在一种类数组的对象,它们不能直接调用数组的方法,但是又和数组比较类似
主要有以下情况中的对象是类数组:
- 函数里面的参数对象 arguments;
- 用 getElementsByTagName/ClassName/Name 获得的 HTMLCollection;
- 用 querySelector 获得的 NodeList
1. 类数组概述
(1)arguments
在日常开发中经常会遇到各种类数组对象,最常见的就是在函数中使用的 arguments,它的对象只定义在函数体中,包括了函数的参数和其他属性。先来看下 arguments 的使用方法:
function foo(name, age, sex) {
console.log(arguments);
console.log(typeof arguments);
console.log(Object.prototype.toString.call(arguments));
}
foo("jack", "18", "male");
打印结果如下: 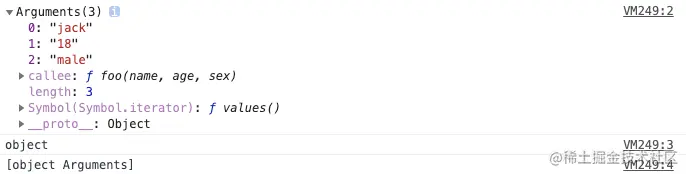 可以看到,typeof 这个 arguments 返回的是 object,通过 Object.prototype.toString.call 返回的结果是 [object arguments],而不是 [object array],说明 arguments 和数组还是有区别的。
可以看到,typeof 这个 arguments 返回的是 object,通过 Object.prototype.toString.call 返回的结果是 [object arguments],而不是 [object array],说明 arguments 和数组还是有区别的。
length 属性就是函数参数的长度。另外 arguments 还有一个 callee 属性,下面看看这个 callee 是干什么的:
function foo(name, age, sex) {
console.log(arguments.callee);
}
foo("jack", "18", "male");
打印结果如下:
ƒ foo(name, age, sex) {
console.log(arguments.callee);
}
可以看出,输出的就是函数自身,如果在函数内部直接执行调用 callee,那它就会不停地执行当前函数,直到执行到内存溢出。
(2)HTMLCollection
HTMLCollection 简单来说是 HTML DOM 对象的一个接口,这个接口包含了获取到的 DOM 元素集合,返回的类型是类数组对象,如果用 typeof 来判断的话,它返回的是 object。它是及时更新的,当文档中的 DOM 变化时,它也会随之变化。
下面来 HTMLCollection 最后返回的是什么,在一个有 form 表单的页面中,在控制台中执行下述代码:
var elem1, elem2;
// document.forms 是一个 HTMLCollection
elem1 = document.forms[0];
elem2 = document.forms.item(0);
console.log(elem1);
console.log(elem2);
console.log(typeof elem1);
console.log(Object.prototype.toString.call(elem1));
打印结果如下: 
可以看到,这里打印出来了页面第一个 form 表单元素,同时也打印出来了判断类型的结果,说明打印的判断的类型和 arguments 返回的也比较类似,typeof 返回的都是 object,和上面的类似。
注意:HTML DOM 中的 HTMLCollection 是即时更新的,当其所包含的文档结构发生改变时,它会自动更新。
(3)NodeList
NodeList 对象是节点的集合,通常是由 querySlector 返回的。NodeList 不是一个数组,也是一种类数组。虽然 NodeList 不是一个数组,但是可以使用 for...of 来迭代。在一些情况下,NodeList 是一个实时集合,也就是说,如果文档中的节点树发生变化,NodeList 也会随之变化。
var list = document.querySelectorAll("input[type=checkbox]");
for (var checkbox of list) {
checkbox.checked = true;
}
console.log(list);
console.log(typeof list);
console.log(Object.prototype.toString.call(list));
打印结果如下: 
2. 类数组应用场景
(1)遍历参数操作
在函数内部可以直接获取 arguments 这个类数组的值,那么也可以对于参数进行一些操作,比如下面这段代码可以将函数的参数默认进行求和操作:
function add() {
var sum =0,
len = arguments.length;
for(var i = 0; i < len; i++){
sum += arguments[i];
}
return sum;
}
add() // 0
add(1) // 1
add(1,2) // 3
add(1,2,3,4); // 10
结合上面这段代码,在函数内部可以将参数直接进行累加操作,以达到预期的效果,参数多少也可以不受限制,根据长度直接计算,返回出最后函数的参数的累加结果,其他操作也类似。
(2)定义连接字符串函数
可以通过 arguments 这个例子定义一个函数来连接字符串。这个函数唯一正式声明了的参数是一个字符串,该参数指定一个字符作为衔接点来连接字符串。该函数定义如下:
function myConcat(separa) {
var args = Array.prototype.slice.call(arguments, 1);
return args.join(separa);
}
myConcat(", ", "red", "orange", "blue");
// "red, orange, blue"
myConcat("; ", "elephant", "lion", "snake");
// "elephant; lion; snake"
myConcat(". ", "one", "two", "three", "four", "five");
// "one. two. three. four. five"
这段代码说明可以传递任意数量的参数到该函数,并使用每个参数作为列表中的项创建列表进行拼接。从这个例子中也可以看出,可以在日常编码中采用这样的代码抽象方式,把需要解决的这一类问题,都抽象成通用的方法,来提升代码的可复用性。
(3)传递参数
可以借助 apply 或 call 与 arguments 相结合,将参数从一个函数传递到另一个函数:
1. // 使用 apply 将 foo 的参数传递给 bar
2. function foo() {
3. bar.apply(this, arguments);
4. }
5. function bar(a, b, c) {
6. console.log(a, b, c);
7. }
8. foo(1, 2, 3) //1 2 3
上述代码中,通过在 foo 函数内部调用 apply 方法,用 foo 函数的参数传递给 bar 函数,这样就实现了借用参数的妙用。
3. 类数组转为数组
(1)借用数组方法
类数组因为不是真正的数组,所以没有数组类型上自带的那些方法,所以就需要利用下面这几个方法去借用数组的方法。比如借用数组的 push 方法,代码如下:
var arrayLike = {
0: "java",
1: "script",
length: 2,
};
Array.prototype.push.call(arrayLike, "jack", "lily");
console.log(typeof arrayLike); // 'object'
console.log(arrayLike);
// {0: "java", 1: "script", 2: "jack", 3: "lily", length: 4}
可以看到,arrayLike 其实是一个对象,模拟数组的一个类数组,从数据类型上说它是一个对象,新增了一个 length 的属性。还可以看出,用 typeof 来判断输出的是 object,它自身是不会有数组的 push 方法的,这里用 call 的方法来借用 Array 原型链上的 push 方法,可以实现一个类数组的 push 方法,给 arrayLike 添加新的元素。
从打印结果可以看出,数组的 push 方法满足了我们想要实现添加元素的诉求。再来看下 arguments 如何转换成数组:
function sum(a, b) {
let args = Array.prototype.slice.call(arguments);
// let args = [].slice.call(arguments); // 这样写也是一样效果
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(a, b) {
let args = Array.prototype.concat.apply([], arguments);
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
可以看到,借用 Array 原型链上的各种方法,来实现 sum 函数的参数相加的效果。一开始都是将 arguments 通过借用数组的方法转换为真正的数组,最后都又通过数组的 reduce 方法实现了参数转化的真数组 args 的相加,最后返回预期的结果。
(2)借用 ES6 方法
还可以采用 ES6 新增的 Array.from 方法以及展开运算符的方法来将类数组转化为数组。那么还是围绕上面这个 sum 函数来进行改变,看下用 Array.from 和展开运算符是怎么实现转换数组的:
function sum(a, b) {
let args = Array.from(arguments);
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(a, b) {
let args = [...arguments];
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(...args) {
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
可以看到,Array.from 和 ES6 的展开运算符,都可以把 arguments 这个类数组转换成数组 args,从而实现调用 reduce 方法对参数进行累加操作。其中第二种和第三种都是用 ES6 的展开运算符,虽然写法不一样,但是基本都可以满足多个参数实现累加的效果。
10.ajax axios fetch 各有什么特点
1.jQuery ajax
$.ajax({
type: "POST",
url: url,
data: data,
dataType: dataType,
success: function () {},
error: function () {},
});
传统 Ajax 指的是 XMLHttpRequest(XHR), 最早出现的发送后端请求技术,隶属于原始 js 中,核心使用 XMLHttpRequest 对象,多个请求之间如果有先后关系的话,就会出现回调地狱。 JQuery ajax 是对原生 XHR 的封装,除此以外还增添了对JSONP的支持。经过多年的更新维护,真的已经是非常的方便了,优点无需多言;如果是硬要举出几个缺点,那可能只有: 1.本身是针对 MVC 的编程,不符合现在前端MVVM的浪潮 2.基于原生的 XHR 开发,XHR 本身的架构不清晰。 3.JQuery 整个项目太大,单纯使用 ajax 却要引入整个 JQuery 非常的不合理(采取个性化打包的方案又不能享受 CDN 服务) 4.不符合关注分离(Separation of Concerns)的原则 5.配置和调用方式非常混乱,而且基于事件的异步模型不友好。
MVVM(Model-View-ViewModel), 源自于经典的 Model–View–Controller(MVC)模式。MVVM 的出现促进了 GUI 前端开发与后端业务逻辑的分离,极大地提高了前端开发效率。MVVM 的核心是 ViewModel 层,它就像是一个中转站(value converter),负责转换 Model 中的数据对象来让数据变得更容易管理和使用,该层向上与视图层进行双向数据绑定,向下与 Model 层通过接口请求进行数据交互,起呈上启下作用。View 层展现的不是 Model 层的数据,而是 ViewModel 的数据,由 ViewModel 负责与 Model 层交互,这就完全解耦了 View 层和 Model 层,这个解耦是至关重要的,它是前后端分离方案实施的最重要一环。 如下图所示:
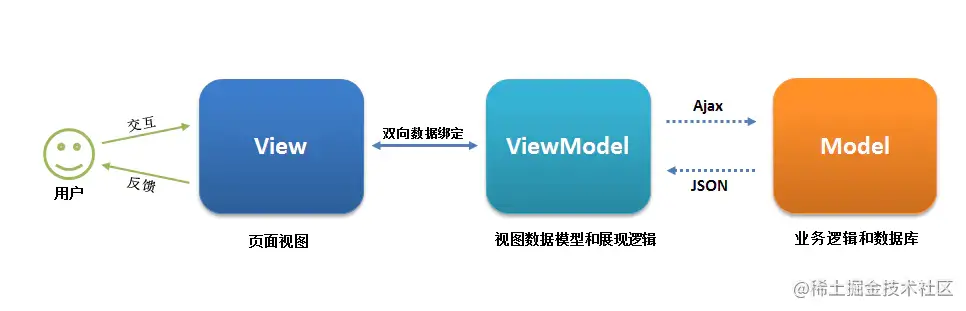
2.axios
axios({
method: "post",
url: "/user/12345",
data: {
firstName: "Fred",
lastName: "Flintstone",
},
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
Vue2.0 之后,尤雨溪推荐大家用 axios 替换 JQuery ajax,想必让 axios 进入了很多人的目光中。 axios 是一个基于 Promise 用于浏览器和 nodejs 的 HTTP 客户端,本质上也是对原生 XHR 的封装,只不过它是 Promise 的实现版本,符合最新的 ES 规范,它本身具有以下特征: 1.从浏览器中创建 XMLHttpRequest 2.支持 Promise API 3.客户端支持防止 CSRF 4.提供了一些并发请求的接口(重要,方便了很多的操作) 5.从 node.js 创建 http 请求 6.拦截请求和响应 7.转换请求和响应数据 8.取消请求 9.自动转换 JSON 数据 防止 CSRF:就是让你的每个请求都带一个从 cookie 中拿到的 key, 根据浏览器同源策略,假冒的网站是拿不到你 cookie 中得 key 的,这样,后台就可以轻松辨别出这个请求是否是用户在假冒网站上的误导输入,从而采取正确的策略。 3.fetch
try {
let response = await fetch(url);
let data = response.json();
console.log(data);
} catch (e) {
console.log("Oops, error", e);
}
fetch 号称是 AJAX 的替代品,是在 ES6 出现的,使用了 ES6 中的 promise 对象。Fetch 是基于 promise 设计的。Fetch 的代码结构比起 ajax 简单多了,参数有点像 jQuery ajax。但是,一定记住fetch 不是 ajax 的进一步封装,而是原生 js,没有使用 XMLHttpRequest 对象。 fetch 的优点: 1.符合关注分离,没有将输入、输出和用事件来跟踪的状态混杂在一个对象里 2.更好更方便的写法 坦白说,上面的理由对我来说完全没有什么说服力,因为不管是 Jquery 还是 Axios 都已经帮我们把 xhr 封装的足够好,使用起来也足够方便,为什么我们还要花费大力气去学习 fetch? 我认为 fetch 的优势主要优势就是:
- 语法简洁,更加语义化
- 基于标准 Promise 实现,支持 async/await
- 同构方便,使用 isomorphic-fetch 4.更加底层,提供的 API 丰富(request, response) 5.脱离了 XHR,是 ES 规范里新的实现方式
最近在使用 fetch 的时候,也遇到了不少的问题: fetch 是一个低层次的 API,你可以把它考虑成原生的 XHR,所以使用起来并不是那么舒服,需要进行封装。 例如:
1)fetch 只对网络请求报错,对 400,500 都当做成功的请求,服务器返回 400,500 错误码时并不会 reject,只有网络错误这些导致请求不能完成时,fetch 才会被 reject。 2)fetch 默认不会带 cookie,需要添加配置项: fetch(url, {credentials: 'include'}) 3)fetch 不支持 abort,不支持超时控制,使用 setTimeout 及 Promise.reject 的实现的超时控制并不能阻止请求过程继续在后台运行,造成了流量的浪费 4)fetch 没有办法原生监测请求的进度,而 XHR 可以
创建一个 AbortController 实例 这个实例拥有一个 signal 属性 把这个 signal 作为 fetch 请求的选项 调用 AbortController 的 abort 属性以取消所有使用这个信号的 fetch 请求。
取消 Fetch 请求
以下是取消 fetch 请求的基本步骤:
调用 abort 后出出现一个 AbortError,所以你可以在 catch 语句里通过对比错误名来监听终止的 fetch 请求:

把一个相同的信号传递给多个 fetch 请求会取消所有拥有此信号 fetch 请求:
Jake Archibald 提供了一个不错的方法来创建可终止的 fetch 请求:

总结:axios 既提供了并发的封装,也没有 fetch 的各种问题,而且体积也较小,当之无愧现在最应该选用的请求的方式。
11.new 的原理
面向对象中的 new 关键字
如上所述 new 操作实质上是定义一个具有构造函数内置对象的实例。其运行过程如下: 1.创建一个 javascript 空对象 {}; 2.将要实例化对象的原形链指向该对象原形。 3.绑定该对象为 this 的指向 4.返回该对象。
“面向对象编程”(Object Oriented Programming,缩写为 OOP)是目前主流的编程范式。
- 创建类实例 - 对象
- 创建实例的时候执行构造函数
class Person {
constructor(name) {
console.log("constructor");
this.name = name;
}
say() {
console.log("My name is ", this.name);
}
}
const b = new Person("b");
Javascript 语言中的变化
- 构造函数的写法的变化
- 通过原型定义属性和方法
- 上下文 this 的引入
function Person(name) {
console.log("constructor");
this.name = name;
}
Person.prototype.say = function () {
console.log("My name is", this.name);
};
new 的作用分析
// TODO: 构造函数被执行
function Person(name) {
console.log("constructor");
// TODO: 将构造函数的this指向新对象
this.name = name;
}
// TODO: 将新建对象的__proto__属性设置为构造函数的prototype
Person.prototype.say = function () {
console.log("My name is", this.name);
};
// TODO: 创建新对象
const b = new Person("b");
b.say();
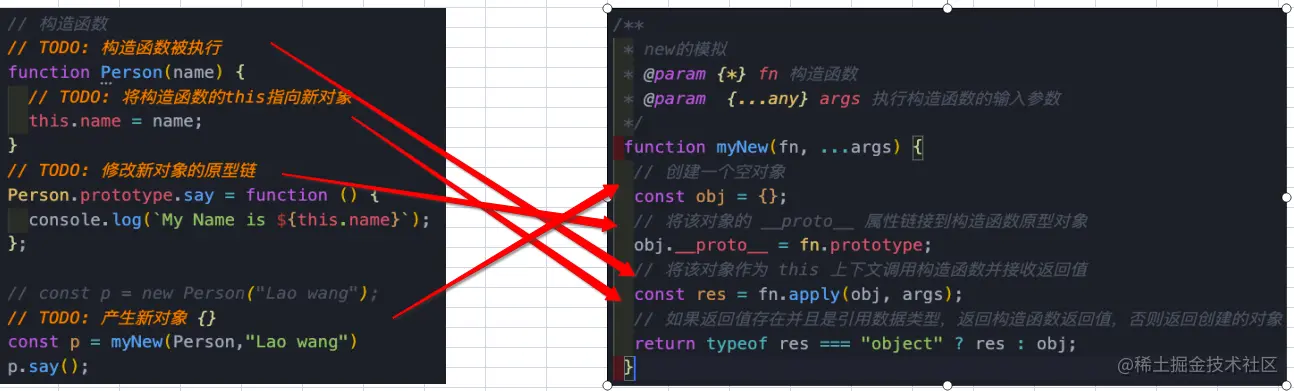
function myNew(fn, ...args) {
// 创建一个空对象
const obj = {};
// 将该对象的 __proto__ 属性链接到构造函数原型对象
obj.__proto__ = fn.prototype;
// 将该对象作为 this 上下文调用构造函数并接收返回值
const res = fn.apply(obj, args);
// 如果返回值存在并且是引用数据类型,返回构造函数返回值,否则返回创建的对象
return typeof res === "object" ? res : obj;
}
const c = myNew(Person, "b");
c.say();
12.js 延迟加载
JS 延迟加载:也就是等页面加载完成之后再加载 JavaScript 文件。
js 的延迟加载有助与提高页面的加载速度。
一般有以下几种方式:
- defer 属性
- async 属性
- 动态创建 DOM 方式
- 使用 jquery 的 getScript 方法
- 使用 settimeout 延迟方法
- 让 js 最后加载。
1、defer 属性
用途:表明脚本在执行时不会影响页面的构造。也就是说,脚本会被延迟到整个页面都解析完毕之后再执行。
HTML 4.01 为<script>标签定义了defer属性。标签定义了 defer 属性元素中设置 defer 属性。
在<script> 元素中设置 defer 属性,等于告诉浏览器立即下载,但延迟执行。
<!DOCTYPE html>
<html>
<head>
<script src="test1.js" defer="defer"></script>
<script src="test2.js" defer="defer"></script>
</head>
<body>
<!-- 这里放内容 -->
</body>
</html>
HTML5规范要求脚本按照它们出现的先后顺序执行。在现实当中,延迟脚本并不一定会按照顺序执行。
defer属性只适用于外部脚本文件。支持 HTML5 的实现会忽略嵌入脚本设置的 defer属性。
2. async 属性
目的:不让页面等待脚本下载和执行,从而异步加载页面其他内容。
HTML5 为 <script>标签定义了 async属性。与defer属性类似,都用于改变处理脚本的行为。同样,只适用于外部脚本文件。
异步脚本一定会在页面 load 事件前执行。 不能保证脚本会按顺序执行。
<!DOCTYPE html>
<html>
<head>
<script src="test1.js" async></script>
<script src="test2.js" async></script>
</head>
<body>
<!-- 这里放内容 -->
</body>
</html>
注意:async 和 defer 一样,都不会阻塞其他资源下载,所以不会影响页面的加载。 缺点:不能控制加载的顺序
3、动态创建 DOM 方式
将创建 DOM 的 script 脚本放置在标签前, 接近页面底部
<script type="text/javascript">
(function(){ var scriptEle = document.createElement("script");
scriptEle.type = "text/javasctipt";
scriptEle.async = true;
scriptEle.src = "http://cdn.bootcss.com/jquery/3.0.0-beta1/jquery.min.js";
var x = document.getElementsByTagName("head")[0];
x.insertBefore(scriptEle, x.firstChild);
})();</script>
4、使用 jQuery 的 getScript
$.getScript("outer.js", function () {
//回调函数,成功获取文件后执行的函数
console.log("脚本加载完成");
});
5、使用 setTimeout 延迟方法
延迟加载 js 代码,给网页加载留出更多时间
<script type="text/javascript">
function testLoad() {
console.log("11");
//.....这里可以写向后端的请求
}
(function(){
setTimeote(function(){ testLoad();
}, 1000); //延迟一秒加载 })()
</script>
6.让 JS 最后加载
把 js 外部引入的文件的标签放到页面底部,来让 js 最后引入,从而加快页面加载速度
13.setTimeout()与 setInterval()
setTimeout()细节
消息队列是用来存储宏任务的,并且主线程会按照顺序取出队列里的任务依次执行,所以为了保证 setTimeout 能够在规定的时间内执行,setTimeout 创建的任务不会被添加到消息队列里,与此同时,浏览器还维护了另外一个队列叫做延迟消息队列,该队列就是用来存放延迟任务,setTimeout 创建的任务会被存放于此,同时它会被记住创建时间,延迟执行时间
setTimeout(function showName() {
console.log("showName");
}, 1000);
setTimeout(function showName() {
console.log("showName1");
}, 1000);
console.log("martincai");
1.从消息队列中取出宏任务进行执行(首次任务直接执行)
2.执行 setTimeout,此时会创建一个延迟任务,延迟任务的回调函数是 showName,发起时间是当前的时间,延迟时间是第二个参数 1000ms,然后该延迟任务会被推入到延迟任务队列
3.执行 console.log('martincai')代码
4.从延迟队列里去筛选所有已过期任务(当前时间 >= 发起时间 + 延迟时间),然后依次执行
- setTimeout 会受到消息队列里的宏任务的执行时间影响,上面我们可以看到延迟消息队列的任务会在消息队列的弹出的当前任务执行完之后再执行,所以当前任务的执行时间会阻碍到 setTimeout 的延迟任务的执行时间
function showName() {
setTimeout(function show() {
console.log("show");
}, 0);
for (let i = 0; i <= 5000; i++) {}
}
showName();
这里去执行一遍可以发现 setTimeout 并不是在 0ms 左右执行,中间会有明显的延迟,因为 setTimeout 在执行的时候首先会将任务放入到延迟消息队列里,等到 showName 执行完之后,才会去延迟队列里去查找已过期的任务,这里 setTimeout 任务会被 showName 耽误
2.setTimeout 嵌套下会有 4ms 的延迟
Chrome 会把嵌套 5 层以上的 setTimeout 后当作阻塞方法,在第 6 次调用 setTimeout 的时候会自动将延时器更改为至少 4ms 的延迟时间
3.未激活的页面的 setTimeout 更改为至少 1000ms
当前 tab 页面不在 active 状态的时候,setTimeout 的延迟至少会被更改 1000ms,这样做是为了减少性能消耗和电量消耗
4.延迟时间有最大值
目前 Chrome、Firefox 等主流浏览器都是用 32bit 去存储延时时间,所以最大值是 2 的 31 次方 - 1
setTimeout(() => {
console.log(1);
}, 2 ** 31);
以上代码会立即执行
setInterval 使用存在的问题
在 setInterval 被推入任务队列时,如果在它前面有很多任务或者某个任务等待时间较长比如网络请求等,那么这个定时器的执行时间和我们预定它执行的时间可能并不一致
考虑极端情况,假如定时器里面的代码需要进行大量的计算(耗费时间较长),或者是 DOM 操作。这样一来,花的时间就比较长,有可能前一次代码还没有执行完,后一次代码就被添加到队列了。也会到时定时器变得不准确,甚至出现同一时间执行两次的情况。
最常见的出现的就是,当我们需要使用 ajax 轮询服务器是否有新数据时,必定会有一些人会使用 setInterval,然而无论网络状况如何,它都会去一遍又一遍的发送请求,最后的间隔时间可能和原定的时间有很大的出入
定时器指定的时间间隔,表示的是何时将定时器的代码添加到消息队列,而不是何时执行代码。所以真正何时执行代码的时间是不能保证的,取决于何时被主线程的事件循环取到,并执行。
setInterval(function, N)
//即:每隔N秒把function事件推到消息队列中
上图可见,setInterval 每隔 100ms 往队列中添加一个事件;100ms 后,添加 T1 定时器代码至队列中,主线程中还有任务在执行,所以等待,some event 执行结束后执行 T1 定时器代码;又过了 100ms,T2 定时器被添加到队列中,主线程还在执行 T1 代码,所以等待;又过了 100ms,理论上又要往队列里推一个定时器代码,但由于此时 T2 还在队列中,所以 T3 不会被添加(T3 被跳过) ,结果就是此时被跳过;这里我们可以看到,T1 定时器执行结束后马上执行了 T2 代码,所以并没有达到定时器的效果。
综上所述,setInterval 有两个缺点:
- 使用 setInterval 时,某些间隔会被跳过;
- 可能多个定时器会连续执行;
可以这么理解:每个 setTimeout 产生的任务会直接 push 到任务队列中;而 setInterval 在每次把任务 push 到任务队列前,都要进行一下判断(看上次的任务是否仍在队列中,如果有则不添加,没有则添加)。
因而我们一般用 setTimeout 模拟 setInterval,来规避掉上面的缺点。
14.Object 方法
Object 常用方法总结:
Object.assign(target,source1,source2,...)
该方法主要用于对象的合并,将源对象 source 的所有可枚举属性合并到目标对象 target 上,此方法只拷贝源对象的自身属性,不拷贝继承的属性。 Object.assign 方法实行的是浅拷贝,而不是深拷贝。也就是说,如果源对象某个属性的值是对象,那么目标对象拷贝得到的是这个对象的引用。同名属性会替换。 Object.assign 只能进行值的复制,如果要复制的值是一个取值函数,那么将求值后再复制。 Object.assign 可以用来处理数组,但是会把数组视为对象。
const target = { x: 0, y: 1 };
const source = { x: 1, z: 2, fn: { number: 1 } };
console.log(Object.assign(target, source));
// target {x : 1, y : 1, z : 2, fn : {number : 1}} // 同名属性会被覆盖
target.fn.number = 2;
console.log(source); // source {x : 1, z : 2, fn : {number : 2}} // 拷贝为对象引用
function Person() {
this.name = 1;
}
Person.prototype.country = "china";
var student = new Person();
student.age = 29;
const young = { name: "zhang" };
Object.assign(young, student);
// young {name : 'zhang', age : 29} // 只能拷贝自身的属性,不能拷贝prototype
Object.assign([1, 2, 3], [4, 5]); // 把数组当作对象来处理
// [4, 5, 3]
Object.create(prototype,[propertiesObject])
使用指定的原型对象及其属性去创建一个新的对象
var parent = { x: 1, y: 1 };
var child = Object.create(parent, {
z: {
// z会成为创建对象的属性
writable: true,
configurable: true,
value: "newAdd",
},
});
console.log(child); //{z:"newAdd"}
console.log(child.x); //1
Object.defineProperties(obj,props)
直接在一个对象上定义新的属性或修改现有属性,并返回该对象。
var obj = {};
Object.defineProperties(obj, {
property1: {
value: true,
writable: true,
},
property2: {
value: "Hello",
writable: false,
},
});
console.log(obj); // {property1: true, property2: "Hello"}
Object.defineProperty(obj,prop,descriptor)
在一个对象上定义一个新属性,或者修改一个对象的现有属性, 并返回这个对象。
Object.defineProperty(Object, "is", {
value: function (x, y) {
if (x === y) {
// 针对+0 不等于 -0的情况
return x !== 0 || 1 / x === 1 / y;
}
// 针对NaN的情况
return x !== x && y !== y;
},
configurable: true,
enumerable: false,
writable: true,
});
// 注意不能同时设置(writable,value) 和 get,set 方法,否则浏览器会报错 : Invalid property descriptor. Cannot both specify accessors and a value or writable attribute
Object.keys(obj)
返回一个由一个给定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和使用 for...in 循环遍历该对象时返回的顺序一致 (两者的主要区别是 一个 for-in 循环还会枚举其原型链上的属性)。
var arr = ["a", "b", "c"];
console.log(Object.keys(arr));
// ['0', '1', '2']
/* Object 对象 */
var obj = { foo: "bar", baz: 42 },
keys = Object.keys(obj);
console.log(keys);
// ["foo","baz"]
Object.values(obj)
方法返回一个给定对象自己的所有可枚举属性值的数组,值的顺序与使用 for...in 循环的顺序相同 ( 区别在于 for-in 循环枚举原型链中的属性 )。 Object.values 会过滤属性名为 Symbol 值的属性。
var an_obj = { 100: "a", 2: "b", 7: "c" };
console.log(Object.values(an_obj)); // ['b', 'c', 'a']
var obj = { 0: "a", 1: "b", 2: "c" };
console.log(Object.values(obj)); // ['a', 'b', 'c']
Object.entries(obj)
返回一个给定对象自身可枚举属性的键值对数组,其排列与使用 for...in 循环遍历该对象时返回的顺序一致(区别在于 for-in 循环也枚举原型链中的属性)。
const obj = { foo: "bar", baz: 42 };
console.log(Object.entries(obj)); // [ ['foo', 'bar'], ['baz', 42] ]
const simuArray = { 0: "a", 1: "b", 2: "c" };
console.log(Object.entries(simuArray)); // [ ['0', 'a'], ['1', 'b'], ['2', 'c'] ]
Object.fromEntries(obj)
把键值对列表转换为一个对象。
Map 转 Object
const map = new Map([
["foo", "bar"],
["baz", 42],
]);
const obj = Object.fromEntries(map);
console.log(obj); // { foo: "bar", baz: 42 }
Array 转 Object
const arr = [
["0", "a"],
["1", "b"],
["2", "c"],
];
const obj = Object.fromEntries(arr);
console.log(obj); // { 0: "a", 1: "b", 2: "c" }
对象转换
对象先通过 Object.entries()转变为数组
然后数组通过 map 过滤一遍
然后返回的新数组再通过Object.fromEntries()转换为对象,达到对象转换的效果
const object1 = { a: 1, b: 2, c: 3 };
const object2 = Object.fromEntries(
Object.entries(object1).map(([key, val]) => [key, val * 2])
);
console.log(object2);
// { a: 2, b: 4, c: 6 }
Object.prototype.hasOwnProperty(key)
判断对象自身属性中是否具有指定的属性。
obj.hasOwnProperty('name')
hasOwnProperty是 Object.prototype 的一个方法
他能判断一个对象是否包含自定义属性而不是原型链上的属性
hasOwnProperty 是 JavaScript 中唯一一个处理属性但是不查找原型链的函数
JavaScript 不会保护 hasOwnProperty 被非法占用,因此如果一个对象碰巧存在这个属性,就需要使用外部的 hasOwnProperty 函数来获取正确的结果
var foo = {
hasOwnProperty: function() { //已经存在的
return false;
},
chang: '收购腾讯'
};
foo.hasOwnProperty('chang'); // 总是返回 false
// 使用{}对象的 hasOwnProperty,并将其上下为设置为foo
{}.hasOwnProperty.call(foo, 'chang'); // true
当检查对象上某个属性是否存在时,hasOwnProperty 是唯一可用的方法。同时在使用 for in loop 遍历对象时,推荐总是使用 hasOwnProperty 方法,这将会避免原型对象扩展带来的干扰
Object.prototype.chang = 1;
var foo = { oo: 2 };
for (var i in foo) {
//for … in 循环不仅可以遍历数字键名,还会遍历原型上的值和手动添加的其他键
console.log(i); // 输出两个属性:chang 和 oo
}
// 没办法改变for in语句的行为,所以想过滤结果就只能使用hasOwnProperty 方法
// 修改代码如下
for (var i in foo) {
if (foo.hasOwnProperty(i)) {
//判断去掉原型上的
console.log(i);
}
}
//使用了 hasOwnProperty,所以这次只输出 oo。
//如果不使用 hasOwnProperty,则这段代码在原生对象原型(比如 Object.prototype)被扩展时可能会出错
//注意通过判断一个属性是否undifined 是不够的 因为一个属性确实存在 只不过它的值被设置为undefined
Object.getOwnPropertyNames()
返回一个由指定对象的所有自身属性的属性名(包括不可枚举属性但不包括 Symbol 值作为名称的属性)组成的数组。
var obj = { 0: "a", 1: "b", 2: "c" };
Object.getOwnPropertyNames(obj).forEach(function (val) {
console.log(val);
});
var obj = {
x: 1,
y: 2,
};
Object.defineProperty(obj, "z", {
enumerable: false,
});
console.log(Object.getOwnPropertyNames(obj)); // ["x", "y", "z"] 包含不可枚举属性 。
console.log(Object.keys(obj)); // ["x", "y"] 只包含可枚举属性 。
console.log(Object.getOwnPropertyNames("")); //['length']
可以枚举属性 遍历键名 是按照顺序进行遍历的 是字典顺序
let str = "111";
let num = ["1", "3", "2", "4"];
console.log(Object.getOwnPropertyNames(str));
//['0', '1', '2', 'length']
console.log(Object.getOwnPropertyNames(num));
//['0', '1', '2', '3', 'length']
let obj = {
1: "a",
3: "b",
4: "c",
2: "d",
};
let obj2 = {
e: "a",
3: "b",
f: "c",
2: "d",
};
console.log(Object.getOwnPropertyNames(obj));
//['1', '2', '3', '4']
console.log(Object.getOwnPropertyNames(obj2));
//['2', '3', 'e', 'f']
Object.getOwnPropertySymbols(obj)
Object.getOwnPropertySymbols返回一个数组,包含对象自身的所有 Symbol 属性。
Object.getOwnPropertyDescriptor()
ES5 有一个Object.getOwnPropertyDescriptor方法,返回某个对象属性的描述对象(descriptor)。
var obj = { p: "a" };
Object.getOwnPropertyDescriptor(obj, "p");
// Object { value: "a",
// writable: true,
// enumerable: true,
// configurable: true
// }
Object.getOwnPropertyDescriptors()
ES2017 引入了Object.getOwnPropertyDescriptors方法,返回指定对象所有自身属性(非继承属性)的描述对象。
const obj = {
foo: 123,
get bar() {
return "abc";
},
};
Object.getOwnPropertyDescriptors(obj);
// { foo:
// { value: 123,
// writable: true,
// enumerable: true,
// configurable: true },
// bar:
// { get: [Function: bar],
// set: undefined,
// enumerable: true,
// configurable: true } }
上面代码中,Object.getOwnPropertyDescriptors方法返回一个对象,所有原对象的属性名都是该对象的属性名,对应的属性值就是该属性的描述对象。
该方法的实现非常容易。
function getOwnPropertyDescriptors(obj) {
const result = {};
for (let key of Reflect.ownKeys(obj)) {
result[key] = Object.getOwnPropertyDescriptor(obj, key);
}
return result;
}
该方法的引入目的,主要是为了解决Object.assign()无法正确拷贝get属性和set属性的问题。
const source = {
set foo(value) {
console.log(value);
},
};
const target1 = {};
Object.assign(target1, source);
Object.getOwnPropertyDescriptor(target1, "foo");
// { value: undefined,
// writable: true,
// enumerable: true,
// configurable: true }
上面代码中,source对象的foo属性的值是一个赋值函数,Object.assign方法将这个属性拷贝给target1对象,结果该属性的值变成了undefined。这是因为Object.assign方法总是拷贝一个属性的值,而不会拷贝它背后的赋值方法或取值方法。
这时,Object.getOwnPropertyDescriptors方法配合Object.defineProperties方法,就可以实现正确拷贝。
const source = {
set foo(value) {
console.log(value);
},
};
const target2 = {};
Object.defineProperties(target2, Object.getOwnPropertyDescriptors(source));
Object.getOwnPropertyDescriptor(target2, "foo");
// { get: undefined,
// set: [Function: foo],
// enumerable: true,
// configurable: true }
上面代码中,将两个对象合并的逻辑提炼出来,就是下面这样。
const shallowMerge = (target, source) =>
Object.defineProperties(target, Object.getOwnPropertyDescriptors(source));
Object.getOwnPropertyDescriptors方法的另一个用处,是配合Object.create方法,将对象属性克隆到一个新对象。这属于浅拷贝。
const clone = Object.create(
Object.getPrototypeOf(obj),
Object.getOwnPropertyDescriptors(obj)
);
// 或者
const shallowClone = (obj) =>
Object.create(
Object.getPrototypeOf(obj),
Object.getOwnPropertyDescriptors(obj)
);
上面代码会克隆对象obj。
另外,Object.getOwnPropertyDescriptors方法可以实现一个对象继承另一个对象。以前,继承另一个对象,常常写成下面这样。
const obj = {
__proto__: prot,
foo: 123,
};
ES6 规定__proto__只有浏览器要部署,其他环境不用部署。如果去除__proto__,上面代码就要改成下面这样。
const obj = Object.create(prot);
obj.foo = 123;
// 或者
const obj = Object.assign(Object.create(prot), {
foo: 123,
});
有了Object.getOwnPropertyDescriptors,我们就有了另一种写法。
const obj = Object.create(
prot,
Object.getOwnPropertyDescriptors({
foo: 123,
})
);
Object.getOwnPropertyDescriptors也可以用来实现 Mixin(混入)模式。
let mix = (object) => ({
with: (...mixins) =>
mixins.reduce(
(c, mixin) => Object.create(c, Object.getOwnPropertyDescriptors(mixin)),
object
),
});
// multiple mixins example
let a = { a: "a" };
let b = { b: "b" };
let c = { c: "c" };
let d = mix(c).with(a, b);
上面代码中,对象a和b被混入了对象c。
出于完整性的考虑,Object.getOwnPropertyDescriptors进入标准以后,还会有Reflect.getOwnPropertyDescriptors方法。
Object.prototype.isPrototypeOf()
判断一个对象是否存在于另一个对象的原型链上。
Object.setPrototypeOf(obj,prototype)
设置对象的原型对象
Object.setPrototypeOf方法的作用与__proto__相同,用来设置一个对象的prototype对象,返回参数对象本身。它是 ES6 正式推荐的设置原型对象的方法。
// 格式
Object.setPrototypeOf(object, prototype);
// 用法
var o = Object.setPrototypeOf({}, null);
该方法等同于下面的函数。
function (obj, proto) {
obj.__proto__ = proto;
return obj;
}
下面是一个例子。
let proto = {};
let obj = { x: 10 };
Object.setPrototypeOf(obj, proto);
proto.y = 20;
proto.z = 40;
obj.x; // 10
obj.y; // 20
obj.z; // 40
上面代码将proto对象设为obj对象的原型,所以从obj对象可以读取proto对象的属性。
如果第一个参数不是对象,会自动转为对象。但是由于返回的还是第一个参数,所以这个操作不会产生任何效果。
Object.setPrototypeOf(1, {}) === 1; // true
Object.setPrototypeOf("foo", {}) === "foo"; // true
Object.setPrototypeOf(true, {}) === true; // true
由于undefined和null无法转为对象,所以如果第一个参数是undefined或null,就会报错。
Object.setPrototypeOf(undefined, {});
// TypeError: Object.setPrototypeOf called on null or undefined
Object.setPrototypeOf(null, {});
// TypeError: Object.setPrototypeOf called on null or undefined
Object.getPrototypeOf(obj)
该方法与Object.setPrototypeOf方法配套,用于读取一个对象的原型对象。
下面是一个例子。
function Rectangle() {
// ...
}
var rec = new Rectangle();
Object.getPrototypeOf(rec) === Rectangle.prototype;
// true
Object.setPrototypeOf(rec, Object.prototype);
Object.getPrototypeOf(rec) === Rectangle.prototype;
// false
如果参数不是对象,会被自动转为对象。
// 等同于 Object.getPrototypeOf(Number(1))
Object.getPrototypeOf(1)
// Number {[[PrimitiveValue]]: 0}
// 等同于 Object.getPrototypeOf(String('foo'))
Object.getPrototypeOf('foo')
// String {length: 0, [[PrimitiveValue]]: ""}
// 等同于 Object.getPrototypeOf(Boolean(true))
Object.getPrototypeOf(true)
// Boolean {[[PrimitiveValue]]: false}
Object.getPrototypeOf(1) === Number.prototype // true
Object.getPrototypeOf('foo') === String.prototype // true
Object.getPrototypeOf(true) === Boolean.prototype // true
如果参数是undefined或null,它们无法转为对象,所以会报错。
Object.getPrototypeOf(null);
// TypeError: Cannot convert undefined or null to object
Object.getPrototypeOf(undefined);
// TypeError: Cannot convert undefined or null to object
Object.is()
判断两个值是否相同。 如果下列任何一项成立,则两个值相同:
两个值都是 undefined 两个值都是 null 两个值都是 true 或者都是 false 两个值是由相同个数的字符按照相同的顺序组成的字符串 两个值指向同一个对象 两个值都是数字并且 都是正零 +0 都是负零 -0 都是 NaN 都是除零和 NaN 外的其它同一个数字
Object.is("foo", "foo"); // true
Object.is(window, window); // true
Object.is("foo", "bar"); // false
Object.is([], []); // false
var test = { a: 1 };
Object.is(test, test); // true
Object.is(null, null); // true
// 特例
Object.is(0, -0); // false
Object.is(-0, -0); // true
Object.is(NaN, 0 / 0); // true
Object.freeze()
冻结一个对象,冻结指的是不能向这个对象添加新的属性,不能修改其已有属性的值,不能删除已有属性,以及不能修改该对象已有属性的可枚举性、可配置性、可写性。也就是说,这个对象永远是不可变的。该方法返回被冻结的对象。
var obj = {
prop: function () {},
foo: "bar",
};
// 新的属性会被添加, 已存在的属性可能
// 会被修改或移除
obj.foo = "baz";
obj.lumpy = "woof";
delete obj.prop;
// 作为参数传递的对象与返回的对象都被冻结
// 所以不必保存返回的对象(因为两个对象全等)
var o = Object.freeze(obj);
o === obj; // true
Object.isFrozen(obj); // === true
// 现在任何改变都会失效
obj.foo = "quux"; // 静默地不做任何事
// 静默地不添加此属性
obj.quaxxor = "the friendly duck";
console.log(obj);
Object.isFrozen()
判断一个对象是否被冻结 .
Object.preventExtensions()
对象不能再添加新的属性。可修改,删除现有属性,不能添加新属性。
var obj = {
name: "lilei",
age: 30,
sex: "male",
};
obj = Object.preventExtensions(obj);
console.log(obj); // {name: "lilei", age: 30, sex: "male"}
obj.name = "haha";
console.log(obj); // {name: "haha", age: 30, sex: "male"}
delete obj.sex;
console.log(obj); // {name: "haha", age: 30}
obj.address = "china";
console.log(obj); // {name: "haha", age: 30}
15.Event 对象
我们对元素进行点击操作时候,会产生一个 Event 的对象
<button id="demo">event</button>
<script>
let demo = document.getElementById('demo');
demo.addEventListener('click', function(event) {
console.log(event)
})
</script>
clientX / clientY
clientX 和 clientY 都是只读属性,提供发生事件时的客户端区域的水平坐标和垂直坐标。不管页面是否滚动,客户端区域的左上角的 clientX 和 clientY 都是 0。
注意:以可视区域(客户端)的左上角位置为原点
offsetX / offsetY
offsetX 和 offsetY 都是只读属性,规定了事件对象与目标节点的内填充边在 X 或 Y 轴上的偏移量。
注意:以目标元素的(含 padding )左上角位置为原点
screenX / screenY
screenX 和 screenY 都是只读属性,提供事件鼠标在全局(屏幕)中的水平和垂直距离。
注意:以屏幕的左上角位置为原点
点击的元素位置相对电脑屏幕的左上角为坐标原点计算。得到的数值感觉不是很准,了解一下就好...
layerX / layerY
layerX 和 layerY 都是只读属性。
若目标元素自身有定位属性的话,就目标元素(包含 padding )的左上角作为原点计算。 若目标元素自身没有定位属性的话,往上找有定位属性的父元素的左上角为原点计算距离。 若父元素都没有定位属性的话,那么就以 body 元素的左上角为原点计算。
pageX / pageY
pageX 和 pageY 都是只读属性,表示相对于整个文档的水平或者垂直坐标。这两个属性是基于文档边缘,考虑任何页面的水平或者垂直方向上的滚动。
注意:以文档的左上角位置为原点
client 部分
clientHeight:内容可视区域的高度,也就是说页面浏览器中可以看到内容的这个区域的高度(不含边框,也不包含滚动条等边线,会随窗口的显示大小改变)
clientLeft,clientTop: 这两个返回的是元素周围边框的厚度(border),如果不指定一个边框或者不定位该元素,他的值就是 0.
offset 部分
计算时都包括此对象的border,padding
offsetLeft:获取对象左侧与定位父级之间的距离
offsetTop:获取对象上侧与定位父级之间的距离
PS:获取对象到父级的距离取决于最近的定位父级position
offsetWidth:获取元素自身的宽度(包含边框)
offsetHeight:获取元素自身的高度(包含边框)
clientX:当事件被触发时鼠标指针相对于窗口左边界的水平坐标,参照点为浏览器内容区域的左上角,该参照点会随之滚动条的移动而移动。
offsetX:当事件被触发时鼠标指针相对于所触发的标签元素的左内边框的水平坐标。
screenX:鼠标位置相对于用户屏幕水平偏移量,而 screenY 也就是垂直方向的,此时的参照点也就是原点是屏幕的左上角。
pageX:参照点是页面本身的body原点,而不是浏览器内容区域左上角,它计算的值不会随着滚动条而变动,它在计算时其实是以 body 左上角原点(即页面本身的左上角,而不是浏览器可见区域的左上角)为参考点计算的,这个相当于已经把滚动条滚过的高或宽计算在内了,所以无论滚动条是否滚动,他都是一样的距离值。
所以基本可以得出结论:
pageX > clientX, pageY > clientY
pageX = clientX + ScrollLeft(滚动条滚过的水平距离)
pageY = clientY + ScrollTop(滚动条滚过的垂直距离)
scroll 部分
scrollLeft:设置或获取当前左滚的距离,即左卷的距离;
scrollTop:设置或获取当前上滚的距离,即上卷的距离;
scrollHeight:获取对象可滚动的总高度;
scrollWidth:获取对象可滚动的总宽度;
scrollHeight = content + padding;(即border之内的内容)
网页可见区域宽: document.body.clientWidth; 网页可见区域高: document.body.clientHeight; 网页可见区域宽: document.body.offsetWidth (包括边线的宽); 网页可见区域高: document.body.offsetHeight (包括边线的宽); 网页正文全文宽: document.body.scrollWidth; 网页正文全文高: document.body.scrollHeight; 网页被卷去的高: document.body.scrollTop; 网页被卷去的左: document.body.scrollLeft; 网页正文部分上: window.screenTop; 网页正文部分左: window.screenLeft; 屏幕分辨率的高: window.screen.height; 屏幕分辨率的宽: window.screen.width; 屏幕可用工作区高度: window.screen.availHeight; 屏幕可用工作区宽度:window.screen.availWidth;
scrollHeight: 获取对象的滚动高度。 scrollLeft:设置或获取位于对象左边界和窗口中目前可见内容的最左端之间的距离 scrollTop:设置或获取位于对象最顶端和窗口中可见内容的最顶端之间的距离 scrollWidth:获取对象的滚动宽度 offsetHeight:获取对象相对于版面或由父坐标 offsetParent 属性指定的父坐标的高度 offsetLeft:获取对象相对于版面或由 offsetParent 属性指定的父坐标的计算左侧位置 offsetTop:获取对象相对于版面或由 offsetTop 属性指定的父坐标的计算顶端位置 event.clientX 相对文档的水平座标 event.clientY 相对文档的垂直座标
event.offsetX 相对容器的水平坐标 event.offsetY 相对容器的垂直坐标 document.documentElement.scrollTop 垂直方向滚动的值 event.clientX+document.documentElement.scrollTop 相对文档的水平座标+垂直方向滚动的量
判断元素到达可视区域
以图片显示为例:
window.innerHeight是浏览器可视区的高度;document.body.scrollTop || document.documentElement.scrollTop是浏览器滚动的过的距离;imgs.offsetTop是元素顶部距离文档顶部的高度(包括滚动条的距离);- 内容达到显示区域的:
img.offsetTop < window.innerHeight + document.body.scrollTop;
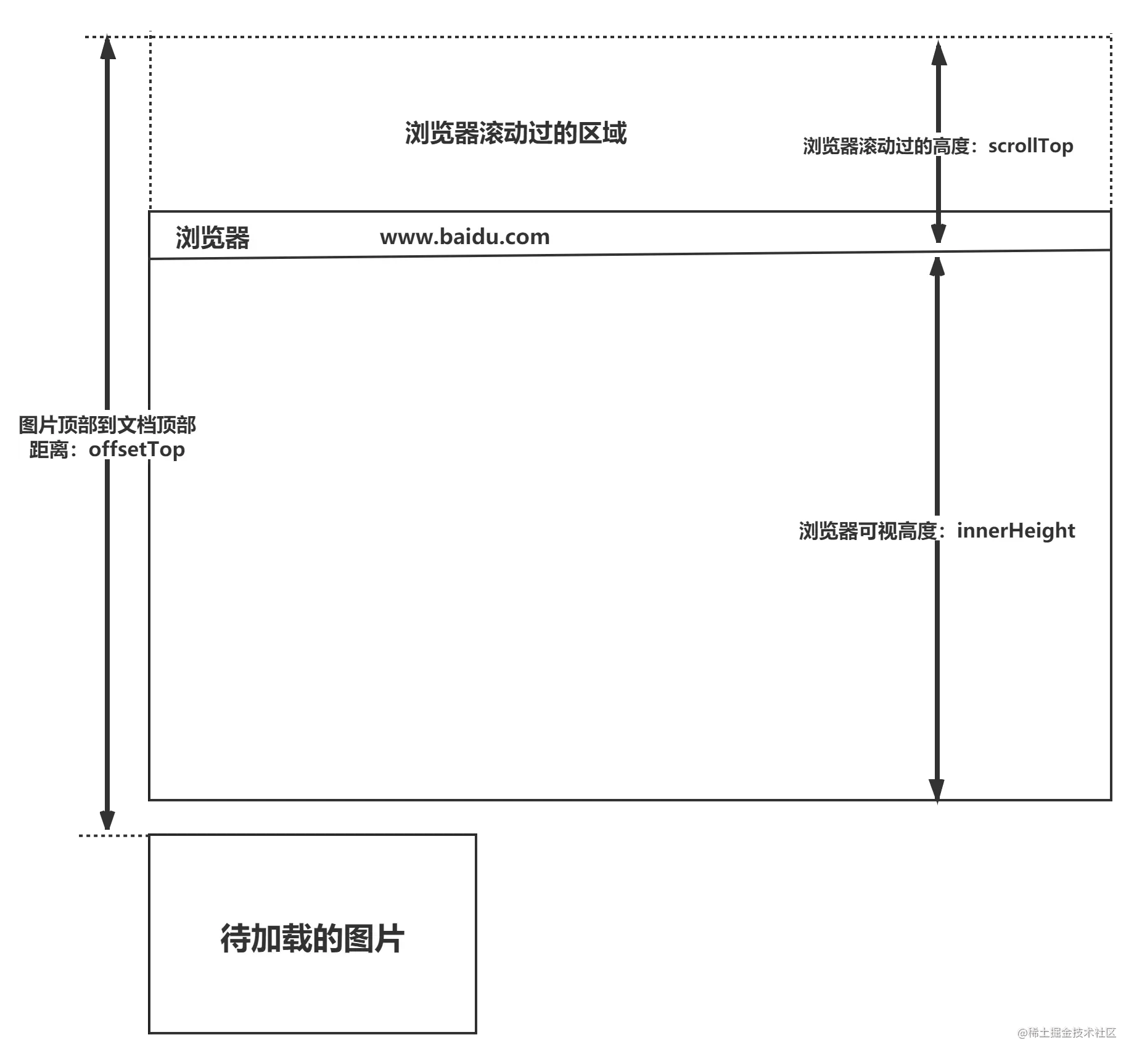
target 和 currentTarget
需求:循环渲染一个 div 盒子,在这个 div 盒子上绑定一个自定义属性和值,但是这个 div 盒子中还有子元素。如果使用 event.Target 的话就容易出现:当鼠标点击在子元素的时候就获取不到我在父元素上绑定自定义属性的值,这时候使用 e.currentTarget 不管点击的是父元素(绑定自定义的属性)还是子元素,函数内所拿到的 event 都是在绑定点击事件的标签处传过来的! 所以,通俗来讲,
event.target 返回的是,触发事件的元素 event.currentTarget 返回的是,绑定事件的元素
如果说是一个单标签绑定的事件 可以使用以上任意两种方法都是可行的;
如果你所绑定事件的标签内还有多个子标签的话建议使用 event.currentTarget。或者使用事件监听 ,这样,event.currentTarget 就能拿到绑定事件的节点,而在其下的各种后代节点就可以用 event.target.(各种类名,id,标签名,属性值)来具体指向到触发事件的节点!
16.Node 和 Element
<div id="parent">
This is parent content.
<div id="child1">This is child1.</div>
<div id="child2">This is child2.</div>
</div>
document.getElementById() 方法应该是我们最常使用的接口之一,那么它的返回值到底是 Node 还是 Element?
我们使用以下代码验证一下:
let parentEle = document.getElementById("parent");
parentEle instanceof Node;
// true
parentEle instanceof Element;
// true
parentEle instanceof HTMLElement;
// true
可以看到,document.getElementById() 获取到的结果既是 Node 也是 Element
Element 继承于 Node。
从而也可以得出一个结论:Element 一定是 Node,但 Node 不一定是 Element。
所以:Element 可以使用 Node 的所有方法
Element.children 获取到的只是父元素点下的所有 div,而 Element.childNodes 获取到的却是父节点下的所有节点(包含文本内容、元素)
- 单个的 HTML 标签算是一个单独的 Node;
- 针对非 HTML 标签(比如文本、空格等),从一个 HTML 标签开始,到碰到的第一个 HTML 标签为止,如果中间有内容(文本、空格等),那这部分内容算是一个 Node。注意:这里的 HTML 标签不分起始和结束
- 比如,
<div> 1 2 3 <span> 4 5 6 </span> 7 8 9 </div>,针对这段代码来说:- div 是一个 Node;
- span 是一个 Node;
- “ 1 2 3 ”、“ 4 5 6 ”和 “ 7 8 9 ”全都是单独的 Node
17.判断对象是否为空,创建空对象
1.将 json 对象转化为 json 字符串,再判断该字符串是否为"{}"
var data = {};
var b = JSON.stringify(data) == "{}";
alert(b); //true
2.for in 循环判断
var obj = {};
var b = function () {
for (var key in obj) {
return false;
}
return true;
};
alert(b()); //true
3.Object.getOwnPropertyNames()方法
此方法是使用 Object 对象的 getOwnPropertyNames 方法,获取到对象中的属性名,存到一个数组中,返回数组对象,我们可以通过判断数组的 length 来判断此对象是否为空
注意:此方法不兼容 ie8,其余浏览器没有测试
var data = {};
var arr = Object.getOwnPropertyNames(data);
alert(arr.length == 0); //true
4.使用 ES6 的 Object.keys()方法
ES6 的新方法, 返回值也是对象中属性名组成的数组
var data = {};
var arr = Object.keys(data);
alert(arr.length == 0); //true
创建空对象
要创建一个干净的空对象,应该使用 Object.create(null)而不是剩下两种。 通过做 Objist.create(NULL),我们显式指定 NULL 作为它的原型。所以它绝对没有属性,甚至没有构造函数、toString、hasOwnProperty 属性,所以如果需要的话,可以在数据结构中使用这些键,而不需要通过 hasOwnProperty 进行判断
var obj1 = {};
var obj2 = Object.create(null);
var obj3 = new Object();
18.js 对象遍历顺序
对待遍历顺序,对象有一套自己既定的规则,在此规则下呢,对象的遍历顺序会受插入元素顺序的影响,但是不完全受插入元素先后顺序的影响。如果您有「必须按插入元素顺序遍历」的场景,可以考虑使用 Map。
遍历对象的方法有很多种,我们经常会使用的有 for...in ,除此之外,还有:
Object.keysObject.entriesObejct.getOwnerProPertyNamesReflect.ownKeys- ......
上面我们列的几个方法,都按照一样的规则去遍历对象。而实际的遍历规则会根据 key 值类型的不同而不同。
在一个对象中,如果我们的 key 值是像 '1'、'200'这种正整数格式的字符串。 遍历的顺序是按照 key 值的大小来排列的。
比如我们看这样的一个例子:
const obj = {};
obj["10"] = "a";
obj["9"] = "b";
obj[8] = "c";
obj[7] = "d";
console.log(Object.keys(obj)); // ["7", "8", "9", "10"]
我们最后的遍历顺序完全忽视了插入顺序,并且,值得我们注意的是,在对象中,就算我们添加属性时的索引值是 Number 类型,最后的结果还是会被隐式的转为字符串。
数组作为对象的一种,也符合上面的规则,又或许,有上面的表现就是因为要兼容数组的缘故呢。除此之外,通过上面的规则,我们还可以推断出,对类数组(key 值是正整数且有 length 属性)进行遍历也是按照索引顺序的。
另外,如果我们的 key 值是不能转为正整数的字符串,这其中包括了可以转换为负数的字符串( 如 '-1' )、小数格式的字符串(如 '1.0' ) 和其他的字符串。他们的遍历顺序会比较符合直觉,就是插入对象的顺序:
const obj2 = {};
obj2["1.1"] = "a";
obj2["1.0"] = "b";
obj2["-1"] = "c";
obj2["jack"] = "d";
console.log(Object.keys(obj2)); // ["1.1", "1.0", "-1", "jack"]
事实上,对象的索引值的类型不仅可以是字符串,还可以是 Symbol 类型。对于 Symbol 类型而言,它的遍历顺序也是单纯的按照插入对象的顺序。
如果我们的对象综合了上面所有的情况,即一个对象的索引值出现了所有的类型(各种形式的字符串、Symbol 类型),它会:
- 先按照我们上面提的关于正整数的规则遍历正整数部分
- 按接下来会插入顺序遍历剩下的字符串
- 最后再按照插入顺序遍历
Symbol类型
相信到这里,大家已经完全明白了对象的遍历顺序问题,最后还有一点值得大家注意的点,是 for...in 的遍历顺序问题。
最开始的时候,for...in 的遍历顺序并没有一个统一的标准,浏览器厂商会按照他们的喜好去设置 for...in 的遍历顺序。如果您对遍历顺序有要求并且要兼容老的浏览器版本,建议不使用它。后来 ES 2019 的 一个提案 对此现象进行了规范,现在 for...in 的顺序也遵循上面的规则。
尽管会遵循上面的规则,但是 for...in 还会遍历原型的属性。所以 for...in 的变量元素的规则是先按照我们上面讲的对象遍历规则去变量对象本身,接下来再按照此规则去遍历对象的原型,以此类推,直到遍历到顶部。
19.js 创建对象方式
平时代码中必定会使用对象,通常是用最直接的字面量方法创建var obj = {},最近在整理JS 继承方式时遇到Object.create()也可以创建对象,另外,也可以用new Object()关键字创建。 那这三种方式有差别吗?
直接字面量创建
var objA = {};
objA.name = "a";
objA.sayName = function () {
console.log(`My name is ${this.name} !`);
};
// var objA = {
// name: 'a',
// sayName: function() {
// console.log(`My name is ${this.name} !`);
// }
// }
objA.sayName();
console.log(objA.__proto__ === Object.prototype); // true
console.log(objA instanceof Object); // true
new 关键字创建
var objB = new Object();
// var objB = Object();
objB.name = "b";
objB.sayName = function () {
console.log(`My name is ${this.name} !`);
};
objB.sayName();
console.log(objB.__proto__ === Object.prototype); // true
console.log(objB instanceof Object); // true
在JS 的指向问题中讲new 绑定时讲了new操作符其实做了以下四步:
var obj = new Object(); // 创建一个空对象
obj.__proto__ = Object.prototype; // obj的__proto__指向构造函数Object的prototype
var result = Object.call(obj); // 把构造函数Object的this指向obj,并执行构造函数Object把结果赋值给result
if (typeof result === "object") {
objB = result; // 构造函数Object的执行结果是引用类型,就把这个引用类型的对象返回给objB
} else {
objB = obj; // 构造函数Object的执行结果是值类型,就返回obj这个空对象给objB
}
这样一比较,其实字面量创建和 new 关键字创建并没有区别,创建的新对象的__proto__都指向Object.prototype,只是字面量创建更高效一些,少了__proto__指向赋值和this。
Object.create()
Object.create()方法创建一个新对象,使用现有的对象来提供新创建的对象的__proto__。 MDN
const person = {
isHuman: false,
printIntroduction: function () {
console.log(`My name is ${this.name}. Am I human? ${this.isHuman}`);
},
};
const me = Object.create(person); // me.__proto__ === person
me.name = "Matthew"; // name属性被设置在新对象me上,而不是现有对象person上
me.isHuman = true; // 继承的属性可以被重写
me.printIntroduction(); // My name is Matthew. Am I human? true
Object.create(proto[, propertiesObject])
proto必填参数,是新对象的原型对象,如上面代码里新对象me的__proto__指向person。注意,如果这个参数是null,那新对象就彻彻底底是个空对象,没有继承Object.prototype上的任何属性和方法,如hasOwnProperty()、toString()等。
var a = Object.create(null);
console.dir(a); // {}
console.log(a.__proto__); // undefined
console.log(a.__proto__ === Object.prototype); // false
console.log(a instanceof Object); // false 没有继承`Object.prototype`上的任何属性和方法,所以原型链上不会出现Object
propertiesObject是可选参数,指定要添加到新对象上的可枚举的属性(即其自定义的属性和方法,可用hasOwnProperty()获取的,而不是原型对象上的)的描述符及相应的属性名称。
var bb = Object.create(null, {
a: {
value: 2,
writable: true,
configurable: true,
},
});
console.dir(bb); // {a: 2}
console.log(bb.__proto__); // undefined
console.log(bb.__proto__ === Object.prototype); // false
console.log(bb instanceof Object); // false 没有继承`Object.prototype`上的任何属性和方法,所以原型链上不会出现Object
// ----------------------------------------------------------
var cc = Object.create(
{ b: 1 },
{
a: {
value: 3,
writable: true,
configurable: true,
},
}
);
console.log(cc); // {a: 3}
console.log(cc.hasOwnProperty("a"), cc.hasOwnProperty("b")); // true false 说明第二个参数设置的是新对象自身可枚举的属性
console.log(cc.__proto__); // {b: 1} 新对象cc的__proto__指向{b: 1}
console.log(cc.__proto__ === Object.protorype); // false
console.log(cc instanceof Object); // true cc是对象,原型链上肯定会出现Object
Object.create()创建的对象的原型指向传入的对象。跟字面量和new关键字创建有区别。
- 自己实现一个 Object.create()
Object.mycreate = function (proto, properties) {
function F() {}
F.prototype = proto;
if (properties) {
Object.defineProperties(F, properties);
}
return new F();
};
var hh = Object.mycreate({ a: 11 }, { mm: { value: 10 } });
console.dir(hh);
总结
- 字面量和
new关键字创建的对象是Object的实例,原型指向Object.prototype,继承内置对象Object Object.create(arg, pro)创建的对象的原型取决于arg,arg为null,新对象是空对象,没有原型,不继承任何对象;arg为指定对象,新对象的原型指向指定对象,继承指定对象
20.Js 中的 JSON
什么是 JSON
JSON 的英文全称是 JavaScript object notation JSON 是一种轻量级的文本数据交换格式 JSON 是独立的语言:JSON 使用 Javascript 语法来描述数据对象,但是 JSON 仍然独立于语言和平台。JSON 解析器和 JSON 库支持许多不同的编程语言。 目前非常多的动态(PHP,JSP,.NET)编程语言都支持 JSON。 JSON 具有自我描述性,更易理解
JSON 语法规则
- 数据为 键/值 对。
- 数据由逗号分隔。
- 大括号保存对象
- 方括号保存数组
JSON 数据
JSON 数据格式为 键/值 对,就像 JavaScript 对象属性。
键/值对包括字段名称(在双引号中),后面一个冒号,然后是值:
"name":"Runoob"
JSON 对象
JSON 对象保存在大括号内。
就像在 JavaScript 中, 对象可以保存多个 键/值 对:
{ "name": "Runoob", "url": "www.runoob.com" }
JSON 数组
JSON 数组保存在中括号内。
就像在 JavaScript 中, 数组可以包含对象:
"sites":[ {"name":"Runoob", "url":"www.runoob.com"}, {"name":"Google", "url":"www.google.com"}, {"name":"Taobao", "url":"www.taobao.com"} ]
在以上实例中,对象 "sites" 是一个数组,包含了三个对象。
JSON.parse
在 ES5 中,增加了一个 JSON 对象,专门用来处理 JSON 格式的数据。
JSON 是一个对象,但只有两个方法:parse 和 stringify,不能作为构造函数,也无属性。
typeof JSON === "object";
JSON.parse() 用来解析 JSON 字符串,得到对应的 JavaScript 值或对象。
JSON.parse("{}"); // {}
JSON.parse("true"); // true
JSON.parse("null"); // null
JSON.parse 语法
JSON.parse(text[, reviver])
- text:要被解析成的字符串。 如果传入数字则会转换成十进制数字输出。 如果传入布尔值则直接输出。 如果传入 null 则输出 null。 不支持其他类型的值,否则报错。
- reviver: 可选,转换器, 可以用来修改解析生成的原始值。 返回值: JavaScript 对象/值, 对应给定 JSON 文本的对象/值。
reviver 参数
reviver 函数,用于转换处理解析到的 JavaScript 值,处理完后返回最终的结果。
转换过程:
- 解析的值本身和它可能包含的所有属性,按照一定遍历顺序分别调用 reviver 函数,属性名和值作为参数两个参数
key和value传入。 遍历顺序:按照层级,从内往外遍历,最终到达最顶层,则是解析值本身。 - reviver 返回 undefined,则删除该对象,如果返回了其他值,则该值会成为当前属性的新值。
- 当遍历到最顶层时,因为没有属性了,参数 key 是空字符串
'',参数 value 则是当前解析值。
对于 reviver 函数的两个参数 key 和 value,不同的数据类型:
- 基本值类型数据(string、number、boolean)和 null,以及空对象
{}和空数组[]: 则 key 是空字符串,value 是对应解析值; 因为已经是最顶层,并没有别的属性。 - Object 对象: 则 key 和 value 都存在,与属性名和值各自对应; 最顶层会返回一个参数 key 为空的值。
- 数组: key 对应数组索引,value 对应元素值; 最顶层会返回一个参数 key 为空的值。
基本类型的转换:
JSON.parse("5", function (key, value) {
console.log(`key:${key}, value:${value}`);
});
// key:, value:5
JSON.parse("null", function (key, value) {
console.log(`key:${key}, value:${value}`);
});
// key:, value:null
JSON.parse("{}", function (key, value) {
console.log(`key:${key}, value:`, value);
});
// key:, value:{}
Object 对象和数组:
JSON.parse("[1, 2]", function (key, value) {
console.log(`key:${key}, value:`, value);
});
// key:0, value: 1
// key:1, value: 2
// key:, value: (2) [empty × 2]
JSON.parse(
'{ "user": "张三", "info": { "age": 25, "sex": 1 } }',
function (key, value) {
console.log(`key:${key}, value::`, value);
}
);
// key:user, value:: 张三
// key:age, value:: 25
// key:sex, value:: 1
// key:info, value:: {}
// key:, value:: {}
数据处理:
JSON.parse("[1, 2]", function (key, value) {
if (key === "") {
return value;
}
return value + 3;
});
// [4, 5]
JSON.parse 特性
在解析 JSON 字符串的时候,需要注意到 JSON 格式的一些规范,不然就容易报错。 JSON 数据对值的类型和格式,都有严格的规定,具体的规则如下:
该方法使用字符串类型 JSON 格式数据。 该方法也支持数字、布尔值和 null 三个类型的值,转换出对应的字面值。 不支持其他类型。
JSON.parse('"中国"');
// '中国'
JSON.parse(null); // null
JSON.parse(111); // 111
JSON.parse(0x12); // 18
JSON.parse(true); // true
JSON.parse([]);
// Uncaught SyntaxError: Unexpected end of JSON input
字符串必须使用双引号,不能使用单引号。
JSON.parse('"String"');
// 'String'
JSON.parse("'String'");
// Uncaught SyntaxError: Unexpected token ' in JSON at position 0
只支持十进制的字符串,但小数点后必须跟上数字。
JSON.parse("111"); // 111
JSON.parse("0x12");
// Uncaught SyntaxError: Unexpected token x in JSON at position 1
JSON.parse("111.232"); // 111.232
JSON.parse("111.");
// Uncaught SyntaxError: Unexpected end of JSON input
不能使用 undefined、Symbol 和 BigInt,数字也不支持 NaN、Infinity 和-Infinity,都会报错。
JSON.parse(undefined);
// Uncaught SyntaxError: Unexpected token u in JSON at position 0
JSON.parse(Symbol());
// Uncaught TypeError: Cannot convert a Symbol value to a string
JSON.parse("12n");
// Uncaught SyntaxError: Unexpected token n in JSON at position 2
复合类型,只能是:[] 和 {} 这样的字面量。
不能使用对象构造函数,因为会当作执行语句,不支持。
不能使用 Object 和 Array,也不能是函数、RegExp 对象、Date 对象、Error 对象等。
JSON.parse("[]");
// []
JSON.parse("Object()");
// Uncaught SyntaxError: Unexpected token O in JSON at position 0
对象的属性名必须使用双引号。
JSON.parse('{"key": 1 }');
// {key: 1}
JSON.parse("{key: 1 }");
// Uncaught SyntaxError: Unexpected token k in JSON at position 1
数组或对象最后一个成员的后面,不能加逗号。
JSON.parse("[1, 2, 3, 4, ]");
// VM2771:1 Uncaught SyntaxError: Unexpected token ] in JSON at position 13
JSON.parse('{"key" : 1, }');
// VM2779:1 Uncaught SyntaxError: Unexpected token } in JSON at position 12
支持 unicode 转义。
JSON.parse('{"\u0066":333}');
// {f: 333}
部分控制字符、转义字符不支持,如'\n'、'\t'等。
JSON.parse('"\n"');
// Uncaught SyntaxError: Unexpected token
解析的其他方法
将 json 字符串转成 json 对象(js 对象值),还可以使用其他方法,但是非安全代码。
const str = '{"name":"json","age":18}';
const json = JSON.parse(str);
const json = eval("(" + str + ")");
const json = new Function("return " + str)();
JSON.stringify
JSON.stringify() 将一个 JavaScript 对象或值转换为 JSON 格式字符串。
JSON.stringify 语法
JSON.stringify(value[, replacer [, space]])
- value:将要序列化成 一个 JSON 字符串的 JavaScript 对象或值。
- replacer 可选,用于处理将要序列化的值。
- space 可选,指定缩进用的空白字符串,用于美化输出。
返回值: 一个表示给定值的 JSON 格式字符串。
replacer 参数
replacer 参数可以以下三种情况:
如果是 null、undefined 或其他类型,则被忽略,不做处理;
JSON.stringify({ key: "json" }, null, null); // '{"key":"json"}'
JSON.stringify({ key: "json" }, true); // '{"key":"json"}'
如果是一个数组,则只有包含在这个数组中的属性名,才会最终被序列化到结果字符串中。 只对对象的属性有效,对数组无效。
const obj = {
json: "JSON",
parse: "PARSE",
stringify: "STRINGIFY",
};
JSON.stringify(obj, ["parse", "stringify"]);
// '{"parse":"PARSE","stringify":"STRINGIFY"}'
如果是一个函数,被序列化的值的每个属性都会经过该函数的转换和处理;
处理过程:
- 函数有两个参数,属性名(key)和属性值(value),都会被序列化;
- 第一次调用时,key 为空字符串,value 则为需要序列化的整个对象;
- 第二次处理时,会把第一次的的结果传过来,后续的每一次的处理都将接收上一次处理的结果;
- 后面,将依次处理每个属性名和属性值,完成后返回。
JSON.stringify({ json: 1, stringify: { val: "rr" } }, (key, value) => {
console.log(`key:${key},value:`, value);
return value;
});
// key:,value: {json: 1, stringify: {…}}
// key:json,value: 1
// key:stringify,value: {val: 'rr'}
// key:val,value: rr
// '{"json":1,"stringify":{"val":"rr"}}'
value 的类型处理:
- 如果返回基本类型字符串、数字、布尔值、null,则直接被添加到序列化后的 JSON 字符串中;
- 如果返回其他对象,则会在后续依次序列化该对象的属性,如果是函数则不作处理;
- 如果返回或 undefined,则不会输出该属性。
- 序列化数组时,如果 value 返回 undefined 或者一个函数,将会被 null 取代。
JSON.stringify({ json: 1, stringify: "rr" }, (key, value) => {
if (typeof value === "number") {
return "ss";
}
return value;
});
// '{"json":"ss","stringify":"rr"}'
JSON.stringify({ json: 1, stringify: "rr" }, (key, value) => {
if (typeof value === "number") {
value = undefined;
}
return value;
});
// '{"stringify":"rr"}'
下面示例,是返回对象值时的处理:
JSON.stringify({ json: 1, stringify: "rr" }, (key, value) => {
if (typeof value === "object") {
// 第一次返回整个对象时,类型是object
return { parse: "dd" };
}
return value;
});
('{"parse":"dd"}');
space 参数
space 参数用来控制结果字符串里面的间距,美化输出。可以输入的值有以下三种情况:
- 如果是数字, 序列化时每一层级比上一层级多缩进对应数字值的空格,范围在 1-10,即最小 1 个最大 10 个空格;
- 如果是字符串,序列化时该字符串会添加在每行前面,每一层级比上一层级多缩进该字符串,最多是个字符,超过则截取字符串;
- 如果是 null、undefined 或其他类型,则被忽略,不做处理。
JSON.stringify({ key: "json" }, null, 2);
// '{\n "key": "json"\n}'
JSON.stringify({ key: "json", list: { str: "str" } }, null, "|-");
// '{\n|-"key": "json",\n|-"list": {\n|-|-"str": "str"\n|-}\n}'
JSON.stringify({ key: "json" }, null, null);
// '{"key":"json"}'
JSON.stringify 特性
基本类型值字符串、数字、布尔值,以及 String、Boolean、Number 对象值,都会转成原始值字符串输出。
JSON.stringify(333); // '333'
JSON.stringify(true); // 'true'
JSON.stringify(new String("333")); //'"333"'
JSON.stringify(Boolean(true)); // 'true'
基本类型的字符串,转换结果会带双引号。 因为在还原时,双引号会让 JavaScript 知道是字符串,而不是变量。
JSON.stringify("json") === "json"; // false
JSON.stringify("json") === '"json"'; // true
undefined、函数、symbol 以及 XML 对象:
- 出现在 Object 对象中时,会被忽略;
- 出现在数组中时,会被序列化成 null;
- 单独出现时,会返回 undefined。
JSON.stringify(Symbol()); // undefined
JSON.stringify([Symbol(), Math.abs, undefined]); // '[null,null,null]'
JSON.stringify({ [Symbol()]: Math.abs, key: undefined }); // '{}'
NaN、Infinity 和-Infinity 等值,还有 null,都会被序列化成 null。
JSON.stringify(null); // 'null'
JSON.stringify(NaN); // 'null'
Object 对象,以及Map/Set/WeakMap/WeakSet等复合类型对象,序列化时会忽略对象的不可遍历属性。
const obj = {};
Object.defineProperties(obj, {
json: { value: "JSON", enumerable: true },
stringify: { value: "STRINGIFY", enumerable: false },
});
JSON.stringify(obj);
// '{"json":"JSON"}'
以 symbol 为属性名的属性将被忽略。
JSON.stringify({ [Symbol()]: 333 }); // '{}'
除了数组,其他对象的属性在序列化时,顺序可能会乱。
const a = { 1: 911, r: 822, 11: 9922 };
JSON.stringify(a);
// '{"1":911,"11":9922,"r":822}'
转换的对象如果定义了 toJSON() 方法,则该方法的返回值就是转换对象的序列化结果。
该过程会忽略其他属性。
const a = { key: "json" };
a.toJSON = () => "JSON";
JSON.stringify(a);
// '"JSON"'
RegExp 对象、Error 对象都会序列化为空对象字符串。
JSON.stringify(/\d/); // "{}"
JSON.stringify(new Error()); // "{}"
想要序列化相应对象,需要设置实现 toJSON 方法才行。
RegExp.prototype.toJSON = RegExp.prototype.toString;
JSON.stringify(/\d/); // '"/\\\\d/"'
Date 对象已经定义了 toJSON(),并将其转换为 string 字符串,因此可被序列化。
同Date.toISOString()。
JSON.stringify(new Date());
// '"2021-12-31T02:24:05.477Z"'
循环引用的对象执行此方法,会抛出错误。 对象之间相互引用,形成无限循环。
const a = {};
a.key = a;
JSON.stringify(a);
// Uncaught TypeError: Converting circular structure to JSON
转换 BigInt 类型的值会抛出 TypeError 错误。 BigInt 值不能 JSON 序列化
JSON.stringify(12n);
// Uncaught TypeError: Do not know how to serialize a BigInt
更好的支持 unicode 转义符
const a = { "\u0066": 333 };
JSON.stringify(a);
// '{"f":333}'
模块化
1.什么是模块化?
将 JS 分割成不同职责的 JS,解耦功能,来用于解决全局变量污染、 变量冲突、代码冗余、依赖关系难以维护等问题的一种 JS 管理思想,这就是模块化的过程。
模块化就是将变量和函数 放入不同的文件中
模块的作用域是私有的 内部定义的代码只能在当前文件中使用 外部使用那么需要将此模块暴露出去
模块化的好处:减少全局变量 避免变量名和函数命名冲突,提高代码的复用性和维护性
2.简述模块化的发展历程?
模块化的发展主要从最初的无模块化,发展到闭包式的 IIFE 立即执行解决模块化,到后来的 CommonJS、 AMD、CMD,直到 ES6 模块化规范的出现
3.CommonJS 和 ES6 模块有什么区别?
CommonJS
规范:
module 模块本身,是 Module 的一个实例
exports 指向 module.exports,可以通过 exports 向 module.exports 对象中添加变量
require 用于加载模块(核心)
所有模块都运行在模块作用域,不会污染全局作用域
模块加载的顺序,按照代码中出现的顺序执行(也就是同步)
模块输入的值是复制(基础类型为复制,引用类型为值引用),第一次加载结果就被缓存了,之后再加载就直接读取缓存中的结果,如果要让模块再次运行,需要清除缓存。或者直接导出函数,每次调用函数重新计算。
特点:
node 使用的是 commonjs 在使用模块的时候是运行时同步加载的 拷贝模块中的对象
模块可以多次加载,但只会在第一次加载 之后会被缓存 引入的是缓存中的值
引入使用:require("path")
1.如果是第三方模块 只需要填入模块名
2.自己定义的模块 需要使用相对路径或者绝对路径
导出模块使用:exports.xxx 或 module.exports.xxx 或 module.exports=xxx 或 this.xxx
!!不管是使用 exports 还是 this ,都需要用点语法的形式导出,因为 他们两个是 module.exports 的指针 重新赋值将会切断关联
本质上还是 module.exports 进行导出
一般情况下 node 内部会进行 module.exports=exports 的操作
如果使用了 module.exports, 会使用优先使用 module.exports, exports 的修改无效 相当于不使用 exports
CommonJS 是 NodeJs 的一种模块同步加载规范,一个文件即是一个模块,使用时直接 require(),即可,但是不适用于客户端,因为加载模块的时候有可能出现‘假死’状况,必须等模块请求成功,加载完毕才可以执行调用的模块。但是在服务期不存在这种状况。
主要实现代码
从代码中可以看出,模块加载实质上就是注入了 exports,require,module 三个全局变量,然后执行模块的源码,最后将模块的 exports 的变量输入
(function (exports, require, module, __filename, __dirname) {
// 模块源码
});
function Module(id, parent) {
this.id = id;
this.expotrs = {};
this.parent = parent;
if (parent && parent.children) {
parent.children.push(this);
}
this.fileanme = null;
this.loaded = false;
this.children = [];
}
// 这里的module是全局变量
module.exports = Module;
// 通过一个path加载模块,并返回exports属性
Module.prototype.require = function (path) {
return Module._load(path, this);
};
Module._load = function (path, parent) {
const filename = path;
var module = new Module(filename, parent);
// 加载模块
module.load(filename);
// 输出模块的exports属性
return module.exports;
};
Module.prototype.load = function (filename) {
// 通过磁盘中读取文件
var content = fs.readFileSync(filename, "utf8");
module._compile(content, filename);
this.loaded = true;
};
// 模块编译
Module.prototype._compile = function (content, filename) {
const self = this;
const args = [self.exports, require, self, filename, dirname];
// 在沙箱中执行代码
return compiledWrapper.apply(self.exports, args);
};
存在问题:
缺少模块封装的能力,CommonJS 规范中每个模块都是一个文件,这意味着每个文件只有一个模块。这在服务器上是可行的,但是在浏览器中就不是很友好,浏览器中需要做到尽可能少的发起请求。
使用同步的方式加载依赖,在浏览器中由于 JS 的加载会阻塞渲染,同步加载会导致长时间的白屏,对于用户体验是致命的。
CommonJS 规范中使用了export的对象来暴露模块,可以讲需要导出的变量附加到export上,但是要导出一个函数确是能使用module.export,这种语法容易让人感到困惑。
ES6 模块
基本使用
默认导出 export default 变量或者函数或者对象
默认引入 import name from "相对或绝对路径"
导出的名字和引入的名字可以不一致
按需导出 export 需要声明 变量用 const var let 函数用 function
按需引入 import {变量名或函数名} form "路径"
全部引入 使用 import * as 自定义 name "路径"
会将默认导出和按需导出 全部引入
特点
CommonJS 模块的require是同步加载模块,而 ESM 会对静态代码分析,即在代码编译时进行模块的加载,在运行时之前就已经确定了依赖关系
ESM 模块是动态引用,变量不会被缓存,而是成为一个指向加载模块的引用,只有真正取值的时候才会进行计算取值
AMD 模块
AMD (Asynchronous Module Definition):异步模块加载机制。requireJS 就是 AMD 规范,使用时,先定义所有依赖,然后在加载完成后的回调函数中执行,属于依赖前置,使用:define()来定义模块,require([module], callback)来使用模块。 AMD 同时也保留 CommonJS 中的 require、exprots、module,可以不把依赖罗列在 dependencies 数组中,而是在代码中用 require 来引入。
// AMD规范
require(["modA"], function (modA) {
modA.start();
});
// AMD使用require加载模块
define(function () {
console.log("main2.js执行");
require(["a"], function (a) {
a.hello();
});
$("#b").click(function () {
require(["b"], function (b) {
b.hello();
});
});
});
缺点:属于依赖前置,需要加载所有的依赖, 不可以像 CommonJS 在用的时候再 require,异步加载后再执行。
CMD 模块
CMD(Common Module Definition):定义模块时无需罗列依赖数组,在 factory 函数中需传入形参 require,exports,module,然后它会调用 factory 函数的 toString 方法,对函数的内容进行正则匹配,通过匹配到的 require 语句来分析依赖,这样就真正实现了 CommonJS 风格的代码。是 seajs 推崇的规范,是依赖就近原则。
// CMD规范
// a.js
define(function (require, exports, module) {
console.log("a.js执行");
return {
hello: function () {
console.log("hello, a.js");
},
};
});
// b.js
define(function (require, exports, module) {
console.log("b.js执行");
return {
hello: function () {
console.log("hello, b.js");
},
};
});
// main.js
define(function (require, exports, module) {
var modA = require("a");
modA.start();
var modA = require("b");
modB.start();
});
ES6 模块化是通过 export 命令显式的指定输出的代码,输入也是用静态命令的形式。属于编译时加载。比 CommonJS 效率高,可以按需加载指定的方法。适合服务端与浏览器端。
// a.js
export var a = "a";
export var b = function () {
console.log(b);
};
export var c = "c";
// main.js
import { a, b } from "a.js";
console.log(a);
console.log(b);
区别:
CommonJS 模块同步加载并执行模块文件,ES6 模块提前加载并执行模块文件,ES6 模块在预处理阶段分析模块依赖,在执行阶段执行模块,两个阶段都采用深度优先遍历
AMD 和 CMD 同样都是异步加载模块,两者加载的机制不同,前者为依赖前置、后者为依赖就近。
CommonJS 为同步加载模块,NodeJS 内部的模块管理规范,不适合浏览器端。
ES6 模块化编译时加载,通过 export,import 静态输出输入代码,效率高,同时适用于服务端与浏览器端。
Commonjs 的特性如下:
- CommonJS 模块由 JS 运行时实现。
- CommonJs 是单个值导出,本质上导出的就是 exports 属性。
- CommonJS 是可以动态加载的,对每一个加载都存在缓存,可以有效的解决循环引用问题。
- CommonJS 模块同步加载并执行模块文件。
ES module 总结
ES module 的特性如下:
- ES6 Module 静态的,不能放在块级作用域内,代码发生在编译时。
- ES6 Module 的值是动态绑定的,可以通过导出方法修改,可以直接访问修改结果。
- ES6 Module 可以导出多个属性和方法,可以单个导入导出,混合导入导出。
- ES6 模块提前加载并执行模块文件,
- ES6 Module 导入模块在严格模式下。
- ES6 Module 的特性可以很容易实现 Tree Shaking 和 Code Splitting。
1. CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
- CommonJS 模块输出的是值的拷贝(浅拷贝),也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。
- ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令 import,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。原始值变了,import 加载的值也会跟着变。因此,ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
2. CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
- 运行时加载: CommonJS 模块就是对象;即在输入时是先加载整个模块,生成一个对象,然后再从这个对象上面读取方法,这种加载称为“运行时加载”。
- 编译时加载: ES6 模块不是对象,而是通过 export 命令显式指定输出的代码,import 时采用静态命令的形式。即在 import 时可以指定加载某个输出值,而不是加载整个模块,这种加载称为“编译时加载”。
CommonJS 加载的是一个对象(即 module.exports 属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
CommonJS 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。
ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令import,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。换句话说,ES6 的import有点像 Unix 系统的“符号连接”,原始值变了,import加载的值也会跟着变。因此,ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
4.export 是什么?
export 是 ES6 中用于向外暴露数据或方法的一个命令。 通常使用 export 关键字来输出一个变量,该变量可以是数据也可以是方法。 而后,使用 import 来引入,并使用它。
// a.js
export var a = "hello";
export function sayHello(name) {
console.log("Hello," + name);
}
// main.js
import { a, sayHello } from "./a.js";
console.log(a);
console.log(sayHello("LiMing"));
5.module.exports、export 与 export defalut 有什么区别?
都是用于向外部暴露数据的命令。 export defalut 与 export 是 ES6 Module 中对外暴露数据的。 export defalut 是向外部默认暴露数据,使用时 import 引入时需要为该模块指定一个任意名称,import 后不可以使用{}; export 是单个暴露数据或方法,利用 import{}来引入,并且{}内名称与 export 一一对应,{}也可以使用 as 为某个数据或方法指定新的名称; module.exports 是 CommonJS 的一个 exports 变量,提供对外的接口。
// export defalut示例
// a.js
var a='Hello World!';
export defalut=a;
// main.js
import A from 'a.js';
console.log(A);
// export 示例
// b.js
export var b='b';
export function sayHello(name){
console.log(name+'Hello World!');
}
// main.js
import {b,sayHello} from 'b.js'
sayHello('LiMing');
console.log(b);
// module.exports示例
// c.js
var c='123';
function getValue(){
return c;
}
function updateValue(value){
c=value;
}
module.exports={
getValue,
updateValue
}
// main.js
import handleEvent from 'c.js';
handleEvent.getValue();
handleEvent.updateValue('456');
6.require 和 import 的区别
require 用于读取并执行 js 文件, 并返回该模块的 exports 对象, 若无指定模块, 会报错。 Node 使用 CommonJS 模块规范, CommonJS 规范加载模块是同步的, 只有加载完成, 才能执行后续操作。
import 用于引入外部模块, 其他脚本等的函数, 对象或者基本类型。 import 属于 ES6 的命令, 它和 require 不一样, 它会生成外部模块的引用而不是加载模块, 等到真正使用到该模块的时候才会去加载模块中的值。
- 导入
require导出exports/module.exports是CommonJS的标准,通常适用范围如Node.js import/export是ES6的标准,通常适用范围如Reactrequire是赋值过程并且是运行时才执行,也就是同步加载require可以理解为一个全局方法,因为它是一个方法所以意味着可以在任何地方执行。import是解构过程并且是编译时执行,理解为异步加载import会提升到整个模块的头部,具有置顶性,但是建议写在文件的顶部。
commonjs输出的,是一个值的拷贝,而es6输出的是值的引用;
commonjs是运行时加载,es6是编译时输出接口;
7.require 原理
查找规则
导入格式如下:require(X)
情况一:X 是一个 Node 核心模块,比如 path、http 直接返回核心模块,并且停止查找
情况二:X 是以 ./ 或 ../ 或 /(根目录)开头的 n 第一步:将 X 当做一个文件在对应的目录下查找;
1.如果有后缀名,按照后缀名的格式查找对应的文件
2.如果没有后缀名,会按照如下顺序:
1> 直接查找文件 X
2> 查找 X.js 文件
3> 查找 X.json 文件
4> 查找 X.node 文件
第二步:没有找到对应的文件,将 X 作为一个目录 查找目录下面的 index 文
1> 查找 X/index.js 文件
2> 查找 X/index.json 文件
3> 查找 X/index.node 文件 如果没有找到,那么报错:not found
模块的加载过程
结论一:模块在被第一次引入时,模块中的 js 代码会被运行一次
结论二:模块被多次引入时,会缓存,最终只加载(运行)一次
为什么只会加载运行一次呢? 这是因为每个模块对象 module 都有一个属性:loaded。 为 false 表示还没有加载,为 true 表示已经加载;
结论三:如果有循环引入,那么加载顺序是什么? 如果出现模块的引用关系,那么加载顺序是什么呢? 这个其实是一种数据结构:图结构; 图结构在遍历的过程中,有深度优先搜索(DFS, depth first search)和广度优先搜索(BFS, breadth first search); Node 采用的是深度优先算法.
模块的加载机制
- 先计算模块路径
- 如果模块在缓存里面,取出缓存
- 加载模块
- 输出模块的
exports属性即可
// require 其实内部调用 Module._load 方法
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
/********************************这里注意了**************************/
// 第三步:生成模块实例,存入缓存
// 这里的Module就是我们上面的1.1定义的Module
var module = new Module(filename, parent);
Module._cache[filename] = module;
/********************************这里注意了**************************/
// 第四步:加载模块
// 下面的module.load实际上是Module原型上有一个方法叫Module.prototype.load
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
8.ES Module 的解析过程
ES Module 的解析过程可以划分为三个阶段:
阶段一:构建(Construction),根据地址查找 js 文件,并且下载,将其解析成模块记录(Module Record);
阶段二:实例化(Instantiation),对模块记录进行实例化,并且分配内存空间,解析模块的导入和导出语句,把模块指向 对应的内存地址。
阶段三:运行(Evaluation),运行代码,计算值,并且将值填充到内存地址中
构造(Construction)
从入口文件开始,并通过代码解析(module specifiers)找到入口文件所依赖的模块,一步一步找到其他模块,并将所有模块解析成模块记录(module record),并缓存到module map中,遇到不同文件获取相同依赖,都会直接在module map缓存中获取,注意这里并不是要把所有模块的依赖关系全部解析完再开始下一步,因为浏览器一次性下载这么多文件会跟 CommonJS 一样阻塞主线程。所以这也就是为什么ESM spec要把 3 个加载过程区分开执行的原因。
实例化(Instantiation)
实例化的过程就是将代码导出的变量一一指向内存。JS 引擎通过优先深度后序遍历遍历整个模块关系图,即从依赖关系的最后一个模块(没有引入其他模块)开始实例化,并将所有模块导出的变量绑定在内存上,然后再将所有模块导入变量绑定到与导出变量同一个内存区域。所以一旦导出值发生变化,导入值也会变化。这也是 ESM 导出的是值引用的原理。同样也解决了循环调用的问题,为什么 CommonJS 无法解决循环调用的详细解释请查看图解 ES Modules
求值(Evaluation)
求值步骤相对简单,只要运行代码把计算出来的值填入之前记录的内存地址就可以了,这里就不展开说明了。
9.CommonJS 和 ES6 模块循环加载处理的区别
CommonJS 模块规范使用 require 语句导入模块,module.exports 导出模块,输出的是值的拷贝,模块导入的也是输出值的拷贝,也就是说,一旦输出这个值,这个值在模块内部的变化是监听不到的。
ES6 模块的规范是使用 import 语句导入模块,export 语句导出模块,输出的是对值的引用。ES6 模块的运行机制和 CommonJS 不一样,遇到模块加载命令 import 时不去执行这个模块,只会生成一个动态的只读引用,等真的需要用到这个值时,再到模块中取值,也就是说原始值变了,那输入值也会发生变化。
循环加载指的是 a 脚本的执行依赖 b 脚本,b 脚本的执行依赖 a 脚本。
1. CommonJS 模块的加载原理
CommonJS 模块就是一个脚本文件,require 命令第一次加载该脚本时就会执行整个脚本,然后在内存中生成该模块的一个说明对象。
{
id: '', //模块名,唯一
exports: { //模块输出的各个接口
...
},
loaded: true, //模块的脚本是否执行完毕
...
}
以后用到这个模块时,就会到对象的 exports 属性中取值。即使再次执行 require 命令,也不会再次执行该模块,而是到缓存中取值。
CommonJS 模块是加载时执行,即脚本代码在 require 时就全部执行。一旦出现某个模块被“循环加载”,就只输出已经执行的部分,没有执行的部分不会输出。
案例说明:
案例来源于 Node 官方说明:nodejs.org/api/modules…
//a.js
exports.done = false;
var b = require("./b.js");
console.log("在a.js中,b.done = %j", b.done);
exports.done = true;
console.log("a.js执行完毕!");
//b.js
exports.done = false;
var a = require("./a.js");
console.log("在b.js中,a.done = %j", a.done);
exports.done = true;
console.log("b.js执行完毕!");
//main.js
var a = require("./a.js");
var b = require("./b.js");
console.log("在main.js中,a.done = %j, b.done = %j", a.done, b.done);
输出结果如下:
//node环境下运行main.js
node main.js
在b.js中,a.done = false
b.js执行完毕!
在a.js中,b.done = true
a.js执行完毕!
在main.js中,a.done = true, b.done = true
JS 代码执行顺序如下:
1)main.js 中先加载 a.js,a 脚本先输出 done 变量,值为 false,然后加载 b 脚本,a 的代码停止执行,等待 b 脚本执行完成后,才会继续往下执行。
2)b.js 执行到第二行会去加载 a.js,这时发生循环加载,系统会去 a.js 模块对应对象的 exports 属性取值,因为 a.js 没执行完,从 exports 属性只能取回已经执行的部分,未执行的部分不返回,所以取回的值并不是最后的值。
3)a.js 已执行的代码只有一行,exports.done = false;所以对于 b.js 来说,require a.js 只输出了一个变量 done,值为 false。往下执行 console.log('在 b.js 中,a.done = %j', a.done);控制台打印出:
在b.js中,a.done = false
4)b.js 继续往下执行,done 变量设置为 true,console.log('b.js 执行完毕!'),等到全部执行完毕,将执行权交还给 a.js。此时控制台输出:
b.js执行完毕!
5)执行权交给 a.js 后,a.js 接着往下执行,执行 console.log('在 a.js 中,b.done = %j', b.done);控制台打印出:
在a.js中,b.done = true
6)a.js 继续执行,变量 done 设置为 true,直到 a.js 执行完毕。
a.js执行完毕!
7)main.js 中第二行不会再次执行 b.js,直接输出缓存结果。最后控制台输出:
在main.js中,a.done = true, b.done = true
总结:
1)在 b.js 中,a.js 没有执行完毕,只执行了第一行,所以循环加载中,只输出已执行的部分。
2)main.js 第二行不会再次执行,而是输出缓存 b.js 的执行结果。exports.done = true;
2. ES6 模块的循环加载
ES6 模块与 CommonJS 有本质区别,ES6 模块对导出变量,方法,对象是动态引用,遇到模块加载命令 import 时不会去执行模块,只是生成一个指向被加载模块的引用,需要开发者保证真正取值时能够取到值,只要引用是存在的,代码就能执行。
案例说明:
//even.js
import { odd } from "./odd";
var counter = 0;
export function even(n) {
counter++;
console.log(counter);
return n == 0 || odd(n - 1);
}
//odd.js
import { even } from "./even.js";
export function odd(n) {
return n != 0 && even(n - 1);
}
//index.js
import * as m from "./even.js";
var x = m.even(5);
console.log(x);
var y = m.even(4);
console.log(y);
执行 index.js,输出结果如下:
babel-node index.js
1
2
3
false
4
5
6
true
可以看出 counter 的值是累加的,ES6 是动态引用。如果上面的引用改为 CommonJS 代码,会报错,因为在 odd.js 里,even.js 代码并没有执行。改成 CommonJS 规范加载的代码为:
//even.js
var odd = require("./odd.js");
var counter = 0;
module.exports = function even(n) {
counter++;
console.log(counter);
return n == 0 || odd(n - 1);
};
//odd.js
var even = require("./even.js");
module.exports = function odd(n) {
return n != 0 && even(n - 1);
};
//index.js
var even = require("./even.js");
var x = even(5);
console.log(x);
var y = even(5);
console.log(y);
执行 index.js,输出结果如下:
$ babel-node index.js
1
/Users/name/Projects/node/ES6/odd.1.js:6
return n != 0 && even(n - 1);
^
TypeError: even is not a function
at odd (/Users/name/Projects/node/ES6/odd.1.js:4:22)
3. 总结
1)CommonJS 模块是加载时执行。一旦出现某个模块被“循环加载”,就只输出已经执行的部分,没有执行的部分不会输出。
2)ES6 模块对导出模块,变量,对象是动态引用,遇到模块加载命令 import 时不会去执行模块,只是生成一个指向被加载模块的引用。
CommonJS 模块规范主要适用于后端 Node.js,后端 Node.js 是同步模块加载,所以在模块循环引入时模块已经执行完毕。推荐前端工程中使用 ES6 的模块规范,通过安装 Babel 转码插件支持 ES6 模块引入的语法。
事件循环机制
1.JS 事件循环机制(eventloop)
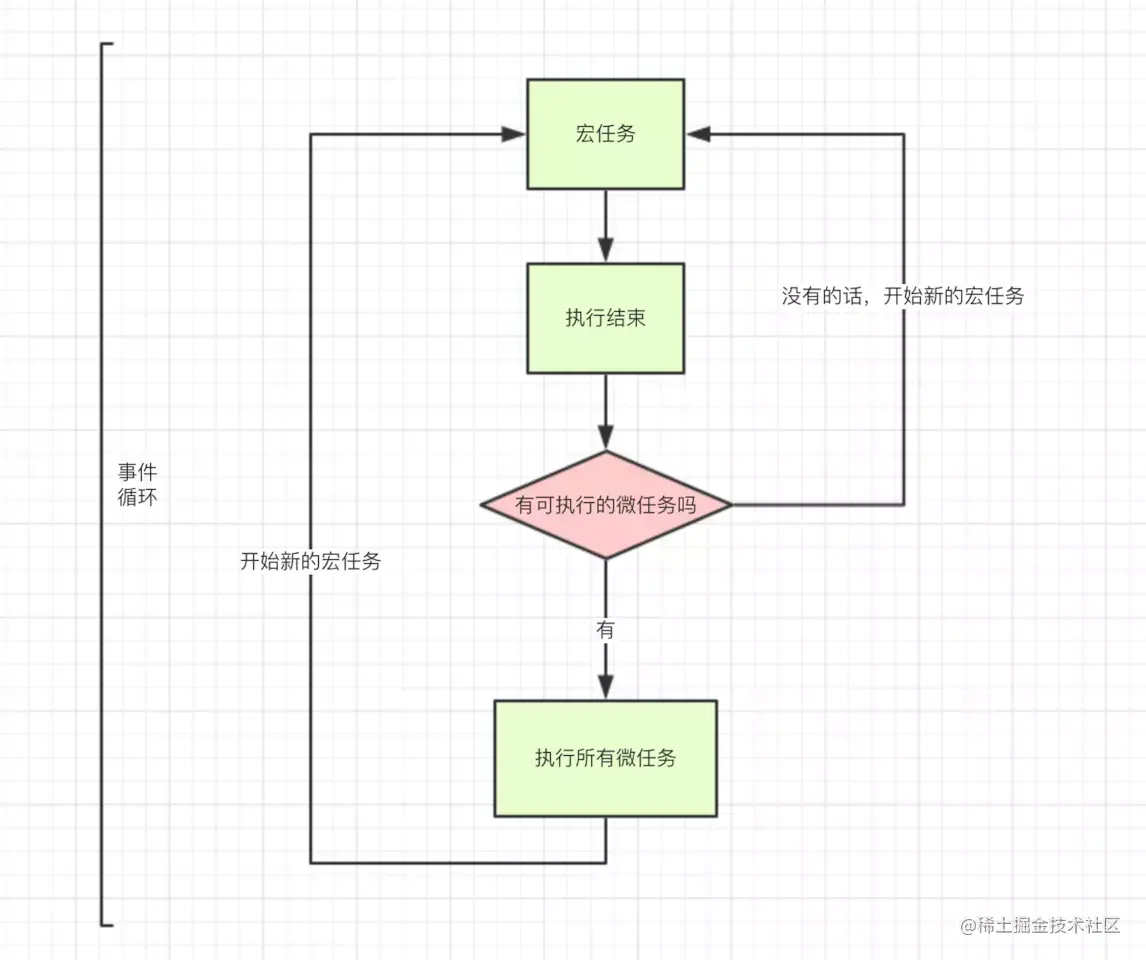
事件循环原理
JavaScript 代码的执行过程中,除了依靠函数调用栈来搞定函数的执行顺序外,还依靠任务队列(task queue)来搞定另外一些代码的执行。整个执行过程,我们称为事件循环过程。一个线程中,事件循环是唯一的,但是任务队列可以拥有多个。任务队列又分为 macro-task(宏任务)与 micro-task(微任务),在最新标准中,它们被分别称为 task 与 jobs。
macro-task 大概包括:
- script(整体代码)
- setTimeout
- setInterval
- setImmediate
- I/O
- UI render
micro-task 大概包括:
- process.nextTick
- Promise
- Async/Await(实际就是 promise)
- MutationObserver(html5 新特性)
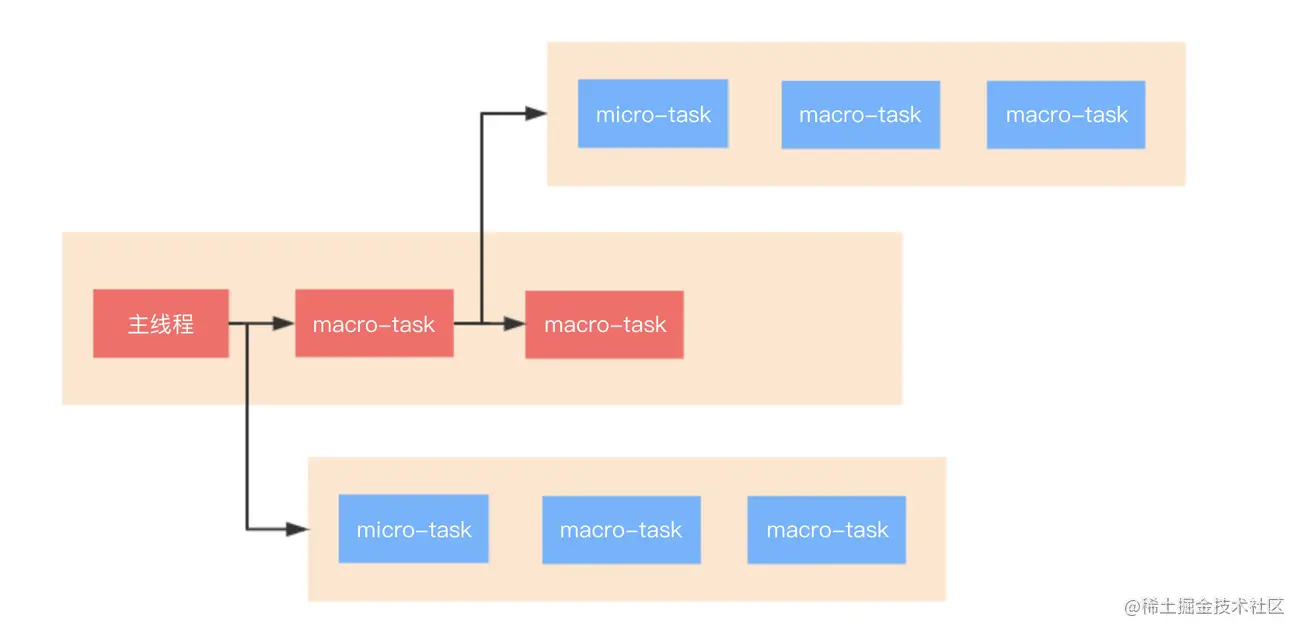
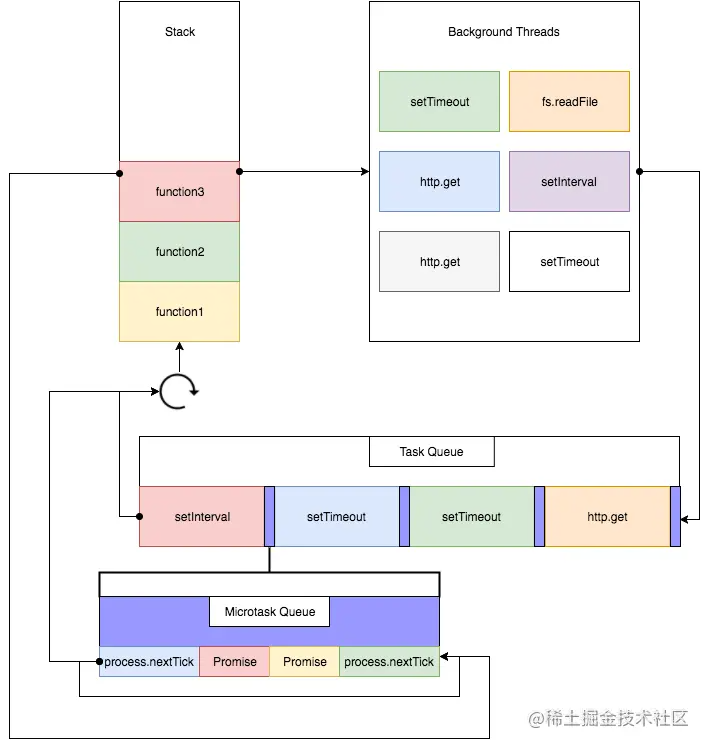
当某个宏任务执行完后,会查看是否有微任务队列。如果有,先执行微任务队列中的所有任务,如果没有,会读取宏任务队列中排在最前的任务,执行宏任务的过程中,遇到微任务,依次加入微任务队列。栈空后,再次读取微任务队列里的任务,依次类推。
总的结论就是,执行宏任务,然后执行该宏任务产生的微任务,若微任务在执行过程中产生了新的微任务,则继续执行微任务,微任务执行完毕后,再回到宏任务中进行下一轮循环
事件循环执行流程如下:
- 检查 Macrotask 队列是否为空,若不为空,则进行下一步,若为空,则跳到 3
- 从 Macrotask 队列中取队首(在队列时间最长)的任务进去执行栈中执行(仅仅一个),执行完后进入下一步
- 检查 Microtask 队列是否为空,若不为空,则进入下一步,否则,跳到 1(开始新的事件循环)
- 从 Microtask 队列中取队首(在队列时间最长)的任务进去事件队列执行,执行完后,跳到 3 其中,在执行代码过程中新增的 microtask 任务会在当前事件循环周期内执行,而新增的 macrotask 任务只能等到下一个事件循环才能执行了。
简而言之,一次事件循环只执行处于 Macrotask 队首的任务,执行完成后,立即执行 Microtask 队列中的所有任务。
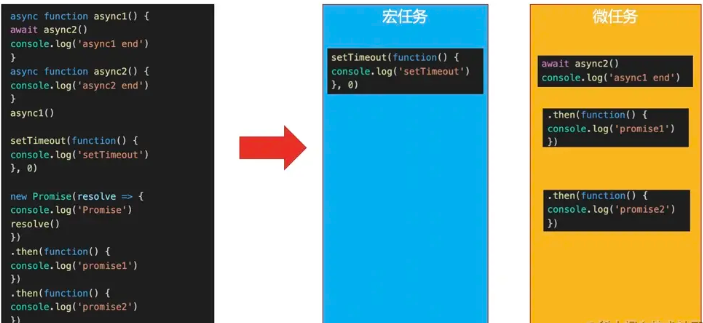
结合流程图理解,答案输出为:async2 end => Promise => async1 end => promise1 => promise2 => setTimeout 但是,对于 async/await 有个细节还要处理一下
async/await 执行顺序
我们知道async隐式返回 Promise 作为结果的函数,那么可以简单理解为,await 后面的函数执行完毕时,await 会产生一个微任务(Promise.then 是微任务)。但是我们要注意这个微任务产生的时机,它是执行完 await 之后,直接跳出 async 函数,执行其他代码(此处就是协程的运作,A 暂停执行,控制权交给 B)。其他代码执行完毕后,再回到 async 函数去执行剩下的代码,然后把 await 后面的代码注册到微任务队列当中。
console.log('script start')
async function async1() {
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2 end')
}
async1()
setTimeout(function() {
console.log('setTimeout')
}, 0)
new Promise(resolve => {
console.log('Promise')
resolve()
})
.then(function() {
console.log('promise1')
})
.then(function() {
console.log('promise2')
})
console.log('script end')
//
script start
async2 end
Promise
script end
async1 end
promise1
promise2
setTimeout
优先级问题
异步任务队列中会优先执行微任务,当执行完所有微任务才会执行下一个宏任务。
宏任务:
- I/O 操作:这种比较耗性能的操作浏览器会交给单独的线程去办,得到结果后再通知回来
- 定时器系列:
setTimeOut、setInterval、requestAnimationFrame
微任务:
- process.nextTick(node)
- Promise.than() / catch() / finaly()
requestAnimationFrame
- 仅对浏览器生效,回调属于高优先级任务
- 会将每一帧中所有 DOM 操作集中一次渲染
- 重绘或回流的时间会随着浏览器的刷新频率动态改变,不能主动控制(使用时用递归调用,可以中途取消)
- 浏览器页面不是激活状态下,会自动暂停执行
- 根据以上特性该方法常用于处理帧动画操作,而不是使用
setInterval
requestIdleCallback
- 回调属于低优先级任务,仅在浏览器空闲时期被调用(目前仍处于实验功能阶段,在微前端中常有应用)
2.node 和浏览器环境区别
1.Node 简介
Node 中的 Event Loop 和浏览器中的是完全不相同的东西。Node.js 采用 V8 作为 js 的解析引擎,而 I/O 处理方面使用了自己设计的 libuv,libuv 是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的 API,事件循环机制也是它里面的实现(下文会详细介绍)。
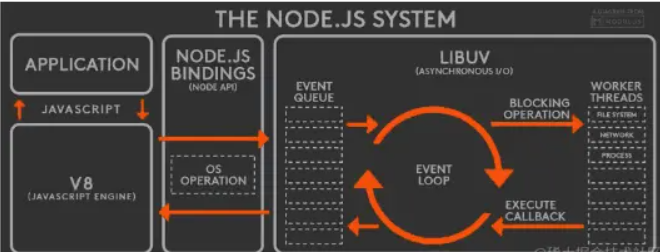
Node.js 的运行机制如下:
- V8 引擎解析 JavaScript 脚本。
- 解析后的代码,调用 Node API。
- libuv 库负责 Node API 的执行。它将不同的任务分配给不同的线程,形成一个 Event Loop(事件循环),以异步的方式将任务的执行结果返回给 V8 引擎。
- V8 引擎再将结果返回给用户。
2.六个阶段
其中 libuv 引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
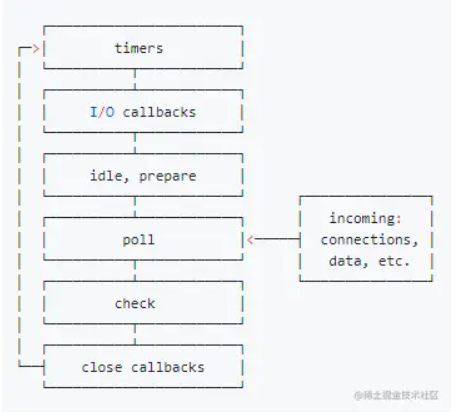
从上图中,大致看出 node 中的事件循环的顺序:
外部输入数据-->轮询阶段(poll)-->检查阶段(check)-->关闭事件回调阶段(close callback)-->定时器检测阶段(timer)-->I/O 事件回调阶段(I/O callbacks)-->闲置阶段(idle, prepare)-->轮询阶段(按照该顺序反复运行)
- timers 阶段:这个阶段执行 timer(setTimeout、setInterval)的回调
- I/O callbacks 阶段:处理一些上一轮循环中的少数未执行的 I/O 回调
- idle, prepare 阶段:仅 node 内部使用
- poll 阶段:获取新的 I/O 事件, 适当的条件下 node 将阻塞在这里
- check 阶段:执行 setImmediate() 的回调
- close callbacks 阶段:执行 socket 的 close 事件回调
注意:上面六个阶段都不包括 process.nextTick()
接下去我们详细介绍timers、poll、check这 3 个阶段,因为日常开发中的绝大部分异步任务都是在这 3 个阶段处理的。
(1) timer
timers 阶段会执行 setTimeout 和 setInterval 回调,并且是由 poll 阶段控制的。 同样,在 Node 中定时器指定的时间也不是准确时间,只能是尽快执行。
(2) poll
poll 是一个至关重要的阶段,这一阶段中,系统会做两件事情
1.回到 timer 阶段执行回调
2.执行 I/O 回调
并且在进入该阶段时如果没有设定了 timer 的话,会发生以下两件事情
- 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
- 如果 poll 队列为空时,会有两件事发生
- 如果有 setImmediate 回调需要执行,poll 阶段会停止并且进入到 check 阶段执行回调
- 如果没有 setImmediate 回调需要执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
(3) check 阶段
setImmediate()的回调会被加入 check 队列中,从 event loop 的阶段图可以知道,check 阶段的执行顺序在 poll 阶段之后。 我们先来看个例子:
console.log("start");
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function () {
console.log("promise1");
});
}, 0);
setTimeout(() => {
console.log("timer2");
Promise.resolve().then(function () {
console.log("promise2");
});
}, 0);
Promise.resolve().then(function () {
console.log("promise3");
});
console.log("end");
//start=>end=>promise3=>timer1=>timer2=>promise1=>promise2
- 一开始执行栈的同步任务(这属于宏任务)执行完毕后(依次打印出 start end,并将 2 个 timer 依次放入 timer 队列),会先去执行微任务(这点跟浏览器端的一样),所以打印出 promise3
- 然后进入 timers 阶段,执行 timer1 的回调函数,打印 timer1,并将 promise.then 回调放入 microtask 队列,同样的步骤执行 timer2,打印 timer2;这点跟浏览器端相差比较大,timers 阶段有几个 setTimeout/setInterval 都会依次执行,并不像浏览器端,每执行一个宏任务后就去执行一个微任务(关于 Node 与浏览器的 Event Loop 差异,下文还会详细介绍)。
3.Micro-Task 与 Macro-Task
Node 端事件循环中的异步队列也是这两种:macro(宏任务)队列和 micro(微任务)队列。
- 常见的 macro-task 比如:setTimeout、setInterval、 setImmediate、script(整体代码)、 I/O 操作等。
- 常见的 micro-task 比如: process.nextTick、new Promise().then(回调)等。
函数式编程
纯函数
仅仅因为你的程序包含函数并不一定意味着你正在做函数式编程。函数式编程区分纯函数和非纯函数。它鼓励你编写纯函数。纯函数必须满足以下两个属性:
- 引用透明性:函数总是为相同的参数提供相同的返回值。 这意味着该函数不能依赖于任何可变状态。
- 无副作用:该函数不会引起任何副作用。副作用可能包括 I/O(例如,写入控制台或日志文件)、修改可变对象、重新赋值变量等。
让我们用几个例子来说明。 首先,multiply 函数是纯函数的一个例子。它总是为相同的输入返回相同的输出,并且不会产生副作用。

以下是非纯函数的示例。 canRide 函数取决于捕获的 heightRequirement 变量。捕获的变量不一定会使函数不纯,但可变(或可重新分配)的变量会。对于本例来说,它是使用 let 声明的,这意味着它可以被重新赋值。 multiply 函数是非纯函数,因为它把日志打印到控制台会产生副作用。

以下列表包含 JavaScript 中内置的几个非纯函数。 你能说出这两个属性中的哪一个不满足吗?
- console.log
- element.addEventListener
- Math.random
- Date.now
- $.ajax(这里的 $ 指的是你选用的 Ajax 库)
生活在一个我们所有的函数都是纯函数的完美世界中会很好,但是从上面的列表中可以看出,任何有意义的程序都将会包含非纯函数。大多数情况下,我们需要进行 Ajax 调用、检查当前日期或获取随机数。一个好的经验法则是遵循 80/20 法则:80% 的函数应该是纯函数,剩下的 20% 是非纯函数。
纯函数有几个好处:
- 它们更容易推理和调试,因为它们不依赖于可变状态。
- 返回值可以被缓存或“记忆”以避免将来重新计算。
- 它们更容易测试,因为没有需要模拟的依赖项(例如日志记录、Ajax、数据库等)。
如果你正在编写或使用的函数返回值是 void(即它没有返回值),则表明它是非纯函数。如果函数没有返回值,那么它要么是空操作,要么会导致一些副作用。同样,如果调用一个函数但不使用它的返回值,那么你可能再次依赖它来产生一些副作用,它是一个非纯函数。
不变性
让我们回到捕获变量的概念。在上面我们看到了 canRide 函数。我们认为它是一个非纯函数,因为 heightRequirement 可以重新赋值。 这是一个人为的示例,展示了重新赋值是如何产生不可预测的结果的:

再次强调一下,捕获的变量不一定会使函数不纯。我们可以重写 canRide 函数使其成为一个纯函数,只需要修改声明 heightRequirement 变量的方式即可。

用 const 声明变量意味着它不可能被重新赋值。如果尝试重新复制,引擎会抛出错误; 但是,如果存储“常量”是一个对象而不是数字时会怎么样?

我们使用了 const 声明变量,因此它无法重新赋值,但仍然有一个问题。对象可以被修改。如下代码所示,要获得真正的不变性,需要防止变量被重新赋值,同时还需要不可变的数据结构。 JavaScript 语言为我们提供了 Object.freeze 方法来防止对象被修改。

不变性适用于所有数据结构,包括 Array、Map 和 Set。这意味着我们不能调用诸如 Array.prototype.push 之类的方法,因为它会修改现有数组。我们可以创建一个新数组,其中包含与原始数组相同的所有项,再加上一个附加项,而不是将一项推入现有数组。事实上,每个修改原数组的方法都可以被一个函数替换,该函数返回一个新数组。

使用 Map 或 Set 时也是如此。我们可以通过返回一个新 Map 或 Set 来避免使用修改原数据的方法。


补充一点,如果你用的是 TypeScript,那么可以使用 **Readonly<T>**、**ReadonlyArray<T>**、**ReadonlyMap<K, V>** 和 **ReadonlySet<T>** 接口,如果尝试改变这些对象中的任何一个,则会出现编译时错误。如果在对象或数组上调用 **Object.freeze**,那么编译器将自动推断它是只读的。

好了,我们可以创建新对象而不是改变现有对象,但这不会对性能产生不利影响吗?没错,的确有影响。请一定在应用程序中进行性能测试。如果需要性能提升,可以考虑使用 Immutable.js。 Immutable.js 使用持久数据结构实现了 List、Stack、Map、Set 和其他数据结构。 这与 Clojure 和 Scala 等函数式编程语言内部使用的技术相同。

复合函数
关于函数组合的几个要点:
- 我们可以组合任意数量的函数(不限于两个)。
- 组合函数的一种方法是从一个函数获取输出并将其传递给下一个函数(即 f(g(x)))。

Ramda 和 lodash 等库提供了一种更优雅的函数组合方式。与其简单地将返回值从一个函数传递给下一个函数,我们可以从数学的意义上来处理函数组合。 我们可以创建一个由其他函数组成的单个复合函数(即 (f g)(x))。

高阶函数
我们都知道 JavaScript 中的函数是一等公民,可以像其他值那样传递。因此,我们把一个函数传递给另一个函数也就不足为奇了。我们也可以从一个函数中返回另一个函数。 没错!我们有高阶函数。 你可能已经熟悉了 Array.prototype 中存在的几个高阶函数。 例如,filter、map 和 reduce 等。 可以这样理解高阶函数:它是一个接受回调函数的函数。让我们看一个使用内置高阶函数的例子:

请注意,我们在数组对象上调用方法,这是面向对象编程的特征。 如果我们想让它更能代表函数式编程,我们可以使用 Ramda 或 lodash/fp 提供的函数。 我们还可以使用我们在上一节中探讨过的复合函数。请注意,如果我们使用 R.compose,我们需要颠倒函数的顺序,因为它从右到左(即从下到上)应用函数;但是,如果我们想从左到右(即从上到下)应用它们,就像上面的例子一样,那么我们可以使用 R.pipe。 下面使用 Ramda 给出这两个示例。 请注意,Ramda 有一个可以用来代替 reduce 的 mean 函数。

函数式编程的优点是它清楚地将数据(即 vehicles )与逻辑(即 filter, map 和 reduce 函数)分开。
柯里化
通俗地说,柯里化是将一个接受 n 个参数的函数转换为 n 个函数的过程,每个函数都接受一个参数。函数的数量是它接受的参数的数量。接受单个参数的函数是一元的,两个参数是二元的,三个参数是三元的,n 个参数是 n 元的。因此,我们可以将柯里化定义为取一个 n 元函数并将其转换为 n 个一元函数的过程。让我们从一个简单的例子开始。

dot 函数是二元的,因为它接受两个参数; 但是,我们可以手动将其转换为两个一元函数,如以下代码示例所示。 请注意 curriedDot 是如何接受一个向量并返回另一个接受第二个向量的一元函数的一元函数。

对我们来说幸运的是,我们不必手动将每个函数转换为柯里化形式。包括 Ramda 和 lodash 在内的库都有这个功能。 实际上,它们进行了一种混合类型的柯里化,你可以一次调用函数一个参数,也可以像原来一样继续一次传递所有参数。
