三画项目面
你能说说为啥使用骨架屏吗?
现在的前端开发领域,都是前后端分离,前端框架主流的都是 SPA,MPA;这就意味着,页面渲染以及等待的白屏时间,成为我们需要解决的问题点;而且大项目,这个问题尤为突出。
webpack 可以实现按需加载,减小我们首屏需要加载的代码体积;再配合上 CDN 以及一些静态代码(框架,组件库等等…)缓存技术,可以很好的缓解这个加载渲染的时间过长的问题。
但即便如此,首屏的加载依然还是存在这个加载以及渲染的等待时间问题;
骨架屏的原理知道吗?
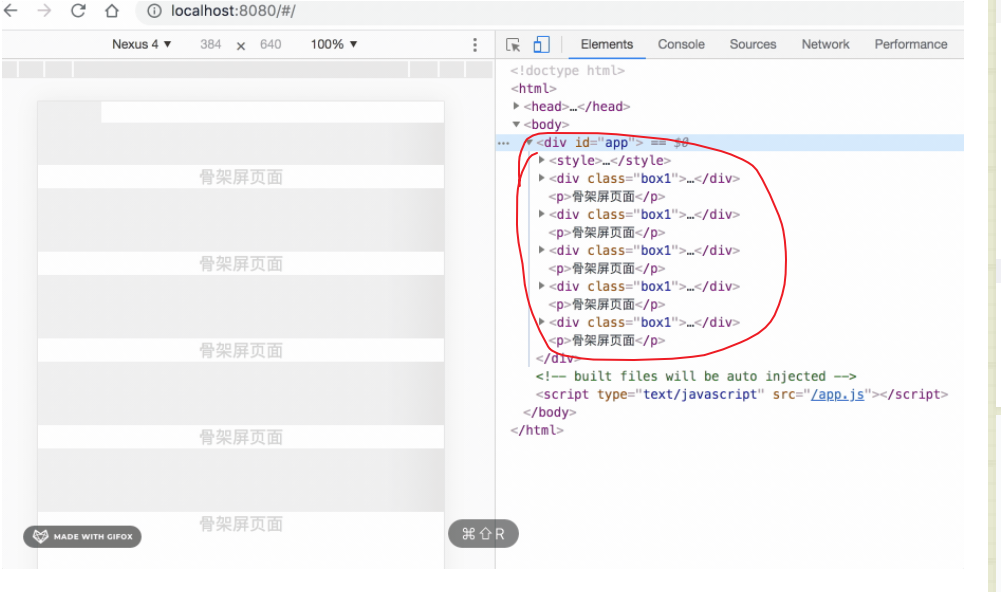
方案一、
在 index.html 中的 div#app 中来实现骨架屏,程序渲染后就会替换掉 index.html 里面的 div#app 骨架屏内容;
方案二、使用一个Base64的图片来作为骨架屏
使用图片作为骨架屏; 简单暴力,让UI同学花点功夫吧;小米商城的移动端页面采用的就是这个方法,它是使用了一个Base64的图片来作为骨架屏。
按照方案一的方案,将这个 Base64 的图片写在我们的 index.html 模块中的 div#app 里面。
方案三、使用 .vue 文件来完成骨架屏
CDN优化
能说说什么是CDN吗?
CDN(Content Delivery Network,内容分发网络)是指一种通过互联网互相连接的电脑网络系统,利用最靠近每位用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,来提供高性能、可扩展性及低成本的网络内容传递给用户。
典型的CDN系统由下面三个部分组成:
- 分发服务系统: 最基本的工作单元就是Cache设备,cache(边缘cache)负责直接响应最终用户的访问请求,把缓存在本地的内容快速地提供给用户。同时cache还负责与源站点进行内容同步,把更新的内容以及本地没有的内容从源站点获取并保存在本地。Cache设备的数量、规模、总服务能力是衡量一个CDN系统服务能力的最基本的指标。
- 负载均衡系统: 主要功能是负责对所有发起服务请求的用户进行访问调度,确定提供给用户的最终实际访问地址。两级调度体系分为全局负载均衡(GSLB)和本地负载均衡(SLB)。全局负载均衡主要根据用户就近性原则,通过对每个服务节点进行“最优”判断,确定向用户提供服务的cache的物理位置。本地负载均衡主要负责节点内部的设备负载均衡
- 运营管理系统: 运营管理系统分为运营管理和网络管理子系统,负责处理业务层面的与外界系统交互所必须的收集、整理、交付工作,包含客户管理、产品管理、计费管理、统计分析等功能。
能具体说说CDN是怎么配置的吗?
可以通过阿里云,百度云,华为云等CDN
通过externals这个配置项进行cdn配置
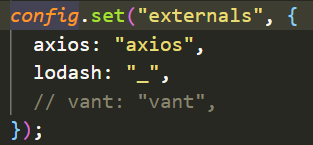
然后通过在index.html中引入相应的cdn资源
cdn资源的话可以通过bootcdn来进行查找
CDN有什么作用知道吗?
CDN一般会用来托管Web资源(包括文本、图片和脚本等),可供下载的资源(媒体文件、软件、文档等),应用程序(门户网站等)。使用CDN来加速这些资源的访问。
(1)在性能方面,引入CDN的作用在于:
- 用户收到的内容来自最近的数据中心,延迟更低,内容加载更快
- 部分资源请求分配给了CDN,减少了服务器的负载
(2)在安全方面,CDN有助于防御DDoS、MITM等网络攻击:
- 针对DDoS:通过监控分析异常流量,限制其请求频率
- 针对MITM:从源服务器到 CDN 节点到 ISP(Internet Service Provider),全链路 HTTPS 通信
除此之外,CDN作为一种基础的云服务,同样具有资源托管、按需扩展(能够应对流量高峰)等方面的优势。
DNS解析与CDN的区别知道吗?
CDN和DNS有着密不可分的联系,先来看一下DNS的解析域名过程,在浏览器输入 www.test.com 的解析过程如下: (1) 检查浏览器缓存 (2)检查操作系统缓存,常见的如hosts文件 (3)检查路由器缓存 (4)如果前几步都没没找到,会向ISP(网络服务提供商)的LDNS服务器查询 (5)如果LDNS服务器没找到,会向根域名服务器(Root Server)请求解析,分为以下几步:
- 根服务器返回顶级域名(TLD)服务器如.com,.cn,.org等的地址,该例子中会返回.com的地址
- 接着向顶级域名服务器发送请求,然后会返回次级域名(SLD)服务器的地址,本例子会返回.test的地址
- 接着向次级域名服务器发送请求,然后会返回通过域名查询到的目标IP,本例子会返回www.test.com的地址
- Local DNS Server会缓存结果,并返回给用户,缓存在系统中
CDN的工作原理知道吗?
(1)用户未使用CDN缓存资源的过程:
- 浏览器通过DNS对域名进行解析(就是上面的DNS解析过程),依次得到此域名对应的IP地址
- 浏览器根据得到的IP地址,向域名的服务主机发送数据请求
- 服务器向浏览器返回响应数据
(2)用户使用CDN缓存资源的过程:
- 对于点击的数据的URL,经过本地DNS系统的解析,发现该URL对应的是一个CDN专用的DNS服务器,DNS系统就会将域名解析权交给CNAME指向的CDN专用的DNS服务器。
- CND专用DNS服务器将CND的全局负载均衡设备IP地址返回给用户
- 用户向CDN的全局负载均衡设备发起数据请求
- CDN的全局负载均衡设备根据用户的IP地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求
- 区域负载均衡设备选择一台合适的缓存服务器来提供服务,将该缓存服务器的IP地址返回给全局负载均衡设备
- 全局负载均衡设备把服务器的IP地址返回给用户
- 用户向该缓存服务器发起请求,缓存服务器响应用户的请求,将用户所需内容发送至用户终端
那ES6 模块与 CommonJS 模块的差异有哪些呢?
1. CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
- CommonJS 模块输出的是值的拷贝(浅拷贝),也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。
- ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令import,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。原始值变了,import加载的值也会跟着变。因此,ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
2. CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
- 运行时加载: CommonJS 模块就是对象;即在输入时是先加载整个模块,生成一个对象,然后再从这个对象上面读取方法,这种加载称为“运行时加载”。
- 编译时加载: ES6 模块不是对象,而是通过 export 命令显式指定输出的代码,import时采用静态命令的形式。即在import时可以指定加载某个输出值,而不是加载整个模块,这种加载称为“编译时加载”。
CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
webpack的编译(打包)流程说说
- 初始化参数:解析webpack配置参数,合并shell传入和webpack.config.js文件配置的参数,形成最后的配置结果;
- 开始编译:上一步得到的参数初始化compiler对象,注册所有配置的插件,插件 监听webpack构建生命周期的事件节点,做出相应的反应,执行对象的run方法开始执行编译;
- *确定入口*:从配置的entry入口,开始解析文件构建AST语法树,找出依赖,递归下去;
- 编译模块:递归中根据文件类型和loader配置,调用所有配置的loader对文件进行转换,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理;
- 完成模块编译并输出:递归完事后,得到每个文件结果,包含每个模块以及他们之间的依赖关系,根据entry或分包配置生成代码块chunk;
- 输出完成:输出所有的chunk到文件系统;
说一下 Webpack 的热更新原理吧?
Webpack 的热更新又称热替换(Hot Module Replacement),缩写为 HMR。 这个机制可以做到不用刷新浏览器而将新变更的模块替换掉旧的模块。
HMR的核心就是客户端从服务端拉去更新后的文件,准确的说是 chunk diff (chunk 需要更新的部分),实际上 WDS(无线路由)与浏览器之间维护了一个 Websocket,当本地资源发生变化时,WDS 会向浏览器推送更新,并带上构建时的 hash,让客户端与上一次资源进行对比。客户端对比出差异后会向 WDS 发起 Ajax 请求来获取更改内容(文件列表、hash),这样客户端就可以再借助这些信息继续向 WDS 发起 jsonp 请求获取该chunk的增量更新。
后续的部分(拿到增量更新之后如何处理?哪些状态该保留?哪些又需要更新?)由 HotModulePlugin 来完成,提供了相关 API 以供开发者针对自身场景进行处理,像react-hot-loader 和 vue-loader 都是借助这些 API 实现 HMR。
你知道哪些loader吗?
- file-loader:把⽂件输出到⼀个⽂件夹中,在代码中通过相对 URL 去引⽤输出的⽂件
- url-loader:和 file-loader 类似,但是能在⽂件很⼩的情况下以 base64 的⽅式把⽂件内容注⼊到代码中去
- source-map-loader:加载额外的 Source Map ⽂件,以⽅便断点调试
- image-loader:加载并且压缩图⽚⽂件
- babel-loader:把 ES6 转换成 ES5
- css-loader:加载 CSS,⽀持模块化、压缩、⽂件导⼊等特性
- style-loader:把 CSS 代码注⼊到 JavaScript 中,通过 DOM 操作去加载 CSS。
- eslint-loader:通过 ESLint 检查 JavaScript 代码
Git
项目里git怎么使用的可以说说吗?
1.在工作区开发,添加,修改文件。
2.将修改后的文件放入暂存区。
3.将暂存区域的文件提交到本地仓库。
4.将本地仓库的修改推送到远程仓库。
知道git的原理吗?说说他的原理吧
Workspace:工作区,就是平时进行开发改动的地方,是当前看到最新的内容,在开发的过程也就是对工作区的操作
Index:暂存区,当执行 git add 的命令后,工作区的文件就会被移入暂存区,暂存区标记了当前工作区中那些内容是被 Git 管理的,当完成某个需求或者功能后需要提交代码,第一步就是通过 git add 先提交到暂存区。
Repository:本地仓库,位于自己的电脑上,通过 git commit 提交暂存区的内容,会进入本地仓库。
Remote:远程仓库,用来托管代码的服务器,远程仓库的内容能够被分布在多个地点的处于协作关系的本地仓库修改,本地仓库修改完代码后通过 git push 命令同步代码到远程仓库。
能说几个git的操作吗?
git add:添加文件到暂存区
git commit
git pull=git fetch+git merge
git fetch
与 git pull 不同的是 git fetch 操作仅仅只会拉取远程的更改,不会自动进行 merge 操作。对你当前的代码没有影响
git fetch
与 git pull 不同的是 git fetch 操作仅仅只会拉取远程的更改,不会自动进行 merge 操作。对你当前的代码没有影响
查看分支 git branch
**克隆项目 git clone
说说vue和react的异同
早就预料到可能会问这个, 因此之前自己有总结过:
相同点:
核心库都只关注ui层面的问题解决,路由/状态管理都由其他库处理。
都使用了虚拟dom来提高重渲染效率。
都采用了组件化思想,将应用中不同功能抽象成一个组件,提高了代码复用性。
都能进行跨平台,react使用react native,vue使用weex
都有自己的构建工具:
vue: vue-cli
react: create-react-app
不同点:
最大的不同是组件的编写方式
vue推荐使用类似于常规html模板的方式来编写组件, 基于vue强大的指令系统来进行数据的绑定和添加事件监听。在vue中,一个组件就是一个.vue文件。
而react中采用jsx语法,每一个jsx表达式都是一个react元素. 在react中,一个组件本质就是一个函数或者一个类。
虚拟dom渲染效率方面
由于vue对数据进行了劫持,因此每一个响应式数据都能进行依赖跟踪。当组件重新渲染时,不必重新渲染它的整个子组件树,而是只渲染应该重渲染的子组件。
在react中,一旦组件状态变化导致重渲染后,其整个子组件树都会默认重新渲染。可以通过pureComponent或者shouldComponentUpdate来进行优化。
响应式方面
vue由于使用defineProperty或者proxy, 能对数据进行劫持。因此只要修改了响应式数据本身就能导致组件的重渲染。
而在react中,并没有对数据本身进行劫持,需要手动调用setState才能触发组件的重渲染。并且react强调使用不可变数据,即每次更改状态时,新状态的引用必须和旧状态不同。如果说没有使用不可变数据并且又在组件内使用了pureComponent或者shouldComponentUpdate进行优化,可能会导致状态变化组件没有重新渲染。
高阶组件
react中存在HOC(高阶组件)的概念,因为react中的每一个组件本质都是一个函数或者类,都是编写在js代码中。因此可以轻松的实现高阶组件来对组件进行扩展。而vue采用模板编译的方式编写组件,无法使用HOC, 通常通过mixin来扩展组件.
指令系统
vue有一套强大的指令系统并且支持自定义指令来封装一些功能。
react则更偏向底层,使用javascript原生代码进行封装功能。
说说vue3的composition api 和 react hook的区别?
这个也算是预判到了, 当时想着如果问了vue和react的对比很有可能会问这个. 之前也做过总结:
react:
由于react没有实现真正的数据双向绑定即没有对数据进行劫持,react是依靠hook的调用顺序来知道重渲染时,本次的state对应于哪一个useState hook。因此在react中使用hook有如下要求:
- 不能在循环/判断/嵌套函数内使用hook
- 总是确保hook出现在函数组件的最顶部
- 对于一些hook如useEffect, useMemo, useCallBack, 必须手动注册依赖项。
而在vue中, 基于vue的响应式系统,composiiton api在调用时可以不用考虑顺序并且能使用在判断/循环/内部函数中。并且由于vue的响应式数据会自动收集依赖,因此使用一些composiiton api如computed以及watchEffect时无需手动注册依赖。
后面基本是一些小的问题比如:
vue中的scoped style是如何实现作用域样式以及为什么vue不使用css module来实现作用域?
为什么vue要将传递给子组件的属性分为props和$attrs? (这个不会, 把props和$attrs的区别说了一下)
说说最近学习的新技术?
我直接坦白了最近都在准备面试没有学新技术, 然后面试官问准备面试过程有哪些提升?
我回答了对vue的响应式系统原理理解更深入了以及对http协议了解更多了, 然后面试官让我说说这些提升在具体中的项目的应用有哪些?
说了this.$nextTick和vue的异步更新队列在项目中的应用。
React和Vue diff算法的区别
vue与react都推崇组件式的开发理念,但是在设计的核心思想上有很大差别。
vue
vue的整体思想仍然是拥抱经典的html(结构)+css(表现)+js(行为)的形式,vue鼓励开发者使用template模板,并提供指令供开发者使用(v-if、v-show、v-for等等),因此在开发vue应用的时候会有一种在写经典web应用(结构、表现、行为分离)的感觉。另一方面,在针对组件数据上,vue2.0通过Object.defineProperty对数据做到了更细致的监听,精准实现组件级别的更新。
react
react整体上是函数式的思想,组件使用jsx语法,all in js,将html与css全都融入javaScript,jsx语法相对来说更加灵活,我一开始刚转过来也不是很适应,感觉写react应用感觉就像是在写javaScript。当组件调用setState或props变化的时候,组件内部render会重新渲染,子组件也会随之重新渲染,可以通过shouldComponentUpdate或者PureComponent可以避免不必要的重新渲染(个人感觉这一点上不如vue做的
。
对框架的理解
因为我是vue2和react都学过, 在简历里面都写了,所以两个框架都问到了。
说说vue和react的异同
早就预料到可能会问这个, 因此之前自己有总结过:
相同点:
核心库都只关注ui层面的问题解决,路由/状态管理都由其他库处理。
都使用了虚拟dom来提高重渲染效率。
都采用了组件化思想,将应用中不同功能抽象成一个组件,提高了代码复用性。
都能进行跨平台,react使用react native,vue使用weex
都有自己的构建工具:
vue: vue-cli
react: create-react-app
不同点:
最大的不同是组件的编写方式
vue推荐使用类似于常规html模板的方式来编写组件, 基于vue强大的指令系统来进行数据的绑定和添加事件监听。在vue中,一个组件就是一个.vue文件。
而react中采用jsx语法,每一个jsx表达式都是一个react元素. 在react中,一个组件本质就是一个函数或者一个类。
虚拟dom渲染效率方面
由于vue对数据进行了劫持,因此每一个响应式数据都能进行依赖跟踪。当组件重新渲染时,不必重新渲染它的整个子组件树,而是只渲染应该重渲染的子组件。
在react中,一旦组件状态变化导致重渲染后,其整个子组件树都会默认重新渲染。可以通过pureComponent或者shouldComponentUpdate来进行优化。
响应式方面
vue由于使用defineProperty或者proxy, 能对数据进行劫持。因此只要修改了响应式数据本身就能导致组件的重渲染。
而在react中,并没有对数据本身进行劫持,需要手动调用setState才能触发组件的重渲染。并且react强调使用不可变数据,即每次更改状态时,新状态的引用必须和旧状态不同。如果说没有使用不可变数据并且又在组件内使用了pureComponent或者shouldComponentUpdate进行优化,可能会导致状态变化组件没有重新渲染。
高阶组件
react中存在HOC(高阶组件)的概念,因为react中的每一个组件本质都是一个函数或者类,都是编写在js代码中。因此可以轻松的实现高阶组件来对组件进行扩展。而vue采用模板编译的方式编写组件,无法使用HOC, 通常通过mixin来扩展组件.
指令系统
vue有一套强大的指令系统并且支持自定义指令来封装一些功能。
react则更偏向底层,使用javascript原生代码进行封装功能。
说说vue3的composition api 和 react hook的区别?
这个也算是预判到了, 当时想着如果问了vue和react的对比很有可能会问这个. 之前也做过总结:
react:
由于react没有实现真正的数据双向绑定即没有对数据进行劫持,react是依靠hook的调用顺序来知道重渲染时,本次的state对应于哪一个useState hook。因此在react中使用hook有如下要求:
- 不能在循环/判断/嵌套函数内使用hook
- 总是确保hook出现在函数组件的最顶部
- 对于一些hook如useEffect, useMemo, useCallBack, 必须手动注册依赖项。
而在vue中, 基于vue的响应式系统,composiiton api在调用时可以不用考虑顺序并且能使用在判断/循环/内部函数中。并且由于vue的响应式数据会自动收集依赖,因此使用一些composiiton api如computed以及watchEffect时无需手动注册依赖。
传统Diff算法
处理方案: 循环递归每一个节点
优化的Diff算法
vue和react的虚拟DOM的diff算法大致相同,其核心是基于两个简单的假设:
- 两个相同的组件产生类似的DOM结构,不同的组件产生不同的DOM结构
- 同一层级的一组节点,他们可以通过唯一的id进行区分
React优化Diff算法
基于以上优化的diff三点策略,react分别进行以下算法优化
- tree diff
- component diff
- element diff
tree diff
react对树的算法进行了分层比较。react 通过 updateDepth对Virtual Dom树进行层级控制,只会对相同层级的节点进行比较,即同一个父节点下的所有子节点。当发现节点不存在,则该节点和其子节点都会被删除。这样是需要遍历一次dom树,就完成了整个dom树的对比
component diff
- 如果是同类型的组件,则直接对比virtual Dom tree
- 如果不是同类型的组件,会直接替换掉组件下的所有子组件
- 如果类型相同,但是可能virtual DOM 没有变化,这种情况下我们可以使用shouldComponentUpdate() 来判断是否需要进行diff
element diff
移动优化
在移动前,会将节点在新集合中的位置和在老集合中lastIndex进行比较,如果if (child._mountIndex < lastIndex) 进行移动操作,否则不进行移动操作。这是一种顺序移动优化。只有在新集合的位置 小于 在老集合中的位置 才进行移动。
如果遍历的过程中,发现在新集合中没有,但是在老集合中的节点,会进行删除操作
所以:element diff 通过唯一key 进行diff 优化。
Vue优化Diff
差异就在于, diff的过程就是调用patch函数,就像打补丁一样修改真实dom
- patchVnode
- updateChildren
- updateChildren是vue diff的核心 过程可以概括为:oldCh和newCh各有两个头尾的变量StartIdx和EndIdx,它们的2个变量相互比较,一共有4种比较方式。如果4种比较都没匹配,如果设置了key,就会用key进行比较,在比较的过程中,变量会往中间靠,一旦StartIdx>EndIdx表明oldCh和newCh至少有一个已经遍历完了,就会结束比较
Vue 2.x vs Vue 3.x
Vue2的核心Diff算法采用了双端比较的算法,同时从新旧children的两端开始进行比较,借助key值找到可复用的节点,再进行相关操作。相比React的Diff算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅
Vue3.x借鉴了 ivi算法和 inferno算法。在创建VNode时就确定其类型,以及在mount/patch的过程中采用位运算来判断一个VNode的类型,在这个基础之上再配合核心的Diff算法,使得性能上较Vue2.x有了提升。(实际的实现可以结合Vue3.x源码看
下面的diff算法中会出现几个方法,在这里进行罗列,并说明其功能
mount(vnode, parent, [refNode]): 通过vnode生成真实的DOM节点。parent为其父级的真实DOM节点,refNode为真实的DOM节点,其父级节点为parent。如果refNode不为空,vnode生成的DOM节点就会插入到refNode之前;如果refNode为空,那么vnode生成的DOM节点就作为最后一个子节点插入到parent中patch(prevNode, nextNode, parent): 可以简单的理解为给当前DOM节点进行更新,并且调用diff算法对比自身的子节点;
一、React-Diff
React的思路是递增法。通过对比新的列表中的节点,在原本的列表中的位置是否是递增,来判断当前节点是否需要移动。
1. 实现原理
来看这样一个例子。
nextList为新的列表,prevList为旧列表。这个例子我们一眼能看出来,新列表是不需要进行移动的。下面我用react的递增思想,解释一下为什么新列表中的节点不需要移动。
我们首先遍历nextList,并且找到每一个节点,在prevList中的位置。
找到位置以后,与上一个节点的位置进行对比,如果当前的位置大于上一个位置,说明当前节点不需要移动。因此我们要定义一个lastIndex来记录上一个节点的位置。
在上面的例子中,nextList每个节点在prevList的位置为0 1 2 3。每一项都要比前一项要大,所以不需要移动,这就是react的diff算法的原理。
2. 找到需要移动的节点
在上一小节中,我们是通过对比值是否相等,查找的对应位置。但是在vdom中,每一个节点都是一个vNode,我们应该如何进行判断呢?
答案就是key,我们通过对每个节点的key进行赋值,并且让处于同一children数组下的vnode的key都不相同,以此来确定每个节点的唯一性,并进行新旧列表的对比。
3. 移动节点
首先我们先明确一点,移动节点所指的节点是DOM节点。vnode.el指向该节点对应的真实DOM节点。patch方法会将更新过后的DOM节点,赋值给新的vnode的el属性。
为了画图方便,我们用
key的值来表示vnode节点。为了行文方便,我们把key值为a的vnode简写为vnode-a,vnode-a对应的真实DOM节点为DOM-A
我们来将上图的例子代入reactDiff中执行。我们遍历新列表,并查找vnode在旧列表中的位置。当遍历到vnode-d时,之前遍历在旧列表的位置为0 < 2 < 3,说明A C D这三个节点都是不需要移动的。此时lastIndex = 3, 并进入下一次循环,发现vnode-b在旧列表的index为1,1 < 3,说明DOM-B要移动。
通过观察我们能发现,只需要把DOM-B移动到DOM-D之后就可以了。也就是找到需要移动的VNode,我们称该VNode为α,将α对应的真实的DOM节点移动到,α在新列表中的前一个VNode对应的真实DOM的后面。
在上述的例子中,就是将vnode-b对应的真实DOM节点DOM-B, 移动到vnode-b在新列表中的前一个VNode——vnode-d对应的真实DOM节点DOM-D的后面。
为什么是这样移动的呢?首先我们列表是从头到尾遍历的。这就意味着对于当前VNode节点来说,该节点之前的所有节点都是排好序的,如果该节点需要移动,那么只需要将DOM节点移动到前一个vnode节点之后就可以,因为在新列表中vnode的顺序就是这样的。
4. 添加节点
上一小节我们只讲了如何移动节点,但是忽略了另外一种情况,就是在新列表中有全新的VNode节点,在旧列表中找不到。遇到这种情况,我们需要根据新的VNode节点生成DOM节点,并插入DOM树中。
至此,我们面临两个问题:1.如何发现全新的节点、2. 生成的DOM节点插入到哪里
我们先来解决第一个问题,找节点还是比较简单的,我们定义一个find变量值为false。如果在旧列表找到了key 相同的vnode,就将find的值改为true。当遍历结束后判断find值,如果为false,说明当前节点为新节点。
找到新节点后,下一步就是插入到哪里了,这里的逻辑其实是和移动节点的逻辑是一样的。我们观察上图可以发现,新的vnode-c是紧跟在vnode-b后面的,并且vnode-b的DOM节点——DOM-B是已经排好序的,所以我们只需要将vnode-c生成的DOM节点插入到DOM-B之后就可以了。
但是这里有一种特殊情况需要注意,就是新的节点位于新列表的第一个,这时候我们需要找到旧列表第一个节点,将新节点插入到原来第一个节点之前就可以了。
5. 移除节点
有增就有减,当旧的节点不在新列表中时,我们就将其对应的DOM节点移除。
6.优化与不足
以上就是React的diff算法的思路。
目前的reactDiff的时间复杂度为O(m*n),我们可以用空间换时间,把key与index的关系维护成一个Map,从而将时间复杂度降低为O(n),具体的代码可以查看此项目。
我们接下来看这样一个例子
根据reactDiff的思路,我们需要先将DOM-A移动到DOM-C之后,然后再将DOM-B移动到DOM-A之后,完成Diff。但是我们通过观察可以发现,只要将DOM-C移动到DOM-A之前就可以完成Diff。
这里是有可优化的空间的,接下来我们介绍vue2.x中的diff算法——双端比较,该算法解决了上述的问题
二、Vue2.X Diff —— 双端比较
所谓双端比较就是新列表和旧列表两个列表的头与尾互相对比,,在对比的过程中指针会逐渐向内靠拢,直到某一个列表的节点全部遍历过,对比停止。
1. 实现原理
我们先用四个指针指向两个列表的头尾
我们根据四个指针找到四个节点,然后进行对比,那么如何对比呢?我们按照以下四个步骤进行对比
- 使用旧列表的头一个节点
oldStartNode与新列表的头一个节点newStartNode对比 - 使用旧列表的最后一个节点
oldEndNode与新列表的最后一个节点newEndNode对比 - 使用旧列表的头一个节点
oldStartNode与新列表的最后一个节点newEndNode对比 - 使用旧列表的最后一个节点
oldEndNode与新列表的头一个节点newStartNode对比
使用以上四步进行对比,去寻找key相同的可复用的节点,当在某一步中找到了则停止后面的寻找。具体对比顺序如下图
对比顺序代码结构如下:
当对比时找到了可复用的节点,我们还是先patch给元素打补丁,然后将指针进行前/后移一位指针。根据对比节点的不同,我们移动的指针和方向也不同,具体规则如下:
- 当旧列表的头一个节点
oldStartNode与新列表的头一个节点newStartNode对比时key相同。那么旧列表的头指针oldStartIndex与新列表的头指针newStartIndex同时向后移动一位。 - 当旧列表的最后一个节点
oldEndNode与新列表的最后一个节点newEndNode对比时key相同。那么旧列表的尾指针oldEndIndex与新列表的尾指针newEndIndex同时向前移动一位。 - 当旧列表的头一个节点
oldStartNode与新列表的最后一个节点newEndNode对比时key相同。那么旧列表的头指针oldStartIndex向后移动一位;新列表的尾指针newEndIndex向前移动一位。 - 当旧列表的最后一个节点
oldEndNode与新列表的头一个节点newStartNode对比时key相同。那么旧列表的尾指针oldEndIndex向前移动一位;新列表的头指针newStartIndex向后移动一位。
在小节的开头,提到了要让指针向内靠拢,所以我们需要循环。循环停止的条件是当其中一个列表的节点全部遍历完成,代码如下
至此整体的循环我们就全部完成了,下面我们需要考虑这样两个问题:
- 什么情况下
DOM节点需要移动 DOM节点如何移动
我们来解决第一个问题:什么情况下需要移动,我们还是以上图为例。
当我们在第一个循环时,在第四步发现旧列表的尾节点oldEndNode与新列表的头节点newStartNode的key相同,是可复用的DOM节点。通过观察我们可以发现,原本在旧列表末尾的节点,却是新列表中的开头节点,没有人比他更靠前,因为他是第一个,所以我们只需要把当前的节点移动到原本旧列表中的第一个节点之前,让它成为第一个节点即可。
然后我们进入第二次循环,我们在第二步发现,旧列表的尾节点oldEndNode和新列表的尾节点newEndNode为复用节点。原本在旧列表中就是尾节点,在新列表中也是尾节点,说明该节点不需要移动,所以我们什么都不需要做。
同理,如果是旧列表的头节点oldStartNode和新列表的头节点newStartNode为复用节点,我们也什么都不需要做。
进入第三次循环,我们在第三部发现,旧列表的头节点oldStartNode和新列表的尾节点newEndNode为复用节点。到这一步聪明如你肯定就一眼可以看出来了,我们只要将DOM-A移动到DOM-B后面就可以了。
依照惯例我们还是解释一下,原本旧列表中是头节点,然后在新列表中是尾节点。那么只要在旧列表中把当前的节点移动到原本尾节点的后面,就可以了。
OK,进入最后一个循环。在第一步旧列表头节点oldStartNode与新列表头节点newStartNode位置相同,所以啥也不用做。然后结束循环,这就是Vue2 双端比较的原理。
2. 非理想情况
上一小节,我们讲了双端比较的原理,但是有一种特殊情况,当四次对比都没找到复用节点时,我们只能拿新列表的第一个节点去旧列表中找与其key相同的节点。
。
找节点的时候其实会有两种情况:一种在旧列表中找到了,另一种情况是没找到。我们先以上图为例,说一下找到的情况。
当我们在旧列表中找到对应的VNode,我们只需要将找到的节点的DOM元素,移动到开头就可以了。这里的逻辑其实和第四步的逻辑是一样的,只不过第四步是移动的尾节点,这里是移动找到的节点。DOM移动后,由我们将旧列表中的节点改为undefined,这是至关重要的一步,因为我们已经做了节点的移动了所以我们不需要进行再次的对比了。最后我们将头指针newStartIndex向后移一位。
如果在旧列表中没有找到复用节点呢?很简单,直接创建一个新的节点放到最前面就可以了,然后后移头指针newStartIndex。
function vue2Diff(prevChildren, nextChildren, parent) {
//...
while (oldStartIndex <= oldEndIndex && newStartIndex <= newEndIndex) {
if (oldStartNode.key === newStartNode.key) {
//...
} else if (oldEndNode.key === newEndNode.key) {
//...
} else if (oldStartNode.key === newEndNode.key) {
//...
} else if (oldEndNode.key === newStartNode.key) {
//...
} else {
// 在旧列表中找到 和新列表头节点key 相同的节点
let newtKey = newStartNode.key,
oldIndex = prevChildren.findIndex(child => child.key === newKey);
if (oldIndex > -1) {
let oldNode = prevChildren[oldIndex];
patch(oldNode, newStartNode, parent)
parent.insertBefore(oldNode.el, oldStartNode.el)
prevChildren[oldIndex] = undefined
} else {
mount(newStartNode, parent, oldStartNode.el)
}
newStartNode = nextChildren[++newStartIndex]
}
}
}
最后当旧列表遍历到undefind时就跳过当前节点。
function vue2Diff(prevChildren, nextChildren, parent) {
//...
while (oldStartIndex <= oldEndIndex && newStartIndex <= newEndIndex) {
if (oldStartNode === undefind) {
oldStartNode = prevChildren[++oldStartIndex]
} else if (oldEndNode === undefind) {
oldEndNode = prevChildren[--oldEndIndex]
} else if (oldStartNode.key === newStartNode.key) {
//...
} else if (oldEndNode.key === newEndNode.key) {
//...
} else if (oldStartNode.key === newEndNode.key) {
//...
} else if (oldEndNode.key === newStartNode.key) {
//...
} else {
// ...
}
}
}
3.添加节点
我们先来看一个例子
这个例子非常简单,几次循环都是尾节点相同,尾指针一直向前移动,直到循环结束,如下图
此时oldEndIndex以及小于了oldStartIndex,但是新列表中还有剩余的节点,我们只需要将剩余的节点依次插入到oldStartNode的DOM之前就可以了。为什么是插入oldStartNode之前呢?原因是剩余的节点在新列表的位置是位于oldStartNode之前的,如果剩余节点是在oldStartNode之后,oldStartNode就会先行对比,这个需要思考一下,其实还是与第四步的思路一样。
4.移除节点
与上一小节的情况相反,当新列表的newEndIndex小于newStartIndex时,我们将旧列表剩余的节点删除即可。这里我们需要注意,旧列表的undefind。在第二小节中我们提到过,当头尾节点都不相同时,我们会去旧列表中找新列表的第一个节点,移动完DOM节点后,将旧列表的那个节点改为undefind。所以我们在最后的删除时,需要注意这些undefind,遇到的话跳过当前循环即可。
5.小结
至此双端比较全部完成,以下是全部代码。
function vue2diff(prevChildren, nextChildren, parent) {
let oldStartIndex = 0,
newStartIndex = 0,
oldStartIndex = prevChildren.length - 1,
newStartIndex = nextChildren.length - 1,
oldStartNode = prevChildren[oldStartIndex],
oldEndNode = prevChildren[oldStartIndex],
newStartNode = nextChildren[newStartIndex],
newEndNode = nextChildren[newStartIndex];
while (oldStartIndex <= oldStartIndex && newStartIndex <= newStartIndex) {
if (oldStartNode === undefined) {
oldStartNode = prevChildren[++oldStartIndex]
} else if (oldEndNode === undefined) {
oldEndNode = prevChildren[--oldStartIndex]
} else if (oldStartNode.key === newStartNode.key) {
patch(oldStartNode, newStartNode, parent)
oldStartIndex++
newStartIndex++
oldStartNode = prevChildren[oldStartIndex]
newStartNode = nextChildren[newStartIndex]
} else if (oldEndNode.key === newEndNode.key) {
patch(oldEndNode, newEndNode, parent)
oldStartIndex--
newStartIndex--
oldEndNode = prevChildren[oldStartIndex]
newEndNode = nextChildren[newStartIndex]
} else if (oldStartNode.key === newEndNode.key) {
patch(oldStartNode, newEndNode, parent)
parent.insertBefore(oldStartNode.el, oldEndNode.el.nextSibling)
oldStartIndex++
newStartIndex--
oldStartNode = prevChildren[oldStartIndex]
newEndNode = nextChildren[newStartIndex]
} else if (oldEndNode.key === newStartNode.key) {
patch(oldEndNode, newStartNode, parent)
parent.insertBefore(oldEndNode.el, oldStartNode.el)
oldStartIndex--
newStartIndex++
oldEndNode = prevChildren[oldStartIndex]
newStartNode = nextChildren[newStartIndex]
} else {
let newKey = newStartNode.key,
oldIndex = prevChildren.findIndex(child => child && (child.key === newKey));
if (oldIndex === -1) {
mount(newStartNode, parent, oldStartNode.el)
} else {
let prevNode = prevChildren[oldIndex]
patch(prevNode, newStartNode, parent)
parent.insertBefore(prevNode.el, oldStartNode.el)
prevChildren[oldIndex] = undefined
}
newStartIndex++
newStartNode = nextChildren[newStartIndex]
}
}
if (newStartIndex > newStartIndex) {
while (oldStartIndex <= oldStartIndex) {
if (!prevChildren[oldStartIndex]) {
oldStartIndex++
continue
}
parent.removeChild(prevChildren[oldStartIndex++].el)
}
} else if (oldStartIndex > oldStartIndex) {
while (newStartIndex <= newStartIndex) {
mount(nextChildren[newStartIndex++], parent, oldStartNode.el)
}
}
}
三、 Vue3 Diff —— 最长递增子序列
vue3的diff借鉴于inferno,该算法其中有两个理念。第一个是相同的前置与后置元素的预处理;第二个则是最长递增子序列,此思想与React的diff类似又不尽相同。下面我们来一一介绍。
1. 前置与后置的预处理
我们看这两段文字
Hello World
Hey World
其实就简单的看一眼我们就能发现,这两段文字是有一部分是相同的,这些文字是不需要修改也不需要移动的,真正需要进行修改中间的几个字母,所以diff就变成以下部分
text1: 'llo'
text2: 'y'
接下来换成vnode,我们以下图为例。
图中的被绿色框起来的节点,他们是不需要移动的,只需要进行打补丁patch就可以了。我们把该逻辑写成代码。
这时候,我们就需要考虑边界情况了,这里有两种情况。一种是j > prevEnd;另一种是j > nextEnd。
我们以这张图为例,此时j > prevEnd且j <= nextEnd,我们只需要把新列表中j到nextEnd之间剩下的节点插入进去就可以了。相反, 如果j > nextEnd时,我们把旧列表中j到prevEnd之间的节点删除就可以了。
我们再继续思考,在我们while循环时,指针是从两端向内逐渐靠拢的,所以我们应该在循环中就应该去判断边界情况,我们使用label语法,当我们触发边界情况时,退出全部的循环,直接进入判断。代码如下:
2. 判断是否需要移动
其实几个算法看下来,套路已经很明显了,就是找到移动的节点,然后给他移动到正确的位置。把该加的新节点添加好,把该删的旧节点删了,整个算法就结束了。这个算法也不例外,我们接下来看一下它是如何做的。
当前/后置的预处理结束后,我们进入真正的diff环节。首先,我们先根据新列表剩余的节点数量,创建一个source数组,并将数组填满-1。
我们先写这块逻辑。
那么这个source数组,是要做什么的呢?他就是来做新旧节点的对应关系的,我们将新节点在旧列表的位置存储在该数组中,我们在根据source计算出它的最长递增子序列用于移动DOM节点。为此,我们先建立一个对象存储当前新列表中的节点与index的关系,再去旧列表中去找位置。
在找节点时要注意,如果旧节点在新列表中没有的话,直接删除就好。除此之外,我们还需要一个数量表示记录我们已经patch过的节点,如果数量已经与新列表剩余的节点数量一样,那么剩下的旧节点我们就直接删除了就可以了
找到位置后,我们观察这个重新赋值后的source,我们可以看出,如果是全新的节点的话,其在source数组中对应的值就是初始的-1,通过这一步我们可以区分出来哪个为全新的节点,哪个是可复用的。
其次,我们要判断是否需要移动。那么如何判断移动呢?很简单,和React一样我们用递增法,如果我们找到的index是一直递增的,说明不需要移动任何节点。我们通过设置一个变量来保存是否需要移动的状态。
3. DOM如何移动
判断完是否需要移动后,我们就需要考虑如何移动了。一旦需要进行DOM移动,我们首先要做的就是找到source的最长递增子序列。
function vue3Diff(prevChildren, nextChildren, parent) {
//...
if (move) {
const seq = lis(source); // [0, 1]
// 需要移动
} else {
//不需要移动
}
}
什么是最长递增子序列:给定一个数值序列,找到它的一个子序列,并且子序列中的值是递增的,子序列中的元素在原序列中不一定连续。
例如给定数值序列为:[ 0, 8, 4, 12 ]。
那么它的最长递增子序列就是:[0, 8, 12]。
当然答案可能有多种情况,例如:[0, 4, 12] 也是可以的。
我们在下一节单独讲解最长递增子序列
上面的代码中,我们调用lis 函数求出数组source的最长递增子序列为[ 0, 1 ]。我们知道 source 数组的值为 [2, 3, 1, -1],很显然最长递增子序列应该是[ 2, 3 ],但为什么计算出的结果是[ 0, 1 ]呢?其实[ 0, 1 ]代表的是最长递增子序列中的各个元素在source数组中的位置索引,如下图所示:
我们根据source,对新列表进行重新编号,并找出了最长递增子序列。
我们从后向前进行遍历source每一项。此时会出现三种情况:
- 当前的值为
-1,这说明该节点是全新的节点,又由于我们是从后向前遍历,我们直接创建好DOM节点插入到队尾就可以了。 - 当前的索引为
最长递增子序列中的值,也就是i === seq[j],这说说明该节点不需要移动 - 当前的索引不是
最长递增子序列中的值,那么说明该DOM节点需要移动,这里也很好理解,我们也是直接将DOM节点插入到队尾就可以了,因为队尾是排好序的。
说完了需要移动的情况,再说说不需要移动的情况。如果不需要移动的话,我们只需要判断是否有全新的节点给他添加进去就可以了。具体代码如下:
至此vue3.0的diff完成。
对微前端的看法?
微前端:云时代的前端开发模式
微前端(Micro-Frontends)概念是2016年底提出,距今已有五年多时间的沉淀,目前在前端领域也有较为广泛地应用。微前端(Micro-Frontends)是一种类似于微服务的架构,是一种由独立交付的多个前端应用组成整体的架构风格,将前端应用分解成一些更小、更简单的能够独立开发、测试、部署的应用,而在用户看来仍然是内聚的单个产品。
vue3中的新特性
值得注意的新特性
Vue 3 中一些需要关注的新功能包括:
- 组合式 API
- Teleport
- 片段
- 触发组件选项
- 来自
@vue/runtime-core的createRendererAPI,用于创建自定义渲染器 - 单文件组件组合式 API 语法糖 (``)
- 单文件组件状态驱动的 CSS 变量 (`
中的v-bind`) - SFC `` 现在可以包含全局规则或只针对插槽内容的规则
- Suspense (实验性)
额外增加的两个配置文件
jsconfig.json
{
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["./src/*"],
}
},
"exclude": ["node_modules", "dist"]
}
当我们使用路径别名@的时候可以提示路径。
.eslintignore
/dist
/src/vender
eslint在做风格检查的时候忽略 dist 和 vender 不去检查。
vuex-持久化
- 在开发的过程中,像用户信息(名字,头像,token)需要vuex中存储且需要本地存储。
- 再例如,购物车如果需要未登录状态下也支持,如果管理在vuex中页需要存储在本地。
- 我们需要category模块存储分类信息,但是分类信息不需要持久化。
1)首先:我们需要安装一个vuex的插件vuex-persistedstate来支持vuex的状态持久化。
npm i vuex-persistedstate
2)然后:在src/store 文件夹下新建 modules 文件,在 modules 下新建 user.js 和 cart.js
src/store/modules/user.js
// 用户模块
export default {
namespaced: true,
state () {
return {
// 用户信息
profile: {
id: '',
avatar: '',
nickname: '',
account: '',
mobile: '',
token: ''
}
}
},
mutations: {
// 修改用户信息,payload就是用户信息对象
setUser (state, payload) {
state.profile = payload
}
}
}
src/store/modules/cart.js
// 购物车状态
export default {
namespaced: true,
state: () => {
return {
list: []
}
}
}
src/store/modules/category.js
// 分类模块
export default {
namespaced: true,
state () {
return {
// 分类信息集合
list: []
}
}
}
3)继续:在 src/store/index.js 中导入 user cart 模块。
import { createStore } from 'vuex'
import user from './modules/user'
import cart from './modules/cart'
import cart from './modules/category'
export default createStore({
modules: {
user,
cart,
category
}
})
4)最后:使用vuex-persistedstate插件来进行持久化
import { createStore } from 'vuex'
+import createPersistedstate from 'vuex-persistedstate'
import user from './modules/user'
import cart from './modules/cart'
import cart from './modules/category'
export default createStore({
modules: {
user,
cart,
category
},
+ plugins: [
+ createPersistedstate({
+ key: 'erabbit-client-pc-store',
+ paths: ['user', 'cart']
+ })
+ ]
})
less的自动化导入
1)准备要用的变量和混入代码
- 变量
src/assets/styles/variables.less
// 主题
@xtxColor:#27BA9B;
// 辅助
@helpColor:#E26237;
// 成功
@sucColor:#1DC779;
// 警告
@warnColor:#FFB302;
// 价格
@priceColor:#CF4444;
- 混入
src/assets/styles/mixins.less
// 鼠标经过上移阴影动画
.hoverShadow () {
transition: all .5s;
&:hover {
transform: translate3d(0,-3px,0);
box-shadow: 0 3px 8px rgba(0,0,0,0.2);
}
}
less混入就是,申明一段css代码(选择器包裹的代码)或者函数,在其他css选择器调用,可复用包裹的代码。
2)完成自动注入公用变量和混入
遇到问题: 每次使用公用的变量和mixin的时候需要单独引入到文件中。

解决方法: 使用vuecli的style-resoures-loader插件来完成自动注入到每个less文件或者vue组件中style标签中。
- 在当前项目下执行一下命令
vue add style-resources-loader,添加一个vuecli的插件

- 安装完毕后会在
vue.config.js中自动添加配置,如下:
module.exports = {
pluginOptions: {
'style-resources-loader': {
preProcessor: 'less',
patterns: []
}
}
}
- 把你需要注入的文件配置一下后,重启服务即可。
+const path = require('path')
module.exports = {
pluginOptions: {
'style-resources-loader': {
preProcessor: 'less',
patterns: [
+ path.join(__dirname, './src/assets/styles/variables.less'),
+ path.join(__dirname, './src/assets/styles/mixins.less')
]
}
}
}
总结: 知道如何定义less变量和混入代码并使用他们,通过vue-resources-loader完成代码注入再每个less文件和vue组件中。
组件数据懒加载
大致步骤:
- 理解
useIntersectionObserver的使用,各个参数的含义 - 改造 home-new 组件成为数据懒加载,掌握
useIntersectionObserver函数的用法 - 封装
useLazyData函数,作为数据懒加载公用函数 - 把
home-new和home-hot改造成懒加载方式
落的代码:
- 先分析下这个
useIntersectionObserver函数:
// stop 是停止观察是否进入或移出可视区域的行为
const { stop } = useIntersectionObserver(
// target 是观察的目标dom容器,必须是dom容器,而且是vue3.0方式绑定的dom对象
target,
// isIntersecting 是否进入可视区域,true是进入 false是移出
// observerElement 被观察的dom
([{ isIntersecting }], observerElement) => {
// 在此处可根据isIntersecting来判断,然后做业务
},
)
- 开始改造
home-new组件:rc/views/home/components/home-new.vue
- 进入可视区后获取数据
<div ref="box" style="position: relative;height: 406px;">
// 省略。。。
<script>
import HomePanel from './home-panel'
import HomeSkeleton from './home-skeleton'
import { findNew } from '@/api/home'
import { ref } from 'vue'
import { useIntersectionObserver } from '@vueuse/core'
export default {
name: 'HomeNew',
components: { HomePanel, HomeSkeleton },
setup () {
const goods = ref([])
const box = ref(null)
const { stop } = useIntersectionObserver(
box,
([{ isIntersecting }]) => {
if (isIntersecting) {
stop()
findNew().then(data => {
goods.value = data.result
})
}
}
)
return { goods, box }
}
}
</script>
- 由于首页面板数据加载都需要实现懒数据加载,所以封装一个钩子函数,得到数据。
src/hooks/index.js
// hooks 封装逻辑,提供响应式数据。
import { useIntersectionObserver } from '@vueuse/core'
import { ref } from 'vue'
// 数据懒加载函数
export const useLazyData = (apiFn) => {
// 需要
// 1. 被观察的对象
// 2. 不同的API函数
const target = ref(null)
const result = ref([])
const { stop } = useIntersectionObserver(
target,
([{ isIntersecting }], observerElement) => {
if (isIntersecting) {
stop()
// 调用API获取数据
apiFn().then(data => {
result.value = data.result
})
}
}
)
// 返回--->数据(dom,后台数据)
return { target, result }
}
- 再次改造
home-new组件:rc/views/home/components/home-new.vue
import { findNew } from '@/api/home'
+import { useLazyData } from '@/hooks'
export default {
name: 'HomeNew',
components: { HomePanel, HomeSkeleton },
setup () {
+ const { target, result } = useLazyData(findNew)
+ return { goods: result, target }
}
}
+ <div ref="target" style="position: relative;height: 426px;">
- 然后改造
home-hot组件:src/views/home/components/home-hot.vue
+ <div ref="target" style="position: relative;height: 426px;">
import { findHot } from '@/api/home'
import HomePanel from './home-panel'
import HomeSkeleton from './home-skeleton'
+import { useLazyData } from '@/hooks'
export default {
name: 'HomeHot',
components: { HomePanel, HomeSkeleton },
setup () {
+ const { target, result } = useLazyData(findHot)
+ return { target, list: result }
}
}
面包屑组件-高级
[^render 选项和 h 函数]:
- 指定组件显示的内容:new Vue({选项})
- el 选项,通过一个选择器找到容器,容器内容就是组件内容
- template 选项,
<div>组件内容</div>作为组件内容 - render选项,它是一个函数,函数回默认传人createElement的函数(h),这个函数用来创建结构,再render函数返回渲染为组件内容。它的优先级更高。
xtx-bread-item.vue
<template>
<div class="xtx-bread-item">
<RouterLink v-if="to" :to="to"><slot /></RouterLink>
<span v-else><slot /></span>
- <i class="iconfont icon-angle-right"></i>
</div>
</template>
xtx-bread.vue
<script>
import { h } from 'vue'
export default {
name: 'XtxBread',
render () {
// 用法
// 1. template 标签去除,单文件组件
// 2. 返回值就是组件内容
// 3. vue2.0 的h函数传参进来的,vue3.0 的h函数导入进来
// 4. h 第一个参数 标签名字 第二个参数 标签属性对象 第三个参数 子节点
// 需求
// 1. 创建xtx-bread父容器
// 2. 获取默认插槽内容
// 3. 去除xtx-bread-item组件的i标签,因该由render函数来组织
// 4. 遍历插槽中的item,得到一个动态创建的节点,最后一个item不加i标签
// 5. 把动态创建的节点渲染再xtx-bread标签中
const items = this.$slots.default()
const dymanicItems = []
items.forEach((item, i) => {
dymanicItems.push(item)
if (i < (items.length - 1)) {
dymanicItems.push(h('i', { class: 'iconfont icon-angle-right' }))
}
})
return h('div', { class: 'xtx-bread' }, dymanicItems)
}
}
</script>
<style lang='less'>
// 去除 scoped 属性,目的:然样式作用到xtx-bread-item组件
.xtx-bread{
display: flex;
padding: 25px 10px;
// ul li:last-child {}
// 先找到父元素,找到所有的子元素,找到最后一个,判断是不是LI,是就是选中,不是就是无效选择器
// ul li:last-of-type {}
// 先找到父元素,找到所有的类型为li的元素,选中最后一个
&-item {
a {
color: #666;
transition: all .4s;
&:hover {
color: @xtxColor;
}
}
}
i {
font-size: 12px;
margin-left: 5px;
margin-right: 5px;
line-height: 22px;
// 样式的方式,不合理
// &:last-child {
// display: none;
// }
}
}
</style>
- 使用代码
<!-- 面包屑 -->
<XtxBread>
<XtxBreadItem to="/">首页</XtxBreadItem>
<XtxBreadItem to="/category/1005000">电器</XtxBreadItem>
<XtxBreadItem >空调</XtxBreadItem>
</XtxBread>
- 总结,一下知识点
- render 是vue提供的一个渲染函数,优先级大于el,template等选项,用来提供组件结构。
- 注意:
- vue2.0 render函数提供h(createElement)函数用来创建节点
- vue3.0 h(createElement)函数有 vue 直接提供,需要按需导入
- this.$slots.default() 获取默认插槽的node结构,按照要求拼接结构。
- h函数的传参 tag 标签名|组件名称, props 标签属性|组件属性, node 子节点|多个节点
- 具体参考 render
- 注意:不要在 xtx-bread 组件插槽写注释,也会被解析。
批量注册组件
大致步骤:
使用
require提供的函数context加载某一个目录下的所有.vue后缀的文件。然后
context函数会返回一个导入函数importFn- 它又一个属性
keys()获取所有的文件路径
- 它又一个属性
通过文件路径数组,通过遍历数组,再使用
importFn根据路径导入组件对象遍历的同时进行全局注册即可
其实就是vue插件,扩展vue功能,全局组件、指令、函数 (vue.30取消过滤器)
// 当你在mian.js导入,使用Vue.use() (vue3.0 app)的时候就会执行install函数
// import XtxSkeleton from './xtx-skeleton.vue'
// import XtxCarousel from './xtx-carousel.vue'
// import XtxMore from './xtx-more.vue'
// import XtxBread from './xtx-bread.vue'
// import XtxBreadItem from './xtx-bread-item.vue'
// 导入library文件夹下的所有组件
// 批量导入需要使用一个函数 require.context(dir,deep,matching)
// 参数:1. 目录 2. 是否加载子目录 3. 加载的正则匹配
const importFn = require.context('./', false, /\.vue$/)
// console.dir(importFn.keys()) 文件名称数组
export default {
install (app) {
// app.component(XtxSkeleton.name, XtxSkeleton)
// app.component(XtxCarousel.name, XtxCarousel)
// app.component(XtxMore.name, XtxMore)
// app.component(XtxBread.name, XtxBread)
// app.component(XtxBreadItem.name, XtxBreadItem)
// 批量注册全局组件
importFn.keys().forEach(key => {
// 导入组件
const component = importFn(key).default
// 注册组件
app.component(component.name, component)
})
// 定义指令
defineDirective(app)
}
}
const defineDirective = (app) => {
// 图片懒加载指令 v-lazyload
app.directive('lazyload', {
// vue2.0 inserted函数,元素渲染后
// vue3.0 mounted函数,元素渲染后
mounted (el, binding) {
// 元素插入后才能获取到dom元素,才能使用 intersectionobserve进行监听进入可视区
// el 是图片元素 binding.value 图片地址
const observe = new IntersectionObserver(([{ isIntersecting }]) => {
if (isIntersecting) {
el.src = binding.value
// 取消观察
observe.unobserve(el)
}
}, {
threshold: 0.01
})
// 进行观察
observe.observe(el)
}
})
}
项目的难点
SKU&SPU概念
官方话术:
- SPU(Standard Product Unit):标准化产品单元。是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。通俗点讲,属性值、特性相同的商品就可以称为一个SPU。
- SKU(Stock Keeping Unit)库存量单位,即库存进出计量的单位, 可以是以件、盒、托盘等为单位。SKU是物理上不可分割的最小存货单元。在使用时要根据不同业态,不同管理模式来处理。

总结一下:
spu代表一个商品,拥有很多相同的属性。
sku代表该商品可选规格的任意组合,他是库存单位的唯一标识。
禁用效果-思路分析

大致步骤:
- 根据后台返回的skus数据得到有效sku组合
- 根据有效的sku组合得到所有的子集集合
- 根据子集集合组合成一个路径字典,也就是对象。
- 在组件初始化的时候去判断每个规格是否点击
- 在点击规格的时候去判断其他规格是否可点击
- 判断的依据是,拿着说有规格和现在已经选中的规则取搭配,得到可走路径。
- 如果可走路径在字典中,可点击
- 如果可走路径不在字典中,禁用
路径字典
[^js算法库 https://github.com/trekhleb/javascript-algorithms]:
/**
* Find power-set of a set using BITWISE approach.
*
* @param {*[]} originalSet
* @return {*[][]}
*/
export default function bwPowerSet(originalSet) {
const subSets = [];
// We will have 2^n possible combinations (where n is a length of original set).
// It is because for every element of original set we will decide whether to include
// it or not (2 options for each set element).
const numberOfCombinations = 2 ** originalSet.length;
// Each number in binary representation in a range from 0 to 2^n does exactly what we need:
// it shows by its bits (0 or 1) whether to include related element from the set or not.
// For example, for the set {1, 2, 3} the binary number of 0b010 would mean that we need to
// include only "2" to the current set.
for (let combinationIndex = 0; combinationIndex < numberOfCombinations; combinationIndex += 1) {
const subSet = [];
for (let setElementIndex = 0; setElementIndex < originalSet.length; setElementIndex += 1) {
// Decide whether we need to include current element into the subset or not.
if (combinationIndex & (1 << setElementIndex)) {
subSet.push(originalSet[setElementIndex]);
}
}
// Add current subset to the list of all subsets.
subSets.push(subSet);
}
return subSets;
}
|
import getPowerSet from '@/vender/power-set'
const spliter = '★'
// 根据skus数据得到路径字典对象
const getPathMap = (skus) => {
const pathMap = {}
skus.forEach(sku => {
// 1. 过滤出有库存有效的sku
if (sku.inventory) {
// 2. 得到sku属性值数组
const specs = sku.specs.map(spec => spec.valueName)
// 3. 得到sku属性值数组的子集
const powerSet = getPowerSet(specs)
// 4. 设置给路径字典对象
powerSet.forEach(set => {
const key = set.join(spliter)
if (pathMap[key]) {
// 已经有key往数组追加
pathMap[key].push(sku.id)
} else {
// 没有key设置一个数组
pathMap[key] = [sku.id]
}
})
}
})
return pathMap
}
★分页组件
- 分页基础布局,依赖数据分析
src/components/library/xtx-pagination.vue
<template>
<div class="xtx-pagination">
<a href="javascript:;" class="disabled">上一页</a>
<span>...</span>
<a href="javascript:;" class="active">3</a>
<a href="javascript:;">4</a>
<a href="javascript:;">5</a>
<a href="javascript:;">6</a>
<a href="javascript:;">7</a>
<span>...</span>
<a href="javascript:;">下一页</a>
</div>
</template>
<script>
export default {
name: 'XtxPagination'
}
</script>
<style scoped lang="less">
.xtx-pagination {
display: flex;
justify-content: center;
padding: 30px;
> a {
display: inline-block;
padding: 5px 10px;
border: 1px solid #e4e4e4;
border-radius: 4px;
margin-right: 10px;
&:hover {
color: @xtxColor;
}
&.active {
background: @xtxColor;
color: #fff;
border-color: @xtxColor;
}
&.disabled {
cursor: not-allowed;
opacity: 0.4;
&:hover {
color: #333
}
}
}
> span {
margin-right: 10px;
}
}
</style>

1)准备渲染数据
setup () {
// 总条数
const myTotal = ref(100)
// 每页条数
const myPageSize = ref(10)
// 当前第几页
const myCurrentPage = ref(1)
// 按钮个数
const btnCount = 5
// 重点:根据上述数据得到(总页数,起始页码,结束页码,按钮数组)
const pager = computed(() => {
// 计算总页数
const pageCount = Math.ceil(myTotal.value / myPageSize.value)
// 计算起始页码和结束页码
// 1. 理想情况根据当前页码,和按钮个数可得到
let start = myCurrentPage.value - Math.floor(btnCount / 2)
let end = start + btnCount - 1
// 2.1 如果起始页码小于1了,需要重新计算
if (start < 1) {
start = 1
end = (start + btnCount - 1) > pageCount ? pageCount : (start + btnCount - 1)
}
// 2.2 如果结束页码大于总页数,需要重新计算
if (end > pageCount) {
end = pageCount
start = (end - btnCount + 1) < 1 ? 1 : (end - btnCount + 1)
}
// 处理完毕start和end得到按钮数组
const btnArr = []
for (let i = start; i <= end; i++) {
btnArr.push(i)
}
return { pageCount, start, end, btnArr }
})
return { pager, myCurrentPage}
}
2)进行渲染
<a v-if="myCurrentPage<=1" href="javascript:;" class="disabled">上一页</a>
<a v-else href="javascript:;">上一页</a>
<span v-if="pager.start>1">...</span>
<a href="javascript:;" :class="{active:i===myCurrentPage}" v-for="i in pager.btnArr" :key="i">{{i}}</a>
<span v-if="pager.end<pager.pageCount">...</span>
<a v-if="myCurrentPage>=pager.pageCount" href="javascript:;" class="disabled">下一页</a>
<a v-else href="javascript:;">下一页</a>
3)切换效果
<div class="xtx-pagination">
<a v-if="myCurrentPage<=1" href="javascript:;" class="disabled">上一页</a>
+ <a @click="changePage(myCurrentPage-1)" v-else href="javascript:;">上一页</a>
<span v-if="pager.start>1">...</span>
+ <a @click="changePage(i)" href="javascript:;" :class="{active:i===myCurrentPage}" v-for="i in pager.btnArr" :key="i">{{i}}</a>
<span v-if="pager.end<pager.pageCount">...</span>
<a v-if="myCurrentPage>=pager.pageCount" href="javascript:;" class="disabled">下一页</a>
+ <a @click="changePage(myCurrentPage+1)" v-else href="javascript:;">下一页</a>
</div>
// 改变页码
const changePage = (newPage) => {
myCurrentPage.value = newPage
}
return { pager, myCurrentPage, changePage }
- 接收外部数据,提供分页事件。
props: {
total: {
type: Number,
default: 100
},
currentPage: {
type: Number,
default: 1
},
pageSize: {
type: Number,
default: 10
}
},
// 监听传人的值改变
watch(props, () => {
myTotal.value = props.total
myPageSize.value = props.pageSize
myCurrentPage.value = props.currentPage
}, { immediate: true })
// 改变页码
const changePage = (newPage) => {
if (myCurrentPage.value !== newPage) {
myCurrentPage.value = newPage
// 通知父组件最新页码
emit('current-change', newPage)
}
}
最后使用组件:
+ // 记录总条数
const commentList = ref([])
+ const total = ref(0)
watch(reqParams, async () => {
const data = await findCommentListByGoods(props.goods.id, reqParams)
commentList.value = data.result
+ total.value = data.result.counts
}, { immediate: true })
// 改变分页函数
const changePager = (np) => {
reqParams.page = np
}
return { commentInfo, currTagIndex, changeTag, reqParams, changeSort, commentList, total, changePager }
<!-- 分页 -->
<XtxPagination @current-change="changePager" :total="total" :current-page="reqParams.page" />
筛选和排序改变后页码回到第一页:
// 改变排序
const changeSort = (type) => {
reqParams.sortField = type
+ reqParams.page = 1
}
const changeTag = (i) => {
currTagIndex.value = i
// 设置有图和标签条件
const currTag = commentInfo.value.tags[i]
if (currTag.type === 'all') {
reqParams.hasPicture = false
reqParams.tag = null
} else if (currTag.type === 'img') {
reqParams.hasPicture = true
reqParams.tag = null
} else {
reqParams.hasPicture = false
reqParams.tag = currTag.title
}
+ reqParams.page = 1
}
优化:有条数才显示分页
购物车线上线下分离操作

总结:
- 购物车的各种操作都会有两种状态的区分,但是不会在组件中去区分。
- 而是在封装在vuex中的actions中去区分,在组件上只需调用actions即可。
- 在actions中通过user信息去区分登录状态
- 未登录,通过mutations修改vuex中的数据即可,vuex已经实现持久化,会同步保持在本地。
- 已登录,通过api接口去服务端操作,响应成功后通过mutations修改vuex中的数据即可,它也会同步在本地。
- 不管何种操作何种状态返回一个promise,然后组件能够判断操作是否完毕是否成功,再而去做其他事情。
注意:
- 登录后,需要合并本地购物车到服务端。
- 退出后,清空vuex数据也会同步清空本地数据。
收货地址-修改
大致步骤:
- 打开对话框的时候传人当前需要修改的地址对象
- 再添加组件open函数处,接收数据赋值给表单,修改标题。
- 封装一个API接口函数实现修改,在提交事件中合并修改操作
- 父组件修改数据
落的代码:
- 打开对话框的时候传人当前需需改的地址对象
src/views/member/pay/checkout-address.vue
<a @click="openAddressEdit(showAddress)" v-if="showAddress" href="javascript:;">修改地址</a>
- 再添加组件open函数处,接收数据赋值给表单,修改标题
src/views/member/pay/address-edit.vue
const formData = reactive({
+ id: '',
receiver: '',
contact: '',
provinceCode: '',
cityCode: '',
countyCode: '',
+ fullLocation: '',
address: '',
postalCode: '',
addressTags: '',
isDefault: 0
})
<XtxDialog :title="(formData.id?'编辑':'添加')+'收货地址'" v-model:visible="dialogVisible">
- 封装一个API接口函数实现修改,在提交事件中合并修改操作
src/api/order.js
/**
* 编辑收货地址信息
* @param {Object} address - 地址对象
*/
export const editAddress = (address) => {
return request('/member/address', 'put', address)
}
src/views/member/pay/address-edit.vue
// 打开对话框函数
const open = (address) => {
// 先填充数据 - 编辑
if (address.id) {
for (const key in formData) {
formData[key] = address[key]
}
} else {
// 先清空数据 - 添加
for (const key in formData) {
if (key !== 'isDefault') {
formData[key] = ''
}
}
}
dialogVisible.value = true
}
// 提交操作
const app = getCurrentInstance()
const submit = () => {
+ if (formData.id) {
+ editAddress(formData).then(data => {
+ // 修改成功
+ Message(app, { text: '修改收货地址成功', type: 'success' })
+ dialogVisible.value = false
+ emit('on-success', formData)
+ })
+ } else {
addAddress(formData).then(data => {
// 添加成功
Message(app, { text: '添加收货地址成功', type: 'success' })
formData.id = data.result.id
dialogVisible.value = false
emit('on-success', formData)
})
+ }
}
- 父组件修改数据
src/views/member/pay/components/checkout-address.vue
// 成功
const successHandler = (formData) => {
+ const editAddress = props.list.find(item => item.id === formData.id)
+ if (editAddress) {
+ // 修改
+ for (const key in editAddress) {
+ editAddress[key] = formData[key]
+ }
+ } else {
// 添加
const json = JSON.stringify(formData) // 需要克隆下,不然使用的是对象的引用
// eslint-disable-next-line vue/no-mutating-props
props.list.unshift(JSON.parse(json))
+ }
需要克隆下,不然使用的是对象的引用
const json = JSON.stringify(formData)
props.list.unshift(JSON.parse(json))
支付倒计时函数封装
// 提供复用逻辑的函数(钩子)
import { useIntersectionObserver, useIntervalFn } from '@vueuse/core'
import { ref, onUnmounted } from 'vue'
import dayjs from 'dayjs'
/**
* 支付倒计时函数
*/
export const usePayTime = () => {
// 倒计时逻辑
const time = ref(0)
const timeText = ref('')
const { pause, resume } = useIntervalFn(() => {
time.value--
timeText.value = dayjs.unix(time.value).format('mm分ss秒')
if (time.value <= 0) {
pause()
}
}, 1000, false)
onUnmounted(() => {
pause()
})
// 开启定时器 countdown 倒计时时间
const start = (countdown) => {
time.value = countdown
timeText.value = dayjs.unix(time.value).format('mm分ss秒')
resume()
}
return {
start,
timeText
}
}
mock.js 进行数据模拟
- 安装
npm i mockjs
- 配置
src/mock/index.js
import Mock from 'mockjs'
// mock的配置
Mock.setup({
// 随机延时500-1000毫秒
timeout: '500-1000'
})
- 使用
src/main.js
import 'normalize.css'
import '@/assets/styles/common.less'
+ import './mock'
- 模拟接口,拦截请求
// 拦截请求,
// 第一个参数:url,使用正则去匹配
// 第二个参数:请求方式
// 第三个参数: 生成数据的函数
Mock.mock(/\/my\/test/, 'get', () => {
return { msg: '请求测试接口成功', result: [] }
})
- 生成随机数据
// 单个数据
Mock.mock('@integer(0,7)')
// 对象数据
Mock.mock({
id: '@id',
name: '@ctitle(2,4)'
})
Teleport
出现的问题
在使用该组件进行传送的时候,由于不够熟练,疏忽了应该在public下的index.html进行挂载标签
<div id="app"></div>
<div id="model"></div>
怎么解决:查看官方文档,找到它的具体使用方法,在根据自己的项目进行结合,找到问题所在
性能优化
vuex的拆包,在选项配置里面得到name,import store路径 使用registerModule api进行注册
Webpack那一套
移动端适配
为什么要移动端适配?
一般情况下设计稿的设计师按照375的尺寸设计,然而,在现在移动终端(就是手机)快速更新的时代,每个品牌的手机都有着不同的物理分辨率,这样就会导致,每台设备的逻辑分辨率也不尽相同,此时375的设计稿,如果想要还原那基本是不可能了,因为如果一个左右布局,左边如果写死,右边自适应的话,每个设备的右边所展示的内容大小就不尽相同,这是移动端适配就显得尤其重要
要知道几个名词:物理像素/逻辑像素/像素dpr==》devicePixelRatio
如何解决1px问题
核心思路:
在web中,浏览器为我们提供了window.devicePixelRatio来帮助我们获取dpr。
在css中,可以使用媒体查询min-device-pixel-ratio,区分dpr
我们根据这个像素比,来算出他对应应该有的大小,但是暴露个非常大的兼容问题

解决1px问题过程会出现什么问题呢?

说说什么是视口(viewport)
viewport 即视窗、视口,用于显示网页部分的区域,在 PC 端视口即是浏览器窗口区域,在移动端,为了让页面展示更多的内容,视窗的宽度默认不为设备的宽度,在移动端视窗有三个概念:布局视窗、视觉视窗、理想视窗
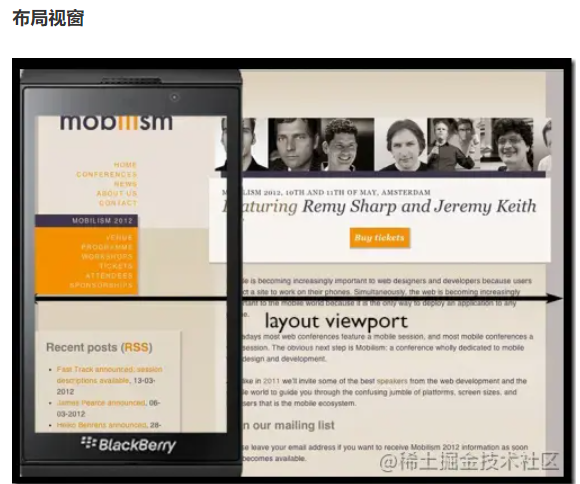
- 布局视窗:在浏览器窗口css的布局区域,布局视口的宽度限制css布局的宽。为了能在移动设备上正常显示那些为pc端浏览器设计的网站,移动设备上的浏览器都会把自己默认的 viewport 设为 980px 或其他值,一般都比移动端浏览器可视区域大很多,所以就会出现浏览器出现横向滚动条的情况
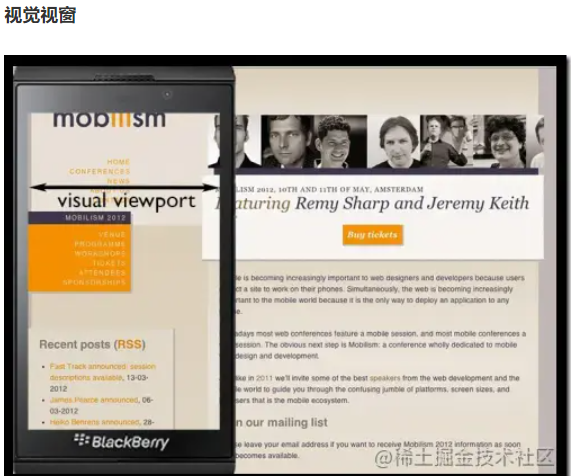
- 视觉视窗:终端设备显示网页的区域
- 理想视窗:针对当前设备最理想的展示页面的视窗,不会出现横向滚动条,页面刚好全部展现在视窗内,理想视窗也就是终端屏幕的宽度。
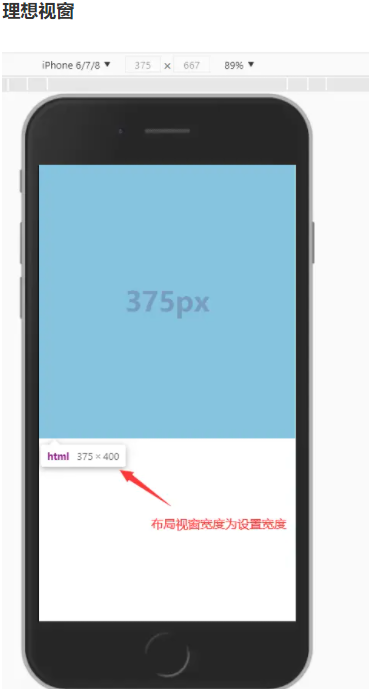
移动端视口配置怎么配的?

移动端适配有哪些方案知道吗?
1、rem布局
2、vw、vh布局
3、媒体查询响应式布局
说说媒体查询吧?
通过媒体查询,可以针对不同的屏幕进行单独设置,但是针对所有的屏幕尺寸做适配显然是不合理的,但是可以用来处理极端情况(例如 IPad 大屏设备)或做简单的适配(隐藏元素或改变元素位置)

说说rem适配吧
rem是CSS3新增的一个相对单位,这个单位引起了广泛关注。这个单位与em有什么区别呢?区别在于使用rem为元素设定字体大小时,仍然是相对大小,但相对的只是HTML根元素。这个单位可谓集相对大小和绝对大小的优点于一身,通过它既可以做到只修改根元素就成比例地调整所有字体大小,又可以避免字体大小逐层复合的连锁反应。目前,除了IE8及更早版本外,所有浏览器均已支持rem。对于不支持它的浏览器,应对方法也很简单,就是多写一个绝对单位的声明。这些浏览器会忽略用rem设定的字体大小
rem的具体适配方案知道吗?
flexible.js适配:阿里早期开源的一个移动端适配解决方案
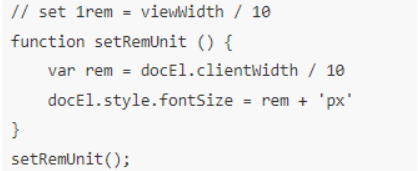
因为当年viewport在低版本安卓设备上还有兼容问题,而vw,vh还没能实现所有浏览器兼容,所以flexible方案用rem来模拟vmin来实现在不同设备等比缩放的“通用”方案,之所以说是通用方案,是因为他这个方案是根据设备大小去判断页面的展示空间大小即屏幕大小,然后根据屏幕大小去百分百还原设计稿,从而让人看到的效果(展示范围)是一样的,这样一来,苹果5 和苹果6p屏幕如果你按照设计稿还原的话,字体大小实际上不一样,而人们在一样的距离上希望看到的大小其实是一样的,本质上,用户使用更大的屏幕,是想看到更多的内容,而不是更大的字。
rem的弊端知道吗
弊端之一:和根元素font-size值强耦合,系统字体放大或缩小时,会导致布局错乱
弊端之二:html文件头部需插入一段js代码
说说vw/vh适配
vh、vw方案即将视觉视口宽度 window.innerWidth和视觉视口高度 window.innerHeight 等分为 100 份
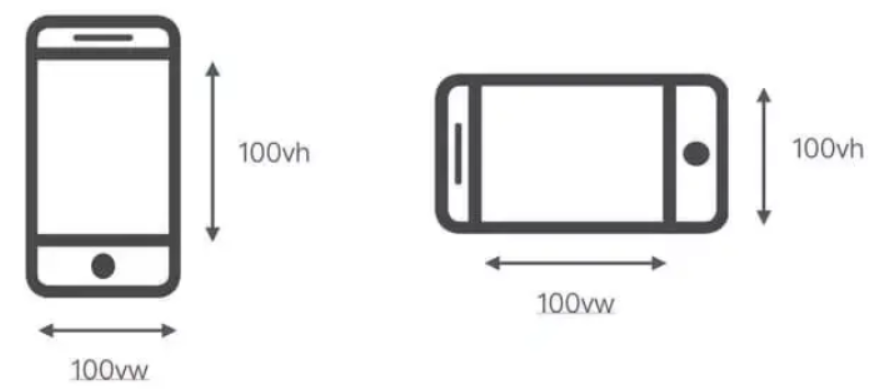
vw和vh有啥不足吗?
vw和vh的兼容性:
Android 4.4 之下和 iOS 8 以下的版本有一定的兼容性问题(但是目前这两版本已经很少有人使用了)
rem的兼容性:
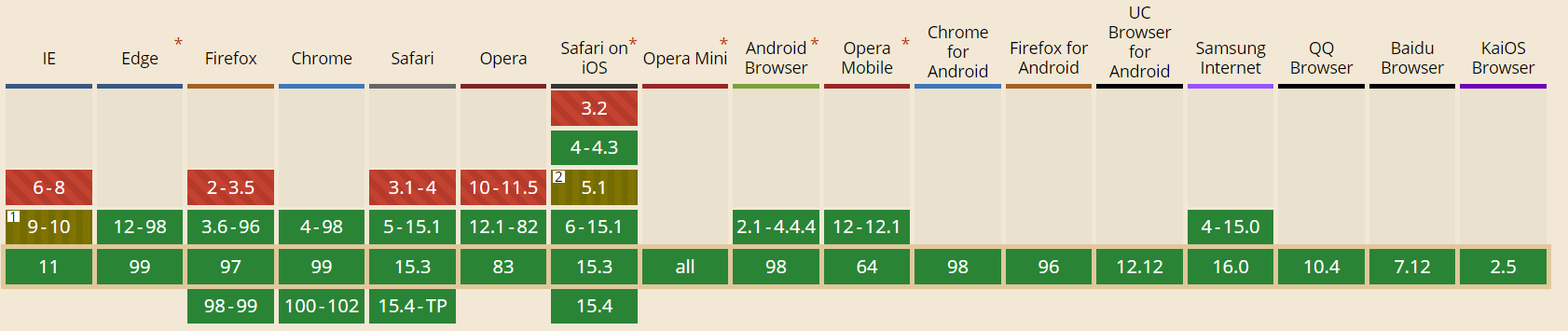
当下主流的写法可以说说吗?

组件库难点
我觉得组件库最难的就是开始的分析吧,
先是代码结构


创建好项目之后,就进行样式的方案分析,因为react和vue不同,vue的样式可以直接卸载style里面,而react可以选择写成一个对象传给组件,也可以成一个文件进行import,选择的scss,然后准备一部分的色彩体系,进行不同组件之间的复用,色彩呢又分为两大体系,一个是系统色板(分为基础色板+中性色板),一个是产品色板(分为品牌色版+功能色板),然后自己定义了想要的品牌色和系统色板,放在一个_variables的文件里,emm然后定义了字体的系统,在字体上用rem,这样也能在移动端上进行一部分的适配,然后 运用normalize.css,它能提供通用的样式在不同的浏览器上,也可以优化css的可用性(@extends)
- 保护有用的浏览器默认样式而不是完全去掉它们
- 一般化的样式:为大部分HTML元素提供
- 修复浏览器自身的bug并保证各浏览器的一致性
- 优化CSS可用性:用一些小技巧
- 解释代码:用注释和详细的文档来

CICD
好处:
功能分支提交后,通过 CICD 进行自动化测试、语法检查等,如未通过 CICD,则无法 CodeReview,更无法合并到生产环境分支进行上线
功能分支提交后,通过 CICD 检查 npm 库的风险、检查构建镜像容器的风险等
功能分支提交后,通过 CICD 对当前分支代码构建独立镜像并生成独立的分支环境地址进行测试,如对每一个功能分支生成一个可供测试的地址,一般是 <branch>.dev.shanyue.tech 此种地址
功能分支测试通过后,合并到主分支,自动构建镜像并部署到生成环境 (一般生成环境需要手动触发、自动部署)
CICD 集成于 CICD 工具及代码托管服务。CICD 有时也可理解为进行 CICD 的构建服务器,而提供 CICD 的服务,如以下产品,将会提供构建服务与 github/gitlab 集成在一起。
`Travis CI
创建.travis.yml文件
language: node_js
node_js:
_"stable"
cache:
directories:
- node_modules
env:
- CI=true注意如果有yarn.lock的话travis默认使用yarn.lock,travis应该使用package.json,所以删除yarn.lock
这时使用
git add.
git commit -m"test travis"
git push就会自动进行打包、测试、语法检测和合并新的分支

构建目标:拉取 github 代码
点击 新建 Item 创建一个
Freestyle Project构建目标:部署到本机
部署前端项目肯定是离不开
nginx的。yum install nginx。安装完成后同样可以使用
systemctl命令管理nginx服务。nginx具体配置这里就不说了。本示例项目中,静态文件托管目录为/usr/share/nginx/html/dist。接着来到
Jenkins这里。想要部署前端项目还需要依赖一个Node环境,需要在 Manage Jenkins -> Manage Plugins 在可选插件中搜索nodejs选择对应插件进行安装,安装完成后需要重启才会生效。构建目标:侦听 git 提交到指定分支进行构建
- 来到
Jenkins中选择 系统管理 -> 系统配置 找到Jenkins URL将其复制。 - 随后在尾部添加
github-webhook/尾部斜杠一定不要丢。 整体结构大致为http://192.168.0.1:8080/github-webhook/ - 登录
github需要集成的项目中添加webhook。在Payload URL中将上述内容填入。
Pipline 构建
上一章节中着重介绍了如何构建
freestyle的任务,但是Jenkins远不止于此。在本章开始之前强烈建议阅读文档,重点关注流水线相关内容。新建任务 -> 选择流水线 其他内容可以都不用管,只关注流水线 有两种选择,演示就选择第一种。
直接在
Jenkins中书写配置。在项目的
Jenkinsfile配置文件中写配置。在正式开始之前应该了解
Jenkins Pipline的基础概念。pipeline {
agent any // 在任何可用的代理上,执行流水线或它的任何阶段。
stages {
stage('Build') { // 定义 "Build" 阶段。
steps {
// 执行与 "Build" 阶段相关的步骤。
}
}
stage('Deploy') { // 定义 "Deploy" 阶段。
steps {
// 执行与 "Deploy" 阶段相关的步骤。
}
}
}
}pipline: 定义流水线整个结构,可以看做是根节点agent:指示Jenkins为整个流水线分配一个执行器,比如可以配置Dockerstages:对整个CI流的包裹,个人认为没多大用,还必须得有。stage: 可以理解为是对某一个环节的描述。注意:参数就是描述内容,可以是任何内容。不要想歪了只能传递BuildDeploy这些。steps: 描述了stage中的步骤,可以存在多个。
- 来到
Pipline 复刻 freestyle
单元测试
1.前端单元测试是什么
首先我们要明确测试是什么:
为检测特定的目标是否符合标准而采用专用的工具或者方法进行验证,并最终得出特定的结果。
对于前端开发过程来说,这里的特定目标就是指我们写的代码,而工具就是我们需要用到的测试框架(库)、测试用例等。检测处的结果就是展示测试是否通过或者给出测试报告,这样才能方便问题的排查和后期的修正。
基于测试“是什么”的说法,为便于刚从事前端开发的同行的进阶理解,那我们就列出单元测试它“不是什么”:
需要访问数据库的测试不是单元测试
需要访问网络的测试不是单元测试
需要访问文件系统的测试不是单元测试
--- 修改代码的艺术
对于单元测试“不是什么”的引用解释,至此点到为止。鉴于篇幅限制,对于引用内容,我想前端开发的同行们看到后会初步有一个属于自己的理解。
2.单元测试的意义以及为什么需要单元测试
- 1为什么需要单元测试
- 首先是一个前端单元测试的根本性原由:JavaScript 是动态语言,缺少类型检查,编译期间无法定位到错误; JavaScript 宿主的兼容性问题。比如 DOM 操作在不同浏览器上的表现。
- 正确性:测试可以验证代码的正确性,在上线前做到心里有底。
- 自动化:当然手工也可以测试,通过console可以打印出内部信息,但是这是一次性的事情,下次测试还需要从头来过,效率不能得到保证。通过编写测试用例,可以做到一次编写,多次运行。
- 解释性:测试用例用于测试接口、模块的重要性,那么在测试用例中就会涉及如何使用这些API。其他开发人员如果要使用这些API,那阅读测试用例是一种很好地途径,有时比文档说明更清晰。
- 驱动开发,指导设计:代码被测试的前提是代码本身的可测试性,那么要保证代码的可测试性,就需要在开发中注意API的设计,TDD将测试前移就是起到这么一个作用。
- 保证重构:互联网行业产品迭代速度很快,迭代后必然存在代码重构的过程,那怎么才能保证重构后代码的质量呢?有测试用例做后盾,就可以大胆的进行重构。
亮点 动态路由
方法一:不管什么角色登陆,在开发的时候,在前端都全部配置好路由的映射关系,只是在展示的时候,对应路由的跳转不展现出来。 引发的问题: 虽然页面没有展示,但是可以通过浏览器的地址栏进行 “套”,就会显示对应映射的组件,但组件上可能是没有什么东西的,虽然这样但也不好,会不安全。
方法二:在前端这里,为不同的角色设置好不同的映射关系(映射数组),请求数据用户的角色是什么,再把该角色的数组加入到 main 对应的 children 内。 引发问题: 若后端又有新的角色出现,那么前端这边也要跟着进行修改,重新进行部署。
方法三:在前端创建好所有路径对应的组件,但是根据后端返回的菜单数据,进行动态的生成路由。后端在返回对应的路径信息时,也要把该路径映射组件的路径一起返回。但是也要后端要增加一个字段,来放置组件的位置。
方法四:在前端创建好所有路径对应的组件,但是根据后端返回的菜单数据,进行动态的生成路由。后端在返回对应的路径信息时,在前端就设置好路径和组件之间的映射关系,在前端根据传过来的路径进行查找,查找到就找到了该路径和组件的映射关系。
大致步骤:
前端在本地写好路由表,以及每个路由对应的角色,也就是哪些角色可以看到这个菜单 / 路由。
登录的时候,向后端请求得到登录用户的角色(管理者,普通用户)
利用路由守卫者(router.beforeEach),根据取到的用户角色,跟本地的路由表进行对比,过滤出用户对应的路由,并利用路由进行菜单渲染
先执行异步请求,确保路由过滤和路径补全已完成。先把routes传入递归函数(filterASyncRoutes),用于做路径的补全和Layout的判断并赋值,并且当routes存在children(子级路由)的时候,路由需要再次回调递归函数(filterASyncRoutes),最后并把处理好的路由栈,返回给路由过滤函数
根据异步请求返回的routes,进行路由的排序,毕竟当用户动态处理了路由后,展示出来的顺序跟处理时的顺序不一致,那就不太好了。
路由都处理完成后,把路由循环,并动态添加进router.options.routes里面,而且路由router里面,要使用addRoute(item),把路由一点点添加进路由表里。
最后执行路由跳转,跳回当前需要跳转的页面
transition group
| 组件 | 说明 |
|---|---|
| Transition | 过渡组件 |
| CSSTransition | 动画进入出入组件 |
| SwitchTransition | 动画却换组件 |
| TransitionGroup | 列表动画组件 |
这些组件包裹一下需要的内容就行
<CSSTransition>
<button>
</CSSTransition>

起初先是这样想的,但是没有动画效果,状态太过于生硬,于是就找到了这个库

react-docgen
react-docgen 是一个 CLI 和工具箱,可帮助从 React 组件中提取信息并从中生成文档。它使用 ast 类型和@ babel / parser 将源解析为 AST,并提供处理此 AST 的方法以提取所需的信息。输出/返回值是一个 JSON blob / JavaScript 对象。简单来说就是:它能提取组件的相关信息
关于react-docgen提取的信息中,解释下下面几个参数
displayName组件名称description组件的类注释methods组件定义的方法props组件的属性参数
其中这里的props是我们组件文档的核心内容,在提取的内容中,已经涵盖了属性的 属性名、属性描述、类型、默认值、是否必传。这些内容满足我们阅读组件文档所需要的属性信息。
然后转换成markdown文件
上面的转换markdown的代码其实做的事情比较少,主要是以下几个步骤
- 遍历
props对象中的每个属性, - 解析属性
prop,提取属性名、类型、默认值、必填、描述、生成对应的markdown表格行。 - 生成markdown内容,通过
prettier美化markdown代码。
经过转换后最终生成我们这个markdown的文件
二维码登录
PC端向服务端发起请求,告诉服务端,我要生成用户登录的二维码,并且把PC端设备信息也传递给服务端
服务端收到请求后,它生成二维码ID,并将二维码ID与PC端设备信息进行绑定
然后把二维码ID返回给PC端
PC端收到二维码ID后,生成二维码(二维码中肯定包含了ID)
为了及时知道二维码的状态,客户端在展现二维码后,PC端不断的轮询服务端,比如每隔一秒就轮询一次,请求服务端告诉当前二维码的状态及相关信息
用户用手机去扫描PC端的二维码,通过二维码内容取到其中的二维码ID
再调用服务端API将移动端的身份信息与二维码ID一起发送给服务端
服务端接收到后,它可以将身份信息与二维码ID进行绑定,生成临时token。然后返回给手机端
因为PC端一直在轮询二维码状态,所以这时候二维码状态发生了改变,它就可以在界面上把二维码状态更新为已扫描
手机端在接收到临时token后会弹出确认登录界面,用户点击确认时,手机端携带临时token用来调用服务端的接口,告诉服务端,我已经确认
服务端收到确认后,根据二维码ID绑定的设备信息与账号信息,生成用户PC端登录的token
这时候PC端的轮询接口,它就可以得知二维码的状态已经变成了"已确认"。并且从服务端可以获取到用户登录的token
到这里,登录就成功了,后端PC端就可以用token去访问服务端的资源了
那么为什么需要返回给手机端一个临时token呢?
临时token与token一样,它也是一种身份凭证,不同的地方在于它只能用一次,用过就失效。在第三步骤中返回临时token,为的就是手机端在下一步操作时,可以用它作为凭证。以此确保扫码,登录两步操作是同一部手机端发出的,
大致的步骤
- 打开pc端显示登录二维码(
pc端未登录的前提下)
这个时候请求服务端生成一个登陆二维码 服务端生成二维码,该二维码包含了这个pc端的唯一标识,比如sessionId,或者是新生成一个uuid跟这个sessionId关联
- pc端同时开启轮询(
有长连接等其他实现,这里以轮询方式介绍)
获取二维码之后,pc端开启定时轮询,轮询二维码的状态,主要有如下状态:NEW,SCANED,CONFIRMED,REFUSED,EXPIRED
- 手机端扫描二维码
手机端已经登录的情况下,扫描网页二维码,二维码状态变为已扫描,然后手机端跳转到确认页面
- 手机端确认
手机端扫描二维码之后,点击确认,二维码状态变为确认
- pc端跳转成功/二维码过期/拒绝
二维码状态变为确认之后,跳转自动登录,完成PC端登录态建立 如果app端拒绝这次请求,则二维码状态变为被拒绝,不再轮询 如果二维码状态在一定时间没有变化,则显示二维码过期,不再轮询
在template中写入如下代码:
<div key="qrCode" style="text-align: center;">
<div id="qrcode" ref="qrcode" class="scan-code">
<div v-if="qrcodeCancel">
<div style="margin-top: 27px;"><span class="qrcode-restart"> 二维码已失效</span></div>
<div style="margin-top: 27px;"> <el-button class="btn confirm " style="width: 101px ;height:25px;" @click="handleClickRestart" >点击刷新</el-button><br></div>
</div>
</div>
</div>
在.vue script 脚本中:
下载模块:
// @ts-ignore
import QRCode from 'qrcodejs2'生成QRCode 二维码对象;
/**
* @description; 扫码登录,生成二维码
* */
public genereateQrCode () {
let qrcode = new QRCode('qrcode',{
width: 127, // 设置宽度,单位像素
height: 127, // 设置高度,单位像素
text: this.qrcodeLink // 设置二维码内容或跳转地址
})
}通过setInterval()轮询去检查二维码状态,来作出对应的交互;根据项目需要的场景;