网络
基本原理
1.OSI 七层模型
ISO为了更好的使网络应用更为普及,推出了OSI参考模型。 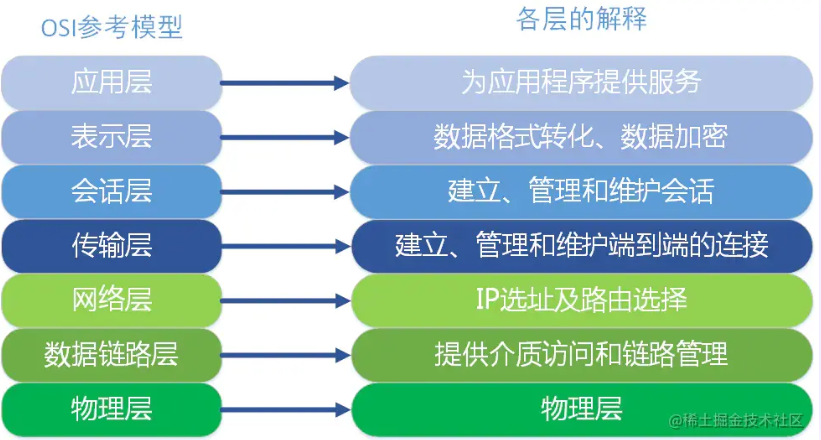
(1)应用层
OSI参考模型中最靠近用户的一层,是为计算机用户提供应用接口,也为用户直接提供各种网络服务。我们常见应用层的网络服务协议有:HTTP,HTTPS,FTP,POP3、SMTP等。
- 在客户端与服务器中经常会有数据的请求,这个时候就是会用到
http(hyper text transfer protocol)(超文本传输协议)或者https.在后端设计数据接口时,我们常常使用到这个协议。 FTP是文件传输协议,在开发过程中,个人并没有涉及到,但是我想,在一些资源网站,比如百度网盘``迅雷应该是基于此协议的。SMTP是simple mail transfer protocol(简单邮件传输协议)。在一个项目中,在用户邮箱验证码登录的功能时,使用到了这个协议。
(2)表示层
表示层提供各种用于应用层数据的编码和转换功能,确保一个系统的应用层发送的数据能被另一个系统的应用层识别。如果必要,该层可提供一种标准表示形式,用于将计算机内部的多种数据格式转换成通信中采用的标准表示形式。数据压缩和加密也是表示层可提供的转换功能之一。
在项目开发中,为了方便数据传输,可以使用base64对数据进行编解码。如果按功能来划分,base64应该是工作在表示层。
(3)会话层
会话层就是负责建立、管理和终止表示层实体之间的通信会话。该层的通信由不同设备中的应用程序之间的服务请求和响应组成。
(4)传输层
传输层建立了主机端到端的链接,传输层的作用是为上层协议提供端到端的可靠和透明的数据传输服务,包括处理差错控制和流量控制等问题。该层向高层屏蔽了下层数据通信的细节,使高层用户看到的只是在两个传输实体间的一条主机到主机的、可由用户控制和设定的、可靠的数据通路。我们通常说的,TCP UDP就是在这一层。端口号既是这里的“端”。
(5)网络层
本层通过IP寻址来建立两个节点之间的连接,为源端的运输层送来的分组,选择合适的路由和交换节点,正确无误地按照地址传送给目的端的运输层。就是通常说的IP层。这一层就是我们经常说的IP协议层。IP协议是Internet的基础。我们可以这样理解,网络层规定了数据包的传输路线,而传输层则规定了数据包的传输方式。
(6)数据链路层
将比特组合成字节,再将字节组合成帧,使用链路层地址 (以太网使用 MAC 地址)来访问介质,并进行差错检测。 网络层与数据链路层的对比,通过上面的描述,我们或许可以这样理解,网络层是规划了数据包的传输路线,而数据链路层就是传输路线。不过,在数据链路层上还增加了差错控制的功能。
(7)物理层
实际最终信号的传输是通过物理层实现的。通过物理介质传输比特流。规定了电平、速度和电缆针脚。常用设备有(各种物理设备)集线器、中继器、调制解调器、网线、双绞线、同轴电缆。这些都是物理层的传输介质。
OSI 七层模型通信特点:对等通信 对等通信,为了使数据分组从源传送到目的地,源端 OSI 模型的每一层都必须与目的端的对等层进行通信,这种通信方式称为对等层通信。在每一层通信过程中,使用本层自己协议进行通信。
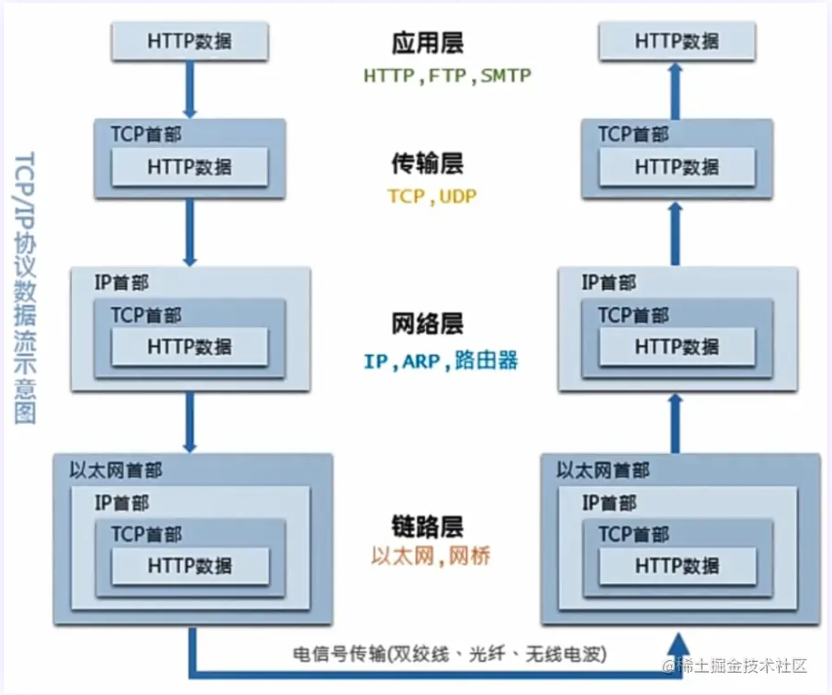
2.TCP/IP 五层协议
TCP/IP五层协议和OSI的七层协议对应关系如下:
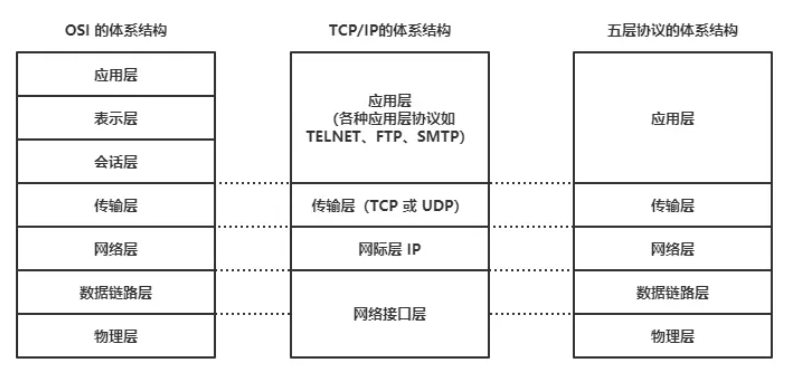
应用层 (application layer):直接为应用进程提供服务。应用层协议定义的是应用进程间通讯和交互的规则,不同的应用有着不同的应用层协议,如 HTTP 协议(万维网服务)、FTP 协议(文件传输)、SMTP 协议(电子邮件)、DNS(域名查询)等。
传输层 (transport layer)
:有时也译为运输层,它负责为两台主机中的进程提供通信服务。该层主要有以下两种协议:
- 传输控制协议 (Transmission Control Protocol,TCP):提供面向连接的、可靠的数据传输服务,数据传输的基本单位是报文段(segment);
- 用户数据报协议 (User Datagram Protocol,UDP):提供无连接的、尽最大努力的数据传输服务,但不保证数据传输的可靠性,数据传输的基本单位是用户数据报。
网络层 (internet layer):有时也译为网际层,它负责为两台主机提供通信服务,并通过选择合适的路由将数据传递到目标主机。
数据链路层 (data link layer):负责将网络层交下来的 IP 数据报封装成帧,并在链路的两个相邻节点间传送帧,每一帧都包含数据和必要的控制信息(如同步信息、地址信息、差错控制等)。
物理层 (physical Layer):确保数据可以在各种物理媒介上进行传输,为数据的传输提供可靠的环境。
从上图中可以看出,TCP/IP模型比OSI模型更加简洁,它把应用层/表示层/会话层全部整合为了应用层。
在每一层都工作着不同的设备,比如我们常用的交换机就工作在数据链路层的,一般的路由器是工作在网络层的。
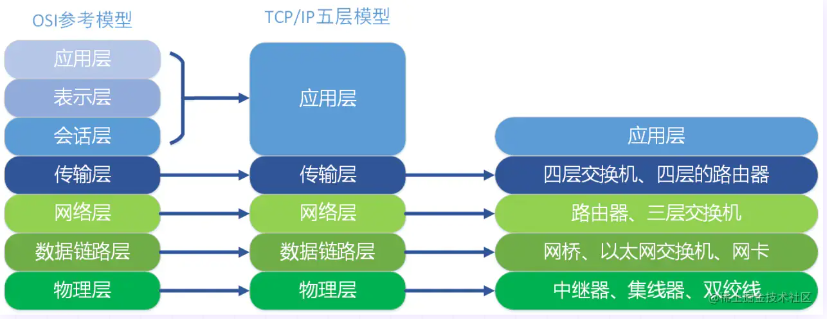
在每一层实现的协议也各不同,即每一层的服务也不同,下图列出了每层主要的传输协议:
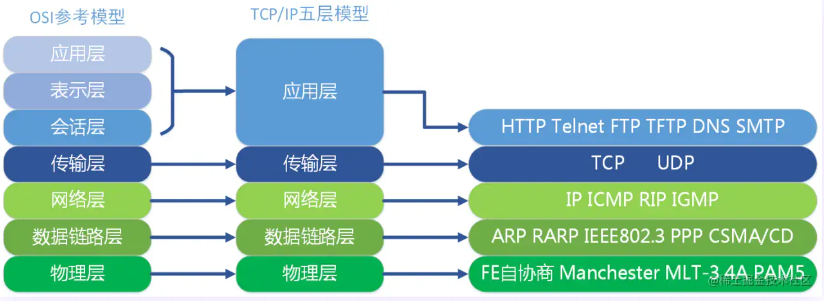
同样,TCP/IP五层协议的通信方式也是对等通信:
3.TCP/IP ⽹络模型
问大家,为什么要有 TCP/IP 网络模型?
对于同一台设备上的进程间通信,有很多种方式,比如有管道、消息队列、共享内存、信号等方式,而对于不同设备上的进程间通信,就需要网络通信,而设备是多样性的,所以要兼容多种多样的设备,就协商出了一套通用的网络协议。
这个网络协议是分层的,每一层都有各自的作用和职责,接下来就根据「 TCP/IP 网络模型」分别对每一层进行介绍。
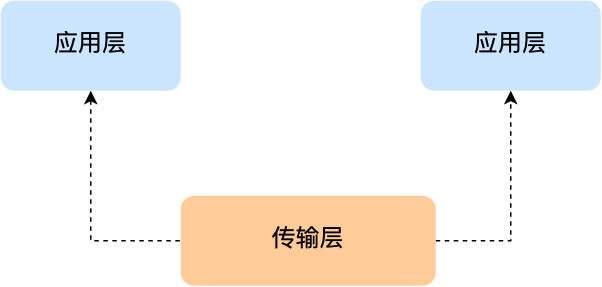
应用层
最上层的,也是我们能直接接触到的就是应用层(Application Layer),我们电脑或手机使用的应用软件都是在应用层实现。那么,当两个不同设备的应用需要通信的时候,应用就把应用数据传给下一层,也就是传输层。
所以,应用层只需要专注于为用户提供应用功能,比如 HTTP、FTP、Telnet、DNS、SMTP 等。
应用层是不用去关心数据是如何传输的,就类似于,我们寄快递的时候,只需要把包裹交给快递员,由他负责运输快递,我们不需要关心快递是如何被运输的。
而且应用层是工作在操作系统中的用户态,传输层及以下则工作在内核态。
传输层
应用层的数据包会传给传输层,传输层(Transport Layer)是为应用层提供网络支持的。
在传输层会有两个传输协议,分别是 TCP 和 UDP。
TCP 的全称叫传输控制协议(Transmission Control Protocol),大部分应用使用的正是 TCP 传输层协议,比如 HTTP 应用层协议。TCP 相比 UDP 多了很多特性,比如流量控制、超时重传、拥塞控制等,这些都是为了保证数据包能可靠地传输给对方。
UDP 相对来说就很简单,简单到只负责发送数据包,不保证数据包是否能抵达对方,但它实时性相对更好,传输效率也高。当然,UDP 也可以实现可靠传输,把 TCP 的特性在应用层上实现就可以,不过要实现一个商用的可靠 UDP 传输协议,也不是一件简单的事情。
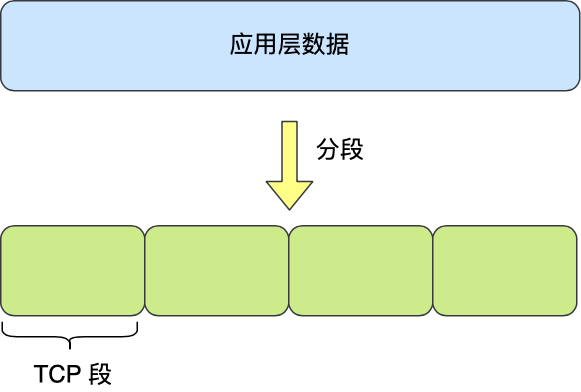
应用需要传输的数据可能会非常大,如果直接传输就不好控制,因此当传输层的数据包大小超过 MSS(TCP 最大报文段长度) ,就要将数据包分块,这样即使中途有一个分块丢失或损坏了,只需要重新发送这一个分块,而不用重新发送整个数据包。在 TCP 协议中,我们把每个分块称为一个 TCP 段(TCP Segment)。
当设备作为接收方时,传输层则要负责把数据包传给应用,但是一台设备上可能会有很多应用在接收或者传输数据,因此需要用一个编号将应用区分开来,这个编号就是端口。
比如 80 端口通常是 Web 服务器用的,22 端口通常是远程登录服务器用的。而对于浏览器(客户端)中的每个标签栏都是一个独立的进程,操作系统会为这些进程分配临时的端口号。
由于传输层的报文中会携带端口号,因此接收方可以识别出该报文是发送给哪个应用。
#网络层
传输层可能大家刚接触的时候,会认为它负责将数据从一个设备传输到另一个设备,事实上它并不负责。
实际场景中的网络环节是错综复杂的,中间有各种各样的线路和分叉路口,如果一个设备的数据要传输给另一个设备,就需要在各种各样的路径和节点进行选择,而传输层的设计理念是简单、高效、专注,如果传输层还负责这一块功能就有点违背设计原则了。
也就是说,我们不希望传输层协议处理太多的事情,只需要服务好应用即可,让其作为应用间数据传输的媒介,帮助实现应用到应用的通信,而实际的传输功能就交给下一层,也就是网络层(Internet Layer)。
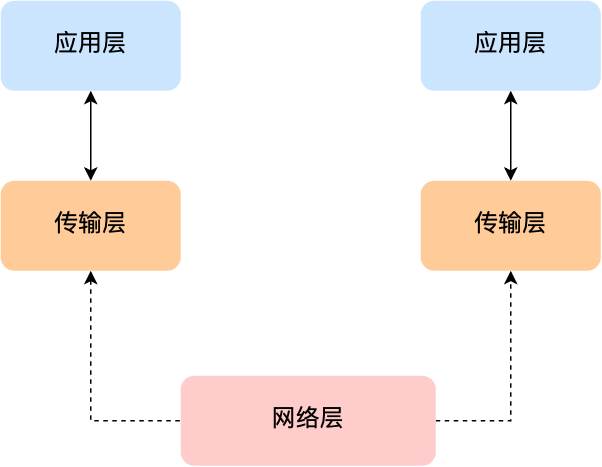
网络层最常使用的是 IP 协议(Internet Protocol),IP 协议会将传输层的报文作为数据部分,再加上 IP 包头组装成 IP 报文,如果 IP 报文大小超过 MTU(以太网中一般为 1500 字节)就会再次进行分片,得到一个即将发送到网络的 IP 报文。
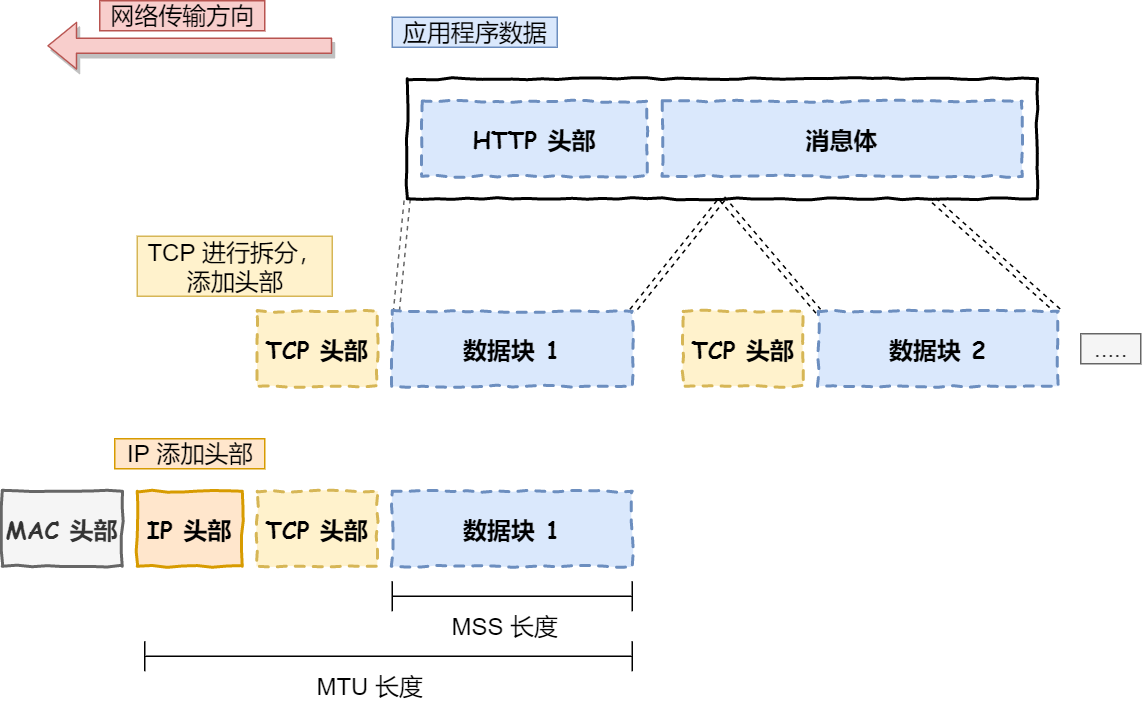
网络层负责将数据从一个设备传输到另一个设备,世界上那么多设备,又该如何找到对方呢?因此,网络层需要有区分设备的编号。
我们一般用 IP 地址给设备进行编号,对于 IPv4 协议, IP 地址共 32 位,分成了四段(比如,192.168.100.1),每段是 8 位。只有一个单纯的 IP 地址虽然做到了区分设备,但是寻址起来就特别麻烦,全世界那么多台设备,难道一个一个去匹配?这显然不科学。
因此,需要将 IP 地址分成两种意义:
- 一个是网络号,负责标识该 IP 地址是属于哪个「子网」的;
- 一个是主机号,负责标识同一「子网」下的不同主机;
怎么分的呢?这需要配合子网掩码才能算出 IP 地址 的网络号和主机号。
举个例子,比如 10.100.122.0/24,后面的/24表示就是 255.255.255.0 子网掩码,255.255.255.0 二进制是「11111111-11111111-11111111-00000000」,大家数数一共多少个 1?不用数了,是 24 个 1,为了简化子网掩码的表示,用/24 代替 255.255.255.0。
知道了子网掩码,该怎么计算出网络地址和主机地址呢?
将 10.100.122.2 和 255.255.255.0 进行按位与运算,就可以得到网络号,如下图:
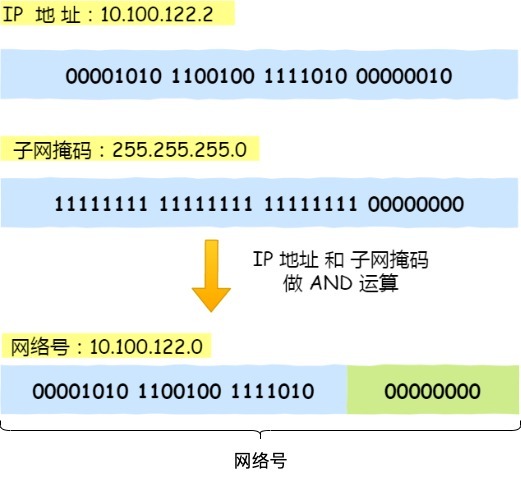
将 255.255.255.0 取反后与 IP 地址进行进行按位与运算,就可以得到主机号。
大家可以去搜索下子网掩码计算器,自己改变下「掩码位」的数值,就能体会到子网掩码的作用了。
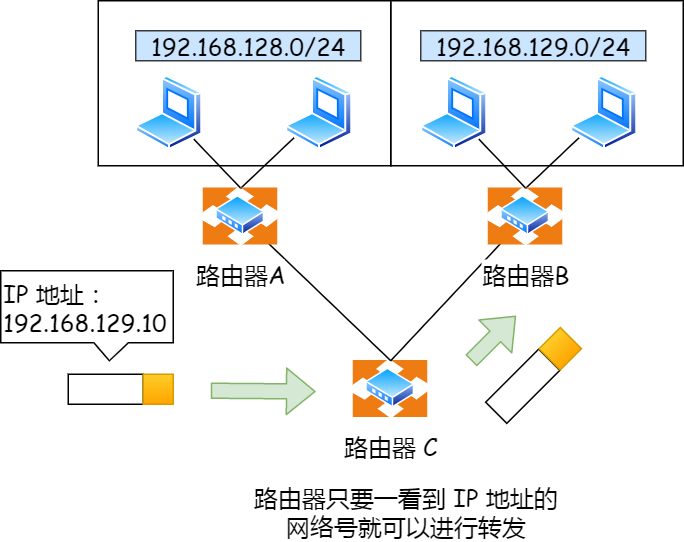
那么在寻址的过程中,先匹配到相同的网络号(表示要找到同一个子网),才会去找对应的主机。
除了寻址能力, IP 协议还有另一个重要的能力就是路由。实际场景中,两台设备并不是用一条网线连接起来的,而是通过很多网关、路由器、交换机等众多网络设备连接起来的,那么就会形成很多条网络的路径,因此当数据包到达一个网络节点,就需要通过路由算法决定下一步走哪条路径。
路由器寻址工作中,就是要找到目标地址的子网,找到后进而把数据包转发给对应的网络内。
所以,IP 协议的寻址作用是告诉我们去往下一个目的地该朝哪个方向走,路由则是根据「下一个目的地」选择路径。寻址更像在导航,路由更像在操作方向盘。
#网络接口层
生成了 IP 头部之后,接下来要交给网络接口层(Link Layer)在 IP 头部的前面加上 MAC 头部,并封装成数据帧(Data frame)发送到网络上。
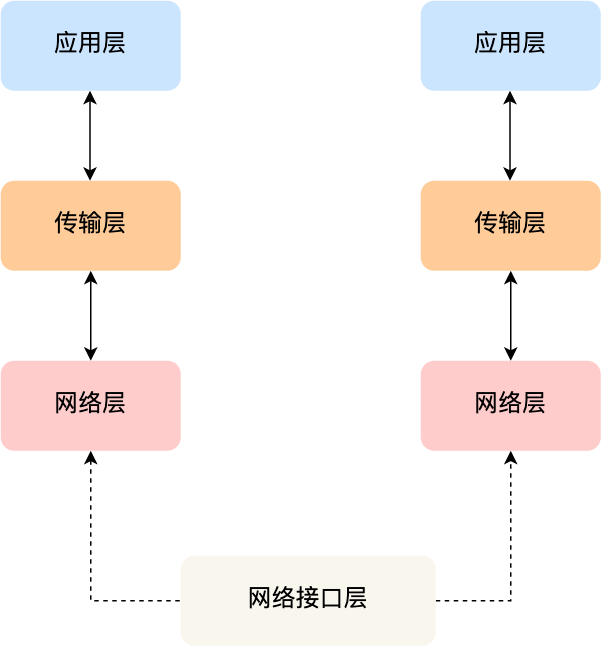
IP 头部中的接收方 IP 地址表示网络包的目的地,通过这个地址我们就可以判断要将包发到哪里,但在以太网的世界中,这个思路是行不通的。
什么是以太网呢?电脑上的以太网接口,Wi-Fi 接口,以太网交换机、路由器上的千兆,万兆以太网口,还有网线,它们都是以太网的组成部分。以太网就是一种在「局域网」内,把附近的设备连接起来,使它们之间可以进行通讯的技术。
以太网在判断网络包目的地时和 IP 的方式不同,因此必须采用相匹配的方式才能在以太网中将包发往目的地,而 MAC 头部就是干这个用的,所以,在以太网进行通讯要用到 MAC 地址。
MAC 头部是以太网使用的头部,它包含了接收方和发送方的 MAC 地址等信息,我们可以通过 ARP 协议获取对方的 MAC 地址。
所以说,网络接口层主要为网络层提供「链路级别」传输的服务,负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标识网络上的设备。
#总结
综上所述,TCP/IP 网络通常是由上到下分成 4 层,分别是应用层,传输层,网络层和网络接口层。
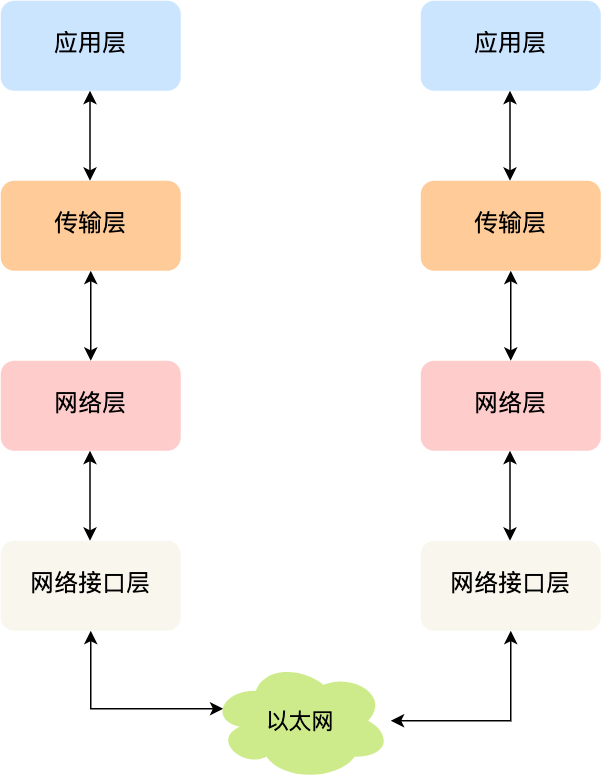
再给大家贴一下每一层的封装格式:
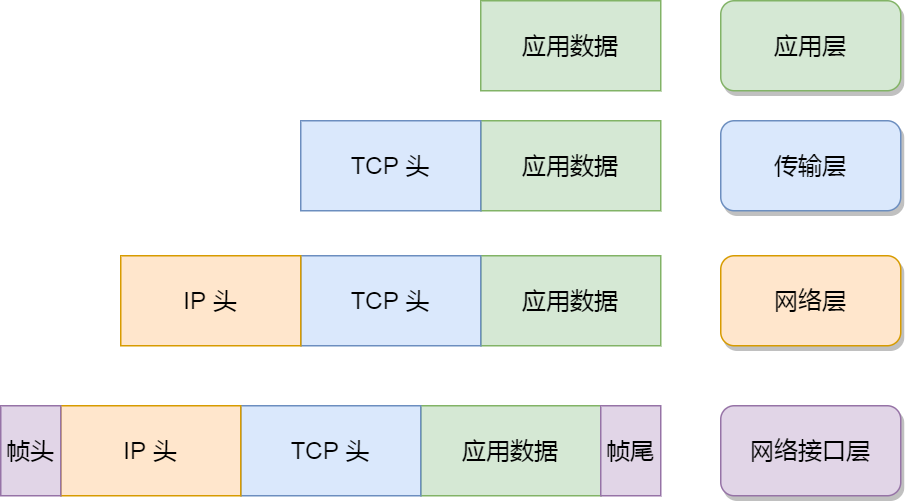
网络接口层的传输单位是帧(frame),IP 层的传输单位是包(packet),TCP 层的传输单位是段(segment),HTTP 的传输单位则是消息或报文(message)。但这些名词并没有什么本质的区分,可以统称为数据包。
Http 协议
1.Http 状态码
状态码的类别:
| 类别 | 原因 | 描述 |
|---|---|---|
| 1xx | Informational(信息性状态码) | 接受的请求正在处理 |
| 2xx | Success(成功状态码) | 请求正常处理完毕 |
| 3xx | Redirection(重定向状态码) | 需要进行附加操作一完成请求 |
| 4xx | Client Error (客户端错误状态码) | 服务器无法处理请求 |
| 5xx | Server Error(服务器错误状态码) | 服务器处理请求出错 |
1. 2XX (Success 成功状态码)
状态码 2XX 表示请求被正常处理了。
(1)200 OK
200 OK 表示客户端发来的请求被服务器端正常处理了。
(2)201 Created
该状态码表示已创建。成功请求并创建了新的资源,该请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经随 Location 头信息返回。
(3)202–Accepted
表示服务器端已接受请求,但尚未处理。正如它可能被拒绝一样,最终该请求可能会也可能不会被执行。适用于异步操作场合,允许服务器接受其他过程请求,而不用让客户端一直保持与服务器的连接知道批处理操作全部完成。
(4)204 No Content
该状态码表示客户端发送的请求已经在服务器端正常处理了,但是没有返回的内容,响应报文中不包含实体的主体部分。一般在只需要从客户端往服务器端发送信息,而服务器端不需要往客户端发送内容时使用。
(5)206 Partial Content
该状态码表示客户端进行了范围请求,而服务器端执行了这部分的 GET 请求。响应报文中包含由 Content-Range 指定范围的实体内容。
2. 3XX (Redirection 重定向状态码)
3XX 响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。
(1)301 Moved Permanently
永久重定向。 该状态码表示请求的资源已经被分配了新的 URI,以后应使用资源指定的 URI。新的 URI 会在 HTTP 响应头中的 Location 首部字段指定。若用户已经把原来的 URI 保存为书签,此时会按照 Location 中新的 URI 重新保存该书签。同时,搜索引擎在抓取新内容的同时也将旧的网址替换为重定向之后的网址。
使用场景:
- 当我们想换个域名,旧的域名不再使用时,用户访问旧域名时用 301 就重定向到新的域名。其实也是告诉搜索引擎收录的域名需要对新的域名进行收录。
- 在搜索引擎的搜索结果中出现了不带 www 的域名,而带 www 的域名却没有收录,这个时候可以用 301 重定向来告诉搜索引擎我们目标的域名是哪一个。
(2)302 Found
临时重定向。 该状态码表示请求的资源被分配到了新的 URI,希望用户(本次)能使用新的 URI 访问资源。和 301 Moved Permanently 状态码相似,但是 302 代表的资源不是被永久重定向,只是临时性质的。也就是说已移动的资源对应的 URI 将来还有可能发生改变。若用户把 URI 保存成书签,但不会像 301 状态码出现时那样去更新书签,而是仍旧保留返回 302 状态码的页面对应的 URI。同时,搜索引擎会抓取新的内容而保留旧的网址。因为服务器返回 302 代码,搜索引擎认为新的网址只是暂时的。
使用场景:
- 当我们在做活动时,登录到首页自动重定向,进入活动页面。
- 未登陆的用户访问用户中心重定向到登录页面。
- 访问 404 页面重新定向到首页。
(3)303 See Other
该状态码表示由于请求对应的资源存在着另一个 URI,应使用 GET 方法定向获取请求的资源。 303 状态码和 302 Found 状态码有着相似的功能,但是 303 状态码明确表示客户端应当采用 GET 方法获取资源。
303 状态码通常作为 PUT 或 POST 操作的返回结果,它表示重定向链接指向的不是新上传的资源,而是另外一个页面,比如消息确认页面或上传进度页面。而请求重定向页面的方法要总是使用 GET。
注意:
- 当 301、302、303 响应状态码返回时,几乎所有的浏览器都会把 POST 改成 GET,并删除请求报文内的主体,之后请求会再次自动发送。
- 301、302 标准是禁止将 POST 方法变成 GET 方法的,但实际大家都会这么做。
(4)304 Not Modified
浏览器缓存相关。 该状态码表示客户端发送附带条件的请求时,服务器端允许请求访问资源,但未满足条件的情况。304 状态码返回时,不包含任何响应的主体部分。304 虽然被划分在 3XX 类别中,但是和重定向没有关系。
带条件的请求(Http 条件请求):使用 Get 方法 请求,请求报文中包含(if-match、if-none-match、if-modified-since、if-unmodified-since、if-range)中任意首部。
状态码 304 并不是一种错误,而是告诉客户端有缓存,直接使用缓存中的数据。返回页面的只有头部信息,是没有内容部分的,这样在一定程度上提高了网页的性能。
(5)307 Temporary Redirect
307 表示临时重定向。 该状态码与 302 Found 有着相同含义,尽管 302 标准禁止 POST 变成 GET,但是实际使用时还是这样做了。
307 会遵守浏览器标准,不会从 POST 变成 GET。但是对于处理请求的行为时,不同浏览器还是会出现不同的情况。规范要求浏览器继续向 Location 的地址 POST 内容。规范要求浏览器继续向 Location 的地址 POST 内容。
3. 4XX (Client Error 客户端错误状态码)
4XX 的响应结果表明客户端是发生错误的原因所在。
(1)400 Bad Request
该状态码表示请求报文中存在语法错误。当错误发生时,需修改请求的内容后再次发送请求。另外,浏览器会像 200 OK 一样对待该状态码。
(2)401 Unauthorized
该状态码表示发送的请求需要有通过 HTTP 认证(BASIC 认证、DIGEST 认证)的认证信息。若之前已进行过一次请求,则表示用户认证失败
返回含有 401 的响应必须包含一个适用于被请求资源的 WWW-Authenticate 首部用以质询(challenge)用户信息。当浏览器初次接收到 401 响应,会弹出认证用的对话窗口。
以下情况会出现 401:
- 401.1 - 登录失败。
- 401.2 - 服务器配置导致登录失败。
- 401.3 - 由于 ACL 对资源的限制而未获得授权。
- 401.4 - 筛选器授权失败。
- 401.5 - ISAPI/CGI 应用程序授权失败。
- 401.7 - 访问被 Web 服务器上的 URL 授权策略拒绝。这个错误代码为 IIS 6.0 所专用。
(3)403 Forbidden
该状态码表明请求资源的访问被服务器拒绝了,服务器端没有必要给出详细理由,但是可以在响应报文实体的主体中进行说明。进入该状态后,不能再继续进行验证。该访问是永久禁止的,并且与应用逻辑密切相关。
IIS 定义了许多不同的 403 错误,它们指明更为具体的错误原因:
- 403.1 - 执行访问被禁止。
- 403.2 - 读访问被禁止。
- 403.3 - 写访问被禁止。
- 403.4 - 要求 SSL。
- 403.5 - 要求 SSL 128。
- 403.6 - IP 地址被拒绝。
- 403.7 - 要求客户端证书。
- 403.8 - 站点访问被拒绝。
- 403.9 - 用户数过多。
- 403.10 - 配置无效。
- 403.11 - 密码更改。
- 403.12 - 拒绝访问映射表。
- 403.13 - 客户端证书被吊销。
- 403.14 - 拒绝目录列表。
- 403.15 - 超出客户端访问许可。
- 403.16 - 客户端证书不受信任或无效。
- 403.17 - 客户端证书已过期或尚未生效
- 403.18 - 在当前的应用程序池中不能执行所请求的 URL。这个错误代码为 IIS 6.0 所专用。
- 403.19 - 不能为这个应用程序池中的客户端执行 CGI。这个错误代码为 IIS 6.0 所专用。
- 403.20 - Passport 登录失败。这个错误代码为 IIS 6.0 所专用。
(4)404 Not Found
该状态码表明服务器上无法找到请求的资源。除此之外,也可以在服务器端拒绝请求且不想说明理由时使用。 以下情况会出现 404:
- 404.0 -(无) – 没有找到文件或目录。
- 404.1 - 无法在所请求的端口上访问 Web 站点。
- 404.2 - Web 服务扩展锁定策略阻止本请求。
- 404.3 - MIME 映射策略阻止本请求。
(5)405 Method Not Allowed
该状态码表示客户端请求的方法虽然能被服务器识别,但是服务器禁止使用该方法。(或者对应接口使用的方法不对)GET 和 HEAD 方法,服务器应该总是允许客户端进行访问。客户端可以通过 OPTIONS 方法(预检)来查看服务器允许的访问方法, 如下
Access-Control-Allow-Methods: GET,HEAD,PUT,PATCH,POST,DELETE
4. 5XX (Server Error 服务器错误状态码)
5XX 的响应结果表明服务器本身发生错误.
(1)500 Internal Server Error
该状态码表明服务器端在执行请求时发生了错误。也有可能是 Web 应用存在的 bug 或某些临时的故障。
(2)502 Bad Gateway
该状态码表明扮演网关或代理角色的服务器,从上游服务器中接收到的响应是无效的。注意,502 错误通常不是客户端能够修复的,而是需要由途经的 Web 服务器或者代理服务器对其进行修复。以下情况会出现 502:
- 502.1 - CGI (通用网关接口)应用程序超时。
- 502.2 - CGI (通用网关接口)应用程序出错。
(3)503 Service Unavailable
该状态码表明服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。如果事先得知解除以上状况需要的时间,最好写入 RetryAfter 首部字段再返回给客户端。
使用场景:
- 服务器停机维护时,主动用 503 响应请求;
- nginx 设置限速,超过限速,会返回 503。
(4)504 Gateway Timeout
该状态码表示网关或者代理的服务器无法在规定的时间内获得想要的响应。他是 HTTP 1.1 中新加入的。
使用场景:代码执行时间超时,或者发生了死循环。
(5) 505
服务器不支持请求中所用的 HTTP 协议版本。(HTTP 版本不受支持)
5. 总结
(1)2XX 成功
- 200 OK,表示从客户端发来的请求在服务器端被正确处理
- 204 No content,表示请求成功,但响应报文不含实体的主体部分
- 205 Reset Content,表示请求成功,但响应报文不含实体的主体部分,但是与 204 响应不同在于要求请求方重置内容
- 206 Partial Content,进行范围请求
(2)3XX 重定向
- 301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
- 302 found,临时性重定向,表示资源临时被分配了新的 URL
- 303 see other,表示资源存在着另一个 URL,应使用 GET 方法获取资源
- 304 not modified,表示服务器允许访问资源,但因发生请求未满足条件的情况
- 307 temporary redirect,临时重定向,和 302 含义类似,但是期望客户端保持请求方法不变向新的地址发出请求
(3)4XX 客户端错误
- 400 bad request,请求报文存在语法错误
- 401 unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息
- 403 forbidden,表示对请求资源的访问被服务器拒绝
- 404 not found,表示在服务器上没有找到请求的资源
(4)5XX 服务器错误
- 500 internal sever error,表示服务器端在执行请求时发生了错误
- 501 Not Implemented,表示服务器不支持当前请求所需要的某个功能
- 502 Bad Gateway 网关错误
- 503 service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求
- 504 Gateway Timeout 网关或者代理的服务器超时
- 505 服务器不支持请求中所用的 HTTP 协议版本
6. 同样是重定向,307,303,302的区别?
302 是 http1.0 的协议状态码,在 http1.1 版本的时候为了细化 302 状态码⼜出来了两个 303 和 307。 303 明确表示客户端应当采⽤ get ⽅法获取资源,他会把 POST 请求变为 GET 请求进⾏重定向。 307 会遵照浏览器标准,不会从 post 变为 get。
2.http 发展历史,各个版本特点
HTTP 1.0 和 HTTP 1.1 有以下区别:
- 连接方面,http1.0 默认使用非持久连接,而 http1.1 默认使用持久连接。http1.1 通过使用持久连接来使多个 http 请求复用同一个 TCP 连接,以此来避免使用非持久连接时每次需要建立连接的时延。
- 资源请求方面,在 http1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,http1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- 缓存方面,在 http1.0 中主要使用 header 里的 If-Modified-Since、Expires 来做为缓存判断的标准,http1.1 则引入了更多的缓存控制策略,例如 Etag、If-Unmodified-Since、If-Match、If-None-Match 等更多可供选择的缓存头来控制缓存策略。
- http1.1 中新增了 host 字段,用来指定服务器的域名。http1.0 中认为每台服务器都绑定一个唯一的 IP 地址,因此,请求消息中的 URL 并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机,并且它们共享一个 IP 地址。因此有了 host 字段,这样就可以将请求发往到同一台服务器上的不同网站。
- http1.1 相对于 http1.0 还新增了很多请求方法,如 PUT、HEAD、OPTIONS 等。
HTTP 1.1 和 HTTP 2.0 的区别
二进制协议:HTTP/2 是一个二进制协议。在 HTTP/1.1 版中,报文的头信息必须是文本(ASCII 编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧",可以分为头信息帧和数据帧。 帧的概念是它实现多路复用的基础。
多路复用: HTTP/2 实现了多路复用,HTTP/2 仍然复用 TCP 连接,但是在一个连接里,客户端和服务器都可以同时发送多个请求或回应,而且不用按照顺序一一发送,这样就避免了"队头堵塞"【1】的问题。
数据流: HTTP/2 使用了数据流的概念,因为 HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的请求。因此,必须要对数据包做标记,指出它属于哪个请求。HTTP/2 将每个请求或回应的所有数据包,称为一个数据流。每个数据流都有一个独一无二的编号。数据包发送时,都必须标记数据流 ID ,用来区分它属于哪个数据流。
头信息压缩: HTTP/2 实现了头信息压缩,由于 HTTP 1.1 协议不带状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如 Cookie 和 User Agent ,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。HTTP/2 对这一点做了优化,引入了头信息压缩机制。一方面,头信息使用 gzip 或 compress 压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就能提高速度了。
服务器推送: HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送。使用服务器推送提前给客户端推送必要的资源,这样就可以相对减少一些延迟时间。这里需要注意的是 http2 下服务器主动推送的是静态资源,和 WebSocket 以及使用 SSE 等方式向客户端发送即时数据的推送是不同的。
队头阻塞是由 HTTP 基本的“请求 - 应答”模型所导致的。HTTP 规定报文必须是“一发一收”,这就形成了一个先进先出的“串行”队列。队列里的请求是没有优先级的,只有入队的先后顺序,排在最前面的请求会被最优先处理。如果队首的请求因为处理的太慢耽误了时间,那么队列里后面的所有请求也不得不跟着一起等待,结果就是其他的请求承担了不应有的时间成本,造成了队头堵塞的现象。
因为浏览器会有并发请求限制,在 HTTP / 1.1 时代,每个请求都需要建立和断开,消耗了好几个 RTT 时间,并且由于 TCP 慢启动的原因,加载体积大的文件会需要更多的时间
在 HTTP / 2.0 中引入了多路复用,能够让多个请求使用同一个 TCP 链接,极大的加快了网页的加载速度。并且还支持 Header 压缩,进一步的减少了请求的数据大小
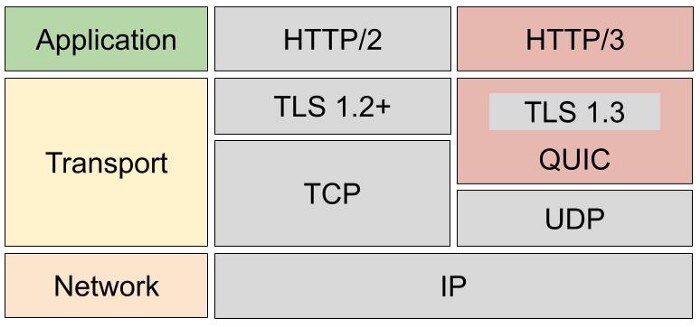
TTP/3 基于 UDP 协议实现了类似于 TCP 的多路复用数据流、传输可靠性等功能,这套功能被称为 QUIC 协议。 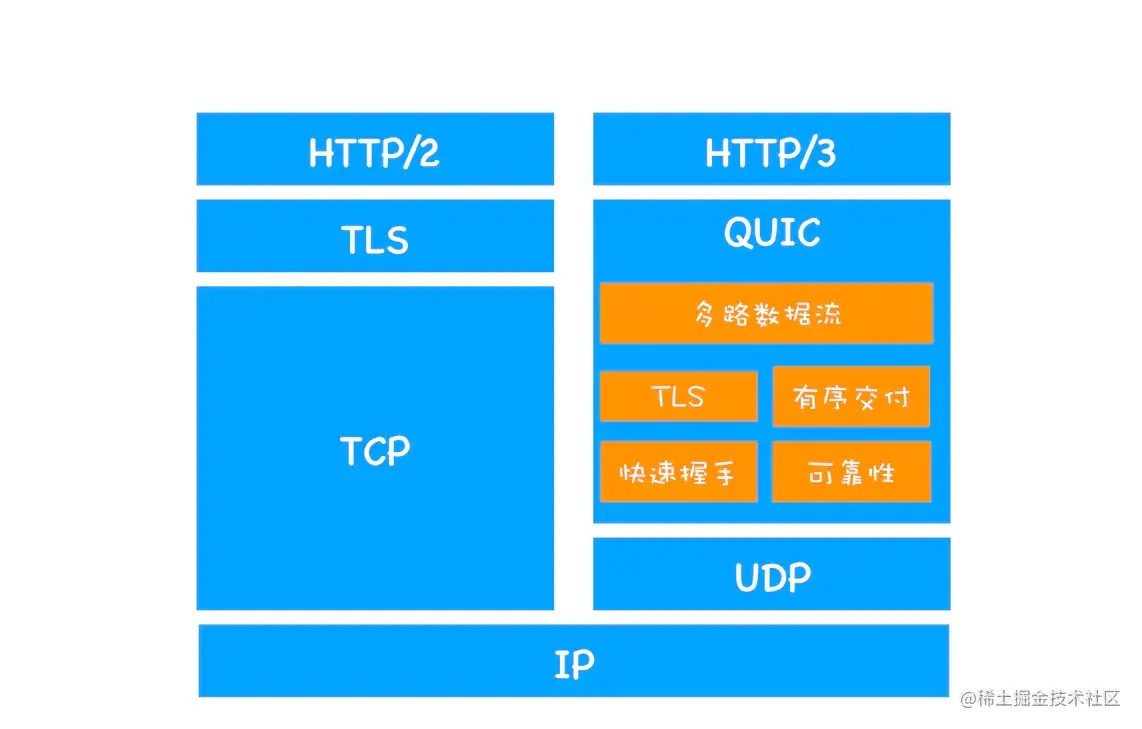
- 流量控制、传输可靠性功能:QUIC 在 UDP 的基础上增加了一层来保证数据传输可靠性,它提供了数据包重传、拥塞控制、以及其他一些 TCP 中的特性。
- 集成 TLS 加密功能:目前 QUIC 使用 TLS1.3,减少了握手所花费的 RTT 数。
- 多路复用:同一物理连接上可以有多个独立的逻辑数据流,实现了数据流的单独传输,解决了 TCP 的队头阻塞问题。
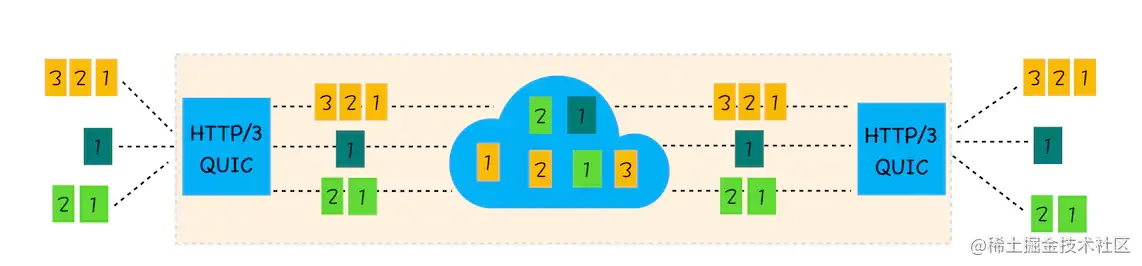
- 快速握手:由于基于 UDP,可以实现使用 0 ~ 1 个 RTT 来建立连接。
3.HTTP3 特点
HTTP/3 现在还没正式推出,不过自 2017 年起, HTTP/3 已经更新到 34 个草案了,基本的特性已经确定下来了,对于包格式可能后续会有变化。
所以,这次 HTTP/3 介绍不会涉及到包格式,只说它的特性。
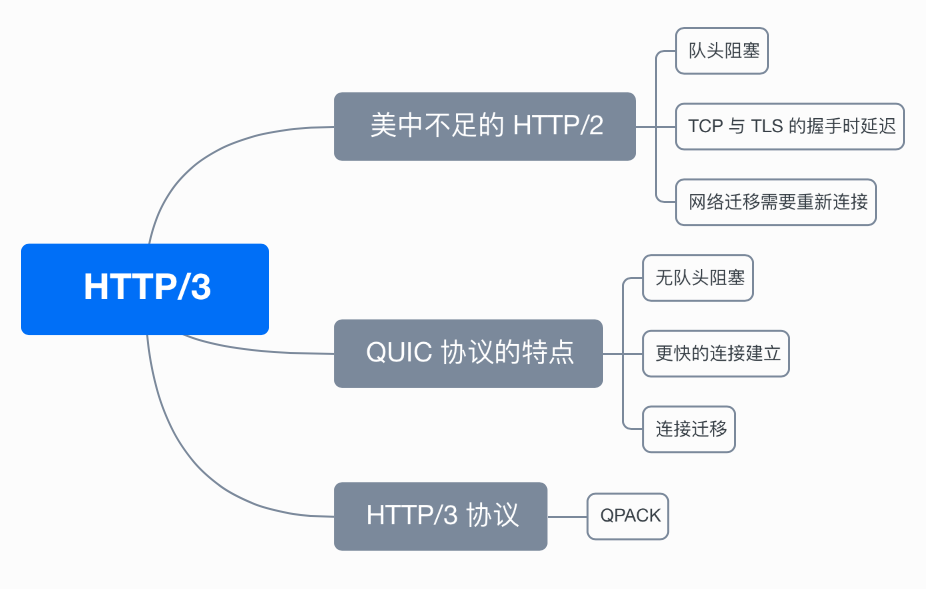
美中不足的 HTTP/2
HTTP/2 通过头部压缩、二进制编码、多路复用、服务器推送等新特性大幅度提升了 HTTP/1.1 的性能,而美中不足的是 HTTP/2 协议是基于 TCP 实现的,于是存在的缺陷有三个。
- 队头阻塞;
- TCP 与 TLS 的握手时延迟;
- 网络迁移需要重新连接;
队头阻塞
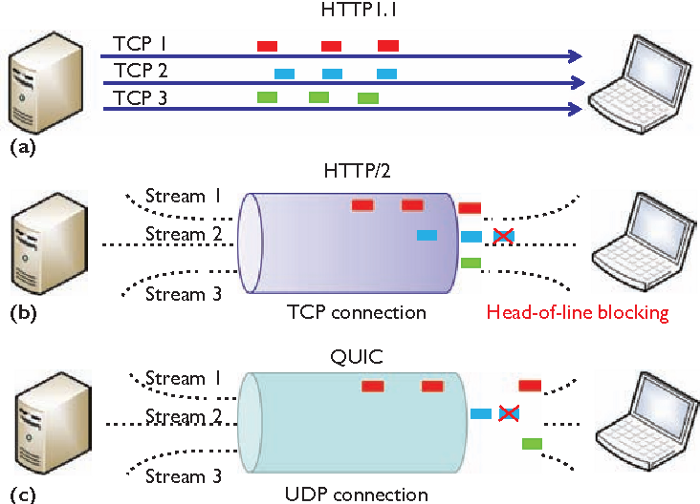
HTTP/2 多个请求是跑在一个 TCP 连接中的,那么当 TCP 丢包时,整个 TCP 都要等待重传,那么就会阻塞该 TCP 连接中的所有请求。
因为 TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且有序的,如果序列号较低的 TCP 段在网络传输中丢失了,即使序列号较高的 TCP 段已经被接收了,应用层也无法从内核中读取到这部分数据,从 HTTP 视角看,就是请求被阻塞了。
举个例子,如下图:
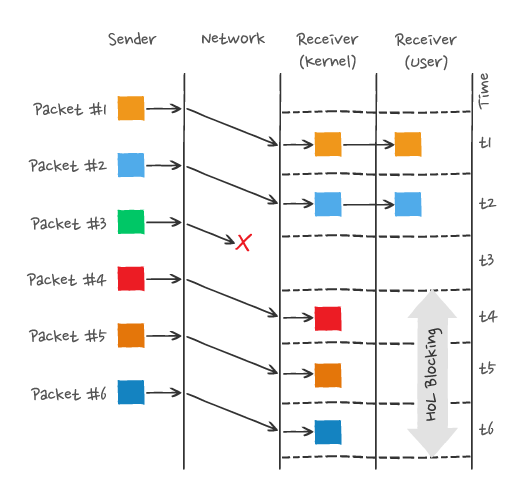
图中发送方发送了很多个 packet,每个 packet 都有自己的序号,你可以认为是 TCP 的序列号,其中 packet 3 在网络中丢失了,即使 packet 4-6 被接收方收到后,由于内核中的 TCP 数据不是连续的,于是接收方的应用层就无法从内核中读取到,只有等到 packet 3 重传后,接收方的应用层才可以从内核中读取到数据,这就是 HTTP/2 的队头阻塞问题,是在 TCP 层面发生的。
TCP 与 TLS 的握手时延迟
发起 HTTP 请求时,需要经过 TCP 三次握手和 TLS 四次握手(TLS 1.2)的过程,因此共需要 3 个 RTT 的时延才能发出请求数据。
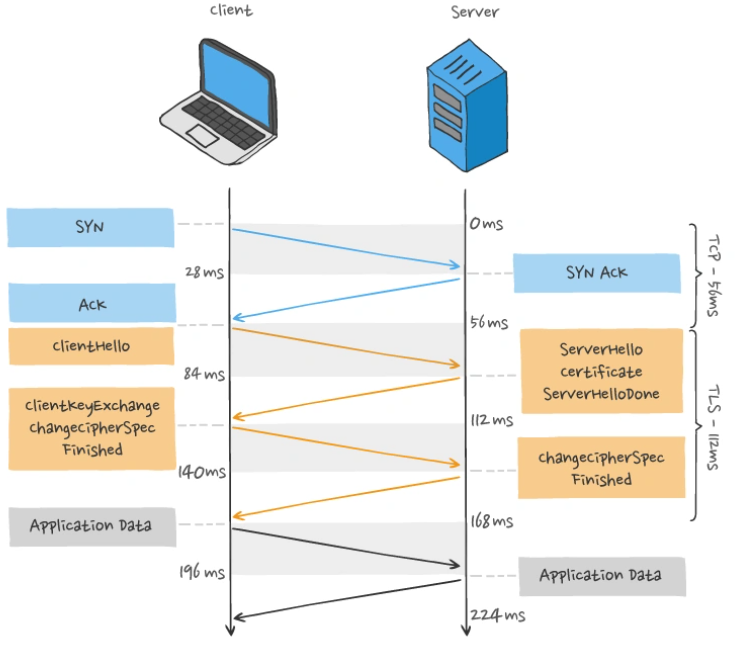
另外, TCP 由于具有「拥塞控制」的特性,所以刚建立连接的 TCP 会有个「慢启动」的过程,它会对 TCP 连接产生"减速"效果。
网络迁移需要重新连接
一个 TCP 连接是由四元组(源 IP 地址,源端口,目标 IP 地址,目标端口)确定的,这意味着如果 IP 地址或者端口变动了,就会导致需要 TCP 与 TLS 重新握手,这不利于移动设备切换网络的场景,比如 4G 网络环境切换成 WIFI。
这些问题都是 TCP 协议固有的问题,无论应用层的 HTTP/2 在怎么设计都无法逃脱。要解决这个问题,就必须把传输层协议替换成 UDP,这个大胆的决定,HTTP/3 做了!
QUIC 协议的特点
我们深知,UDP 是一个简单、不可靠的传输协议,而且是 UDP 包之间是无序的,也没有依赖关系。
而且,UDP 是不需要连接的,也就不需要握手和挥手的过程,所以天然的就比 TCP 快。
当然,HTTP/3 不仅仅只是简单将传输协议替换成了 UDP,还基于 UDP 协议在「应用层」实现了 QUIC 协议,它具有类似 TCP 的连接管理、拥塞窗口、流量控制的网络特性,相当于将不可靠传输的 UDP 协议变成“可靠”的了,所以不用担心数据包丢失的问题。
QUIC 协议的优点有很多,这里举例几个,比如:
- 无队头阻塞;
- 更快的连接建立;
- 连接迁移;
无队头阻塞
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
由于 QUIC 使用的传输协议是 UDP,UDP 不关心数据包的顺序,如果数据包丢失,UDP 也不关心。
不过 QUIC 协议会保证数据包的可靠性,每个数据包都有一个序号唯一标识。当某个流中的一个数据包丢失了,即使该流的其他数据包到达了,数据也无法被 HTTP/3 读取,直到 QUIC 重传丢失的报文,数据才会交给 HTTP/3。
而其他流的数据报文只要被完整接收,HTTP/3 就可以读取到数据。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。
更快的连接建立
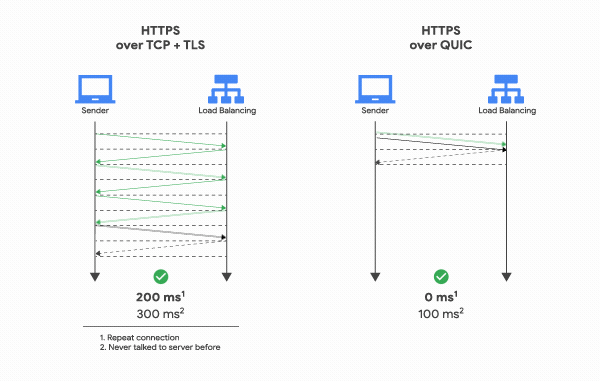
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、openssl 库实现的表示层,因此它们难以合并在一起,需要分批次来握手,先 TCP 握手,再 TLS 握手。
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与密钥协商,甚至在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
如下图右边部分,HTTP/3 当会话恢复时,有效负载数据与第一个数据包一起发送,可以做到 0-RTT:
#连接迁移
在前面我们提到,基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接,那么当移动设备的网络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接,而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
HTTP/3 协议
了解完 QUIC 协议的特点后,我们再来看看 HTTP/3 协议在 HTTP 这一层做了什么变化。
HTTP/3 同 HTTP/2 一样采用二进制帧的结构,不同的地方在于 HTTP/2 的二进制帧里需要定义 Stream,而 HTTP/3 自身不需要再定义 Stream,直接使用 QUIC 里的 Stream,于是 HTTP/3 的帧的结构也变简单了。
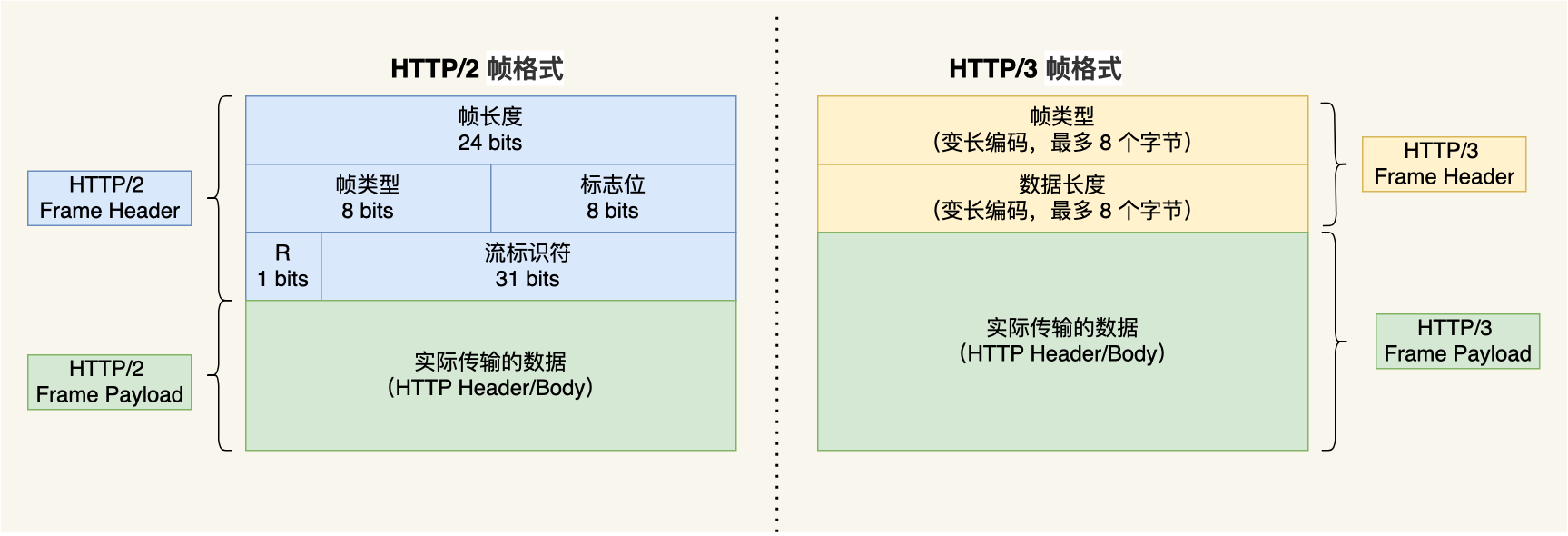
从上图可以看到,HTTP/3 帧头只有两个字段:类型和长度。
根据帧类型的不同,大体上分为数据帧和控制帧两大类,HEADERS 帧(HTTP 头部)和 DATA 帧(HTTP 包体)属于数据帧。
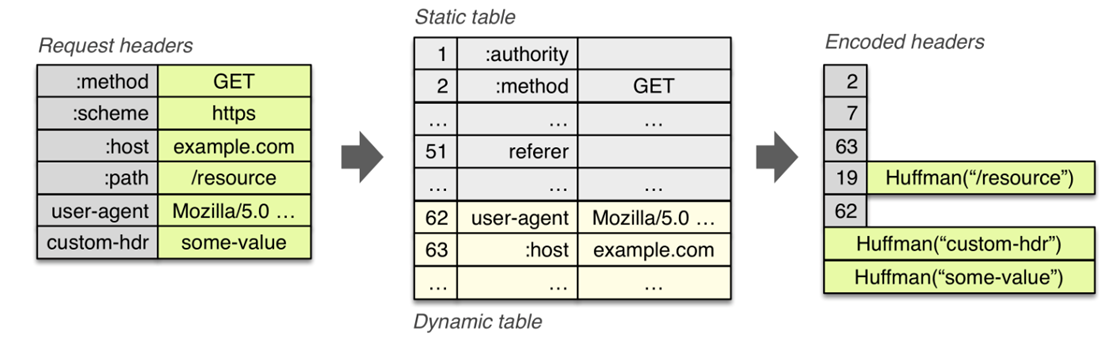
HTTP/3 在头部压缩算法这一方便也做了升级,升级成了 QPACK。与 HTTP/2 中的 HPACK 编码方式相似,HTTP/3 中的 QPACK 也采用了静态表、动态表及 Huffman 编码。
对于静态表的变化,HTTP/2 中的 HPACK 的静态表只有 61 项,而 HTTP/3 中的 QPACK 的静态表扩大到 91 项。
HTTP/2 和 HTTP/3 的 Huffman 编码并没有多大不同,但是动态表编解码方式不同。
所谓的动态表,在首次请求-响应后,双方会将未包含在静态表中的 Header 项更新各自的动态表,接着后续传输时仅用 1 个数字表示,然后对方可以根据这 1 个数字从动态表查到对应的数据,就不必每次都传输长长的数据,大大提升了编码效率。
可以看到,动态表是具有时序性的,如果首次出现的请求发生了丢包,后续的收到请求,对方就无法解码出 HPACK 头部,因为对方还没建立好动态表,因此后续的请求解码会阻塞到首次请求中丢失的数据包重传过来。
HTTP/3 的 QPACK 解决了这一问题,那它是如何解决的呢?
QUIC 会有两个特殊的单向流,所谓的单项流只有一端可以发送消息,双向则指两端都可以发送消息,传输 HTTP 消息时用的是双向流,这两个单向流的用法:
- 一个叫 QPACK Encoder Stream, 用于将一个字典(key-value)传递给对方,比如面对不属于静态表的 HTTP 请求头部,客户端可以通过这个 Stream 发送字典;
- 一个叫 QPACK Decoder Stream,用于响应对方,告诉它刚发的字典已经更新到自己的本地动态表了,后续就可以使用这个字典来编码了。
这两个特殊的单向流是用来同步双方的动态表,编码方收到解码方更新确认的通知后,才使用动态表编码 HTTP 头部。
4.http2.0 为什么更快
HTTP/1.1 协议的性能问题
我们得先要了解下 HTTP/1.1 协议存在的性能问题,因为 HTTP/2 协议就是把这些性能问题逐个攻破了。
现在的站点相比以前变化太多了,比如:
- 消息的大小变大了,从几 KB 大小的消息,到几 MB 大小的消息;
- 页面资源变多了,从每个页面不到 10 个的资源,到每页超 100 多个资源;
- 内容形式变多样了,从单纯到文本内容,到图片、视频、音频等内容;
- 实时性要求变高了,对页面的实时性要求的应用越来越多;
这些变化带来的最大性能问题就是 HTTP/1.1 的高延迟,延迟高必然影响的就是用户体验。主要原因如下几个:
- 延迟难以下降,虽然现在网络的「带宽」相比以前变多了,但是延迟降到一定幅度后,就很难再下降了,说白了就是到达了延迟的下限;
- 并发连接有限,谷歌浏览器最大并发连接数是 6 个,而且每一个连接都要经过 TCP 和 TLS 握手耗时,以及 TCP 慢启动过程给流量带来的影响;
- 队头阻塞问题,同一连接只能在完成一个 HTTP 事务(请求和响应)后,才能处理下一个事务;
- HTTP 头部巨大且重复,由于 HTTP 协议是无状态的,每一个请求都得携带 HTTP 头部,特别是对于有携带 cookie 的头部,而 cookie 的大小通常很大;
- 不支持服务器推送消息,因此当客户端需要获取通知时,只能通过定时器不断地拉取消息,这无疑浪费大量了带宽和服务器资源。
为了解决 HTTP/1.1 性能问题,具体的优化手段你可以看这篇文章「HTTP/1.1 如何优化? (opens new window)」,这里我举例几个常见的优化手段:
- 将多张小图合并成一张大图供浏览器 JavaScript 来切割使用,这样可以将多个请求合并成一个请求,但是带来了新的问题,当某张小图片更新了,那么需要重新请求大图片,浪费了大量的网络带宽;
- 将图片的二进制数据通过 base64 编码后,把编码数据嵌入到 HTML 或 CSS 文件中,以此来减少网络请求次数;
- 将多个体积较小的 JavaScript 文件使用 webpack 等工具打包成一个体积更大的 JavaScript 文件,以一个请求替代了很多个请求,但是带来的问题,当某个 js 文件变化了,需要重新请求同一个包里的所有 js 文件;
- 将同一个页面的资源分散到不同域名,提升并发连接上限,因为浏览器通常对同一域名的 HTTP 连接最大只能是 6 个;
尽管对 HTTP/1.1 协议的优化手段如此之多,但是效果还是不尽人意,因为这些手段都是对 HTTP/1.1 协议的“外部”做优化,而一些关键的地方是没办法优化的,比如请求-响应模型、头部巨大且重复、并发连接耗时、服务器不能主动推送等,要改变这些必须重新设计 HTTP 协议,于是 HTTP/2 就出来了!
兼容 HTTP/1.1
HTTP/2 出来的目的是为了改善 HTTP 的性能。协议升级有一个很重要的地方,就是要兼容老版本的协议,否则新协议推广起来就相当困难,所幸 HTTP/2 做到了兼容 HTTP/1.1 。
那么,HTTP/2 是怎么做的呢?
第一点,HTTP/2 没有在 URI 里引入新的协议名,仍然用「http://」表示明文协议,用「https://」表示加密协议,于是只需要浏览器和服务器在背后自动升级协议,这样可以让用户意识不到协议的升级,很好的实现了协议的平滑升级。
第二点,只在应用层做了改变,还是基于 TCP 协议传输,应用层方面为了保持功能上的兼容,HTTP/2 把 HTTP 分解成了「语义」和「语法」两个部分,「语义」层不做改动,与 HTTP/1.1 完全一致,比如请求方法、状态码、头字段等规则保留不变。
但是,HTTP/2 在「语法」层面做了很多改造,基本改变了 HTTP 报文的传输格式。
头部压缩
HTTP 协议的报文是由「Header + Body」构成的,对于 Body 部分,HTTP/1.1 协议可以使用头字段 「Content-Encoding」指定 Body 的压缩方式,比如用 gzip 压缩,这样可以节约带宽,但报文中的另外一部分 Header,是没有针对它的优化手段。
HTTP/1.1 报文中 Header 部分存在的问题:
- 含很多固定的字段,比如 Cookie、User Agent、Accept 等,这些字段加起来也高达几百字节甚至上千字节,所以有必要压缩;
- 大量的请求和响应的报文里有很多字段值都是重复的,这样会使得大量带宽被这些冗余的数据占用了,所以有必须要避免重复性;
- 字段是 ASCII 编码的,虽然易于人类观察,但效率低,所以有必要改成二进制编码;
HTTP/2 对 Header 部分做了大改造,把以上的问题都解决了。
HTTP/2 没使用常见的 gzip 压缩方式来压缩头部,而是开发了 HPACK 算法,HPACK 算法主要包含三个组成部分:
- 静态字典;
- 动态字典;
- Huffman 编码(压缩算法);
客户端和服务器两端都会建立和维护「字典」,用长度较小的索引号表示重复的字符串,再用 Huffman 编码压缩数据,可达到 50%~90% 的高压缩率。
静态表编码
HTTP/2 为高频出现在头部的字符串和字段建立了一张静态表,它是写入到 HTTP/2 框架里的,不会变化的,静态表里共有 61 组,如下图:
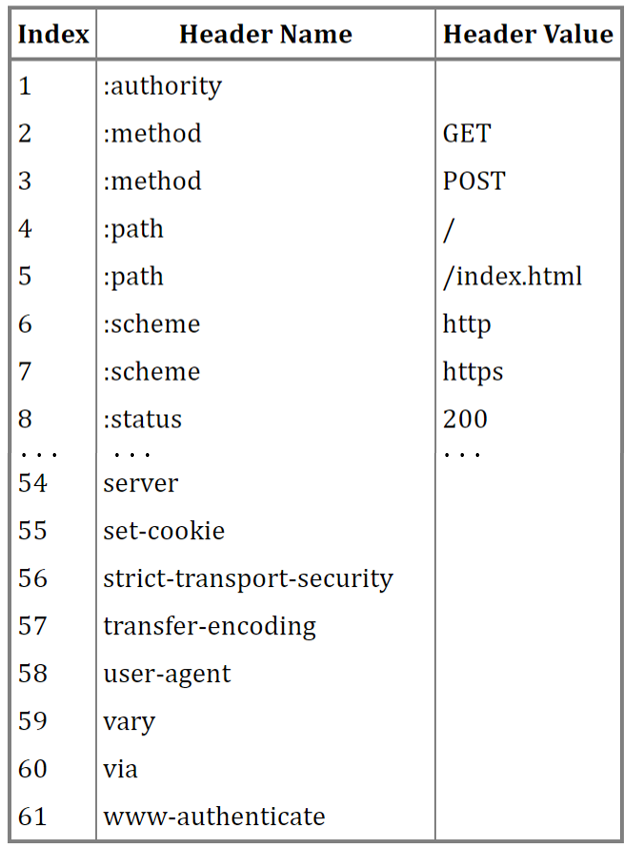
表中的 Index 表示索引(Key),Header Value 表示索引对应的 Value,Header Name 表示字段的名字,比如 Index 为 2 代表 GET,Index 为 8 代表状态码 200。
你可能注意到,表中有的 Index 没有对应的 Header Value,这是因为这些 Value 并不是固定的而是变化的,这些 Value 都会经过 Huffman 编码后,才会发送出去。
这么说有点抽象,我们来看个具体的例子,下面这个 server 头部字段,在 HTTP/1.1 的形式如下:
server: nghttpx\r\n
算上冒号空格和末尾的\r\n,共占用了 17 字节,而使用了静态表和 Huffman 编码,可以将它压缩成 8 字节,压缩率大概 47 %。
我抓了个 HTTP/2 协议的网络包,你可以从下图看到,高亮部分就是 server 头部字段,只用了 8 个字节来表示 server 头部数据。
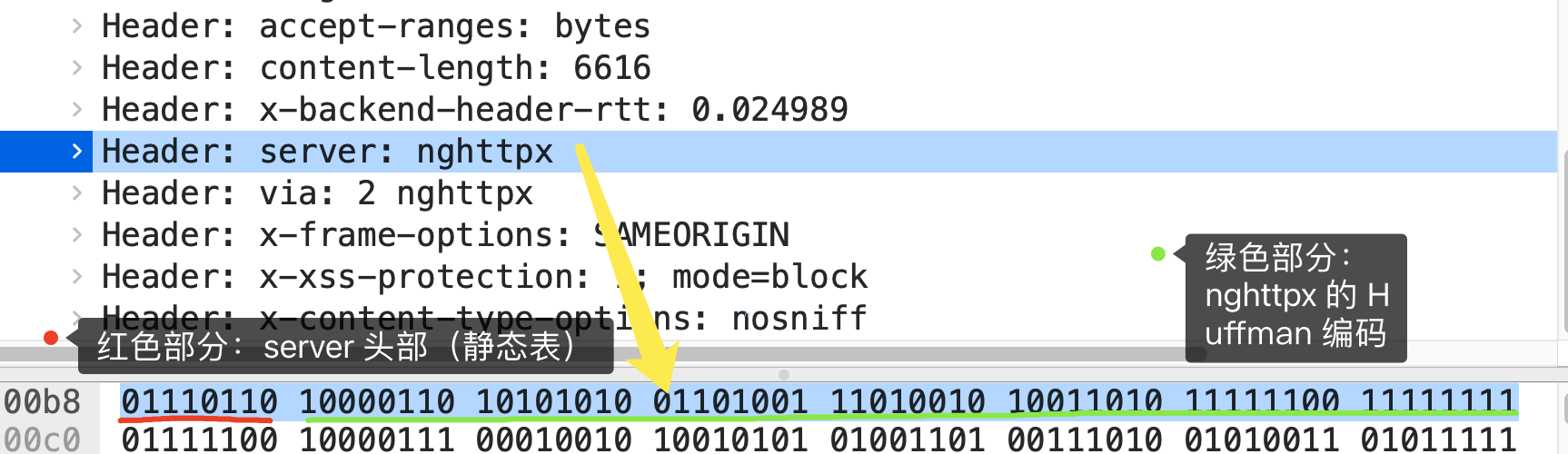
根据 RFC7541 规范,如果头部字段属于静态表范围,并且 Value 是变化,那么它的 HTTP/2 头部前 2 位固定为 01,所以整个头部格式如下图:

HTTP/2 头部由于基于二进制编码,就不需要冒号空格和末尾的\r\n 作为分隔符,于是改用表示字符串长度(Value Length)来分割 Index 和 Value。
接下来,根据这个头部格式来分析上面抓包的 server 头部的二进制数据。
首先,从静态表中能查到 server 头部字段的 Index 为 54,二进制为 110110,再加上固定 01,头部格式第 1 个字节就是 01110110,这正是上面抓包标注的红色部分的二进制数据。
然后,第二个字节的首个比特位表示 Value 是否经过 Huffman 编码,剩余的 7 位表示 Value 的长度,比如这次例子的第二个字节为 10000110,首位比特位为 1 就代表 Value 字符串是经过 Huffman 编码的,经过 Huffman 编码的 Value 长度为 6。
最后,字符串 nghttpx 经过 Huffman 编码后压缩成了 6 个字节,Huffman 编码的原理是将高频出现的信息用「较短」的编码表示,从而缩减字符串长度。
于是,在统计大量的 HTTP 头部后,HTTP/2 根据出现频率将 ASCII 码编码为了 Huffman 编码表,可以在 RFC7541 文档找到这张静态 Huffman 表,我就不把表的全部内容列出来了,我只列出字符串 nghttpx 中每个字符对应的 Huffman 编码,如下图:
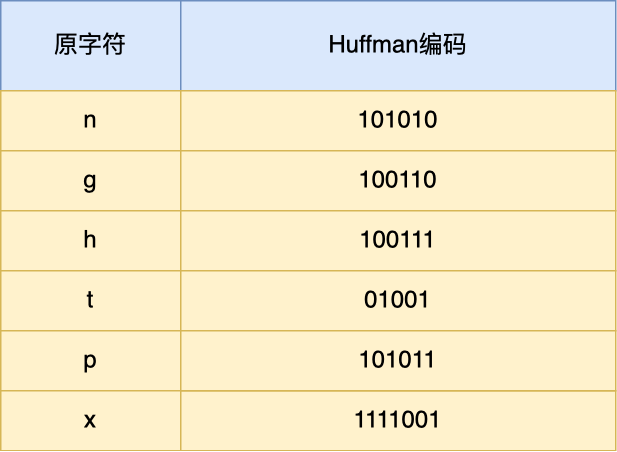
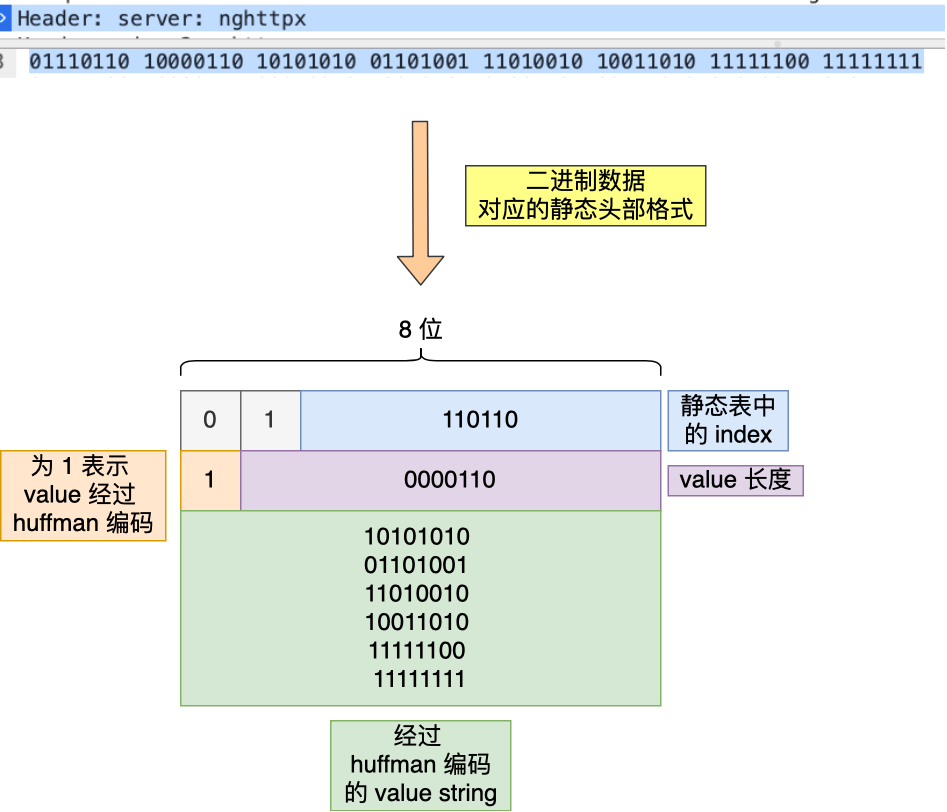
通过查表后,字符串 nghttpx 的 Huffman 编码在下图看到,共 6 个字节,每一个字符的 Huffman 编码,我用相同的颜色将他们对应起来了,最后的 7 位是补位的。

最终,server 头部的二进制数据对应的静态头部格式如下:
动态表编码
静态表只包含了 61 种高频出现在头部的字符串,不在静态表范围内的头部字符串就要自行构建动态表,它的 Index 从 62 起步,会在编码解码的时候随时更新。
比如,第一次发送时头部中的「user-agent 」字段数据有上百个字节,经过 Huffman 编码发送出去后,客户端和服务器双方都会更新自己的动态表,添加一个新的 Index 号 62。那么在下一次发送的时候,就不用重复发这个字段的数据了,只用发 1 个字节的 Index 号就好了,因为双方都可以根据自己的动态表获取到字段的数据。
所以,使得动态表生效有一个前提:必须同一个连接上,重复传输完全相同的 HTTP 头部。如果消息字段在 1 个连接上只发送了 1 次,或者重复传输时,字段总是略有变化,动态表就无法被充分利用了。
因此,随着在同一 HTTP/2 连接上发送的报文越来越多,客户端和服务器双方的「字典」积累的越来越多,理论上最终每个头部字段都会变成 1 个字节的 Index,这样便避免了大量的冗余数据的传输,大大节约了带宽。
理想很美好,现实很骨感。动态表越大,占用的内存也就越大,如果占用了太多内存,是会影响服务器性能的,因此 Web 服务器都会提供类似 http2_max_requests 的配置,用于限制一个连接上能够传输的请求数量,避免动态表无限增大,请求数量到达上限后,就会关闭 HTTP/2 连接来释放内存。
综上,HTTP/2 头部的编码通过「静态表、动态表、Huffman 编码」共同完成的。
二进制帧
HTTP/2 厉害的地方在于将 HTTP/1 的文本格式改成二进制格式传输数据,极大提高了 HTTP 传输效率,而且二进制数据使用位运算能高效解析。
你可以从下图看到,HTTP/1.1 的响应 和 HTTP/2 的区别:
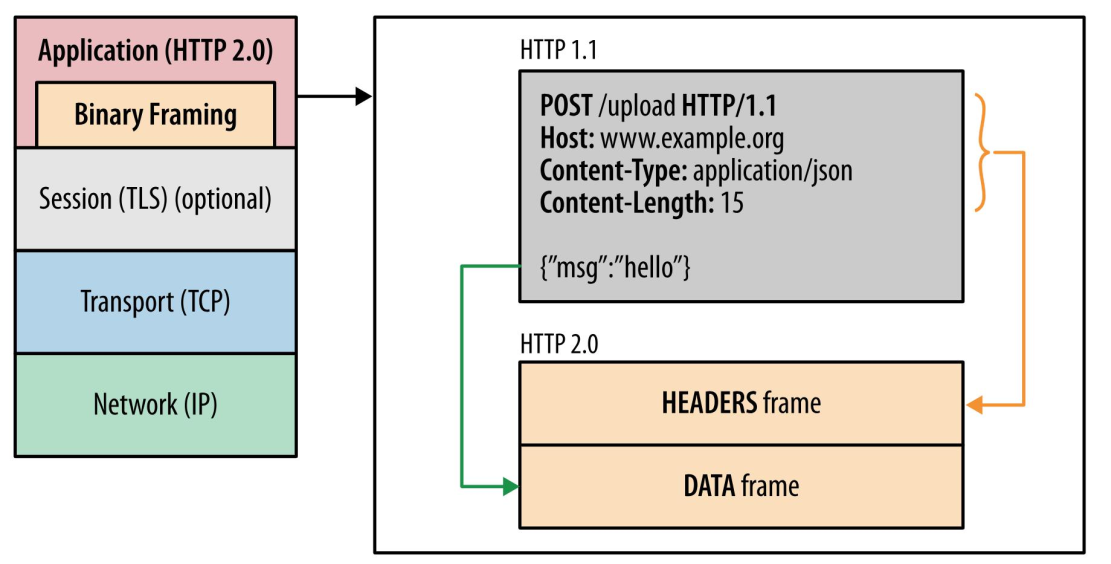
HTTP/2 把响应报文划分成了两类帧(*Frame*),图中的 HEADERS(首部)和 DATA(消息负载) 是帧的类型,也就是说一条 HTTP 响应,划分成了两类帧来传输,并且采用二进制来编码。
HTTP/2 二进制帧的结构如下图:

帧头(Frame Header)很小,只有 9 个字节,帧开头的前 3 个字节表示帧数据(Frame Playload)的长度。
帧长度后面的一个字节是表示帧的类型,HTTP/2 总共定义了 10 种类型的帧,一般分为数据帧和控制帧两类,如下表格:
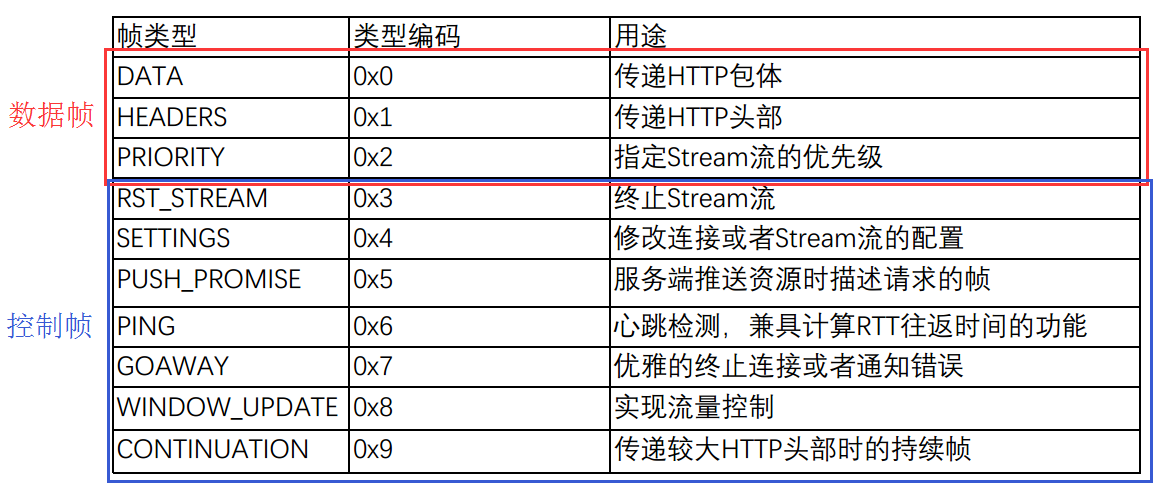
帧类型后面的一个字节是标志位,可以保存 8 个标志位,用于携带简单的控制信息,比如:
- END_HEADERS 表示头数据结束标志,相当于 HTTP/1 里头后的空行(“\r\n”);
- END_STREAM 表示单方向数据发送结束,后续不会再有数据帧。
- PRIORITY 表示流的优先级;
帧头的最后 4 个字节是流标识符(Stream ID),但最高位被保留不用,只有 31 位可以使用,因此流标识符的最大值是 2^31,大约是 21 亿,它的作用是用来标识该 Frame 属于哪个 Stream,接收方可以根据这个信息从乱序的帧里找到相同 Stream ID 的帧,从而有序组装信息。
最后面就是帧数据了,它存放的是通过 HPACK 算法压缩过的 HTTP 头部和包体。
并发传输
知道了 HTTP/2 的帧结构后,我们再来看看它是如何实现并发传输的。
我们都知道 HTTP/1.1 的实现是基于请求-响应模型的。同一个连接中,HTTP 完成一个事务(请求与响应),才能处理下一个事务,也就是说在发出请求等待响应的过程中,是没办法做其他事情的,如果响应迟迟不来,那么后续的请求是无法发送的,也造成了队头阻塞的问题。
而 HTTP/2 就很牛逼了,通过 Stream 这个设计,多个 Stream 复用一条 TCP 连接,达到并发的效果,解决了 HTTP/1.1 队头阻塞的问题,提高了 HTTP 传输的吞吐量。
为了理解 HTTP/2 的并发是怎样实现的,我们先来理解 HTTP/2 中的 Stream、Message、Frame 这 3 个概念。
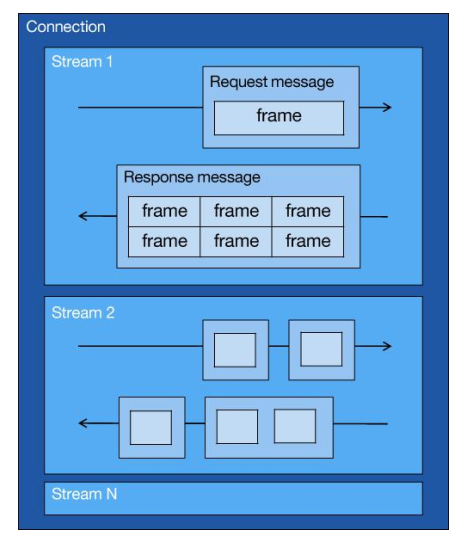
你可以从上图中看到:
- 1 个 TCP 连接包含一个或者多个 Stream,Stream 是 HTTP/2 并发的关键技术;
- Stream 里可以包含 1 个或多个 Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成;
- Message 里包含一条或者多个 Frame,Frame 是 HTTP/2 最小单位,以二进制压缩格式存放 HTTP/1 中的内容(头部和包体);
因此,我们可以得出 2 个结论:HTTP 消息可以由多个 Frame 构成,以及 1 个 Frame 可以由多个 TCP 报文构成。
在 HTTP/2 连接上,不同 Stream 的帧是可以乱序发送的(因此可以并发不同的 Stream ),因为每个帧的头部会携带 Stream ID 信息,所以接收端可以通过 Stream ID 有序组装成 HTTP 消息,而同一 Stream 内部的帧必须是严格有序的。
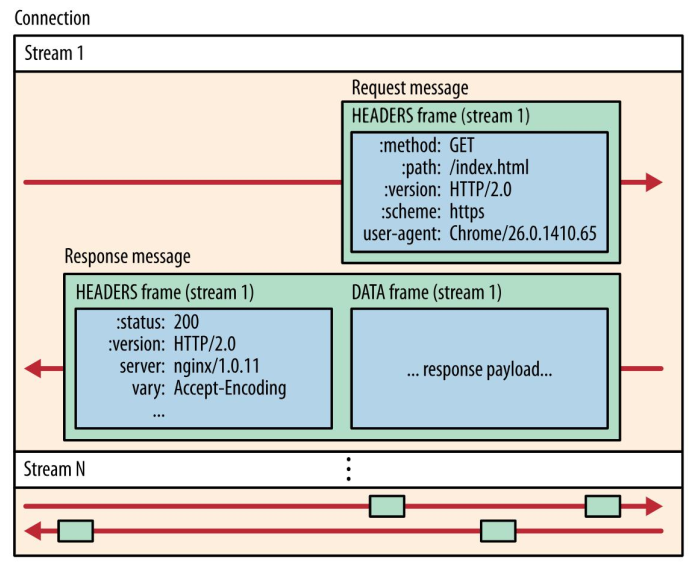
客户端和服务器双方都可以建立 Stream, Stream ID 也是有区别的,客户端建立的 Stream 必须是奇数号,而服务器建立的 Stream 必须是偶数号。
同一个连接中的 Stream ID 是不能复用的,只能顺序递增,所以当 Stream ID 耗尽时,需要发一个控制帧 GOAWAY,用来关闭 TCP 连接。
在 Nginx 中,可以通过 http2_max_concurrent_streams 配置来设置 Stream 的上限,默认是 128 个。
HTTP/2 通过 Stream 实现的并发,比 HTTP/1.1 通过 TCP 连接实现并发要牛逼的多,因为当 HTTP/2 实现 100 个并发 Stream 时,只需要建立一次 TCP 连接,而 HTTP/1.1 需要建立 100 个 TCP 连接,每个 TCP 连接都要经过 TCP 握手、慢启动以及 TLS 握手过程,这些都是很耗时的。
HTTP/2 还可以对每个 Stream 设置不同优先级,帧头中的「标志位」可以设置优先级,比如客户端访问 HTML/CSS 和图片资源时,希望服务器先传递 HTML/CSS,再传图片,那么就可以通过设置 Stream 的优先级来实现,以此提高用户体验。
服务器主动推送资源
HTTP/1.1 不支持服务器主动推送资源给客户端,都是由客户端向服务器发起请求后,才能获取到服务器响应的资源。
比如,客户端通过 HTTP/1.1 请求从服务器那获取到了 HTML 文件,而 HTML 可能还需要依赖 CSS 来渲染页面,这时客户端还要再发起获取 CSS 文件的请求,需要两次消息往返,如下图左边部分:
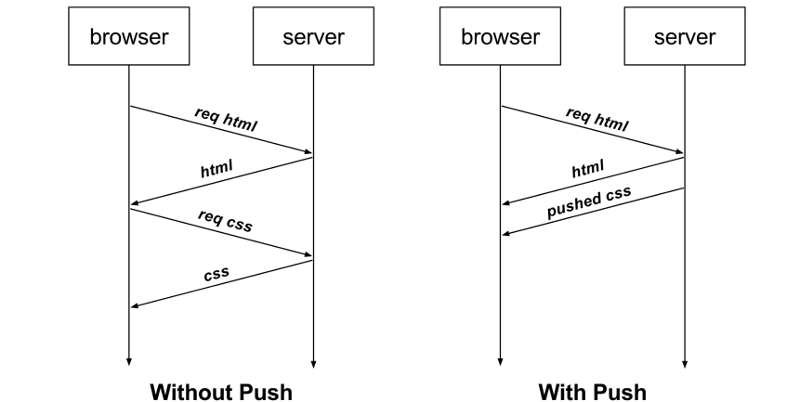
如上图右边部分,在 HTTP/2 中,客户端在访问 HTML 时,服务器可以直接主动推送 CSS 文件,减少了消息传递的次数。
在 Nginx 中,如果你希望客户端访问 /test.html 时,服务器直接推送 /test.css,那么可以这么配置:
location /test.html {
http2_push /test.css;
}
那 HTTP/2 的推送是怎么实现的?
客户端发起的请求,必须使用的是奇数号 Stream,服务器主动的推送,使用的是偶数号 Stream。服务器在推送资源时,会通过 PUSH_PROMISE 帧传输 HTTP 头部,并通过帧中的 Promised Stream ID 字段告知客户端,接下来会在哪个偶数号 Stream 中发送包体。
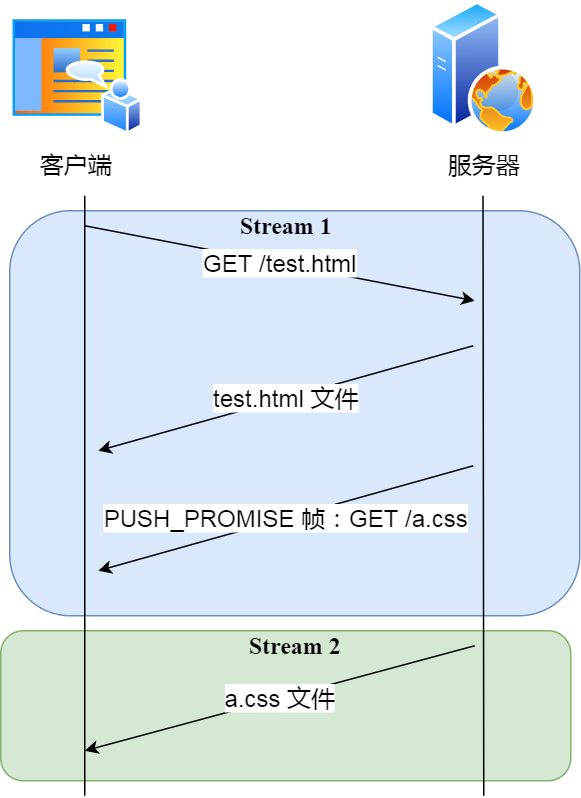
如上图,在 Stream 1 中通知客户端 CSS 资源即将到来,然后在 Stream 2 中发送 CSS 资源,注意 Stream 1 和 2 是可以并发的。
总结
HTTP/2 协议其实还有很多内容,比如流控制、流状态、依赖关系等等。
这次主要介绍了关于 HTTP/2 是如何提升性能的几个方向,它相比 HTTP/1 大大提高了传输效率、吞吐能力。
第一点,对于常见的 HTTP 头部通过静态表和 Huffman 编码的方式,将体积压缩了近一半,而且针对后续的请求头部,还可以建立动态表,将体积压缩近 90%,大大提高了编码效率,同时节约了带宽资源。
不过,动态表并非可以无限增大, 因为动态表是会占用内存的,动态表越大,内存也越大,容易影响服务器总体的并发能力,因此服务器需要限制 HTTP/2 连接时长或者请求次数。
第二点,HTTP/2 实现了 Stream 并发,多个 Stream 只需复用 1 个 TCP 连接,节约了 TCP 和 TLS 握手时间,以及减少了 TCP 慢启动阶段对流量的影响。不同的 Stream ID 才可以并发,即时乱序发送帧也没问题,但是同一个 Stream 里的帧必须严格有序。
另外,可以根据资源的渲染顺序来设置 Stream 的优先级,从而提高用户体验。
第三点,服务器支持主动推送资源,大大提升了消息的传输性能,服务器推送资源时,会先发送 PUSH_PROMISE 帧,告诉客户端接下来在哪个 Stream 发送资源,然后用偶数号 Stream 发送资源给客户端。
HTTP/2 通过 Stream 的并发能力,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2 还是存在“队头阻塞”的问题,只不过问题不是在 HTTP 这一层面,而是在 TCP 这一层。
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
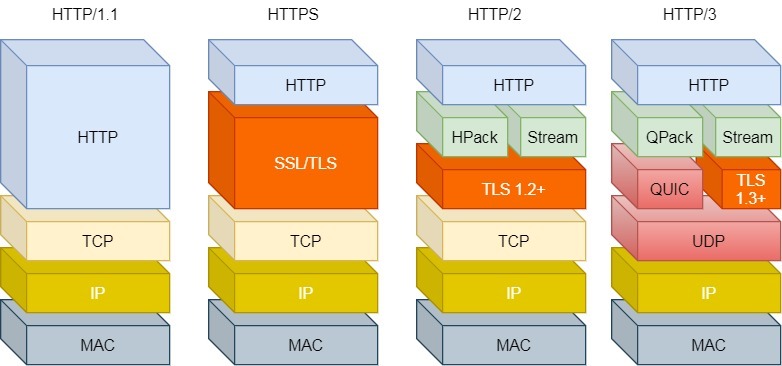
有没有什么解决方案呢?既然是 TCP 协议自身的问题,那干脆放弃 TCP 协议,转而使用 UDP 协议作为传输层协议,这个大胆的决定, HTTP/3 协议做了!
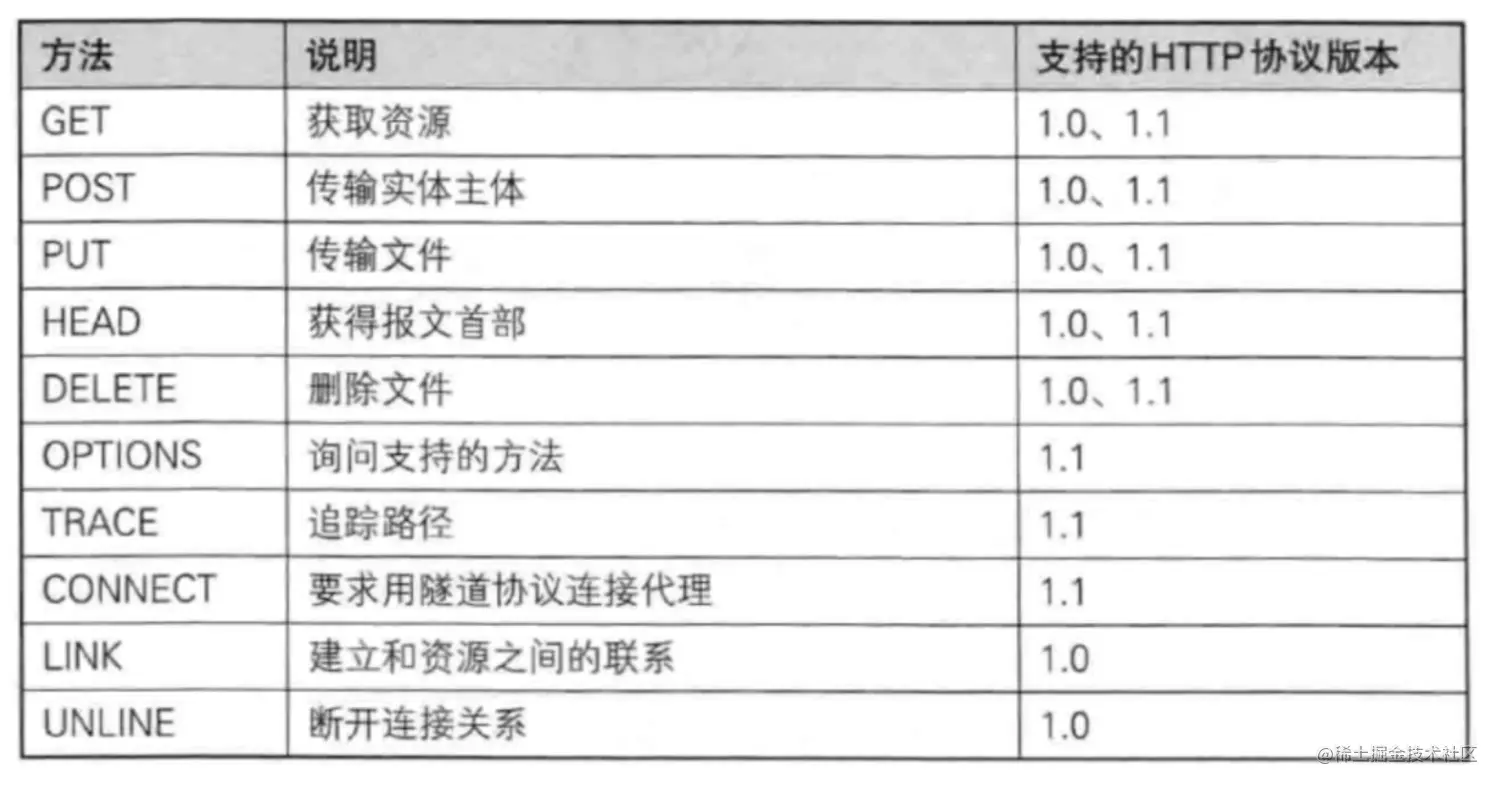
5.常见的 HTTP 请求方法
- GET: 向服务器获取数据;
- POST:将实体提交到指定的资源,通常会造成服务器资源的修改;
- PUT:上传文件,更新数据;
- DELETE:删除服务器上的对象;
- HEAD:获取报文首部,与 GET 相比,不返回报文主体部分;
- OPTIONS:询问支持的请求方法,用来跨域请求;
- CONNECT:要求在与代理服务器通信时建立隧道,使用隧道进行 TCP 通信;
- TRACE: 回显服务器收到的请求,主要⽤于测试或诊断。
get 和 post 区别
1.相同点和最本质的区别
1.1 相同点
GET 请求和 POST 请求底层都是基于 TCP/IP 协议实现的,使用二者中的任意一个,都可以实现客户端和服务器端的双向交互。
1.2 最本质的区别
GET 和 POST 最本质的区别是“约定和规范”上的区别,在规范中,定义 GET 请求是用来获取资源的,也就是进行查询操作的,而 POST 请求是用来传输实体对象的,因此会使用 POST 来进行添加、修改和删除等操作。 当然如果严格按照规范来说,删除操作应该使用 DELETE 请求才对,但在实际开发中,使用 POST 来进行删除的用法更常见一些。 按照约定来说,GET 和 POST 的参数传递也是不同的,GET 请求是将参数拼加到 URL 上进行参数传递的,而 POST 是将请参数写入到请求正文中传递的,如下图所示: 
2.非本质区别
2.1 缓存不同
GET 请求一般会被缓存,比如常见的 CSS、JS、HTML 请求等都会被缓存;而 POST 请求默认是不进行缓存的。
2.2 参数长度限制不同
GET 请求的参数是通过 URL 传递的,而 URL 的长度是有限制的,通常为 2k,当然浏览器厂商不同、版本不同这个限制的大小值可能也不同,但相同的是它们都会对 URL 的大小进行限制;而 POST 请求参数是存放在请求正文(request body)中的,所以没有大小限制。
2.3 回退和刷新不同
GET 请求可以直接进行回退和刷新,不会对用户和程序产生任何影响;而 POST 请求如果直接回滚和刷新将会把数据再次提交,如下图所示: 
2.4 历史记录不同
GET 请求的参数会保存在历史记录中,而 POST 请求的参数不会保留到历史记录中。
2.5 书签不同
GET 请求的地址可被收藏为书签,而 POST 请求的地址不能被收藏为书签。
总结
GET 和 POST 是 HTTP 请求中最常用的两种请求方法,它们的底层都是基于 TCP/IP 实现的。它们的区别主要体现在 5 个方面:缓存不同、参数长度限制不同、回退和刷新不同、历史记录不同、能否保存为书签不同,但它们最大的区别是规范和约定上的不同,规范中定义 GET 是用来获取信息的,而 POST 是用来传递实体的,并且 GET 请求的参数要放在 URL 上,而 POST 请求的参数要放在请求正文中。
6.常见的 HTTP 请求头和响应头
HTTP Request Header 常见的请求头:
- Accept:浏览器能够处理的内容类型
Accept: text/html 浏览器可以接受服务器回发的类型为 text/html。
Accept: */* 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)
MIME 类型
text/plain
text/html
image/jpeg
image/png
audio/mpeg
audio/ogg
audio/*
video/mp4
application/*
application/json
application/javascript
application/ecmascript
application/octet-stream
- Accept-Charset:浏览器能够显示的字符集
这个标识的是当前客户端可以接受的字符编码(所谓字符编码就是对于可见或者不可见字符的编码方式,如 utf-8,GBK 等)
- Accept-Encoding:浏览器能够处理的压缩编码
Accept-Encoding: gzip, deflate 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate)(注意:这不是只字符编码)
- Accept-Language:浏览器当前设置的语言
zh-CN,zh;q=0.9,en;q=0.8 请求头允许客户端声明它可以理解的自然语言,以及优先选择的区域方言。;q= (q 因子权重) 值代表优先顺序,用相对质量价值表示,又称作权重
- Connection:浏览器与服务器之间连接的类型
Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Connection: close 代表一个 Request 完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接会关闭, 当客户端再次发送 Request,需要重新建立 TCP 连接。
- Cookie:当前页面设置的任何 Cookie
- Range: 用于断点续传
Range:bytes=0-5 指定第一个字节的位置和最后一个字节的位置。用于告诉服务器自己想取对象的哪部分。
- Host:发出请求的页面所在的域
Host:baidu.com请求报头域主要用于指定被请求资源的 Internet 主机和端口号,它通常从 HTTP URL 中提取出来的。
Origin :源,源就是客户端网页页面的那个服务器
Referer:发出请求的页面的 URL 为了防止自己网站的文件被外网直接引用,可以通过比较 referer,即请求的地址,与本地地址比较,设置防盗链
Referer:https://baidu.com/?tn=62095104_8_oem_dg 当浏览器向 web 服务器发送请求的时候,一般会带上 Referer,告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。
- User-Agent:浏览器的用户代理字符串
User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36 告诉 HTTP 服务器, 客户端使用的操作系统和浏览器的名称和版本
HTTP Responses Header 常见的响应头:
- Date:表示消息发送的时间,时间的描述格式由 rfc822 定义
- server:服务器名称
- Connection:浏览器与服务器之间连接的类型
- Cache-Control:控制 HTTP 缓存
- content-type:表示后面的文档属于什么 MIME 类型
- Refresh:
5; url=http://baidu.com用于重定向 - Content-Range: bytes 0-5/7877 指定整个实体中的一部分的插入位置,他也指示了整个实体的长度。在服务器向客户返回一个部分响应,它必须描述响应覆盖的范围和整个实体长度
content-type表示 http 的请求的 body 内容的格式,服务端会依据这个类型自动做解析
常见的 Content-Type 属性值有以下几种:
(1)application/x-www-form-urlencoded:浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。该种方式提交的数据放在 body 里面,数据按照 key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL 转码。
<form method="post">
<input name="xxx" />
<submit>提交</submit>
</form>
(2)multipart/form-data:该种方式也是一个常见的 POST 提交方式,通常表单上传文件时使用该种方式。
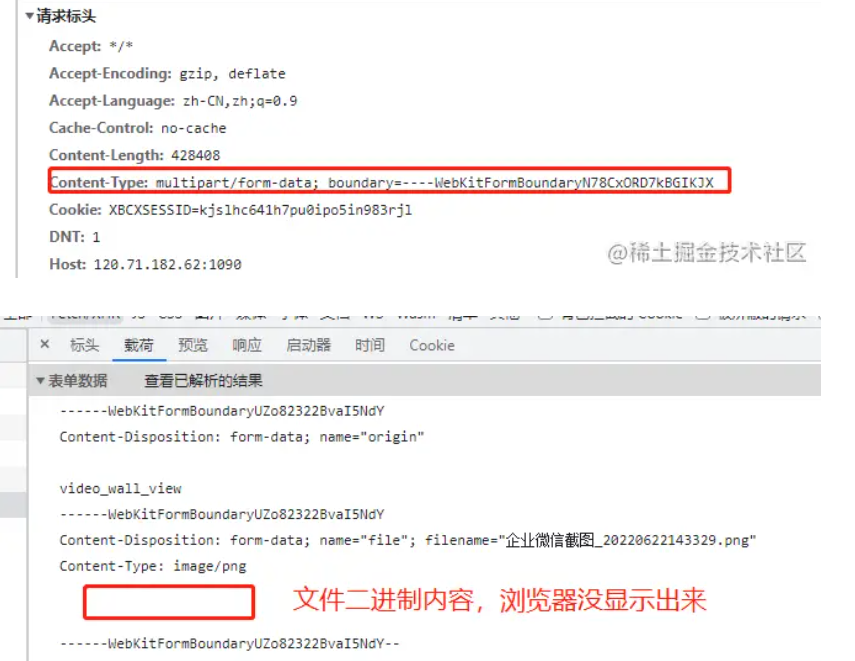
可以看到浏览器会自动生成 boundary,就是分隔符,因为发送的内容都在 body 里面,需要用分隔符来解析字符串
(3)application/json:服务器消息主体是序列化后的 JSON 字符串。
(4)text/xml:该种方式主要用来提交 XML 格式的数据。
(5)text/plain;charset=UTF-8:文本类型
7.与缓存相关的 HTTP 请求头有哪些
强缓存:
- Expires
- Cache-Control
协商缓存:
- Etag、If-None-Match
- Last-Modified、If-Modified-Since
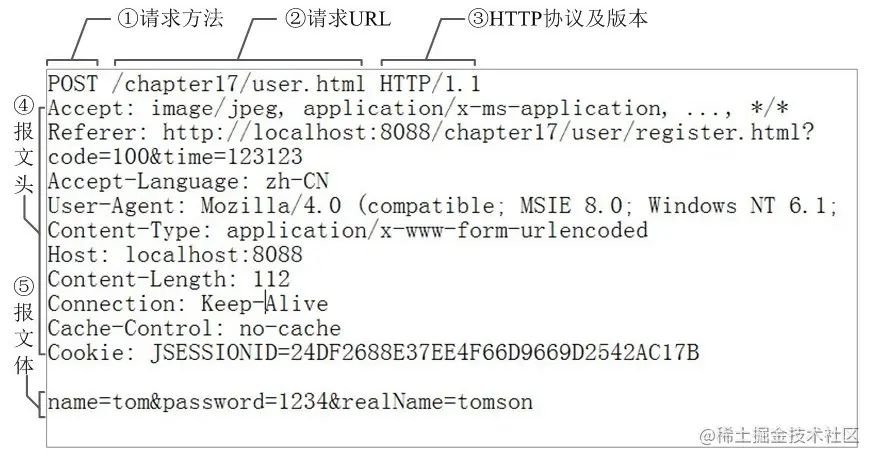
8.报文组成
1.请求报文
请求行:
- 请求方法 :get 和 post
2.URL
3.HTTP 版本号
请求头部:大多数请求头并不是必需的,但 Content-Length 除外。对于 POST 请求来说 Content-Length 必须出现
空行:告诉服务器,请求头部到此为止
请求数据:若方法字段是 GET,则此项为空,没有数据;若方法字段是 POST,则通常来说此处放置的就是要提交的数据
2.响应报文
响应行:
1.协议版本:HTTP/1.1 或者 HTTP/1.0,
2.状态码
3.描述
响应头:响应头用于描述服务器的基本信息,以及数据的描述,服务器通过这些数据的描述信息,可以通知客户端如何处理等一会儿它回送的数据
空行:告诉服务器请求头部到此为止
响应体:响应体就是响应的消息体,如果是纯数据就是返回纯数据,如果请求的是 HTML 页面,那么返回的就是 HTML 代码,如果是 JS 就是 JS 代码,如此之类

Https 协议
基本原理
防窃听 防篡改 防冒充
SSL(Secure Sockets Layer)译为「安全套接字协议」,TLS(Transport Layer Security)译为「传输层安全性协议」。
简单回顾一下它们的发展历史吧:
1994 年,网景公司设计了 SSL 协议(Secure Sockets Layer)的 1.0 版,但是未发布。 1995 年,网景公司发布 SSL 2.0 版,但很快发现有严重漏洞。 1996 年,SSL 3.0 版问世,得到大规模应用。 1999 年,互联网标准化组织 ISOC 接替网景公司,发布了 SSL 的升级版 TLS 1.0 版。 2006 年和 2008 年,TLS 进行了两次升级,分别为 TLS 1.1 版和 TLS 1.2 版。 SSL/TLS 协议处于「传输层」和「应用层」之间,主要作用是对网络连接进行加解密,如下图:
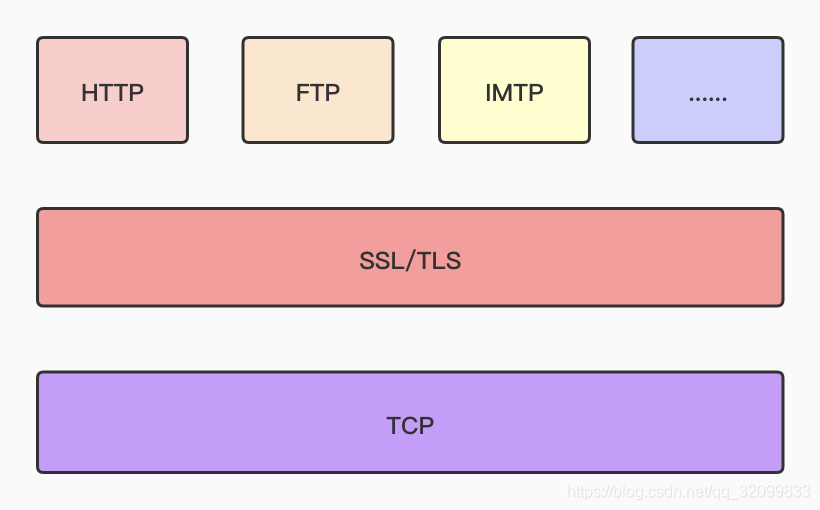
超文本传输安全协议(Hypertext Transfer Protocol Secure,简称:HTTPS)是一种通过计算机网络进行安全通信的传输协议。HTTPS 经由 HTTP 进行通信,利用 SSL/TLS 来加密数据包。HTTPS 的主要目的是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。 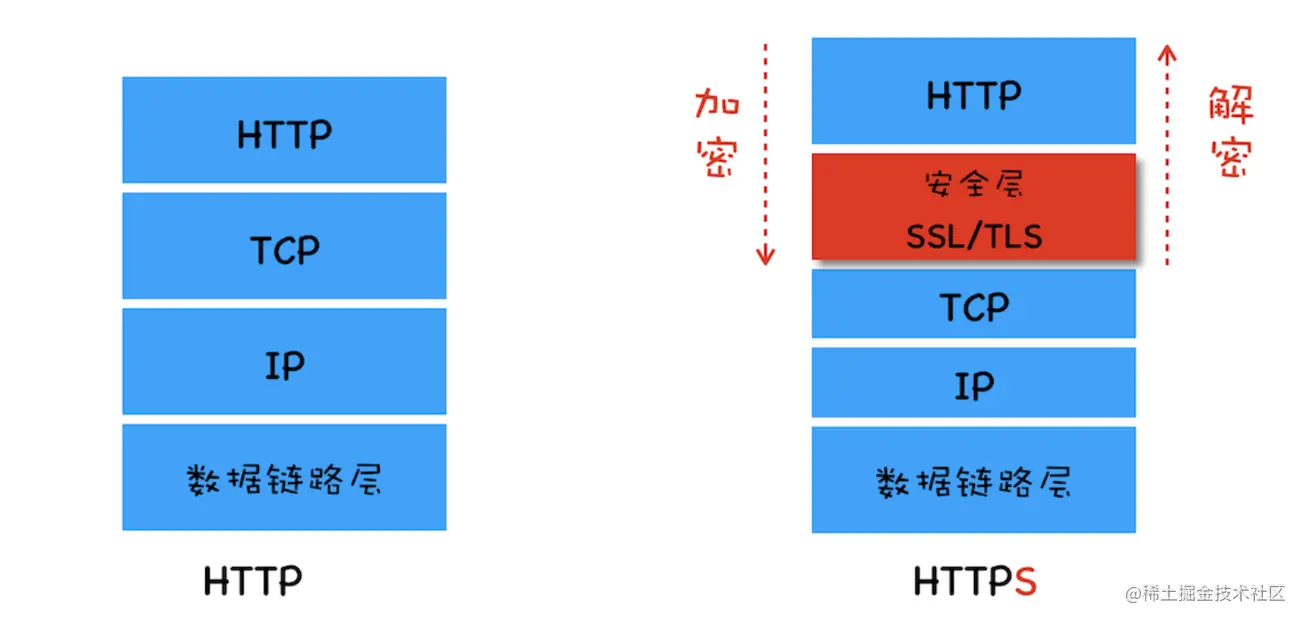 HTTP 协议采用明文传输信息,存在信息窃听、信息篡改和信息劫持的风险,而协议 TLS/SSL 具有身份验证、信息加密和完整性校验的功能,可以避免此类问题发生。
HTTP 协议采用明文传输信息,存在信息窃听、信息篡改和信息劫持的风险,而协议 TLS/SSL 具有身份验证、信息加密和完整性校验的功能,可以避免此类问题发生。
安全层的主要职责就是对发起的 HTTP 请求的数据进行加密操作 和 对接收到的 HTTP 的内容进行解密操作。
1.TLS/SSL 的工作原理
TLS/SSL全称安全传输层协议(Transport Layer Security), 是介于 TCP 和 HTTP 之间的一层安全协议,不影响原有的 TCP 协议和 HTTP 协议,所以使用 HTTPS 基本上不需要对 HTTP 页面进行太多的改造。
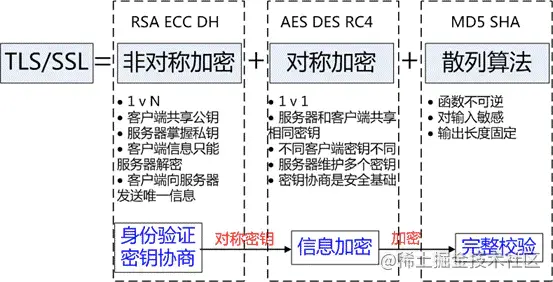
TLS/SSL 的功能实现主要依赖三类基本算法:散列函数 hash、对称加密、非对称加密。这三类算法的作用如下:
- 基于散列函数验证信息的完整性
- 对称加密算法采用协商的秘钥对数据加密
- 非对称加密实现身份认证和秘钥协商
(1)散列函数 hash
常见的散列函数有 MD5、SHA1、SHA256。该函数的特点是单向不可逆,对输入数据非常敏感,输出的长度固定,任何数据的修改都会改变散列函数的结果,可以用于防止信息篡改并验证数据的完整性。
特点: 在信息传输过程中,散列函数不能三都实现信息防篡改,由于传输是明文传输,中间人可以修改信息后重新计算信息的摘要,所以需要对传输的信息和信息摘要进行加密。
(2)对称加密
对称加密的方法是,双方使用同一个秘钥对数据进行加密和解密。但是对称加密的存在一个问题,就是如何保证秘钥传输的安全性,因为秘钥还是会通过网络传输的,一旦秘钥被其他人获取到,那么整个加密过程就毫无作用了。 这就要用到非对称加密的方法。
常见的对称加密算法有 AES-CBC、DES、3DES、AES-GCM 等。相同的秘钥可以用于信息的加密和解密。掌握秘钥才能获取信息,防止信息窃听,其通讯方式是一对一。
特点: 对称加密的优势就是信息传输使用一对一,需要共享相同的密码,密码的安全是保证信息安全的基础,服务器和 N 个客户端通信,需要维持 N 个密码记录且不能修改密码。
(3)非对称加密
非对称加密的方法是,我们拥有两个秘钥,一个是公钥,一个是私钥。公钥是公开的,私钥是保密的。用私钥加密的数据,只有对应的公钥才能解密,用公钥加密的数据,只有对应的私钥才能解密。我们可以将公钥公布出去,任何想和我们通信的客户, 都可以使用我们提供的公钥对数据进行加密,这样我们就可以使用私钥进行解密,这样就能保证数据的安全了。但是非对称加密有一个缺点就是加密的过程很慢,因此如果每次通信都使用非对称加密的方式的话,反而会造成等待时间过长的问题。
常见的非对称加密算法有 RSA、ECC、DH 等。秘钥成对出现,一般称为公钥(公开)和私钥(保密)。公钥加密的信息只有私钥可以解开,私钥加密的信息只能公钥解开,因此掌握公钥的不同客户端之间不能相互解密信息,只能和服务器进行加密通信,服务器可以实现一对多的的通信,客户端也可以用来验证掌握私钥的服务器的身份。
特点: 非对称加密的特点就是信息一对多,服务器只需要维持一个私钥就可以和多个客户端进行通信,但服务器发出的信息能够被所有的客户端解密,且该算法的计算复杂,加密的速度慢。
综合上述算法特点,TLS/SSL 的工作方式就是客户端使用非对称加密与服务器进行通信,实现身份的验证并协商对称加密使用的秘钥。对称加密算法采用协商秘钥对信息以及信息摘要进行加密通信,不同节点之间采用的对称秘钥不同,从而保证信息只能通信双方获取。这样就解决了两个方法各自存在的问题。
2.HTTPS 通信(握手)过程
SSL/TLS 协议基本流程:
- 客户端向服务器索要并验证服务器的公钥。
- 双方协商生产「会话秘钥」。
- 双方采用「会话秘钥」进行加密通信。
前两步也就是 SSL/TLS 的建立过程,也就是 TLS 握手阶段。
SSL/TLS 的「握手阶段」涉及四次通信, 基于 RSA 握手过程的 HTTPS (opens new window)见下图:
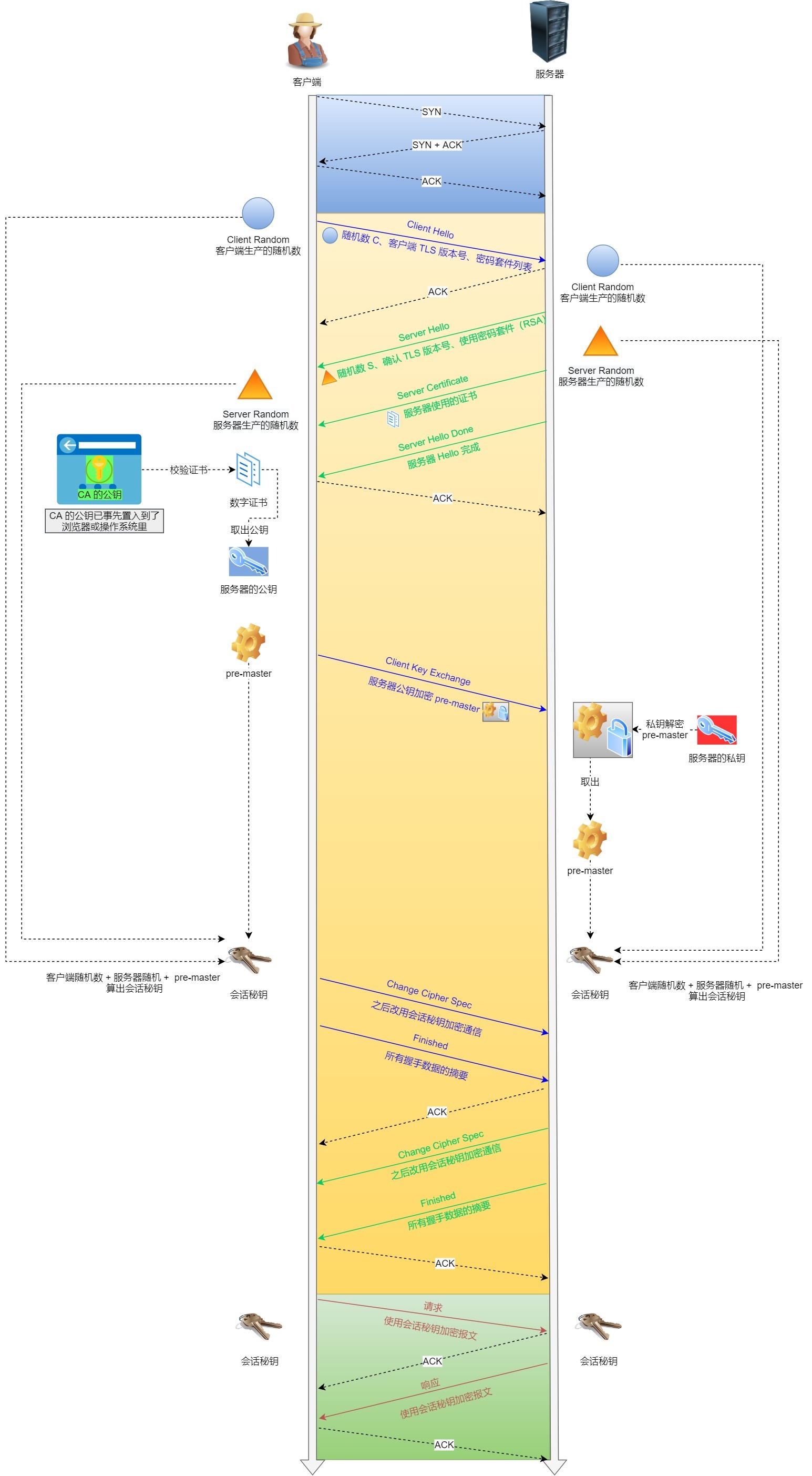
SSL/TLS 协议建立的详细流程:
1. ClientHello
首先,由客户端向服务器发起加密通信请求,也就是 ClientHello 请求。
在这一步,客户端主要向服务器发送以下信息:
(1)客户端支持的 SSL/TLS 协议版本,如 TLS 1.2 版本。
(2)客户端生产的随机数(Client Random),后面用于生成「会话秘钥」条件之一。
(3)客户端支持的密码套件列表,如 RSA 加密算法。
2. SeverHello
服务器收到客户端请求后,向客户端发出响应,也就是 SeverHello。服务器回应的内容有如下内容:
(1)确认 SSL/ TLS 协议版本,如果浏览器不支持,则关闭加密通信。
(2)服务器生产的随机数(Server Random),也是后面用于生产「会话秘钥」条件之一。
(3)确认的密码套件列表,如 RSA 加密算法。
(4)服务器的数字证书。
3.客户端回应
客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
(1)一个随机数(pre-master key)。该随机数会被服务器公钥加密。
(2)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(3)客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供服务端校验。
上面第一项的随机数是整个握手阶段的第三个随机数,会发给服务端,所以这个随机数客户端和服务端都是一样的。
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
4. 服务器的最后回应
服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。
然后,向客户端发送最后的信息:
(1)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供客户端校验。
至此,整个 SSL/TLS 的握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的 HTTP 协议,只不过用「会话秘钥」加密内容。
总结
HTTPS 的通信过程如下:
- 客户端向服务器发起请求,请求中包含使用的协议版本号、生成的一个随机数、以及客户端支持的加密方法。
- 服务器端接收到请求后,确认双方使用的加密方法、并给出服务器的证书、以及一个服务器生成的随机数。
- 客户端确认服务器证书有效后,生成一个新的随机数,并使用数字证书中的公钥,加密这个随机数,然后发给服 务器。并且还会提供一个前面所有内容的 hash 的值,用来供服务器检验。
- 服务器使用自己的私钥,来解密客户端发送过来的随机数。并提供前面所有内容的 hash 值来供客户端检验。
- 客户端和服务器端根据约定的加密方法使用前面的三个随机数,生成对话秘钥,以后的对话过程都使用这个秘钥来加密信息。
3.数字证书
一个数字证书通常包含了: 公钥; 持有者信息; 证书认证机构(CA)的信息; CA 对这份一件的数字签名及使用的算法; 证书有效期; 还有一些其他额外信息; 那数字证书的作用,是用来认证公钥持有者的身份,以防止第三方进行冒充。说简单些,证书就是用来告诉客户端,该服务端是否是合法的,因为只有证书合法,才代表服务端身份是可信的。
为了让服务端的公钥被大家信任,服务端的证书都是由 CA (Certificate Authority,证书认证机构)签名的,CA 就是网络世界的公安局、公证中心,具有极高的可信度,所以由它来给各个公钥签名,信任的一方签发的证书, 那必然证书也是被信任的。 之所以要签名,是因为签名的作用可以避免中间人在获取证书时对证书内容的篡改。
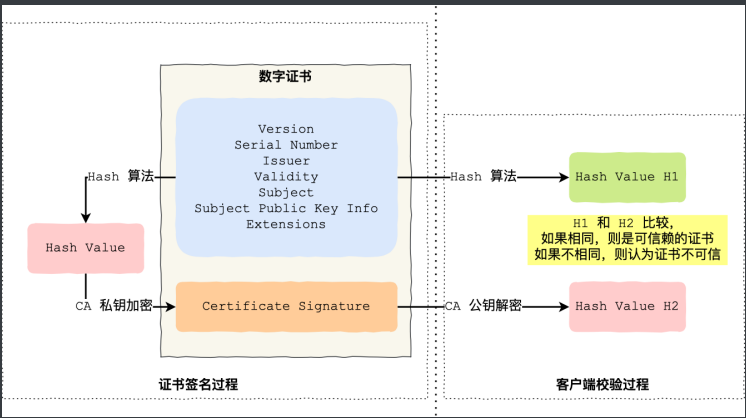
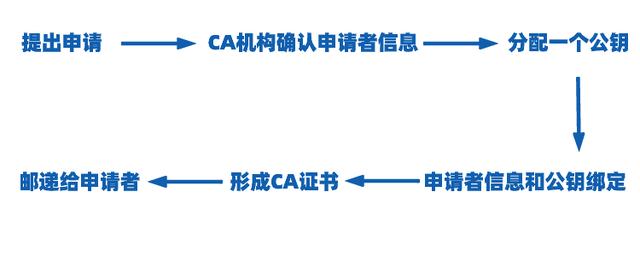
CA 签发证书的过程,如上图左边部分:
- 首先 CA 会把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,然后对这些信息进行 Hash 计算,得到一个 Hash 值;
- 然后 CA 会使用自己的私钥将该 Hash 值加密,生成 Certificate Signature,也就是 CA 对证书做了签名;
- 最后将 Certificate Signature 添加在文件证书上,形成数字证书;
客户端校验服务端的数字证书的过程,如上图右边部分:
- 首先客户端会使用同样的 Hash 算法获取该证书的 Hash 值 H1;
- 通常浏览器和操作系统中集成了 CA 的公钥信息,浏览器收到证书后可以使用 CA 的公钥解密 Certificate Signature 内容,得到一个 Hash 值 H2 ;
- 最后比较 H1 和 H2,如果值相同,则为可信赖的证书,否则则认为证书不可信。
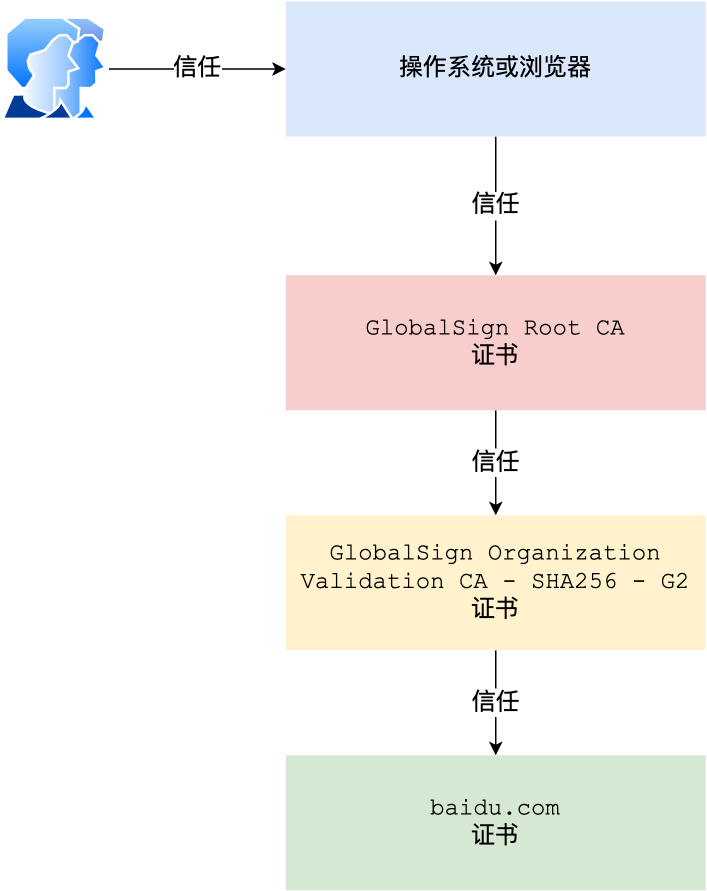
但事实上,证书的验证过程中还存在一个证书信任链的问题,因为我们向 CA 申请的证书一般不是根证书签发的,而是由中间证书签发的,比如百度的证书,从下图你可以看到,证书的层级有三级:

对于这种三级层级关系的证书的验证过程如下:
- 客户端收到 baidu.com 的证书后,发现这个证书的签发者不是根证书,就无法根据本地已有的根证书中的公钥去验证 baidu.com 证书是否可信。于是,客户端根据 baidu.com 证书中的签发者,找到该证书的颁发机构是 “GlobalSign Organization Validation CA - SHA256 - G2”,然后向 CA 请求该中间证书。
- 请求到证书后发现 “GlobalSign Organization Validation CA - SHA256 - G2” 证书是由 “GlobalSign Root CA” 签发的,由于 “GlobalSign Root CA” 没有再上级签发机构,说明它是根证书,也就是自签证书。应用软件会检查此证书有否已预载于根证书清单上,如果有,则可以利用根证书中的公钥去验证 “GlobalSign Organization Validation CA - SHA256 - G2” 证书,如果发现验证通过,就认为该中间证书是可信的。
- “GlobalSign Organization Validation CA - SHA256 - G2” 证书被信任后,可以使用 “GlobalSign Organization Validation CA - SHA256 - G2” 证书中的公钥去验证 baidu.com 证书的可信性,如果验证通过,就可以信任 baidu.com 证书。
在这四个步骤中,最开始客户端只信任根证书 GlobalSign Root CA 证书的,然后 “GlobalSign Root CA” 证书信任 “GlobalSign Organization Validation CA - SHA256 - G2” 证书,而 “GlobalSign Organization Validation CA - SHA256 - G2” 证书又信任 baidu.com 证书,于是客户端也信任 baidu.com 证书。
总括来说,由于用户信任 GlobalSign,所以由 GlobalSign 所担保的 baidu.com 可以被信任,另外由于用户信任操作系统或浏览器的软件商,所以由软件商预载了根证书的 GlobalSign 都可被信任。
操作系统里一般都会内置一些根证书,比如我的 MAC 电脑里内置的根证书有这么多:
这样的一层层地验证就构成了一条信任链路,整个证书信任链验证流程如下图所示:
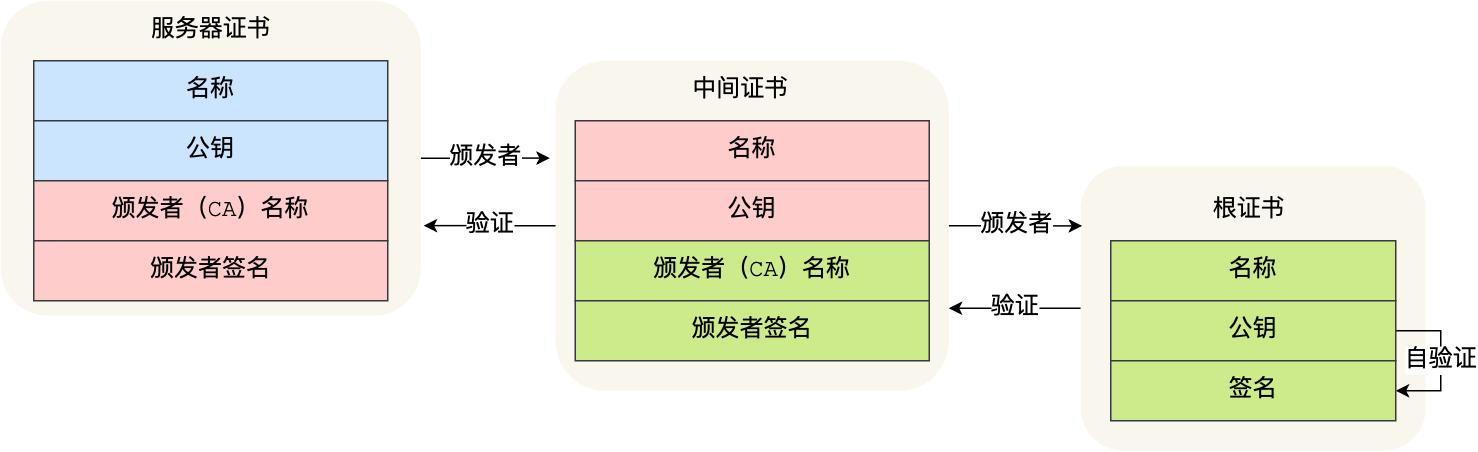
最后一个问题,为什么需要证书链这么麻烦的流程?Root CA 为什么不直接颁发证书,而是要搞那么多中间层级呢?
这是为了确保根证书的绝对安全性,将根证书隔离地越严格越好,不然根证书如果失守了,那么整个信任链都会有问题。
如何保证 CA 的公钥是安全不被篡改的?答案也是一样的,就是给 CA 也颁发证书,那这个证书由谁来颁发呢?自然是 CA 的上一级 CA 了。CA 的上一级 CA 如何保证安全?那就 CA 的上一级 CA 的上一级 CA 给它颁发证书了。最终就会形成一个证书信用链,如下:

客户端要想验证服务器的 C3 证书是否合法,会跑去 CA2 验证,要验证 CA2 就去 CA1 验证,以此类推。对于根证书,是没法验证的,只能无条件相信。因为 Root CA 都是国际上公认的机构,一般用户的操作系统或浏览器在发布时,就会在里面嵌入这些机构的 Root 证书
4.HTTP 与 HTTPS
HTTP 与 HTTPS 有哪些区别?
- HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
- HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- HTTP 的端口号是 80,HTTPS 的端口号是 443。
- HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
HTTPS 解决了 HTTP 的哪些问题?
HTTP 由于是明文传输,所以安全上存在以下三个风险:
窃听风险,比如通信链路上可以获取通信内容,用户号容易没。
篡改风险,比如强制植入垃圾广告,视觉污染,用户眼容易瞎。
冒充风险,比如冒充淘宝网站,用户钱容易没。
混合加密的方式实现信息的机密性,解决了窃听的风险。
摘要算法的方式来实现完整性,它能够为数据生成独一无二的「指纹」,指纹用于校验数据的完整性,解决了篡改的风险。
将服务器公钥放入到数字证书中,解决了冒充的风险。
5.https 是绝对安全的吗?
不是绝对安全的,可以通过中间人攻击。HTTPS 是保护用户和服务器之间的通讯不被第三方窃取或者篡改。这个第三方攻击者才是中间人。对于用户对客户端逻辑的逆向和篡改,HTTPS 是不能起到防护作用的
HTTPS 的实现原理
大家可能都听说过 HTTPS 协议之所以是安全的是因为 HTTPS 协议会对传输的数据进行加密,而加密过程是使用了非对称加密实现。但其实,HTTPS 在内容传输的加密上使用的是对称加密,非对称加密只作用在证书验证阶段
HTTPS 的整体过程分为证书验证和数据传输阶段,具体的交互过程如下:
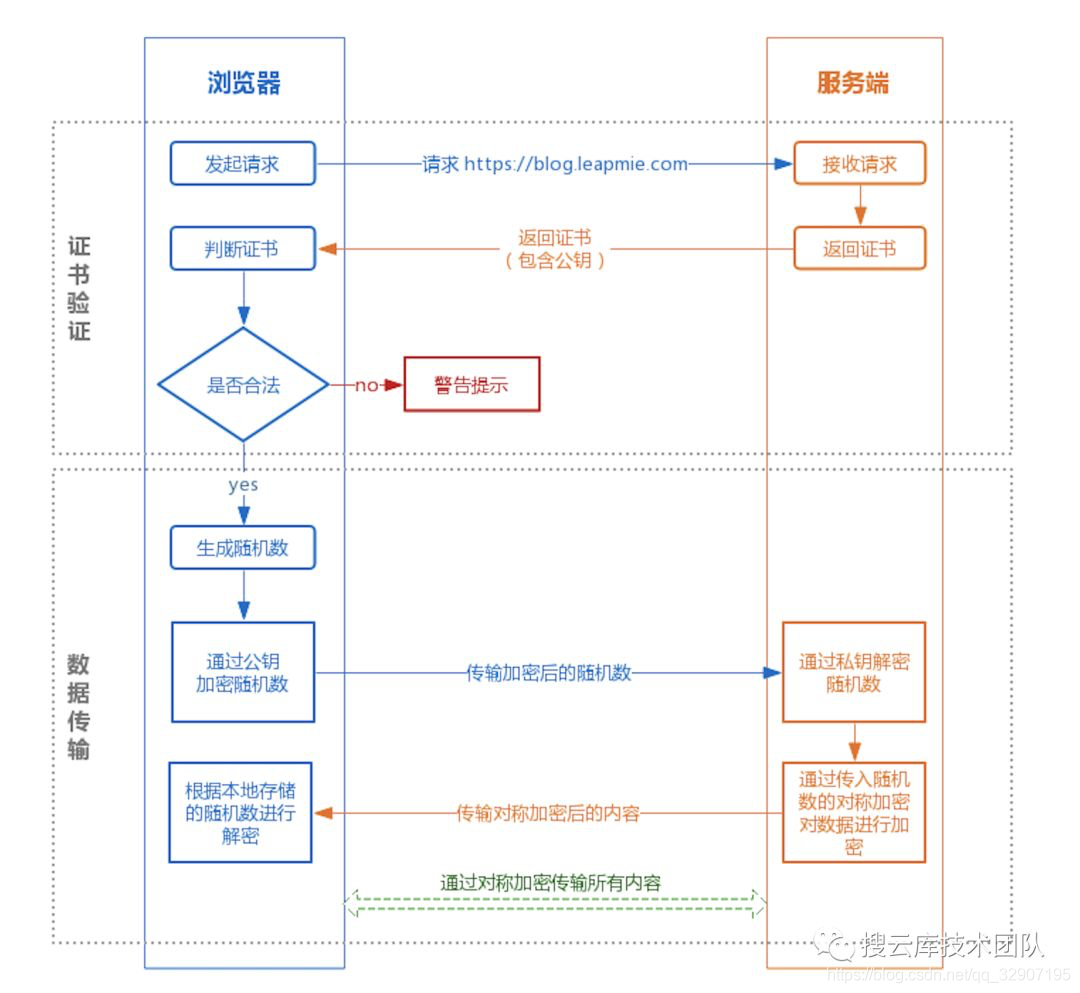
证书验证阶段
1、浏览器发起 HTTPS 请求 2、服务端返回 HTTPS 证书 3、客户端验证证书是否合法,如果不合法则提示告警
数据传输阶段
1、当证书验证合法后,在本地生成随机数 2、通过公钥加密随机数,并把加密后的随机数传输到服务端 3、服务端通过私钥对随机数进行解密 4、服务端通过客户端传入的随机数构造对称加密算法,对返回结果内容进行加密后传输
为什么数据传输是用对称加密?
首先,非对称加密的加解密效率是非常低的,而 http 的应用场景中通常端与端之间存在大量的交互,非对称加密的效率是无法接受的;
另外,在 HTTPS 的场景中只有服务端保存了私钥,一对公私钥只能实现单向的加解密,所以 HTTPS 中内容传输加密采取的是对称加密,而不是非对称加密。
为什么需要 CA 认证机构颁发证书?
HTTP 协议被认为不安全是因为传输过程容易被监听者勾线监听、伪造服务器,而 HTTPS 协议主要解决的便是网络传输的安全性问题。
首先我们假设不存在认证机构,任何人都可以制作证书,这带来的安全风险便是经典的“中间人攻击”问题。
什么是中间人攻击
中间人攻击是指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。
HTTPS 使用了 SSL 加密协议,是一种非常安全的机制,目前并没有方法直接对这个协议进行攻击,一般都是在建立 SSL 连接时,拦截客户端的请求,利用中间人获取到 CA 证书、非对称加密的公钥、对称加密的密钥;有了这些条件,就可以对请求和响应进行拦截和篡改。
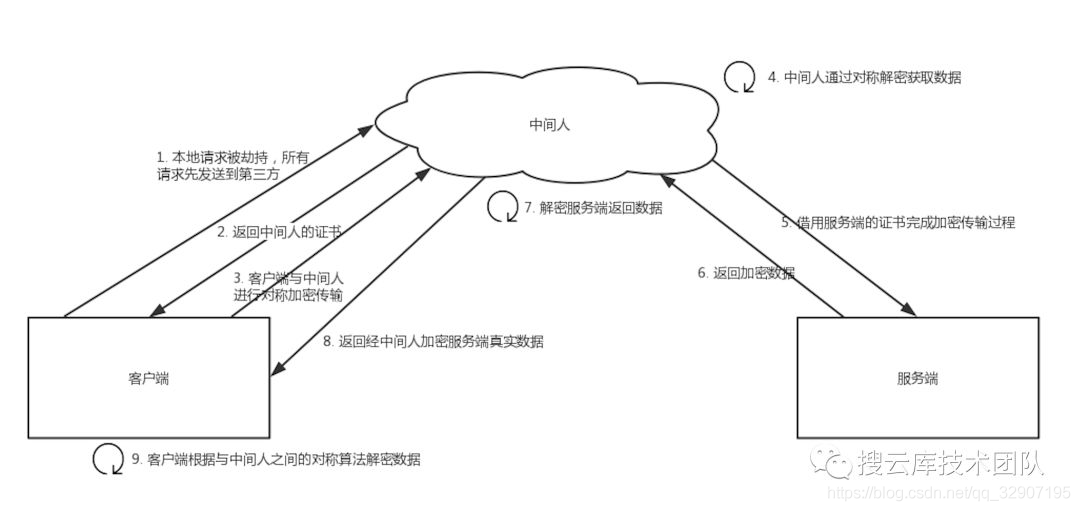
过程原理:
- 本地请求被劫持(如 DNS 劫持等),所有请求均发送到中间人的服务器
- 中间人服务器返回中间人自己的证书
- 客户端创建随机数,通过中间人证书的公钥对随机数加密后传送给中间人,然后凭随机数构造对称加密对传输内容进行加密传输
- 中间人因为拥有客户端的随机数,可以通过对称加密算法进行内容解密
- 中间人以客户端的请求内容再向官方网站发起请求
- 因为中间人与服务器的通信过程是合法的,官方网站通过建立的安全通道返回加密后的数据
- 中间人凭借与官方网站建立的对称加密算法对内容进行解密
- 中间人通过与客户端建立的对称加密算法对官方内容返回的数据进行加密传输
- 客户端通过与中间人建立的对称加密算法对返回结果数据进行解密
由于缺少对证书的验证,所以客户端虽然发起的是 HTTPS 请求,但客户端完全不知道自己的网络已被拦截,传输内容被中间人全部窃取。
如何防止中间人攻击?
https 无法防止中间人攻击,只有做证书固定 ssl-pinning 或者 apk 中预置证书做自签名验证可以防中间人攻击
浏览器是如何确保 CA 证书的合法性?
一、证书包含什么信息?
颁发机构信息、公钥、公司信息、域名、有效期、指纹......
二、证书的合法性依据是什么?
首先,权威机构是要有认证的,不是随便一个机构都有资格颁发证书,不然也不叫做权威机构。另外,证书的可信性基于信任制,权威机构需要对其颁发的证书进行信用背书,只要是权威机构生成的证书,我们就认为是合法的。所以权威机构会对申请者的信息进行审核,不同等级的权威机构对审核的要求也不一样,于是证书也分为免费的、便宜的和贵的。
三、浏览器如何验证证书的合法性?
浏览器发起 HTTPS 请求时,服务器会返回网站的 SSL 证书,浏览器需要对证书做以下验证:
- 验证域名、有效期等信息是否正确。证书上都有包含这些信息,比较容易完成验证;
- 判断证书来源是否合法。每份签发证书都可以根据验证链查找到对应的根证书,操作系统、浏览器会在本地存储权威机构的根证书,利用本地根证书可以对对应机构签发证书完成来源验证;
- 判断证书是否被篡改。需要与 CA 服务器进行校验;
- 判断证书是否已吊销。通过 CRL(Certificate Revocation List 证书注销列表)和 OCSP(Online Certificate Status Protocol 在线证书状态协议)实现,其中 OCSP 可用于第 3 步中以减少与 CA 服务器的交互,提高验证效率。
以上任意一步都满足的情况下浏览器才认为证书是合法的。
本地随机数被窃取怎么办?
证书验证是采用非对称加密实现,但是传输过程是采用对称加密,而其中对称加密算法中重要的随机数是由本地生成并且存储于本地的,HTTPS 如何保证随机数不会被窃取?
其实 HTTPS 并不包含对随机数的安全保证,HTTPS 保证的只是传输过程安全,而随机数存储于本地,本地的安全属于另一安全范畴,应对的措施有安装杀毒软件、反木马、浏览器升级修复漏洞等。
https 可以抓包吗
HTTPS 的数据是加密的,常规下抓包工具代理请求后抓到的包内容是加密状态,无法直接查看。
但是,我们可以通过抓包工具来抓包。它的原理其实是模拟一个中间人。
通常 HTTPS 抓包工具的使用方法是会生成一个证书,用户需要手动把证书安装到客户端中,然后终端发起的所有请求通过该证书完成与抓包工具的交互,然后抓包工具再转发请求到服务器,最后把服务器返回的结果在控制台输出后再返回给终端,从而完成整个请求的闭环。
如何防止抓包?
对于 HTTPS API 接口,如何防止抓包呢?既然问题出在证书信任问题上,那么解决方法就是在我们的 APP 中预置证书。在 TLS/SSL 握手时,用预置在本地的证书中的公钥校验服务器的数字签名,只有签名通过才能成功握手。由于数字签名是使用私钥生成的,而私钥只掌握在我们手上,中间人无法伪造一个有效的签名,因此攻击失败,无法抓包。
同时,为了防止预置证书被替换,在证书存储上,可以将证书进行加密后进行「嵌入存储」,如嵌入在图片中或一段语音中。
预置证书/公钥更新问题
这样做虽然解决了抓包问题,但是也带来了另外一个问题:我们购买的证书都是有有效期的,到期前需要对证书进行更新。主要有两种方式:
提供预置证书更新接口。在当前证书快过期时,APP 请求获取新的预置证书,这过渡时期,两个证书同时有效,直到安全完成证书切换。这种方式有一定的维护成本,且不易测试。 在 APP 中只预埋公钥,这样只要私钥不变,即使证书更新也不用更新该公钥。但是,这样不太符合周期性更新私钥的安全审计需求。一个折中的方法是,一次性预置多个公钥,只要任意一个公钥验证通过即可。考虑到我们的证书一般购买周期是 3-5 年,那么 3 个公钥,可以使用 9-15 年,同时,我们在此期间还可以发布新版本废弃老公钥,添加新公钥,这样可以使公钥一直更新下去。
总结:
Q: HTTPS 为什么安全? A: 因为 HTTPS 保证了传输安全,防止传输过程被监听、防止数据被窃取,可以确认网站的真实性。
Q: HTTPS 的传输过程是怎样的? A: 客户端发起 HTTPS 请求,服务端返回证书,客户端对证书进行验证,验证通过后本地生成用于改造对称加密算法的随机数,通过证书中的公钥对随机数进行加密传输到服务端,服务端接收后通过私钥解密得到随机数,之后的数据交互通过对称加密算法进行加解密。
Q: 为什么需要证书? A: 防止”中间人“攻击,同时可以为网站提供身份证明。
Q: 使用 HTTPS 会被抓包吗? A: 会被抓包,HTTPS 只防止用户在不知情的情况下通信被监听,如果用户主动授信,是可以构建“中间人”网络,代理软件可以对传输内容进行解密。
TCP 与 UDP
基本认识
tcp 头
我们先来看看 TCP 头的格式,标注颜色的表示与本文关联比较大的字段,其他字段不做详细阐述。
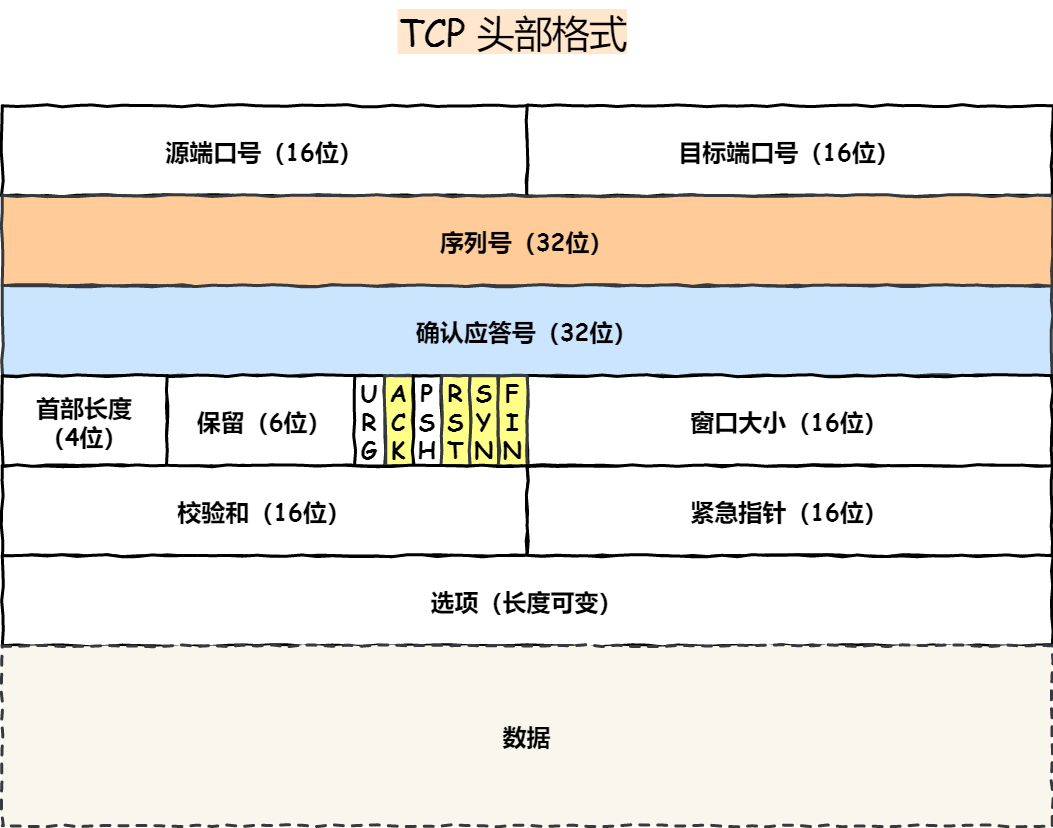
序列号:在建立连接时由计算机生成的随机数作为其初始值,通过 SYN 包传给接收端主机,每发送一次数据,就「累加」一次该「数据字节数」的大小。用来解决网络包乱序问题。
确认应答号:指下一次「期望」收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。用来解决丢包的问题。
控制位:
- ACK:该位为
1时,「确认应答」的字段变为有效,TCP 规定除了最初建立连接时的SYN包之外该位必须设置为1。 - RST:该位为
1时,表示 TCP 连接中出现异常必须强制断开连接。 - SYN:该位为
1时,表示希望建立连接,并在其「序列号」的字段进行序列号初始值的设定。 - FIN:该位为
1时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换FIN位为 1 的 TCP 段。
为什么需要 TCP 协议? TCP 工作在哪一层?
IP 层是「不可靠」的,它不保证网络包的交付、不保证网络包的按序交付、也不保证网络包中的数据的完整性。
如果需要保障网络数据包的可靠性,那么就需要由上层(传输层)的 TCP 协议来负责。
因为 TCP 是一个工作在传输层的可靠数据传输的服务,它能确保接收端接收的网络包是无损坏、无间隔、非冗余和按序的。
UDP 不提供复杂的控制机制,利用 IP 提供面向「无连接」的通信服务。
UDP 头
UDP 协议真的非常简,头部只有 8 个字节( 64 位),UDP 的头部格式如下:
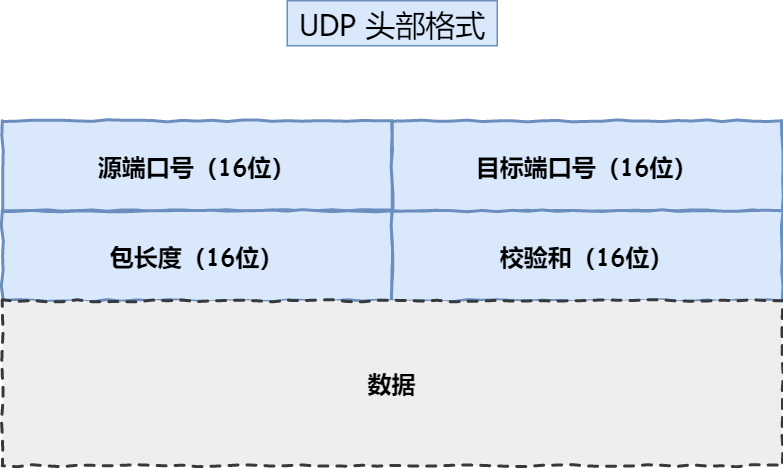
- 目标和源端口:主要是告诉 UDP 协议应该把报文发给哪个进程。
- 包长度:该字段保存了 UDP 首部的长度跟数据的长度之和。
- 校验和:校验和是为了提供可靠的 UDP 首部和数据而设计,防止收到在网络传输中受损的 UDP 包。
1.TCP 和 UDP 的概念及特点
TCP 和 UDP 都是传输层协议,他们都属于 TCP/IP 协议族:
(1)UDP
UDP 的全称是用户数据报协议,在网络中它与 TCP 协议一样用于处理数据包,是一种无连接的协议。在 OSI 模型中,在传输层,处于 IP 协议的上一层。UDP 有不提供数据包分组、组装和不能对数据包进行排序的缺点,也就是说,当报文发送之后,是无法得知其是否安全完整到达的。
它的特点如下:
1)面向无连接
首先 UDP 是不需要和 TCP 一样在发送数据前进行三次握手建立连接的,想发数据就可以开始发送了。并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作。
具体来说就是:
- 在发送端,应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头标识下是 UDP 协议,然后就传递给网络层了
- 在接收端,网络层将数据传递给传输层,UDP 只去除 IP 报文头就传递给应用层,不会任何拼接操作
2)有单播,多播,广播的功能
UDP 不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能。
3)面向报文
发送方的 UDP 对应用程序交下来的报文,在添加首部后就向下交付 IP 层。UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文
4)不可靠性
首先不可靠性体现在无连接上,通信都不需要建立连接,想发就发,这样的情况肯定不可靠。
并且收到什么数据就传递什么数据,并且也不会备份数据,发送数据也不会关心对方是否已经正确接收到数据了。
再者网络环境时好时坏,但是 UDP 因为没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。
5)头部开销小,传输数据报文时是很高效的。 
UDP 头部包含了以下几个数据:
- 两个十六位的端口号,分别为源端口(可选字段)和目标端口
- 整个数据报文的长度
- 整个数据报文的检验和(IPv4 可选字段),该字段用于发现头部信息和数据中的错误
因此 UDP 的头部开销小,只有 8 字节,相比 TCP 的至少 20 字节要少得多,在传输数据报文时是很高效的。
(2)TCP TCP 的全称是传输控制协议是一种面向连接的、可靠的、基于字节流的传输层通信协议。TCP 是面向连接的、可靠的流协议(流就是指不间断的数据结构)。
它有以下几个特点:
1)面向连接
面向连接,是指发送数据之前必须在两端建立连接。建立连接的方法是“三次握手”,这样能建立可靠的连接。建立连接,是为数据的可靠传输打下了基础。
2)仅支持单播传输
每条 TCP 传输连接只能有两个端点,只能进行点对点的数据传输,不支持多播和广播传输方式。
3)面向字节流
TCP 不像 UDP 一样那样一个个报文独立地传输,而是在不保留报文边界的情况下以字节流方式进行传输。
4)可靠传输
对于可靠传输,判断丢包、误码靠的是 TCP 的段编号以及确认号。TCP 为了保证报文传输的可靠,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的字节发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据(假设丢失了)将会被重传。
5)提供拥塞控制
当网络出现拥塞的时候,TCP 能够减小向网络注入数据的速率和数量,缓解拥塞。
6)提供全双工通信
TCP 允许通信双方的应用程序在任何时候都能发送数据,因为 TCP 连接的两端都设有缓存,用来临时存放双向通信的数据。当然,TCP 可以立即发送一个数据段,也可以缓存一段时间以便一次发送更多的数据段(最大的数据段大小取决于 MSS)
2.Tcp 建立和断开过程
(1)三次握手
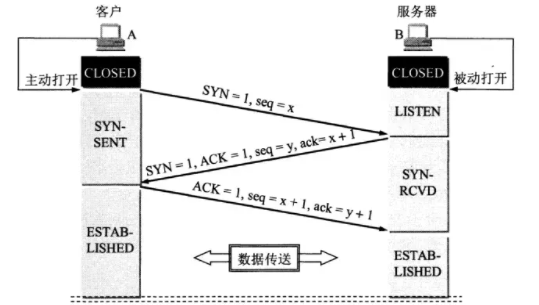 三次握手(Three-way Handshake)其实就是指建立一个 TCP 连接时,需要客户端和服务器总共发送 3 个包。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。实质上其实就是连接服务器指定端口,建立 TCP 连接,并同步连接双方的序列号和确认号,交换 TCP 窗口大小信息。
三次握手(Three-way Handshake)其实就是指建立一个 TCP 连接时,需要客户端和服务器总共发送 3 个包。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。实质上其实就是连接服务器指定端口,建立 TCP 连接,并同步连接双方的序列号和确认号,交换 TCP 窗口大小信息。
刚开始客户端处于 Closed 的状态,服务端处于 Listen 状态。
- 第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN,此时客户端处于 SYN_SEND 状态。
首部的同步位 SYN=1,初始序号 seq=x,SYN=1 的报文段不能携带数据,但要消耗掉一个序号。
- 第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN。同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_REVD 的状态。
在确认报文段中 SYN=1,ACK=1,确认号 ack=x+1,初始序号 seq=y
- 第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 ESTABLISHED 状态。服务器收到 ACK 报文之后,也处于 ESTABLISHED 状态,此时,双方已建立起了连接。
确认报文段 ACK=1,确认号 ack=y+1,序号 seq=x+1(初始为 seq=x,第二个报文段所以要+1),ACK 报文段可以携带数据,不携带数据则不消耗序号。
(2)四次挥手
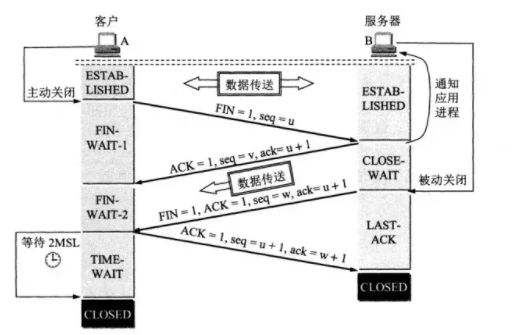 刚开始双方都处于 ESTABLISHED 状态,假如是客户端先发起关闭请求。四次挥手的过程如下:
刚开始双方都处于 ESTABLISHED 状态,假如是客户端先发起关闭请求。四次挥手的过程如下:
- 第一次挥手: 客户端会发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于 FIN_WAIT1 状态。
即发出连接释放报文段(FIN=1,序号 seq=u),并停止再发送数据,主动关闭 TCP 连接,进入 FIN_WAIT1(终止等待 1)状态,等待服务端的确认。
- 第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 +1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT 状态。
即服务端收到连接释放报文段后即发出确认报文段(ACK=1,确认号 ack=u+1,序号 seq=v),服务端进入 CLOSE_WAIT(关闭等待)状态,此时的 TCP 处于半关闭状态,客户端到服务端的连接释放。客户端收到服务端的确认后,进入 FIN_WAIT2(终止等待 2)状态,等待服务端发出的连接释放报文段。
- 第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
即服务端没有要向客户端发出的数据,服务端发出连接释放报文段(FIN=1,ACK=1,序号 seq=w,确认号 ack=u+1),服务端进入 LAST_ACK(最后确认)状态,等待客户端的确认。
- 第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 +1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态,服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
即客户端收到服务端的连接释放报文段后,对此发出确认报文段(ACK=1,seq=u+1,ack=w+1),客户端进入 TIME_WAIT(时间等待)状态。此时 TCP 未释放掉,需要经过时间等待计时器设置的时间 2MSL 后,客户端才进入 CLOSED 状态。
(3)TCP4 次挥手时等待为 2MSL
MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为 TCP 报文基于是 IP 协议的,而 IP 头中有一个 TTL 字段,是 IP 数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报文通知源主机。
MSL 与 TTL 的区别: MSL 的单位是时间,而 TTL 是经过路由跳数。所以 MSL 应该要大于等于 TTL 消耗为 0 的时间,以确保报文已被自然消亡。
2MSL 的时间是从客户端接收到 FIN 后发送 ACK 开始计时的。如果在 TIME-WAIT 时间内,因为客户端的 ACK 没有传输到服务端,客户端又接收到了服务端重发的 FIN 报文,那么 2MSL 时间将重新计时。
TIME_WAIT 至少需要持续 2MSL 时长,这 2 个 MSL 中的第一个 MSL 是为了等自己发出去的最后一个 ACK 从网络中消失,而第二 MSL 是为了等在对端收到 ACK 之前的一刹那可能重传的 FIN 报文从网络中消失。
概念:MSL 是报文在网络中最长生存时间,这是一个工程值(经验值),不同的系统中可能不同。
场景:
- A 发出 ACK 后,等待一段时间 T,确保如果 B 重传 FIN 自己一定能收到
分析:
- ACK 从 A 到 B 最多经过 1MSL,超过这个时间 B 会重发 FIN
- B 重发的 FIN 最多经过 1MSL 到达 A
结论:如果 B 重发了 FIN,且网络没有故障(重发的 FIN 被丢弃或错误转发),那么 A 一定能在 2MSL 之内收到该 FIN,因此 A 只需要等待 2MSL。
3.Tcp 为什么是三次握手和四次挥手
为什么要三次握手呢?两次不行吗?
- 为了确认双方的接收能力和发送能力都正常
- 如果是用两次握手,则会出现下面这种情况:
如客户端发出连接请求,但因连接请求报文丢失而未收到确认,于是客户端再重传一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接,客户端共发出了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达服务端,此时服务端误认为客户端又发出一次新的连接请求,于是就向客户端发出确认报文段,同意建立连接,不采用三次握手,只要服务端发出确认,就建立新的连接了,此时客户端忽略服务端发来的确认,也不发送数据,则服务端一致等待客户端发送数据,浪费资源。
简单来说就是以下三步:
- 第一次握手: 客户端向服务端发送连接请求报文段。该报文段中包含自身的数据通讯初始序号。请求发送后,客户端便进入 SYN-SENT 状态。
- 第二次握手: 服务端收到连接请求报文段后,如果同意连接,则会发送一个应答,该应答中也会包含自身的数据通讯初始序号,发送完成后便进入 SYN-RECEIVED 状态。
- 第三次握手: 当客户端收到连接同意的应答后,还要向服务端发送一个确认报文。客户端发完这个报文段后便进入 ESTABLISHED 状态,服务端收到这个应答后也进入 ESTABLISHED 状态,此时连接建立成功。
TCP 三次握手的建立连接的过程就是相互确认初始序号的过程,告诉对方,什么样序号的报文段能够被正确接收。 第三次握手的作用是客户端对服务器端的初始序号的确认。如果只使用两次握手,那么服务器就没有办法知道自己的序号是否 已被确认。同时这样也是为了防止失效的请求报文段被服务器接收,防止旧的重复连接初始化造成混乱,而出现错误的情况。
我们考虑一个场景,客户端先发送了 SYN(seq = 90) 报文,然后客户端宕机了,而且这个 SYN 报文还被网络阻塞了,服务端并没有收到,接着客户端重启后,又重新向服务端建立连接,发送了 SYN(seq = 100) 报文(注意不是重传 SYN,重传的 SYN 的序列号是一样的)。
避免历史连接
看看三次握手是如何阻止历史连接的:
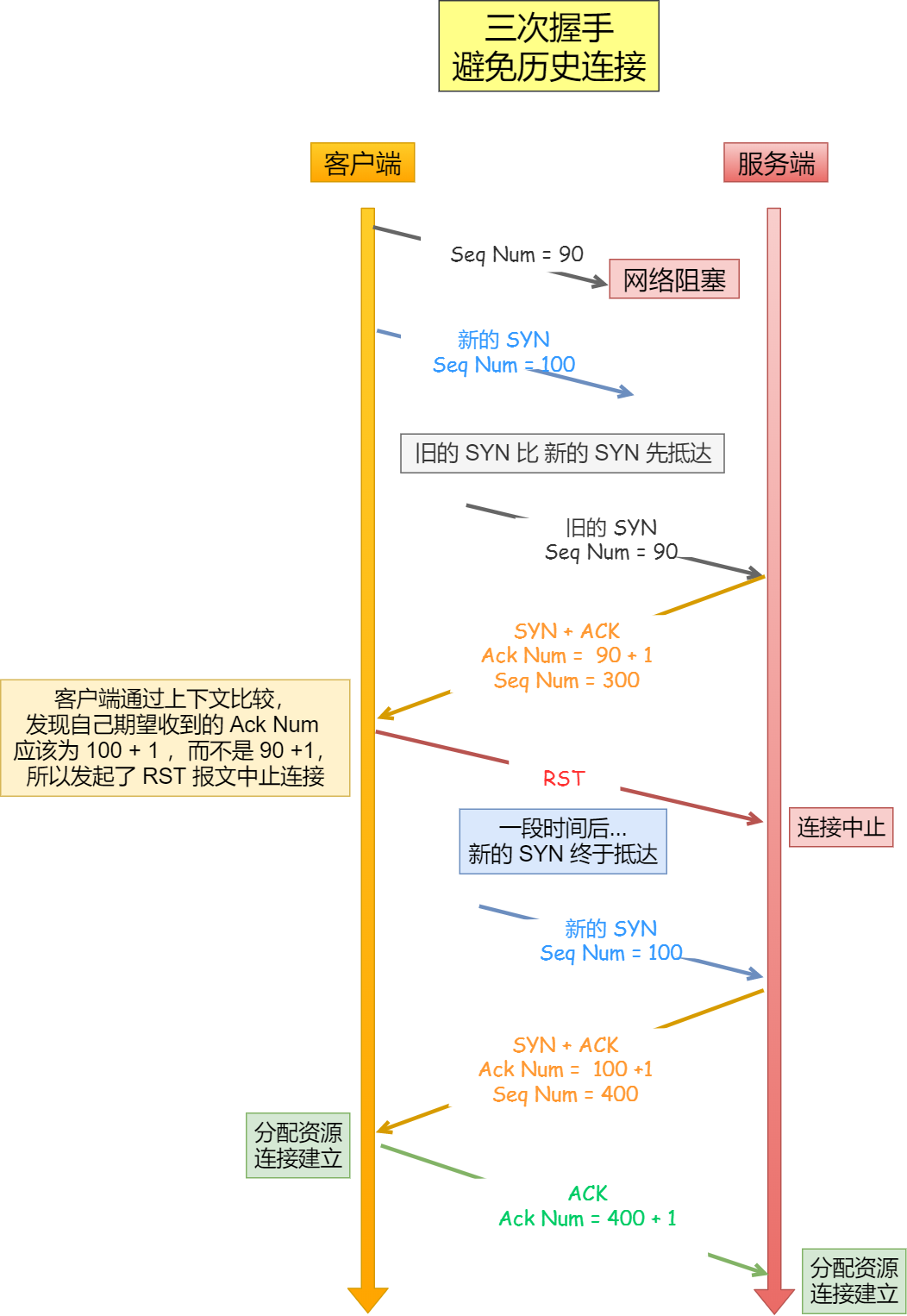
客户端连续发送多次 SYN 建立连接的报文,在网络拥堵情况下:
- 一个「旧 SYN 报文」比「最新的 SYN 」 报文早到达了服务端;
- 那么此时服务端就会回一个
SYN + ACK报文给客户端; - 客户端收到后可以根据自身的上下文,判断这是一个历史连接(序列号过期或超时),那么客户端就会发送
RST报文给服务端,表示中止这一次连接。
在两次握手的情况下,「被动发起方」没有中间状态给「主动发起方」来阻止历史连接,导致「被动发起方」可能建立一个历史连接,造成资源浪费。
同步双方初始序列号
TCP 协议的通信双方, 都必须维护一个「序列号」, 序列号是可靠传输的一个关键因素,它的作用:
- 接收方可以去除重复的数据;
- 接收方可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中, 哪些是已经被对方收到的(通过 ACK 报文中的序列号知道);
可见,序列号在 TCP 连接中占据着非常重要的作用,所以当客户端发送携带「初始序列号」的 SYN 报文的时候,需要服务端回一个 ACK 应答报文,表示客户端的 SYN 报文已被服务端成功接收,那当服务端发送「初始序列号」给客户端的时候,依然也要得到客户端的应答回应,这样一来一回,才能确保双方的初始序列号能被可靠的同步。
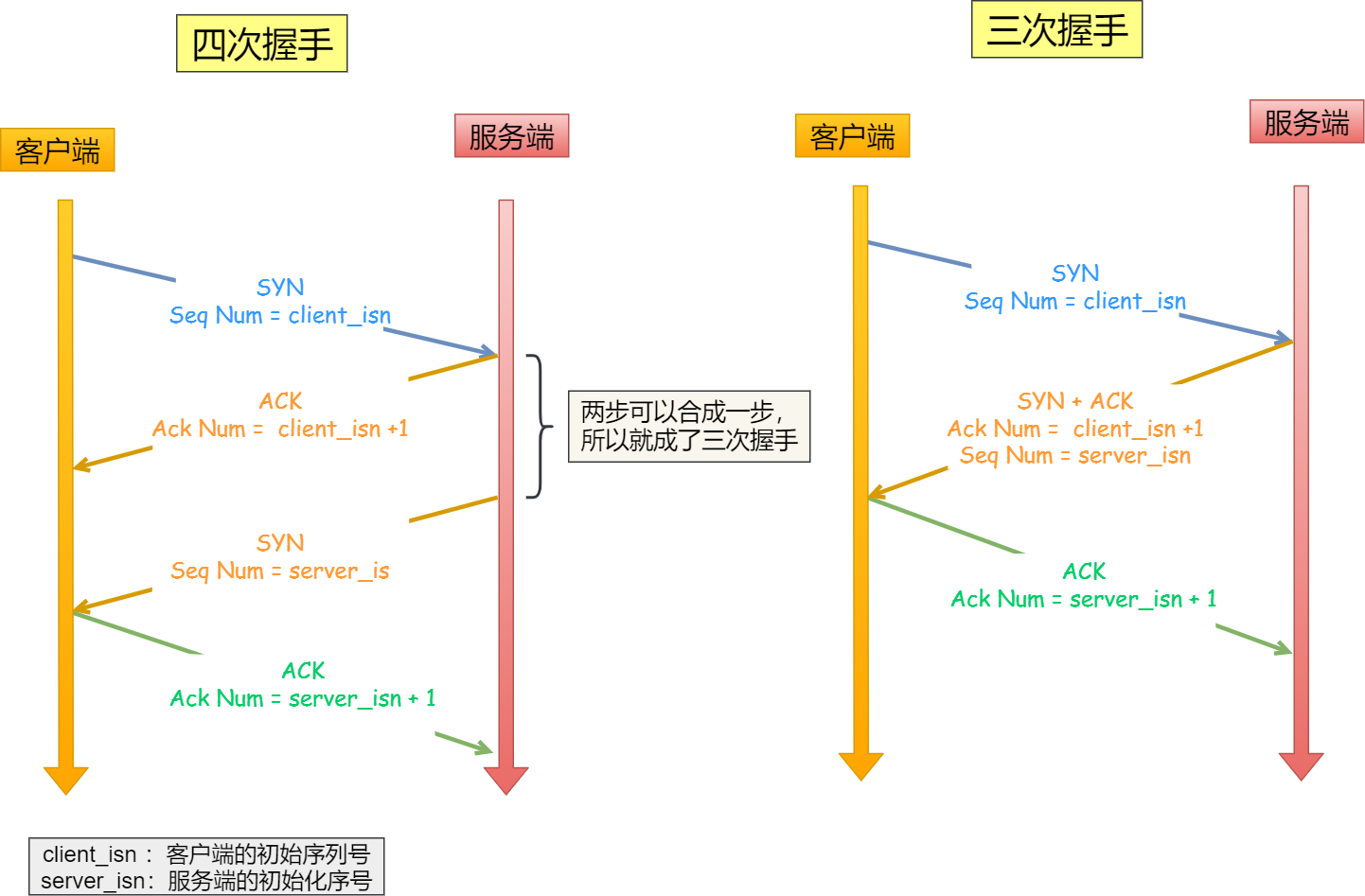
四次握手其实也能够可靠的同步双方的初始化序号,但由于第二步和第三步可以优化成一步,所以就成了「三次握手」。
而两次握手只保证了一方的初始序列号能被对方成功接收,没办法保证双方的初始序列号都能被确认接收。
避免资源浪费
如果只有「两次握手」,当客户端的 SYN 请求连接在网络中阻塞,客户端没有接收到 ACK 报文,就会重新发送 SYN ,由于没有第三次握手,服务器不清楚客户端是否收到了自己发送的建立连接的 ACK 确认信号,所以每收到一个 SYN 就只能先主动建立一个连接,这会造成什么情况呢?
如果客户端的 SYN 阻塞了,重复发送多次 SYN 报文,那么服务器在收到请求后就会建立多个冗余的无效链接,造成不必要的资源浪费。
为什么需要四次挥手呢?
因为当服务端收到客户端的 SYN 连接请求报文后,可以直接发送 SYN+ACK 报文。其中 ACK 报文是用来应答的,SYN 报文是用来同步的。但是关闭连接时,当服务端收到 FIN 报文时,很可能并不会立即关闭 SOCKET,所以只能先回复一个 ACK 报文,告诉客户端,“你发的 FIN 报文我收到了”。只有等到我服务端所有的报文都发送完了,我才能发送 FIN 报文,因此不能一起发送,故需要四次挥手。
简单来说就是以下四步:
- 第一次挥手: 若客户端认为数据发送完成,则它需要向服务端发送连接释放请求。
- 第二次挥手:服务端收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入 CLOSE_WAIT 状态,此时表明客户端到服务端的连接已经释放,不再接收客户端发的数据了。但是因为 TCP 连接是双向的,所以服务端仍旧可以发送数据给客户端。
- 第三次挥手:服务端如果此时还有没发完的数据会继续发送,完毕后会向客户端发送连接释放请求,然后服务端便进入 LAST-ACK 状态。
- 第四次挥手: 客户端收到释放请求后,向服务端发送确认应答,此时客户端进入 TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有服务端的重发请求的话,就进入 CLOSED 状态。当服务端收到确认应答后,也便进入 CLOSED 状态。
TCP 使用四次挥手的原因是因为 TCP 的连接是全双工的,所以需要双方分别释放到对方的连接,单独一方的连接释放,只代 表不能再向对方发送数据,连接处于的是半释放的状态。
最后一次挥手中,客户端会等待一段时间再关闭的原因,是为了防止发送给服务器的确认报文段丢失或者出错,从而导致服务器 端不能正常关闭。
防止历史连接中的数据,被后面相同四元组的连接错误的接收
为了能更好的理解这个原因,我们先来了解序列号(SEQ)和初始序列号(ISN)。
- 序列号,是 TCP 一个头部字段,标识了 TCP 发送端到 TCP 接收端的数据流的一个字节,因为 TCP 是面向字节流的可靠协议,为了保证消息的顺序性和可靠性,TCP 为每个传输方向上的每个字节都赋予了一个编号,以便于传输成功后确认、丢失后重传以及在接收端保证不会乱序。序列号是一个 32 位的无符号数,因此在到达 4G 之后再循环回到 0。
- 初始序列号,在 TCP 建立连接的时候,客户端和服务端都会各自生成一个初始序列号,它是基于时钟生成的一个随机数,来保证每个连接都拥有不同的初始序列号。初始化序列号可被视为一个 32 位的计数器,该计数器的数值每 4 微秒加 1,循环一次需要 4.55 小时。
给大家抓了一个包,下图中的 Seq 就是序列号,其中红色框住的分别是客户端和服务端各自生成的初始序列号。
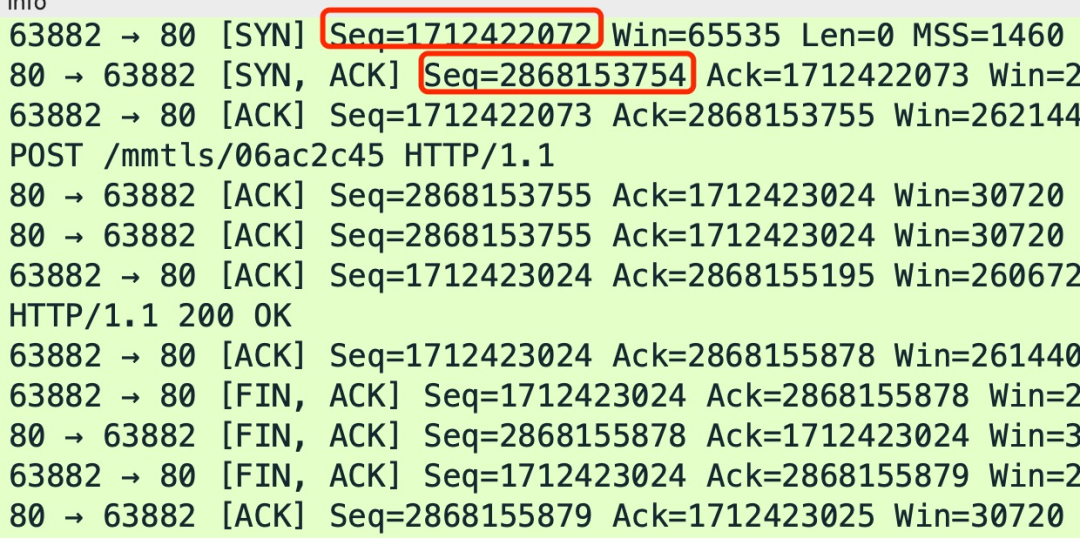
通过前面我们知道,序列号和初始化序列号并不是无限递增的,会发生回绕为初始值的情况,这意味着无法根据序列号来判断新老数据。
假设 TIME-WAIT 没有等待时间或时间过短,被延迟的数据包抵达后会发生什么呢?
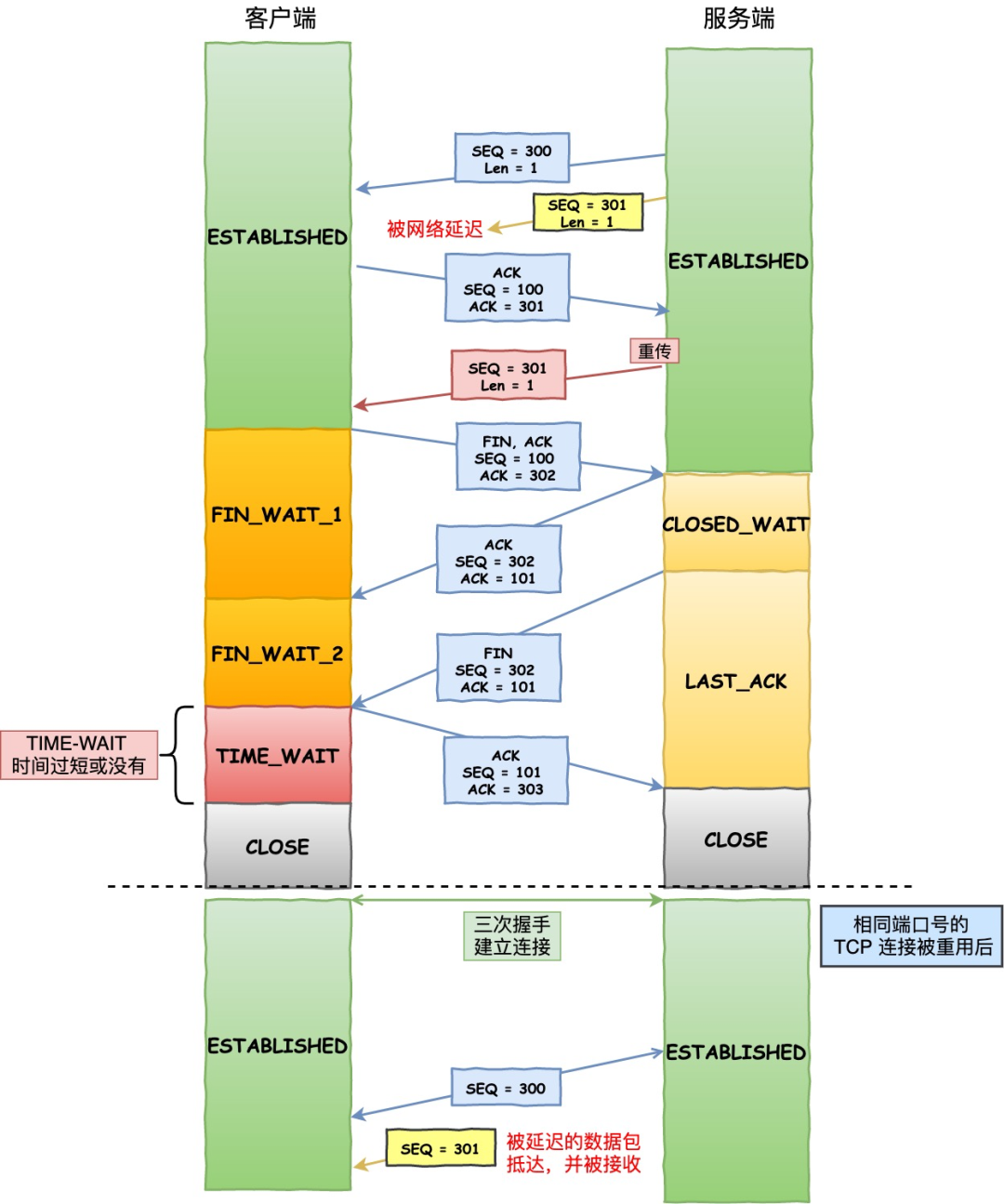
如上图:
- 服务端在关闭连接之前发送的
SEQ = 301报文,被网络延迟了。 - 接着,服务端以相同的四元组重新打开了新连接,前面被延迟的
SEQ = 301这时抵达了客户端,而且该数据报文的序列号刚好在客户端接收窗口内,因此客户端会正常接收这个数据报文,但是这个数据报文是上一个连接残留下来的,这样就产生数据错乱等严重的问题。
为了防止历史连接中的数据,被后面相同四元组的连接错误的接收,因此 TCP 设计了 TIME_WAIT 状态,状态会持续 2MSL 时长,这个时间足以让两个方向上的数据包都被丢弃,使得原来连接的数据包在网络中都自然消失,再出现的数据包一定都是新建立连接所产生的。
4.TCP 和 UDP 的区别
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输(数据顺序和正确性),使用流量控制和拥塞控制 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅 8 字节 | 首部最小 20 字节,最大 60 字节 |
| 适用场景 | 适用于实时应用,例如视频会议、直播 | 适用于要求可靠传输的应用,例如文件传输 |
5.TCP 和 UDP 的特点和应用场景
- TCP 应用场景: 效率要求相对低,但对准确性要求相对高的场景。因为传输中需要对数据确认、重发、排序等操作,相比之下效率没有 UDP 高。例如:文件传输(准确高要求高、但是速度可以相对慢)、接受邮件、远程登录。
- UDP 应用场景: 效率要求相对高,对准确性要求相对低的场景。例如:QQ 聊天、在线视频、网络语音电话(即时通讯,速度要求高,但是出现偶尔断续不是太大问题,并且此处完全不可以使用重发机制)、广播通信(广播、多播)。
6.TCP 的重传机制
由于 TCP 的下层网络(网络层)可能出现丢失、重复或失序的情况,TCP 协议提供可靠数据传输服务。为保证数据传输的正确性,TCP 会重传其认为已丢失(包括报文中的比特错误)的包。TCP 使用两套独立的机制来完成重传,一是基于时间,二是基于确认信息。
TCP 在发送一个数据之后,就开启一个定时器,若是在这个时间内没有收到发送数据的 ACK 确认报文,则对该报文进行重传,在达到一定次数还没有成功时放弃并发送一个复位信号。
7.UDP 协议为什么不可靠
UDP 在传输数据之前不需要先建立连接,远地主机的运输层在接收到 UDP 报文后,不需要确认,提供不可靠交付。总结就以下四点:
- 不保证消息交付:不确认,不重传,无超时
- 不保证交付顺序:不设置包序号,不重排,不会发生队首阻塞
- 不跟踪连接状态:不必建立连接或重启状态机
- 不进行拥塞控制:不内置客户端或网络反馈机制
8.TCP 的拥塞控制机制
TCP 的拥塞控制机制主要是以下四种机制:
- 慢启动(慢开始)
- 拥塞避免
- 快速重传
- 快速恢复
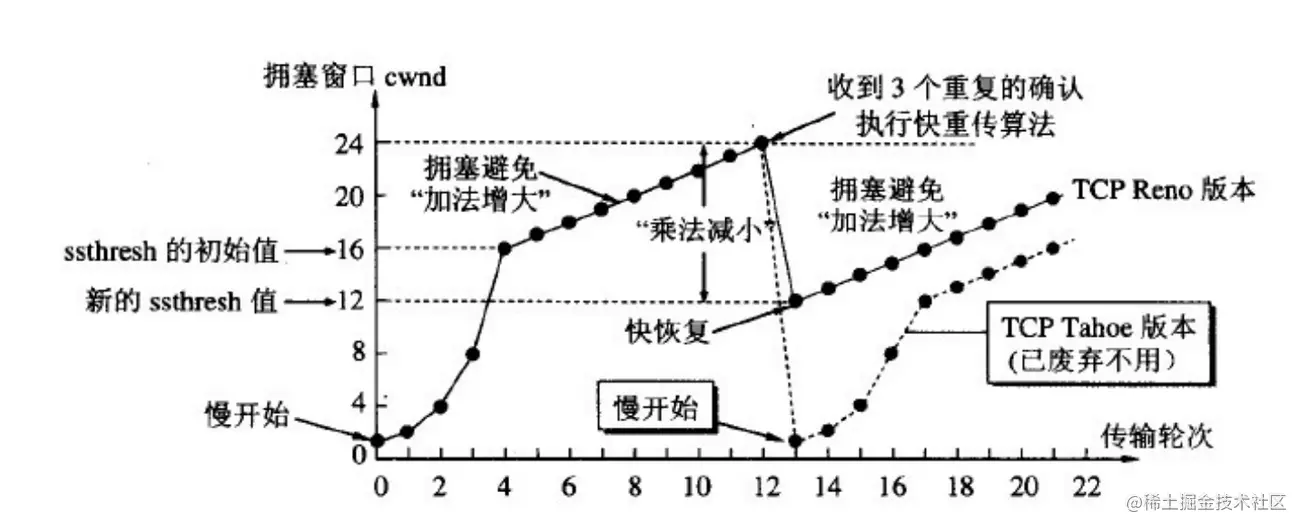
(1)慢启动(慢开始)
- 在开始发送的时候设置 cwnd = 1(cwnd 指的是拥塞窗口)
- 思路:开始的时候不要发送大量数据,而是先测试一下网络的拥塞程度,由小到大增加拥塞窗口的大小。
- 为了防止 cwnd 增长过大引起网络拥塞,设置一个慢开始门限(ssthresh 状态变量)
- 当 cnwd < ssthresh,使用慢开始算法
- 当 cnwd = ssthresh,既可使用慢开始算法,也可以使用拥塞避免算法
- 当 cnwd > ssthresh,使用拥塞避免算法
(2)拥塞避免
- 拥塞避免未必能够完全避免拥塞,是说在拥塞避免阶段将拥塞窗口控制为按线性增长,使网络不容易出现阻塞。
- 思路: 让拥塞窗口 cwnd 缓慢的增大,即每经过一个返回时间 RTT 就把发送方的拥塞控制窗口加一
- 无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞,就把慢开始门限设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口设置为 1,执行慢开始算法。如图所示:
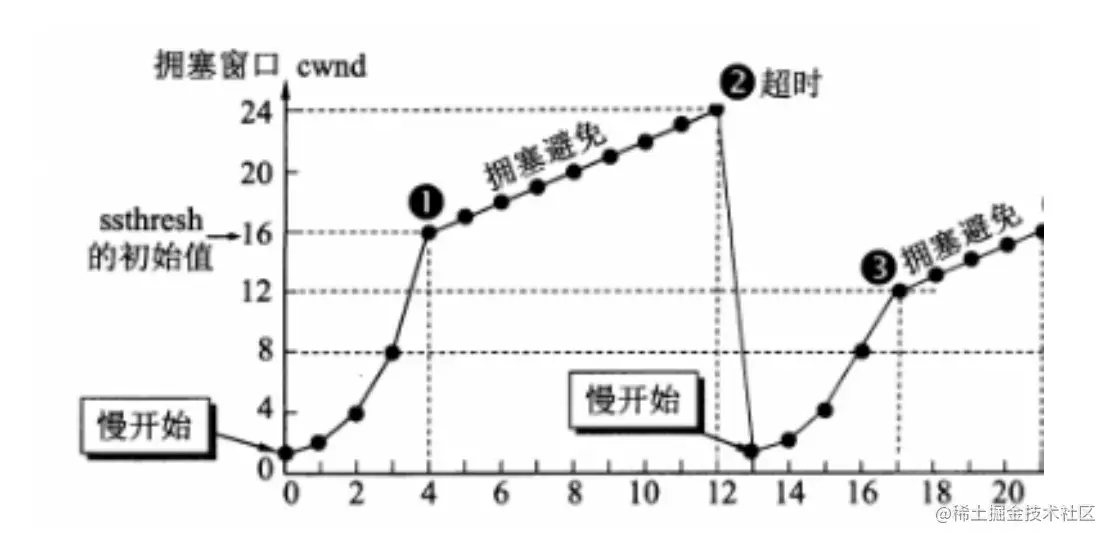 其中,判断网络出现拥塞的根据就是没有收到确认,虽然没有收到确认可能是其他原因的分组丢失,但是因为无法判定,所以都当做拥塞来处理。
其中,判断网络出现拥塞的根据就是没有收到确认,虽然没有收到确认可能是其他原因的分组丢失,但是因为无法判定,所以都当做拥塞来处理。
(3)快速重传
- 快重传要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)。发送方只要连续收到三个重复确认就立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。
- 由于不需要等待设置的重传计时器到期,能尽早重传未被确认的报文段,能提高整个网络的吞吐量
(4)快速恢复
- 当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把 ssthresh 门限减半。但是接下去并不执行慢开始算法。
- 考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将 cwnd 设置为 ssthresh 的大小,然后执行拥塞避免算法。
9.TCP 的流量控制机制
一般来说,流量控制就是为了让发送方发送数据的速度不要太快,要让接收方来得及接收。TCP 采用大小可变的滑动窗口进行流量控制,窗口大小的单位是字节。这里说的窗口大小其实就是每次传输的数据大小。
- 当一个连接建立时,连接的每一端分配一个缓冲区来保存输入的数据,并将缓冲区的大小发送给另一端。
- 当数据到达时,接收方发送确认,其中包含了自己剩余的缓冲区大小。(剩余的缓冲区空间的大小被称为窗口,指出窗口大小的通知称为窗口通告 。接收方在发送的每一确认中都含有一个窗口通告。)
- 如果接收方应用程序读数据的速度能够与数据到达的速度一样快,接收方将在每一确认中发送一个正的窗口通告。
- 如果发送方操作的速度快于接收方,接收到的数据最终将充满接收方的缓冲区,导致接收方通告一个零窗口 。发送方收到一个零窗口通告时,必须停止发送,直到接收方重新通告一个正的窗口。
10.TCP 的可靠传输机制
TCP 的可靠传输机制是基于连续 ARQ 协议和滑动窗口协议的。
TCP 协议在发送方维持了一个发送窗口,发送窗口以前的报文段是已经发送并确认了的报文段,发送窗口中包含了已经发送但 未确认的报文段和允许发送但还未发送的报文段,发送窗口以后的报文段是缓存中还不允许发送的报文段。当发送方向接收方发 送报文时,会依次发送窗口内的所有报文段,并且设置一个定时器,这个定时器可以理解为是最早发送但未收到确认的报文段。 如果在定时器的时间内收到某一个报文段的确认回答,则滑动窗口,将窗口的首部向后滑动到确认报文段的后一个位置,此时如 果还有已发送但没有确认的报文段,则重新设置定时器,如果没有了则关闭定时器。如果定时器超时,则重新发送所有已经发送 但还未收到确认的报文段,并将超时的间隔设置为以前的两倍。当发送方收到接收方的三个冗余的确认应答后,这是一种指示, 说明该报文段以后的报文段很有可能发生丢失了,那么发送方会启用快速重传的机制,就是当前定时器结束前,发送所有的已发 送但确认的报文段。
接收方使用的是累计确认的机制,对于所有按序到达的报文段,接收方返回一个报文段的肯定回答。如果收到了一个乱序的报文 段,那么接方会直接丢弃,并返回一个最近的按序到达的报文段的肯定回答。使用累计确认保证了返回的确认号之前的报文段都 已经按序到达了,所以发送窗口可以移动到已确认报文段的后面。
发送窗口的大小是变化的,它是由接收窗口剩余大小和网络中拥塞程度来决定的,TCP 就是通过控制发送窗口的长度来控制报文 段的发送速率。
但是 TCP 协议并不完全和滑动窗口协议相同,因为许多的 TCP 实现会将失序的报文段给缓存起来,并且发生重传时,只会重 传一个报文段,因此 TCP 协议的可靠传输机制更像是窗口滑动协议和选择重传协议的一个混合体。
TCP 的可靠传输机制是基于连续 ARQ 协议和滑动窗口协议的。
发送窗口的大小是变化的,它是由接收窗口剩余大小和网络中拥塞程度来决定的,TCP 就是通过控制发送窗口的长度来控制报文段的发送速率。
自动重传请求 ARQ
1,数据帧出错或丢失—超时重传
等待时间超过预设时间,没有收到确认号,则重传数据。
2,确认信号丢失:
发送方重传,接收方丢弃重复的分组,但依旧发送确认信息
3,确认信息迟到:
发送发重传,接收方丢弃重复的分组,收到迟到的确认信息但是不采取行动
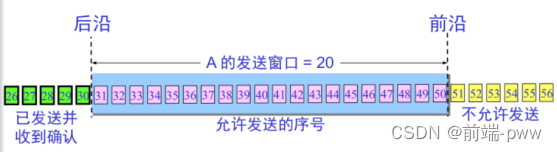
滑动窗口原理
- 在接收端和发送端分别设置发送窗口和接收窗口。
发送窗口大小代表在还没有收到对方确认消息的情况下,发送端最多可以发送多少数据。
接收窗口中是期望接收的数据的序号。
接收窗口向前滑动时,发送窗口才可能向前滑动。
发送端:
◆ 只允许序列号在发送窗口内的数据发送
◆ 未收到确认前,发送窗口位置不变。
◆ 若发送窗口内的序号都已用完,但还没有再收到确认,必须停止发送。
起始的序号发送完并接收到确认号,才可以移动窗口
接收端
◆ 只有当收到的数据的发送序号落入接收窗口时,才允许接收。
◆ 接收端按顺序接收数据后,接收窗口向前滑动,同时向发送方发送确认。
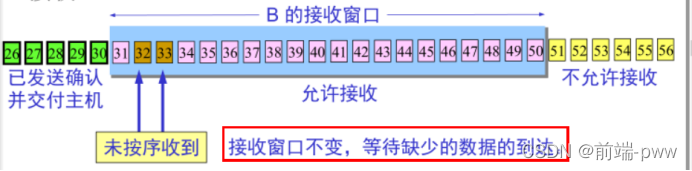
只有在窗口内的序号才可以接收,前面的序号接收到就可以滑动窗口
11.TCP 粘包是怎么回事,如何处理?
默认情况下, TCP 连接会启⽤延迟传送算法 (Nagle 算法), 在数据发送之前缓存他们. 如果短时间有多个数据发送, 会缓冲到⼀起作⼀次发送 (缓冲⼤⼩⻅ socket.bufferSize ), 这样可以减少 IO 消耗提⾼性能.
如果是传输⽂件的话, 那么根本不⽤处理粘包的问题, 来⼀个包拼⼀个包就好了。但是如果是多条消息, 或者是别的⽤途的数据那么就需要处理粘包.
下面看⼀个例⼦, 连续调⽤两次 send 分别发送两段数据 data1 和 data2, 在接收端有以下⼏种常⻅的情况: A. 先接收到 data1, 然后接收到 data2 . B. 先接收到 data1 的部分数据, 然后接收到 data1 余下的部分以及 data2 的全部. C. 先接收到了 data1 的全部数据和 data2 的部分数据, 然后接收到了 data2 的余下的数据. D. ⼀次性接收到了 data1 和 data2 的全部数据.
其中的 BCD 就是我们常⻅的粘包的情况. ⽽对于处理粘包的问题, 常⻅的解决⽅案有:
- 多次发送之前间隔⼀个等待时间:只需要等上⼀段时间再进⾏下⼀次 send 就好, 适⽤于交互频率特别低的场景. 缺点也很明显, 对于⽐较频繁的场景⽽⾔传输效率实在太低,不过⼏乎不⽤做什么处理.
- 关闭 Nagle 算法:关闭 Nagle 算法, 在 Node.js 中你可以通过 socket.setNoDelay() ⽅法来关闭 Nagle 算法, 让每⼀次 send 都不缓冲直接发送。该⽅法⽐较适⽤于每次发送的数据都⽐较⼤ (但不是⽂件那么⼤), 并且频率不是特别⾼的场景。如果是每次发送的数据量⽐较⼩, 并且频率特别⾼的, 关闭 Nagle 纯属⾃废武功。另外, 该⽅法不适⽤于⽹络较差的情况, 因为 Nagle 算法是在服务端进⾏的包合并情况, 但是如果短时间内客户端的⽹络情况不好, 或者应⽤层由于某些原因不能及时将 TCP 的数据 recv, 就会造成多个包在客户端缓冲从⽽粘包的情况。 (如果是在稳定的机房内部通信那么这个概率是⽐较⼩可以选择忽略的)
- 进⾏封包/拆包: 封包/拆包是⽬前业内常⻅的解决⽅案了。即给每个数据包在发送之前, 于其前/后放⼀些有特征的数据, 然后收到数据的时 候根据特征数据分割出来各个数据包。
12.为什么udp不会粘包?
- TCP 协议是⾯向流的协议,UDP 是⾯向消息的协议。UDP 段都是⼀条消息,应⽤程序必须以消息为单位提取数据,不能⼀次提取任意字节的数据
- UDP 具有保护消息边界,在每个 UDP 包中就有了消息头(消息来源地址,端⼝等信息),这样对于接收端来说就容易进⾏区分处理了。传输协议把数据当作⼀条独⽴的消息在⽹上传输,接收端只能接收独⽴的消息。接收端⼀次只能接收发送端发出的⼀个数据包,如果⼀次接受数据的⼤⼩⼩于发送端⼀次发送的数据⼤⼩,就会丢失⼀部分数据,即使丢失,接受端也不会分两次去接收。
IP
1.基本认识
IP 在 TCP/IP 参考模型中处于第三层,也就是网络层。
网络层的主要作用是:实现主机与主机之间的通信,也叫点对点(end to end)通信。
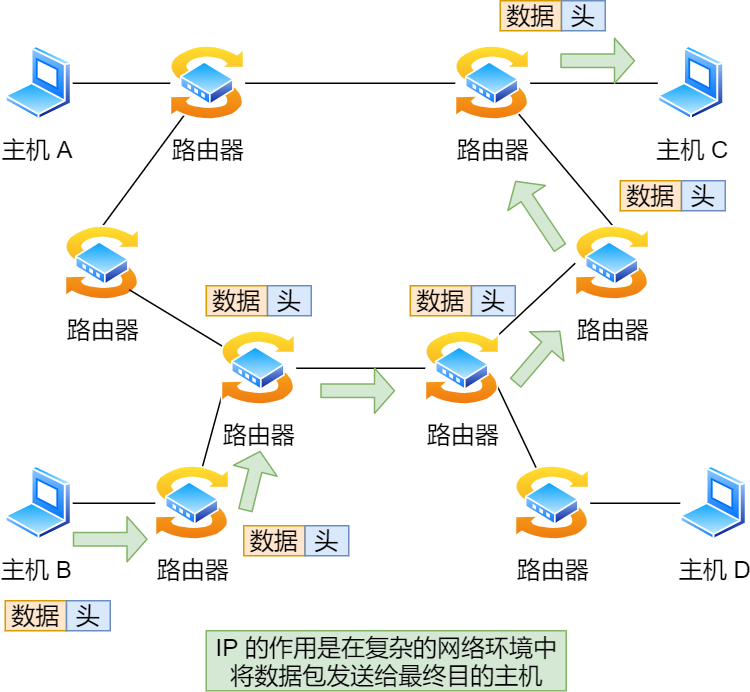
网络层与数据链路层有什么关系呢?
有的小伙伴分不清 IP(网络层) 和 MAC (数据链路层)之间的区别和关系。
其实很容易区分,在上面我们知道 IP 的作用是主机之间通信用的,而 MAC 的作用则是实现「直连」的两个设备之间通信,而 IP 则负责在「没有直连」的两个网络之间进行通信传输。
举个生活的栗子,小林要去一个很远的地方旅行,制定了一个行程表,其间需先后乘坐飞机、地铁、公交车才能抵达目的地,为此小林需要买飞机票,地铁票等。
飞机票和地铁票都是去往特定的地点的,每张票只能够在某一限定区间内移动,此处的「区间内」就如同通信网络中数据链路。
在区间内移动相当于数据链路层,充当区间内两个节点传输的功能,区间内的出发点好比源 MAC 地址,目标地点好比目的 MAC 地址。
整个旅游行程表就相当于网络层,充当远程定位的功能,行程的开始好比源 IP,行程的终点好比目的 IP 地址。
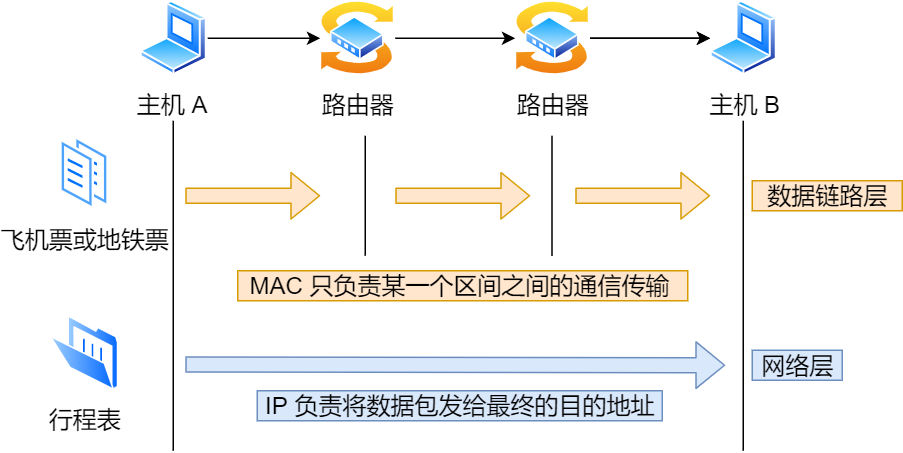
如果小林只有行程表而没有车票,就无法搭乘交通工具到达目的地。相反,如果除了车票而没有行程表,恐怕也很难到达目的地。因为小林不知道该坐什么车,也不知道该在哪里换乘。
因此,只有两者兼备,既有某个区间的车票又有整个旅行的行程表,才能保证到达目的地。与此类似,计算机网络中也需要「数据链路层」和「网络层」这个分层才能实现向最终目标地址的通信。
还有重要一点,旅行途中我们虽然不断变化了交通工具,但是旅行行程的起始地址和目的地址始终都没变。其实,在网络中数据包传输中也是如此,源 IP 地址和目标 IP 地址在传输过程中是不会变化的,只有源 MAC 地址和目标 MAC 一直在变化。**
2.基础知识
在 TCP/IP 网络通信时,为了保证能正常通信,每个设备都需要配置正确的 IP 地址,否则无法实现正常的通信。
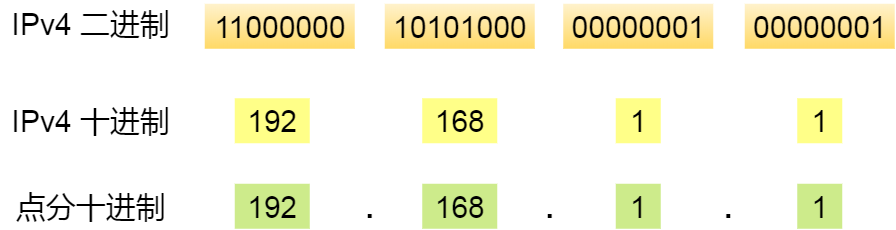
IP 地址(IPv4 地址)由 32 位正整数来表示,IP 地址在计算机是以二进制的方式处理的。
而人类为了方便记忆采用了点分十进制的标记方式,也就是将 32 位 IP 地址以每 8 位为组,共分为 4 组,每组以「.」隔开,再将每组转换成十进制。
那么,IP 地址最大值也就是

也就说,最大允许 43 亿台计算机连接到网络。
实际上,IP 地址并不是根据主机台数来配置的,而是以网卡。像服务器、路由器等设备都是有 2 个以上的网卡,也就是它们会有 2 个以上的 IP 地址。

因此,让 43 亿台计算机全部连网其实是不可能的,更何况 IP 地址是由「网络标识」和「主机标识」这两个部分组成的,所以实际能够连接到网络的计算机个数更是少了很多。
可能有的小伙伴提出了疑问,现在不仅电脑配了 IP, 手机、IPad 等电子设备都配了 IP 呀,照理来说肯定会超过 43 亿啦,那是怎么能够支持这么多 IP 的呢?
因为会根据一种可以更换 IP 地址的技术 NAT,使得可连接计算机数超过 43 亿台。 NAT 技术后续会进一步讨论和说明。
IP 地址的分类
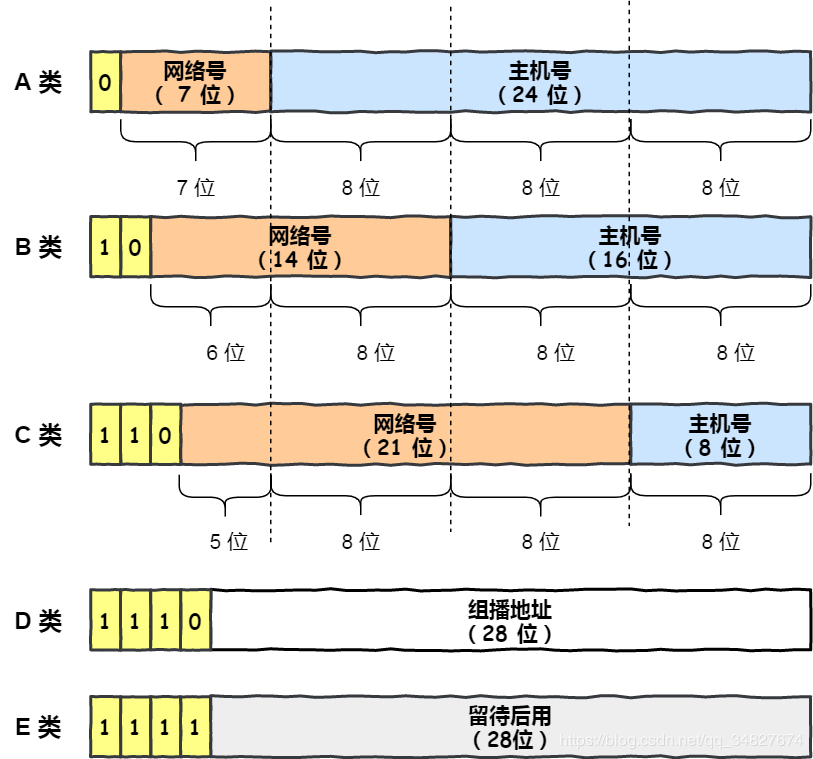
互联网诞生之初,IP 地址显得很充裕,于是计算机科学家们设计了分类地址。
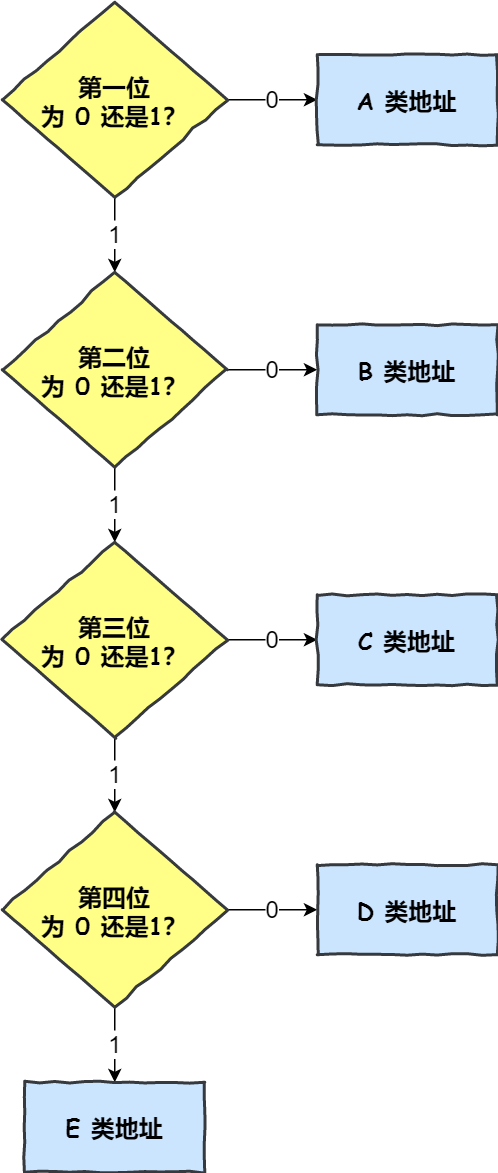
IP 地址分类成了 5 种类型,分别是 A 类、B 类、C 类、D 类、E 类。
上图中黄色部分为分类号,用以区分 IP 地址类别。
什么是 A、B、C 类地址?
其中对于 A、B、C 类主要分为两个部分,分别是网络号和主机号。这很好理解,好比小林是 A 小区 1 栋 101 号,你是 B 小区 1 栋 101 号。
我们可以用下面这个表格, 就能很清楚的知道 A、B、C 分类对应的地址范围、最大主机个数。

A、B、C 分类地址最大主机个数是如何计算的呢?
最大主机个数,就是要看主机号的位数,如 C 类地址的主机号占 8 位,那么 C 类地址的最大主机个数:
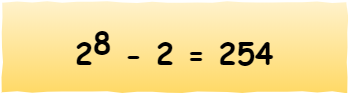
为什么要减 2 呢?
因为在 IP 地址中,有两个 IP 是特殊的,分别是主机号全为 1 和 全为 0 地址。
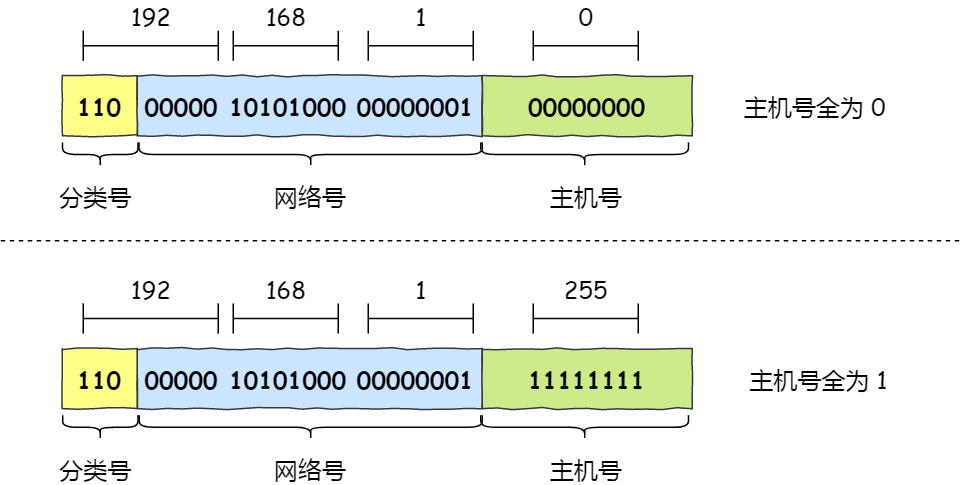
- 主机号全为 1 指定某个网络下的所有主机,用于广播
- 主机号全为 0 指定某个网络
因此,在分配过程中,应该去掉这两种情况。
广播地址用于什么?
广播地址用于在同一个链路中相互连接的主机之间发送数据包。
学校班级中就有广播的例子,在准备上课的时候,通常班长会喊:“上课, 全体起立!”,班里的同学听到这句话是不是全部都站起来了?这个句话就有广播的含义。
当主机号全为 1 时,就表示该网络的广播地址。例如把 172.20.0.0/16 用二进制表示如下:
10101100.00010100.00000000.00000000
将这个地址的主机部分全部改为 1,则形成广播地址:
10101100.00010100.11111111.11111111
再将这个地址用十进制表示,则为 172.20.255.255。
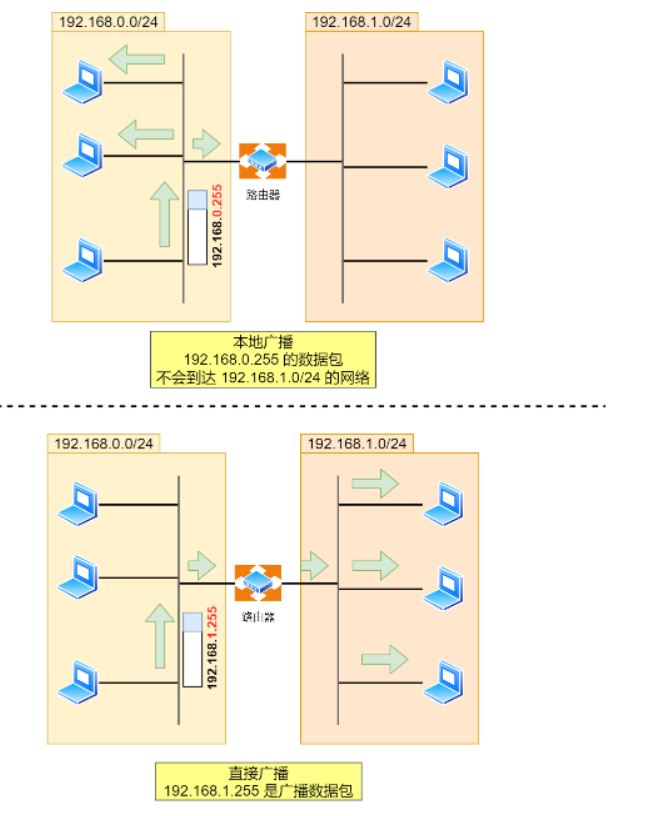
广播地址可以分为本地广播和直接广播两种。
- 在本网络内广播的叫做本地广播。例如网络地址为 192.168.0.0/24 的情况下,广播地址是 192.168.0.255 。因为这个广播地址的 IP 包会被路由器屏蔽,所以不会到达 192.168.0.0/24 以外的其他链路上。
- 在不同网络之间的广播叫做直接广播。例如网络地址为 192.168.0.0/24 的主机向 192.168.1.255/24 的目标地址发送 IP 包。收到这个包的路由器,将数据转发给 192.168.1.0/24,从而使得所有 192.168.1.1~192.168.1.254 的主机都能收到这个包(由于直接广播有一定的安全问题,多数情况下会在路由器上设置为不转发。) 。
什么是 D、E 类地址?
而 D 类和 E 类地址是没有主机号的,所以不可用于主机 IP,D 类常被用于多播,E 类是预留的分类,暂时未使用。

多播地址用于什么?
多播用于将包发送给特定组内的所有主机。
还是举班级的栗子,老师说:“最后一排的同学,上来做这道数学题。”,老师指定的是最后一排的同学,也就是多播的含义了。
由于广播无法穿透路由,若想给其他网段发送同样的包,就可以使用可以穿透路由的多播。
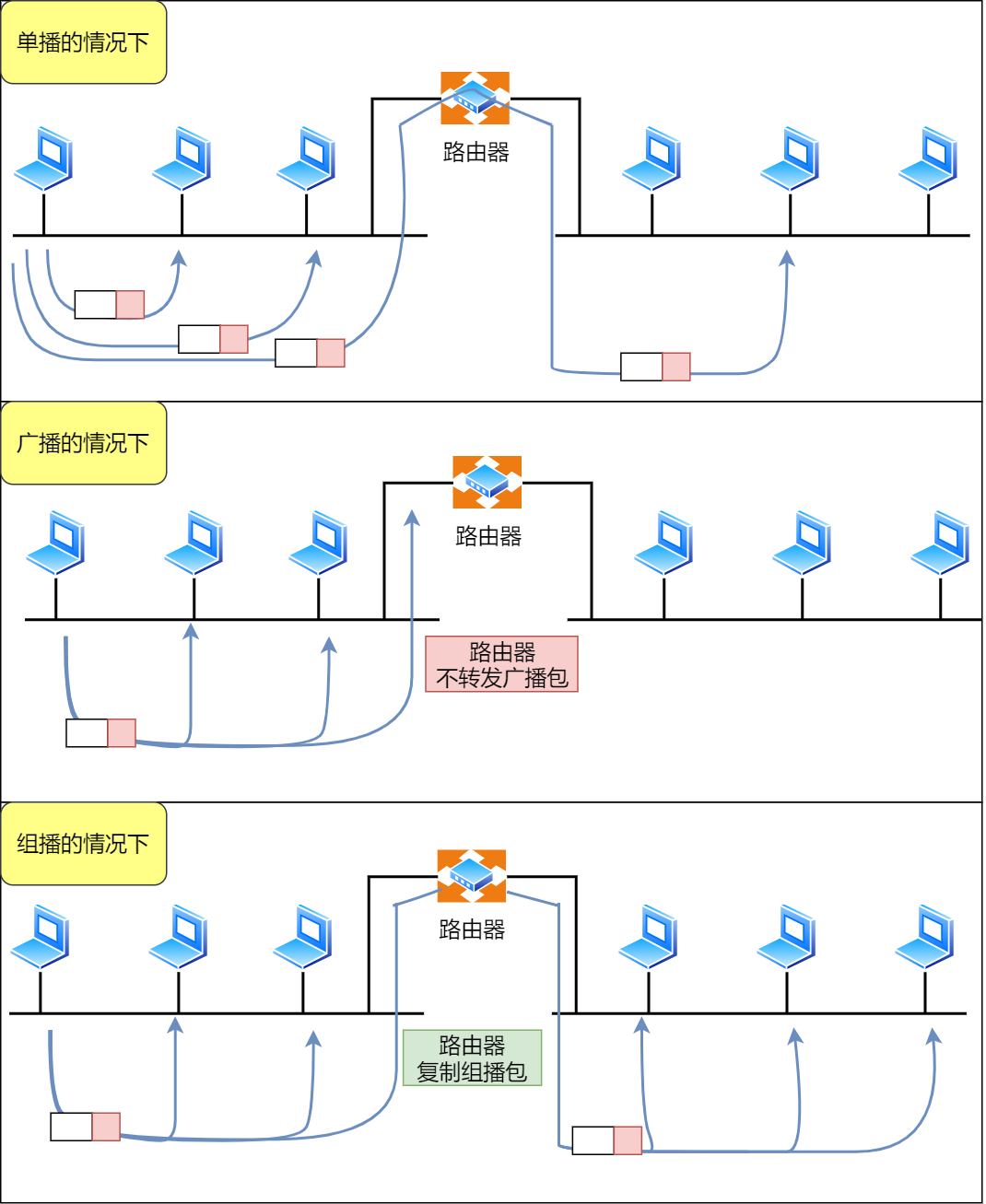
多播使用的 D 类地址,其前四位是 1110 就表示是多播地址,而剩下的 28 位是多播的组编号。
从 224.0.0.0 ~ 239.255.255.255 都是多播的可用范围,其划分为以下三类:
- 224.0.0.0 ~ 224.0.0.255 为预留的组播地址,只能在局域网中,路由器是不会进行转发的。
- 224.0.1.0 ~ 238.255.255.255 为用户可用的组播地址,可以用于 Internet 上。
- 239.0.0.0 ~ 239.255.255.255 为本地管理组播地址,可供内部网在内部使用,仅在特定的本地范围内有效。
IP 分类的优点
不管是路由器还是主机解析到一个 IP 地址时候,我们判断其 IP 地址的首位是否为 0,为 0 则为 A 类地址,那么就能很快的找出网络地址和主机地址。
其余分类判断方式参考如下图:
所以,这种分类地址的优点就是简单明了、选路(基于网络地址)简单。
IP 分类的缺点
缺点一
同一网络下没有地址层次,比如一个公司里用了 B 类地址,但是可能需要根据生产环境、测试环境、开发环境来划分地址层次,而这种 IP 分类是没有地址层次划分的功能,所以这就缺少地址的灵活性。
缺点二
A、B、C 类有个尴尬处境,就是不能很好的与现实网络匹配。
- C 类地址能包含的最大主机数量实在太少了,只有 254 个,估计一个网吧都不够用。
- 而 B 类地址能包含的最大主机数量又太多了,6 万多台机器放在一个网络下面,一般的企业基本达不到这个规模,闲着的地址就是浪费。
这两个缺点,都可以在 CIDR 无分类地址解决。
无分类地址 CIDR
正因为 IP 分类存在许多缺点,所以后面提出了无分类地址的方案,即 CIDR。
这种方式不再有分类地址的概念,32 比特的 IP 地址被划分为两部分,前面是网络号,后面是主机号。
怎么划分网络号和主机号的呢?
表示形式 a.b.c.d/x,其中 /x 表示前 x 位属于网络号, x 的范围是 0 ~ 32,这就使得 IP 地址更加具有灵活性。
比如 10.100.122.2/24,这种地址表示形式就是 CIDR,/24 表示前 24 位是网络号,剩余的 8 位是主机号。
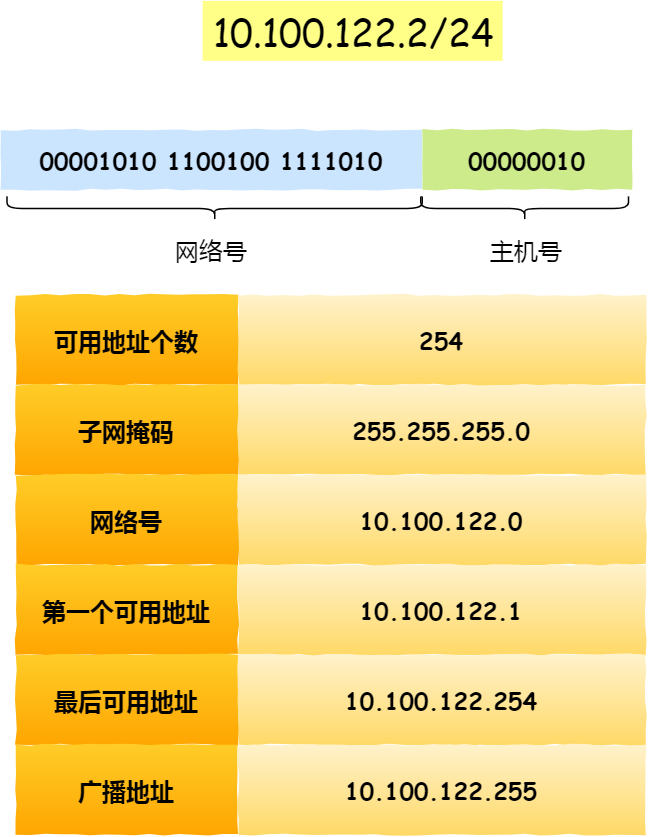
还有另一种划分网络号与主机号形式,那就是子网掩码,掩码的意思就是掩盖掉主机号,剩余的就是网络号。
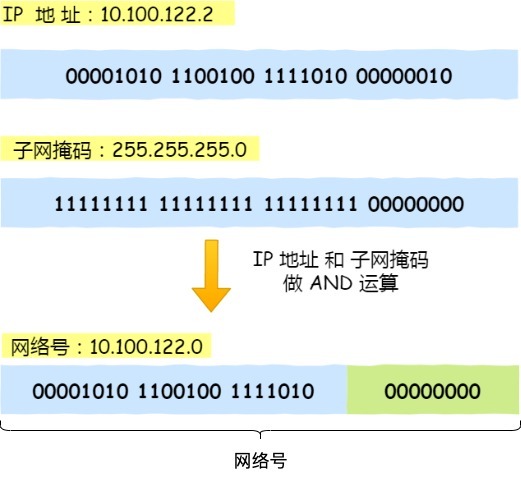
将子网掩码和 IP 地址按位计算 AND,就可得到网络号。
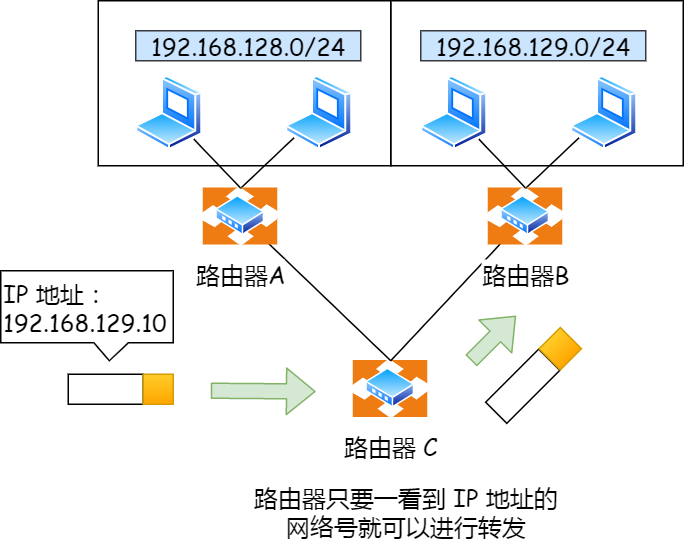
为什么要分离网络号和主机号?
因为两台计算机要通讯,首先要判断是否处于同一个广播域内,即网络地址是否相同。如果网络地址相同,表明接受方在本网络上,那么可以把数据包直接发送到目标主机。
路由器寻址工作中,也就是通过这样的方式来找到对应的网络号的,进而把数据包转发给对应的网络内。
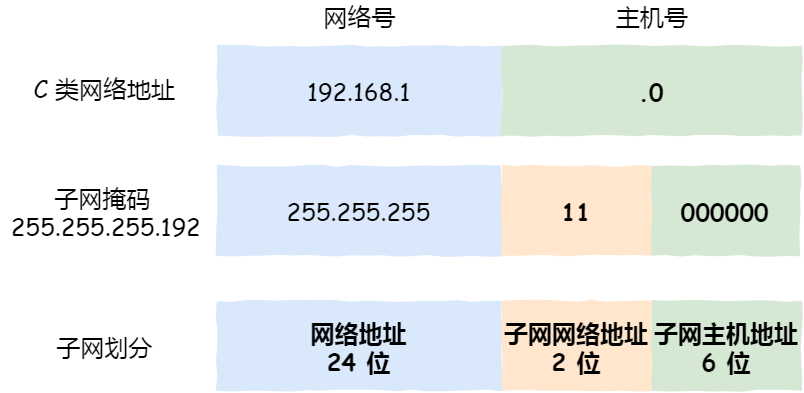
怎么进行子网划分?
在上面我们知道可以通过子网掩码划分出网络号和主机号,那实际上子网掩码还有一个作用,那就是划分子网。
子网划分实际上是将主机地址分为两个部分:子网网络地址和子网主机地址。形式如下:

- 未做子网划分的 ip 地址:网络地址+主机地址
- 做子网划分后的 ip 地址:网络地址+(子网网络地址+子网主机地址)
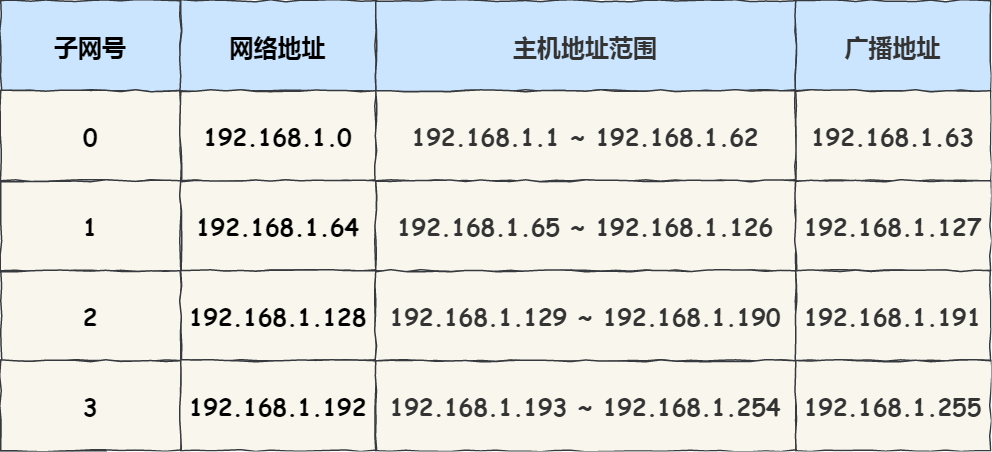
假设对 C 类地址进行子网划分,网络地址 192.168.1.0,使用子网掩码 255.255.255.192 对其进行子网划分。
C 类地址中前 24 位是网络号,最后 8 位是主机号,根据子网掩码可知从 8 位主机号中借用 2 位作为子网号。
由于子网网络地址被划分成 2 位,那么子网地址就有 4 个,分别是 00、01、10、11,具体划分如下图:

划分后的 4 个子网如下表格:
公有 IP 地址与私有 IP 地址
在 A、B、C 分类地址,实际上有分公有 IP 地址和私有 IP 地址。
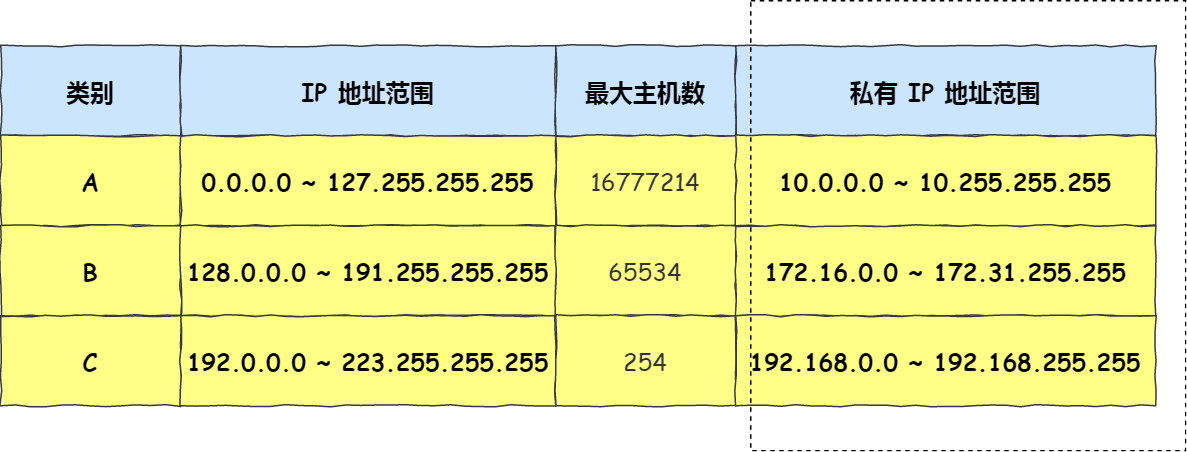
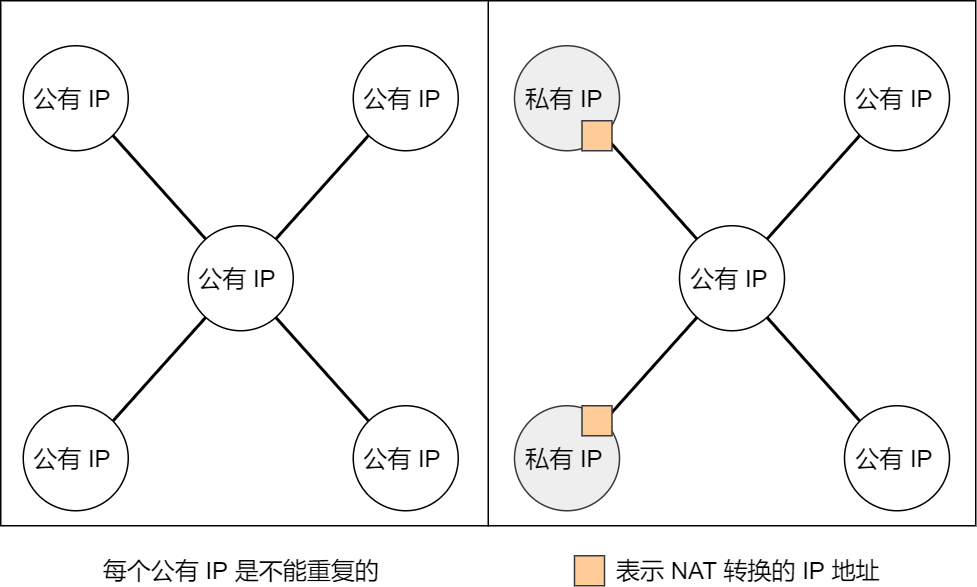
平时我们办公室、家里、学校用的 IP 地址,一般都是私有 IP 地址。因为这些地址允许组织内部的 IT 人员自己管理、自己分配,而且可以重复。因此,你学校的某个私有 IP 地址和我学校的可以是一样的。
就像每个小区都有自己的楼编号和门牌号,你小区家可以叫 1 栋 101 号,我小区家也可以叫 1 栋 101,没有任何问题。但一旦出了小区,就需要带上中山路 666 号(公网 IP 地址),是国家统一分配的,不能两个小区都叫中山路 666。
所以,公有 IP 地址是有个组织统一分配的,假设你要开一个博客网站,那么你就需要去申请购买一个公有 IP,这样全世界的人才能访问。并且公有 IP 地址基本上要在整个互联网范围内保持唯一。
公有 IP 地址由谁管理呢?
私有 IP 地址通常是内部的 IT 人员管理,公有 IP 地址是由 ICANN 组织管理,中文叫「互联网名称与数字地址分配机构」。
IANA 是 ICANN 的其中一个机构,它负责分配互联网 IP 地址,是按州的方式层层分配。
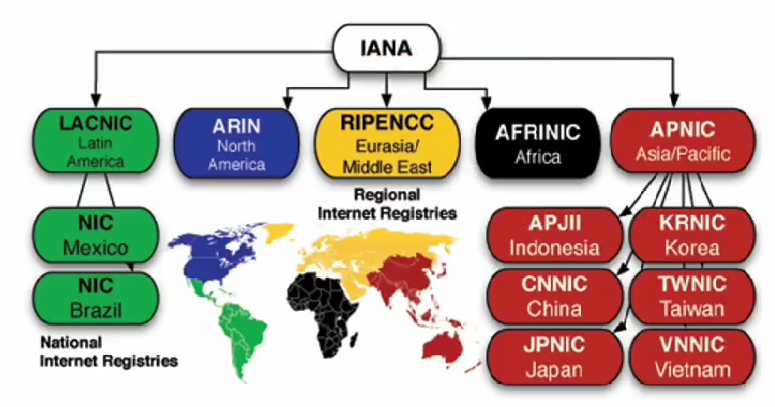
- ARIN 北美地区
- LACNIC 拉丁美洲和一些加勒比群岛
- RIPE NCC 欧洲、中东和中亚
- AfriNIC 非洲地区
- APNIC 亚太地区
其中,在中国是由 CNNIC 的机构进行管理,它是中国国内唯一指定的全局 IP 地址管理的组织。
IP 地址与路由控制
IP 地址的网络地址这一部分是用于进行路由控制。
路由控制表中记录着网络地址与下一步应该发送至路由器的地址。在主机和路由器上都会有各自的路由器控制表。
在发送 IP 包时,首先要确定 IP 包首部中的目标地址,再从路由控制表中找到与该地址具有相同网络地址的记录,根据该记录将 IP 包转发给相应的下一个路由器。如果路由控制表中存在多条相同网络地址的记录,就选择相同位数最多的网络地址,也就是最长匹配。
下面以下图的网络链路作为例子说明:
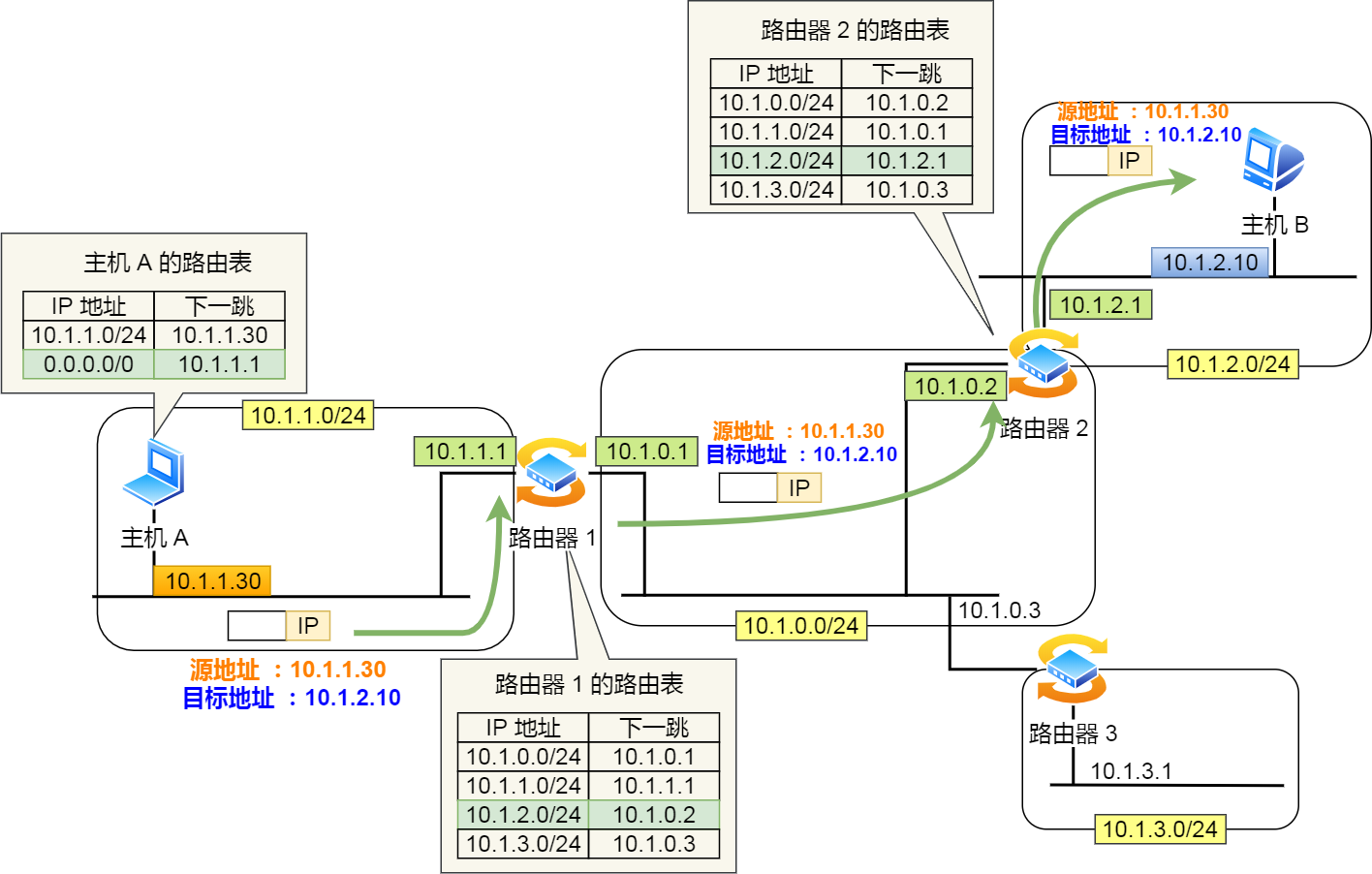
- 主机 A 要发送一个 IP 包,其源地址是
10.1.1.30和目标地址是10.1.2.10,由于没有在主机 A 的路由表找到与目标地址10.1.2.10相同的网络地址,于是包被转发到默认路由(路由器1) - 路由器
1收到 IP 包后,也在路由器1的路由表匹配与目标地址相同的网络地址记录,发现匹配到了,于是就把 IP 数据包转发到了10.1.0.2这台路由器2 - 路由器
2收到后,同样对比自身的路由表,发现匹配到了,于是把 IP 包从路由器2的10.1.2.1这个接口出去,最终经过交换机把 IP 数据包转发到了目标主机
环回地址是不会流向网络
环回地址是在同一台计算机上的程序之间进行网络通信时所使用的一个默认地址。
计算机使用一个特殊的 IP 地址 127.0.0.1 作为环回地址。与该地址具有相同意义的是一个叫做 localhost 的主机名。使用这个 IP 或主机名时,数据包不会流向网络。
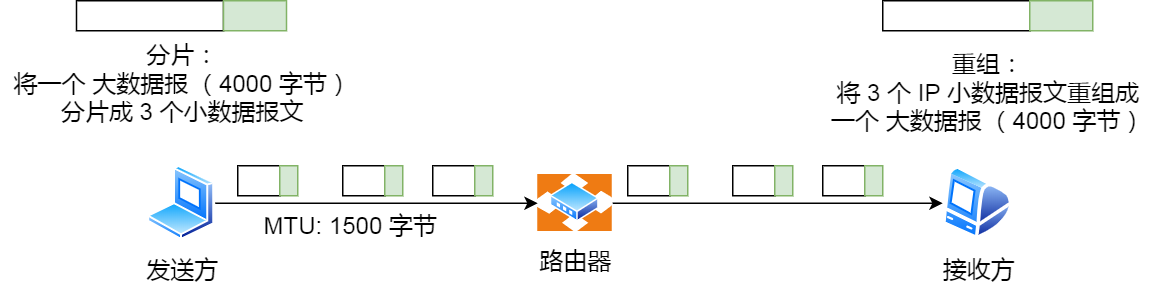
IP 分片与重组
每种数据链路的最大传输单元 MTU 都是不相同的,如 FDDI 数据链路 MTU 4352、以太网的 MTU 是 1500 字节等。
每种数据链路的 MTU 之所以不同,是因为每个不同类型的数据链路的使用目的不同。使用目的不同,可承载的 MTU 也就不同。
其中,我们最常见数据链路是以太网,它的 MTU 是 1500 字节。
那么当 IP 数据包大小大于 MTU 时, IP 数据包就会被分片。
经过分片之后的 IP 数据报在被重组的时候,只能由目标主机进行,路由器是不会进行重组的。
假设发送方发送一个 4000 字节的大数据报,若要传输在以太网链路,则需要把数据报分片成 3 个小数据报进行传输,再交由接收方重组成大数据报。
在分片传输中,一旦某个分片丢失,则会造成整个 IP 数据报作废,所以 TCP 引入了 MSS 也就是在 TCP 层进行分片不由 IP 层分片,那么对于 UDP 我们尽量不要发送一个大于 MTU 的数据报文。
IPv6 基本认识
IPv4 的地址是 32 位的,大约可以提供 42 亿个地址,但是早在 2011 年 IPv4 地址就已经被分配完了。
但是 IPv6 的地址是 128 位的,这可分配的地址数量是大的惊人,说个段子 IPv6 可以保证地球上的每粒沙子都能被分配到一个 IP 地址。
但 IPv6 除了有更多的地址之外,还有更好的安全性和扩展性,说简单点就是 IPv6 相比于 IPv4 能带来更好的网络体验。
但是因为 IPv4 和 IPv6 不能相互兼容,所以不但要我们电脑、手机之类的设备支持,还需要网络运营商对现有的设备进行升级,所以这可能是 IPv6 普及率比较慢的一个原因。
IPv6 的亮点
IPv6 不仅仅只是可分配的地址变多了,它还有非常多的亮点。
- IPv6 可自动配置,即使没有 DHCP 服务器也可以实现自动分配 IP 地址,真是便捷到即插即用啊。
- IPv6 包头包首部长度采用固定的值
40字节,去掉了包头校验和,简化了首部结构,减轻了路由器负荷,大大提高了传输的性能。 - IPv6 有应对伪造 IP 地址的网络安全功能以及防止线路窃听的功能,大大提升了安全性。
- ... (由你发现更多的亮点)
IPv6 地址的标识方法
IPv4 地址长度共 32 位,是以每 8 位作为一组,并用点分十进制的表示方式。
IPv6 地址长度是 128 位,是以每 16 位作为一组,每组用冒号 「:」 隔开。

如果出现连续的 0 时还可以将这些 0 省略,并用两个冒号 「::」隔开。但是,一个 IP 地址中只允许出现一次两个连续的冒号。

IPv6 地址的结构
IPv6 类似 IPv4,也是通过 IP 地址的前几位标识 IP 地址的种类。
IPv6 的地址主要有以下类型地址:
- 单播地址,用于一对一的通信
- 组播地址,用于一对多的通信
- 任播地址,用于通信最近的节点,最近的节点是由路由协议决定
- 没有广播地址
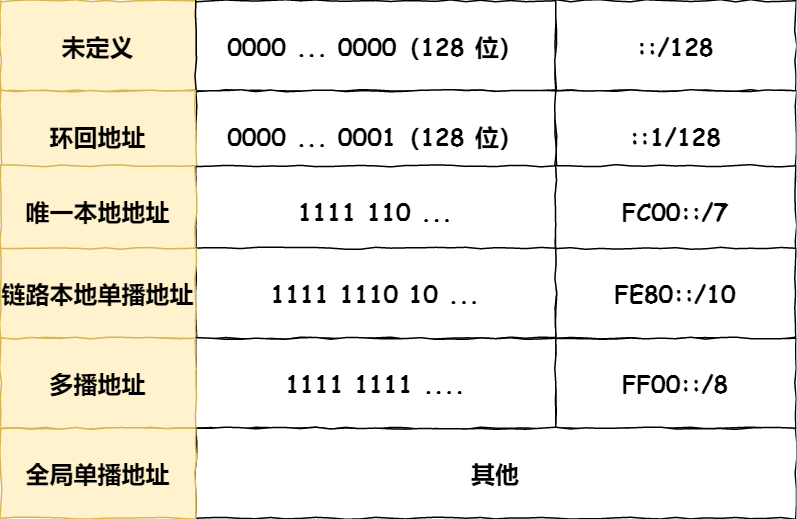
IPv6 单播地址类型
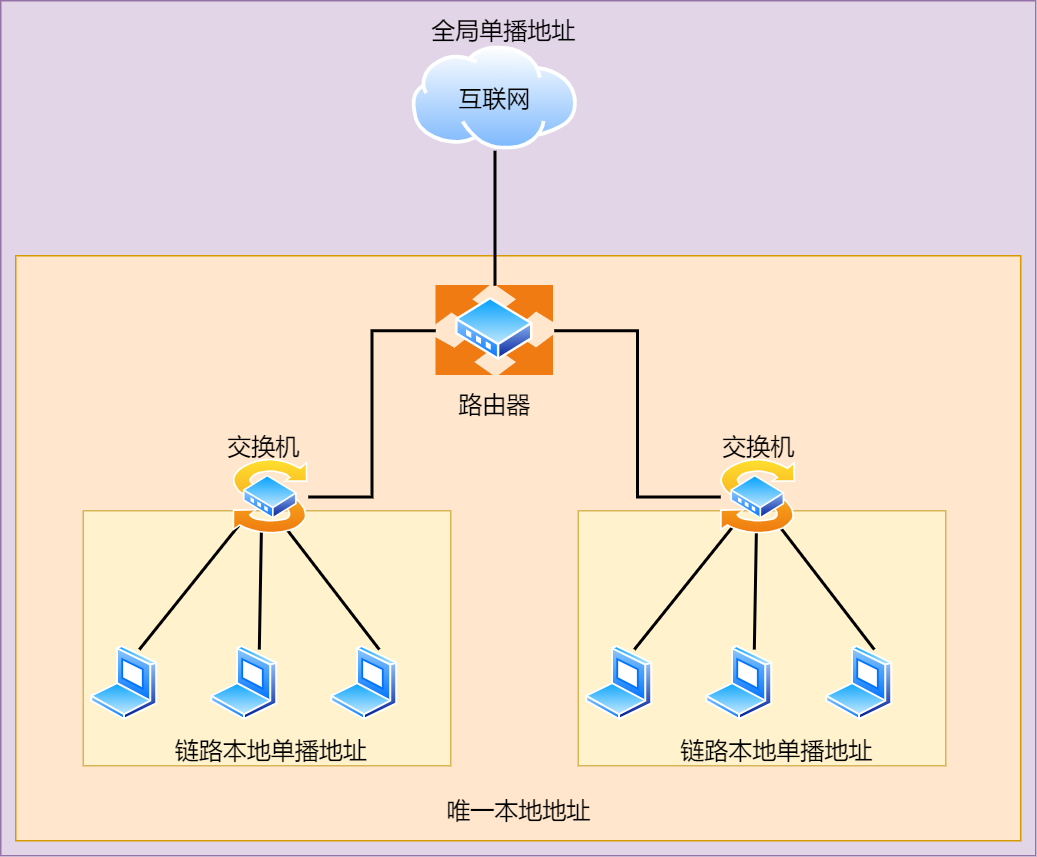
对于一对一通信的 IPv6 地址,主要划分了三类单播地址,每类地址的有效范围都不同。
- 在同一链路单播通信,不经过路由器,可以使用链路本地单播地址,IPv4 没有此类型
- 在内网里单播通信,可以使用唯一本地地址,相当于 IPv4 的私有 IP
- 在互联网通信,可以使用全局单播地址,相当于 IPv4 的公有 IP
IPv4 首部与 IPv6 首部
IPv4 首部与 IPv6 首部的差异如下图:

IPv6 相比 IPv4 的首部改进:
- 取消了首部校验和字段。 因为在数据链路层和传输层都会校验,因此 IPv6 直接取消了 IP 的校验。
- 取消了分片/重新组装相关字段。 分片与重组是耗时的过程,IPv6 不允许在中间路由器进行分片与重组,这种操作只能在源与目标主机,这将大大提高了路由器转发的速度。
- 取消选项字段。 选项字段不再是标准 IP 首部的一部分了,但它并没有消失,而是可能出现在 IPv6 首部中的「下一个首部」指出的位置上。删除该选项字段使的 IPv6 的首部成为固定长度的
40字节
3.IP 协议相关技术
跟 IP 协议相关的技术也不少,接下来说说与 IP 协议相关的重要且常见的技术。
- DNS 域名解析
- ARP 与 RARP 协议
- DHCP 动态获取 IP 地址
- NAT 网络地址转换
- ICMP 互联网控制报文协议
- IGMP 因特网组管理协
DNS
我们在上网的时候,通常使用的方式是域名,而不是 IP 地址,因为域名方便人类记忆。
那么实现这一技术的就是 DNS 域名解析,DNS 可以将域名网址自动转换为具体的 IP 地址。
域名的层级关系
DNS 中的域名都是用句点来分隔的,比如 server.com,这里的句点代表了不同层次之间的界限。
在域名中,越靠右的位置表示其层级越高。
毕竟域名是外国人发明,所以思维和中国人相反,比如说一个城市地点的时候,外国喜欢从小到大的方式顺序说起(如 XX 街道 XX 区 XX 市 XX 省),而中国则喜欢从大到小的顺序(如 XX 省 XX 市 XX 区 XX 街道)。
根域是在最顶层,它的下一层就是 com 顶级域,再下面是 server.com。
所以域名的层级关系类似一个树状结构:
- 根 DNS 服务器
- 顶级域 DNS 服务器(com)
- 权威 DNS 服务器(server.com)
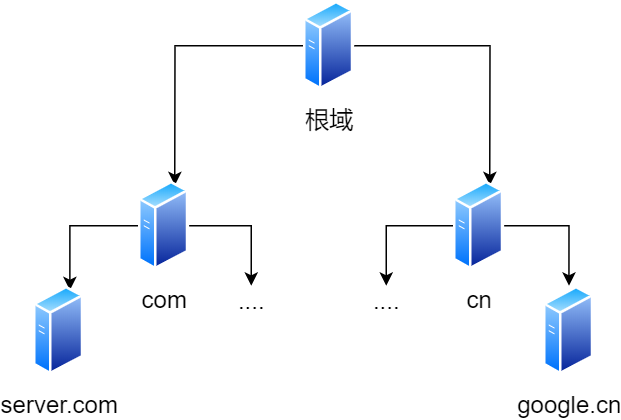
根域的 DNS 服务器信息保存在互联网中所有的 DNS 服务器中。这样一来,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器了。
因此,客户端只要能够找到任意一台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再一路顺藤摸瓜找到位于下层的某台目标 DNS 服务器。
域名解析的工作流程
浏览器首先看一下自己的缓存里有没有,如果没有就向操作系统的缓存要,还没有就检查本机域名解析文件 hosts,如果还是没有,就会 DNS 服务器进行查询,查询的过程如下:
- 客户端首先会发出一个 DNS 请求,问 server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
- 本地域名服务器收到客户端的请求后,如果缓存里的表格能找到 server.com,则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:“老大, 能告诉我 server.com 的 IP 地址吗?” 根域名服务器是最高层次的,它不直接用于域名解析,但能指明一条道路。
- 根 DNS 收到来自本地 DNS 的请求后,发现后置是 .com,说:“server.com 这个域名归 .com 区域管理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。”
- 本地 DNS 收到顶级域名服务器的地址后,发起请求问“老二, 你能告诉我 server.com 的 IP 地址吗?”
- 顶级域名服务器说:“我给你负责 server.com 区域的权威 DNS 服务器的地址,你去问它应该能问到”。
- 本地 DNS 于是转向问权威 DNS 服务器:“老三,server.com 对应的 IP 是啥呀?” server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
- 本地 DNS 再将 IP 地址返回客户端,客户端和目标建立连接。
至此,我们完成了 DNS 的解析过程。现在总结一下,整个过程我画成了一个图。
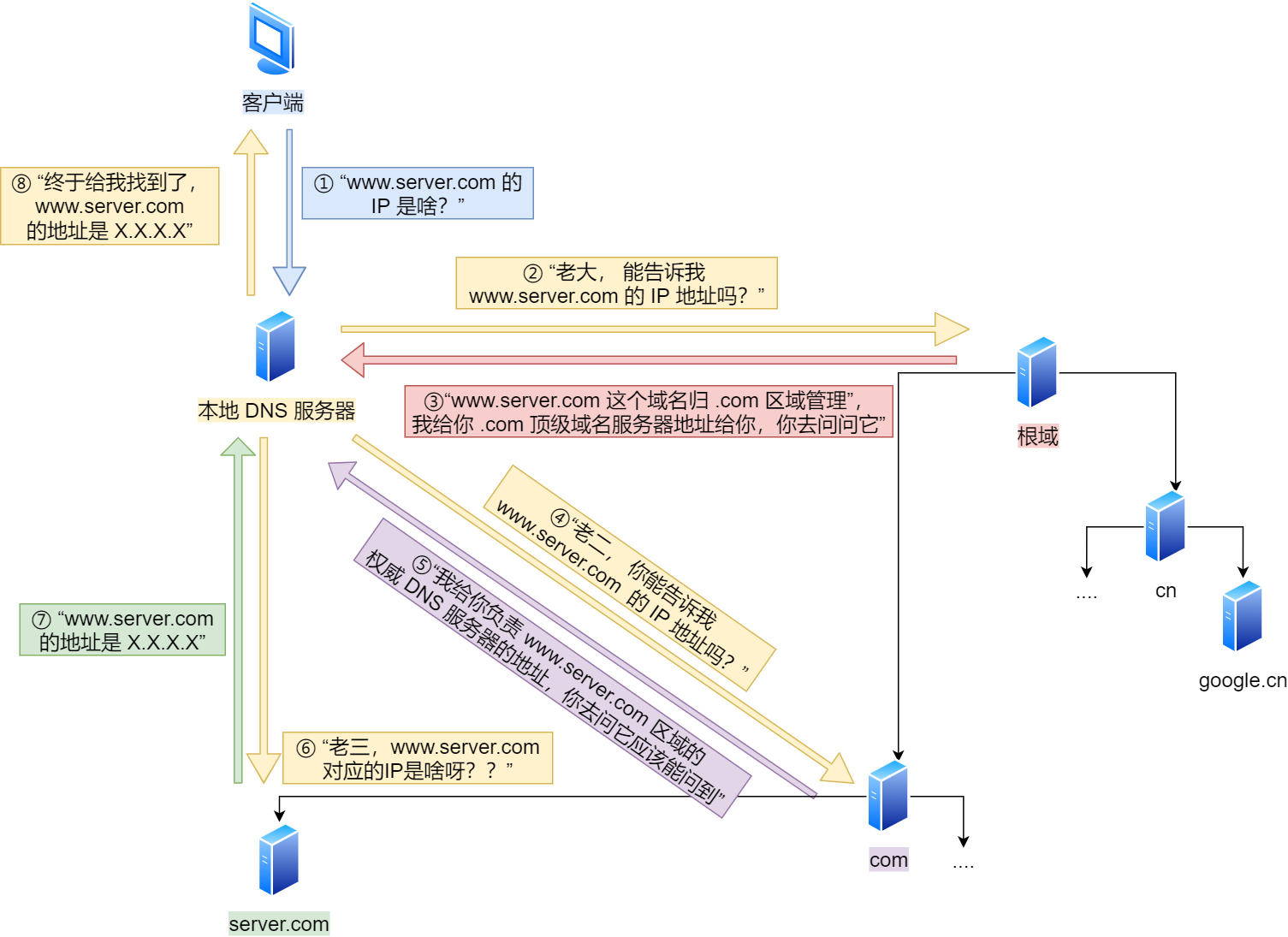
DNS 域名解析的过程蛮有意思的,整个过程就和我们日常生活中找人问路的过程类似,只指路不带路。
ARP
在传输一个 IP 数据报的时候,确定了源 IP 地址和目标 IP 地址后,就会通过主机「路由表」确定 IP 数据包下一跳。然而,网络层的下一层是数据链路层,所以我们还要知道「下一跳」的 MAC 地址。
由于主机的路由表中可以找到下一跳的 IP 地址,所以可以通过 ARP 协议,求得下一跳的 MAC 地址。
那么 ARP 又是如何知道对方 MAC 地址的呢?
简单地说,ARP 是借助 ARP 请求与 ARP 响应两种类型的包确定 MAC 地址的。
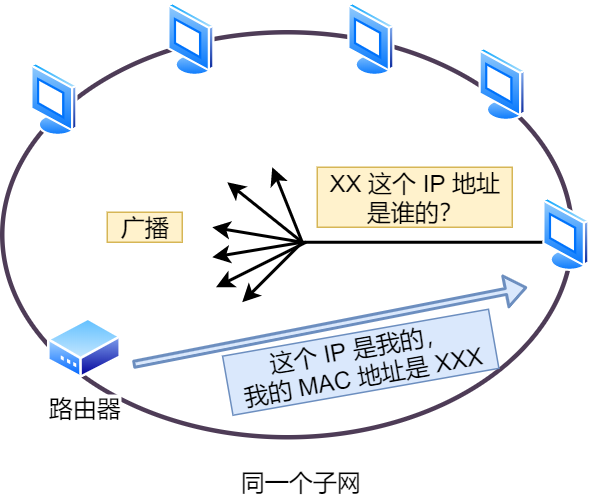
- 主机会通过广播发送 ARP 请求,这个包中包含了想要知道的 MAC 地址的主机 IP 地址。
- 当同个链路中的所有设备收到 ARP 请求时,会去拆开 ARP 请求包里的内容,如果 ARP 请求包中的目标 IP 地址与自己的 IP 地址一致,那么这个设备就将自己的 MAC 地址塞入 ARP 响应包返回给主机。
操作系统通常会把第一次通过 ARP 获取的 MAC 地址缓存起来,以便下次直接从缓存中找到对应 IP 地址的 MAC 地址。
不过,MAC 地址的缓存是有一定期限的,超过这个期限,缓存的内容将被清除。
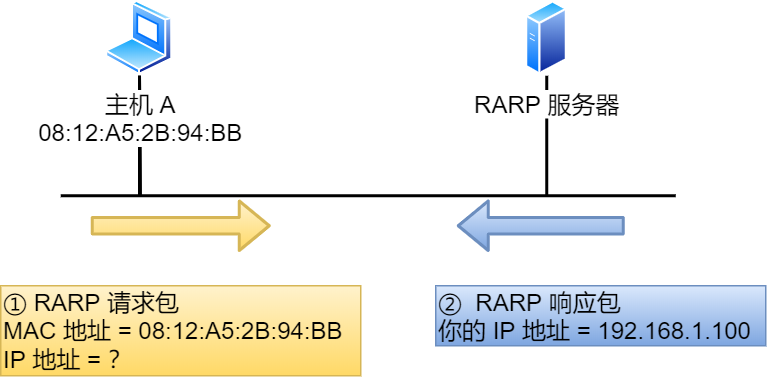
RARP 协议你知道是什么吗?
ARP 协议是已知 IP 地址求 MAC 地址,那 RARP 协议正好相反,它是已知 MAC 地址求 IP 地址。例如将打印机服务器等小型嵌入式设备接入到网络时就经常会用得到。
通常这需要架设一台 RARP 服务器,在这个服务器上注册设备的 MAC 地址及其 IP 地址。然后再将这个设备接入到网络,接着:
- 该设备会发送一条「我的 MAC 地址是 XXXX,请告诉我,我的 IP 地址应该是什么」的请求信息。
- RARP 服务器接到这个消息后返回「MAC 地址为 XXXX 的设备,IP 地址为 XXXX」的信息给这个设备。
最后,设备就根据从 RARP 服务器所收到的应答信息设置自己的 IP 地址。
DHCP
DHCP 在生活中我们是很常见的了,我们的电脑通常都是通过 DHCP 动态获取 IP 地址,大大省去了配 IP 信息繁琐的过程。
接下来,我们来看看我们的电脑是如何通过 4 个步骤的过程,获取到 IP 的。
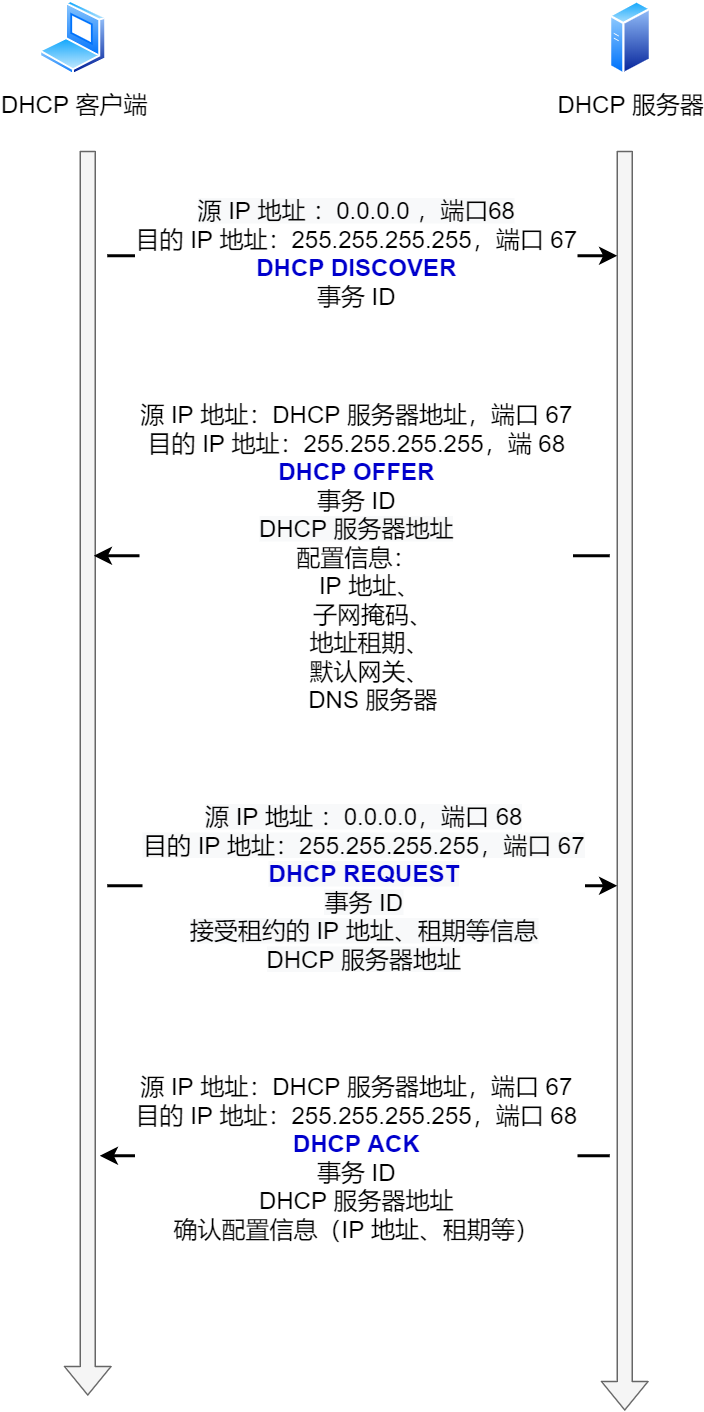
先说明一点,DHCP 客户端进程监听的是 68 端口号,DHCP 服务端进程监听的是 67 端口号。
这 4 个步骤:
- 客户端首先发起 DHCP 发现报文(DHCP DISCOVER) 的 IP 数据报,由于客户端没有 IP 地址,也不知道 DHCP 服务器的地址,所以使用的是 UDP 广播通信,其使用的广播目的地址是 255.255.255.255(端口 67) 并且使用 0.0.0.0(端口 68) 作为源 IP 地址。DHCP 客户端将该 IP 数据报传递给链路层,链路层然后将帧广播到所有的网络中设备。
- DHCP 服务器收到 DHCP 发现报文时,用 DHCP 提供报文(DHCP OFFER) 向客户端做出响应。该报文仍然使用 IP 广播地址 255.255.255.255,该报文信息携带服务器提供可租约的 IP 地址、子网掩码、默认网关、DNS 服务器以及 IP 地址租用期。
- 客户端收到一个或多个服务器的 DHCP 提供报文后,从中选择一个服务器,并向选中的服务器发送 DHCP 请求报文(DHCP REQUEST进行响应,回显配置的参数。
- 最后,服务端用 DHCP ACK 报文对 DHCP 请求报文进行响应,应答所要求的参数。
一旦客户端收到 DHCP ACK 后,交互便完成了,并且客户端能够在租用期内使用 DHCP 服务器分配的 IP 地址。
如果租约的 DHCP IP 地址快期后,客户端会向服务器发送 DHCP 请求报文:
- 服务器如果同意继续租用,则用 DHCP ACK 报文进行应答,客户端就会延长租期。
- 服务器如果不同意继续租用,则用 DHCP NACK 报文,客户端就要停止使用租约的 IP 地址。
可以发现,DHCP 交互中,全程都是使用 UDP 广播通信。
咦,用的是广播,那如果 DHCP 服务器和客户端不是在同一个局域网内,路由器又不会转发广播包,那不是每个网络都要配一个 DHCP 服务器?
所以,为了解决这一问题,就出现了 DHCP 中继代理。有了 DHCP 中继代理以后,对不同网段的 IP 地址分配也可以由一个 DHCP 服务器统一进行管理。
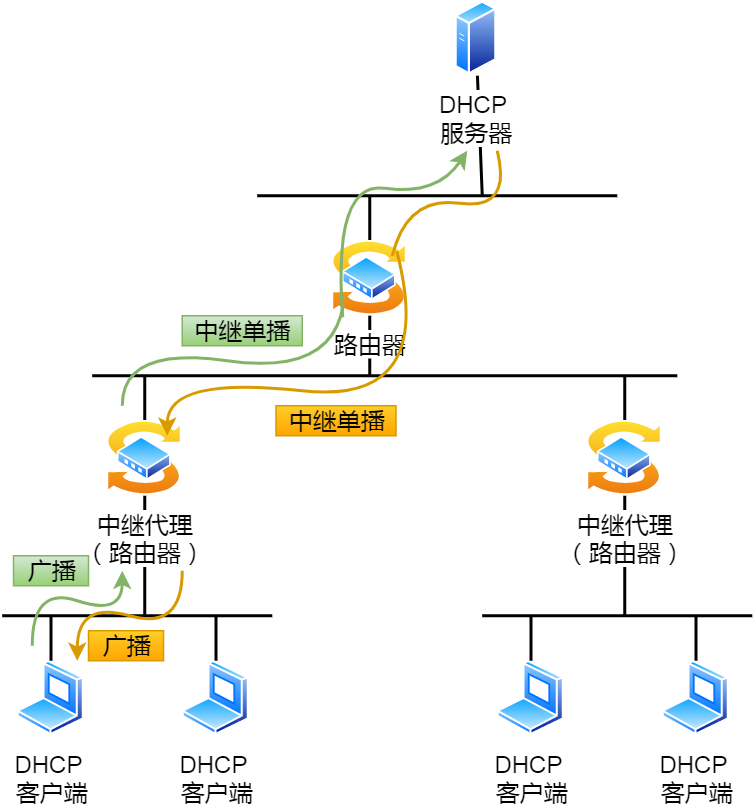
- DHCP 客户端会向 DHCP 中继代理发送 DHCP 请求包,而 DHCP 中继代理在收到这个广播包以后,再以单播的形式发给 DHCP 服务器。
- 服务器端收到该包以后再向 DHCP 中继代理返回应答,并由 DHCP 中继代理将此包广播给 DHCP 客户端 。
因此,DHCP 服务器即使不在同一个链路上也可以实现统一分配和管理 IP 地址。
NAT
IPv4 的地址是非常紧缺的,在前面我们也提到可以通过无分类地址来减缓 IPv4 地址耗尽的速度,但是互联网的用户增速是非常惊人的,所以 IPv4 地址依然有被耗尽的危险。
于是,提出了一种网络地址转换 NAT 的方法,再次缓解了 IPv4 地址耗尽的问题。
简单的来说 NAT 就是同个公司、家庭、教室内的主机对外部通信时,把私有 IP 地址转换成公有 IP 地址。
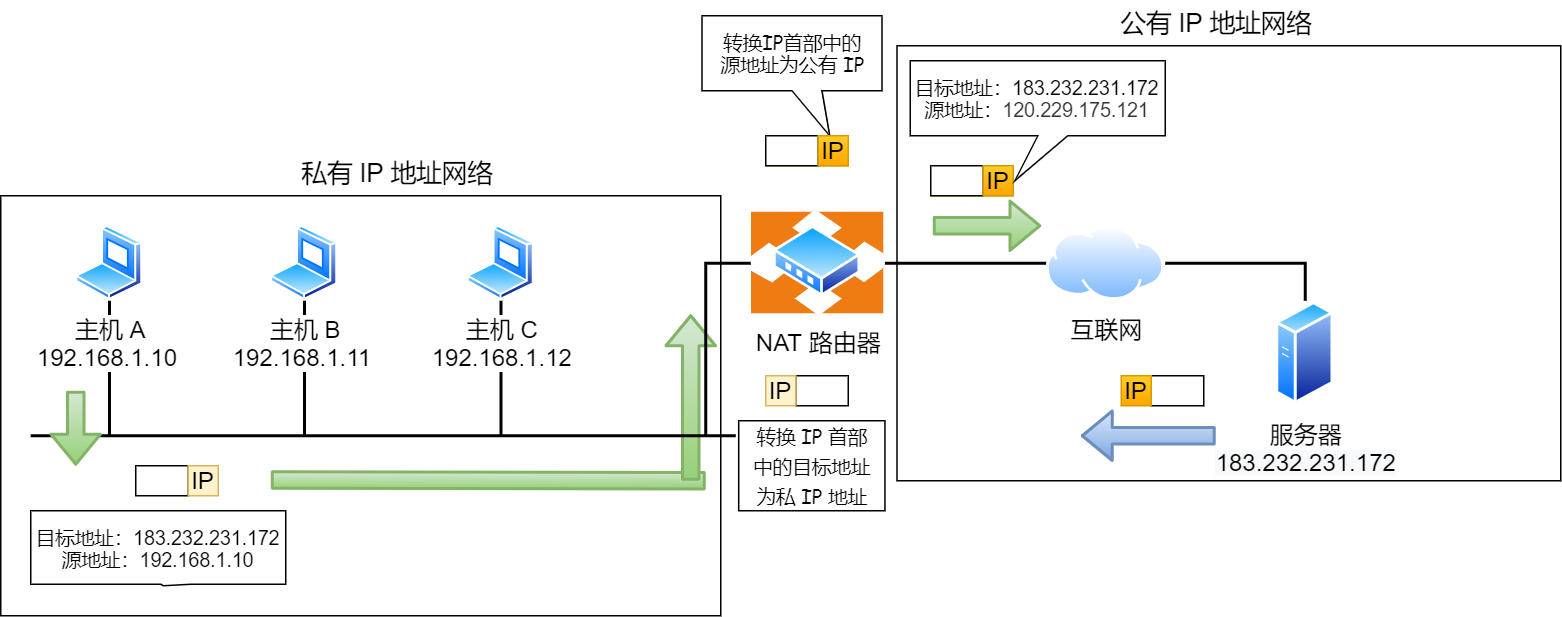
那不是 N 个私有 IP 地址,你就要 N 个公有 IP 地址?这怎么就缓解了 IPv4 地址耗尽的问题?这不瞎扯吗?
确实是,普通的 NAT 转换没什么意义。
由于绝大多数的网络应用都是使用传输层协议 TCP 或 UDP 来传输数据的。
因此,可以把 IP 地址 + 端口号一起进行转换。
这样,就用一个全球 IP 地址就可以了,这种转换技术就叫网络地址与端口转换 NAPT。
很抽象?来,看下面的图解就能瞬间明白了。
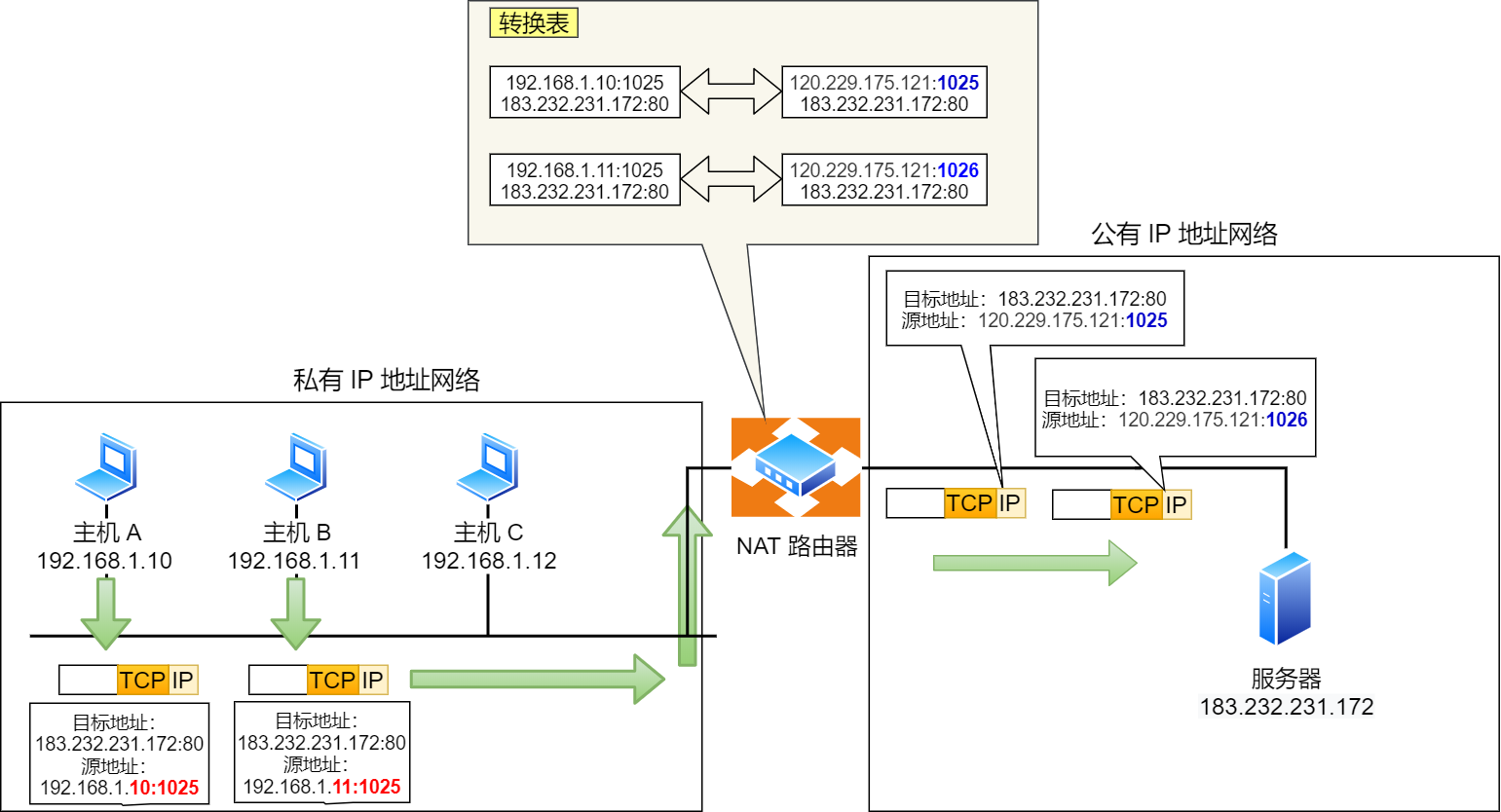
图中有两个客户端 192.168.1.10 和 192.168.1.11 同时与服务器 183.232.231.172 进行通信,并且这两个客户端的本地端口都是 1025。
此时,两个私有 IP 地址都转换 IP 地址为公有地址 120.229.175.121,但是以不同的端口号作为区分。
于是,生成一个 NAPT 路由器的转换表,就可以正确地转换地址跟端口的组合,令客户端 A、B 能同时与服务器之间进行通信。
这种转换表在 NAT 路由器上自动生成。例如,在 TCP 的情况下,建立 TCP 连接首次握手时的 SYN 包一经发出,就会生成这个表。而后又随着收到关闭连接时发出 FIN 包的确认应答从表中被删除。
NAT 那么牛逼,难道就没缺点了吗?
当然有缺陷,肯定没有十全十美的方案。
由于 NAT/NAPT 都依赖于自己的转换表,因此会有以下的问题:
- 外部无法主动与 NAT 内部服务器建立连接,因为 NAPT 转换表没有转换记录。
- 转换表的生成与转换操作都会产生性能开销。
- 通信过程中,如果 NAT 路由器重启了,所有的 TCP 连接都将被重置。
如何解决 NAT 潜在的问题呢?
解决的方法主要有两种方法。
第一种就是改用 IPv6
IPv6 可用范围非常大,以至于每台设备都可以配置一个公有 IP 地址,就不搞那么多花里胡哨的地址转换了,但是 IPv6 普及速度还需要一些时间。
第二种 NAT 穿透技术
NAT 穿越技术拥有这样的功能,它能够让网络应用程序主动发现自己位于 NAT 设备之后,并且会主动获得 NAT 设备的公有 IP,并为自己建立端口映射条目,注意这些都是 NAT 设备后的应用程序自动完成的。
也就是说,在 NAT 穿透技术中,NAT 设备后的应用程序处于主动地位,它已经明确地知道 NAT 设备要修改它外发的数据包,于是它主动配合 NAT 设备的操作,主动地建立好映射,这样就不像以前由 NAT 设备来建立映射了。
说人话,就是客户端主动从 NAT 设备获取公有 IP 地址,然后自己建立端口映射条目,然后用这个条目对外通信,就不需要 NAT 设备来进行转换了。
ICMP
ICMP 全称是 Internet Control Message Protocol,也就是互联网控制报文协议。
里面有个关键词 —— 控制,如何控制的呢?
网络包在复杂的网络传输环境里,常常会遇到各种问题。
当遇到问题的时候,总不能死个不明不白,没头没脑的作风不是计算机网络的风格。所以需要传出消息,报告遇到了什么问题,这样才可以调整传输策略,以此来控制整个局面。
ICMP 功能都有啥?
ICMP 主要的功能包括:确认 IP 包是否成功送达目标地址、报告发送过程中 IP 包被废弃的原因和改善网络设置等。
在 IP 通信中如果某个 IP 包因为某种原因未能达到目标地址,那么这个具体的原因将由 ICMP 负责通知。
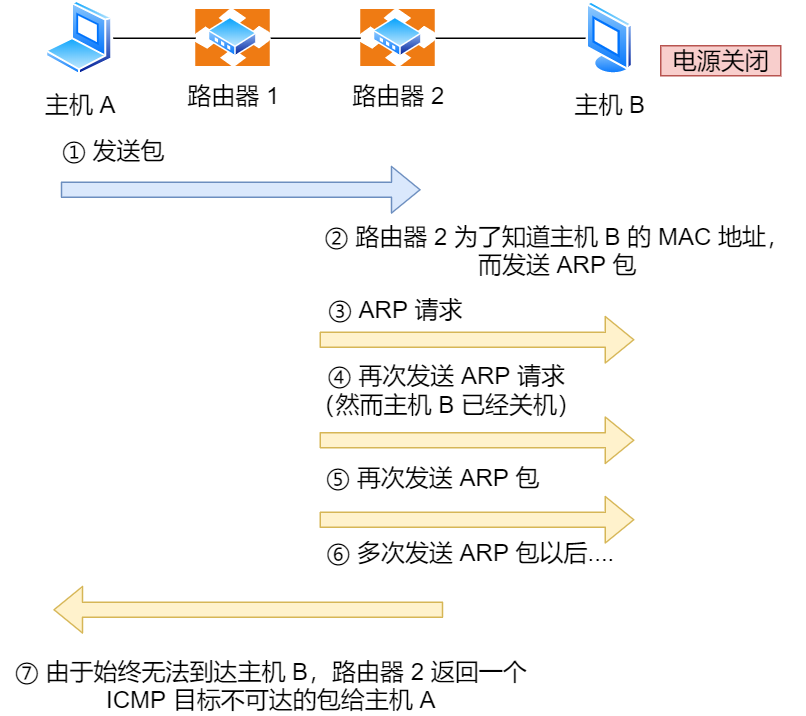
如上图例子,主机 A 向主机 B 发送了数据包,由于某种原因,途中的路由器 2 未能发现主机 B 的存在,这时,路由器 2 就会向主机 A 发送一个 ICMP 目标不可达数据包,说明发往主机 B 的包未能成功。
ICMP 的这种通知消息会使用 IP 进行发送 。
因此,从路由器 2 返回的 ICMP 包会按照往常的路由控制先经过路由器 1 再转发给主机 A 。收到该 ICMP 包的主机 A 则分解 ICMP 的首部和数据域以后得知具体发生问题的原因。
ICMP 类型
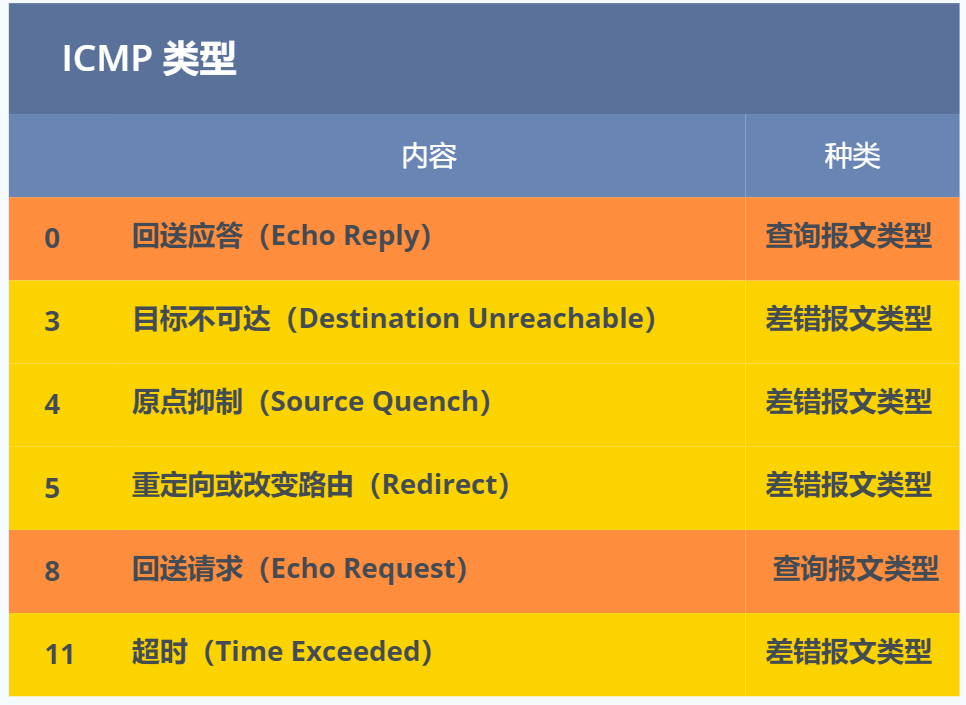
ICMP 大致可以分为两大类:
- 一类是用于诊断的查询消息,也就是「查询报文类型」
- 另一类是通知出错原因的错误消息,也就是「差错报文类型」
IGMP
ICMP 跟 IGMP 是一点关系都没有的,就好像周杰与周杰伦的区别,大家不要混淆了。
在前面我们知道了组播地址,也就是 D 类地址,既然是组播,那就说明是只有一组的主机能收到数据包,不在一组的主机不能收到数组包,怎么管理是否是在一组呢?那么,就需要 IGMP 协议了。

IGMP 是因特网组管理协议,工作在主机(组播成员)和最后一跳路由之间,如上图中的蓝色部分。
- IGMP 报文向路由器申请加入和退出组播组,默认情况下路由器是不会转发组播包到连接中的主机,除非主机通过 IGMP 加入到组播组,主机申请加入到组播组时,路由器就会记录 IGMP 路由器表,路由器后续就会转发组播包到对应的主机了。
- IGMP 报文采用 IP 封装,IP 头部的协议号为 2,而且 TTL 字段值通常为 1,因为 IGMP 是工作在主机与连接的路由器之间。
IGMP 工作机制
IGMP 分为了三个版本分别是,IGMPv1、IGMPv2、IGMPv3。
接下来,以 IGMPv2 作为例子,说说常规查询与响应和离开组播组这两个工作机制。
常规查询与响应工作机制
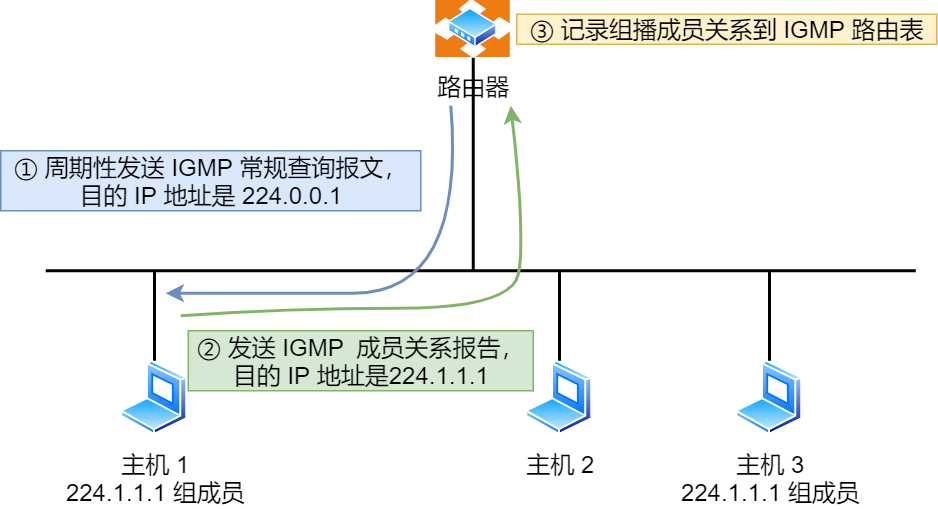
- 路由器会周期性发送目的地址为
224.0.0.1(表示同一网段内所有主机和路由器) IGMP 常规查询报文。 - 主机 1 和 主机 3 收到这个查询,随后会启动「报告延迟计时器」,计时器的时间是随机的,通常是 0~10 秒,计时器超时后主机就会发送 IGMP 成员关系报告报文(源 IP 地址为自己主机的 IP 地址,目的 IP 地址为组播地址)。如果在定时器超时之前,收到同一个组内的其他主机发送的成员关系报告报文,则自己不再发送,这样可以减少网络中多余的 IGMP 报文数量。
- 路由器收到主机的成员关系报文后,就会在 IGMP 路由表中加入该组播组,后续网络中一旦该组播地址的数据到达路由器,它会把数据包转发出去。
离开组播组工作机制
离开组播组的情况一,网段中仍有该组播组:
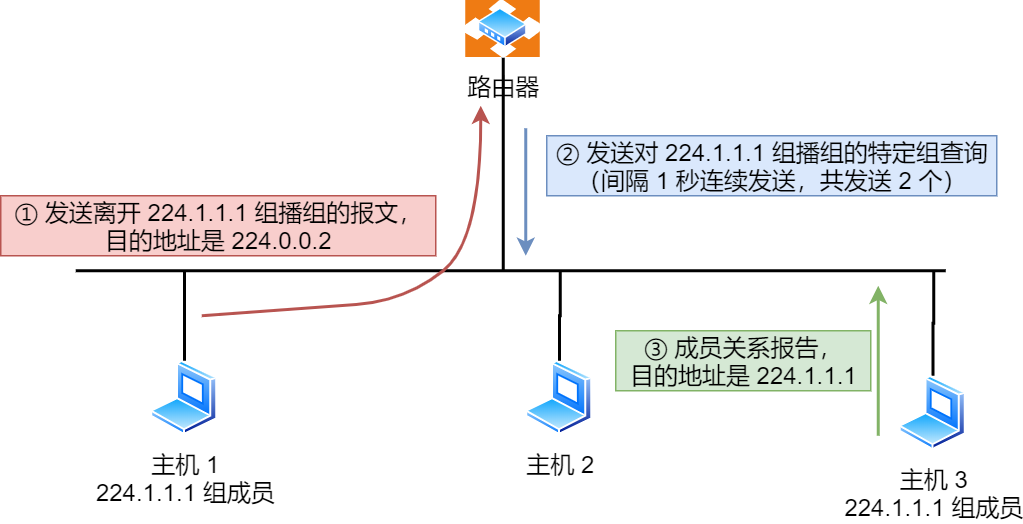
- 主机 1 要离开组 224.1.1.1,发送 IGMPv2 离组报文,报文的目的地址是 224.0.0.2(表示发向网段内的所有路由器)
- 路由器 收到该报文后,以 1 秒为间隔连续发送 IGMP 特定组查询报文(共计发送 2 个),以便确认该网络是否还有 224.1.1.1 组的其他成员。
- 主机 3 仍然是组 224.1.1.1 的成员,因此它立即响应这个特定组查询。路由器知道该网络中仍然存在该组播组的成员,于是继续向该网络转发 224.1.1.1 的组播数据包。
离开组播组的情况二,网段中没有该组播组:
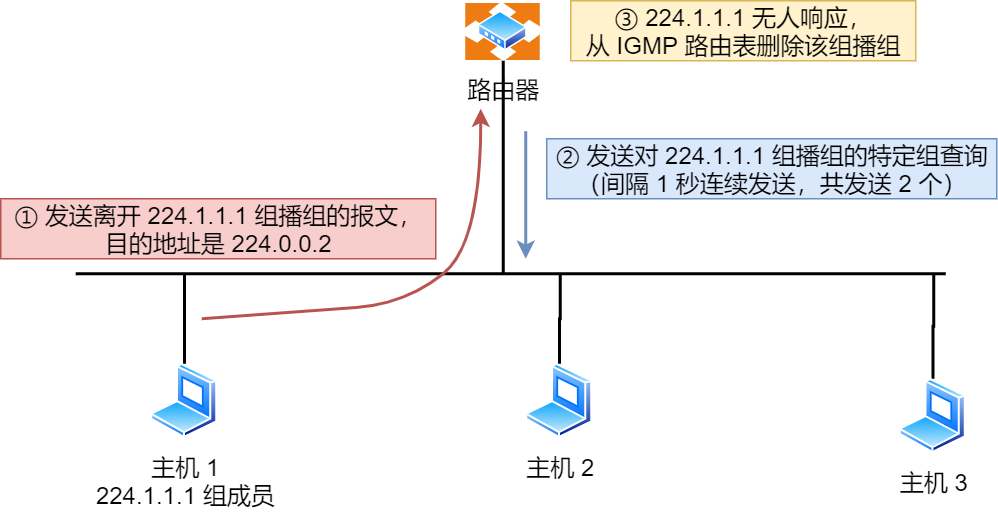
- 主机 1 要离开组播组 224.1.1.1,发送 IGMP 离组报文。
- 路由器收到该报文后,以 1 秒为间隔连续发送 IGMP 特定组查询报文(共计发送 2 个)。此时在该网段内,组 224.1.1.1 已经没有其他成员了,因此没有主机响应这个查询。
- 一定时间后,路由器认为该网段中已经没有 224.1.1.1 组播组成员了,将不会再向这个网段转发该组播地址的数据包。
4.ping 的工作原理
IP 协议的助手 —— ICMP 协议
ping 是基于 ICMP 协议工作的,所以要明白 ping 的工作,首先我们先来熟悉 ICMP 协议。
ICMP 是什么?
ICMP 全称是 Internet Control Message Protocol,也就是互联网控制报文协议。
里面有个关键词 —— 控制,如何控制的呢?
网络包在复杂的网络传输环境里,常常会遇到各种问题。当遇到问题的时候,总不能死的不明不白,没头没脑的作风不是计算机网络的风格。所以需要传出消息,报告遇到了什么问题,这样才可以调整传输策略,以此来控制整个局面。
ICMP 功能都有啥?
ICMP 主要的功能包括:确认 IP 包是否成功送达目标地址、报告发送过程中 IP 包被废弃的原因和改善网络设置等。
在 IP 通信中如果某个 IP 包因为某种原因未能达到目标地址,那么这个具体的原因将由 ICMP 负责通知。
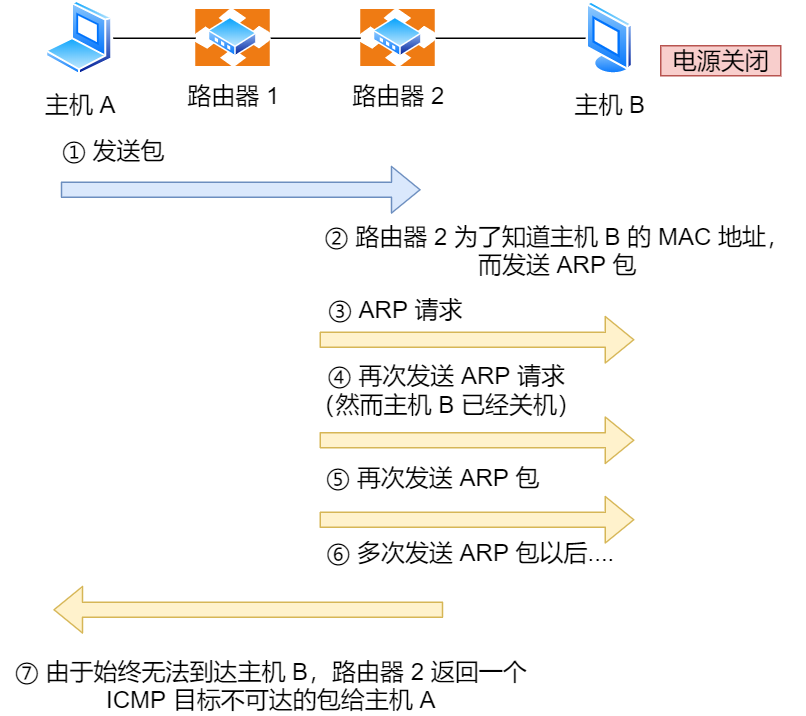
如上图例子,主机 A 向主机 B 发送了数据包,由于某种原因,途中的路由器 2 未能发现主机 B 的存在,这时,路由器 2 就会向主机 A 发送一个 ICMP 目标不可达数据包,说明发往主机 B 的包未能成功。
ICMP 的这种通知消息会使用 IP 进行发送 。
因此,从路由器 2 返回的 ICMP 包会按照往常的路由控制先经过路由器 1 再转发给主机 A 。收到该 ICMP 包的主机 A 则分解 ICMP 的首部和数据域以后得知具体发生问题的原因。
ICMP 包头格式
ICMP 报文是封装在 IP 包里面,它工作在网络层,是 IP 协议的助手。
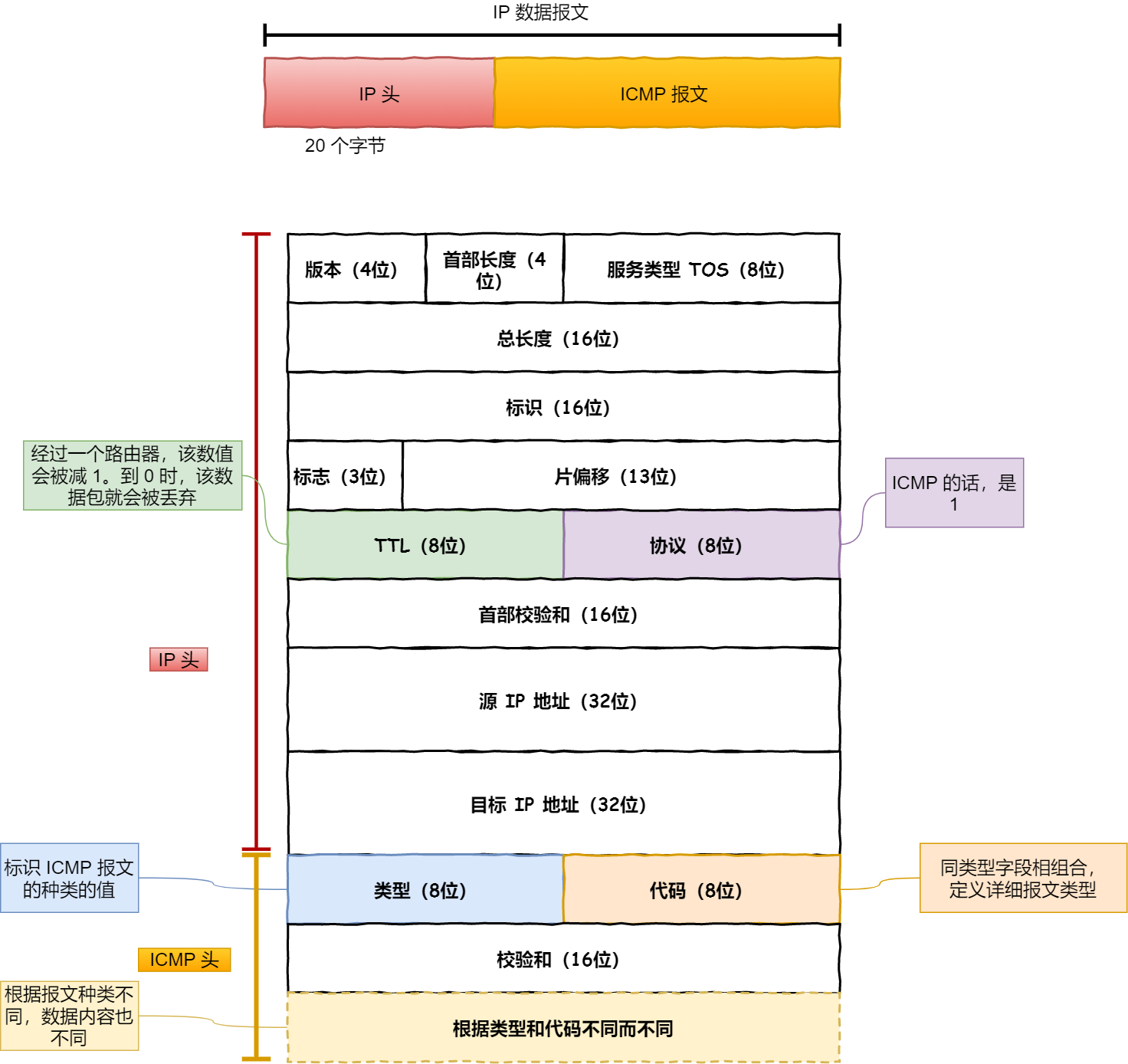
ICMP 包头的类型字段,大致可以分为两大类:
- 一类是用于诊断的查询消息,也就是「查询报文类型」
- 另一类是通知出错原因的错误消息,也就是「差错报文类型」
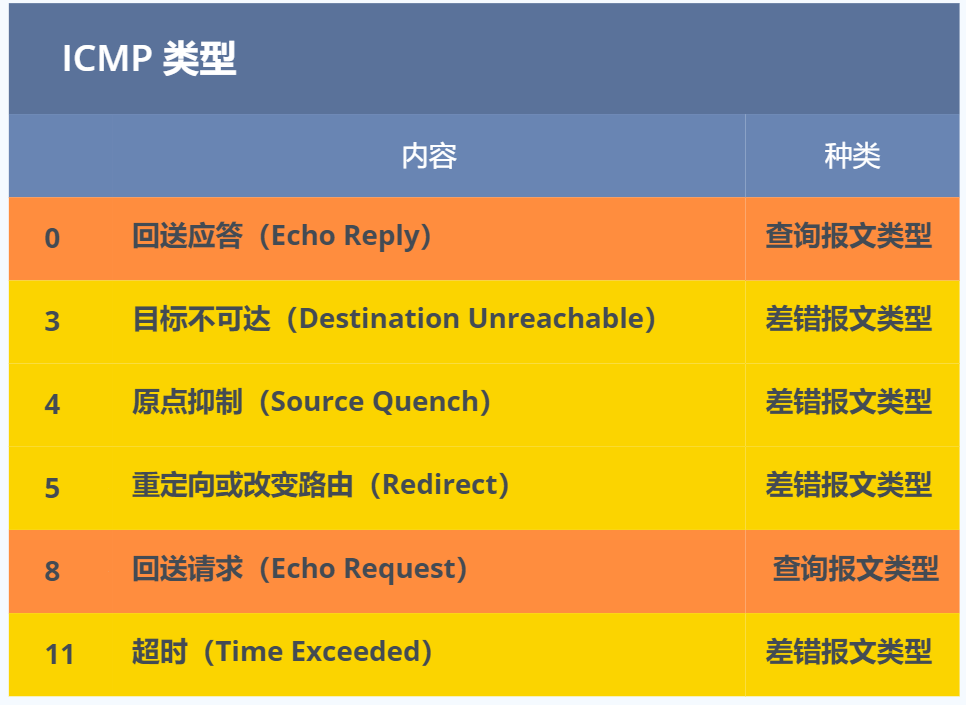
查询报文类型
回送消息 —— 类型
0和8
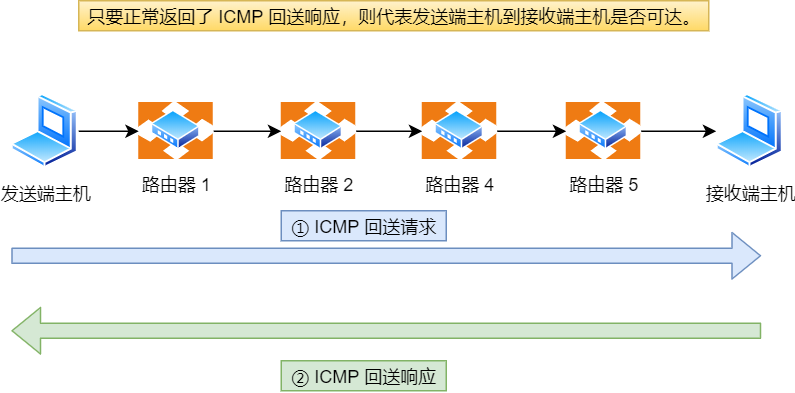
回送消息用于进行通信的主机或路由器之间,判断所发送的数据包是否已经成功到达对端的一种消息,ping 命令就是利用这个消息实现的。
可以向对端主机发送回送请求的消息(ICMP Echo Request Message,类型 8),也可以接收对端主机发回来的回送应答消息(ICMP Echo Reply Message,类型 0)。
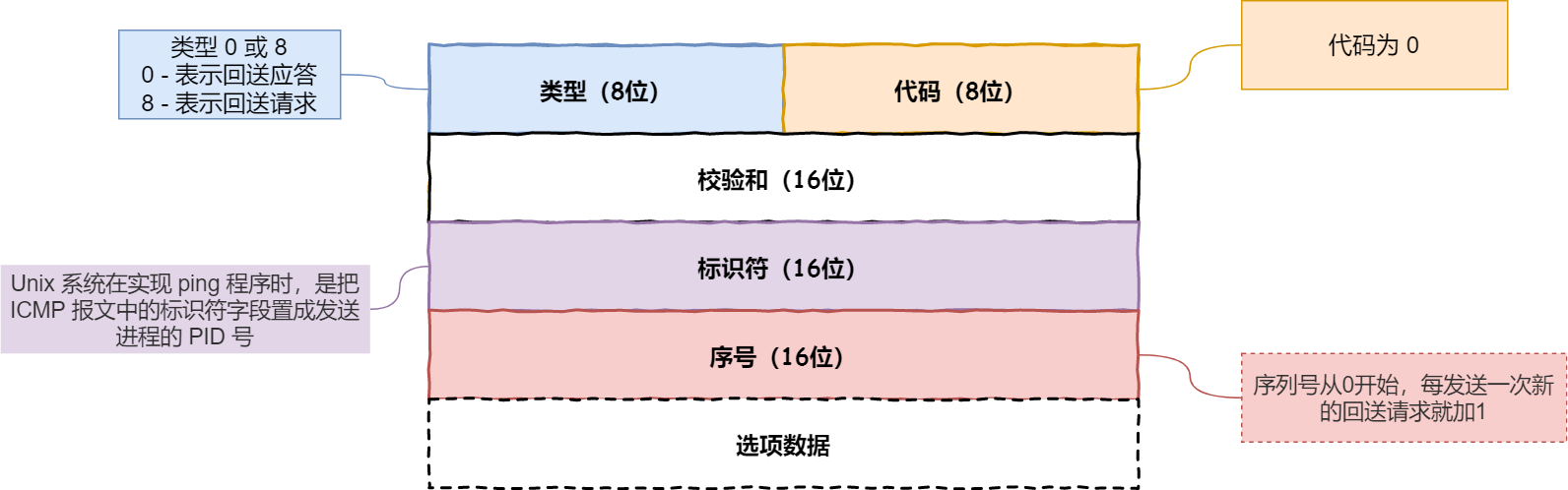
相比原生的 ICMP,这里多了两个字段:
- 标识符:用以区分是哪个应用程序发 ICMP 包,比如用进程
PID作为标识符; - 序号:序列号从
0开始,每发送一次新的回送请求就会加1, 可以用来确认网络包是否有丢失。
在选项数据中,ping 还会存放发送请求的时间值,来计算往返时间,说明路程的长短。
差错报文类型
接下来,说明几个常用的 ICMP 差错报文的例子:
- 目标不可达消息 —— 类型 为
3 - 原点抑制消息 —— 类型
4 - 重定向消息 —— 类型
5 - 超时消息 —— 类型
11
目标不可达消息(Destination Unreachable Message) —— 类型为
3
IP 路由器无法将 IP 数据包发送给目标地址时,会给发送端主机返回一个目标不可达的 ICMP 消息,并在这个消息中显示不可达的具体原因,原因记录在 ICMP 包头的代码字段。
由此,根据 ICMP 不可达的具体消息,发送端主机也就可以了解此次发送不可达的具体原因。
举例 6 种常见的目标不可达类型的代码:

- 网络不可达代码为
0 - 主机不可达代码为
1 - 协议不可达代码为
2 - 端口不可达代码为
3 - 需要进行分片但设置了不分片位代码为
4
为了给大家说清楚上面的目标不可达的原因,小林牺牲自己给大家送 5 次外卖。
为什么要送外卖?别问,问就是为 35 岁的老林做准备 ...
a. 网络不可达代码为 0
外卖版本:
小林第一次送外卖时,小区里只有 A 和 B 区两栋楼,但送餐地址写的是 C 区楼,小林表示头上很多问号,压根就没这个地方。
正常版本:
IP 地址是分为网络号和主机号的,所以当路由器中的路由器表匹配不到接收方 IP 的网络号,就通过 ICMP 协议以网络不可达(Network Unreachable)的原因告知主机。
自从不再有网络分类以后,网络不可达也渐渐不再使用了。
b. 主机不可达代码为 1
外卖版本:
小林第二次送外卖时,这次小区有 5 层楼高的 C 区楼了,找到地方了,但送餐地址写的是 C 区楼 601 号房 ,说明找不到这个房间。
正常版本:
当路由表中没有该主机的信息,或者该主机没有连接到网络,那么会通过 ICMP 协议以主机不可达(Host Unreachable)的原因告知主机。
c. 协议不可达代码为 2
外卖版本:
小林第三次送外卖时,这次小区有 C 区楼,也有 601 号房,找到地方了,也找到房间了,但是一开门人家是外国人说的是英语,我说的是中文!语言不通,外卖送达失败~
正常版本:
当主机使用 TCP 协议访问对端主机时,能找到对端的主机了,可是对端主机的防火墙已经禁止 TCP 协议访问,那么会通过 ICMP 协议以协议不可达的原因告知主机。
d. 端口不可达代码为 3
外卖版本:
小林第四次送外卖时,这次小区有 C 区楼,也有 601 号房,找到地方了,也找到房间了,房间里的人也是说中文的人了,但是人家说他要的不是外卖,而是快递。。。
正常版本:
当主机访问对端主机 8080 端口时,这次能找到对端主机了,防火墙也没有限制,可是发现对端主机没有进程监听 8080 端口,那么会通过 ICMP 协议以端口不可达的原因告知主机。
e. 需要进行分片但设置了不分片位代码为 4
外卖版本:
小林第五次送外卖时,这次是个吃播博主点了 100 份外卖,但是吃播博主要求一次性要把全部外卖送达,小林的一台电动车装不下呀,这样就没办法送达了。
正常版本:
发送端主机发送 IP 数据报时,将 IP 首部的分片禁止标志位设置为1。根据这个标志位,途中的路由器遇到超过 MTU 大小的数据包时,不会进行分片,而是直接抛弃。
随后,通过一个 ICMP 的不可达消息类型,代码为 4 的报文,告知发送端主机。
原点抑制消息(ICMP Source Quench Message) —— 类型
4
在使用低速广域线路的情况下,连接 WAN 的路由器可能会遇到网络拥堵的问题。
ICMP 原点抑制消息的目的就是为了缓和这种拥堵情况。
当路由器向低速线路发送数据时,其发送队列的缓存变为零而无法发送出去时,可以向 IP 包的源地址发送一个 ICMP 原点抑制消息。
收到这个消息的主机借此了解在整个线路的某一处发生了拥堵的情况,从而增大 IP 包的传输间隔,减少网络拥堵的情况。
然而,由于这种 ICMP 可能会引起不公平的网络通信,一般不被使用。
重定向消息(ICMP Redirect Message) —— 类型
5
如果路由器发现发送端主机使用了「不是最优」的路径发送数据,那么它会返回一个 ICMP 重定向消息给这个主机。
在这个消息中包含了最合适的路由信息和源数据。这主要发生在路由器持有更好的路由信息的情况下。路由器会通过这样的 ICMP 消息告知发送端,让它下次发给另外一个路由器。
好比,小林本可以过条马路就能到的地方,但小林不知道,所以绕了一圈才到,后面小林知道后,下次小林就不会那么傻再绕一圈了。
超时消息(ICMP Time Exceeded Message) —— 类型
11
IP 包中有一个字段叫做 TTL (Time To Live,生存周期),它的值随着每经过一次路由器就会减 1,直到减到 0 时该 IP 包会被丢弃。
此时,路由器将会发送一个 ICMP 超时消息给发送端主机,并通知该包已被丢弃。
设置 IP 包生存周期的主要目的,是为了在路由控制遇到问题发生循环状况时,避免 IP 包无休止地在网络上被转发。
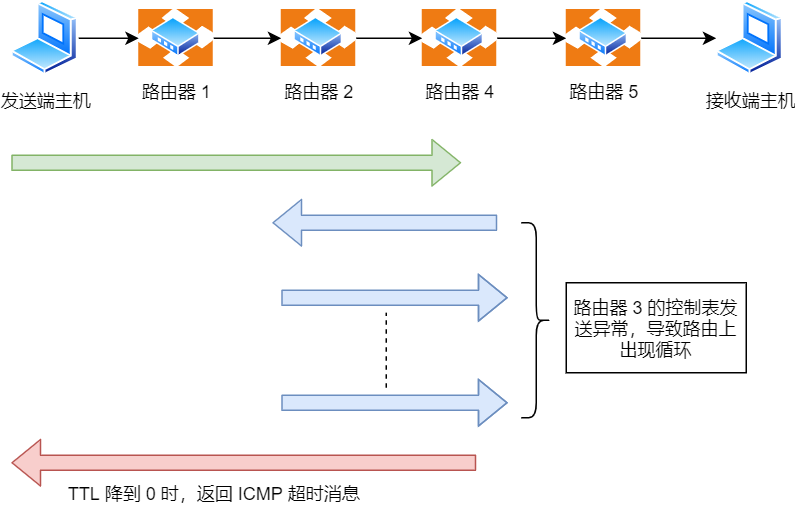
此外,有时可以用 TTL 控制包的到达范围,例如设置一个较小的 TTL 值。
ping —— 查询报文类型的使用
接下来,我们重点来看 ping 的发送和接收过程。
同个子网下的主机 A 和 主机 B,主机 A 执行ping 主机 B 后,我们来看看其间发送了什么?
ping 命令执行的时候,源主机首先会构建一个 ICMP 回送请求消息数据包。
ICMP 数据包内包含多个字段,最重要的是两个:
- 第一个是类型,对于回送请求消息而言该字段为
8; - 另外一个是序号,主要用于区分连续 ping 的时候发出的多个数据包。
每发出一个请求数据包,序号会自动加 1。为了能够计算往返时间 RTT,它会在报文的数据部分插入发送时间。

然后,由 ICMP 协议将这个数据包连同地址 192.168.1.2 一起交给 IP 层。IP 层将以 192.168.1.2 作为目的地址,本机 IP 地址作为源地址,协议字段设置为 1 表示是 ICMP 协议,再加上一些其他控制信息,构建一个 IP 数据包。

接下来,需要加入 MAC 头。如果在本地 ARP 映射表中查找出 IP 地址 192.168.1.2 所对应的 MAC 地址,则可以直接使用;如果没有,则需要发送 ARP 协议查询 MAC 地址,获得 MAC 地址后,由数据链路层构建一个数据帧,目的地址是 IP 层传过来的 MAC 地址,源地址则是本机的 MAC 地址;还要附加上一些控制信息,依据以太网的介质访问规则,将它们传送出去。

主机 B 收到这个数据帧后,先检查它的目的 MAC 地址,并和本机的 MAC 地址对比,如符合,则接收,否则就丢弃。
接收后检查该数据帧,将 IP 数据包从帧中提取出来,交给本机的 IP 层。同样,IP 层检查后,将有用的信息提取后交给 ICMP 协议。
主机 B 会构建一个 ICMP 回送响应消息数据包,回送响应数据包的类型字段为 0,序号为接收到的请求数据包中的序号,然后再发送出去给主机 A。

在规定的时候间内,源主机如果没有接到 ICMP 的应答包,则说明目标主机不可达;如果接收到了 ICMP 回送响应消息,则说明目标主机可达。
此时,源主机会检查,用当前时刻减去该数据包最初从源主机上发出的时刻,就是 ICMP 数据包的时间延迟。
针对上面发送的事情,总结成了如下图:
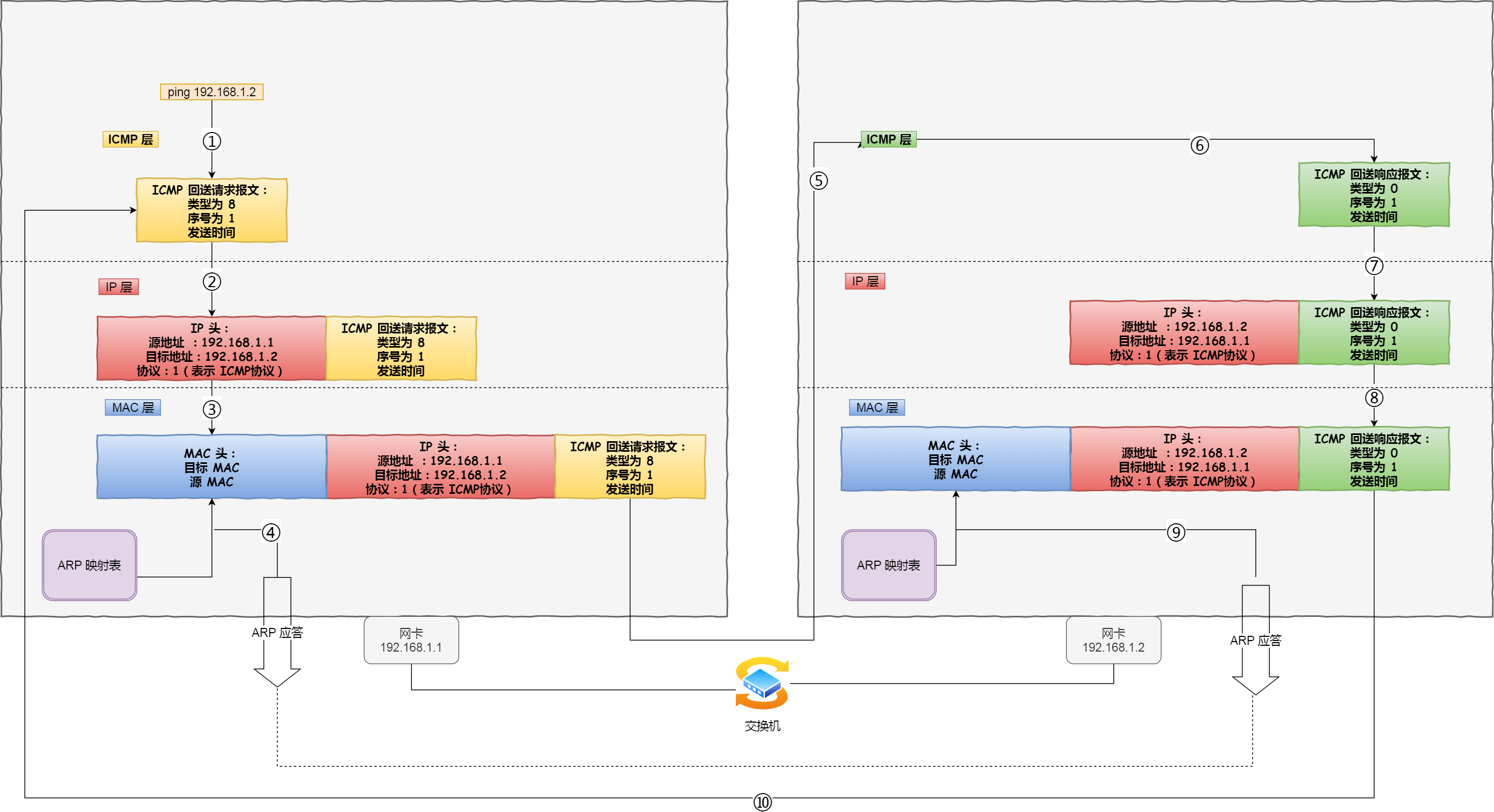
当然这只是最简单的,同一个局域网里面的情况。如果跨网段的话,还会涉及网关的转发、路由器的转发等等。
但是对于 ICMP 的头来讲,是没什么影响的。会影响的是根据目标 IP 地址,选择路由的下一跳,还有每经过一个路由器到达一个新的局域网,需要换 MAC 头里面的 MAC 地址。
说了这么多,可以看出 ping 这个程序是使用了 ICMP 里面的 ECHO REQUEST(类型为 8 ) 和 ECHO REPLY (类型为 0)。
traceroute —— 差错报文类型的使用
有一款充分利用 ICMP 差错报文类型的应用叫做 traceroute(在 UNIX、MacOS 中是这个命令,而在 Windows 中对等的命令叫做 tracert )。
1. traceroute 作用一
traceroute 的第一个作用就是故意设置特殊的 TTL,来追踪去往目的地时沿途经过的路由器。
traceroute 的参数指向某个目的 IP 地址:
traceroute 192.168.1.100
这个作用是如何工作的呢?
它的原理就是利用 IP 包的生存期限 从 1 开始按照顺序递增的同时发送 UDP 包,强制接收 ICMP 超时消息的一种方法。
比如,将 TTL 设置 为 1,则遇到第一个路由器,就牺牲了,接着返回 ICMP 差错报文网络包,类型是时间超时。
接下来将 TTL 设置为 2,第一个路由器过了,遇到第二个路由器也牺牲了,也同时返回了 ICMP 差错报文数据包,如此往复,直到到达目的主机。
这样的过程,traceroute 就可以拿到了所有的路由器 IP。
当然有的路由器根本就不会返回这个 ICMP,所以对于有的公网地址,是看不到中间经过的路由的。
发送方如何知道发出的 UDP 包是否到达了目的主机呢?
traceroute 在发送 UDP 包时,会填入一个不可能的端口号值作为 UDP 目标端口号(大于 3000 )。当目的主机,收到 UDP 包后,会返回 ICMP 差错报文消息,但这个差错报文消息的类型是「端口不可达」。
所以,当差错报文类型是端口不可达时,说明发送方发出的 UDP 包到达了目的主机。
2. traceroute 作用二
traceroute 还有一个作用是故意设置不分片,从而确定路径的 MTU。
这么做是为了什么?
这样做的目的是为了路径 MTU 发现。
因为有的时候我们并不知道路由器的 MTU 大小,以太网的数据链路上的 MTU 通常是 1500 字节,但是非以外网的 MTU 值就不一样了,所以我们要知道 MTU 的大小,从而控制发送的包大小。
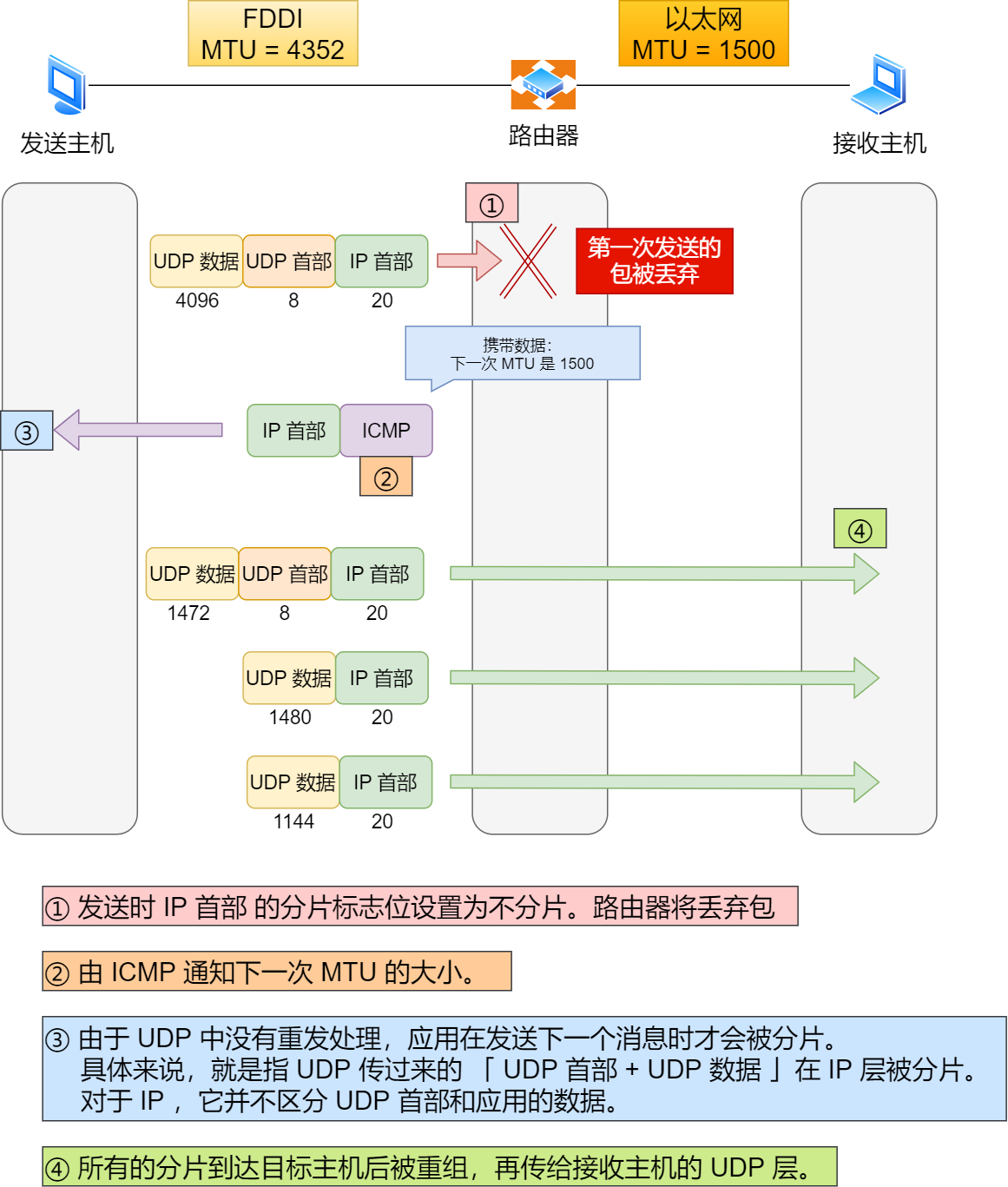
它的工作原理如下:
首先在发送端主机发送 IP 数据报时,将 IP 包首部的分片禁止标志位设置为 1。根据这个标志位,途中的路由器不会对大数据包进行分片,而是将包丢弃。
随后,通过一个 ICMP 的不可达消息将数据链路上 MTU 的值一起给发送主机,不可达消息的类型为「需要进行分片但设置了不分片位」。
发送主机端每次收到 ICMP 差错报文时就减少包的大小,以此来定位一个合适的 MTU 值,以便能到达目标主机。
DNS
1.DNS 协议是什么
概念: DNS 是域名系统 (Domain Name System) 的缩写,提供的是一种主机名到 IP 地址的转换服务,就是我们常说的域名系统。它是一个由分层的 DNS 服务器组成的分布式数据库,是定义了主机如何查询这个分布式数据库的方式的应用层协议。能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的 IP 数串。
作用: 将域名解析为 IP 地址,客户端向 DNS 服务器(DNS 服务器有自己的 IP 地址)发送域名查询请求,DNS 服务器告知客户机 Web 服务器的 IP 地址。
2.DNS 同时使用 TCP 和 UDP 协议?
DNS 占用 53 号端口,同时使用 TCP 和 UDP 协议。 (1)在区域传输的时候使用 TCP 协议
- 辅域名服务器会定时(一般 3 小时)向主域名服务器进行查询以便了解数据是否有变动。如有变动,会执行一次区域传送,进行数据同步。区域传送使用 TCP 而不是 UDP,因为数据同步传送的数据量比一个请求应答的数据量要多得多。
- TCP 是一种可靠连接,保证了数据的准确性。
(2)在域名解析的时候使用 UDP 协议
- 客户端向 DNS 服务器查询域名,一般返回的内容都不超过 512 字节,用 UDP 传输即可。不用经过三次握手,这样 DNS 服务器负载更低,响应更快。理论上说,客户端也可以指定向 DNS 服务器查询时用 TCP,但事实上,很多 DNS 服务器进行配置的时候,仅支持 UDP 查询包。
3.DNS 完整的查询过程
DNS 服务器解析域名的过程:
- 首先会在浏览器的缓存中查找对应的 IP 地址,如果查找到直接返回,若找不到继续下一步
- 将请求发送给本地 DNS 服务器,在本地域名服务器缓存中查询,如果查找到,就直接将查找结果返回,若找不到继续下一步
- 本地 DNS 服务器向根域名服务器发送请求,根域名服务器会返回一个所查询域的顶级域名服务器地址
- 本地 DNS 服务器向顶级域名服务器发送请求,接受请求的服务器查询自己的缓存,如果有记录,就返回查询结果,如果没有就返回相关的下一级的权威域名服务器的地址
- 本地 DNS 服务器向权威域名服务器发送请求,域名服务器返回对应的结果
- 本地 DNS 服务器将返回结果保存在缓存中,便于下次使用
- 本地 DNS 服务器将返回结果返回给浏览器
比如要查询 baidu.com 的 IP 地址,首先会在浏览器的缓存中查找是否有该域名的缓存,如果不存在就将请求发送到本地的 DNS 服务器中,本地 DNS 服务器会判断是否存在该域名的缓存,如果不存在,则向根域名服务器发送一个请求,根域名服务器返回负责 .com 的顶级域名服务器的 IP 地址的列表。然后本地 DNS 服务器再向其中一个负责 .com 的顶级域名服务器发送一个请求,负责 .com 的顶级域名服务器返回负责 .baidu 的权威域名服务器的 IP 地址列表。然后本地 DNS 服务器再向其中一个权威域名服务器发送一个请求,最后权威域名服务器返回一个对应的主机名的 IP 地址列表。
4.迭代查询与递归查询
实际上,DNS 解析是一个包含迭代查询和递归查询的过程。
- 递归查询指的是查询请求发出后,域名服务器代为向下一级域名服务器发出请求,最后向用户返回查询的最终结果。使用递归 查询,用户只需要发出一次查询请求。
- 迭代查询指的是查询请求后,域名服务器返回单次查询的结果。下一级的查询由用户自己请求。使用迭代查询,用户需要发出 多次的查询请求。
一般我们向本地 DNS 服务器发送请求的方式就是递归查询,因为我们只需要发出一次请求,然后本地 DNS 服务器返回给我 们最终的请求结果。而本地 DNS 服务器向其他域名服务器请求的过程是迭代查询的过程,因为每一次域名服务器只返回单次 查询的结果,下一级的查询由本地 DNS 服务器自己进行。
5.DNS 记录和报文
DNS 服务器中以资源记录的形式存储信息,每一个 DNS 响应报文一般包含多条资源记录。一条资源记录的具体的格式为
(Name,Value,Type,TTL)
其中 TTL 是资源记录的生存时间,它定义了资源记录能够被其他的 DNS 服务器缓存多长时间。
常用的一共有四种 Type 的值,分别是 A、NS、CNAME 和 MX ,不同 Type 的值,对应资源记录代表的意义不同:
- 如果 Type = A,则 Name 是主机名,Value 是主机名对应的 IP 地址。因此一条记录为 A 的资源记录,提供了标 准的主机名到 IP 地址的映射。
- 如果 Type = NS,则 Name 是个域名,Value 是负责该域名的 DNS 服务器的主机名。这个记录主要用于 DNS 链式 查询时,返回下一级需要查询的 DNS 服务器的信息。
- 如果 Type = CNAME,则 Name 为别名,Value 为该主机的规范主机名。该条记录用于向查询的主机返回一个主机名 对应的规范主机名,从而告诉查询主机去查询这个主机名的 IP 地址。主机别名主要是为了通过给一些复杂的主机名提供 一个便于记忆的简单的别名。
- 如果 Type = MX,则 Name 为一个邮件服务器的别名,Value 为邮件服务器的规范主机名。它的作用和 CNAME 是一 样的,都是为了解决规范主机名不利于记忆的缺点。
CDN
1.为什么需要 CDN
CDN 的全称是 Content Delivery Network,即内容分发网络。
CDN 是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率
互联网中的三个一公里
CDN 并非网络基础设施,而是构建在实体网络基础设施的一个"应用层"

这幅图展示了互联网通信领域中常说的"三公里":
- 第一公里 网站服务器接入互联网公网的链路,这里的带宽也决定了网站的负载能力,也称为网站的接入带宽。
- 中间一公里 中间一公里主要是接入网、城域网、骨干网组成的链路实体,其中会涉及多家运营商,也就出现了运营商之间互联互通的数据交换问题。
- 最后一公里 这是用户接入互联网获取信息的最后环节,换句话说就是你们小区的网络、你们家楼的网,往往这部分的带宽不高,影响也比较明显。
运营商的互联互通问题
运营商之间数据的互联互通问题,比如 A 市联通要访问 A 市电信的数据资源,按照互联互通的规则限制,不同运营商的数据要在指定的交换中心进行数据交换,假如交换中心位于较远的 B 市,那么就存在如下图的关系:
换句话说,本来两个运营商是同一个城市的,但由于运营商的网络差异需要到几百公里之外的交换中心所在的城市进行数据交换,实现资源的访问。
对于不同运营商间的互联互通,一般是采用 BGP peering(对等)的方式进行。两家运营商相互协商,在特定地点建立连接,通过一系列的配置,运营商 A 的用户就能访问运营商 B 的资源了。 在中国,运营商之间通过“国家级互联网骨干直联点”进行连接,2001 到 2014 年,国内只有北上广三个直联点,导致跨网访问体验极差,流量无法本地中转需要长途迂回,大大增加了延迟。 三批国家级互联网骨干直联点: 第一批 2001 年投入使用:北京、上海、广州 第二批 2014 年投入使用:成都、郑州、武汉、西安、沈阳、南京、重庆 第三批 2017 年投入使用:杭州、贵阳、福州
难兄难弟
试想北美的海外用户要访问在服务器在深圳的资源,物理距离就有几万公里,算上三个一公里的消耗,恐怕用户的体验会非常糟糕。
同样的,网站服务器的接入带宽是有限的,对于海量用户的接入访问非常容易出现拥塞,这样很容易把网站服务器压垮。
同时,对于运营商来说也很糟糕,骨干网充斥着大量相同的请求,网络基建压力很大,如果把这些请求在本地处理掉该多好!
可见,如果没有 CDN 这一层 Cache 应用,网站、用户、运营商都会很崩溃。
CDN 的思想和某东物流建立的区域仓库、前置仓库很像,用户下单后优先在最近的仓库配货,极限情况下几小时就可以送到用户手里,用户体验好、物流压力小
2.CDN 的基本原理
CDN 和 DNS 的调度
假如没有 CDN,我们访问资源时会使用 DNS 进行解析获取资源服务器的 IP 地址进行数据交互。
- 传统模式下 DNS 的调度过程
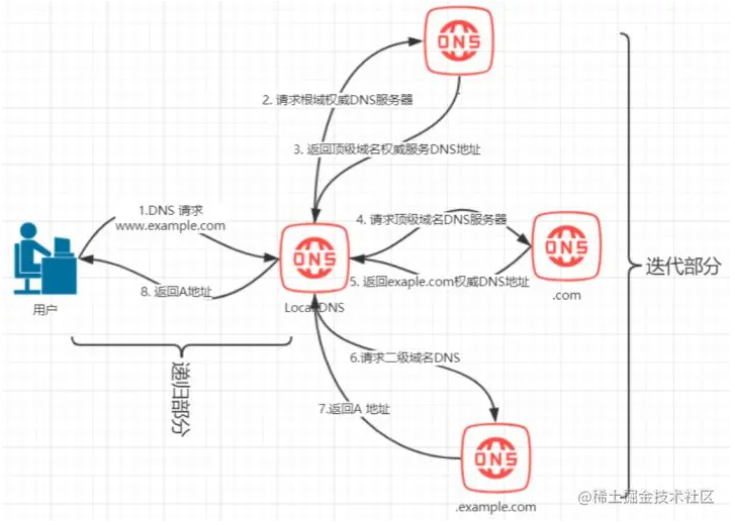
图中我们看到用户从 LocalDNS 开始查询,如果找不到就到根权威 DNS 服务器,再向顶级权威 DNS 服务器访问,依次迭代最终获取待访问域名的 IP 地址。
- 有 CDN 参与的 DNS 调度过程
前面我们曾经提到CDN 是构建在承载网上的一个 Cache 应用层,也就是 CDN 作为用户和网站服务器之间的 Cache 来参与整个过程。
这样就出现一个问题:用户如何获取 CDN 资源节点的 IP 地址呢?
没错,其中一种常见的调度方案就是 DNS 调度,如图所示:
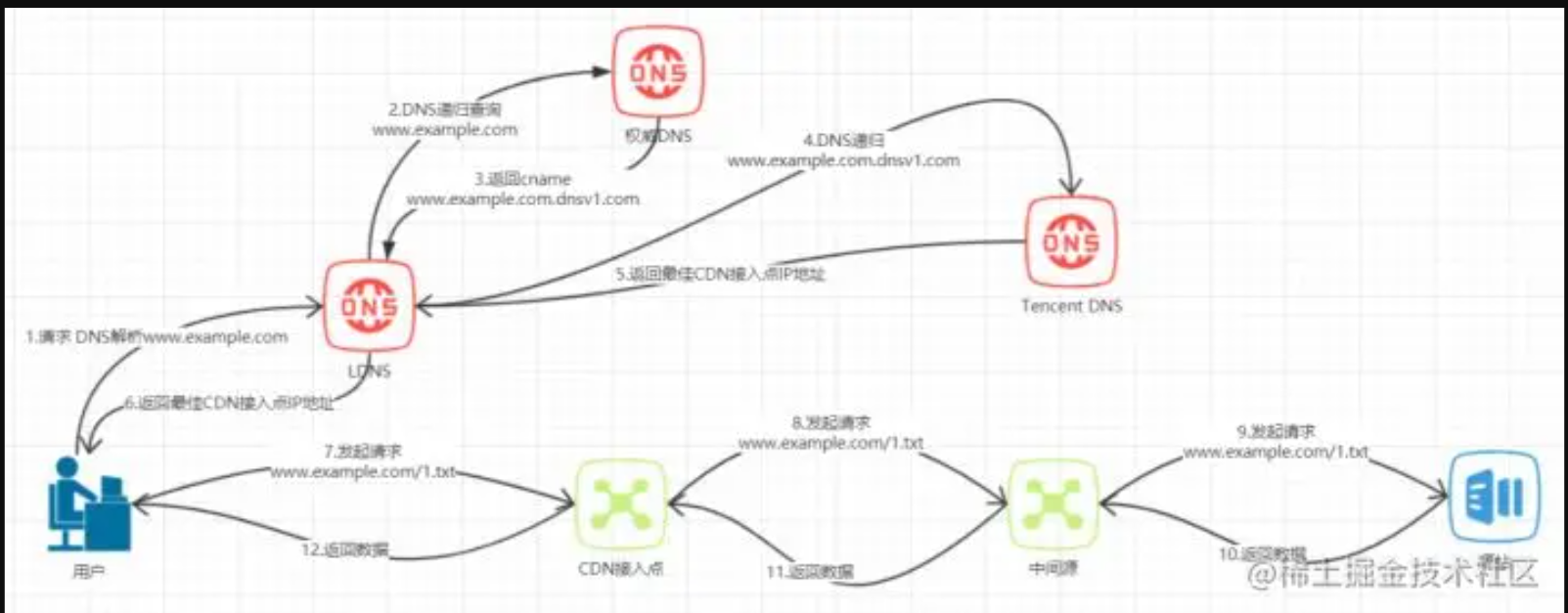
前半部分和传统模式类似,重要的区别在于专用 DNS 调度服务器的出现,图中为 TenCent DNS Server,这台 CDN 服务商提供的专用 DNS 调度服务器根据CDN 系统内部节点的位置、负载情况、资源分配等因素选出最优的 CDN 资源节点 IP 地址返回给用户。
3.CDN 工作过程
- 当用户输入网址回车后,经过本地 DNS 系统解析,DNS 会将最终的域名解析权交给 CNAME 指向的 CDN 专用 DNS 服务器。
- CDN 的 DNS 服务器将 CDN 的全局负载均衡 设备 ip 地址返回给浏览器
- 用户向 CDN 的全局负载均衡服务器 发起内容 url 请求
- CDN 全局负载均衡服务器根据 用户请求的 IP 地址,url 等信息,选择一台用户所属区域的负载均衡设备,告诉用户向这台设备发起请求。
- CDN 区域负载均衡服务器会为用户 选择一台合适的缓存服务器提供服务,选择的依据主要是:离用户距离要近,缓存服务器上是否用户所需内容,以及各个缓存当前的一个负载均衡情况。选择出一个最优的 缓存服务器 ip 地址。
- 全局负载均衡服务器将 缓存服务器的 ip 地址给到用户。
- 用户向缓存服务器发起请求。缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果缓存服务器上没有用户想要的内容,那么这台服务器就会向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器,并将内容拉取到本地。
细节流程图:
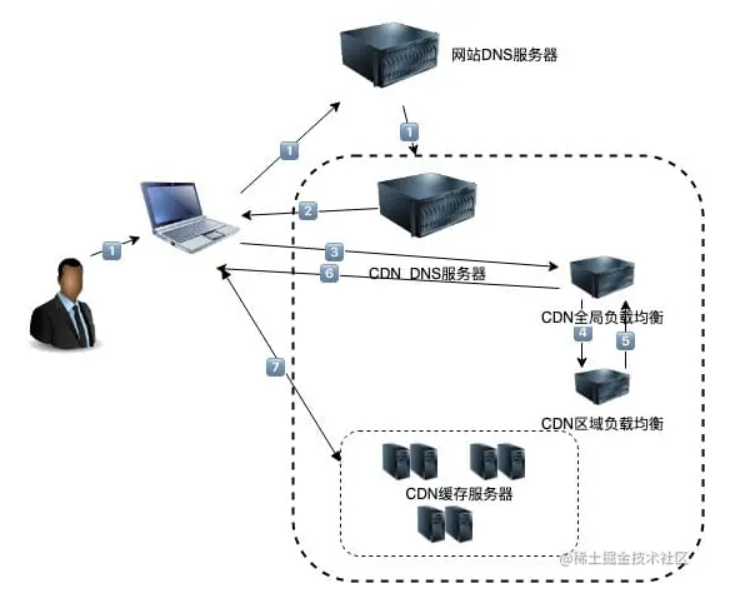
专用 CDN 调度过程
要实现 CDN 资源节点的调度,需要网站做一些准备工作:
- 网站去 CDN 服务商进行域名加速
比如为源站abc.com到阿里云进行域名加速,配置完成后阿里云会自动关联生成加速域名的别名如abc.com.aliyuncdn.net,这个别名也称为 CNAME。
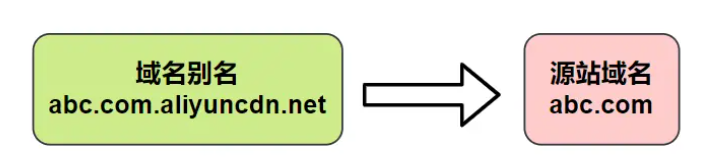
这里我们提两个重要的概念:CNAME 和 A 记录,它们是理解 CDN 的基础概念。
CNAME 记录,也叫别名记录,比如 xx.com 的别名是 yy.com,CNAME 记录是一种指向关系,把 yy.com 指向了 xx.com,一个域名可以有多个别名,存在多对一的关系。 A 记录,即 Address 记录,我们可以把它理解为一种域名和 IP 地址的映射关系。
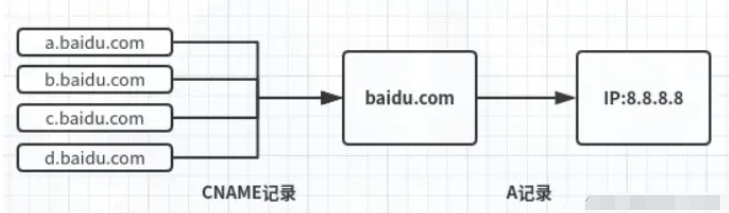
由于加速域名已经进行了 CDN 的 CNAME 配置,在权威 DNS 服务器的解析下得到的并不是 IP 地址,而是 CNAME。
- 权威 DNS 服务器的请求转发
当用户访问abc.com时,传统的权威 DNS 服务器对abc.com进行解析时得到的是abc.com.aliyuncdn.net这个配置的 CNAME,从而通过 CNAME 顺利将请求转到 CDN 服务商专用的 DNS 服务器,由该服务器返回 CDN 的资源节点。
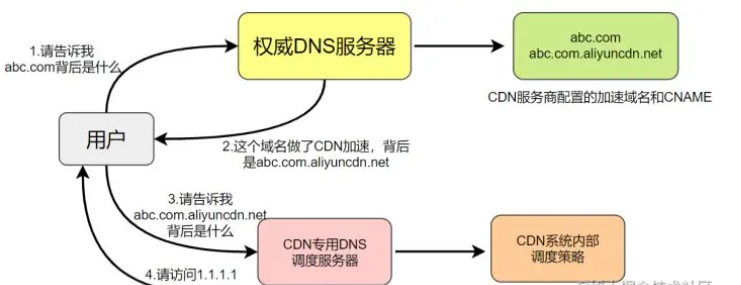
其他调度模式
除了 DNS 调度,还有 httpDNS 调度、302 调度等场景,来简单看一下。
- httpDNS 调度
HTTPDNS 技术是一种针对 DNS 防劫持的有效手段,以 HTTP 的方式代替传统 DNS 协议传递解析结果,能够有效避开 DNS 层面的拦截和故障。该方案可以根据客户端的来访 IP,直接通过 Httpdns 服务器获取最精准的解析结果,避免因为 DNS 多出口,DNS 攻击导致的 DNS 解析失败的问题。 客户端直接调用 HttpDNS 接口获取缓存服务器 IP 组,再择优向 IP 组中的缓存服务器发送请求,替代常规 DNS 调度策略,适用于客户端,且客户端需稍作修改进行 HttpDNS 接口调用。
- 302 调度
基于终端用户的 IP,做 HTTP 的精确重定向,需要协议支持、具有相当的时延,一般用于流媒体类加速场景。 该调度方式是通过 DNS 解析获得 CDN 的 GLSB 集群的 IP 地址,用户发送 HTTP 请求,GLSB 服务器返回 302 Found,将访问重定向到合适的服务节点。 该方式也存在着一些不足: 1、仅限 HTTP 的应用,可拓展性不足
2、调度过程多了 302 跳转的重定向过程,相对 DNS 调度时延较长
httpsDNS 和 302 调度都有自己的优势和使用场景,不同的网站可以采用一种或者多种调度方案来综合实施加速,三种方案并不对立,而是相互补充。
CDN 内部架构简介
有了 CDN 的加速,用户就可以访问近距离的服务器节点,大大提升了用户体验,同时源站的带宽压力也得到了分流,运营商骨干网压力也随之降低,看起来确实是个 win-win-win 的方案呀。
我们以阿里云官方文档为蓝本进行展开:
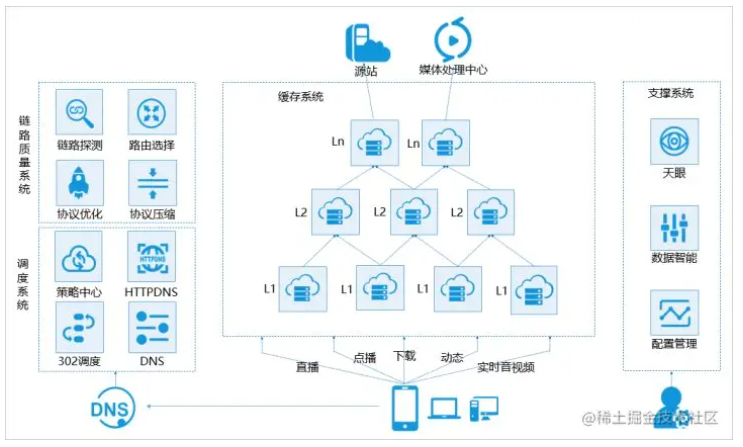
- 调度系统
支持 DNS、HTTPDNS 和 302 调度模式,当终端用户发起访问请求时,用户的访问请求会先进行域名 DNS 解析,然后通过 CDN 的调度系统处理用户的解析请求,就是我们前面介绍的 CDN 参与下的 DNS 调度过程。
- 质量系统
实时监测缓存系统中的所有节点和链路的实时负载以及健康状况,根据用户请求中携带的 IP 地址解析用户的运营商和区域归属,综合链路质量信息为用户分配一个最佳接入节点。 这里算是进行 CDN 节点选择的一个策略和质量监控的闭环系统。
- 缓存系统
用户在最佳接入节点访问数据,如果节点已经缓存了资源,会直接将资源返回给用户,如果 L1 和 L2 节点都没有缓存户请求的资源,此时回源站去获取资源并存储到缓存系统。
- 支撑系统
支撑服务系统包括数据智能和配置管理系统,实现资源监测和数据分析,例如对 CDN 加速域名的 QPS、带宽、HTTP 状态码等常见指标的监控,用户可以分析 CDN 加速域名的 PV、UV 等数据。
静态资源和动态资源的加速
CDN 本质上就是一层 Cache,有缓存就一定会有数据不一致问题,以及哪些资源适合做缓存,哪些不适合的问题。
- 静态资源
如果每个用户访问得到的资源一样,就像电视台播放节目,大家看到的都一样,并非个性化的结果,这类资源就可以称为静态资源。 比如网站的图片、视频、软件安装包、各类下载资源文件等。
这些资源变化很小,因此非常使用 CDN 加速,对改善网站性能效果明显。
- 动态资源
区别于静态资源,动态资源则更倾向于接口、个性化内容,用户每次请求得到的结果可能不同,这些资源并不适合 CDN 场景,如果强行使用会带来数据更新缓慢和不一致问题,但是动态资源有其特有的加速方法。
动态资源就意味着回源站进行数据请求,这其中就涉及到最优回源路径的选择,让路更好走,数据获取更快捷,实现动态资源的加速。
WebSocket
1.WebSocket 基本理论
WebSocket 是 HTML5 提供的一种浏览器与服务器进行全双工通讯的网络技术,属于应用层协议。它基于 TCP 传输协议,并复用 HTTP 的握手通道。浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接, 并进行双向数据传输。
WebSocket 的出现就解决了半双工通信的弊端。它最大的特点是:服务器可以向客户端主动推动消息,客户端也可以主动向服务器推送消息。
WebSocket 原理:客户端向 WebSocket 服务器通知(notify)一个带有所有接收者 ID(recipients IDs)的事件(event),服务器接收后立即通知所有活跃的(active)客户端,只有 ID 在接收者 ID 序列中的客户端才会处理这个事件。
WebSocket 特点的如下:
- 支持双向通信,实时性更强
- 可以发送文本,也可以发送二进制数据‘’
- 建立在 TCP 协议之上,服务端的实现比较容易
- 数据格式比较轻量,性能开销小,通信高效
- 没有同源限制,客户端可以与任意服务器通信
- 协议标识符是 ws(如果加密,则为 wss),服务器网址就是 URL
- 与 HTTP 协议有着良好的兼容性。默认端口也是 80 和 443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
Websocket 的使用方法如下:
在客户端中:
// 在index.html中直接写WebSocket,设置服务端的端口号为 9999
let ws = new WebSocket("ws://localhost:9999");
// 在客户端与服务端建立连接后触发
ws.onopen = function () {
console.log("Connection open.");
ws.send("hello");
};
// 在服务端给客户端发来消息的时候触发
ws.onmessage = function (res) {
console.log(res); // 打印的是MessageEvent对象
console.log(res.data); // 打印的是收到的消息
};
// 在客户端与服务端建立关闭后触发
ws.onclose = function (evt) {
console.log("Connection closed.");
};
WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。
在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接, 并进行双向数据传输。(维基百科)
WebSocket 本质上一种计算机网络应用层的协议,用来弥补 http 协议在持久通信能力上的不足。
WebSocket 协议在 2008 年诞生,2011 年成为国际标准。现在最新版本浏览器都已经支持了。
它的最大特点就是,服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话,属于服务器推送技术的一种。
WebSocket 的其他特点包括:
(1)建立在 TCP 协议之上,服务器端的实现比较容易。
(2)与 HTTP 协议有着良好的兼容性。默认端口也是 80 和 443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
(3)数据格式比较轻量,性能开销小,通信高效。
(4)可以发送文本,也可以发送二进制数据。
(5)没有同源限制,客户端可以与任意服务器通信。
(6)协议标识符是ws(如果加密,则为wss),服务器网址就是 URL。
ws://example.com:80/some/path
2.WebSocket 和 Socket 区别?
- TPC/IP 协议是传输层协议,主要解决数据如何在网络中传输;
- Socket 是对 TCP/IP 协议的封装和应用(程序员层面上);
- 而 HTTP 是应用层协议,主要解决如何包装数据。
TCP/IP 和 HTTP 协议的关系是:“我们在传输数据时,可以只使用(传输层)TCP/IP 协议,但是那样的话,如果没有应用层,便无法识别数据内容。如果想要使传输的数据有意义,则必须使用到应用层协议。应用层协议有很多,比如 HTTP、FTP、TELNET 等,也可以自己定义应用层协议。WEB 使用 HTTP 协议作应用层协议,以封装 HTTP 文本信息,然后使用 TCP/IP 做传输层协议将它发到网络上。”
Socket 是什么呢,实际上 socket 是对 TCP/IP 协议的封装,Socket 本身并不是协议,而是一个调用接口(API)。通过 Socket,我们才能使用 TCP/IP 协议。 Socket 跟 TCP/IP 协议关系是:“TCP/IP 只是一个协议栈,就像操作系统的运行机制一样,必须要具体实现,同时还要提供对外的操作接口。这个就像操作系统会提供标准的编程接口,比如 win32 编程接口一样,TCP/IP 也要提供可供程序员做网络开发所用的接口,这就是 Socket 编程接口。”
网络中的 Socket 并不是什么协议,而是为了使用 TCP,UDP 而抽象出来的一层 API,它是位于应用层和传输层之间的一个抽象层。Socket 是对 TCP/IP 的封装;HTTP 是轿车,提供了封装或者显示数据的具体形式;Socket 是发动机,提供了网络通信的能力。在 Unix 一切皆文件哲学的思想下,Socket 是一种"打开—读/写—关闭"模式的实现,服务器和客户端各自维护一个"文件",在建立连接打开后,可以向自己文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件。所以如果你想基于 TCP/IP 来构建服务,那么 Socket API 可能就是你会接触到的 API。
websocket 是为了解决基于浏览器的程序需要拉取资源时必须发起多个 HTTP 请求和长时间的轮训的问题而创建的
- Socket 是传输控制层的接口。用户可以通过 Socket 来操作底层 TCP/IP 协议族通信。
- WebSocket 是一个完整应用层协议。
- Socket 更灵活,WebSocket 更易用。
- 两者都能做即时通讯
3.为什么需要 WebSocket?
我们已经有了 HTTP 协议,为什么还需要另一个协议?它能带来什么好处?
因为 HTTP 协议有一个缺陷:通信只能由客户端发起,不具备服务器推送能力。
举例来说,我们想了解查询今天的实时数据,只能是客户端向服务器发出请求,服务器返回查询结果。HTTP 协议做不到服务器主动向客户端推送信息。
这种单向请求的特点,注定了如果服务器有连续的状态变化,客户端要获知就非常麻烦。我们只能使用"轮询":每隔一段时候,就发出一个询问,了解服务器有没有新的信息。最典型的场景就是聊天室。轮询的效率低,非常浪费资源(因为必须不停连接,或者 HTTP 连接始终打开)。
在 WebSocket 协议出现以前,创建一个和服务端进双通道通信的 web 应用,需要依赖 HTTP 协议,进行不停的轮询,这会导致一些问题:
- 服务端被迫维持来自每个客户端的大量不同的连接
- 大量的轮询请求会造成高开销,比如会带上多余的 header,造成了无用的数据传输。
http 协议本身是没有持久通信能力的,但是我们在实际的应用中,是很需要这种能力的,所以,为了解决这些问题,WebSocket 协议由此而生,于 2011 年被 IETF 定为标准 RFC6455,并被 RFC7936 所补充规范。
并且在 HTML5 标准中增加了有关 WebSocket 协议的相关 api,所以只要实现了 HTML5 标准的客户端,就可以与支持 WebSocket 协议的服务器进行全双工的持久通信了
4.WebSocket 与 HTTP 的区别
相同点: 都是一样基于 TCP 的,都是可靠性传输协议。都是应用层协议。
联系: WebSocket 在建立握手时,数据是通过 HTTP 传输的。但是建立之后,在真正传输时候是不需要 HTTP 协议的。
1、WebSocket 是双向通信协议,模拟 Socket 协议,可以双向发送或接受信息,而 HTTP 是单向的;
2、WebSocket 是需要浏览器和服务器握手进行建立连接的,而 http 是浏览器发起向服务器的连接。

虽然 HTTP/2 也具备服务器推送功能,但 HTTP/2 只能推送静态资源,无法推送指定的信息
5.WebSocket 协议的原理
与 http 协议一样,WebSocket 协议也需要通过已建立的 TCP 连接来传输数据。具体实现上是通过 http 协议建立通道,然后在此基础上用真正的 WebSocket 协议进行通信,所以 WebSocket 协议和 http 协议是有一定的交叉关系的。
首先,WebSocket 是一个持久化的协议,相对于 HTTP 这种非持久的协议来说
HTTP 的生命周期通过 Request 来界定,也就是一个 Request 一个 Response ,那么在 HTTP1.0 中,这次 HTTP 请求就结束了。
在 HTTP1.1 中进行了改进,使得有一个 keep-alive,也就是说,在一个 HTTP 连接中,可以发送多个 Request,接收多个 Response。但是请记住 Request = Response, 在 HTTP 中永远是这样,也就是说一个 Request 只能有一个 Response。而且这个 Response 也是被动的,不能主动发起。
首先 WebSocket 是基于 HTTP 协议的,或者说借用了 HTTP 协议来完成一部分握手。
首先我们来看个典型的 WebSocket 握手
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
Origin: http://example.com
熟悉 HTTP 的童鞋可能发现了,这段类似 HTTP 协议的握手请求中,多了这么几个东西。
Upgrade: websocket;
Connection: Upgrade;
这个就是 WebSocket 的核心了,告诉 Apache 、 Nginx 等服务器:注意啦,我发起的请求要用 WebSocket 协议,快点帮我找到对应的助理处理~而不是那个老土的 HTTP。
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
首先, Sec-WebSocket-Key 是一个 Base64 encode 的值,这个是浏览器随机生成的,告诉服务器:泥煤,不要忽悠我,我要验证你是不是真的是 WebSocket 助理。
然后, Sec_WebSocket-Protocol 是一个用户定义的字符串,用来区分同 URL 下,不同的服务所需要的协议。简单理解:今晚我要服务 A,别搞错啦~
最后, Sec-WebSocket-Version 是告诉服务器所使用的 WebSocket Draft (协议版本),在最初的时候,WebSocket 协议还在 Draft 阶段,各种奇奇怪怪的协议都有,而且还有很多期奇奇怪怪不同的东西,什么 Firefox 和 Chrome 用的不是一个版本之类的,当初 WebSocket 协议太多可是一个大难题。。不过现在还好,已经定下来啦~大家都使用同一个版本: 服务员,我要的是 13 岁的噢 →_→
然后服务器会返回下列东西,表示已经接受到请求, 成功建立 WebSocket 啦!
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: HSmrc0sMlYUkAGmm5OPpG2HaGWk=
Sec-WebSocket-Protocol: chat
这里开始就是 HTTP 最后负责的区域了,告诉客户,我已经成功切换协议啦~
Upgrade: websocket;
Connection: Upgrade;
依然是固定的,告诉客户端即将升级的是 WebSocket 协议,而不是 mozillasocket,lurnarsocket 或者 shitsocket。
然后, Sec-WebSocket-Accept 这个则是经过服务器确认,并且加密过后的 Sec-WebSocket-Key 。 服务器:好啦好啦,知道啦,给你看我的 ID CARD 来证明行了吧。
后面的, Sec-WebSocket-Protocol 则是表示最终使用的协议。
至此,HTTP 已经完成它所有工作了,接下来就是完全按照 WebSocket 协议进行了。
总结,WebSocket 连接的过程是:
首先,客户端发起 http 请求,经过 3 次握手后,建立起 TCP 连接;http 请求里存放 WebSocket 支持的版本号等信息,如:Upgrade、Connection、WebSocket-Version 等;
然后,服务器收到客户端的握手请求后,同样采用 HTTP 协议回馈数据;
最后,客户端收到连接成功的消息后,开始借助于 TCP 传输信道进行全双工通信。
6.Websocket 应用场景
优点:
- WebSocket 协议一旦建议后,互相沟通所消耗的请求头是很小的
- 服务器可以向客户端推送消息了
缺点:
- 少部分浏览器不支持,浏览器支持的程度与方式有区别(IE10)
推荐使用的场景
即时聊天通信
多玩家游戏
在线协同编辑/编辑
实时数据流的拉取与推送
体育/游戏实况
实时地图位置
即时Web应用程序:即时Web应用程序使用一个Web套接字在客户端显示数据,这些数据由后端服务器连续发送。在WebSocket 中,数据被连续推送/传输到已经打开的同一连接中,这就是为什么WebSocket更快并提高了应用程序性能的原因。 例如在交易网站或比特币交易中,这是最不稳定的事情,它用于显示价格波动,数据被后端服务器使用 Web 套接字通道连续推送到客户端。
游戏应用程序:在游戏应用程序中,你可能会注意到,服务器会持续接收数据,而不会刷新用户界面。屏幕上的用户界面会自动刷新,而且不需要建立新的连接,因此在WebSocket游戏应用程序中非常有帮助。
聊天应用程序:聊天应用程序仅使用WebSocket建立一次连接,便能在订阅户之间交换,发布和广播消息。它重复使用相同的WebSocket连接,用于发送和接收消息以及一对一的消息传输。
不推荐使用的场景
如果我们需要通过网络传输的任何实时更新或连续数据流,则可以使用WebSocket。如果我们要获取旧数据,或者只想获取一次数据供应用程序使用,则应该使用HTTP协议,不需要很频繁或仅获取一次的数据可以通过简单的HTTP请求查询,因此在这种情况下最好不要使用WebSocket。
注意:如果仅加载一次数据,则RESTful Web服务足以从服务器获取数据。
7.websocket 断线重连
心跳就是客户端定时的给服务端发送消息,证明客户端是在线的, 如果超过一定的时间没有发送则就是离线了。
如何判断在线离线?
当客户端第一次发送请求至服务端时会携带唯一标识、以及时间戳,服务端到 db 或者缓存去查询改请求的唯一标识,如果不存在就存入 db 或者缓存中,
第二次客户端定时再次发送请求依旧携带唯一标识、以及时间戳,服务端到 db 或者缓存去查询改请求的唯一标识,如果存在就把上次的时间戳拿取出来,使用当前时间戳减去上次的时间,
得出的毫秒秒数判断是否大于指定的时间,若小于的话就是在线,否则就是离线;
如何解决断线问题
通过查阅资料了解到 nginx 代理的 websocket 转发,无消息连接会出现超时断开问题。网上资料提到解决方案两种,一种是修改 nginx 配置信息,第二种是 websocket 发送心跳包。
下面就来总结一下本次项目实践中解决的 websocket 的断线 和 重连 这两个问题的解决方案。
主动触发包括主动断开连接,客户端主动发送消息给后端
- 主动断开连接
ws.close();
主动断开连接,根据需要使用,基本很少用到。
- 主动发送消息
ws.send("hello world");
针对 websocket 断线我们来分析一下,
断线的可能原因 1:websocket 超时没有消息自动断开连接,应对措施:
这时候我们就需要知道服务端设置的超时时长是多少,在小于超时时间内发送心跳包,有 2 中方案:一种是客户端主动发送上行心跳包,另一种方案是服务端主动发送下行心跳包。
下面主要讲一下客户端也就是前端如何实现心跳包:
首先了解一下心跳包机制
跳包之所以叫心跳包是因为:它像心跳一样每隔固定时间发一次,以此来告诉服务器,这个客户端还活着。事实上这是为了保持长连接,至于这个包的内容,是没有什么特别规定的,不过一般都是很小的包,或者只包含包头的一个空包。
在 TCP 的机制里面,本身是存在有心跳包的机制的,也就是 TCP 的选项:SO_KEEPALIVE。系统默认是设置的 2 小时的心跳频率。但是它检查不到机器断电、网线拔出、防火墙这些断线。而且逻辑层处理断线可能也不是那么好处理。一般,如果只是用于保活还是可以的。
心跳包一般来说都是在逻辑层发送空的 echo 包来实现的。
下一个定时器,在一定时间间隔下发送一个空包给客户端,然后客户端反馈一个同样的空包回来,服务器如果在一定时间内收不到客户端发送过来的反馈包,那就只有认定说掉线了。在长连接下,有可能很长一段时间都没有数据往来。理论上说,这个连接是一直保持连接的,但是实际情况中,如果中间节点出现什么故障是难以知道的。更要命的是,有的节点(防火墙)会自动把一定时间之内没有数据交互的连接给断掉。在这个时候,就需要我们的心跳包了,用于维持长连接,保活。
心跳检测步骤:
- 客户端每隔一个时间间隔发生一个探测包给服务器
- 客户端发包时启动一个超时定时器
- 服务器端接收到检测包,应该回应一个包
- 如果客户机收到服务器的应答包,则说明服务器正常,删除超时定时器
- 如果客户端的超时定时器超时,依然没有收到应答包,则说明服务器挂了
// 前端解决方案:心跳检测
var heartCheck = {
timeout: 30000, //30秒发一次心跳
timeoutObj: null,
serverTimeoutObj: null,
reset: function () {
clearTimeout(this.timeoutObj);
clearTimeout(this.serverTimeoutObj);
return this;
},
start: function () {
var self = this;
this.timeoutObj = setTimeout(function () {
//这里发送一个心跳,后端收到后,返回一个心跳消息,
//onmessage拿到返回的心跳就说明连接正常
ws.send("ping");
console.log("ping!");
self.serverTimeoutObj = setTimeout(function () {
//如果超过一定时间还没重置,说明后端主动断开了
ws.close(); //如果onclose会执行reconnect,我们执行ws.close()就行了.如果直接执行reconnect 会触发onclose导致重连两次
}, self.timeout);
}, this.timeout);
},
};断线的可能原因 2:websocket 异常包括服务端出现中断,交互切屏等等客户端异常中断等等
当若服务端宕机了,客户端怎么做、服务端再次上线时怎么做?
客户端则需要断开连接,通过 onclose 关闭连接,服务端再次上线时则需要清除之间存的数据,若不清除 则会造成只要请求到服务端的都会被视为离线。
针对这种异常的中断解决方案就是处理重连,下面我们给出的重连方案是使用 js 库处理:引入 reconnecting-websocket.min.js,ws 建立链接方法使用 js 库 api 方法:
var ws = new ReconnectingWebSocket(url);
// 断线重连:
reconnectSocket(){
if ('ws' in window) {
ws = new ReconnectingWebSocket(url);
} else if ('MozWebSocket' in window) {
ws = new MozWebSocket(url);
} else {
ws = new SockJS(url);
}
}断网监测支持使用 js 库:offline.min.js
onLineCheck(){
Offline.check();
console.log(Offline.state,'---Offline.state');
console.log(this.socketStatus,'---this.socketStatus');
if(!this.socketStatus){
console.log('网络连接已断开!');
if(Offline.state === 'up' && websocket.reconnectAttempts > websocket.maxReconnectInterval){
window.location.reload();
}
reconnectSocket();
}else{
console.log('网络连接成功!');
websocket.send("heartBeat");
}
}
// 使用:在websocket断开链接时调用网络中断监测
websocket.onclose => () {
onLineCheck();
};
8.WebSocket 总结
WebSocket 是为了在 web 应用上进行双通道通信而产生的协议,相比于轮询 HTTP 请求的方式,WebSocket 有节省服务器资源,效率高等优点。
WebSocket 中的掩码是为了防止早期版本中存在中间缓存污染攻击等问题而设置的,客户端向服务端发送数据需要掩码,服务端向客户端发送数据不需要掩码。
WebSocket 中 Sec-WebSocket-Key 的生成算法是拼接服务端和客户端生成的字符串,进行 SHA1 哈希算法,再用 base64 编码。
WebSocket 协议握手是依靠 HTTP 协议的,依靠于 HTTP 响应 101 进行协议升级转换。
9.Socket.IO
简单来说 Socket.IO 就是对 WebSocket 的封装,并且实现了 WebSocket 的服务端代码。Socket.IO 将 WebSocket 和轮询(Polling)机制以及其它的实时通信方式封装成了通用的接口,并且在服务端实现了这些实时机制的相应代码。也就是说,WebSocket 仅仅是 Socket.IO 实现实时通信的一个子集。Socket.IO 简化了 WebSocket API,统一了返回传输的 API。传输种类包括:
- WebSocket
- Flash Socket
- AJAX long-polling
- AJAX multipart streaming
- IFrame
- JSONP polling。
我们来看一下服务端的 Socket.IO 基本 API:
// 引入socke.io
const io = require('socket.io')(80)
// 监听客户端连接,回调函数会传递本次连接的socket
io.on('connection',function(socket))
// 给所有客户端广播消息
io.sockets.emit('String',data)
// 给指定的客户端发送消息
io.sockets.socket(socketid).emit('String', data)
// 监听客户端发送的信息
socket.on('String',function(data))
// 给该socket的客户端发送消息
socket.emit('String', data)
另外,Socket.IO 还提供了一个 Node.JS API,它看起来很像客户端 API。所以我们来看看它的实际应用吧:
// socket-server.js
// 需要使用HTTP模块来启动服务器和Socket.IO
const http= require('http'),
const io= require('socket.io')
const server= http.createServer(function(req, res){
// 发送HTML的headers和message
res.writeHead(200,{ 'Content-Type': 'text/html' })
res.end('<p>Hello Socket.IO!<p>')
});
// 在8080端口启动服务器
server.listen(8080)
// 创建一个Socket.IO实例,并把它传递给服务器
const socket= io.listen(server)
// 添加一个连接监听器
socket.on('connection', function(client) {
// 连接成功,开始监听
client.on('message',function(event){
console.log('Received message from client!',event)
})
// 连接失败
client.on('disconnect',function(){
clearInterval(interval)
console.log('Server has disconnected')
})
})
然后我们就可以启动这个文件了:
node socket-server.js
然后我们就可以创建一个每秒钟发送消息到客户端的发送器了;
var interval= setInterval(function() {
client.send('This is a message from the server,hello world' + new Date().getTime());
},1000);
注:需要注意的是,如果我们想在前端使用 socket.IO,我们需要下载这个:
npm install socket.io-client --save
然后再连接网络:
import io from 'socket.io-client'
const socket = io('ws://localhost:8080')
10.即时通讯:短轮询、长轮询、SSE 和 WebSocket
短轮询和长轮询的目的都是用于实现客户端和服务器端的一个即时通讯。
短轮询的基本思路: 浏览器每隔一段时间向浏览器发送 http 请求,服务器端在收到请求后,不论是否有数据更新,都直接进行响应。这种方式实现的即时通信,本质上还是浏览器发送请求,服务器接受请求的一个过程,通过让客户端不断的进行请求,使得客户端能够模拟实时地收到服务器端的数据的变化。这种方式的优点是比较简单,易于理解。缺点是这种方式由于需要不断的建立 http 连接,严重浪费了服务器端和客户端的资源。当用户增加时,服务器端的压力就会变大,这是很不合理的。
长轮询的基本思路: 首先由客户端向服务器发起请求,当服务器收到客户端发来的请求后,服务器端不会直接进行响应,而是先将这个请求挂起,然后判断服务器端数据是否有更新。如果有更新,则进行响应,如果一直没有数据,则到达一定的时间限制才返回。客户端 JavaScript 响应处理函数会在处理完服务器返回的信息后,再次发出请求,重新建立连接。长轮询和短轮询比起来,它的优点是明显减少了很多不必要的 http 请求次数,相比之下节约了资源。长轮询的缺点在于,连接挂起也会导致资源的浪费。
SSE 的基本思想: 服务器使用流信息向服务器推送信息。严格地说,http 协议无法做到服务器主动推送信息。但是,有一种变通方法,就是服务器向客户端声明,接下来要发送的是流信息。也就是说,发送的不是一次性的数据包,而是一个数据流,会连续不断地发送过来。这时,客户端不会关闭连接,会一直等着服务器发过来的新的数据流,视频播放就是这样的例子。SSE 就是利用这种机制,使用流信息向浏览器推送信息。它基于 http 协议,目前除了 IE/Edge,其他浏览器都支持。它相对于前面两种方式来说,不需要建立过多的 http 请求,相比之下节约了资源。
WebSocket 是 HTML5 定义的一个新协议议,与传统的 http 协议不同,该协议允许由服务器主动的向客户端推送信息。使用 WebSocket 协议的缺点是在服务器端的配置比较复杂。WebSocket 是一个全双工的协议,也就是通信双方是平等的,可以相互发送消息,而 SSE 的方式是单向通信的,只能由服务器端向客户端推送信息,如果客户端需要发送信息就是属于下一个 http 请求了。
上面的四个通信协议,前三个都是基于 HTTP 协议的。
对于这四种即使通信协议,从性能的角度来看: WebSocket > 长连接(SEE) > 长轮询 > 短轮询 但是,我们如果考虑浏览器的兼容性问题,顺序就恰恰相反了: 短轮询 > 长轮询 > 长连接(SEE) > WebSocket 所以,还是要根据具体的使用场景来判断使用哪种方式。
网络鉴权
1.Cookie、Session、Token、JWT.
什么是认证(Authentication)
- 通俗地讲就是验证当前用户的身份,证明“你是你自己”(比如:你每天上下班打卡,都需要通过指纹打卡,当你的指纹和系统里录入的指纹相匹配时,就打卡成功)
- 互联网中的认证:
- 用户名密码登录
- 邮箱发送登录链接
- 手机号接收验证码
- 只要你能收到邮箱/验证码,就默认你是账号的主人
什么是授权(Authorization)
- 用户授予第三方应用访问该用户某些资源的权限
- 你在安装手机应用的时候,APP 会询问是否允许授予权限(访问相册、地理位置等权限)
- 你在访问微信小程序时,当登录时,小程序会询问是否允许授予权限(获取昵称、头像、地区、性别等个人信息)
- 实现授权的方式有:cookie、session、token、OAuth
什么是凭证(Credentials)
实现认证和授权的前提
是需要一种
媒介(证书)
来标记访问者的身份
- 在战国时期,商鞅变法,发明了照身帖。照身帖由官府发放,是一块打磨光滑细密的竹板,上面刻有持有人的头像和籍贯信息。国人必须持有,如若没有就被认为是黑户,或者间谍之类的。
- 在现实生活中,每个人都会有一张专属的居民身份证,是用于证明持有人身份的一种法定证件。通过身份证,我们可以办理手机卡/银行卡/个人贷款/交通出行等等,这就是认证的凭证。
- 在互联网应用中,一般网站(如掘金)会有两种模式,游客模式和登录模式。游客模式下,可以正常浏览网站上面的文章,一旦想要点赞/收藏/分享文章,就需要登录或者注册账号。当用户登录成功后,服务器会给该用户使用的浏览器颁发一个令牌(token),这个令牌用来表明你的身份,每次浏览器发送请求时会带上这个令牌,就可以使用游客模式下无法使用的功能。
什么是 Cookie
- HTTP 是无状态的协议(对于事务处理没有记忆能力,每次客户端和服务端会话完成时,服务端不会保存任何会话信息):每个请求都是完全独立的,服务端无法确认当前访问者的身份信息,无法分辨上一次的请求发送者和这一次的发送者是不是同一个人。所以服务器与浏览器为了进行会话跟踪(知道是谁在访问我),就必须主动的去维护一个状态,这个状态用于告知服务端前后两个请求是否来自同一浏览器。而这个状态需要通过 cookie 或者 session 去实现。
- cookie 存储在客户端: cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。
- cookie 是不可跨域的: 每个 cookie 都会绑定单一的域名,无法在别的域名下获取使用,一级域名和二级域名之间是允许共享使用的(靠的是 domain)。
什么是 Session
- session 是另一种记录服务器和客户端会话状态的机制
- session 是基于 cookie 实现的,session 存储在服务器端,sessionId 会被存储到客户端的 cookie 中
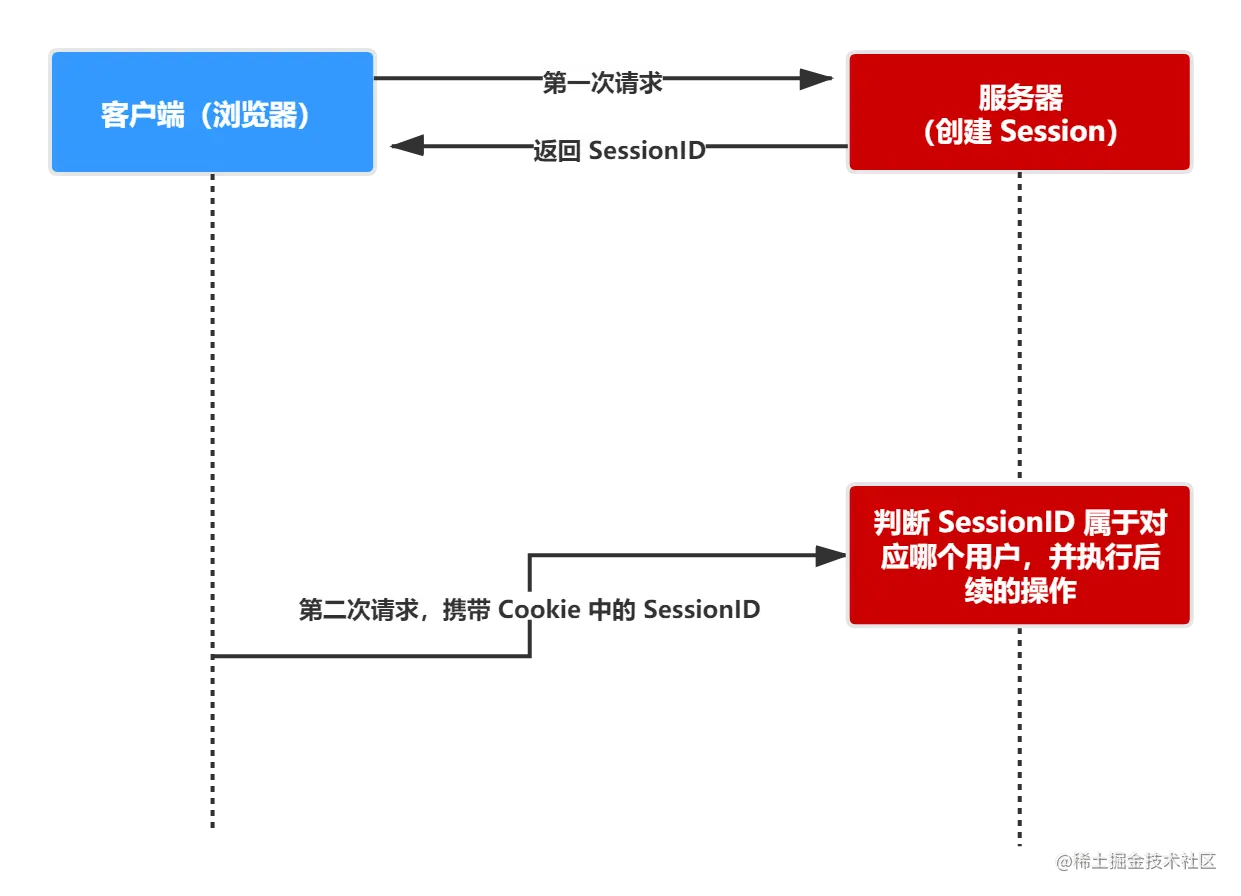
- session 认证流程:
- 用户第一次请求服务器的时候,服务器根据用户提交的相关信息,创建对应的 Session
- 请求返回时将此 Session 的唯一标识信息 SessionID 返回给浏览器
- 浏览器接收到服务器返回的 SessionID 信息后,会将此信息存入到 Cookie 中,同时 Cookie 记录此 SessionID 属于哪个域名
- 当用户第二次访问服务器的时候,请求会自动判断此域名下是否存在 Cookie 信息,如果存在自动将 Cookie 信息也发送给服务端,服务端会从 Cookie 中获取 SessionID,再根据 SessionID 查找对应的 Session 信息,如果没有找到说明用户没有登录或者登录失效,如果找到 Session 证明用户已经登录可执行后面操作。
根据以上流程可知,SessionID 是连接 Cookie 和 Session 的一道桥梁,大部分系统也是根据此原理来验证用户登录状态。
Cookie 和 Session 的区别
- 安全性: Session 比 Cookie 安全,Session 是存储在服务器端的,Cookie 是存储在客户端的。
- 存取值的类型不同:Cookie 只支持存字符串数据,想要设置其他类型的数据,需要将其转换成字符串,Session 可以存任意数据类型。
- 有效期不同: Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭(默认情况下)或者 Session 超时都会失效。
- 存储大小不同: 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie,但是当访问量过多,会占用过多的服务器资源。
什么是 Token(令牌)
Acesss Token
- 访问资源接口(API)时所需要的资源凭证
- 简单 token 的组成: uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token 的前几位以哈希算法压缩成的一定长度的十六进制字符串)
- 特点:
- 服务端无状态化、可扩展性好
- 支持移动端设备
- 安全
- 支持跨程序调用
- token 的身份验证流程:
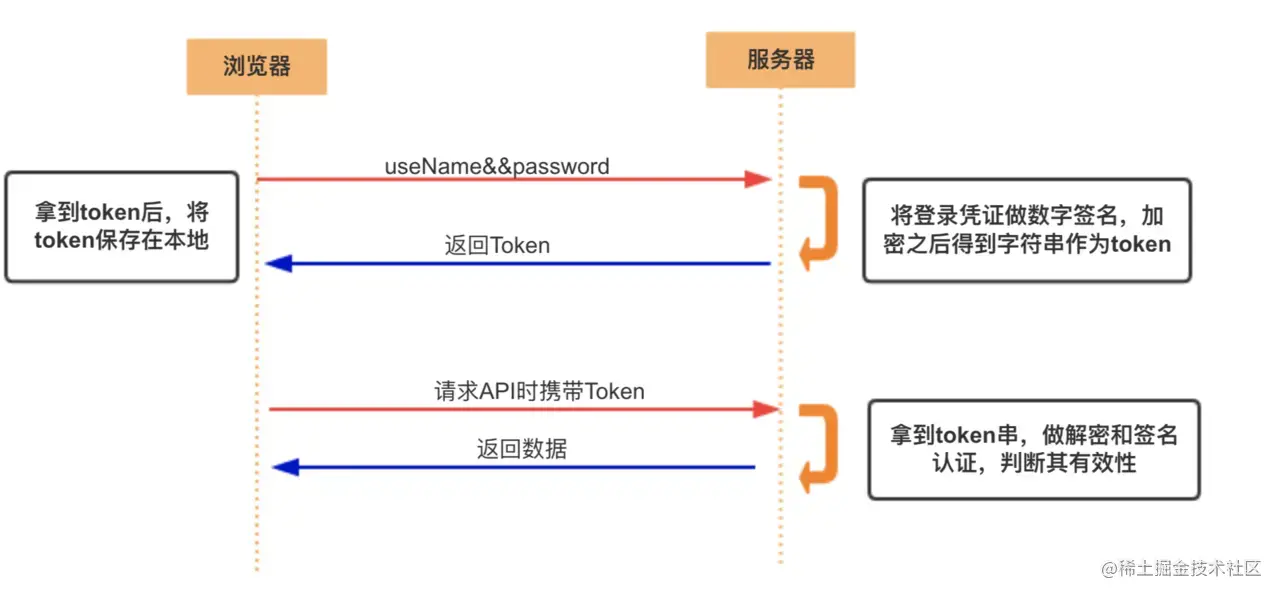
- 客户端使用用户名跟密码请求登录
- 服务端收到请求,去验证用户名与密码
- 验证成功后,服务端会签发一个 token 并把这个 token 发送给客户端
- 客户端收到 token 以后,会把它存储起来,比如放在 cookie 里或者 localStorage 里
- 客户端每次向服务端请求资源的时候需要带着服务端签发的 token
- 服务端收到请求,然后去验证客户端请求里面带着的 token ,如果验证成功,就向客户端返回请求的数据
- 每一次请求都需要携带 token,需要把 token 放到 HTTP 的 Header 里
- 基于 token 的用户认证是一种服务端无状态的认证方式,服务端不用存放 token 数据。用解析 token 的计算时间换取 session 的存储空间,从而减轻服务器的压力,减少频繁的查询数据库
- token 完全由应用管理,所以它可以避开同源策略
Refresh Token
- 另外一种 token——refresh token
- refresh token 是专用于刷新 access token 的 token。如果没有 refresh token,也可以刷新 access token,但每次刷新都要用户输入登录用户名与密码,会很麻烦。有了 refresh token,可以减少这个麻烦,客户端直接用 refresh token 去更新 access token,无需用户进行额外的操作。
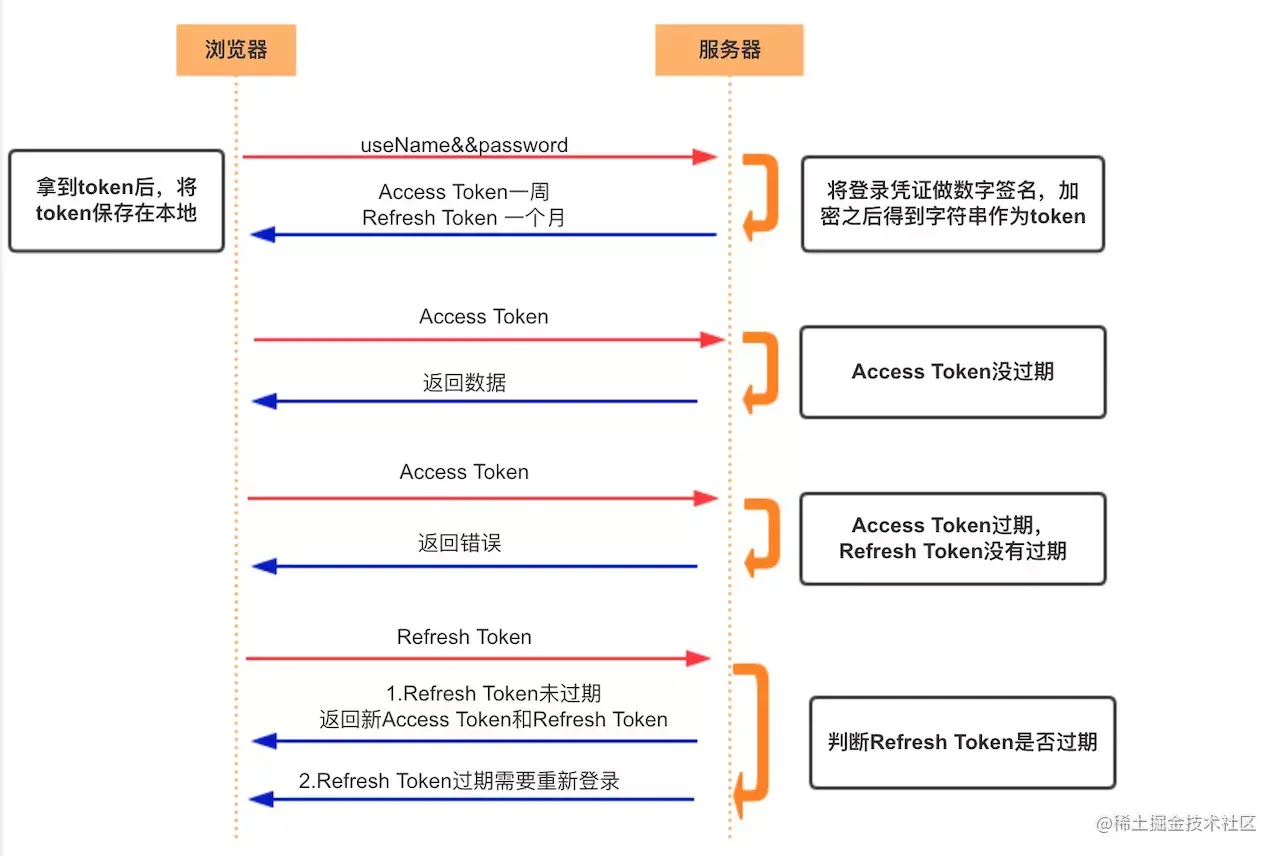
- Access Token 的有效期比较短,当 Acesss Token 由于过期而失效时,使用 Refresh Token 就可以获取到新的 Token,如果 Refresh Token 也失效了,用户就只能重新登录了。
- Refresh Token 及过期时间是存储在服务器的数据库中,只有在申请新的 Acesss Token 时才会验证,不会对业务接口响应时间造成影响,也不需要向 Session 一样一直保持在内存中以应对大量的请求。
Token 和 Session 的区别
- Session 是一种记录服务器和客户端会话状态的机制,使服务端有状态化,可以记录会话信息。而 Token 是令牌,访问资源接口(API)时所需要的资源凭证。Token 使服务端无状态化,不会存储会话信息。
- Session 和 Token 并不矛盾,作为身份认证 Token 安全性比 Session 好,因为每一个请求都有签名还能防止监听以及重放攻击,而 Session 就必须依赖链路层来保障通讯安全了。如果你需要实现有状态的会话,仍然可以增加 Session 来在服务器端保存一些状态。
- 所谓 Session 认证只是简单的把 User 信息存储到 Session 里,因为 SessionID 的不可预测性,暂且认为是安全的。而 Token ,如果指的是 OAuth Token 或类似的机制的话,提供的是 认证 和 授权 ,认证是针对用户,授权是针对 App 。其目的是让某 App 有权利访问某用户的信息。这里的 Token 是唯一的。不可以转移到其它 App 上,也不可以转到其它用户上。Session 只提供一种简单的认证,即只要有此 SessionID ,即认为有此 User 的全部权利。是需要严格保密的,这个数据应该只保存在站方,不应该共享给其它网站或者第三方 App。所以简单来说:如果你的用户数据可能需要和第三方共享,或者允许第三方调用 API 接口,用 Token 。如果永远只是自己的网站,自己的 App,用什么就无所谓了。
什么是 JWT
- JSON Web Token(简称 JWT)是目前最流行的跨域认证解决方案。
- 是一种认证授权机制。
- JWT 是为了在网络应用环境间传递声明而执行的一种基于 JSON 的开放标准(RFC 7519)。JWT 的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源。比如用在用户登录上。
- 可以使用 HMAC 算法或者是 RSA 的公/私秘钥对 JWT 进行签名。因为数字签名的存在,这些传递的信息是可信的。
- 阮一峰老师的 JSON Web Token 入门教程
JWT 通常由三部分组成: 头信息(header), 消息体(payload)和签名(signature)。
头信息指定了该 JWT 使用的签名算法:
header = '{"alg":"HS256","typ":"JWT"}';
HS256 表示使用了 HMAC-SHA256 来生成签名。
消息体包含了 JWT 的意图:
payload = '{"loggedInAs":"admin","iat":1422779638}'; //iat表示令牌生成的时间
未签名的令牌由base64url编码的头信息和消息体拼接而成(使用”.”分隔),签名则通过私有的 key 计算而成:
key = "secretkey";
unsignedToken = encodeBase64(header) + "." + encodeBase64(payload);
signature = HMAC - SHA256(key, unsignedToken);
最后在未签名的令牌尾部拼接上base64url编码的签名(同样使用”.”分隔)就是 JWT 了:
token = encodeBase64(header) + '.' + encodeBase64(payload) + '.' + encodeBase64(signature)
# token看起来像这样: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJsb2dnZWRJbkFzIjoiYWRtaW4iLCJpYXQiOjE0MjI3Nzk2Mzh9.gzSraSYS8EXBxLN_oWnFSRgCzcmJmMjLiuyu5CSpyHI
JWT 常常被用作保护服务端的资源(resource),客户端通常将 JWT 通过 HTTP 的Authorization header 发送给服务端,服务端使用自己保存的 key 计算、验证签名以判断该 JWT 是否可信:
Authorization: Bearer eyJhbGci*...<snip>...*yu5CSpyHI
JWT 的原理
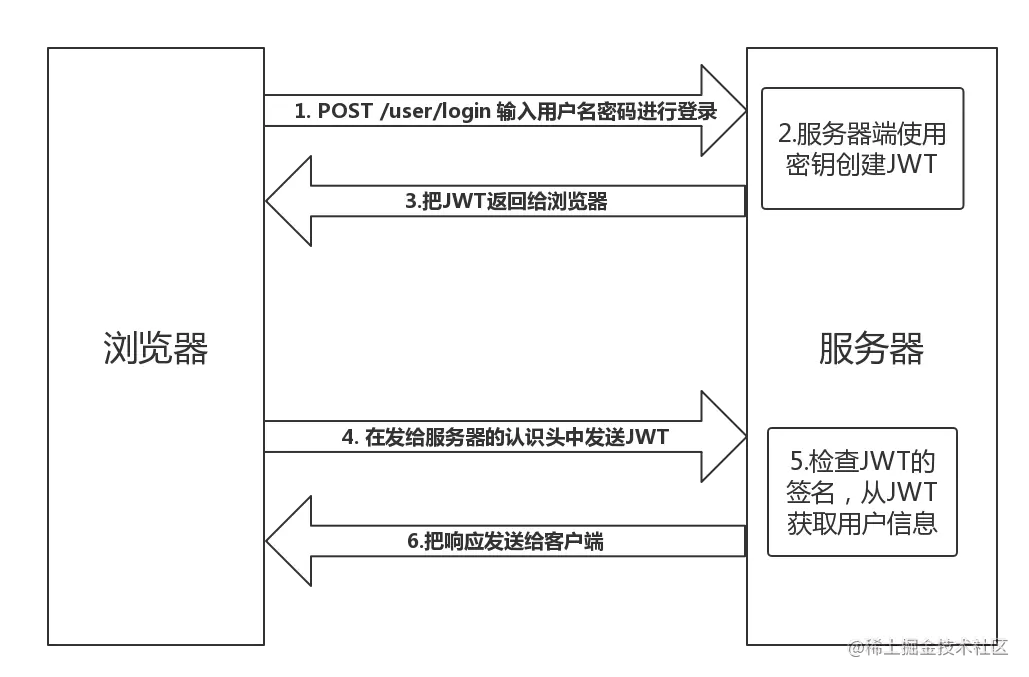
- JWT 认证流程:
- 用户输入用户名/密码登录,服务端认证成功后,会返回给客户端一个 JWT
- 客户端将 token 保存到本地(通常使用 localstorage,也可以使用 cookie)
- 当用户希望访问一个受保护的路由或者资源的时候,需要请求头的 Authorization 字段中使用 Bearer 模式添加 JWT,其内容看起来是下面这样
Authorization: Bearer <token>
- 服务端的保护路由将会检查请求头 Authorization 中的 JWT 信息,如果合法,则允许用户的行为
- 因为 JWT 是自包含的(内部包含了一些会话信息),因此减少了需要查询数据库的需要
- 因为 JWT 并不使用 Cookie 的,所以你可以使用任何域名提供你的 API 服务而不需要担心跨域资源共享问题(CORS)
- 因为用户的状态不再存储在服务端的内存中,所以这是一种无状态的认证机制
JWT 的使用方式
- 客户端收到服务器返回的 JWT,可以储存在 Cookie 里面,也可以储存在 localStorage。
方式一
当用户希望访问一个受保护的路由或者资源的时候,可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP 请求头信息的 Authorization 字段里,使用 Bearer 模式添加 JWT。
GET /calendar/v1/events
Host: api.example.com
Authorization: Bearer <token>- 用户的状态不会存储在服务端的内存中,这是一种 无状态的认证机制
- 服务端的保护路由将会检查请求头 Authorization 中的 JWT 信息,如果合法,则允许用户的行为。
- 由于 JWT 是自包含的,因此减少了需要查询数据库的需要
- JWT 的这些特性使得我们可以完全依赖其无状态的特性提供数据 API 服务,甚至是创建一个下载流服务。
- 因为 JWT 并不使用 Cookie ,所以你可以使用任何域名提供你的 API 服务而不需要担心跨域资源共享问题(CORS)
方式二
- 跨域的时候,可以把 JWT 放在 POST 请求的数据体里。
方式三
- 通过 URL 传输
http://example.com/user?token=xxx
Token 和 JWT 的区别
相同:
- 都是访问资源的令牌
- 都可以记录用户的信息
- 都是使服务端无状态化
- 都是只有验证成功后,客户端才能访问服务端上受保护的资源
区别:
- Token:服务端验证客户端发送过来的 Token 时,还需要查询数据库获取用户信息,然后验证 Token 是否有效。
- JWT: 将 Token 和 Payload 加密后存储于客户端,服务端只需要使用密钥解密进行校验(校验也是 JWT 自己实现的)即可,不需要查询或者减少查询数据库,因为 JWT 自包含了用户信息和加密的数据。
2.单点登录和 OAuth2.0
SSO 是 Single Sign On 的缩写,OAuth 是 Open Authority 的缩写,这两者都是使用令牌的方式来代替用户密码访问应用。流程上来说他们非常相似,但概念上又十分不同。SSO大家应该比较熟悉,它将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。OAuth2.0 原理可能比较陌生,但平时用的却很多,比如访问某网站想留言又不想注册时使用了微信授权。以上两者,你在业务系统中都没有账号和密码,账号密码是存放在登录中心或微信服务器中的,这就是所谓的使用令牌代替账号密码访问应用。
单点登录
sso 需要一个独立的认证中心,只有认证中心能接受用户的用户名密码等安全信息,其他系统不提供登录入口,只接受认证中心的间接授权。
间接授权通过令牌实现,sso 认证中心验证用户的用户名密码没问题,创建授权令牌,在接下来的跳转过程中,授权令牌作为参数发送给各个子系统,子系统拿到令牌,即得到了授权,可以借此创建局部会话,局部会话登录方式与单系统的登录方式相同。
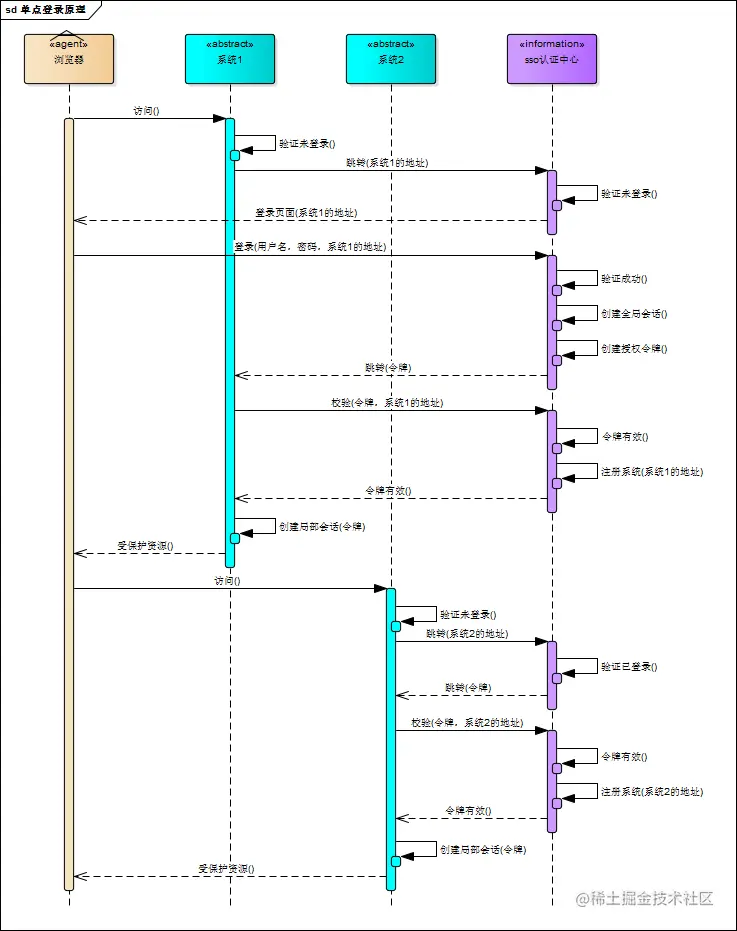
- 用户访问系统 1 的受保护资源,系统 1 发现用户未登录,跳转至 sso 认证中心,并将自己的地址作为参数
- sso 认证中心发现用户未登录,将用户引导至登录页面(带系统 1 地址)
- 用户输入用户名密码提交登录申请
sso认证中心校验用户信息,创建用户与sso认证中心之间的会话,称为全局会话(这时该会话信息保存到cookie中),同时创建授权令牌- sso 认证中心带着令牌跳转到最初的请求地址(系统 1)
- 系统 1 拿到令牌,去 sso 认证中心校验令牌是否有效
- sso 认证中心校验令牌,返回有效,注册系统 1
系统1使用该令牌创建与用户的会话,称为局部会话(seesion),返回受保护资源- 用户访问系统 2 的受保护资源
- 系统 2 发现用户未登录,跳转至 sso 认证中心,并将自己的
地址和之前和sso认证中心的会话cookie信息作为参数 - sso 认证中心发现用户已登录,跳转回系统 2 的地址,并附上令牌
- 系统 2 拿到令牌,去 sso 认证中心校验令牌是否有效
- sso 认证中心校验令牌,返回有效,注册系统 2
- 系统 2 使用该令牌创建与用户的局部会话,返回受保护资源
OAuth2.0
OAuth2 流程
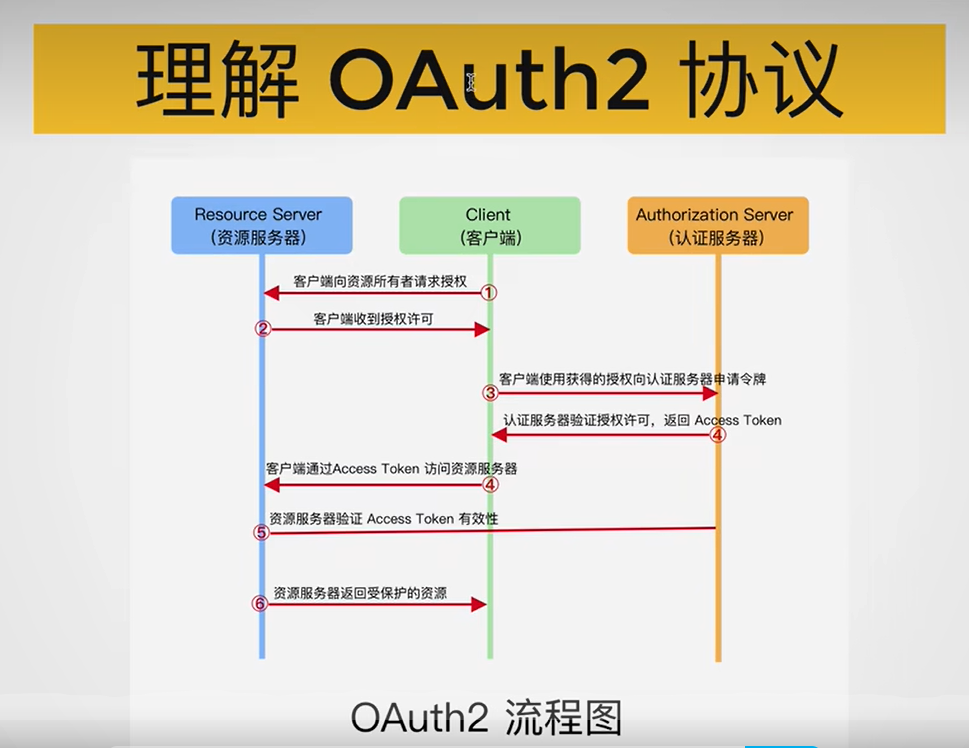
OAuth2.0 授权码模式,这种方式是最常用的流程,安全性也最高,它适用于那些有后端的 Web 应用;OAuth2.0 的流程跟 SSO 差不多,在OAuth2中,有授权服务器、资源服务器、客户端这样几个角色,当我们用它来实现SSO的时候是不需要资源服务器这个角色的,有授权服务器和客户端就够了。授权服务器当然是用来做认证的,客户端就是各个应用系统,我们只需要登录成功后拿到用户信息以及用户所拥有的权限即可
- 用户在某网站上点击使用微信授权,这里的某网站就类似业务系统,微信授权服务器就类似单点登录系统
- 之后微信授权服务器返回一个确认授权页面,类似登录界面,这个页面当然是微信的而不是业务系统的
- 用户确认授权,类似填写了账号和密码,提交后微信鉴权并返回一个 ticket,并重定向业务系统。
- 业务系统带上 ticket 访问微信服务器,微信服务器返回正式的 token,业务系统就可以使用 token 获取用户信息了
OAuth2.0 授权方式
OAuth2.0 的授权简单理解其实就是获取令牌(token)的过程,OAuth 协议定义了四种获得令牌的授权方式(authorization grant )如下:
- 授权码(
authorization-code) - 隐藏式(
implicit) - 密码式(
password): - 客户端凭证(
client credentials)
但值得注意的是,不管我们使用哪一种授权方式,在三方应用申请令牌之前,都必须在系统中去申请身份唯一标识:客户端 ID(client ID)和 客户端密钥(client secret)。这样做可以保证 token 不被恶意使用。
下面我们会分析每种授权方式的原理,在进入正题前,先了解 OAuth2.0 授权过程中几个重要的参数:
response_type:code 表示要求返回授权码,token 表示直接返回令牌client_id:客户端身份标识client_secret:客户端密钥redirect_uri:重定向地址scope:表示授权的范围,read只读权限,all读写权限grant_type:表示授权的方式,AUTHORIZATION_CODE(授权码)、password(密码)、client_credentials(凭证式)、refresh_token更新令牌state:应用程序传递的一个随机数,用来防止CSRF攻击。
1、授权码
OAuth2.0四种授权中授权码方式是最为复杂,但也是安全系数最高的,比较常用的一种方式。这种方式适用于兼具前后端的Web项目,因为有些项目只有后端或只有前端,并不适用授权码模式。
下图我们以用WX登录掘金为例,详细看一下授权码方式的整体流程。
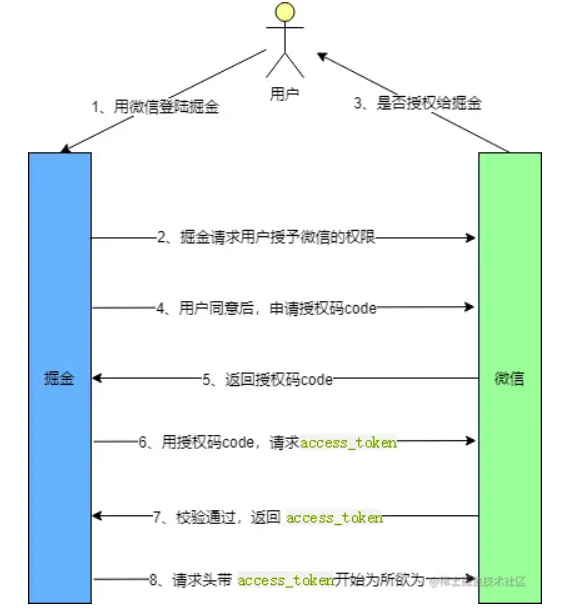
用户选择WX登录掘金,掘金会向WX发起授权请求,接下来 WX询问用户是否同意授权(常见的弹窗授权)。response_type 为 code 要求返回授权码,scope 参数表示本次授权范围为只读权限,redirect_uri 重定向地址。
https://wx.com/oauth/authorize?
response_type=code&
client_id=CLIENT_ID&
redirect_uri=http://juejin.im/callback&
scope=read
用户同意授权后,WX 根据 redirect_uri重定向并带上授权码。
http://juejin.im/callback?code=AUTHORIZATION_CODE
当掘金拿到授权码(code)时,带授权码和密匙等参数向WX申请令牌。grant_type表示本次授权为授权码方式 authorization_code ,获取令牌要带上客户端密匙 client_secret,和上一步得到的授权码 code。
https://wx.com/oauth/token?
client_id=CLIENT_ID&
client_secret=CLIENT_SECRET&
grant_type=authorization_code&
code=AUTHORIZATION_CODE&
redirect_uri=http://juejin.im/callback
最后 WX 收到请求后向 redirect_uri 地址发送 JSON 数据,其中的access_token 就是令牌。
{
"access_token":"ACCESS_TOKEN",
"token_type":"bearer",
"expires_in":2592000,
"refresh_token":"REFRESH_TOKEN",
"scope":"read",
......
}
2、隐藏式
上边提到有一些Web应用是没有后端的, 属于纯前端应用,无法用上边的授权码模式。令牌的申请与存储都需要在前端完成,跳过了授权码这一步。
前端应用直接获取 token,response_type 设置为 token,要求直接返回令牌,跳过授权码,WX授权通过后重定向到指定 redirect_uri 。
https://wx.com/oauth/authorize?
response_type=token&
client_id=CLIENT_ID&
redirect_uri=http://juejin.im/callback&
scope=read
3、密码式
密码模式比较好理解,用户在掘金直接输入自己的WX用户名和密码,掘金拿着信息直接去WX申请令牌,请求响应的 JSON结果中返回 token。grant_type 为 password 表示密码式授权。
https://wx.com/token?
grant_type=password&
username=USERNAME&
password=PASSWORD&
client_id=CLIENT_ID
这种授权方式缺点是显而易见的,非常的危险,如果采取此方式授权,该应用一定是可以高度信任的。
4、凭证式
凭证式和密码式很相似,主要适用于那些没有前端的命令行应用,可以用最简单的方式获取令牌,在请求响应的 JSON 结果中返回 token。
grant_type 为 client_credentials 表示凭证式授权,client_id 和 client_secret 用来识别身份。
https://wx.com/token?
grant_type=client_credentials&
client_id=CLIENT_ID&
client_secret=CLIENT_SECRET
几个名词的区别( Spring Security 、Shiro、OAuth2、JWT、SSO)
首先,SSO是一种思想,或者说是一种解决方案,是抽象的,我们要做的就是按照它的这种思想去实现它
其次,OAuth2是用来允许用户授权第三方应用访问他在另一个服务器上的资源的一种协议,它不是用来做单点登录的,但我们可以利用它来实现单点登录。在本例实现 SSO 的过程中,受保护的资源就是用户的信息(包括,用户的基本信息,以及用户所具有的权限),而我们想要访问这这一资源就需要用户登录并授权,OAuth2服务端负责令牌的发放等操作,这令牌的生成我们采用JWT,也就是说JWT是用来承载用户的Access_Token的
最后,Spring Security、Shiro是用于安全访问的,用来做访问权限控制,都是一个用Java写的框架
3.cookie 实现登陆过程
HTTP 是无状态协议,它不对之前发生过的请求和响应的状态进行保存。因为无法管理用户状态,对于要登录的页面,每次跳转新页面时都需要再次登录。
cookie 管理状态
于是引入了 Cookie 来管理用户状态:
① 首先客户端发起不带 Cookie 信息的登录请求
② 服务端接收到请求,验证用户数据正确后,添加响应头 Set-Cookie
③ 客户端收到响应报文后,检查到响应头 Set-Cookie,在本地保存 Cookie
④ 之后每次向该域发起请求时,自动添加请求头 Cookie,发送给服务端
⑤ 服务端获取请求头 Cookie,根据 Cookie 的值,就可以判断出用户是否登录
但是 Cookie 极容易被篡改和伪造,于是产生了 Session,Session 将用户信息保存在服务端,那么 Session 是如何管理用户状态的呢?
① 首先客户端发起不带 Cookie 信息的登录请求
② 服务端接收到请求,检查到没有携带口令,验证用户密码正确后生成 Session,将用户信息保存在 Session,设置响应头 Set-Cookie,通常是将 Session ID 作为口令值
③ 客户端检查到 Set-Cookie 响应头,在本地保存 Cookie 信息
④ 之后每次发起请求时,自动在请求头 Cookie 中携带口令,发送给服务端
⑤ 服务端获取 Cookie 携带的口令值,找到对应的 Session,就可以判断用户状态
让 Session 口令值更安全
虽然口令值由服务端生成,用户不容易伪造,But nothing is impossible;而且口令值存在客户端,就有可能被盗用。一旦口令值被伪造或盗用,攻击者就可以伪装成用户访问服务端的数据。
那么如何让 Session 口令值更安全呢?
① 将客户端的某些独有信息+口令值作为原值,对其进行签名
② 将口令值拼接签名返回给客户端,将 Cookie 设置为 HttpOnly(禁止用户通过脚本来获取和更改 Cookie)
③ 服务端再次收到请求,取客户端信息与口令值签名,与客户端携带的签名对比,不相等,说明请求不合法
这样的话:
① 即使攻击者知道了口令值,由于不知道密钥,无法伪造签名
② 即使攻击者通过某种方式得到了真实的口令值和签名,但是由于攻击者的客户端信息不一样,发送到服务端后,会得到不一样的签名,签名校验不能通过
4.用户获取用户数据的 token 被窃取了怎么办
- 用 https 协议
- 设置 token 有效期
- 每次请求后刷新 token
签发 token 的时候加入一些验证信息,比如 IP 如果当前 request IP 和签发时候的 IP 不一致就加 blacklist 里
不嫌麻烦的话,搞一个验签。拿到 token 也没有
ip 这种也想过,不过,做不了,因为,我们是多个子系统的,后端需要请求 uc,那么每次来的都是后端 ip
csrf 那种么?
目前方案是一定时间失效再申请
现在都是 HTTPS,为什么会被抓包呢?所以不存在这个问题 你要说是在用户设备上抓包,那么他都拿到了用户的物理机器,这个应该不在防范的考虑范围之内吧。就跟你拿到服务器的实体,可以不输密码重启进入安全模式一样
下发包含 refresh_token 的,强制 3600s access_token 过期,如果要使 access_token 不过期,就用 refresh_token 去刷新,如果都过期了就重新登录
5.二维码扫码登录是什么原理
了解一下移动互联网下的系统认证机制。
前面我们说过,为了安全,手机端它是不会存储你的登录密码的。 但是在日常使用过程中,我们应该会注意到,只有在你的应用下载下来后,第一次登录的时候,才需要进行一个账号密码的登录, 那之后呢 即使这个应用进程被杀掉,或者手机重启,都是不需要再次输入账号密码的,它可以自动登录。
其实这背后就是一套基于 token 的认证机制,我们来看一下这套机制是怎么运行的,
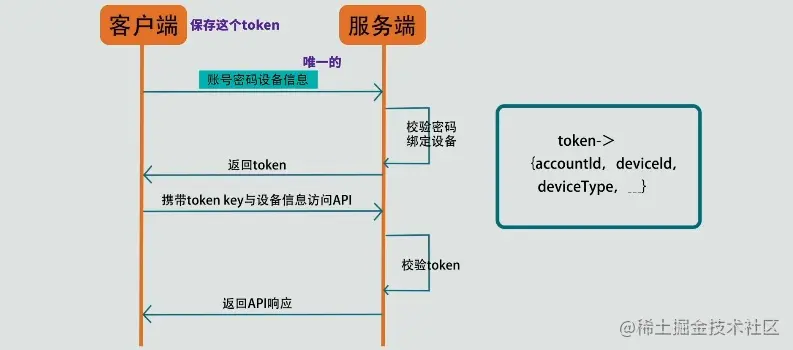
- 账号密码登录时,客户端会将设备信息一起传递给服务端,
- 如果账号密码校验通过,服务端会把账号与设备进行一个绑定,存在一个数据结构中,这个数据结构中包含了账号 ID,设备 ID,设备类型等等
const token = {
acountid: "账号ID",
deviceid: "登录的设备ID",
deviceType: "设备类型,如 iso,android,pc......",
};
然后服务端会生成一个 token,用它来映射数据结构,这个 token 其实就是一串有着特殊意义的字符串,它的意义就在于,通过它可以找到对应的账号与设备信息,
- 客户端得到这个 token 后,需要进行一个本地保存,每次访问系统 API 都携带上 token 与设备信息。
- 服务端就可以通过 token 找到与它绑定的账号与设备信息,然后把绑定的设备信息与客户端每次传来的设备信息进行比较, 如果相同,那么校验通过,返回 AP 接口响应数据, 如果不同,那就是校验不通过拒绝访问
从前面这个流程,我们可以看到,客户端不会也没必要保存你的密码,相反,它是保存了 token。可能有些同学会想,这个 token 这么重要,万一被别人知道了怎么办。实际上,知道了也没有影响, 因为设备信息是唯一的,只要你的设备信息别人不知道, 别人拿其他设备来访问,验证也是不通过的。
可以说,客户端登录的目的,就是获得属于自己的 token。
那么在扫码登录过程中,PC 端是怎么获得属于自己的 token 呢?不可能手机端直接把自己的 token 给 PC 端用!token 只能属于某个客户端私有,其他人或者是其他客户端是用不了的
大概流程
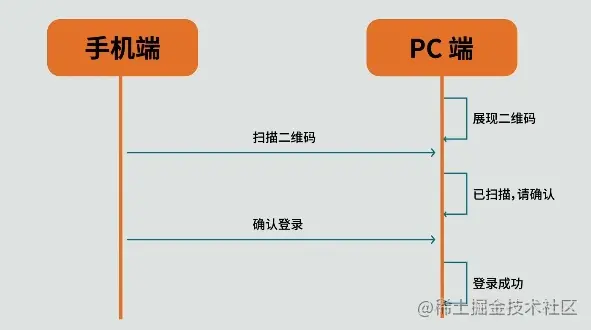
- 扫码前,手机端应用是已登录状态,PC 端显示一个二维码,等待扫描
- 手机端打开应用,扫描 PC 端的二维码,扫描后,会提示"已扫描,请在手机端点击确认"
- 用户在手机端点击确认,确认后 PC 端登录就成功了
可以看到,二维码在中间有三个状态, 待扫描,已扫描待确认,已确认。 那么可以想象
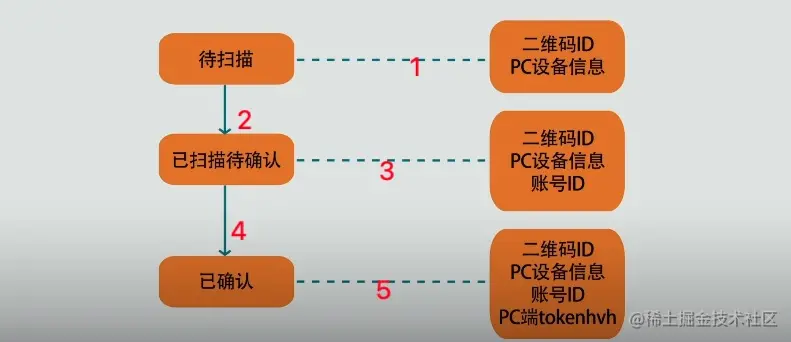
- 二维码的背后它一定存在一个唯一性的 ID,当二维码生成时,这个 ID 也一起生成,并且绑定了 PC 端的设备信息
- 手机去扫描这个二维码
- 二维码切换为 已扫描待确认状态, 此时就会将账号信息与这个 ID 绑定
- 当手机端确认登录时,它就会生成 PC 端用于登录的 token,并返回给 PC 端
二维码准备
按二维码不同状态来看, 首先是等待扫描状态,用户打开 PC 端,切换到二维码登录界面时。
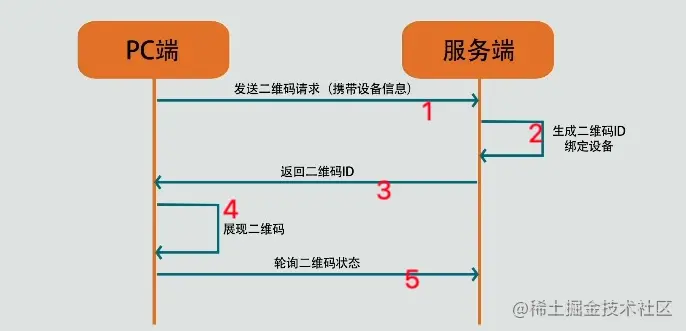
- PC 端向服务端发起请求,告诉服务端,我要生成用户登录的二维码,并且把 PC 端设备信息也传递给服务端
- 服务端收到请求后,它生成二维码 ID,并将二维码 ID 与 PC 端设备信息进行绑定
- 然后把二维码 ID 返回给 PC 端
- PC 端收到二维码 ID 后,生成二维码(二维码中肯定包含了 ID)
- 为了及时知道二维码的状态,客户端在展现二维码后,PC 端不断的轮询服务端,比如每隔一秒就轮询一次,请求服务端告诉当前二维码的状态及相关信息
二维码已经准好了,接下来就是扫描状态
扫描状态切换
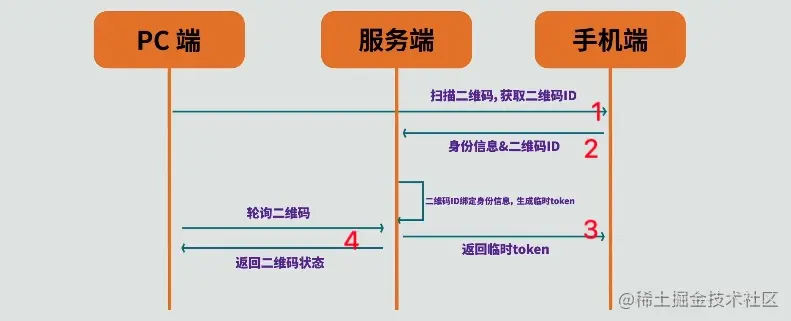
- 用户用手机去扫描 PC 端的二维码,通过二维码内容取到其中的二维码 ID
- 再调用服务端 API 将移动端的身份信息与二维码 ID 一起发送给服务端
- 服务端接收到后,它可以将身份信息与二维码 ID 进行绑定,生成临时 token。然后返回给手机端
- 因为 PC 端一直在轮询二维码状态,所以这时候二维码状态发生了改变,它就可以在界面上把二维码状态更新为已扫描
那么为什么需要返回给手机端一个临时 token 呢?临时 token 与 token 一样,它也是一种身份凭证,不同的地方在于它只能用一次,用过就失效。
在第三步骤中返回临时 token,为的就是手机端在下一步操作时,可以用它作为凭证。以此确保扫码,登录两步操作是同一部手机端发出的,
状态确认
最后就是状态的确认了。
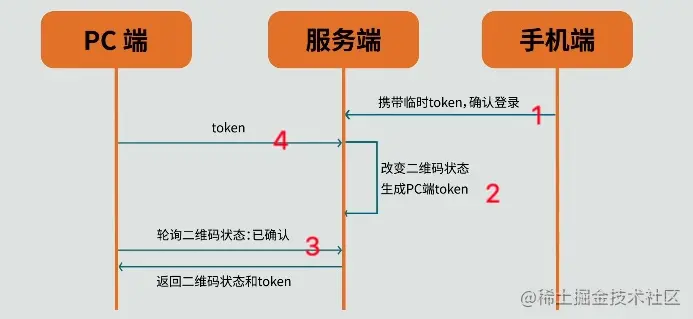
- 手机端在接收到临时 token 后会弹出确认登录界面,用户点击确认时,手机端携带临时 token 用来调用服务端的接口,告诉服务端,我已经确认
- 服务端收到确认后,根据二维码 ID 绑定的设备信息与账号信息,生成用户 PC 端登录的 token
- 这时候 PC 端的轮询接口,它就可以得知二维码的状态已经变成了"已确认"。并且从服务端可以获取到用户登录的 token
- 到这里,登录就成功了,后端 PC 端就可以用 token 去访问服务端的资源了
带有 scene value 的,从相册选取和直接扫的 scene 肯定不一样。多加一个判断就可以了
6.登录安全问题
1、第一次登录的时候,前端调后端的登陆接口,发送用户名和密码 2、后端收到请求,验证用户名和密码,验证成功,就给前端返回一个 token 3、前端拿到 token,将 token 存储到localStorage和 vuex 中,并跳转路由页面 4、前端每次跳转路由,就判断 localStroage 中有无 token ,没有就跳转到登录页面,有则跳转到对应路由页面 5、每次调后端接口,都要在请求头中加 token 6、后端判断请求头中有无 token,有 token,就拿到 token 并验证 token,验证成功就返回数据,验证失败(例如:token 过期)就返回 401,请求头中没有 token 也返回 401 7、如果前端拿到状态码为 401,就清除 token 信息并跳转到登录页面 // 导航守卫 // 使用 router.beforeEach 注册一个全局前置守卫,判断用户是否登陆
router.beforeEach((to, from, next) => {
if (to.path === ‘/login’) {
next();
} else {
let token = localStorage.getItem(‘Authorization’);
if (token === null || token === '') {
next('/login');
} else {
next();
}
}
});
export default router;
在设计一个登录接口时,不仅仅是功能上的实现,在安全方面,我们还需要考虑哪些地方。
暴力破解:通过各种方式获得了网站的用户名之后,通过编写程序来遍历所有可能的密码,直至找到正确的密码为止 防范 1. 验证码 在它密码错误达到一定次数时,增加验证码校验!比如我们设置,当用户密码错误达到 3 次之后,则需要用户输入图片验证码才可以继续登录操作: 这样确实可以过滤掉一些非法的攻击,但是以目前的 OCR 技术来说的话,普通的图片验证码真的很难做到有效的防止机器人(我们就在这个上面吃过大亏)。当然,我们也可以花钱购买类似于三方公司提供的滑动验证等验证方案,但是也并不是 100%的安全,一样可以被破解(惨痛教训)。 2. 登录限制 直接限制非正常用户的登录操作,当它密码错误达到一定次数时,直接拒绝用户的登录,隔一段时间再恢复。比如我们设置某个账号在登录时错误次数达到 10 次时,则 5 分钟内拒绝该账号的所有登录操作。 但是,这样会带来另一个风险:攻击者虽然不能获取到网站的用户信息,但是它可以让我们网站所有的用户都无法登录! 攻击者只需要无限循环遍历所有的用户名(即使没有,随机也行)进行登录,那么这些用户会永远处于锁定状态,导致正常的用户无法登录网站! 3. IP 限制 设定某个 IP 下调用登录接口错误次数达到一定时,则禁止该 IP 进行登录操作。 但是这里还是存在问题: 比如现在很多学校、公司都是使用同一个出口 IP,如果直接按 IP 限制,可能会误杀其它正常的用户 现在这么多 VPN,攻击者完全可以在 IP 被封后切换 VPN 来攻击 4. 手机验证 当用户输入密码次数大于 3 次时,要求用户输入验证码(最好使用滑动验证) 当用户输入密码次数大于 10 次时,弹出手机验证,需要用户使用手机验证码和密码双重认证进行登录
中间人攻击:简单一点来说就是,A 和 B 在通讯过程中,攻击者通过嗅探、拦截等方式获取或修改 A 和 B 的通讯内容。 防范: HTTPS 防范中间人攻击最简单也是最有效的一个操作,更换 HTTPS,把网站中所有的 HTTP 请求修改为强制使用 HTTPS。 TTPS 实际上就是在 HTTP 和 TCP 协议中间加入了 SSL/TLS 协议,用于保障数据的安全传输。相比于 HTTP,HTTPS 主要有以下几个特点:
- 内容加密
- 数据完整性
- 身份验证
加密传输 在 HTTPS 之外,我们还可以手动对敏感数据进行加密传输: 用户名可以在客户端使用非对称加密,在服务端解密 密码可以在客户端进行 MD5 之后传输,防止暴露密码明文
其他 操作日志,用户的每次登录和敏感操作都需要记录日志(包括 IP、设备等) 异常操作或登录提醒,有了上面的操作日志,那我们就可以基于日志做风险提醒,比如用户在进行非常登录地登录、修改密码、登录异常时,可以短信提醒用户 拒绝弱密码 注册或修改密码时,不允许用户设置弱密码 防止用户名被遍历 有些网站在注册时,在输入完用户名之后,会提示用户名是否存在。这样会存在网站的所有用户名被泄露的风险(遍历该接口即可),需要在交互或逻辑上做限制
综合问题
1.输入 URL 后发生了什么(浏览器层面)
(1)解析 URL: 首先会对 URL 进行解析,分析所需要使用的传输协议和请求的资源的路径。如果输入的 URL 中的协议或者主机名不合法,将会把地址栏中输入的内容传递给搜索引擎。如果没有问题,浏览器会检查 URL 中是否出现了非法字符,如果存在非法字符,则对非法字符进行转义后再进行下一过程。
(2)缓存判断: 浏览器会判断所请求的资源是否在缓存里,如果请求的资源在缓存里并且没有失效,那么就直接使用,否则向服务器发起新的请求。
(3)DNS 解析: 下一步首先需要获取的是输入的 URL 中的域名的 IP 地址,首先会判断本地是否有该域名的 IP 地址的缓存,如果有则使用,如果没有则向本地 DNS 服务器发起请求。本地 DNS 服务器也会先检查是否存在缓存,如果没有就会先向根域名服务器发起请求,获得负责的顶级域名服务器的地址后,再向顶级域名服务器请求,然后获得负责的权威域名服务器的地址后,再向权威域名服务器发起请求,最终获得域名的 IP 地址后,本地 DNS 服务器再将这个 IP 地址返回给请求的用户。用户向本地 DNS 服务器发起请求属于递归请求,本地 DNS 服务器向各级域名服务器发起请求属于迭代请求。
(4)获取 MAC 地址: 当浏览器得到 IP 地址后,数据传输还需要知道目的主机 MAC 地址,因为应用层下发数据给传输层,TCP 协议会指定源端口号和目的端口号,然后下发给网络层。网络层会将本机地址作为源地址,获取的 IP 地址作为目的地址。然后将下发给数据链路层,数据链路层的发送需要加入通信双方的 MAC 地址,本机的 MAC 地址作为源 MAC 地址,目的 MAC 地址需要分情况处理。通过将 IP 地址与本机的子网掩码相与,可以判断是否与请求主机在同一个子网里,如果在同一个子网里,可以使用 APR 协议获取到目的主机的 MAC 地址,如果不在一个子网里,那么请求应该转发给网关,由它代为转发,此时同样可以通过 ARP 协议来获取网关的 MAC 地址,此时目的主机的 MAC 地址应该为网关的地址。
(5)TCP 三次握手: 下面是 TCP 建立连接的三次握手的过程,首先客户端向服务器发送一个 SYN 连接请求报文段和一个随机序号,服务端接收到请求后向服务器端发送一个 SYN ACK 报文段,确认连接请求,并且也向客户端发送一个随机序号。客户端接收服务器的确认应答后,进入连接建立的状态,同时向服务器也发送一个 ACK 确认报文段,服务器端接收到确认后,也进入连接建立状态,此时双方的连接就建立起来了。
(6)HTTPS 握手: 如果使用的是 HTTPS 协议,在通信前还存在 TLS 的一个四次握手的过程。首先由客户端向服务器端发送使用的协议的版本号、一个随机数和可以使用的加密方法。服务器端收到后,确认加密的方法,也向客户端发送一个随机数和自己的数字证书。客户端收到后,首先检查数字证书是否有效,如果有效,则再生成一个随机数,并使用证书中的公钥对随机数加密,然后发送给服务器端,并且还会提供一个前面所有内容的 hash 值供服务器端检验。服务器端接收后,使用自己的私钥对数据解密,同时向客户端发送一个前面所有内容的 hash 值供客户端检验。这个时候双方都有了三个随机数,按照之前所约定的加密方法,使用这三个随机数生成一把秘钥,以后双方通信前,就使用这个秘钥对数据进行加密后再传输。
(7)返回数据: 当页面请求发送到服务器端后,服务器端会返回一个 html 文件作为响应,浏览器接收到响应后,开始对 html 文件进行解析,开始页面的渲染过程。
(8)页面渲染: 浏览器首先会根据 html 文件构建 DOM 树,根据解析到的 css 文件构建 CSSOM 树,如果遇到 script 标签,则判端是否含有 defer 或者 async 属性,要不然 script 的加载和执行会造成页面的渲染的阻塞。当 DOM 树和 CSSOM 树建立好后,根据它们来构建渲染树。渲染树构建好后,会根据渲染树来进行布局。布局完成后,最后使用浏览器的 UI 接口对页面进行绘制。这个时候整个页面就显示出来了。
(9)TCP 四次挥手: 最后一步是 TCP 断开连接的四次挥手过程。若客户端认为数据发送完成,则它需要向服务端发送连接释放请求。服务端收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入 CLOSE_WAIT 状态,此时表明客户端到服务端的连接已经释放,不再接收客户端发的数据了。但是因为 TCP 连接是双向的,所以服务端仍旧可以发送数据给客户端。服务端如果此时还有没发完的数据会继续发送,完毕后会向客户端发送连接释放请求,然后服务端便进入 LAST-ACK 状态。客户端收到释放请求后,向服务端发送确认应答,此时客户端进入 TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有服务端的重发请求的话,就进入 CLOSED 状态。当服务端收到确认应答后,也便进入 CLOSED 状态。
浏览器进程: • 用户输入内容,进行 URL 解析(编码) • 如果是文本,则拼接成默认搜索引擎加关键字的 URL 进行搜索 • 如果是 URL 就进行页面访问请求,并加上协议头(http、https 的区别)
网络进程: • 查询缓存(缓存相关知识) • 如果有浏览器本地缓存可用则使用本地缓存 • DNS 解析(DNS 相关) • 通过 DNS 来查询 IP 地址 • DNS 先查本地、后查运营商、逐级网上查。(域名解析是从后往前查的) • 拿到 IP 地址发起 HTTP 请求(这块可以问网络相关各种基础知识,TCP、IP、UDP、HTTPS、HTTP2) • 建立 TCP 三次握手连接 • 如果是 HTTPS 建立 TLS 安全通道连接(HTTPS 加密方式) • 发送 HTTP 请求,这个请求可能回到代理服务器或者源服务器。(服务器代理) • 拿到 HTTP 响应(HTTP 响应码) • 根据 Content-Type 来判断响应文件类型(常用 HTTP 响应头的作用) • stream 类,浏览器启动下载界面下载文件。 • text、图片类,浏览器直接展示在页面上 • html 类型,浏览器会进行页面解析。 渲染进程: • 页面解析 • 网络进程向渲染进程传输 HTML 数据 • 对 HTML 进行词法分析,通过堆栈算法构建 DOM 树。(AST 语法树) • 如果遇到外部资源,浏览器会交给网络进程去下载。 • 构建完 DOM 树的同时,将 CSS 代码转为浏览器可以理解的 StyleSheets • 标准化样式属性值(单位、大小) • 计算出 DOM 树每个节点的具体样式 • 计算每个 DOM 节点的父节点们的样式(样式继承) • DOM 树构建完成后, 合并 StyleSheets 构建出 CSSOM 渲染树。 • 排版:遍历渲染树,计算元素的坐标位置。 • 分层:为节点生成图层 • 绘制:用浏览器指令逐条绘制页面元素。(如何避免重绘重排) • 栅格化 • 合成
2.输入 URL 后发生了什么(网络层面)
接下来以下图较简单的网络拓扑模型作为例子,探究探究其间发生了什么?
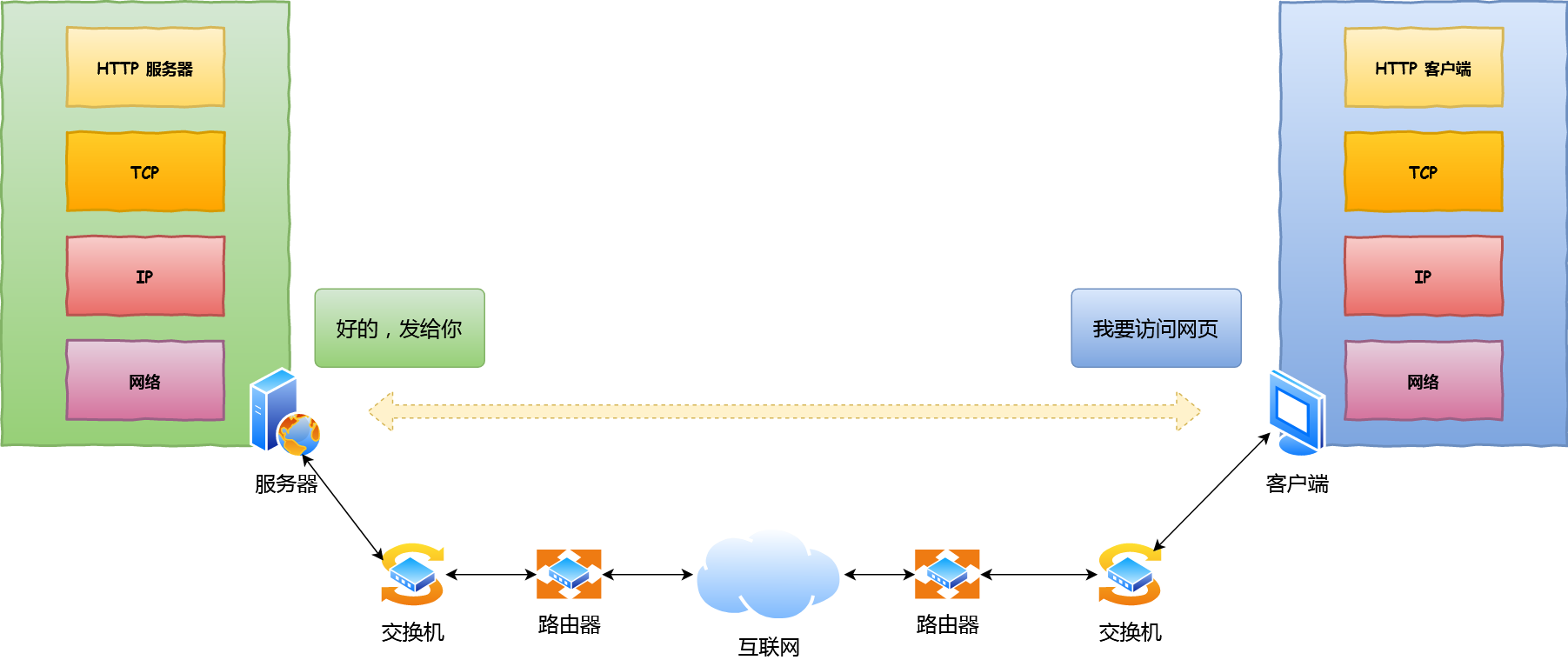
#孤单小弟 —— HTTP
浏览器做的第一步工作是解析 URL
首先浏览器做的第一步工作就是要对 URL 进行解析,从而生成发送给 Web 服务器的请求信息。
让我们看看一条长长的 URL 里的各个元素的代表什么,见下图:
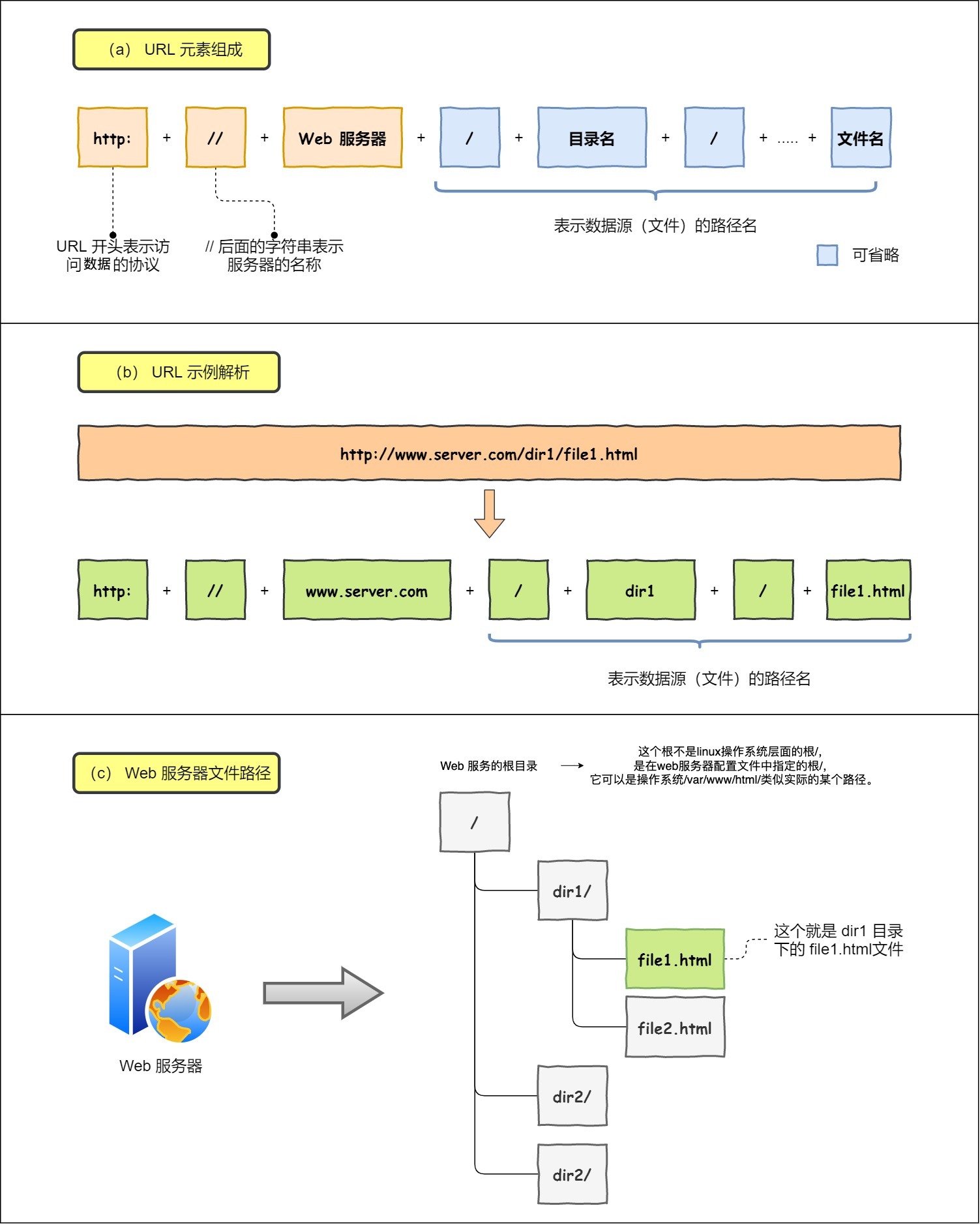
所以图中的长长的 URL 实际上是请求服务器里的文件资源。
要是上图中的蓝色部分 URL 元素都省略了,那应该是请求哪个文件呢?
当没有路径名时,就代表访问根目录下事先设置的默认文件,也就是 /index.html 或者 /default.html 这些文件,这样就不会发生混乱了。
生产 HTTP 请求信息
对 URL 进行解析之后,浏览器确定了 Web 服务器和文件名,接下来就是根据这些信息来生成 HTTP 请求消息了。
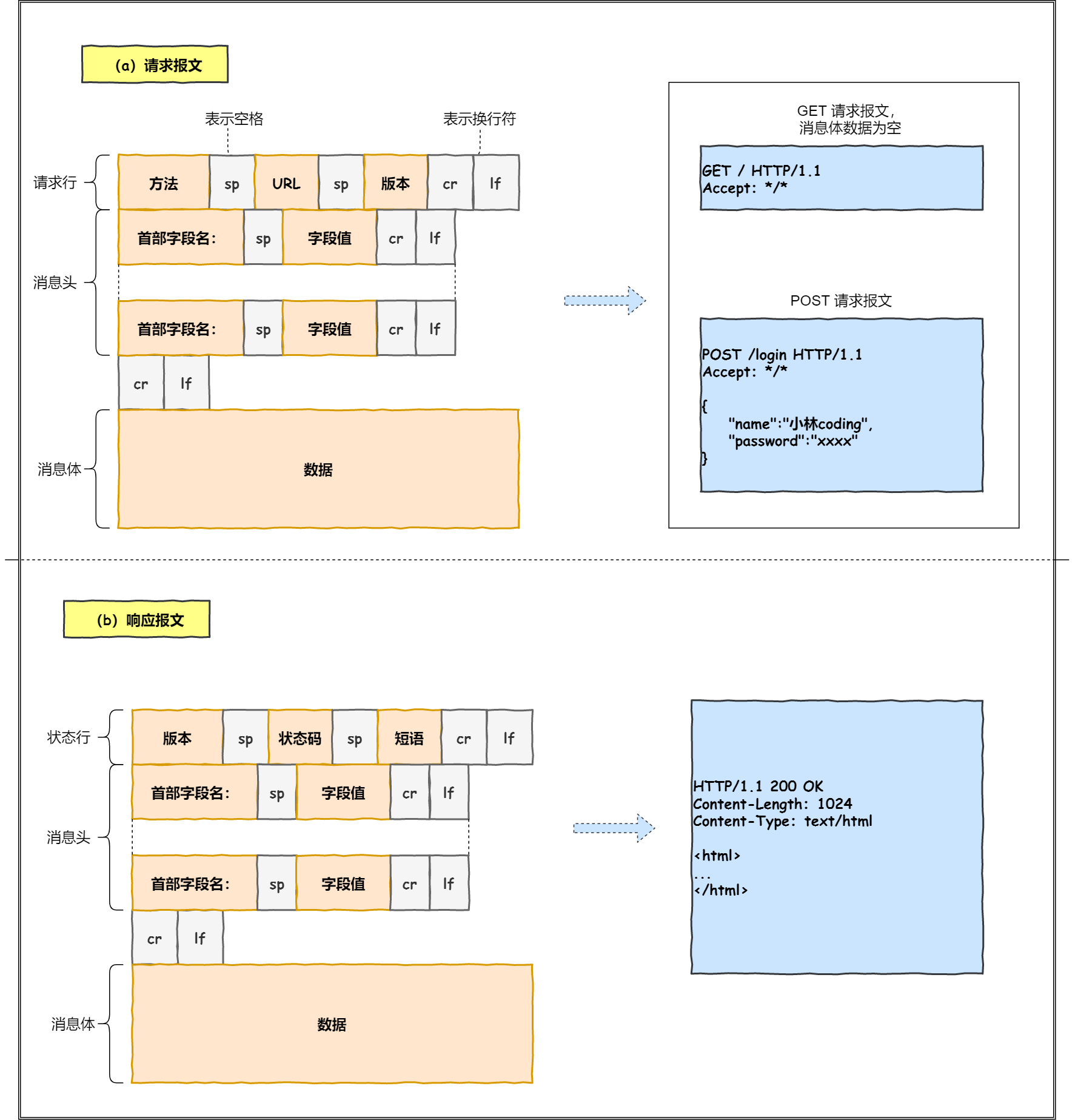
一个孤单 HTTP 数据包表示:“我这么一个小小的数据包,没亲没友,直接发到浩瀚的网络,谁会知道我呢?谁能载我一程呢?谁能保护我呢?我的目的地在哪呢?”。充满各种疑问的它,没有停滞不前,依然踏上了征途!
#真实地址查询 —— DNS
通过浏览器解析 URL 并生成 HTTP 消息后,需要委托操作系统将消息发送给 Web 服务器。
但在发送之前,还有一项工作需要完成,那就是查询服务器域名对应的 IP 地址,因为委托操作系统发送消息时,必须提供通信对象的 IP 地址。
比如我们打电话的时候,必须要知道对方的电话号码,但由于电话号码难以记忆,所以通常我们会将对方电话号 + 姓名保存在通讯录里。
所以,有一种服务器就专门保存了 Web 服务器域名与 IP 的对应关系,它就是 DNS 服务器。
域名的层级关系
DNS 中的域名都是用句点来分隔的,比如 server.com,这里的句点代表了不同层次之间的界限。
在域名中,越靠右的位置表示其层级越高。
毕竟域名是外国人发明,所以思维和中国人相反,比如说一个城市地点的时候,外国喜欢从小到大的方式顺序说起(如 XX 街道 XX 区 XX 市 XX 省),而中国则喜欢从大到小的顺序(如 XX 省 XX 市 XX 区 XX 街道)。
实际上域名最后还有一个点,比如 server.com.,这个最后的一个点代表根域名。
也就是,. 根域是在最顶层,它的下一层就是 .com 顶级域,再下面是 server.com。
所以域名的层级关系类似一个树状结构:
- 根 DNS 服务器(.)
- 顶级域 DNS 服务器(.com)
- 权威 DNS 服务器(server.com)
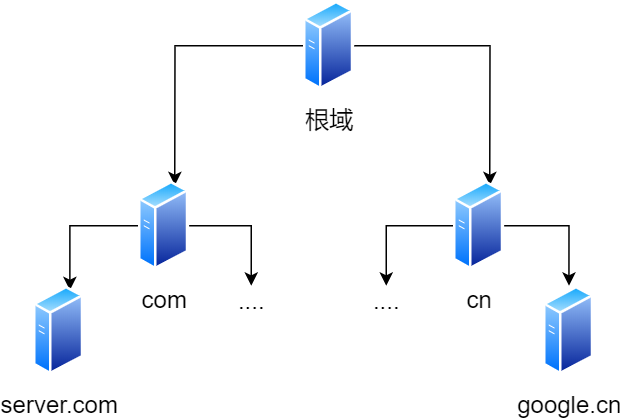
根域的 DNS 服务器信息保存在互联网中所有的 DNS 服务器中。
这样一来,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器了。
因此,客户端只要能够找到任意一台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再一路顺藤摸瓜找到位于下层的某台目标 DNS 服务器。
域名解析的工作流程
- 客户端首先会发出一个 DNS 请求,问 server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
- 本地域名服务器收到客户端的请求后,如果缓存里的表格能找到 server.com,则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:“老大, 能告诉我 server.com 的 IP 地址吗?” 根域名服务器是最高层次的,它不直接用于域名解析,但能指明一条道路。
- 根 DNS 收到来自本地 DNS 的请求后,发现后置是 .com,说:“server.com 这个域名归 .com 区域管理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。”
- 本地 DNS 收到顶级域名服务器的地址后,发起请求问“老二, 你能告诉我 server.com 的 IP 地址吗?”
- 顶级域名服务器说:“我给你负责 server.com 区域的权威 DNS 服务器的地址,你去问它应该能问到”。
- 本地 DNS 于是转向问权威 DNS 服务器:“老三,server.com 对应的 IP 是啥呀?” server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
- 本地 DNS 再将 IP 地址返回客户端,客户端和目标建立连接。
至此,我们完成了 DNS 的解析过程。现在总结一下,整个过程我画成了一个图。
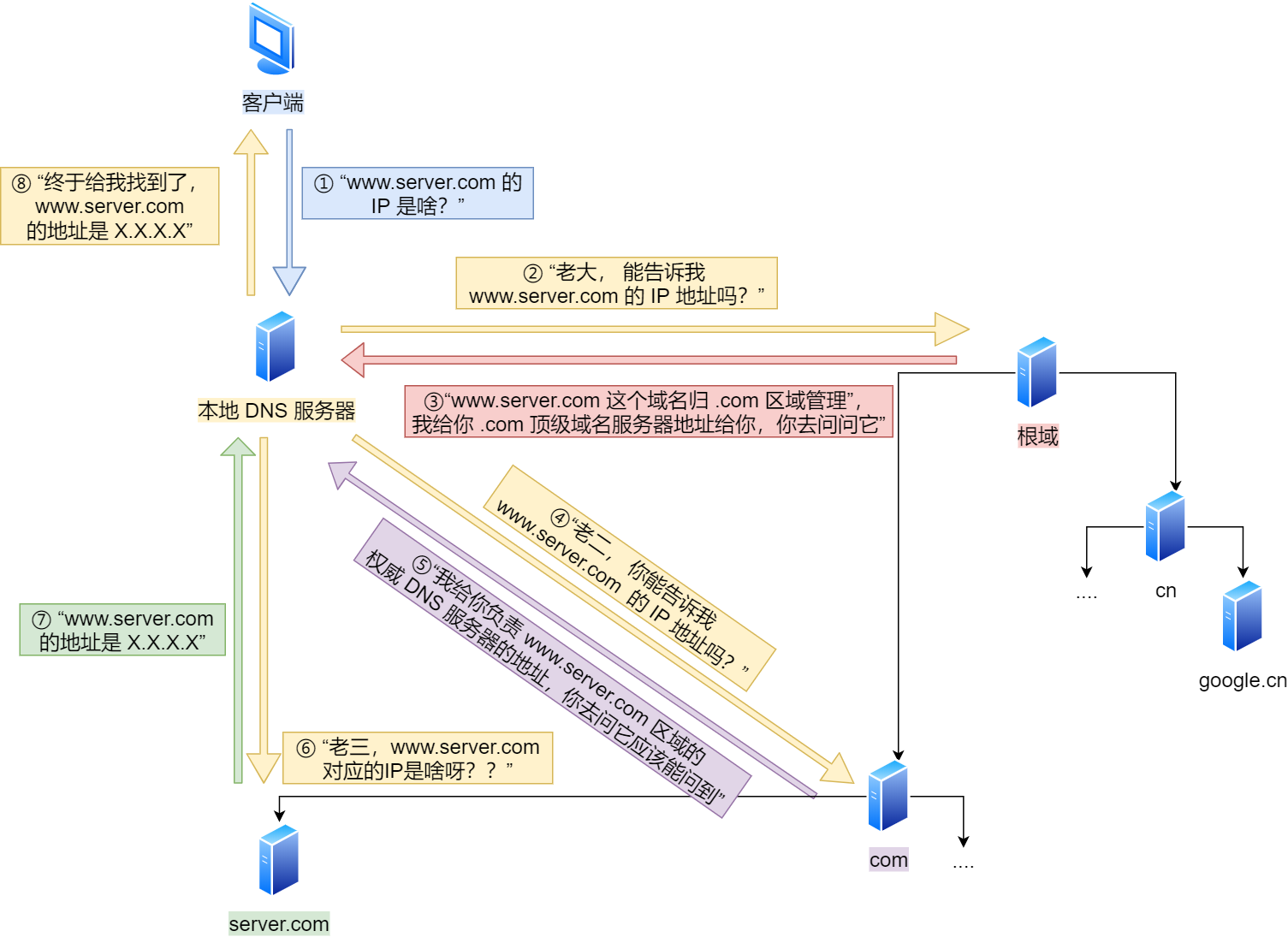
DNS 域名解析的过程蛮有意思的,整个过程就和我们日常生活中找人问路的过程类似,只指路不带路。
那是不是每次解析域名都要经过那么多的步骤呢?
当然不是了,还有缓存这个东西的嘛。
浏览器会先看自身有没有对这个域名的缓存,如果有,就直接返回,如果没有,就去问操作系统,操作系统也会去看自己的缓存,如果有,就直接返回,如果没有,再去 hosts 文件看,也没有,才会去问「本地 DNS 服务器」。
数据包表示:“DNS 老大哥厉害呀,找到了目的地了!我还是很迷茫呀,我要发出去,接下来我需要谁的帮助呢?”
#指南好帮手 —— 协议栈
通过 DNS 获取到 IP 后,就可以把 HTTP 的传输工作交给操作系统中的协议栈。
协议栈的内部分为几个部分,分别承担不同的工作。上下关系是有一定的规则的,上面的部分会向下面的部分委托工作,下面的部分收到委托的工作并执行。
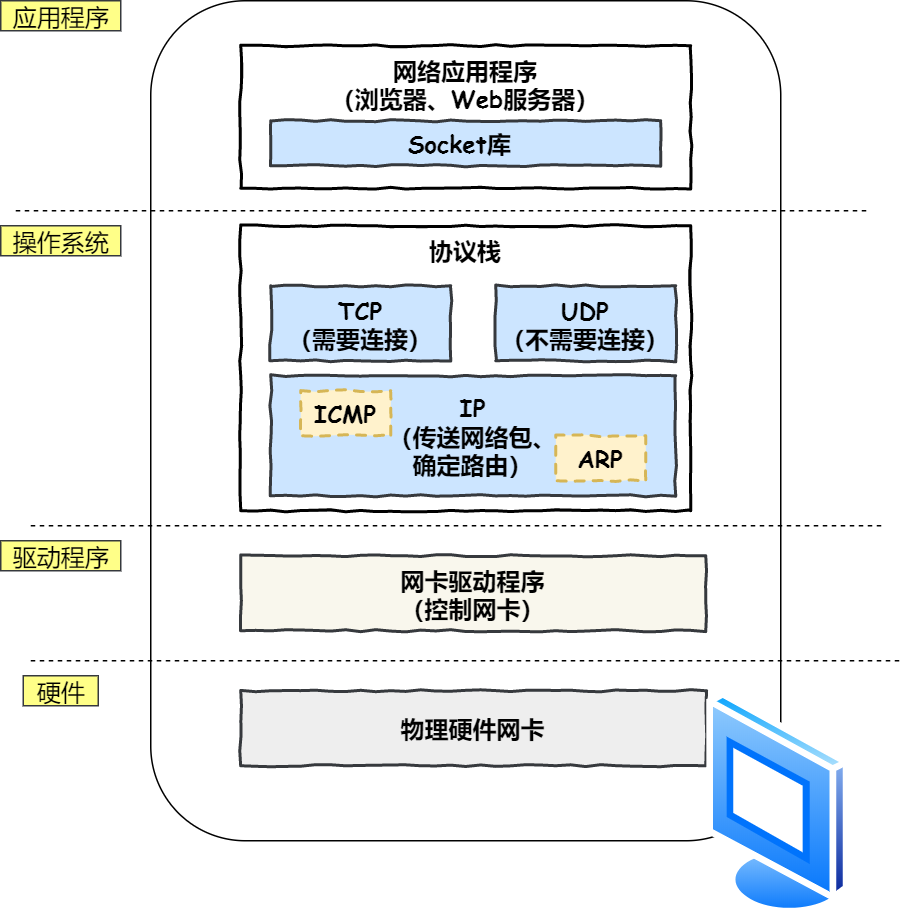
应用程序(浏览器)通过调用 Socket 库,来委托协议栈工作。协议栈的上半部分有两块,分别是负责收发数据的 TCP 和 UDP 协议,这两个传输协议会接受应用层的委托执行收发数据的操作。
协议栈的下面一半是用 IP 协议控制网络包收发操作,在互联网上传数据时,数据会被切分成一块块的网络包,而将网络包发送给对方的操作就是由 IP 负责的。
此外 IP 中还包括 ICMP 协议和 ARP 协议。
ICMP用于告知网络包传送过程中产生的错误以及各种控制信息。ARP用于根据 IP 地址查询相应的以太网 MAC 地址。
IP 下面的网卡驱动程序负责控制网卡硬件,而最下面的网卡则负责完成实际的收发操作,也就是对网线中的信号执行发送和接收操作。
数据包看了这份指南表示:“原来我需要那么多大佬的协助啊,那我先去找找 TCP 大佬!”
#可靠传输 —— TCP
HTTP 是基于 TCP 协议传输的,所以在这我们先了解下 TCP 协议。
TCP 包头格式
我们先看看 TCP 报文头部的格式:
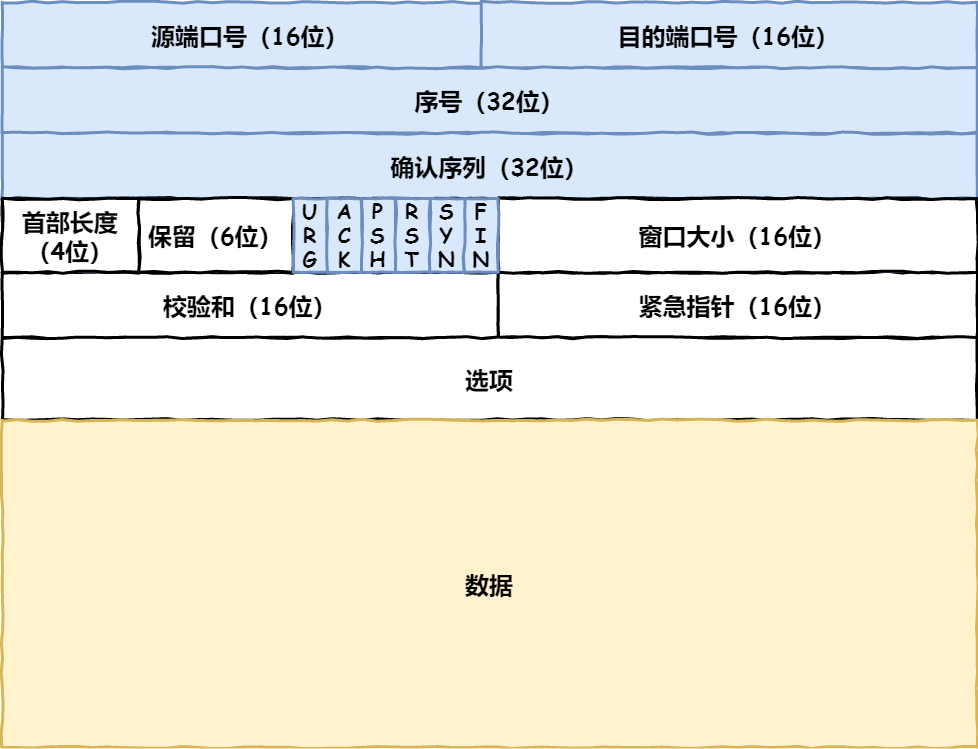
首先,源端口号和目标端口号是不可少的,如果没有这两个端口号,数据就不知道应该发给哪个应用。
接下来有包的序号,这个是为了解决包乱序的问题。
还有应该有的是确认号,目的是确认发出去对方是否有收到。如果没有收到就应该重新发送,直到送达,这个是为了解决不丢包的问题。
接下来还有一些状态位。例如 SYN 是发起一个连接,ACK 是回复,RST 是重新连接,FIN 是结束连接等。TCP 是面向连接的,因而双方要维护连接的状态,这些带状态位的包的发送,会引起双方的状态变更。
还有一个重要的就是窗口大小。TCP 要做流量控制,通信双方各声明一个窗口(缓存大小),标识自己当前能够的处理能力,别发送的太快,撑死我,也别发的太慢,饿死我。
除了做流量控制以外,TCP 还会做拥塞控制,对于真正的通路堵车不堵车,它无能为力,唯一能做的就是控制自己,也即控制发送的速度。不能改变世界,就改变自己嘛。
TCP 传输数据之前,要先三次握手建立连接
在 HTTP 传输数据之前,首先需要 TCP 建立连接,TCP 连接的建立,通常称为三次握手。
这个所谓的「连接」,只是双方计算机里维护一个状态机,在连接建立的过程中,双方的状态变化时序图就像这样。
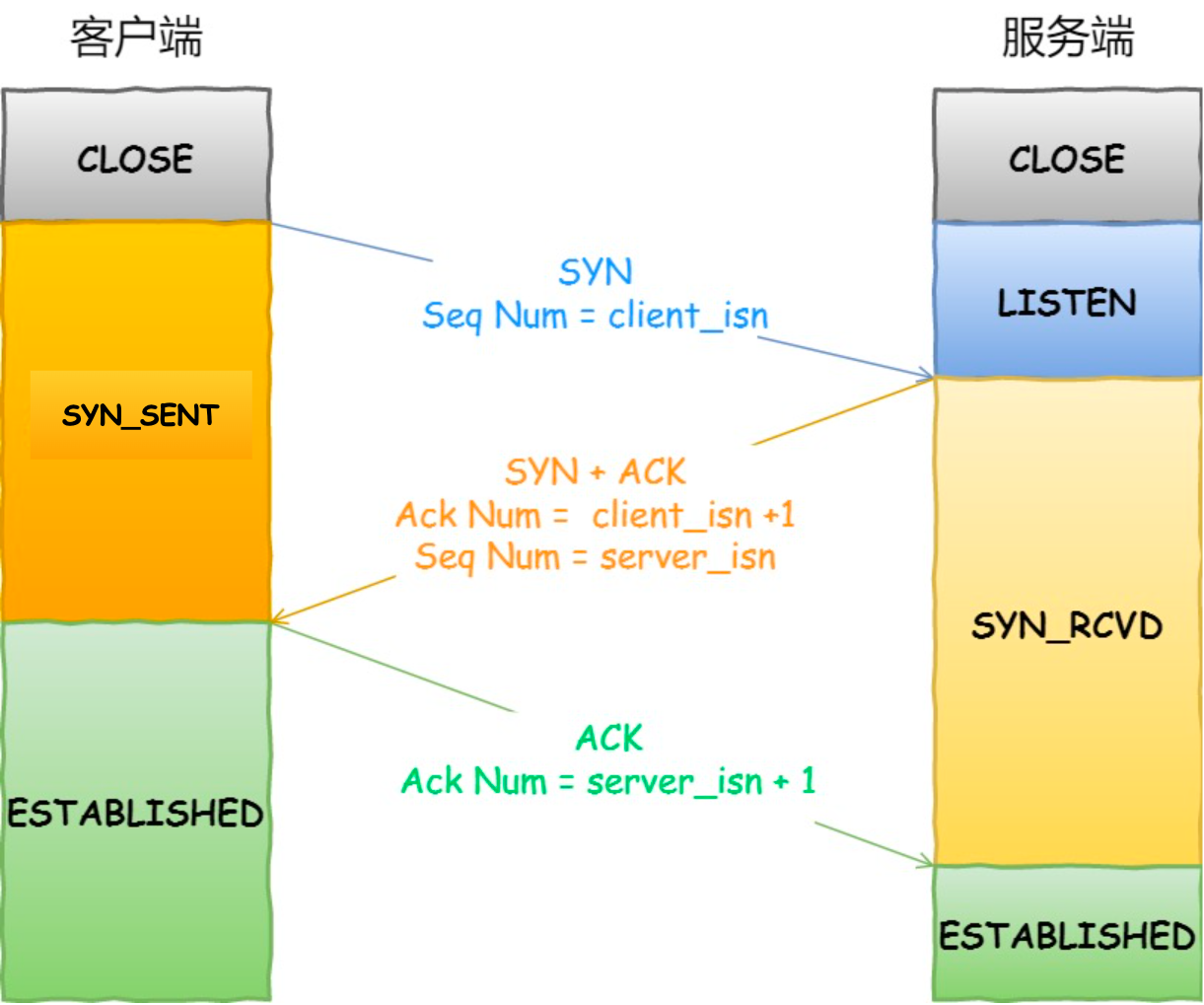
- 一开始,客户端和服务端都处于
CLOSED状态。先是服务端主动监听某个端口,处于LISTEN状态。 - 然后客户端主动发起连接
SYN,之后处于SYN-SENT状态。 - 服务端收到发起的连接,返回
SYN,并且ACK客户端的SYN,之后处于SYN-RCVD状态。 - 客户端收到服务端发送的
SYN和ACK之后,发送对SYN确认的ACK,之后处于ESTABLISHED状态,因为它一发一收成功了。 - 服务端收到
ACK的ACK之后,处于ESTABLISHED状态,因为它也一发一收了。
所以三次握手目的是保证双方都有发送和接收的能力。
如何查看 TCP 的连接状态?
TCP 的连接状态查看,在 Linux 可以通过 netstat -napt 命令查看。

TCP 分割数据
如果 HTTP 请求消息比较长,超过了 MSS 的长度,这时 TCP 就需要把 HTTP 的数据拆解成一块块的数据发送,而不是一次性发送所有数据。
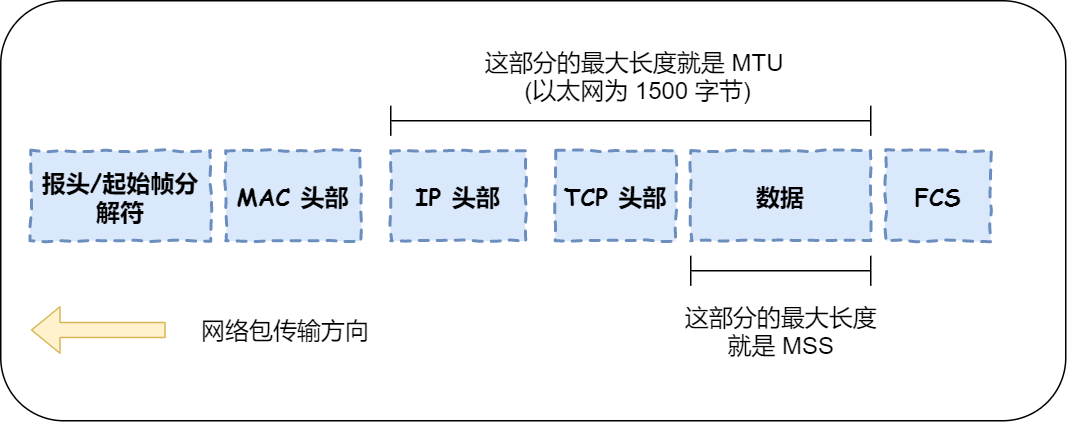
MTU:一个网络包的最大长度,以太网中一般为1500字节。MSS:除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度。
数据会被以 MSS 的长度为单位进行拆分,拆分出来的每一块数据都会被放进单独的网络包中。也就是在每个被拆分的数据加上 TCP 头信息,然后交给 IP 模块来发送数据。
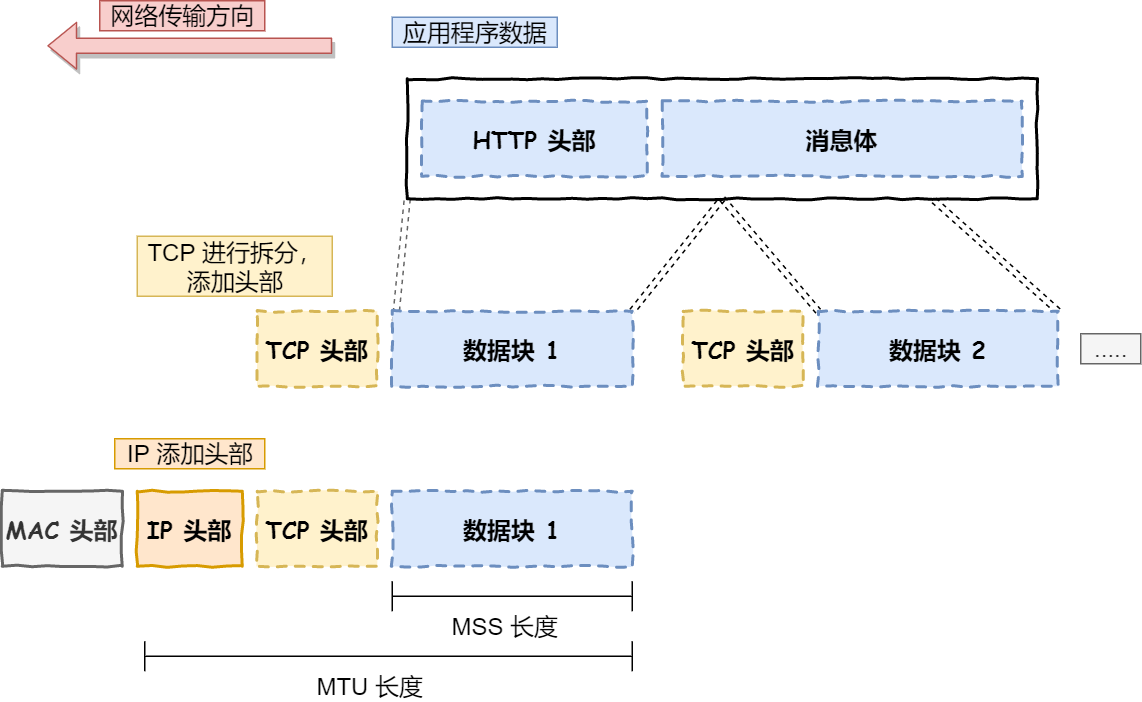
TCP 报文生成
TCP 协议里面会有两个端口,一个是浏览器监听的端口(通常是随机生成的),一个是 Web 服务器监听的端口(HTTP 默认端口号是 80, HTTPS 默认端口号是 443)。
在双方建立了连接后,TCP 报文中的数据部分就是存放 HTTP 头部 + 数据,组装好 TCP 报文之后,就需交给下面的网络层处理。
至此,网络包的报文如下图。
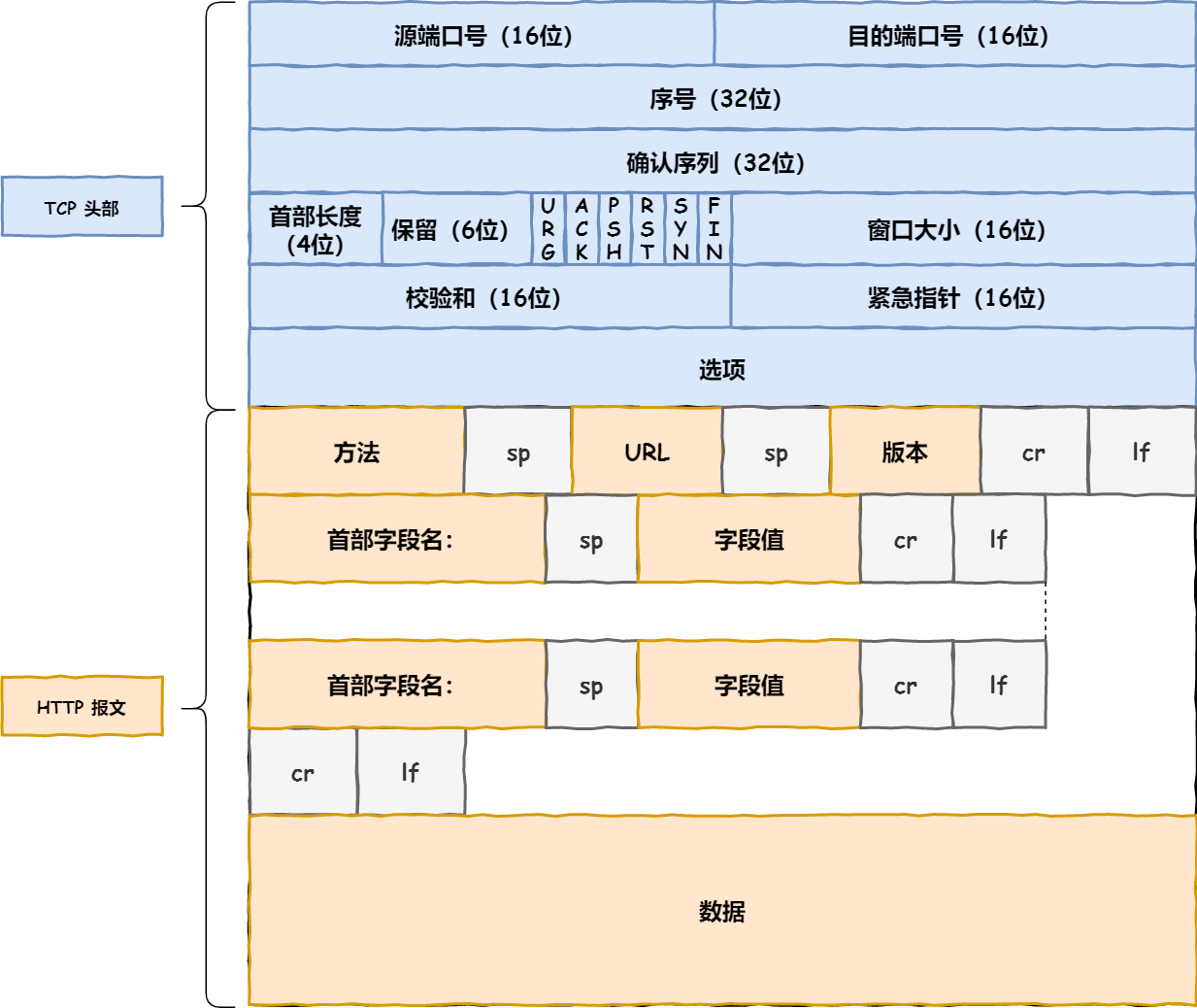
此时,遇上了 TCP 的 数据包激动表示:“太好了,碰到了可靠传输的 TCP 传输,它给我加上 TCP 头部,我不再孤单了,安全感十足啊!有大佬可以保护我的可靠送达!但我应该往哪走呢?”
#远程定位 —— IP
TCP 模块在执行连接、收发、断开等各阶段操作时,都需要委托 IP 模块将数据封装成网络包发送给通信对象。
IP 包头格式
我们先看看 IP 报文头部的格式:
在 IP 协议里面需要有源地址 IP 和 目标地址 IP:
- 源地址 IP,即是客户端输出的 IP 地址;
- 目标地址,即通过 DNS 域名解析得到的 Web 服务器 IP。
因为 HTTP 是经过 TCP 传输的,所以在 IP 包头的协议号,要填写为 06(十六进制),表示协议为 TCP。
假设客户端有多个网卡,就会有多个 IP 地址,那 IP 头部的源地址应该选择哪个 IP 呢?
当存在多个网卡时,在填写源地址 IP 时,就需要判断到底应该填写哪个地址。这个判断相当于在多块网卡中判断应该使用哪个一块网卡来发送包。
这个时候就需要根据路由表规则,来判断哪一个网卡作为源地址 IP。
在 Linux 操作系统,我们可以使用 route -n 命令查看当前系统的路由表。
举个例子,根据上面的路由表,我们假设 Web 服务器的目标地址是 192.168.10.200。
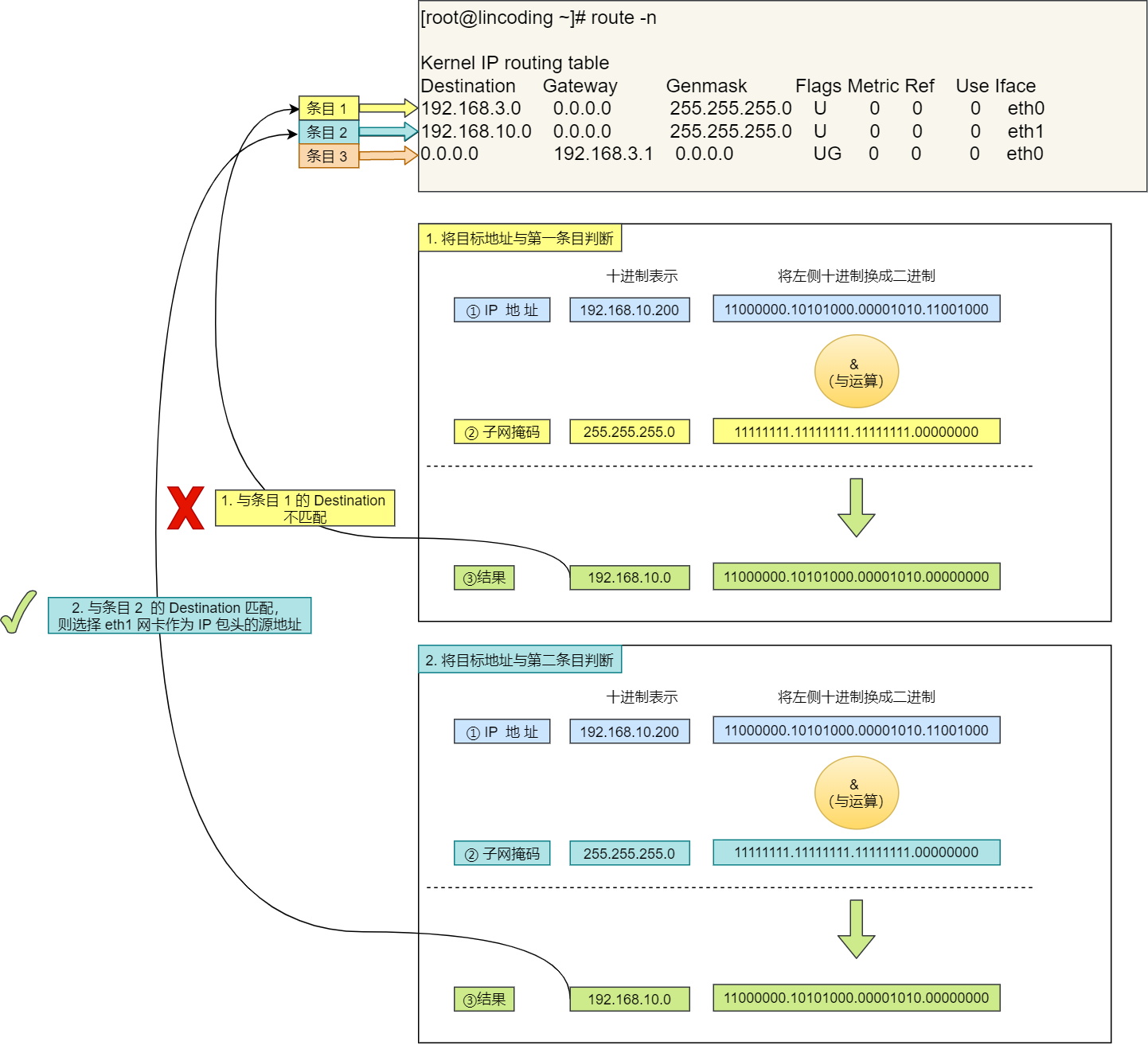
- 首先先和第一条目的子网掩码(
Genmask)进行 与运算,得到结果为192.168.10.0,但是第一个条目的Destination是192.168.3.0,两者不一致所以匹配失败。 - 再与第二条目的子网掩码进行 与运算,得到的结果为
192.168.10.0,与第二条目的Destination 192.168.10.0匹配成功,所以将使用eth1网卡的 IP 地址作为 IP 包头的源地址。
那么假设 Web 服务器的目标地址是 10.100.20.100,那么依然依照上面的路由表规则判断,判断后的结果是和第三条目匹配。
第三条目比较特殊,它目标地址和子网掩码都是 0.0.0.0,这表示默认网关,如果其他所有条目都无法匹配,就会自动匹配这一行。并且后续就把包发给路由器,Gateway 即是路由器的 IP 地址。
IP 报文生成
至此,网络包的报文如下图。
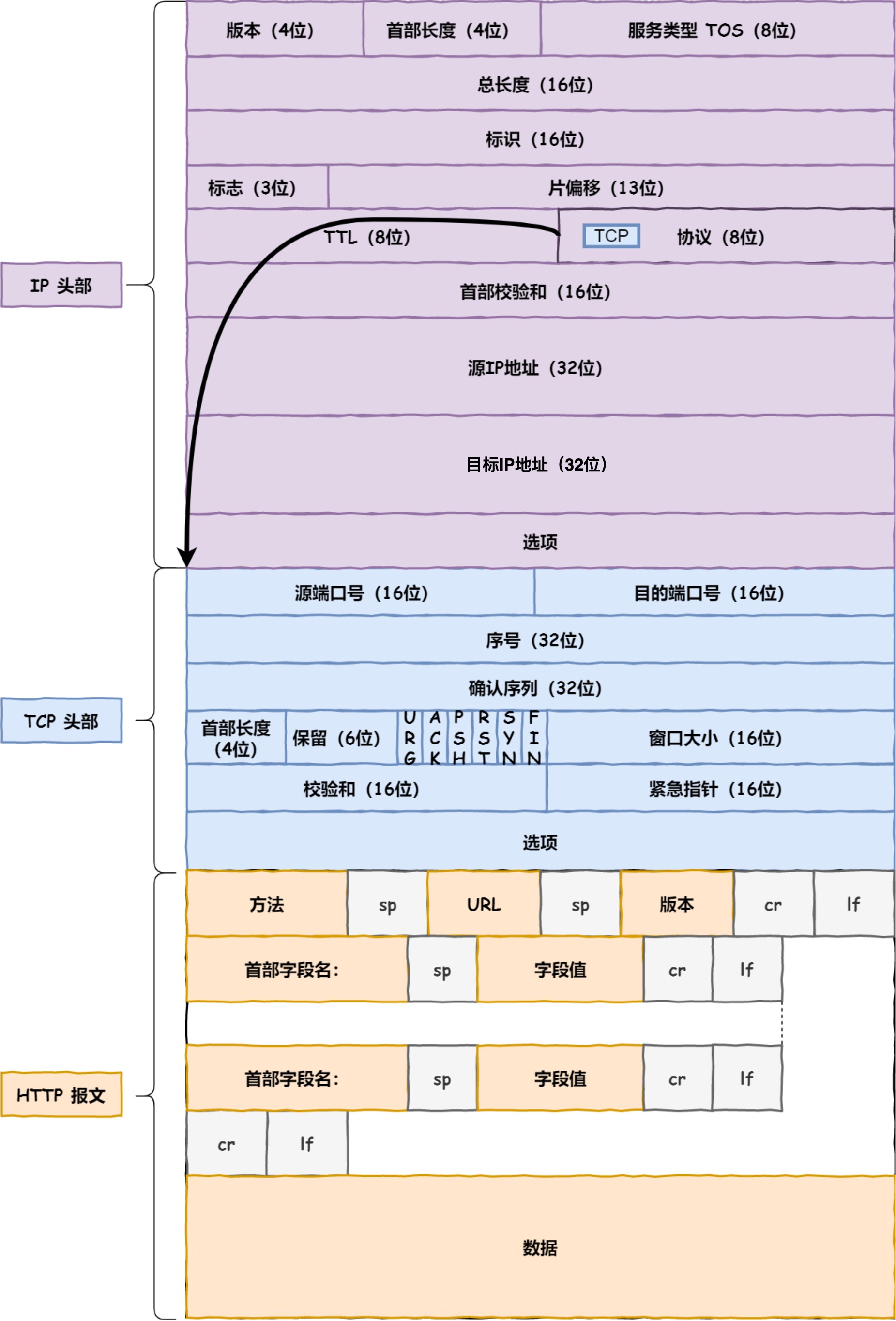
此时,加上了 IP 头部的数据包表示 :“有 IP 大佬给我指路了,感谢 IP 层给我加上了 IP 包头,让我有了远程定位的能力!不会害怕在浩瀚的互联网迷茫了!可是目的地好远啊,我下一站应该去哪呢?”
#两点传输 —— MAC
生成了 IP 头部之后,接下来网络包还需要在 IP 头部的前面加上 MAC 头部。
MAC 包头格式
MAC 头部是以太网使用的头部,它包含了接收方和发送方的 MAC 地址等信息。
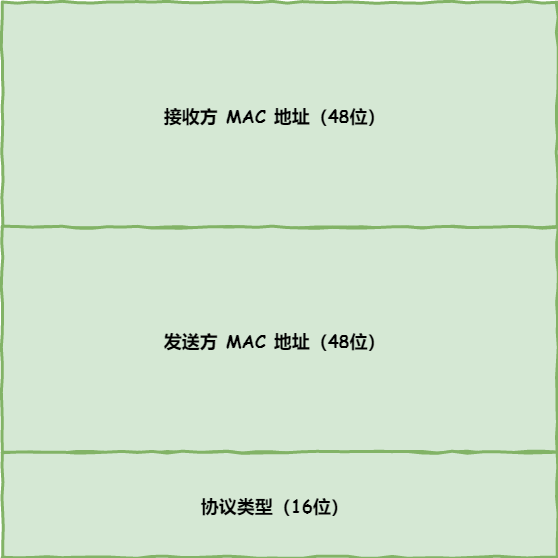
在 MAC 包头里需要发送方 MAC 地址和接收方目标 MAC 地址,用于两点之间的传输。
一般在 TCP/IP 通信里,MAC 包头的协议类型只使用:
0800: IP 协议0806: ARP 协议
MAC 发送方和接收方如何确认?
发送方的 MAC 地址获取就比较简单了,MAC 地址是在网卡生产时写入到 ROM 里的,只要将这个值读取出来写入到 MAC 头部就可以了。
接收方的 MAC 地址就有点复杂了,只要告诉以太网对方的 MAC 的地址,以太网就会帮我们把包发送过去,那么很显然这里应该填写对方的 MAC 地址。
所以先得搞清楚应该把包发给谁,这个只要查一下路由表就知道了。在路由表中找到相匹配的条目,然后把包发给 Gateway 列中的 IP 地址就可以了。
既然知道要发给谁,按如何获取对方的 MAC 地址呢?
不知道对方 MAC 地址?不知道就喊呗。
此时就需要 ARP 协议帮我们找到路由器的 MAC 地址。
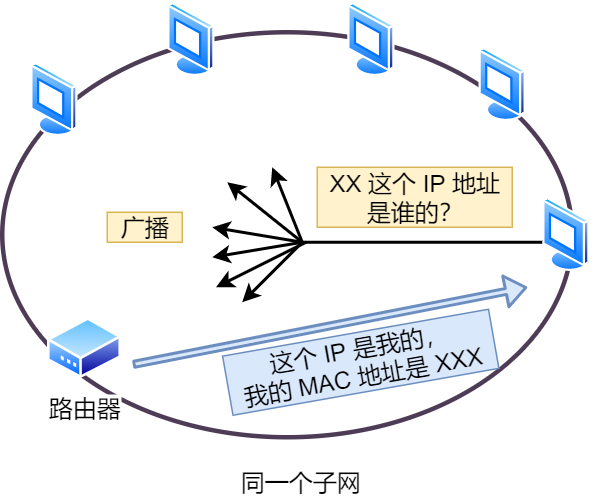
ARP 协议会在以太网中以广播的形式,对以太网所有的设备喊出:“这个 IP 地址是谁的?请把你的 MAC 地址告诉我”。
然后就会有人回答:“这个 IP 地址是我的,我的 MAC 地址是 XXXX”。
如果对方和自己处于同一个子网中,那么通过上面的操作就可以得到对方的 MAC 地址。然后,我们将这个 MAC 地址写入 MAC 头部,MAC 头部就完成了。
好像每次都要广播获取,这不是很麻烦吗?
放心,在后续操作系统会把本次查询结果放到一块叫做 ARP 缓存的内存空间留着以后用,不过缓存的时间就几分钟。
也就是说,在发包时:
- 先查询 ARP 缓存,如果其中已经保存了对方的 MAC 地址,就不需要发送 ARP 查询,直接使用 ARP 缓存中的地址。
- 而当 ARP 缓存中不存在对方 MAC 地址时,则发送 ARP 广播查询。
查看 ARP 缓存内容
在 Linux 系统中,我们可以使用 arp -a 命令来查看 ARP 缓存的内容。
MAC 报文生成
至此,网络包的报文如下图。
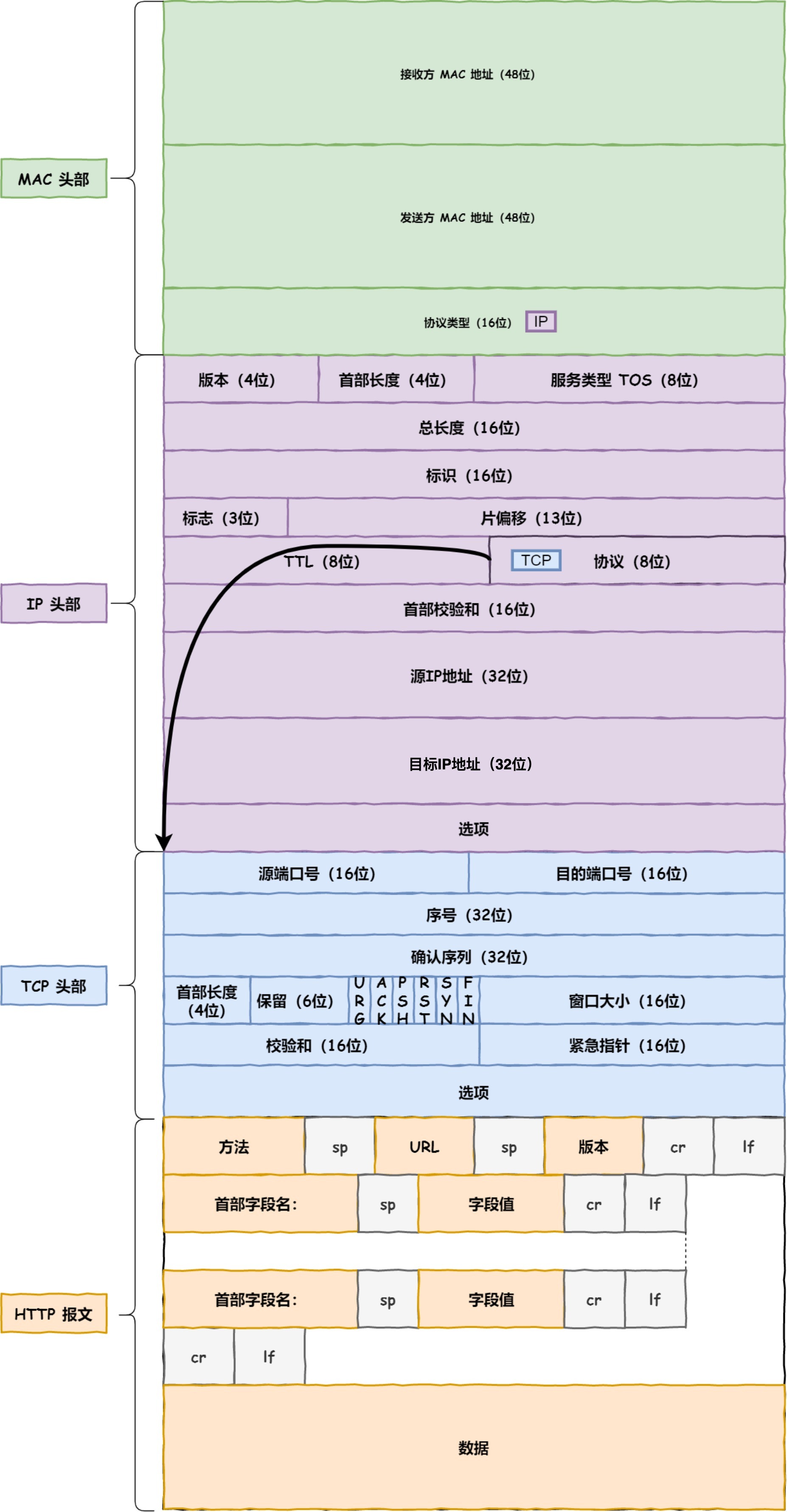
此时,加上了 MAC 头部的数据包万分感谢,说道 :“感谢 MAC 大佬,我知道我下一步要去哪了!我现在有很多头部兄弟,相信我可以到达最终的目的地!”。 带着众多头部兄弟的数据包,终于准备要出门了。
#出口 —— 网卡
网络包只是存放在内存中的一串二进制数字信息,没有办法直接发送给对方。因此,我们需要将数字信息转换为电信号,才能在网线上传输,也就是说,这才是真正的数据发送过程。
负责执行这一操作的是网卡,要控制网卡还需要靠网卡驱动程序。
网卡驱动获取网络包之后,会将其复制到网卡内的缓存区中,接着会在其开头加上报头和起始帧分界符,在末尾加上用于检测错误的帧校验序列。
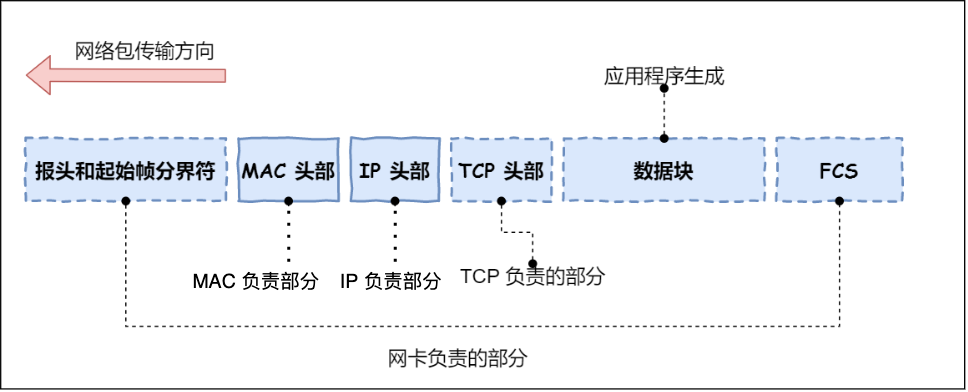
- 起始帧分界符是一个用来表示包起始位置的标记
- 末尾的
FCS(帧校验序列)用来检查包传输过程是否有损坏
最后网卡会将包转为电信号,通过网线发送出去。
唉,真是不容易,发一个包,真是历经千辛万苦。致此,一个带有许多头部的数据终于踏上寻找目的地的征途了!
#送别者 —— 交换机
下面来看一下包是如何通过交换机的。交换机的设计是将网络包原样转发到目的地。交换机工作在 MAC 层,也称为二层网络设备。
交换机的包接收操作
首先,电信号到达网线接口,交换机里的模块进行接收,接下来交换机里的模块将电信号转换为数字信号。
然后通过包末尾的 FCS 校验错误,如果没问题则放到缓冲区。这部分操作基本和计算机的网卡相同,但交换机的工作方式和网卡不同。
计算机的网卡本身具有 MAC 地址,并通过核对收到的包的接收方 MAC 地址判断是不是发给自己的,如果不是发给自己的则丢弃;相对地,交换机的端口不核对接收方 MAC 地址,而是直接接收所有的包并存放到缓冲区中。因此,和网卡不同,交换机的端口不具有 MAC 地址。
将包存入缓冲区后,接下来需要查询一下这个包的接收方 MAC 地址是否已经在 MAC 地址表中有记录了。
交换机的 MAC 地址表主要包含两个信息:
- 一个是设备的 MAC 地址,
- 另一个是该设备连接在交换机的哪个端口上。
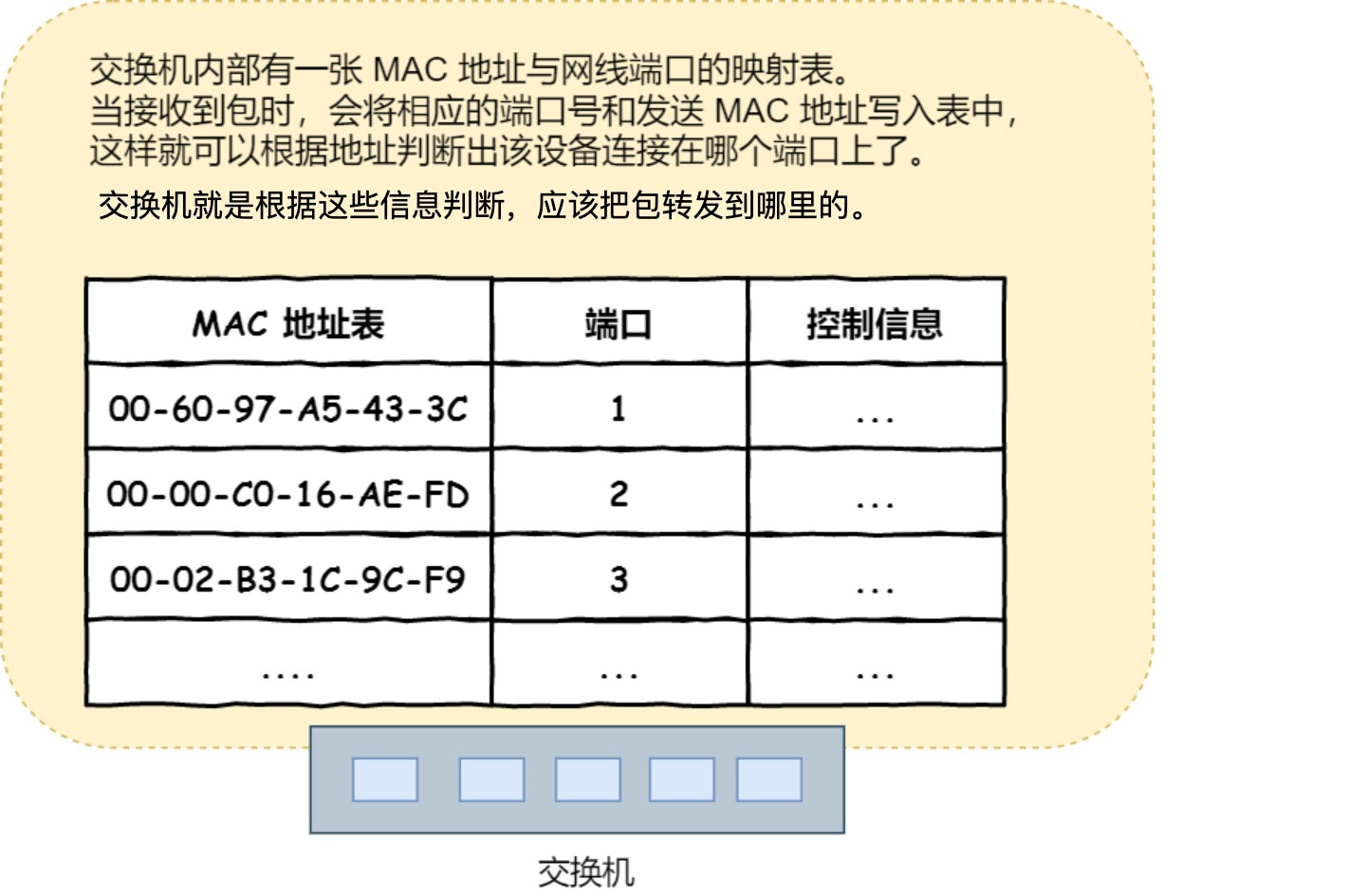
举个例子,如果收到的包的接收方 MAC 地址为 00-02-B3-1C-9C-F9,则与图中表中的第 3 行匹配,根据端口列的信息,可知这个地址位于 3 号端口上,然后就可以通过交换电路将包发送到相应的端口了。
所以,交换机根据 MAC 地址表查找 MAC 地址,然后将信号发送到相应的端口。
当 MAC 地址表找不到指定的 MAC 地址会怎么样?
地址表中找不到指定的 MAC 地址。这可能是因为具有该地址的设备还没有向交换机发送过包,或者这个设备一段时间没有工作导致地址被从地址表中删除了。
这种情况下,交换机无法判断应该把包转发到哪个端口,只能将包转发到除了源端口之外的所有端口上,无论该设备连接在哪个端口上都能收到这个包。
这样做不会产生什么问题,因为以太网的设计本来就是将包发送到整个网络的,然后只有相应的接收者才接收包,而其他设备则会忽略这个包。
有人会说:“这样做会发送多余的包,会不会造成网络拥塞呢?”
其实完全不用过于担心,因为发送了包之后目标设备会作出响应,只要返回了响应包,交换机就可以将它的地址写入 MAC 地址表,下次也就不需要把包发到所有端口了。
局域网中每秒可以传输上千个包,多出一两个包并无大碍。
此外,如果接收方 MAC 地址是一个广播地址,那么交换机会将包发送到除源端口之外的所有端口。
以下两个属于广播地址:
- MAC 地址中的
FF:FF:FF:FF:FF:FF - IP 地址中的
255.255.255.255
数据包通过交换机转发抵达了路由器,准备要离开土生土长的子网了。此时,数据包和交换机离别时说道:“感谢交换机兄弟,帮我转发到出境的大门,我要出远门啦!”
#出境大门 —— 路由器
路由器与交换机的区别
网络包经过交换机之后,现在到达了路由器,并在此被转发到下一个路由器或目标设备。
这一步转发的工作原理和交换机类似,也是通过查表判断包转发的目标。
不过在具体的操作过程上,路由器和交换机是有区别的。
- 因为路由器是基于 IP 设计的,俗称三层网络设备,路由器的各个端口都具有 MAC 地址和 IP 地址;
- 而交换机是基于以太网设计的,俗称二层网络设备,交换机的端口不具有 MAC 地址。
路由器基本原理
路由器的端口具有 MAC 地址,因此它就能够成为以太网的发送方和接收方;同时还具有 IP 地址,从这个意义上来说,它和计算机的网卡是一样的。
当转发包时,首先路由器端口会接收发给自己的以太网包,然后路由表查询转发目标,再由相应的端口作为发送方将以太网包发送出去。
路由器的包接收操作
首先,电信号到达网线接口部分,路由器中的模块会将电信号转成数字信号,然后通过包末尾的 FCS 进行错误校验。
如果没问题则检查 MAC 头部中的接收方 MAC 地址,看看是不是发给自己的包,如果是就放到接收缓冲区中,否则就丢弃这个包。
总的来说,路由器的端口都具有 MAC 地址,只接收与自身地址匹配的包,遇到不匹配的包则直接丢弃。
查询路由表确定输出端口
完成包接收操作之后,路由器就会去掉包开头的 MAC 头部。
MAC 头部的作用就是将包送达路由器,其中的接收方 MAC 地址就是路由器端口的 MAC 地址。因此,当包到达路由器之后,MAC 头部的任务就完成了,于是 MAC 头部就会被丢弃。
接下来,路由器会根据 MAC 头部后方的 IP 头部中的内容进行包的转发操作。
转发操作分为几个阶段,首先是查询路由表判断转发目标。
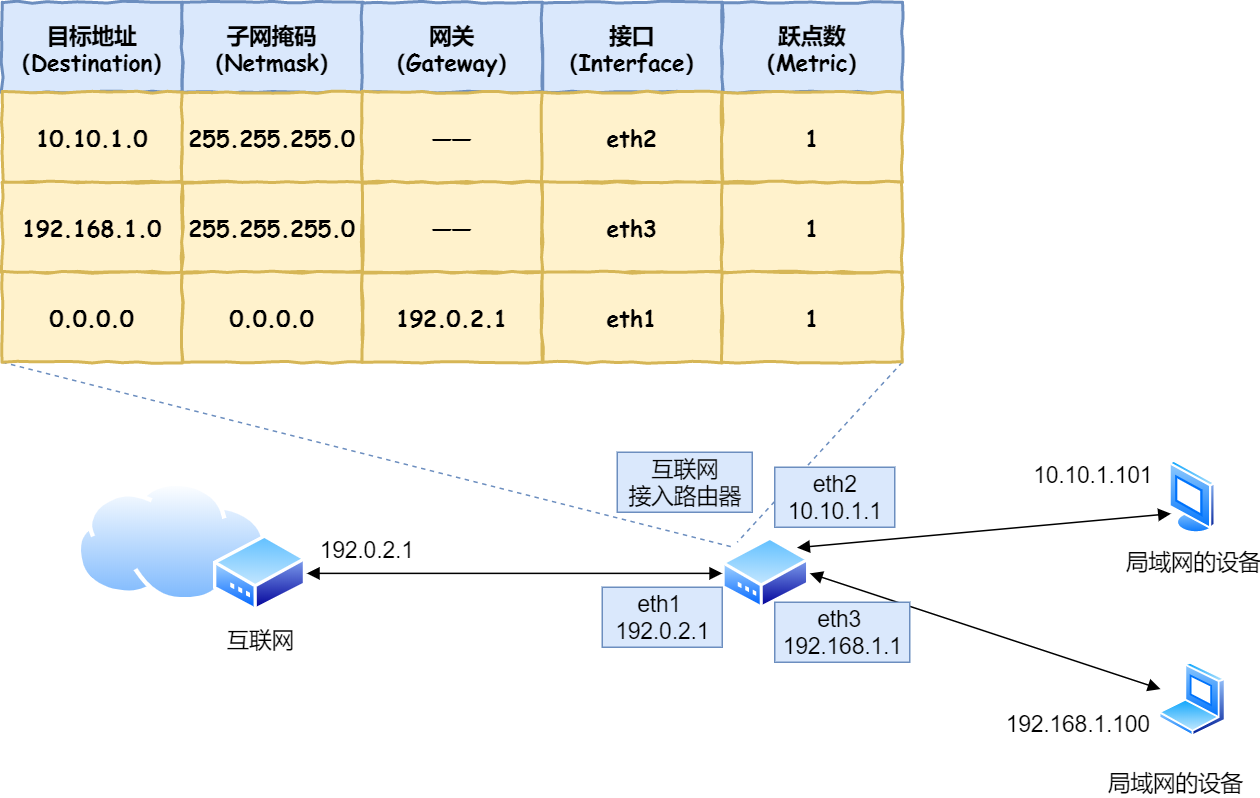
具体的工作流程根据上图,举个例子。
假设地址为 10.10.1.101 的计算机要向地址为 192.168.1.100 的服务器发送一个包,这个包先到达图中的路由器。
判断转发目标的第一步,就是根据包的接收方 IP 地址查询路由表中的目标地址栏,以找到相匹配的记录。
路由匹配和前面讲的一样,每个条目的子网掩码和 192.168.1.100 IP 做 & 与运算后,得到的结果与对应条目的目标地址进行匹配,如果匹配就会作为候选转发目标,如果不匹配就继续与下个条目进行路由匹配。
如第二条目的子网掩码 255.255.255.0 与 192.168.1.100 IP 做 & 与运算后,得到结果是 192.168.1.0 ,这与第二条目的目标地址 192.168.1.0 匹配,该第二条目记录就会被作为转发目标。
实在找不到匹配路由时,就会选择默认路由,路由表中子网掩码为 0.0.0.0 的记录表示「默认路由」。
路由器的发送操作
接下来就会进入包的发送操作。
首先,我们需要根据路由表的网关列判断对方的地址。
- 如果网关是一个 IP 地址,则这个 IP 地址就是我们要转发到的目标地址,还未抵达终点,还需继续需要路由器转发。
- 如果网关为空,则 IP 头部中的接收方 IP 地址就是要转发到的目标地址,也是就终于找到 IP 包头里的目标地址了,说明已抵达终点。
知道对方的 IP 地址之后,接下来需要通过 ARP 协议根据 IP 地址查询 MAC 地址,并将查询的结果作为接收方 MAC 地址。
路由器也有 ARP 缓存,因此首先会在 ARP 缓存中查询,如果找不到则发送 ARP 查询请求。
接下来是发送方 MAC 地址字段,这里填写输出端口的 MAC 地址。还有一个以太类型字段,填写 0800 (十六进制)表示 IP 协议。
网络包完成后,接下来会将其转换成电信号并通过端口发送出去。这一步的工作过程和计算机也是相同的。
发送出去的网络包会通过交换机到达下一个路由器。由于接收方 MAC 地址就是下一个路由器的地址,所以交换机会根据这一地址将包传输到下一个路由器。
接下来,下一个路由器会将包转发给再下一个路由器,经过层层转发之后,网络包就到达了最终的目的地。
不知你发现了没有,在网络包传输的过程中,源 IP 和目标 IP 始终是不会变的,一直变化的是 MAC 地址,因为需要 MAC 地址在以太网内进行两个设备之间的包传输。
数据包通过多个路由器道友的帮助,在网络世界途经了很多路程,最终抵达了目的地的城门!城门值守的路由器,发现了这个小兄弟数据包原来是找城内的人,于是它就将数据包送进了城内,再经由城内的交换机帮助下,最终转发到了目的地了。数据包感慨万千的说道:“多谢这一路上,各路大侠的相助!”
#互相扒皮 —— 服务器 与 客户端
数据包抵达了服务器,服务器肯定高兴呀,正所谓有朋自远方来,不亦乐乎?
服务器高兴的不得了,于是开始扒数据包的皮!就好像你收到快递,能不兴奋吗?
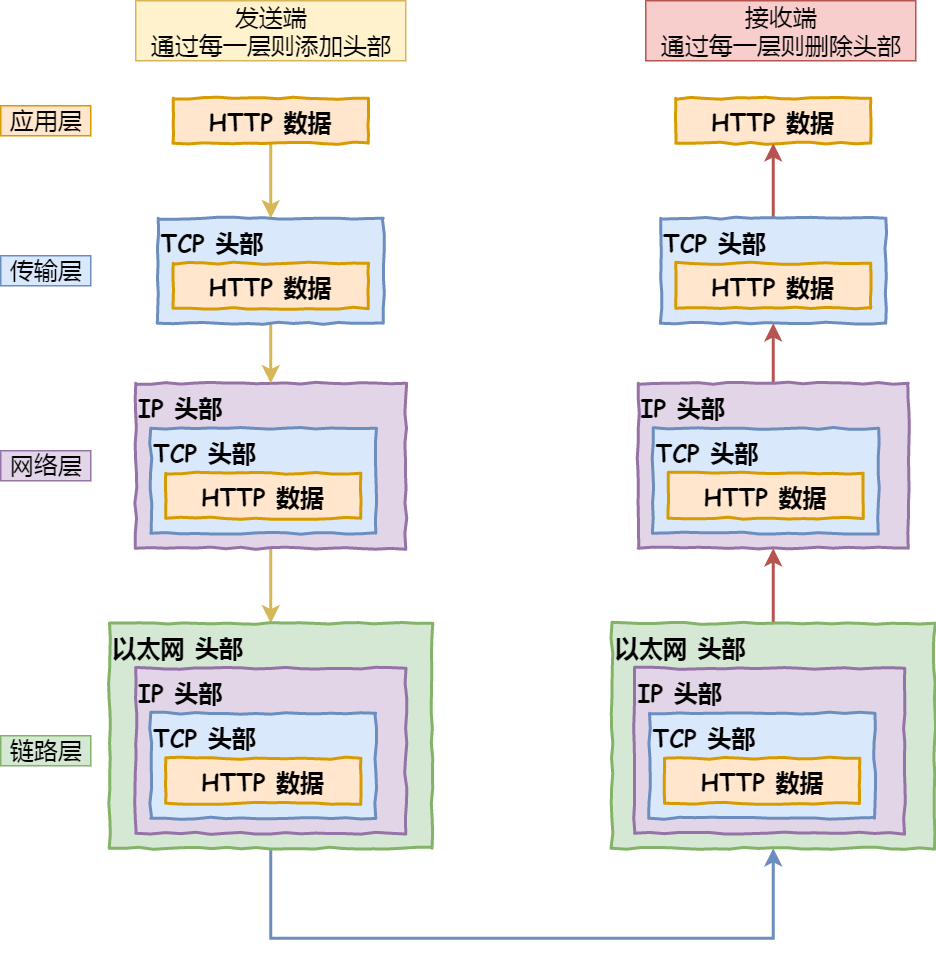
数据包抵达服务器后,服务器会先扒开数据包的 MAC 头部,查看是否和服务器自己的 MAC 地址符合,符合就将包收起来。
接着继续扒开数据包的 IP 头,发现 IP 地址符合,根据 IP 头中协议项,知道自己上层是 TCP 协议。
于是,扒开 TCP 的头,里面有序列号,需要看一看这个序列包是不是我想要的,如果是就放入缓存中然后返回一个 ACK,如果不是就丢弃。TCP 头部里面还有端口号, HTTP 的服务器正在监听这个端口号。
于是,服务器自然就知道是 HTTP 进程想要这个包,于是就将包发给 HTTP 进程。
服务器的 HTTP 进程看到,原来这个请求是要访问一个页面,于是就把这个网页封装在 HTTP 响应报文里。
HTTP 响应报文也需要穿上 TCP、IP、MAC 头部,不过这次是源地址是服务器 IP 地址,目的地址是客户端 IP 地址。
穿好头部衣服后,从网卡出去,交由交换机转发到出城的路由器,路由器就把响应数据包发到了下一个路由器,就这样跳啊跳。
最后跳到了客户端的城门把守的路由器,路由器扒开 IP 头部发现是要找城内的人,于是又把包发给了城内的交换机,再由交换机转发到客户端。
客户端收到了服务器的响应数据包后,同样也非常的高兴,客户能拆快递了!
于是,客户端开始扒皮,把收到的数据包的皮扒剩 HTTP 响应报文后,交给浏览器去渲染页面,一份特别的数据包快递,就这样显示出来了!
最后,客户端要离开了,向服务器发起了 TCP 四次挥手,至此双方的连接就断开了。
#一个数据包臭不要脸的感受
下面内容的 「我」,代表「臭美的数据包角色」。注:(括号的内容)代表我的吐槽,三连呸!
我一开始我虽然孤单、不知所措,但没有停滞不前。我依然满怀信心和勇气开始了征途。(你当然有勇气,你是应用层数据,后面有底层兄弟当靠山,我呸!)
我很庆幸遇到了各路神通广大的大佬,有可靠传输的 TCP、有远程定位功能的 IP、有指明下一站位置的 MAC 等(你当然会遇到,因为都被计算机安排好的,我呸!)。
这些大佬都给我前面加上了头部,使得我能在交换机和路由器的转发下,抵达到了目的地!(哎,你也不容易,不吐槽了,放过你!)
这一路上的经历,让我认识到了网络世界中各路大侠协作的重要性,是他们维护了网络世界的秩序,感谢他们!(我呸,你应该感谢众多计算机科学家!)
URL 输入到浏览器解析
很多大公司面试喜欢问这样一道面试题,输入URL到看见页面发生了什么?,今天我们来总结一下。 简单来说,共有以下几个过程
- DNS 解析
- 发起 TCP 连接
- 发送 HTTP 请求
- 服务器处理请求并返回 HTTP 报文
- 浏览器解析渲染页面
- 连接结束。
下面我们来看看具体的细节
DNS 解析
DNS 解析实际上就是寻找你所需要的资源的过程。假设你输入baidu.com,而这个网址并不是百度的真实地址,互联网中每一台机器都有唯一标识的 IP 地址,这个才是关键,但是它不好记,乱七八糟一串数字谁记得住啊,所以就需要一个网址和 IP 地址的转换,也就是 DNS 解析。下面看看具体的解析过程
具体解析
DNS 解析其实是一个递归的过程 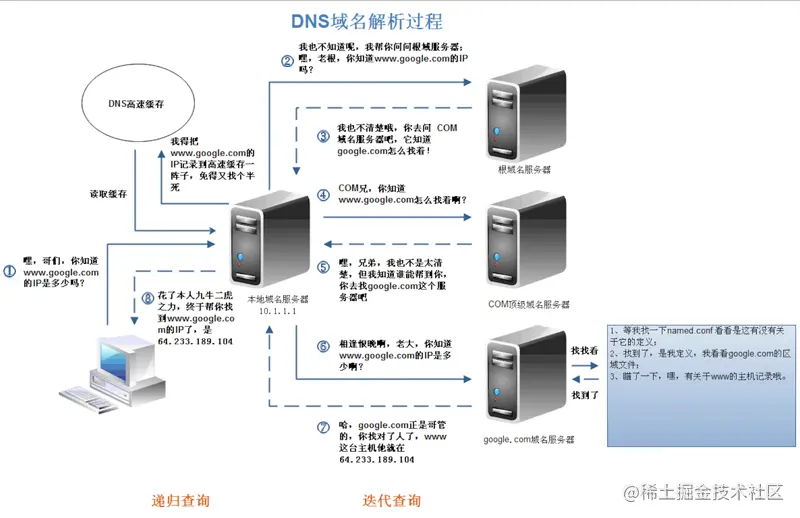 输入
输入google.com网址后,首先在本地的域名服务器中查找,没找到去根域名服务器查找,没有再去com顶级域名服务器查找,,如此的类推下去,直到找到 IP 地址,然后把它记录在本地,供下次使用。大致过程就是. -> .com -> google.com. -> google.com.。 (你可能觉得我多写 .,并木有,这个.对应的就是根域名服务器,默认情况下所有的网址的最后一位都是.,既然是默认情况下,为了方便用户,通常都会省略,浏览器在请求 DNS 的时候会自动加上)
DNS 优化
既然已经懂得了解析的具体过程,我们可以看到上述一共经过了 N 个过程,每个过程有一定的消耗和时间的等待,因此我们得想办法解决一下这个问题!
DNS 缓存
DNS 存在着多级缓存,从离浏览器的距离排序的话,有以下几种: 浏览器缓存,系统缓存,路由器缓存,IPS 服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
- 在你的 chrome 浏览器中输入:chrome://dns/,你可以看到 chrome 浏览器的 DNS 缓存。
- 系统缓存主要存在/etc/hosts(Linux 系统)中
DNS 负载均衡
不知道你们有没有注意这样一件事,你访问baidu.com的时候,每次响应的并非是同一个服务器(IP 地址不同),一般大公司都有成百上千台服务器来支撑访问,假设只有一个服务器,那它的性能和存储量要多大才能支撑这样大量的访问呢?DNS 可以返回一个合适的机器的 IP 给用户,例如可以根据每台机器的负载量,该机器离用户地理位置的距离等等,这种过程就是 DNS 负载均衡
发起 TCP 连接
TCP 提供一种可靠的传输,这个过程涉及到三次握手,四次挥手,下面我们详细看看 TCP 提供一种面向连接的,可靠的字节流服务。 其首部的数据格式如下 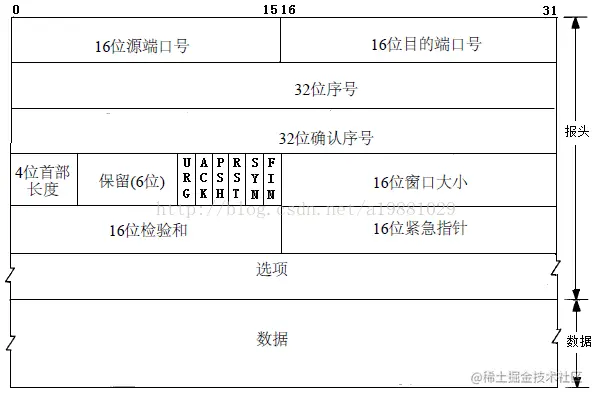
字段分析
- 源端口:源端口和 IP 地址的作用是标识报文的返回地址。
- 目的端口:端口指明接收方计算机上的应用程序接口。
TCP 报头中的源端口号和目的端口号同 IP 数据报中的源 IP 与目的 IP 唯一确定一条 TCP 连接。
- 序号:是 TCP 可靠传输的关键部分。序号是该报文段发送的数据组的第一个字节的序号。在 TCP 传送的流中,每一个字节都有一个序号。比如一个报文段的序号为 300,报文段数据部分共有 100 字节,则下一个报文段的序号为 400。所以序号确保了 TCP 传输的有序性。
- 确认号:即 ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当 ACK 标志为 1 时才有效。比如建立连接时,SYN 报文的 ACK 标志位为 0。
- 首部长度/数据偏移:占 4 位,它指出 TCP 报文的数据距离 TCP 报文段的起始处有多远。由于首部可能含有可选项内容,因此 TCP 报头的长度是不确定的,报头不包含任何任选字段则长度为 20 字节,4 位首部长度字段所能表示的最大值为 1111,转化为 10 进制为 15,15*32/8=60,故报头最大长度为 60 字节。首部长度也叫数据偏移,是因为首部长度实际上指示了数据区在报文段中的起始偏移值。
- 保留:占 6 位,保留今后使用,但目前应都位 0。
- 控制位:URG ACK PSH RST SYN FIN,共 6 个,每一个标志位表示一个控制功能。
- 紧急 URG:当 URG=1,表明紧急指针字段有效。告诉系统此报文段中有紧急数据
- 确认 ACK:仅当 ACK=1 时,确认号字段才有效。TCP 规定,在连接建立后所有报文的传输都必须把 ACK 置 1。
- 推送 PSH:当两个应用进程进行交互式通信时,有时在一端的应用进程希望在键入一个命令后立即就能收到对方的响应,这时候就将 PSH=1。
- 复位 RST:当 RST=1,表明 TCP 连接中出现严重差错,必须释放连接,然后再重新建立连接。
- 同步 SYN:在连接建立时用来同步序号。当 SYN=1,ACK=0,表明是连接请求报文,若同意连接,则响应报文中应该使 SYN=1,ACK=1。
- 终止 FIN:用来释放连接。当 FIN=1,表明此报文的发送方的数据已经发送完毕,并且要求释放。
- 窗口:滑动窗口大小,用来告知发送端接受端的缓存大小,以此控制发送端发送数据的速率,从而达到流量控制。窗口大小时一个 16bit 字段,因而窗口大小最大为 65535。
- 校验和:奇偶校验,此校验和是对整个的 TCP 报文段,包括 TCP 头部和 TCP 数据,以 16 位字进行计算所得。由发送端计算和存储,并由接收端进行验证。
- 紧急指针:只有当 URG 标志置 1 时紧急指针才有效。紧急指针是一个正的偏移量,和顺序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式。
- 选项和填充:最常见的可选字段是最长报文大小,又称为 MSS(Maximum Segment Size),每个连接方通常都在通信的第一个报文段(为建立连接而设置 SYN 标志为 1 的那个段)中指明这个选项,它表示本端所能接受的最大报文段的长度。选项长度不一定是 32 位的整数倍,所以要加填充位,即在这个字段中加入额外的零,以保证 TCP 头是 32 的整数倍。
- 数据部分: TCP 报文段中的数据部分是可选的。在一个连接建立和一个连接终止时,双方交换的报文段仅有 TCP 首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超时的许多情况中,也会发送不带任何数据的报文段。
需要注意的是:
(A)不要将确认序号 Ack 与标志位中的 ACK 搞混了。 (B)确认方 Ack=发起方 Req+1,两端配对。
三次握手
第一次握手:
客户端发送 syn 包(Seq=x)到服务器,并进入 SYN_SEND 状态,等待服务器确认;
第二次握手:
服务器收到 syn 包,必须确认客户的 SYN(ack=x+1),同时自己也发送一个 SYN 包(Seq=y),即 SYN+ACK 包,此时服务器进入 SYN_RECV 状态;
第三次握手:
客户端收到服务器的 SYN + ACK 包,向服务器发送确认包 ACK(ack=y+1),此包发送完毕,客户端和服务器进入 ESTABLISHED 状态,完成三次握手。
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP 连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
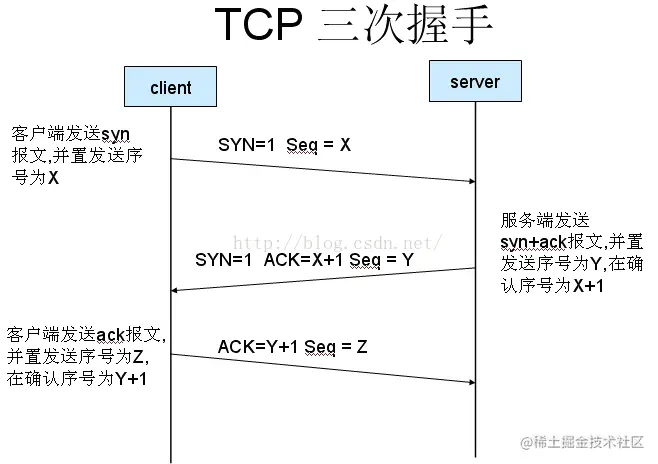
为什么会采用三次握手,若采用二次握手可以吗? 四次呢?
建立连接的过程是利用客户服务器模式,假设主机 A 为客户端,主机 B 为服务器端。
采用三次握手是为了防止失效的连接请求报文段突然又传送到主机 B,因而产生错误。失效的连接请求报文段是指:主机 A 发出的连接请求没有收到主机 B 的确认,于是经过一段时间后,主机 A 又重新向主机 B 发送连接请求,且建立成功,顺序完成数据传输。考虑这样一种特殊情况,主机 A 第一次发送的连接请求并没有丢失,而是因为网络节点导致延迟达到主机 B,主机 B 以为是主机 A 又发起的新连接,于是主机 B 同意连接,并向主机 A 发回确认,但是此时主机 A 根本不会理会,主机 B 就一直在等待主机 A 发送数据,导致主机 B 的资源浪费。
采用两次握手不行,原因就是上面说的失效的连接请求的特殊情况。而在三次握手中, client 和 server 都有一个发 syn 和收 ack 的过程, 双方都是发后能收, 表明通信则准备工作 OK.
为什么不是四次握手呢? 大家应该知道通信中著名的蓝军红军约定, 这个例子说明, 通信不可能 100%可靠, 而上面的三次握手已经做好了通信的准备工作, 再增加握手, 并不能显著提高可靠性, 而且也没有必要。
四次挥手
数据传输完毕后,双方都可释放连接。最开始的时候,客户端和服务器都是处于 ESTABLISHED 状态,假设客户端主动关闭,服务器被动关闭。
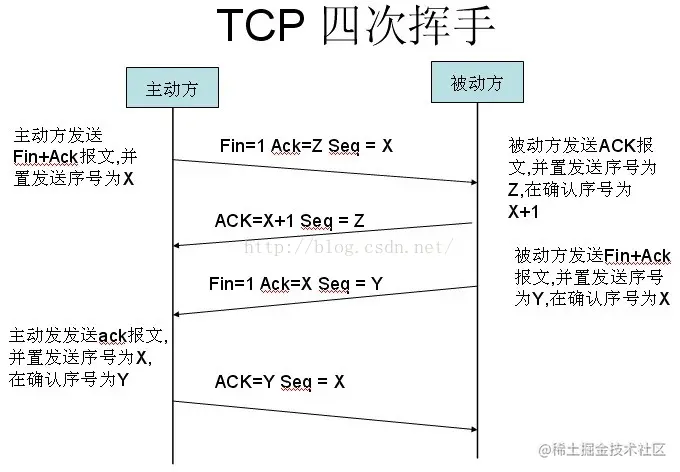
第一次挥手:
客户端发送一个 FIN,用来关闭客户端到服务器的数据传送,也就是客户端告诉服务器:我已经不 会再给你发数据了(当然,在 fin 包之前发送出去的数据,如果没有收到对应的 ack 确认报文,客户端依然会重发这些数据),但是,此时客户端还可 以接受数据。 FIN=1,其序列号为 seq=u(等于前面已经传送过来的数据的最后一个字节的序号加 1),此时,客户端进入 FIN-WAIT-1(终止等待 1)状态。 TCP 规定,FIN 报文段即使不携带数据,也要消耗一个序号。
第二次挥手:
服务器收到 FIN 包后,发送一个 ACK 给对方并且带上自己的序列号 seq,确认序号为收到序号+1(与 SYN 相同,一个 FIN 占用一个序号)。此时,服务端就进入了 CLOSE-WAIT(关闭等待)状态。TCP 服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个 CLOSE-WAIT 状态持续的时间。
此时,客户端就进入 FIN-WAIT-2(终止等待 2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
第三次挥手:
服务器发送一个 FIN,用来关闭服务器到客户端的数据传送,也就是告诉客户端,我的数据也发送完了,不会再给你发数据了。由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为 seq=w,此时,服务器就进入了 LAST-ACK(最后确认)状态,等待客户端的确认。
第四次挥手:
主动关闭方收到 FIN 后,发送一个 ACK 给被动关闭方,确认序号为收到序号+1,此时,客户端就进入了 TIME-WAIT(时间等待)状态。注意此时 TCP 连接还没有释放,必须经过 2∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的 TCB 后,才进入 CLOSED 状态。
服务器只要收到了客户端发出的确认,立即进入 CLOSED 状态。同样,撤销 TCB 后,就结束了这次的 TCP 连接。可以看到,服务器结束 TCP 连接的时间要比客户端早一些。
至此,完成四次挥手。
为什么客户端最后还要等待 2MSL?
MSL(Maximum Segment Lifetime),TCP 允许不同的实现可以设置不同的 MSL 值。
第一,保证客户端发送的最后一个 ACK 报文能够到达服务器,因为这个 ACK 报文可能丢失,站在服务器的角度看来,我已经发送了 FIN+ACK 报文请求断开了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于是服务器又会重新发送一次,而客户端就能在这个 2MSL 时间段内收到这个重传的报文,接着给出回应报文,并且会重启 2MSL 计时器。
第二,防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个 2MSL 时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连接中不会出现旧连接的请求报文。
为什么建立连接是三次握手,关闭连接确是四次挥手呢?
建立连接的时候, 服务器在 LISTEN 状态下,收到建立连接请求的 SYN 报文后,把 ACK 和 SYN 放在一个报文里发送给客户端。 而关闭连接时,服务器收到对方的 FIN 报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送 FIN 报文给对方来表示同意现在关闭连接,因此,己方 ACK 和 FIN 一般都会分开发送,从而导致多了一次。
发送 HTTP 请求
首先科补一个小知识,HTTP 的端口为 80/8080,而 HTTPS 的端口为 443
发送 HTTP 请求的过程就是构建 HTTP 请求报文并通过 TCP 协议中发送到服务器指定端口 请求报文由请求行,请求抱头,请求正文组成。
请求行
请求行的格式为Method Request-URL HTTP-Version CRLF eg: GET index.html HTTP/1.1 常用的方法有: GET, POST, PUT, DELETE, OPTIONS, HEAD。
常见的请求方法区别
这里主要展示POST和GET的区别
常见的区别
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求。
- GET 产生的 URL 地址可以被 Bookmark,而 POST 不可以。
- GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置。
- GET 请求只能进行 url 编码,而 POST 支持多种编码方式。
- GET 请求参数会被完整保留在浏览器历史记录里,而 POST 中的参数不会被保留。
- GET 请求在 URL 中传送的参数是有长度限制的,而 POST 么有。
- 对参数的数据类型,GET 只接受 ASCII 字符,而 POST 没有限制。
- GET 比 POST 更不安全,因为参数直接暴露在 URL 上,所以不能用来传递敏感信息。
- GET 参数通过 URL 传递,POST 放在 Request body 中。
注意一点你也可以在 GET 里面藏 body,POST 里面带参数
重点区别
GET会产生一个TCP数据包,而POST会产生两个TCP数据包。
详细的说就是:
- 对于 GET 方式的请求,浏览器会把 http header 和 data 一并发送出去,服务器响应 200(返回数据);
- 而对于 POST,浏览器先发送 header,服务器响应 100 continue,浏览器再发送 data,服务器响应 200 ok(返回数据)。
注意一点,并不是所有的浏览器都会发送两次数据包,Firefox 就发送一次
请求报头
请求报头允许客户端向服务器传递请求的附加信息和客户端自身的信息。  从图中可以看出,请求报头中使用了 Accept, Accept-Encoding, Accept-Language, Cache-Control, Connection, Cookie 等字段。Accept 用于指定客户端用于接受哪些类型的信息,Accept-Encoding 与 Accept 类似,它用于指定接受的编码方式。Connection 设置为 Keep-alive 用于告诉客户端本次 HTTP 请求结束之后并不需要关闭 TCP 连接,这样可以使下次 HTTP 请求使用相同的 TCP 通道,节省 TCP 连接建立的时间。
从图中可以看出,请求报头中使用了 Accept, Accept-Encoding, Accept-Language, Cache-Control, Connection, Cookie 等字段。Accept 用于指定客户端用于接受哪些类型的信息,Accept-Encoding 与 Accept 类似,它用于指定接受的编码方式。Connection 设置为 Keep-alive 用于告诉客户端本次 HTTP 请求结束之后并不需要关闭 TCP 连接,这样可以使下次 HTTP 请求使用相同的 TCP 通道,节省 TCP 连接建立的时间。
请求正文
当使用 POST, PUT 等方法时,通常需要客户端向服务器传递数据。这些数据就储存在请求正文中。在请求包头中有一些与请求正文相关的信息,例如: 现在的 Web 应用通常采用 Rest 架构,请求的数据格式一般为 json。这时就需要设置Content-Type: application/json。
更重要的事情-HTTP 缓存
HTTP 属于客户端缓存,我们常认为浏览器有一个缓存数据库,用来保存一些静态文件,下面我们分为以下几个方面来简单介绍 HTTP 缓存
- 缓存的规则
- 缓存的方案
- 缓存的优点
- 不同刷新的请求执行过程
缓存的规则
缓存规则分为强制缓存和协商缓存
强制缓存
当缓存数据库中有客户端需要的数据,客户端直接将数据从其中拿出来使用(如果数据未失效),当缓存服务器没有需要的数据时,客户端才会向服务端请求。 
协商缓存
又称对比缓存。客户端会先从缓存数据库拿到一个缓存的标识,然后向服务端验证标识是否失效,如果没有失效服务端会返回 304,这样客户端可以直接去缓存数据库拿出数据,如果失效,服务端会返回新的数据 
强制缓存的优先级高于协商缓存,若两种缓存皆存在,且强制缓存命中目标,则协商缓存不再验证标识。
缓存的方案
上面的内容让我们大概了解了缓存机制是怎样运行的,但是,服务器是如何判断缓存是否失效呢?我们知道浏览器和服务器进行交互的时候会发送一些请求数据和响应数据,我们称之为 HTTP 报文。报文中包含首部 header 和主体部分 body。与缓存相关的规则信息就包含在 header 中。boby 中的内容是 HTTP 请求真正要传输的部分。举个 HTTP 报文 header 部分的例子如下:  我们依旧分为强制缓存和协商缓存来分析。
我们依旧分为强制缓存和协商缓存来分析。
强制缓存
对于强制缓存,服务器响应的 header 中会用两个字段来表明——Expires 和 Cache-Control。
Expires
Exprires 的值为服务端返回的数据到期时间。当再次请求时的请求时间小于返回的此时间,则直接使用缓存数据。但由于服务端时间和客户端时间可能有误差,这也将导致缓存命中的误差,另一方面,Expires 是 HTTP1.0 的产物,故现在大多数使用 Cache-Control 替代。
Cache-Control
Cache-Control 有很多属性,不同的属性代表的意义也不同。
- private:客户端可以缓存
- public:客户端和代理服务器都可以缓存
- max-age=t:缓存内容将在 t 秒后失效
- no-cache:需要使用协商缓存来验证缓存数据
- no-store:所有内容都不会缓存。
协商缓存
协商缓存需要进行对比判断是否可以使用缓存。浏览器第一次请求数据时,服务器会将缓存标识与数据一起响应给客户端,客户端将它们备份至缓存中。再次请求时,客户端会将缓存中的标识发送给服务器,服务器根据此标识判断。若未失效,返回 304 状态码,浏览器拿到此状态码就可以直接使用缓存数据了。
对于协商缓存来说,缓存标识我们需要着重理解一下,下面我们将着重介绍它的两种缓存方案。
Last-Modified
Last-Modified:服务器在响应请求时,会告诉浏览器资源的最后修改时间。
if-Modified-Since:浏览器再次请求服务器的时候,请求头会包含此字段,后面跟着在缓存中获得的最后修改时间。服务端收到此请求头发现有 if-Modified-Since,则与被请求资源的最后修改时间进行对比,如果一致则返回 304 和响应报文头,浏览器只需要从缓存中获取信息即可。
从字面上看,就是说:从某个时间节点算起,是否文件被修改了
- 如果真的被修改:那么开始传输响应一个整体,服务器返回:200 OK
- 如果没有被修改:那么只需传输响应 header,服务器返回:304 Not Modified
if-Unmodified-Since:从字面上看, 就是说: 从某个时间点算起, 是否文件没有被修改- 如果没有被修改:则开始`继续'传送文件: 服务器返回: 200 OK
- 如果文件被修改:则不传输,服务器返回: 412 Precondition failed (预处理错误)
这两个的区别是一个是修改了才下载一个是没修改才下载。
Last-Modified 说好却也不是特别好,因为如果在服务器上,一个资源被修改了,但其实际内容根本没发生改变,会因为 Last-Modified 时间匹配不上而返回了整个实体给客户端(即使客户端缓存里有个一模一样的资源)。为了解决这个问题,HTTP1.1 推出了 Etag。
Etag
Etag:服务器响应请求时,通过此字段告诉浏览器当前资源在服务器生成的唯一标识(生成规则由服务器决定)
- If-None-Match:再次请求服务器时,浏览器的请求报文头部会包含此字段,后面的值为在缓存中获取的标识。服务器接收到次报文后发现 If-None-Match 则与被请求资源的唯一标识进行对比。
- 不同,说明资源被改动过,则响应整个资源内容,返回状态码 200。
- 相同,说明资源无心修改,则响应 header,浏览器直接从缓存中获取数据信息。返回状态码 304.
但是实际应用中由于 Etag 的计算是使用算法来得出的,而算法会占用服务端计算的资源,所有服务端的资源都是宝贵的,所以就很少使用 Etag 了。
缓存的优点
- 减少了冗余的数据传递,节省宽带流量
- 减少了服务器的负担,大大提高了网站性能
- 加快了客户端加载网页的速度 这也正是 HTTP 缓存属于客户端缓存的原因。
不同刷新的请求执行过程
浏览器地址栏中写入 URL,回车
- 浏览器发现缓存中有这个文件了,不用继续请求了,直接去缓存拿。(最快)
F5
- F5 就是告诉浏览器,别偷懒,好歹去服务器看看这个文件是否有过期了。于是浏览器就战战兢兢的发送一个请求带上 If-Modify-since。
Ctrl+F5
- 告诉浏览器,你先把你缓存中的这个文件给我删了,然后再去服务器请求个完整的资源文件下来。于是客户端就完成了强行更新的操作.
服务器处理请求并返回 HTTP 报文
它会对 TCP 连接进行处理,对 HTTP 协议进行解析,并按照报文格式进一步封装成 HTTP Request 对象,供上层使用。这一部分工作一般是由 Web 服务器去进行,我使用过的 Web 服务器有 Tomcat, Nginx 和 Apache 等等 HTTP 报文也分成三份,状态码 ,响应报头和响应报文
状态码
状态码是由 3 位数组成,第一个数字定义了响应的类别,且有五种可能取值:
- 1xx:指示信息–表示请求已接收,继续处理。
- 2xx:成功–表示请求已被成功接收、理解、接受。
- 3xx:重定向–要完成请求必须进行更进一步的操作。
- 4xx:客户端错误–请求有语法错误或请求无法实现。
- 5xx:服务器端错误–服务器未能实现合法的请求。
平时遇到比较常见的状态码有:200, 204, 301, 302, 304, 400, 401, 403, 404, 422, 500
常见状态码区别
200 成功
请求成功,通常服务器提供了需要的资源。
204 无内容
服务器成功处理了请求,但没有返回任何内容。
301 永久移动
请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 临时移动
服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
304 未修改
自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
400 错误请求
服务器不理解请求的语法。
401 未授权
请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 禁止
服务器拒绝请求。
404 未找到
服务器找不到请求的网页。
422 无法处理
请求格式正确,但是由于含有语义错误,无法响应
500 服务器内部错误
服务器遇到错误,无法完成请求。
响应报头
常见的响应报头字段有: Server, Connection...。
响应报文
你从服务器请求的 HTML,CSS,JS 文件就放在这里面
浏览器解析渲染页面
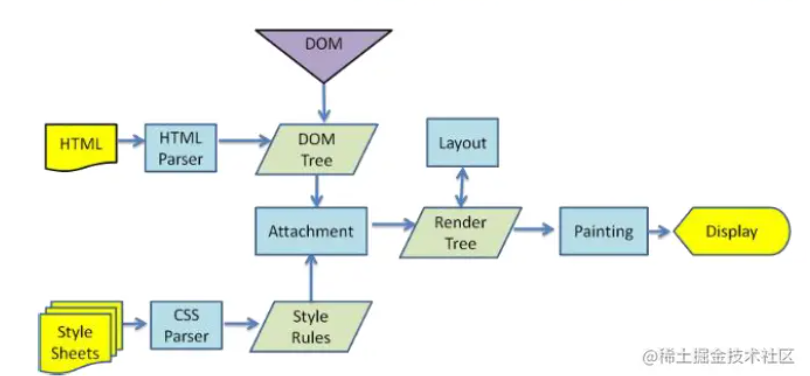
这个图就是Webkit解析渲染页面的过程。
- 解析 HTML 形成 DOM 树
- 解析 CSS 形成 CSSOM 树
- 合并 DOM 树和 CSSOM 树形成渲染树
- 浏览器开始渲染并绘制页面
这个过程涉及两个比较重要的概念回流和重绘,DOM 结点都是以盒模型形式存在,需要浏览器去计算位置和宽度等,这个过程就是回流。等到页面的宽高,大小,颜色等属性确定下来后,浏览器开始绘制内容,这个过程叫做重绘。浏览器刚打开页面一定要经过这两个过程的,但是这个过程非常非常非常消耗性能,所以我们应该尽量减少页面的回流和重绘
性能优化之回流重绘
回流
当 Render Tree 中部分或全部元素的尺寸、结构、或某些属性发生改变时,浏览器重新渲染部分或全部文档的过程称为回流。
会导致回流的操作:
- 页面首次渲染
- 浏览器窗口大小发生改变
- 元素尺寸或位置发生改变
- 元素内容变化(文字数量或图片大小等等)
- 元素字体大小变化
- 添加或者删除可见的 DOM 元素
- 激活 CSS 伪类(例如::hover)
- 查询某些属性或调用某些方法
一些常用且会导致回流的属性和方法:
clientWidth、clientHeight、clientTop、clientLeftoffsetWidth、offsetHeight、offsetTop、offsetLeftscrollWidth、scrollHeight、scrollTop、scrollLeftscrollIntoView()、scrollIntoViewIfNeeded()getComputedStyle()getBoundingClientRect()scrollTo()
重绘
当页面中元素样式的改变并不影响它在文档流中的位置时(例如:color、background-color、visibility 等),浏览器会将新样式赋予给元素并重新绘制它,这个过程称为重绘。
优化
CSS
- 避免使用 table 布局。
- 尽可能在 DOM 树的最末端改变 class。
- 避免设置多层内联样式。
- 将动画效果应用到 position 属性为 absolute 或 fixed 的元素上。
- 避免使用 CSS 表达式(例如:calc())。
JavaScript
- 避免频繁操作样式,最好一次性重写 style 属性,或者将样式列表定义为 class 并一次性更改 class 属性。
- 避免频繁操作 DOM,创建一个 documentFragment,在它上面应用所有 DOM 操作,最后再把它添加到文档中。
- 也可以先为元素设置 display: none,操作结束后再把它显示出来。因为在 display 属性为 none 的元素上进行的 DOM 操作不会引发回流和重绘。
- 避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
- 对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素及后续元素频繁回流。
JS 的解析
JS 的解析是由浏览器的 JS 引擎完成的。由于 JavaScript 是单线程运行,也就是说一个时间只能干一件事,干这件事情时其他事情都有排队,但是有些人物比较耗时(例如 IO 操作),所以将任务分为同步任务和异步任务,所有的同步任务放在主线程上执行,形成执行栈,而异步任务等待,当执行栈被清空时才去看看异步任务有没有东西要搞,有再提取到主线程执行,这样往复循环(冤冤相报何时了,阿弥陀佛),就形成了 Event Loop 事件循环,下面来看看大人物
Event Loop
先看一段代码
setTimeout(function () {
console.log("定时器开始啦");
});
new Promise(function (resolve) {
console.log("马上执行for循环啦");
for (var i = 0; i < 10000; i++) {
i == 99 && resolve();
}
}).then(function () {
console.log("执行then函数啦");
});
console.log("代码执行结束");
结果我想大家都应该知道。主要来介绍 JavaScript 的解析,至于 Promise 等下一节再说
JavaScript
JavaScript 是一门单线程语言,尽管 H5 中提出了Web-Worker,能够模拟实现多线程,但本质上还是单线程,说它是多线程就是扯淡。
事件循环
既然是单线程,每个事件的执行就要有顺序,比如你去银行取钱,前面的人在进行,后面的就得等待,要是前面的人弄个一两个小时,估计后面的人都疯了,因此,浏览器的 JS 引擎处理 JavaScript 时分为同步任务和异步任务  这张图我们可以清楚看到
这张图我们可以清楚看到
- 同步和异步任务分别进入不同的执行"场所",同步的进入主线程,异步的进入 Event Table 并注册函数。
- 当指定的事情完成时,Event Table 会将这个函数移入 Event Queue。
- 主线程内的任务执行完毕为空,会去 Event Queue 读取对应的函数,进入主线程执行。
- 上述过程会不断重复,也就是常说的 Event Loop(事件循环)。
js 引擎存在 monitoring process 进程,会持续不断的检查主线程执行栈是否为空,一旦为空,就会去 Event Queue 那里检查是否有等待被调用的函数。 估计看完这些你对事件循环有一定的了解,但是事实上我们看对的没这么简单,通常我们会看到 Promise,setTimeout,process.nextTick(),这个时候你和我就懵逼。
除了同步任务和异步任务,我们还分为宏任务和微任务,常见的有以下几种
- macro-task(宏任务):包括整体代码 script,setTimeout,setInterval
- micro-task(微任务):Promise,process.nextTick
不同任务会进入不同的任务队列来执行。 JS 引擎开始工作后,先在宏任务中开始第一次循环(script里面先执行,不过我喜欢把它拎出来,直接称其进入执行栈),当主线程执行栈全部任务被清空后去微任务看看,如果有等待执行的任务,执行全部的微任务(其实将其回调函数推入执行栈来执行),再去宏任务找最先进入队列的任务执行,执行这个任务后再去主线程执行任务(例如执行```console.log("hello world")这种任务),执行栈被清空后再去微任务,这样往复循环(冤冤相报何时了)
Tip:微任务会全部执行,而宏任务会一个一个来执行
下面来看一段代码
setTimeout(function() {
console.log('setTimeout');
})
new Promise(function(resolve) {
console.log('promise');
resolve();
}).then(function() {
console.log('then');
})
console.log('console');
我们看看它的执行情况
- 第一轮
- 这段代码进入主线程
- 遇到 setTimeout,将其回调函数注册后分发到宏任务
- 第二轮
- 遇到 Promise,new Promise 立即执行(这个不解释,想了解的我后续文章会介绍),输出
promise,遇到then,将其分发到微任务
- 遇到 Promise,new Promise 立即执行(这个不解释,想了解的我后续文章会介绍),输出
- 第三轮
- 遇到
console.log("console"),直接输出console
- 遇到
- 第四轮
- 主线程执行栈已经清空,先去微任务看看,执行 then 函数,输出
then
- 主线程执行栈已经清空,先去微任务看看,执行 then 函数,输出
- 第五轮
- 微任务执行完了,看看宏任务,有个 setTimeout,输出
setTimeout,整体执行完毕。
- 微任务执行完了,看看宏任务,有个 setTimeout,输出
具体的执行过程大致就是这样,可能我有疏忽的地方,还望指正。  再来看看一段复杂的代码
再来看看一段复杂的代码
console.log("1");
setTimeout(function () {
console.log("2");
process.nextTick(function () {
console.log("3");
});
new Promise(function (resolve) {
console.log("4");
resolve();
}).then(function () {
console.log("5");
});
});
process.nextTick(function () {
console.log("6");
});
new Promise(function (resolve) {
console.log("7");
resolve();
}).then(function () {
console.log("8");
});
setTimeout(function () {
console.log("9");
process.nextTick(function () {
console.log("10");
});
new Promise(function (resolve) {
console.log("11");
resolve();
}).then(function () {
console.log("12");
});
});
我们来分析一下
- 整体 script 进入主线程,遇到
console.log('1'),直接输出 - 遇到
setTimeout,将其回调函数分发到宏任务事件队列,暂时标记为 setTimeout1 - 遇到
process.nextTick(),将其回调函数分发到微任务事件队列,标记为process.nextTick1(这个地方有点出入,我一般认为```process.nextTick()推入主线程执行栈栈底,作为执行栈最后一个任务执行) - 遇到 Promise,立即执行,输出
7,then 函数分发的微任务事件队列,标记为 Promise1。 - 遇到 setTimeout,将其回调函数分发到宏任务事件队列,标记为 setTimeout2。
- 现在已经输出了
1,7,宏任务和微任务的事件队列 情况如下
 我们接着来看
我们接着来看
- 现在主线程执行栈被清空,去微任务看看,发现有两个事件等待,由于队列是先进先出,执行
process.nextTick1,输出6,接着执行Promise1,输出8。
至此,第一轮循环已经结束,输出了
1,7,6,8,接下来执行第二轮循环 ,先从宏任务的setTimeout1开始
- 遇到
console.log('2'),执行输出。 - 遇到
process.nextTick(),将其回调函数分发到微任务,标记为process.nextTick2,又遇到
Promise`,立即执行,输出`4`,将then函数推入微任务事件队列,标记为`Promise2
- 到此宏任务的一个任务执行完毕,输出了
2,4,来看看事件队列
- 去微任务看看,我们先处理
process.nextTick2,输出3,接着再来执行Promise2,输出5。
第二轮循环执行完毕。现在一共输出了1,7,6,8,2,4,3,5
- 从
setTimeout2开始第三轮循环 ,先直接输出9,遇到process.nextTick(),将其回调函数分发到微任务事件队列,标记为process.nextTick3,又遇到恶心的 Promise,立即执行输出11,将 then 函数分发到微任务,标记为 Promise3。 - 执行微任务,看看还有撒子事件
 居然还有事件,能咋办,接着执行呗,输出
居然还有事件,能咋办,接着执行呗,输出10,12。 至此,全部任务执行完毕,输出顺序为1,7,6,8,2,4,3,5,9,11,10,12.
注意,这段代码执行结果可能与 node 等环境不同而发生变化。
输入一个 URL 到页面显示-渲染篇
构建 DOM
浏览器加载网页时会收到对应的 HTML 文件。因为浏览器无法直接理解和使用 HTML 所以需要将其转换为浏览器能理解的结构——DOM
HTML 首先经过 tokensier(标记化)将字符串转换为 Token 同时会标识出当前 Token 是 startTag 还是 endTag,亦或是文本等信息。
HTML 解析器会在内部维护一个栈,同时会创建一个 document 的空 dom 节点,并将 document startTag 入栈。
当遇到文本(非元素节点) Token 时会向 DOM 结构中插入一个文本节点,但不会放入栈中。
当遇到一个 startTag token,会创建一个相应的 dom 节点,插入 DOM 结构中,并且将 startTag 压入栈中。
当遇到一个 endTag token 时,HTML 解析器会查看栈顶的 token,是不是其对应的 startTag token,如果是,则弹出,表示该元素已经解析完了。
直到最后 document 的 endTag token 出栈,整个文件就算解析完了。
CSSOM 树
有了 DOM 树之后,还需要每个节点的计算样式,这样浏览器才知道如何摆放这些节点。所以需要构建 CSSOM 树。
CSSOM 的构建与 DOM 树的构建非常类似,不同之处在于计算样式涉及层叠与继承。
布局树
有了 DOM 树与 CSSOM 树接下来进入布局阶段,这一阶段浏览器要做的事情是创建布局树和弄清楚各个节点在页面中的确切位置和大小。
合成布局树浏览器做了下面这些工作:
- 遍历 DOM 树中的所有可见节点,并把这些节点加到布局中
- 忽略不可见节点,例如
head标签和display:none的元素
布局的计算过程非常复杂,有兴趣的同学请自行查阅
分层
页面通常会包含复杂的 3D 变换、脱离文档流的元素、z-index 做 z 轴排序等。如果不为这些节点创建正确的图层顺序就会出现意料之外的错误。
一般来说拥有层叠上下文属性的元素会被提升为单独的一层。如果一个节点没有对应的层,那么这个节点就从属于父节点的图层
图层绘制
浏览器会遍历布局树生成图层树,并对图层树中的每个图层进行绘制,创建绘制指令列表。绘制指令列表其实就是描述如何绘制一个节点。
当图层的绘制列表准备好之后,主线程会把该绘制列表提交(commit)给合成线程进行栅格化。
栅格化
栅格化过程中有一个重要的点是,通常一个页面可能很大,但是用户只能看到其中的一部分。在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
基于此,合成线程会将图层划分为图块(tile),这些图块的大小通常是 256x256 或者 512x512
图块会被发送给栅格线程,栅格线程栅格化每个图块,将其存储在 GPU 内存中
合成和显示
一旦所有图块都被光栅化,合成线程就会收集称为 draw quads 的图块信息,这些信息记录了图块在内存中的信息和在页面哪个位置绘制图块的信息,根据这些信息合成器线程形成了一个合成器帧,通过 IPC 传送给浏览器进程,浏览器进程将合成器帧发送到 GPU,接着 GPU 渲染,然后就可以看到页面了 。
阻塞
HTML 解析过程中会遇到各种资源,其中最重要的是 CSS 和 JS。CSS 析并不会阻塞 HTML 的解析,但是会阻塞渲染。因为我们必须要知道节点的具体大小和位置信息才可以渲染。而 JS 会阻塞 HTML 的解析,究其原因是 JS 有改变 DOM 的能力,如果我们一边解析一边修改 DOM 那么 HTML 的解析将会毫无意义。这也是为什么要把 JS 放在正确的位置或使用合适的关键字的原因。
满分回答之从输入 URL 到页面显示经历了什么?
阶段一:用户输入阶段
用户在地址栏输入内容之后,浏览器会首先判断用户输入的是合法的 URL 还是搜索内容,如果是搜索内容就合成 URL,如果是合法的 URL 就开始进行加载。
阶段二:发起 URL 请求阶段
发起 URL 请求阶段主要包括以下步骤:
- 构建请求行:浏览器进程首先会构建请求行信息,然后通过进程间通信 IPC 将 URL 请求发送给网络进程。
- 查找缓存:网络进程获取到 URL 之后,会先去本地缓存中查找是否有缓存资源,如果有则直接将缓存资源返回给浏览器进程,否则进入网络请求阶段。
- DNS 解析:网络进程请求首先会从 DNS 数据缓存服务器中查找是否缓存过当前域名的信息,有则直接返回,否则,会进行 DNS 解析域名对应的 IP 和端口号。
- 等待 TCP 队列:chrome 有个机制,同一个域名同时最多只能建立 6 个 TCP 连接,如果超过这个数量的连接必须要进入排队等待状态。
- 建立 TCP 连接:通过 TCP 三次握手与服务器建立连接,然后进行数据传输。
- 发起 HTTP 请求:浏览器首先会向服务器发送请求行,请求行中包含了请求方法、请求 URI 和 HTTP 版本,还会发送请求头,告诉服务器一些浏览器的相关信息,比如浏览器内核、请求域名、Cookie 等信息。
- 服务器处理请求:服务器首先返回相应行,包括协议版本和状态码,然后会返回响应头包含返回的数据类型,服务器要在客户端保存的 Cookie 等。
- 断开 TCP 连接:数据传输完成后,通过四次挥手来断开连接。
阶段三:准备渲染进程阶段
- 网络进程将获取的数据进行解析,根据响应头中的 Content-type 来判断响应数据的类型,如果是字节流类型,就将该请求交给下载管理器去下载,如果是 text/html 类型,就通知浏览器进程获取到的是 HTML,准备渲染进程。
- 一般情况下浏览器的一个 tab 页面对应一个渲染进程,如果从当前页面打开的新页面并且属于同一站点,这种情况会复用渲染进程,其他情况则需要创建新的渲染进程。
阶段四:提交文档阶段
- 渲染进程准备好之后,浏览器会发出提交文档的消息给渲染进程,渲染进程收到消息后,会和网络进程建立数据传输的管道,文档数据传输完成后,渲染进程会返回确认提交的消息给浏览器进程。
- 浏览器收到确认提交的消息后,会更新浏览器的页面状态,包括了安全状态,地址栏的 URL,前进后退的历史状态,并更新 web 页面为空白。
阶段五:页面渲染阶段
- 文档提交之后,渲染进程将开始页面解析并加载子资源。
- 构建 DOM 树:HTML 经过解析后输出的是一个以 document 为顶层节点的树状结构的 DOM。
- 样式计算:将从 link 标签引入的外部样式,style 标签里的样式和元素身上的样式转换成浏览器能够理解的样式表,然后将样式表中的属性值进行标准化,例如 color:red 转换为 color 的 rgb 形式,然后根据 CSS 的继承和层叠规则计算出 DOM 树种每个节点的具体样式。
- 布局阶段:会生成一棵只包含可见元素的布局树,然后根据布局树的每个节点计算出其具体位置和大小。
- 分层:对页面种的复杂效果例如 3D 转换,页面滚动或者 z 轴排序等生成图层树。
- 绘制:为每个图层生成绘制列表,并将其提交到合成线程中。
- 光栅化:优先选择可视窗口内的图块来生成位图数据。
- 合成:所有图块都被光栅话之后开始显示页面。
简答输入 url 到显示
(1)解析 URL: 首先会对 URL 进行解析,分析所需要使用的传输协议和请求的资源的路径。如果输入的 URL 中的协议或者主机名不合法,将会把地址栏中输入的内容传递给搜索引擎。如果没有问题,浏览器会检查 URL 中是否出现了非法字符,如果存在非法字符,则对非法字符进行转义后再进行下一过程。
(2)缓存判断: 浏览器会判断所请求的资源是否在缓存里,如果请求的资源在缓存里并且没有失效,那么就直接使用,否则向服务器发起新的请求。
(3)DNS 解析: 下一步首先需要获取的是输入的 URL 中的域名的 IP 地址,首先会判断本地是否有该域名的 IP 地址的缓存,如果有则使用,如果没有则向本地 DNS 服务器发起请求。本地 DNS 服务器也会先检查是否存在缓存,如果没有就会先向根域名服务器发起请求,获得负责的顶级域名服务器的地址后,再向顶级域名服务器请求,然后获得负责的权威域名服务器的地址后,再向权威域名服务器发起请求,最终获得域名的 IP 地址后,本地 DNS 服务器再将这个 IP 地址返回给请求的用户。用户向本地 DNS 服务器发起请求属于递归请求,本地 DNS 服务器向各级域名服务器发起请求属于迭代请求。
(4)获取 MAC 地址: 当浏览器得到 IP 地址后,数据传输还需要知道目的主机 MAC 地址,因为应用层下发数据给传输层,TCP 协议会指定源端口号和目的端口号,然后下发给网络层。网络层会将本机地址作为源地址,获取的 IP 地址作为目的地址。然后将下发给数据链路层,数据链路层的发送需要加入通信双方的 MAC 地址,本机的 MAC 地址作为源 MAC 地址,目的 MAC 地址需要分情况处理。通过将 IP 地址与本机的子网掩码相与,可以判断是否与请求主机在同一个子网里,如果在同一个子网里,可以使用 APR 协议获取到目的主机的 MAC 地址,如果不在一个子网里,那么请求应该转发给网关,由它代为转发,此时同样可以通过 ARP 协议来获取网关的 MAC 地址,此时目的主机的 MAC 地址应该为网关的地址。
(5)TCP 三次握手: 下面是 TCP 建立连接的三次握手的过程,首先客户端向服务器发送一个 SYN 连接请求报文段和一个随机序号,服务端接收到请求后向服务器端发送一个 SYN ACK 报文段,确认连接请求,并且也向客户端发送一个随机序号。客户端接收服务器的确认应答后,进入连接建立的状态,同时向服务器也发送一个 ACK 确认报文段,服务器端接收到确认后,也进入连接建立状态,此时双方的连接就建立起来了。
(6)HTTPS 握手: 如果使用的是 HTTPS 协议,在通信前还存在 TLS 的一个四次握手的过程。首先由客户端向服务器端发送使用的协议的版本号、一个随机数和可以使用的加密方法。服务器端收到后,确认加密的方法,也向客户端发送一个随机数和自己的数字证书。客户端收到后,首先检查数字证书是否有效,如果有效,则再生成一个随机数,并使用证书中的公钥对随机数加密,然后发送给服务器端,并且还会提供一个前面所有内容的 hash 值供服务器端检验。服务器端接收后,使用自己的私钥对数据解密,同时向客户端发送一个前面所有内容的 hash 值供客户端检验。这个时候双方都有了三个随机数,按照之前所约定的加密方法,使用这三个随机数生成一把秘钥,以后双方通信前,就使用这个秘钥对数据进行加密后再传输。
(7)返回数据: 当页面请求发送到服务器端后,服务器端会返回一个 html 文件作为响应,浏览器接收到响应后,开始对 html 文件进行解析,开始页面的渲染过程。
(8)页面渲染: 浏览器首先会根据 html 文件构建 DOM 树,根据解析到的 css 文件构建 CSSOM 树,如果遇到 script 标签,则判端是否含有 defer 或者 async 属性,要不然 script 的加载和执行会造成页面的渲染的阻塞。当 DOM 树和 CSSOM 树建立好后,根据它们来构建渲染树。渲染树构建好后,会根据渲染树来进行布局。布局完成后,最后使用浏览器的 UI 接口对页面进行绘制。这个时候整个页面就显示出来了。
(9)TCP 四次挥手: 最后一步是 TCP 断开连接的四次挥手过程。若客户端认为数据发送完成,则它需要向服务端发送连接释放请求。服务端收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入 CLOSE_WAIT 状态,此时表明客户端到服务端的连接已经释放,不再接收客户端发的数据了。但是因为 TCP 连接是双向的,所以服务端仍旧可以发送数据给客户端。服务端如果此时还有没发完的数据会继续发送,完毕后会向客户端发送连接释放请求,然后服务端便进入 LAST-ACK 状态。客户端收到释放请求后,向服务端发送确认应答,此时客户端进入 TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有服务端的重发请求的话,就进入 CLOSED 状态。当服务端收到确认应答后,也便进入 CLOSED 状态。
从输入 URL 开始建立前端知识体系
前置内容 浏览器主要进程
浏览器是多进程的,主要分为:
- 浏览器主进程:只有一个,主要控制页面的创建、销毁、网络资源管理、下载等。
- 第三方插件进程:每一种类型的插件对应一个进程,仅当使用该插件时才创建。
- GPU 进程:最多一个,用于 3D 绘制等。
- 浏览器渲染进程(浏览器内核):每个 Tab 页对应一个进程,互不影响。
第一部分 输入网址并解析
这里我们只考虑输入的是一个 URL 结构字符串,如果是非 URL 结构的字符串,则会用浏览器默认的搜索引擎搜索该字符串。
解析 URL
URL 的组成
URL 主要由 协议、主机、端口、路径、查询参数、锚点6 部分组成!
输入 URL 后,浏览器会解析出协议、主机、端口、路径等信息,并构造一个 HTTP 请求。
- 浏览器发送请求前,根据请求头的
expires和cache-control判断是否命中(包括是否过期)强缓存策略,如果命中,直接从缓存获取资源,并不会发送请求。如果没有命中,则进入下一步。 - 没有命中强缓存规则,浏览器会发送请求,根据请求头的
If-Modified-Since和If-None-Match判断是否命中协商缓存,如果命中,直接从缓存获取资源。如果没有命中,则进入下一步。 - 如果前两步都没有命中,则直接从服务端获取资源。
HSTS
由于安全隐患,会使用 HSTS 强制客户端使用 HTTPS 访问页面。详见:你所不知道的 HSTS。 当你的网站均采用 HTTPS,并符合它的安全规范,就可以申请加入 HSTS 列表,之后用户不加 HTTPS 协议再去访问你的网站,浏览器都会定向到 HTTPS。无论匹配到没有,都要开始 DNS 查询工作了。
浏览器缓存
强缓存
强制缓存就是向浏览器缓存查找该请求结果,并根据该结果的缓存规则来决定是否使用该缓存结果的过程。强缓存又分为两种Expires和Cache-Control
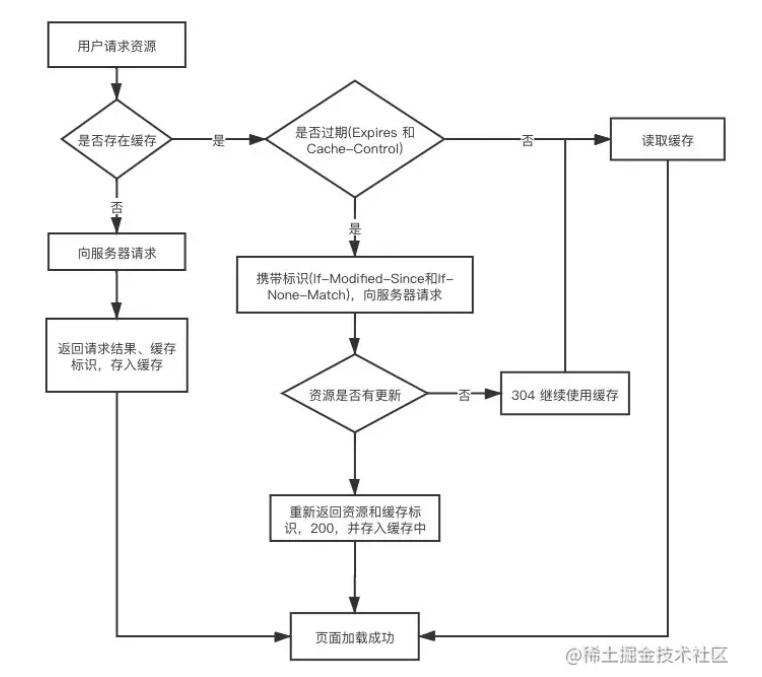
Expires
- 版本:HTTP/1.0
- 来源:存在于服务端返回的响应头中
- 语法:Expires: Wed, 22 Nov 2019 08:41:00 GMT
- 缺点:服务器的时间和浏览器的时间可能并不一致导致失效
Cache-Control
- 版本:HTTP/1.1
- 来源:响应头和请求头
- 语法:Cache-Control:max-age=3600
- 缺点:时间最终还是会失效
请求头:
| 字段名称 | 说明 |
|---|---|
| no-cache | 告知(代理)服务器不直接使用缓存,要求向原服务器发起请求 |
| no-store | 所有内容都不会被保存到缓存或 Internet 临时文件中 |
| max-age=delta-seconds | 告知服务器客户端希望接收一个存在时间不大于 delta-secconds 秒的资源 |
| max-stale[=delta-seconds] | 告知(代理)服务器客户端愿意接收一个超过缓存时间的资源,若有定义 delta-seconds 则为 delta-seconds 秒,若没有则为任意超出时间 |
| min-fresh=delta-seconds | 告知(代理)服务器客户端希望接收一个在小于 delta-seconds 秒内被更新过的资源 |
| no-transform | 告知(代理)服务器客户端希望获取实体数据没有被转换(比如压缩)过的资源 |
| noly-if-cached | 告知(代理)服务器客户端希望获取缓存的内容(若有),而不用向原服务器发去请求 |
| cache-extension | 自定义扩展值,若服务器不识别该值将被忽略掉 |
响应头:
| 字段名称 | 说明 |
|---|---|
| public | 表明任何情况下都得缓存该资源(即使是需要 HTTP 认证的资源) |
| Private=[field-name] | 表明返回报文中全部或部分(若指定了 field-name 则为 field-name 的字段数据)仅开放给某些用户(服务器指定的 share-user,如代理服务器)做缓存使用,其他用户则不能缓存这些数据 |
| no-cache | 不直接使用缓存,要求向服务器发起(新鲜度校验)请求 |
| no-store | 所以内容都不会被保存到缓存或 Internet 临时文件中 |
| no-transform | 告知客户端缓存文件时不得对实体数据做任何改变 |
| noly-if-cached | 告知(代理)服务器客户端希望获取缓存的内容(若有),而不用向原服务器发去请求 |
| must-revalidate | 当前资源一定是向原方法服务器发去验证请求的,如请求是吧会返回 504(而非代理服务器上的缓存) |
| proxy-revalidate | 与 must-revalidate 类似,但仅能应用于共享缓存(如代理) |
| max-age=delta-seconds | 告知客户端该资源在 delta-seconds 秒内是新鲜的,无需向服务器发请求 |
| s-maxage=delta-seconds | 同 max-age,但仅能应用于共享缓存(如代理) |
| cache-extension | 自定义扩展值,若服务器不识别该值将被忽略掉 |
示例:
// server.js
const http = require("http");
const fs = require("fs");
http
.createServer(function (request, response) {
console.log("request come", request.url);
if (request.url === "/") {
const html = fs.readFileSync("test.html", "utf8");
response.writeHead(200, {
"Content-Type": "text/html",
});
response.end(html);
}
if (request.url === "/script.js") {
response.writeHead(200, {
"Content-Type": "text/javascript",
"Cache-Control": "max-age=20,public", // 缓存20s 多个值用逗号分开
});
response.end('console.log("script loaded")');
}
})
.listen(8888);
console.log("server listening on 8888");
// test.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>Document</title>
</head>
<body></body>
<script src="/script.js"></script>
</html>
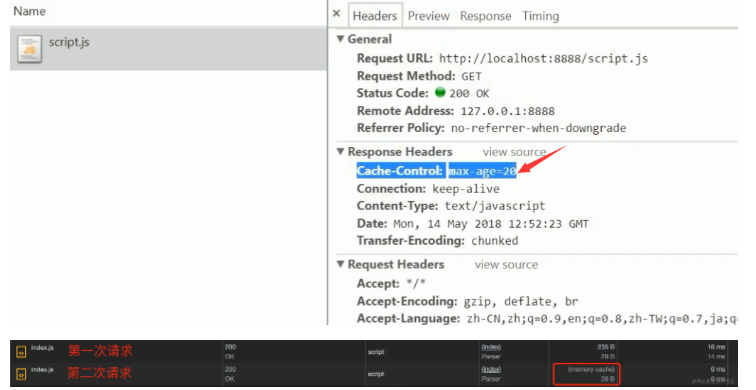
协商缓存
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程。
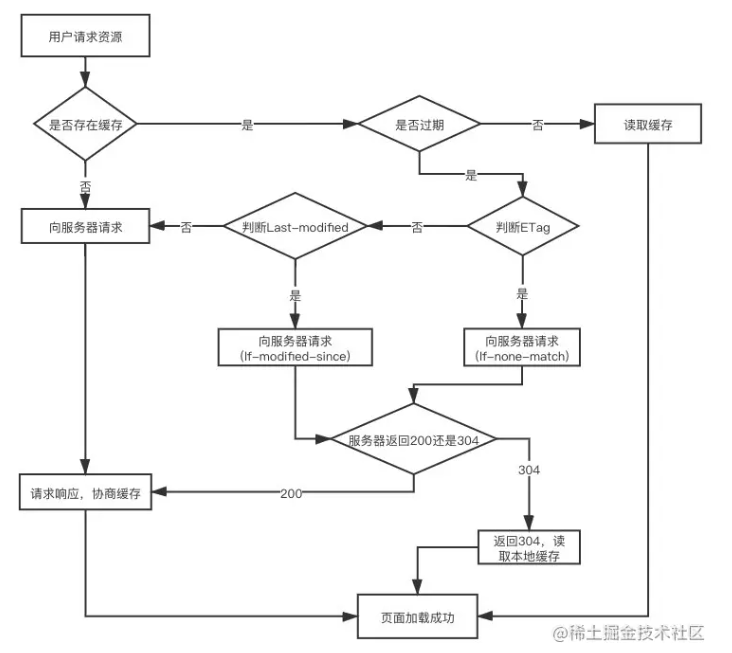
模拟 Last-Modified
if (request.url === "/index.js") {
const filePath = path.join(__dirname, request.url); // 拼接当前脚本文件地址
const stat = fs.statSync(filePath); // 获取当前脚本状态
const mtime = stat.mtime.toGMTString(); // 文件的最后修改时间
const requestMtime = request.headers["if-modified-since"]; // 来自浏览器传递的值
console.log(stat);
console.log(mtime, requestMtime);
// 走协商缓存
if (mtime === requestMtime) {
response.statusCode = 304;
response.end();
return;
}
// 协商缓存失效,重新读取数据设置 Last-Modified 响应头
console.log("协商缓存 Last-Modified 失效");
response.writeHead(200, {
"Content-Type": "text/javascript",
"Last-Modified": mtime,
});
const readStream = fs.createReadStream(filePath);
readStream.pipe(response);
}

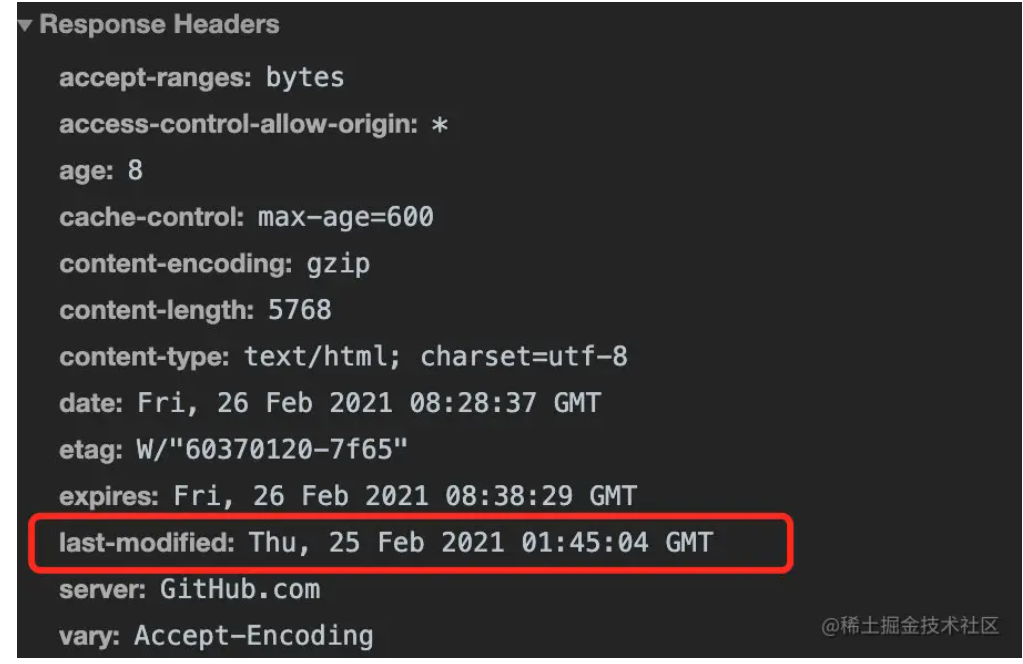
模拟 ETag
if (request.url === "/index.js") {
const filePath = path.join(__dirname, request.url); // 拼接当前脚本文件地址
const buffer = fs.readFileSync(filePath); // 获取当前脚本状态
const fileMd5 = md5(buffer); // 文件的 md5 值
const noneMatch = request.headers["if-none-match"]; // 来自浏览器端传递的值
if (noneMatch === fileMd5) {
response.statusCode = 304;
response.end();
return;
}
console.log("Etag 缓存失效");
response.writeHead(200, {
"Content-Type": "text/javascript",
"Cache-Control": "max-age=0",
ETag: fileMd5,
});
const readStream = fs.createReadStream(filePath);
readStream.pipe(response);
}
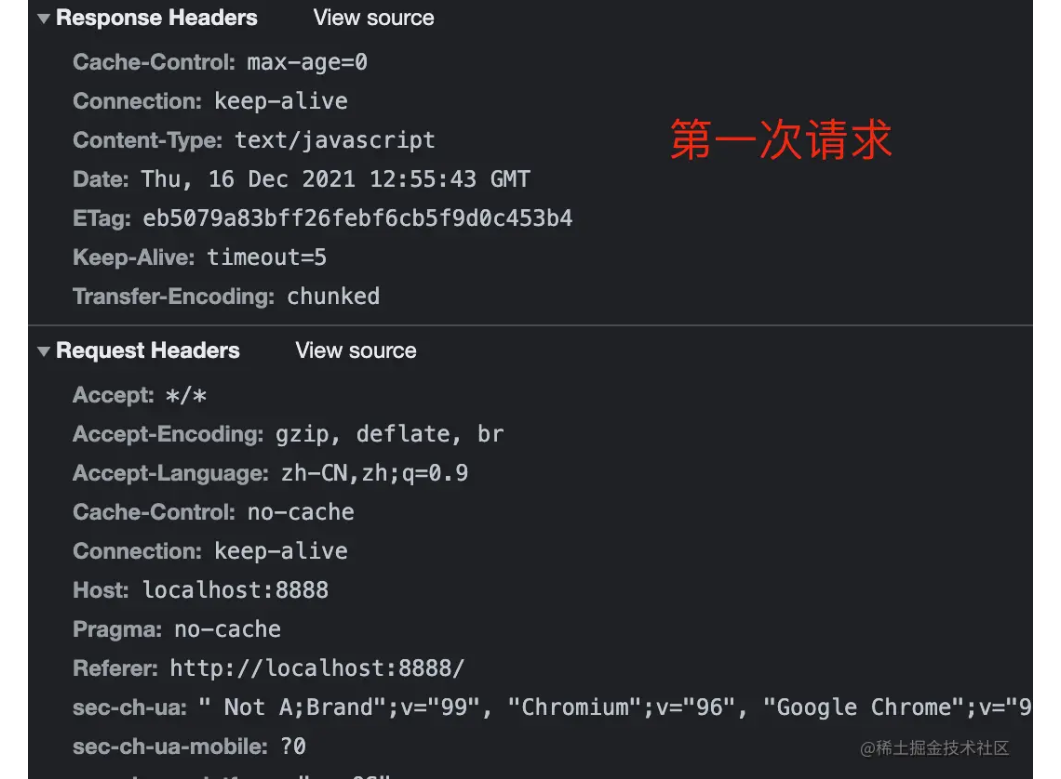
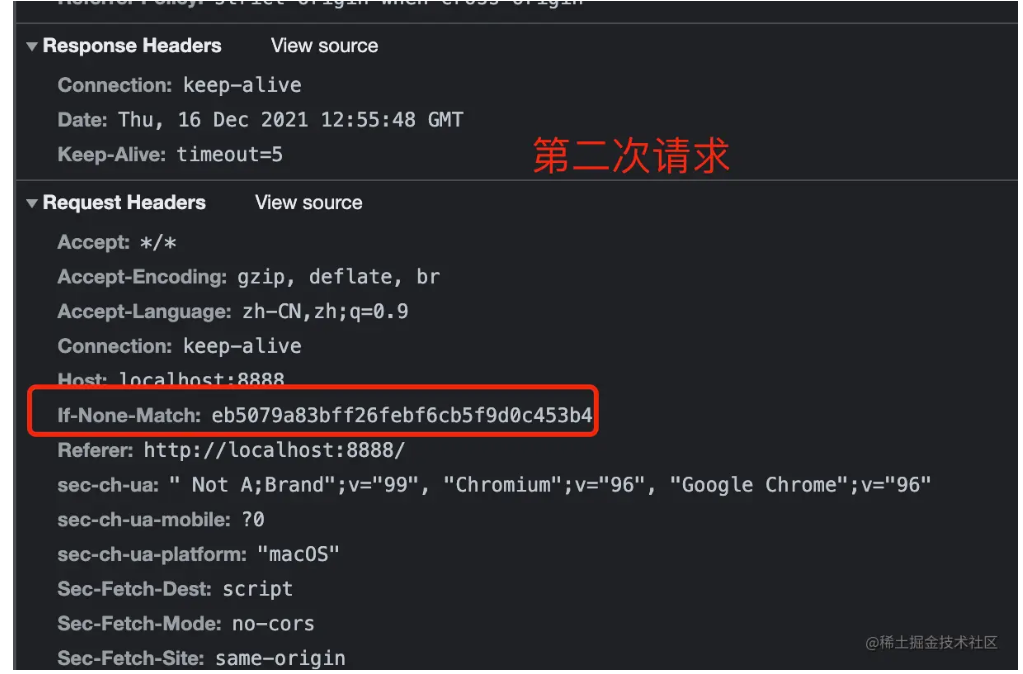
Last-Modified(响应头),If-Modified-Since(请求头)
在浏览器第一次给服务器发送请求后,服务器会在响应头中加上这个字段。 浏览器接收到后,如果再次请求,会在请求头中携带If-Modified-Since字段,这个字段的值也就是服务器传来的最后修改时间。 服务器拿到请求头中的If-Modified-Since的字段后,其实会和这个服务器中该资源的最后修改时间Last-Modified对比,询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来。
但是如果在本地打开缓存文件,就会造成 Last-Modified 被修改,所以在 HTTP / 1.1 出现了 ETag。
ETag(响应头)、If-None-Match(请求头)
ETag是服务器根据当前文件的内容,给文件生成的唯一标识,只要里面的内容有改动,这个值就会变。服务器通过响应头把这个值给浏览器。 浏览器接收到 ETag 的值,会在下次请求时,将这个值作为If-None-Match这个字段的内容,并放到请求头中,然后发给服务器。
如果两种方式都支持的话,服务器会优先考虑 ETag
存储位置
- Service Worker
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。
当 Service Worker 没有命中缓存的时候,我们需要去调用 fetch 函数获取数据。也就是说,如果我们没有在 Service Worker 命中缓存的话,会根据缓存查找优先级去查找数据。但是不管我们是从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示我们是从 Service Worker中获取的内容。
- Memory Cache
Memory Cache 也就是内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。 一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。
那么既然内存缓存这么高效,我们是不是能让数据都存放在内存中呢? 这是不可能的。计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存必然不多。
需要注意的事情是,内存缓存在缓存资源时并不关心返回资源的 HTTP 缓存头
Cache-Control是什么值,同时资源的匹配也并非仅仅是对 URL 做匹配,还可能会对Content-Type,CORS 等其他特征做校验。
- Disk Cache
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。
- Push Cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在 Chrome 浏览器中只有 5 分钟左右,同时它也并非严格执行 HTTP 头中的缓存指令。
- 所有的资源都能被推送,并且能够被缓存,但是
Edge和Safari浏览器支持相对比较差 - 可以推送
no-cache和no-store的资源 - 一旦连接被关闭,
Push Cache就被释放 - 多个页面可以使用同一个
HTTP/2的连接,也就可以使用同一个Push Cache。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的 tab 标签使用同一个 HTTP 连接。 Push Cache中的缓存只能被使用一次- 浏览器可以拒绝接受已经存在的资源推送
- 你可以给其他域名推送资源
DNS 域名解析
在发起 http 请求之前,浏览器首先要做去获得我们想访问网页的 IP 地址,浏览器会发送一个 UDP 的包给 DNS 域名解析服务器。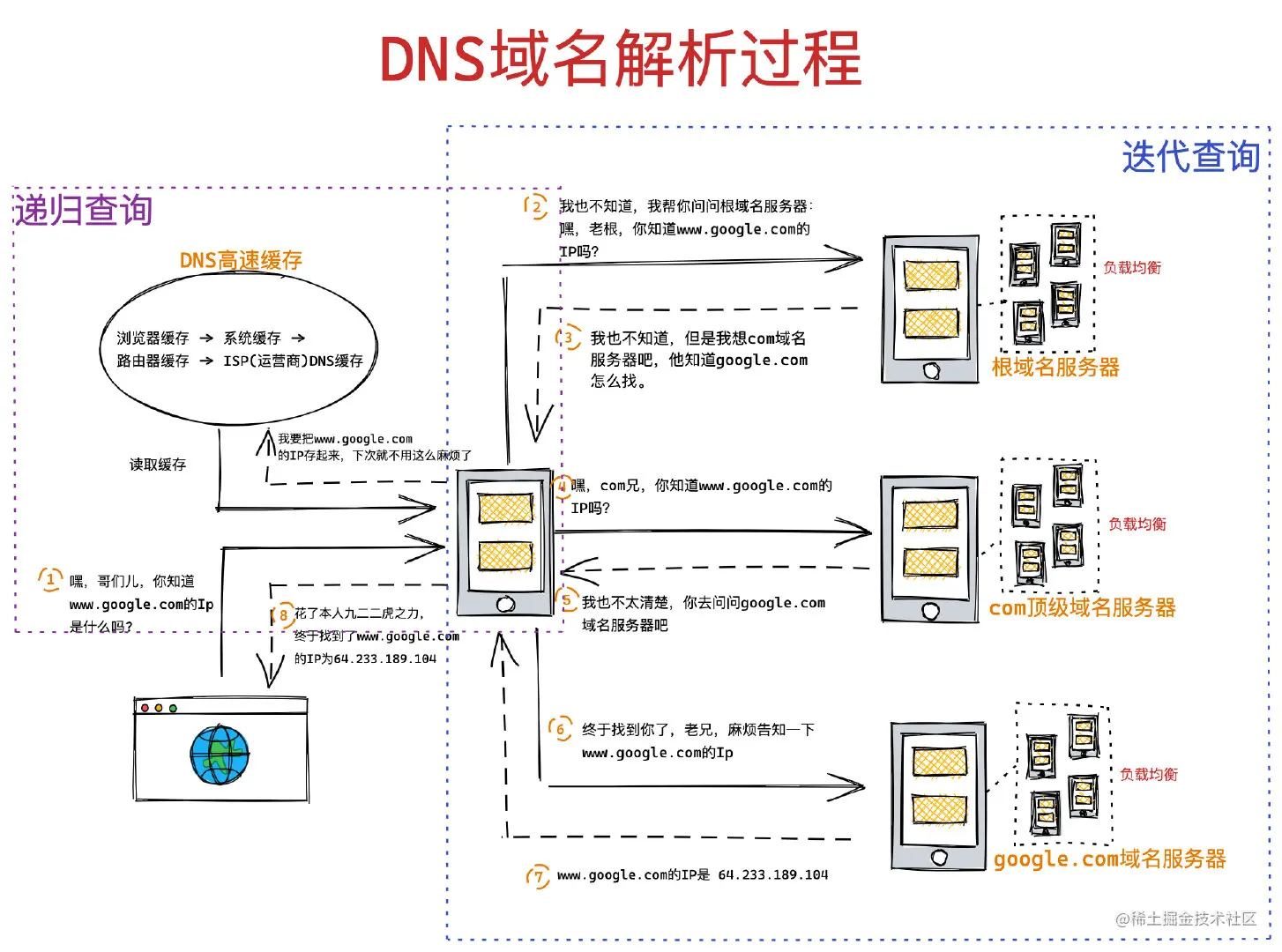
递归查询
我们的浏览器、操作系统、路由器都会缓存一些 URL 对应的 IP 地址,统称为 DNS 高速缓存。这是为了加快 DNS 解析速度,使得不必每次都到根域名服务器中去查询。

迭代查询
迭代查询的方式就是,局部的 DNS 服务器并不会自己向其他服务器进行查询,而是把能够解析该域名的服务器 IP 地址返回给客户端,客户端会不断的向这些服务器进行查询,直到查询到了位置,迭代的话只会帮你找到相关的服务器,然后说我现在比较忙,你自己去找吧。
DNS 负载均衡
DNS 还有负载均衡的作用,现在很多网站都有多个服务器,当一个网站访问量过大的时候,如果所有请求都请求在同一个服务器上,可能服务器就会崩掉,这时候就用到了 DNS 负载均衡技术,当一个网站有多个服务器地址时,在应答 DNS 查询的时候,DNS 服务器会对每个查询返回不同的解析结果,也就是返回不同的 IP 地址,从而把访问引导到不同的服务器上去,来达到负载均衡的目的。例如可以根据每台机器的负载量,或者该机器距离用户的地理位置距离等等条件。
DNS 预解析
大型网站,有多个不同服务器资源的情况下,都可采取 DNS 预解析,提前解析,减少页面卡顿。
第二部分 TCP/IP 连接:三次握手
网络协议分层
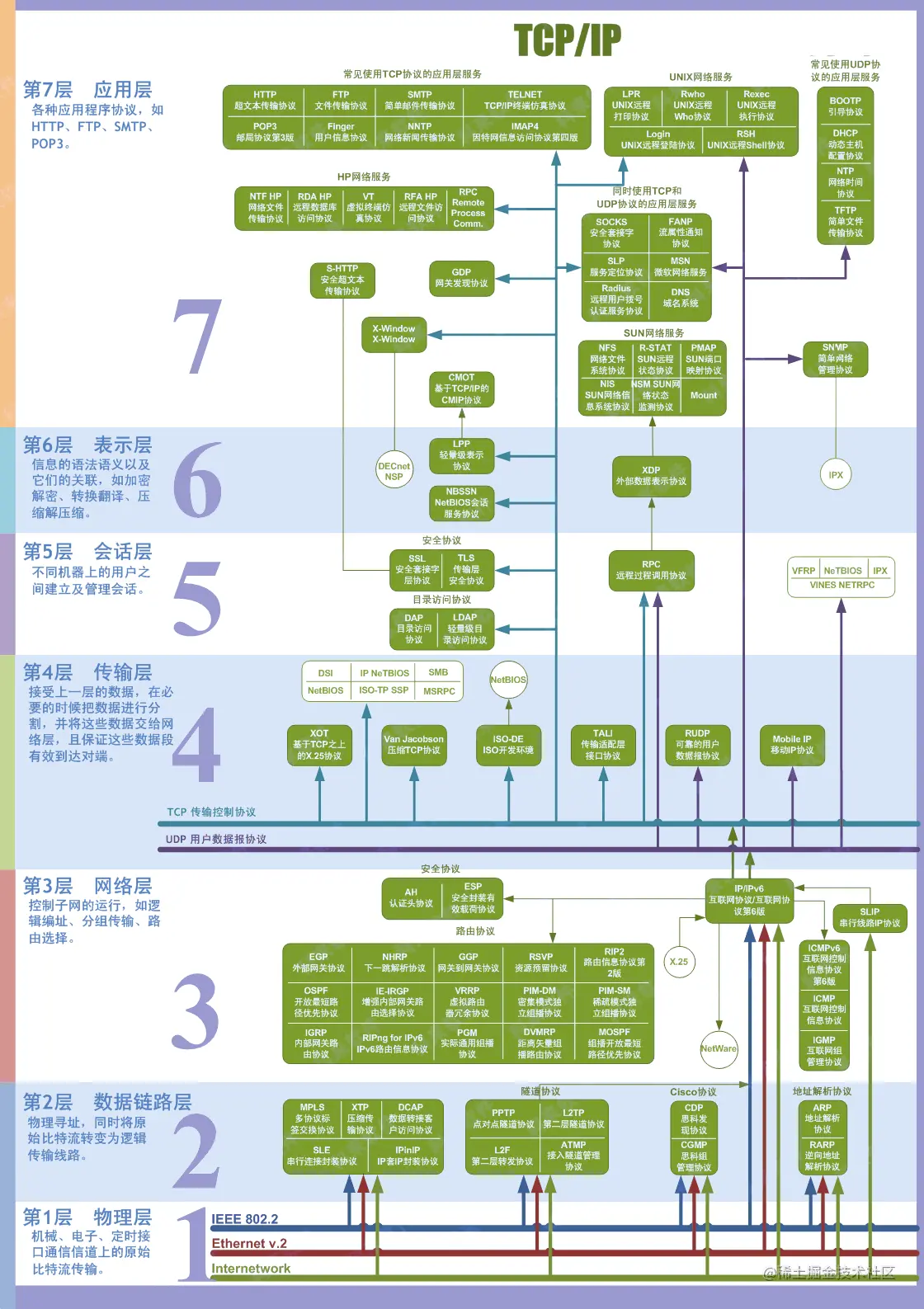
TCP/IP 协议
TCP(Transmission Control Protocol)传输控制协议。 TCP/IP 协议将应用层、表示层、会话层合并为应用层,物理层和数据链路层合并为网络接口层。
TCP/IP 协议不仅仅指的是 TCP 和 IP 两个协议,⽽是指的⼀个由 FTP,SMTP,TCP,UDP,IP,ARP 等等协议构成的协议集合。
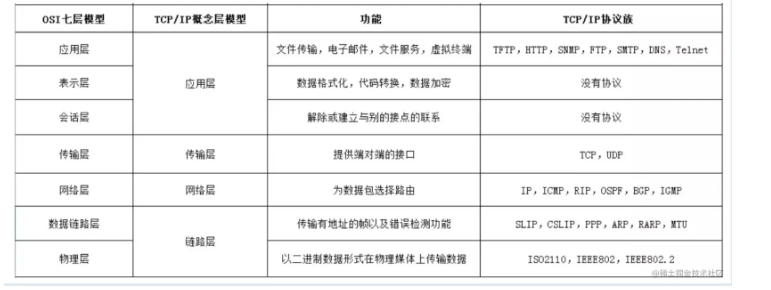
三次握手
客服端和服务端在进行 http 请求和返回的工程中,需要创建一个TCP connection(由客户端发起),http不存在连接这个概念,它只有请求和响应。请求和响应都是数据包,它们之间的传输通道就是TCP connection。
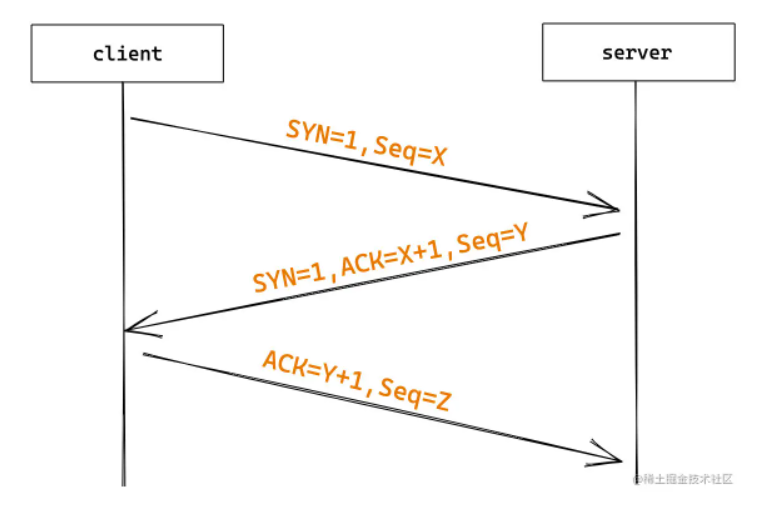
位码即 tcp 标志位,有 6 种标示:
- SYN(synchronous 建立联机)
- ACK(acknowledgement 确认)
- PSH(push 传送)
- FIN(finish 结束)
- RST(reset 重置)
- URG(urgent 紧急)
第一次握手:主机 A 发送位码为SYN=1,随机产生Seq number=1234567的数据包到服务器,主机 B 由SYN=1知道,A 要求建立联机;(第一次握手,由浏览器发起,告诉服务器我要发送请求了)
第二次握手:主机 B 收到请求后要确认联机信息,向 A 发送ack number=(主机A的seq+1),SUN=1,ACK=1234567 + 1,随机产生Seq=7654321的包;(第二次握手,由服务器发起,告诉浏览器我准备接受了,你赶紧发送吧)
第三次握手:主机 A 收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码SYN是否为 1,若正确,主机 A 会再发送ack number=(主机B的seq+1),ack=7654321 + 1,主机 B 收到后确认Seq值与ACK=7654321+ 1则连接建立成功;(第三次握手,由浏览器发送,告诉服务器,我马上就发了,准备接受吧)
总是要问:为什么需要三次握手,两次不行吗?其实这是由 TCP 的自身特点可靠传输决定的。客户端和服务端要进行可靠传输,那么就需要确认双方的
接收和发送能力。第一次握手可以确认客服端的发送能力,第二次握手,服务端SYN=1,Seq=Y就确认了发送能力,ACK=X+1就确认了接收能力,所以第三次握手才可以确认客户端的接收能力。不然容易出现丢包的现象。
第三次握手的必要性?
试想如果是用两次握手,则会出现下面这种情况: 如客户端发出连接请求,但因连接请求报文丢失而未收到确认,于是客户端再重传一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接,客户端共发出了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达服务端,此时服务端误认为客户端又发出一次新的连接请求,于是就向客户端发出确认报文段,同意建立连接,不采用三次握手,只要服务端发出确认,就建立新的连接了,此时客户端忽略服务端发来的确认,也不发送数据,则服务端一致等待客户端发送数据,浪费资源。
什么是半连接队列?
服务器第一次收到客户端的 SYN 之后,就会处于 SYN_RCVD 状态,此时双方还没有完全建立其连接,服务器会把此种状态下请求连接放在一个队列里,我们把这种队列称之为半连接队列。
当然还有一个全连接队列,就是已经完成三次握手,建立起连接的就会放在全连接队列中。如果队列满了就有可能会出现丢包现象。
这里在补充一点关于 SYN-ACK 重传次数的问题: 服务器发送完 SYN-ACK 包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传。如果重传次数超过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。
注意,每次重传等待的时间不一定相同,一般会是指数增长,例如间隔时间为 1s,2s,4s,8s…
ISN 是固定的吗?
当一端为建立连接而发送它的 SYN 时,它为连接选择一个初始序号。ISN 随时间而变化,因此每个连接都将具有不同的 ISN。ISN 可以看作是一个 32 比特的计数器,每 4ms 加 1 。这样选择序号的目的在于防止在网络中被延迟的分组在以后又被传送,而导致某个连接的一方对它做错误的解释。
三次握手的其中一个重要功能是客户端和服务端交换 ISN(Initial Sequence Number),以便让对方知道接下来接收数据的时候如何按序列号组装数据。如果 ISN 是固定的,攻击者很容易猜出后续的确认号,因此 ISN 是动态生成的。
三次握手过程中可以携带数据吗?
其实第三次握手的时候,是可以携带数据的。但是,第一次、第二次握手不可以携带数据。
为什么这样呢?大家可以想一个问题,假如第一次握手可以携带数据的话,如果有人要恶意攻击服务器,那他每次都在第一次握手中的 SYN 报文中放入大量的数据。因为攻击者根本就不理服务器的接收、发送能力是否正常,然后疯狂着重复发 SYN 报文的话,这会让服务器花费很多时间、内存空间来接收这些报文。
也就是说,第一次握手不可以放数据,其中一个简单的原因就是会让服务器更加容易受到攻击了。而对于第三次的话,此时客户端已经处于 ESTABLISHED 状态。对于客户端来说,他已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据也没啥毛病。
SYN 攻击?
服务器端的资源分配是在二次握手时分配的,而客户端的资源是在完成三次握手时分配的,所以服务器容易受到 SYN 洪泛攻击。SYN 攻击就是 Client 在短时间内伪造大量不存在的 IP 地址,并向 Server 不断地发送 SYN 包,Server 则回复确认包,并等待 Client 确认,由于源地址不存在,因此 Server 需要不断重发直至超时,这些伪造的 SYN 包将长时间占用未连接队列,导致正常的 SYN 请求因为队列满而被丢弃,从而引起网络拥塞甚至系统瘫痪。SYN 攻击是一种典型的 DoS/DDoS 攻击。
检测 SYN 攻击非常的方便,当你在服务器上看到大量的半连接状态时,特别是源 IP 地址是随机的,基本上可以断定这是一次 SYN 攻击。在 Linux/Unix 上可以使用系统自带的 netstats 命令来检测 SYN 攻击。
netstat -n -p TCP | grep SYN_RECV
常见的防御 SYN 攻击的方法有如下几种:
- 缩短超时(SYN Timeout)时间
- 增加最大半连接数
- 过滤网关防护
- SYN cookies 技术
第三部分 HTTP 请求
HTTP 发展历史
HTTP/0.9
- 只有一个命令 GET
- 响应类型: 仅 超文本
- 没有 header 等描述数据的信息
- 服务器发送完毕,就关闭 TCP 连接
HTTP/1.0
- 增加了很多命令(post HESD )
- 增加
status code和header - 多字符集支持、多部分发送、权限、缓存等
- 响应:不再只限于超文本 (Content-Type 头部提供了传输 HTML 之外文件的能力 — 如脚本、样式或媒体文件)
HTTP/1.1
- 持久连接。TCP 三次握手会在任何连接被建立之前发生一次。最终,当发送了所有数据之后,服务器发送一个消息,表示不会再有更多数据向客户端发送了;则客户端才会关闭连接(断开 TCP)
- 支持的方法:
GET,HEAD,POST,PUT,DELETE,TRACE,OPTIONS - 进行了重大的性能优化和特性增强,分块传输、压缩/解压、内容缓存磋商、虚拟主机(有单个 IP 地址的主机具有多个域名)、更快的响应,以及通过增加缓存节省了更多的带宽
HTTP2
- 所有数据以二进制传输。HTTP1.x 是基于文本的,无法保证健壮性,HTTP2.0 绝对使用新的二进制格式,方便且健壮
- 同一个连接里面发送多个请求不再需要按照顺序来
- 头信息压缩以及推送等提高效率的功能
HTTP3
- QUIC“快速 UDP 互联网连接”(Quick UDP Internet Connections)
HTTP3 的主要改进在传输层上。传输层不会再有我前面提到的那些繁重的 TCP 连接了。现在,一切都会走 UDP。
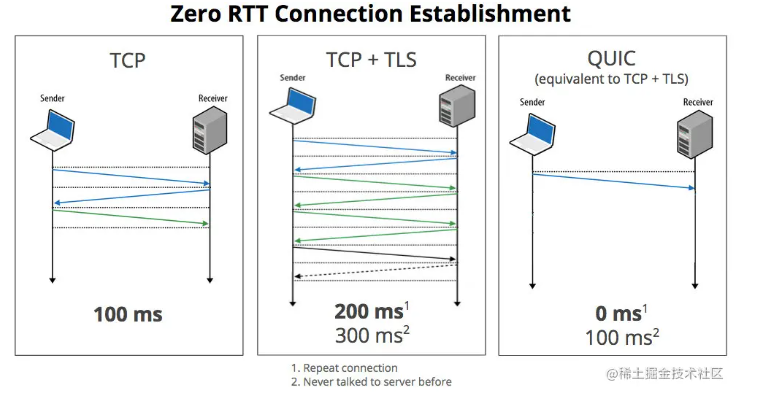
HTTP 协议特点
支持客户/服务器模式。
简单快速客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有 GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于 HTTP 协议简单,使得 HTTP 服务器的程序规模小,因而通信速度很快。
灵活:HTTP 允许传输任意类型的数据对象。正在传输的类型由 Content-Type(Content-Type 是 HTTP 包中用来表示内容类型的标识)加以标记。
无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
无状态:HTTP 协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
现在 HTTP3 最快!
HTTP 报文
请求报文:
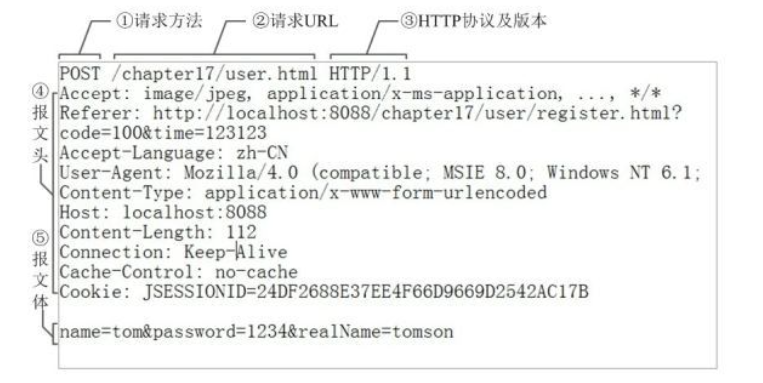
响应报文:

各协议与 HTTP 协议关系
- DNS 服务:解析域名至对应的 IP 地址
- HTTP 协议:生成针对目标 Web 服务器的 HTTP 请求报文
- TCP 协议:将请求报文按序号分割成多个报文段
- IP 协议:搜索对方的地址,一边中转一边传送
- TCP 协议:按序号以原来的顺序重组请求报文请求的处理结果也同样利用 TCP/IP 协议向用户进行回传
- TCP 是底层通讯协议,定义的是数据传输和连接方式的规范;
- HTTP 是应用层协议,定义的是传输数据的内容的规范;
- HTTP 协议中的数据是利用 TCP 协议传输的,所以支持 HTTP 也就一定支持 TCP。
HTTPS
在 HTTP 的基础上再加一层 TLS(传输层安全性协议)或者 SSL(安全套接层),就构成了 HTTPS 协议。
HTTPS 默认工作在 TCP 协议 443 端口,它的工作流程一般如以下方式:
- TCP 三次同步握手
- 客户端验证服务器数字证书
- DH 算法协商对称加密算法的密钥、hash 算法的密钥
- SSL 安全加密隧道协商完成
- 网页以加密的方式传输,用协商的对称加密算法和密钥加密,保证数据机密性;用协商的 hash 算法进行数据完整性保护,保证数据不被篡改。
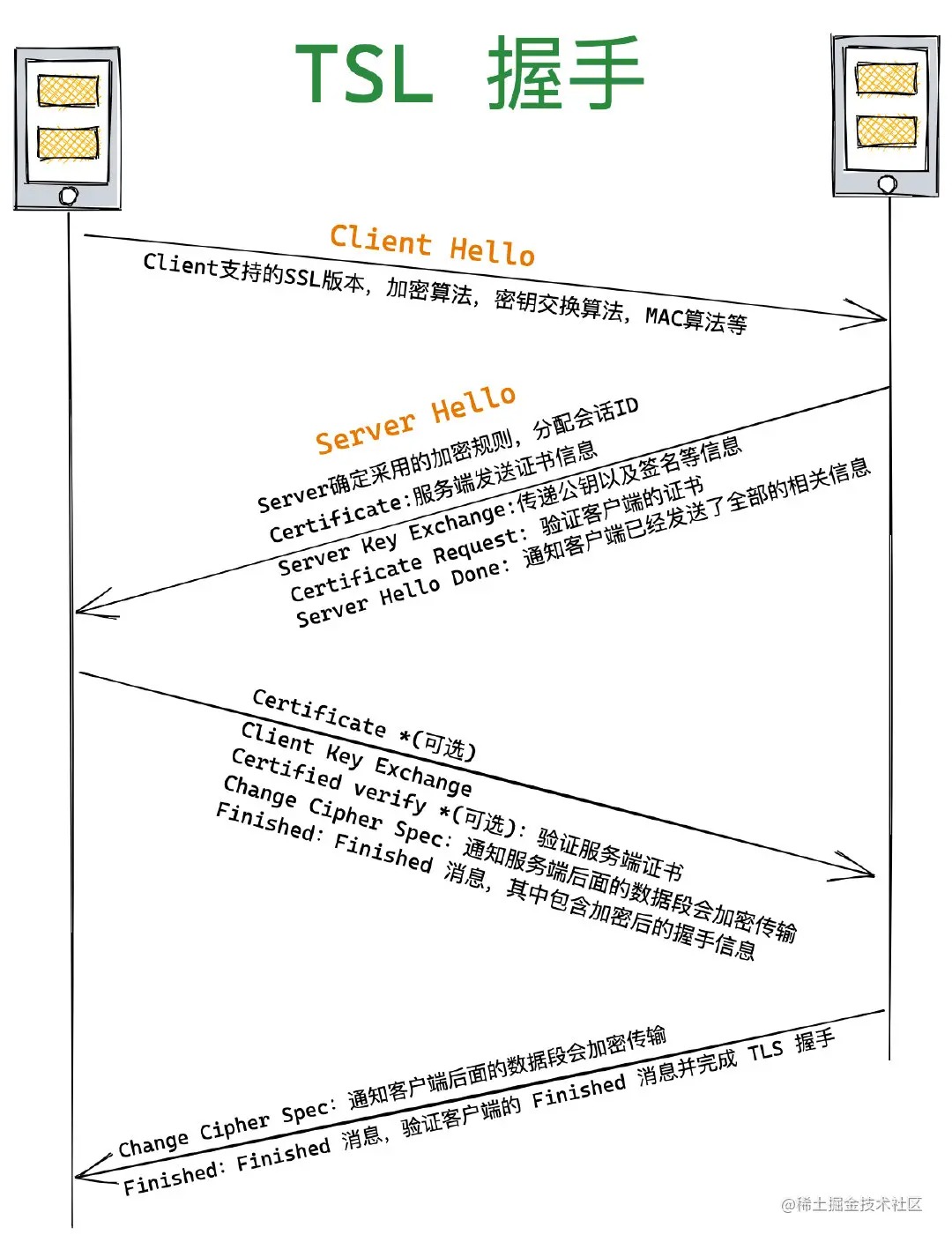
- 客户端向服务端发送
Client Hello消息,其中携带客户端支持的协议版本、加密算法、压缩算法以及客户端生成的随机数; - 服务端收到客户端支持的协议版本、加密算法等信息后;
- 向客户端发送
Server Hello消息,并携带选择特定的协议版本、加密方法、会话 ID 以及服务端生成的随机数; - 向客户端发送
Certificate消息,即服务端的证书链,其中包含证书支持的域名、发行方和有效期等信息; - 向客户端发送
Server Key Exchange消息,传递公钥以及签名等信息; - 向客户端发送可选的消息
Certificate Request,验证客户端的证书; - 向客户端发送
Server Hello Done消息,通知服务端已经发送了全部的相关信息;
- 向客户端发送
- 客户端收到服务端的协议版本、加密方法、会话 ID 以及证书等信息后,验证服务端的证书;
- 向服务端发送
Client Key Exchange消息,包含使用服务端公钥加密后的随机字符串,即预主密钥(Pre Master Secret); - 向服务端发送
Change Cipher Spec消息,通知服务端后面的数据段会加密传输; - 向服务端发送
Finished消息,其中包含加密后的握手信息;
- 向服务端发送
- 服务端收到
Change Cipher Spec和Finished消息后;- 向客户端发送
Change Cipher Spec消息,通知客户端后面的数据段会加密传输; - 向客户端发送
Finished消息,验证客户端的Finished消息并完成 TLS 握手;
- 向客户端发送
TLS 握手的关键在于利用通信双发生成的随机字符串和服务端的证书公钥生成一个双方经过协商后的对称密钥,这样通信双方就可以使用这个对称密钥在后续的数据传输中加密消息数据,防止中间人的监听和攻击,保证通讯安全。
HTTPS 连接 需要 7 次握手,3 次 TCP + 4 次 TLS。
第四部分 服务器处理请求并返回 HTTP 报文
每台服务器上都会安装处理请求的应用——Web Server。常见的 Web Server 产品有 apache、nginx、IIS 或 Lighttpd 等。
HTTP 请求一般可以分为两类,静态资源 和 动态资源。
请求访问静态资源,这个就直接根据 url 地址去服务器里找就好了。
请求动态资源的话,就需要 web server 把不同请求,委托给服务器上处理相应请求的程序进行处理(例如 CGI 脚本,JSP 脚本,servlets,ASP 脚本,服务器端 JavaScript,或者一些其它的服务器端技术等),然后返回后台程序处理产生的结果作为响应,发送到客户端。
服务器在处理请求的时候主要有三种方式:
- 第一种:是用一个线程来处理所有的请求,并且同时只能处理一个请求,但是这样的话性能是非常的低的。
- 第二种:是每一个请求都给他分配一个线程但是当链接和请求比较多的时候就会导致服务器的 cpu 不堪重负。
- 第三种:就是采用复用 I/O 的方式来处理例如通过 epoll 方式监视所有链接当链接状态发生改变的时候才去分配空间进行处理。
第五部分 浏览器渲染页面
DOM 树
字节 → 字符 → 令牌 → 节点 → 对象模型。
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>
- 转换: 浏览器从磁盘或网络读取 HTML 的原始字节,并根据文件的指定编码(例如 UTF-8)将它们转换成各个字符。
- 令牌化: 浏览器将字符串转换成 W3C HTML5 标准规定的各种令牌,例如,“”、“”,以及其他尖括号内的字符串。每个令牌都具有特殊含义和一组规则。
- 词法分析: 发出的令牌转换成定义其属性和规则的“对象”。
- DOM 构建: 最后,由于 HTML 标记定义不同标记之间的关系(一些标记包含在其他标记内),创建的对象链接在一个树数据结构内,此结构也会捕获原始标记中定义的父项-子项关系: HTML 对象是 body 对象的父项,body 是 paragraph 对象的父项,依此类推。
CSS 对象模型 (CSSOM)
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }

布局树 Layout Tree
- DOM 树与 CSSOM 树合并后形成渲染树。
- 渲染树只包含渲染网页所需的节点。
- 布局计算每个对象的精确位置和大小。
- 最后一步是绘制,使用最终渲染树将像素渲染到屏幕上。
渲染
渲染流程:
- 获取 DOM 后分割为多个图层
- 对每个图层的节点计算样式结果 (Recalculate style--样式重计算)
- 为每个节点生成图形和位置 (Layout--重排,回流)
- 将每个节点绘制填充到图层位图中 (Paint--重绘)
- 图层作为纹理上传至 GPU
- 组合多个图层到页面上生成最终屏幕图像 (Composite Layers--图层重组)
创建图层
<div class="position_">position</div>
<div class="box_3d">3d变换</div>
<div class="will-change">will-change</div>
<div class="transform"></div>
<iframe src="https://baidu.com"></iframe>
div {width: 100px;height: 100px;}
.position_ {background: pink;position: fixed;z-index: 20;}
.box_3d {background: red;transform: translate3d(100px,30px,10px);}
.will-change {background: #f12312;will-change: transform;}
.transform {background: #302912;transform: skew(30deg, 20deg);}
在 chrome 上查看 Layers.
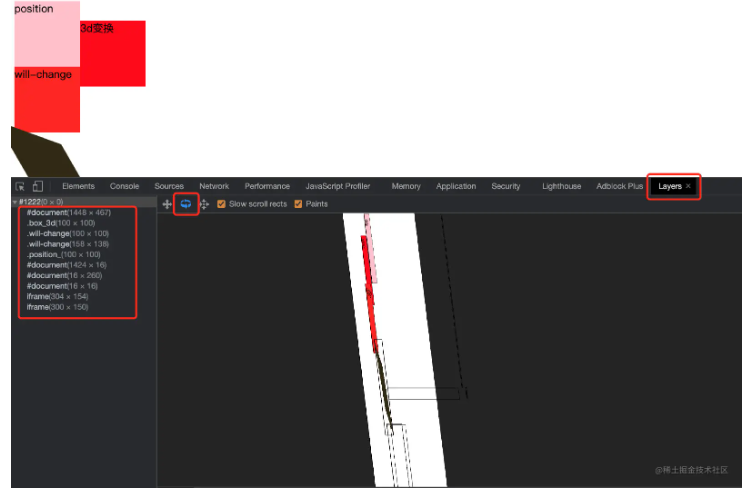
如果没有打开 Layers,按下图打开:
知道图层的存在,我们可以手动打开一个图层,通过添加
transform: translateZ(0)这样回流和重绘的代价就小了,效率就会大大提高。但是不要滥用这个属性,否则会大大增加内存消耗。—— 开启 GPU 加速。
回流和重绘
- 重绘
当页面中元素样式的改变并不影响它在文档流中的位置时(例如:color、background-color、visibility 等),浏览器会将新样式赋予给元素并重新绘制它,这个过程称为重绘。
- 回流
当 Render Tree 中部分或全部元素的尺寸、结构、或某些属性发生改变时,浏览器重新渲染部分或全部文档的过程称为回流。
回流必将引起重绘,而重绘不一定会引起回流。
引起回流:
- 页面首次渲染
- 浏览器窗口大小发生改变
- 元素尺寸或位置发生改变
- 元素内容变化(文字数量或图片大小等等)
- 元素字体大小变化
- 添加或者删除可见的 DOM 元素
- 激活 CSS 伪类(例如::hover)
- 查询某些属性或调用某些方法
引起回流的属性和方法:
- clientWidth、clientHeight、clientTop、clientLeft
- offsetWidth、offsetHeight、offsetTop、offsetLeft
- scrollWidth、scrollHeight、scrollTop、scrollLeft
- scrollIntoView()、scrollIntoViewIffNeeded()
- getComputedStyle()
- getBoundingClientRect()
- scrollTo()
如何减少回流
- css
- 避免使用 table 布局;
- 尽可能在 DOM 树的最末端改变 class;
- 避免设置多层内联样式;
- 将动画效果应用到 position 属性为 absolute 或 fixed 的元素上;
- 避免使用 CSS 表达式(例如:calc())。
- JS
- 避免频繁操作样式,最好一次性重写 style 属性,或者将样式列表定义为 class 并一次性更改 class 属性。
- 避免频繁操作 DOM,创建一个 documentFragment,在它上面应用所有 DOM 操作,最后再把它添加到文档中。
- 也可以先为元素设置 display: none,操作结束后再把它显示出来。因为在 display 属性为 none 的元素上进行的 DOM 操作不会引发回流和重绘。
- 避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
- 对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素及后续元素频繁回流。
第六部分 断开连接:TCP 四次分手
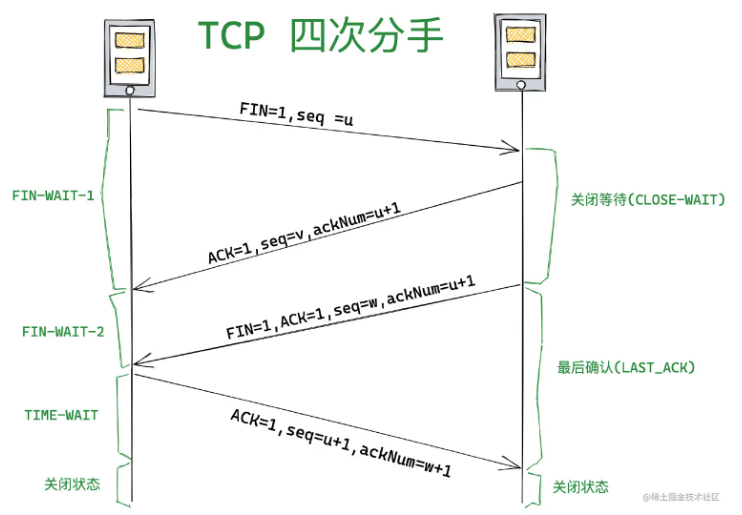
- 刚开始双方都处于 established 状态,假如是客户端先发起关闭请求
- 第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于 FIN_WAIT1 状态
- 第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值+1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT 状态
- 第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发送 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态
- 需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态,服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
挥手为什么需要四次?
因为当服务端收到客户端的 SYN 连接请求报文后,可以直接发送 SYN+ACK 报文。其中 ACK 报文是用来应答的,SYN 报文是用来同步的。但是关闭连接时,当服务端收到 FIN 报文时,很可能并不会立即关闭 SOCKET,所以只能先回复一个 ACK 报文,告诉客户端,“你发的 FIN 报文我收到了”。只有等到我服务端所有的报文都发送完了,我才能发送 FIN 报文,因此不能一起发送。故需要四次挥手。
为什么客户端发送 ACK 之后不直接关闭,而是要等一阵子才关闭?
客户端收到服务端的连接释放报文段后,对此发出确认报文段(ACK=1,seq=u+1,ack=w+1),客户端进入 TIME_WAIT(时间等待)状态。此时 TCP 未释放掉,需要经过时间等待计时器设置的时间 2MSL 后,客户端才进入 CLOSED 状态。如果不等待,客户端直接跑路,当服务端还有很多数据包要给客户端发,且还在路上的时候,若客户端的端口此时刚好被新的应用占用,那么就接收到了无用数据包,造成数据包混乱。
为什么 TIME_WAIT 状态需要经过 2MSL(最大报文生存时间)才能返回到 CLOSE 状态?
理论上,四个报文都发送完毕,就可以直接进入 CLOSE 状态了,但是可能网络是不可靠的,有可能最后一个 ACK 丢失。所以 TIME_WAIT 状态就是用来重发可能丢失的 ACK 报文。 1 个 MSL 确保四次挥手中主动关闭方最后的 ACK 报文最终能达到对端; 1 个 MSL 确保对端没有收到 ACK 重传的 FIN 报文可以到达。
总结
浏览器主进程处理用户 URL 输入:
- 触发旧页面的
beforeunload事件; - 判断是搜索内容还是页面请求的 URL;
- 如果是搜索内容,地址栏会使用浏览器默认的搜索引擎,来合成新的带搜索关键字的 URL。
- 如果判断输入内容符合 URL 规则,比如输入的是
juejin.cn那么地址栏会根据规则,把这段内容加上协议,合成为完整的 URL,如https://juejin.cn。
- 浏览器主进程把收到的 URL 转给网络进程;
- 触发旧页面的
网络进程处理 HTTP 请求:
- 构建请求;
- 查找缓存,有缓存就直接返回了;
- DNS (基于 UDP)解析,准备 IP 地址及端口号(递归查询,迭代查询),如果没有端口号,http 默认 80,https 默认 443;
- 等待 TCP 队列;
- 建立 TCP 连接,三次握手(为了确认客户端和服务端的接收和发送能力);
- 如果是 https 请求 还有 TSL,四次握手;
- 排队等待,最多可以发送 6 个 http 请求,发送 HTTP 请求(请求行 请求头 请求体);
- chrome 针对同一域名只能建立 6 个 tcp 链接,
- 同一域名下,同一 GET 请求的并发数是 1,也就是说上一个请求结束,才会执行下一个请求,否则置入队列等待发送;
- 同一域名下,不同 GET/POST 请求的并发数量是 6。当发送的请求数量达到 6 个,并且都没有得到响应时,后面的请求会置入队列等待发送
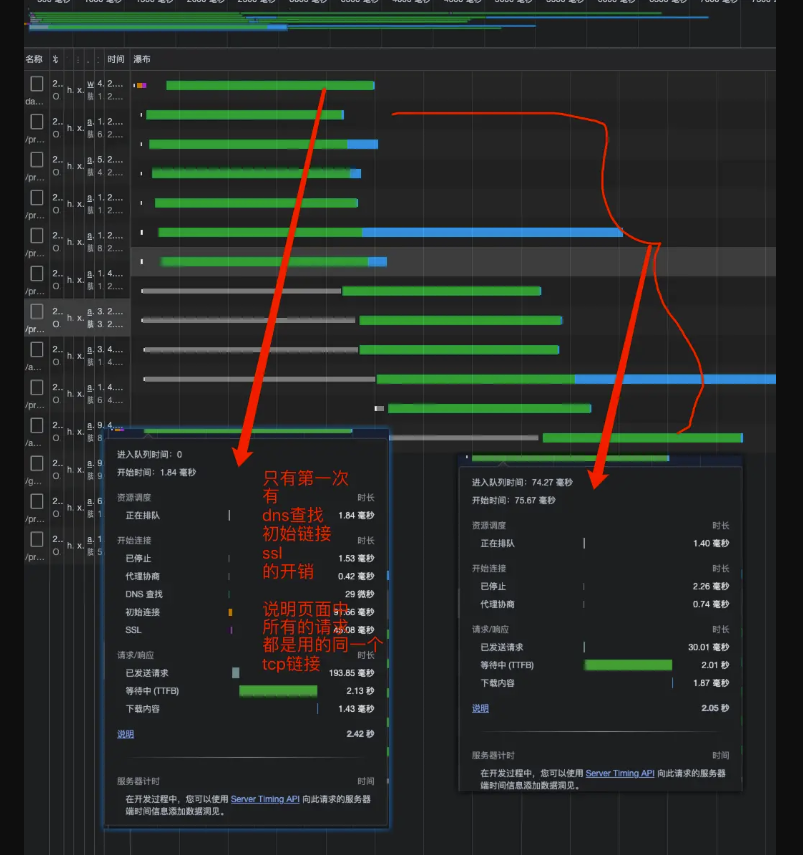
检查状态码
- 如果是 301/302,则需要重定向,从 Location 自动中读取地址,重新进行第 4 步 ,如果是 200,则继续处理请求。
- 200 响应处理:检查响应类型
Content-Type,如果是字节流类型,则将该请求提交给下载管理器,该导航流程结束,不再进行后续的渲染,如果是 html 则通知浏览器进程准备渲染进程准备进行渲染。 - 304 去查询浏览器缓存进行返回(协商缓存)
- http/1.1 默认是不会断开(keep-alive)
- 断开 TCP 连接,四次挥手(接收完响应数据后才会断开 TCP 连接);
准备渲染进程、提交文档、确认文档被提交
- 网络进程收到响应头数据,将数据发送给浏览器主进程;
- 浏览器主进程收到网络进程传来的响应头数据,准备渲染进程;
- 浏览器进程检查当前 url 是否和之前打开的渲染进程根域名是否相同,如果相同,则复用原来的进程,如果不同,则开启新的渲染进程
- 准备好渲染进程后,浏览器主进程向渲染进程发起“提交文档”的消息;
- 渲染进程收到浏览器主进程传来的“提交文档”消息,之后会与网络进程建立传输 HTML 页面数据管道;
- 当网络进程中的响应体接收完毕,通过管道将 HTML 页面数据传输给渲染进程;
- 当 HTML 页面数据传输完成后,渲染进程会返回“确认文档提交”消息给浏览器主进程;
- 浏览器主进程收到“确认文档提交”消息后,就会更新浏览器界面的状态,比如安全状态、地址栏 URL、历史记录状态,并刷新 Web 页面;
渲染阶段
- 渲染进程将 HTML 脚本解析成浏览器能识别处理的 DOM 树;
- 渲染进程将 CSS 脚本解析成浏览器能识别处理的
styleSheets,标准化处理属性值,并完成各节点的样式计算; - 创建布局树,忽略不可见的节点,进行布局计算,并将节点的布局信息重写回布局树;
- 对布局树进行分层,生成分层树(Layer Tree);如一些复杂的
3D变换、页面滚动,或者使用z-indexing做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree) - 为每个图层生成绘制列表,并提交给合成线程;(每个图层有自己的绘制步骤)
- 合成线程进行分块,并在栅格化线程池中将图块转化为位图(含 GPU 栅格化);(有的图层,太大了,需要滚动才能出现在视口中,这种就需要分块,没必要一次性渲染,影响性能!)
- 通常,栅格化过程都会使用 GPU 来加速生成,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中。
- 浏览器主进程viz 组件收到合成线程的绘制指令
DrawQuad,先在内存中绘制页面,并最终显示在浏览器标签页上。