常见计算机基础
编码和加密
1.摘要算法
摘要
- 摘要是哈希值,我们通过散列算法比如 MD5 算法就可以得到这个哈希值。
- 摘要只是用于验证数据完整性和唯一性的哈希值,不管原始数据是什么样的,得到的哈希值都是固定长度的。
- 不管原始数据是什么样的,得到的哈希值都是固定长度的,也就是说摘要并不是原始数据加密后的密文,只是一个验证身份的令牌。所以我们无法通过摘要解密得到原始数据。
加密
加密是通过 “加密算法” 将 "明文" 加密成 “密文”。 我们可以通过 “密钥” 和 “解密算法” 将 “密文” 还原成 “明文”。
MD5 算法
MD5 算法就是一种常见的摘要算法。该算法可以生成压缩包的一个 128 bit 的二进制串。除了压缩包,也可以应用于其他文件和字符串。比如数据库中不会直接存储账号密码,比如我就习惯将 密码拼接一个无规律的字符串 然后计算出 MD5 摘要放入数据库中
特点
MD5的主要特点有:长度固定、计算简单、抗修改性以及强抗碰撞性。
- 长度固定:
MD5加密后值固定长度是 128 位,使用 32 个 16 进制数字进行表示。 - 计算简单:
MD5加密采用的是散列算法(哈希算法),进行MD5计算时简单易得,加密速度快。 - 抗修改性:
MD5值是 16 进制数,当修改原数据的 1 个字节,所代表MD5值也是截然不同,只要有任何改动都能够察觉。 - 强抗碰撞性:碰撞性就是通过
MD5加密算法得到MD5值中与其它明文加密得到的MD5值相同的概率。强抗碰撞性指要找到散列值相同的两条不同的消息是非常困难的,得到相同MD5的概率低。
原理
- 填充数据:首先将输入的数据长度(
bit)进行 512 求余,如果取余得到结果不等于 448,则对其进行填充bit使其取余结果 448。具体填充方式是在其第一位 bit 填充 1,其余 N 位bit进行补 0,这样得到的数据长度为 512*N+448。 - 记录数据长度:其次将填充前的数据长度用 64 位进行存储,而后将其追加在填充后的数据后面,使其数据长度为 N×512+448+64=(N+1)×512bit。
- 装入标准幻数:其实就是将 128bit 的 MD5 值按照每 32bit 就是一个标准幻数,可以得到四个标准幻数
A=01234567、B=89ABCDEF、C=FEDCBA98以及D=76543210。 - 四轮循环运算:上面数据处理后的数据长度是(N+1)/512,按照每 512 位(64 字节)作为一块,总共要循环 N+1 次,并将块细分为 16 个小组,每组的长度为 32 位(4 字节),这 16 个小组即为一轮,总共得循环 4 轮,即 64 次循环。总的来说我们需要
(N+1)个主循环,每个主循环包含了 64 次子循环,来不断的改变幻数 A,B,C,D 才能最终得到数据的 MD5 值。
SHA-1 算法也是一种哈希算法,输出 160bit,它的同类型算法有 SHA-256 和 SHA-512,输出的长度分别是 256bit 和 512bit
2.base64 编码
我们的图片大部分都是可以转换成 base64 编码的 data:image。 这个在将 canvas 保存为 img 的时候尤其有用。现代浏览器都已经支持原生的基于 base64 的 encode 和 decode,例如btoa和atob
看一下 Base64 的索引表,字符选用了"A-Z、a-z、0-9、+、/" 64 个可打印字符。数值代表字符的索引,这个是标准 Base64 协议规定的,不能更改。64 个字符用 6 个 bit 位就可以全部表示,一个字节有 8 个 bit 位,剩下两个 bit 就浪费掉了,这样就不得不牺牲一部分空间了。这里需要弄明白的就是一个 Base64 字符是 8 个 bit,但是有效部分只有右边的 6 个 bit,左边两个永远是 0。
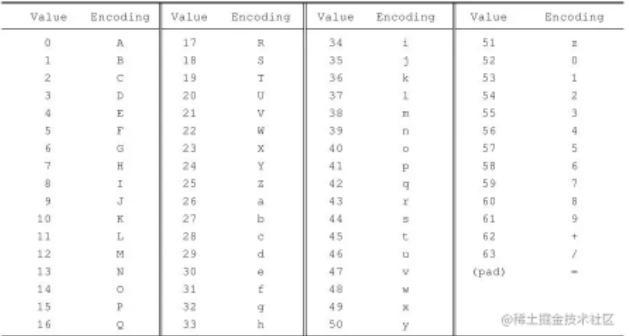
那么怎么用 6 个有效 bit 来表示传统字符的 8 个 bit 呢?8 和 6 的最小公倍数是 24,也就是说 3 个传统字节可以由 4 个 Base64 字符来表示,保证有效位数是一样的,这样就多了 1/3 的字节数来弥补 Base64 只有 6 个有效 bit 的不足。
将原数据每 6 位对应成 Base 64 索引表中的⼀个字符编排成⼀个字符串(每个字符 8 位)
你也可以说用两个 Base64 字符也能表示一个传统字符,但是采用最小公倍数的方案其实是最减少浪费的。结合下边的图比较容易理解。Man 是三个字符,一共 24 个有效 bit,只好用 4 个 Base64 字符来凑齐 24 个有效位。红框表示的是对应的 Base64,6 个有效位转化成相应的索引值再对应 Base64 字符表,查出"Man"对应的 Base64 字符是"TWFU"。
说到这里有个原则不知道你发现了没有,要转换成 Base64 的最小单位就是三个字节,对一个字符串来说每次都是三个字节三个字节的转换,对应的是 Base64 的四个字节。这个搞清楚了其实就差不多了。
但是转换到最后你发现不够三个字节了怎么办呢?愿望终于实现了,我们可以用两个 Base64 来表示一个字符或用三个 Base64 表示两个字符,像下图的 A 对应的第二个 Base64 的二进制位只有两个,把后边的四个补 0 就是了。所以 A 对应的 Base64 字符就是 QQ。
上边已经说过了,原则是 Base64 字符的最小单位是四个字符一组,那这才两个字符,后边补两个"="吧。其实不用"="也不耽误解码,之所以用"=",可能是考虑到多段编码后的 Base64 字符串拼起来也不会引起混淆。由此可见 Base64 字符串只可能最后出现一个或两个"=",中间是不可能出现"="的。下图中字符"BC"的编码过程也是一样的。
Base64 编码的过程如下:
- (1)首先对待编码字符串进行每 3 个字节分组,如果当前分组不够 3 个字节,则通过补零来构成 3 字节一组。
- (2)将每组的 24 位按照 6 位划分,得到 4 个 6 位二进制数组。
- (3)对每个 6 位二进制数组进行高位补零,形成 8 位二进制数数组。
- (4)查表获取每个字节的十进制对应的字符。
- (5)将(1)中补充的字节数兑换成 = 的个数,拼接到(4)得到的完整字符串的尾部。
总结
说起 Base64 编码可能有些奇怪,因为大多数的编码都是由字符转化成二进制的过程,而从二进制转成字符的过程称为解码。而 Base64 的概念就恰好反了,由二进制转到字符称为编码,由字符到二进制称为解码。
Base64 编码主要用在传输、存储、表示二进制等领域,还可以用来加密,但是这种加密比较简单,只是一眼看上去不知道什么内容罢了,当然也可以对 Base64 的字符序列进行定制来进行加密。
Base64 编码是从二进制到字符的过程,像一些中文字符用不同的编码转为二进制时,产生的二进制是不一样的,所以最终产生的 Base64 字符也不一样。例如"上网"对应 utf-8 格式的 Base64 编码是"5LiK572R",对应 GB2312 格式的 Base64 编码是"yc/N+A=="。
3.字符编码理论
1. 字符集(Character set)
字符类似 a,b,你,&等各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字,emoji 等是一个字符。而字符的集合就称之为字符集。我们常见字符集有 ASCCII 字符集、Unicode 字符集、GBK 字符集等。
ASCCII 字符集 主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯 数字和西文符号)。
Unicode 字符集 ASCCII 具有很大的局限性,只能表示至多 127 个字符,而诸如汉字,阿拉伯语等都有自己的文字字符,ASCCII 字符集是不能表示的。Unicode 字符集可以简单的理解为通用所有字符的一个集合。
每个字符对应一个数字,每个数字对应一个字符,而这个数字也称之为码点。根据码点就可以字符集中索引到对应的字符。
2. 字符编码
计算机系统中所有的数据都是用二进制进行传输和存储的,当然字符也不例外。把一个数值与字符集中的字符进行匹配建立一一对应关系的规则称之为字符编码。跟我们差字典一样,同一本字典(编码)第几页第几个字(字符)就能确定唯一一个字符。通常来讲,每一个字符在字符集中都有一个码点,我们对根据码点就能确认一个字符,我们对码点就行储存和编码就能达到对字符进行传输和存储的目的。
2.1. UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对 Unicode 的可变长度字符编码,也是一种前缀码。它可以用来表示 Unicode 标准中的任何字符,且其编码中的第一个字节仍与 ASCII 兼容。
UTF-8 是一种变长的字符编码,一个字符的 UTF-8 编码可能占 1-4 个字节,而占某个字符具体占几个字节取决,字符码点的值。
具体表示的时候,
- 如果第一个字节的第一 bit 为 0,表示当前字符只用一个字节就可以表示。具体的码点值,就是当前字节除 0 位之外其他 7 个字节。
- 如果第一个字节的第一个 bit 不为 0,则从开头知道碰到第一个 0 的过程中有几个 1,就用几个字节表示。好像描述的不太好,看图更明了。如下图
Unicode符号范围(码点范围) | UTF-8编码模板
(十六进制) | (二进制)
---------------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx |可用7bit
0000 0080-0000 07FF | 110xxxxx 10xxxxxx |可用11bit
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |可用16bit
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |可用21bit
上表表示如何从一个从 Unicode 转化到 UTF-8
对于任意字符,UInicode 码点的值,在上表中找到对应的编码模板,然后把码点值转换为 2 进制,依次从后往前填入码位(上表中的 x),不足的用 0 补齐。
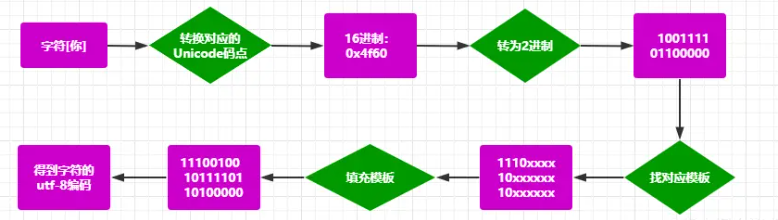
比如 :[你] 这个字的 Unicode 编码是 0x4f60。0x6C49 在 0x0800-0xFFFF 之间,使用 3 字节模板:1110xxxx 10xxxxxx 10xxxxxx。将 ox4f60 写成二进制是: 1001111 01100000 , 从这个二进制值从低到高取出比特,从模板的低位到高位替换模板中的 x 的位置,不足的用 0 补齐,得到:11100100 10111101 10100000。可见[你]这个字符 utf-8 编码占 3 个字节
3. URL
URi 和 URL 和 URN 之间的关系
URi
uri 的全称为:uniform resource identifier,中文为统一资源标识符,用来表示唯一的标识资源。web 上可用的每一种资源,例如 html 文档,图像,视频片段,程序等都是由一个通用资源标识符进行定位。
uri 组成
1、访问资源的命名机制 2、存放资源的主机名 3、资源自身的名称,由路由表示
我们以http://www.baidu.com/index.html为例:
这个 uri 是这样的:这是一个 http 协议访问的资源,位于www.baidu.com主机上,通过路径/index.html来进行访问。
绝对 uri
uri 存在绝对 uri 和相对 uri 之分,绝对 uri 指的是 scheme(后面跟着冒号)开头的 uri。前面的http://www.baidu.com/index.html就是一个绝对的uri。还存在其他的例子:mailto:jeff@javajeff.com.等等到时绝对的uri.
相对的 uri
相对的 uri 不含任何命名规则。它的路径通查指同一台机器上的资源。
例如:<img src="../icons/logo.png">就是相对的uri。
在 html 中,uri 被用来 1、链接到另一个文档或资源 2、链接到一个外部样式表或者脚本 3、在页内包含图形等
URL
url 是 uniform resource locator,指的是统一资源名称,它是一种具体的 uri,即 url 可以用来标识一个资源。
1、internet 资源类型,指出 www 客户程序用来操作的工具。 2、服务器地址(host):指出 www 网页所在的服务器域名。必需的。 3、端口(port):有时(并非总是这样),对某些资源的访问来说,需给出相应的服务器提供端口。可选的。 4、路径:指明服务器上某资源的位置。与端口一样,路径并非总是需要的,可选。
URN
URN:uniform resource name,统一资源命名,是通过名字来标识,比如
mailto:java-net@java.sun.comURN 可以理解为通过名称来标识位置。但是其流行还需要假以时日,因为他需要更精密软件支持。
关系

uri 是统一资源标识符,用来唯一确定资源,他是一种抽象,也就是说不管用什么方法,只要可以唯一确定资源,那么那就是 uri。
url:统一资源定位符,urn:统一资源名称。 url 和 urn 是 uri 的子集,url 可以理解为用地址来定位资源,urn 可以理解为用名称来定位资源。
3.1. URL 格式
统一资源定位符的完整格式如下:
foo://example.com:8042/over/there?name=ferret#nose
\_/ \______________/\_________/ \_________/ \__/
| | | | |
scheme authority path query fragment
| _____________________|__
/ \ / \
urn:example:animal:ferret:nose
一个完整的 URL 主要有以下部分组成这些部分被 URL 的保留字符相连。
- 协议(sheme)。
- 层级 URL 标记符号,为[//],是固定不变的
- 访问资源需要的凭证信息(authority)
- 服务器地址(host)。通常为域名,有时为 IP 地址
- 端口号(port)。以数字方式表示,若为默认值可省略
- 路径(path)。以“/”字符区别路径中的每一个路径名称
- 查询(query)。键值对参数,以“?”字符为起点,每个参数键值对以“&”隔开,再以“=”分开参数名称和值
- 片段。以“#”字符为起点
3.2. URL 中的字符
RFC 中规定,URL 中只有可显的 asscii 字符集中的字符是合法的。
URL 的字符中有特殊的含义通常用来做分隔符如
www.google.com?a=12&b=34中:/?&都为 url 中的保留字符。2005 年规定的保留字符:
! * ' ( ) ; : @ & = + $ , ? # [ ]
URL 字符中,大写字母(A-Z)、小写字母(a-z)、数字(0-9)等为非保留字符。这些字符含义只是表示字面量在协议中不允许特殊的语义。
2005 年规定的非保留字符:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z 0 1 2 3 4 5 6 7 8 9 - _ . ~
- URL 字符中除了保留字符和非保留字符之外的字符,比如百分号符(%),这些其他字符,允许有一些特殊的语义但是不强制。
4. URL encoding 百分号编码
4.1. 为什么要 URL encoding
- 在具体的 URL 中诸如 path 或者 query 部分,如果存在着保留字段会有语义上的不合法性。 比如:
http://www.abac.com/a/?abc=1&2&ef=24。&为保留字符,用以链接两个 query 键值对。而在这个 URL 中想要传递键为 abc 值为 1&2 的时候在语法上是不合法的。 - URL 的字符集只是 ASCII 字符集的一个字集,如果要传递 URL 合法的字符以外的字符,是没办法表示的。比如要在 url 的 path 中有"好"这个字符。
- 另,URL 字符集中的其他字符集有可能存在不安全的字符。是有一些特殊语义的。
基于以上三点,我们需要一种编码来解决 URl 使用过程中的一些歧义。来解决这个编码问题的就是 URLEncode。
4.2. URL encoding 的规则
2005 年 1 月发布的 RFC 3986
对可能会引起歧义的保留字符、不在 ASCII 码之外的字符和 URL 字符集范围内的其他字符进行 URlEncode,以保证 URL 语义的正确性。URLEncode 的规则:
- 未保留字符不需要百分号编码。比如字符 a 百分号编码后之后还是 a。
- 对保留字符的百分号编码。编码逻辑为:对应字符的 ASCII 的值表示为两个 16 进制的值,然后在其前面放置%字符。比如,保留字符?对应的 ASCII 码点值为 6(十进制)对应 16 进制为 3F,然后在 16 进制值前面加上%字符最终得到保留字符?的 url 编码为%3F。注意:对字节百分号编码后里 16 进制的表示都为大写字母比如%3F,且在 URL 编码后默认不区分大小写。
- 对于其他字符百分号编码。编码逻辑为:把对应字符用某种编码格式(如 utf-8)转为字节序列,然后把每个字节序列的值进行百分号编码。这里展开说一下,所谓的对每个字节进行编码,把每个字节的值转为 16 进制,然后再 16 进制前加百分号就得到了对应的百分号编码。
将需要转码的字符转为 16 进制,然后从右到左,取 4 位(不足 4 位直接处理),每 2 位做一位,前面加上%,编码成%XY 格式。
比如:
空格 ASCII 码是 32,对应 16 进制是 20,那么 urlencode 编码结果是:%20,但在新标准中空格对应的是+,见 RFC-1738
比如:
中 ASCII 码是-10544,对应的 16 进制是 D6D0,那么 urlencode 编码结果是:%D6%D0
4.3. URL encoding 用途
http post 形式发送时指定 Content-Type 为
application/x-www-form-urlencode时,postbody 中的键值对都会进行百分号编码以保证数据的无歧义。当我们的 http url 中,query 和 path 部分的内容如果需要被 urlencode 也要进行百分号编码,不做赘述。
4.常见加密算法
MD5 用的是 哈希函数,它的典型应用是对一段信息产生 信息摘要,以 防止被篡改。严格来说,MD5 不是一种 加密算法 而是 摘要算法。无论是多长的输入,MD5 都会输出长度为 128bits 的一个串 (通常用 16 进制 表示为 32 个字符)。
SHA1 是和 MD5 一样流行的 消息摘要算法,然而 SHA1 比 MD5 的 安全性更强。对于长度小于 2 ^ 64 位的消息,SHA1 会产生一个 160 位的 消息摘要。基于 MD5、SHA1 的信息摘要特性以及 不可逆 (一般而言),可以被应用在检查 文件完整性 以及 数字签名 等场景。
HMAC 是密钥相关的 哈希运算消息认证码(Hash-based Message Authentication Code),HMAC 运算利用 哈希算法 (MD5、SHA1 等),以 一个密钥 和 一个消息 为输入,生成一个 消息摘要 作为 输出。
HMAC 发送方 和 接收方 都有的 key 进行计算,而没有这把 key 的第三方,则是 无法计算 出正确的 散列值的,这样就可以 防止数据被篡改。
AES、DES、3DES 都是 对称 的 块加密算法,加解密 的过程是 可逆的。常用的有 AES128、AES192、AES256 (默认安装的 JDK 尚不支持 AES256,需要安装对应的 jce 补丁进行升级 jce1.7,jce1.8)。
RSA 加密算法是目前最有影响力的 公钥加密算法,并且被普遍认为是目前 最优秀的公钥方案 之一。RSA 是第一个能同时用于 加密 和 数字签名 的算法,它能够 抵抗 到目前为止已知的 所有密码攻击,已被 ISO 推荐为公钥数据加密标准。
RSA加密算法 基于一个十分简单的数论事实:将两个大 素数 相乘十分容易,但想要对其乘积进行 因式分解 却极其困难,因此可以将 乘积 公开作为 加密密钥。
ECC 也是一种 非对称加密算法,主要优势是在某些情况下,它比其他的方法使用 更小的密钥,比如 RSA 加密算法,提供 相当的或更高等级 的安全级别。不过一个缺点是 加密和解密操作 的实现比其他机制 时间长 (相比 RSA 算法,该算法对 CPU 消耗严重)。
5.登录密码加密
Hash 特点: 1.算法是公开的 2.对相同数据运算,得到的结果是一样的 3.对不同数据运算,如 MD5 得到的结果默认是 128 位,32 个字符(16 进制标识)。 4.没法逆运算 5.信息摘要,信息“指纹”,是用来做数据识别的。
hash 加密: 1.md5. 2.sha1 2.sha256 3.sha516
用户密码加密 1.首先密码加密不能用 rsa 加密,因为 rsa 加密虽然在传输过程中是相对安全的,但是一旦开发人员变动带走了私钥与密钥,是很容易的获取用户的登录密码
2.hash 加密,hash 加密是不可逆的,加密后传输至服务端后,开发人员是获取不出用户的登录密码的,只需要将加密的 hash 值存入数据库中,但是这个方法现在也是不安全的。https://www.cmd5.com,这个网址可以查出大部分的密码
3.hash 加盐:所谓的 hash 加盐就是在原密码的基础上,添加上一段随机字符串(该字符串是由客户端开发人员写死的),然后进行 hash 加密,但是这种方法对于开发者的依赖比较大还有就是灵活性不高,当用户量大了后,如果想更换盐成本会很大
4.hamc 加密:也可以说是动态加盐(一个用户一个盐),当用户注册的时候,服务端会返回给客户端一个盐,然后进行两次 hash 加密,传输给服务端。这样不会对开发人员产生依赖,且由于是一个用户一个盐,这样更换起来也会比较方便
6.前后端鉴权
傻傻分不清之 Cookie、Session、Token、JWT
Token
token 即使是在计算机领域中也有不同的定义,这里我们说的 token,是指访问资源的凭据。例如当你调用 Google API,需要带上有效 token 来表明你请求的合法性。这个 token 是 Google 给你的,这代表 Google 给你的授权使得你有能力访问 API 背后的资源。
请求 API 时携带 token 的方式也有很多种,通过 HTTP Header 或者 url 参数 或者 google 提供的类库都可以:
// HTTP Header:
GET /drive/v2/files HTTP/1.1
Authorization: Bearer <token>
Host: www.googleapis.com/
// URL query string parameter
GET https://www.googleapis.com/drive/v2/files?token=<token>
// Python:
from googleapiclient.discovery import build
drive = build('drive', 'v2', credentials=credentials)
更具体的说,上面用于调用 API 的 token 我们称为细分为 access token。通常 access token 是有有效期限的,如果过期就需要重新获取。那么如何重新获取?现在我们要让时光倒流一会,回顾第一次获取 token 的流程是怎样的:
- 首先你需要向 Google API 注册你的应用程序,注册完毕之后你会拿到认证信息(credentials)包括 ID 和 secret。不是所有的程序类型都有 secret。
- 接下来就要向 Google 请求 access token。这里我们先忽略一些细节,例如请求参数(当然需要上面申请到的 secret)以及不同类型的程序的请求方式等。重要的是,如果你想访问的是用户资源,这里就会提醒用户进行授权。
- 如果用户授权完毕。Google 就会返回 access token。又或者是返回授权代码(authorization code),你再通过代码取得 access token
- token 获取到之后,就能够带上 token 访问 API 了
注意在第三步通过 code 兑换 access token 的过程中,Google 并不会仅仅返回 access token,还会返回额外的信息,这其中和之后更新相关的就是 refresh token
一旦 access token 过期,你就可以通过 refresh token 再次请求 access token。
以上只是大致的流程,并且故意省略了一些额外的概念。比如更新 access token 当然也可以不需要 refresh token,这要根据你的请求方式和访问的资源类型而定。
单点登录 SSO (Single sign-on)
通常公司内部会有非常多的工具平台供大家使用,比如人力资源,代码管理,日志监控,预算申请等等。如果每一个平台都实现自己的用户体系的话无疑是巨大的浪费,所以公司内部会有一套公用的用户体系,用户只要登陆之后,就能够访问所有的系统。这就是单点登录(SSO: Single Sign-On)
实例
最初的时候,服务的提供者只做了一个单系统,所有的功能都在单系统上,此时不需要SSO,一次登录就可以访问所有功能,后来用户量越来越大且功能服务越来越多,为了合理利用资源和降低耦合性,服务商将功能划分为多个子系统,而子系统的用户登录凭证是相互隔离的,如果在这个子系统登录完成,再访问另一个子系统还需要登录,这显然不太合适,而SSO就是对于这种问题的解决方案,在多个系统中,用户只需要某一个系统中登录,在其他系统中都无需再次验证用户身份即可静默登录,例如在百度一次登录,再访问贴吧、网盘等都可以静默登录。
OAUTH 与 SSO 区别
- 从信任角度来看,
OAUTH开放授权的服务端和第三方客户端不属于一个互相信任的应用群,而单点登录的子系统都在一个互相信任的应用群,通常是同一个公司提供的服务。 - 从资源角度来看,
OAUTH开放授权主要是让用户自行决定在服务端的个人资源是否允许第三方应用访问,而单点登录的资源本身都在子系统这边,主要服务是用于登录,以及管理用户在各个子系统的权限信息。
实现方案
共享 SESSION
如果系统是使用SESSION来记录用户信息的话,那么就可以采用共享SESSION的方式进行实现单点登录,使用SESSION信息作为单点登录的方式就需要解决两个问题,一是子系统的SESSION是相互隔离的问题,二是用户的SESSIONID如何在客户端共享的问题。
SESSION的一致性的解决方案主要有SESSION同步、SESSION集中存储的方式,SESSION同步比较消耗资源,所以一般还是使用SESSION集中存储的方式。
对于SESSIONID在客户端共享的问题,SESSIONID主要还是存储在COOKIE中,所以需要解决的问题是COOKIE的跨域问题,对于同一个顶级域名下的二级域名,可以通过在SET-COOKIE时设置domain属性为顶级域名,即可实现在顶级域名与二级域名三级域名下的COOKIE共享,若是需要非子域名下的COOKIE共享,可以考虑使用P3P隐私参考项目平台Platform for Privacy Preferences的header的方式跨域SET-COOKIE。
Ticket
Ticket方式也称为SSO-Token,其是一个用户身份的标识,这个标识在所有子系统群中是唯一的,并且所有的子系统SERVER都可以验证这个Token并同时能够拿到这个Token所代表的用户信息,同样这种方式也需要解决COOKIE的跨域问题,同样一般也是需要使用顶级域名的domain属性或者P3P的header的跨域SET-COOKIE。
CAS
CAS中央认证服务Central Authentication Service,将认证服务单独抽出作为一个子系统,所有的登录认证服务都在CAS认证中心进行。CAS系统像是一个中转中心,可以认证所有用户的身份,同样也可以直接通过在CAS系统登录后以登录态跳转到其他各个系统。
假如我们存在三个子系统,A系统A.com、B系统B.com、认证服务SSO.com,当用户已经注册,登录时的主要流程:
- 用户打开系统
A,此时用户未登录,系统自动跳转到认证服务系统SSO.com并携带参数存储跳转地址A.com。 - 用户在
SSO.com输入账号密码,点击登录验证成功后,中央认证服务器返回一个Ticket,并将已经登录的COOKIE写入SSO.com认证服务的域名下,SSO.com认证服务重定向至跳转到认证服务时携带的地址,也就是上一步的A.com,并携带中央认证服务端下发的Ticket。 - 系统
A得到Ticket并向本系统的服务器传递Ticket,服务端验证Ticket无误后获取Ticket中携带的用户信息,并设置当前A系统的此用户为登录态,下发COOKIE信息等用户凭据,至此该用户可正常使用A系统的服务。 - 此时用户打开
B系统,由于用户未在B系统登录,系统自动跳转到认证服务系统SSO.com并携带参数存储跳转地址B.com。 - 用户在
SSO.com已经处于登录状态,此时直接从中央认证服务器获取Ticket,然后重定向至跳转到认证服务时携带的地址,也就是上一步的B.com,并携带中央认证服务端下发的Ticket。 - 系统
B得到Ticket并向本系统的服务器传递Ticket,服务端验证Ticket无误后获取Ticket中携带的用户信息,并设置当前B系统的此用户为登录态,下发COOKIE信息等用户凭据,至此该用户可正常使用B系统的服务。
OAuth 2.0
OAuth2.0 原理图解:第三方网站为什么可以使用微信登录
- 用户通过客户端(可以是浏览器也可以是手机应用)想要访问 SP 上的资源,但是 SP 告诉用户需要进行认证,将用户重定向至 IdP
- IdP 向用户询问 SP 是否可以访问用户信息,如果用户同意,IdP 向客户端返回 access code
- 客户端拿 code 向 IdP 换 access token,并拿着 access token 向 SP 请求资源
- SP 接受到请求之后拿着附带 token 向 IdP 验证用户的身份
用户从 IdP 返回客户端的方式是通过 URL 重定向,这里的 URL 允许自定义 schema,所以即使在手机上也能拉起应用;另一方面因为 IdP 向客户端传递的是 code,而不是 XML 信息,所以 code 可以很轻易的附着在重定向 URL 上进行传递
但以上的 SSO 流程体现不出 OAuth 的本意。OAuth 的本意是一个应用允许另一个应用在用户授权的情况下访问自己的数据,OAuth 的设计本意更倾向于授权而非认证(当然授权用户信息就间接实现了认证), 虽然 Google 的 OAuth 2.0 API 同时支持授权和认证。所以你在使用 Facebook 或者 Gmail 账号登陆第三方站点时,会出授权对话框告诉你第三方站点可以访问你的哪些信息,需要征得你的同意:
Refresh Token
为什么我们需要 refresh token?
这样的处理是为了职责的分离:refresh token 负责身份认证,access token 负责请求资源。虽然 refresh token 和 access token 都由 IdP 发出,但是 access token 还要和 SP 进行数据交换,如果公用的话这样就会有身份泄露的可能。并且 IdP 和 SP 可能是完全不同的服务提供的。而在第一小节中我们之所以没有这样的顾虑是因为 IdP 和 SP 都是 Google
7.分布式 SESSION 一致性
SESSION是服务器为客户端创建的一个会话,存储用户的相关信息,用以标识用户身份等。在单服务器环境下是不需要考虑会话的一致性的问题的,但是在集群环境下就会出现一些问题,假如一个用户在登录请求时负载均衡到了A服务器,A服务器为其分配了SESSION,下次请求数据时被分配到了B服务器,此时由于B服务器不存在此用户的SESSION,此用户会被重定向到登录页面,这种情况是不合理的业务逻辑,所以需要维护SESSION的一致性。
解决方案
[SESSION]同步
多个服务器之间互相同步SESSION,即A服务器生成一个SESSION信息后同步传输到B、C、D等服务器,同样B、C、D服务器生成SESSION信息后也需要同步到A,这样每个服务器之间都包含全部的SESSION
优点
- 大部分应用服务器都提供了
SESSION复制的功能来实现集群
缺点
SESSION需要网络传输进行同步,其会占用带宽,并且存在一定的延迟- 一旦某台机器的
SESSION信息有所变化,必须同步更新所有服务器SESSION内容 - 每个服务器都会存储全部的用户信息,性能随着服务器增加急剧下降,而且容易引起广播风暴
SESSION 映射
通过将负载均衡服务器进行修改,通过对返回给用户的SESSION ID或者用户请求的IP地址进行标记,也就是使用第四层传输层中读取网络层的IP或者是在第七层中读取HTTP协议中某些属性来做HASH,保证对于此用户的请求全部落到同一台服务器上
优点
- 实现相对简单
- 只要分配服务器时均匀,则多台服务器是负载均衡的
缺点
- 一旦某台服务器宕机,则会影响落在此服务器请求上的全部用户
- 负载均衡服务器变为了一个有状态的节点,内存消耗会更大,容灾更麻烦
客户端存储
将数据直接存储到客户端比如Cookie或请求头中,每次请求客户端自动携带数据信息
优点
- 简单,高效
- 服务端不需要储存标记用户信息
缺点
- 安全性较差,对于敏感信息必须加密
- 每次请求可能携带大量数据,占用外网带宽
- 数据存储在客户端就会存在泄密、篡改、窃取等隐患
后端集中存储
将SESSION存储在一台单独的服务器中的数据库中,例如Mysql、Oracle、SqlServer、Redis、Mongodb等等,各SERVER服务器需要用户信息时携带SESSION ID对于集中存储服务器进行请求,进而获取用户信息
优点
- 没有安全隐患
- 可以方便的水平拓展
SERVER服务器重启不会造成SESSION丢失
缺点
- 每次请求都增加了一次对于存储服务器的网络请求
- 会对集中存储服务器存在大量请求,数据库压力比较大
正则表达式

限定符
? 指前面的一个字符出现 0 次或者 1 次 可有可无
* 指前面的一个字符出现 0 次或者多次
+ 指前面的一个字符出现至少 1 次 就相当于正区间
{} 指前面的一个字符出现次数范围 {2,6} 2-6 次 {2,} 至少 2 次
{ab}+ 这样匹配了 ab 多次
或运算符
a (cat|dog) 可以匹配 a cat 或者 a dog
字符类
[abc]+ 匹配有abc的字符
[a-z] [A-Z] [0-9] [a-zA-Z] [a-zA-Z0-9]
^ [^0-9]+ 不含数字的字符
元字符
\d 数字字符
\D 非数字字符
\w 单词字符(英文,数字以及下划线)
\W 非单词字符
\s 空白字符(包含 Tab,制表符以及换行符)
\S 非空白字符
. 任意字符 不包含换行符
^ 只匹配行首
$ 只匹配行尾
贪婪与懒惰匹配
* + {} 会尽可能多的去匹配字符
比如匹配 html 标签 <.+?> ?将贪婪模式设置为懒惰模式
\b 和 \B
\b 是单词边界,具体就是 \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置
(?=p) 和 (?!p)
分组
/a+/ 匹配连续出现的 "a",而要匹配连续出现的 "ab" 时,需要使用 /(ab)+/。 其中括号是提供分组功能,使量词 + 作用于 "ab" 这个整体,测试如下:
var regex = /(ab)+/g;
var string = "ababa abbb ababab";
console.log(string.match(regex));
// => ["abab", "ab", "ababab"]
分组引用是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作
假设格式是 yyyy-mm-dd 的,我们可以先写一个简单的正则:
var regex = /\d{4}-\d{2}-\d{2}/;
然后再修改成括号版的:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
正则引擎在匹配过程中,给每一个分组都开辟一个空间,用来存储每一个分组匹配到的数据
比如提取出年、月、日,可以这么做:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log(string.match(regex));
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
match 返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的内容,然后是匹配下标,最后是输入的文本
也可以使用正则实例对象的 exec 方法:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log(regex.exec(string));
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
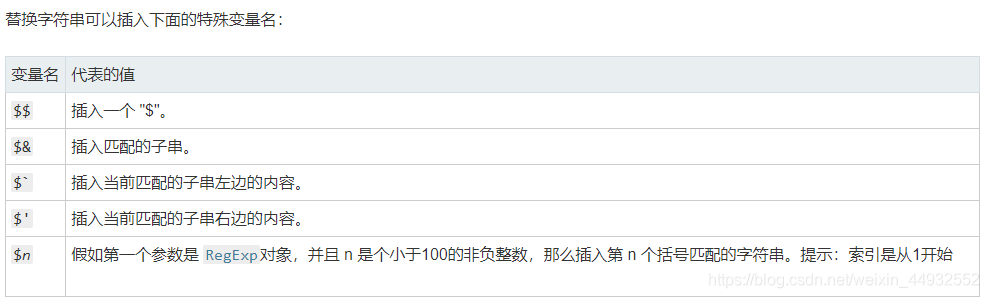
也可以使用构造函数的全局属性 $1 至 $9 来获取:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
regex.test(string); // 正则操作即可,例如
//regex.exec(string);
//string.match(regex);
console.log(RegExp.$1); // "2017"
console.log(RegExp.$2); // "06"
console.log(RegExp.$3); // "12"
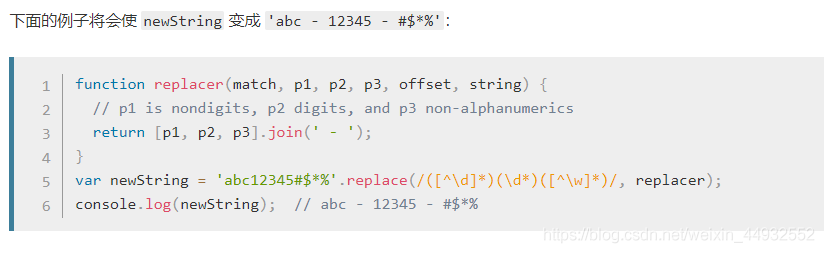
想把 yyyy-mm-dd 格式,替换成 mm/dd/yyyy 怎么做?
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/12/2017"
其中 replace 中的,第二个参数里用 $1、$2、$3 指代相应的分组。等价于如下的形式:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function () {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "06/12/2017"
也等价于:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function (match, year, month, day) {
return month + "/" + day + "/" + year;
});
console.log(result);
// => "06/12/2017"
实例
RGB 颜色值匹配
#[a-fA-F0-9]{6}\b \b 设置单词字符的边界
16 进制颜色
/#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g
时间匹配
时刻匹配
/^[01][0-9]|[2][0-3]):[0-5][0-9]$/
如果省略 0
/^(0?[0-9]|1[0-9]|[2][0-3]):(0?[0-9]|[1-5][0-9])$/
日期匹配
/^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01]$/g
IPv4 匹配
\d+.\d+.\d+.\d+
js 用法
var re = /ab+c/
var re = new RegExp('ab+c')
regex.test(str)
是否匹配
var str = "hello world!";
var result = /^hello/.test(str); // true
regex.exec(str)
得到匹配后的数组
var myRe = /d(b+)d/g;
myRe.exec("cdbbdbsdbdbz"); // ["dbbd", "bb", index: 1, input: "cdbbdbsdbdbz"]
myRe.exec("cdbbdbsdbdbz"); // ["dbd", "b", index: 7, input: "cdbbdbsdbdbz"]
myRe.exec("cdbbdbsdbdbz"); // null
str.match(regex)
如果是 global 匹配则出所有匹配的数组,如果不是,则出第一个匹配的字符串,以及相应的捕获内容
"cdbbdbsdbdbz".match(/d(b+)d/g); // ["dbbd", "dbd"]
"cdbbdbsdbdbz".match(/d(b+)d/); // ["dbbd", "bb", index: 1, input: "cdbbdbsdbdbz"]
str.search(regex)
得到第一次匹配的位置
"cdbbdbsdbdbz".search(/d(b+)d/); // 1
"xxx".search(/d(b+)d/); // -1 没有匹配
str.split(regex)
按照匹配拆分字符串
var names = "Harry Trump ;Fred Barney; Helen Rigby ; Bill Abel ;Chris Hand ";
var re = /\s*;\s*/;
var nameList = names.split(re);
// [ "Harry Trump", "Fred Barney", "Helen Rigby", "Bill Abel", "Chris Hand " ]
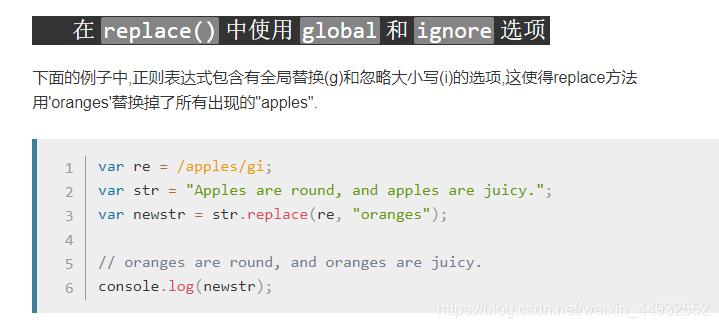
str.replace(regex)

按照匹配覆盖字符串
var re = /apples/gi;
var str = "Apples are round, and apples are juicy.";
var newstr = str.replace(re, "oranges");
// // oranges are round, and oranges are juicy.
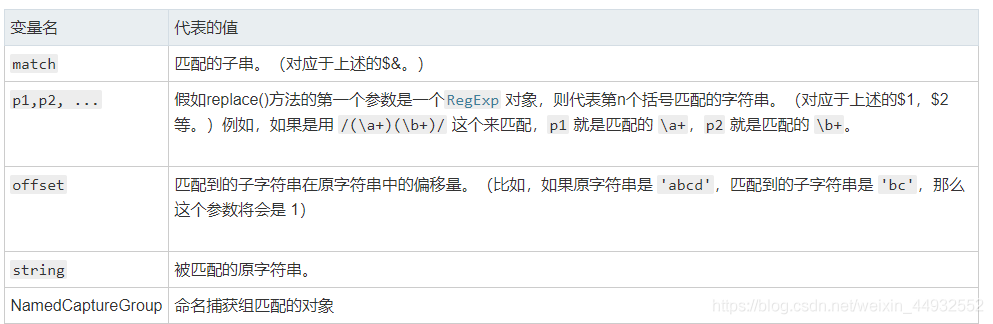
如果第二个参数是字符串,可以使用特殊的字符序列,将正则表达式操作得到的值插入到结果字符串中
$n:匹配第 n 个捕获组的子字符串。

返回值:
一个部分或全部匹配由替代模式所取代的新的字符串。
补充理解的知识点: 1.如果第一个参数是字符串,那么只会替换第一个子字符串。要想替换所有子字符串,唯一的方法就是提供一个正则表达式,指定全局匹配 g 模式。 2.该方法并不改变调用它的字符串本身,而只是返回一个新的替换后的字符串。 3.可以指定一个函数作为第二个参数。在这种情况下,当匹配执行后,该函数就会执行。 函数的返回值作为替换字符串。 (注意:上面提到的特殊替换参数在这里不能被使用。) 另外要注意的是,如果第一个参数是正则表达式,并且其为全局匹配模式,那么这个方法将被多次调用,每次匹配都会被调用。
面向对象理论
1.为什么选择面向对象编程
① 易扩展:由于面向对象编程封装、继承、多态的三大特性,使得设计出来的系统高内聚、低耦合,整个系统灵活、易扩展,而且成本较低。 ② 程序的鲁棒性好:开发过程中可以重用已有的并在相关领域经过长期测试的代码,这对系统的鲁棒性有良好的促进作用。 ③ 效率高:在软件开发时,根据需要将现实世界的事物抽象成类,类的属性表示事物的特有性质、类的方法表示事物的行为。一个类对象表示一个事物的实例。这种方式更贴近人类的日常思维,能够提高程序的开发效率和质量。
2.面向对象的特性
(1)封装
即隐藏对象的属性和实现细节,仅对外公开接口。 封装的优点如下: ① 防止使用者有意无意地篡改重要的系统属性 ② 提高了各个子系统之间的松耦合性,提高系统的独立性。当一个系统内部发生改动时,只要对外提供的接口不变,就不会影响到其他的系统。 ③ 提高软件的可重用性。每个系统都是一个相对独立的整体,可以在多种环境中得到重用。 ④ 降低了建构大型系统的风险。即使整个系统不成功,个别独立的子系统依然是有价值的。
(2)继承
子类可以继承父类的属性和方法。同时,子类中还可以扩展出新的属性和方法。 继承的优点如下: 提高了系统的可重用性和可扩展性。
(3)多态
多态指当系统 A 访问系统 B 的服务时,系统 B 可以通过多种实现方式来提供服务。主要包括:重载(overload)和重写(override)两种方式。 重载必须满足以下条件: ① 方法名相同 ② 参数的个数、顺序、类型至少有 1 项不同 ③ 返回类型可以不同(两个方法不能仅有返回类型不同!!!) ④ 修饰符可以不同
重写发生在父类与子类之间,必须满足以下条件: ① 方法名、参数、返回值一定要相同 ② 子类方法不能缩小父类方法的访问权限 ③ 子类方法不能比父类抛出更多的异常 ④ 父类的非静态方法不能被子类覆盖为静态方法 ⑤ 父类的静态方法不能被子类覆盖为非静态的方法 ⑥ 子类可以定义与父类静态方法同名的静态方法 ⑦ 子类不能覆盖父类的私有方法
注:重载与重写的区别: ① 重载要求两个函数的函数名相同,但参数的个数、种类或者类型不同、返回类型不同(可以仅仅参数不同,不能仅仅只有返回类型不同);重写要求两个函数的返回值类型、函数名、参数完全相同
3.面向对象编程的原则
(1)单一职责原则:设计一个类时要考虑好类的属性和方法。不要有多余的方法,否则会出现权责不明,对程序的开发和维护都十分不利。 (2)开放封闭原则:对类的扩展是开放的(可以创建子类继承父类或者抽象方法、也可以创建类来实现接口,这样可以提高代码的可重用性),对类的更改是封闭的(尽量减少对已有类的更改,否则可能会引发一系列错误)。 (3)依赖倒置原则:在 MVC 设计模式中,Control 层依赖于 Service 层,Service 层依赖于 Dao 层,这叫依赖实现编程,这种方式有一个缺点就是各层之间的耦合性太强; 现将 MVC 各层抽象,在 Control 层和 Service 层之间建立关系,在 Service 和 Dao 层之间建立关系,这叫依赖抽象编程,这种方式降低了各层之间的耦合性,提高了独立性。 从“依赖实现编程”到“依赖抽象编程”的转变,即是依赖倒置原则 (4)里氏代换原则:子类必须能够替换掉他们的父类 (5)迪米特原则:两个没有直接联系的类之间要发生相互作用,可以通过第三个类来实现。 (6)组合原则:尽量少用类之间的继承,尽量使用组合。过多的继承会是整个系统变得复杂。而组合是一种用多个简单子系统组装出复杂系统的有效手段。
操作系统原理
1.进程和线程
进程(Process)是系统进行资源分配和调度的基本单位。
进程也是抢占处理机的调度单位,它拥有一个完整的虚拟地址空间。当进程发生调度时,不同的进程拥有不同的虚拟地址空间,而同一进程内的不同线程共享同一地址空间。
与进程相对应,线程与资源分配无关,它属于某一个进程,并与进程内的其他线程一起共享进程的资源。
线程只由相关堆栈(系统栈或用户栈)寄存器和线程控制表 TCB 组成。寄存器可被用来存储线程内的局部变量,但不能存储其他线程的相关变量。
调度与操作系统的线程的实现有关,如果是管态线程与目态线程是一一对应,则调度的最小单位可以是线程,但我觉得这也就是理论上,一般的商用操作系统可能操作系统调度的单位也是进程。
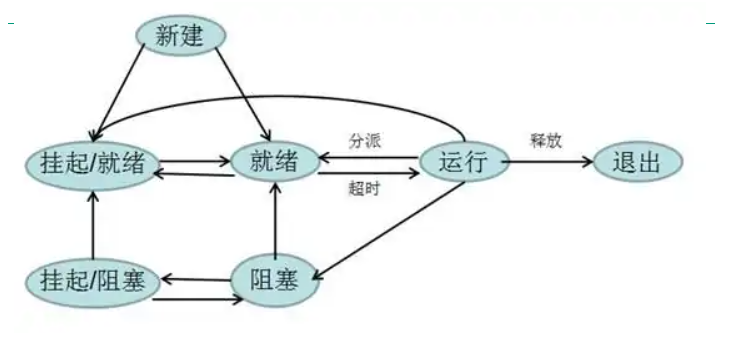
进程一般有三个状态:就绪状态、执行状态和等待状态【或称阻塞状态】;进程只能由父进程建立,系统中所有的进程形成一种进程树的层次体系;挂起命令可由进程自己和其他进程发出,但是解除挂起命令只能由其他进程发出。
进程控制块(PCB):PCB 不但可以记录进程的属性信息,以便操作系统对进程进行控制和管理,而且 PCB 标志着进程的存在,操作系统根据系统中是否有该进程的进程控制块 PCB 而知道该进程存在与否。
系统建立进程的同时就建立该进程的 PCB,在撤销一个进程时,也就撤销其 PCB,故进程的 PCB 对进程来说是它存在的具体的物理标志和体现。一般 PCB 包括以下三类信息:进程标识信息;处理器状态信息;进程控制信息。
2.进程间通信
前端领域已经不是单纯写在浏览器里跑的页面就可以了,还要会 electron、nodejs 等,而这俩技术都需要掌握进程通信。
nodejs 是 js 的一个运行时,和浏览器不同,它扩展了很多封装操作系统能力的 api,其中就包括进程、线程相关 api,而学习进程 api 就要学习进程之间的通信机制。
electron 是基于 chromium 和 nodejs 的桌面端开发方案,它的架构是一个主进程,多个渲染进程,这两种进程之间也需要通信,要学习 electron 的进程通信机制。
这篇文章我们就来深入了解一下进程通信。
本文会讲解以下知识点:
- 进程是什么
- 本地进程通信的四种方式
- ipc、lpc、rpc 都是什么
- electron 如何做进程通信
- nodejs 的 child_process 和 cluster 如何做进程通信
- 进程通信的本质
进程
我们写完的代码要在操作系统之上跑,操作系统为了更好的利用硬件资源,支持了多个程序的并发和硬件资源的分配,分配的单位就是进程,这个进程就是程序的执行过程。比如记录程序执行到哪一步了,申请了哪些硬件资源、占用了什么端口等。
进程包括要执行的代码、代码操作的数据,以及进程控制块 PCB(Processing Control Block),因为程序就是代码在数据集上的执行过程,而执行过程的状态和申请的资源需要记录在一个数据结构(PCB)里。所以进程由代码、数据、PCB 组成。

pcb 中记录着 pid、执行到的代码地址、进程的状态(阻塞、运行、就绪等)以及用于通信的信号量、管道、消息队列等数据结构。

进程从创建到代码不断的执行,到申请硬件资源(内存、硬盘文件、网络等),中间还可能会阻塞,最终执行完会销毁进程。这是一个进程的生命周期。
进程对申请来的资源是独占式的,每个进程都只能访问自己的资源,那进程之间怎么通信呢?
进程通信
不同进程之间因为可用的内存不同,所以要通过一个中间介质通信。
信号量
如果是简单的标记,通过一个数字来表示,放在 PCB 的一个属性里,这叫做信号量,比如锁的实现就可以通过信号量。
这种信号量的思想我们写前端代码也经常用,比如实现节流的时候,也要加一个标记变量。
管道
但是信号量不能传递具体的数据啊,传递具体数据还得用别的方式。比如我们可以通过读写文件的方式来通信,这就是管道,如果是在内存中的文件,叫做匿名管道,没有文件名,如果是真实的硬盘的文件,是有文件名的,叫做命名管道。
文件需要先打开,然后再读和写,之后再关闭,这也是管道的特点。管道是基于文件的思想封装的,之所以叫管道,是因为只能一个进程读、一个进程写,是单向的(半双工)。而且还需要目标进程同步的消费数据,不然就会阻塞住。
这种管道的方式实现起来很简单,就是一个文件读写,但是只能用在两个进程之间通信,只能同步的通信。其实管道的同步通信也挺常见的,就是 stream 的 pipe 方法。
消息队列
管道实现简单,但是同步的通信比较受限制,那如果想做成异步通信呢?加个队列做缓冲(buffer)不就行了,这就是消息队列。
消息队列也是两个进程之间的通信,但是不是基于文件那一套思路,虽然也是单向的,但是有了一定的异步性,可以放很多消息,之后一次性消费。
共享内存
管道、消息队列都是两个进程之间的,如果多个进程之间呢?
我们可以通过申请一段多进程都可以操作的内存,叫做共享内存,用这种方式来通信。各进程都可以向该内存读写数据,效率比较高。
共享内存虽然效率高、也能用于多个进程的通信,但也不全是好处,因为多个进程都可以读写,那么就很容易乱,要自己控制顺序,比如通过进程的信号量(标记变量)来控制。
共享内存适用于多个进程之间的通信,不需要通过中间介质,所以效率更高,但是使用起来也更复杂。
上面说的这些几乎就是本地进程通信的全部方式了,为什么要加个本地呢?
ipc、rpc、lpc
进程通信就是 ipc(Inter-Process Communication),两个进程可能是一台计算机的,也可能网络上的不同计算机的进程,所以进程通信方式分为两种:
本地过程调用 LPC(local procedure call)、远程过程调用 RPC(remote procedure call)。
本地过程调用就是我们上面说的信号量、管道、消息队列、共享内存的通信方式,但是如果是网络上的,那就要通过网络协议来通信了,这个其实我们用的比较多,比如 http、websocket。
所以,当有人提到 ipc 时就是在说进程通信,可以分为本地的和远程的两种来讨论。
远程的都是基于网络协议封装的,而本地的都是基于信号量、管道、消息队列、共享内存封装出来的,比如我们接下来要探讨的 electron 和 nodejs。
electron 进程通信
electron 会先启动主进程,然后通过 BrowserWindow 创建渲染进程,加载 html 页面实现渲染。这两个进程之间的通信是通过 electron 提供的 ipc 的 api。
ipcMain、ipcRenderer
主进程里面通过 ipcMain 的 on 方法监听事件
import { ipcMain } from "electron";
ipcMain.on("异步事件", (event, arg) => {
event.sender.send("异步事件返回", "yyy");
});
渲染进程里面通过 ipcRenderer 的 on 方法监听事件,通过 send 发送消息
import { ipcRenderer } from "electron";
ipcRender.on("异步事件返回", function (event, arg) {
const message = `异步消息: ${arg}`;
});
ipcRenderer.send("异步事件", "xxx");
api 使用比较简单,这是经过 c++ 层的封装,然后暴露给 js 的事件形式的 api。
我们可以想一下它是基于哪种机制实现的呢?
很明显有一定的异步性,而且是父子进程之间的通信,所以是消息队列的方式实现的。
remote
除了事件形式的 api 外,electron 还提供了远程方法调用 rmi (remote method invoke)形式的 api。
其实就是对消息的进一步封装,也就是根据传递的消息,调用不同的方法,形式上就像调用本进程的方法一样,但其实是发消息到另一个进程来做的,和 ipcMain、ipcRenderer 的形式本质上一样。
比如在渲染进程里面,通过 remote 来直接调用主进程才有的 BrowserWindow 的 api。
const { BrowserWindow } = require("electron").remote;
let win = new BrowserWindow({ width: 800, height: 600 });
win.loadURL("https://github.com");
小结一下,electron 的父子进程通信方式是基于消息队列封装的,封装形式有两种,一种是事件的方式,通过 ipcMain、ipcRenderer 的 api 使用,另一种则是进一步封装成了不同方法的调用(rmi),底层也是基于消息,执行远程方法但是看上去像执行本地方法一样。
nodejs
nodejs 提供了创建进程的 api,有两个模块: child_process 和 cluster。很明显,一个是用于父子进程的创建和通信,一个是用于多个进程。
child_process
child_process 提供了 spawn、exec、execFile、fork 的 api,分别用于不同的进程的创建:
spawn、exec
如果想通过 shell 执行命令,那就用 spawn 或者 exec。因为一般执行命令是需要返回值的,这俩 api 在返回值的方式上有所不同。
spawn 返回的是 stream,通过 data 事件来取,exec 进一步分装成了 buffer,使用起来简单一些,但是可能会超过 maxBuffer。
const { spawn } = require('child_process');
var app = spawn('node','main.js' {env:{}});
app.stderr.on('data',function(data) {
console.log('Error:',data);
});
app.stdout.on('data',function(data) {
console.log(data);
});
其实 exec 是基于 spwan 封装出来的,简单场景可以用,有的时候要设置下 maxBuffer。
const { exec } = require('child_process');
exec('find . -type f', { maxBuffer: 1024*1024 }(err, stdout, stderr) => {
if (err) {
console.error(`exec error: ${err}`); return;
}
console.log(stdout);
});
execFile
除了执行命令外,如果要执行可执行文件就用 execFile 的 api:
const { execFile } = require("child_process");
const child = execFile("node", ["--version"], (error, stdout, stderr) => {
if (error) {
throw error;
}
console.log(stdout);
});
fork
还有如果是想执行 js ,那就用 fork:
const { fork } = require("child_process");
const xxxProcess = fork("./xxx.js");
xxxProcess.send("111111");
xxxProcess.on("message", (sum) => {
res.end("22222");
});
小结
简单小结一下 child_process 的 4 个 api:
如果想执行 shell 命令,用 spawn 和 exec,spawn 返回一个 stream,而 exec 进一步封装成了 buffer。除了 exec 有的时候需要设置下 maxBuffer,其他没区别。
如果想执行可执行文件,用 execFile。
如果想执行 js 文件,用 fork。
child_process 的进程通信
说完了 api 我们来说下 child_process 创建的子进程怎么和父进程通信,也就是怎么做 ipc。
pipe
首先,支持了 pipe,很明显是通过管道的机制封装出来的,能同步的传输流的数据。
const { spawn } = require("child_process");
const find = spawn("cat", ["./aaa.js"]);
const wc = spawn("wc", ["-l"]);
find.stdout.pipe(wc.stdin);
比如上面通过管道把一个进程的输出流传输到了另一个进程的输入流,和下面的 shell 命令效果一样:
cat ./aaa.js | wc -l
message
spawn 支持 stdio 参数,可以设置和父进程的 stdin、stdout、stderr 的关系,比如指定 pipe 或者 null。还有第四个参数,可以设置 ipc,这时候就是通过事件的方式传递消息了,很明显,是基于消息队列实现的。
const { spawn } = require("child_process");
const child = spawn("node", ["./child.js"], {
stdio: ["pipe", "pipe", "pipe", "ipc"],
});
child.on("message", (m) => {
console.log(m);
});
child.send("xxxx");
而 fork 的 api 创建的子进程自带了 ipc 的传递消息机制,可以直接用。
const { fork } = require("child_process");
const xxxProcess = fork("./xxx.js");
xxxProcess.send("111111");
xxxProcess.on("message", (sum) => {
res.end("22222");
});
cluster
cluster 不再是父子进程了,而是更多进程,也提供了 fork 的 api。
比如 http server 会根据 cpu 数启动多个进程来处理请求。
import cluster from "cluster";
import http from "http";
import { cpus } from "os";
import process from "process";
const numCPUs = cpus().length;
if (cluster.isPrimary) {
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
const server = http.createServer((req, res) => {
res.writeHead(200);
res.end("hello world\n");
});
server.listen(8000);
process.on("message", (msg) => {
if (msg === "shutdown") {
server.close();
}
});
}
它同样支持了事件形式的 api,用于多个进程之间的消息传递,因为多个进程其实也只是多个父子进程的通信,子进程之间不能直接通信,所以还是基于消息队列实现的。
共享内存
子进程之间通信还得通过父进程中转一次,要多次读写消息队列,效率太低了,就不能直接共享内存么?
现在 nodejs 还是不支持的,可以通过第三方的包 shm-typed-array 来实现,感兴趣可以看一下。
总结
进程包括代码、数据和 PCB,是程序的一次执行的过程,PCB 记录着各种执行过程中的信息,比如分配的资源、执行到的地址、用于通信的数据结构等。
进程之间需要通信,可以通过信号量、管道、消息队列、共享内存的方式。
- 信号量就是一个简单的数字的标记,不能传递具体数据。
- 管道是基于文件的思想,一个进程写另一个进程读,是同步的,适用于两个进程。
- 消息队列有一定的 buffer,可以异步处理消息,适用于两个进程。
- 共享内存是多个进程直接操作同一段内存,适用于多个进程,但是需要控制访问顺序。
这四种是本地进程的通信方式,而网络进程则基于网络协议的方式也可以做进程通信。
进程通信叫做 ipc,本地的叫做 lpc,远程的叫 rpc。
其中,如果把消息再封装一层成具体的方法调用,叫做 rmi,效果就像在本进程执行执行另一个进程的方法一样。
electron 和 nodejs 都是基于上面的操作系统机制的封装:
- elctron 支持 ipcMain 和 ipcRenderer 的消息传递的方式,还支持了 remote 的 rmi 的方式。
- nodejs 有 child_process 和 cluster 两个模块和进程有关,child_process 是父子进程之间,cluster 是多个进程:
- child_process 提供了用于执行 shell 命令的 spawn、exec,用于执行可执行文件的 execFile,用于执行 js 的 fork。提供了 pipe 和 message 两种 ipc 方式。
- cluster 也提供了 fork,提供了 message 的方式的通信。
当然,不管封装形式是什么,都离不开操作系统提供的信号量、管道、消息队列、共享内存这四种机制。
ipc 是开发中频繁遇到的需求,希望这篇文章能够帮大家梳理清楚从操作系统层到不同语言和运行时的封装层次的脉络。
3.死锁产生原因和解决
死锁:两个或多个并发进程中,如果每个进程持有某种资源而又都等待着别的进程释放它或它们现在保持着的资源,否则就不能向前推进。此时称这一组进程为死锁
引起死锁的原因和必要条件 引起死锁的原因: ① 系统资源不足 ② 进程推进顺序非法
产生死锁的必要条件 ① 互斥条件——涉及的资源是非共享的,即为临界资源 ② 不剥夺条件——进程所获得的资源在未使用完毕之前,不能被其它进程强行夺走 ③ 部分分配——进程每次申请它所需要的一部分资源。在等待新资源的同时,进程继续占用已分配到的资源 ④ 环路条件——存在一种进程的循环链,链中的每一个进程已获得的资源同时被链中下一个进程所请求
为了使系统不发生死锁,必须要破坏产生死锁的四个必要条件之一
① 采用资源静态分配方法预防死锁 ② 采用资源动态分配、有控分配方法来避免死锁 ③ 当死锁发生时检测出死锁,并设法修复 ④ 忽略死锁,一旦发生死锁便重启系统(这种方法被绝大多数操作系统所采用)
死锁的动态避免就是采用资源动态分配的方式 ① 有序资源分配方法:系统中所有资源都给一个唯一的编号,所有分配请求必须以上升的次序进行,当遵守上升次序的规则时,若资源可用,则予以分配;否则,请求者等待。 ② 银行家算法:申请者事先说明对各类资源的最大需求量。在进程活动期间动态申请某类资源时,由系统审查现有该类资源的数目是否能满足当前进程的最大需求量,如能满足就予以分配,否则拒绝。
4.操作系统资源分配
资源管理目的:为用户提供一种简单而有效地使用资源的方法 任务:1、资源数据结构的描述 2、确定资源的分配原则和调度原则 3、执行资源分配 4、存取控制和安全保护
操作系统对资源区分两种不同的概念 ① 物理资源——系统中那些物理、可实际使用的资源 ② 虚拟资源——逻辑资源。是经过操作系统改造的、用户看到的,使用方便的虚资源
目的:① 方便用户使用 ② 资源可动态分配,提高资源利用率
资源分配机制 资源描述器:描述各类资源的最小分配单位的数据结构 资源信息块:描述某类资源的请求者、可利用的资源以及该类资源分配程序的地址
资源分配策略:在众多个请求者中选一个满足条件的请求者原则
资源分配策略具体如何体现? 体现在资源请求队列的排序原则上 (1)先请求先服务策略(FIFO) ① 排序原则——按请求的先后次序排序:每一个新产生的请求均排在资源请求队列的队尾。 ② 资源可用时的处理:资源可用时,取资源请求队列队首元素,将该资源分配给请求者。
(2)优先调度策略 ① 排序原则——按请求的优先级高低排序 对每一个进程制定一个优先级 按优先级的高低排序——每一个新产生的请求按对应进程的优先级高低插入到队列的相应位置。 (3)针对设备特性的调度策略 调度目标:当有大量的 I/O 请求时,降低完成这些 I/O 服务的总时间 移臂调度:最短寻道时间优先算法(SSTF)、扫描算法(SCAN) 旋转调度
如何确定移动臂磁盘组中磁盘块的物理位置
计算机组成原理
1.怎么存储数
- 在 JS 中能否表示的数字的绝对值范围是 5e-324 ~ 1.7976931348623157e+308,这一点可以通过
Number.MAX_VALUE和Number.MIN_VALUE来得到证实 - 在 JS 中能够表示的最大安全整数的范围是:-9007199254740991 ~ 9007199254740991,这一点可以通过
Number.MIN_SAFE_INTEGER和Number.MAX_SAFE_INTEGER来求证
存在的问题
在四则运算中存在精度丢失的问题,比如:
01 + 0.2 //0.30000000000000004超过最大安全整数的运算是不安全的,比如:
9007199254740991 + 2 // 9007199254740992把这个浮点数转成对应的二进制数,并用科学计数法表示
把这个数值通过IEEE 754标准表示成真正会在计算机中存储的值
我们知道,JS 中的 Number 类型使用的是双精度浮点型,也就是其他语言中的 double 类型。而双精度浮点数使用 64 bit 来进行存储,结构图如下:
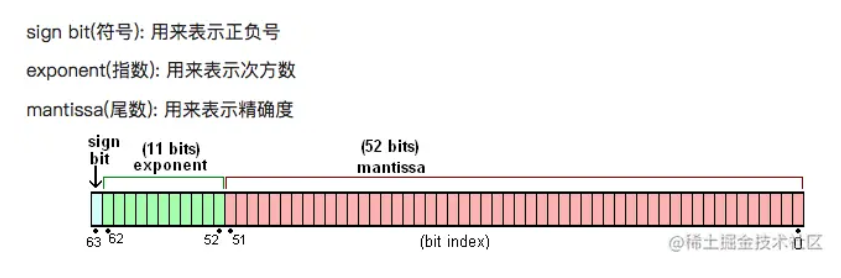
也就是说一个 Number 类型的数字在内存中会被表示成:s x m x 2^e这样的格式。
在ES 规范中规定 e 的范围在-1074 ~ 971,而 m 最大能表示的最大数是 52 个 1,最小能表示的是 1,这里需要注意:
2.什么是补码
原码
一个 8 位的存储单元可以存储 00000000 ~ 11111111 共 256 种数字,真值(即真实数值,用 10 进制表示)从 0 ~ 255。为了引入负数,所以设计出了原码:用存储单元的第一位表示符号,1 位负,0 为正,后面的位表示真值的绝对值。同样以 8 位存储单元位例,在用原码的方式下我们依然可以表示 256 个数,从 11111111 ~ 01111111,真值范围为 -127 ~ 127,可能你发现真值一共只有255 个,因为 10000000 和 00000000 表示的都是 0,即-0和+0。
反码
由于原码中,+x和-x使用二进制加法(利用加法电路)相加不能等于 0,设计了反码,即:如果是正数则保持不变,如果是负数,则除符号位之外按位取反。这样正负 2 数相加就变成了 11111111 ,也就是-0,注意这里的结果也是反码。
补码
补码的定义就是正数和 0 的补码就是原码,负数的补码是其反码 +1。-1 的原码是 10000001,反码是 11111110,补码在反码的基础上 +1,即为 11111111。-0 取补码后跟 0 是一致的,没有了两个 0 的问题,没了-0 后多出的10000000表示-128,真值数也变回了 256。这也就是我们今天计算机所用的存储和计算的方式
由于高位溢出舍弃,采用补码的方式,无论是从11111111(-1)到00000000(0),还是从01111111(127)到100000000(-128)都是连续的,所有数其实是一个类似钟表上数字的闭合的环。0 是 0 点位置,-128 是 6 点位置。反码、补码,通过数学上的同余定理中的同余式相加,达到了用加法来实现减法的效果。
3.指令,汇编语言,机器码有什么区别和联系
指令
1.机器码由 0 和 1 组成的二进制序列,其可读性差,但运行速度快,为方便阅读,人们发明了指令。
2.指令就是把机器码中特定的 0 和 1 序列简化为对应的指令,一般为英文缩写。如 jmp,add,mov 等。
3.不同平台对应的同一操作的机器码可能不同。
指令集
1.不同平台所支持的指令有所差异,把每个平台所支持的指令,称为该平台对应的指令集
2 常见的指令集
x86 指令集,对应的是x86 框架的平台
ARM 指令集,······
汇编语言
1.在提高指令阅读性的基础上,又发明了汇编语言
2.用助记符代替机器指令的操作码,用地址符号或标号代替指令或操作数的地址
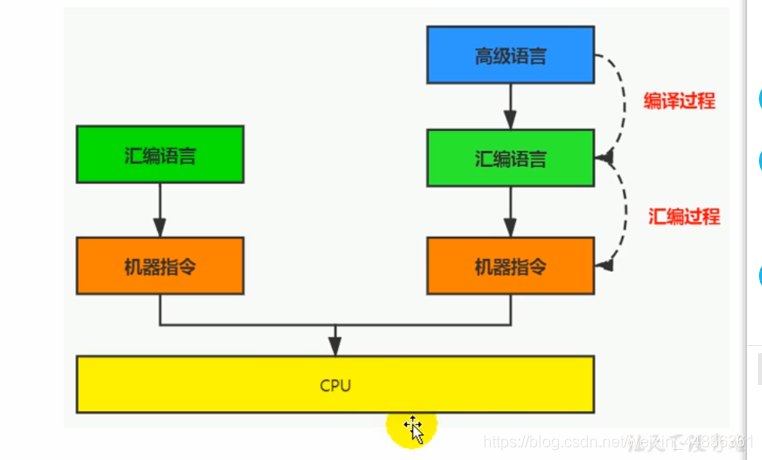
编译原理
1.C 语言是怎么进行编译的

高级语言 → 汇编语言 → 机器语言(二进制)
1.预处理
由.c 文件到.i 文件,这个过程叫预处理。在源文件被编译前,首先要进行预处理的工作,也就是对源代码进行相对应的展开、替换和清理。
① 在这个过程中,主要处理的事情:
② 把代码注释部分去掉,不让其参与编译
③ 将所有的#define 删除,并且展开所有的宏定义,简单来说就是字符替换
④ 处理所有的条件编译指令,例如#ifdef、#ifndef、#endif,简单来说就是带#的那些
⑤ 把“stdio.h”文件包含进来,即用“stdio.h”中的内容替换在“#include”位置
2.编译
由.i 文件到.s 文件,这个过程叫编译。编译的过程实质上是把高级语言翻译成机器语言的过程。简单来说,源文件被预处理之后,再以字符流的形式进行处理,进行词法和语法的分析,然后通过汇编器将源代码指令转变成汇编指令、生成相应的汇编文件。
3.汇编
由.s 文件到.o 文件,这个过程叫汇编。汇编是指把汇编语言代码翻译成目标机器指令的过程,也就是把汇编码转换成机器所能识别的二进制,通过把经过汇编之后生成的文件称为目标文件。
4.链接
由.o 文件到可执行文件,这个过程叫链接。经过汇编之后生成的目标文件并不能立即被执行,还需要由链接器将代码在执行过程中用到的其他目标代码及库文件进行链接,最终生成一个可执行程序。
假如.c 文件中有用到 printf 函数,那么就需要找到包含该函数的标准库文件,对它进行链接。
2.词法分析和文法分析
https://zhuanlan.zhihu.com/p/31096468
什么是编译器?
对外部来说,编译器是一个黑盒子,能够把一种源语言翻译为语义上等价的另一种目标语言。从现代高级编译器的角度讲,源语言是高级程序设计语言,容易阅读与编写,而目标语言是机器语言,即二进制代码,能够被计算机直接识别。从语言系统的处理角度来看,由源程序生成可执行程序的整体工作流程如图 1 所示:
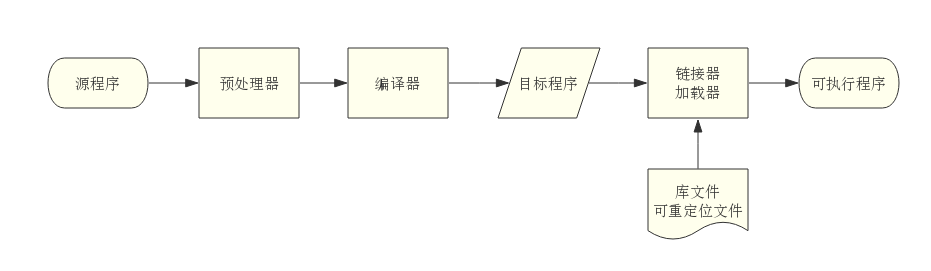
其中,编译器又分为前端和后端两个部分。前端包括词法分析、语法分析、语义分析、中间代码生成,具有机器无关性,比较有代表性的工具是 Flex、Bison。后端包括中间代码优化、目标代码生成,具有机器相关性,比较有代表性的工具是 LLVM。在 Web 前端工程领域,由于宿主环境浏览器与 Node.js 的跨平台特性,我们只需关注编译器前端部分,就可以充分发挥它的应用价值。为了更好地理解编译器前端的工作原理,本文将主要以目前被广泛使用的 Babel 为例,阐述它是如何将源代码编译为目标代码。
Babel
作为新生代 ES 语法编译器,Babel 在前端工具链中占据了非常重要的地位,它严格按照 ECMA-262 语言规范,实现对最新语法的解析,而无需等待浏览器升级来提供对新特性的支持。Babel 内部所使用的语法解析器是 Babylon,抽象语法树(简写为 AST)的结点类型定义则参考了 Mozilla JS 引擎 SpiderMonkey,并对其进行扩展增强,且支持对 Flow、JSX、TypeScript 语法的解析。它所使用的 Babylon 实现了编译器中两个部分,词法分析和语法分析。
词法分析
词法分析是处理源程序的第一部分,主要任务是逐个扫描输入字符,转换为词法单元(Token)序列,传递给语法分析器进行语法分析。Token 是一个不可分割的最小单元。例如 var 这三个字符,它只能作为一个整体,语义上不能再被分解,因此它是一个 Token。每个 Token 对象都有能够被单独识别的类型属性和其它附加属性(操作符优先级、行列号等)。在 Babylon 词法分析器里,每个关键字是一个 Token ,每个标识符是一个 Token,每个操作符是一个 Token,每个标点符号也都是一个 Token。除此之外,还会过滤掉源程序中的注释和空白字符(换行符、空格、制表符等)。
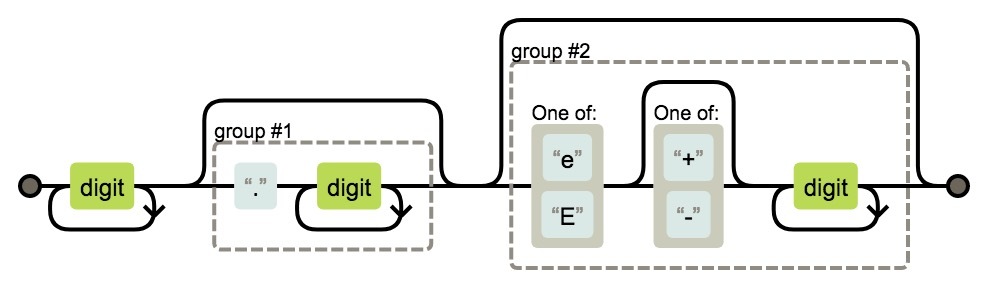
对于 Token 的匹配规则,可以根据正则表达式来描述。举个例子,要匹配一个 Number 类型的 Token,可以检测是否以 [0-9] 开头,接着循环或递归扫描紧连的后续字符,且需要特别留意 0b、0o、0x 开头的非十进制数值、科学计数法 e 或 E、小数点等特殊字符,指针不断后移直至不满足匹配规则或者到达行末尾。最后生成一个 Number 类型的 Token,附带值、文件位置等属性,并加入到 Token 序列中,继续下一轮扫描。
一个简单的 Number 类型状态转换如图 2 所示:
当然除了 Babylon 手写词法分析器之外,这个过程还可以采用有穷自动机(DFA/NFA)的方式实现,通过词法分析器生成器,把输入程序(模式匹配规则)自动转换成一个词法分析器,这里不展开阐述。
语法分析
语法分析是词法分析的下一步,主要任务是扫描来自词法分析器产生的 Token 序列,根据文法和结点类型定义构造出一棵 AST,传递给编译器前端余下部分。文法描述了程序设计语言的构造规则,用于指导整个语法分析的过程。它由四个部分组成,一组终结符号(也称 Token)、一组非终结符号、一组产生式和一个开始符号。例如,函数声明语句的产生式表示形式如图 3 所示:
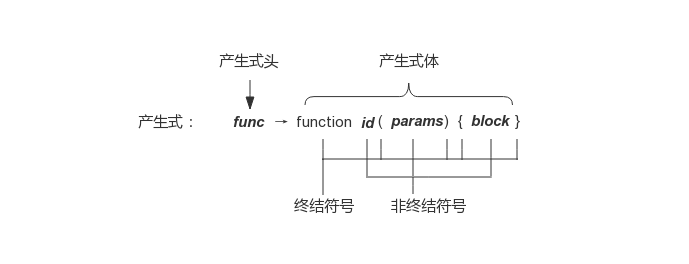
根据文法,语法分析器将 Token 逐个读入,不断替换文法产生式体的非终结符号,直至全部将非终结符号替换为终结符号,这个过程被称为推导。推导又分为两种方式,最左推导和最右推导。如果总是优先替换产生式体最左侧的非终结符号,被称为最左推导,如果总是优先替换产生式体最右侧的非终结符号,被称为最右推导。
语法分析器按照工作方式来划分,分为自顶向下分析法和自底向上分析法。自顶向下分析法要求通过最左推导从顶部 ( 根结点 ) 开始构造 AST,常用的分析器有递归下降语法分析器、 LL 语法分析器。而自底向上分析法要求通过最右推导从底部 ( 叶子结点 ) 开始构造 AST,常用的分析器有 LR 语法分析器、SLR 语法分析器、LALR 语法分析器。这两种分析方式在 Babylon 中都有所实践。
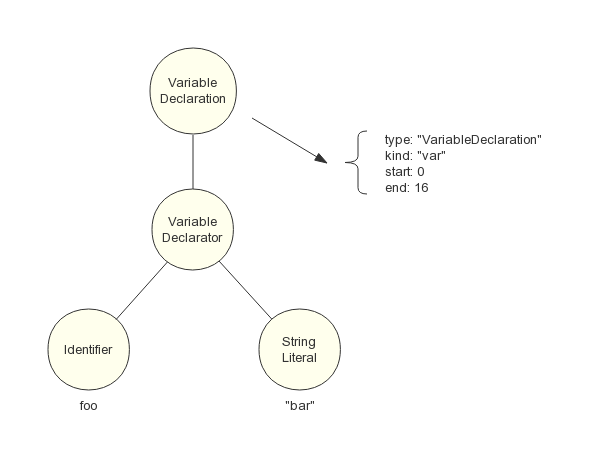
首先是自顶向下分析法,例如变量声明语句:
var foo = "bar";
经由词法分析器处理后,会生成 Token 序列:
Token("var");
Token("foo");
Token("=");
Token('"bar"');
Token(";");
由 LL(1) 语法分析器进行递归下降分析,每次向前查看一个输入 Token,来决定该用哪种产生式展开。对于变量声明语句的 FIRST 集合(推导结果的首个 Token 集合),只需检查输入 Token 为 Token('var')、Token('let')、Token('const') 三者其中之一,那么就使用该产生式展开。首先构造 AST 最顶层结点 VariableDeclaration,把 Token('var') 的值加入到该结点属性中, 接着逐个读入其余 Token,根据产生式的非终结符号从左到右的顺序,依次构造它的子结点,不断递归下降分析,直至所有 Token 读入完毕。最后生成的一棵 AST 如图 4 所示:
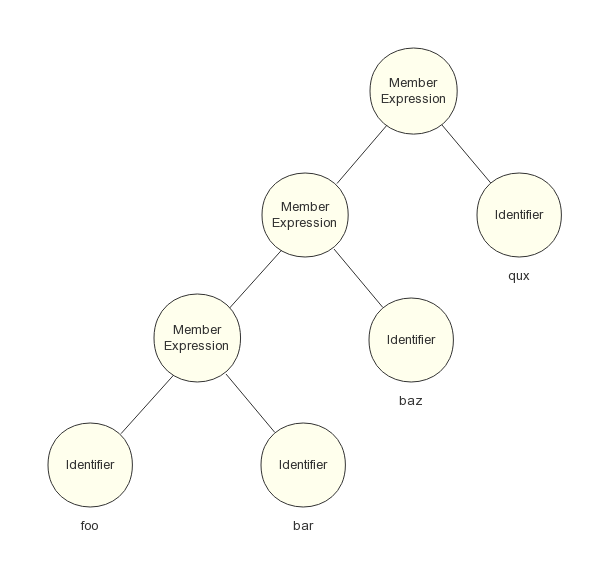
另一种是自底向上分析法,例如成员表达式语句:
foo.bar.baz.qux;
我们都知道这条语句等价于:
foo.bar.baz.qux;
而不是:
foo.(bar.(baz.qux))
原因就在于它所设计的文法是左递归的,而 LL 语法分析器是无法做到解析左递归的文法,这时候只能使用 LR 语法分析器的方式,自底向上地构造 AST。LR 语法分析器的核心是移入 - 归约分析技术,通过维护一个栈,由下一个输入 Token 来决定是把它移入栈中还是将栈顶的部分符号进行归约(把产生式体替换为产生式头),先构造子结点,再构造父结点,直至栈中所有符号全部归约。最后生成的一棵 AST 如图 5 所示:
此外,由 Babylon 构建的完整的 AST 还拥有特殊顶层结点 File 和 Program,它们描述了文件的基本信息、模块类型等等。
生成代码
工业级别的语言编译器,通常还会有语义分析阶段,检查程序上下文是否和语言所定义的语义一致,比如类型检查,作用域检查,另一个则是生成中间代码,比如三地址代码,用地址和指令来线性描述程序。但由于 Babel 的定位仅仅是对 ES 语法的转换,这一部分工作可以交给 JS 解释器引擎来处理。而 Babel 最为特色的部分是它的插件机制,针对不同的浏览器版本环境,调用不同的 Babel 插件。通过访问者模式(一种设计模式)的接口定义,对 AST 进行一遍深度优先遍历,对指定的匹配到的结点进行修改、删除、新增、移位,使原先的 AST 转换为另一棵经过修改的 AST。
一个访问者模式的接口定义如下:
visitor: {
Identifier(path) {
enter() {
//遍历AST进入Identifier结点时执行
...
},
exit() {
//遍历AST离开Identifier结点时执行
...
}
},
...
}
最后一个阶段则是生成目标代码,从 AST 的根结点出发,递归下降遍历,对每个结点都调用一个相关函数,执行语义动作,不断打印代码片段,最终生成目标代码,即经过 babel 编译后的代码。
模板引擎
再讲到模板引擎,最早诞生于服务端动态页面的开发,如 JSP、PHP、ASP 等模板引擎,自 Node.js 快速发展以后,前端界又产出了非常多的轮子,包括 EJS、Handlebars、Pug (前身为 Jade)、Mustache 等等,数不胜数。模板引擎技术使得结合数据渲染视图变得更加灵活,给逻辑的抽象带来了更多的可能性,数据与内容互不依赖。模板引擎的实现方式有很多种,比较简单的模板引擎,直接利用字符串替换、拼接的方式实现,比较复杂的模板引擎,例如 Pug,则会有比较完整的词法分析和语法分析过程,将模板预编译成 JS 代码再去动态执行。
例如模板语句:
h1 hello #{name}
经由 Pug 解析器生成的 AST 如图 6 所示:
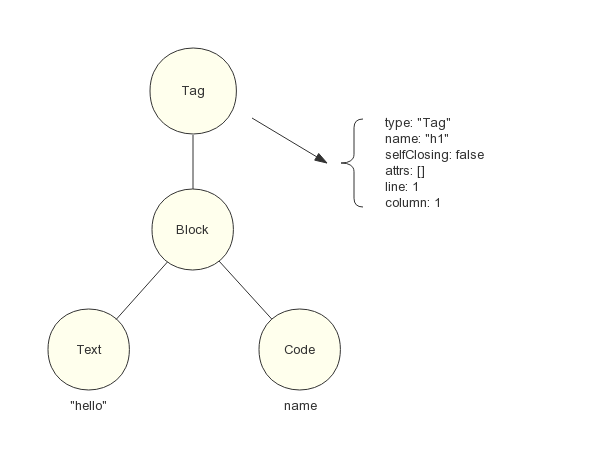
生成器生成的目标代码为(伪代码):
"<h1>" + "hello" + name + "<h1>";
运行时再调用 new Function 来动态执行代码:
var compiledFn = new Function(
"local",
`
with (local) {
return '<h1>' + 'hello' + name + '<h1>';
}
`
);
compiledFn({
name: "world",
});
最后输出 HTML 语句:
<h1>hello world</h1>
整个过程由两部分组成,预编译阶段和运行时阶段。当然一个好的模板引擎还会考虑功能、性能与安全兼备,上面的with语句是要避免的,还要引入缓存机制,XSS 防范机制,以及更加强大、友好、易于使用的语法糖。
另外值得一提的是以 Angular、React、Vue 为代表的前端 MVVM 框架,无一不引入了模板编译技术。Vue 作为渐进式的前端解决方案,受到众多开发者们的青睐,它对视图的渲染提供了渲染函数和模板两种方式。使用渲染函数需要调用核心 API 来构建 Virtual DOM 类型,过程相对复杂,编码量非常大,一旦 DOM 层次嵌套过深,就会造成代码难以掌控和维护的局面。为了应对这种复杂性,另一种方式则是编写基于 HTML 的模板,并加入 Vue 特有的标签、指令、插值等语法,由编译器来进行从模板到渲染函数的编译和优化,相对前者更优雅、便捷、易于编码。
CSS 预处理器
前端布局方式从刀耕火种的纯 CSS 年代演进到以 Sass、Less、Stylus 为代表的预处理语言,赋予了 CSS 可编程的能力,定义变量,函数,表达式计算、模块化等特性,极大地提升了开发人员的生产效率。这些都是编译技术所带来的变化。同样,编译器对原样式代码进行词法分析,产生 Token 序列。接着,语法分析,生成中间表示,一棵符合定义的 AST。同时,还会为每个程序块建立一个符号表来记录变量的名字,属性,为代码生成阶段的变量作用域分析提供帮助。最后,递归下降访问 AST,生成能够在浏览器环境中直接执行的 CSS 代码。
以预处理器 Stylus 语法为例:
foo = 14px
body
font-size foo
编译生成的 AST 为图 7 所示:
最后生成的目标代码为:
body {
font-size: 14px;
}
看似简单容易的代码转换背后,编译器为我们做了许多语法层面的处理,给 CSS 带来了从未有过的强大的扩展能力,以及底层对编译速度的持续优化,让 CSS 的编写方式更加简洁高效,易于维护和管理。
3.js 预编译原理
首先 JavaScript 这个预编译和传统的编译是不一样的(可以把 js 预编译理解为特殊的编译过程)
- 我们应该已经知道:JavaScript 是解释型语言。(解释型语言,就是编译一行,执行一行)
- 传统的编译会经历很多步骤,分词、解析、代码生成什么的
- 下面就给大家分享一下我所理解的 JS 预编译
JavaScript 运行三部曲 脚本执行 js,引擎都做了什么呢?
- 语法分析
先全部扫一遍 看有没有语法错误.
2.预编译(执行前一刻)
变量 声明提升 函数声明整体提升
3.解释执行
解释一行执行一行
函数中:预编译执行四部曲
- 创建 AO 对象 (Activation Object (执行期上下文))
- 找形参和变量声明,将变量和形参名作为 AO 属性名,值为 undefined
- 将实参值和形参统一
- 在函数体里面找函数声明,值赋予函数体
全局中:预编译三部曲
- 创建 GO 对象(Global Object window 就是全局)
- 找变量声明,将变量声明作为 GO 对象的属性名,值赋予 undifined
- 找全局里的函数声明,将函数名作为 GO 对象的属性名,值赋予函数体
实例分析
<script>
var a = 1;
console.log(a);
function test(a) {
console.log(a);
var a = 123;
console.log(a);
function a() {}
console.log(a);
var b = function() {}
console.log(b);
function d() {}
}
var c = function (){
console.log("I at C function");
}
console.log(c);
test(2);
</script>
分析过程如下:
- 页面产生便创建 GO 全局对象(Global Object)(也就是 window 对象);
- 第一个脚本文件加载;
- 脚本加载完毕后,分析语法是否合法;
- 开始预编译
- 查找变量声明,作为 GO 属性,值赋予 undefined;
- 查找函数声明,作为 GO 属性,值赋予函数体;
全局预编译结束后,GO 中存储的值
//抽象描述
GO/window = {
a: undefined,
c: undefined,
test: function(a) {
console.log(a);
var a = 123;
console.log(a);
function a() {}
console.log(a);
var b = function() {}
console.log(b);
function d() {}
}
}
解释执行代码(直到执行完 test(2)语句)
GO/window = {
a: 1,
c: function (){
console.log("I at C function");
}
test: function(a) {
console.log(a);
var a = 123;
console.log(a);
function a() {}
console.log(a);
var b = function() {}
console.log(b);
function d() {}
}
}
执行函数 test()之前,再次发生预编译
根据函数中:预编译执行四部曲可知
预编译第一和第二两小步如下:
//抽象描述
AO = {
a: undefined,
b: undefined,
};
预编译之第 3 步如下:
//抽象描述
AO = {
a: 123,
b: undefined,
};
预编译之第 4 步如下:
//抽象描述
AO = {
a:function a() {},
b:undefined
d:function d() {}
}
执行 test()函数时如下过程变化:
//抽象描述
AO = {
a:function a() {},
b:undefined
d:function d() {}
}
--->
AO = {
a:123,
b:undefined
d:function d() {}
}
--->
AO = {
a:123,
b:function() {}
d:function d() {}
}
执行结果:
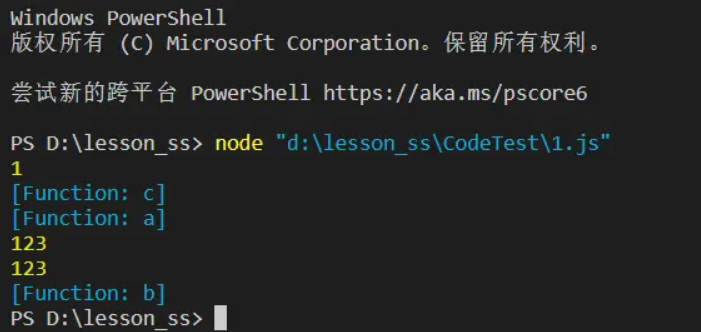
注意: 预编译阶段发生变量声明和函数声明,没有赋值行为,匿名函数不参与预编译 ;只有在解释执行阶段才会进行变量初始化 。
预编译小节
- 预编译两个小规则
- 函数声明整体提升—(无论函数调用和声明的位置是前是后,系统总会把函数声明移到调用前面)
- 变量 声明提升—(无论变量调用和声明的位置是前是后,系统总会把声明移到调用前,注意仅仅只是声明,所以值是 undefined)
- 预编译前奏
- 即任何变量,如果未经声明就赋值,则此变量就位全局变量所有。(全局域就是 Window)
- 一切声明的全局变量,全是 window 的属性,如:var a=12;等同于 Window.a = 12;
- 函数预编译发生在函数执行前一刻。
4.v8 引擎是怎么编译 js 的
一个接受 Javascript 代码,编译代码然后执行的 C++程序,编译后的代码可以在多种操作系统多种处理器上运行
主要工作
- 编译 js 代码
- 处理调用栈
- 内存分配
- 垃圾的回收
重要组件
大部分 js 引擎在编译和执行 js 代码,都会用到三个重要的组件
- 解析器:负责将 JS 源代码解析成抽象语法树(AST)
- 解释器: 负责将 AST 解释成字节码 bytecode,同时解释器也有直接解释执行 bytecode 的能力
- 编译器:负责编译出运行更加高效的机器代码
优化后的 V8
语法树的解析还是基本保持一致的,但在获得抽象语法树之后,v8 引擎加入了解释器 Ignition,语法树通过解释器 Ignition 生成了 bytecode 字节码,此时 AST 就被清除掉了,释放内存空间,生成 bytecode 直接被解释器执行,同时生成的 bytecode 将作为基准执行模型,字节码更加简洁。生成的 bytecode 大小相当于等效的基准机器代码的 25 到 50%左右。
在代码不断运行过程中,解释器收集到了很多可以用来优化代码的信息,比如变量的类型、那些函数执行的频率较高,这些信息被发送给编译器 TruboFan,编译起 TruboFan 会根据这些信息来编译出经过优化的机器代码。
优化的机器码也有可能被反向编译为字节码,这个过程叫 deoptimization 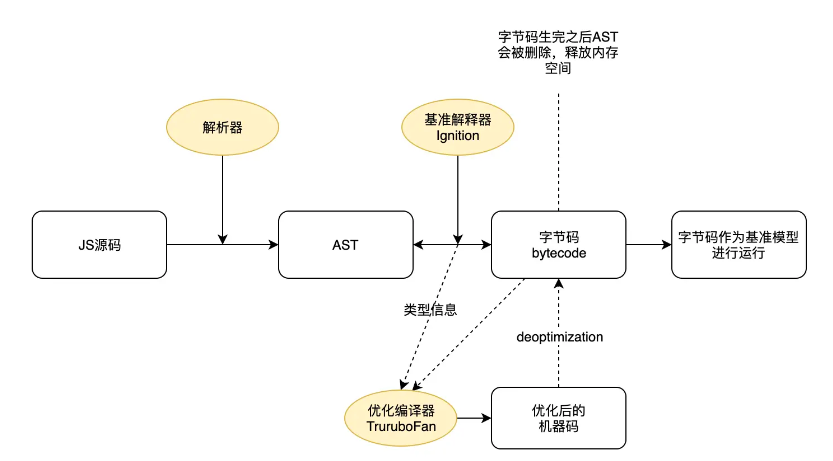
优化策略
- 函数只声明未被调用,不会被解析成 AST
- 函数只被调用一次,bytecode 直接被解释执行
- 如果函数被调用多次,可能会被标记为热点函数,可能会被编译成机器代码
优点
- 由于不需要直接编译成机器码,而是使用了中间层的字节码,字节码生成速度远远大于机器吗,所以网页初始化解析执行 js 的时间缩短了
- 在生成的优化机器代码时,不需要再从源码开始编译,而是直接使用字节码编译。而且需要 deoptimization 时,只需要回归到中间层字节码解释执行就可以了
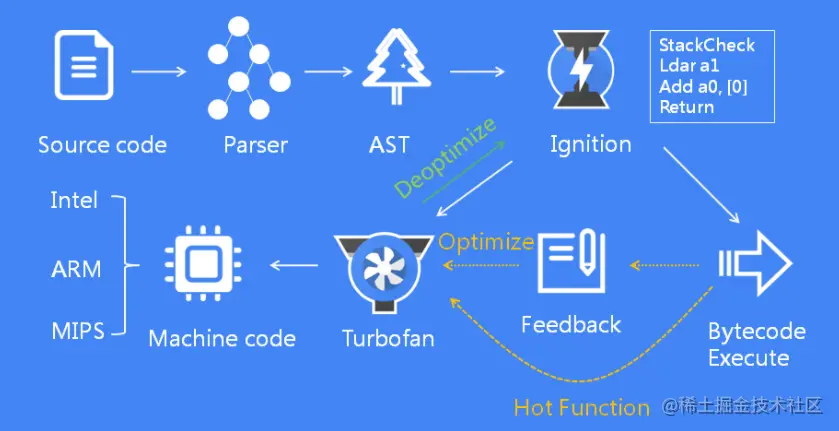
- 首先 V8 引擎会扫描所有的源代码,进行词法分析,生成 Tokens;
- Parser 解析器根据 Tokens 生成 AST;
- Ignition 解释器将 AST 转换为字节码,并解释执行;
- TurboFan 编译器负责将热点函数优化编译为机器指令执行;
词法分析
V8 引擎首先会扫描所有的源代码,进行词法分析(词法分析是通过 Scanner 模块来完成的,本文不进行详细介绍)。
什么是词法分析?
词法分析(Tokenizing/Lexing)其作用是将一行行的源码拆解成一个个 token。所谓词法单元 token,指的是语法上不可能再分的、最小的单个字符或字符串。
ECMAScript 中明确定义了 Token 包含的内容。
我们来看下var a = 2; 这句代码经过词法分析后会被分解出哪些 tokens ? 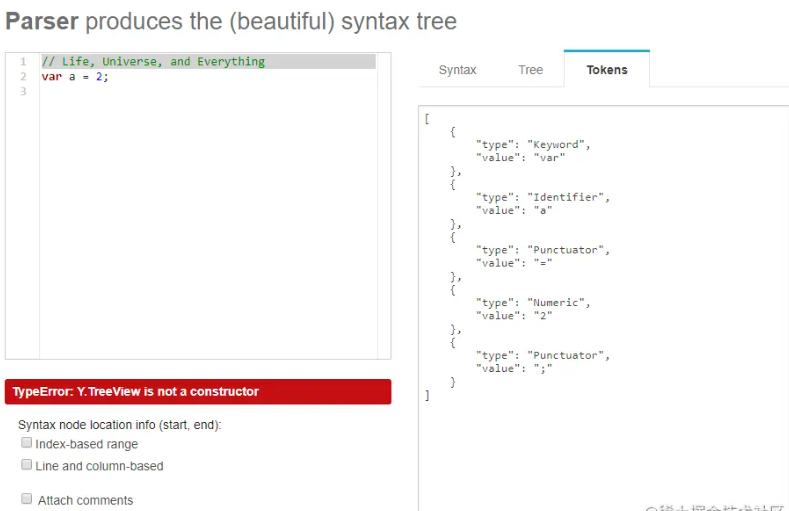
从上图中可以看到,这句代码最终被分解出了五个词法单元:
var关键字a标识符=运算符(符号)2数值;分号(符号)
Tokens 在线查看网站:esprima.org/demo/parse.…
语法分析
Parser
Parser 是 V8 的解析器,负责根据生成的 Tokens 进行语法分析。Parser 的主要工作包括:
分析语法错误:遇到错误的语法会抛出异常;
输出 AST:将词法分析输出的词法单元流(数组)转换为一个由元素逐级嵌套所组成的代表了程序语法结构的树——抽象语法树(Abstract Syntax Tree, AST);
确定词法作用域;
生成执行上下文;
什么是抽象语法树(Abstract Syntax Tree, AST)?
还是上面的例子,我们来看下 var a = 2; 经过语法分析后生成的 AST 是什么样子的:
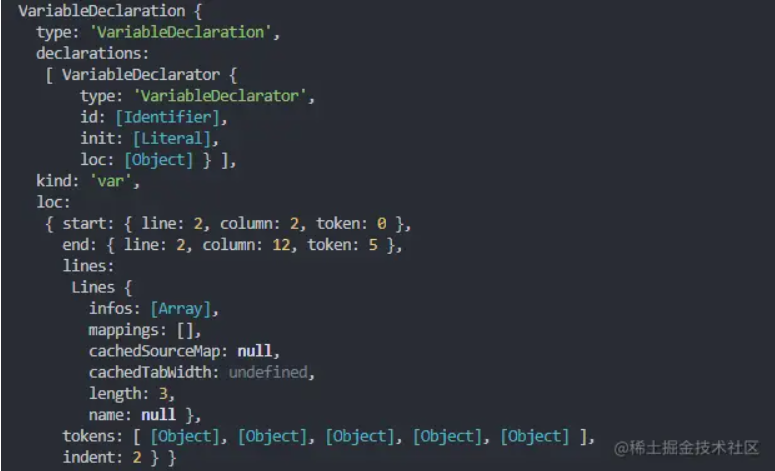
可以看到这段程序的类型是 VariableDeclaration,也就是说这段代码是用来声明变量的。
AST 在线查看网站:astexplorer.net/
AST 的结构和代码的结构非常相似,其实你也可以把 AST 看成代码的结构化表示,编译器或者解释器后续的工作都需要依赖于 AST,而不是源代码。
AST 是非常重要的一种数据结构,在很多项目中有着广泛的应用。其中最著名的一个项目就是 Babel。Babel 是一个被广泛使用的代码转码器,可以将 ES6 代码转为 ES5 代码,这意味着你可以现在就用 ES6 编写程序,而不用担心现有环境是否支持 ES6。Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。 除了 Babel 外,还有 ESLint 也使用 AST。ESLint 是一个用来检查 JavaScript 编写规范的插件,其检测流程也是需要将源码转换为 AST,然后再利用 AST 来检查代码规范化的问题。
Pre-Parser
什么是预解析 Pre-Parser?
我们先来看看下面这段代码:
function foo() {
console.log("function foo");
}
function bar() {
console.log("function bar");
}
foo();
上面这段代码中,如果使用 Parser 解析后,会生成 foo 函数 和 bar 函数的 AST。然而 bar 函数并没有被调用,所以生成 bar 函数的 AST 实际上是没有任何意义且浪费时间的。那么有没有办法解决呢?此时就用到了 Pre-Parser 技术。
在 V8 中有两个解析器用于解析 JavaScript 代码,分别是 Parser 和 Pre-Parser 。
- Parser 解析器又称为 full parser(全量解析) 或者 eager parser(饥饿解析)。它会解析所有立即执行的代码,包括语法检查,生成 AST,以及确定词法作用域。
- Pre-Parser 又称为惰性解析,它只解析未被立即执行的代码(如函数),不生成 AST ,只确定作用域,以此来提高性能。当预解析后的代码开始执行时,才进行 Parser 解析。
我们还是以示例来说明:
function foo() {
console.log('a');
function inline() {
console.log('b')
}
}
(function bar() {
console.log('c')
})();
foo();
- 当 V8 引擎遇到 foo 函数声明时,发现它未被立即执行,就会采用 Pre-Parser 对其进行解析(inline 函数同)。
- 当 V8 遇到
(function bar() {console.log(c)})()时,它会知道这是一个立即执行表达式(IIFE),会立即被执行,所以会使用 Parser 对其解析。 - 当 foo 函数被调用时,会使用 Parser 对 foo 函数进行解析,此时会对 inline 函数再进行一次预解析,也就是说 inline 函数被预解析了两次。如果嵌套层级较深,那么内层的函数会被预解析多次,所以在写代码时,尽可能避免嵌套多层函数,会影响性能。
Ignition
Ignition 是 V8 的解释器,它负责的工作包括:
- 将 AST 转换为中间代码(字节码 Bytecode)
- 逐行解释执行字节码:在该阶段,就已经可以开始执行 JavaScript 代码了。
什么是字节码?
字节码(Bytecode)是介于 AST 和机器码之间的一种中间码,它比机器码更抽象,也更轻量,需要直译器转译后才能成为机器码。
早期版本的 V8 ,并没有生成中间字节码的过程,而是直接将 AST 转换为机器码,由于执行机器码的效率是非常高效的,所以这种方式在发布后的一段时间内运行效果是非常好的。但是随着 Chrome 在手机上的广泛普及,特别是运行在 512M 内存的手机上,内存占用问题也暴露出来了,因为 V8 需要消耗大量的内存来存放转换后的机器码。为了解决内存占用问题,V8 团队大幅重构了引擎架构,引入字节码,并且抛弃了之前的编译器,最终花了将进四年的时间,实现了现在的这套架构。

从图中可以看出,机器码所占用的空间远远超过了字节码,所以使用字节码可以减少系统内存的占用。
TurboFan
TurboFan 是 V8 的优化编译器,负责将字节码和一些分析数据作为输入并生成优化的机器代码。
上面我们说到,当 Ignition 将 JavaScript 代码转换为字节码后,程序就可以执行了,那么 TurboFan 还有什么用呢?
我们再来看下 V8 的工作流程图: 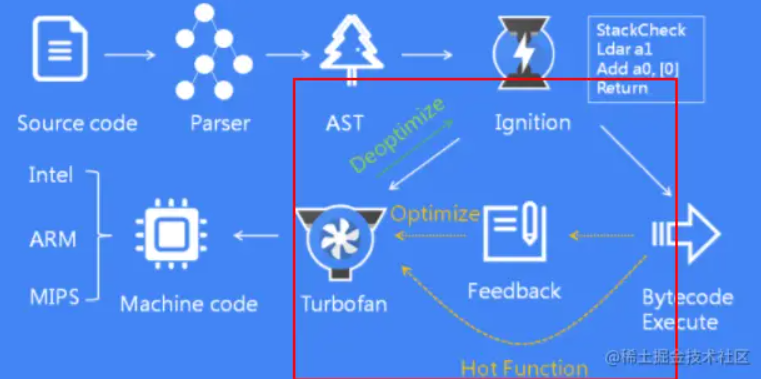
我们主要关注 Ignition 和 TurboFan 的交互: 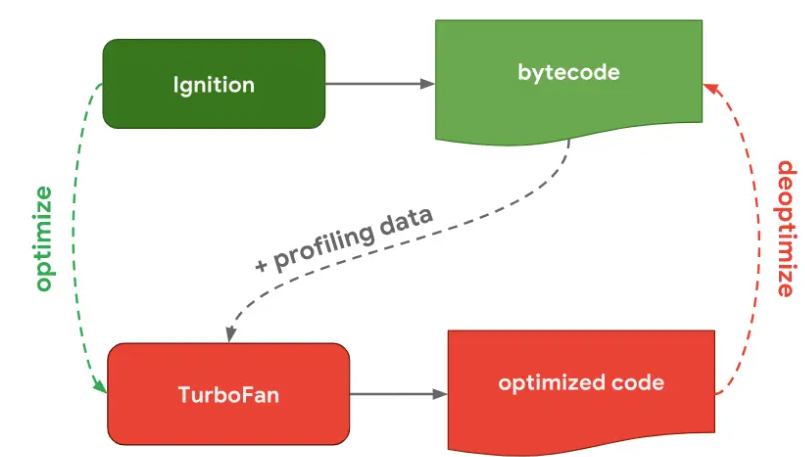
当 Ignition 开始执行 JavaScript 代码后,V8 会一直观察 JavaScript 代码的执行情况,并记录执行信息,如每个函数的执行次数、每次调用函数时,传递的参数类型等。
如果一个函数被调用的次数超过了内设的阈值,监视器就会将当前函数标记为热点函数(Hot Function),并将该函数的字节码以及执行的相关信息发送给 TurboFan。TurboFan 会根据执行信息做出一些进一步优化此代码的假设,在假设的基础上将字节码编译为优化的机器代码。如果假设成立,那么当下一次调用该函数时,就会执行优化编译后的机器代码,以提高代码的执行性能。
V8 的解释器和编译器的取名也很有意思。解释器 Ignition 是点火器的意思,编译 TurboFan 是涡轮增压的意思,寓意着代码启动时通过点火器慢慢发动,一旦启动,涡轮增压介入,其执行效率随着执行时间越来越高效率,因为热点代码都被编译器 TurboFan 转换了机器码,直接执行机器码就省去了字节码“翻译”为机器码的过程。我们把这种技术称为即时编译(JIT)
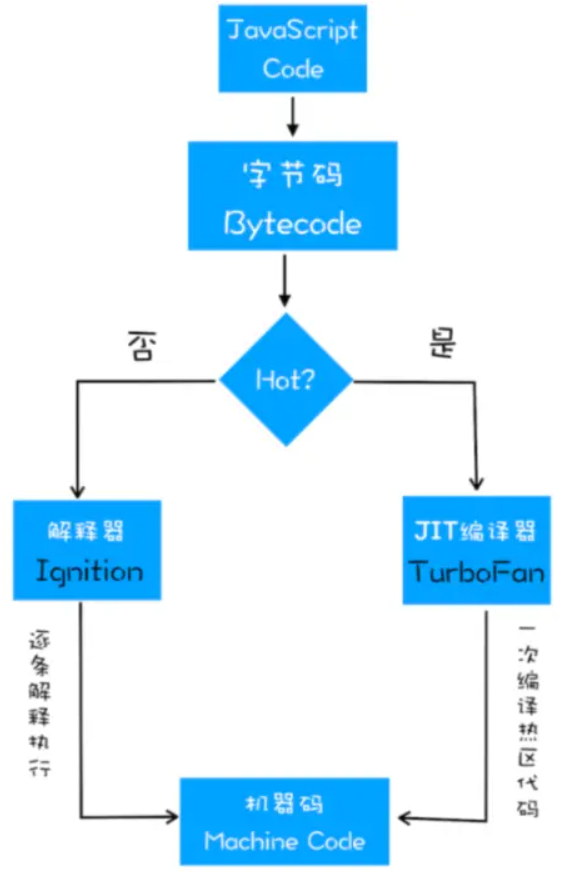
那如果假设不成立呢?不知道你们有没有注意到上图中有一条由 optimized code 指向 bytecode 的红色指向线。此过程叫做 deoptimize(优化回退),将优化编译后的机器代码还原为字节码。
读到这里,你可能有些疑惑:这个假设是什么假设呢?以及为什么要优化回退?我们来看下面的例子。
function sum(a, b) {
return a + b;
}
我们都知道 JavaScript 是基于动态类型的,a 和 b 可以是任意类型数据,当执行 sum 函数时,Ignition 解释器会检查 a 和 b 的数据类型,并相应地执行加法或者连接字符串的操作。
如果 sum 函数被调用多次,每次执行时都要检查参数的数据类型是很浪费时间的。此时 TurboFan 就出场了。它会分析监视器收集的信息,如果以前每次调用 sum 函数时传递的参数类型都是数字,那么 TurboFan 就预设 sum 的参数类型是数字类型,然后将其编译为机器指令。
但是当某一次的调用传入的参数不再是数字时,表示 TurboFan 的假设是错误的,此时优化编译生成的机器代码就不能再使用了,于是就需要进行优化回退。
Orinoco
Orinoco 是 V8 的垃圾回收模块(garbage collector),负责将程序不再需要的内存空间回收(标记清除法);
5.编译型语言和解释型语言
所谓的二进制指令,也就是机器码,是 CPU 能够识别的硬件层面的“代码”,简陋的硬件(比如古老的单片机)只能使用几十个指令,强大的硬件(PC 和智能手机)能使用成百上千个指令。
然而,究竟在什么时候将源代码转换成二进制指令呢?不同的编程语言有不同的规定:
- 有的编程语言要求必须提前将所有源代码一次性转换成二进制指令,也就是生成一个可执行程序(Windows 下的 .exe),比如 C 语言、C++、Golang、Pascal(Delphi)、汇编等,这种编程语言称为编译型语言,使用的转换工具称为编译器。
- 有的编程语言可以一边执行一边转换,需要哪些源代码就转换哪些源代码,不会生成可执行程序,比如 Python、JavaScript、PHP、Shell、MATLAB 等,这种编程语言称为解释型语言,使用的转换工具称为解释器。
简单理解,编译器就是一个“翻译工具”,类似于将中文翻译成英文、将英文翻译成俄文。但是,翻译源代码是一个复杂的过程,大致包括词法分析、语法分析、语义分析、性能优化、生成可执行文件等五个步骤
Java 和 C# 是一种比较奇葩的存在,它们是半编译半解释型的语言,源代码需要先转换成一种中间文件(字节码文件),然后再将中间文件拿到虚拟机中执行。Java 引领了这种风潮,它的初衷是在跨平台的同时兼顾执行效率;C# 是后来的跟随者,但是 C# 一直止步于 Windows 平台,在其它平台鲜有作为。
编译型语言
对于编译型语言,开发完成以后需要将所有的源代码都转换成可执行程序,比如 Windows 下的.exe文件,可执行程序里面包含的就是机器码。只要我们拥有可执行程序,就可以随时运行,不用再重新编译了,也就是“一次编译,无限次运行”。
在运行的时候,我们只需要编译生成的可执行程序,不再需要源代码和编译器了,所以说编译型语言可以脱离开发环境运行。
编译型语言一般是不能跨平台的,也就是不能在不同的操作系统之间随意切换。
编译型语言不能跨平台表现在两个方面:
1) 可执行程序不能跨平台
可执行程序不能跨平台很容易理解,因为不同操作系统对可执行文件的内部结构有着截然不同的要求,彼此之间也不能兼容。不能跨平台是天经地义,能跨平台反而才是奇葩。
比如,不能将 Windows 下的可执行程序拿到 Linux 下使用,也不能将 Linux 下的可执行程序拿到 Mac OS 下使用(虽然它们都是类 Unix 系统)。
另外,相同操作系统的不同版本之间也不一定兼容,比如不能将 x64 程序(Windows 64 位程序)拿到 x86 平台(Windows 32 位平台)下运行。但是反之一般可行,因为 64 位 Windows 对 32 位程序作了很好的兼容性处理。
2) 源代码不能跨平台
不同平台支持的函数、类型、变量等都可能不同,基于某个平台编写的源代码一般不能拿到另一个平台下编译。我们以 C 语言为例来说明。
【实例 1】在 C 语言中要想让程序暂停可以使用“睡眠”函数,在 Windows 平台下该函数是 Sleep(),在 Linux 平台下该函数是 sleep(),首字母大小写不同。其次,Sleep() 的参数是毫秒,sleep() 的参数是秒,单位也不一样。
以上两个原因导致使用暂停功能的 C 语言程序不能跨平台,除非在代码层面做出兼容性处理,非常麻烦。
【实例 2】虽然不同平台的 C 语言都支持 long 类型,但是不同平台的 long 的长度却不同,例如,Windows 64 位平台下的 long 占用 4 个字节,Linux 64 位平台下的 long 占用 8 个字节。
我们在 Linux 64 位平台下编写代码时,将 0x2f1e4ad23 赋值给 long 类型的变量是完全没有问题的,但是这样的赋值在 Windows 平台下就会导致数值溢出,让程序产生错误的运行结果。
让人苦恼的,这样的错误一般不容易察觉,因为编译器不会报错,我们也记不住不同类型的取值范围。
解释型语言
对于解释型语言,每次执行程序都需要一边转换一边执行,用到哪些源代码就将哪些源代码转换成机器码,用不到的不进行任何处理。每次执行程序时可能使用不同的功能,这个时候需要转换的源代码也不一样。
因为每次执行程序都需要重新转换源代码,所以解释型语言的执行效率天生就低于编译型语言,甚至存在数量级的差距。计算机的一些底层功能,或者关键算法,一般都使用 C/C++ 实现,只有在应用层面(比如网站开发、批处理、小工具等)才会使用解释型语言。
在运行解释型语言的时候,我们始终都需要源代码和解释器,所以说它无法脱离开发环境。
当我们说“下载一个程序(软件)”时,不同类型的语言有不同的含义:
- 对于编译型语言,我们下载到的是可执行文件,源代码被作者保留,所以编译型语言的程序一般是闭源的。
- 对于解释型语言,我们下载到的是所有的源代码,因为作者不给源代码就没法运行,所以解释型语言的程序一般是开源的。
相比于编译型语言,解释型语言几乎都能跨平台,“一次编写,到处运行”是真是存在的,而且比比皆是。那么,为什么解释型语言就能快平台呢?
这一切都要归功于解释器!
我们所说的跨平台,是指源代码跨平台,而不是解释器跨平台。解释器用来将源代码转换成机器码,它就是一个可执行程序,是绝对不能跨平台的。
官方需要针对不同的平台开发不同的解释器,这些解释器必须要能够遵守同样的语法,识别同样的函数,完成同样的功能,只有这样,同样的代码在不同平台的执行结果才是相同的。
你看,解释型语言之所以能够跨平台,是因为有了解释器这个中间层。在不同的平台下,解释器会将相同的源代码转换成不同的机器码,解释器帮助我们屏蔽了不同平台之间的差异。
总结
我们将编译型语言和解释型语言的差异总结为下表:
| 类型 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 编译型语言 | 通过专门的编译器,将所有源代码一次性转换成特定平台(Windows、Linux 等)执行的机器码(以可执行文件的形式存在)。 | 编译一次后,脱离了编译器也可以运行,并且运行效率高。 | 可移植性差,不够灵活。 |
| 解释型语言 | 由专门的解释器,根据需要将部分源代码临时转换成特定平台的机器码。 | 跨平台性好,通过不同的解释器,将相同的源代码解释成不同平台下的机器码。 | 一边执行一边转换,效率很低。 |
解释器
解释器是一条一条的解释执行源语言(边解释边运行)。比如 php,postscritp,javascript 就是典型的解释性语言。 运行效率低,所以通常会进行一些预编译的优化。
编译器是把源代码整个编译成目标代码,执行时不在需要编译器,直接在支持目标代码的平台上运行,这样执行效率比解释执行快很多。比如 C 语言代码被编译成二进制代码(exe 程序),在 windows 平台上执行。
 他们**最大的区别是程序运行时需要解释器边解释边执行,而编译器则在运行时是完全不需要的**。
他们**最大的区别是程序运行时需要解释器边解释边执行,而编译器则在运行时是完全不需要的**。解释器的优点是比较容易让用户实现自己跨平台的代码,比如 java,php 等,同一套代码可以在几乎所有的操作系统上执行,而无需根据操作系统做修改; 编译器的目的就是生成目标代码再由连接器生成可执行的机器码,这样的话需要根据不同的操作系统编制代码,虽然有像 Qt 这样的源代码级跨平台的编程工具库,但在不同的平台上仍然需要重新编译连接成可执行文件,但其执行效率要远远高于解释运行的程序
6.eslint 原理
我们在前端工程化中可以这样使用 ESLint:
- 基于业界现有的 ESLint 规范和团队代码习惯定制一套统一的 ESLint 代码规则
- 将统一代码规则封装成 ESLint 规则包接入
- 将 ESLint 接入脚手架、编辑器以及研发工作流中
ESLint 的用法包括两部分: 通过配置文件配置 lint 规则; 通过命令行执行 lint,找出不符合规范的地方
这是 eslint 的主要代码执行逻辑,主要流程如下:
解析命令行参数,校验参数正确与否及打印相关信息;
初始化 根据配置实例一个 engine 对象
CLIEngine实例;engine.executeOnFiles读取源代码进行检查,返回报错信息和修复结果。
后端开发理论
1.什么是 ioc 和 aop
IOC
概述
IoC (Inversion of control )控制反转/反转控制。它是一种思想不是一个技术实现。描述的是:Java 开发领域对象的创建以及管理的问题。
例如:现有类 A 依赖于类 B
- 传统的开发方式 :往往是在类 A 中手动通过 new 关键字来 new 一个 B 的对象出来
- 使用 IoC 思想的开发方式 :不通过 new 关键字来创建对象,而是通过 IoC 容器(Spring 框架) 来帮助我们实例化对象。我们需要哪个对象,直接从 IoC 容器里面过去即可。
从以上两种开发方式的对比来看:我们 “丧失了一个权力” (创建、管理对象的权力),从而也得到了一个好处(不用再考虑对象的创建、管理等一系列的事情)
为什么叫 控制反转
控制 :指的是对象创建(实例化、管理)的权力
反转 :控制权交给外部环境(Spring 框架、IoC 容器)
IoC 解决了什么问题
IoC 的思想就是两方之间不互相依赖,由第三方容器来管理相关资源。这样有什么好处呢?
- 对象之间的耦合度或者说依赖程度降低;
- 资源变的容易管理;比如你用 Spring 容器提供的话很容易就可以实现一个单例。
例如:现有一个针对 User 的操作,利用 Service 和 Dao 两层结构进行开发
在没有使用 IoC 思想的情况下,Service 层想要使用 Dao 层的具体实现的话,需要通过 new 关键字在UserServiceImpl 中手动 new 出 IUserDao 的具体实现类 UserDaoImpl(不能直接 new 接口类)。
开发过程中突然接到一个新的需求,针对对IUserDao 接口开发出另一个具体实现类。因为 Server 层依赖了IUserDao的具体实现,所以我们需要修改UserServiceImpl中 new 的对象。如果只有一个类引用了IUserDao的具体实现,可能觉得还好,修改起来也不是很费力气,但是如果有许许多多的地方都引用了IUserDao的具体实现的话,一旦需要更换IUserDao 的实现方式,那修改起来将会非常的头疼。
使用 IoC 的思想,我们将对象的控制权(创建、管理)交有 IoC 容器去管理,我们在使用的时候直接向 IoC 容器 “要” 就可以了
AOP
AOP:Aspect oriented programming 面向切面编程,AOP 是 OOP(面向对象编程)的一种延续。
下面我们先看一个 OOP 的例子。
例如:现有三个类,Horse、Pig、Dog,这三个类中都有 eat 和 run 两个方法。
通过 OOP 思想中的继承,我们可以提取出一个 Animal 的父类,然后将 eat 和 run 方法放入父类中,Horse、Pig、Dog通过继承Animal类即可自动获得 eat() 和 run() 方法。这样将会少些很多重复的代码。
OOP 编程思想可以解决大部分的代码重复问题。但是有一些问题是处理不了的。比如在父类 Animal 中的多个方法的相同位置出现了重复的代码,OOP 就解决不了
这部分重复的代码,一般统称为 横切逻辑代码。
横切逻辑代码存在的问题:
- 代码重复问题
- 横切逻辑代码和业务代码混杂在一起,代码臃肿,不变维护
AOP 另辟蹊径,提出横向抽取机制,将横切逻辑代码和业务逻辑代码分离
img
代码拆分比较容易,难的是如何在不改变原有业务逻辑的情况下,悄无声息的将横向逻辑代码应用到原有的业务逻辑中,达到和原来一样的效果。
AOP 解决了什么问题
通过上面的分析可以发现,AOP 主要用来解决:在不改变原有业务逻辑的情况下,增强横切逻辑代码,根本上解耦合,避免横切逻辑代码重复。
AOP 为什么叫面向切面编程
切 :指的是横切逻辑,原有业务逻辑代码不动,只能操作横切逻辑代码,所以面向横切逻辑
面 :横切逻辑代码往往要影响的是很多个方法,每个方法如同一个点,多个点构成一个面。这里有一个面的概念
2.前后端分离中,后端负责了什么
后端工作
后端专注于:后端控制层(Restful API) & 服务层 & 数据访问层;
前端专注于:前端控制层(Nodejs) & 视图层
1、项目设计阶段,前后端架构负责人将项目整体进行分析,讨论并确定 API 风格、职责分配、开发协助模式,确定人员配备;设计确定后,前后端人员共同制定开发接口。
2、项目开发阶段,前后端分离是各自分工,协同敏捷开发,后端提供 Restful API,并给出详细文档说明,前端人员进行页面渲染前台的任务是发送 API 请(GET,PUT,POST,DELETE 等)获取数据(json,xml)后渲染页面。
3、项目测试阶段,API 完成之前,前端人员会使用 mock server 进行模拟测试,后端人员采用 junit 进行 API 单元测试,不用互相等待;API 完成之后,前后端再对接测试一下就可以了,当然并不是所有的接口都可以提前定义,有一些是在开发过程中进行调整的。
4、项目部署阶段,利用 nginx 做反向代理,即 Java + nodejs + nginx 方式进行。
后端技术发展
互联网,尤其是移动互联网开始兴起以后,海量的用户呼啸而来,一个单机部署的小小 War 包肯定是撑不住了,必须得做分布式。
原来的单个 Tomcat 得变成 Tomcat 的集群,前边弄个 Web 服务器做请求的负载均衡,不仅如此,还得考虑状态问题,session 的一致性。
业务越来越复杂,我们不得不把某些业务放到一个机器(或集群)上,把另外一部分业务放到另外一个机器(或集群)上,虽然系统的计算能力,处理能力大大增强,但是这些系统之间的通信就变成了头疼的问题,消息队列(MQ),RPC 框架(如 Dubbo)应运而生,为了提高通信效率,各种序列化的工具(如 Protobuf)也争先空后地问世。
单个数据库也撑不住了,那就做数据库的读写分离,如果还不行,就做分库和分表,把原有的数据库垂直地切一切,或者水平地切一切, 但不管怎么切,都会让应用程序的访问非常麻烦,因为数据要跨库做 Join/排序,还需要事务,为了解决这个问题,又有各种各样“数据访问中间件”的工具和产品诞生。
为了最大程度地提高性能,缓存肯定少不了,可以在本机做缓存(如 Ehcache),也可以做分布式缓存(如 Redis),如何搞数据分片,数据迁移,失效转移,这又是一个超级大的主题了。
互联网用户喜欢上传图片和文件,还得搞一个分布式的文件系统(如 FastDFS),要求高可用,高可靠。
数据量大了,搜索的需求就自然而然地浮出水面,你得弄一个支持全文索引的搜索引擎(如 Elasticsearch ,Solr)出来。
林子大了,什么鸟都有,必须得考虑安全,数据的加密/解密,签名、证书,防止 SQL 注入,XSS/CSRF 等各种攻击。
后端模式
MVC 模式把一个 web 应用分成三个层面,分别是 control 层(控制层),model 层(模型层)和 view 层(视图层)

MVC 模式的三个层面分别负责不同的功能。模型层负责专门的业务处理,视图层负责专门的 UI 绘制,而控制层则负责作为中转控制连接模型层和视图层。这样子的开发方式将一个 web 应用分成三个部分。
每个部分的代码量减少了,出现代码错误排错起来更方便。而且原先把控制视图的代码和控制逻辑的代码混合在一起,对于 UI 的调试不方便,也容易出现一些奇怪的错误(比如 java 的 servlet 中如果用页面流的方式输出 HTML 代码,不仅影响 servlet 的代码美观,HTML 代码中如果出现一些特殊符号(比如双引号)导致页面流提前结束,代码就会出错)。
这种将一个代码中不同功能进行模块拆分的方法,在软件工程中叫松耦合。从字面意思理解,就是降低功能和功能之间的耦合度,使一个功能在出错的时候不至于同时影响另一个功能。
在原本的 MVC 中,JSP 是负责动态生成 HTML 的。但在长期的编程中发现,有些页面在动态生成的 HTML 中有大部分数据是相同的,只有小部分数据是需要更新的,这时候的思路就从动态生成整个 HTML 页面转变成了使用静态页面再对小部分数据动态刷新。因此 Ajax 诞生了。Ajax 通过与服务器交互,获取需要动态生成的数据(以 json 或者 XML 进行传输),然后再通过 JavaScript 渲染在静态页面上,从而实现页面的生成。这样子后端就不再需要分配多余的资源给 JSP 动态生成页面了(每一个 JSP 其实都是一个特殊的 servlet,会占用服务器的资源)。于此同时,前后端也彻底分离,后端只需要负责使用 json 与前端进行交互即可,前端也只需要负责找后端获取数据渲染即可。使用 json 进行前后端的联系。这样的方式,是比传统 MVC 更松的耦合。
因为前后端是通过 json 的方式来进行数据联系,所以前后端的测试也变得更加简单。以往前后端要一起进行测试,现在使用 json 分离前后端,前端只需要使用静态的 json 就能对前端页面进行测试,而后端只需要测试生成的 json 是否符合要求即可。
3.restful api 怎么进行设计
RestFul (REpresentational State Transfer)风格目标: 用来规范资源解释方式 与操作规则。
传统 URL 资源定义弊端
- 通过的 URL 没有统一的规范,将动词与名字合并,且很难通过 URL 资源定向标记,了解具体的业务意义
- 当不规范的 URL 随着在大型的项目中带来的问题是难以管理与维护
- 每个人对资源规则有独特的理解,那么真正的标准是什么,众多的规范,识别度底,最终干脆随心所欲,随后资源标签就腐化了
RestFul 作用
- 每一个 URI 代表一种资源
- 通过统一的标准风格规范来约束资源的表达方式,它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用
- 过四个 HTTP 动词,对服务器端资源进行操作,实现"表现层状态转化"
(一) 优点:
- 它是面向资源的(名词)
- 通过 URL 就知道需要什么资源
- 通过 Http Method(get/post...)就知道针对资源干什么
- 通过 Http Status Code 就知道结果如何
(二) 优点解释:
(1)通过 URL 就知道需要什么资源:表示 Restful 风格的 API 可以直接通过 URL 就可以看到需要操作的是什么资源,有语义化。
(2)Restful 风格的 API 是面向资源(名称)的,既 URL 中不会带相应的动词,针对资源的操作是通过 Http Method(既:post-增、delete-删、put-改(一般是提供实体的全部信息)、patch-改(修改实体的某些属性)、get-查)来实现的。
(3)通过 Http Status Code 就知道结果如何: 如常见的 200(成功)、400(错误的请求参数)、500(服务器错误)等。
接口规范
1、动作
GET (SELECT):从服务器检索特定资源,或资源列表。POST (CREATE):在服务器上创建一个新的资源。PUT (UPDATE):更新服务器上的资源,提供整个资源。PATCH (UPDATE):更新服务器上的资源,仅提供更改的属性。DELETE (DELETE):从服务器删除资源。
首先是四个半种动作:post、delete、put/patch、get 因为 put/patch 只能算作一类,所以将 patch 归为半个。
另外还有有两个较少知名的 HTTP 动词:HEAD - 检索有关资源的元数据,例如数据的哈希或上次更新时间。OPTIONS - 检索关于客户端被允许对资源做什么的信息。
2、路径(接口命名)
路径又称"终点"(endpoint),表示 API 的具体网址。
在 RESTful 架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以 API 中的名词也应该使用复数。
举例来说,有一个 API 提供动物园(zoo)的信息,还包括各种动物和雇员的信息,则它的路径应该设计成下面这样。
接口尽量使用名词,禁止使用动词,下面是一些例子。
GET /zoos:列出所有动物园
POST /zoos:新建一个动物园
GET /zoos/ID:获取某个指定动物园的信息
PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
DELETE /zoos/ID:删除某个动物园
GET /zoos/ID/animals:列出某个指定动物园的所有动物
DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
反例:
/getAllCars
/createNewCar
/deleteAllRedCars
再比如,某个 URI 是/posts/show/1,其中 show 是动词,这个 URI 就设计错了,正确的写法应该是/posts/1,然后用 GET 方法表示 show。
如果某些动作是 HTTP 动词表示不了的,你就应该把动作做成一种资源。比如网上汇款,从账户 1 向账户 2 汇款 500 元,错误的 URI 是:
POST /accounts/1/transfer/500/to/2
正确的写法是把动词 transfer 改成名词 transaction,资源不能是动词,但是可以是一种服务:
POST /transaction HTTP/1.1
Host: 127.0.0.1
from=1&to=2&amount=500.00
理清资源的层次结构,比如业务针对的范围是学校,那么学校会是一级资源(/school),老师(/school/teachers),学生(/school/students)就是二级资源。
3、版本(Versioning)
应该将 API 的版本号放入 URL。如:
https://api.example.com/v1/
另一种做法是,将版本号放在 HTTP 头信息中,但不如放入 URL 方便和直观。Github 采用这种做法。
4、过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API 应该提供参数,过滤返回结果。下面是一些常见的参数。
?limit=10:指定返回记录的数量
?offset=10:指定返回记录的开始位置。
?page_number=2&page_size=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,
GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
5、状态码(Status Codes)
状态码范围
1xx 信息,请求收到,继续处理。范围保留用于底层HTTP的东西,你很可能永远也用不到。
2xx 成功,行为被成功地接受、理解和采纳
3xx 重定向,为了完成请求,必须进一步执行的动作
4xx 客户端错误,请求包含语法错误或者请求无法实现。范围保留用于响应客户端做出的错误,例如。他们提供不良数据或要求不存在的东西。这些请求应该是幂等的,而不是更改服务器的状态。
5xx 范围的状态码是保留给服务器端错误用的。这些错误常常是从底层的函数抛出来的,甚至
开发人员也通常没法处理,发送这类状态码的目的以确保客户端获得某种响应。
当收到5xx响应时,客户端不可能知道服务器的状态,所以这类状态码是要尽可能的避免。
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的 HTTP 动词)。
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE]:用户删除数据成功。
400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
502 网关错误
503 Service Unavailable
504 网关超时
4.RESTful 架构与 RPC 架构
在RESTful架构中,关注点在于资源,操作资源时使用标准方法检索并操作信息片段,在RPC架构中,关注点在于方法,调用方法时将像调用本地方法一样调用服务器的方法。
RESTful 架构
REST即表述性状态传递Representational State Transfer,是一种软件架构风格,也可以称作是一种设计API的模式,REST通过HTTP协议定义的通用动词方法GET、POST、PUT、DELETE,以URI对网络资源进行唯一标识,响应端根据请求端的不同需求,通过无状态通信,对其请求的资源进行表述,符合REST设计规范的架构就称为RESTful架构。
主要原则
- 网络上的所有事物都被抽象为资源
- 每个资源都有一个唯一的资源标识符
- 对资源的各种操作不会改变资源标识符
- 所有的操作都是无状态的
- 同一个资源具有多种表现形式如
xml、json等
统一资源接口
安全性是指访问REST接口时不会对服务端资源状态发生改变。
幂等性是指对于同一REST接口的URI多次访问时,得到的资源状态是相同的。
GET: 安全的,幂等的,用于读取资源POST: 不安全的,不幂等的,用于服务端自动产生的实例号创建资源,更新部分资源PUT: 不安全的,幂等的,用于客户端的实例号创建资源,更新资源DELETE: 不安全的,幂等的,用于客户端实例号删除资源
实例
- 查询
user,GET https://127.0.0.1/user/1,通过直接携带params查询用户 - 新增
user,POST https://127.0.0.1/user,请求body附带用户注册信息 - 修改
user,PUT https://127.0.0.1/user,请求body附带userid标识信息 - 删除
user,DELETE https://127.0.0.1/user,请求body附带userid标识信息 - 通过请求头
Accept来获取同一资源的不同形式,如application/json与application/xml等 - 若将版本号看作同一资源的不同表现形式的话,同样应该在
Accept字段来区分版本而不是直接在URI中添加版本号
RPC 架构
RPC即远程过程调用Remote Procedure Call,简单的理解是一个节点请求另一个节点提供的服务,远程过程调用,是相对于本地过程调用来说的,当调用方法时就像调用本地方法一样调用远程服务器的方法,做到了轻量、无感知通信。
结构组成
- 客户端
client:服务的调用方 - 服务端
server:服务的提供方 - 客户端存根
client stub:将客户端请求参数打包成网络消息,再发给服务方 - 服务端存根
server stub:接收客户端发来的消息,将消息解包,并调用本地方法
通信过程
客户端
- 将这个调用映射为 Call Id
- 将这个 Call Id 与参数等序列化,以二进制形式打包
- 将序列化数据包通过网络通信发送到服务端
- 等待服务端响应
- 服务端调用成功并返回结果,反序列化后进行下一步操作
服务端
- 在本地维护一个 Call Id 的 Map,用以保证 Id 与调用方法的对应
- 等待客户端请求
- 得到一个请求后,将数据包反序列化,得到 Call Id 与参数等
- 通过 Map 寻找 Call Id 所对应的函数指针
- 通过函数指针调用函数,并将数据包反序列化后的参数传递,得到结果
- 将结果序列化之后通过网络通信返回到客户端
注: 此处的客户端指的是本地调用者,也可以是一台服务器 此处的服务端指的是被调用者,也可以是一台服务器 数据包通信时无论是使用 socket 进行 TCP 传输,或使用 HTTP 进行传输都是可行的 Copy to clipboardErrorCopied
相关比较
- 在通信协议方面来说,
RESTful是使用HTTP协议进行数据传输,RPC一般是使用TCP协议数据传输,当然传输协议并不是RPC的重点,一般使用TCP协议传输是因为其效率高,使用HTTP协议传输是完全可行的。 - 在性能方面,
RPC的传输效率高于RESTful数据传输的效率,因为RCP具有高效紧凑的进程通信机制,且传输数据量小,在交换大量消息时效率高。 - 在灵活度方面,
RESTful架构的灵活度高于RPC架构,使用RESTful架构具有比较好的可读性,RPC在编写与调试时略显繁琐。 - 使用
RESTful架构的接口进行数据传输可以得到多语言支持,HTTP协议相对更规范、更通用、更标准,对于中间件而言最先支持的几种协议都包含RESTful数据传输规范。 - 内部服务的相互调用推荐使用
RPC,而对外的接口推荐使用RESTful,例如微服务架构模式一般就采用对内RPC对外RESTful的模式。
前端工具
脚手架 cli
当你使用 vue-cli 时, 你有没有想过什么?一起来实现一个精简版吧
命令注册
通过npm init生成你的package.json文件, 在里面加入 bin
"bin": {
"xxx": "bin/index.js"
},
这样, 当你全局装包的时候才会把你xxx命令注册到环境变量中。
接下来就是bin/index.js的事了。
使用commander完成命令行中的命令
program
.command("init [project-name]")
.description("create a project")
.option("-c, --clone", `it will clone from ${tmpUrl}`)
.option("--offline", "use cached template")
.action(function (name, options) {
console.log('we are try to create "%s"....', name);
downloadAndGenerate(name, options);
})
.on("--help", function () {
console.log("");
console.log("Examples:");
console.log("");
console.log(" $ masoneast init my-project");
console.log(` $ path: ${home}`);
});
program.parse(process.argv);
通过上面代码, 你就有了init命令, 和clone, offline参数了, 此时你就有了:
$ masoneast init my-project
$ masoneast init my-project --clone
$ masoneast init my-project --offline
关于commander包的具体使用, 可以看这里: commander
实现下载和 clone 模板
这里你需要有有个模板的地址供你下载和 clone, 如果你只是玩玩的话也可以直接使用vue提供的模板地址, 或者我的模板地址: 模板
下载实现代码:
这里依赖了两个库: git-clone和download。
function download(name, clone, fn) {
if (clone) {
gitclone(tmpUrl, tmpPath, (err) => {
if (err) fn(err);
rm(tmpPath + "/.git");
fn();
});
} else {
const url = tmpUrl.replace(/\.git*/, "") + "/archive/master.zip";
console.log(url);
downloadUrl(url, tmpPath, {
extract: true,
strip: 1,
mode: "666",
headers: { accept: "application/zip" },
})
.then(function (data) {
fn();
})
.catch(function (err) {
fn(err);
});
}
}
实现询问交互
交互的实现, 主要依赖了inquirer库。
function askQuestion(prompts) {
//询问交互
return (files, metalsmith, done) => {
async.eachSeries(
Object.keys(prompts),
(key, next) => {
prompt(metalsmith.metadata(), key, prompts[key], next);
},
done
);
};
}
将询问得到的答案存贮起来, 留给后面渲染使用
function prompt(data, key, prompt, done) {
//将用户操作存储到metaData中
inquirer
.prompt([
{
type: prompt.type,
name: key,
message: prompt.message || prompt.label || key,
default: prompt.default,
choices: prompt.choices || [],
validate: prompt.validate || (() => true),
},
])
.then((answers) => {
if (Array.isArray(answers[key])) {
data[key] = {};
answers[key].forEach((multiChoiceAnswer) => {
data[key][multiChoiceAnswer] = true;
});
} else if (typeof answers[key] === "string") {
data[key] = answers[key].replace(/"/g, '\\"');
} else {
data[key] = answers[key];
}
done();
})
.catch(done);
}
实现模板渲染
模板渲染, 依赖了前端模板引擎handlebar和解析模板引擎的consolidate库。 上面看到的vue-template模板里的{{#router}}其实就是handlebar的语法。
function renderTemplateFiles() {
return (files, metalsmith, done) => {
const keys = Object.keys(files);
const metalsmithMetadata = metalsmith.metadata(); //之前用户操作后的数据存在这里面
async.each(
keys,
(file, next) => {
//对模板进行遍历, 找到需要渲染内容的文件
const str = files[file].contents.toString();
if (!/{{([^{}]+)}}/g.test(str)) {
//正则匹配文件内容, 如果没有就不需要修改文件, 直接去往下一个
return next();
}
render(str, metalsmithMetadata, (err, res) => {
if (err) {
err.message = `[${file}] ${err.message}`;
return next(err);
}
files[file].contents = new Buffer(res);
next();
});
},
done
);
};
}
复制代码;
实现将文件从本地写到你的项目目录中
这里用到了一个核心库: metalsmith。它主要功能就是读取你的文件, 并通过一系列的中间件对你的文件进行处理, 然后写到你想要的路径中去。就是通过这个库, 将我们的各个流程串联起来, 实现对模板的改造, 写出你想要的项目。
metalsmith
.use(askQuestion(options.prompts)) //这一段是generator的精华, 通过各种中间件对用户选择的模板进行处理
.use(filterFiles(options.filters)) //文件筛选过滤
.use(renderTemplateFiles()) //模板内部变量渲染
.source(".")
.destination(projectPath) //项目创建的路径
.build((err, files) => {
if (err) console.log(err);
});
我这里实现的 demo 就是vue-cli的精简版, 主要功能有:
- 1.从 git 上 download 和 clone 项目模板
- 2.保存模板到本地,方便离线使用
- 3.询问问题, 按用户需求定制模板
前端包管理工具
npm 和 yarn
早期的 npm
其实在最早期的npm版本(npm v2),npm的设计可以说是非常的简单,在安装依赖的时候会将依赖放到 node_modules文件中; 同时,如果某个直接依赖 A 依赖于其他的依赖包 B,那么依赖 B 会作为间接依赖,安装到依赖 A 的文件夹node_modules中,然后可能多个包之间也会有出现同样的依赖递归的,如果项目一旦过大,那么必然会形成一棵巨大的依赖树,依赖包会出现重复,形成嵌套地狱。
那么我们如何去理解"嵌套地狱"呢?
- 首先,项目的依赖树的层级过于深,如果有问题不利于排查和调试
- 在依赖的分支中,可能会出现同样版本的相互依赖的问题
那么这样的重复问题会带来什么后果呢?
- 首先,会使得安装的结果占据了大量的空间资源,造成了资源的浪费
- 同时,因为安装的依赖重复,会造成在安装依赖时,安装时间过长
- 甚至是,因为目录层级过深,导致文件路径过长,会在
windows系统下删除node_modules文件,出现删除不掉的情况
那么, 后面的版本是如何一步步进行优化的呢?后面会陆续的揭晓。
npm 的安装机制和核心原理
我们可以先来看看 npm 的核心目标
Bring the best of open source to you, your team and your company.
意思是 给你和你的团队、你的公司带来最好的开源库和依赖。 通过这句话,我们可以了解到 npm 最重要的一点就是安装和维护依赖。那么,让我们先来看一看npm的安装机制是怎样的呢?
npm 的安装机制
下面我们会通过一个流程图来具体学习npm install的安装机制
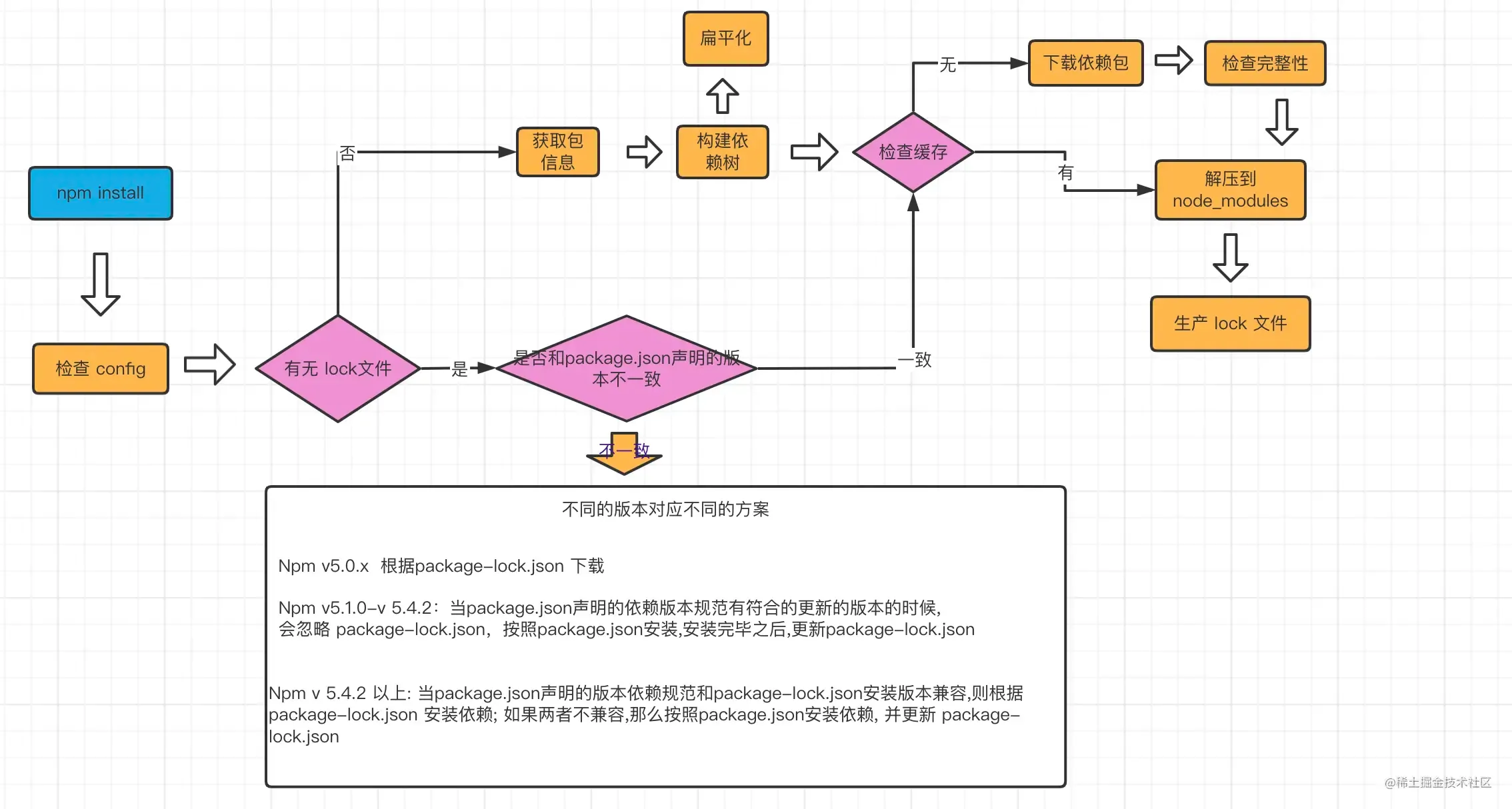
npm install执行之后, 首先会检查和获取 npm的配置,这里的优先级为:
项目级的.npmrc文件 > 用户级的 .npmrc文件 > 全局级的 .npmrc > npm内置的 .npmrc 文件
然后检查项目中是否有 package-lock.json文件
- 如果有, 检查
package-lock.json和package.json声明的依赖是否一致:- 一致, 直接使用
package-lock.json中的信息,从网络或者缓存中加载依赖 - 不一致, 根据上述流程中的不同版本进行处理
- 一致, 直接使用
- 如果没有, 那么会根据
package.json递归构建依赖树,然后就会根据构建好的依赖去下载完整的依赖资源,在下载的时候,会检查有没有相关的资源缓存:- 存在, 直接解压到
node_modules文件中 - 不存在, 从 npm 远端仓库下载包,校验包的完整性,同时添加到缓存中,解压到
node_modules中
- 存在, 直接解压到
最后, 生成 package-lock.json 文件
其实, 在我们实际的项目开发中,使用 npm 作为团队的最佳实践: 同一个项目团队,应该保持npm 版本的一致性。
从上面的安装流程,不知道大家注意到了一点没有,在实际的项目开发中,如果每次都去安装对应依赖时,如果相关的依赖包体积过大或者是依赖于网络,无疑会增加安装的时间成本;那么,缓存在这里的就是一个解决问题的好办法,后面我们会做具体的介绍。
yarn 的出现
yarn 是一个由Facebook、Google、Exponent和Tilde构建的新的 JavaScript 包管理器。它的出现是为了解决历史上npm的某些不足(比如 npm 对于依赖的完整性和一致性的保证,以及 npm 安装过程中速度很慢的问题)
当 npm 还处于v3时期的时候,一个叫yarn的包管理工具横空出世.在 2016 年, npm 还没有 package-lock.json 文件,安装的时候速度很慢,稳定性很差,yarn的出现很好的解决了一下的一些问题:
- 确定性: 通过 yarn.lock 等机制,即使是不同的安装顺序,相同的依赖关系在任何的环境和容器中,都可以以相同的方式安装。(那么,此时的 npm v5 之前,并没有 package-lock.json 机制,只有默认并不会使用 npm-shrinkwrap.json)
- 采用模块扁平化的安装模式: 将不同版本的依赖包,按照一定的策略,归结为单个版本;以避免创建多个版本造成工程的冗余(目前版本的 npm 也有相同的优化)
- 网络性能更好:
yarn采用了请求排队的理念,类似于并发池连接,能够更好的利用网络资源;同时也引入了一种安装失败的重试机制 - 采用缓存机制,实现了离线模式 (目前的 npm 也有类似的实现)
我们可以来看一下 yarn.lock的结构:
"@babel/cli@^7.1.6", "@babel/cli@^7.5.5":
version "7.8.4"
resolved "http://npm.in.zhihu.com/@babel%2fcli/-/cli-7.8.4.tgz#505fb053721a98777b2b175323ea4f090b7d3c1c"
integrity sha1-UF+wU3IamHd7KxdTI+pPCQt9PBw=
dependencies:
commander "^4.0.1"
convert-source-map "^1.1.0"
fs-readdir-recursive "^1.1.0"
glob "^7.0.0"
lodash "^4.17.13"
make-dir "^2.1.0"
slash "^2.0.0"
source-map "^0.5.0"
optionalDependencies:
chokidar "^2.1.8"
熟悉 npm 的package-lock.json文件的朋友,可能一眼就看到了一些不同; package-lock.json采用的是JSON的结构,而yarn并没有采用这种结构,而是一种自定义的标记方式;我们可以看出新的自定义的方式,也同样保持了高度的可读性。
相比于 npm,Yarn 另一个显著的区别就是 yarn.lock 的子依赖的版本不是固定的版本。这其实就说明了一个问题: 一个单独的yarn.lock的问题并不能确定 ✅node-modules的文件结构,还需要package.json的配合。
其实到了这里,我会有一个问题,如何实现 npm 到 yarn 的切换呢?
这里 我了解到有一个专门的工具synp,它可以将yarn.lock转换为package-lock.json,反之亦然。
这里可以顺带提一嘴,yarn默认采用的是perfer-online模式,即优先使用网络资源。如果网络资源请求失败,再去请求缓存数据。
到这里我们应该对yarn有了初步的了解,那我们继续去看一下它的安装机制
yarn 的安装机制
上面一小节我们对 npm 的安装机制有了一些基本的了解,现在让我们先来简单的看一下Yarn的安装理念。
简单来说, Yarn的安装大致分为 5 个步骤:
检测(checking) ---> 解析包(Resolving Packages) ---> 获取包(Fetching) ---> 链接包(Linking Packages) ---> 构建包(Building Packages)
那么接下来我们要开始具体分析这些过程中都做了哪些事情:
检测包
这一步,最主要的目的就是检测我们的项目中是否存在 npm 相关的文件,比如package-lock.json等;如果有,就会有相关的提示用户注意:这些文件可能会存在冲突。在这一步骤中 也会检测系统 OS, CPU 等信息。
解析包
这一步会解析依赖树中的每一个包的信息:
首先呢,获取到首层依赖: 也就是我们当前所处的项目中的package.json定义的dependencies、devDependencies、optionalDependencies的内容。
紧接着会采用遍历首层依赖的方式来获取包的依赖信息,以及递归查找每个依赖下嵌套依赖的版本信息,并将解析过的包和正在进行解析包呢用Set数据结构进行存储,这样就可以保证同一版本范围内的包不会进行重复的解析:
举个例子
- 对于没有解析过的包 A, 首次尝试从
yarn.lock中获取版本信息,并且标记为已解析 - 如果在
yarn.lock中没有找到包 A, 则向Registry发起请求获取满足版本范围内的已知的最高版本的包信息,获取之后将该包标记为已解析。
总之,经过解析包这一步之后呢,我们就已经确定了解析包的具体版本信息和包的下载地址。
获取包
这一步首先我们会检查缓存中是否有当前依赖的包,同时呢将缓存中不存在的包下载到缓存的目录中。但是这里有一个小问题需要大家思考一下:
比如: 如何去判断缓存中有当前的依赖包呢?
其实呢,在 Yarn 中会根据 cacheFolder+slug+node_modules+pkg.name 生成一个路径;判断系统中是否存在该 path,如果存在证明已经有缓存,不用重新下载。这个 path 也就是依赖包缓存的具体路径。
那么对于没有命中的缓存包呢?在 Yarn 中存在一个 Fetch 队列,按照具体的规则进行网络请求。如果下载的包是一个 file 协议,或者是相对路径,就说明指向一个本地目录,此时会调用 Fetch From Local 从离线缓存中获取包;否则调用 Fetch From External 获取包,最终获取的结果使用 fs.createWriteStream 写入到缓存目录。
链接包
我们上一步已经把依赖放到了缓存目录,那么下一步,我们应该要做什么事情呢?是不是应该把项目中的依赖复制到node_modules目录下呢,没错;只不过此时需要遵循一个扁平化的原则。复制依赖之前, Yarn会先解析 peerDepdencies,如果找不到符合要求的peerDepdencies的包,会有 warning提示,并最终拷贝依赖到项目中。
构建包
如果依赖包中存在二进制包需要进行编译,那么会在这一步进行。
千呼万唤始出来,这里要插一句话,感谢大家的捧场。 为伊消得人憔悴,最近想的事情比较多,一直拖着实在是不好意思。那我们大家继续来一起整理:
其实, 从大家的评论中我去认真讨论和学到了一些新的东西pnmp和Lerna;之后如果时间充裕的话,我也会去研究研究和大伙一起讨论的,感谢大家伙的支持 💗。
npm 的缓存机制
回归正题,接下来让我们看来一下 npm的对于同一个版本的依赖包是如何进行本地化缓存的
这是 npm 查看本地缓存的命令:
npm config get cache
复制代码
从图中我们可以看出 npm 配置缓存的位置在 /Users/zhaoxxxx/.npm(mac os 的默认的缓存的位置)当中。
其实你也看到了_cacache的目录有三个文件:
- content-v2
- index-v5
- tmp
其中, content-v2 里面存放的是一些二进制的文件。为了使二进制的文件可读,我把文件做了压缩和解压缩处理。
然后把下面的文件进行解压处理就可以得到我们想要的 npm 的具体的资源:
压缩结果
这里推荐一个 the unarchiver 解压缩工具,支持更多的格式,强力推荐。
而在 index-v5 文件中呢, 我们使用和刚才一样的操作可以得到一些描述性的文件。
事实上这些内容就是 content-v2 文件的索引。
那么这里我也有一个问题这里的缓存是如何存储并且被利用的呢?
这里就要提一下 npm install的安装机制, 当 npm 执行的时候,通过 pacote 把相应的包解压到对应的 node_modules下面。(这里顺嘴提一句 pacote感兴趣的可以来一起研究一下细节,我目前有点不太能看懂; 大概的思路是结合网络请求和文件读写配置进行本地的缓存写入和生成对应的压缩文件,这里通过对一位大佬文章学习有所得)
npm 主要有会有三个地方用到 pacote:
- 当你执行 npm install xxx (这时候会通过
pacote.extract把对应的包解压到对应的node_modules下面,pacote源码地址: extract.js) - 当你执行 npm cache add xxx (这时候会通过
pacote.tarball 下的 tarballStream往我们之前看到的_cacache文件下去添加缓存,pacote源码地址: tarballStream) - 当你执行 npm pack xxx 通过
pacote.tarball 下的 _toFile在当前路径生成对应的压缩文件, 源码地址:_toFile )
当npm下载依赖的时候, 先下载到缓存当中,再解压到我们的项目的 node_modules中。 其实 pacote是依赖 npm-registry-fetch来下载包, npm-registry-fetch 可以通过设置 cache 字段进行相关的缓存工作。

紧接着呢, 我们在每次去安装资源的时候,会根据package-lock.json中的
- integrity
- verison
- name
integrity、verison、name 相关信息会生成一个唯一的 key;这个 key 就能够对应上 index-v5 目录下的缓存记录; 如果发现有缓存资源,就会去找到 tar 包对应的hash值. 根据 hash再去找缓存中的tar包,然后再次通过 pacote将二进制文件解压缩进我们项目的 node_modules目录中,这样就省去了资源下载的网络开销。
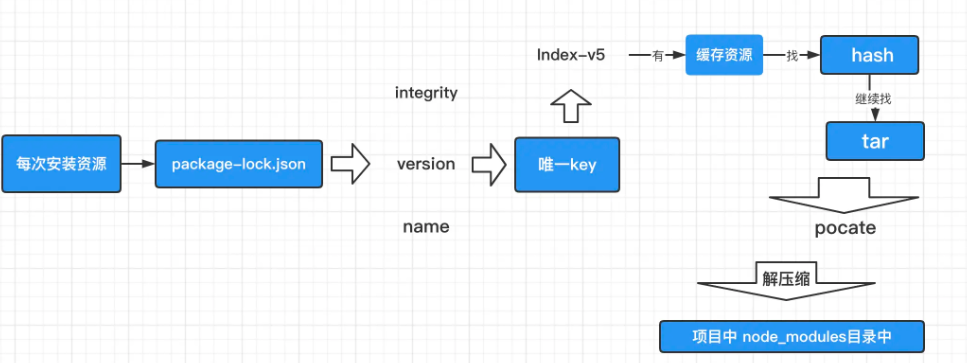
这里需要注意的是, 这里的缓存策略是在 npm v5 开始的,那么在 v5 之前呢, 每个缓存模块是在我们之前提到的 ~./npmrc 文件中以模块名的格式直接存储的
存储的格式:{cache}{name}{version}
npm or yarn 开发中的一点疑惑
你在实际的开发会不会出现这样的一些情况
- 当你项目依赖出现问题的时候, 我们会不会是直接删除
node_modules 和 lockfiles依赖, 再重新npm install,删除大法是否真的好用?这样的使用方案会不会带来什么问题? - 把所有的依赖包都安装到
dependencies中,对devDependencies不区分会不会有问题? - 一个项目中, 你使用
yarn, 我使用npm,会不会有问题呢? - 还有一个问题,
lockfiles 文件我们提交代码的时候需不需要提交到仓库中呢?
为什么要 lockfiles,要不要提交 lockfiles 到仓库?
其实从前文中 我们已经知道了,npm 从v5开始, 增加了package-lock.json 文件。那么 package-lock.json文件的作用是什么呢? 锁定依赖的安装结构, 这么做的目的是为了保证在任意的机器上我们去执行npm install 都会得到完全相同的 node_modules安装结果。
这里其实我是有一个疑问的?为啥单一的 package.json 不能确定唯一的依赖树呢?
- 首先是不同版本的 npm 的安装依赖的策略和算法可能是不一样的
- npm install 将根据
package.json中的 semver-range version 更新依赖,可能某些依赖自上次安装以后,己经发布了新的版本。
因此, 保证能够完整准确的还原项目依赖 就是lockfiles出现的原因。
首先我们这里需要了解一下 package-lock.json的作用机制。 举个例子:
"@babel/core": {
"version": "7.2.0",
"integrity": "sha1-pN04FJAZmOkzQPAIbphn/voWOto=",
"dev": true,
"requires": {
"@babel/code-frame": "^7.0.0",
// ...
},
"dependencies": {
"@babel/generator": {
"version": "7.2.0",
"resolved": "http://www.npm.com/@babel%2fgenerator/-/generator-7.2.0.tgz",
"integrity": "sha1-6vOCH6AwHZ1K74jmPUvMGbc7oWw=",
"dev": true,
"requires": {
"@babel/types": "^7.2.0",
"jsesc": "^2.5.1",
"lodash": "^4.17.10",
"source-map": "^0.5.0",
"trim-right": "^1.0.1"
}
},
// ...
}
},
// ...
}
那么, 通过上面的示例, 我们可以看到: 一个 package-lock.json 的 dependency 主要是有以下的几部分组成的:
- Version: 依赖包的版本号
- Resolved: 依赖包的安装源(其实就是可以理解为下载地址)
- Intergrity: 表明完整性的 Hash 值
- Dev: 表示该模块是否为顶级模块的开发依赖或者是一个的传递依赖关系
- requires: 依赖包所需要的所有依赖项,对应依赖包 package.json 里 dependencices 中的依赖项
- dependencices: 依赖包 node_modeles 中依赖的包(特殊情况下才存在)
事实上, 并不是所有的子依赖都有 dependencies 属性,只有子依赖的依赖和当前已安装在根目录的 node_modules 中的依赖冲突之后, 才会有这个属性。 这可能涉及嵌套情况的依赖管理,大家找些资料看看。
至于我们要不要提交 lockfiles 到仓库中? 这个就需要看我们具体的项目的定位了。
- 如果是开发一个应用, 我的理解是
package-lock.json文件提交到代码版本仓库.这样可以保证项目中成员、运维部署成员或者是 CI 系统, 在执行npm install后, 保证在不同的节点能得到完全一致的依赖安装的内容 - 如果你的目标是开发一个给外部环境用的库,那么就需要认真考虑一下了, 因为库文件一般都是被其他项目依赖的,在不使用 package-lock.json 的情况下,就可以复用主项目已经加载过的包,减少依赖重复和体积
- 如果说我们开发的库依赖了一个精确版本号的模块, 那么在我们去提交 lockfiles 到仓库中可能就会出现, 同一个依赖被不同版本都被下载的情况。如果我们作为一个库的开发者, 其实如果真的使用到某个特定的版本依赖的需求, 那么定义peerDependencies 是一个更好的选择。
所以, 我个人比较推荐的一个做法是:把 package-lock.json一起提交到仓库中去, 不需要 ignore. 但是在执行 npm publish 命令的时候,也就是发布一个库的时候, 它其实应该是被忽略的不应该被发布出去的。
当然,我这里了解到对 lockfiles的处理,可能需要一个更加细颗粒度的理解,这里我会推荐大家去结合前文去理解。
- 在 npm 早期所用到的锁定版本的方式是通过使用
npm-shrinkwrap.json, 它与之前我们提到的package-lock.json最大的不同之处在于: npm 包发布的时候默认是将npm-shrinkwrap.json发布的, 因此类库和组件需要慎重。 - 我们在可以使用到
package-lock.json是在 npm v5.x 版本新增的特性,而在 npm v5.6 之后才趋于逐步稳定的状态, 在 5.0 - 5.6 中间, 其实是对package-lock.json的处理逻辑进行过几次更新。 - 在 npm v5.0.x 版本中, npm install 时都会根据 package-lock.json 文件下载,不管你的
package.json的内容究竟是什么。 - npm v5.1.0 版本到 npm v5.4.2, npm install 会无视
package-lock.json文件下载的, 会去下载最新版本的 npm 包,并且会更新package-lock.json. - npm 5.4.2 版本之后呢,我们继续细化分析:
- 如果在我们的实际开发的项目中, 只有
package.json文件时, npm install 之后, 会根据它生成一个package-lock.json文件 - 如果在项目中存在了
package.json和package-lock.json文件, 同时package.json的semver-range 版本 和package-lock.json中版本兼容,即使此时会有新的适用的版本,npm install还是会根据package-lock.json下载的 - 如果在项目中存在了
package.json和package-lock.json文件, 同时package.json的semver-range 版本 和package-lock.json中版本不兼容,npm install会把package-lock.json更新到兼容package.json的版本。 - 如果
package-lock.json和npm-shrinkwrap.json同时存在于项目的根目录中的时候,package-lock.json将会被忽略的。
- 如果在我们的实际开发的项目中, 只有
对于上面的过程分析,我之前的文章中做了一个过程的流程图的分析,大家可以结合前文做一个更加精细化的理解
那么,下面我们继续来看下一个问题, 我们不管是使用 npm 或 yarn 都有可能会把包依赖安装到不同的依赖模块中, 你有没有去思考为什么会这样做呢?这么做会有什么必要关系和我们之后的开发和发布?
为什么会有 xxxDependencies?
其实, npm 设计了以下的几种依赖类型声明:
- dependencies 项目依赖
- devDependencies 开发依赖
- peerDependencies 同版本的依赖
- bundledDependencies 捆绑依赖
- optionalDependencies 可选依赖
它们起到的作用和声明意义是各不相同的。下面我们来具体介绍一下:
dependencies 表示项目依赖,这些依赖都会成为你的线上生产环境中的代码组成的部分。当 它关联到 npm 包被下载的时候, dependencies下的模块也会作为依赖, 一起被下载。
devDependencies表示开发依赖, 不会被自动下载的。因为 devDependencies 一般是用于开发阶段起作用或是只能用于开发环境中被用到的。 比如说我们用到的 Webpack,预处理器 babel-loader、scss-loader,测试工具E2E等, 这些都相当于是辅助的工具包, 无需在生产环境被使用到的。
这里有一点还是需要我去啰嗦一下的,并不是只有在dependencies中的模块才会被一起打包, 而是在 devDependencies 中的依赖一定不会被打包的。 实际上, 依赖是否是被打包,完全是取决你的项目里的是否是被引入了该模块。
peerDependencies 表示同版本的依赖, 简单一点说就是: 如果你已经安装我了, 那么你最好也安装我对应的依赖。 这里举个小例子: 加入我们需要开发一个react-ui 就是一个基于react 开发的 UI 组件库, 它本身是会需要一个宿主环境去运行的, 这个宿主环境还需要指定的 react版本来搭配使用的, 所以需要我们去 package.json中去配置:
"peerDependencies": {
"React": "^17.0.0"
}
bundledDependencies 和 npm pack 打包命令有关。假设我们在 package.json中有如下的配置:
{
"name": "test",
"version": "1.0.0",
"dependencies": {
"dep": "^0.0.2",
...
},
"devDependencies": {
...
"devD1": "^1.0.0"
},
"bundledDependencies": [
"bundleD1",
"bundleD2"
]
}
那我们此时执行 npm pack的时候, 就会生成一个 test-1.0.0.tgz的压缩包, 在该压缩包中还包含了 bundleD1和 bundleD2 两个安装包。 实际使用到 这个压缩包的时候
npm install test-1.0.0.tgz 的命令时, bundleD1和 bundleD2 也会被安装的。
这里其实也有需要注意的是: 在 bundledDependencies 中指定的依赖包, 必须先在dependencies 和 devDependencies 声明过, 否则 npm pack 阶段是会报错的。
optionalDependencies表示可选依赖,就是说当你安装对应的依赖项安装失败了, 也不会对整个安装过程有影响的。一般我们很少会用到它, 这里我是 不建议大家去使用, 可能会增加项目的不确定性和复杂性。
到现在为止,大家是不是已经对 npm 规范中相关依赖声明的含义了呢? 接下来我想和大家去聊一聊版本的规范, 我们一起来看一下解析依赖库锁版本的行为。
版本规范——依赖库锁版本行为解析
首先, npm 遵循的是 SemVer版本规范, 至于具体的内容这个链接供大家学习语义化版本我就不去啰嗦了。 我们会主要针对一个细节点---- 依赖库锁版本的行为。
每个 vue 包的新版本发布时,一个相应版本的 vue-template-compiler 也会随之发布。编译器的版本必须和基本的 vue 包保持同步,这样 vue-loader 就会生成兼容运行时的代码。这意味着你每次升级项目中的 vue 包时,也应该匹配升级 vue-template-compiler。
根据上面说的意思, 我们如果作为一个库的开发者需要考虑的是: 如何去保证依赖包之间的强制的最低版本的要求?
其实我们可以去借鉴一下 create-react-app的做法, 在 create-react-app的核心 react-script 中, 它利用了verifyPackageTree方法, 对业务项目中的依赖进行了一系列的对比和限制的工作。 我们可以去看一下源码:
function verifyPackageTree() {
const depsToCheck = [
'babel-eslint',
'babel-jest',
'babel-loader',
'eslint',
'jest',
'webpack',
'webpack-dev-server',
];
const getSemverRegex = () =>
/\bv?(?:0|[1-9]\d*)\.(?:0|[1-9]\d*)\.(?:0|[1-9]\d*)(?:-[\da-z-]+(?:\.[\da-z-]+)*)?(?:\+[\da-z-]+(?:\.[\da-z-]+)*)?\b/gi;
const ownPackageJson = require('../../package.json');
const expectedVersionsByDep = {};
depsToCheck.forEach(dep => {
const expectedVersion = ownPackageJson.dependencies[dep];
if (!expectedVersion) {
throw new Error('This dependency list is outdated, fix it.');
}
if (!getSemverRegex().test(expectedVersion)) {
throw new Error(
`The ${dep} package should be pinned, instead got version ${expectedVersion}.`
);
}
expectedVersionsByDep[dep] = expectedVersion;
});
let currentDir = __dirname;
while (true) {
const previousDir = currentDir;
currentDir = path.resolve(currentDir, '..');
if (currentDir === previousDir) {
// We've reached the root.
break;
}
const maybeNodeModules = path.resolve(currentDir, 'node_modules');
if (!fs.existsSync(maybeNodeModules)) {
continue;
}
depsToCheck.forEach(dep => {
const maybeDep = path.resolve(maybeNodeModules, dep);
if (!fs.existsSync(maybeDep)) {
return;
}
const maybeDepPackageJson = path.resolve(maybeDep, 'package.json');
if (!fs.existsSync(maybeDepPackageJson)) {
return;
}
const depPackageJson = JSON.parse(
fs.readFileSync(maybeDepPackageJson, 'utf8')
);
const expectedVersion = expectedVersionsByDep[dep];
if (!semver.satisfies(depPackageJson.version, expectedVersion)) {
console.error(//...);
process.exit(1);
}
});
}
}
其实我们去看这一段代码的时候, create-react-app会对项目中的babel-eslint、 babel-jest、babel-loader、eslint、jest、webpack、webpack-dev-server 这些核心的依赖都会去进行检索的 --- 是否是符合 create-react-app 对于这些核心模块依赖的版本要求。如果不符合依赖版本要求, 那么 create-react-app 的构建过程会直接报错并退出的。
那么为啥 create-react-app这么做的理由是什么呢?
我的理解是:需要上述依赖项的某些确定的版本, 以保障 create-react-app 源码相关的功能稳定
不知道你对于这样的一种处理方式会不会有一些思考呢?
那么最好我想去分享一些,自己在对 npm 实操的一些小建议, 大家伙可以来讨论一下是不是可行的
或许是最佳的实操建议
下面我会给出具体的实操的建议, 供大家来参考:
- 优先去使用 npm 官方已经稳定的支持的版本, 以保证 npm 的最基本先进性和稳定性
- 当我们的项目第一次去搭建的时候, 使用
npm install安装依赖包, 并去提交package.json、package-lock.json, 至于node_moduled目录是不用提交的。 - 当我们作为项目的新成员的时候,
checkout/clone项目的时候, 执行一次npm install去安装依赖包。 - 当我们出现了需要升级依赖的需求的时候:
- 升级小版本的时候, 依靠 npm update
- 升级大版本的时候, 依靠 npm install@
- 当然我们也有一种方法, 直接去修改 package.json 中的版本号, 并去执行 npm install 去升级版本
- 当我们本地升级新版本后确认没有问题之后, 去提交新的 package.json 和 package-lock.json 文件。
- 对于降级的依赖包的需求: 我们去执行npm install @ 命令后,验证没有问题之后, 是需要提交新的 package.json 和 package-lock.json 文件。
- 删除某些依赖的时候:
- 当我们执行 npm uninstall 命令后, 需要去验证,提交新的 package.json 和 package-lock.json 文件。
- 或者是更加暴力一点, 直接操作
package.json, 删除对应的依赖, 执行 npm install 命令, 需要去验证,提交新的package.json 和 package-lock.json 文件。
- 当你把更新后的package.json 和 package-lock.json提交到代码仓库的时候, 需要通知你的团队成员, 保证其他的团队成员拉取代码之后, 更新依赖可以有一个更友好的开发环境保障持续性的开发工作。
- 任何时候我们都不要去修改 package-lock.json,这是交过智商税的。
- 如果你的 package-lock.json 出现冲突或问题, 我的建议是将本地的 package-lock.json文件删掉, 然后去找远端没有冲突的 package.json 和 package-lock.json, 再去执行
npm install命令。
package.json 与 package-lock.json
package.json
管理包
大家都知道,package.json 用来描述项目及项目所依赖的模块信息。,就是帮我们管理项目中的依赖包的,让我们远离了依赖地狱。
通过 npm 管理,使用一些简单的命令,自动生成package.json, 安装包依赖关系都由package.json来管理,我们几乎不必考虑它们。
语义版本控制
首先我们先来了解下依赖包的版本号的定义
版本号由三部分组成:major.minor.patch,主版本号.次版本号.修补版本号。
例如:1.2.3,主要版本 1,次要版本 2,补丁 3。
补丁中的更改表示不会破坏任何内容的错误修复。次要版本的更改表示不会破坏任何内容的新功能。主要版本的更改代表了一个破坏兼容性的大变化。 如果用户不适应主要版本更改,则内容将无法正常工作。
安装依赖包的版本如何指定
相信大家都会经历过,我们安装一些依赖包的时候,版本号前面都会带 ^ 或者 ~ 的符号,这两个符号代表什么意思呢?
~ 会匹配最近的小版本依赖包,比如 ~1.2.3 会匹配所有 1.2.x 版本,但是不包括 1.3.0
^ 会匹配最新的大版本依赖包,比如 ^1.2.3 会匹配所有 1.x.x 的包,包括 1.3.0,但是不包括 2.0.0
* 安装最新版本的依赖包,比如 *1.2.3 会匹配 x.x.x,
那么该如何选择呢?当然你可以指定特定的版本号,直接写 1.2.3,前面什么前缀都没有,这样固然没问题,但是如果依赖包发布新版本修复了一些小 bug,那么需要手动修改 package.json 文件;~ 和 ^ 则可以解决这个问题。
但是需要注意 ^ 版本更新可能比较大,会造成项目代码错误,所以 建议使用 ~ 来标记版本号,这样可以保证项目不会出现大的问题,也能保证包中的小 bug 可以得到修复。
版本号写 *,这意味着安装最新版本的依赖包,但缺点同上,可能会造成版本不兼容,慎用!
多人开发时依赖包安装的问题
看了上面版本号的指定后,我们可以知道,当我们使用了 ^ 或者 ~ 来控制依赖包版本号的时候 ,多人开发,就有可能存在大家安装的依赖包版本不一样的情况,就会存在项目运行的结果不一样。
我们举个例子:
假设我们中安装了 vue, 当我们运行安装 npm install vue -save 的时候,在项目中的 package.json 的 vue 版本是 vue: ^3.0.0, 我们电脑安装的 vue 版本就是 3.0.0 版本,我们把项目代码提交后,过了一段时间,vue 发布了新版本 3.0.1,这时新来一个同事,从新 git clone 克隆项目,执行 npm install安装的时候,在他电脑的 vue 版本就是 3.0.1 了,因为^只是锁了主要版本,这样我们电脑中的 vue 版本就会不一样,从理论上讲(大家都遵循语义版本控制的话),它们应该仍然是兼容的,但也许 bugfix 会影响我们正在使用的功能,而且当使用 vue 版本 3.0.0 和 3.0.1 运行时,我们的应用程序会产生不同的结果。
大家思考思考,这样的话,不同人电脑安装的依赖版项目,是不是都有可能不一样,就会导致每个人电脑运行的应用程序产生不同的结果。就会存在 bug 的隐患。
这时也许有同学想到,那么我们在package.json上面锁死依赖包的版本号不就可以了? 直接写 vue: 3.0.0锁死,这样大家安装 vue 的版本都是 3.0.0 版本了。
这个想法固然是不错的,但是你只能控制你自己的项目锁死版本号,那你项目中依赖包的依赖包呢?你怎么控制限制别人锁死版本号呢?
为了解决这个不同人电脑安装的所有依赖版本都是一致的,确保项目代码在安装所执行的运行结果都一样,这时 package-lock.json 就应运而生了。
package-lock.json
package-lock.json 是在 npm(^5.x.x.x)后才有,中途有几次更改
介绍
官方文档是这样解释的:package-lock.json 它会在 npm 更改 node_modules 目录树 或者 package.json 时自动生成的 ,它准确的描述了当前项目 npm 包的依赖树,并且在随后的安装中会根据 package-lock.json 来安装,保证是相同的一个依赖树,不考虑这个过程中是否有某个依赖有小版本的更新。
它的产生就是来对整个依赖树进行版本固定的(锁死)。
当我们在一个项目中npm install时候,会自动生成一个package-lock.json文件,和package.json在同一级目录下。package-lock.json记录了项目的一些信息和所依赖的模块。这样在每次安装都会出现相同的结果. 不管你在什么机器上面或什么时候安装。
当我们下次再npm install时候,npm 发现如果项目中有 package-lock.json 文件,会根据 package-lock.json 里的内容来处理和安装依赖而不再根据 package.json。
注意,使用
cnpm install时候,并不会生成package-lock.json文件,也不会根据package-lock.json来安装依赖包,还是会使用package.json来安装。
package-lock.json 生成逻辑
简单描述一下 package-lock.json 生成的逻辑。假设我们现在有三个 package,在项目 lock-test 中,安装依赖 A,A 项目面有 B,B 项目面有 C
// package lock-test
{ "name": "lock-test", "dependencies": { "A": "^1.0.0" }}
// package A
{ "name": "A", "version": "1.0.0", "dependencies": { "B": "^1.0.0" }}
// package B
{ "name": "B", "version": "1.0.0", "dependencies": { "C": "^1.0.0" }}
// package C
{ "name": "C", "version": "1.0.0" }
在这种情况下 package-lock.json, 会生成类似下面铺平的结构
// package-lock.json
{
"name": "lock-test",
"version": "1.0.0",
"dependencies": {
"A": { "version": "1.0.0" },
"B": { "version": "1.0.0" },
"C": { "version": "1.0.0" }
}
}
如果后续无论是直接依赖的 A 发版,或者间接依赖的 B, C 发版,只要我们不动 package.json, package-lock.json 都不会重新生成。
A 发布了新版本 1.1.0,虽然我们 package.json 写的是 ^1.0.0 但是因为 package-lock.json 的存在,npm i 并不会自动升级,
我们可以手动运行 npm i A@1.1.0 来实现升级。
因为 1.1.0 package-lock.json 里记录的 A@1.0.0 是不一致的,因此会更新 package-lock.json 里的 A 的版本为 1.1.0。
B 发布了新版本 1.0.1, 1.0.2, 1.1.0, 此刻如果我们不做操作是不会自动升级 B 的版本的,但如果此刻 A 发布了 1.1.1,虽然并没有升级 B 的依赖,但是如果我们项目里升级 A@1.1.1,此时 package-lock.json 里会把 B 直接升到 1.1.0 ,因为此刻^1.0.0 的最新版本就是 1.1.0。
经过这些操作后 项目 lock-test 的 package.json 变成
// package
lock-test{ "dependencies": { "A": "^1.1.0" }}
对应的 package-lock.json 文件
{
"name": "lock-test",
"version": "1.0.0",
"dependencies": {
"A": { "version": "1.1.0" },
"B": { "version": "1.1.0" },
"C": { "version": "1.0.0" }
}
}
这个时候我们将 B 加入我们 lock-test 项目的依赖, B@^1.0.0,package.json 如下
{ "dependencies": { "A": "^1.1.0", "B": "^1.0.0" }}
我们执行这个操作后,package-lock.json 并没有被改变,因为现在 package-lock.json 里 B@1.1.0 满足 ^1.0.0 的要求
但是如果我们将 B 的版本固定到 2.x 版本, package-lock.json 就会发生改变
{ "dependencies": { "A": "^1.1.0", "B": "^2.0.0" }}
因为存在了两个冲突的 B 版本,package-lock.json 文件会变成如下形式
{
"name": "lock-test",
"version": "1.0.0",
"dependencies": {
"A": {
"version": "1.1.0",
"dependencies": {
"B": { "version": "1.1.0" }
}
},
"B": { "version": "2.0.0" },
"C": { "version": "1.0.0" }
}
}
因为 B 的版本出现了冲突,npm 使用嵌套描述了这种行为
我们实际开发中并不需要关注这种生成的算法逻辑,我们只需要了解,package-lock.json 的生成逻辑是为了能够精准的反映出我们 node_modules 的结构,并保证能够这种结构被还原。
package-lock.json 可能被意外更改的原因
- package.json 文件修改了
- 挪动了包的位置
将部分包的位置从 dependencies 移动到 devDependencies 这种操作,虽然包未变,但是也会影响 package-lock.json,会将部分包的 dev 字段设置为 true
- registry 的影响
经过实际使用发现,如果我们 node_modules 文件夹下的包中下载时,就算版本一样,安装源 registry 不同,执行 npm i 时也会修改 package-lock.json
可能还存在其他的原因,但是 package-lock.json 是不会无缘无故被更改的,一定是因为 package.json 或者 node_modules 被更改了,因为 正如上面提到的 package-lock.json 为了能够精准的反映出我们 node_modules 的结构
开发的建议
一般情况下 npm install 是可以的,他能保证根据 package-lock.json 还原出开发时的 node_modules。
但是为了防止出现刚刚提到的意外情况,除非涉及到对包的调整,其他情况下建议使用 npm ci 来安装依赖,会避免异常的修改 package-lock.json,
持续集成工具中更推荐是用 npm ci,保证构建环境的准确性,npm i 和 npm ci 的区别 可以参考官方文档 npm-ci
pnpm
npm2
用 node 版本管理工具把 node 版本降到 4,那 npm 版本就是 2.x 了。
然后找个目录,执行下 npm init -y,快速创建个 package.json。
然后执行 npm install express,那么 express 包和它的依赖都会被下载下来:
展开 express,它也有 node_modules:
再展开几层,每个依赖都有自己的 node_modules:
也就是说 npm2 的 node_modules 是嵌套的。
这很正常呀?有什么不对么?
这样其实是有问题的,多个包之间难免会有公共的依赖,这样嵌套的话,同样的依赖会复制很多次,会占据比较大的磁盘空间。
这个还不是最大的问题,致命问题是 windows 的文件路径最长是 260 多个字符,这样嵌套是会超过 windows 路径的长度限制的。
当时 npm 还没解决,社区就出来新的解决方案了,就是 yarn:
yarn
yarn 是怎么解决依赖重复很多次,嵌套路径过长的问题的呢?
铺平。所有的依赖不再一层层嵌套了,而是全部在同一层,这样也就没有依赖重复多次的问题了,也就没有路径过长的问题了。
我们把 node_modules 删了,用 yarn 再重新安装下,执行 yarn add express:
这时候 node_modules 就是这样了:
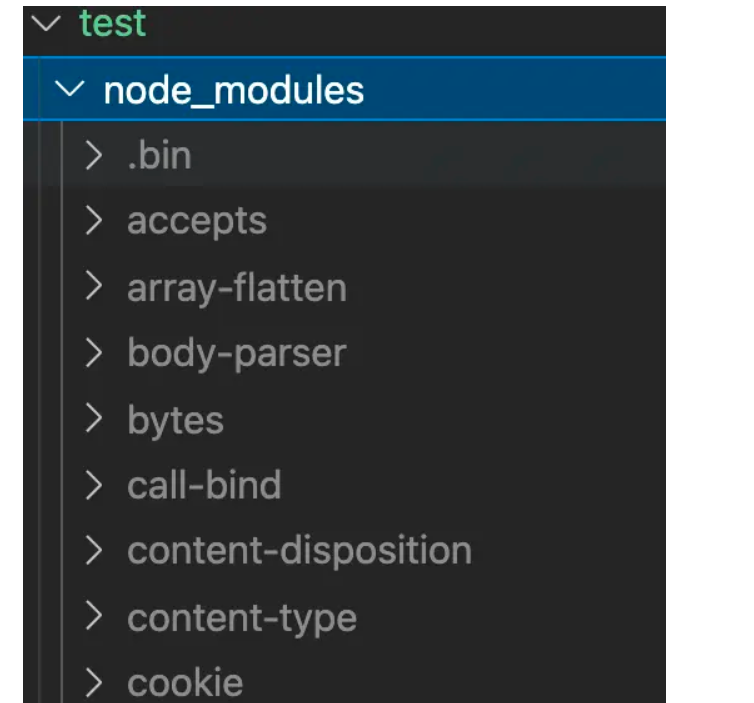
全部铺平在了一层,展开下面的包大部分是没有二层 node_modules 的:
当然也有的包还是有 node_modules 的,比如这样:
为什么还有嵌套呢?
因为一个包是可能有多个版本的,提升只能提升一个,所以后面再遇到相同包的不同版本,依然还是用嵌套的方式。
npm 后来升级到 3 之后,也是采用这种铺平的方案了,和 yarn 很类似:
当然,yarn 还实现了 yarn.lock 来锁定依赖版本的功能,不过这个 npm 也实现了。
yarn 和 npm 都采用了铺平的方案,这种方案就没有问题了么?
并不是,扁平化的方案也有相应的问题。
最主要的一个问题是幽灵依赖,也就是你明明没有声明在 dependencies 里的依赖,但在代码里却可以 require 进来。
这个也很容易理解,因为都铺平了嘛,那依赖的依赖也是可以找到的。
但是这样是有隐患的,因为没有显式依赖,万一有一天别的包不依赖这个包了,那你的代码也就不能跑了,因为你依赖这个包,但是现在不会被安装了。
这就是幽灵依赖的问题。
而且还有一个问题,就是上面提到的依赖包有多个版本的时候,只会提升一个,那其余版本的包不还是复制了很多次么,依然有浪费磁盘空间的问题。
那社区有没有解决这俩问题的思路呢?
当然有,这不是 pnpm 就出来了嘛。
那 pnpm 是怎么解决这俩问题的呢?
pnpm
回想下 npm3 和 yarn 为什么要做 node_modules 扁平化?不就是因为同样的依赖会复制多次,并且路径过长在 windows 下有问题么?
那如果不复制呢,比如通过 link。
首先介绍下 link,也就是软硬连接,这是操作系统提供的机制,硬连接就是同一个文件的不同引用,而软链接是新建一个文件,文件内容指向另一个路径。当然,这俩链接使用起来是差不多的。
如果不复制文件,只在全局仓库保存一份 npm 包的内容,其余的地方都 link 过去呢?
这样不会有复制多次的磁盘空间浪费,而且也不会有路径过长的问题。因为路径过长的限制本质上是不能有太深的目录层级,现在都是各个位置的目录的 link,并不是同一个目录,所以也不会有长度限制。
没错,pnpm 就是通过这种思路来实现的。
再把 node_modules 删掉,然后用 pnpm 重新装一遍,执行 pnpm install。
你会发现它打印了这样一句话:
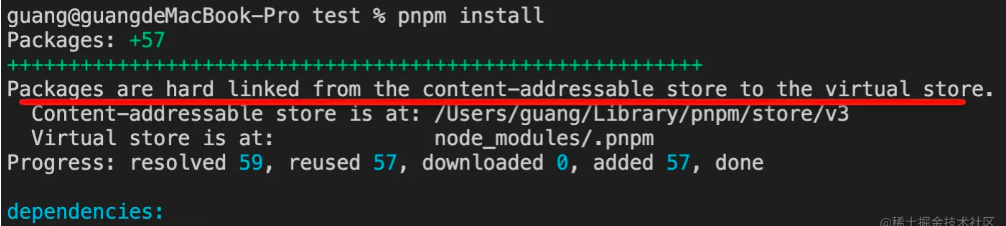
包是从全局 store 硬连接到虚拟 store 的,这里的虚拟 store 就是 node_modules/.pnpm。
我们打开 node_modules 看一下:
确实不是扁平化的了,依赖了 express,那 node_modules 下就只有 express,没有幽灵依赖。
展开 .pnpm 看一下:
所有的依赖都在这里铺平了,都是从全局 store 硬连接过来的,然后包和包之间的依赖关系是通过软链接组织的。
比如 .pnpm 下的 expresss,这些都是软链接,
也就是说,所有的依赖都是从全局 store 硬连接到了 node_modules/.pnpm 下,然后之间通过软链接来相互依赖。
官方给了一张原理图,配合着看一下就明白了:
这就是 pnpm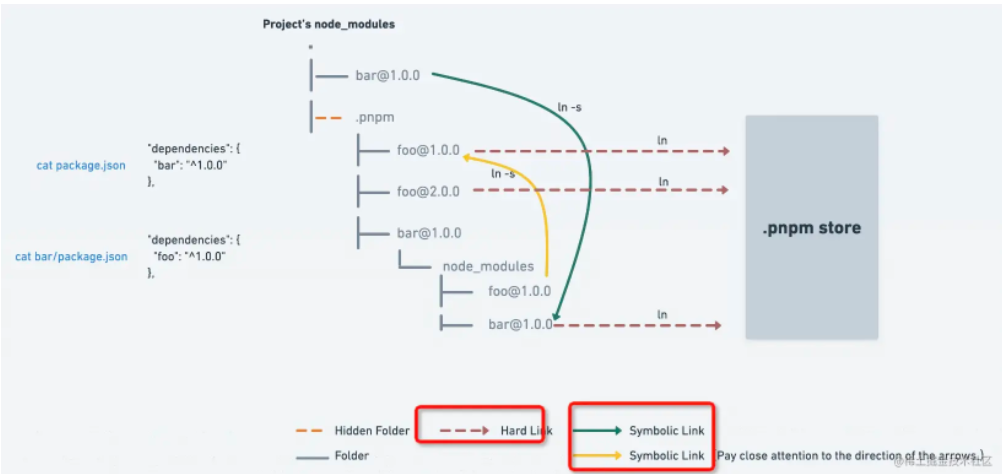 实现原理。
实现原理。
那么回过头来看一下,pnpm 为什么优秀呢?
首先,最大的优点是节省磁盘空间呀,一个包全局只保存一份,剩下的都是软硬连接,这得节省多少磁盘空间呀。
其次就是快,因为通过链接的方式而不是复制,自然会快。
相比 npm2 的优点就是不会进行同样依赖的多次复制。
相比 yarn 和 npm3+ 呢,那就是没有幽灵依赖,也不会有没有被提升的依赖依然复制多份的问题。
这就已经足够优秀了,对 yarn 和 npm 可以说是降维打击。
总结
pnpm 最近经常会听到,可以说是爆火。本文我们梳理了下它爆火的原因:
npm2 是通过嵌套的方式管理 node_modules 的,会有同样的依赖复制多次的问题。
npm3+ 和 yarn 是通过铺平的扁平化的方式来管理 node_modules,解决了嵌套方式的部分问题,但是引入了幽灵依赖的问题,并且同名的包只会提升一个版本的,其余的版本依然会复制多次。
pnpm 则是用了另一种方式,不再是复制了,而是都从全局 store 硬连接到 node_modules/.pnpm,然后之间通过软链接来组织依赖关系。
这样不但节省磁盘空间,也没有幽灵依赖问题,安装速度还快,从机制上来说完胜 npm 和 yarn。
pnpm 就是凭借这个对 npm 和 yarn 降维打击的。
monorepo
什么是 Monorepo ?
Monorepo 是一种代码管理模式,指在一个项目仓库 (repo) 中管理多个模块/包 (package)。与 Monorepo 相对的是 Multirepo(或 Polyrepo),也就是我们常见的每个模块建一个 仓库。 Google、Facebook、微软等公司已经使用了很多年,Vue3、Yarn2 等知名项目现在也改用了 Monorepo。
一个 Monorepo 项目目录可能是这样的:
├── CHANGELOG.md
├── README.md // monorepo 配置,注册子项目
├── package.json
├── packages // 子项目目录
│ ├── package1
│ │ └── package.json
│ └── package2
│ │ └── package.json
│ └── package3
│ └── package.json
为什么使用 Monorepo ?
当你需要维护多个项目,多个项目之间有依赖,这些项目共用相同的基础设施(构建工具、lint)的时候,使用 monorepo 会带来很多好处。
- 常用的包管理工具像 yarn、npm 都会做依赖提升,使用 monorepo 能减少依赖安装时间,同时也减少空间占用。
- 有依赖的项目之间调试非常方便,上层应用能够感知其依赖的变化,可以很方便的对依赖项进行修改和调试。
- 几个项目共用基础设施,不用重复配置。
Workspaces
Workspaces 是设置包架构的一种新方式。他的目的是更方便地使用 monorepo,具体就是能让你的多个项目集中在在同一个仓库,并能够相互引用 -- 被依赖的项目代码修改会实时反馈到依赖项目中。Monorepo 中的子项目称为一个 workspace,多个 workspace 构成 workspaces。
使用 workspaces(以 yarn 为例)好处:
依赖包可以被 linked 到一起,这意味着你的工作区可以相互依赖,代码是实时更新的。这是比 `yarn link`` 更好的方式因为这只会影响工作区部分,不会影响整个文件系统。
所有项目的依赖会被一起安装,这让 Yarn 更方便的优化安装依赖。
Yarn 只有一个 lock 文件,而不是每个子项目就有一个,这意味着更少的冲突。
hoist
为什么使用 monorepo 能减少项目依赖安装时间和所占的空间呢 ?我们先回顾一下独立项目依赖安装的过程。
npm v3 之前,依赖安装规则很简单,在安装依赖时将依赖放到项目的 node_modules 文件中;同时如果某个直接依赖 A 还依赖其他模块 B,作为间接依赖,模块 B 将会被下载到 A 的 node_modules 文件夹中,依此递归执行,最终形成了一颗巨大的依赖模块树。
这样的 node_modules 结构,简单明了、符合预期,但对于大型项目来说可能会安装很多重复的包,比如项目直接依赖 A 和 B,但 A 和 B 都依赖相同版本的模块 C,那么 C 会重复出现在 A 和 B 依赖的 node_modules 中。
这种重复问题使得安装结果浪费了较大的空间资源,也使得安装过程过慢。因此 npm v3 之后,node_modules 的结构改成了扁平结构。
pnpm 节约更多的磁盘空间和更快的安装速度
pnpm。pnpm 开创了一套与 npm v7、yarn 完全不同的新的依赖管理机制,解决了 hoist 的问题,改进依赖提升可能会导致本地开发正常,线上无法编译的问题
monorepo 把子项目的依赖提升到根目录中,减少了部分依赖重复安装。但是如果有多个 monorepo 项目,并且多个 monorepo 之中有相同的依赖,那么依赖依然会被安装多次。所以依赖安装还有优化空间,pnpm 就把这个事情做到了极致,他将依赖存储在一个可内容寻址的 store 中,基于此:
- 如果使用了同一个依赖的不同版本,只会把不同的文件存储到 store 中。比如,如果 express 有 100 个文件,一次版本更新只改了其中 1 个文件,
pnpm update只会把这个新的文件加入到 store 中,而不会克隆整个依赖。 - 所有的文件都被存储到磁盘上一个单独的地方。当依赖被安装的时候,这些文件就会被硬链接到那个地方,而不用消耗额外的磁盘空间。这就能让我们跨项目的复用相同版本的依赖
pnpm 全新的依赖管理机制
我们用 pnpm 初始化一个项目,并且安装一个依赖
pnpm init -y
pnpm install express
看一下此时的 node_modules 里的内容:
.pnpm
express
.modules.yaml
node_modules 里只有文件夹 .npm 和 express,详细结构可以在这里看。
这样就保证项目中只能访问到我们安装过的 express,不会再出现没有在 package.json声明但是能使用的情况。
pnpm 与 monorepo
- 一致的 node_modules 结构:项目声明的依赖只在项目的 node_modules 下存在,peerDependencies 也能被正确 resolve
- 不同项目的 lock 项是独立的。pnpm 为每一个版本的依赖都单独维护了一个 lock 项,对于上面的
react@^16.13.1的问题,在 pnpm 将pattern和version分开了,如果一个项目的 package.json 没有改变过,那么其依赖就不会变(PS: rushjs 的 lock 也是基于特定的工具,所以如果 rush 用 yarn 装依赖,也会有类似问题)。 - pnpm 原生支持只对特定子项目安装依赖,同时保持一致的 node_modules 结构
- pnpm 更快,依赖安装速度是 yarn 的 2-3 倍
CI&CD
基于 Jenkins 从 0 到 1 实现前端的 CI/CD
CI/CD 是一种通过在应用开发阶段引入自动化来频繁向客户交付应用的方法。
CI/CD 的核心概念是持续集成、持续交付和持续部署。它是作为一个面向开发和运营团队的解决方案,主要针对在集成新代码时所引发的问题(也称为:“集成地狱”)。
CI/CD 可让持续自动化和持续监控贯穿于应用的整个生命周期(从集成和测试阶段,到交付和部署)。
这些关联的事务通常被统称为 CI/CD 管道,由开发和运维团队以敏捷方式协同支持。
CI 持续集成(Continuous Integration)
协同开发是目前主流的开发方式,也就是多位开发人员可以同时处理同一个应用的不同模块或者功能。
但是,如果企业计划在同一天,将所有开发分支代码集成在一起,最终可能会花费很多时间和进行很多重复劳动,费事费力。因为代码冲突是难以避免的。
如果开发人员本地的环境和线上不一致的话,那么这个问题就更加复杂了。
持续集成(CI)可以帮助开发者更加方便地将代码更改合并到主分支。
一旦开发人员将改动的代码合并到主分支,系统就会通过自动构建应用,并运行不同级别的自动化测试(通常是单元测试和集成测试)来验证这些更改,确保这些更改没有对应用造成破坏。
如果自动化测试发现新代码和现有代码之间存在冲突,CI 可以更加轻松地快速修复这些错误。
CD 持续交付(Continuous Delivery)
CI 在完成了构建、单元测试和集成测试这些自动化流程后,持续交付可以自动把已验证的代码发布到企业自己的存储库。
持续交付旨在建立一个可随时将开发环境的功能部署到生产环境的代码库。
在持续交付过程中,每个步骤都涉及到了测试自动化和代码发布自动化。
在流程结束时,运维团队可以快速、轻松地将应用部署到生产环境中。
CD 持续部署(Continuous Deployment)
对于一个完整、成熟的 CI/CD 管道来说,最后的阶段是持续部署。
它是作为持续交付的延伸,持续部署可以自动将应用发布到生产环境。
实际上,持续部署意味着开发人员对应用的改动,在编写完成后的几分钟内就能及时生效(前提是它通过了自动化测试)。这更加便于运营团队持续接收和整合用户反馈。
总而言之,所有这些 CI/CD 的关联步骤,都极大地降低了应用的部署风险。
不过,由于还需要编写自动化测试以适应 CI/CD 管道中的各种测试和发布阶段,因此前期工作量还是很大的。
Jenkins
Jenkins是开源 CI&CD 软件领导者,提供超过 1000 个插件来支持构建、部署、自动化,满足任何项目的需要。
一句话概括:Jenkins 是一款以插件化的方式实现 CI/CD 的软件。
1.现实的工作中,一个团队往往有多个团队成员
团队成员往往有多种角色:产品,后端,前端,UI,测试,运维
一个项目往往有多个阶段:需求阶段,评审阶段,编码阶段,测试阶段,部署阶段
一个项目有多个环境:本地调试环境,开发环境,测试环境,预发布/生产环境
2.CI(持续集成)
集成,每个团队成员将手中任务编码,单元测试完成后;将自己的完成的工作集成在一起;项目迭代内容集成在一起交由测试人员进行测试;
说通俗点,把整个迭代所有团队成员的完成的内容集成在一个环境交给测试人员进行测试
传统集成:
1,每个开发人员改完一部分内容,将代码编译,在本地进行测试;
2,每个开发人员开发完自己的工作之后,迁入合并代码;拉取最新代码;
3,编译打包
4,手动部署每一个服务到测试环境进行测试
持续集成:
1,每个人开发一部分工作之后,将代码迁入合并;
2,Jekins 自动构建代码,部署到测试环境
3,整个过程强调自动化,开发人员只需要迁入自己的修改
4,自动化的代码测试
5,快速确保迁入的内容是合格的
3.CD(持续交付)
所有迭代或者项目内容测试完成之后,确保有一个可随时部署到生产环境的代码库或编译版本
4.CD(持续部署)
将交付的结果部署,自动化的部署到生产环境;任何一个更改都可以在任何时候进行部署
5.CI/CD
强调的是整个过程的流水线集成,过程自动化;这种自动化的过程尤其对于大型项目,大型团队,多个服务时会带来更高效的开发人员,测试人员,运维人员之间的合作
DevOps 是 CICD 思想的延伸,CICD 是 DevOps 的基础核心,
如果没有 CICD 自动化的工具和流程,DevOps 是没有意义的
6.大公司的 CICD 往往做的比较复杂;它们会包括 docker,k8s,云,git,jenkins,镜像仓库等
但它们的最简化的流程则是 git,jenkins,本地 IDE;
本地项目发起一个 git 提交,剩下的单元测试,打包构建,代码部署,邮件提醒等全部自动化完成。
准备工作
1.先准备一个项目,我这里直接使用 vue-cli 脚手架生成了一个项目,其他技术栈也一样,只要是个项目就行。
2.建立这个项目的远端 git 仓库,并把本地代码提交上去。我这里用的码云,github 也一致。 3.准备一台能外网访问的服务器,非要用你自己的电脑当服务器也可以,保证外网可访问即可。 4.服务器上配好 Java 环境。
Jenkins 的安装与启动
linux 下:ubuntu 14.04 中安装 Jenkins windows 下:
- 从 Jenkins 官网下载最新 war 文件。
- 运行
java -jar jenkins.war即可。
Jenkins 初始化
- jenkins 的默认端口是 8080,启动成功后在浏览器打开。
- 进入后会让我们输管理员密码,打开网页上提示路径下的文件,复制密码粘贴输入即可。
- 然后会让安装需要的插件,此处选默认即可,等待安装完成。
- 创建一个管理员账户。
创建任务
- 点击创建一个新任务
- 选择自由风格的软件项目,并起一个名字
至此,基础准备工作已经完成,我们在服务器上安装了 Jenkins 并启动,然后进行了初始化配置,建立了一个新任务。接下来我们开始配置我们需要的功能。
实现 git 钩子功能
首先我们要实现一个 git 钩子功能,就是我们向 github/码云等远程仓库 push 我们的代码时,jenkins 能知道我们提交了代码,这是自动构建自动部署的前提,钩子的实现原理是在远端仓库上配置一个 Jenkins 服务器的接口地址,当本地向远端仓库发起 push 时,远端仓库会向配置的 Jenkins 服务器的接口地址发起一个带参数的请求,jenkins 收到后开始工作。
打开刚创建的任务,选择配置,添加远程仓库地址,配置登录名及密码及分支。
安装 Generic Webhook Trigger Plugin 插件(系统管理-插件管理-搜索 Generic Webhook Trigger Plugin)如果可选插件列表为空,点击高级标签页,替换升级站点的 URL 为:
http://mirror.xmission.com/jenkins/updates/update-center.json并且点击提交和立即获取。添加触发器
第 2 步安装的触发器插件功能很强大,可以根据不同的触发参数触发不同的构建操作,比如我向远程仓库提交的是 master 分支的代码,就执行代码部署工作,我向远程仓库提交的是某个 feature 分支,就执行单元测试,单元测试通过后合并至 dev 分支。灵活性很高,可以自定义配置适合自己公司的方案,这里方便演示我们不做任何条件判断,只要有提交就触发。在任务配置里勾选 Generic Webhook Trigger 即可
仓库配置钩子 此处以码云为例,github 的配置基本一致,进入码云项目主页后,点击管理-webhooks-添加,会跳出一个这样的框来。
URL 格式为
http://<User ID>:<API Token>@<Jenkins IP地址>:端口/generic-webhook-trigger/invokeuserid 和 api token 在 jenkins 的系统管理-管理用户-admin-设置里,
Jenkins IP 地址和端口是你部署 jenkins 服务器的 ip 地址,端口号没改过的话就是 8080。
密码填你和上面 userid 对应的密码,我这里是 root。
下面的几个选项是你在仓库执行什么操作的时候触发钩子,这里默认用 push。
点击提交完成配置。
测试钩子
点击测试,如果配置是成功的,你的 Jenkins 左侧栏构建执行状态里将会出现一个任务。
另外,你也可以试下本地提交代码,提交代码后,jenkins 也会开始一个任务,目前我们没有配置任务开始后让它做什么,所以默认它只会在你提交新代码后,将新代码拉取到 jenkins 服务器上。到此为止,git 钩子我们配置完成。
gif 效果图:
实现自动化构建
git push 触发钩子后,jenkins 就要开始工作了,自动化的构建任务可以有很多种,比如说安装升级依赖包,单元测试,e2e 测试,压缩静态资源,批量重命名等等,无论是 npm script 还是 webpack,gulp 之类的工作流,你之前在本地能做的,在这里同样可以做。 作为演示,这里只演示三个基本常用的工作流程,安装依赖包->单元测试->打包,也就是下面这三个命令。
npm install
npm run test
npm run build
首先,和本地运行 npm script 一样,我们要想在 jenkins 里面执行 npm 命令,先要在 jenkins 里面配置 node 的环境,可以通过配置环境变量的方式引入 node,也可以通过安装插件的方式,这里使用了插件的方式,安装一下 nvm wrapper 这个插件。
打开刚刚的 jenkins 任务,点击配置里面的构建环境,勾选这个,并指定一个 node 版本。
点击构建,把要执行的命令输进去,多个命令使用&&分开。
\4. 保存。 \5. 此时本地修改一下代码 push 测试一下(也可以点击立即构建测试),点击本次触发的那个任务,选择控制台输出,将会看到 Jenkins 在云端执行的过程。
命令行最后一行是 Finished 状态的如果是 SUCCESS(蓝色)则证明执行的任务都顺利进行,是 FAILURE(红色)则证明中间有重大错误导致任务失败,UNSTABLE(黄色)代表有虽然有些小问题,但不阻碍任务进行,黄色或者红色可以去命令行看下错误输出,看下哪里出了问题。
\6. 如果上一步是 SUCCESS,点击项目的工作空间,将会发现多了 dist 和 node_modules 两个文件夹。
至此,我们已经搭建了一个简易的构建工作流程,构建完成了,我们需要自动化部署。
实现自动化部署
自动化部署可能是我们最需要的功能了,公司就一台服务器,我们可以使用人工部署的方式,但是如果公司有 100 台服务器呢,人工部署就有些吃力了,而且一旦线上出了问题,回滚也很麻烦。所以这一节实现一下自动部署的功能。
- 首先,先在 Jenkins 上装一个插件 Publish Over SSH,我们将通过这个工具实现服务器部署功能。
- 在要部署代码的服务器上创建一个文件夹用于接收 Jenkins 传过来的代码,我在服务器上建了一个 testjenkins 的文件夹。
- Jenkins 想要往服务器上部署代码必须登录服务器才可以,这里有两种登录验证方式,一种是 ssh 验证,一种是密码验证,就像你自己登录你的服务器,你可以使用 ssh 免密登录,也可以每次输密码登录,系统管理-系统设置里找到 Publish over SSH 这一项。 重点参数说明:
Passphrase:密码(key的密码,没设置就是空)
Path to key:key文件(私钥)的路径
Key:将私钥复制到这个框中(path to key和key写一个即可)
SSH Servers的配置:
SSH Server Name:标识的名字(随便你取什么)
Hostname:需要连接ssh的主机名或ip地址(建议ip)
Username:用户名
Remote Directory:远程目录(上面第二步建的testjenkins文件夹的路径)
高级配置:
Use password authentication, or use a different key:勾选这个可以使用密码登录,不想配ssh的可以用这个先试试
Passphrase / Password:密码登录模式的密码
Port:端口(默认22)
Timeout (ms):超时时间(毫秒)默认300000
复制代码
配置完成后,点击 Test Configuration 测试一下是否可以连接上,如果成功会返回 success,失败会返回报错信息,根据报错信息改正即可。
\4. 接下来进入我们创建的任务,点击构建,增加 2 行代码,意思是将 dist 里面的东西打包成一个文件,因为我们要传输。
cd dist&&
tar -zcvf dist.tar.gz *
复制代码
\5. 点击构建后操作,增加构建后操作步骤,选择 send build artificial over SSH, 参数说明:
Name:选择一个你配好的ssh服务器
Source files :写你要传输的文件路径
Remove prefix :要去掉的前缀,不写远程服务器的目录结构将和Source files写的一致
Remote directory :写你要部署在远程服务器的那个目录地址下,不写就是SSH Servers配置里默认远程目录
Exec command :传输完了要执行的命令,我这里执行了解压缩和解压缩完成后删除压缩包2个命令
复制代码
\6. 现在当我们在本地将Welcome to Your Vue.js App修改为Jenkins后发出一个 git push,过一会就会发现我们的服务器上已经部署好了最新的代码,是不是很 6。
至此,我们的自动化部署也完成了,但是如果过程中有异常怎么办,或是我们想知道每次 Jenkins 运行的日志及运行结果,我们可以通过配置邮件服务来让 Jenkins 每次完成任务后通知相关人员。
实现邮件提醒
这里我们不用 E-mail Notification,因为它的邮件服务功能太少,无法自定义邮件内容及自定义触发钩子,而且只能在异常情况下才能发邮件。我们使用 Editable Email Notification 这个。
1.打开系统管理-系统配置-Extended E-mail Notification,不是系统管理-系统配置-邮件通知,千万不要配错了,否则不起作用。配置一下用来发邮件的邮箱,我这里用的是我自己的 qq 邮箱。
要是用别的厂家的邮箱服务就查下别的邮箱厂家 smtp 怎么配,用 qq 邮箱的除了 user Name 和 password 其他的和我写一样就行。另外 password 写的不是 qq 邮箱的密码,而是开启 smtp 服务后发短信获取的密码。
2.打开创建的那个任务,增加构建后操作步骤选择 Editable Email Notification,Project Recipient List 那里写你要发给谁邮件,可以多个,用分号隔开。
3.然后点击 Advanced Settings-Triggers-Add Trigger,选择 always,意思是无论什么情况任务执行完就发邮件,也可以选择其他模式,如任务执行异常了才发邮件。
我这里配置的接收邮件的地址也是我的 qq 邮箱,这个可以根据自己公司的工作流程配。
4.现在当我们在本地修改代码后发出一个 git push,Jenkins 自动构建部署完成后就会给我发一封邮件,邮件附件里会有本次任务的日志。
Nginx
基本概念
Nginx 是什么?
Nginx (engine x) 是一个轻量级、高性能的 HTTP和反向代理服务器,同时也是一个通用代理服务器(TCP/UDP/IMAP/POP3/SMTP),最初由俄罗斯人 Igor Sysoev 编写。
简单的说:
Nginx是一个拥有高性能 HTTP 和反向代理服务器,其特点是占用内存少,并发能力强,并且在现实中,nginx 的并发能力要比在同类型的网页服务器中表现要好Nginx专为性能优化而开发,最重要的要求便是性能,且十分注重效率,有报告 nginx 能支持高达 50000 个并发连接数
正向代理和反向代理
Nginx 是一个反向代理服务器,那么反向代理是什么呢?我们先看看什么叫做正向代理
正向代理:局域网中的电脑用户想要直接访问网络是不可行的,只能通过代理服务器(Server)来访问,这种代理服务就被称为正向代理。
就好比我们俩在一块,直接对话即可,但如果我和你分隔两地,我们要想对话,必须借助一个通讯设备(如:电话)来沟通,那么这个通讯设备就是"代理服务器",这种行为称为“正向代理”
那么反向代理是什么呢?
反向代理:客户端无法感知代理,因为客户端访问网络不需要配置,只要把请求发送到反向代理服务器,由反向代理服务器去选择目标服务器获取数据,然后再返回到客户端,此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器地址,隐藏了真实服务器 IP 地址。
在正向代理中,我向你打电话,你能看到向你打电话的电话号码,由电话号码知道是我给你打的,那么此时我用虚拟电话给你打过去,你看到的不再是我的手机号,而是虚拟号码,你便不知道是我给你打的,这种行为变叫做"反向代理"。
在以上述的例子简单的说下:
- 正向代理:我通过我的手机(proxy Server)去给你打电话,相当于我和我的手机是一个整体,与你的手机(Server)是分开的
- 反向代理:我通过我的手机(proxy Server)通过软件转化为虚拟号码去给你打电话,此时相当于我的手机和你的手机是一个整体,和我是分开的
正向代理
- 一个位于客户端和原始服务器(
origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。
- 特点:
- 代理服务器和客户端处于同一个局域网内;
- 客户端明确要访问的服务器地址;
- 屏蔽或者隐藏了真实客户端信息。
- 作用:
- 访问原来无法访问的资源,如
Google; - 可以做缓存,加速访问资源;
- 对客户端访问授权,上网进行认证;
- 代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息。
- 访问原来无法访问的资源,如
反向代理
- 运行方式是代理服务器接受网络上的连接请求。它将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给网络上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
- 特点:
- 代理服务器和源站则处于同一个局域网内;
- 客户端是无感知代理的存在的,反向代理对外都是透明的;
- 隐藏了服务器的信息。
- 作用:
- 保证内网的安全,通常将反向代理作为公网访问地址,
Web服务器是内网;; - 负载均衡,通过反向代理服务器来优化网站的负载。
- 保证内网的安全,通常将反向代理作为公网访问地址,
负载均衡
- 多在高并发情况下需要使用。其原理就是将数据流量分摊到多个服务器执行,减轻每台服务器的压力,多台服务器(集群)完成工作任务,从而提高了数据的吞吐量。
- 负载均衡策略:轮询(默认)、加权(权重)、
ip_hash、url_hash(第三方)、fair(第三方)
负载均衡:是高可用网络基础架构的关键组件,通常用于将工作负载分布到多个服务器**来提高网站、应用、数据库或其他服务的性能和可靠性。
如果没有负载均衡,客户端与服务端的操作通常是:客户端请求服务端,然后服务端去数据库查询数据,将返回的数据带给客户端:
但随着客户端越来越多,数据,访问量飞速增长,这种情况显然无法满足,我们从上图发现,客户端的请求和相应都是通过服务端的,那么我们加大服务端的量,让多个服务端分担,是不是就能解决这个问题了呢?
但此时对于客户端而言,他去访问这个地址就是固定的,才不会去管那个服务端有时间,你只要给我返回出数据就 OK 了,所以我们就需要一个“管理者“,将这些服务端找个老大过来,客户端直接找老大,再由老大分配谁处理谁的数据,从而减轻服务端的压力,而这个”老大“就是反向代理服务器,而端口号就是这些服务端的工号。
像这样,当有 15 个请求时,反向代理服务器会平均分配给服务端,也就是各处理 5 个,这个过程就称之为:**负载均衡
动静分离
nginx提供的动静分离是指把动态请求和静态请求分离开,合适的服务器处理相应的请求,使整个服务器系统的性能、效率更高。nginx可以根据配置对不同的请求做不同转发,这是动态分离的基础。静态请求对应的静态资源可以直接放在nginx上做缓冲,更好的做法是放在相应的缓冲服务器上。动态请求由相应的后端服务器处理。- 基本代码示例:
server {
...
# 所有静态请求都由nginx处理,存放目录为html
location ~ \.(gif|jpg|jpeg|png|bmp|swf|css|js)$ {
root e:\wwwroot;
}
# 所有动态请求都转发给 tomcat 处理
location ~ \.(jsp|do)$ {
proxy_pass http://test;
}
}
当客户端发起请求时,正常的情况是这样的:
就好比你去找客服,一般先是先说一大堆官方的话,你问什么,他都会这么说,那么这个就叫静态资源(可以理解为是 html,css)
而回答具体的问题时,每个回答都是不同的,而这些不同的就叫做动态资源(会改变,可以理解为是变量)
在未分离的时候,可以理解为每个客服都要先说出官方的话,在打出具体的回答,这无异加大了客服的工作量,所以为了更好的有效利用客服的时间,我们把这些官方的话分离出来,找个机器人,让他代替客服去说,这样就减轻了客服的工作量。
也就是说,我们将动态资源和静态资源分离出来,交给不同的服务器去解析,这样就加快了解析的速度,从而降低由单个服务器的压力
安装使用
一、 安装依赖包
//一键安装上面四个依赖
yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel
二、 下载并解压安装包
//创建一个文件夹
cd /usr/local
mkdir nginx
cd nginx
//下载tar包
wget http://nginx.org/download/nginx-1.13.7.tar.gz
tar -xvf nginx-1.13.7.tar.gz
三、 安装 nginx
//进入nginx目录
cd /usr/local/nginx
//进入目录
cd nginx-1.13.7
//执行命令
./configure
//执行make命令
make
//执行make install命令
make install
四、 配置 nginx.conf
# 打开配置文件
vi /usr/local/nginx/conf/nginx.conf
将端口号改成 8089,因为可能 apeache 占用 80 端口,apeache 端口尽量不要修改,我们选择修改 nginx 端口。
localhost 修改为你服务器 ip 地址。
五、 启动 nginx
/usr/local/nginx/sbin/nginx -s reload
如果出现报错:nginx: [error] open() "/usr/local/nginx/logs/nginx.pid" failed
则运行:
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
再次启动即可!
六、 查看 nginx 进程是否启动
ps -ef | grep nginx
七、 关闭虚拟机的防火墙
若想使用外部主机连接上虚拟机访问端口,需要关闭虚拟机的防火墙:
centOS6及以前版本使用命令: systemctl stop iptables.service
centOS7关闭防火墙命令: systemctl stop firewalld.service
把 dist 部署到 Nginx 上
我们 nginx 安装好了,现在就进入主题:前端仔,快把 dist 部署到 Nginx 上。
在/usr/local/nginx/conf 中的 server 对象中设置 alias 配置 dist 的目录路径即可。
就比如我 dist 文件夹放在/home/tsVue/vue/dist/下;
修改完后,记得重启一下 nginx。 ./nginx -s reload
nginx 配置
文件结构
... # 全局块
events { # events块
...
}
http # http块
{
... # http全局块
server # server块
{
... # server全局块
location [PATTERN] # location块
{
...
}
location [PATTERN]
{
...
}
}
server
{
...
}
... # http全局块
}
全局块:配置影响 nginx 全局的指令。一般有运行 nginx 服务器的用户组,nginx 进程 pid 存放路径,日志存放路径,配置文件引入,允许生成 worker process 数等。
events 块:配置影响 nginx 服务器或与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。
http 块:可以嵌套多个 server ,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。如文件引入,mime-type 定义,日志自定义,是否使用 sendfile 传输文件,连接超时时间,单连接请求数等。
server 块:配置虚拟主机的相关参数,一个 http 中可以有多个 server。
location 块:配置请求的路由,以及各种页面的处理情况。
配置文件实例
########### 每个指令必须有分号结束。#################
#user administrator administrators; #配置用户或者组,默认为 nobody nobody。
#worker_processes 2; #允许生成的进程数,默认为1
#pid /nginx/pid/nginx.pid; #指定nginx进程运行文件存放地址
error_log log/error.log debug; #制定日志路径,级别。这个设置可以放入全局块,http块,server块,级别以此为:debug|info|notice|warn|error|crit|alert|emerg
events {
accept_mutex on; #设置网路连接序列化,防止惊群现象发生,默认为on
multi_accept on; #设置一个进程是否同时接受多个网络连接,默认为off
#use epoll; #事件驱动模型,select|poll|kqueue|epoll|resig|/dev/poll|eventport
worker_connections 1024; #最大连接数,默认为512
}
http {
include mime.types; #文件扩展名与文件类型映射表
default_type application/octet-stream; #默认文件类型,默认为text/plain
#access_log off; #取消服务日志
log_format myFormat '$remote_addr–$remote_user [$time_local] $request $status $body_bytes_sent $http_referer $http_user_agent $http_x_forwarded_for'; #自定义格式
access_log log/access.log myFormat; #combined为日志格式的默认值
sendfile on; #允许sendfile方式传输文件,默认为off,可以在http块,server块,location块。
sendfile_max_chunk 100k; #每个进程每次调用传输数量不能大于设定的值,默认为0,即不设上限。
keepalive_timeout 65; #连接超时时间,默认为75s,可以在http,server,location块。
upstream mysvr {
server 127.0.0.1:7878;
server 192.168.10.121:3333 backup; #热备
}
error_page 404 https://www.baidu.com; #错误页
server {
keepalive_requests 120; #单连接请求上限次数。
listen 4545; #监听端口
server_name 127.0.0.1; #监听地址
location ~*^.+$ { #请求的url过滤,正则匹配,~为区分大小写,~*为不区分大小写。
#root path; #根目录
#index vv.txt; #设置默认页
proxy_pass http://mysvr; #请求转向mysvr 定义的服务器列表
deny 127.0.0.1; #拒绝的ip
allow 172.18.5.54; #允许的ip
}
}
}
每个指令必须有分号结束(配置编写完成后,可使用 nginx -t 检查是否正确)。
$remote_addr 与 $http_x_forwarded_for 用以记录客户端的 ip 地址;
$remote_user 用来记录客户端用户名称;
$time_local 用来记录访问时间与时区;
$request 用来记录请求的 url 与 http 协议;
$status 用来记录请求状态(成功是 200);
$body_bytes_s ent 记录发送给客户端文件主体内容大小;
$http_referer 用来记录从那个页面链接访问过来的;
$http_user_agent 记录客户端浏览器的相关信息。
nginx 命令
帮助
nginx -h
检查版本
nginx -v
检查配置文件是否有效
nginx -t
查看/停止进程
ps aux|grep nginx
sudo kill -9 [进程id]
启动
nginx
nginx -c /usr/local/etc/nginx/conf/nginx.conf // 启动指定配置文件
重启
nginx -s reload
停止服务
nginx -s stop // 暴力停止
nginx -s quit // 优雅停止
Git 命令

在实际开发中,会使用 git 作为版本控制工具来完成团队协作。因此,对基本的 git 操作指令进行总结是十分有必要的,本文对一些术语或者理论基础,不重新码字,可以参考廖雪峰老师的博文,本文只对命令做归纳总结。

基本使用
1.基本原理和使用
git 的通用操作流程如下图(来源于网络)
主要涉及到四个关键点:
- 工作区:本地电脑存放项目文件的地方,比如 learnGitProject 文件夹;
- 暂存区(Index/Stage):在使用 git 管理项目文件的时候,其本地的项目文件会多出一个.git 的文件夹,将这个.git 文件夹称之为版本库。其中.git 文件夹中包含了两个部分,一个是暂存区(Index 或者 Stage),顾名思义就是暂时存放文件的地方,通常使用 add 命令将工作区的文件添加到暂存区里;
- 本地仓库:.git 文件夹里还包括 git 自动创建的 master 分支,并且将 HEAD 指针指向 master 分支。使用 commit 命令可以将暂存区中的文件添加到本地仓库中;
- 远程仓库:不是在本地仓库中,项目代码在远程 git 服务器上,比如项目放在 github 上,就是一个远程仓库,通常使用 clone 命令将远程仓库拷贝到本地仓库中,开发后推送到远程仓库中即可;
更细节的来看:
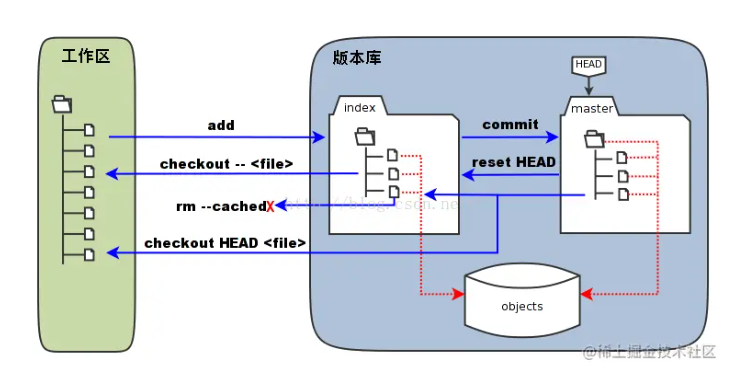
日常开发时代码实际上放置在工作区中,也就是本地的 XXX.java 这些文件,通过 add 等这些命令将代码文教提交给暂存区(Index/Stage),也就意味着代码全权交给了 git 进行管理,之后通过 commit 等命令将暂存区提交给 master 分支上,也就是意味打了一个版本,也可以说代码提交到了本地仓库中。另外,团队协作过程中自然而然还涉及到与远程仓库的交互。
因此,经过这样的分析,git 命令可以分为这样的逻辑进行理解和记忆:
git 管理配置的命令;
几个核心存储区的交互命令:
工作区与暂存区的交互;
暂存区与本地仓库(分支)上的交互;
本地仓库与远程仓库的交互。
2.git 配置命令
查询配置信息
- 列出当前配置:
git config --list; - 列出 repository 配置:
git config --local --list; - 列出全局配置:
git config --global --list; - 列出系统配置:
git config --system --list;
第一次使用 git,配置用户信息
- 配置用户名:
git config --global user.name "your name"; - 配置用户邮箱:
git config --global user.email "youremail@github.com";
其他配置
- 配置解决冲突时使用哪种差异分析工具,比如要使用 vimdiff:
git config --global merge.tool vimdiff; - 配置 git 命令输出为彩色的:
git config --global color.ui auto; - 配置 git 使用的文本编辑器:
git config --global core.editor vi;
3.工作区上的操作命令
新建仓库
- 将工作区中的项目文件使用 git 进行管理,即创建一个新的本地仓库:
git init; - 从远程 git 仓库复制项目:
git clone <url>,如:git clone git://github.com/wasd/example.git;克隆项目时如果想定义新的项目名,可以在 clone 命令后指定新的项目名:git clone git://github.com/wasd/example.git mygit;
提交
- 提交工作区所有文件到暂存区:
git add . - 提交工作区中指定文件到暂存区:
git add <file1> <file2> ...; - 提交工作区中某个文件夹中所有文件到暂存区:
git add [dir];
撤销
- 删除工作区文件,并且也从暂存区删除对应文件的记录:
git rm <file1> <file2>; - 从暂存区中删除文件,但是工作区依然还有该文件:
git rm --cached <file>; - 取消暂存区已经暂存的文件:
git reset HEAD <file>...; - 撤销上一次对文件的操作:
git checkout --<file>。要确定上一次对文件的修改不再需要,如果想保留上一次的修改以备以后继续工作,可以使用 stashing 和分支来处理; - 隐藏当前变更,以便能够切换分支:
git stash; - 查看当前所有的储藏:
git stash list; - 应用最新的储藏:
git stash apply,如果想应用更早的储藏:git stash apply stash@{2};重新应用被暂存的变更,需要加上--index参数:git stash apply --index; - 使用 apply 命令只是应用储藏,而内容仍然还在栈上,需要移除指定的储藏:
git stash drop stash{0};如果使用 pop 命令不仅可以重新应用储藏,还可以立刻从堆栈中清除:git stash pop; - 在某些情况下,你可能想应用储藏的修改,在进行了一些其他的修改后,又要取消之前所应用储藏的修改。Git 没有提供类似于 stash unapply 的命令,但是可以通过取消该储藏的补丁达到同样的效果:
git stash show -p stash@{0} | git apply -R;同样的,如果你沒有指定具体的某个储藏,Git 会选择最近的储藏:git stash show -p | git apply -R;
更新文件
- 重命名文件,并将已改名文件提交到暂存区:
git mv [file-original] [file-renamed];
查新信息
- 查询当前工作区所有文件的状态:
git status; - 比较工作区中当前文件和暂存区之间的差异,也就是修改之后还没有暂存的内容:git diff;指定文件在工作区和暂存区上差异比较:
git diff <file-name>;
4.暂存区上的操作命令
提交文件到版本库
- 将暂存区中的文件提交到本地仓库中,即打上新版本:
git commit -m "commit_info"; - 将所有已经使用 git 管理过的文件暂存后一并提交,跳过 add 到暂存区的过程:
git commit -a -m "commit_info"; - 提交文件时,发现漏掉几个文件,或者注释写错了,可以撤销上一次提交:
git commit --amend;
查看信息
- 比较暂存区与上一版本的差异:
git diff --cached; - 指定文件在暂存区和本地仓库的不同:
git diff <file-name> --cached; - 查看提交历史:git log;参数
-p展开每次提交的内容差异,用-2显示最近的两次更新,如git log -p -2;
打标签
Git 使用的标签有两种类型:轻量级的(lightweight)和含附注的(annotated)。轻量级标签就像是个不会变化的分支,实际上它就是个指向特定提交对象的引用。而含附注标签,实际上是存储在仓库中的一个独立对象,它有自身的校验和信息,包含着标签的名字,电子邮件地址和日期,以及标签说明,标签本身也允许使用 GNU Privacy Guard (GPG) 来签署或验证。一般我们都建议使用含附注型的标签,以便保留相关信息;当然,如果只是临时性加注标签,或者不需要旁注额外信息,用轻量级标签也没问题。
- 列出现在所有的标签:
git tag; - 使用特定的搜索模式列出符合条件的标签,例如只对 1.4.2 系列的版本感兴趣:
git tag -l "v1.4.2.*"; - 创建一个含附注类型的标签,需要加
-a参数,如git tag -a v1.4 -m "my version 1.4"; - 使用 git show 命令查看相应标签的版本信息,并连同显示打标签时的提交对象:
git show v1.4; - 如果有自己的私钥,可以使用 GPG 来签署标签,只需要在命令中使用
-s参数:git tag -s v1.5 -m "my signed 1.5 tag"; - 验证已签署的标签:git tag -v ,如
git tag -v v1.5; - 创建一个轻量级标签的话,就直接使用 git tag 命令即可,连
-a,-s以及-m选项都不需要,直接给出标签名字即可,如git tag v1.5; - 将标签推送到远程仓库中:git push origin ,如
git push origin v1.5; - 将本地所有的标签全部推送到远程仓库中:
git push origin --tags;
分支管理
- 创建分支:
git branch <branch-name>,如git branch testing; - 从当前所处的分支切换到其他分支:
git checkout <branch-name>,如git checkout testing; - 新建并切换到新建分支上:
git checkout -b <branch-name>; - 删除分支:
git branch -d <branch-name>; - 将当前分支与指定分支进行合并:
git merge <branch-name>; - 显示本地仓库的所有分支:
git branch; - 查看各个分支最后一个提交对象的信息:
git branch -v; - 查看哪些分支已经合并到当前分支:
git branch --merged; - 查看当前哪些分支还没有合并到当前分支:
git branch --no-merged; - 把远程分支合并到当前分支:
git merge <remote-name>/<branch-name>,如git merge origin/serverfix;如果是单线的历史分支不存在任何需要解决的分歧,只是简单的将 HEAD 指针前移,所以这种合并过程可以称为快进(Fast forward),而如果是历史分支是分叉的,会以当前分叉的两个分支作为两个祖先,创建新的提交对象;如果在合并分支时,遇到合并冲突需要人工解决后,再才能提交; - 在远程分支的基础上创建新的本地分支
:git checkout -b <branch-name> <remote-name>/<branch-name>,如git checkout -b serverfix origin/serverfix; - 从远程分支 checkout 出来的本地分支,称之为跟踪分支。在跟踪分支上向远程分支上推送内容:
git push。该命令会自动判断应该向远程仓库中的哪个分支推送数据;在跟踪分支上合并远程分支:git pull; - 将一个分支里提交的改变移到基底分支上重放一遍:
git rebase <rebase-branch> <branch-name>,如git rebase master server,将特性分支 server 提交的改变在基底分支 master 上重演一遍;使用 rebase 操作最大的好处是像在单个分支上操作的,提交的修改历史也是一根线;如果想把基于一个特性分支上的另一个特性分支变基到其他分支上,可以使用--onto操作:git rebase --onto <rebase-branch> <feature branch> <sub-feature-branch>,如git rebase --onto master server client;使用 rebase 操作应该遵循的原则是:一旦分支中的提交对象发布到公共仓库,就千万不要对该分支进行 rebase 操作; - 将一个分支上的某个
commit合并到另一个分支:git cherry-pick <commitHash>先切换分支再指定提交你需要另一个分支的所有代码变动,那么就采用合并(git merge)。另一种情况是,你只需要部分代码变动(某几个提交),这时可以采用 Cherry pick
5.本地仓库上的操作
- 查看本地仓库关联的远程仓库:
git remote;在克隆完每个远程仓库后,远程仓库默认为origin;加上-v的参数后,会显示远程仓库的url地址; - 添加远程仓库,一般会取一个简短的别名:
git remote add [remote-name] [url],比如:git remote add example git://github.com/example/example.git; - 从远程仓库中抓取本地仓库中没有的更新:
git fetch [remote-name],如git fetch origin;使用 fetch 只是将远端数据拉到本地仓库,并不自动合并到当前工作分支,只能人工合并。如果设置了某个分支关联到远程仓库的某个分支的话,可以使用git pull来拉去远程分支的数据,然后将远端分支自动合并到本地仓库中的当前分支; - 将本地仓库某分支推送到远程仓库上:
git push [remote-name] [branch-name],如git push origin master;如果想将本地分支推送到远程仓库的不同名分支:git push <remote-name> <local-branch>:<remote-branch>,如git push origin serverfix:awesomebranch;如果想删除远程分支:git push [romote-name] :<remote-branch>,如git push origin :serverfix。这里省略了本地分支,也就相当于将空白内容推送给远程分支,就等于删掉了远程分支。 - 查看远程仓库的详细信息:
git remote show origin; - 修改某个远程仓库在本地的简称:
git remote rename [old-name] [new-name],如git remote rename origin org; - 移除远程仓库:
git remote rm [remote-name];
6.忽略文件.gitignore
一般我们总会有些文件无需纳入 Git 的管理,也不希望它们总出现在未跟踪文件列表。通常都是些自动生成的文件,比如日志文件,或者编译过程中创建的临时文件等。我们可以创建一个名为 .gitignore 的文件,列出要忽略的文件模式。如下例:
# 此为注释 – 将被 Git 忽略
# 忽略所有 .a 结尾的文件
*.a
# 但 lib.a 除外
!lib.a
# 仅仅忽略项目根目录下的 TODO 文件,不包括 subdir/TODO
/TODO
# 忽略 build/ 目录下的所有文件
build/
# 会忽略 doc/notes.txt 但不包括 doc/server/arch.txt
doc/*.txt
# 忽略 doc/ 目录下所有扩展名为 txt 的文件
doc/**/*.txt
一张脑图带你掌握 Git 命令
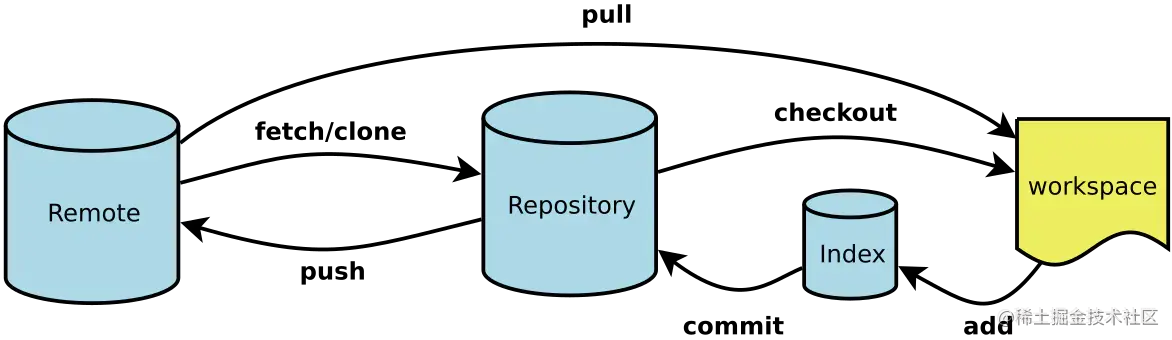
版本库 👉.git
- 当我们使用 git 管理文件时,比如
git init时,这个时候,会多一个.git文件,我们把这个文件称之为版本库。 .git文件另外一个作用就是它在创建的时候,会自动创建 master 分支,并且将 HEAD 指针指向 master 分支。
工作区
- 本地项目存放文件的位置
- 可以理解成图上的 workspace
暂存区 (Index/Stage)
- 顾名思义就是暂时存放文件的地方,通过是通过 add 命令将工作区的文件添加到缓冲区
本地仓库(Repository)
- 通常情况下,我们使用 commit 命令可以将暂存区的文件添加到本地仓库
- 通常而言,HEAD 指针指向的就是 master 分支
远程仓库(Remote)
- 举个例子,当我们使用 GitHub 托管我们项目时,它就是一个远程仓库。
- 通常我们使用 clone 命令将远程仓库代码拷贝下来,本地代码更新后,通过 push 托送给远程仓库。
Git 文件状态
- 通常我们需要查看一个文件的状态
git status
Changes not staged for commit- 表示得大概就是工作区有该内容,但是缓存区没有,需要我们
git add
- 表示得大概就是工作区有该内容,但是缓存区没有,需要我们
Changes to be committed- 一般而言,这个时候,文件放在缓存区了,我们需要
git commit
- 一般而言,这个时候,文件放在缓存区了,我们需要
nothing to commit, working tree clean- 这个时候,我们将本地的代码推送到远端即可
常见命令
git 配置命令

- 列出当前配置
git config --list
- 列出 Repository 配置
git config --local --list
- 列出全局配置
git config --global --list
- 列出系统配置
git config --system --list
- 配置用户名
git config --global user.name "your name"
- 配置用户邮箱
git config --global user.email "youremail@github.com"
分支管理

- 查看本地分支
git branch
- 查看远程分支
git branch -r
- 查看本地和远程分支
git branch -a
- 从当前分支,切换到其他分支
git checkout <branch-name>
// 举个例子
git checkout feature/tiantian
- 创建并切换到新建分支
git checkout -b <branch-name>
// 举个例子👇
git checkout -b feature/tiantian
- 删除分支
git branch -d <branch-name>
// 举个例子👇
git branch -d feature/tiantian
- 当前分支与指定分支合并
git merge <branch-name>
// 举个例子👇
git merge feature/tiantian
- 查看哪些分支已经合并到当前分支
git branch --merged
- 查看哪些分支没有合并到当前分支
git branch --no-merged
- 查看各个分支最后一个提交对象的信息
git branch -v
- 删除远程分支
git push origin -d <branch-name>
- 重命名分支
git branch -m <oldbranch-name> <newbranch-name>
- 拉取远程分支并创建本地分支
git checkout -b 本地分支名x origin/远程分支名x
// 另外一种方式,也可以完成这个操作。
git fetch origin <branch-name>:<local-branch-name>
// fetch这个指令的话,后续会梳理
fetch 指令

我理解的就是将远程仓库内容更新到本地,最近与师姐开发项目过程中,使用的就是这个命令。
具体是这样子的 👇
fetch 推荐写法
git fetch origin <branch-name>:<local-branch-name>
- 一般而言,这个 origin 是远程主机名,一般默认就是 origin。
branch-name你要拉取的分支local-branch-name通常而言,就是你本地新建一个新分支,将 origin 下的某个分支代码下载到本地分支。
举个例子 👇
git fetch origin feature/template_excellent:feature/template_layout
// 你的工作目录下,就会有feature/template_layout
// 一般情况下,我们需要做的就是在这个分支上开发新需求
// 完成代码后,我们需要做的就是上传我们的分支
fetch 其他写法
- 将某个远程主机的更新,全部取回本地。
git fetch <远程主机名>
- 这样子的话,取回的是所有的分支更新,如果想取回特定分支,可以指定分支名 👇
git fetch <远程主机名> <分支名>
- 当你想将某个分支的内容取回到本地下某个分支的话,如下 👇
git fetch origin :<local-branch-name>
// 等价于👇
git fetch origin master:<local-branch-name>
花式撤销

撤销工作区修改
- git checkout --
暂存区文件撤销 (不覆盖工作区)
- git reset HEAD
版本回退
git reset --(soft | mixed | hard ) < HEAD ~(num) > |
指令 作用范围 --hard 回退全部,包括 HEAD,index,working tree --mixed 回退部分,包括 HEAD,index --soft 只回退 HEAD
git revert 用于回滚某一个(或多个)提交引入的更改
反转该提交引入的更改 并创建一个新的「回滚提交」记录反转更改 然后更新分支引用 使其指向该提交
状态查询
- 查看状态
- git status
- 查看历史操作记录
- git reflog
- 查看日志
- git log
文档查询
- 展示 Git 命令大纲
- git help (--help)
- 展示 Git 命令大纲全部列表
- git help -a
- 展示具体命令说明手册
- git help
文件暂存

- 添加改动到 stash
- git stash save -a “message”
- 删除暂存
- git stash drop `stash@{ID}`
- 查看 stash 列表
- git stash list
- 删除全部缓存
- git stash clear
- 恢复改动
- git stash pop `stash@{ID}`
差异比较

比较工作区与缓存区
- git diff
比较缓存区与本地库最近一次 commit 内容
- git diff -- cached
比较工作区与本地最近一次 commit 内容
- git diff HEAD
比较两个 commit 之间差异
- git diff
分支命名
master 分支
- 主分支,用于部署生产环境的分支,确保稳定性。
- master 分支一般由 develop 以及 hotfix 分支合并,任何情况下都不能直接修改代码。
develop 分支
- develop 为开发分支,通常情况下,保存最新完成以及 bug 修复后的代码。
- 开发新功能时,feature 分支都是基于 develop 分支下创建的。
feature 分支
- 开发新功能,基本上以 develop 为基础创建 feature 分支。
- 分支命名:feature/ 开头的为特性分支, 命名规则: feature/user_module、 feature/cart_module。
这点我深有体会,我在网易,mentor 就是这么教我的,通常建一个 feature 分支。
release 分支
- release 为预上线分支,发布提测阶段,会 release 分支代码为基准提测。
hotfix 分支
- 分支命名:hotfix/ 开头的为修复分支,它的命名规则与 feature 分支类似。
- 线上出现紧急问题时,需要及时修复,以 master 分支为基线,创建 hotfix 分支,修复完成后,需要合并到 master 分支和 develop 分支。
基本操作
有了上述的基本了解后,那么我们就来看看整体的一个流程吧。
创建本地仓库 git init
git init
链接本地仓库与远端仓库
git remote add origin
origin 默认是远端仓库别名 url 可以是可以使用 https 或者 ssh 的方式新建
检查配置信息
- git config --list
Git user name 与 email
git config --global user.name "yourname"
git config --global user.email "your_email"
生成 SSH 密钥
ssh-keygen -t rsa -C "这里换上你的邮箱"
cd ~/.ssh 里面有一个文件名为 id_rsa.pub,把里面的内容复制到 git 库的我的 SSHKEYs 中
常看远端仓库信息
- git remote -v
远端仓库重新命名
- git remote rename old new
提交到缓存区
- git add . 全部上传到缓存区
- git add 指定文件
提交到本地仓库
- git commit -m 'some message'
提交远程仓库
- git push <远程主机名> <本地分支名>:<远程分支名>
查看分支
- git branch
创建新分支
- git branch
切换分支
- git checkout
创建分支并切换
- git checkout -b
删除分支
- git branch -d
删除远程分支
- git push -d
切换分支
- git checkout
Git 撤销操作实践之 Reset Revert Rebase
数据准备
# 新建 git 环境
mkdir demo; cd demo ; git init
# 新建 reset 分支
git checkout -b dev
echo AAAAA > reset.txt
git add reset.txt
git commit -m "AAAAA"
echo BBBBB >> reset.txt
git add reset.txt
git commit -m "BBBBB"
echo CCCCC >> reset.txt
git add reset.txt
git commit -m "CCCCC"
echo DDDDD >> reset.txt
git add reset.txt
git commit -m "DDDDD"
# 此时的 git log 如下
$ git log --pretty=format:"%h %s" --graph
* d6212d8 DDDDD
* e807553 CCCCC
* 3609018 BBBBB
* a9fb808 AAAAA
# 此时的文件如下
$ cat reset.txt
AAAAA
BBBBB
CCCCC
DDDDD
git reset
该命令用于回退版本,可以指定退回某一次提交的版本,常见模式如下:
--mixed默认参数回退版本并将修改放入工作区--soft回退版本并将修改放入暂存区--hard回退版本并将修改丢弃
# 回退到上一版本
$ git reset HEAD^
# 指定文件回退到上一版本
$ git reset HEAD^ hello.php
# 回退到指定版本
$ git reset 3609018
比如上面的 demo 仓库现在需要回到 BBBBB 的提交:
$ git reset --hard f64fbe6
HEAD is now at f64fbe6 BBBBB
$ cat reset.txt
AAAAA
BBBBB
$ git log --pretty=format:"%h %s" --graph
* f64fbe6 BBBBB
* 17a6e45 AAAAA
git revert
该命令与 reset 功能基本一致。需要注意的是此次操作之前和之后的 commit 和 history 都会保留,并且把这次撤销作为一次最新的提交。比如实现 demo 仓库现在需要回到 BBBBB 的提交对应的操作为:
# 1. 执行撤销到的 commit
$ git revert f64fbe6
error: could not revert f64fbe6... BBBBB
# 2. 解决冲突
# 3. 提交修改
$ git commit -am "revert commit"
# 验证结果
$ cat reset.txt
AAAAA
BBBBB
$ git log --pretty=format:"%h %s" --graph
* a6fa241 revert commit
* 7dedf32 DDDDD
* a513f6c CCCCC
* f64fbe6 BBBBB
* 17a6e45 AAAAA
对比 git reset 来看 git revert保留了完整的提交历史,不会改变项目历史,对那些已经发布到共享仓库的提交来说这是一个安全的操作。
当然 revert 还可以指定回退的提交记录, 比如回退 BBBBB、CCCCC 两次提交:
注意 git diff 17a6e45..a513f6c 左开右闭的区间。
# 先 diff 查看对应的差异
git diff 17a6e45..a513f6c
# 回退revert
$ git reset --hard HEAD^
# 解决冲突
# 查看日志
$ git log --pretty=format:"%h %s" --graph
* 81a5d64 revert BC
* 7dedf32 DDDDD
* a513f6c CCCCC
* f64fbe6 BBBBB
* 17a6e45 AAAAA
git rebase
该命令是一个非常强大的命令,功能有很多。主要的功能是修改 git 的提交历史,常见的场景为合并提交记录、修改 commit message 等。
下面依旧是 git revert 中的例子撤销 BBBBB、CCCCC 两次提交:
# 先 diff 查看对应的差异
git diff 17a6e45..a513f6c
# rebase 前三次提交
$ git rebase -i HEAD~3
# 修改 commit
d 515cfeb BBBBB
d 879218f CCCCC
pick 6a664ef DDDDD
# 解决冲突并存入暂存区间(git add reset.txt)
# 继续 rebase (弹出后默认保存既可,如需修改commit log 直接编辑)
git rebase --continue
# 查看commit log
$ git log --pretty=format:"%h %s" --graph
* 989618e DDDDD
* 17a6e45 AAAAA
总结
git reset最佳场景本地 commit,一般是回退到指定版本。git rebase可以新增、修改、删除 commit log,一般适用于展示完美的 commit log,方便于代码的 review。git revert可以删除一次或多次 commit,并新增 commit log 的方式完成。适用于远程仓库的提交记录。记录所有的修改历史,方便 review commit log。
代码冲突解决
使用 git 产生冲突的条件:如果在远程的某一个文件内容发生修改了,而本地没有进行 pull 拉取,就会导致本地的分支落后,当修改完成之后 push 到远程的时候,就会产生冲突,而本地如果进行 pull 拉取远程文件的话,相等于你现在本地的文件就是远程的文件,不会有分支落后,当修改完 push 的时候,就不会产生冲突,所以建议使用 git 的时候,先 pull 之后,再去修改,修改完成之后再去 push。
首先代码合并冲突一般是怎么产生的那,比如日常开发中,本次迭代分为一个 dev,一个 branch,在需求方突然增加了需求,并且是同一个需求场景的不同更改,并且是作为一次迭代上线。那么就需要另外拉取一个 dev 分支开发,现在开发分支分为 dev1 和 dev2: 当 dev1 已经合并到 branch 后,dev2 在合并的过程中提示代码冲突,那么怎么解决那.
// 首先,同步当前自己dev2最新代码
git fetch dev2
// 然后切换分支到远程branch,拉取最新代码
git pull dev2
git checkout -b branch
git pull origin branch
// 查看和修改冲突代码
git merge --no-ff branch
// 修改代码提交到branch
git add .
git commit -m '解决冲突'
git push origin branch
解决冲突,删除代码中矛盾的代码,然后上传或者下拉
git pull 或 git push 时出现 MERGING,说明代码合并冲突 打开冲突文件,一般情况下冲突后的文件会是:
<<<<<<<<HEAD
//你的代码
========
//别人的代码
>>>>>>>>your branch name
解决代码冲突时,尽量把所有不同的代码保留,共同的代码只留一份 解决代码冲突之后,重新 add 和 commit 最后 push
2.找回 git pull 之前的本地代码
输入 git reflog 查看你本地提交记录,找到最新一次提交的版本号,
然后 git reset --hard HEAD@{版本号}回退到操作前的本地代码

或者 git reset --hard id 回退到指定版本,这个 id 是 git log 提交日志中的每一次提交对应的 commit id,这个 id 很长,只复制前 7 位就可以
3.丢弃 删除下载的,或者上传的代码(git checkout --<file>可以丢弃工作区的修改),然后分别 check out 两个分支
如果系统中有一些配置文件在服务器上做了配置修改,然后后续开发又新添加一些配置项的时候,
在发布这个配置文件的时候,会发生代码冲突:
error: Your local changes to the following files would be overwritten by merge:
protected/config/main.php
Please, commit your changes or stash them before you can merge.
如果希望保留生产服务器上所做的改动,仅仅并入新配置项, 处理方法如下:
git stash //暂存代码
git pull //分支名 从远程仓库拉取最新代码
git stash pop //合并代码到本地仓库 此时代码是将暂存的代码和远程仓库的代码合并
然后可以使用 git diff -w +文件名 来确认代码自动合并的情况.
反过来,如果希望用代码库中的文件完全覆盖本地工作版本. 方法如下:
git reset --hard
git pull
其中 git reset 是针对版本,如果想针对文件回退本地修改,使用
git checkout HEAD file/to/restore
合并冲突
一、准备
使用 gitee 创建一个项目,项目初始有一个README.MD和两个分支dev、master。
1-1、dev 分支里面的 README
TEST- dev
1-2、master 分支里面的 README
TEST- master
1-3、说明
两个分支同一个文件里面的代码不一样,如果合并就会冲突。
现在我们就来合并分支 dev > master
二、冲突
2-1、合并结果

此 Pull Request 无法自动合并,你应该手动合并它
注:实际我们多用的是 gitlab,上面的英文翻译一下大意也是如此。
解决冲突的步骤:
把两个分支的代码都拉到你本地
手动去把代码整合一下
提交你的本地代码
2-2、解决冲突一(有 master 分支操作权限)
如果你有 master 分支的权限,你可以使用这个办法。
一般冲突后会提示你解决的办法,也是此办法。
2-2-1、更新远程分支
这一步一般不做,大部分这两个分支本地都有,但是可能出现没有的情况,所以运行一下也没什么关系。
git fetch
2-2-2、切换 master 分支、并拉取 master 分支代码
git checkout master
git pull origin master
2-2-3、拉取 dev 分支代码(当前分支是 master)
git pull origin dev
2-2-4、解决冲突
这个时候你的本地代码会如下:

我们按照正确的代码格式,把本地代码整理成如下

2-2-5、提交代码
# 添加全部的文件,这里为了演示方便,你可以添加具体的文件
git add .
# 提交代码到本地仓库
git commit -m '解决冲突'
# 提交代码到线上仓库
git push origin master
提交到线上后,我们的那个分支合并,也会自动合并好了。
2-3、解决冲突二(无 master 分支权限)
- 实际开发中我们很可能没有这个分支的提交权限,我们只能拉取代码。
使用上面的方式再来重新制造一个冲突。

其实原理是一样的,之前我们是在master分支上解决冲突,现在我们在dev分支上去解决冲突。
2-3-1、更新远程分支
这一步一般不做,大部分这两个分支本地都有,但是可能出现没有的情况,所以运行一下也没什么关系。
git fetch
2-3-2、切换 dev 分支、并拉取 dev 分支代码
git checkout dev
git pull origin dev
2-3-3、拉取 master 分支代码(当前是 dev 分支)
git pull origin master
2-3-4、解决冲突
如上面一样,按照自己正确的代码进行调整
2-3-5、提交代码
# 添加全部的文件,这里为了演示方便,你可以添加具体的文件
git add .
# 提交代码到本地仓库
git commit -m '解决冲突'
# 提交代码到线上仓库
git push origin dev
这时候合并请求便会如下:

这个意思是现在已经没有冲突了,但是你没权限合并,找有权限的人给你合并。
三、其它
- 这里的 dev 分支代表你的开发分支,master 分支标识要合并的分支
- 我这里使用的
gitee提示都是中文的,如果你使用gitlab提示是英文的,大意都是一样的 - 如果你没有合并权限的时候可能会出现
合并冲突、没有需要合并的、找有权限的人给你合并,记得翻译一下英文,不然可能闹出笑话。 - 如果你明白了上面的含义,实际上遇到冲突了只可能是冲突文件比较复杂会难得处理,但不会手足无措。
- 我这里为了通用性都是使用的
git命令,实际开发大家可以结合具体的软件(IDEA、VSCODE)可能会更简单。
提交冲突
一:git 命令在提交代码前,没有 pull 拉最新的代码,因此再次提交出现了冲突。
error: You have not concluded your merge (MERGE_HEAD exists). hint: Please, commit your changes before merging. fatal: Exiting because of unfinished merge.

解决方法如下两种:
1.保留你本地的修改
git merge --abort
git reset --merge
合并后记得一定要提交这个本地的合并(add-->commit-->push-->pull)
然后在获取线上仓库
git pull
2.down 下线上代码版本,抛弃本地的修改
不建议这样做,但是如果你本地修改不大,或者自己有一份备份留存,可以直接用线上最新版本覆盖到本地
git fetch --all
git reset --hard origin/master
git fetch
二:从 git 远程仓库中 pull 最新的代码,出现如下错误:Please commit your changes or stash them before you merge.

解决方法如下:(git stash 可用来暂存当前正在进行的工作, 比如想 pull 最新代码, 又不想加新 commit, 或者另外一种情况,为了 fix 一个紧急的 bug, 先 stash, 使返回到自己上一个 commit, 改完 bug 之后再 stash pop, 继续原来的工作。)
1: git stash //暂存代码
2: git pull 分支名//从远程仓库拉取最新代码
3: git stash pop //合并代码到本地仓库 此时代码是将暂存的代码和远程仓库的代码合并,如下图:

4:这时候需要手动修改合并所需的代码即可。
5:git stash clear//需要清空 git 栈执行该命令
git stash: 备份当前的工作区的内容,从最近的一次提交中读取相关内容,让工作区保证和上次提交的内容一致。同时,将当前的工作区内容保存到 Git 栈中。 git stash pop: 从 Git 栈中读取最近一次保存的内容,恢复工作区的相关内容。由于可能存在多个 Stash 的内容,所以用栈来管理,pop 会从最近的一个 stash 中读取内容并恢复。 git stash list: 显示 Git 栈内的所有备份,可以利用这个列表来决定从那个地方恢复。 git stash clear: 清空 Git 栈。此时使用 gitg 等图形化工具会发现,原来 stash 的哪些节点都消失了
三:git push 报错,如下:

解决命令:git pull --rebase origin 你的分支名称,如下图所示

再次执行 push 命令:如下图所示:

四:git push 还会报下面的错(如图所示):这多是多人开发有了冲突。
hint: Updates were rejected because the remote contains work that you do hint: not have locally. This is usually caused by another repository pushing hint: to the same ref. You may want to first integrate the remote changes hint: (e.g., 'git pull ...') before pushing again. hint: See the 'Note about fast-forwards' in 'git push --help' for details.

解决命令如下:
git push -u 代码所在的分支 -f //强制提交,此时远程上的修改已经被覆盖。这种方法一般不建议使用,除非你把远程上修改的代码复制到本地。
五:本地回退历史版本,当提交代码发生冲突或者想回退到某一个版本,操作如下:
1:git log (获取提交的历史日志)

2: 执行命令:git reset --hard 版本号(就是 git log 中的 commit 后面的哈希值(上图中的黄色部分 commit 后面的值))
3:想要修改远程上的代码还需要执行如下命令:
git push -u 代码所在的分支 -f //强制提交,此时远程上的修改已经被覆盖。这种方法一般不建议使用,除非你把远程上修改的代码复制到本地。