响应式原理
深入响应式原理
响应式对象
initState
在 Vue 的初始化阶段,_init 方法执行的时候,会执行 initState(vm)
export function initState(vm: Component) {
vm._watchers = [];
const opts = vm.$options;
if (opts.props) initProps(vm, opts.props);
if (opts.methods) initMethods(vm, opts.methods);
if (opts.data) {
initData(vm);
} else {
observe((vm._data = {}), true /* asRootData */);
}
if (opts.computed) initComputed(vm, opts.computed);
if (opts.watch && opts.watch !== nativeWatch) {
initWatch(vm, opts.watch);
}
}
initState 方法主要是对 props、methods、data、computed 和 wathcer 等属性做了初始化操作。
initProps
props 的初始化主要过程,就是遍历定义的 props 配置。
遍历的过程主要做两件事情:
一个是调用 defineReactive 方法把每个 prop 对应的值变成响应式,可以通过 vm._props.xxx 访问到定义 props 中对应的属性
另一个是通过 proxy 把 vm._props.xxx 的访问代理到 vm.xxx 上
initData
data 的初始化主要过程也是做两件事
一个是对定义 data 函数返回对象的遍历,通过 proxy 把每一个值 vm._data.xxx 都代理到 vm.xxx 上
另一个是调用 observe 方法观测整个 data 的变化,把 data 也变成响应式,可以通过 vm._data.xxx 访问到定义 data 返回函数中对应的属性
proxy
代理的作用是把 props 和 data 上的属性代理到 vm 实例
const sharedPropertyDefinition = {
enumerable: true,
configurable: true,
get: noop,
set: noop,
};
export function proxy(target: Object, sourceKey: string, key: string) {
sharedPropertyDefinition.get = function proxyGetter() {
return this[sourceKey][key];
};
sharedPropertyDefinition.set = function proxySetter(val) {
this[sourceKey][key] = val;
};
Object.defineProperty(target, key, sharedPropertyDefinition);
}
proxy 方法的实现很简单,通过 Object.defineProperty 把 target[sourceKey][key] 的读写变成了对 target[key] 的读写
所以对于 props 而言,对 vm._props.xxx 的读写变成了 vm.xxx 的读写,而对于 vm._props.xxx 我们可以访问到定义在 props 中的属性,所以我们就可以通过 vm.xxx 访问到定义在 props 中的 xxx 属性了
对于 data 而言,对 vm._data.xxxx 的读写变成了对 vm.xxxx 的读写,而对于 vm._data.xxxx 我们可以访问到定义在 data 函数返回对象中的属性,所以我们就可以通过 vm.xxxx 访问到定义在 data 函数返回对象中的 xxxx 属性了
observe
observe 的功能就是用来监测数据的变化
首先实例化 Dep 对象,接着通过执行 def 函数把自身实例添加到数据对象 value 的 __ob__ 属性上
def 函数是一个非常简单的Object.defineProperty的封装,这就是为什么我在开发中输出data上对象类型的数据,会发现该对象多了一个ob` 的属性
export function def(obj: Object, key: string, val: any, enumerable?: boolean) {
Object.defineProperty(obj, key, {
value: val,
enumerable: !!enumerable,
writable: true,
configurable: true,
});
}
Observer 的构造函数,接下来会对 value 做判断,对于数组会调用 observeArray 方法,否则对纯对象调用 walk 方法。可以看到 observeArray 是遍历数组再次调用 observe 方法,而 walk 方法是遍历对象的 key 调用 defineReactive 方法
export class Observer {
value: any;
dep: Dep;
vmCount: number;
constructor(value: any) {
this.value = value;
this.dep = new Dep();
this.vmCount = 0;
def(value, "__ob__", this);
if (Array.isArray(value)) {
//需要判断数组类型
const augment = hasProto ? protoAugment : copyAugment;
augment(value, arrayMethods, arrayKeys);
this.observeArray(value);
} else {
this.walk(value);
}
}
//不是数组就采用递归
walk(obj: Object) {
const keys = Object.keys(obj);
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i]);
}
}
observeArray(items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i]);
}
}
}
defineReactive
defineReactive 的功能就是定义一个响应式对象,给对象动态添加 getter 和 setter
defineReactive 函数最开始初始化 Dep 对象的实例,接着拿到 obj 的属性描述符,然后对子对象递归调用 observe 方法,这样就保证了无论 obj 的结构多复杂,它的所有子属性也能变成响应式的对象,这样我们访问或修改 obj 中一个嵌套较深的属性,也能触发 getter 和 setter。最后利用 Object.defineProperty 去给 obj 的属性 key 添加 getter 和 setter
export function defineReactive(
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
const dep = new Dep();
const property = Object.getOwnPropertyDescriptor(obj, key);
if (property && property.configurable === false) {
return;
}
// cater for pre-defined getter/setters
const getter = property && property.get;
const setter = property && property.set;
if ((!getter || setter) && arguments.length === 2) {
val = obj[key];
}
let childOb = !shallow && observe(val);
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
const value = getter ? getter.call(obj) : val;
if (Dep.target) {
dep.depend();
if (childOb) {
childOb.dep.depend();
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value;
},
set: function reactiveSetter(newVal) {
const value = getter ? getter.call(obj) : val;
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return;
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== "production" && customSetter) {
customSetter();
}
if (setter) {
setter.call(obj, newVal);
} else {
val = newVal;
}
childOb = !shallow && observe(newVal);
dep.notify();
},
});
}
总结
1.initState 过程中 initProps initData 一方面是为了转化为响应式
另一方面是为了进行代理 vm._props.xxx 的访问代理到 vm.xxx 上
vm._data.xxx 访问到定义 data 返回函数中对应的属性
2.实例化 Dep 对象,接着通过执行 def 函数把自身实例添加到数据对象 value 的 __ob__ 属性上 def 函数是一个非常简单的Object.defineProperty` 的封装
3.defineReactive 函数最开始初始化 Dep 对象的实例
getter 会返回 value 会执行 dep.depend()
setter 会设置 newvalue 会执行 dep.notify()
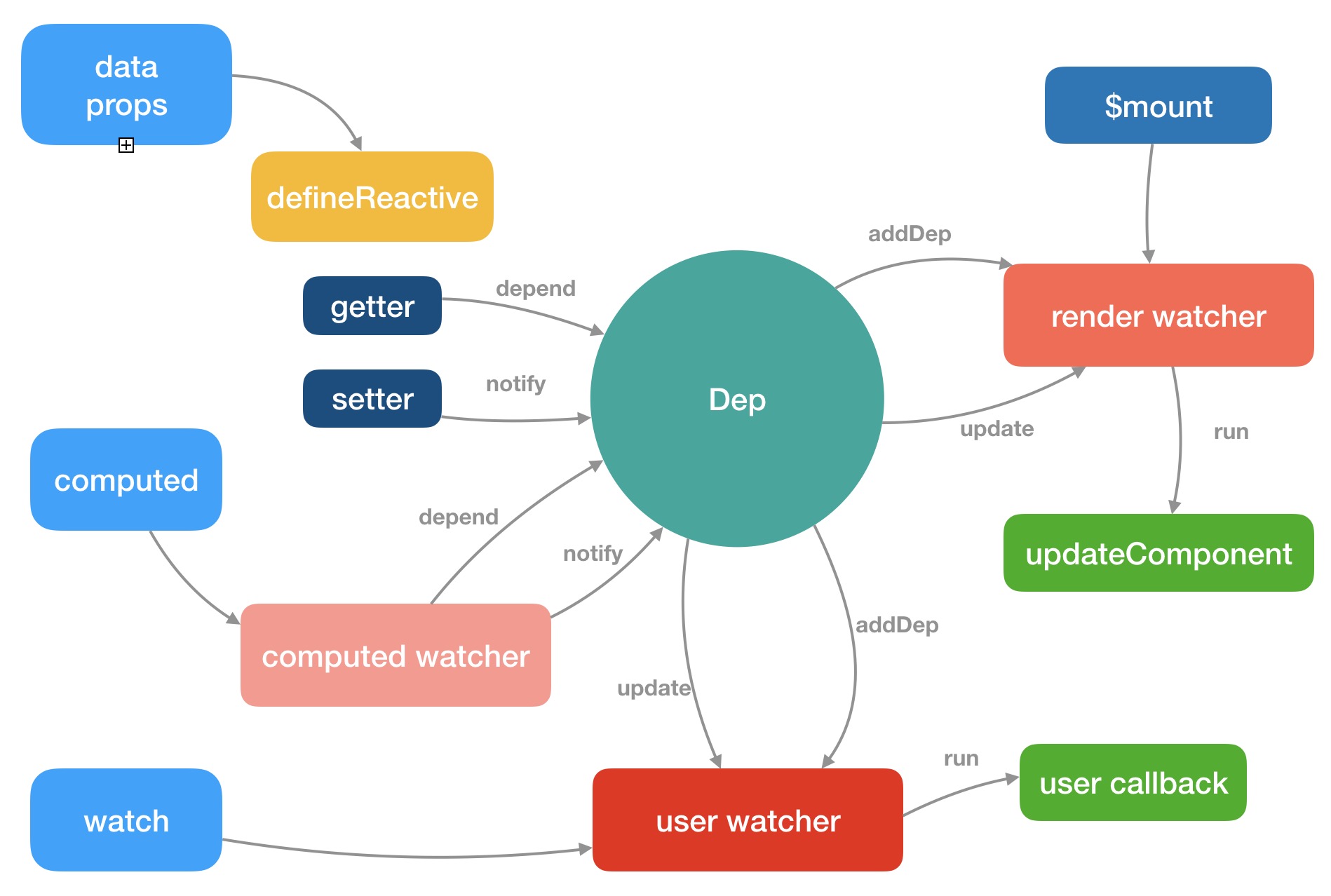
依赖收集
getter
const dep = new Dep() 实例化一个 Dep 的实例,另一个是在 get 函数中通过 dep.depend 做依赖收集
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
const value = getter ? getter.call(obj) : val;
if (Dep.target) {
dep.depend();
if (childOb) {
childOb.dep.depend();
if (Array.isArray(value)) {
dpendArray(value);
}
}
}
},
});
Dep
Dep 是整个 getter 依赖收集的核心
Dep 是一个 Class,它定义了一些属性和方法,这里需要特别注意的是它有一个静态属性 target,这是一个全局唯一 Watcher,这是一个非常巧妙的设计,因为在同一时间只能有一个全局的 Watcher 被计算,另外它的自身属性 subs 也是 Watcher 的数组。
Dep 实际上就是对 Watcher 的一种管理,Dep 脱离 Watcher 单独存在是没有意义的
import type Watcher from "./watcher";
import { remove } from "../util/index";
let uid = 0;
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array<Watcher>;
constructor() {
this.id = uid++;
this.subs = [];
}
addSub(sub: Watcher) {
this.subs.push(sub);
}
removeSub(sub: Watcher) {
remove(this.subs, sub);
}
depend() {
if (Dep.target) {
Dep.target.addDep(this);
}
}
notify() {
// stabilize the subscriber list first
const subs = this.subs.slice();
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update();
}
}
}
//重置为空
Dep.target = null;
const targetStack = [];
export function pushTarget(_target: ?Watcher) {
if (Dep.target) targetStack.push(Dep.target);
Dep.target = _target;
}
export function popTarget() {
Dep.target = targetStack.pop();
}
Watcher
Watcher是一个 Class,在它的构造函数中,定义了一些和Dep` 相关的属性:
this.deps = [];
this.newDeps = [];
this.depIds = new Set();
this.newDepIds = new Set();
其中,this.deps 和 this.newDeps 表示 Watcher 实例持有的 Dep 实例的数组;而 this.depIds 和 this.newDepIds 分别代表 this.deps 和 this.newDeps 的 id Set
let uid = 0;
/**
* A watcher parses an expression, collects dependencies,
* and fires callback when the expression value changes.
* This is used for both the $watch() api and directives.
*/
export default class Watcher {
vm: Component;
expression: string;
cb: Function;
id: number;
deep: boolean;
user: boolean;
computed: boolean;
sync: boolean;
dirty: boolean;
active: boolean;
dep: Dep;
deps: Array<Dep>;
newDeps: Array<Dep>;
depIds: SimpleSet;
newDepIds: SimpleSet;
before: ?Function;
getter: Function;
value: any;
constructor(
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
this.vm = vm;
if (isRenderWatcher) {
vm._watcher = this;
}
vm._watchers.push(this);
// options
if (options) {
this.deep = !!options.deep;
this.user = !!options.user;
this.computed = !!options.computed;
this.sync = !!options.sync;
this.before = options.before;
} else {
this.deep = this.user = this.computed = this.sync = false;
}
this.cb = cb;
this.id = ++uid; // uid for batching
this.active = true;
this.dirty = this.computed; // for computed watchers
this.deps = [];
this.newDeps = [];
this.depIds = new Set();
this.newDepIds = new Set();
this.expression =
process.env.NODE_ENV !== "production" ? expOrFn.toString() : "";
// parse expression for getter
if (typeof expOrFn === "function") {
this.getter = expOrFn;
} else {
this.getter = parsePath(expOrFn);
if (!this.getter) {
this.getter = function () {};
process.env.NODE_ENV !== "production" &&
warn(
`Failed watching path: "${expOrFn}" ` +
"Watcher only accepts simple dot-delimited paths. " +
"For full control, use a function instead.",
vm
);
}
}
if (this.computed) {
this.value = undefined;
this.dep = new Dep();
} else {
this.value = this.get();
}
}
/**
* Evaluate the getter, and re-collect dependencies.
*/
get() {
pushTarget(this);
let value;
const vm = this.vm;
try {
value = this.getter.call(vm, vm);
} catch (e) {
if (this.user) {
handleError(e, vm, `getter for watcher "${this.expression}"`);
} else {
throw e;
}
} finally {
// "touch" every property so they are all tracked as
// dependencies for deep watching
if (this.deep) {
traverse(value);
}
popTarget();
this.cleanupDeps();
}
return value;
}
/**
* Add a dependency to this directive.
*/
addDep(dep: Dep) {
const id = dep.id;
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id);
this.newDeps.push(dep);
if (!this.depIds.has(id)) {
dep.addSub(this);
}
}
}
/**
* Clean up for dependency collection.
*/
cleanupDeps() {
let i = this.deps.length;
while (i--) {
const dep = this.deps[i];
if (!this.newDepIds.has(dep.id)) {
dep.removeSub(this);
}
}
let tmp = this.depIds;
this.depIds = this.newDepIds;
this.newDepIds = tmp;
this.newDepIds.clear();
tmp = this.deps;
this.deps = this.newDeps;
this.newDeps = tmp;
this.newDeps.length = 0;
}
// ...
}
过程分析
之前我们介绍当对数据对象的访问会触发他们的 getter 方法,那么这些对象什么时候被访问呢?Vue 的 mount 过程是通过 mountComponent 函数,其中有一段比较重要的逻辑,大致如下:
updateComponent = () => {
vm._update(vm._render(), hydrating);
};
new Watcher(
vm,
updateComponent,
noop,
{
before() {
if (vm._isMounted) {
callHook(vm, "beforeUpdate");
}
},
},
true /* isRenderWatcher */
);
当我们去实例化一个渲染 watcher 的时候,首先进入 watcher 的构造函数逻辑,然后会执行它的 this.get() 方法,进入 get 函数,首先会执行:
pushTarget(this);
pushTarget 的定义在 src/core/observer/dep.js 中:
export function pushTarget(_target: Watcher) {
if (Dep.target) targetStack.push(Dep.target);
Dep.target = _target;
}
实际上就是把 Dep.target 赋值为当前的渲染 watcher 并压栈(为了恢复用)。接着又执行了:
value = this.getter.call(vm, vm);
this.getter 对应就是 updateComponent 函数,这实际上就是在执行:
vm._update(vm._render(), hydrating);
它会先执行 vm._render() 方法,因为之前分析过这个方法会生成 渲染 VNode,并且在这个过程中会对 vm 上的数据访问,这个时候就触发了数据对象的 getter。
那么每个对象值的 getter 都持有一个 dep,在触发 getter 的时候会调用 dep.depend() 方法,也就会执行 Dep.target.addDep(this)。
刚才我们提到这个时候 Dep.target 已经被赋值为渲染 watcher,那么就执行到 addDep 方法:
addDep (dep: Dep) {
const id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}
这时候会做一些逻辑判断(保证同一数据不会被添加多次)后执行 dep.addSub(this),那么就会执行 this.subs.push(sub),也就是说把当前的 watcher 订阅到这个数据持有的 dep 的 subs 中,这个目的是为后续数据变化时候能通知到哪些 subs 做准备。
所以在 vm._render() 过程中,会触发所有数据的 getter,这样实际上已经完成了一个依赖收集的过程。那么到这里就结束了么,其实并没有,在完成依赖收集后,还有几个逻辑要执行,首先是:
if (this.deep) {
traverse(value);
}
这个是要递归去访问 value,触发它所有子项的 getter,这个之后会详细讲。接下来执行:
popTarget();
popTarget 的定义在 src/core/observer/dep.js 中:
Dep.target = targetStack.pop();
实际上就是把 Dep.target 恢复成上一个状态,因为当前 vm 的数据依赖收集已经完成,那么对应的渲染Dep.target 也需要改变。最后执行:
this.cleanupDeps();
其实很多人都分析过并了解到 Vue 有依赖收集的过程,但我几乎没有看到有人分析依赖清空的过程,其实这是大部分同学会忽视的一点,也是 Vue 考虑特别细的一点。
cleanupDeps () {
let i = this.deps.length
while (i--) {
const dep = this.deps[i]
if (!this.newDepIds.has(dep.id)) {
dep.removeSub(this)
}
}
let tmp = this.depIds
this.depIds = this.newDepIds
this.newDepIds = tmp
this.newDepIds.clear()
tmp = this.deps
this.deps = this.newDeps
this.newDeps = tmp
this.newDeps.length = 0
}
考虑到 Vue 是数据驱动的,所以每次数据变化都会重新 render,那么 vm._render() 方法又会再次执行,并再次触发数据的 getters,所以 Watcher 在构造函数中会初始化 2 个 Dep 实例数组,newDeps 表示新添加的 Dep 实例数组,而 deps 表示上一次添加的 Dep 实例数组。
在执行 cleanupDeps 函数的时候,会首先遍历 deps,移除对 dep.subs 数组中 Wathcer 的订阅,然后把 newDepIds 和 depIds 交换,newDeps 和 deps 交换,并把 newDepIds 和 newDeps 清空。
那么为什么需要做 deps 订阅的移除呢,在添加 deps 的订阅过程,已经能通过 id 去重避免重复订阅了。
考虑到一种场景,我们的模板会根据 v-if 去渲染不同子模板 a 和 b,当我们满足某种条件的时候渲染 a 的时候,会访问到 a 中的数据,这时候我们对 a 使用的数据添加了 getter,做了依赖收集,那么当我们去修改 a 的数据的时候,理应通知到这些订阅者。那么如果我们一旦改变了条件渲染了 b 模板,又会对 b 使用的数据添加了 getter,如果我们没有依赖移除的过程,那么这时候我去修改 a 模板的数据,会通知 a 数据的订阅的回调,这显然是有浪费的。
因此 Vue 设计了在每次添加完新的订阅,会移除掉旧的订阅,这样就保证了在我们刚才的场景中,如果渲染 b 模板的时候去修改 a 模板的数据,a 数据订阅回调已经被移除了,所以不会有任何浪费,真的是非常赞叹 Vue 对一些细节上的处理。
总结
1.Vue 的 mount 过程中通过 mountComponent 函数 进行new Watcher()
2.先执行构造函数 然后执行 this.get()
3.进入 get() 首先会执行pushTarget(this)
4.在 pushTarget 中会 把Dep.target 赋值为当前的渲染 watcher 并压栈
5.然后执行了 value = this.getter.call(vm, vm),this.getter 对应就是 updateComponent 函数 实际上是在执行 vm._update(vm._render(), hydrating)
6.会先执行 vm._render() 方法 生成 渲染 VNode,并且在这个过程中会对 vm 上的数据访问,这个时候就触发了数据对象的 getter
7.每个对象值的 getter 都持有一个 dep,在触发 getter 的时候会调用 dep.depend() 方法,也就会执行 Dep.target.addDep(this) 第四步 的时候 Dep.target 已经被赋值为 watcher 所以能执行 Watcher 的方法 addDep 而这个 this 是 Dep, addDep 内会执行 dep 的 addSub
Dep内部
addSub (sub: Watcher) {
this.subs.push(sub)
}
depend () {
if (Dep.target) {
Dep.target.addDep(this) Dep.target是watcher
this传的是watcher
}
}
Watcher内部
addDep (dep: Dep) {
const id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}
8.addSub 内执行 this.subs.push(sub),也就是说把当前的 watcher 订阅到这个数据持有的 dep 的 subs 中,这个目的是为后续数据变化时候能通知到哪些 subs 做准备 实际上就是 执行在 watcher 内执行了 dep 的 addsub 方法把自己(Watcher 给加了进去)
9.在 vm._render() 过程中,会触发所有数据的 getter,这样实际上已经完成了一个依赖收集的过程 然后进行收尾工作
10.递归去访问 value,触发它所有子项的 getter
if (this.deep) { traverse(value) }
11.然后执行 Dep 内部的popTarget() 把 Dep.target 恢复成上一个状态
因为当前 vm 的数据依赖收集已经完成,那么对应的渲染Dep.target 也需要改变
12.最后执行 Watcher 的 cleanupDeps()方法 依赖清空
13.考虑到 Vue 是数据驱动的,所以每次数据变化都会重新 render,那么 vm._render() 方法又会再次执行,并再次触发数据的 getters,所以 Watcher 在构造函数中会初始化 2 个 Dep 实例数组,newDeps 表示新添加的 Dep 实例数组,而 deps 表示上一次添加的 Dep 实例数组
在执行 cleanupDeps 函数的时候,会首先遍历 deps,移除对 dep.subs 数组中 Wathcer 的订阅,然后把 newDepIds 和 depIds 交换,newDeps 和 deps 交换,并把 newDepIds 和 newDeps 清空。
派发更新
收集的目的就是为了当我们修改数据的时候,可以对相关的依赖派发更新
setter
set: function reactiveSetter(newVal) {
const value = getter ? getter.call(obj) : val;
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return;
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== "production" && customSetter) {
customSetter();
}
if (setter) {
setter.call(obj, newVal);
} else {
val = newVal;
}
childOb = !shallow && observe(newVal);
dep.notify();
}
setter 的逻辑有 2 个关键的点,
一个是 childOb = !shallow && observe(newVal),如果 shallow 为 false 的情况,会对新设置的值变成一个响应式对象;
另一个是 dep.notify(),通知所有的订阅者
过程分析
在组件中对响应的数据做了修改,就会触发 setter 的逻辑,最后调用 dep.notify() 方法, 它是 Dep 的一个实例方法
class Dep {
// ...
notify() {
// stabilize the subscriber list first
const subs = this.subs.slice();
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update();
}
}
}
遍历所有的 subs,也就是 Watcher 的实例数组,然后调用每一个 watcher 的 update 方法
class Watcher {
// ...
update() {
/* istanbul ignore else */
if (this.computed) {
// A computed property watcher has two modes: lazy and activated.
// It initializes as lazy by default, and only becomes activated when
// it is depended on by at least one subscriber, which is typically
// another computed property or a component's render function.
if (this.dep.subs.length === 0) {
// In lazy mode, we don't want to perform computations until necessary,
// so we simply mark the watcher as dirty. The actual computation is
// performed just-in-time in this.evaluate() when the computed property
// is accessed.
this.dirty = true;
} else {
// In activated mode, we want to proactively perform the computation
// but only notify our subscribers when the value has indeed changed.
this.getAndInvoke(() => {
this.dep.notify();
});
}
} else if (this.sync) {
this.run();
} else {
queueWatcher(this);
}
}
}
对于 Watcher 的不同状态,会执行不同的逻辑
在一般组件数据更新的场景,会走到最后一个 queueWatcher(this) 的逻辑
在 scheduler 中
const queue: Array<Watcher> = [];
let has: { [key: number]: ?true } = {};
let waiting = false;
let flushing = false;
/**
* Push a watcher into the watcher queue.
* Jobs with duplicate IDs will be skipped unless it's
* pushed when the queue is being flushed.
*/
export function queueWatcher(watcher: Watcher) {
const id = watcher.id;
if (has[id] == null) {
has[id] = true;
if (!flushing) {
queue.push(watcher);
} else {
// if already flushing, splice the watcher based on its id
// if already past its id, it will be run next immediately.
let i = queue.length - 1;
while (i > index && queue[i].id > watcher.id) {
i--;
}
queue.splice(i + 1, 0, watcher);
}
// queue the flush
if (!waiting) {
waiting = true;
nextTick(flushSchedulerQueue);
}
}
}
这里引入了一个队列的概念,这也是 Vue 在做派发更新的时候的一个优化的点,它并不会每次数据改变都触发 watcher 的回调,而是把这些 watcher 先添加到一个队列里,然后在 nextTick 后执行 flushSchedulerQueue
首先用 has 对象保证同一个 Watcher 只添加一次;接着对 flushing 的判断;最后通过 waiting 保证对 nextTick(flushSchedulerQueue) 的调用逻辑只有一次,可以理解它是在下一个 tick,也就是异步的去执行 flushSchedulerQueue
flushSchedulerQueue 的实现
let flushing = false;
let index = 0;
/**
* Flush both queues and run the watchers.
*/
function flushSchedulerQueue() {
flushing = true;
let watcher, id;
// Sort queue before flush.
// This ensures that:
// 1. Components are updated from parent to child. (because parent is always
// created before the child)
// 2. A component's user watchers are run before its render watcher (because
// user watchers are created before the render watcher)
// 3. If a component is destroyed during a parent component's watcher run,
// its watchers can be skipped.
queue.sort((a, b) => a.id - b.id);
// do not cache length because more watchers might be pushed
// as we run existing watchers
for (index = 0; index < queue.length; index++) {
watcher = queue[index];
if (watcher.before) {
watcher.before();
}
id = watcher.id;
has[id] = null;
watcher.run();
// in dev build, check and stop circular updates.
if (process.env.NODE_ENV !== "production" && has[id] != null) {
circular[id] = (circular[id] || 0) + 1;
if (circular[id] > MAX_UPDATE_COUNT) {
warn(
"You may have an infinite update loop " +
(watcher.user
? `in watcher with expression "${watcher.expression}"`
: `in a component render function.`),
watcher.vm
);
break;
}
}
}
// keep copies of post queues before resetting state
const activatedQueue = activatedChildren.slice();
const updatedQueue = queue.slice();
resetSchedulerState();
// call component updated and activated hooks
callActivatedHooks(activatedQueue);
callUpdatedHooks(updatedQueue);
// devtool hook
/* istanbul ignore if */
if (devtools && config.devtools) {
devtools.emit("flush");
}
}
- 队列排序
queue.sort((a, b) => a.id - b.id) 对队列做了从小到大的排序,这么做主要有以下要确保以下几点:
1.组件的更新由父到子;因为父组件的创建过程是先于子的,所以 watcher 的创建也是先父后子,执行顺序也应该保持先父后子。
2.用户的自定义 watcher 要优先于渲染 watcher 执行;因为用户自定义 watcher 是在渲染 watcher 之前创建的。
3.如果一个组件在父组件的 watcher 执行期间被销毁,那么它对应的 watcher 执行都可以被跳过,所以父组件的 watcher 应该先执行。
- 队列遍历
在对 queue 排序后,接着就是要对它做遍历,拿到对应的 watcher,执行 watcher.run()。这里需要注意一个细节,在遍历的时候每次都会对 queue.length 求值,因为在 watcher.run() 的时候,很可能用户会再次添加新的 watcher,这样会再次执行到 queueWatcher,如下:
export function queueWatcher(watcher: Watcher) {
const id = watcher.id;
if (has[id] == null) {
has[id] = true;
if (!flushing) {
queue.push(watcher);
} else {
// if already flushing, splice the watcher based on its id
// if already past its id, it will be run next immediately.
let i = queue.length - 1;
while (i > index && queue[i].id > watcher.id) {
i--;
}
queue.splice(i + 1, 0, watcher);
}
// ...
}
}
可以看到,这时候 flushing 为 true,就会执行到 else 的逻辑,然后就会从后往前找,找到第一个待插入 watcher 的 id 比当前队列中 watcher 的 id 大的位置。把 watcher 按照 id的插入到队列中,因此 queue 的长度发生了变化。
- 状态恢复
这个过程就是执行 resetSchedulerState 函数,它的定义在 src/core/observer/scheduler.js 中。
const queue: Array<Watcher> = [];
let has: { [key: number]: ?true } = {};
let circular: { [key: number]: number } = {};
let waiting = false;
let flushing = false;
let index = 0;
/**
* Reset the scheduler's state.
*/
function resetSchedulerState() {
index = queue.length = activatedChildren.length = 0;
has = {};
if (process.env.NODE_ENV !== "production") {
circular = {};
}
waiting = flushing = false;
}
逻辑非常简单,就是把这些控制流程状态的一些变量恢复到初始值,把 watcher 队列清空
watcher.run() 的逻辑
class Watcher {
/**
* Scheduler job interface.
* Will be called by the scheduler.
*/
run() {
if (this.active) {
this.getAndInvoke(this.cb);
}
}
getAndInvoke(cb: Function) {
const value = this.get();
if (
value !== this.value ||
// Deep watchers and watchers on Object/Arrays should fire even
// when the value is the same, because the value may
// have mutated.
isObject(value) ||
this.deep
) {
// set new value
const oldValue = this.value;
this.value = value;
this.dirty = false;
if (this.user) {
try {
cb.call(this.vm, value, oldValue);
} catch (e) {
handleError(e, this.vm, `callback for watcher "${this.expression}"`);
}
} else {
cb.call(this.vm, value, oldValue);
}
}
}
}
run 函数实际上就是执行 this.getAndInvoke 方法,并传入 watcher 的回调函数。getAndInvoke 函数逻辑也很简单,先通过 this.get() 得到它当前的值,然后做判断,如果满足新旧值不等、新值是对象类型、deep 模式任何一个条件,则执行 watcher 的回调,注意回调函数执行的时候会把第一个和第二个参数传入新值 value 和旧值 oldValue,这就是当我们添加自定义 watcher 的时候能在回调函数的参数中拿到新旧值的原因。
那么对于渲染 watcher 而言,它在执行 this.get() 方法求值的时候,会执行 getter 方法:
updateComponent = () => {
vm._update(vm._render(), hydrating);
};
所以这就是当我们去修改组件相关的响应式数据的时候,会触发组件重新渲染的原因,接着就会重新执行 patch 的过程,但它和首次渲染有所不同
总结
1.修改数据,触发 setter 的逻辑,调用 dep.notify() 方法
2.dep.notify() 遍历所有的 subs,也就是 Watcher 的实例数组,然后调用每一个 watcher 的 update 方法
3.update()方法 对于 Watcher 的不同状态,会执行不同的逻辑
组件更新 会走到最后一个 queueWatcher(this) 的逻辑
4.Vue 在做派发更新的时候,并不会每次数据改变都触发 watcher 的回调,而是把这些 watcher 先添加到一个队列里,然后在 nextTick 后执行 flushSchedulerQueue
5.flushSchedulerQueue 的实现
队列排序queue.sort((a, b) => a.id - b.id) 对队列做了从小到大的排序
队列遍历 在对 queue 排序后,接着就是要对它做遍历,拿到对应的 watcher,执行 watcher.run() 在遍历的时候每次都会对 queue.length 求值
状态恢复 执行 resetSchedulerState 函数 把控制流程状态的一些变量恢复到初始值,把 watcher 队列清空
6.watcher.run() 实际上就是执行 this.getAndInvoke 方法,并传入 watcher 的回调函数
getAndInvoke 函数 先通过 this.get() 得到它当前的值,然后做判断,如果满足新旧值不等、新值是对象类型、deep 模式任何一个条件,则执行 watcher 的回调,注意回调函数执行的时候会把第一个和第二个参数传入新值 value 和旧值 oldValue,这就是当我们添加自定义 watcher 的时候能在回调函数的参数中拿到新旧值的原因
getAndInvoke (cb: Function) {
const value = this.get()
if (
value !== this.value ||
isObject(value) ||
this.deep
) {
// set new value
const oldValue = this.value
this.value = value
this.dirty = false
if (this.user) {
try {
cb.call(this.vm, value, oldValue)
} catch (e) {
handleError(e, this.vm, `callback for watcher "${this.expression}"`)
}
} else {
cb.call(this.vm, value, oldValue)
}
7.对于渲染 watcher 而言,它在执行 this.get() 方法求值的时候,会执行 getter 方法:
updateComponent = () => { vm._update(vm._render(), hydrating) }
当我们去修改组件相关的响应式数据的时候,会触发组件重新渲染
nextTick
JS 运行机制
JS 执行是单线程的,它是基于事件循环的。事件循环大致分为以下几个步骤:
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行
(4)主线程不断重复上面的第三步
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是 macro task 和 micro task,并且每个 macro task 结束后,都要处理所有的 micro task
for (macroTask of macroTaskQueue) {
// 1. Handle current MACRO-TASK
handleMacroTask();
// 2. Handle all MICRO-TASK
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}
在浏览器环境中,常见的 macro task 有 setTimeout、MessageChannel、postMessage、setImmediate;常见的 micro task 有 MutationObsever 和 Promise.then
Vue 的实现
next-tick.js
import { noop } from "shared/util";
import { handleError } from "./error";
import { isIOS, isNative } from "./env";
const callbacks = [];
let pending = false;
function flushCallbacks() {
pending = false;
const copies = callbacks.slice(0);
callbacks.length = 0;
for (let i = 0; i < copies.length; i++) {
copies[i]();
}
}
let microTimerFunc;
let macroTimerFunc;
let useMacroTask = false;
if (typeof setImmediate !== "undefined" && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks);
};
} else if (
typeof MessageChannel !== "undefined" &&
(isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === "[object MessageChannelConstructor]")
) {
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = flushCallbacks;
macroTimerFunc = () => {
port.postMessage(1);
};
} else {
/* istanbul ignore next */
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0);
};
}
if (typeof Promise !== "undefined" && isNative(Promise)) {
const p = Promise.resolve();
microTimerFunc = () => {
p.then(flushCallbacks);
if (isIOS) setTimeout(noop);
};
} else {
// fallback to macro
microTimerFunc = macroTimerFunc;
}
export function withMacroTask(fn: Function): Function {
return (
fn._withTask ||
(fn._withTask = function () {
useMacroTask = true;
const res = fn.apply(null, arguments);
useMacroTask = false;
return res;
})
);
}
export function nextTick(cb?: Function, ctx?: Object) {
let _resolve;
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx);
} catch (e) {
handleError(e, ctx, "nextTick");
}
} else if (_resolve) {
_resolve(ctx);
}
});
if (!pending) {
pending = true;
if (useMacroTask) {
macroTimerFunc();
} else {
microTimerFunc();
}
}
// $flow-disable-line
if (!cb && typeof Promise !== "undefined") {
return new Promise((resolve) => {
_resolve = resolve;
});
}
}
申明了 microTimerFunc 和 macroTimerFunc 2 个变量,它们分别对应的是 micro task 的函数和 macro task 的函数
对于 macro task 的实现,优先检测是否支持原生 setImmediate,这是一个高版本 IE 和 Edge 才支持的特性,不支持的话再去检测是否支持原生的 MessageChannel,如果也不支持的话就会降级为 setTimeout 0
对于 micro task 的实现,则检测浏览器是否原生支持 Promise,不支持的话直接指向 macro task 的实现 新版本废弃了 mutationOberserver
对外暴露了 2 个函数,先来看 nextTick,在派发更新时nextTick(flushSchedulerQueue) 所用到的函数。
它的逻辑也很简单,把传入的回调函数 cb 压入 callbacks 数组,最后一次性地根据 useMacroTask 条件执行 macroTimerFunc 或者是 microTimerFunc,
而它们都会在下一个 tick 执行 flushCallbacks,flushCallbacks 的逻辑非常简单,对 callbacks 遍历,然后执行相应的回调函数。
这里使用 callbacks 而不是直接在 nextTick 中执行回调函数的原因是保证在同一个 tick 内多次执行 nextTick,不会开启多个异步任务,而把这些异步任务都压成一个同步任务,在下一个 tick 执行完毕
withMacroTask函数的作用是给回调函数做一层包装,当事件触发时,如果因为回调中修改了数据而触发更新DOM的操作,那么该更新操作会被推送到宏任务( macrotask )的任务队列中
nextTick 函数最后还有一段逻辑:
if (!cb && typeof Promise !== "undefined") {
return new Promise((resolve) => {
_resolve = resolve;
});
}
当 nextTick 不传 cb 参数的时候,提供一个 Promise 化的调用,比如:
nextTick().then(() => {});
当 _resolve 函数执行,就会跳到 then 的逻辑中
还对外暴露了withMacroTask函数,它是对函数做一层包装,确保函数执行过程中对数据任意的修改,触发变化执行nextTick的时候强制走macroTimerFunc。比如对于一些 DOM 交互事件,如 v-on` 绑定的事件回调函数的处理,会强制走 macro task
总结
1.结合 setter 分析,了解到数据的变化到 DOM 的重新渲染是一个异步过程,发生在下一个 tick
microTimerFunc 和 macroTimerFunc 2 个变量,它们分别对应的是 micro task 的函数和 macro task 的函数 函数会传入 flushCallbacks
2.macro task 会分别检测 setImmediate MessageChannel 都不支持则 setTimeout 0
micro task 会检测是否原生支持 Promise,不支持的话直接指向 macro task 的实现
3.在派发更新时候 传入的回调函数 cb 压入 callbacks 数组,最后一次性地根据 useMacroTask 条件执行 都会在下一个 tick 执行 flushCallbacks,对 callbacks 遍历,然后执行相应的回调函数
4.使用 callbacks保证在同一个 tick 内多次执行 nextTick,不会开启多个异步任务,而把这些异步任务都压成一个同步任务
5.nexttick 使用场景 比如从服务端接口去获取数据的时候,数据做了修改,如果我们的某些方法去依赖了数据修改后的 DOM 变化,我们就必须在 nextTick 后执行
getData(res).then(() => {
this.xxx = res.data;
this.$nextTick(() => {
// 这里我们可以获取变化后的 DOM
});
});
Vue.js 提供了 2 种调用 nextTick 的方式,一种是全局 API Vue.nextTick,一种是实例上的方法 vm.$nextTick,无论我们使用哪一种,最后都是调用 next-tick.js 中实现的 nextTick 方法
检测变化的注意事项
对象添加属性
对于使用 Object.defineProperty 实现响应式的对象,当我们去给这个对象添加一个新的属性的时候,是不能够触发它的 setter 的,比如:
var vm = new Vue({
data: {
a: 1,
},
});
// vm.b 是非响应的
vm.b = 2;
添加新属性的场景我们在平时开发中会经常遇到,那么 Vue 为了解决这个问题,定义了一个全局 API Vue.set 方法
在src/core/global-api/index.js中 初始化Vue.set = set
在 src/core/observer/index.js 中 定义 set 方法
export function set(target: Array<any> | Object, key: any, val: any): any {
if (
process.env.NODE_ENV !== "production" &&
(isUndef(target) || isPrimitive(target))
) {
warn(
`Cannot set reactive property on undefined, null, or primitive value: ${(target: any)}`
);
}
if (Array.isArray(target) && isValidArrayIndex(key)) {
target.length = Math.max(target.length, key);
target.splice(key, 1, val);
return val;
}
if (key in target && !(key in Object.prototype)) {
target[key] = val;
return val;
}
const ob = (target: any).__ob__;
if (target._isVue || (ob && ob.vmCount)) {
process.env.NODE_ENV !== "production" &&
warn(
"Avoid adding reactive properties to a Vue instance or its root $data " +
"at runtime - declare it upfront in the data option."
);
return val;
}
if (!ob) {
target[key] = val;
return val;
}
defineReactive(ob.value, key, val);
ob.dep.notify();
return val;
}
set 方法接收 3 个参数,target 可能是数组或者是普通对象,key 代表的是数组的下标或者是对象的键值,val 代表添加的值
首先判断如果 target 是数组且 key 是一个合法的下标,则之前通过 splice 去添加进数组然后返回,这里的 splice 其实已经不仅仅是原生数组的 splice 了
然后判断 key 已经存在于 target 中,则直接赋值返回,因为这样的变化是可以观测到了
再获取到 target.__ob__ 并赋值给 ob,它是在 Observer 的构造函数执行的时候初始化的,表示 Observer 的一个实例,如果它不存在,则说明 target 不是一个响应式的对象,则直接赋值并返回
最后通过 defineReactive(ob.value, key, val) 把新添加的属性变成响应式对象,然后再通过 ob.dep.notify() 手动的触发依赖通知
在 getter 过程中判断了 childOb,并调用了 childOb.dep.depend() 收集了依赖,这就是为什么执行 Vue.set 的时候通过 ob.dep.notify() 能够通知到 watcher,从而让添加新的属性到对象也可以检测到变化。这里如果 value 是个数组,那么就通过 dependArray 把数组每个元素也去做依赖收集
export function defineReactive(
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
// ...
let childOb = !shallow && observe(val);
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
const value = getter ? getter.call(obj) : val;
if (Dep.target) {
dep.depend();
if (childOb) {
childOb.dep.depend();
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value;
},
// ...
});
}
数组
接着说一下数组的情况,Vue 也是不能检测到以下变动的数组:
1.当你利用索引直接设置一个项时,例如:vm.items[indexOfItem] = newValue
2.当你修改数组的长度时,例如:vm.items.length = newLength
对于第一种情况,可以使用:Vue.set(example1.items, indexOfItem, newValue);而对于第二种情况,可以使用 vm.items.splice(newLength)。
对于 Vue.set 的实现,当 target 是数组的时候,也是通过 target.splice(key, 1, val) 来添加的,能让添加的对象变成响应式的呢。
在通过 observe 方法去观察对象的时候会实例化 Observer,在它的构造函数中是专门对数组做了处理,它的定义在 src/core/observer/index.js 中。
export class Observer {
constructor(value: any) {
this.value = value;
this.dep = new Dep();
this.vmCount = 0;
def(value, "__ob__", this);
if (Array.isArray(value)) {
const augment = hasProto ? protoAugment : copyAugment;
augment(value, arrayMethods, arrayKeys);
this.observeArray(value);
} else {
// ...
}
}
}
这里我们只需要关注 value 是 Array 的情况,首先获取 augment,这里的 hasProto 实际上就是判断对象中是否存在 __proto__,如果存在则 augment 指向 protoAugment, 否则指向 copyAugment,来看一下这两个函数的定义:
/**
* Augment an target Object or Array by intercepting
* the prototype chain using __proto__
*/
function protoAugment(target, src: Object, keys: any) {
/* eslint-disable no-proto */
target.__proto__ = src;
/* eslint-enable no-proto */
}
/**
* Augment an target Object or Array by defining
* hidden properties.
*/
/* istanbul ignore next */
function copyAugment(target: Object, src: Object, keys: Array<string>) {
for (let i = 0, l = keys.length; i < l; i++) {
const key = keys[i];
def(target, key, src[key]);
}
}
protoAugment 方法是直接把 target.__proto__ 原型直接修改为 src,而 copyAugment 方法是遍历 keys,通过 def,也就是 Object.defineProperty 去定义它自身的属性值。
对于大部分现代浏览器都会走到 protoAugment,那么它实际上就把 value 的原型指向了 arrayMethods,arrayMethods 的定义在 src/core/observer/array.js 中:
import { def } from "../util/index";
const arrayProto = Array.prototype;
export const arrayMethods = Object.create(arrayProto);
const methodsToPatch = [
"push",
"pop",
"shift",
"unshift",
"splice",
"sort",
"reverse",
];
/**
* Intercept mutating methods and emit events
*/
methodsToPatch.forEach(function (method) {
// cache original method
const original = arrayProto[method];
def(arrayMethods, method, function mutator(...args) {
const result = original.apply(this, args);
const ob = this.__ob__;
let inserted;
switch (method) {
case "push":
case "unshift":
inserted = args;
break;
case "splice":
inserted = args.slice(2);
break;
}
if (inserted) ob.observeArray(inserted);
// notify change
ob.dep.notify();
return result;
});
});
可以看到,通过以 Array.prototype 为原型来构造,使得arrayMethods 首先继承了 Array,
然后对数组中所有能改变数组自身的方法,如 push、pop 等这些方法进行重写。重写后的方法会先执行它们本身原有的逻辑,并对能增加数组长度的 3 个方法 push、unshift、splice 方法做了判断,获取到插入的值,
然后把新添加的值变成一个响应式对象,并且再调用 ob.dep.notify() 手动触发依赖通知,这就很好地解释了之前的示例中调用 vm.items.splice(newLength) 方法可以检测到变化
总结
对象添加属性
1.给对象添加一个新的属性,需要使用 Vue.set(target,key,value)
2.如果 target 是数组且 key 是一个合法的下标,则之前通过 splice 去添加进数组然后返回
3.接着又判断 key 已经存在于 target 中,则直接赋值返回,因为这样的变化是可以观测到了
4.再获取到 target.__ob__ 并赋值给 ob,之前分析过它是在 Observer 的构造函数执行的时候初始化的,表示 Observer 的一个实例,如果它不存在,则说明 target 不是一个响应式的对象,则直接赋值并返回
5.最后通过 defineReactive(ob.value, key, val) 把新添加的属性变成响应式对象,然后再通过 ob.dep.notify() 手动的触发依赖通知
数组
1.根据索引更改数组和长度修改, Observer在它的构造函数中是专门对数组做了处理
2.value 是 Array 的情况,首先获取 augment,这里的 hasProto 实际上就是判断对象中是否存在 __proto__,如果存在则 augment 指向 protoAugment, 实现target.__proto__ = src 否则指向 copyAugment 遍历 keys,通过 def,也就是 Object.defineProperty 去定义它自身的属性值
3.对于大部分现代浏览器都会走到 protoAugment,那么它实际上就把 value 的原型指向了 arrayMethods
const arrayProto = Array.prototype;
export const arrayMethods = Object.create(arrayProto);
const methodsToPatch = [
"push",
"pop",
"shift",
"unshift",
"splice",
"sort",
"reverse",
];
4.arrayMethods 通过以 Array.prototype 为原型来构造,使得arrayMethods 首先继承了 Array,然后对数组中所有能改变数组自身的方法,如 push、pop 等这些方法进行重写
methodsToPatch.forEach(function (method) {
// cache original method
const original = arrayProto[method];
def(arrayMethods, method, function mutator(...args) {
const result = original.apply(this, args);
const ob = this.__ob__;
let inserted;
switch (method) {
case "push":
case "unshift":
inserted = args;
break;
case "splice":
inserted = args.slice(2);
break;
}
if (inserted) ob.observeArray(inserted);
// notify change
ob.dep.notify();
return result;
});
});
5.对能增加数组长度的 3 个方法 push、unshift、splice 方法做了判断,获取到插入的值,然后把新添加的值变成一个响应式对象 再调用 ob.dep.notify() 手动触发依赖通知
调用 vm.items.splice(newLength) 方法可以检测到变化
计算属性 VS 侦听属性
computed
计算属性的初始化是发生在 Vue 实例初始化阶段的 initState 函数中,执行了 if (opts.computed) initComputed(vm, opts.computed) initComputed 的定义在 src/core/instance/state.js 中:
const computedWatcherOptions = { computed: true };
function initComputed(vm: Component, computed: Object) {
// $flow-disable-line
const watchers = (vm._computedWatchers = Object.create(null));
// computed properties are just getters during SSR
const isSSR = isServerRendering();
for (const key in computed) {
const userDef = computed[key];
const getter = typeof userDef === "function" ? userDef : userDef.get;
if (process.env.NODE_ENV !== "production" && getter == null) {
warn(`Getter is missing for computed property "${key}".`, vm);
}
if (!isSSR) {
// create internal watcher for the computed property.
watchers[key] = new Watcher(
vm,
getter || noop,
noop,
computedWatcherOptions
);
}
// component-defined computed properties are already defined on the
// component prototype. We only need to define computed properties defined
// at instantiation here.
if (!(key in vm)) {
defineComputed(vm, key, userDef);
} else if (process.env.NODE_ENV !== "production") {
if (key in vm.$data) {
warn(`The computed property "${key}" is already defined in data.`, vm);
} else if (vm.$options.props && key in vm.$options.props) {
warn(
`The computed property "${key}" is already defined as a prop.`,
vm
);
}
}
}
}
函数首先创建 vm._computedWatchers 为一个空对象,
接着对 computed 对象做遍历,拿到计算属性的每一个 userDef,然后尝试获取这个 userDef 对应的 getter 函数,拿不到则在开发环境下报警告。
接下来为每一个 getter 创建一个 watcher,这个 watcher 和渲染 watcher 有一点很大的不同,它是一个 computed watcher,因为 设置了const computedWatcherOptions = { computed: true }。computed watcher 和普通 watcher 存在差别。
最后对判断如果 key 不是 vm 的属性,则调用 defineComputed(vm, key, userDef),否则判断计算属性对于的 key 是否已经被 data 或者 prop 所占用,如果是的话则在开发环境报相应的警告。
defineComputed 的实现
export function defineComputed(
target: any,
key: string,
userDef: Object | Function
) {
const shouldCache = !isServerRendering();
if (typeof userDef === "function") {
sharedPropertyDefinition.get = shouldCache
? createComputedGetter(key)
: userDef;
sharedPropertyDefinition.set = noop;
} else {
sharedPropertyDefinition.get = userDef.get
? shouldCache && userDef.cache !== false
? createComputedGetter(key)
: userDef.get
: noop;
sharedPropertyDefinition.set = userDef.set ? userDef.set : noop;
}
if (
process.env.NODE_ENV !== "production" &&
sharedPropertyDefinition.set === noop
) {
sharedPropertyDefinition.set = function () {
warn(
`Computed property "${key}" was assigned to but it has no setter.`,
this
);
};
}
Object.defineProperty(target, key, sharedPropertyDefinition);
}
利用 Object.defineProperty 给计算属性对应的 key 值添加 getter 和 setter
setter 通常是计算属性是一个对象,并且拥有 set 方法的时候才有,否则是一个空函数
平时的开发场景中,计算属性有 setter 的情况比较少
getter 部分,缓存的配置也先忽略,最终 getter 对应的是 createComputedGetter(key) 的返回值
function createComputedGetter(key) {
return function computedGetter() {
const watcher = this._computedWatchers && this._computedWatchers[key];
if (watcher) {
watcher.depend();
return watcher.evaluate();
}
};
}
createComputedGetter 返回一个函数 computedGetter,它就是计算属性对应的 getter
computed watcher 实现过程
var vm = new Vue({
data: {
firstName: "Foo",
lastName: "Bar",
},
computed: {
fullName: function () {
return this.firstName + " " + this.lastName;
},
},
});
当初始化这个 computed watcher 实例的时候,构造函数部分逻辑稍有不同:
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
// ...
if (this.computed) {
this.value = undefined
this.dep = new Dep()
} else {
this.value = this.get()
}
}
可以发现 computed watcher 会并不会立刻求值,但是同时持有一个 dep 实例。
然后当我们的 render 函数执行访问到 this.fullName 的时候,就触发了计算属性的 getter,它会拿到计算属性对应的 watcher,然后执行 watcher.depend(),来看一下它的定义:
/**
* Depend on this watcher. Only for computed property watchers.
*/
depend () {
if (this.dep && Dep.target) {
this.dep.depend()
}
}
注意,这时候的 Dep.target 是渲染 watcher,所以 this.dep.depend() 相当于渲染 watcher 订阅了这个 computed watcher 的变化。
然后再执行 watcher.evaluate() 去求值,来看一下它的定义:
/**
* Evaluate and return the value of the watcher.
* This only gets called for computed property watchers.
*/
evaluate () {
if (this.dirty) {
this.value = this.get()
this.dirty = false
}
return this.value
}
evaluate 的逻辑非常简单,判断 this.dirty,如果为 true 则通过 this.get() 求值,然后把 this.dirty 设置为 false。在求值过程中,会执行 value = this.getter.call(vm, vm),这实际上就是执行了计算属性定义的 getter 函数,在我们这个例子就是执行了 return this.firstName + ' ' + this.lastName。
这里需要特别注意的是,由于 this.firstName 和 this.lastName 都是响应式对象,这里会触发它们的 getter,根据我们之前的分析,它们会把自身持有的 dep 添加到当前正在计算的 watcher 中,这个时候 Dep.target 就是这个 computed watcher。
最后通过 return this.value 拿到计算属性对应的值。我们知道了计算属性的求值过程,那么接下来看一下它依赖的数据变化后的逻辑。
一旦我们对计算属性依赖的数据做修改,则会触发 setter 过程,通知所有订阅它变化的 watcher 更新,执行 watcher.update() 方法:
/* istanbul ignore else */
if (this.computed) {
// A computed property watcher has two modes: lazy and activated.
// It initializes as lazy by default, and only becomes activated when
// it is depended on by at least one subscriber, which is typically
// another computed property or a component's render function.
if (this.dep.subs.length === 0) {
// In lazy mode, we don't want to perform computations until necessary,
// so we simply mark the watcher as dirty. The actual computation is
// performed just-in-time in this.evaluate() when the computed property
// is accessed.
this.dirty = true;
} else {
// In activated mode, we want to proactively perform the computation
// but only notify our subscribers when the value has indeed changed.
this.getAndInvoke(() => {
this.dep.notify();
});
}
} else if (this.sync) {
this.run();
} else {
queueWatcher(this);
}
那么对于计算属性这样的 computed watcher,它实际上是有 2 种模式,lazy 和 active。如果 this.dep.subs.length === 0 成立,则说明没有人去订阅这个 computed watcher 的变化,仅仅把 this.dirty = true,只有当下次再访问这个计算属性的时候才会重新求值。在我们的场景下,渲染 watcher 订阅了这个 computed watcher 的变化,那么它会执行:
this.getAndInvoke(() => {
this.dep.notify()
})
getAndInvoke (cb: Function) {
const value = this.get()
if (
value !== this.value ||
// Deep watchers and watchers on Object/Arrays should fire even
// when the value is the same, because the value may
// have mutated.
isObject(value) ||
this.deep
) {
// set new value
const oldValue = this.value
this.value = value
this.dirty = false
if (this.user) {
try {
cb.call(this.vm, value, oldValue)
} catch (e) {
handleError(e, this.vm, `callback for watcher "${this.expression}"`)
}
} else {
cb.call(this.vm, value, oldValue)
}
}
}
getAndInvoke 函数会重新计算,然后对比新旧值,如果变化了则执行回调函数,那么这里这个回调函数是 this.dep.notify(),在我们这个场景下就是触发了渲染 watcher 重新渲染。
通过以上的分析,我们知道计算属性本质上就是一个 computed watcher,也了解了它的创建过程和被访问触发 getter 以及依赖更新的过程,其实这是最新的计算属性的实现,之所以这么设计是因为 Vue 想确保不仅仅是计算属性依赖的值发生变化,而是当计算属性最终计算的值发生变化才会触发渲染 watcher 重新渲染,本质上是一种优化。
watch
侦听属性的初始化也是发生在 Vue 的实例初始化阶段的 initState 函数中,在 computed 初始化之后,执行了:
if (opts.watch && opts.watch !== nativeWatch) {
initWatch(vm, opts.watch);
}
来看一下 initWatch 的实现,它的定义在 src/core/instance/state.js 中:
function initWatch(vm: Component, watch: Object) {
for (const key in watch) {
const handler = watch[key];
if (Array.isArray(handler)) {
for (let i = 0; i < handler.length; i++) {
createWatcher(vm, key, handler[i]);
}
} else {
createWatcher(vm, key, handler);
}
}
}
这里就是对 watch 对象做遍历,拿到每一个 handler,因为 Vue 是支持 watch 的同一个 key 对应多个 handler,所以如果 handler 是一个数组,则遍历这个数组,调用 createWatcher 方法,否则直接调用 createWatcher:
function createWatcher(
vm: Component,
expOrFn: string | Function,
handler: any,
options?: Object
) {
if (isPlainObject(handler)) {
options = handler;
handler = handler.handler;
}
if (typeof handler === "string") {
handler = vm[handler];
}
return vm.$watch(expOrFn, handler, options);
}
这里的逻辑也很简单,首先对 hanlder 的类型做判断,拿到它最终的回调函数,最后调用 vm.$watch(keyOrFn, handler, options) 函数,$watch 是 Vue 原型上的方法,它是在执行 stateMixin 的时候定义的:
Vue.prototype.$watch = function (
expOrFn: string | Function,
cb: any,
options?: Object
): Function {
const vm: Component = this;
if (isPlainObject(cb)) {
return createWatcher(vm, expOrFn, cb, options);
}
options = options || {};
options.user = true;
const watcher = new Watcher(vm, expOrFn, cb, options);
if (options.immediate) {
cb.call(vm, watcher.value);
}
return function unwatchFn() {
watcher.teardown();
};
};
也就是说,侦听属性 watch 最终会调用 $watch 方法,
这个方法首先判断 cb 如果是一个对象,则调用 createWatcher 方法,这是因为 $watch 方法是用户可以直接调用的,它可以传递一个对象,也可以传递函数。
接着执行 const watcher = new Watcher(vm, expOrFn, cb, options) 实例化了一个 watcher,这里需要注意一点这是一个 user watcher,因为 options.user = true。
通过实例化 watcher 的方式,一旦我们 watch 的数据发送变化,它最终会执行 watcher 的 run 方法,执行回调函数 cb,并且如果我们设置了 immediate 为 true,则直接会执行回调函数 cb。
最后返回了一个 unwatchFn 方法,它会调用 teardown 方法去移除这个 watcher。
所以本质上侦听属性也是基于 Watcher 实现的,它是一个 user watcher。其实 Watcher 支持了不同的类型,
Watcher options
Watcher 的构造函数对 options 做的了处理,代码如下:
if (options) {
this.deep = !!options.deep;
this.user = !!options.user;
this.computed = !!options.computed;
this.sync = !!options.sync;
// ...
} else {
this.deep = this.user = this.computed = this.sync = false;
}
所以 watcher 总共有 4 种类型,我们来一一分析它们,看看不同的类型执行的逻辑有哪些差别。
deep watcher
通常,如果我们想对一下对象做深度观测的时候,需要设置这个属性为 true,考虑到这种情况:
var vm = new Vue({
data() {
a: {
b: 1;
}
},
watch: {
a: {
handler(newVal) {
console.log(newVal);
},
},
},
});
vm.a.b = 2;
这个时候是不会 log 任何数据的,因为我们是 watch 了 a 对象,只触发了 a 的 getter,并没有触发 a.b 的 getter,所以并没有订阅它的变化,导致我们对 vm.a.b = 2 赋值的时候,虽然触发了 setter,但没有可通知的对象,所以也并不会触发 watch 的回调函数了。
而我们只需要对代码做稍稍修改,就可以观测到这个变化了
watch: {
a: {
deep: true,
handler(newVal) {
console.log(newVal)
}
}
}
这样就创建了一个 deep watcher 了,在 watcher 执行 get 求值的过程中有一段逻辑:
get() {
let value = this.getter.call(vm, vm)
// ...
if (this.deep) {
traverse(value)
}
}
在对 watch 的表达式或者函数求值后,会调用 traverse 函数,它的定义在 src/core/observer/traverse.js 中:
import { _Set as Set, isObject } from "../util/index";
import type { SimpleSet } from "../util/index";
import VNode from "../vdom/vnode";
const seenObjects = new Set();
/**
* Recursively traverse an object to evoke all converted
* getters, so that every nested property inside the object
* is collected as a "deep" dependency.
*/
export function traverse(val: any) {
_traverse(val, seenObjects);
seenObjects.clear();
}
function _traverse(val: any, seen: SimpleSet) {
let i, keys;
const isA = Array.isArray(val);
if (
(!isA && !isObject(val)) ||
Object.isFrozen(val) ||
val instanceof VNode
) {
return;
}
if (val.__ob__) {
const depId = val.__ob__.dep.id;
if (seen.has(depId)) {
return;
}
seen.add(depId);
}
if (isA) {
i = val.length;
while (i--) _traverse(val[i], seen);
} else {
keys = Object.keys(val);
i = keys.length;
while (i--) _traverse(val[keys[i]], seen);
}
}
traverse 的逻辑也很简单,它实际上就是对一个对象做深层递归遍历,因为遍历过程中就是对一个子对象的访问,会触发它们的 getter 过程,这样就可以收集到依赖,也就是订阅它们变化的 watcher,这个函数实现还有一个小的优化,遍历过程中会把子响应式对象通过它们的 dep id 记录到 seenObjects,避免以后重复访问。
那么在执行了 traverse 后,我们再对 watch 的对象内部任何一个值做修改,也会调用 watcher 的回调函数了。
对 deep watcher 的理解非常重要,今后工作中如果大家观测了一个复杂对象,并且会改变对象内部深层某个值的时候也希望触发回调,一定要设置 deep 为 true,但是因为设置了 deep 后会执行 traverse 函数,会有一定的性能开销,所以一定要根据应用场景权衡是否要开启这个配置。
user watcher
通过 vm.$watch 创建的 watcher 是一个 user watcher,其实它的功能很简单,在对 watcher 求值以及在执行回调函数的时候,会处理一下错误,如下:
get() {
if (this.user) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
} else {
throw e
}
},
getAndInvoke() {
// ...
if (this.user) {
try {
this.cb.call(this.vm, value, oldValue)
} catch (e) {
handleError(e, this.vm, `callback for watcher "${this.expression}"`)
}
} else {
this.cb.call(this.vm, value, oldValue)
}
}
handleError 在 Vue 中是一个错误捕获并且暴露给用户的一个利器。
computed watcher
computed watcher 几乎就是为计算属性量身定制的
sync watcher
在我们之前对 setter 的分析过程知道,当响应式数据发送变化后,触发了 watcher.update(),只是把这个 watcher 推送到一个队列中,在 nextTick 后才会真正执行 watcher 的回调函数。而一旦我们设置了 sync,就可以在当前 Tick 中同步执行 watcher 的回调函数。
update () {
if (this.computed) {
// ...
} else if (this.sync) {
this.run()
} else {
queueWatcher(this)
}
}
只有当我们需要 watch 的值的变化到执行 watcher 的回调函数是一个同步过程的时候才会去设置该属性为 true
总结
计算属性本质上是 computed watcher,而侦听属性本质上是 user watcher
计算属性适合用在模板渲染中,某个值是依赖了其它的响应式对象甚至是计算属性计算而来;而侦听属性适用于观测某个值的变化去完成一段复杂的业务逻辑
computed
1.计算属性的初始化是发生在 Vue 实例初始化阶段的 initState 函数 执行了 if (opts.computed) initComputed(vm, opts.computed)
2.先创建 vm._computedWatchers 为一个空对象,接着对 computed 对象做遍历,拿到计算属性的每一个 userDef,然后尝试获取这个 userDef 对应的 getter 函数为每一个 3.getter 创建一个 watcher 它是一个 computed watcher,因为进行了设置 const computedWatcherOptions = { computed: true }
4.最后对判断如果 key 不是 vm 的属性,则调用 defineComputed(vm, key, userDef) 否则判断计算属性对于的 key 是否已经被 data 或者 prop 所占用
5.defineComputed 实际上就是利用 Object.defineProperty 给计算属性对应的 key 值添加 getter 和 setter,setter 通常是计算属性是一个对象,并且拥有 set 方法的时候才有,否则是一个空函数
6.getter 部分,缓存的配置也先忽略,最终 getter 对应的是 createComputedGetter(key) 返回的一个函数 computedGetter,它就是计算属性对应的 getter
computed watcher
1.初始化这个 computed watcher 实例 computed watcher 会并不会立刻求值,但是同时持有一个 dep 实例。
2.当 render 函数执行访问到 属性的时候,就触发了计算属性的 getter,它会拿到计算属性对应的 watcher,然后执行 watcher.depend()
3.Dep.target 是渲染 watcher,所以 this.dep.depend() 相当于渲染 watcher 订阅了这个 computed watcher 的变化
4.然后再执行 watcher.evaluate() 去求值,evaluate 的逻辑非常简单,判断 this.dirty,如果为 true 则通过 this.get() 求值,然后把 this.dirty 设置为 false
5.在求值过程中,会执行 value = this.getter.call(vm, vm),这实际上就是执行了计算属性定义的 getter 函数 得到了 computed()函数的返回值
6.由于 this.xxx是响应式对象,这里会触发它们的 getter 它们会把自身持有的 dep 添加到当前正在计算的 watcher 中,这个时候 Dep.target 就是这个 computed watcher 最后通过 return this.value 拿到计算属性对应的值
7.一旦我们对计算属性依赖的数据做修改,则会触发 setter 过程,通知所有订阅它变化的 watcher 更新,执行 watcher.update() 方法
8.update()方法中有 2 种模式,lazy 和 active。
this.dep.subs.length === 0 说明没有人去订阅这个 computed watcher 的变化
就把 this.dirty = true,只有当下次再访问这个计算属性的时候才会重新求值
否则执行 this.getAndInvoke(() => { this.dep.notify() })
9.getAndInvoke 函数会重新计算,然后对比新旧值,如果变化了则执行回调函数,那么这里这个回调函数是 this.dep.notify(),在我们这个场景下就是触发了渲染 watcher 重新渲染
Vue 想确保不仅仅是计算属性依赖的值发生变化,而是当计算属性最终计算的值发生变化才会触发渲染 watcher 重新渲染,本质上是一种优化
watch
1.侦听属性*的初始化也是发生在 Vue 的实例初始化阶段的 initState 函数中,在 computed 初始化之后,执行了 initWatch(vm, opts.watch)
2.initWatch 的实现,这里就是对 watch 对象做遍历,拿到每一个 handler,因为 Vue 是支持 watch 的同一个 key 对应多个 handler,所以如果 handler 是一个数组,则遍历这个数组,调用 createWatcher 方法,否则直接调用 createWatcher
3.createWatcher 的逻辑也很简单,首先对 hanlder 的类型做判断,拿到它最终的回调函数,最后调用 vm.$watch(keyOrFn, handler, options) 函数,
4.$watch 是 Vue 原型上的方法,它是在执行 stateMixin 的时候定义的,侦听属性 watch 最终会调用 $watch 方法
5.$watch方法首先判断 cb 如果是一个对象,则调用 createWatcher 方法,这是因为 $watch 方法是用户可以直接调用的,它可以传递一个对象,也可以传递函数。
6.接着执行 const watcher = new Watcher(vm, expOrFn, cb, options) 实例化了一个 watcher,这里需要注意一点这是一个 user watcher,因为 options.user = true。
7.通过实例化 watcher 的方式,一旦我们 watch 的数据发送变化,它最终会执行 watcher 的 run 方法,执行回调函数 cb,并且如果我们设置了 immediate 为 true,则直接会执行回调函数 cb。
8.最后返回了一个 unwatchFn 方法,它会调用 teardown 方法去移除这个 watcher。
所以本质上侦听属性也是基于 Watcher 实现的,它是一个 user watcher。其实 Watcher 支持了不同的类型,
组件更新
更新判断
当数据发生变化的时候,会触发渲染 watcher 的回调函数,进而执行组件的更新过程
updateComponent = () => {
vm._update(vm._render(), hydrating);
};
new Watcher(
vm,
updateComponent,
noop,
{
before() {
if (vm._isMounted) {
callHook(vm, "beforeUpdate");
}
},
},
true /* isRenderWatcher */
);
组件的更新还是调用了 vm._update 方法 在 src/core/instance/lifecycle.js 中:
Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) {
const vm: Component = this;
// ...
const prevVnode = vm._vnode;
if (!prevVnode) {
// initial render
vm.$el = vm.__patch__(vm.$el, vnode, hydrating, false /* removeOnly */);
} else {
// updates
vm.$el = vm.__patch__(prevVnode, vnode);
}
// ...
};
组件更新的过程,会执行 vm.$el = vm.__patch__(prevVnode, vnode),它仍然会调用 patch 函数,在 src/core/vdom/patch.js 中定义:
return function patch(oldVnode, vnode, hydrating, removeOnly) {
if (isUndef(vnode)) {
if (isDef(oldVnode)) invokeDestroyHook(oldVnode);
return;
}
let isInitialPatch = false;
const insertedVnodeQueue = [];
if (isUndef(oldVnode)) {
// empty mount (likely as component), create new root element
isInitialPatch = true;
createElm(vnode, insertedVnodeQueue);
} else {
const isRealElement = isDef(oldVnode.nodeType);
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// patch existing root node
patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly);
} else {
if (isRealElement) {
// ...
}
// replacing existing element
const oldElm = oldVnode.elm;
const parentElm = nodeOps.parentNode(oldElm);
// create new node
createElm(
vnode,
insertedVnodeQueue,
// extremely rare edge case: do not insert if old element is in a
// leaving transition. Only happens when combining transition +
// keep-alive + HOCs. (#4590)
oldElm._leaveCb ? null : parentElm,
nodeOps.nextSibling(oldElm)
);
// update parent placeholder node element, recursively
if (isDef(vnode.parent)) {
let ancestor = vnode.parent;
const patchable = isPatchable(vnode);
while (ancestor) {
for (let i = 0; i < cbs.destroy.length; ++i) {
cbs.destroy[i](ancestor);
}
ancestor.elm = vnode.elm;
if (patchable) {
for (let i = 0; i < cbs.create.length; ++i) {
cbs.create[i](emptyNode, ancestor);
}
// #6513
// invoke insert hooks that may have been merged by create hooks.
// e.g. for directives that uses the "inserted" hook.
const insert = ancestor.data.hook.insert;
if (insert.merged) {
// start at index 1 to avoid re-invoking component mounted hook
for (let i = 1; i < insert.fns.length; i++) {
insert.fns[i]();
}
}
} else {
registerRef(ancestor);
}
ancestor = ancestor.parent;
}
}
// destroy old node
if (isDef(parentElm)) {
removeVnodes(parentElm, [oldVnode], 0, 0);
} else if (isDef(oldVnode.tag)) {
invokeDestroyHook(oldVnode);
}
}
}
invokeInsertHook(vnode, insertedVnodeQueue, isInitialPatch);
return vnode.elm;
};
这里执行 patch 的逻辑和首次渲染是不一样的,因为 oldVnode 不为空,并且它和 vnode 都是 VNode 类型,接下来会通过 sameVNode(oldVnode, vnode) 判断它们是否是相同的 VNode 来决定走不同的更新逻辑:
function sameVnode(a, b) {
return (
a.key === b.key &&
((a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)) ||
(isTrue(a.isAsyncPlaceholder) &&
a.asyncFactory === b.asyncFactory &&
isUndef(b.asyncFactory.error)))
);
}
sameVnode 的逻辑非常简单,如果两个 vnode 的 key 不相等,则是不同的;否则继续判断对于同步组件,则判断 isComment、data、input 类型等是否相同,对于异步组件,则判断 asyncFactory 是否相同。
所以根据新旧 vnode 是否为 sameVnode,会走到不同的更新逻辑,我们先来说一下不同的情况。
新旧节点不同
如果新旧 vnode 不同,那么更新的逻辑非常简单,它本质上是要替换已存在的节点,大致分为 3 步
- 创建新节点
const oldElm = oldVnode.elm;
const parentElm = nodeOps.parentNode(oldElm);
// create new node
createElm(
vnode,
insertedVnodeQueue,
// extremely rare edge case: do not insert if old element is in a
// leaving transition. Only happens when combining transition +
// keep-alive + HOCs. (#4590)
oldElm._leaveCb ? null : parentElm,
nodeOps.nextSibling(oldElm)
);
以当前旧节点为参考节点,创建新的节点,并插入到 DOM 中,createElm 的逻辑我们之前分析过。
- 更新父的占位符节点
// update parent placeholder node element, recursively
if (isDef(vnode.parent)) {
let ancestor = vnode.parent;
const patchable = isPatchable(vnode);
while (ancestor) {
for (let i = 0; i < cbs.destroy.length; ++i) {
cbs.destroy[i](ancestor);
}
ancestor.elm = vnode.elm;
if (patchable) {
for (let i = 0; i < cbs.create.length; ++i) {
cbs.create[i](emptyNode, ancestor);
}
// #6513
// invoke insert hooks that may have been merged by create hooks.
// e.g. for directives that uses the "inserted" hook.
const insert = ancestor.data.hook.insert;
if (insert.merged) {
// start at index 1 to avoid re-invoking component mounted hook
for (let i = 1; i < insert.fns.length; i++) {
insert.fns[i]();
}
}
} else {
registerRef(ancestor);
}
ancestor = ancestor.parent;
}
}
我们只关注主要逻辑即可,找到当前 vnode 的父的占位符节点,先执行各个 module 的 destroy 的钩子函数,如果当前占位符是一个可挂载的节点,则执行 module 的 create 钩子函数。
- 删除旧节点
// destroy old node
if (isDef(parentElm)) {
removeVnodes(parentElm, [oldVnode], 0, 0);
} else if (isDef(oldVnode.tag)) {
invokeDestroyHook(oldVnode);
}
把 oldVnode 从当前 DOM 树中删除,如果父节点存在,则执行 removeVnodes 方法:
function removeVnodes(parentElm, vnodes, startIdx, endIdx) {
for (; startIdx <= endIdx; ++startIdx) {
const ch = vnodes[startIdx];
if (isDef(ch)) {
if (isDef(ch.tag)) {
removeAndInvokeRemoveHook(ch);
invokeDestroyHook(ch);
} else {
// Text node
removeNode(ch.elm);
}
}
}
}
function removeAndInvokeRemoveHook(vnode, rm) {
if (isDef(rm) || isDef(vnode.data)) {
let i;
const listeners = cbs.remove.length + 1;
if (isDef(rm)) {
// we have a recursively passed down rm callback
// increase the listeners count
rm.listeners += listeners;
} else {
// directly removing
rm = createRmCb(vnode.elm, listeners);
}
// recursively invoke hooks on child component root node
if (
isDef((i = vnode.componentInstance)) &&
isDef((i = i._vnode)) &&
isDef(i.data)
) {
removeAndInvokeRemoveHook(i, rm);
}
for (i = 0; i < cbs.remove.length; ++i) {
cbs.remove[i](vnode, rm);
}
if (isDef((i = vnode.data.hook)) && isDef((i = i.remove))) {
i(vnode, rm);
} else {
rm();
}
} else {
removeNode(vnode.elm);
}
}
function invokeDestroyHook(vnode) {
let i, j;
const data = vnode.data;
if (isDef(data)) {
if (isDef((i = data.hook)) && isDef((i = i.destroy))) i(vnode);
for (i = 0; i < cbs.destroy.length; ++i) cbs.destroy[i](vnode);
}
if (isDef((i = vnode.children))) {
for (j = 0; j < vnode.children.length; ++j) {
invokeDestroyHook(vnode.children[j]);
}
}
}
删除节点逻辑很简单,就是遍历待删除的 vnodes 做删除,
其中 removeAndInvokeRemoveHook 的作用是从 DOM 中移除节点并执行 module 的 remove 钩子函数,
并对它的子节点**递归调用** removeAndInvokeRemoveHook 函数;
invokeDestroyHook 是执行 module 的 destory 钩子函数以及 vnode 的 destory 钩子函数,并对它的子 vnode 递归调用 invokeDestroyHook 函数;removeNode 就是调用平台的 DOM API 去把真正的 DOM 节点移除。
在之前介绍组件生命周期的时候提到 beforeDestroy & destroyed 这两个生命周期钩子函数,它们就是在执行 invokeDestroyHook 过程中,执行了 vnode 的 destory 钩子函数,它的定义在 src/core/vdom/create-component.js 中:
const componentVNodeHooks = {
destroy(vnode: MountedComponentVNode) {
const { componentInstance } = vnode;
if (!componentInstance._isDestroyed) {
if (!vnode.data.keepAlive) {
componentInstance.$destroy();
} else {
deactivateChildComponent(componentInstance, true /* direct */);
}
}
},
};
当组件并不是 keepAlive 的时候,会执行 componentInstance.$destroy() 方法,然后就会执行 beforeDestroy & destroyed 两个钩子函数。
新旧节点相同
对于新旧节点不同的情况,这种创建新节点 -> 更新占位符节点 -> 删除旧节点的逻辑是很容易理解的。还有一种组件 vnode 的更新情况是新旧节点相同,它会调用 patchVNode 方法,它的定义在 src/core/vdom/patch.js 中:
function patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly) {
if (oldVnode === vnode) {
return;
}
const elm = (vnode.elm = oldVnode.elm);
if (isTrue(oldVnode.isAsyncPlaceholder)) {
if (isDef(vnode.asyncFactory.resolved)) {
hydrate(oldVnode.elm, vnode, insertedVnodeQueue);
} else {
vnode.isAsyncPlaceholder = true;
}
return;
}
// reuse element for static trees.
// note we only do this if the vnode is cloned -
// if the new node is not cloned it means the render functions have been
// reset by the hot-reload-api and we need to do a proper re-render.
if (
isTrue(vnode.isStatic) &&
isTrue(oldVnode.isStatic) &&
vnode.key === oldVnode.key &&
(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))
) {
vnode.componentInstance = oldVnode.componentInstance;
return;
}
let i;
const data = vnode.data;
if (isDef(data) && isDef((i = data.hook)) && isDef((i = i.prepatch))) {
i(oldVnode, vnode);
}
const oldCh = oldVnode.children;
const ch = vnode.children;
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode);
if (isDef((i = data.hook)) && isDef((i = i.update))) i(oldVnode, vnode);
}
if (isUndef(vnode.text)) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch)
updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly);
} else if (isDef(ch)) {
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, "");
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue);
} else if (isDef(oldCh)) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
} else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, "");
}
} else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text);
}
if (isDef(data)) {
if (isDef((i = data.hook)) && isDef((i = i.postpatch))) i(oldVnode, vnode);
}
}
patchVnode 的作用就是把新的 vnode patch 到旧的 vnode 上,这里我们只关注关键的核心逻辑,我把它拆成四步骤:
- 执行
prepatch钩子函数
let i;
const data = vnode.data;
if (isDef(data) && isDef((i = data.hook)) && isDef((i = i.prepatch))) {
i(oldVnode, vnode);
}
当更新的 vnode 是一个组件 vnode 的时候,会执行 prepatch 的方法,它的定义在 src/core/vdom/create-component.js 中:
const componentVNodeHooks = {
prepatch(oldVnode: MountedComponentVNode, vnode: MountedComponentVNode) {
const options = vnode.componentOptions;
const child = (vnode.componentInstance = oldVnode.componentInstance);
updateChildComponent(
child,
options.propsData, // updated props
options.listeners, // updated listeners
vnode, // new parent vnode
options.children // new children
);
},
};
prepatch 方法就是拿到新的 vnode 的组件配置以及组件实例,去执行 updateChildComponent 方法,它的定义在 src/core/instance/lifecycle.js 中:
export function updateChildComponent(
vm: Component,
propsData: ?Object,
listeners: ?Object,
parentVnode: MountedComponentVNode,
renderChildren: ?Array<VNode>
) {
if (process.env.NODE_ENV !== "production") {
isUpdatingChildComponent = true;
}
// determine whether component has slot children
// we need to do this before overwriting $options._renderChildren
const hasChildren = !!(
(
renderChildren || // has new static slots
vm.$options._renderChildren || // has old static slots
parentVnode.data.scopedSlots || // has new scoped slots
vm.$scopedSlots !== emptyObject
) // has old scoped slots
);
vm.$options._parentVnode = parentVnode;
vm.$vnode = parentVnode; // update vm's placeholder node without re-render
if (vm._vnode) {
// update child tree's parent
vm._vnode.parent = parentVnode;
}
vm.$options._renderChildren = renderChildren;
// update $attrs and $listeners hash
// these are also reactive so they may trigger child update if the child
// used them during render
vm.$attrs = parentVnode.data.attrs || emptyObject;
vm.$listeners = listeners || emptyObject;
// update props
if (propsData && vm.$options.props) {
toggleObserving(false);
const props = vm._props;
const propKeys = vm.$options._propKeys || [];
for (let i = 0; i < propKeys.length; i++) {
const key = propKeys[i];
const propOptions: any = vm.$options.props; // wtf flow?
props[key] = validateProp(key, propOptions, propsData, vm);
}
toggleObserving(true);
// keep a copy of raw propsData
vm.$options.propsData = propsData;
}
// update listeners
listeners = listeners || emptyObject;
const oldListeners = vm.$options._parentListeners;
vm.$options._parentListeners = listeners;
updateComponentListeners(vm, listeners, oldListeners);
// resolve slots + force update if has children
if (hasChildren) {
vm.$slots = resolveSlots(renderChildren, parentVnode.context);
vm.$forceUpdate();
}
if (process.env.NODE_ENV !== "production") {
isUpdatingChildComponent = false;
}
}
updateChildComponent 的逻辑也非常简单,由于更新了 vnode,那么 vnode 对应的实例 vm 的一系列属性也会发生变化,包括占位符 vm.$vnode 的更新、slot 的更新,listeners 的更新,props 的更新等等。
- 执行
update钩子函数
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode);
if (isDef((i = data.hook)) && isDef((i = i.update))) i(oldVnode, vnode);
}
回到 patchVNode 函数,在执行完新的 vnode 的 prepatch 钩子函数,会执行所有 module 的 update 钩子函数以及用户自定义 update 钩子函数,对于 module 的钩子函数,之
- 完成
patch过程
const oldCh = oldVnode.children;
const ch = vnode.children;
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode);
if (isDef((i = data.hook)) && isDef((i = i.update))) i(oldVnode, vnode);
}
if (isUndef(vnode.text)) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch)
updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly);
} else if (isDef(ch)) {
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, "");
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue);
} else if (isDef(oldCh)) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
} else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, "");
}
} else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text);
}
如果 vnode 是个文本节点且新旧文本不相同,则直接替换文本内容。如果不是文本节点,则判断它们的子节点,并分了几种情况处理:
1.oldCh 与 ch 都存在且不相同时,使用 updateChildren 函数来更新子节点,这个后面重点讲。
2.如果只有 ch 存在,表示旧节点不需要了。如果旧的节点是文本节点则先将节点的文本清除,然后通过 addVnodes 将 ch 批量插入到新节点 elm 下。
3.如果只有 oldCh 存在,表示更新的是空节点,则需要将旧的节点通过 removeVnodes 全部清除。
4.当只有旧节点是文本节点的时候,则清除其节点文本内容。
- 执行
postpatch钩子函数
if (isDef(data)) {
if (isDef((i = data.hook)) && isDef((i = i.postpatch))) i(oldVnode, vnode);
}
再执行完 patch 过程后,会执行 postpatch 钩子函数,它是组件自定义的钩子函数,有则执行。
那么在整个 pathVnode 过程中,最复杂的就是 updateChildren 方法了
updateChildren
function updateChildren(
parentElm,
oldCh,
newCh,
insertedVnodeQueue,
removeOnly
) {
let oldStartIdx = 0;
let newStartIdx = 0;
let oldEndIdx = oldCh.length - 1;
let oldStartVnode = oldCh[0];
let oldEndVnode = oldCh[oldEndIdx];
let newEndIdx = newCh.length - 1;
let newStartVnode = newCh[0];
let newEndVnode = newCh[newEndIdx];
let oldKeyToIdx, idxInOld, vnodeToMove, refElm;
// removeOnly is a special flag used only by <transition-group>
// to ensure removed elements stay in correct relative positions
// during leaving transitions
const canMove = !removeOnly;
if (process.env.NODE_ENV !== "production") {
checkDuplicateKeys(newCh);
}
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]; // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue);
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue);
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue);
canMove &&
nodeOps.insertBefore(
parentElm,
oldStartVnode.elm,
nodeOps.nextSibling(oldEndVnode.elm)
);
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue);
canMove &&
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
} else {
if (isUndef(oldKeyToIdx))
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx);
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx);
if (isUndef(idxInOld)) {
// New element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
} else {
vnodeToMove = oldCh[idxInOld];
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue);
oldCh[idxInOld] = undefined;
canMove &&
nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm);
} else {
// same key but different element. treat as new element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
}
}
newStartVnode = newCh[++newStartIdx];
}
}
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm;
addVnodes(
parentElm,
refElm,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
);
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
}
updateChildren 的逻辑比较复杂,直接读源码比较晦涩,我们可以通过一个具体的示例来分析它。
<template>
<div id="app">
<div>
<ul>
<li v-for="item in items" :key="item.id">{{ item.val }}</li>
</ul>
</div>
<button @click="change">change</button>
</div>
</template>
<script>
export default {
name: 'App',
data() {
return {
items: [
{id: 0, val: 'A'},
{id: 1, val: 'B'},
{id: 2, val: 'C'},
{id: 3, val: 'D'}
]
}
},
methods: {
change() {
this.items.reverse().push({id: 4, val: 'E'})
}
}
}
</script>
当我们点击 change 按钮去改变数据,最终会执行到 updateChildren 去更新 li 部分的列表数据,我们通过图的方式来描述一下它的更新过程:
第一步: 
第二步: 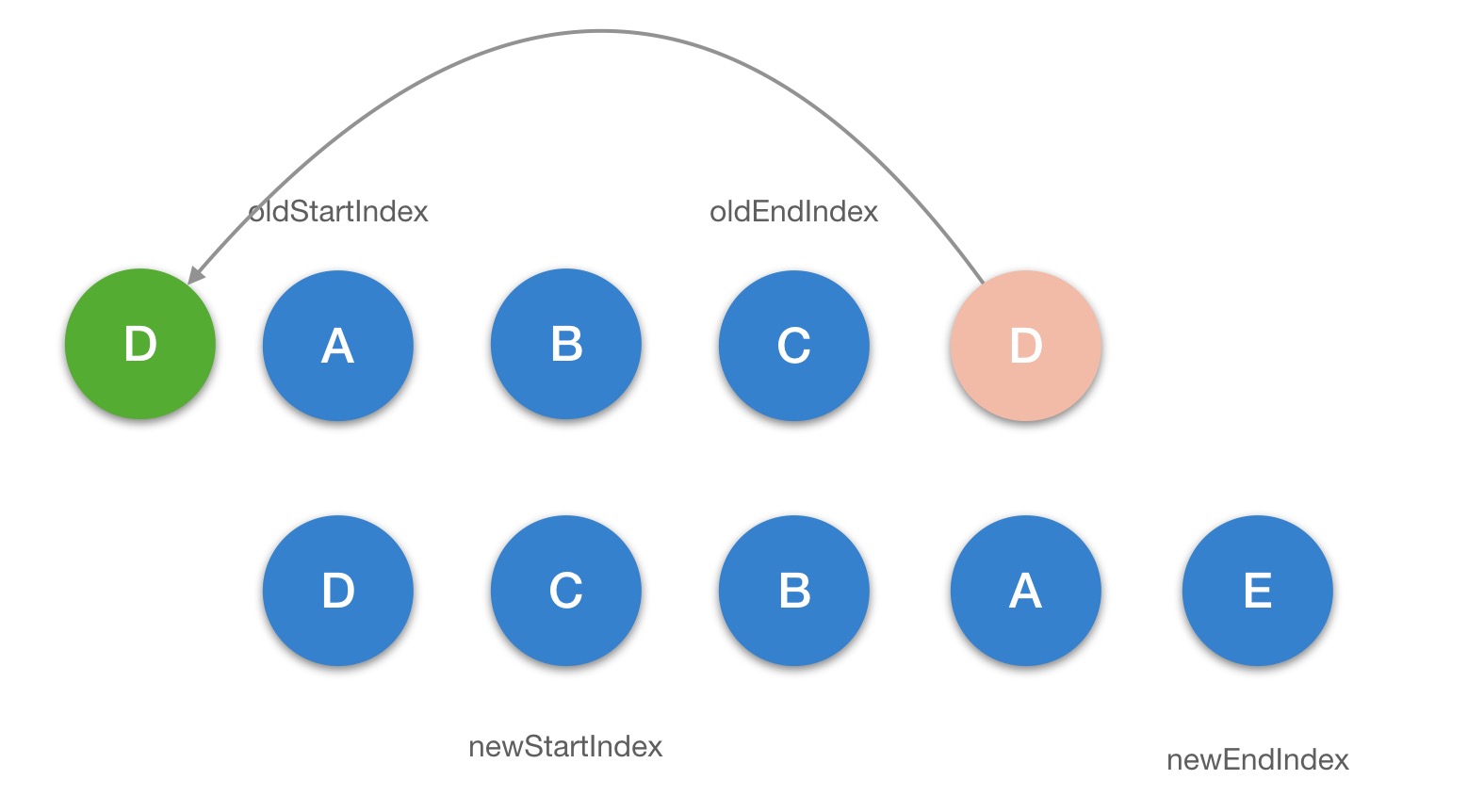
第三步: 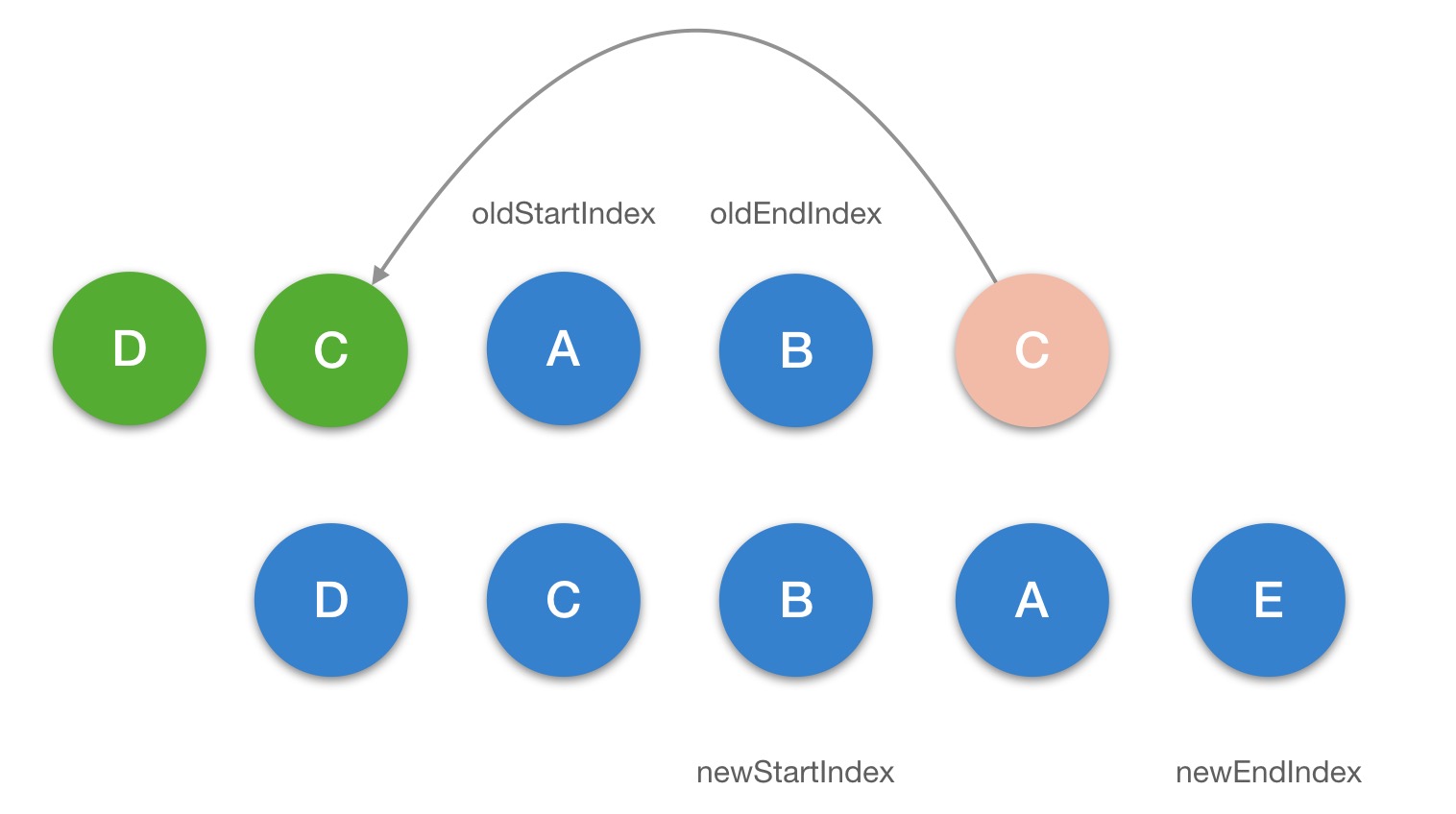
第四步: 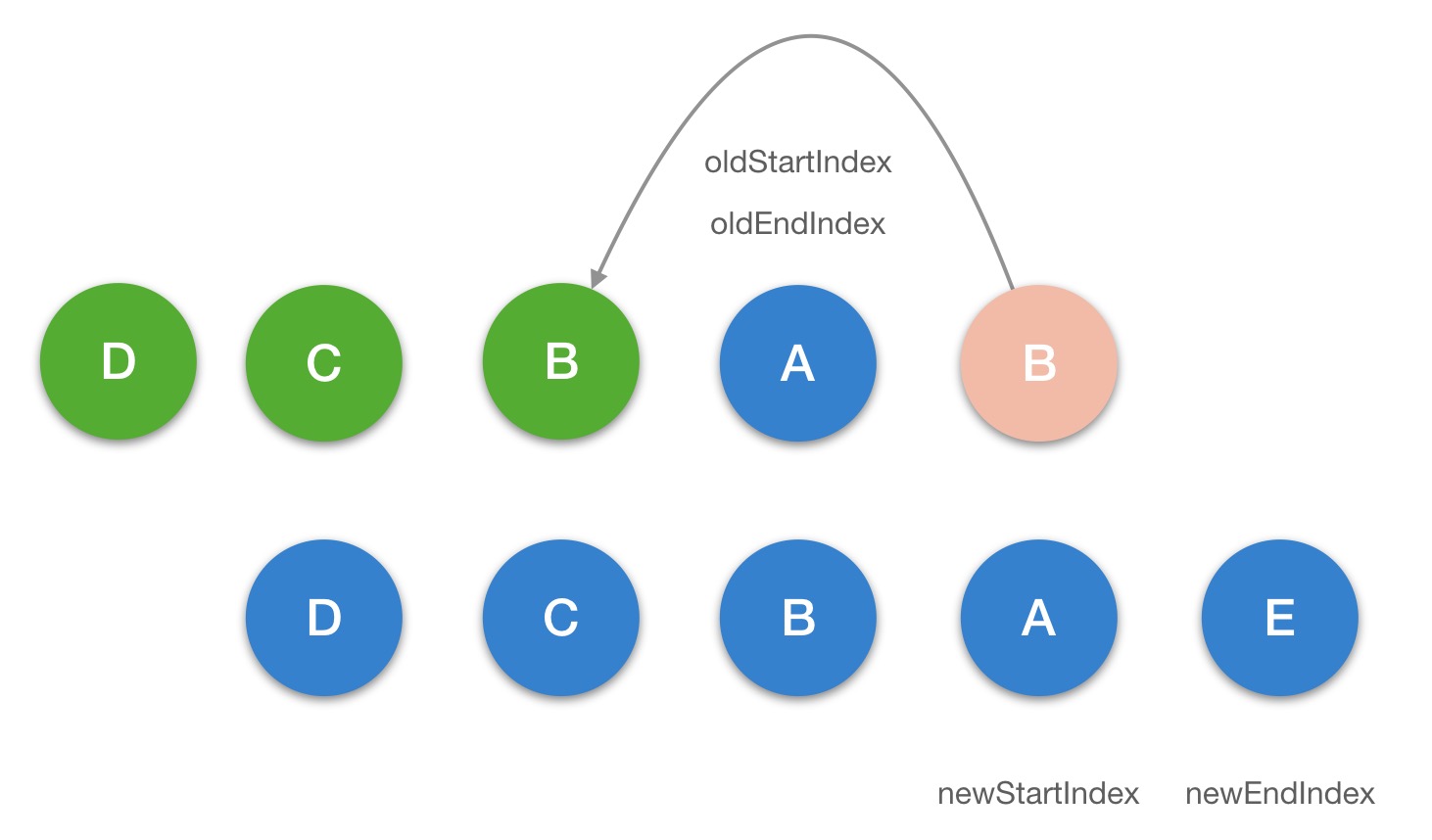
第五步: 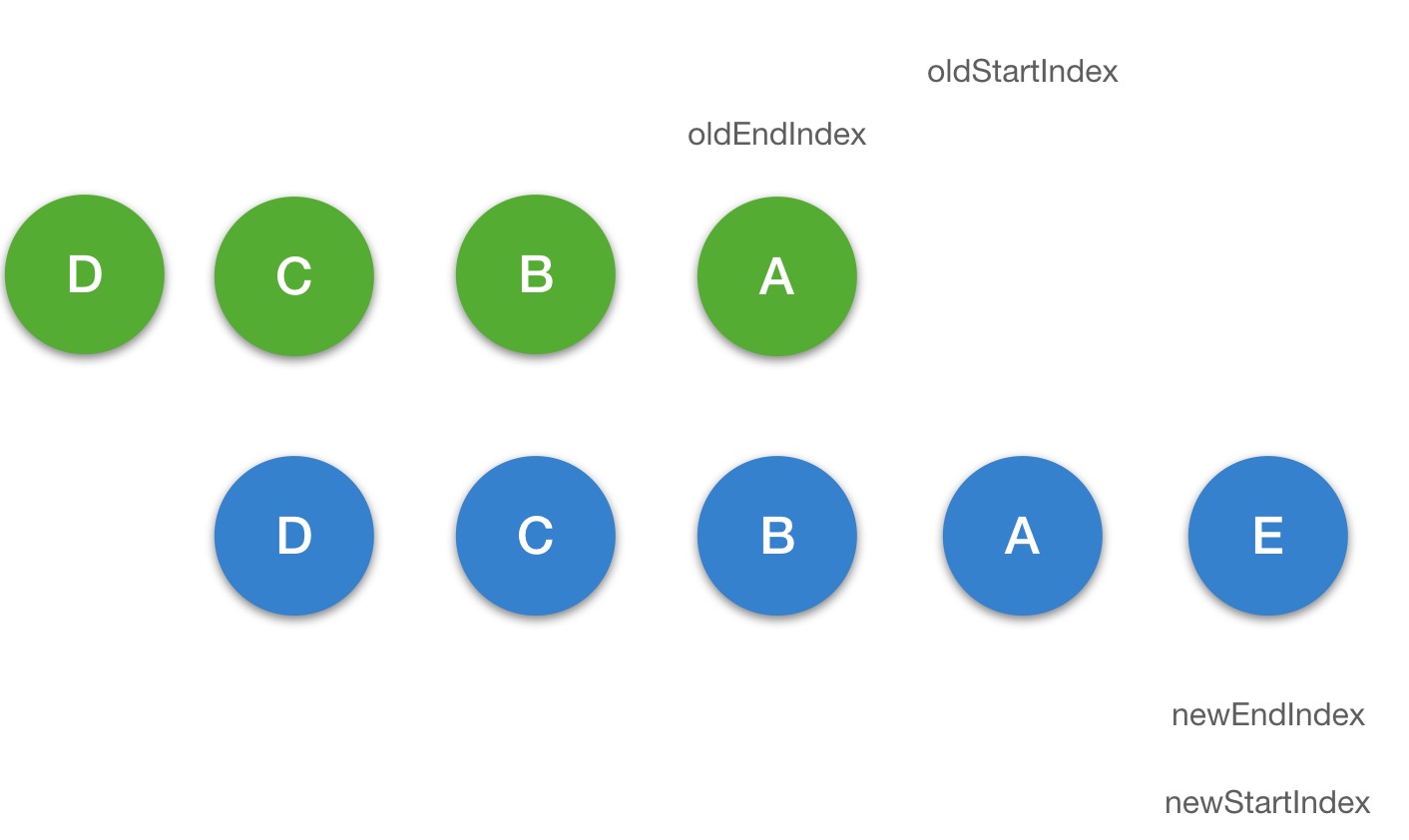
第六步: 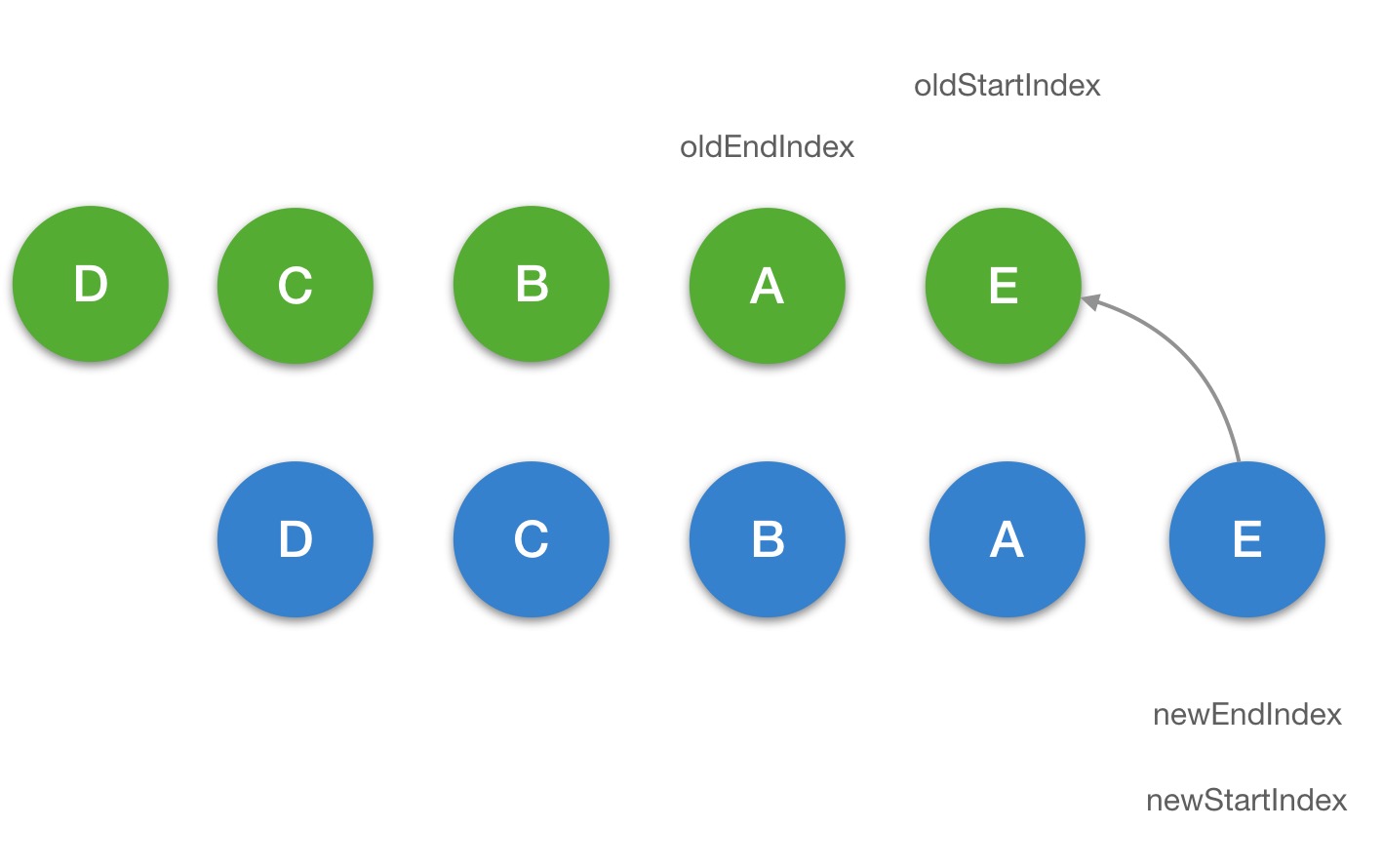
总结
组件更新逻辑判断
1.当数据发生变化的时候,会触发渲染 watcher 的回调函数,进而执行组件的更新过程,组件的更新还是通过 updateComponent 调用了 vm._update 方法
2.组件更新的过程,会执行 vm.$el = vm.__patch__(prevVnode, vnode),它仍然会调用 patch 函数
3.patch 的逻辑和首次渲染是不一样的,因为 oldVnode 不为空,并且它和 vnode 都是 VNode 类型
4.然后会通过 sameVNode(oldVnode, vnode) 判断它们是否是相同的 VNode 来决定走不同的更新逻辑
如果两个 vnode 的 key 不相等,则是不同的;否则继续判断对于同步组件,则判断 isComment、data、input 类型等是否相同,对于异步组件,则判断 asyncFactory 是否相同
根据新旧 vnode 是否为 sameVnode,会走到不同的更新逻辑
新旧节点不同
如果新旧 vnode 不同,那么更新的逻辑非常简单,它本质上是要替换已存在的节点,大致分为 3 步
1.创建新节点 通过 createElm() 以当前旧节点为参考节点,创建新的节点,并插入到 DOM 中
2.更新父的占位符节点 找到当前 vnode 的父的占位符节点,先执行各个 module 的 destroy 的钩子函数,如果当前占位符是一个可挂载的节点,则执行 module 的 create 钩子函数
3.删除旧节点 把 oldVnode 从当前 DOM 树中删除,如果父节点存在,则执行 removeVnodes 方法
removeAndInvokeRemoveHook 的作用是从 DOM 中移除节点并执行 module 的 remove 钩子函数,并对它的子节点递归调用 removeAndInvokeRemoveHook 函数
invokeDestroyHook 是执行 module 的 destory 钩子函数以及 vnode 的 destory 钩子函数,并对它的子 vnode 递归调用 invokeDestroyHook 函数
removeNode 就是调用平台的 DOM API 去把真正的 DOM 节点移除
4.beforeDestroy & destroyed 这两个生命周期钩子函数 就是在执行 invokeDestroyHook 过程中,执行了 vnode 的 destory 钩子函数 当组件并不是 keepAlive 的时候,会执行 componentInstance.$destroy() 方法,然后就会执行 beforeDestroy & destroyed 两个钩子函数
新旧节点相同
组件 vnode 的更新情况是新旧节点相同,它会调用 patchVNode 方法 , patchVnode 的作用就是把新的 vnode patch 到旧的 vnode 上,拆成四步骤:
1.执行 prepatch 钩子函数
当更新的 vnode 是一个组件 vnode 的时候,会执行 prepatch 的方法
prepatch 方法就是拿到新的 vnode 的组件配置以及组件实例,去执行 updateChildComponent 方法
updateChildComponent 的逻辑也非常简单,由于更新了 vnode,那么 vnode 对应的实例 vm 的一系列属性也会发生变化,包括占位符 vm.$vnode 的更新、slot 的更新,listeners 的更新,props 的更新等
2.执行 update 钩子函数
回到 patchVNode 函数,在执行完新的 vnode 的 prepatch 钩子函数,会执行所有 module 的 update 钩子函数以及用户自定义 update 钩子函数,对于 module 的钩子函数
3.完成 patch 过程
如果 vnode 是个文本节点且新旧文本不相同,则直接替换文本内容。如果不是文本节点,则判断它们的子节点
(1)oldCh 与 ch 都存在且不相同时,使用 updateChildren 函数来更新子节点,。
(2)如果只有 ch 存在,表示旧节点不需要了。如果旧的节点是文本节点则先将节点的文本清除,然后通过 addVnodes 将 ch 批量插入到新节点 elm 下。
(3)如果只有 oldCh 存在,表示更新的是空节点,则需要将旧的节点通过 removeVnodes 全部清除。
(4)当只有旧节点是文本节点的时候,则清除其节点文本内容
4.执行 postpatch 钩子函数
在执行完 patch 过程后,会执行 postpatch 钩子函数,它是组件自定义的钩子函数,有则执行。
那么在整个 pathVnode 过程中,最复杂的就是 updateChildren 方法。
updateChildren
diff 算法主要是对相同节点的子节点进行的比较和更新,也就是相同级别节点的比较算法。dom 对比更新,本着尽量减少 dom 的销毁和重建,所以 diff 算法尽量先移动,后增删
定义变量
let oldStartIdx = 0;
let newStartIdx = 0;
let oldEndIdx = oldCh.length - 1;
let oldStartVnode = oldCh[0];
let oldEndVnode = oldCh[oldEndIdx];
let newEndIdx = newCh.length - 1;
let newStartVnode = newCh[0];
let newEndVnode = newCh[newEndIdx];
进行循环 索引遍历节点
首先会判断是否为空 isUndef(oldStartVnode) isUndef(oldEndVnode)
export function isUndef(v: any): boolean %checks {
return v === undefined || v === null;
}
sameVnode(oldStartVnode, newStartVnode)
sameVnode(oldEndVnode, newEndVnode)
sameVnode(oldStartVnode, newEndVnode)
sameVnode(oldEndVnode, newStartVnode)
如果上述四种情况都不存在,则用新 VNode 当前的 newStartVnode 去旧 VNode 里找(尽量不新建 dom,找到了就移动,找不到再新建)
如果找到了,则调用 patchVnode 去比较详细内容,并且移动这个节点到 newStartIdx 位置,
如果没找到,则创建新节点并插入
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]; // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue);
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue);
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue);
canMove &&
nodeOps.insertBefore(
parentElm,
oldStartVnode.elm,
nodeOps.nextSibling(oldEndVnode.elm)
);
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue);
canMove &&
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
} else {
if (isUndef(oldKeyToIdx))
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx);
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx);
if (isUndef(idxInOld)) {
// New element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
} else {
vnodeToMove = oldCh[idxInOld];
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue);
oldCh[idxInOld] = undefined;
canMove &&
nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm);
} else {
// same key but different element. treat as new element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
);
}
}
newStartVnode = newCh[++newStartIdx];
}
}
循环结束 遍历完成(走出 while 循环时说明肯定有新/旧节点被遍历完了):
结束判断 1:当结束时 oldStartIdx > oldEndIdx ,说明旧节点遍历完了,新节点没遍历完,则说明新节点比老节点多,把 newStartIdx >到 newEndIdx 直接的节点插入到老节点后面
结束判断 2:当结束时 newStartIdx > newEndIdx ,说明新节点遍历完了,旧节点没遍历完,则说明老节点比新节点多,把的 oldStartIdx 到 oldEndIdx 之间的节点删除
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm;
addVnodes(
parentElm,
refElm,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
);
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
Props
规范化
在初始化 props 之前,首先会对 props 做一次 normalize,它发生在 mergeOptions 的时候,在 src/core/util/options.js 中:
export function mergeOptions(
parent: Object,
child: Object,
vm?: Component
): Object {
// ...
normalizeProps(child, vm);
// ...
}
function normalizeProps(options: Object, vm: ?Component) {
const props = options.props;
if (!props) return;
const res = {};
let i, val, name;
if (Array.isArray(props)) {
i = props.length;
while (i--) {
val = props[i];
if (typeof val === "string") {
name = camelize(val);
res[name] = { type: null };
} else if (process.env.NODE_ENV !== "production") {
warn("props must be strings when using array syntax.");
}
}
} else if (isPlainObject(props)) {
for (const key in props) {
val = props[key];
name = camelize(key);
res[name] = isPlainObject(val) ? val : { type: val };
}
} else if (process.env.NODE_ENV !== "production") {
warn(
`Invalid value for option "props": expected an Array or an Object, ` +
`but got ${toRawType(props)}.`,
vm
);
}
options.props = res;
}
合并配置它主要就是处理我们定义组件的对象 option,然后挂载到组件的实例 this.$options 中。
重点看 normalizeProps 的实现,其实这个函数的主要目的就是把我们编写的 props 转成对象格式,因为实际上 props 除了对象格式,还允许写成数组格式。
当 props 是一个数组,每一个数组元素 prop 只能是一个 string,表示 prop 的 key,转成驼峰格式,prop 的类型为空。
当 props 是一个对象,对于 props 中每个 prop 的 key,我们会转驼峰格式,而它的 value,如果不是一个对象,我们就把它规范成一个对象。
如果 props 既不是数组也不是对象,就抛出一个警告。
举个例子:
export default {
props: ["name", "nick-name"],
};
经过 normalizeProps 后,会被规范成:
options.props = {
name: { type: null },
nickName: { type: null },
};
export default {
props: {
name: String,
nickName: {
type: Boolean,
},
},
};
经过 normalizeProps 后,会被规范成:
options.props = {
name: { type: String },
nickName: { type: Boolean },
};
由于对象形式的 props 可以指定每个 prop 的类型和定义其它的一些属性,推荐用对象形式定义 props。
初始化
Props 的初始化主要发生在 new Vue 中的 initState 阶段,在 src/core/instance/state.js 中:
export function initState(vm: Component) {
// ....
const opts = vm.$options;
if (opts.props) initProps(vm, opts.props);
// ...
}
function initProps(vm: Component, propsOptions: Object) {
const propsData = vm.$options.propsData || {};
const props = (vm._props = {});
// cache prop keys so that future props updates can iterate using Array
// instead of dynamic object key enumeration.
const keys = (vm.$options._propKeys = []);
const isRoot = !vm.$parent;
// root instance props should be converted
if (!isRoot) {
toggleObserving(false);
}
for (const key in propsOptions) {
keys.push(key);
const value = validateProp(key, propsOptions, propsData, vm);
/* istanbul ignore else */
if (process.env.NODE_ENV !== "production") {
const hyphenatedKey = hyphenate(key);
if (
isReservedAttribute(hyphenatedKey) ||
config.isReservedAttr(hyphenatedKey)
) {
warn(
`"${hyphenatedKey}" is a reserved attribute and cannot be used as component prop.`,
vm
);
}
defineReactive(props, key, value, () => {
if (!isRoot && !isUpdatingChildComponent) {
warn(
`Avoid mutating a prop directly since the value will be ` +
`overwritten whenever the parent component re-renders. ` +
`Instead, use a data or computed property based on the prop's ` +
`value. Prop being mutated: "${key}"`,
vm
);
}
});
} else {
defineReactive(props, key, value);
}
// static props are already proxied on the component's prototype
// during Vue.extend(). We only need to proxy props defined at
// instantiation here.
if (!(key in vm)) {
proxy(vm, `_props`, key);
}
}
toggleObserving(true);
}
initProps 主要做 3 件事情:校验、响应式和代理。
校验
校验的逻辑很简单,遍历 propsOptions,执行 validateProp(key, propsOptions, propsData, vm) 方法。这里的 propsOptions 就是我们定义的 props 在规范后生成的 options.props 对象,propsData 是从父组件传递的 prop 数据。所谓校验的目的就是检查一下我们传递的数据是否满足 prop的定义规范。再来看一下 validateProp 方法,它定义在 src/core/util/props.js 中:
export function validateProp(
key: string,
propOptions: Object,
propsData: Object,
vm?: Component
): any {
const prop = propOptions[key];
const absent = !hasOwn(propsData, key);
let value = propsData[key];
// boolean casting
const booleanIndex = getTypeIndex(Boolean, prop.type);
if (booleanIndex > -1) {
if (absent && !hasOwn(prop, "default")) {
value = false;
} else if (value === "" || value === hyphenate(key)) {
// only cast empty string / same name to boolean if
// boolean has higher priority
const stringIndex = getTypeIndex(String, prop.type);
if (stringIndex < 0 || booleanIndex < stringIndex) {
value = true;
}
}
}
// check default value
if (value === undefined) {
value = getPropDefaultValue(vm, prop, key);
// since the default value is a fresh copy,
// make sure to observe it.
const prevShouldObserve = shouldObserve;
toggleObserving(true);
observe(value);
toggleObserving(prevShouldObserve);
}
if (
process.env.NODE_ENV !== "production" &&
// skip validation for weex recycle-list child component props
!(__WEEX__ && isObject(value) && "@binding" in value)
) {
assertProp(prop, key, value, vm, absent);
}
return value;
}
validateProp 主要就做 3 件事情:处理 Boolean 类型的数据,处理默认数据,prop 断言,并最终返回 prop 的值。
先来看 Boolean 类型数据的处理逻辑:
const prop = propOptions[key];
const absent = !hasOwn(propsData, key);
let value = propsData[key];
// boolean casting
const booleanIndex = getTypeIndex(Boolean, prop.type);
if (booleanIndex > -1) {
if (absent && !hasOwn(prop, "default")) {
value = false;
} else if (value === "" || value === hyphenate(key)) {
// only cast empty string / same name to boolean if
// boolean has higher priority
const stringIndex = getTypeIndex(String, prop.type);
if (stringIndex < 0 || booleanIndex < stringIndex) {
value = true;
}
}
}
先通过 const booleanIndex = getTypeIndex(Boolean, prop.type) 来判断 prop 的定义是否是 Boolean 类型的。
function getType(fn) {
const match = fn && fn.toString().match(/^\s*function (\w+)/);
return match ? match[1] : "";
}
function isSameType(a, b) {
return getType(a) === getType(b);
}
function getTypeIndex(type, expectedTypes): number {
if (!Array.isArray(expectedTypes)) {
return isSameType(expectedTypes, type) ? 0 : -1;
}
for (let i = 0, len = expectedTypes.length; i < len; i++) {
if (isSameType(expectedTypes[i], type)) {
return i;
}
}
return -1;
}
getTypeIndex 函数就是找到 type 和 expectedTypes 匹配的索引并返回。
prop 类型定义的时候可以是某个原生构造函数,也可以是原生构造函数的数组,比如:
export default {
props: {
name: String,
value: [String, Boolean],
},
};
如果 expectedTypes 是单个构造函数,就执行 isSameType 去判断是否是同一个类型;
如果是数组,那么就遍历这个数组,找到第一个同类型的,返回它的索引。
回到 validateProp 函数,通过 const booleanIndex = getTypeIndex(Boolean, prop.type) 得到 booleanIndex
如果 prop.type 是一个 Boolean 类型,则通过 absent && !hasOwn(prop, 'default') 来判断如果父组件没有传递这个 prop 数据并且没有设置 default 的情况,则 value 为 false。
接着判断value === '' || value === hyphenate(key) 的情况,如果满足则先通过 const stringIndex = getTypeIndex(String, prop.type) 获取匹配 String 类型的索引,
然后判断 stringIndex < 0 || booleanIndex < stringIndex 的值来决定 value 的值是否为 true。这块逻辑稍微有点绕,我们举 2 个例子来说明:
例如你定义一个组件 Student:
export default {
name: String,
nickName: [Boolean, String],
};
然后在父组件中引入这个组件:
<template>
<div>
<student name="Kate" nick-name></student>
</div>
</template>
或者是:
<template>
<div>
<student name="Kate" nick-name="nick-name"></student>
</div>
</template>
第一种情况没有写属性的值,满足 value === '',第二种满足 value === hyphenate(key) 的情况,
另外 nickName 这个 prop 的类型是 Boolean 或者是 String,并且满足 booleanIndex < stringIndex,所以对 nickName 这个 prop 的 value 为 true。
接下来看一下默认数据处理逻辑:
// check default value
if (value === undefined) {
value = getPropDefaultValue(vm, prop, key);
// since the default value is a fresh copy,
// make sure to observe it.
const prevShouldObserve = shouldObserve;
toggleObserving(true);
observe(value);
toggleObserving(prevShouldObserve);
}
当 value 的值为 undefined 的时候,说明父组件根本就没有传这个 prop,那么我们就需要通过 getPropDefaultValue(vm, prop, key) 获取这个 prop 的默认值。
我们这里只关注 getPropDefaultValue 的实现,toggleObserving 和 observe 的作用我们之后会说。
function getPropDefaultValue(
vm: ?Component,
prop: PropOptions,
key: string
): any {
// no default, return undefined
if (!hasOwn(prop, "default")) {
return undefined;
}
const def = prop.default;
// warn against non-factory defaults for Object & Array
if (process.env.NODE_ENV !== "production" && isObject(def)) {
warn(
'Invalid default value for prop "' +
key +
'": ' +
"Props with type Object/Array must use a factory function " +
"to return the default value.",
vm
);
}
// the raw prop value was also undefined from previous render,
// return previous default value to avoid unnecessary watcher trigger
if (
vm &&
vm.$options.propsData &&
vm.$options.propsData[key] === undefined &&
vm._props[key] !== undefined
) {
return vm._props[key];
}
// call factory function for non-Function types
// a value is Function if its prototype is function even across different execution context
return typeof def === "function" && getType(prop.type) !== "Function"
? def.call(vm)
: def;
}
检测如果 prop 没有定义 default 属性,那么返回 undefined,通过这块逻辑我们知道除了 Boolean 类型的数据,其余没有设置 default 属性的 prop 默认值都是 undefined。
接着是开发环境下对 prop 的默认值是否为对象或者数组类型的判断,如果是的话会报警告,
因为对象和数组类型的 prop,他们的默认值必须要返回一个工厂函数。
接下来的判断是如果上一次组件渲染父组件传递的 prop 的值是 undefined,则直接返回 上一次的默认值 vm._props[key],这样可以避免触发不必要的 watcher 的更新。
最后就是判断 def 如果是工厂函数且 prop 的类型不是 Function 的时候,返回工厂函数的返回值,否则直接返回 def。
至此,我们讲完了 validateProp 函数的 Boolean 类型数据的处理逻辑和默认数据处理逻辑,最后来看一下 prop 断言逻辑。
if (
process.env.NODE_ENV !== "production" &&
// skip validation for weex recycle-list child component props
!(__WEEX__ && isObject(value) && "@binding" in value)
) {
assertProp(prop, key, value, vm, absent);
}
在开发环境且非 weex 的某种环境下,执行 assertProp 做属性断言。
function assertProp(
prop: PropOptions,
name: string,
value: any,
vm: ?Component,
absent: boolean
) {
if (prop.required && absent) {
warn('Missing required prop: "' + name + '"', vm);
return;
}
if (value == null && !prop.required) {
return;
}
let type = prop.type;
let valid = !type || type === true;
const expectedTypes = [];
if (type) {
if (!Array.isArray(type)) {
type = [type];
}
for (let i = 0; i < type.length && !valid; i++) {
const assertedType = assertType(value, type[i]);
expectedTypes.push(assertedType.expectedType || "");
valid = assertedType.valid;
}
}
if (!valid) {
warn(getInvalidTypeMessage(name, value, expectedTypes), vm);
return;
}
const validator = prop.validator;
if (validator) {
if (!validator(value)) {
warn(
'Invalid prop: custom validator check failed for prop "' + name + '".',
vm
);
}
}
}
assertProp 函数的目的是断言这个 prop 是否合法。
首先判断如果 prop 定义了 required 属性但父组件没有传递这个 prop 数据的话会报一个警告。
接着判断如果 value 为空且 prop 没有定义 required 属性则直接返回。
然后再去对 prop 的类型做校验,先是拿到 prop 中定义的类型 type,并尝试把它转成一个类型数组,然后依次遍历这个数组,执行 assertType(value, type[i]) 去获取断言的结果,直到遍历完成或者是 valid 为 true 的时候跳出循环。
const simpleCheckRE = /^(String|Number|Boolean|Function|Symbol)$/;
function assertType(
value: any,
type: Function
): {
valid: boolean,
expectedType: string,
} {
let valid;
const expectedType = getType(type);
if (simpleCheckRE.test(expectedType)) {
const t = typeof value;
valid = t === expectedType.toLowerCase();
// for primitive wrapper objects
if (!valid && t === "object") {
valid = value instanceof type;
}
} else if (expectedType === "Object") {
valid = isPlainObject(value);
} else if (expectedType === "Array") {
valid = Array.isArray(value);
} else {
valid = value instanceof type;
}
return {
valid,
expectedType,
};
}
assertType 的逻辑很简单,先通过 getType(type) 获取 prop 期望的类型 expectedType,然后再去根据几种不同的情况对比 prop 的值 value 是否和 expectedType 匹配,最后返回匹配的结果。
如果循环结束后 valid 仍然为 false,那么说明 prop 的值 value 与 prop 定义的类型都不匹配,那么就会输出一段通过 getInvalidTypeMessage(name, value, expectedTypes) 生成的警告信息,就不细说了。
最后判断当 prop 自己定义了 validator 自定义校验器,则执行 validator 校验器方法,如果校验不通过则输出警告信息。
响应式
回到 initProps 方法,当我们通过 const value = validateProp(key, propsOptions, propsData, vm) 对 prop 做验证并且获取到 prop 的值后,接下来需要通过 defineReactive 把 prop 变成响应式。
defineReactive 我们之前已经介绍过,这里要注意的是,在开发环境中我们会校验 prop 的 key 是否是 HTML 的保留属性,并且在 defineReactive 的时候会添加一个自定义 setter,当我们直接对 prop 赋值的时候会输出警告:
if (process.env.NODE_ENV !== "production") {
const hyphenatedKey = hyphenate(key);
if (
isReservedAttribute(hyphenatedKey) ||
config.isReservedAttr(hyphenatedKey)
) {
warn(
`"${hyphenatedKey}" is a reserved attribute and cannot be used as component prop.`,
vm
);
}
defineReactive(props, key, value, () => {
if (!isRoot && !isUpdatingChildComponent) {
warn(
`Avoid mutating a prop directly since the value will be ` +
`overwritten whenever the parent component re-renders. ` +
`Instead, use a data or computed property based on the prop's ` +
`value. Prop being mutated: "${key}"`,
vm
);
}
});
}
关于 prop 的响应式有一点不同的是当 vm 是非根实例的时候,会先执行 toggleObserving(false),它的目的是为了响应式的优化,我们先跳过,之后会详细说明。
代理
在经过响应式处理后,我们会把 prop 的值添加到 vm._props 中,比如 key 为 name 的 prop,它的值保存在 vm._props.name 中,但是我们在组件中可以通过 this.name 访问到这个 prop,这就是代理做的事情。
// static props are already proxied on the component's prototype
// during Vue.extend(). We only need to proxy props defined at
// instantiation here.
if (!(key in vm)) {
proxy(vm, `_props`, key);
}
通过 proxy 函数实现了上述需求。
const sharedPropertyDefinition = {
enumerable: true,
configurable: true,
get: noop,
set: noop,
};
export function proxy(target: Object, sourceKey: string, key: string) {
sharedPropertyDefinition.get = function proxyGetter() {
return this[sourceKey][key];
};
sharedPropertyDefinition.set = function proxySetter(val) {
this[sourceKey][key] = val;
};
Object.defineProperty(target, key, sharedPropertyDefinition);
}
当访问 this.name 的时候就相当于访问 this._props.name。
其实对于非根实例的子组件而言,prop 的代理发生在 Vue.extend 阶段,在 src/core/global-api/extend.js 中:
Vue.extend = function (extendOptions: Object): Function {
// ...
const Sub = function VueComponent(options) {
this._init(options);
};
// ...
// For props and computed properties, we define the proxy getters on
// the Vue instances at extension time, on the extended prototype. This
// avoids Object.defineProperty calls for each instance created.
if (Sub.options.props) {
initProps(Sub);
}
if (Sub.options.computed) {
initComputed(Sub);
}
// ...
return Sub;
};
function initProps(Comp) {
const props = Comp.options.props;
for (const key in props) {
proxy(Comp.prototype, `_props`, key);
}
}
这么做的好处是不用为每个组件实例都做一层 proxy,是一种优化手段。
Props 更新
我们知道,当父组件传递给子组件的 props 值变化,子组件对应的值也会改变,同时会触发子组件的重新渲染。那么接下来我们就从源码角度来分析这两个过程。
子组件 props 更新
首先,prop 数据的值变化在父组件,我们知道在父组件的 render 过程中会访问到这个 prop 数据,所以当 prop 数据变化一定会触发父组件的重新渲染,那么重新渲染是如何更新子组件对应的 prop 的值呢?
在父组件重新渲染的最后,会执行 patch 过程,进而执行 patchVnode 函数,patchVnode 通常是一个递归过程,当它遇到组件 vnode 的时候,会执行组件更新过程的 prepatch 钩子函数,在 src/core/vdom/patch.js 中:
function patchVnode(
oldVnode,
vnode,
insertedVnodeQueue,
ownerArray,
index,
removeOnly
) {
// ...
let i;
const data = vnode.data;
if (isDef(data) && isDef((i = data.hook)) && isDef((i = i.prepatch))) {
i(oldVnode, vnode);
}
// ...
}
prepatch 函数定义在 src/core/vdom/create-component.js 中:
prepatch (oldVnode: MountedComponentVNode, vnode: MountedComponentVNode) {
const options = vnode.componentOptions
const child = vnode.componentInstance = oldVnode.componentInstance
updateChildComponent(
child,
options.propsData, // updated props
options.listeners, // updated listeners
vnode, // new parent vnode
options.children // new children
)
}
内部会调用 updateChildComponent 方法来更新 props,注意第二个参数就是父组件的 propData,那么为什么 vnode.componentOptions.propsData 就是父组件传递给子组件的 prop 数据呢(这个也同样解释了第一次渲染的 propsData 来源)?原来在组件的 render 过程中,对于组件节点会通过 createComponent 方法来创建组件 vnode:
export function createComponent(
Ctor: Class<Component> | Function | Object | void,
data: ?VNodeData,
context: Component,
children: ?Array<VNode>,
tag?: string
): VNode | Array<VNode> | void {
// ...
// extract props
const propsData = extractPropsFromVNodeData(data, Ctor, tag);
// ...
const vnode = new VNode(
`vue-component-${Ctor.cid}${name ? `-${name}` : ""}`,
data,
undefined,
undefined,
undefined,
context,
{ Ctor, propsData, listeners, tag, children },
asyncFactory
);
// ...
return vnode;
}
在创建组件 vnode 的过程中,首先从 data 中提取出 propData,然后在 new VNode 的时候,作为第七个参数 VNodeComponentOptions 中的一个属性传入,所以我们可以通过 vnode.componentOptions.propsData 拿到 prop 数据。
接着看 updateChildComponent 函数,它的定义在 src/core/instance/lifecycle.js 中:
export function updateChildComponent(
vm: Component,
propsData: ?Object,
listeners: ?Object,
parentVnode: MountedComponentVNode,
renderChildren: ?Array<VNode>
) {
// ...
// update props
if (propsData && vm.$options.props) {
toggleObserving(false);
const props = vm._props;
const propKeys = vm.$options._propKeys || [];
for (let i = 0; i < propKeys.length; i++) {
const key = propKeys[i];
const propOptions: any = vm.$options.props; // wtf flow?
props[key] = validateProp(key, propOptions, propsData, vm);
}
toggleObserving(true);
// keep a copy of raw propsData
vm.$options.propsData = propsData;
}
// ...
}
我们重点来看更新 props 的相关逻辑,这里的 propsData 是父组件传递的 props 数据,vm 是子组件的实例。vm._props 指向的就是子组件的 props 值,propKeys 就是在之前 initProps 过程中,缓存的子组件中定义的所有 prop 的 key。主要逻辑就是遍历 propKeys,然后执行 props[key] = validateProp(key, propOptions, propsData, vm) 重新验证和计算新的 prop 数据,更新 vm._props,也就是子组件的 props,这个就是子组件 props 的更新过程。
子组件重新渲染
其实子组件的重新渲染有 2 种情况,一个是 prop 值被修改,另一个是对象类型的 prop 内部属性的变化。
先来看一下 prop 值被修改的情况,当执行 props[key] = validateProp(key, propOptions, propsData, vm) 更新子组件 prop 的时候,会触发 prop 的 setter 过程,只要在渲染子组件的时候访问过这个 prop 值,那么根据响应式原理,就会触发子组件的重新渲染。
再来看一下当对象类型的 prop 的内部属性发生变化的时候,这个时候其实并没有触发子组件 prop 的更新。但是在子组件的渲染过程中,访问过这个对象 prop,所以这个对象 prop 在触发 getter 的时候会把子组件的 render watcher 收集到依赖中,然后当我们在父组件更新这个对象 prop 的某个属性的时候,会触发 setter 过程,也就会通知子组件 render watcher 的 update,进而触发子组件的重新渲染。
以上就是当父组件 props 更新,触发子组件重新渲染的 2 种情况。
toggleObserving
最后我们在来聊一下 toggleObserving,它的定义在 src/core/observer/index.js 中:
export let shouldObserve: boolean = true;
export function toggleObserving(value: boolean) {
shouldObserve = value;
}
它在当前模块中定义了 shouldObserve 变量,用来控制在 observe 的过程中是否需要把当前值变成一个 Observer 对象。
那么为什么在 props 的初始化和更新过程中,多次执行 toggleObserving(false) 呢,接下来我们就来分析这几种情况。
在 initProps 的过程中:
const isRoot = !vm.$parent;
// root instance props should be converted
if (!isRoot) {
toggleObserving(false);
}
for (const key in propsOptions) {
// ...
const value = validateProp(key, propsOptions, propsData, vm);
defineReactive(props, key, value);
// ...
}
toggleObserving(true);
对于非根实例的情况,我们会执行 toggleObserving(false),然后对于每一个 prop 值,去执行 defineReactive(props, key, value) 去把它变成响应式。
回顾一下 defineReactive 的定义:
export function defineReactive(
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
// ...
let childOb = !shallow && observe(val);
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
// ...
},
set: function reactiveSetter(newVal) {
// ...
},
});
}
通常对于值 val 会执行 observe 函数,然后遇到 val 是对象或者数组的情况会递归执行 defineReactive 把它们的子属性都变成响应式的,但是由于 shouldObserve 的值变成了 false,这个递归过程被省略了。为什么会这样呢?
因为正如我们前面分析的,对于对象的 prop 值,子组件的 prop 值始终指向父组件的 prop 值,只要父组件的 prop 值变化,就会触发子组件的重新渲染,所以这个 observe 过程是可以省略的。
最后再执行 toggleObserving(true) 恢复 shouldObserve 为 true。
在 validateProp 的过程中:
// check default value
if (value === undefined) {
value = getPropDefaultValue(vm, prop, key);
// since the default value is a fresh copy,
// make sure to observe it.
const prevShouldObserve = shouldObserve;
toggleObserving(true);
observe(value);
toggleObserving(prevShouldObserve);
}
这种是父组件没有传递 prop 值对默认值的处理逻辑,因为这个值是一个拷贝,所以我们需要 toggleObserving(true),然后执行 observe(value) 把值变成响应式。
在 updateChildComponent 过程中:
// update props
if (propsData && vm.$options.props) {
toggleObserving(false);
const props = vm._props;
const propKeys = vm.$options._propKeys || [];
for (let i = 0; i < propKeys.length; i++) {
const key = propKeys[i];
const propOptions: any = vm.$options.props; // wtf flow?
props[key] = validateProp(key, propOptions, propsData, vm);
}
toggleObserving(true);
// keep a copy of raw propsData
vm.$options.propsData = propsData;
}
其实和 initProps 的逻辑一样,不需要对引用类型 props 递归做响应式处理,所以也需要 toggleObserving(false)。