场景问题
优化层面
1.后端一次给你 10 万条数据,如何优雅展示?
直接渲染
最直接的方式就是直接渲染出来,但是这样的做法肯定是不可取的,因为一次性渲染出10w个节点,是非常耗时间的,咱们可以来看一下耗时,差不多要消耗12秒,非常消耗时间

const renderList = async () => {
console.time("列表时间");
const list = await getList();
list.forEach((item) => {
const div = document.createElement("div");
div.className = "sunshine";
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`;
container.appendChild(div);
});
console.timeEnd("列表时间");
};
renderList();
setTimeout 分页渲染
这个方法就是,把10w按照每页数量limit分成总共Math.ceil(total / limit)页,然后利用setTimeout,每次渲染 1 页数据,这样的话,渲染出首页数据的时间大大缩减了

const renderList = async () => {
console.time("列表时间");
const list = await getList();
console.log(list);
const total = list.length;
const page = 0;
const limit = 200;
const totalPage = Math.ceil(total / limit);
const render = (page) => {
if (page >= totalPage) return;
setTimeout(() => {
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i];
const div = document.createElement("div");
div.className = "sunshine";
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`;
container.appendChild(div);
}
render(page + 1);
}, 0);
};
render(page);
console.timeEnd("列表时间");
};
requestAnimationFrame
使用requestAnimationFrame代替setTimeout,减少了重排的次数,极大提高了性能,建议大家在渲染方面多使用requestAnimationFrame
const renderList = async () => {
console.time("列表时间");
const list = await getList();
console.log(list);
const total = list.length;
const page = 0;
const limit = 200;
const totalPage = Math.ceil(total / limit);
const render = (page) => {
if (page >= totalPage) return;
// 使用requestAnimationFrame代替setTimeout
requestAnimationFrame(() => {
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i];
const div = document.createElement("div");
div.className = "sunshine";
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`;
container.appendChild(div);
}
render(page + 1);
});
};
render(page);
console.timeEnd("列表时间");
};
文档碎片 + requestAnimationFrame
文档碎片的好处
- 1、之前都是每次创建一个
div标签就appendChild一次,但是有了文档碎片可以先把 1 页的div标签先放进文档碎片中,然后一次性appendChild到container中,这样减少了appendChild的次数,极大提高了性能 - 2、页面只会渲染
文档碎片包裹着的元素,而不会渲染文档碎片
const renderList = async () => {
console.time("列表时间");
const list = await getList();
console.log(list);
const total = list.length;
const page = 0;
const limit = 200;
const totalPage = Math.ceil(total / limit);
const render = (page) => {
if (page >= totalPage) return;
requestAnimationFrame(() => {
// 创建一个文档碎片
const fragment = document.createDocumentFragment();
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i];
const div = document.createElement("div");
div.className = "sunshine";
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`;
// 先塞进文档碎片
fragment.appendChild(div);
}
// 一次性appendChild
container.appendChild(fragment);
render(page + 1);
});
};
render(page);
console.timeEnd("列表时间");
};
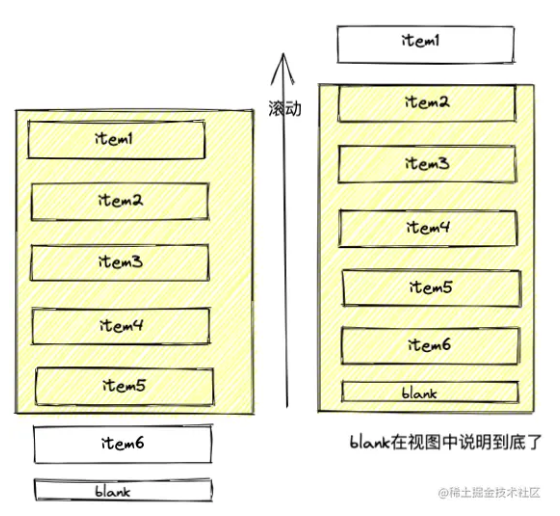
懒加载
为了比较通俗的讲解,咱们启动一个vue前端项目,后端服务还是开着
其实实现原理很简单,咱们通过一张图来展示,就是在列表尾部放一个空节点blank,然后先渲染第 1 页数据,向上滚动,等到blank出现在视图中,就说明到底了,这时候再加载第二页,往后以此类推。
至于怎么判断blank出现在视图上,可以使用getBoundingClientRect方法获取top属性
IntersectionObserver性能更好,但是我这里就拿getBoundingClientRect来举例
<script setup lang="ts">
import { onMounted, ref, computed } from 'vue'
const getList = () => {
// 跟上面一样的代码
}
const container = ref<HTMLElement>() // container节点
const blank = ref<HTMLElement>() // blank节点
const list = ref<any>([]) // 列表
const page = ref(1) // 当前页数
const limit = 200 // 一页展示
// 最大页数
const maxPage = computed(() => Math.ceil(list.value.length / limit))
// 真实展示的列表
const showList = computed(() => list.value.slice(0, page.value * limit))
const handleScroll = () => {
// 当前页数与最大页数的比较
if (page.value > maxPage.value) return
const clientHeight = container.value?.clientHeight
const blankTop = blank.value?.getBoundingClientRect().top
if (clientHeight === blankTop) {
// blank出现在视图,则当前页数加1
page.value++
}
}
onMounted(async () => {
const res = await getList()
list.value = res
})
</script>
<template>
<div id="container" @scroll="handleScroll" ref="container">
<div class="sunshine" v-for="(item) in showList" :key="item.tid">
<img :src="item.src" />
<span>{{ item.text }}</span>
</div>
<div ref="blank"></div>
</div>
</template>
虚拟列表
虚拟滚动,就是根据
容器可视区域的列表容积数量,监听用户滑动或滚动事件,动态截取长列表数据中的部分数据渲染到页面上,动态使用空白站位填充容器上下滚动区域内容,模拟实现原生滚动效果
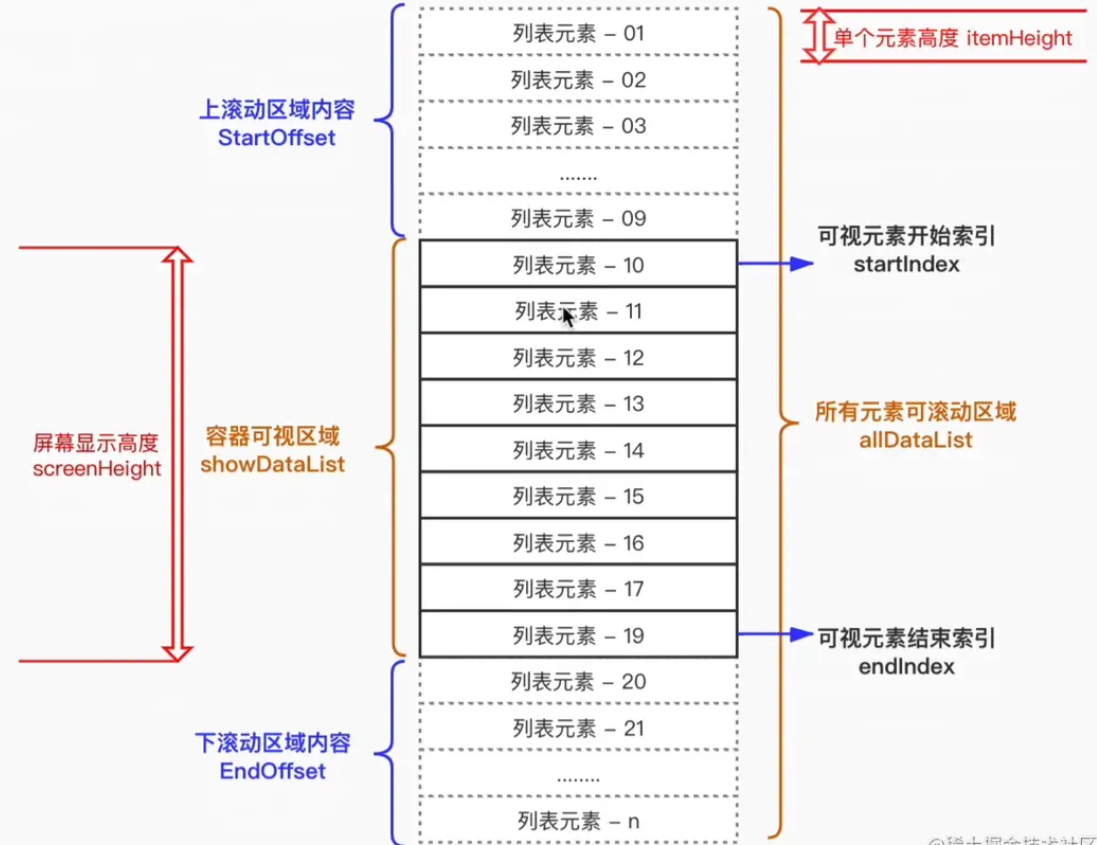
- 浏览器渲染:一次性渲染 10000 个肯定会使浏览器压力大,造成用户体验差
- 容器可视区域:10000 个排队去渲染,比如一次渲染 10 个
- 上方下方区域:轮不到你渲染,你就乖乖进空白区待着
基本实现
- 可视区域的高度
- 列表项的高度
- 可视区域能展示的列表项个数 = ~~(可视区域高度 / 列表项高度) + 2
- 开始索引
- 结束索引
- 预加载(防止滚动过快,造成暂时白屏)
- 根据开始索引和结束索引,截取数据展示在可视区域
- 滚动节流
- 上下空白区使用 padding 实现
- 滑动到底,再次请求数据并拼接
<template>
<div class="v-scroll" @scroll.passive="doScroll" ref="scrollBox">
<div :style="blankStyle" style="height: 100%">
<div v-for="item in tempSanxins" :key="item.id" class="scroll-item">
<span>{{ item.msg }}</span>
<img :src="item.src" />
</div>
</div>
</div>
</template>
<script>
import { throttle } from "../../utils/tools";
export default {
data() {
return {
allSanxins: [], // 所有数据
itemHiehgt: 150, // 列表每一项的宽度
boxHeight: 0, // 可视区域的高度
startIndex: 0, // 元素开始索引
};
},
created() {
// 模拟请求数据
this.getAllSanxin(30);
},
mounted() {
// 在mounted时获取可视区域的高度
this.getScrollBoxHeight();
// 监听屏幕变化以及旋转,都要重新获取可视区域的高度
window.onresize = this.getScrollBoxHeight;
window.onorientationchange = this.getScrollBoxHeight;
},
methods: {
getAllSanxin(count) {
// 模拟获取数据
const length = this.allSanxins.length;
for (let i = 0; i < count; i++) {
this.allSanxins.push({
id: `sanxin${length + i}`,
msg: `我是三心${length + i}号`,
// 这里随便选一张图片就行
src: require("../../src/asset/images/sanxin.jpg").default,
});
}
},
// 使用节流,提高性能
doScroll: throttle(function () {
// 监听可视区域的滚动事件
// 公式:~~(滚动的距离 / 列表项 ),就能算出已经滚过了多少个列表项,也就能知道现在的startIndex是多少
// 例如我滚动条滚过了160px,那么index就是1,因为此时第一个列表项已经被滚上去了,可视区域里的第一项的索引是1
const index = ~~(this.$refs.scrollBox.scrollTop / this.itemHiehgt);
if (index === this.startIndex) return;
this.startIndex = index;
if (this.startIndex + this.itemNum > this.allSanxins.length - 1) {
this.getAllSanxin(30);
}
}, 200),
getScrollBoxHeight() {
// 获取可视区域的高度
this.boxHeight = this.$refs.scrollBox.clientHeight;
},
},
computed: {
itemNum() {
// 可视区域可展示多少个列表项? 计算公式:~~(可视化区域高度 / 列表项高度) + 2
// ~~是向下取整的运算符,等同于Math.floor(),为什么要 +2 ,是因为可能最上面和最下面的元素都只展示一部分
return ~~(this.boxHeight / this.itemHiehgt) + 2;
},
endIndex() {
// endIndex的计算公式:(开始索引 + 可视区域可展示多少个列表项 * 2)
// 比如可视区域可展示8个列表项,startIndex是0的话endIndex就是0 + 8 * 2 = 16,startIndex是1的话endIndex就是1 + 8 * 2 = 17,以此类推
// 为什么要乘2呢,因为这样的话可以预加载出一页的数据,防止滚动过快,出现暂时白屏现象
let index = this.startIndex + this.itemNum * 2;
if (!this.allSanxins[index]) {
// 到底的情况,比如startIndex是99995,那么endIndex本应该是99995 + 8 * 2 = 10011
// 但是列表数据总数只有10000条,此时就需要让endIndex = (列表数据长度 - 1)
index = this.allSanxins.length - 1;
}
return index;
},
tempSanxins() {
// 可视区域展示的截取数据,使用了数组的slice方法,不改变原数组又能截取
let startIndex = 0;
if (this.startIndex <= this.itemNum) {
startIndex = 0;
} else {
startIndex = this.startIndex + this.itemNum;
}
return this.allSanxins.slice(startIndex, this.endIndex + 1);
},
blankStyle() {
// 上下方的空白处使用padding来充当
let startIndex = 0;
if (this.startIndex <= this.itemNum) {
startIndex = 0;
} else {
startIndex = this.startIndex - this.itemNum;
}
return {
// 上方空白的高度计算公式:(开始index * 列表项高度)
// 比如你滚过了3个列表项,那么上方空白区高度就是3 * 150 = 450,这样才能假装10000个数据的滚动状态
paddingTop: startIndex * this.itemHiehgt + "px",
// 下方空白的高度计算公式:(总数据的个数 - 结束index - 1) * 列表项高度
// 例如现在结束index是100,那么下方空白高度就是:(10000 - 100 - 1) * 150 = 1,484,850
paddingBottom:
(this.allSanxins.length - this.endIndex - 1) * this.itemHiehgt + "px",
// 不要忘了加px哦
};
},
},
};
</script>
<style lang="scss" scoped>
.v-scroll {
height: 100%;
/* padding-bottom: 500px; */
overflow: auto;
.scroll-item {
height: 148px;
/* width: 100%; */
border: 1px solid black;
display: flex;
justify-content: space-between;
align-items: center;
padding: 0 20px;
img {
height: 100%;
}
}
}
</style>
2.如何进行首屏优化提高渲染速度
gzip 压缩
gzip是一种压缩文件格式并且也是一个在类 Unix 上的一种文件解压缩的软件。在基于 HTTP 协议的网络传输中,gzip 是一种在万维网中加速传输 HTML 和其他内容的技术 (gzip 通过减小文件体积,去节省带宽和加快传输速度),它是在 RFC 2016 中规定的三种标准 HTTP 压缩格式之一。
gzip 算法
gzip 算法的核心是 Deflate,DEFLATE 是LZ77 与哈夫曼编码的一个组合体。
LZ77的核心思路是如果一个串中有两个重复的串,那么只需要知道第一个串的内容和后面串相对于第一个串起始位置的距离 + 串的长度。例如,ABCDEFGABCDEFH (经过该算法变成)→ ABCDEFG(7,6)H
哈夫曼编码通过构造 Huffman Tree 的方式给字符重新编码, 用较短的编码代替较常用的字母,用较长的编码代替较少用的字母,从而减少了文本的总长度。
步骤大致是:统计出现频率,并从小到大排序 → 以频率作为叶节点,频率最小的两个点组出底层的叶子节点,父节点为两者之和,以此自下而上构成一颗二叉树 → 根据这棵二叉树来对文本进行编码,左分支当成 0,遇到右分支当成 1,从根节点访问各个字母。
HTTP 上的 gzip
gzip 是一种优秀的压缩算法,我们可以在 HTTP 请求上对一些文本文件,设置 gzip 压缩。
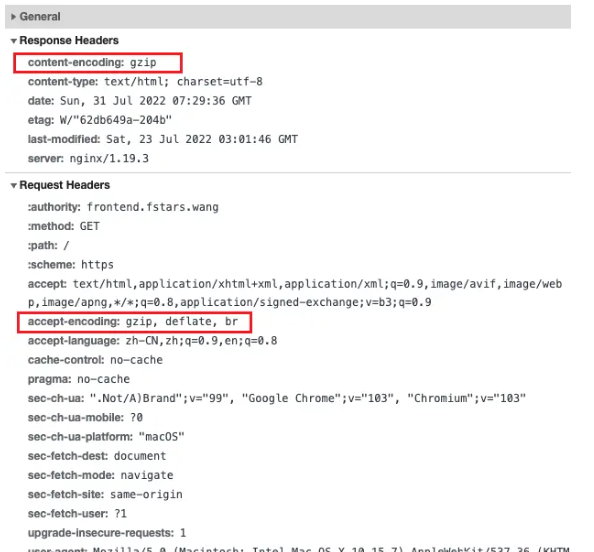
服务端将响应头设置上 Content-encoding: gzip,表示当前资源会使用 gzip 压缩,提示客户端解压使用。
当然前提是客户端支持该压缩算法,服务端会通过客户端发送的请求头中的 Accept-Encoding 字段来确定是否支持。
只对文本文件进行压缩,是因为文本类压缩效果好,而图片视频这些文件则本身就是进行压缩过的,压缩起来不仅效果差,还因为体积大耗费时间。
使用 gzip 去压缩哪些文件
虽然gzip可以压缩所有的文件,但是这不代表我们要对所有文件进行 gzip 压缩。css,js之类的文件会有很好的压缩效果。
对于特定类型的文件来说,比如 jpeg 图片文件,已经是进行过压缩的了。有时候再次进行额外的压缩无助于负载体积的减小,反而有可能会使其增大。
由谁去压缩文件
服务端响应请求时候压缩(实时压缩):当我们点击网页发送一个请求时候,服务端会找到对应的文件,然后对文件进行压缩,然后返回压缩后的内容。
如果上游配有 nginx 转发处理层,最好交给 nginx 来处理这些,因为它们有专门为此构建的内容,可以更好的利用缓存并减小开销。
服务端压缩使用 Nginx 默认集成的ngx_http_gzip_module模块,该模块使用chunked 编码动态压缩,nginx 配置如下:
http {
gzip on; // 打开或者关闭gzip压缩的功能
gzip_min_length 1k; // 被压缩响应的最小长度
gzip_buffers 4 16k; // 压缩响应的缓冲区的数量(number)和大小(size)
gzip_http_version 1.1;
gzip_comp_level 6; // 压缩级别
gzip_types text/javascript application/javascript text/css; // 针对指定的 MIME 类型启用 gzip 响应
gzip_disable "MSIE [1-6]\.";
gzip_vary on;
}
Nginx 每次请求服务端都要压缩很久才回返回信息回来,不仅服务器开销会增大很多,请求方也会等的不耐烦。如果我们在 Webpack 打包时就直接生成高压缩等级的文件,作为静态资源放在服务器上,是不是能提高效率呢?所以有了以下的应用构建时候压缩的方式。
- 应用构建时候压缩:使用 Nginx 的
ngx_http_gzip_static_module模块。
ngx_http_gzip_static_module模块使用的是静态编码,数据以*.gz 作为后缀名存储在服务器上,如果客户端的浏览器支持压缩,将直接返回压缩后的数据。nginx 配置如下:
location ~ .*\.(js|css)$ {
gzip_static on;
gzip_proxied expired no-cache no-store private auth;
}
gzip_static可选值off | on | always。on为开启并检查客户端浏览器是否支持 gzip 压缩功能,off为关闭,always一直发送 gzip 压缩文件,而不检查浏览器是否支持 gzip 压缩。
ngx_http_gzip_static_module模块是一个可选模块,需要使用--with-http_gzip_static_module指令进行编译 (可以使用nginx -V查看是否已安装)。
应用构建时压缩的实现
流程梳理
- webpack 开启 gzip 压缩,构建打包,生成压缩后的文件*.gz 上传到服务器。
- 浏览器发送请求给服务器, 请求中有
Accept-Encoding: gzip, deflate, br。 (告诉服务器,浏览器支持 gzip 压缩) - 服务端找到对应压缩后文件返回(nginx 开启静态压缩
gzip_static on) - 浏览器接收到数据后,根据
Content-Encoding:gzip来对内容进行解码,然后显示出网页。
关于解压的浏览器兼容:基本不用考虑兼容性的问题,几乎所有浏览器都支持它。
webpack配置
const plugins = [
...new CompressionWebpackPlugin({
asset: "[path].gz[query]", // 生成的资源名称
algorithm: "gzip", // 压缩算法
test: /\.(js|css)$/, // 压缩资源匹配的正则
threshold: 10240, // 只处理比这个值大的资源,示例为大于1K
// 示例:一个1024b大小的文件,压缩后大小为768b,minRatio : 0.75
minRatio: 0.8, // 只有压缩率比这个值小的资源才会被处理
}),
];
nginx配置
location ~ .*\.(js|css)$ {
gzip_static on;
gzip_proxied expired no-cache no-store private auth;
}
验证成功开启gzip
通过查看response headers和request headers,如下图: !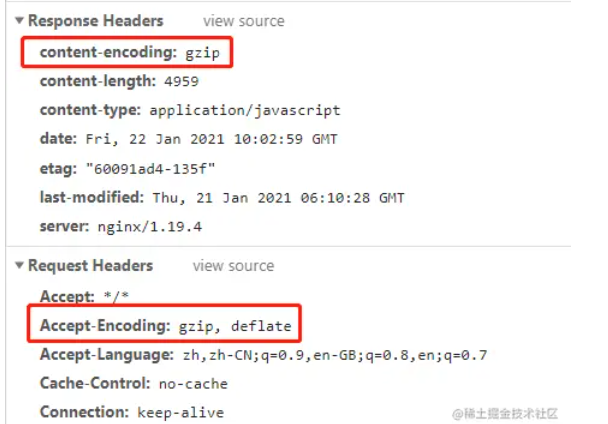
关于 Content-Encoding
Content-Encoding 是一个实体消息首部,用于对特定媒体类型的数据进行压缩。这个消息首部用来告知客户端应该怎样解码才能获取在 Content-Type 中标示的媒体类型内容,参数值为
gzip | compress | deflate | identity | br
gzip:表示采用 Lempel-Ziv coding (LZ77) 压缩算法,以及 32 位 CRC 校验的编码方式。compress:采用 Lempel-Ziv-Welch (LZW) 压缩算法。deflate:采用 zlib 结构 和 deflate 压缩算法。identity:用于指代自身(例如:未经过压缩和修改)。除非特别指明,这个标记始终可以被接受。br: 表示采用 Brotli 算法的编码方式。
Nginx 上开启 gzip
Nginx 默认是不开启 gzip 的,你需要这样设置:
http {
# 开启 gzip 压缩
gzip on;
# 使用 gzip 压缩的文件类型
# 此外,text/html 是自带的,不用写上
gzip_types text/plain text/css application/javascript application/json text/xml application/xml application/xml+rss;
# 小于 256 字节的不压缩
# 这是因为压缩是需要时间的,太小的话压缩收益不大
gzip_min_length 256;
# 开启静态压缩
# 压缩的资源会被缓存下来,下次请求时就直接使用缓存
gzip_static on;
}
关键路径渲染
关键渲染路径** (Critical Rendering Path)
关键渲染路径是浏览器将 HTML CSS JavaScript 转换为在屏幕上呈现的像素内容所经历的一系列步骤。
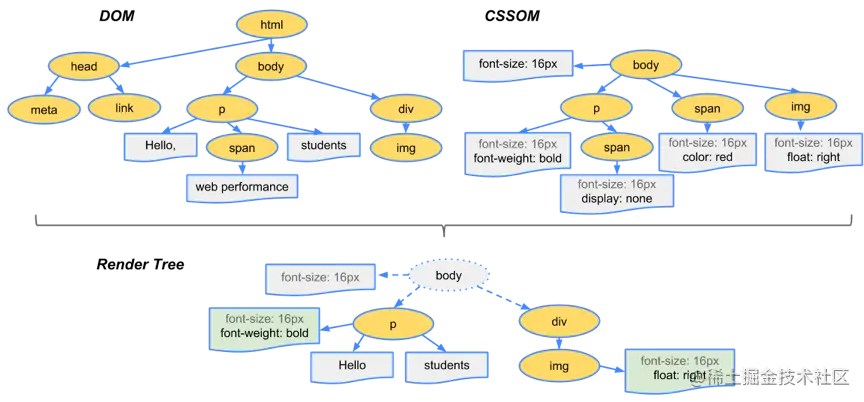
将 HTML 转换成 DOM 树
当我们请求某个 URL 以后,浏览器获得响应的数据并将所有的标记转换到我们在屏幕上所看到的 HTML,有没有想过这中间发生了什么?
浏览器会遵循定义好的完善步骤,从处理 HTML 和构建 DOM 开始:
- 浏览器从磁盘或网络中读取 HTML 原始字节,并根据文件的指定编码将它们转成字符。
- 当遇到 HTML 标记时,浏览器会发出一个令牌,生成诸如
StartTag: HTMLStartTag:headTag: metaEndTag: head这样的令牌 ,整个浏览由令牌生成器来完成。 - 在令牌生成的同时,另一个流程会同时消耗这些令牌并转换成
HTMLhead这些节点对象,起始和结束令牌表明了节点之间的关系。 - 当所有的令牌消耗完以后就转换成了 DOM(文档对象模型)。
DOM 是一个树结构,表示了 HTML 的内容和属性以及各个节点之间的关系。

比如以下代码:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<link href="style.css" rel="stylesheet" />
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
</body>
</html>
最终就转成下面的 DOM 树:
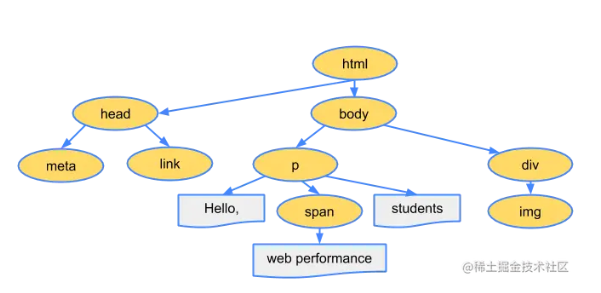
浏览器现在有了页面的内容,那么该如何展示这个页面本身呢?
将 CSS 转换成 CSSOM 树
与转换 HTML 类似,浏览器首先会识别 CSS 正确的令牌,然后将这些令牌转成 CSS 节点,子节点会继承父节点的样式规则,这就是层叠规则和层叠样式表。
比如上面的 HTML 代码有以下的 CSS :
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }
复制代码
最终就转成下面的 CSSOM 树:
这里需要特别区分的是,DOM 树会逐步构建来使页面更快地呈现,但是 CSSOM 树构建时会阻止页面呈现。
原因很简单,如果 CSSOM 树也可以逐步呈现页面的话,那么之后新生成的子节点样式规则有可能会覆盖之前的规则,这就会导致页面的错误渲染。
让我们来做一个思考题,请看以下的 HTML 代码:
<div>
<h1>H1 title</h1>
<p>Lorem...</p>
</div>
复制代码
对于以下两个样式规则,哪个样式规则会渲染得更快?
h1 { font-size: 16px }
div p { font-size: 12px }
复制代码
直觉上很容易觉得第二个规则是更具体的,应该会渲染更快,但实际上恰恰相反:
- 第一条规则是非常简单的,一旦遇到 h1 标记,就会将字号设成 16px。
- 第二条规则更复杂,首先它规定了我们应该满足所有 p 标记,但是当我们找到 p 标记时,还需要向上遍历 DOM 树,只有当父节点是 div 时才会应用这个规则。
- 所以更加具体的标记要求浏览器处理的工作更多,实际编写中应该尽可能避免编写过于具体的选择器。
那么到现在为止,DOM 树包含了页面的所有内容,CSSOM 树包含了页面的所有样式,接下来如何将内容和样式转成像素显示到屏幕上呢?
将 DOM 和 CSSOM 树组成渲染树
浏览器会从 DOM 树的根部开始看有没有相符的 CSS 规则,如果有的话就将节点和样式复制到渲染树上,没有的话就只将节点复制过来,然后继续向下遍历。
特别要注意的是,渲染树最重要的特性是只捕获可见内容 :
- 对于特殊节点(html head)等,因为它们不会被渲染,因此会直接跳过。
- 如果一个节点的属性标记为
display: none,表示这个节点不应该呈现,则这个节点和其子项都会直接跳过。
比如以下将 DOM 树和 CSSOM 树合并成渲染树的结果:
现在我们已经有了渲染树,接下来要做的是确定元素在页面上的位置。
布局与绘制
我们考虑以下的代码:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>
浏览器在渲染时会将这里父 div 的宽度设置成 body 的 50%,将子 div 的宽度设成父 div 的 50%,那么这里 body 的宽度是如何确定的?
注意我们在 meta 标签中设置了一行代码:
<meta name="viewport" content="width=device-width,initial-scale=1" />
我们在实际进行自适应网页设计时都会加上这行代码表示布局视口的宽度等于设备的宽度,因此呈现出来就是这样:
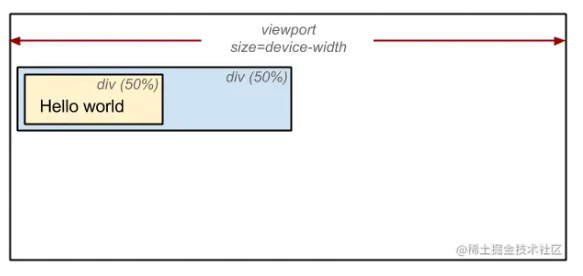
最后一步就是将所有准备好的内容 绘制 到页面上。
任何时候我们想要更新渲染树时,可能都会重新进行布局和绘制这一过程,浏览器本身会采取各种智能的功能尝试重新绘制最低请求区域,但具体还是取决于我们向渲染树应用了哪种类型的更新。
如何优化
在谈优化之前,我们先定义一下用来描述 CRP 的词汇:
- 关键资源: 可能阻止网页首次渲染的资源。
- 关键路径长度: 获取所有关键资源所需的往返次数或总时间。
- 关键字节: 实现网页首次渲染所需的总字节数,等同于所有关键资源传送文件大小的总和。
结合我们谈过的步骤,我们着重会考虑的优化策略是在合成渲染树之前。
首先我们可以优化 DOM,具体体现在以下几步:
- 删除不必要的代码和注释包括空格,尽量做到最小化文件。
- 可以利用 GZIP 压缩文件。
- 结合 HTTP 缓存文件。
然后是优化 CSSOM,缩小、压缩以及缓存同样重要,对于 CSSOM 我们前面重点提过了它会阻止页面呈现,因此我们可以从这方面考虑去优化,让我们看下面的代码:
body {
font-size: 16px;
}
@media screen and (orientation: landscape) {
.menu {
float: right;
}
}
@media print {
body {
font-size: 12px;
}
}
当浏览器遇到 CSS 时,会阻止呈现页面直到 CSSOM 解析完毕,但是对于一些特定场合才会运用的 CSS (比如上面两个媒体查询),浏览器会依旧请求,但不会阻塞渲染了,这也是为什么我们有时会将 CSS 文件拆分到不同的文件,上面的样式表声明可以优化成这样:
<link href="style.css" rel="stylesheet" />
<link href="landscape.css" rel="stylesheet" media="orientation:landscape" />
<link href="print.css" rel="stylesheet" media="print" />
当我们用 PageSpeed Insights 检测我们的网站时,经常出现的一条就是 建议减少关键 CSS 元素数量 。
Google 官方文档 也建议: 当我们声明样式表时,请密切关注媒体查询的类型,它们极大地影响了 CRP 的性能 。
接下来让我们考虑 JavaScript 外部依赖可以优化的地方,再看下面的代码:
<p>
Awesome page
<script src="write.js"></script>
is awesome
</p>
当浏览器遇到 script 标记时,会阻止解析器继续操作,直到 CSSOM 构建完毕,JavaScript 才会运行并继续完成 DOM 构建过程,对于 JavaScript 依赖的优化,我们最常用的一种方法是当网页加载完成,浏览器发出 onload 事件后再去执行脚本(或者直接放在底部),但实际上还有更简单的策略:
async: 当我们在 script 标记添加async属性以后,浏览器遇到这个 script 标记时会继续解析 DOM,同时脚本也不会被 CSSOM 阻止,即不会阻止 CRP。defer: 与async的区别在于,脚本需要等到文档解析后(DOMContentLoaded事件前)执行,而async允许脚本在文档解析时位于后台运行(两者下载的过程不会阻塞 DOM,但执行会)。- 当我们的脚本不会修改 DOM 或 CSSOM 时,推荐使用
async。
这里给出一个参考图:

浏览器还有一个特殊的流程,叫做预加载扫描器,它会提前扫描文档并发现关键的 CSS 和 JS 资源来下载,这个过程不会阻塞渲染,想详细了解它的原理可以浏览这篇文章 How the Browser Pre-loader Makes Pages Load Faster,实际的应用可浏览 前端性能优化之关键路径渲染优化
总结一下,为了首屏最快地渲染,我们通常会采取下列步骤:
- 分析并用 关键资源数 关键字节数 关键路径长度 来描述我们的 CRP 。
- 最小化关键资源数: 消除它们(内联)、推迟它们的下载(defer)或者使它们异步解析(async)等等 。
- 优化关键字节数(缩小、压缩)来减少下载时间 。
- 优化加载剩余关键资源的顺序: 让关键资源(CSS)尽早下载以减少 CRP 长度 。
关于性能优化
在开始之前,我们需要明白一个原则:性能优化的最终目的是提升用户体验。 简而言之就是让用户感觉这个网站很「快」(至少不慢 hh),这里的「快」有两种,一种是「真的快」一种是「觉得快」
- 「真的快」:可以客观衡量的指标,像网页访问时间、交互响应时间、跳转页面时间
- 「觉得快」:用户主观感知的性能,通过视觉引导等手段转移用户对等待时间的关注
**
对症下药
我们知道是 app.js 文件太大,加载时间太长导致了首屏加载速度过慢,我们就需要对症下药减小 app.js 的大小,提高网站访问速度。
一、压缩:
对代码进行压缩,我们可以减小代码的体积量。
二、路由懒加载:
当我们使用路由懒加载后,项目就会进行按需加载,其原理就是利用 webpack 大法的 code splitting,当你使用路由加载的写法,webpack 就会对 app.js 进行代码分割,减小 app.js 的体积,从而提高首屏加载数点。
没使用路由懒加载前的 app.js:
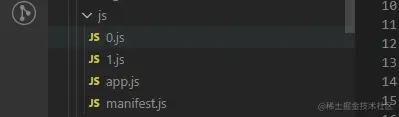
使用路由懒加载后对 app.js 进行 code splitting:
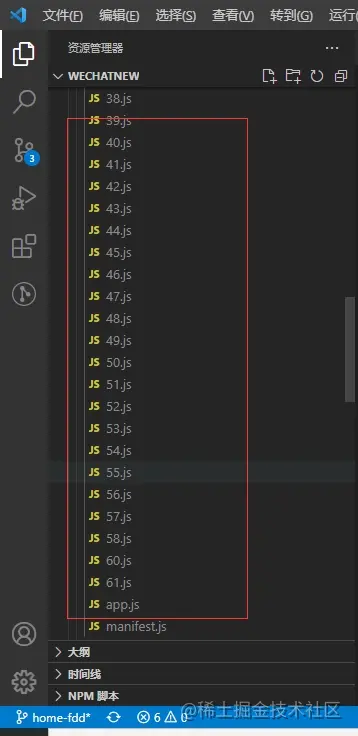
三、CDN 引入:
采用 CDN 引入,在 index.html 使用 CDN 引入,并在 webpack 配置。打包之后 webpack 进会从外部打包第三方引入的库,减小 app.js 的体积,从而提高首屏加载速度。
没使用 CDN 引入前 app.js 的大小:
使用 CDN 引入后 app.js 的大小:
四、SSR 服务器渲染:
有局限性,禁用了 beforeCreate()和 created()之外的其他生命周期,我自己没有亲自测试过,但这是一种方案。
五、增加带宽:
增加带宽可以提高资源的访问速度,从而提高首批的加载速度,我司项目带宽由 2M 升级到 5M,效果明显。
六、提取第三方库 vendor:
这是也是 webpack 大法的 code splitting,提取一些第三方的库,从而减小 app.js 的大小。
代码层面做好懒加载,网络层面把 CDN、本地缓存用好,前端页面问题基本解决一大半了。剩下主要就是接口层面和“视觉上的快”的优化了,骨架屏先搞起,渲染一个“假页面”占位;接口该合并的合并,该拆分的拆分,如果是可滚动的长页面,就分批次请求
3.长列表渲染
为什么选择分页+虚拟列表这个方案呢?
首先,我们将每个方案可以解决的问题和不能解决的问题做一个梳理,具体的优缺点如下:
- 分页加载:解决了数据过多问题,通过数据分页的方式减少了
首次页面加载的数据和DOM数量。是现今绝大部分的应用都会采用的实施手段。随着页面浏览的页面数据增多,DOM 数量也越来越多,还是会存在部分问题。 - 分片加载:与分页加载相同,只是将用户触底行为获取最新数据的时间节点在一开始进行了切片加载,优先显示页面数据在加载其他数据。
会出现页面阻塞和性能问题。 - 虚拟列表:将驱动交给数据,通过区间来直接
渲染区间内容中的数据DOM,解决了页面列表内元素过多操作卡顿的问题, 与数据加载无挂钩。
当列举了三种常见的方式后,我们发现单一的方案很难满足我们的诉求。因此,我选择使用分页的方式处理数据加载,同时将渲染页面的事情交给虚拟列表进行渲染。通过结合两种不同侧重点的方案,来满足我们初步的诉求。
通过下面的示意图,我们将整体列表划分为滚动窗口和可视窗口。左边是真实的列表,所有的列表项都是真实的 DOM 元素,而虚拟列表从图中可以看到,只有出现在可视窗口内的列表项才是真实的 DOM 元素,而未出现在可视窗口中的元素则只是虚拟数据,并未加载到页面上。
与真实列表不同的是,虚拟列表的滚动都是通过 transform 或者是 marginTop 做的偏移量,本身列表中只显示视窗区的 DOM 元素。
下面,我们就来从 0 到 1 实现一个基本的虚拟列表吧。
基本布局
如下结构图,我们先分析下基本页面构成:
- 第一层为
容器层,选定一个固定高度,也就是我们说的可视化窗口 - 第二层为
内容层,一般在这里撑开高度,使容器形成scroll。 - 第三层为
子内容层,居于内容层内部,也就是列表中的列表项。 ......
分析后,我将结构图中代码使用JSX实现后,就是下面这个简单的结构:
页面布局代码
<div>
<div>
... List Item Element
</div>
</div>;
.App {
font-family: sans-serif;
text-align: center;
}
.showElement {
display: flex;
justify-content: center;
align-items: center;
border: 1px solid #000;
margin-bottom: 8px;
border-radius: 4px;
}
先搭建一个简单的页面,然后通过currentViewList渲染出对应的列表项内容。
初始化页面
当我们确定了页面的基本结构后,我们再来完善一些布局与配置,实现一个真实渲染上千条数据的列表。
我先定义了一些配置,包含容器高度、列表项高度、预加载偏移数量等需要用到的固定内容。
- 容器高度:当前虚拟列表的高度
- 列表项高度: 列表项的高度
- 预加载偏移:可视窗上下做预加载时需要额外展示几个预备内容
页面属性
/** @name 页面容器高度 */
const SCROLL_VIEW_HEIGHT: number = 500;
/** @name 列表项高度 */
const ITEM_HEIGHT: number = 50;
/** @name 预加载数量 */
const PRE_LOAD_COUNT: number = SCROLL_VIEW_HEIGHT / ITEM_HEIGHT;
接着,创建一个useRef用来存储元素,然后获取视窗高度和偏移属性。
/** 容器Ref */
const containerRef = useRef<HTMLDivElement | null>(null);
然后,创建数据源,并且生成3000条随机数据做显示处理。
const [sourceData, setSourceData] = useState<number[]>([]);
/**
* 创建列表显示数据
*/
const createListData = () => {
const initnalList: number[] = Array.from(Array(4000).keys());
setSourceData(initnalList);
};
useEffect(() => {
createListData();
}, []);
最后,为相对应的容器绑定高度。在最外层 div 标签设置高度为SCROLL_VIEW_HEIGHT,对列表 div 的高度则设置为sourceData.length * ITEM_HEIGHT。
获取列表整体高度
/**
* scrollView整体高度
*/
const scrollViewHeight = useMemo(() => {
return sourceData.length * ITEM_HEIGHT;
}, [sourceData]);
绑定页面视图
<div
ref={containerRef}
style={{
height: SCROLL_VIEW_HEIGHT,
overflow: "auto",
}}
onScroll={onContainerScroll}
>
<div
style={{
width: "100%",
height: scrollViewHeight - scrollViewOffset,
marginTop: scrollViewOffset,
}}
>
{sourceData.map((e) => (
<div
style={{
height: ITEM_HEIGHT,
}}
className="showElement"
key={e}
>
Current Position: {e}
</div>
))}
</div>
</div>;
当数据初始化后,我们的列表页面就初步完成了,来看下效果吧。
内容截取
对于虚拟列表来说,并不需要全量将数据渲染在页面上。那么,在这里我们就要开始做数据截取的工作了。
首先,如下图,我们通过showRange来控制页面显示元素的数量。通过Array.slice的函数方法对sourceData进行数据截取, 返回值就是我们在页面上去显示的列表数据了。我将上面代码中直接遍历souceData换成我们的新数据列表。如下:
{
currentViewList.map((e) => (
<div
style={{
height: ITEM_HEIGHT,
}}
className="showElement"
key={e.data}
>
Current Position: {e.data}
</div>
));
}
上面使用到的currentViewList是一个useMemo的返回值,它会随着showRange和sourceData的更新发生变化。
/**
* 当前scrollView展示列表
*/
const currentViewList = useMemo(() => {
return sourceData.slice(showRange.start, showRange.end).map((el, index) => ({
data: el,
index,
}));
}, [showRange, sourceData]);
滚动计算
至此,已经完成了一个基本的虚拟列表雏形,下一步我们就需要监听视窗滚动事件来计算showRange中的start和end的偏移量,同时调整对应的滚动条进度来实现一个真正的列表效果。
首先,我先为滚动视窗(scrollContainer)绑定 onScroll 事件,也就是下面的onContainerScroll函数方法。
/**
* onScroll事件回调
* @param event { UIEvent<HTMLDivElement> } scrollview滚动参数
*/
const onContainerScroll = (event: UIEvent<HTMLDivElement>) => {
event.preventDefault();
calculateRange();
};
在事件主要做的事情就计算当前showRange中的start和end所处位置,同时更新页面视图数据。下面,我们来看看它是怎么处理的吧!
首先,通过containerRef.current.scrollTop可以知道元素滚动条内的顶部隐藏列表的高度,然后使用Math.floor方法向下取整后,来获取当前偏移的元素数量,在减去一开始的上下文预加载数量PRE_LOAD_COUNT,就可以得出截取内容开始的位置。
其次,通过containerRef.current.clientHeight可以获取滚动视窗的高度,那么通过containerRef.current.clientHeight / ITEM_HEIGHT这个公式就可以得出当前容器窗口可以容纳几个列表项。
当我通过当前滚动条位置下之前滚动的元素个数且已经计算出截取窗口的起始位置后,就可以通过启动位置 + 容器显示个数 + 预加载个数这个公式计算出了当前截取窗口的结束位置。使用setShowPageRange方法更新新的位置下标后,当我上下滑动窗口,显示的数据会根据showRange切割成为不同的数据渲染在页面上。
/**
* 计算元素范围
*/
const calculateRange = () => {
const element = containerRef.current;
if (element) {
const offset: number = Math.floor(element.scrollTop / ITEM_HEIGHT) + 1;
console.log(offset, "offset");
const viewItemSize: number = Math.ceil(element.clientHeight / ITEM_HEIGHT);
const startSize: number = offset - PRE_LOAD_COUNT;
const endSize: number = viewItemSize + offset + PRE_LOAD_COUNT;
setShowPageRange({
start: startSize < 0 ? 0 : startSize,
end: endSize > sourceData.length ? sourceData.length : endSize,
});
}
};
滚动条偏移
上面,我们提到会根据containerRef.current.scrollTop计算当前滚动过的高度。那么问题来了,页面上其实并没有真实的元素,又该如何去撑开这个高度呢?
目前而言,比较流行的解决方案分为MarinTop和TranForm做距离顶部的偏移来实现高度的撑开。
- margin 是属于布局属性,该属性的变化会导致页面的重排
- transform 是合成属性,浏览器会为元素创建一个独立的复合层,当元素内容没有发生变化,该层不会被重绘,通过重新复合来创建动画帧。
两种方案并没有太大的区别,都可以用来实现距离顶部位置的偏移,达到撑开列表实际高度的作用。
下面,我就以MarinTop的方法来处理这个问题,来完善当前的虚拟列表。
首先,我们需要计算出列表页面距离顶部的MarginTop的距离,通过公式:当前虚拟列表的起始位置 * 列表项高度,我们可以计算出当前的scrollTop距离。
通过useMemo将逻辑做一个缓存处理,依赖项为showRange.start, 当showRange.start发生变化时会更新marginTop的高度计算。
/**
* scrollView 偏移量
*/
const scrollViewOffset = useMemo(() => {
console.log(showRange.start, "showRange.start");
return showRange.start * ITEM_HEIGHT;
}, [showRange.start]);
在页面上为列表窗口绑定marginTop: scrollViewOffset属性,并且在总高度中减去scrollViewOffset来维持平衡,防止多出距离的白底。
如下代码
<div
style={{
width: "100%",
height: scrollViewHeight - scrollViewOffset,
marginTop: scrollViewOffset
}}
>
至此,我们已经完成了一个基本的虚拟列表,下面我们来一起看看实际的效果吧。
结合分页加载
当我们有了一个虚拟列表后,就可以尝试结合分页加载来实现一个懒加载的长虚拟列表了。
如果做过分页滚动加载的小伙伴可能立马就想到实现思路了,不了解的同学也不要着急,下面我就带大家一起来实现一个带分页加载的虚拟列表,相信你看完之后会对这类问题有一个更加深入的理解。
判断是否到底部
想要实现列表的分页加载,我们需要绑定onScroll事件来判断当前滚动视窗是否滚动到了底部,当滚动到底部后需要为sourceData进行数据的添加。同时将挪动指针,将数据指向下一个起始点。
具体实现代码如下,reachScrollBottom函数的返回值是当前滚动窗口是否已经到达了底部。因此,我们通过函数的返回值进行条件判断。到达底部后,我们模拟一批数据后通过setSourceData设置源数据。结束之后在执行calculateRange重新设置内容截取的区间。
/**
* onScroll事件回调
* @param event { UIEvent<HTMLDivElement> } scrollview滚动参数
*/
const onContainerScroll = (event: UIEvent<HTMLDivElement>) => {
event.preventDefault();
if (reachScrollBottom()) {
// 模拟数据添加,实际上是 await 异步请求做为数据的添加
let endIndex = showRange.end;
let pushData: number[] = [];
for (let index = 0; index < 20; index++) {
pushData.push(endIndex++);
}
setSourceData((arr) => {
return [...arr, ...pushData];
});
}
calculateRange();
};
那么,calculatScrollTop是如何判断当前是否已经触底呢?
分析上图,我通过containerRef可以拿到滚动窗口的高度scrollHeight或者直接使用soureData.length * ITEM_HEIGHT充当滚动窗口的高度两者作用是一样的。
同时,我也可以拿到scrollTop滚动位置距离顶部的高度和clientHeight当前视窗高度。通过三者的关系,可以得出条件公式:scrollTop + clientHeight >= scrollHeight,满足这个条件就说明当前窗口已经到达底部。我们将其写成reachScrollBottom方法,如下:
/**
* 计算当前是否已经到底底部
* @returns 是否到达底部
*/
const reachScrollBottom = (): boolean => {
//滚动条距离顶部
const contentScrollTop = containerRef.current?.scrollTop || 0;
//可视区域
const clientHeight = containerRef.current?.clientHeight || 0;
//滚动条内容的总高度
const scrollHeight = containerRef.current?.scrollHeight || 0;
if (contentScrollTop + clientHeight >= scrollHeight) {
return true;
}
return false;
};
本篇文章中,我讲了针对商城项目中出现长列表的部分场景,同时针对这些场景列举了不同的解决方案及其优缺点。在选择分页 + 虚拟列表的组合方式来解决问题的过程中,我一步一步带大家实现了一个简单的分页虚拟列表,帮助大家了解其内部的原理。
当然,这个方案还有很多需要完善的地方,我也在这里说说它需要优化的地方。
- 滚动事件可以添加节流事件避免造成性能浪费。
- 列表项高度不固定需要给定一个默认高度后设置新的高度在重新刷新容易截取的开始和结束位置。
- 滑动过快出现白屏问题可以尝试动态加载 loading 显示过渡,优化一些细节体验。
- 列表项中存在阴影元素需要考虑缓存处理,不然滚动时必然会引起重新加载。
4.图片懒加载分析
https://www.cnblogs.com/tugenhua0707/p/3525668.html
懒加载与预加载的基本概念。
懒加载也叫延迟加载:前一篇文章有介绍:JS 图片延迟加载 延迟加载图片或符合某些条件时才加载某些图片。
预加载:提前加载图片,当用户需要查看时可直接从本地缓存中渲染。
两种技术的本质:两者的行为是相反的,一个是提前加载,一个是迟缓甚至不加载。懒加载对服务器前端有一定的缓解压力作用,预加载则会增加服务器前端压力。
懒加载的意义及实现方式有:
意义: 懒加载的主要目的是作为服务器前端的优化,减少请求数或延迟请求数。
实现方式:
1.第一种是纯粹的延迟加载,使用 setTimeOut 或 setInterval 进行加载延迟.
2.第二种是条件加载,符合某些条件,或触发了某些事件才开始异步下载。
3.第三种是可视区加载,即仅加载用户可以看到的区域,这个主要由监控滚动条来实现,一般会在距用户看到某图片前一定距离遍开始加载,这样能保证用户拉下时正好能看到图片。
预加载的意义及实现方式有:
预加载可以说是牺牲服务器前端性能,换取更好的用户体验,这样可以使用户的操作得到最快的反映。实现预载的方法非常多,可以用 CSS(background)、JS(Image)、HTML()都可以。常用的是 new Image();,设置其 src 来实现预载,再使用 onload 方法回调预载完成事件。只要浏览器把图片下载到本地,同样的 src 就会使用缓存,这是最基本也是最实用的预载方法。当 Image 下载完图片头后,会得到宽和高,因此可以在预载前得到图片的大小(方法是用记时器轮循宽高变化)。
怎么样才能实现预加载?
我们可以通过 google 一搜索:可以看到很多人用这种方式进行预加载:代码如下:
function loadImage(url,callback) {
var img = new Image();
img.src = url;
img.onload = function(){
img.onload = null;
callback.call(img);
}
}
在 google 或者火狐下测试 都是正常的 不管我怎么刷新都是正常的,但是在 IE6 下不是这样的 我点击一下 是正常 再次点击或者重新刷新都不正常。下面的 jsfiddle 地址:有兴趣的同学可以试试 点击按钮后 弹出正常结果 再次点击在 IE6 下就不执行 onload 里面的方法了,接着重新刷新也不行。
为什么其他浏览器正常的:其实原因很简单,就是浏览器缓存了,除了 IE6 以外(即说 opera 也会,但是我特意用 opera 试了下,没有,可能版本的问题吧,或许现在已经修复了。),其他浏览器重新点击会再次执行 onload 方法,但是 IE6 是直接从浏览器取的。
那现在怎么办?最好的情况是 Image 可以有一个状态值表明它是否已经载入成功了。从缓存加载的时候,因为不需要等待,这个状态值就直接是表明已经下载了,而从 http 请求加载时,因为需要等待下载,这个值显示为未完成。这样的话,就可以搞定了。经过 google 搜索下即介绍:发现有一个为各个浏览器所兼容的 Image 的属性——complete。所以,在图片 onload 事件之前先对这个值做一下判断即可。最后,代码变成如下的样子:
function loadImage(url,callback) {
var img = new Image();
img.src = url;
if(img.complete) { // 如果图片已经存在于浏览器缓存,直接调用回调函数
callback.call(img);
return; // 直接返回,不用再处理onload事件
}
img.onload = function(){
img.onload = null;
callback.call(img);
}
}
也就是说如果图片已经在浏览器缓存里面 那么支持直接从浏览器缓存取得直接执行 img.complete 里面的函数 接着返回.
但是我们可以看到上面的代码:必须等图片加载完成后,可以执行回调函数,也可以说等图片加载后,我们可以获取图片的宽度和高度。那么如果我们想提前获取图片的尺寸那怎么办?上网经验告诉我:浏览器在加载图片的时候你会看到图片会先占用一块地然后才慢慢加载完毕,并且不需要预设 width 与 height 属性,因为浏览器能够获取图片的头部数据。基于此,只需要使用 javascript 定时侦测图片的尺寸状态便可得知图片尺寸就绪的状态。代码如下:(但是有个前提是 这个方式不是我想的,也不是我写的代码,是网上朋友总结的代码 我只是知道有这么一个原理)
var imgReady = (function(){
var list = [],
intervalId = null;
// 用来执行队列
var queue = function(){
for(var i = 0; i < list.length; i++){
list[i].end ? list.splice(i--,1) : list[i]();
}
!list.length && stop();
};
// 停止所有定时器队列
var stop = function(){
clearInterval(intervalId);
intervalId = null;
}
return function(url, ready, error) {
var onready = {},
width,
height,
newWidth,
newHeight,
img = new Image();
img.src = url;
// 如果图片被缓存,则直接返回缓存数据
if(img.complete) {
ready.call(img);
return;
}
width = img.width;
height = img.height;
// 加载错误后的事件
img.onerror = function () {
error && error.call(img);
onready.end = true;
img = img.onload = img.onerror = null;
};
// 图片尺寸就绪
var onready = function() {
newWidth = img.width;
newHeight = img.height;
if (newWidth !== width || newHeight !== height ||
// 如果图片已经在其他地方加载可使用面积检测
newWidth * newHeight > 1024
) {
ready.call(img);
onready.end = true;
};
};
onready();
// 完全加载完毕的事件
img.onload = function () {
// onload在定时器时间差范围内可能比onready快
// 这里进行检查并保证onready优先执行
!onready.end && onready();
// IE gif动画会循环执行onload,置空onload即可
img = img.onload = img.onerror = null;
};
// 加入队列中定期执行
if (!onready.end) {
list.push(onready);
// 无论何时只允许出现一个定时器,减少浏览器性能损耗
if (intervalId === null) {
intervalId = setInterval(queue, 40);
};
};
}
})();
用方式如下:
imgReady('http://img01.taobaocdn.com/imgextra/i1/397746073/T2BDE8Xb0bXXXXXXXX-397746073.jpg',function(){ alert('width:' + this.width + 'height:' + this.height); });
具体实现原理
有时候一个网页会包含很多的图片,例如淘宝京东这些购物网站,商品图片多只之又多,页面图片多,加载的图片就多。服务器压力就会很大。不仅影响渲染速度还会浪费带宽。比如一个 1M 大小的图片,并发情况下,达到 1000 并发,即同时有 1000 个人访问,就会产生 1 个 G 的带宽。
为了解决以上问题,提高用户体验,就出现了懒加载方式来减轻服务器的压力,优先加载可视区域的内容,其他部分等进入了可视区域再加载,从而提高性能。
vue 项目中的打包,是把 html、css、js 进行打包,还有图片压缩。但是打包时把 css 和 js 都分成了几部分,这样就不至于一个 css 和就是文件非常大。也是优化性能的一种方式。 效果动图如下:
进入正题------懒加载
1.懒加载原理
一张图片就是一个<img>标签,浏览器是否发起请求图片是根据<img>的 src 属性,所以实现懒加载的关键就是,在图片没有进入可视区域时,先不给<img>的 src 赋值,这样浏览器就不会发送请求了,等到图片进入可视区域再给 src 赋值。
2.懒加载思路及实现 实现懒加载有四个步骤,如下: 1.加载 loading 图片 2.判断哪些图片要加载【重点】 3.隐形加载图片 4.替换真图片
1.加载 loading 图片是在 html 部分就实现的,代码如下:
2.如何判断图片进入可视区域是关键。 引用网友的一张图,可以很清楚的看出可视区域。
如上图所示,让在浏览器可视区域的图片显示,可视区域外的不显示,所以当图片距离顶部的距离 top-height 等于可视区域 h 和滚动区域高度 s 之和时说明图片马上就要进入可视区了,就是说当 top-height<=s+h 时,图片在可视区。 这里介绍下几个 API 函数: 页可见区域宽: document.body.clientWidth; 网页可见区域高: document.body.clientHeight; 网页可见区域宽: document.body.offsetWidth (包括边线的宽); 网页可见区域高: document.body.offsetHeight (包括边线的宽); 网页正文全文宽: document.body.scrollWidth; 网页正文全文高: document.body.scrollHeight; 网页被卷去的高: document.body.scrollTop; 网页被卷去的左: document.body.scrollLeft; 网页正文部分上: window.screenTop; 网页正文部分左: window.screenLeft; 屏幕分辨率的高: window.screen.height; 屏幕分辨率的宽: window.screen.width; 屏幕可用工作区高度: window.screen.availHeight;
HTMLElement.offsetTop 为只读属性,它返回当前元素相对于其 offsetParent 元素的顶部的距离。 window.innerHeight:浏览器窗口的视口(viewport)高度(以像素为单位);如果有水平滚动条,也包括滚动条高度。
具体实现的 js 代码为:
// onload 是等所有的资源文件加载完毕以后再绑定事件 window.onload = function(){ // 获取图片列表,即 img 标签列表 var imgs = document.querySelectorAll('img');
// 获取到浏览器顶部的距离
function getTop(e){
return e.offsetTop;
}
// 懒加载实现
function lazyload(imgs){
// 可视区域高度
var h = window.innerHeight;
//滚动区域高度
var s = document.documentElement.scrollTop || document.body.scrollTop;
for(var i=0;i<imgs.length;i++){
//图片距离顶部的距离大于可视区域和滚动区域之和时懒加载
if ((h+s)>getTop(imgs[i])) {
// 真实情况是页面开始有2秒空白,所以使用setTimeout定时2s
(function(i){
setTimeout(function(){
// 不加立即执行函数i会等于9
// 隐形加载图片或其他资源,
//创建一个临时图片,这个图片在内存中不会到页面上去。实现隐形加载
var temp = new Image();
temp.src = imgs[i].getAttribute('data-src');//只会请求一次
// onload判断图片加载完毕,真是图片加载完毕,再赋值给dom节点
temp.onload = function(){
// 获取自定义属性data-src,用真图片替换假图片
imgs[i].src = imgs[i].getAttribute('data-src')
}
},2000)
})(i)
}
}
}
lazyload(imgs);
// 滚屏函数
window.onscroll =function(){
lazyload(imgs);
}
效果如下:
随着鼠标向下滚动,其余图片也逐渐显示并发起请求。
效果动图如下:
5.项目重构
什么是重构
我们开发惯指的 重构 ,一般都是指技术重构。简单点说就是基于项目进行代码层面的重构。推倒了重新来,老房子扒掉重新造,肯定是有钱了想让自己更舒适,程序代码推倒了重新写,还不是因为代码质量经过长年累月需求迭代,祖传代码越来越难维护,更别说在这个基础上去老树开花,开发一些新功能。(代码太烂,遗留的坑太多,就是程序的拓展性和维护性不好呗画外音,前浪们留下的一堆堆精华 💩 ,需要后狼们一铲一铲地拍在 上……)
那么问题来了,你的项目到底需不需要重构呢
考虑到项目重构带来的人力、时间、项目风险等因素,在商业项目中,推倒重来是一个风险高,收益低,吃力不太讨好的事情。而且,推翻之前的项目重做,也不定会写出比以前更好的代码。那为什么还要重构呢,或许我们从业务和团队角度分析能得到一些答案。
业务角度分析
- 业务转型了,基于原有业务做得系统自然成了前朝遗老,不招人稀罕了,别说重构,废弃都是有可能的。
- 业务体量变化,原先的技术架构可能对于百人内的团队,性能上瓶颈不明显,但是随着业务体量的上涨,对于产品性能、扩展性、稳定性的要求越来越高,会推动当前产品迭代及重构的需求
团队角度分析
- 当前技术方案的问题:单签方案是否影响团队开发效率,项目技术方案是否比较陈旧,难以维护,是否存在家属架构及依赖包过于老旧的问题。如果你的项目依赖文件人家官方都已经不维护了,而且官方文档也给出了相关替换方案,那你的项目确实该进行升级、迭代,甚至是换一套新的技术栈进行重构了。
- 当前项目的代码本身的问题:代码是否基于团队规范标准开发,代码是否有较好的拓展性、健壮性和可维护性。项目代码经过长期迭代,多人轮换,没有规范标准的情况下,代码会变得越来越难维护,一个文件动辄千八百行代码,不用驼峰,不用清晰语义命名,不写代码注释,分分钟逼死强逼症,这样的代码,加个新功能,都要反反复复的翻以前的代码,即使改好了,还有可能因为,之前项目代码不够健壮,报出来其他奇奇怪怪的问题。
那前端开发在项目重构中能干点啥呢
- 无用的三方库看着不碍眼吗,删掉啊
- 一些三方库只用了一两次,自写功能成本也不是很高,留着干啥
- 删除无用变量|无用 import 文件
- 删除用不到的逻辑,精简、抽分通用逻辑
- 拆分大文件,动辄千八百行的代码文件,不抽分,后期只会越来越多,后期维护成本越来越高,重构代价也越来越大
- 减少全局样式,采用 css modules 做样式隔离,避免绞尽脑计想命名,也避免跟某个组件库样式冲突
- 代码结构重构,优化项目工程目录结构,项目迭代下来,会有很多重复的文件目录结构,应该从项目整体角度考虑,合理划分目录结构
- 代码命名、模块抽分、合理注释总得加一下吧
- 一些无用的,当时测试用的 console,debugger 看到就删掉呗
- 做一些必要的依赖升级,项目依赖包一直在升级,为了项目长期稳定的使用依赖包的一些能力,必要的依赖包升级还是有必要的
重构时应该注意哪些问题呢
- 首先,很认真的问下自己,问下团队相关成员,这个项目是真的需要重构吗,软件迭代是必需的,但是重构真的不是必要的,必要打碎了,重新来过,不一定比之前做的更好
- 重构时,你要对重构的项目有必要的理解,知道当初这个功能实现的初衷,才能保证重构后的版本,不会有其他不好的影响,建议重构过程中,多看之前的逻辑实现,多问当时参与的人,相关的产品经理、开发,甚至是测试,了解到被注释掉的代码,是否是没用了,真没用了,再扔掉,否则,一刀切,很可能,后期你还得补回来
- 重构的目的要清楚,你是重构一个组件,一个模块,还是整个系统,整个系统推倒重来,对于任何公司来说都是一个慎重的事情,比较好的做法是,渐进式的重构,把系统切成相互独立的小块,一点一点迭代,可以作为日常迭代,也可以做成专项迭代,看业务需求
- 架构选型,不一定是什么新,什么流行用什么,得考虑团队或者个人的学习成本,可能这个新技术确实很好,但是现有团队业务开发任务很重,没有必要一步登天,折磨自己,折磨别人,一句话适合自己的才是最好的
- 明确重构的目的是为了,让项目不像老代码那样臃肿,难以维护,那么定一些标准化的参考规则是很有必要的,最起码保证相当长的时间内,看着像一个正经的项目
我个人在重构过程中的一些习惯(仅供参考)
- 首先,我会梳理现有项目代码,对照项目页面,给老项目加一点注释标记
- 创建项目结构 + 功能脑图,项目干了点啥,需要哪些功能一目了然,后期开发,参照起来,安排排期、预估开发进度,个人感觉还挺有用的
- 标记问题,老项目缺少注释,文件结构混乱是常有的事儿,遇到不理解的,多思多问是个好习惯,提前把风险点记录下来,可以用来评估,这个项目重构带来的结果是不是正向的
- 参照通用规范,梳理开发标准,像 css、js 的变量命名,模块抽分标准这样还是要有个可参考的开发标准的
- 基础技术栈统一,一个项目 js、ts 混着用,可能是不好的,鉴于现在前端的发展趋势,大方向上使用 ts 会是未来几年的大趋势,也避免了 js 弱类型带来的一些负面影响,样式管理的话,我这边采用的是 less + css module 来做,这样命名相对清晰,也不会造成样式文件相互影响
6.性能问题排查
如果某天你发现自己写的程序运行缓慢,你可能需要查看一下是否是 DOM 元素过多,这时候你就 F12 打开控制台,并且输入下面的代码,查看 DOM 元素的总数是否过大:
$$("*").length; // 或者是document.querySelectorAll('*').length
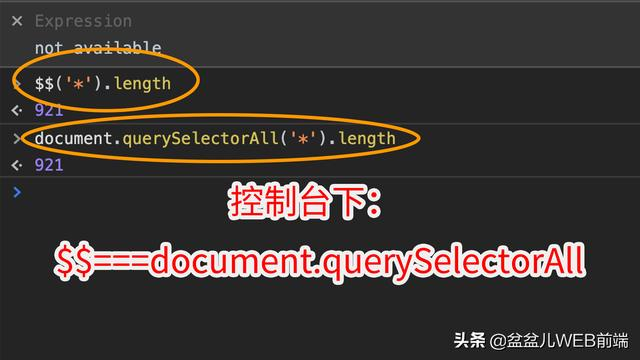
结果发现并不是 DOM 元素的问题。于是你又开始怀疑是不是 window 对象上挂载了太多的事件监听(EventListeners),于是你再次打开控制台,输入下面的代码,查看 window 对象上都挂载了哪些事件处理函数:
getEventListeners(window);
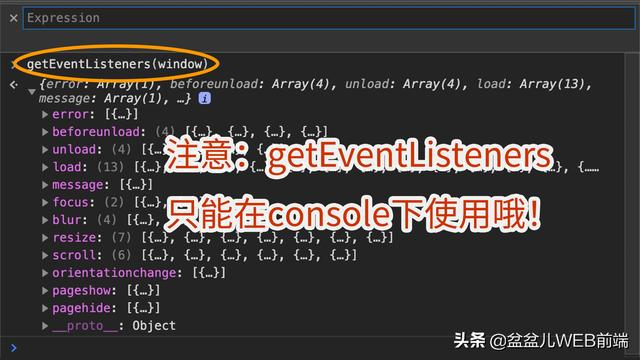
结果你可能有发现并不是事件监听过多的问题。这时,你又怀疑到了是否是 CPU 占用率过高,导致了 JS 执行缓慢呢?于是你又打开 chrome 开发工具,切换到性能面板(performance),对运行时的代码做一段记录,然后查看结果:
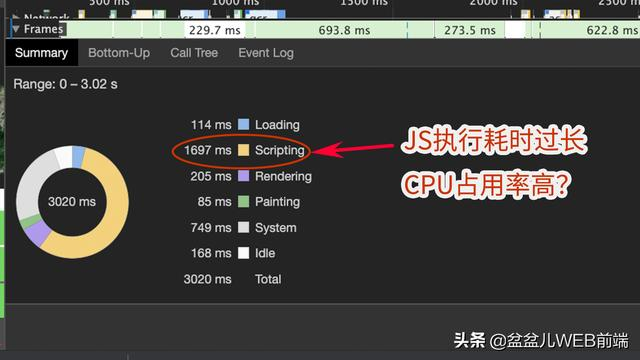
通过对 summary 视图的分析,你可能会怀疑是否是 CPU 占用过高?
综上,chrome 确实也提供了一系列的功能方便我们来定位可能存在的性能问题。但是上面提到的这个查找过程显得过于盲目了,不能很快速的定位了问题的原因。
为了解决上面我提出的问题,我们今天的主角闪亮登场了,它就是 chrome devtool 中的 performance monitor , 它能实时地监控程序运行过程中影响到性能的常见指标,以便于我们快速的找到问题,非常的方便。下面就说说它应该怎么使用:
F12 打开开发者工具,然后 MAC : command + shift + pWIN : ctrl + shift + p 搜索 show performance monitor , 并选择 此时就打开了 performanc monitor
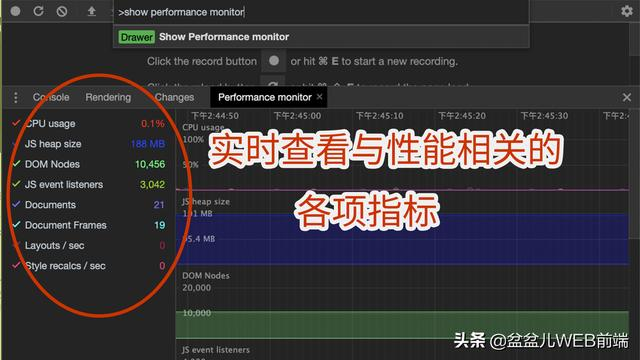
从上图可以看到,这个面板中列出以下的一些指标:
- CPU usage : CPU 占用率。
- JS heap size : JS 占用内存大小。如果内存占用一直很大,可以考虑是否有内存溢出,如果内存一直增长却不见回收,考虑是否存在内存泄漏。
- DOM nodes: DOM 节点的个数。需要注意的事,这儿的 DOM 节点个数不仅仅是真实存在于页面上的节点个数,它也包含了内存中 DOM 节点的个数。
- JS event listeners: 绑定事件的个数
- Document & Document Frames : document 和 iframe 的个数
- Layouts / sec & Style recalcs / sec : 每秒进行重绘 & 重排的次数
有了这些指标,我们就能很方便地实时定位出什么指标出了问题
7.怎么优化白屏时间 怎么排查解决白屏问题
白屏 = 开始显示 body 的时间 - 开始请求的时间
首屏 = 首屏内容渲染结束的时间 - 开始请求的时间
白屏时间:即用户点击一个链接或打开浏览器输入 URL 地址后,从屏幕空白到显示第一个画面的时间。
建立 TCP 连接请求
浏览器服务器的通信是基于TCP/IP,这个协议是由网络层 IP 层和传输层 TCP 层,IP 是每台电脑在互联网中的唯一标识; TCP 通过三次握手进行数据链接与传输;
服务端请求处理响应
TCP 链接建立以后,服务器接受请求,开始处理,同时浏览器开始等待服务器的处响应;
Web 服务器按照请求的类型进行响应。静态资源文件,css 文件,html 文件都是直接返回;一些需要转发的请求,转发给对应额服务器,然后将数据按照约定响应给浏览器;
客户端下载解析,渲染页面
服务端将浏览器的请求响应后,浏览器就会进行 html 文件的下载,解析,响应,渲染;
1.如果响应的类型为 gzip,浏览器先解压 html;
2.解析 html 的头部文件, 解析对应的 css 文件和脚本文件;
3.解析 html 的文件和样式文件资源,构建 DOM 树和 CSSOM 树;
4.遍历 DOM 树和 CSSDOM 树,根据节点计算大小,颜色等构建渲染树;
5.渲染页面
需要注意的点:
1.浏览器在渲染页面的时候,遇到 js 脚本资源,就会造成阻塞; 当 css 文件没有下载完成到,浏览器解析 html 文件时又遇到了内联的 js 代码,根据浏览器的安全策略机制, 浏览器会暂停js文件执行,暂停html的解析,优先下载css文件,直到css文件下载完成,完成CSSDOM树,重新恢复原来的js,所以一定要合理的放置 js 文件;
2.使用 import 引入的 css 样式, 并不会一次性下载完成,只有在运行到那个页面的时候才会下载对应的 css 文件,这样很容易造成页面样式错乱等;所以尽量不要使用 import 引入样式
1.使用 DNS 缓存优化; 2.DNS 预解析; 3.稳定可靠的 DNS 服务器;
建立 TCP 连接请求
链路层的优化, 主要在于花钱来解决
服务端请求处理响应
服务端的的优化是个非常庞大, 包括 Redis 缓存、数据库存储优化或是系统内的各种中间件以及 Gzip 压缩等...
客户端下载解析,渲染页面
- 优化 css 代码,html 代码等,减少冗余代码;
2.合理正确的放置 css 代码和 js 代码的位置; 3. 尽量不要使用 import 引入 css 以及较少内联的 js 的使用
webpack 打包过程中,经常出现 app.js 一个文件好几兆的情况,这偏偏又是网页最先加载的文件,由于从上到下的执行顺序,前面的脚本在加载时会阻塞页面渲染,白屏时间由此而来。
webpack 的 externals 选项适用于以下情况,当我们使用了外部库,例如 jquery 这种会在全局创建一个命名空间用($)来存放相应的方法,vue(Vue),vue-router(VueRouter),element-ui(ELEMENT)等等,就是这个意思。
通常情况下我们只会使用一个库的某几个方法,全部打包到生产环境中显然不合适,这时候可以配置 externals,让 webpack 在打包时忽略掉这些库,并自动在全局中挂载上相应的全局变量。具体的库你再通过 CDN 的方式引入即可,这样对应起来就可以将依赖抽离出来稍后再加载。例如:
/**
* vue.config.js
*/
configureWebpack: config => {
config.externals = {
marked: 'marked',
jquery: '&',
// 这里要注意,键名就是npm包名,值就是库对应的全局变量
// 如果有特殊符号最好用引号包起来,例如:
'highlight.js': 'hljs'
}
}
}
由于全家桶 vue,vue-router 等页面一开始加载就需要使用了,所以即使换成 CDN 也是需要放到页面最上方,实际体验差不多,主要是还很麻烦,所以对于这类必须的依赖
配置 cacheGroups 选项 代码分割
cheGroups 字面意思缓存组,其实就是定义分包股则,满足条件就将这些依赖提取到一个模块中,是 splitChunks 的关键配置。webpack 就是通过这里判断如何拆分模块的。
一般情况下,越早使用的模块越先加载。该项目中我将依赖分为:
- vue 全家桶
- UI 组件
- 其他依赖
分包的意义在于提升传输效率,而不是压缩体积
8.骨架屏怎么设计
vue 项目中的入口 index.html 只有简单的内容:
当 js 执行完之后,会用 vue 渲染成的 dom 将div#root完全替换掉。
我们在div#root中加入模拟骨架屏,在 Chrome 开发者工具调整网速:
将骨架屏内容直接插入div#root中即可实现骨架屏。
我们需要骨架屏也是一个单独的.vue文件,因此我们需要用到vue-server-renderer。对 vue 服务端渲染有所了解的同学一定知道,这个插件能够将 vue 项目在 node 端打包成一个 bundle,然后由 bundle 生成对应的 html
9.服务器端渲染
优点
- 有利于 SEO。
- 首屏加载速度快。因为 SPA 引用需要在首屏获取所有资源,而服务器端渲染直接拿了成品展示出来就行了。
- 无需占用客户端资源。解析模板工作交给服务器完成,对于客户端资源占用更少,尤其是移动端,也可以更省电。
缺点
- 占用服务器资源。服务器端完成 html 模板解析,如果请求较多,会对服务器造成一定的访问压力。而如果是前端渲染,就是把这些压力分摊给了前端。
- 不利于前后端分离。
可以在服务器(后端)环境中,使用 vue.js 来构建组件和页面,然后将渲染好的静态 html 字符串传给客户端展示
10.如何排查页面卡顿?
网络链路
网络链路往往是页面性能的扼要之处,域名解析、交换机、路由器、网络服务提供商、内容分发网络、服务器,链路上的节点出问题或响应过慢都会有不好的体验。
服务器资源
在 HTTP 的大环境下,所有请求最终都要服务器来处理,服务器爸爸处理不当无法响应或响应过慢也会直接影响页面与用户的互动。
前端资源渲染
浏览器获取所需 HTML、CSS、脚本、图片等静态资源,绘制首屏呈现给用户的过程;或用户与页面交互后,浏览器重新计算需要呈现的内容,然后重新绘制的过程。这些过程的处理效率也是影响性能的重要因素。
用户硬件
发起网络请求,解析网络响应,页面渲染绘制等过程都需要消耗计算机硬件资源。所以计算机资源,特别是 CPU 和 GPU 资源短缺时(比如打显卡杀手类的游戏),也会影响页面性能。
当然,以上的维度不是划线而治的,它们更多是犬牙交错的关系。例如在渲染过程中浏览器反应很慢,有可能是脚本写得太烂遭遇性能瓶颈,也有可能是显卡杀手游戏占用了过多计算机资源;又如在分析前端资源渲染时,往往要结合网络瀑布图分析资源的获取时间,因为渲染页也是个动态的过程,有些关键资源需要等待,有些则可以在渲染的同时加载。
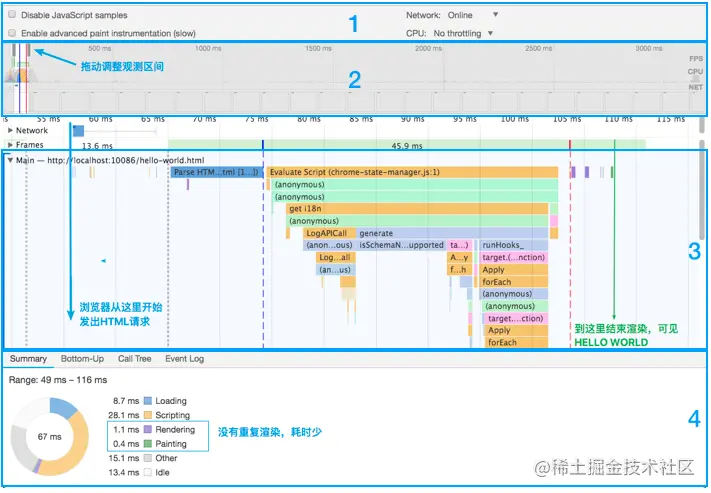
reload 方式收集渲染数据,将 beforeunload -> unload -> Send Request(第一个资源请求) -> load 的过程都记录下来
在工具自动停止记录后,我们得到了这样一份报告:
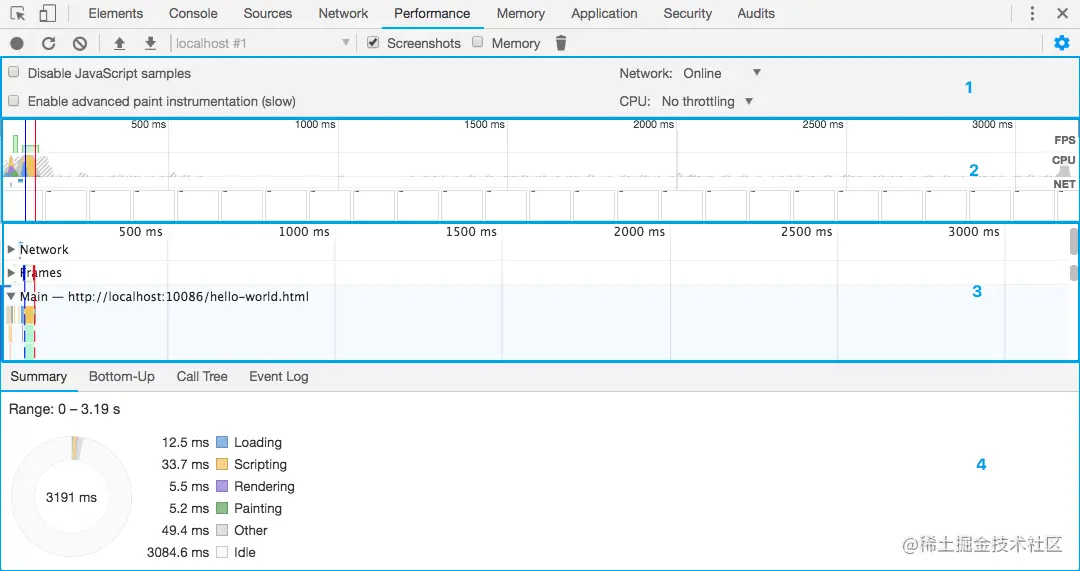
图中划出的 4 个区域分别是:
1:控制面板,用来控制工具的特性。「Network」与「CPU」:分别限制网络和计算资源,模拟不同终端环境,可以更容易观测到性能瓶颈。「Disable JavaScript samples」选项开启会使工具忽略记录 JS 的调用栈,这个我们之后会再提到。打开「Enable advanced paint instrumentation」则会详细记录某些渲染事件的细节,这个功能我们在了解这些事件后再聊。
2:概览面板,其中有描述帧率(FPS)、CPU 使用率、网络资源情况的 3 个图表。帧率是描绘每秒钟渲染多少帧图像的指标,帧率越高则在观感上更流畅。网络情况是以瀑布图的形式呈现,图中观察到各资源的加载时间与顺序。CPU 使用率面积图的其实是一张连续的堆积柱状图(下面 CPU 面积图放大版为示意图,数据非严谨对应):
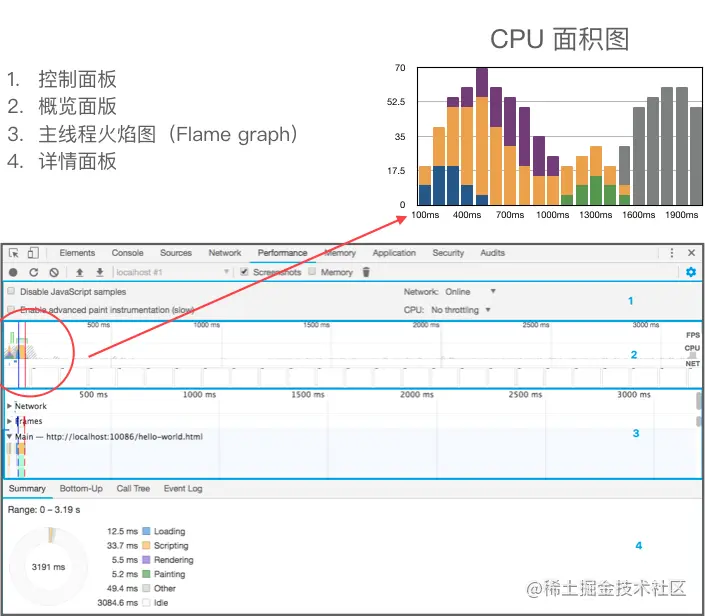
其纵轴是 CPU 使用率,横轴是时间,不同的颜色代表着不同的事件类型,其中:
- 蓝色:加载(Loading)事件
- 黄色:脚本运算(Scripting)事件
- 紫色:渲染(Rendering)事件
- 绿色:绘制(Painting)事件
- 灰色:其他(Other)
- 闲置:浏览器空闲
举例来说,示意图的第一列:总 CPU 使用率为 18,加载事件(蓝色)和脚本运算事件(黄色)各占了一半(9)。随着时间增加,脚本运算事件的 CPU 使用率逐渐增加,而加载事件的使用率在 600ms 左右降为 0;另一方面渲染事件(紫色)的使用率先升后降,在 1100ms 左右将为 0。整张图可以清晰地体现哪个时间段什么事件占据 CPU 多少比例的使用率。
3:线程面板,用以观察细节事件,在概览面板缩小观察范围可以看到线程图的细节。其中主线程火焰图是用来分析渲染性能的主要图表。不同于「正常」火焰图,这里展示的火焰图是倒置的,即最上层是父级函数或应用,越往下则调用栈越浅,最底层的一小格(如果时间维度拉得不够长,看起来像是一小竖线)表示的是函数调用栈顶层。默认情况下火焰图会记录已执行 JS 程序调用栈中的每层函数(精确到单个函数的粒度),非常详细。而开启「Disable JS Samples」后,火焰图只会精确到事件级别(调用某个 JS 文件中的函数是一个事件),忽略该事件下的所有函数调用栈。
此外,帧线程时序图(Frames)和网络瀑布图(Network)可以从时间维度分别查看绘制出的页面和资源加载情况。
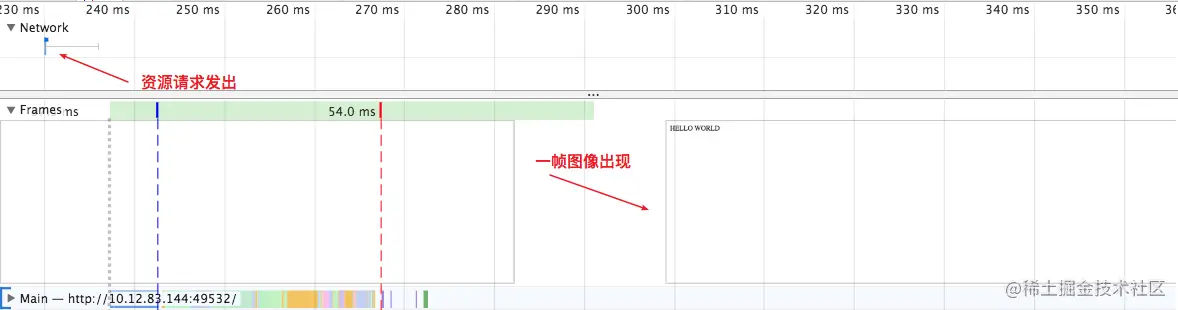
4:详情面板。Performance 工具中,所有的记录的最细粒度就是事件。这里的事件不是指 JS 中的事件,而是一个抽象概念,我们打开主线程火焰图,随意点击一个方块,就可以在详情面板里看到该事件的详情,包括事件名、事件耗时、发起者等信息。举几个例子:Parse HTML 是一种 Loading 事件(蓝色),它表示在在事件时间内,Chrome 正在执行其 HTML 解析算法;Event 是一种 Scripting 事件(黄色),它表示正在执行 JS 事件(例如 click);Paint 是一种绘制事件(绿色),表示 Chrome 将合成的图层绘制出来。
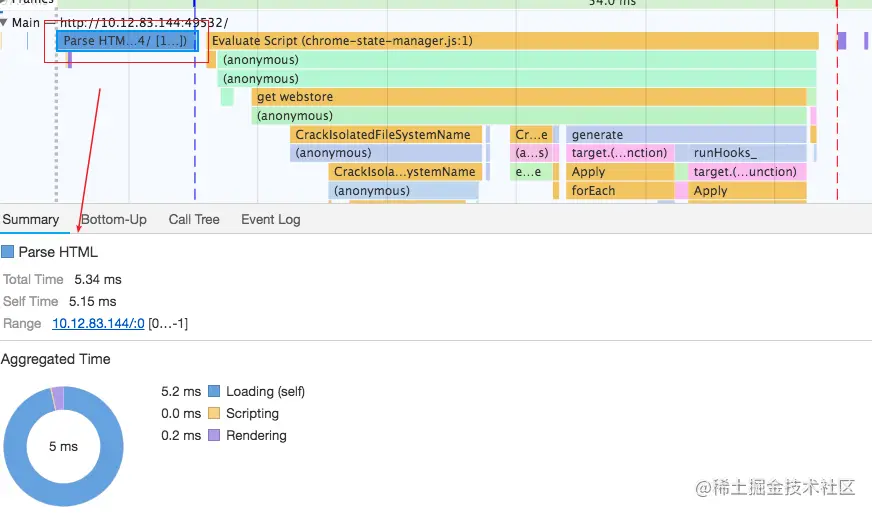
以下是一些常见事件,有个印象就好,由于每次做性能分析必会跟它们打交道,我们想不记住他们也难。

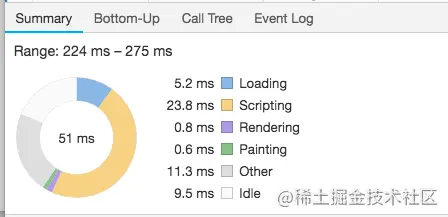
详情面板还有非常重要的一部分就是事件耗时饼状图,它列出了你选择的时间段内,不同类型事件(加载、脚本运算、渲染、绘制、其他事件、发呆:) )所占的比例和耗费的时间。分析占比同分析 CPU 面积图有相通的意义 —— 到底是哪种事件造成了性能瓶颈。
至此,我们扫了一遍 Performance 工具的主要功能
界面上 UI 的更改都是通过 DOM 操作实现的,并不是通过传统的刷新页面实现 的。尽管 DOM 提供了丰富接口供外部调用,但 DOM 操作的代价很高,页面前端代码的性能瓶颈也大多集中在 DOM 操作上,所以前端性能优化的一个主要的关注 点就是 DOM 操作的优化。
DOM 操作优化的总原则是尽量减少 DOM 操作。
监控 FPS
,通过浏览器的 requestAnimationFrame API (可以使用 setInterval polyfill)来实现。
代码类似:
var lastTime = performance.now();
var frame = 0;
var lastFameTime = performance.now();
var loop = function (time) {
var now = performance.now();
var fs = now - lastFameTime;
lastFameTime = now;
var fps = Math.round(1000 / fs);
frame++;
if (now > 1000 + lastTime) {
var fps = Math.round((frame * 1000) / (now - lastTime));
frame = 0;
lastTime = now;
}
window.requestAnimationFrame(loop);
};
通俗地解释就是,通过 requestAnimationFrame API 来定时执行一些 JS 代码,如果浏览器卡顿,无法很好地保证渲染的频率,1s 中 frame 无法达到 60 帧,即可间接地反映浏览器的渲染帧率。
用的日志通道上报到大数据平台进行分析即可。
那如何通过 FPS 确定网页存在卡顿呢?按照我们对卡顿的观察,连续出现 3 个低于 20 的 FPS 即可认为网页存在卡顿。
function isBlocking(fpsList, below = 20, last = 3) {
var count = 0;
for (var i = 0; i < fpsList.length; i++) {
if (fpsList[i] && fpsList[i] < below) {
count++;
} else {
count = 0;
}
if (count >= last) {
return true;
}
}
return false;
}
先来看看 DOM 操作为什么会影响性能?
在浏览器中,DOM 的实现和ECMAScript的实现是分离的。比如 在 IE 中,ECMAScrit的实现在jscript.dll中,而 DOM 的实现在mshtml.dll中;在 Chrome 中使用 WebKit 中的 WebCore处理 DOM 和渲染,但ECMAScript是在 V8 引擎中实现的,其他浏览器的情况类似。所以通过 JavaScript 代码调用 DOM 接 口,相当于两个独立模块的交互。相比较在同一模块中的调用,这种跨模块的调用其性能损耗是很高的。但DOM 操作对性能影响最大其实还是因为它导致了浏览器 的重绘(repaint)和回流(reflow)。
这里我们先了解下浏览器的渲染原理:
从下载文档到渲染页面的过程中,浏览器会通过解析 HTML 文档来构建 DOM 树,解析 CSS 产生 CSS 规则树。JavaScript 代码在解析过程中, 可能会修改生成的 DOM 树和 CSS 规则树(这也是为什么常常把 js 放在页面底部最后才渲染的原因)。之后根据 DOM 树和 CSS 规则树构建渲染树,在这个过程中 CSS 会根据选择器匹配 HTML 元素。渲染树包括了每 个元素的大小、边距等样式属性,渲染树中不包含隐藏元素及 head 元素等不可见元素。 最后浏览器根据元素的坐标和大小来计算每个元素的位置,并绘制这些元 素到页面上。重绘指的是页面的某些部分要重新绘制,比如颜色或背景色的修改,元素的位置和尺寸并没用改变;回流则是元素的位置或尺寸发生了改变,浏览器需 要重新计算渲染树,导致渲染树的一部分或全部发生变化。渲染树重新建立后,浏览器会重新绘制页面上受影响的元素。回流的代价比重绘的代价高很多,重绘会影 响部分的元素,而回流则有可能影响全部的元素。如下的这些 DOM 操作会导致重绘或回流:
- 增加、删除和修改可见 DOM 元素
- 页面初始化的渲染
- 移动 DOM 元素
- 修改 CSS 样式,改变 DOM 元素的尺寸
- DOM 元素内容改变,使得尺寸被撑大
- 浏览器窗口尺寸改变
- 浏览器窗口滚动
如何避免或者处理 DOM 操作造成的页面卡顿问题
1.合并多次的 DOM 操作为单次的 DOM 操作
最常见频繁进行 DOM 操作的是频繁修改 DOM 元素的样式,代码类似如下:
element.style.borderColor = '#f00';
element.style.borderStyle = 'solid';
element.style.borderWidth = '1px';
复制代码
这种编码方式会因为频繁更改 DOM 元素的样式,触发页面多次的回流或重绘,上面介绍过,现代浏览器针对这种情况有性能的优化,它会合并 DOM 操作,但并不是所有的浏览器都存在这样的优化。推荐的方式是把 DOM 操作尽量合并,如上的代码可以优化为:
// 优化方案1
element.style.cssText += 'border: 1px solid #f00;';
// 优化方案2
element.className += 'empty';
复制代码
示例的代码有两种优化的方案,都做到了把多次的样式设置合并为一次设置。方案 2 比方案 1 稍微有一些性能上的损耗,因为它需要查询 CSS 类。但方案 2 的维护性最好,这在上一章曾经讨论过。很多时候,如果性能问题并不突出,选择编码方案时需要优先考虑的是代码的维护性。
类似的操作还有通过 innerHTML 接口修改 DOM 元素的内容。不要直接通过此接口来拼接 HTML 代码,而是以字符串方式拼接好代码后,一次性赋值给 DOM 元素的 innerHTML 接口。
2.把 DOM 元素离线或隐藏后修改
把 DOM 元素从页面流中脱离或隐藏,这样处理后,只会在 DOM 元素脱离和添加时,或者是隐藏和显示时才会造成页面的重绘或回流,对脱离了页面布局流的 DOM 元素操作就不会导致页面的性能问题。这种方式适合那些需要大批量修改 DOM 元素的情况。具体的方式主要有三种:
- (1)使用文档片段
文档片段是一个轻量级的 document 对象,并不会和特定的页面关联。通过在文档片段上进行 DOM 操作,可以降低 DOM 操作对页面性能的影响,这 种方式是创建一个文档片段,并在此片段上进行必要的 DOM 操作,操作完成后将它附加在页面中。对页面性能的影响只存在于最后把文档片段附加到页面的这一步 操作上。代码类似如下:
var fragment = document.createDocumentFragment();
// 一些基于fragment的大量DOM操作
...
document.getElementById('myElement').appendChild(fragment);
复制代码
- (2)通过设置 DOM 元素的 display 样式为 none 来隐藏元素
这种方式是通过隐藏页面的 DOM 元素,达到在页面中移除元素的效果,经过大量的 DOM 操作后恢复元素原来的 display 样式。对于这类会引起页面重绘或回流的操作,就只有隐藏和显示 DOM 元素这两个步骤了。代码类似如下:
var myElement = document.getElementById('myElement');
myElement.style.display = 'none';
// 一些基于myElement的大量DOM操作
...
myElement.style.display = 'block';
复制代码
- (3)克隆 DOM 元素到内存中
这种方式是把页面上的 DOM 元素克隆一份到内存中,然后再在内存中操作克隆的元素,操作完成后使用此克隆元素替换页面中原来的 DOM 元素。这样一来,影响性能的操作就只是最后替换元素的这一步操作了,在内存中操作克隆元素不会引起页面上的性能损耗。代码类似如下:
var old = document.getElementById('myElement');
var clone = old.cloneNode(true);
// 一些基于clone的大量DOM操作
...
old.parentNode.replaceChild(clone, old);
复制代码
在现代的浏览器中,因为有了 DOM 操作的优化,所以应用如上的方式后可能并不能明显感受到性能的改善。但是在仍然占有市场的一些旧浏览器中,应用以上这三种编码方式则可以大幅提高页面渲染性能。
3. 设置具有动画效果的 DOM 元素的 position 属性为 fixed 或 absolute
把页面中具有动画效果的元素设置为绝对定位,使得元素脱离页面布局流,从而避免了页面频繁的回流,只涉及动画元素自身的回流了。这种做法可以提高动 画效果的展示性能。如果把动画元素设置为绝对定位并不符合设计的要求,则可以在动画开始时将其设置为绝对定位,等动画结束后恢复原始的定位设置。在很多的 网站中,页面的顶部会有大幅的广告展示,一般会动画展开和折叠显示。如果不做性能的优化,这个效果的性能损耗是很明显的。使用这里提到的优化方案,则可以 提高性能。
4. 谨慎取得 DOM 元素的布局信息
前面讨论过,获取 DOM 的布局信息会有性能的损耗,所以如果存在重复调用,最佳的做法是尽量把这些值缓存在局部变量中。考虑如下的一个示例:
for (var i=0; i < len; i++) {
myElements[i].style.top = targetElement.offsetTop + i*5 + 'px';
}
复制代码
如上的代码中,会在一个循环中反复取得一个元素的 offsetTop 值,事实上,在此代码中该元素的 offsetTop 值并不会变更,所以会存在不必要的性能损耗。优化的方案是在循环外部取得元素的 offsetTop 值,相比较之前的方案,此方案只是调用了一遍元素的 offsetTop 值。更改后的代码如下:
var targetTop = targetElement.offsetTop;
for (var i=0; i < len; i++) {
myElements[i].style.top = targetTop+ i*5 + 'px';
}
复制代码
另外,因为取得 DOM 元素的布局信息会强制浏览器刷新渲染树,并且可能会导致页面的重绘或回流,所以在有大批量 DOM 操作时,应避免获取 DOM 元素 的布局信息,使得浏览器针对大批量 DOM 操作的优化不被破坏。如果需要这些布局信息,最好是在 DOM 操作之前就取得。考虑如下一个示例:
var newWidth = div1.offsetWidth + 10;
div1.style.width = newWidth + 'px';
var newHeight = myElement.offsetHeight + 10; // 强制页面回流
myElement.style.height = newHeight + 'px'; // 又会回流一次
复制代码
根据上面的介绍,代码在遇到取得 DOM 元素的信息时会触发页面重新计算渲染树,所以如上的代码会导致页面回流两次,如果把取得 DOM 元素的布局信息提前,因为浏览器会优化连续的 DOM 操作,所以实际上只会有一次的页面回流出现,优化后的代码如下:
var newWidth = div1.offsetWidth + 10;
var newHeight = myElement.offsetHeight + 10;
div1.style.width = newWidth + 'px';
myElement.style.height = newHeight + 'px';
复制代码
5. 使用事件托管方式绑定事件
在 DOM 元素上绑定事件会影响页面的性能,一方面,绑定事件本身会占用处理时间,另一方面,浏览器保存事件绑定,所以绑定事件也会占用内存。页面中 元素绑定的事件越多,占用的处理时间和内存就越大,性能也就相对越差,所以在页面中绑定的事件越少越好。一个优雅的手段是使用事件托管方式,即利用事件冒 泡机制,只在父元素上绑定事件处理,用于处理所有子元素的事件,在事件处理函数中根据传入的参数判断事件源元素,针对不同的源元素做不同的处理。这样就不 需要给每个子元素都绑定事件了,管理的事件绑定数量变少了,自然性能也就提高了。这种方式也有很大的灵活性,可以很方便地添加或删除子元素,不需要考虑因 元素移除或改动而需要修改事件绑定。示例代码如下:
// 获取父节点,并添加一个click事件
document.getElementById('list').addEventListener("click",function(e) { // 检查事件源元素 if(e.target && e.target.nodeName.toUpperCase == "LI") { // 针对子元素的处理 ...
}
});
复制代码
上述代码中,只在父元素上绑定了 click 事件,当点击子节点时,click 事件会冒泡,父节点捕获事件后通过 e.target 检查事件源元素并做相应地处理。 在 JavaScript 中,事件绑定方式存在浏览器兼容问题,所以在很多框架中也提供了相似的接口方法用于事件托管。比如在 jQuery 中可以使用如下方式实现事件的托管(示例代码来自 jQuery 官方网站):
$("table").on("click", "td", function () {
$(this).toggleClass("chosen");
});
11.淘宝首页性能优化实践
存在多个影响首页性能的因素:
- 依赖系统过多,数据的请求分为三块,其一是静态资源(如 js/css/image/iconfont 等);其二是推到 CDN 的静态数据(如运营填写的数据、前端配置信息等);其三是后端接口,不同的模块对应不同的业务,而且页面中还有不少的广告内容,粗略估计页面刚加载时首屏发出的接口请求就有 8 个,滚到最底下,得发出 20 多个请求。
- 无法直接输出首屏数据,首屏很多数据是通过异步请求获取的,由于系统限制,这些请求不可避免,而且请求个数较多,十分影响首屏时间。
- 模块过多,为了能够在后台隔离运营之间填写数据的权限,模块必须做细粒度的拆分,一个简单的模块必须拆分成多个行业小模块,页面中其他位置也是如此,而且这些被拆分出来的模块还不一定会展现出来,需要让算法告诉前端展示哪些模块。
- 图片过多,翻页往下滚动,很明显看到,页面整屏整屏的图片,有些图片是运营填写,有些图片由个性化接口提供,这些图片都没有固定的尺寸。
性能指标
FPS
最能反映页面性能的一个指标是 FPS(frame per second),一般系统设定屏幕的刷新率为 60fps,当页面元素动画、滚动或者渐变时绘制速率小于 60,就会不流畅,小于 24 就会卡顿,小于 12 基本认定卡爆了。
1 帧的时长约 16ms,除去系统上下文切换开销,每一帧中只留给我们 10ms 左右的程序处理时间,如果一段脚本的处理时间超过 10ms,那么这一帧就可以被认定为丢失,如果处理时间超过 26ms,可以认定连续两帧丢失,依次类推。我们不能容忍页面中多次出现连续丢失五六帧的情况,也就是说必须想办法分拆执行时间超过 80ms 的代码程序,这个工作并不轻松。
页面在刚开始载入的时候,需要初始化很多程序,也可能有大量耗时的 DOM 操作,所以前 1s 的必要操作会导致帧率很低,我们可以忽略。当然,这是对 PC 而言,Mobile 内容少,无论是 DOM 还是 JS 脚本量都远小于 PC,1s 可能就有点长了。
DOMContentLoaded 和 Load
DOM 加载并且解析完成才会触发 DOMContentLoaded 事件,倘若源码输出的内容过多,客户端解析 DOM 的时间也会响应加长,不要小看这里的解析时间,如果 DOM 数量增加 2000 个并且嵌套层级较深,解析时间也会相应增加 50-200ms,这个消耗对大多数页面来说其实是没必要的,保证首屏输出即可,后续的内容只保留钩子,利用 JS 动态渲染。
Load 时间可以用来衡量首屏加载中,客户端接受的信息总量,如果在首屏中充满了大尺寸图片或者客户端与后端建立连接次数较多,Load 时间也会相应被拖长。
流畅度
流畅度是对 FPS 的视觉反馈,FPS 值越高,视觉呈现越流畅。为了保障页面的加载速度,很多内容不会在页面打开的时候全部加载到客户端。这里提到的流畅度是等待过程中的视觉缓冲
优化措施
关键模块优先
不论用户首屏的面积有多大,保证关键模块优先加载
除必须立即加载的模块外,关键模块被加到懒加载监控,原因是,部分用户进入页面就可能急速往下拖拽页面,此时,没必要渲染这些首屏模块。
非关键模块统一送到 lazyQueue 队列,没有基于将非关键模块加入到懒加载监控,这里有两个原因:
- 一旦加入监控,程序滚动就需要对每个模块做计算判断,模块太多,这里可能存在性能损失
- 如果关键模块还没有加载好,非关键模块进入视窗就会开始渲染,这势必会影响关键模块的渲染
两种请求下会开始将非关键模块加入懒加载监控
- 当页面中触发
mousemove scroll mousedown touchstart touchmove keydown resize onload这些事件的时候,说明用户开始与页面交互了,程序必须开始加载。 - 如果用户没有交互,但是页面已经 onload 了,程序当然不能浪费这个绝佳的空档机会,趁机加载内容;经测试,部分情况下,onload 事件没有触发(原因尚不知),所以还设定了一个超时加载,5s 之后,不论页面加载情况如何,都会将剩下的非关键模块加入到懒加载监控。
懒执行,有交互才执行
如果说上面的优化叫做懒加载,那么这里的优化可以称之为懒执行。
首页上有几个模块是包含交互的,如头条区域的 tab ,便民服务的浮层和主题市场的浮层,部分用户进入页面可能根本不会使用这些功能,所以程序上并没有对这些模块做彻底的初始化,而是等到用户 hover 到这个模块上再执行全部逻辑。
更懒的执行,刷新页面才执行
首屏中有两个次要请求,一个是主题市场的 hot 标,将用户最常逛的三个类目打标;第二个是个人中心的背景,不同的城市会展示不同的背景图片,这里需要请求拿到城市信息。
这两处的渲染策略都是,在程序的 idle(空闲)时期,或者 window.onload 十秒之后去请求,然后将请求的结果缓存到本地,当用户第二次访问淘宝首页时能够看到效果。这是一种更懒的执行,用户刷新页面才看得到.这种优化是产品能够接受,也是技术上合理的优化手段。
图片尺寸的控制和懒加载
不论图片链接的来源是运营填写还是接口输出,都难以保证图片具备恰当的宽高,加上如今 retina 的屏幕越来越多,对于这种用户也要提供优质的视觉体验,图片这块的处理并不轻松。
12.京东微信购物首页性能优化实践
一般来说产品是按以下方式进行迭代的,我认为循环的起点应该是「收集用户反馈」,我们对页面的优化依据和目标一个重要来源就是用户的反馈,因此说网页优化我们先从网页监控开始聊起。
监控系统简介
京东前端监控涉及的系统主要有两个:测速系统和智能监控平台。
测速系统
网页将各个关键节点的测速信息(时间戳)上传给系统,系统收集信息后对每个节点按省份、时间、网络类型、客户端类型等多个维度进行统计,并提供可视化分析结果,可以很方便的监控网页的加载情况。
智能监控平台
网页按照约定格式上报信息给系统,系统收集信息后按照预设的分析模式统计分析结果,若分析结果不符合预期还提供给告警功能。
我们在微信首页 CSS 加载完成、HTML 加载完成、JS 加载完成、首屏图片加载完成、第一张图片加载完成等关键节点插入测速点,并根据业务特点对关键内容上报智能监控平台,如查询首屏 DOM 节点是否存在上报首屏可用率、检测重要接口返回信息上报接口可用率。这样我们就能对微信首页的运行健康情况有一个比较全面的了解。
微信首页监控的两个阶段
第一阶段:主要关注首屏内容的加载优化( 2014 ~ 2019.5 )
这个阶段我们我们关注网页的加载速度,我们选取首屏图片加载完成时间作为核心监控点,重点关注 CSS 加载完成时间、HTML 加载完成时间、JS 加载完成时间、第一张图片加载完成时间。
第一阶段我们的目标是首屏图片加载完成时间控制在 1000ms 以内,其他时间越短越好。为达到这个目的,我们采取了一下措施。
1、首屏直出
首屏直出,也就是服务端渲染( SSR ),微信首页使用的是一个高效的 C++ 模板- CS 模板生成微信首页首屏内容。
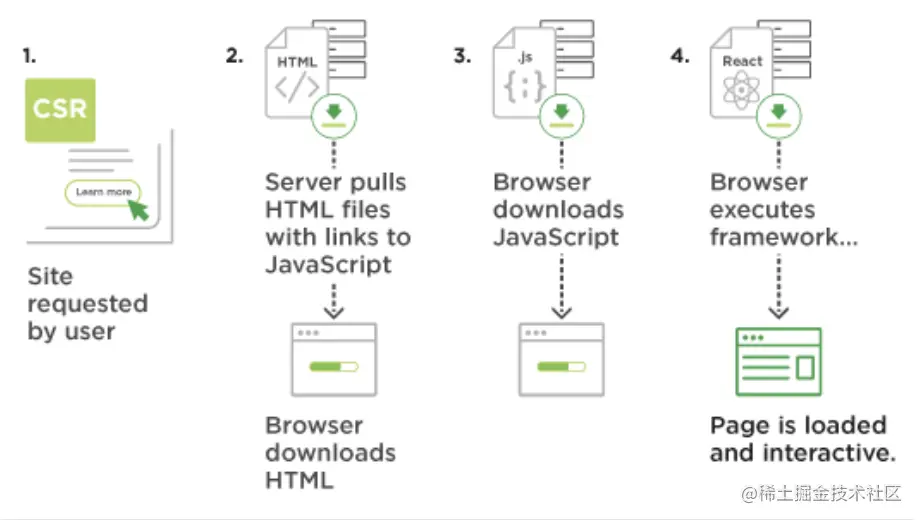
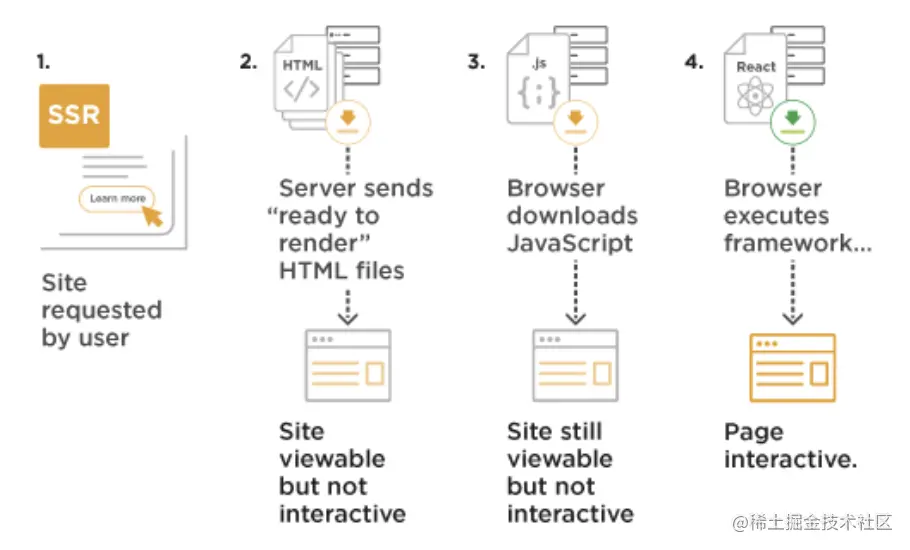
以上是服务端渲染( SSR )和客户端渲染( CSR )在浏览器中的呈现区别,根据我们测试系统检测采用首屏 SSR 后首屏图片加载完成时间减少了 1200ms 左右,而且体验更好了。
2、关键渲染路径优化
关键渲染路径( Critical Render Path )简称 CRP ,是指一系列在首屏渲染中必须发生事件,优化关键渲染路径就是优先显示与当前用户操作有关的内容。
这是一个不太「精确」的概念,主要是关键渲染的规定,这和业务息息相关。关键渲染通常来说是指首屏渲染(用户第一眼可见区域)、页面的核心内容部分(这个也有点抽象)。
关键渲染路径的三个属性
- 关键资源:可能阻止网页首次渲染的资源。划重点:阻止网页首页渲染。
- 关键路劲长度:获取所有关键资源所需的往返次数或总时间。就是获取所有关键资源要请求多少次。
- 关键字节:实现网页首次渲染所需的总字节数,它是所有关键资源传送文件大小的总和。
阻止网页首页渲染的资源
根据浏览器工作原理,首先浏览器是构建内 DOM 树和 CSSOM 树,然后将 DOM 树和 CSSOM 树合成「渲染树」,通过渲染树计算出布局信息然后渲染到屏幕上。
因此从渲染流程上来说,HTML 和 CSS 肯定是阻止网页首页渲染的资源,因为没有它们就不能构建出渲染树。 JavaScript 因为可能修改 DOM 或 CSSOM ,因此默认情况下浏览器在解析到 script 标签时会停止 DOM 树的构建,等 JavaScript 执行完再从 script 标签位置重新开始构建 DOM ,所以说 JavaScript 也是阻止网页首页渲染的资源。
根据关键渲染路径理论,我们可以从三个方面去优化网页:
- 尽量减少网页首次渲染的资源
- 减少关键路径长度,减少请求次数
- 减少关键资源大小
2.1、尽量减少网页首次渲染的资源——拆分首屏和非首屏
拆分首屏和非首屏目的是划分出关键资源,我们定义除底部 tab 以上的的部分为首屏内容,这部分内容用户会最先看到,后面的优化措施就是尽量让首屏内容尽快展示。
对于非首屏内容采取延迟加载的方式处理。JS、CSS 异步加载 ,图片资源懒加载(快进入可视区域时加载)。
2.2、减少关键路径长度,减少请求次数
关键渲染路径长度是指获取关键资源网络请求次数
对于这块的优化,我们采取了一下措施:
- 首屏样式和 JS 内联
- 合并 JS 文件到一个 JS
- 首屏 ICON 图片内联处理
- 底部导航图标合成雪碧图
2.3、减少关键资源大小
对于首屏资源我们按类别分别作了一下优化处理。
对于 HTML,我们使用 html-minifier 工具精简 HTML 内容,去除不必要的空格和换行。
对于 JS,我们基于 webpack 对其进行 Treeshaking ,使用 webpack 对 JS 进行 treeshaking 依赖 ES2015(ES6) 模块系统中的静态结构特性,因此这部分的优化需要对 JS 进行 ES6 改造。
对于 CSS,开发过程中经常出现某次活动的样式在活动下线后忘记去掉,到最后不敢轻易去掉,造成不少无用样式存在。打包的时候我们使用 purifyCSS 对这种样式进行删除。改工具的实现原理可以开阔为:将 CSS 选择器名称切割成一个个单词,然后在所有可能用到的文件中查找这些单词,若单词在没有出现在任何地方说明该 CSS 选择器对应的样式没有用到,可以删除。
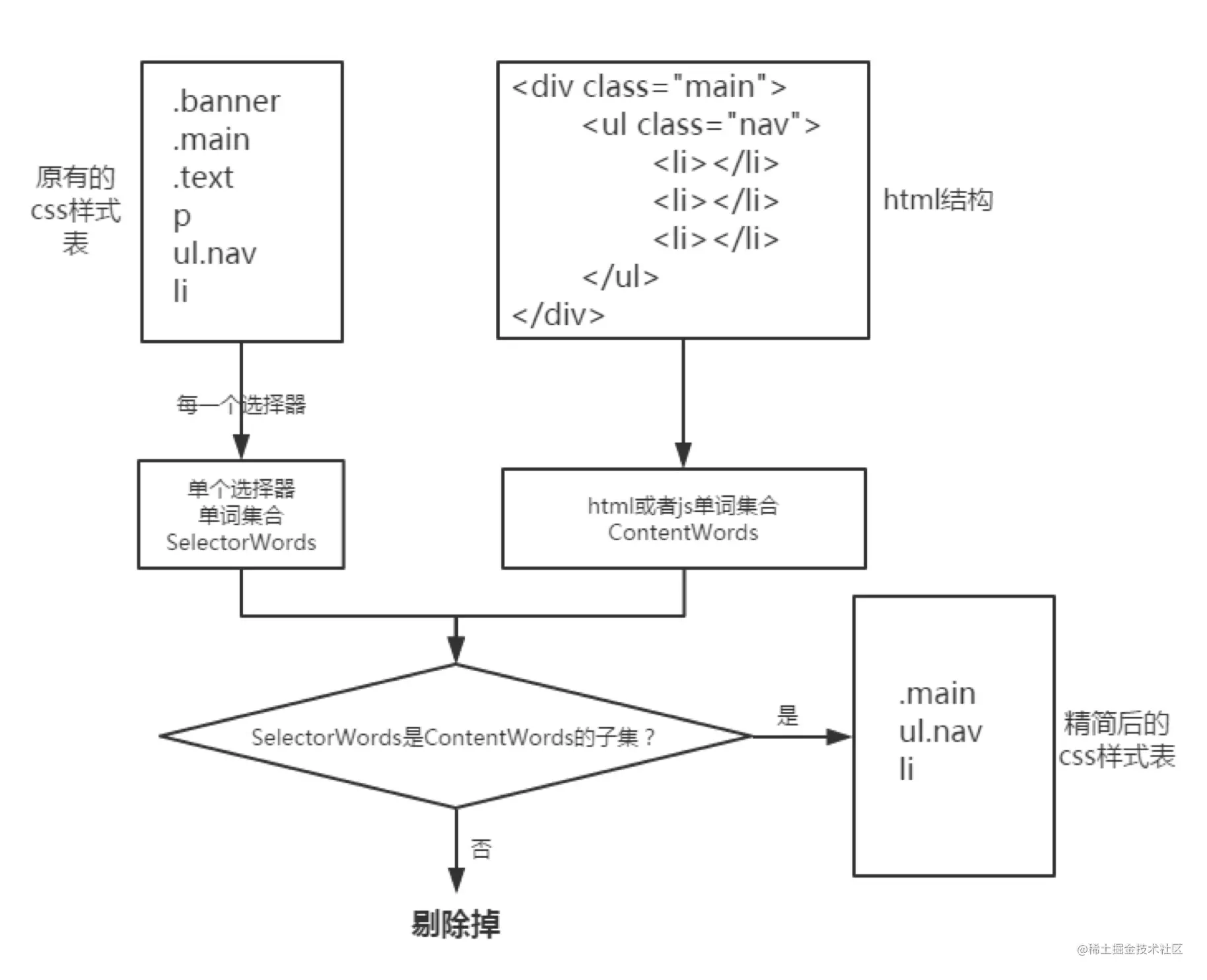
微信首页由于历史的积累,存在不少无用样式,使用 purifyCSS 工具处理后能节省 58KB 的关键资源大小。
对于 JSON 文件 ,首页内容大都需要运营配置,因此存在大量 JSON 数据,经过长年的积累对性能的消耗已不容忽视,如下面的一个配置的解析就占用了 200ms。这块我们一是推动推动运营删除过期数据,二是推动优化 JSON 数据接口,接口智能删除过期数据。
3.图片的优化
3.1、使用 WEBP 和 DPG 格式代替 PNG 和 JPG。
我们在客户端检测当前环境是否支持 WEBP 和 DPG,并提供统一的转换函数,服务端也提供了相同的功能。
根据我们实验对比发现:
1、DPG 格式和 WEBP 格式均有明显的压缩效果,压缩比例平均在 60%以下;
2、DPG 压缩比 WEBP 压缩的效果稍微更好一些;
3、DPG + WEBP 双压缩比单种格式压缩有更明显的提升,达到 30%。
3.2、图片无损压缩
这块包含两方面的措施,一是我们在使用工具发布微信首页时,对页面直接依赖的图片做无损压缩,这是后图片大都是设计师给的切图,切图存在大量无用的信息,这时候无损压缩一半能节省一半的大小。
另一方面是借助京东图片服务压缩图片,我们需要按图片服务要求格式访问图片即可获得压缩处理后的图片。
3.3 使用 MP4 代替 GIF
根据我们测试对比,绝大情况下 MP4 的大小要比 GIF 小很多
4.资源预加载
4.1、Preload
Preload 是一个新的控制特定资源如何被加载的新的 Web 标准,这是已经在 2016 年 1 月废弃的 subresource prefetch 的升级版。一般来说,最好使用 preload 来加载你最重要的资源,比如图像,CSS ,JavaScript 和字体文件。这不要与浏览器预加载混淆,浏览器预加载只预先加载在 HTML 中声明的资源。Preload 指令事实上克服了这个限制并且允许预加载在 CSS 和 JavaScript 中定义的资源,并允许决定何时应用每个资源。
4.2 Preconnect
Preconnect 是 HTTP 请求正式发给服务器前预先执行一些操作,这包括 DNS 解析,TLS 协商,TCP 握手,这消除了往返延迟并为用户节省了时间。我们对页面中常用域名做了 Preconnect 。
4.3 DNS prefetch/ Link-prefetch/Prerending
DNS prefetching 允许浏览器在用户浏览页面时在后台运行 DNS 的解析。如此一来,DNS 的解析在用户点击一个链接时已经完成,所以可以减少延迟。可以在一个 link 标签的属性中添加 rel="dns-prefetch" 来对指定的 URL 进行 DNS prefetching。
Link prefetching 假设用户将请求指定的 url,浏览器在空闲的时候获取资源并将他们存储在缓存中。
Prerendering 和 prefetching 非常相似,它们都优化了可能导航到的下一页上的资源的加载,区别是 prerendering 在后台渲染了整个页面,整个页面所有的资源。
第二阶段:以 RAIL 模型为基础的多维度优化( 2019.5 ~ now )
一直以来,我们都用「页面首屏图片加载时间」这个指标来作为优化我们性能的关键 KPI。但是此指标对于「页面白屏时间很长」、「进度条加载慢」、「搜索框、轮播 banner、底部导航三个模块出来比较慢」几个体验问题,是无法衡量的。即使我们把「页面首屏图片加载时间」这个数据优化的很小,也并不意味着页面的性能和体验很好。这说明拿这个来衡量页面性能远远不够,我们需要更多维度的性能指标来衡量页面的性能。另外,「页面首屏图片加载时间」是一个复合动作后的数据结果,包含了 css/js 加载和解析,以及图片的加载和渲染等综合情况,并不能很好的指导页面做性能优化。再者,这个指标并不是一个标准指标,跟开发同学具体的埋点很有关系,有些页面还很不好埋点(比如有些内容新人才可见,怎么算首屏)。综上来说,我们需要有更多维度的、更标准的性能指标来描述页面的性能,并指导页面做性能优化。
我们采用 Google 的 RAIL 模型,此模型关注 Web 应用生命周期的四个方面:响应( Response ,响应时间不超过 100ms ),动画( Animation,10ms 完成一帧),空闲( Idle,空闲时间越多越好),加载( Load,1000ms 内完成加载),并提出以用户为中心的性能指标。
RAIL 模型的愿景
- 网页性能优化要以用户为中心;最终目标不是让您的网站在任何特定设备上都能运行很快,而是使用户满意。
- 网页应该立即响应用户;在 100 毫秒以内确认用户输入。
- 网页应该在设置动画或滚动时,在 10 毫秒以内生成帧。
- 网页应该最大程度增加主线程的空闲时间。
- 网页应该持续吸引用户;在 1000 毫秒以内呈现交互内容。
RAIL 模型对应的四个评估维度
- Response:页面响应用户的操作应该 100ms 内
- Animation:对于页面中的动画,应该再 10ms 内生成一帧
- Idle:要实现小于 100 毫秒的响应,应用必须在每 50 毫秒内将控制返回给主线程
- Load:要求您的网页在 1000ms 内呈现关键路径内容给用户
新性能模型下监控侧重点
当我们采用以用户为中心的性能模型时,我们肯定也需要采用以用户为中心的性能指标。
1、首次绘制时间(FP): FP 标记浏览器渲染任何在视觉上不同于导航前屏幕内容之内容的时间点
2、首次内容绘制时间(FCP): FCP 标记的是浏览器渲染来自 DOM 第一位内容的时间点,该内容可能是文本、图像、SVG 甚至 canvas 元素
4、首次有效绘制(FMP):这是一个「模糊」的概念,是指页面的主要元素开始绘制的时间
5、可交互时间(TTI): 用于标记应用已进行视觉渲染并能可靠响应用户输入的时间点。
6、Long Tasks 监控:根据实测,使用支持最好的 Chrome 实验,获得的监控结果也不太有用,因此 Long Task 监控展示作罢。
第二阶段的性能优化
第二阶段的性能优化基于第一阶段的基础上,为了能达到 RAIL 模型要求,我们进一步做了一下事情。
1、进一步深化关键渲染路径的优化
我们站在用户的角度,结合京东微信购物首页流量转化情况,分析认为首页除了首屏广告 banner,搜索框和底部导航作为用户使用频率最高的几个模块应该提前渲染。并以首屏广告 banner 作为首次有效绘制。
对于搜索框,之前需要加载 3 个 JS 请求和 1 个 CSS 请求才能渲染出来,致使搜索框的渲染严重滞后。我们把之前通过 JS 渲染的 DOM 直接以页面片形式引入,并将 CSS 样式内联,这样搜索框能在首屏加载时就显示出来,然后我们将 3 个 JS 文件合并成一个,这样就加快了搜索框的初始化。
对于底部导航依赖了一个独立的 CSS 文件,而且在很靠下的位置,我们把底部导航的代码提前到搜索框的下面,并将样式内联。
2、动画优化
动画是造成页面卡顿的重要元凶之一,尤其是是用 setInterval 实现的动画,容易造成丢帧现象。因此我们用 requestAnimationFarme 代替 setInterval ,解决了部分机型动画卡顿问题 。
3、滚动优化
当直接监听页面滚动时间时,由于滚动事件触发频率很高,即使一个简单的 handler 函数也会造成大量的开销。因此我们对滚动事件做了节流,只允许一个函数在 X 毫秒内执行一次,只有当上一次函数执行后过了你规定的时间间隔,才能进行下一次该函数的调用。
4、图片懒加载优化
为了实现图片 DOM 渲染时不加载,等到快进入可视区域时加载,我们需要不听的观察图片是否进入了可视区域。之前我们做法是开启定时任务,无限循环查询 img 标签是否在可视区,很容易生成 Long Task,造成页面响应迟钝。
使用最新的 IntersectionObserver 接口代替定时任务,将监控 img 是否可见的任务交给浏览器,能显著提高效率。
13.首页白屏解决方案
白屏原因:
vue 首页白屏的原因是打包后的 js 和 css 文件过大,浏览器初始访问网站时,会先加载该项目的 js 和 css 文件,加载完成后才会进行页面渲染。如果打包的文件过大,加载时间就会变长,出现视觉上的页面白屏.
白屏时间(FP)
白屏时间(First paint):指浏览器从响应用户输入网址地址,到浏览器开始显示内容的时间。
- 白屏时间= 页面开始展示的时间点——开始请求的时间点
首屏时间(FCP)
首屏时间(First Contentful Paint):指浏览器从响应用户输入网络地址,到首屏内容渲染完成的时间。
- 首屏时间= 首屏内容渲染结束时间点——开始请求的时间点
最基本、简单解决方法
首页添加一个 loading,在 index.html 里加一个 loadingcss 效果,当页面加载完成后消失。
代码解决方案:
路由懒加载
- 未使用路由懒加载的写法
import HelloWorld from '@/components/HelloWorld'
routes:[{
path:'/',
name:'HelloWorld',
component:HelloWorld
}]
复制代码
使用路由懒加载
routes:[{
path:'/index',
name:'index',
component:() => import('@/views/index')
}]
复制代码
总结:使用懒加载,打包后才根据路由生成多个 js 和 css 文件,当访问到对应的路由时,才加载对应的文件
在移动端页面的首页时,先加载可视区域的内容,剩下的内容等它进入可视区域后再按需加载
CDN 资源优化
随着项目越做越大,需要依赖的第三方 npm 包也越多,构建后的文件也越大。
- 将 vue、vue-router、vuex、axios 等 vue 的全家桶资源,全部改为通过 CDN 链接获取,在 index.html 里插入相应的链接
<body>
<div id="app"></div>
<script src="https://cdn.bootcss.com/vue/2.6.10/vue.min.js"></script>
<script src="https://cdn.bootcss.com/axios/0.19.0-beta.1/axios.min.js"></script>
<script src="https://cdn.bootcss.com/vuex/3.1.0/vuex.min.js"></script>
<script src="https://cdn.bootcss.com/vue-router/3.0.2/vue-router.min.js"></script>
<script src="https://cdn.bootcss.com/element-ui/2.6.1/index.js"></script>
</body>
复制代码
- 在vue.config.js中配置externals属性
复制代码
module.exports = {
...
externals:{
'vue':'Vue',
'vuex':'Vuex',
'vue-router':'VueRouter',
'axios':'axios'
}
}
复制代码
- 卸载相关依赖的npm包
复制代码
npm uninstall vue vue-router vuex axios
复制代码
缓存
- 接口缓存
- 端内所有请求都走 Native,实现接口缓存
- 静态资源缓存
- 静态资源长期不需要修改的,使用强缓存,设置 Cache-Control 实现,设置 Cache-Control:max-age=31536000,浏览器在一年内直接使用本地缓存文件,不向服务器发送请求。
- 资源随时变动,设置 ETag 实现协商缓存,初次请求资源时,设置 ETag,并返回 200,之后请求时带上 If-none-match 字段,询问服务器当前版本是否可用。
并行化处理
利用 HTTP2.0 多路复用的特点,单个文件可以单独上线,不需要再做 JS 文件合并了。采用二进制数据帧和流的方式进行传输。
搭建性能平台(埋点)
目的:为了能获取到一部分上报数据。 例如:页面访问次数,那些位置、入口点击数最高等
手动埋点 原理:调用埋点 SDK 的函数,在需要埋点的业务逻辑功能位置调用接口上报埋点数据
- 手动埋点的技术本质是,能获取到那些内容:
- 域名:document.domainURLdomcument.URl
- 页面标题:document.title
- 分辨率:window.screen.height & window.screen.width
- 颜色深度:window.screen.colorDepth
- Referrer:cocument.referrer
- 埋点做法
// 命令式埋点
()=>{
//...逻辑代码
sendData(params);//这里是发送埋点数据,params是封装的埋点数据
}
// 声明式埋点
<div data-spm-data="{name:'点击',event:'touch',agent:'...'}">Touch</div>
复制代码- 手动埋点的技术本质是,能获取到那些内容:
利用 window.Performance(API)
可以拿到 DNS 解析时间、TCP 建立连接时间、首页白屏时间、DOM 渲染完成时间、页面 load 时间等
SSR
服务端渲染,在服务端将渲染逻辑处理好,然后将处理好的 HTML 直接返回给前端展示,可以解决白屏问题。
预渲染
- 利用 webpack 的插件 prerender-spa-plugin 做预渲染 配置如下
const path = require('path')
const PrerenderSPAPlugin = require('prerender-spa-plugin') const Renderer = PrerenderSPAPlugin.PuppeteerRenderer module.exports = {
configureWebpack: config => {
let plugins = []
plugins.push(new PrerenderSPAPlugin({
staticDir: path.resolve(__dirname, 'dist'),
routes: ['/', '/about'],
minify: {
collapseBooleanAttributes: true,
collapseWhitespace: true,
decodeEntities: true,
keepClosingSlash: true,
sortAttributes: true
},
renderer: new Renderer({
renderAfterDocumentEvent: 'custom-render-trigger'
})
}))
config.plugins = [
...config.plugins, ...plugins ]
}
}
复制代码
staticDir:预渲染输出的文件地址 routes:要做预渲染的路由 minify:压缩相关的配置 renderer 渲染引擎相关的配置 总结:最后的结果是预渲染插件在编译阶段就将对应的路由编译好插入到 app 节点,这样就能在 js 文件解析过程中有内容展示,js 解析完成后,Vue 会将 app 节点内的内容替换成 Vue 渲染好的内容。
Chrome Dev Tools 计算性能指标
可以使用 Chrome Dev Tools 计算性能指标
- Network:页面中各种资源请求的情况(资源名称、状态、协议、资源类型和大小)等
- Performance:页面各项性能指标的火焰图,(白屏时间、FPS、资源加载时间线)
骨架屏
意义:骨架屏就是在页面尚未加载之前先给用户展示页面的大致结构,在骨架页面中,图片、文字、图标都将通过灰色矩形块或圆形块显示,直到页面请求数据后渲染页面。
原理: 通过 puppeteer 在服务端操控 headless Chrome 打开开发中的需要生成骨架页面的页面,在等待页面加载渲染完成之后,保留页面布局样式的前提下,通过对页面中元素进行删减或增添,通过样式覆盖,使其展示为灰色块。
element-plus 中有骨架屏
<el-skeleton>
设计方法
如何设计组件
组件设计规范
1.扁平的,面向数据的 state/props 扁平 props 也可以很好地清除组件正在使用的数据值。如果你传给组件一个对象但是你并不能清楚的知道对象内部的属性值,所以找出实际需要的数据值是来自组件具体的属性值则是额外的工作。 state / props 还应该只包含组件渲染所需的数据。 (此外,对于数据繁重的应用程序,数据规范化可以带来巨大的好处,除了扁平化之外,你可能还需要考虑一些别的优化方法)。
2.更加纯粹的 State 变化 对 state 的更改通常应该响应某种事件,例如用户单击按钮或 API 的响应。此外它们不应该因为别的 state 的变化而做出响应,因为 state 之间这种关联可能会导致难以理解和维护的组件行为。state 变化应该没有副作用。
3.松耦合 组件的核心思想是它们是可复用的,为此要求它们必须具有功能性和完整性。
“耦合”是指实体彼此依赖的术语。
松散耦合的实体应该能够独立运行,而不依赖于其他模块。
就前端组件而言,耦合的主要部分是组件的功能依赖于其父级及其传递的 props 的多少,以及内部使用的子组件(当然还有引用的部分,如第三方模块或用户脚本)。
如果不是要设计需要服务于特定的一次性场景的组件,那么设计组件的最终目标是让它与父组件松散耦合,呈现更好的复用性,而不是受限于特定的上下文环境
4.辅助代码分离 一个有效的原则就是将辅助代码分离出来放在特定的地方,这样你在处理组件时就不必考虑这些。例如:
配置代码 假数据 5.及时模块化 我们在实际进行组件抽离工作的时候,需要考虑到不要过度的组件化 在决定是否将代码分开时,无论是 Javascript 逻辑还是抽离为新的组件,都需要考虑以下几点:
是否有足够的页面结构/逻辑来保证它? 代码重复(或可能重复)? 它会减少需要书写的模板吗? 性能会收到影响吗? 是否会在测试代码的所有部分时遇到问题? 是否有一个明确的理由? 这些好处是否超过了成本? 6.集中统一的状态管理 许多大型应用程序使用 Redux 或 Vuex 等状态管理工具(或者具有类似 React 中的 Context API 状态共享设置)。这意味着他们从 store 获得 props 而不是通过父级传递。在考虑组件的可重用性时,你不仅要考虑直接的父级中传递而来的 props,还要考虑 从 store 中获取到的 props。
由于将组件挂接到 store(或上下文)很容易并且无论组件的层次结构位置如何都可以完成,因此很容易在 store 和 web 应用的组件之间快速创建大量紧密耦合(不关心组件所处的层级)
组件设计原则
标准性
任何一个组件都应该遵守一套标准,可以使得不同区域的开发人员据此标准开发出一套标准统一的组件
独立性
描述了组件的细粒度,遵循单一职责原则,保持组件的纯粹性 属性配置等 API 对外开放,组件内部状态对外封闭,尽可能的少与业务耦合
复用与易用
UI 差异,消化在组件内部(注意并不是写一堆 if/else) 输入输出友好,易用
追求短小精悍
适用 SPOT 法则
Single Point Of Truth,就是尽量不要重复代码,出自《The Art of Unix Programming》
避免暴露组件内部实现
避免直接操作 DOM,避免使用 ref
使用父组件的 state 控制子组件的状态而不是直接通过 ref 操作子组件入口处检查参数的有效性,出口处检查返回的正确性
无环依赖原则(ADP)
设计不当导致环形依赖示意图
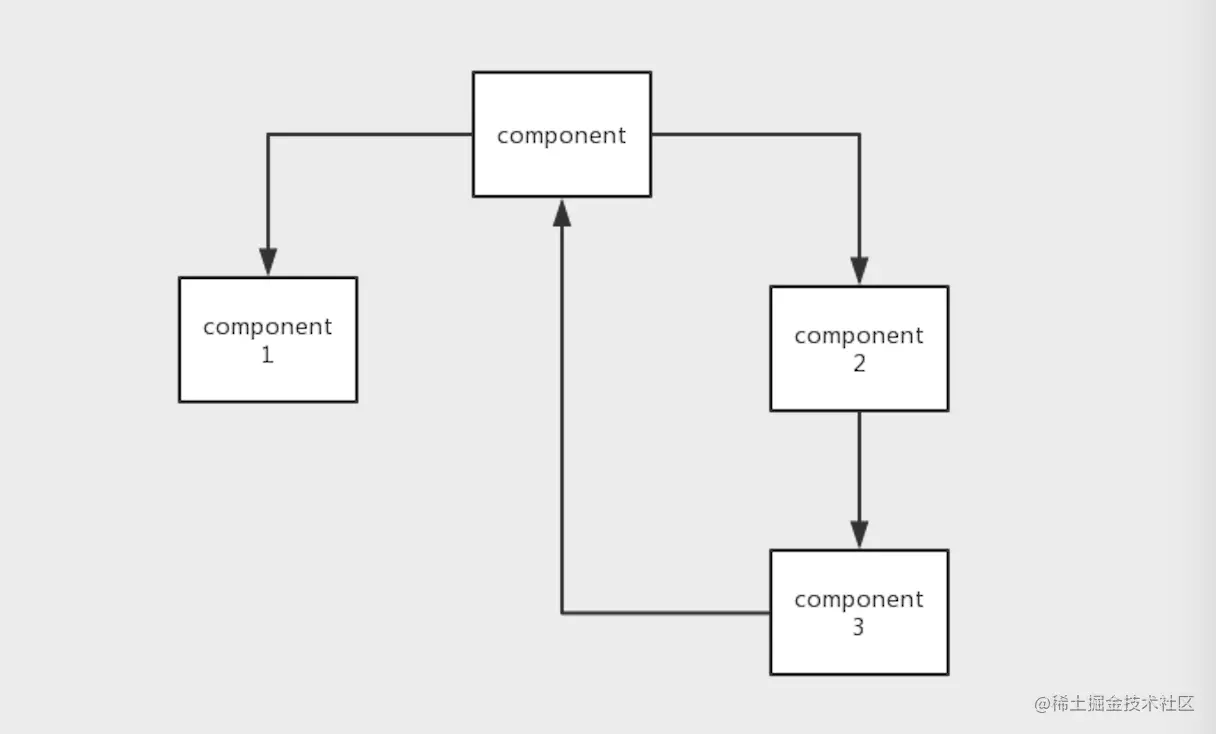
影响
组件间耦合度高,集成测试难 一处修改,处处影响,交付周期长 因为组件之间存在循环依赖,变成了“先有鸡还是先有蛋”的问题
那倘若我们真的遇到了这种问题,就要考虑如何处理
消除环形依赖
我们的追求是沿着逆向的依赖关系即可寻找到所有受影响的组件
创建一个共同依赖的新组件

稳定抽象原则(SAP)
- 组件的抽象程度与其稳定程度成正比,
- 一个稳定的组件应该是抽象的(逻辑无关的)
- 一个不稳定的组件应该是具体的(逻辑相关的)
- 为降低组件之间的耦合度,我们要针对抽象组件编程,而不是针对业务实现编程
避免冗余状态
如果一个数据可以由另一个 state 变换得到,那么这个数据就不是一个 state,只需要写一个变换的处理函数,在 Vue 中可以使用计算属性
如果一个数据是固定的,不会变化的常量,那么这个数据就如同 HTML 固定的站点标题一样,写死或作为全局配置属性等,不属于 state
如果兄弟组件拥有相同的 state,那么这个 state 应该放到更高的层级,使用 props 传递到两个组件中
合理的依赖关系
- 父组件不依赖子组件,删除某个子组件不会造成功能异常
扁平化参数
- 除了数据,避免复杂的对象,尽量只接收原始类型的值
良好的接口设计
把组件内部可以完成的工作做到极致,虽然提倡拥抱变化,但接口不是越多越好
如果常量变为 props 能应对更多的场景,那么就可以作为 props,原有的常量可作为默认值。
如果需要为了某一调用者编写大量特定需求的代码,那么可以考虑通过扩展等方式构建一个新的组件。
保证组件的属性和事件足够的给大多数的组件使用。
API 尽量和已知概念保持一致、
组件分类
将组件应分为以下几类
- 基础组件(通常在组件库里就解决了)
- 容器型组件(Container)
- 展示型组件(stateless)
- 业务组件
- 通用组件
- UI 组件
- 逻辑组件
- 高阶组件(HOC)
容器型组件
一个容器性质的组件,一般当作一个业务子模块的入口,比如一个路由指向的组件
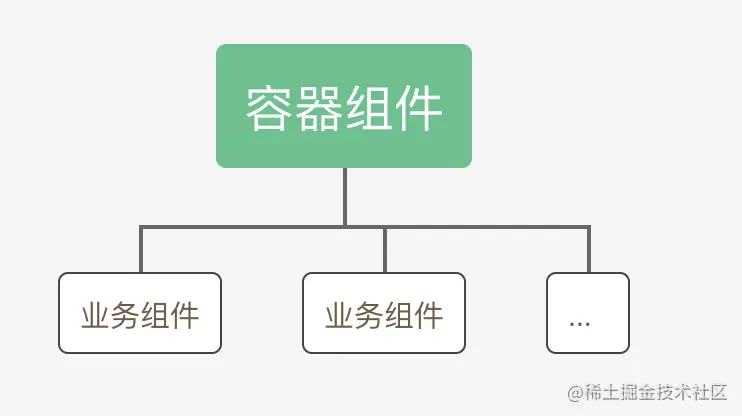
特点
- 容器组件内的子组件通常具有业务或数据依赖关系
- 集中/统一的状态管理,向其他展示型/容器型组件提供数据(充当数据源)和行为逻辑处理(接收回调)
- 如果使用了全局状态管理,那么容器内部的业务组件可以自行调用全局状态处理业务
- 业务模块内子组件的通信等统筹处理,充当子级组件通信的状态中转站
- 模版基本都是子级组件的集合,很少包含
DOM标签 - 辅助代码分离
表现形式(vue)
<template>
<div class="purchase-box">
<!-- 面包屑导航 -->
<bread-crumbs />
<div class="scroll-content">
<!-- 搜索区域 -->
<Search v-show="toggleFilter" :form="form"/>
<!--展开收起区域-->
<Toggle :toggleFilter="toggleFilter"/>
<!-- 列表区域-->
<List :data="listData"/>
</div>
</template>
展示型(stateless)组件
主要表现为组件是怎样渲染的,就像一个简单的模版渲染过程
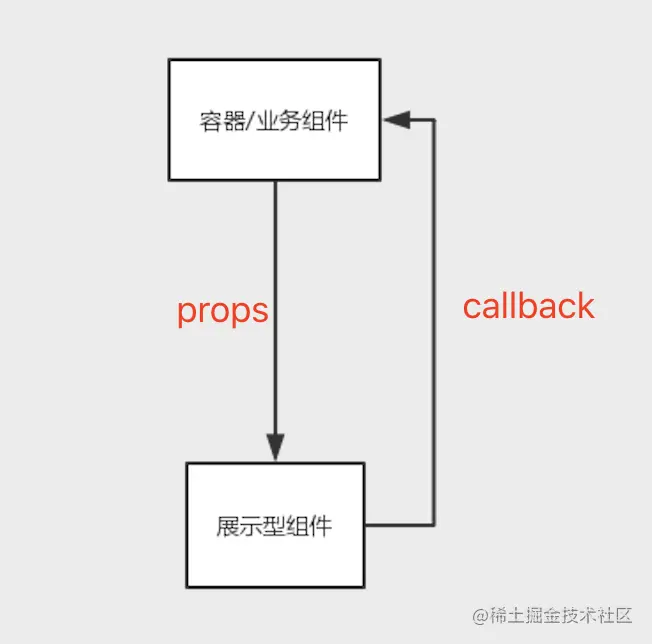
特点
- 只通过 props 接受数据和回调函数,不充当数据源
- 可能包含展示和容器组件 并且一般会有 Dom 标签和 css 样式
- 通常用 props.children(react) 或者 slot(vue)来包含其他组件
- 对第三方没有依赖(对于一个应用级的组件来说可以有)
- 可以有状态,在其生命周期内可以操纵并改变其内部状态,职责单一,将不属于自己的行为通过回调传递出去,让父级去处理(搜索组件的搜索事件/表单的添加事件)
表现形式(vue)
<template>
<div class="purchase-box">
<el-table
:data="data"
:class="{'is-empty': !data || data.length ==0 }"
>
<el-table-column
v-for = "(item, index) in listItemConfig"
:key="item + index"
:prop="item.prop"
:label="item.label"
:width="item.width ? item.width : ''"
:min-width="item.minWidth ? item.minWidth : ''"
:max-width="item.maxWidth ? item.maxWidth : ''">
</el-table-column>
<!-- 操作 -->
<el-table-column label="操作" align="right" width="60">
<template slot-scope="scope">
<slot :data="scope.row" name="listOption"></slot>
</template>
</el-table-column>
<!-- 列表为空 -->
<template slot="empty">
<common-empty />
</template>
</el-table>
</div>
</template>
<script>
export default {
props: {
listItemConfig:{ //列表项配置
type:Array,
default: () => {
return [{
prop:'sku_name',
label:'商品名称',
minWidth:200
},{
prop:'sku_code',
label:'SKU',
minWidth:120
},{
prop:'product_barcode',
label:'条形码',
minWidth:120
}]
}
}}
}
</script>
业务组件
通常是根据最小业务状态抽象而出,有些业务组件也具有一定的复用性,但大多数是一次性组件
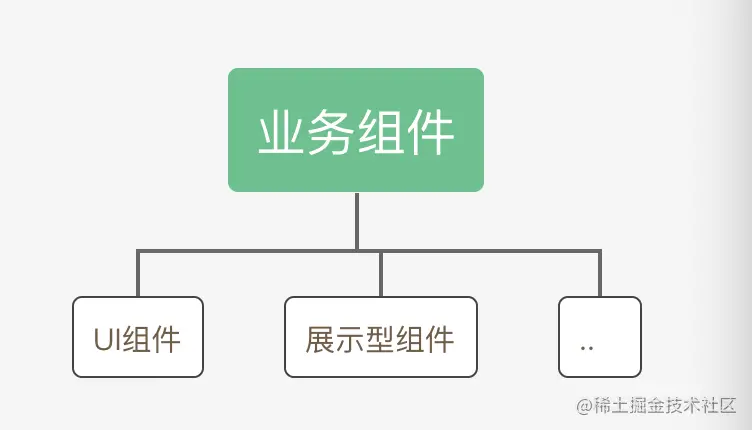
通用组件
可以在一个或多个 APP 内通用的组件
UI 组件
- 界面扩展类组件,比如弹窗
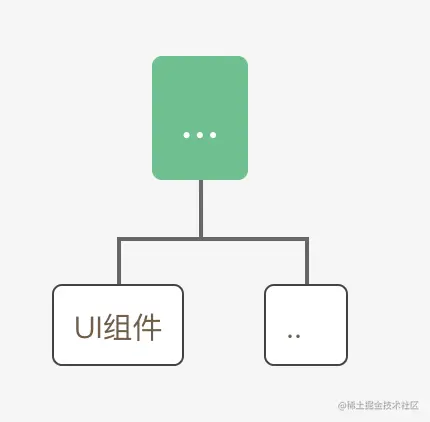
特点:复用性强,只通过 props、events 和 slots 等组件接口与外部通信
表现形式(vue)
<template>
<div class="empty">
<img src="/images/empty.png" alt>
<p>暂无数据</p>
</div>
</template>
逻辑组件
- 不包含 UI 层的某个功能的逻辑集合
高阶组件(HOC)
高阶组件可以看做是函数式编程中的组合 可以把高阶组件看做是一个函数,他接收一个组件作为参数,并返回一个功能增强的组件
高阶组件可以抽象组件公共功能的方法而不污染你本身的组件 比如 debounce 与 throttle
用一张图来表示
React 中高阶组件是比较常用的组件封装形式,Vue 官方内置了一个高阶组件keep-alive通过维护一个 cache 实现数据持久化,但并未推荐使用 HOC :(
在 React 中写组件就是在写函数,函数拥有的功能组件都有
Vue 更像是高度封装的函数,能够让你轻松的完成一些事情,但与高度的封装相对的就是损失一定的灵活,你需要按照一定规则才能使系统更
如何实现上拉加载,下拉刷新?
下拉刷新和上拉加载这两种交互方式通常出现在移动端中
本质上等同于 PC 网页中的分页,只是交互形式不同
开源社区也有很多优秀的解决方案,如iscroll、better-scroll、pulltorefresh.js库等等
这些第三方库使用起来非常便捷
我们通过原生的方式实现一次上拉加载,下拉刷新,有助于对第三方库有更好的理解与使用
下拉刷新和上拉加载这两种交互方式通常出现在移动端中
本质上等同于 PC 网页中的分页,只是交互形式不同
开源社区也有很多优秀的解决方案,如iscroll、better-scroll、pulltorefresh.js库等等
这些第三方库使用起来非常便捷
我们通过原生的方式实现一次上拉加载,下拉刷新,有助于对第三方库有更好的理解与使用
首先可以看一张图
上拉加载
上拉加载的本质是页面触底,或者快要触底时的动作
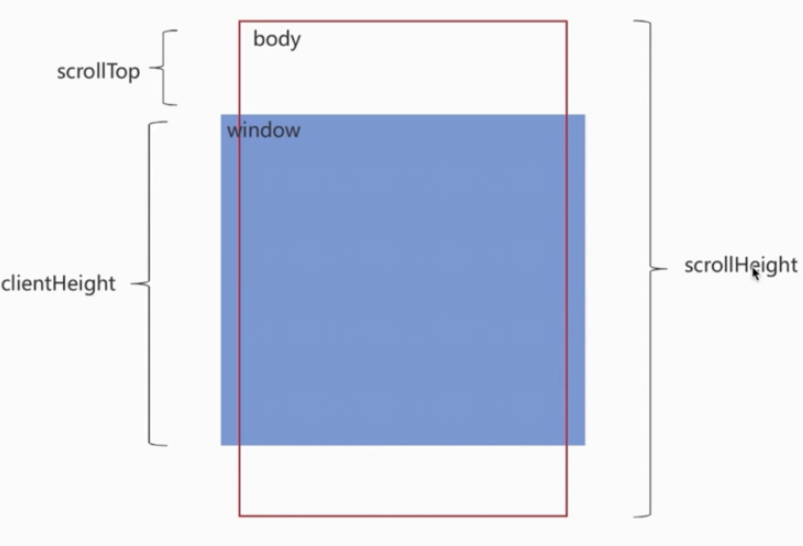
判断页面触底我们需要先了解一下下面几个属性
scrollTop:滚动视窗的高度距离window顶部的距离,它会随着往上滚动而不断增加,初始值是 0,它是一个变化的值clientHeight:它是一个定值,表示屏幕可视区域的高度;scrollHeight:页面不能滚动时是不存在的,body长度超过window时才会出现,所表示body所有元素的长度
综上我们得出一个触底公式:
scrollTop + clientHeight >= scrollHeight;
let clientHeight = document.documentElement.clientHeight; //浏览器高度
let scrollHeight = document.body.scrollHeight;
let scrollTop = document.documentElement.scrollTop;
let distance = 50; //距离视窗还用50的时候,开始触发;
if (scrollTop + clientHeight >= scrollHeight - distance) {
console.log("开始加载数据");
}
下拉刷新
下拉刷新的本质是页面本身置于顶部时,用户下拉时需要触发的动作
关于下拉刷新的原生实现,主要分成三步:
- 监听原生
touchstart事件,记录其初始位置的值,e.touches[0].pageY; - 监听原生
touchmove事件,记录并计算当前滑动的位置值与初始位置值的差值,大于0表示向下拉动,并借助 CSS3 的translateY属性使元素跟随手势向下滑动对应的差值,同时也应设置一个允许滑动的最大值; - 监听原生
touchend事件,若此时元素滑动达到最大值,则触发callback,同时将translateY重设为0,元素回到初始位置
举个例子:
Html结构如下:
<main>
<p class="refreshText"></p>
<ul id="refreshContainer">
<li>111</li>
<li>222</li>
<li>333</li>
<li>444</li>
<li>555</li>
...
</ul>
</main>
监听touchstart事件,记录初始的值
var _element = document.getElementById("refreshContainer"),
_refreshText = document.querySelector(".refreshText"),
_startPos = 0, // 初始的值
_transitionHeight = 0; // 移动的距离
_element.addEventListener(
"touchstart",
function (e) {
_startPos = e.touches[0].pageY; // 记录初始位置
_element.style.position = "relative";
_element.style.transition = "transform 0s";
},
false
);
监听touchmove移动事件,记录滑动差值
_element.addEventListener(
"touchmove",
function (e) {
// e.touches[0].pageY 当前位置
_transitionHeight = e.touches[0].pageY - _startPos; // 记录差值
if (_transitionHeight > 0 && _transitionHeight < 60) {
_refreshText.innerText = "下拉刷新";
_element.style.transform = "translateY(" + _transitionHeight + "px)";
if (_transitionHeight > 55) {
_refreshText.innerText = "释放更新";
}
}
},
false
);
最后,就是监听touchend离开的事件
_element.addEventListener(
"touchend",
function (e) {
_element.style.transition = "transform 0.5s ease 1s";
_element.style.transform = "translateY(0px)";
_refreshText.innerText = "更新中...";
// todo...
},
false
);
从上面可以看到,在下拉到松手的过程中,经历了三个阶段:
- 当前手势滑动位置与初始位置差值大于零时,提示正在进行下拉刷新操作
- 下拉到一定值时,显示松手释放后的操作提示
- 下拉到达设定最大值松手时,执行回调,提示正在进行更新操作
如何实现前端皮肤切换
CSS 变量实现
基本用法
声明一个变量,属性名需要以两个减号(--)开始,属性值则可以是任何有效的 CSS 值。
element {
--main-bg-color: brown;
}
选择器是指定变量的可见作用域,该变量仅用于匹配当前选择器及其子孙,通常的最佳实践是定义在根伪类 :root 下,这样就可以在 HTML 文档的任何地方访问到它了。
:root {
--main-bg-color: brown;
}
使用一个局部变量时用 var() 函数包裹以表示一个合法的属性值:
element {
background-color: var(--main-bg-color);
}
备用值
用 var() 函数可以定义多个备用值(fallback value),当给定值未定义时将会用备用值替换
备用值并不是用于实现浏览器兼容性的。如果浏览器不支持 CSS 自定义属性,备用值也没什么用
color: var(--my-var, red);
background-color: var(--my-var, var(--my-background, pink));
有效性
传统的 CSS 概念里,有效性和属性是绑定的,这对变量来说并不适用。当变量被解析,浏览器不知道它们什么时候会被使用,所以必须认为这些值都是有效的。
即便这些值是有效的,但当通过 var() 函数调用时,它在特定上下文环境下也可能不会奏效。属性和自定义变量会导致无效的 CSS 语句,这引入了一个新的概念:计算时有效性。
<p>This paragraph is initial black.</p>
:root { --text-color: 16px; }
p { color: blue; }
p { color: var(--text-color); }
浏览器将 --text-color 的值替换给了 var(--text-color),但是 16px 并不是 color 的合法属性值。代换之后,该属性不会产生任何作用。浏览器会执行如下两个步骤:
- 检查属性 color 是否为继承属性。是,但是
<p>没有任何父元素定义了 color 属性。转到下一步。 - 将该值设置为它的默认初始值,black。
当 CSS 属性-值对中存在语法错误,该行则会被忽略。然而如果自定义属性(变量)的值无效,它并不会被忽略,从而会导致该值被覆盖为默认值。
JavaScript 中的值
// 获取一个 Dom 节点上的 CSS 变量
element.style.getPropertyValue("--my-var"); // MDN上给的,但获取一直是空的,其他两个倒是没问题
// 获取任意 Dom 节点上的 CSS 变量
getComputedStyle(element).getPropertyValue("--my-var");
// 修改一个 Dom 节点上的 CSS 变量
element.style.setProperty("--my-var", jsVar + 4);
代码实现
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
* {
margin: 0;
padding: 0;
}
:root {
--bg: #000;
--fontSize: 25px;
}
.pink-theme {
--bg: hotpink;
}
body {
transition: background 1s;
background: var(--bg);
}
button {
position: fixed;
top: 50%;
left: 50%;
transition: color 1s;
transform: translate(-50%, -50%);
padding: 20px;
border: none;
background: #fff;
font-size: var(--fontSize);
color: var(--bg);
}
</style>
</head>
<body>
<button>点击切换</button>
<script>
document.querySelector("button").addEventListener("click", () => {
if (document.body.classList.contains("pink-theme")) {
document.body.classList.remove("pink-theme");
} else {
document.body.classList.add("pink-theme");
}
});
</script>
</body>
</html>
前端监控(埋点)
埋点分析,是网站分析的一种常用的数据采集方法
性能监控
在小项目时,由于用户数量不多,大家觉得过得去就行,而当用户数量激增以后,性能监控,就显得非常重要,因为,这样你能就能知道潜在的一些问题和 bug,并且能快速迭代,获得更好的用户体验!一般情况下,我们在性能监控时需要注意那么几点:
- 1、白屏时长
- 2、重要页面的 http 请求时间
- 3、重要页面的渲染时间
- 4、首屏加载时长
有人就会问了,这个白屏时长和首屏加载时长不是一回事吗?这里的白屏时长其实指的时,页面从请求到达到渲染条件,出现 ui 骨架的时间(这里测试的是请求域名到 dns 解析完毕,返回页面骨架的时间)而首屏加载时长是页面所有动态内容加载完成的时间,其中包括 ajax 数据后渲染到页面的时间
数据监控
所谓数据监控就是能拿到用户的行为,我们也需要注意那么几点:
- 1、PV 访问来量(Page View)
- 2、UV 访问数(Unique Visitor)
- 3、记录操作系统和浏览器
- 4、记录用户在页面的停留时间
- 5、进入当前页面的来源网页(也就是从哪进来的转化)
如何埋点
手动埋点也叫代码埋点,他的本质其实就是用 js 代码拿到一些基本信息,然后在一些特定的位置返回给服务端,比如:

如上图我们可以拿到这些内容,再比如:
我还可以拿到这些,有人就有疑问了,这些我咋拿到呢?
Performance
通过 Performance 我们便能拿到 DNS 解析时间、TCP 建立连接时间、首页白屏时间、DOM 渲染完成时间、页面 load 时间等,等等 废话少说上代码:
//拿到Performance并且初始化一些参数
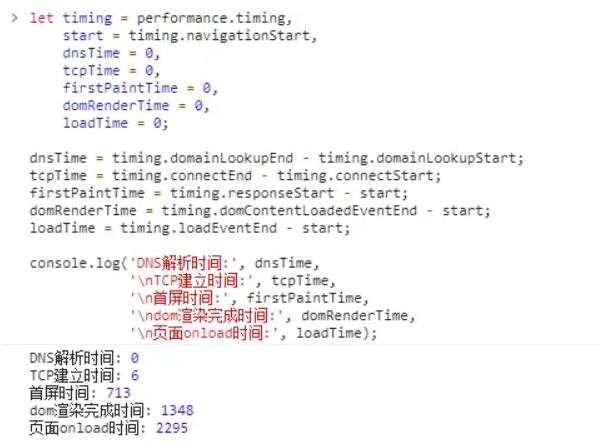
let timing = performance.timing,
start = timing.navigationStart,
dnsTime = 0,
tcpTime = 0,
firstPaintTime = 0,
domRenderTime = 0,
loadTime = 0;
//根据提供的api和属性,拿到对应的时间
dnsTime = timing.domainLookupEnd - timing.domainLookupStart;
tcpTime = timing.connectEnd - timing.connectStart;
firstPaintTime = timing.responseStart - start;
domRenderTime = timing.domContentLoadedEventEnd - start;
loadTime = timing.loadEventEnd - start;
console.log(
"DNS解析时间:",
dnsTime,
"\nTCP建立时间:",
tcpTime,
"\n首屏时间:",
firstPaintTime,
"\ndom渲染完成时间:",
domRenderTime,
"\n页面onload时间:",
loadTime
);
拿到数据以后我们可以在提交,或者通过图片的方式去提交埋点内容
// 页面加载时发送埋点请求
$(document).ready(function(){
// ... 这里存在一些业务逻辑
sendRequest(params);
});
// 按钮点击时发送埋点请求
$('button').click(function(){
// 这里存在一些业务逻辑
sendRequest(params);
});
// 通过伪装成 Image 对象,传递给后端,防止跨域
let img = new Image(1, 1);
let src = `http://aaaaa/api/test.jpg?args=${encodeURIComponent(args)}`;
img.src = src;
//css实现的埋点
.link:active::after{
content: url("http://www.example.com?action=yourdata");
}
<a class="link">点击我,会发埋点数据</a>
//data自定义属性,rangjs去拿到属性绑定事件,实现埋点
//<button data-mydata="{key:'uber_comt_share_ck', act: 'click',msg:{}}">打车</button>
这种埋点方式虽然能精准的监控到用户的行为,和网页性能等数据,但是你会发现,非常繁琐,需要大量的工作量,当然这部分工作也有人帮我们做了,比如像友盟、百度统计等给我们其实提供了服务。我们可以按照他们的流程使用手动埋点
无埋点
无埋点并不是没有任何埋点,所谓无只是不需要工程师在业务代码里面插入侵入式的代码。只需要简单的加载了一段定义好的 SDK 代码,技术门槛更低,使用与部署也简单,避免了需求变更,埋点错误导致的重新埋点。这也是大多网站的选择,因为实在太简单了 我们先来看看百度埋点长什么样子:
<script>
var _hmt = _hmt || []
;(function() {
var hm = document.createElement('script')
hm.src =
'https://hm.baidu.com/hm.js?<%= htmlWebpackPlugin.options.baiduCode %>'
var s = document.getElementsByTagName('script')[0]
s.parentNode.insertBefore(hm, s)
})()
</script>
上图一段代码插入我们的 html 中
我们便能清晰的看到统计数据,省时省力,就是不省钱!但是缺点就是由于是自动完成,无法针对特定场景拿到数据,由后端来过滤和计算出有用的数据。导致服务器压力山大,不过,既然花了钱了,咱也就不管了!
要让你设计一个前端统计 SDK ,你会如何设计?
前端统计的范围
- 访问量 PV
- 自定义事件(如统计一个按钮被点击了多少次)
- 性能
- 错误
统计数据的流程 (只做前端 SDK ,但是要了解全局)
- 前端发送统计数据给服务端
- 服务端接受,并处理统计数据
- 查看统计结果
如何设计一个 h5 抽奖页面
- 获取用户信息(同时判断是否登录)
- 如果登录,判断该用户是否已经抽奖,以判断他是否还能继续抽奖
- 抽奖接口
- 可能还需要调用登录接口
- 当然也可以直接输入手机号抽奖,需明确需求
- 埋点统计
- pv
- 自定义事件
- 微信分享
有没有看 elementUI 源码,为什么那么设计
button 组件分析
首先 Element 有几个版本,我看的是基于 Vue 的版本,所以每个组件到底就是一个 vue 文件,就和我们平时工作写的代码一样,写好一个 vue 组件,然后在需要的页面引入即可。不过更重要的是要知道如何写好这个组件(健壮吗,可扩展吗,易维护吗等)。一个 vue 组件一般可分为三部分,template、script 和 style。在这里我们就不考虑 style 了,直接在页面引用 Element 的样式就好,因为这不是我们主要关心的,我们只要知道 Element 的样式一般是这样(el-组件名--状态,比如 el-button--primary)命名的就行。所以我们组件里是没有写 style 部分的,这样做能帮我们省下好多时间和精力。
// 直接在页面中引入 Element 的样式
<link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css">
先看 template 部分
那么接下来我们就先看看 template 的部分怎么写。其实这部分是很简单的(对于这个组件来说 😁),我们可以先打开 Element 文档看一下 button 的外观样式,再来写这部分,它大概长下面这样:
 ok,假设你已经看过 button 组件的大部分外观,接下来我们就可以在脑海中先想一下(抽离并化简一下
ok,假设你已经看过 button 组件的大部分外观,接下来我们就可以在脑海中先想一下(抽离并化简一下 html 结构的公共部分),大概就是一个 div(button 标签)里面包了一个 i 图标和 span 文本这样的结构,嗯好像是这样,那就试着写一下吧!(提示:Element 组件一般最外层的样式都是用 el-组件名 包起来的)
<template>
<button class="el-button">
<i></i>
<span></span>
</button>
</template>
看上面的结构像那么回事,也简单明了。不过,然后呢 😯。。。 然后就是我们的 script 部分啦,这个才是组件的灵魂所在,重中之重,也是需要我们去啃的部分。好在这个组件简单,让我们继续往下看吧。
再看 script 部分
我们看这部分的时候,可能无从下手,但其实还是有点门道的。敲锣啦 👏👏👏。。。。不管神马组件,都有三个较为重要的组成部分:props、event 和 slot,这三个部分是组件对内对外沟通的桥梁,使得组件变得灵活起来。所以这三个 api 在发布之前一定构思好和确定好,因为后期再改就很难了,可能就是会牵一发动全身那样子。但后期对组件的处理其实不应该是这样的效果,而应该是不影响和改动之前的 api,但又可以扩展和新增功能。ok👌,就让我们一个一个娓娓道来吧 👇。 首先看下 props 的部分,你需要在脑海中想象一下 button 组件的哪些内容是可变的(根据需要外部传参的改变而改变),不用着急往下看,先好好想一下 💤。。。。
...
1)最明显的就是 button 的背景色吧,这显然是可变的,就是 type;
2)然后是有没有图标,就是 icon;
3)还有就是有没有禁用,就是 disabled;
4)再来是有没有圆角,就是 round;
5)尺寸大小也是可变的吧,就是 size;
6)好像按钮还可以是文本的样子,就是 plain;
....
好了,那我们就试着写一下 props 部分吧!(注意:props 的部分最好用对象的写法,这样能够对每个属性进行自定义设置,相比数组的写法,更为规范严谨)。
<script>
export default {
props: {
type: {
type: String,
default: "",
},
size: {
type: String,
default: "medium",
},
icon: {
type: String,
default: "",
},
disabled: Boolean,
plain: Boolean,
round: Boolean,
},
};
</script>
接下来是 slot 部分啦,如果不懂 slot 用法的同学可以先出门左拐学习一下再来 ✋。很明显,对于 button 组件来说,文本就是 slot 啦,所以 template 里面的内容可以小改一下,代码如下:
<template>
<button class="el-button">
<i></i>
<span><slot></slot></span>
</button>
</template>
然后是 event 部分,很显然啦,按钮能有什么功能呢,就是点击嘛,没了,所以它也就一个事件,就是当按钮被点击的时候,我们需要触发一个事件向上传递,也就是 $emit。于是乎,我们把事件添加到组件中,代码如下:
<template>
<button class="el-button" @click="handleClick">
<i></i>
<span><slot></slot></span>
</button>
</template>
<script>
export default {
props: {
...
},
methods: {
handleClick (e) {
this.$emit('click', e);
}
}
}
</script>
好像 event 的部分就那么多,嗯,是的,比想象中的简单 ✊。。。。
再看 template 部分
你以为组件写完了,不,并没有,你不觉得 template 里面太空了么,而且 props 这部分的属性都还没用上呢(只是声明了一下),所以我们还需要完善点东西。。。 比如 slot 部分吧,通过 $slots.default 我们可以获取到 slot 中的内容,不过这里需要加个判断,因为用户可能没有传文字,那我们就不用渲染了; 又比如图标 i 的部分,和 slot 一样,有传值我们才渲染,所以也加个判断(这里 icon 的值为 el-icon-图标名 格式)。
<template>
<button class="el-button" @click="handleClick">
<i :class="icon" v-if="icon"></i>
<span v-if="$slots.default"><slot></slot></span>
</button>
</template>
再看 props 中的属性,其实当中大部分都是用来控制样式变化的,比如 type,size,round,disabled,plain 等。。。所以就让我们为组件加上些 class 吧。
<template>
<button
class="el-button"
@click="handleClick"
:disabled="disabled"
:class="[
type ? 'el-button--' + type : '',
size ? 'el-button--' + size : '',
{
'is-disabled': disabled,
'is-plain': plain,
'is-round': round
}
]"
>
<i :class="icon" v-if="icon"></i>
<span v-if="$slots.default"><slot></slot></span>
</button>
</template>
至此我们就写完了一个较为完整的 button 组件,是不是给人一种这么简单的么的感觉,虽然它还不够完善,但也覆盖了源码 90% 的部分,剩下的 10% 大家可以自己去补充补充。其实组件主要还是要看你 🤔 思考 🤔 得有多全面,想的越多写的越多。
tag 组件分析
参数
| 参数 | 说明 | 类型 | 可选值 | 默认值 |
|---|---|---|---|---|
| type | 类型 | string | success/info/warning/danger | — |
| closable | 是否可关闭 | boolean | — | false |
| disable-transitions | 是否禁用渐变动画 | boolean | — | false |
| hit | 是否有边框描边 | boolean | — | false |
| color | 背景色 | string | — | — |
| size | 尺寸 | string | medium / small / mini | — |
| effect | 主题 | string | dark / light / plain | light |
hit、color、size、effect、type
- hit、size、effect、type 通过控制 class 设置不同的样式
- color 直接用 style 属性设置中标签上
props: {
type: String,
hit: Boolean,
color: String,
size: String,
effect: {
type: String,
default: 'light',
validator(val) {
return ['dark', 'light', 'plain'].indexOf(val) !== -1;
}
}
}
computed: {
tagSize() {
return this.size || (this.$ELEMENT || {}).size;
}
},
const classes = [
'el-tag',
type ? `el-tag--${type}` : '',
tagSize ? `el-tag--${tagSize}` : '',
effect ? `el-tag--${effect}` : '',
hit && 'is-hit'
];
const tagEl = (
<span
class={ classes }
style={{ backgroundColor: this.color }}>
...
</span>
);
closable
是否展示删除的按钮,删除的 icon 会出现在内容之后。
props: {
closable: Boolean,
},
const tagEl = (
<span>
{ this.$slots.default }
{
this.closable && <i class="el-tag__close el-icon-close" on-click={ this.handleClose }></i>
}
</span>
);
disable-transitions
动画的实现方法:使用 transition 组件嵌套一层。
props: {
disableTransitions: Boolean,
},
...
return this.disableTransitions ? tagEl : <transition name="el-zoom-in-center">{ tagEl }</transition>;
事件 close、click
分别绑定给关闭的 icon、组件根元素 span
const tagEl = (
<span
on-click={ this.handleClick }>
{ this.$slots.default }
{
this.closable && <i class="el-tag__close el-icon-close" on-click={ this.handleClose }></i>
}
</span>
);
methods: {
handleClose(event) {
event.stopPropagation();
this.$emit('close', event);
},
handleClick(event) {
this.$emit('click', event);
}
},
全部源码(不含样式)
<script>
export default {
name: 'ElTag',
props: {
text: String,
closable: Boolean,
type: String,
hit: Boolean,
disableTransitions: Boolean,
color: String,
size: String,
effect: {
type: String,
default: 'light',
validator(val) {
return ['dark', 'light', 'plain'].indexOf(val) !== -1;
}
}
},
methods: {
handleClose(event) {
event.stopPropagation();
this.$emit('close', event);
},
handleClick(event) {
this.$emit('click', event);
}
},
computed: {
tagSize() {
return this.size || (this.$ELEMENT || {}).size;
}
},
render(h) {
const { type, tagSize, hit, effect } = this;
const classes = [
'el-tag',
type ? `el-tag--${type}` : '',
tagSize ? `el-tag--${tagSize}` : '',
effect ? `el-tag--${effect}` : '',
hit && 'is-hit'
];
const tagEl = (
<span
class={ classes }
style={{ backgroundColor: this.color }}
on-click={ this.handleClick }>
{ this.$slots.default }
{
this.closable && <i class="el-tag__close el-icon-close" on-click={ this.handleClose }></i>
}
</span>
);
return this.disableTransitions ? tagEl : <transition name="el-zoom-in-center">{ tagEl }</transition>;
}
};
</script>
link 组件分析
参数
| 参数 | 说明 | 类型 | 可选值 | 默认值 |
|---|---|---|---|---|
| type | 类型 | string | primary / success / warning / danger / info | default |
| underline | 是否下划线 | boolean | — | true |
| disabled | 是否禁用状态 | boolean | — | false |
| href | 原生 href 属性 | string | — | - |
| icon | 图标类名 | string | — | - |
type、underline、disabled、href
- type、underline、disabled 都是对样式的控制
- disabled 控制是否可点击
- href 点击后跳转的链接
:class="[
'el-link',
type ? `el-link--${type}` : '',
disabled && 'is-disabled',
underline && !disabled && 'is-underline'
]"
:href="disabled ? null : href"
props: {
type: {
type: String,
default: 'default'
},
underline: {
type: Boolean,
default: true
},
disabled: Boolean,
href: String,
},
icon
- 传了 icon 参数,icon 会出现在左侧
- 直接把 icon 作为 slot 也可以,任意设置位置
<i :class="icon" v-if="icon"></i>
<span v-if="$slots.default" class="el-link--inner">
<slot></slot>
</span>
<template v-if="$slots.icon"><slot v-if="$slots.icon" name="icon"></slot></template>
props: {
icon: String
},
click 事件
设置 click 事件
@click="handleClick"
methods: {
handleClick(event) {
if (!this.disabled) {
if (!this.href) {
this.$emit('click', event);
}
}
}
}
全部源码(不含样式)
<template>
<a
:class="[
'el-link',
type ? `el-link--${type}` : '',
disabled && 'is-disabled',
underline && !disabled && 'is-underline'
]"
:href="disabled ? null : href"
v-bind="$attrs"
@click="handleClick"
>
<i :class="icon" v-if="icon"></i>
<span v-if="$slots.default" class="el-link--inner">
<slot></slot>
</span>
<template v-if="$slots.icon"><slot v-if="$slots.icon" name="icon"></slot></template>
</a>
</template>
<script>
export default {
name: 'ElLink',
props: {
type: {
type: String,
default: 'default'
},
underline: {
type: Boolean,
default: true
},
disabled: Boolean,
href: String,
icon: String
},
methods: {
handleClick(event) {
if (!this.disabled) {
if (!this.href) {
this.$emit('click', event);
}
}
}
}
};
</script>
el-table 的实现
实现下面 el-table 组件的使用,包含通过 prop 显示列,通过 template 自定义列
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<script src="https://cdn.bootcdn.net/ajax/libs/vue/2.6.12/vue.js"></script>
</head>
<body>
<div id="app">
<el-table :data="tableData">
<el-table-column prop="name" label="姓名"></el-table-column>
<el-table-column label="地址">
<template slot-scope="scope">{{scope.row.address}}</template>
</el-table-column>
</el-table>
</div>
</body>
<script>
var vm = new Vue({
el: "#app",
data: {
tableData: [
{
name: "张三",
address: "成都市青羊区清源路1号",
},
{
name: "李四",
address: "成都市青羊区清源路2号",
},
],
},
});
</script>
定义状态管理器
仿造 vuex 的结构,创建一个 TableStore 类,定义 commit 方法和 mutations 对象
// 状态管理器
class TableStore {
constructor() {
this.states = {
data: null, //table的数据
columns: [], //table的列定义
};
}
commit(name, ...args) {
//调用mutations
this.mutations[name].apply(this, [this.states].concat(args));
}
}
//mutations的定义
TableStore.prototype.mutations = {
//设置table的数据
setData(states, data) {
states.data = data;
},
//插入列定义
insertColumn(states, column) {
states.columns.push(column);
},
};
定义 el-table 组件
负责:
- 初始化状态管理器
- 通过默认插槽,接受 table-column 组件
- 使用 table-header 组件和 table-body 组件
Vue.component('el-table',{ template: `
<div class="el-table">
<!-- 隐藏列: slot里容纳table-column -->
<div class="hidden-columns">
<slot></slot>
</div>
<!-- 表头 -->
<div class="el-table__header-wrapper">
<!--表头组件-->
<table-header :store="store"></table-header>
</div>
<!-- 表体 -->
<div class="el-table__body-wrapper">
<!--表体组件-->
<table-body :store="store"></table-body>
</div>
</div>
`, props: ['data'],//table数据 data(){ return { store: new TableStore()
//状态管理器 } }, watch: { data: { immediate: true, handler(value) { //
将data添加到状态管理器中,供 table-body 使用 this.store.commit('setData', value)
} } } })
定义 el-table-column 组件
负责:生成列定义(包含表头名称,列字段名,渲染方法),放到状态管理器中,提供给 table-header 组件和 table-body 组件使用
Vue.component("el-table-column", {
template: `<div></div>`,
props: ["label", "prop"],
computed: {
owner() {
// 寻找拥有table的外层组件
return this.$parent;
},
},
created() {
// 生成列定义
let column = {
label: this.label, //列表头显示名称
property: this.prop, //列用到的字段名称
renderCell: null, //渲染用的方法
};
let renderCell = column.renderCell;
let _self = this;
// 生成列的渲染方法
column.renderCell = function (createElement, data) {
// 有插槽的情况
if (_self.$scopedSlots.default) {
//渲染作用域插槽
renderCell = () => _self.$scopedSlots.default(data);
//使用效果:
//<template slot-scope="{row}">
//<span>{{row.address}}</span>
//</template>
} else {
// 没有插槽的情况
renderCell = function () {
let { row } = data;
let property = column.property;
// 直接返回时间紧
return row[property];
};
/*实现效果:<div className="cell">张三</div>*/
}
//生成一个render函数
return createElement(
"div",
{
class: {
cell: true,
},
},
renderCell()
);
};
//生成列定义
this.columnConfig = column;
},
mounted() {
// 将列定义添加到状态管理器中,供 table-body table-header 使用
this.owner.store.commit("insertColumn", this.columnConfig);
},
});
定义 table-header 组件
负责根据状态管理器中列定义,渲染列表的表头
Vue.component("table-header", {
props: ["store"],
computed: {
columns() {
//获取状态管理器中的列定义
return this.store.states.columns;
},
},
render(createElement) {
//通过createElement创建vNode
/*
效果:
<table class="el-table__header">
<thead>
<th><div>姓名</div></th>
<th><div>地址</div></th>
</thead>
</table>
*/
return createElement("table", { class: { "el-table__header": true } }, [
createElement(
"thead",
this.columns.map((column) => {
return createElement("th", [createElement("div", column.label)]);
})
),
]);
},
});
定义 table-body 组件
负责通过状态管理器中的列定义和数据,渲染表体数据
// table-body组件
Vue.component("table-body", {
props: ["store"],
computed: {
data() {
//获取状态管理器中的列表数据
return this.store.states.data;
},
columns() {
//获取状态管理器中的列定义
return this.store.states.columns;
},
},
render(createElement) {
//通过createElement创建vNode
/*
效果:
<table class="el-el-table__body">
<tr>
<td>...</td>
</tr>
</table>
*/
return createElement(
"table",
{ class: { "el-el-table__body": true } },
this.data.map((row) => {
return createElement(
"tr",
this.columns.map((column) => {
return createElement("td", [
column.renderCell.call(null, createElement, { row }),
]);
})
);
})
);
},
});
render 函数的作用
1.概述
vue 的 render 方法,即渲染函数,它比模板更接近于编译器,也意味在执行效率上会比模板好,如果我们要写更好的组件,或者阅读别人的代码,我们就需要学习 render 方法
2.语法
render 方法和 createElement 接受的参数说明如下
Vue.component('component-name', {
render(createElement){
// @returns {VNode} 返回虚拟dom节点对象
return createElement(
// {String | Object | Function}
// 一个 HTML 标签名、组件选项对象,或者
// resolve 了上述任何一种的一个 async 函数。必填项。
'div',
// {Object}
// 一个与模板中 attribute 对应的数据对象
{},
// {String | Array}
// 子级虚拟节点 (VNodes),由 `createElement()` 构建而成,
// 也可以使用字符串来生成“文本虚拟节点”。可选。
[]
)
}
}
复制代码
3.例子
3.1 最简单的
Vue.component('el-title', {
data(){return {title: '这是一个标题'}},
render(createElement) {
/*
<el-title/>等效于
<h1>这是一个标题</h1>
*/
return createElement('h1', this.title)
}
}
复制代码
3.2 指定属性
Vue.component('el-title', {
data(){return {title: '这是一个标题'}},
render(createElement) {
/*
<el-title/>等效于
<h1 class="title">这是一个标题</h1>
*/
return createElement('h1',{class: {title: true}}, this.title)
}
}
3.3 使用插槽
Vue.component('el-title', {
render(createElement) {
/*
<el-title><h1 class="title">这是一个标题</h1></el-title>等效于
<div class="title"><h1 class="title">这是一个标题</h1></div>
*/
return createElement('div',{class: {title: true}}, this.$slots.default)
}
}
复制代码
3.4 使用作用域插槽
Vue.component('el-title', {
data(){return {title: '这是一个标题'}},
render(createElement) {
/*
<el-title><template slot-scope="scope"><h1>{{scope.text}}</h1></template></el-title>等效于
<div class="title"><h1>这是一个标题</h1></div>
*/
return createElement('div',{class: {title: true}},
this.$scopedSlots.default({
text: this.title
}))
}
}
复制代码
3.5 多个子元素
Vue.component('el-title', {
render(createElement) {
/*
<el-title></el-title>等效于
<div class="title"><h1>标题1</h1><h1>标题2</h1></div>
*/
return createElement('div',{class: {title: true}}, [
createElement('h1', '标题1'),
createElement('h1', '标题2')
])
}
}
复制代码
3.6 循环生成子元素
Vue.component('el-table', {
data(){return {
columns = [
{label: '标题1'},
{label: '标题2'}
]}
},
render(createElement) {
/*
<el-table></el-table>等效于
<table class="el-table__header">
<thead>
<th><div>标题1</div></th>
<th><div>标题2</div></th>
</thead>
</table>
*/
return createElement('table',{class: {'el-table__header': true}}, [
createElement('thead', this.columns.map(column=>{
return createElement('th',[createElement('div',column.label)])
}))
])
}
}
权限管理
首先,权限管理⼀般需求是两个:⻚⾯权限和按钮权限。
- 权限管理⼀般需求是⻚⾯权限和按钮权限的管理
- 具体实现的时候分后端和前端两种⽅案:
前端⽅案会把所有路由信息在前端配置,通过路由守卫要求⽤户登录,⽤户登录后根据⻆⾊过滤出路由表。⽐如我会配置⼀个 asyncRoutes 数组,需要认证的⻚⾯在其路由的 meta 中添加⼀个 roles 字段,等获取⽤户⻆⾊之后取两者的交集,若结果不为空则说明可以访问。此过滤过程结束,剩下的路由就是该⽤户能访问的⻚⾯,最后通过 router.addRoutes(accessRoutes) ⽅式动态添加路由即可。
后端⽅案会把所有⻚⾯路由信息存在数据库中,⽤户登录的时候根据其⻆⾊查询得到其能访问的所有⻚⾯路由信息返回给前端,前端再通过 addRoutes 动态添加路由信息。
按钮权限的控制通常会实现⼀个指令,例如 v-permission ,将按钮要求⻆⾊通过值传给 v-permission 指令,在指令的 moutned 钩⼦中可以判断当前⽤户⻆⾊和按钮是否存在交集,有则保留按钮,⽆则移除按钮。
纯前端⽅案的优点是实现简单,不需要额外权限管理⻚⾯,但是维护起来问题⽐较⼤,有新的⻚⾯和⻆⾊需求 就要修改前端代码重新打包部署;服务端⽅案就不存在这个问题,通过专⻔的⻆⾊和权限管理⻚⾯,配置⻚⾯ 和按钮权限信息到数据库,应⽤每次登陆时获取的都是最新的路由信息,可谓⼀劳永逸!
roles 就是个数组,需要判断那个权限,就判断自己的 roles 里边还有没有 对应的权限标识啊,也就是过滤 对应 role 的 权限
Vue 要做权限管理该怎么做?如果控制到按钮级别的权限怎么做?
Vue 要做权限管理该怎么做?如果控制到按钮级别的权限怎么做?
path: '/permission',
component: Layout,
redirect: '/permission/index',
alwaysShow: true, // will always show the root menu
meta: {
title: 'permission',
icon: 'lock',
roles: ['admin', 'editor'] // you can set roles in root nav
},
children: [{
path: 'page',
component: () => import('@/views/permission/page'),
name: 'pagePermission',
meta: {
title: 'pagePermission',
roles: ['admin'] // or you can only set roles in sub nav
}
}, {
path: 'directive',
component: () => import('@/views/permission/directive'),
name: 'directivePermission',
meta: {
title: 'directivePermission'
// if do not set roles, means: this page does not require permission
}
}]
}]
这种方式有以下四种缺点:
- 加载所有的路由,如果路由很多,而用户并不是所有的路由都有权限访问,对性能会有影响。
- 全局路由守卫里,每次路由跳转都要做权限判断。
- 菜单信息写死在前端,要改个显示文字或权限信息,需要重新编译
- 菜单跟路由耦合在一起,定义路由的时候还有添加菜单显示标题,图标之类的信息,而且路由不一定作为菜单显示,还要多加字段进行标识
按钮权限
方案 1
按钮权限也可以用它 v-if 来判断,但是如果页面过多,每个页面都需要获取用户权限 role 和路由表里的 meta.btnPermissions,然后再做判断,这种凡是就不展开列举了
方案 2
通过自定义指令进行按钮权限的判断
1.首先配置路由
{
path: '/permission',
component: Layout,
name: '权限测试',
meta: {
btnPermissions: ['admin', 'supper', 'normal']
},
//页面需要的权限
children: [{
path: 'supper',
component: _import('system/supper'),
name: '权限测试页',
meta: {
btnPermissions: ['admin', 'supper']
} //页面需要的权限
},
{
path: 'normal',
component: _import('system/normal'),
name: '权限测试页',
meta: {
btnPermissions: ['admin']
} //页面需要的权限
}]
}
2.自定义权限指令
import Vue from "vue";
/**权限指令**/
const has = Vue.directive("has", {
bind: function (el, binding, vnode) {
// 获取页面按钮权限
let btnPermissionsArr = [];
if (binding.value) {
// 如果指令传值,获取指令参数,根据指令参数和当前登录人按钮权限做比较。
btnPermissionsArr = Array.of(binding.value);
} else {
// 否则获取路由中的参数,根据路由的btnPermissionsArr和当前登录人按钮权限做比较。
btnPermissionsArr = vnode.context.$route.meta.btnPermissions;
}
if (!Vue.prototype.$_has(btnPermissionsArr)) {
el.parentNode.removeChild(el);
}
},
});
// 权限检查方法
Vue.prototype.$_has = function (value) {
let isExist = false;
// 获取用户按钮权限
let btnPermissionsStr = sessionStorage.getItem("btnPermissions");
if (btnPermissionsStr == undefined || btnPermissionsStr == null) {
return false;
}
if (value.indexOf(btnPermissionsStr) > -1) {
isExist = true;
}
return isExist;
};
export { has };
3.在使用的按钮中只需要引用 v-has 指令
<el-button @click='editClick' type="primary" v-has>编辑</el-button>
总结:
1.权限控制目前我在项目中用到的有接口验证,比如有些页面只有当用户登录了才能有相应页面的权限,此权限控制一般也是使用 jwt 方式或者跳转到 404 页面。跳转到登录页面 让用户进行登录,登录后获取用户的 token,保存起来,然后使用 axios 进行请求拦截,对于一些需要验证的页面请求的时候加上用户的 token 进行条状
2.还有就是一些按钮权限,比如再任务发布模块的发布按钮,由于每个职员的权限不一样,只有特定职员才有发布的权限,我在项目中用到的是使用 v-if 去判断 3.还有就是路由权限,给路由设置元信息,每次对于一些特殊路由跳转的时候,根绝这个元信息去判断是否拥有这个权限再进行下一步跳转
RBAC 权限模型
RBAC 是个啥
RBAC 就是一个权限控制模型,这个模型是经过时间沉淀之后,相当通用、成熟且被大众接受认可的一个模型。我的理解是 RBAC 和数学公式是一个道理,数学题可以套用数学公式,而权限系统也可以套用 RBAC 权限模型。
RBAC(Role-Based Access Control)权限模型的概念,即:基于角色的权限控制。通过角色关联用户,角色关联权限的方式间接赋予用户权限。
按照小白(我)的逻辑呢,权限嘛,只要给用户分配权限就好咯,何必多此一举,中间加一个角色,把权限倒个手。
其实之所以在中间加一层角色,是为了增加安全性和效率,而且后续扩展上也会提升不少。
打个比方,比如多个用户拥有相同的权限,在分配的时候就要分别为这几个用户指定相同的权限,修改时也要为这几个用户的权限进行一一修改。有了角色后,只需要为该角色制定好权限后,将相同权限的用户都指定为同一个角色即可,便于权限管理。对于批量的用户权限调整,只需调整用户关联的角色权限,无需对每一个用户都进行权限调整,既大幅提升权限调整的效率,又降低了漏调权限的概率。
下图就是 RABC 权限模型
 这个模型中又包含了 2 种:
这个模型中又包含了 2 种:
1.用户和角色是多对一关系,即:一个用户只充当一种角色,一种角色可以有多个用户担当。
2.用户和角色是多对多关系,即:一个用户可同时充当多种角色,一种角色可以有多个用户担当。(我们的系统就是使用的多对多)
那么,什么时候该使用多对一的权限体系,什么时候又该使用多对多的权限体系呢?
如果系统功能比较单一,使用人员较少,岗位权限相对清晰且确保不会出现兼岗的情况,此时可以考虑用多对一的权限体系。其余情况尽量使用多对多的权限体系,保证系统的可扩展性。如:张三既是行政,也负责财务工作,那张三就同时拥有行政和财务两个角色的权限。
RBAC 权限模型的类型
上面说的是 RBAC0 模型,也是基础、最简单的,相当于底层逻辑,在此基础上,又升级出 RBAC1、RBAC2、RBAC3 模型
1.RBAC1 模型
相对于 RBAC0 模型,增加了子角色,引入了继承概念,即子角色可以继承父角色的所有权限。

使用场景:如某个业务部门,有经理、主管、专员。主管的权限不能大于经理,专员的权限不能大于主管,如果采用 RBAC0 模型做权限系统,极可能出现分配权限失误,最终出现主管拥有经理都没有的权限的情况。
而 RBAC1 模型就很好解决了这个问题,创建完经理角色并配置好权限后,主管角色的权限继承经理角色的权限,并且支持在经理权限上删减主管权限。
2.RBAC2 模型
基于 RBAC0 模型,增加了对角色的一些限制:角色互斥、基数约束、先决条件角色等。
- 角色互斥:同一用户不能分配到一组互斥角色集合中的多个角色,互斥角色是指权限互相制约的两个角色。案例:请款系统中一个用户不能同时被指派给申请角色和审批员角色。
- 基数约束:一个角色被分配的用户数量受限,它指的是有多少用户能拥有这个角色。案例:一个角色专门为公司 CEO 创建的,那这个角色的数量是有限的。
- 先决条件角色:指要想获得较高的权限,要首先拥有低一级的权限。案例:先有副总经理权限,才能有总经理权限。
- 运行时互斥:例如,允许一个用户具有两个角色的成员资格,但在运行中不可同时激活这两个角色,案例:同一个用户拥有多个角色,角色的权限有重叠,以较大权限为准。
3.RBAC3 模型
称为统一模型,它包含了 RBAC1 和 RBAC2,利用传递性,也把 RBAC0 包括在内,综合了 RBAC0、RBAC1 和 RBAC2 的所有特点,既有角色分层又有约束的一种模型。
每一种模型都不是一成不变的,在 RBAC0 的基础上延伸的 1.2.3 只是对基础模型的一种扩展,包含但不限于,要根据实际需求来选择如何使用。
用户组又是什么?
当平台用户基数增大,角色类型增多时,如果直接给用户配角色,管理员的工作量就会很大。这时候我们可以引入一个概念“用户组”,就是将相同属性的用户归类到一起。
例如:加入用户组的概念后,可以将部门看做一个用户组,再给这个部门直接赋予角色(1 万员工部门可能就几十个),使部门拥有部门权限,这样这个部门的所有用户都有了部门权限,而不需要为每一个用户再单独指定角色,极大的减少了分配权限的工作量。
同时,也可以为特定的用户指定角色,这样用户除了拥有所属用户组的所有权限外,还拥有自身特定的权限。
用户组的优点,除了减少工作量,还有更便于理解、增加多级管理关系等。如:我们在进行组织机构配置的时候,除了加入部门,还可以加入职级、岗位等层级,来为用户组内部成员的权限进行等级上的区分。
日常问题
如何看待前端工程化?
目前来说,web 业务日益复杂化和多元化,前端开发从 WebPage 模式为主转变为 WebApp 模式为主了。前端的开发工作在一些场景被认为只是日常的一项简单工作,或者只是某个项目的附属品,并没有被当作一个“软件”而认真对待。
在模式的转变下,前端都已经不是过去的拼几个页面和搞几个 jq 插件就能完成。当工程复杂就会产生很多问题,比如:
- 如何进行高效的多人协作?
- 如何保证项目的可维护性?
- 如何提高项目的开发质量?
- 如何降低项目生产的风险?
- …
前端工程化是使用软件工程的技术和方法来进行前端的开发流程、技术、工具、经验等规范化、标准化,其主要目的是为了提高效率和降低成本,即提高开发过程中的开发效率,减少不必要的重复工作时间,而前端工程本质上是软件工程的一种,因此我们应该从软件工程的角度来研究前端工程。
“前端工程化”里面的工程指软件工程。
#如何做“前端工程化”? 前端工程化就是为了让前端开发能够自成体系,个人认为应该从模块化、组件化、规范化、自动化四个方面思考。
模块化
简单来说,模块化就是将一个大文件拆分成相互依赖的小文件,再进行统一的拼装和加载。
- JS 的模块化
在 ES6 之前,javascript 一直没有模块系统,这对开发大型复杂的前端工程造成了巨大的障碍。对此社区制定了一些模块加载方案,如 CommonJS、AMD 和 CMD 等。
现在 ES6 已经在语言层面上规定了模块系统,完全可以取代现有的 CommonJS 和 AMD 规范,而且使用起来相当简洁,并且有静态加载的特性。
- 用 webpack+babel 将所有模块打包成一个文件同步加载,也可以搭乘多个 chunk 异步加载;
- 用 system+babel 主要是分模块异步加载;
- 用浏览器
<script type="module">加载。
- css 的模块化
虽然 sass、less、stylus 等预处理器实现了 css 的文件拆分,但没有解决 css 模块化的一个重要问题:选择器的全局污染问题。
按道理,一个模块化的文件应该要隐藏内部作用域,只暴露少量接口给使用者。而按照目前预处理器的方式,导入一个 css 模块后,已存在的样式有被覆盖的风险。虽然重写样式是 css 的一个优势,但这并不利于多人协作。
为了避免全局选择器的冲突,需要制定 css 命名风格:
- ben 风格
- bootstrap 风格
- …
从工具层面,社区又创造出 Shadow DOM、CSS in JS 和 CSS Modules 三种解决方案。
- Shadow DOM 是 webComponents 的标准。它能解决全局污染问题,但目前很多浏览器不兼容,对我们来说还很久远。
- css in js 是彻底抛弃 css,使用 js 或者 json 来写样式。这种方法很激进,不能利用现有的 css 技术,而且处理伪类等问题比较困难;
- css modules 仍然使用 css,只是让 js 来管理依赖。它能够最大化地结合 css 生态和 js 模块化能力,目前来看是最好的解决方案。vue 的 scoped style 也算是一种。
- 资源的模块化
webpack 的强大之处不仅仅在于它统一了 js 的各种模块系统,取代了 browserify、requireJS、SeaJS 的工作。更重要的是它的万能模块加载理念,即所有的资源都可以且也应该模块化。
资源模块化后,优点是:
- 依赖关系单一化。所有 css 和图片等资源的依赖关系统一走 js 路线,无需额外处理 css 预处理器的依赖关系,也不需处理代码迁移时的图片合并、字体图片等路径问题;
- 资源处理集成化。现在可以用 loader 对各种资源做各种事情,比如复杂的 vue-loader 等等;
- 项目结构清晰化。使用 webpack 后,你的项目结构总可以表示成这样的函数:
dest=webpack(src, config)。
组件化
从 ui 拆分下来的每个包含模板(html)+样式(css)+逻辑(js)功能完备的结构单元,我们称之为组件。
组件化 ≠ 模块化。模块化只是在文件层面上,对代码或资源的拆分;而组件化是在设计层面上,对 ui(用户界面)的拆分。
其实,组件化更重要是一种分治思想。
页面上所有的东西都是组件。页面是个大型组件,可以拆成若干个中型组件,然后中型组件还可以再拆,拆成若干个小型组件,小型组件也可以再拆,直到拆成 dom 元素为止。dom 元素可以看成是浏览器自身的组件,作为组件的基本单元。
传统前端框架/类库的思想是先组织 dom,然后把某些可服用的逻辑封装成组件来操作 dom,是 dom 优先;而组件化框架/类库的思想是先来构思组件,然后用 dom 这种基本单元结合相应逻辑来实现组件,是组件优先。这是两者本质的区别。
其次,组件化实际是一种按照模板(html)+样式(css)+逻辑(js)三位一体的形式对面向对象的进一步抽象。
所以我们除了封装组件本身,还要合理处理组件之间的关系,比如(逻辑)继承、(样式)扩展、(模板)嵌套和包含等,这些关系都可以归为依赖。
目前市面上的组件化框架很多,主要有 vue、react、angular。
规范化
规范化其实是工程化中很重要的一个部分,项目初期规范制定的好坏会直接影响到后期的开发质量。
比如:
- 目录结构的制定
- 编码规范
- 前后端接口规范
- 文档规范
- 组件管理
- git 分支管理
- commit 描述规范
- 视觉图表规范
- ……
自动化
前端工程化的很多脏活累活都应该交给自动化工具来完成。
图标合并
持续继承
自动化构建
自动化部署
自动化测试
git 工作流 - 如何提交代码? Node 中间层 - 用于渲染一部分模板和路由等。 CI/CD - 主要利用 git hooks 通知 CI,执行对应的脚本(如 gitlab)。 监控 - 前端监控主要分为性能监控和业务监控,它应支持自由配置各种报表和一系列报警规则。
在项目开发过程之前是否有提前进行一些工程化和模块化的分工?
分工安排主要包含以下内容: 1.公共组件(包括 common.css 和 common.js) 一人维护,各子频道专人负责,每个频道正常情况下由一人负责,要详细写明注释,如果多人合作,维护的人员注意添加注释信息。 2.视觉设计师设计完设计图后,先后交互设计师沟通,确定设计可行,然后先将设计图给公共组件维护者,看设计图是否需要提取公共组件,然后再提交给相应频道的前端工程师。如果有公共组件要提取,公共组件维护者需对频道前端工程师说明。 3.如果确定没有公共组件需提取,交互设计师直接和各栏目的前端工程师交流,对照着视觉设计师的设计图进行需求说明,前端工程师完成需求。 4.前端工程师在制作页面时,需先去 common 文件中查询是否已经存在设计图中的组件,如果有,直接调用;如果没有,则在 app.css 和 app.js 中添加相应的代码(app 指各频道自己的文件)。 5.前端工程师在制作过程中,发现高度重用的模块,却未被加入到公共组件中,需向公共组件维护人员进行说明,然后公共组件维护人员决定是否添加该组件。如果确定添加,则向前端工程师说明添加了新组件,让前端工程师检查之前是否添加了类似的组件,统一更新成新组件的用法,删除之前自定义的 css 和 js。虽然麻烦,但始终把可维护性放在首位。 6.公共组件维护者的公共组件说明文档,需提供配套的图片和说明文字,方便阅读。
怎么进行前后端联调?
一.首先明白什么是前后端?
前端:前端即网页前台部分,运行在 PC 端,移动端等以浏览器的方式展现给用户浏览的网页,我自己的理解是拆开的:前指可视的样子就像人与人相交流,端指设备终端。
后端:简单来说,后端开发就是开发人员编写的不能直接看到的代码。后端主要负责应用程序中的业务逻辑,以及从前端提取和检索数据。还有就是是从数据库或其他数据源写入、读取和处理数据。
二.什么是前后端分离开发模式?
前后端分离的开发模式:系统分析阶段,系分和前端开发人员约定好页面上所需的逻辑变量,进入功能开发阶段,前端开发人员进行前台页面结构,样式,行为层的代码编写,并根据约定好的变量,逻辑规则,完成不同情况展示不同的表现。而后端开发人员,只需要按照约定,赋予这些变量含义,并提供前后端交互所需要的数据即可。
三.如何实现前后端良好的联调协作那?
沟通:项目开发之前,尽可能主动的和系统分析师和交互设计师多沟通,确定页面中交互与服务器端交换数据的接口、方式、格式等,让前后端约定更丰满一些。因为她越丰满,后面的纠结就越少。
协作:功能开发过程中,需要建立一个共同调试的环境,方便前后端同学协同开发。
接口文档:一个规范的接口文档在前后端联调协作的时候至关重要。
四.为什么要写接口文档?
1、项目开发过程中前后端工程师有一个统一的文件进行沟通交流开发
2、项目维护中或者项目人员更迭,方便后期人员查看、维护
五.接口规范是什么?
1、方法:新增(post) 修改(put) 删除(delete) 获取(get)
2、uri:以/a 开头,如果需要登录才能调用的接口(如新增、修改;前台的用户个人信息,资金信息等)后面需要加/u,即:/a/u;中间一般放表名或者能表达这个接口的单词;get 方法,如果是后台通过搜索查询列表,那么以/search 结尾,如果是前台的查询列表,以/list 结尾;url 参数就不说了。
3、请求参数和返回参数,都分为 5 列:字段、说明、类型、备注、是否必填
字段是类的属性;说明是中文释义;类型是属性类型,只有 String、Number、Object、Array 四种类型;备注是一些解释,或者可以写一下例子,比如负责 json 结构的情况,最好写上例子,好让前端能更好理解;是否必填是字段的是否必填。
4、返回参数结构有几种情况:1、如果只返回接口调用成功还是失败(如新增、删除、修改等),则只有一个结构体:code 和 message 两个参数;2、如果要返回某些参数,则有两个结构体:1 是 code/mesage/data,2 是 data 里写返回的参数,data 是 object 类型;3、如果要返回列表,那么有三个结构体,1 是 code/mesage/data,data 是 object,里面放置 page/size/total/totalPage/list 5 个参数,其中 list 是 Arrary 类型,list 里放 object,object 里是具体的参数。
6.生成接口文档的工具有哪些
1.swagger:通过源代码注释生成接口文档的工具
2.apipost:通过对接口测试,返回的响应生成接口文档。可以生成在线版,html、markdown、word 等格式的接口文档。
flex 布局,还问项目一般用什么布局?
一、静态布局(Static Layout)
1. 布局概念
最传统、原始的 Web 布局设计。网页最外层容器(outer)有固定的大小,所有的内容以该容器为标准,超出宽高的部分用滚动条(overflow:scroll)来实现滚动查阅。
2. 优点
采用的是 css2 之前的写法,不存在浏览器兼容性。布局简单。
3. 缺点
但是移动端不可以使用 pc 端的页面,两个页面的布局不一致,移动端需要自己另外设计一个布局并使用不同域名呈现。
4. 实现方法
PC 端:
最外层居中,使用固定的宽(高)度,超出部分用滚动条查阅。
例如百度首页外层 body 设置了一个min-width:1000px;,当我打开调试器的时候,底部x 轴滚动条就出现了。
移动端 由于静态布局不适用于手机端,所以一般都会另设计一个布局,并使用另一个域名。
再看一下最近比较'火'的京东的案例:分别访问
- jd.com
- m.jd.com
可以发现: PC 端限制了最小的宽度, 低于了则以最小宽度出现滚动条 移动端限制了最大的宽度, 超过了则以最大宽度居中显示如刚刚百度的 PC 端我们切换成手机模拟器访问试试:
二、流式布局(Liquid Layout)
1. 布局概念
流式布局也叫百分比布局
这边引入一下自适应布局: 分别为不同的屏幕设置布局格式,当屏幕大小改变时,会出现不同的布局,意思就是在这个屏幕下这个元素块在这个地方,但是在那个屏幕下,这个元素块又会出现在那个地方。只是布局改变,元素不变。可以看成是不同屏幕下由多个静态布局组成的。
而流式布局的特点是随着屏幕的改变,页面的布局没有发生大的变化,可以进行适配调整,这个正好与自适应布局相补。
流式布局常用的设计模板: 左侧固定+右侧自适应 左右固定宽度+中间自适应(参考京东手机版)
页面元素的宽度按照屏幕进行适配调整,主要的问题是如果屏幕尺度跨度太大,那么在相对其原始设计而言过小或过大的屏幕上不能正常显示 。 你看到的页面,元素的大小会变化而位置不会变化——这就导致如果屏幕太大或者太小都会导致元素无法正常显示。
2. 优点
元素的宽高用百分比做单位,元素宽高按屏幕分辨率调整,布局不发生变化
3. 缺点
屏幕尺度跨度过大的情况下,页面不能正常显示。
三、响应式布局(Responsive layout)
采用自适应布局和流式布局的综合方式,为不同屏幕分辨率范围创建流式布局
现在优秀的页面都追求一套代码可以实现三端的浏览; 从概念可以看出来,自适应布局的诞生是为了实现不同屏幕分辨率的终端上浏览网页的不同展示方式。
通过响应式设计能使网站在手机和平板电脑上有更好的浏览阅读体验。屏幕尺寸不一样展示给用户的网页内容也不一样.
利用媒体查询可以检测到屏幕的尺寸(主要检测宽度),并设置不同的 CSS 样式,就可以实现响应式的布局。
大名鼎鼎的 bootstrap 就是响应式布局的专家。
官方放出狠话: Bootstrap 提供了一套响应式、移动设备优先的流式栅格系统,随着屏幕或视口(viewport)尺寸的增加,系统会自动分为最多 12 列。它包含了易于使用的预定义类,还有强大的 mixin 用于生成更具语义的布局。
连我们最热爱的 React 官方也热衷于响应式布局设计
在前端常用的 debug 的手段?chrome 的哪些部分分别能看到什么方面?
调试一般步骤
当出现异常时,按照这个基本逻辑排查,一般可以快速定位问题。
检查控制台是否报错
可以快速确定页面不符合预期的原因
- 是何种错误
- 当前页面是否需要请求获取数据
是何种错误
- 安全错误:与后端协商解决
- SyntaxError/ReferenceError/TypeError :编译阶段一般不会放过太低级的书写错误,可以认为这类错误都是写错了 ,一般很容易发现,找到错误堆栈进行解决
- 数据不符合预期引起的错误(TypeError 等):访问不存在的属性得到了
undefined/null/NaN等值之后,会引发后续的异常。要先从检查数据入手。
当前页面是否需要请求获取数据
网络请求是不稳定因素之一,可能会带来难以预料的复杂情况,出现问题的时候检查网络请求和数据的优先级很高。
网络请求是否成功发送
检查开发者工具 Network/网络面板,查看需要获取数据的接口是否成功获取到数据。
取不到数据的原因有两类,一类是责任在前端,一类是后端。主要通过请求提交的内容是否合法,接口返回内容是否符合预期两个方面判断。
查看的关键点:
- 方法是否正确
- URL 是否正确
- 跨域
- 请求的 Content-Type 是符合要求
- 请求体格式是否符合要求(JSON/Form)
- 是否携带了身份信息
合法请求没有得到预期返回,就找后端解决,请求与预期不符就是代码写错了,到错误地方查看代码。
- 500 等不该出现的异常:500 大概可能是后端问题
- 404 URL 写错
- 权限问题:检查请求报文携带的身份信息
定位到代码应当执行的位置(大概即可)
如果是控制台有错误信息的,利用 sourcemap 可以快速定位到问题出在哪一行。如果没有报错信息,就需要凭借当前页面的状态自己判断出问题的区域,按照代码执行的顺序排查。这一步可以利用的手段比较多,情况也更复杂,需要具体分析。
查看代码运行状态:
- 按照预期执行顺序检查代码
- 检查渲染需要的数据是否与预期相同
按照预期执行顺序检查代码
通过断点、日志等手段判断程序有没有按照自己想要的顺序执行,简单来说就是排查。
检查渲染需要的数据是否与预期相同
检查运行过程中每一步的数据变化,是否与预期的相同。
异常代码一般分析方法
- 代码注释法 利用二分法思想逐行去注释代码,直到定位问题
- 类库异常,兼容问题 这种场景也会经常遇到,我们需要用可以调试页面异常的方式,如
Safari,Whistle,vConsole查看异常日志,从而迅速定位类库位置,从而找寻替换或是兼容方案。 - try catch 如果你的项目没有异常监控,那么在可疑的代码片段中去
Try Catch吧。 - ES6 语法兼容 一般我们都会通过
Babel来编译ES6,但是额外的第三方类库如果有不兼容的语法,低版本的移动设备就会异常。所以,先用上文讲述的调试方法,确定异常,然后去增加 polyfill 来兼容吧
是否了解过正则表达式?用来做什么?

最初见到正则表达式是在表单验证里,多少会用些 validate 的库,基本的电话 / 邮箱之类的校验都有现成的,真正自己写正则去校验输入格式的机会并不多
1、老项目迁移,所有的 T.dom.getElementById('abc') 代码都要改成新的写法 $('#abc')
2、组件库升级,所有的 <el-dialog v-model="a" 必须改成 <el-dialog :visible.sync="a"
都是真实工作中的脏活累活,故事 1 中的项目有近 100 个页面,由于 T 库弃用了,不仅 T.dom.getElementById 还有 getElementByClass 等等调用都要改成 jquery 的写法。如果完全靠人肉,那是多么的苦力。
故事 2 中的组件库其实就是我们的 Element,我们原先很多项目都是 Element 1.x,要升级到 2.x,这个对话框的 breaking change 影响还挺大的,在 2.x 中通过 v-model 是无法唤起对话框的。因此要确保每个 el-dialog 都检查一遍,而模板代码里 el-dialog 的 v-model 可能不在第一个,属性多的时候还会换行,都需要火眼金睛。
聪明的读者肯定知道,靠人肉是个没有办法的办法,而且看多了也会眼花,最好还要 double check。虽然写正则表达式去找,也不能保证 100% 都覆盖,毕竟老项目里各种迷之代码都有,但正则能帮我们找出大部分,并且 replace 的时候也能避免输入错误,这样可以把精力放在 double check 上。
表单校验
url 参数提取
引号的替换
字符串去重替换
定制 .vue 单文件模板
最近在做微信小程序,每个页面都必须写 wxml / wxss / js / json 这 4 个文件,当项目里页面多的时候文件就巨多无比。假如没有用任何开发框架,可以自己定制一个单文件模板,有点类似 .vue 文件
现在我们的目标是把这个文件拆成模板、样式、js 和 json 配置对应的 4 个文件,抛弃原来的 split 大法或者逐行读文件,正则表达式可以帮我们优雅地解决问题。
你知道你的项目是怎么从变成一个 html 文件的吗?
HtmlWebpackPlugin
html-webpack-plugin 的作用是:当使用 webpack打包时,创建一个 html 文件,并把 webpack 打包后的静态文件自动插入到这个 html 文件当中。
安装
npm install html-webpack-plugin --save-dev
使用默认配置
const HtmlWebpackPlugin = require("html-webpack-plugin");
module.exports = {
entry: "index.js",
output: {
path: __dirname + "/dist",
filename: "index_bundle.js",
},
plugins: [new HtmlWebpackPlugin()],
};
html-webpack-plugin 默认将会在 output.path 的目录下创建一个 index.html 文件, 并在这个文件中插入一个 script 标签,标签的 src 为 output.filename。
生成的文件如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Webpack App</title>
</head>
<body>
<script src="bundle.js"></script>
</body>
</html>
当配置多个入口文件
entry时, 生成的将都会使用script引入。
如果
webpack的输出中有任何 CSS 资源 (例如,使用mini-css-extract-plugin提取的CSS),那么这些资源将包含在HTML头部的link标记中。
更多配置
在实际的项目中,需要自定义一些 html-webpack-plugin 的配置, 像指定生成目录和文件, 使用指定模版生成文件, 更改 document.title 信息等, 这就更改默认配置来实现。
| 属性名 | 字段类型 | 默认值 | 说明 |
|---|---|---|---|
| title | String | Webpack App | 网页 document.title 的配置, 在 index.html 文件中可以使用 <%= htmlWebpackPlugin.options.title %> 设置网页标题为这里设置的值。 |
| filename | String | index.html | html 文件生成的名称,可以使用 assets/index.html 来指定生成的文件目录和文件名, 重点 1:生成文件的跟路径为ouput.path的目录。 重点 2: ‘assets/index.html’ 和 ./assets/index.html 这两种方式的效果时一样的, 都是在 output.path 目录下生成 assets/index.html |
| template | String | 空 | 生成 filename 文件的模版, 如果存在 src/index.ejs, 那么默认将会使用这个文件作为模版。 重点:与 filename 的路径不同, 当匹配模版路径的时候将会从项目的跟路径开始 |
| templateParameters | Boolean|Object|Function | 空 | 覆盖默认的模版中使用的参数 |
| inject | Boolean|String | true | 制定 webpack 打包的 js css 静态资源插入到 html 的位置, 为 true 或者 body 时, 将会把 js 文件放到 body 的底部, 为 head 时, 将 js 脚本放到 head 元素中。 |
| favicon | String | 空 | 为生成的 html 配置一个 favicon |
| mete | Object | {} | 为生成的 html 文件注入一些 mete 信息, 例如: {viewport: 'width=device-width, initial-scale=1, shrink-to-fit=no'} |
| base | Object|String|false | false | 在生成文件中注入 base 标签, 例如 base: "https://example.com/path/page.html <base> 标签为页面上所有的链接规定默认地址或默认目标 |
| minify | Boolean|Object | 如果 mode 设置为 production 默认为 true 否则设置为 false | 设置静态资源的压缩情况 |
| hash | Boolean | false | 如果为真,则向所有包含的 js 和 CSS 文件附加一个惟一的 webpack 编译散列。这对于更新每次的缓存文件名称非常有用 |
| cache | Boolean | true | 设置 js css 文件的缓存,当文件没有发生变化时, 是否设置使用缓存 |
| showErrors | Boolean | true | 当文件发生错误时, 是否将错误显示在页面 |
| xhtml | Boolean | false | 当设置为 true 的时候,将会讲 <link> 标签设置为符合 xhtml 规范的自闭合形式 |
属性的使用方法
webpack.config.js
{
entry: 'index.js',
output: {
path: __dirname + '/dist',
filename: 'bundle.js'
},
plugins: [
new HtmlWebpackPlugin({
title: 'My App',
filename: 'assets/admin.html' // 在 output.path 目录下生成 assets/admin.html 文件
})
]
}
生成多个 html 文件
生成多个 html 文件只需要多次在 plugins 中使用 HtmlWebpackPlugin webpack.config.js
{
entry: 'index.js',
output: {
path: __dirname + '/dist',
filename: 'bundle.js'
},
plugins: [
new HtmlWebpackPlugin(),
new HtmlWebpackPlugin({
title: 'My App',
filename: 'assets/admin.html' // 在 output.path 目录下生成 assets/admin.html 文件
})
]
}
使用自定义模版生成 html 文件
如果默认的 html 模版不能满足业务需求, 比如需要蛇生成文件里提前写一些 css 'js' 资源的引用, 最简单的方式就是新建一个模版文件, 并使用 template 属性指定模版文件的路径,html-webpack-plugin 插件将会自动向这个模版文件中注入打包后的 js 'css' 文件资源。
webpack.config.js
plugins: [
new HtmlWebpackPlugin({
title: "My App",
template: "public/index.html",
}),
];
public/index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title><%= htmlWebpackPlugin.options.title %></title>
<link src="xxx/xxx.css">
</head>
<body>
</body>
</html>
使用自定义的模版接收
HtmlWebpackPlugin中定义的title需要使用<%= htmlWebpackPlugin.options.title %>
Minification
如果 minify 选项设置为 true (webpack 模式为 production 时的默认值),生成的 HTML 将使用 HTML-minifier 和以下选项进行压缩:
{
collapseWhitespace: true,
removeComments: true,
removeRedundantAttributes: true,
removeScriptTypeAttributes: true,
removeStyleLinkTypeAttributes: true,
useShortDoctype: true
}
若要使用自定义
html压缩器选项,请传递一个对象来配置。此对象不会与上面的默认值合并。
若要在生产模式期间禁用
minification,请将minify选项设置为false。