node.js
Node.js 面试题
Node.js 基础
Node.js 特点
一、是什么
Node.js 是一个开源与跨平台的 JavaScript 运行时环境
在浏览器外运行 V8 JavaScript 引擎(Google Chrome 的内核),利用事件驱动、非阻塞和异步输入输出模型等技术提高性能
可以理解为 Node.js 就是一个服务器端的、非阻塞式 I/O 的、事件驱动的JavaScript运行环境
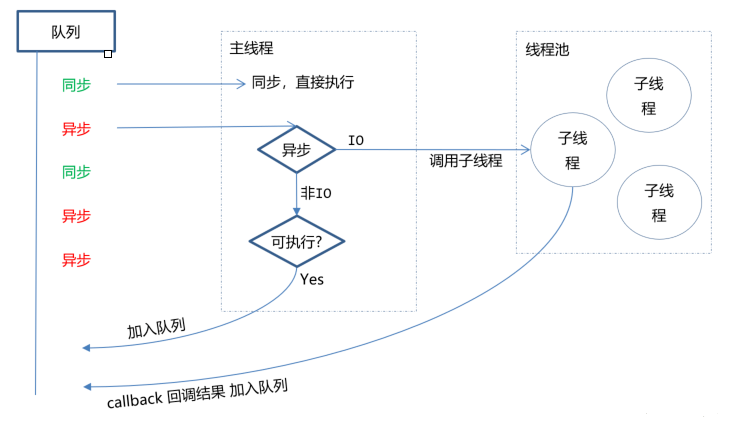
非阻塞异步
Nodejs采用了非阻塞型I/O机制,在做I/O操作的时候不会造成任何的阻塞,当完成之后,以时间的形式通知执行操作
例如在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率
事件驱动
事件驱动就是当进来一个新的请求的时,请求将会被压入一个事件队列中,然后通过一个循环来检测队列中的事件状态变化,如果检测到有状态变化的事件,那么就执行该事件对应的处理代码,一般都是回调函数
比如读取一个文件,文件读取完毕后,就会触发对应的状态,然后通过对应的回调函数来进行处理
可扩展性 Scalability
Node.js 和 Java 都可以异步执行请求,这使得两个工具构建的应用程序具有高度可伸缩性。这些请求可以并行执行,无需等待前一个请求完成。
但是,node.js 通过添加更多的硬件来显示更好的水平可伸缩性。同时,由于添加处理能力而产生的垂直可扩展性 Node.js 并不是那么好,因为它的单线程性质,线程只使用单核。对于多核系统,需要使用允许创建使用所有核心的子进程的集群模块(cluster module)。不过,我们应该注意,运行集群可能是一个非常消耗内存的解决方案。
反过来,Java 不会向外扩展或横向扩展。它在一定数量的服务器上运行良好,但在某些时候添加更多服务器不再能提供预期的性能提升。
速度
有时候,Node.js 远超 java,在其他情况下,情况则相反。它取决于用来比较速度的度量,不同的度量使得他们的排名也不太一样。
执行速度与两个工具处理输入/输出(IOs)请求的方式有关。node.js 以非阻塞方式处理输入/输出(IOs),这意味着它的单个线程可以同时管理多个输入/输出(IOs)请求。无需等待一个请求完成,即可开始处理其他请求。
Java 使用阻塞和非阻塞 IO。阻塞 IO 意味着第一个 IO 请求阻塞所有其他请求。这大大降低了速度,因为应用程序需要等待线程逐个处理请求。可以通过添加线程来提高速度,但这种选择相当不经济。
同时,对于 Java,采用了非阻塞 IO 作为标准,而它的流比 Node.js 中的非阻塞流复杂。
非阻塞 IO 处理使得 node.js 成为适合创建涉及大量读写操作的应用程序的工具,如日志记录、数据采集、备份、事务处理和实时应用程序。
二、优缺点
优点:
- 处理高并发场景性能更佳
- 适合 I/O 密集型应用,值的是应用在运行极限时,CPU 占用率仍然比较低,大部分时间是在做 I/O 硬盘内存读写操作
因为Nodejs是单线程,带来的缺点有:
- 不适合 CPU 密集型应用
- 只支持单核 CPU,不能充分利用 CPU
- 可靠性低,一旦代码某个环节崩溃,整个系统都崩溃
三、应用场景
借助Nodejs的特点和弊端,其应用场景分类如下:
- 善于
I/O,不善于计算。因为 Nodejs 是一个单线程,如果计算(同步)太多,则会阻塞这个线程 - 大量并发的 I/O,应用程序内部并不需要进行非常复杂的处理
- 与 websocket 配合,开发长连接的实时交互应用程序
具体场景可以表现为如下:
- 第一大类:用户表单收集系统、后台管理系统、实时交互系统、考试系统、联网软件、高并发量的 web 应用程序
- 第二大类:基于 web、canvas 等多人联网游戏
- 第三大类:基于 web 的多人实时聊天客户端、聊天室、图文直播
- 第四大类:单页面浏览器应用程序
- 第五大类:操作数据库、为前端和移动端提供基于
json的 API
其实,Nodejs能实现几乎一切的应用,只考虑适不适合使用它
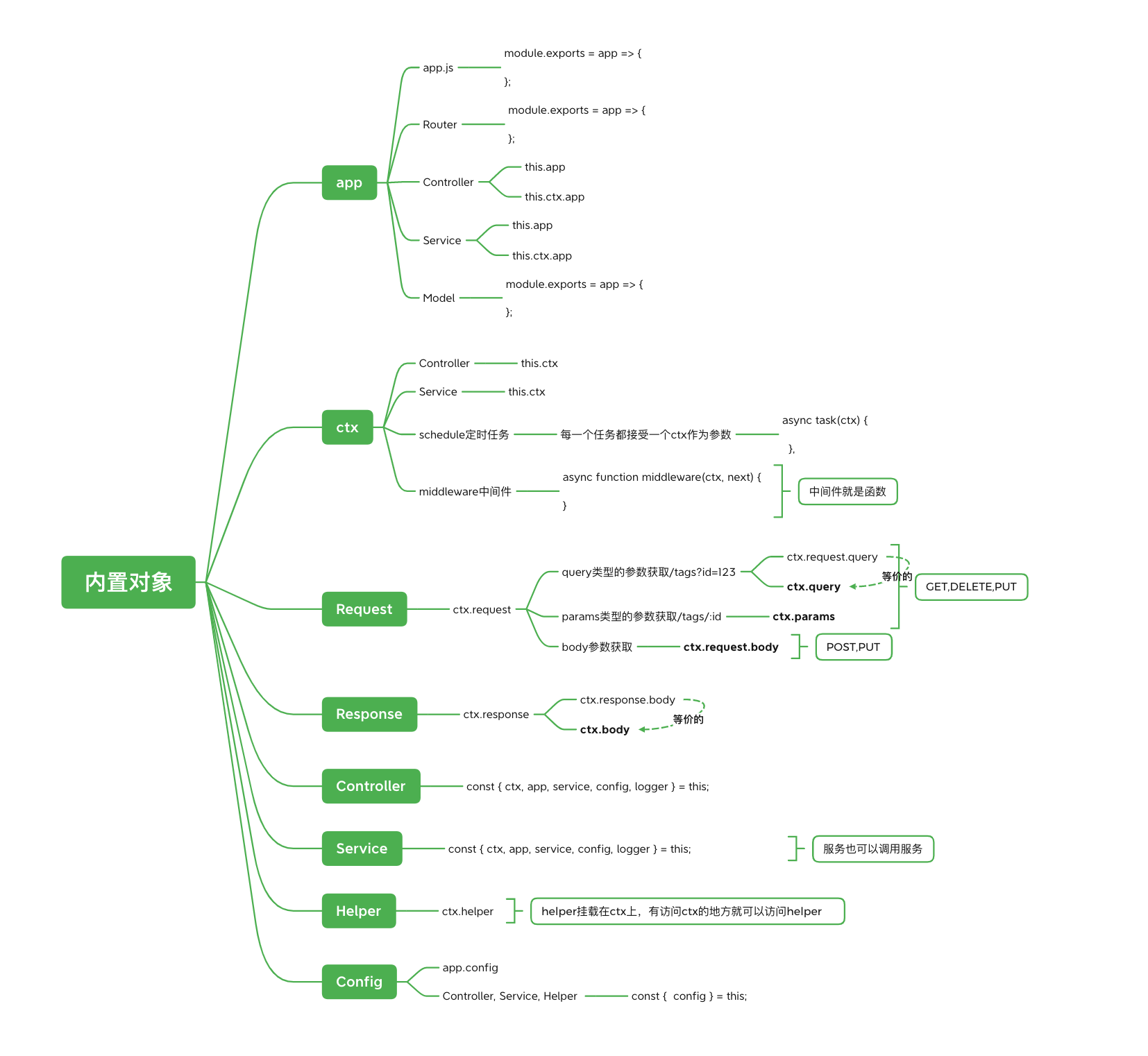
进程信息模块 process
一、是什么
process 对象是一个全局变量,提供了有关当前 Node.js进程的信息并对其进行控制,作为一个全局变量
我们都知道,进程计算机系统进行资源分配和调度的基本单位,是操作系统结构的基础,是线程的容器
当我们启动一个js文件,实际就是开启了一个服务进程,每个进程都拥有自己的独立空间地址、数据栈,像另一个进程无法访问当前进程的变量、数据结构,只有数据通信后,进程之间才可以数据共享
由于JavaScript是一个单线程语言,所以通过node xxx启动一个文件后,只有一条主线程
二、属性与方法
关于process常见的属性有如下:
- process.env:环境变量,例如通过 `process.env.NODE_ENV 获取不同环境项目配置信息
- process.nextTick:这个在谈及
EventLoop时经常为会提到 - process.pid:获取当前进程 id
- process.ppid:当前进程对应的父进程
- process.cwd():获取当前进程工作目录,
- process.platform:获取当前进程运行的操作系统平台
- process.uptime():当前进程已运行时间,例如:pm2 守护进程的 uptime 值
- 进程事件: process.on(‘uncaughtException’,cb) 捕获异常信息、 process.on(‘exit’,cb)进程推出监听
- 三个标准流: process.stdout 标准输出、 process.stdin 标准输入、 process.stderr 标准错误输出
- process.title 指定进程名称,有的时候需要给进程指定一个名称
下面再稍微介绍下某些方法的使用:
process.cwd()
返回当前 Node进程执行的目录
一个Node 模块 A 通过 NPM 发布,项目 B 中使用了模块 A。在 A 中需要操作 B 项目下的文件时,就可以用 process.cwd() 来获取 B 项目的路径
process.argv
在终端通过 Node 执行命令的时候,通过 process.argv 可以获取传入的命令行参数,返回值是一个数组:
- 0: Node 路径(一般用不到,直接忽略)
- 1: 被执行的 JS 文件路径(一般用不到,直接忽略)
- 2~n: 真实传入命令的参数
所以,我们只要从 process.argv[2] 开始获取就好了
const args = process.argv.slice(2);
process.env
返回一个对象,存储当前环境相关的所有信息,一般很少直接用到。
一般我们会在 process.env 上挂载一些变量标识当前的环境。比如最常见的用 process.env.NODE_ENV 区分 development 和 production
在 vue-cli 的源码中也经常会看到 process.env.VUE_CLI_DEBUG 标识当前是不是 DEBUG 模式
process.nextTick()
我们知道NodeJs是基于事件轮询,在这个过程中,同一时间只会处理一件事情
在这种处理模式下,process.nextTick()就是定义出一个动作,并且让这个动作在下一个事件轮询的时间点上执行
例如下面例子将一个foo函数在下一个时间点调用
function foo() {
console.error("foo");
}
process.nextTick(foo);
console.error("bar");
输出结果为bar、foo
虽然下述方式也能实现同样效果:
setTimeout(foo, 0);
console.log("bar");
两者区别在于:
- process.nextTick()会在这一次 event loop 的 call stack 清空后(下一次 event loop 开始前)再调用 callback
- setTimeout()是并不知道什么时候 call stack 清空的,所以何时调用 callback 函数是不确定的
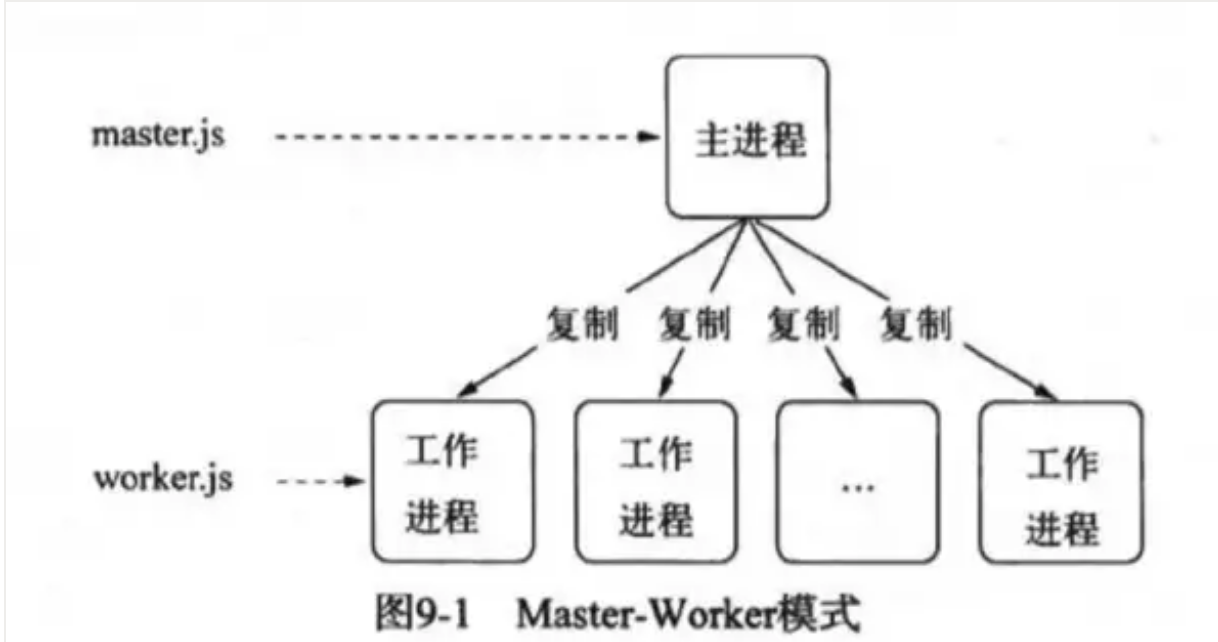
node 的多进程架构
面对 node 单线程对多核 CPU 使用不足的情况,Node 提供了
child_process模块,来实现进程的复制,node 的多进程架构是主从模式,如下所示:
var fork = require("child_process").fork;
var cpus = require("os").cpus();
for (var i = 0; i < cpus.length; i++) {
fork("./worker.js");
}
在 linux 中,我们通过
ps aux | grep worker.js查看进程

这就是著名的主从模式,Master-Worker
创建子进程的方法
spawn():启动一个子进程来执行命令exec(): 启动一个子进程来执行命令,与 spawn()不同的是其接口不同,它有一个回调函数获知子进程的状况execFlie(): 启动一个子进程来执行可执行文件fork(): 与spawn()类似,不同电在于它创建 Node 子进程需要执行 js 文件spawn()与exec()、execFile()不同的是,后两者创建时可以指定timeout属性设置超时时间,一旦创建的进程超过设定的时间就会被杀死exec()与execFile()不同的是,exec()适合执行已有命令,execFile()适合执行文件。
实现一个 node 子进程被杀死,然后自动重启代码
在创建子进程的时候就让子进程监听 exit 事件,如果被杀死就重新 fork 一下
var createWorker = function () {
var worker = fork(__dirname + "worker.js");
worker.on("exit", function () {
console.log("Worker" + worker.pid + "exited");
// 如果退出就创建新的worker
createWorker();
});
};
文件系统模块 fs
是什么?

fs(filesystem),该模块提供本地文件的读写能力,基本上是POSIX文件操作命令的简单包装
可以说,所有与文件的操作都是通过fs核心模块实现
导入模块如下:
const fs = require("fs");
这个模块对所有文件系统操作提供异步(不具有sync 后缀)和同步(具有 sync 后缀)两种操作方式,而供开发者选择
文件知识
在计算机中有关于文件的知识:
- 权限位 mode
- 标识位 flag
- 文件描述为 fd
权限位 mode
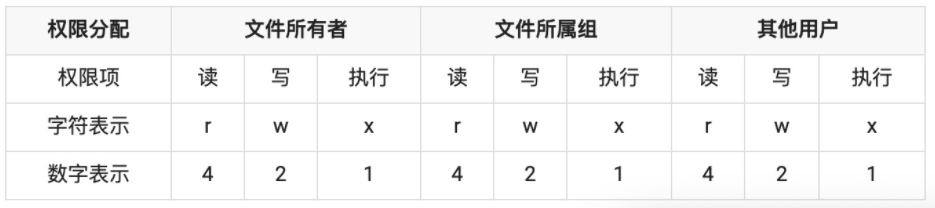
针对文件所有者、文件所属组、其他用户进行权限分配,其中类型又分成读、写和执行,具备权限位 4、2、1,不具备权限为 0
如在linux查看文件权限位:
drwxr-xr-x 1 PandaShen 197121 0 Jun 28 14:41 core
-rw-r--r-- 1 PandaShen 197121 293 Jun 23 17:44 index.md
在开头前十位中,d为文件夹,-为文件,后九位就代表当前用户、用户所属组和其他用户的权限位,按每三位划分,分别代表读(r)、写(w)和执行(x),- 代表没有当前位对应的权限
标识位
标识位代表着对文件的操作方式,如可读、可写、即可读又可写等等,如下表所示:
| 符号 | 含义 |
|---|---|
| r | 读取文件,如果文件不存在则抛出异常。 |
| r+ | 读取并写入文件,如果文件不存在则抛出异常。 |
| rs | 读取并写入文件,指示操作系统绕开本地文件系统缓存。 |
| w | 写入文件,文件不存在会被创建,存在则清空后写入。 |
| wx | 写入文件,排它方式打开。 |
| w+ | 读取并写入文件,文件不存在则创建文件,存在则清空后写入。 |
| wx+ | 和 w+ 类似,排他方式打开。 |
| a | 追加写入,文件不存在则创建文件。 |
| ax | 与 a 类似,排他方式打开。 |
| a+ | 读取并追加写入,不存在则创建。 |
| ax+ | 与 a+ 类似,排他方式打开。 |
文件描述为 fd
操作系统会为每个打开的文件分配一个名为文件描述符的数值标识,文件操作使用这些文件描述符来识别与追踪每个特定的文件
Window系统使用了一个不同但概念类似的机制来追踪资源,为方便用户,NodeJS抽象了不同操作系统间的差异,为所有打开的文件分配了数值的文件描述符
在 NodeJS中,每操作一个文件,文件描述符是递增的,文件描述符一般从 3 开始,因为前面有 0、1、2三个比较特殊的描述符,分别代表 process.stdin(标准输入)、process.stdout(标准输出)和 process.stderr(错误输出)
读取文件
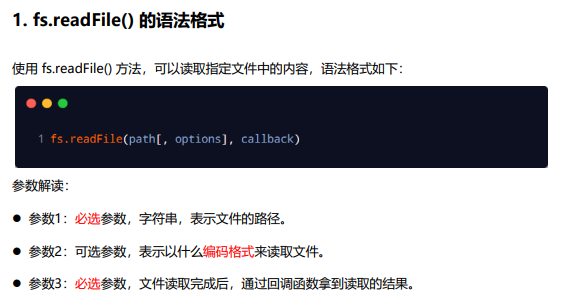
fs.readFile
异步读取方法 readFile 与 readFileSync 的前两个参数相同,最后一个参数为回调函数,函数内有两个参数 err(错误)和 data(数据),该方法没有返回值,回调函数在读取文件成功后执行
const fs = require("fs");
fs.readFile("1.txt", "utf8", (err, data) => {
if (!err) {
console.log(data); // Hello
}
});
fs.readFileSync
同步读取,参数如下:
- 第一个参数为读取文件的路径或文件描述符
- 第二个参数为 options,默认值为 null,其中有 encoding(编码,默认为 null)和 flag(标识位,默认为 r),也可直接传入 encoding
结果为返回文件的内容
const fs = require("fs");
let buf = fs.readFileSync("1.txt");
let data = fs.readFileSync("1.txt", "utf8");
console.log(buf); // <Buffer 48 65 6c 6c 6f>
console.log(data); // Hello
写入文件
writeFile
异步写入,writeFile 与 writeFileSync 的前三个参数相同,最后一个参数为回调函数,函数内有一个参数 err(错误),回调函数在文件写入数据成功后执行
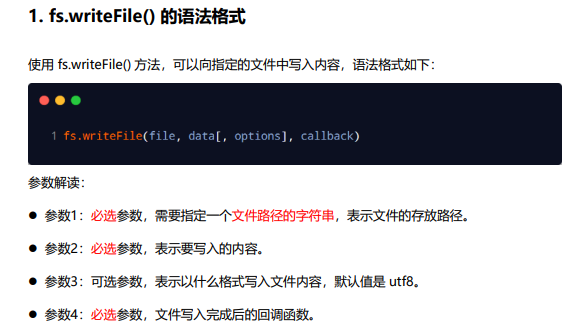
const fs = require("fs");
fs.writeFile("2.txt", "Hello world", (err) => {
if (!err) {
fs.readFile("2.txt", "utf8", (err, data) => {
console.log(data); // Hello world
});
}
});
writeFileSync
同步写入,有三个参数:
- 第一个参数为写入文件的路径或文件描述符
- 第二个参数为写入的数据,类型为 String 或 Buffer
- 第三个参数为 options,默认值为 null,其中有 encoding(编码,默认为 utf8)、 flag(标识位,默认为 w)和 mode(权限位,默认为 0o666),也可直接传入 encoding
const fs = require("fs");
fs.writeFileSync("2.txt", "Hello world");
let data = fs.readFileSync("2.txt", "utf8");
console.log(data); // Hello world
文件追加写入
appendFileSync
参数如下:
- 第一个参数为写入文件的路径或文件描述符
- 第二个参数为写入的数据,类型为 String 或 Buffer
- 第三个参数为 options,默认值为 null,其中有 encoding(编码,默认为 utf8)、 flag(标识位,默认为 a)和 mode(权限位,默认为 0o666),也可直接传入 encoding
const fs = require("fs");
fs.appendFileSync("3.txt", " world");
let data = fs.readFileSync("3.txt", "utf8");
appendFile
异步追加写入方法 appendFile 与 appendFileSync 的前三个参数相同,最后一个参数为回调函数,函数内有一个参数 err(错误),回调函数在文件追加写入数据成功后执行
const fs = require("fs");
fs.appendFile("3.txt", " world", (err) => {
if (!err) {
fs.readFile("3.txt", "utf8", (err, data) => {
console.log(data); // Hello world
});
}
});
文件拷贝
copyFileSync
同步拷贝
const fs = require("fs");
fs.copyFileSync("3.txt", "4.txt");
let data = fs.readFileSync("4.txt", "utf8");
console.log(data); // Hello world
copyFile
异步拷贝
const fs = require("fs");
fs.copyFile("3.txt", "4.txt", () => {
fs.readFile("4.txt", "utf8", (err, data) => {
console.log(data); // Hello world
});
});
创建目录
mkdirSync
同步创建,参数为一个目录的路径,没有返回值,在创建目录的过程中,必须保证传入的路径前面的文件目录都存在,否则会抛出异常
// 假设已经有了 a 文件夹和 a 下的 b 文件夹
fs.mkdirSync("a/b/c");
mkdir
异步创建,第二个参数为回调函数
fs.mkdir("a/b/c", (err) => {
if (!err) console.log("创建成功");
});
拼接路径错误问题

路径模块 path


路径拼接


获取文件名


获取拓展名

http 模块
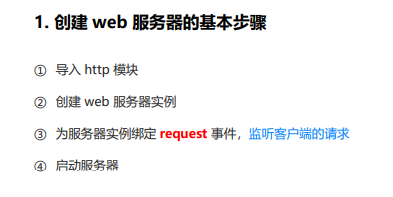
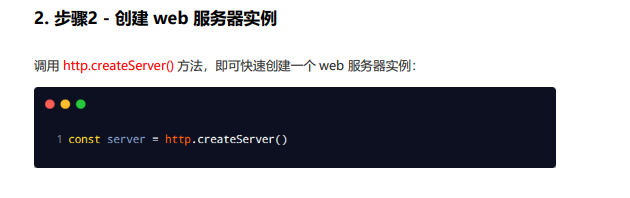
创建 web 服务器步骤

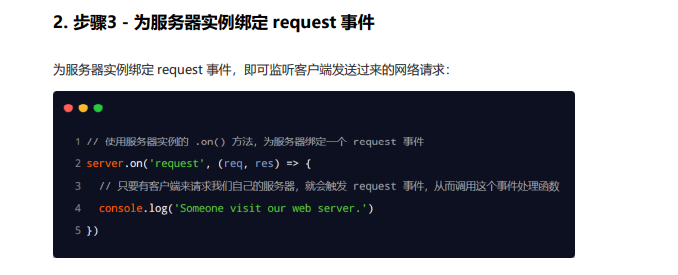
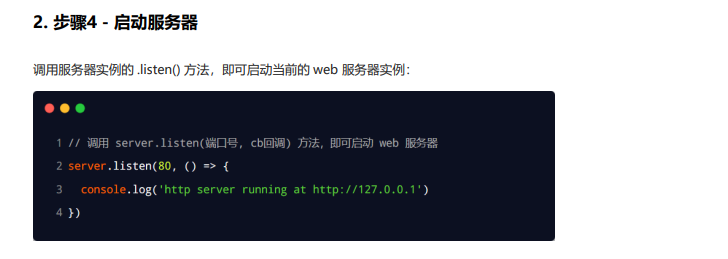
req 请求对象
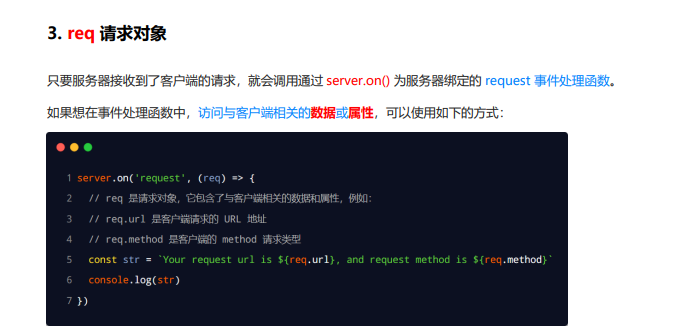
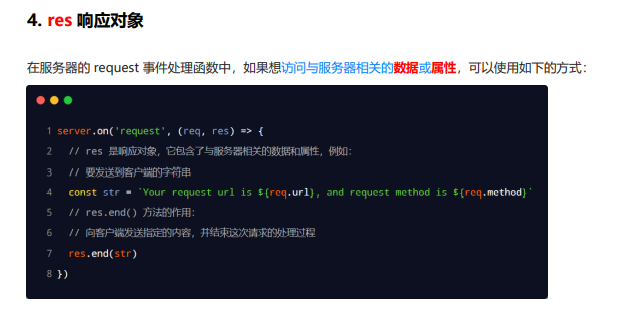
res 响应对象
解决中文乱码问题
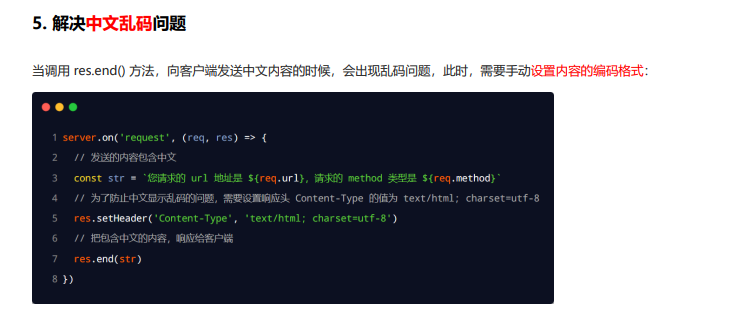
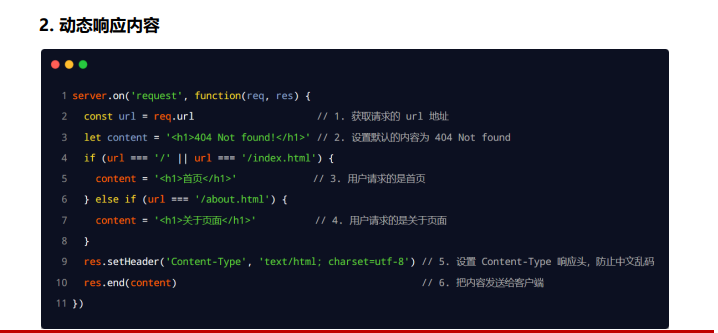
根据不同 url 响应不同的 html 内容(核心)

Node.js 中的 Stream
一、是什么
流(Stream),是一个数据传输手段,是端到端信息交换的一种方式,而且是有顺序的,是逐块读取数据、处理内容,用于顺序读取输入或写入输出
Node.js中很多对象都实现了流,总之它是会冒数据(以 Buffer 为单位)
它的独特之处在于,它不像传统的程序那样一次将一个文件读入内存,而是逐块读取数据、处理其内容,而不是将其全部保存在内存中
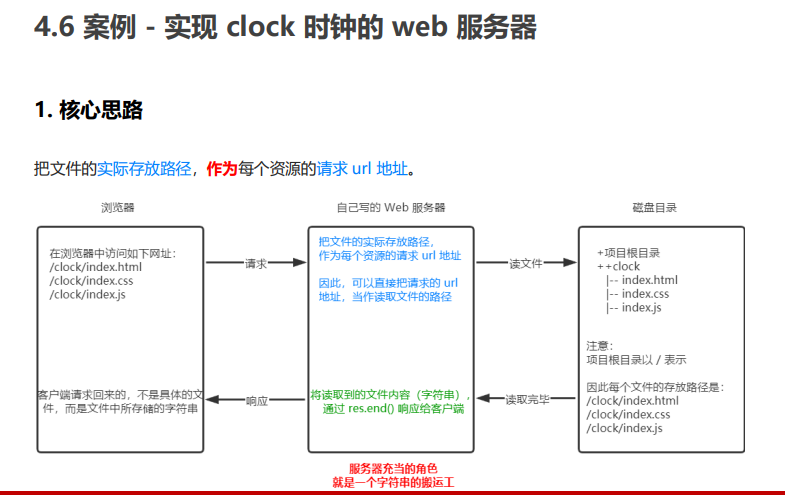
流可以分成三部分:source、dest、pipe
在source和dest之间有一个连接的管道pipe,它的基本语法是source.pipe(dest),source和dest就是通过 pipe 连接,让数据从source流向了dest,如下图所示:

二、种类
在NodeJS,几乎所有的地方都使用到了流的概念,分成四个种类:
- 可写流:可写入数据的流。例如 fs.createWriteStream() 可以使用流将数据写入文件
- 可读流: 可读取数据的流。例如 fs.createReadStream() 可以从文件读取内容
- 双工流: 既可读又可写的流。例如 net.Socket
- 转换流: 可以在数据写入和读取时修改或转换数据的流。例如,在文件压缩操作中,可以向文件写入压缩数据,并从文件中读取解压数据
在NodeJS中HTTP服务器模块中,request 是可读流,response 是可写流。还有fs 模块,能同时处理可读和可写文件流
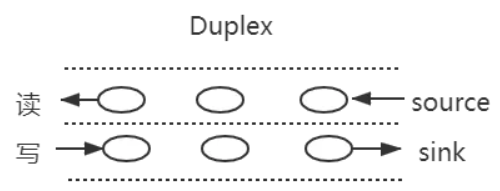
可读流和可写流都是单向的,比较容易理解,而另外两个是双向的
双工流
之前了解过websocket通信,是一个全双工通信,发送方和接受方都是各自独立的方法,发送和接收都没有任何关系
如下图所示:
基本代码如下:
const { Duplex } = require("stream");
const myDuplex = new Duplex({
read(size) {
// ...
},
write(chunk, encoding, callback) {
// ...
},
});
双工流的演示图如下所示:
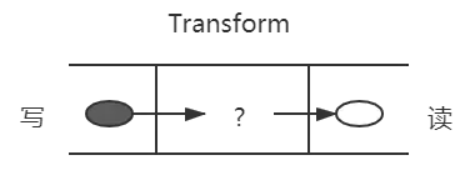
除了上述压缩包的例子,还比如一个 babel,把es6转换为,我们在左边写入 es6,从右边读取 es5
基本代码如下所示:
const { Transform } = require("stream");
const myTransform = new Transform({
transform(chunk, encoding, callback) {
// ...
},
});
三、应用场景
stream的应用场景主要就是处理IO操作,而http请求和文件操作都属于IO操作
试想一下,如果一次IO操作过大,硬件的开销就过大,而将此次大的IO操作进行分段操作,让数据像水管一样流动,直到流动完成
常见的场景有:
- get 请求返回文件给客户端
- 文件操作
- 一些打包工具的底层操作
get 请求返回文件给客户端
使用stream流返回文件,res也是一个stream对象,通过pipe管道将文件数据返回
const server = http.createServer(function (req, res) {
const method = req.method; // 获取请求方法
if (method === "GET") {
// get 请求
const fileName = path.resolve(__dirname, "data.txt");
let stream = fs.createReadStream(fileName);
stream.pipe(res); // 将 res 作为 stream 的 dest
}
});
server.listen(8000);
文件操作
创建一个可读数据流readStream,一个可写数据流writeStream,通过pipe管道把数据流转过去
const fs = require("fs");
const path = require("path");
// 两个文件名
const fileName1 = path.resolve(__dirname, "data.txt");
const fileName2 = path.resolve(__dirname, "data-bak.txt");
// 读取文件的 stream 对象
const readStream = fs.createReadStream(fileName1);
// 写入文件的 stream 对象
const writeStream = fs.createWriteStream(fileName2);
// 通过 pipe执行拷贝,数据流转
readStream.pipe(writeStream);
// 数据读取完成监听,即拷贝完成
readStream.on("end", function () {
console.log("拷贝完成");
});
一些打包工具的底层操作
目前一些比较火的前端打包构建工具,都是通过node.js编写的,打包和构建的过程肯定是文件频繁操作的过程,离不来stream,如gulp
Node.js 中的 Buffer
一、是什么
在Node应用中,需要处理网络协议、操作数据库、处理图片、接收上传文件等,在网络流和文件的操作中,要处理大量二进制数据,而Buffer就是在内存中开辟一片区域(初次初始化为 8KB),用来存放二进制数据
在上述操作中都会存在数据流动,每个数据流动的过程中,都会有一个最小或最大数据量
如果数据到达的速度比进程消耗的速度快,那么少数早到达的数据会处于等待区等候被处理。反之,如果数据到达的速度比进程消耗的数据慢,那么早先到达的数据需要等待一定量的数据到达之后才能被处理
这里的等待区就指的缓冲区(Buffer),它是计算机中的一个小物理单位,通常位于计算机的 RAM 中
简单来讲,Nodejs不能控制数据传输的速度和到达时间,只能决定何时发送数据,如果还没到发送时间,则将数据放在Buffer中,即在RAM中,直至将它们发送完毕
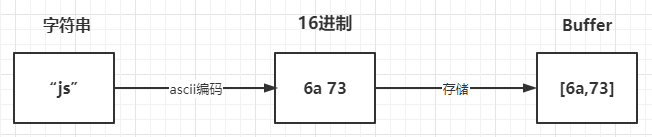
上面讲到了Buffer是用来存储二进制数据,其的形式可以理解成一个数组,数组中的每一项,都可以保存 8 位二进制:00000000,也就是一个字节
例如:
const buffer = Buffer.from("why");
1
其存储过程如下图所示:
二、使用方法
Buffer 类在全局作用域中,无须require导入
创建Buffer的方法有很多种,我们讲讲下面的两种常见的形式:
- Buffer.from()
- Buffer.alloc()
Buffer.from()
const b1 = Buffer.from("10");
const b2 = Buffer.from("10", "utf8");
const b3 = Buffer.from([10]);
const b4 = Buffer.from(b3);
console.log(b1, b2, b3, b4); // <Buffer 31 30> <Buffer 31 30> <Buffer 0a> <Buffer 0a>
Buffer.alloc()
const bAlloc1 = Buffer.alloc(10); // 创建一个大小为 10 个字节的缓冲区
const bAlloc2 = Buffer.alloc(10, 1); // 建一个长度为 10 的 Buffer,其中全部填充了值为 `1` 的字节
console.log(bAlloc1); // <Buffer 00 00 00 00 00 00 00 00 00 00>
console.log(bAlloc2); // <Buffer 01 01 01 01 01 01 01 01 01 01>
在上面创建buffer后,则能够toString的形式进行交互,默认情况下采取utf8字符编码形式,如下
const buffer = Buffer.from("你好");
console.log(buffer);
// <Buffer e4 bd a0 e5 a5 bd>
const str = buffer.toString();
console.log(str);
// 你好
如果编码与解码不是相同的格式则会出现乱码的情况,如下:
const buffer = Buffer.from("你好", "utf-8 ");
console.log(buffer);
// <Buffer e4 bd a0 e5 a5 bd>
const str = buffer.toString("ascii");
console.log(str);
// d= e%=
当设定的范围导致字符串被截断的时候,也会存在乱码情况,如下:
const buf = Buffer.from("Node.js 技术栈", "UTF-8");
console.log(buf); // <Buffer 4e 6f 64 65 2e 6a 73 20 e6 8a 80 e6 9c af e6 a0 88>
console.log(buf.length); // 17
console.log(buf.toString("UTF-8", 0, 9)); // Node.js �
console.log(buf.toString("UTF-8", 0, 11)); // Node.js 技
所支持的字符集有如下:
- ascii:仅支持 7 位 ASCII 数据,如果设置去掉高位的话,这种编码是非常快的
- utf8:多字节编码的 Unicode 字符,许多网页和其他文档格式都使用 UTF-8
- utf16le:2 或 4 个字节,小字节序编码的 Unicode 字符,支持代理对(U+10000 至 U+10FFFF)
- ucs2,utf16le 的别名
- base64:Base64 编码
- latin:一种把 Buffer 编码成一字节编码的字符串的方式
- binary:latin1 的别名,
- hex:将每个字节编码为两个十六进制字符
三、应用场景
Buffer的应用场景常常与流的概念联系在一起,例如有如下:
- I/O 操作
- 加密解密
- zlib.js
I/O 操作
通过流的形式,将一个文件的内容读取到另外一个文件
const fs = require("fs");
const inputStream = fs.createReadStream("input.txt"); // 创建可读流
const outputStream = fs.createWriteStream("output.txt"); // 创建可写流
inputStream.pipe(outputStream); // 管道读写
加解密
在一些加解密算法中会遇到使用 Buffer,例如 crypto.createCipheriv 的第二个参数 key 为 string 或 Buffer 类型
zlib.js
zlib.js 为 Node.js 的核心库之一,其利用了缓冲区(Buffer)的功能来操作二进制数据流,提供了压缩或解压功能
Node.js 中的 EventEmitter
一、是什么
我们了解到,Node采用了事件驱动机制,而EventEmitter就是Node实现事件驱动的基础
在EventEmitter的基础上,Node几乎所有的模块都继承了这个类,这些模块拥有了自己的事件,可以绑定/触发监听器,实现了异步操作
Node.js 里面的许多对象都会分发事件,比如 fs.readStream 对象会在文件被打开的时候触发一个事件
这些产生事件的对象都是 events.EventEmitter 的实例,这些对象有一个 eventEmitter.on() 函数,用于将一个或多个函数绑定到命名事件上
二、使用方法
Node的events模块只提供了一个EventEmitter类,这个类实现了Node异步事件驱动架构的基本模式——观察者模式
在这种模式中,被观察者(主体)维护着一组其他对象派来(注册)的观察者,有新的对象对主体感兴趣就注册观察者,不感兴趣就取消订阅,主体有更新的话就依次通知观察者们
基本代码如下所示:
const EventEmitter = require("events");
class MyEmitter extends EventEmitter {}
const myEmitter = new MyEmitter();
function callback() {
console.log("触发了event事件!");
}
myEmitter.on("event", callback);
myEmitter.emit("event");
myEmitter.removeListener("event", callback);
通过实例对象的on方法注册一个名为event的事件,通过emit方法触发该事件,而removeListener用于取消事件的监听
关于其常见的方法如下:
- emitter.addListener/on(eventName, listener) :添加类型为 eventName 的监听事件到事件数组尾部
- emitter.prependListener(eventName, listener):添加类型为 eventName 的监听事件到事件数组头部
- emitter.emit(eventName[, ...args]):触发类型为 eventName 的监听事件
- emitter.removeListener/off(eventName, listener):移除类型为 eventName 的监听事件
- emitter.once(eventName, listener):添加类型为 eventName 的监听事件,以后只能执行一次并删除
- emitter.removeAllListeners([eventName]): 移除全部类型为 eventName 的监听事件
三、实现过程
通过上面的方法了解,EventEmitter是一个构造函数,内部存在一个包含所有事件的对象
class EventEmitter {
constructor() {
this.events = {};
}
}
其中events存放的监听事件的函数的结构如下:
{
"event1": [f1,f2,f3],
"event2": [f4,f5],
...
}
然后开始一步步实现实例方法,首先是emit,第一个参数为事件的类型,第二个参数开始为触发事件函数的参数,实现如下:
emit(type, ...args) {
this.events[type].forEach((item) => {
Reflect.apply(item, this, args);
});
}
当实现了emit方法之后,然后实现on、addListener、prependListener这三个实例方法,都是添加事件监听触发函数,实现也是大同小异
on(type, handler) {
if (!this.events[type]) {
this.events[type] = [];
}
this.events[type].push(handler);
}
addListener(type,handler){
this.on(type,handler)
}
prependListener(type, handler) {
if (!this.events[type]) {
this.events[type] = [];
}
this.events[type].unshift(handler);
}
紧接着就是实现事件监听的方法removeListener/on
removeListener(type, handler) {
if (!this.events[type]) {
return;
}
this.events[type] = this.events[type].filter(item => item !== handler);
}
off(type,handler){
this.removeListener(type,handler)
}
最后再来实现once方法, 再传入事件监听处理函数的时候进行封装,利用闭包的特性维护当前状态,通过fired属性值判断事件函数是否执行过
once(type, handler) {
this.on(type, this._onceWrap(type, handler, this));
}
_onceWrap(type, handler, target) {
const state = { fired: false, handler, type , target};
const wrapFn = this._onceWrapper.bind(state);
state.wrapFn = wrapFn;
return wrapFn;
}
_onceWrapper(...args) {
if (!this.fired) {
this.fired = true;
Reflect.apply(this.handler, this.target, args);
this.target.off(this.type, this.wrapFn);
}
}
完整代码如下:
class EventEmitter {
constructor() {
this.events = {};
}
on(type, handler) {
if (!this.events[type]) {
this.events[type] = [];
}
this.events[type].push(handler);
}
addListener(type, handler) {
this.on(type, handler);
}
prependListener(type, handler) {
if (!this.events[type]) {
this.events[type] = [];
}
this.events[type].unshift(handler);
}
removeListener(type, handler) {
if (!this.events[type]) {
return;
}
this.events[type] = this.events[type].filter((item) => item !== handler);
}
off(type, handler) {
this.removeListener(type, handler);
}
emit(type, ...args) {
this.events[type].forEach((item) => {
Reflect.apply(item, this, args);
});
}
once(type, handler) {
this.on(type, this._onceWrap(type, handler, this));
}
_onceWrap(type, handler, target) {
const state = { fired: false, handler, type, target };
const wrapFn = this._onceWrapper.bind(state);
state.wrapFn = wrapFn;
return wrapFn;
}
_onceWrapper(...args) {
if (!this.fired) {
this.fired = true;
Reflect.apply(this.handler, this.target, args);
this.target.off(this.type, this.wrapFn);
}
}
}
测试代码如下:
const ee = new EventEmitter();
// 注册所有事件
ee.once("wakeUp", (name) => {
console.log(`${name} 1`);
});
ee.on("eat", (name) => {
console.log(`${name} 2`);
});
ee.on("eat", (name) => {
console.log(`${name} 3`);
});
const meetingFn = (name) => {
console.log(`${name} 4`);
};
ee.on("work", meetingFn);
ee.on("work", (name) => {
console.log(`${name} 5`);
});
ee.emit("wakeUp", "xx");
ee.emit("wakeUp", "xx"); // 第二次没有触发
ee.emit("eat", "xx");
ee.emit("work", "xx");
ee.off("work", meetingFn); // 移除事件
ee.emit("work", "xx"); // 再次工作
node 模块化

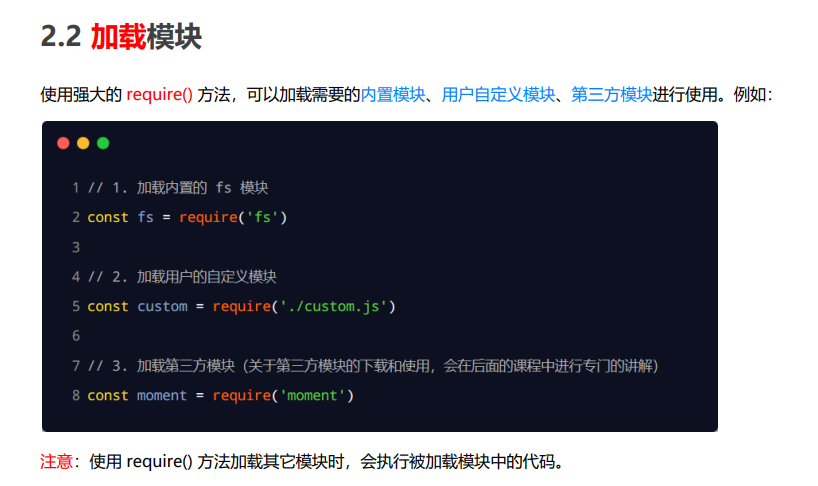
加载模块
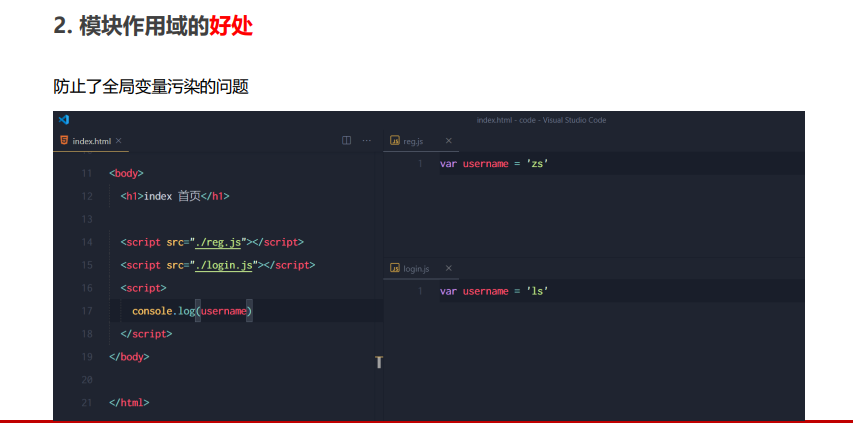
模块作用域

模块作用域的好处
nodemon
npm i --save nodemon

pm2
pm2 是我们在使用 Node 开发时常用的服务托管工具,功能很强大,但大部分人可能只停留在使用层面,没有去了解过它的原理,其实 pm2的原理并没有你想象中的复杂。
在了解 pm2 的工作原理前,先来聊聊一些前置知识。
前置知识
Node Cluster
熟悉 js 的朋友都知道,js 是单线程的,在 Node 中,采用的是 多进程单线程 的模型。由于单线程的限制,在多核服务器上,我们往往需要启动多个进程才能最大化服务器性能。
Node 在 V0.8 版本之后引入了 cluster 模块,通过一个主进程 (master) 管理多个子进程 (worker) 的方式实现集群。
以下是官网上的一个简单示例
const cluster = require("cluster");
const http = require("http");
const numCPUs = require("os").cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on("exit", (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
// In this case it is an HTTP server
http
.createServer((req, res) => {
res.writeHead(200);
res.end("hello world\n");
})
.listen(8000);
console.log(`Worker ${process.pid} started`);
}
通信
Node 中主进程和子进程之间通过进程间通信 (IPC) 实现进程间的通信,进程间通过 send 方法发送消息,监听 message 事件收取信息,这是 cluster模块 通过集成 EventEmitter 实现的。还是一个简单的官网的进程间通信例子
const cluster = require("cluster");
const http = require("http");
if (cluster.isMaster) {
// Keep track of http requests
let numReqs = 0;
setInterval(() => {
console.log(`numReqs = ${numReqs}`);
}, 1000);
// Count requests
function messageHandler(msg) {
if (msg.cmd && msg.cmd === "notifyRequest") {
numReqs += 1;
}
}
// Start workers and listen for messages containing notifyRequest
const numCPUs = require("os").cpus().length;
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
for (const id in cluster.workers) {
cluster.workers[id].on("message", messageHandler);
}
} else {
// Worker processes have a http server.
http
.Server((req, res) => {
res.writeHead(200);
res.end("hello world\n");
// Notify master about the request
process.send({ cmd: "notifyRequest" });
})
.listen(8000);
}
负载均衡
了解 cluster 的话会知道,子进程是通过 cluster.fork() 创建的。在 linux 中,系统原生提供了 fork 方法,那么为什么 Node 选择自己实现 cluster模块 ,而不是直接使用系统原生的方法?主要的原因是以下两点:
- fork 的进程监听同一端口会导致端口占用错误
- fork 的进程之间没有负载均衡,容易导致惊群现象
在 cluster模块 中,针对第一个问题,通过判断当前进程是否为 master进程,若是,则监听端口,若不是则表示为 fork 的 worker进程,不监听端口。
针对第二个问题,cluster模块 内置了负载均衡功能,master进程 负责监听端口接收请求,然后通过调度算法(默认为 Round-Robin,可以通过环境变量 NODE_CLUSTER_SCHED_POLICY 修改调度算法)分配给对应的 worker进程。
pm2 的实现
pm2 基于 cluster模块 进行了封装,它能自动监控进程状态、重启进程、停止不稳定进程、日志存储等。利用 pm2 时,可以在不修改代码的情况下实现负载均衡集群。
架构

这篇文章我们要关注的是 pm2 的 Satan进程、God Deamon守护进程 以及 两者之间的 进程间远程调用RPC。
撒旦(Satan),主要指《圣经》中的堕天使(也称堕天使撒旦),被看作与上帝的力量相对的邪恶、黑暗之源,是 God 的对立面。
其中 Satan.js 提供程序的退出、杀死等方法,God.js 负责维持进程的正常运行,God 进程启动后一直运行,相当于 cluster 中的 Master 进程,维持 worker 进程的正常运行。
RPC 是指远程过程调用协议,具体释义就不细讲了,感兴趣的自行查阅。在 pm2 中用于同一机器上的不同进程之间的方法调用。
执行流程

以上是 pm2 的执行流程图,每次命令行输入时都会执行一次 Satan 程序,然后判断 God 进程是否正在运行,确保 God 进程正常运行后, Satan 会通过 RPC 调用 God 中对应的方法启动服务。
nvm
Express
express 是基于 nodejs 的 web 开发框架。优点是易上手、高性能、扩展性强。
- 易上手:nodejs 最初就是为了开发高性能 web 服务器而被设计出来的,然而相对底层的 API 会让不少新手望而却步。express 对 web 开发相关的模块进行了适度的封装,屏蔽了大量复杂繁琐的技术细节,让开发者只需要专注于业务逻辑的开发,极大的降低了入门和学习的成本。
- 高性能:express 仅在 web 应用相关的 nodejs 模块上进行了适度的封装和扩展,较大程度避免了过度封装导致的性能损耗。
- 扩展性强:基于中间件的开发模式,使得 express 应用的扩展、模块拆分非常简单,既灵活,扩展性又强。
项目目录结构
看下 demo 应用的目录结构。大部分时候,我们的应用目录结构跟这个保持一致就可以了。也可以根据需要自行调整,express 并没有对目录结构进行限制。
从目录结构可以大致看出,express 应用的核心概念主要包括:路由、中间件、模板引擎。
express-demo tree -L 1
.
├── app.js # 应用的主入口
├── bin # 启动脚本
├── node_modules # 依赖的模块
├── package.json # node模块的配置文件
├── public # 静态资源,如css、js等存放的目录
├── routes # 路由规则存放的目录
└── views # 模板文件存放的目录
5 directories, 2 files
核心概念简介
上面提到,express 主要包含三个核心概念:路由、中间件、模板引擎。
注意,笔者这里用的是
核心概念这样的字眼,而不是核心模块,为什么呢?这是因为,虽然 express 的中间件有它的定义规范,但是 express 的内核源码中,其实是没有所谓的中间件这样的模块的。
言归正传,三者简要的来说就是。
中间件:可以毫不夸张的说,在 express 应用中,一切皆中间件。各种应用逻辑,如 cookie 解析、会话处理、日志记录、权限校验等,都是通过中间件来完成的。路由:地球人都知道,负责寻址的。比如用户发送了个 http 请求,该定位到哪个资源,就是路由说了算。模板引擎:负责视图动态渲染。下面会介绍相关配置,以及如何开发自己的模板引擎。
核心概念:路由
路由分类
粗略来说,express 主要支持四种类型的路由,下面会分别举例进行说明
- 字符串类型
- 字符串模式类型
- 正则表达式类型
- 参数类型
分别举例如下,细节可参考官方文档。
var express = require("express");
var app = express();
// 路由:字符串类型
app.get("/book", function (req, res, next) {
res.send("book");
});
// 路由:字符串模式
app.get("/user/*man", function (req, res, next) {
res.send("user"); // 比如: /user/man, /user/woman
});
// 路由:正则表达式
app.get(/animals?$/, function (req, res, next) {
res.send("animal"); // 比如: /animal, /animals
});
// 路由:命名参数
app.get("/employee/:uid/:age", function (req, res, next) {
res.json(req.params); // 比如:/111/30,返回 {"uid": 111, "age": 30}
});
app.listen(3000);
路由拆分
当你用的应用越来越复杂,不可避免的,路由规则也会越来越复杂。这个时候,对路由进行拆分是个不错的选择。
我们分别看下两段代码,路由拆分的好处就直观的体现出来了。
路由拆分前
var express = require('express');
var app = express();
app.get('/user/list', function(req, res, next){
res.send('/list');
});
app.get('/user/detail', function(req, res, next){
res.send('/detail');
});
app.listen(3000);
这样的代码会带来什么问题呢?无论是新增还是修改路由,都要带着/user前缀,这对于代码的可维护性来说是大忌。这对小应用来说问题不大,但应用复杂度一上来就会是个噩梦。
路由拆分后
可以看到,通过express.Router()进行了路由拆分,新增、修改路由都变得极为便利。
var express = require('express');
var app = express();
var user = express.Router();
user.get('/list', function(req, res, next){
res.send('/list');
});
user.get('/detail', function(req, res, next){
res.send('/detail');
});
app.use('/user', user); // mini app,通常做应用拆分
app.listen(3000);
核心概念:中间件
一般学习 js 的时候,我们都会听到一句话:一切皆对象。而在学习 express 的过程中,很深的一个感受就是:一切皆中间件。比如常见的请求参数解析、cookie 解析、gzip 等,都可以通过中间件来完成。
工作机制
贴上官网的一张图镇楼,图中所示就是传说中的中间件了。

首先,我们自己编写一个极简的中间件。虽然没什么实用价值,但中间件就长这样子。
参数:三个参数,熟悉http.createServer()的同学应该比较眼熟,其实就是 req(客户端请求实例)、res(服务端返回实例),只不过进行了扩展,添加了一些使用方法。next:回调方法,当 next()被调用时,就进入下一个中间件。
function logger(req, res, next) {
console.log("here comes request");
next();
}
来看下实际例子:
var express = require("express");
var app = express();
app.use(function (req, res, next) {
console.log("1");
next();
});
app.use(function (req, res, next) {
console.log("2");
next();
});
app.use(function (req, res, next) {
console.log("3");
res.send("hello");
});
app.listen(3000);
请求 http://127.0.0.1:3000,看下控制台输出,以及浏览器返回内容。
middleware git:(master) node chains.js
1
2
3
应用级中间件 vs 路由级中间件
根据作用范围,中间件分为两大类:
- 应用级中间件
- 路由级中间件。
两者的区别不容易说清楚,因为从本质来讲,两类中间件是完全等同的,只是使用场景不同。同一个中间件,既可以是应用级中间件、也可以是路由级中间件。
直接上代码可能更直观。参考下面代码,可以简单粗暴的认为:
- 应用级中间件:
app.use()、app.METHODS()接口中使用的中间件。 - 路由级中间件:
router.use()、router.METHODS()接口中使用的中间件。
var express = require("express");
var app = express();
var user = express.Router();
// 应用级
app.use(function (req, res, next) {
console.log("收到请求,地址为:" + req.url);
next();
});
// 应用级
app.get("/profile", function (req, res, next) {
res.send("profile");
});
// 路由级
user.use("/list", function (req, res, next) {
res.send("/user/list");
});
// 路由级
user.get("/detail", function (req, res, next) {
res.send("/user/detail");
});
app.use("/user", user);
app.listen(3000);
开发中间件
上面也提到了,中间件的开发是是分分钟的事情,不赘述。
function logger(req, res, next) {
doSomeBusinessLogic(); // 业务逻辑处理,比如权限校验、数据库操作、设置cookie等
next(); // 如果需要进入下一个中间件进行处理,则调用next();
}
常用中间件
包括但不限于如下。更多常用中间件,可以点击 这里
- body-parser
- compression
- serve-static
- session
- cookie-parser
- morgan
核心概念:模板引擎
模板引擎大家不陌生了,关于 express 模板引擎的介绍可以参考官方文档。
下面主要讲下使用配置、选型等方面的内容。
可选的模版引擎
包括但不限于如下模板引擎
- jade
- ejs
- dust.js
- dot
- mustache
- handlerbar
- nunjunks
配置说明
先看代码。
// view engine setup
app.set("views", path.join(__dirname, "views"));
app.set("view engine", "jade");
有两个关于模版引擎的配置:
views:模版文件放在哪里,默认是在项目根目录下。举个例子:app.set('views', './views')view engine:使用什么模版引擎,举例:app.set('view engine', 'jade')
可以看到,默认是用jade做模版的。如果不想用jade怎么办呢?下面会提供一些模板引擎选择的思路。
选择标准
需要考虑两点:实际业务需求、个人偏好。
首先考虑业务需求,需要支持以下几点特性。
- 支持模版继承(extend)
- 支持模版扩展(block)
- 支持模版组合(include)
- 支持预编译
对比了下,jade、nunjunks都满足要求。个人更习惯nunjunks的风格,于是敲定。那么,怎么样使用呢?
支持 nunjucks
首先,安装依赖
npm install --save nunjucks
然后,添加如下配置
var nunjucks = require('nunjucks');
nunjucks.configure('views', {
autoescape: true,
express: app
});
app.set('view engine', 'html');
看下views/layout.html
<!DOCTYPE html>
<html>
<head>
<title>
{% block title %}
layout title
{% endblock %}
</title>
</head>
<body>
<h1>
{% block appTitle %}
layout app title
{% endblock %}
</h1>
<p>正文</p>
</body>
</html>
看下views/index.html
{% extends "layout.html" %} {% block title %}首页{% endblock %} {% block
appTitle %}首页{% endblock %}
开发模板引擎
通过app.engine(engineExt, engineFunc)来注册模板引擎。其中
- engineExt:模板文件后缀名。比如
jade。 - engineFunc:模板引擎核心逻辑的定义,一个带三个参数的函数(如下)
// filepath: 模板文件的路径
// options:渲染模板所用的参数
// callback:渲染完成回调
app.engine(engineExt, function (filepath, options, callback) {
// 参数一:渲染过程的错误,如成功,则为null
// 参数二:渲染出来的字符串
return callback(null, "Hello World");
});
比如下面例子,注册模板引擎 + 修改配置一起,于是就可以愉快的使用后缀为tmpl的模板引擎了。
app.engine("tmpl", function (filepath, options, callback) {
// 参数一:渲染过程的错误,如成功,则为null
// 参数二:渲染出来的字符串
return callback(null, "Hello World");
});
app.set("views", "./views");
app.set("view engine", "tmpl");
相关链接
模板引擎对比:点击这里
express 模版引擎介绍:点击这里
开发模版引擎:点击这里
更多内容
前面讲了一些 express 的入门基础,感兴趣的同学可以查看官方文档。篇幅所限,有些内容在后续文章展开,比如下面列出来的内容等。
- 进程管理
- 会话管理
- 日志管理
- 性能优化
- 调试
- 错误处理
- 负载均衡
- 数据库支持
- HTTPS 支持
- 业务实践
express 源码分析
const express = require("./express");
const res = require("./response");
const app = express();
app.get(
"/test1",
(req, res, next) => {
console.log("one");
next();
},
(req, res) => {
console.log("two");
res.end("two");
}
);
app.get(
"/test2",
(req, res, next) => {
console.log("three");
next();
},
(req, res) => {
console.log("four");
res.end("four");
}
);
app.listen(3000);
构成
Application 表示一个 Express 应用,通过 express()即可进行创建。
Router 路由系统,用于调度整个系统的运行,在上述代码中该路由系统包含 app.get('/test1',……)和 app.get('/test2',……)两大部分
Layer 代表一层,对于上述代码中 app.get('/test1',……)和 app.get('/test2',……)都可以成为一个 Layer
Route 一个 Layer 中会有多个处理函数的情况,这多个处理函数构成了 Route,而 Route 中的每一个函数又成为 Route 中的 Layer。对于上述代码中,app.get('/test1',……)中的两个函数构成一个 Route,每个函数又是 Route 中的 Layer。
首先启动服务,然后客户端发起了http://localhost:3000/test2的请求,该过程应该如何运行呢?
启动服务时会依次执行程序,将该路由系统中的路径、请求方法、处理函数进行存储(这些信息根据一定结构存储在 Router、Layer 和 Route 中)
对相应的地址进行监听,等待请求到达。
请求到达,首先根据请求的 path 去从上到下进行匹配,路径匹配正确则进入该 Layer,否则跳出该 Layer。
若匹配到该 Layer,则进行请求方式的匹配,若匹配方式匹配正确,则执行该对应 Route 中的函数。
首先会进行 app 实例初始化、然后调用一系列中间件,最后建立监听
主要分为两个阶段:初始化阶段、请求处理阶段,以 app.get()为例
初始化阶段
工程的初始化阶段
首先来看一下app.get()的内容(源代码中 app.get()是通过遍历 methods 的方式产生)
app.get = function (path) {
// ……
this.lazyrouter();
var route = this._router.route(path);
route.get.apply(route, slice.call(arguments, 1));
return this;
};在 app.lazyrouter()会完成 router 的实例化过程
app.lazyrouter = function lazyrouter() {
if (!this._router) {
this._router = new Router({
caseSensitive: this.enabled("case sensitive routing"),
strict: this.enabled("strict routing"),
});
// 此处会使用一些中间件
this._router.use(query(this.get("query parser fn")));
this._router.use(middleware.init(this));
}
};注意:该过程中其实是利用了单例模式,保证整个过程中获取 router 实例的唯一性。
调用router.route()方法完成layer 的实例化、处理及保存,并返回实例化后的 route。(注意源码中是 proto.route)
router.prototype.route = function route(path) {
var route = new Route(path);
var layer = new Layer(
path,
{
sensitive: this.caseSensitive,
strict: this.strict,
end: true,
},
route.dispatch.bind(route)
);
layer.route = route; // 把route放到layer上
this.stack.push(layer); // 把layer放到数组中
return route;
};将该 app.get()中的函数存储到 route 的 stack 中。(注意源码中也是通过遍历 method 的方式将 get 挂载到 route 的 prototype 上)
Route.prototype.get = function () {
var handles = flatten(slice.call(arguments));
for (var i = 0; i < handles.length; i++) {
var handle = handles[i];
// ……
// 给route添加layer,这个层中需要存放方法名和handler
var layer = Layer("/", {}, handle);
layer.method = method;
this.methods[method] = true;
this.stack.push(layer);
}
return this;
};
注意:上述代码均删除了源码中一些异常判断逻辑,方便读者看清整体框架。
通过上述的分析,可以看出初始化阶段主要做了两件事情:
- 将路由处理方式(app.get()、app.post()……)、app.use()等划分为路由系统中的一个 Layer。
- 对于每一个层中的处理函数全部存储至 Route 对象中,一个 Route 对象与一个 Layer 相互映射。
请求处理阶段
当服务启动后即进入监听状态,等待请求到达后进行处理。
app.listen()使服务进入监听状态(实质上是调用了 http 模块)
app.listen = function listen() {
var server = http.createServer(this);
return server.listen.apply(server, arguments);
};当连接建立会调用 app 实例,app 实例中会立即执行app.handle()函数,app.handle()函数会立即调用路由系统的处理函数router.handle()
app.handle = function handle(req, res, callback) {
var router = this._router;
// 如果路由系统中处理不了这个请求,就调用done方法
var done =
callback ||
finalhandler(req, res, {
env: this.get("env"),
onerror: logerror.bind(this),
});
//……
router.handle(req, res, done);
};router.handle()主要是根据路径获取是否有匹配的 layer,当匹配到之后则调用 layer.prototype.handle_request()去执行 route 中内容的处理
router.prototype.handle = function handle(req, res, out) {
// 这个地方参数out就是done,当所有都匹配不到,就从路由系统中出来,名字很形象
var self = this;
// ……
var stack = self.stack;
// ……
next();
function next(err) {
// ……
// get pathname of request
var path = getPathname(req);
// find next matching layer
var layer;
var match;
var route;
while (match !== true && idx < stack.length) {
layer = stack[idx++];
match = matchLayer(layer, path);
route = layer.route;
// ……
}
// no match
if (match !== true) {
return done(layerError);
}
// ……
// Capture one-time layer values
req.params = self.mergeParams
? mergeParams(layer.params, parentParams)
: layer.params;
var layerPath = layer.path;
// this should be done for the layer
self.process_params(layer, paramcalled, req, res, function (err) {
if (err) {
return next(layerError || err);
}
if (route) {
return layer.handle_request(req, res, next);
}
trim_prefix(layer, layerError, layerPath, path);
});
}
function trim_prefix(layer, layerError, layerPath, path) {
// ……
if (layerError) {
layer.handle_error(layerError, req, res, next);
} else {
layer.handle_request(req, res, next);
}
}
};layer.handle_request()会调用route.dispatch()触发 route 中内容的执行
Layer.prototype.handle_request = function handle(req, res, next) {
var fn = this.handle;
if (fn.length > 3) {
// not a standard request handler
return next();
}
try {
fn(req, res, next);
} catch (err) {
next(err);
}
};route 中的通过判断请求的方法和 route 中 layer 的方法是否匹配,匹配的话则执行相应函数,若所有 route 中的 layer 都不匹配,则调到外层的 layer 中继续执行。
Route.prototype.dispatch = function dispatch(req, res, done) {
var idx = 0;
var stack = this.stack;
if (stack.length === 0) {
return done();
}
var method = req.method.toLowerCase();
// ……
next();
// 此next方法是用户调用的next,如果调用next会执行内层的next方法,如果没有匹配到会调用外层的next方法
function next(err) {
// ……
var layer = stack[idx++];
if (!layer) {
return done(err);
}
if (layer.method && layer.method !== method) {
return next(err);
}
// 如果当前route中的layer的方法匹配到了,执行此layer上的handler
if (err) {
layer.handle_error(err, req, res, next);
} else {
layer.handle_request(req, res, next);
}
}
};
通过上述的分析,可以看出初始化阶段主要做了两件事情:
- 首先判断 layer 中的 path 和请求的 path 是否一致,一致则会进入 route 进行处理,否则调到下一层 layer
- 在 route 中会判断 route 中的 layer 与请求方法是否一致,一致的话则函数执行,否则不执行,所有 route 中的 layer 执行完后跳到下层的 layer 进行执行。
Koa2
1.Koa 基础
koa 支持 async 和 await 的用法
这就意味着在 koa 中可以抛去 express 中回调函数的写法 用一种更优雅的方式来解决异步场景
基本使用
与 express 不同的是 koa 导出的不是函数 而是一个名为 Application 的对象
所以在使用上我们只需要 new 一个实例即可 其他用法和 Express 基本相似
const Koa = require("koa");
const app = new Koa();
app.listen(3000, () => {
console.log("server start...");
});
Koa 本身十分纯净 几乎大部分的功能都是通过插件的方式来实现
路由
这里我们借助第三方模块 koa-router
新建一个 user.js 的路由模块
Koa 将 express 中的 request 和 response 都合成到了上下文对象 context 中 简写为 ctx
const Router = require("koa-router");
const userRouter = new Router({ prefix: "/user" });
userRouter.get("/home", (ctx, next) => {
ctx.body = "welcome~~";
});
userRouter.post("/login", (ctx, next) => {
ctx.body = "login...";
});
module.exports = userRouter;
然后在 index 中引入 user.js
const Koa = require("koa");
const userRouter = require("./router/user");
const app = new Koa();
app.use(userRouter.routes());
app.listen(3000, () => {
console.log("server start...");
});
处理请求
koa 中需要引入 koa-bodyparser 来解析 json 和 urlencoded
const Koa = require("koa");
const Router = require("koa-router");
const bodyParser = require("koa-bodyparser");
const app = new Koa();
const router = new Router();
app.use(bodyParser());
app.use(router.routes());
// 解析query
router.get("/query", (ctx, next) => {
console.log(ctx.request.query);
});
// 解析params
router.get("/params/:id", (ctx, next) => {
console.log(ctx.request.params);
});
// 解析urlencoded
router.post("/urlencoded", (ctx, next) => {
console.log(ctx.request.body);
});
// 解析json
router.post("/json", (ctx, next) => {
console.log(ctx.request.body);
});
app.listen(8080, () => {
console.log("start");
});
注意 koa-bodyparser 中间件需要最先被使用
异步处理
Koa 的中间件支持 async / await 的语法 例如下面这个 demo 就可以正常拼接 ABC 输出
const express = require("express");
const app = express();
const middlewareA = (req, res, next) => {
req.message = "";
req.message += "A";
next();
res.end(req.message);
};
const middlewareB = async (req, res, next) => {
req.message += await Promise.resolve("B");
await next();
};
const middlewareC = (req, res, next) => {
req.message += "C";
next();
};
app.use(middlewareA);
app.use(middlewareB);
app.use(middlewareC);
app.listen(3000, () => {
console.log("server start...");
});
洋葱模型
洋葱模型其实不是什么高大尚的概念 先来看一个 demo
const Koa = require("koa");
const app = new Koa();
const middlewareA = (ctx, next) => {
console.log("middlewareA");
next();
console.log("middlewareA");
};
const middlewareB = (ctx, next) => {
console.log("middlewareB");
next();
console.log("middlewareB");
};
const middlewareC = (ctx, next) => {
console.log("middlewareC");
next();
console.log("middlewareC");
};
app.use(middlewareA);
app.use(middlewareB);
app.use(middlewareC);
app.listen(3000, () => {
console.log("server start");
});
访问 3000 端口 我们可以看到 控制台输出
middlewareA;
middlewareB;
middlewareC;
middlewareC;
middlewareB;
middlewareA;
通过下图我们不难发现 所有中间件都会被 request 访问两次 就像剥洋葱一样 这就是洋葱模型
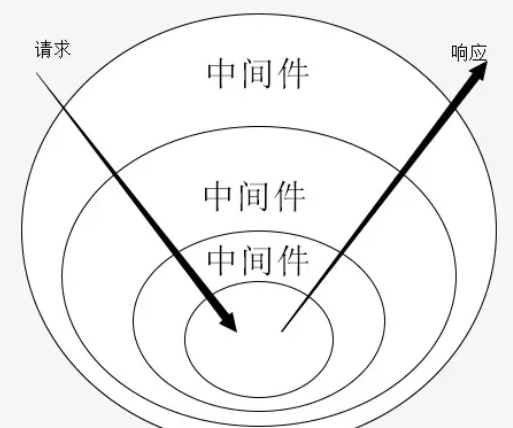
注意 Express 同样也是洋葱模型
2.Koa 的中间件使用和原理
中间件(Middleware)是介于应用系统和系统软件之间的一类软件,它使用系统软件所提供的基础服务(功能),衔接网络上应用系统的各个部分或不同的应用,能够达到资源共享、功能共享的目的
在NodeJS中,中间件主要是指封装http请求细节处理的方法
例如在express、koa等web框架中,中间件的本质为一个回调函数,参数包含请求对象、响应对象和执行下一个中间件的函数

在这些中间件函数中,我们可以执行业务逻辑代码,修改请求和响应对象、返回响应数据等操作
Koa 是一个由 Express 原班人马打造的新的 web 框架,Koa 本身并没有捆绑任何中间件,只提供了应用(Application)、上下文(Context)、请求(Request)、响应(Response)四个模块(源码中可以发现)。原本 Express 中的路由(Router)模块已经被移除,改为通过中间件的方式实现。相比较 Express,Koa 能让使用者更大程度上构建个性化的应用。
Koa 是一个中间件框架,本身没有捆绑任何中间件。本身支持的功能并不多,功能都可以通过中间件拓展实现。通过添加不同的中间件,实现不同的需求,从而构建一个 Koa 应用
中间件基本使用
const Koa = require("Koa");
const app = new Koa();
// async 函数
app.use(async (ctx, next) => {
const start = Date.now();
await next();
const ms = Date.now() - start;
console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
});
// 普通函数
app.use((ctx, next) => {
const start = Date.now();
return next().then(() => {
const ms = Date.now() - start;
console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
});
});
app.listen(3001, () => {
console.log(`Server port is 3000.`);
});
Koa 的中间件就是函数,可以是 async 函数,或是普通函数。而next()函数则是一个异步 promise 函数。
中间件执行顺序
// 最外层的中间件
app.use(async (ctx, next) => {
await console.log(`第 1 个执行`);
await next();
await console.log(`第 6 个执行`);
});
// 第二层中间件
app.use(async (ctx, next) => {
await console.log(`第 2 个执行`);
await next();
await console.log(`第 5 个执行`);
});
// 最里层的中间件
app.use(async (ctx, next) => {
await console.log(`第 3 个执行`);
ctx.body = "Hello world.";
await console.log(`第 4 个执行`);
});
中间件的执行顺序受 next()函数影响,以 next()为界分为上下两部分,next()上面的部分为从上到下顺序执行,直到执行到最深处 ctx上下文执行返回结果后(无 next 函数),再从下到上执行,直到执行到最外层
把关注点集中在 next()函数和ctx上下文,再看一遍:
// 最外层的中间件
app.use(async (ctx, next) => {
// 这里是针对ctx.request做一些处理
ctx.request.query.name = ctx.request.query.name + "_query1";
await next();
// 这里是针对ctx.response做一些处理
ctx.response.body = ctx.response.body + "_query1";
ctx.res.end(ctx.response.body);
});
// 第二层中间件
app.use(async (ctx, next) => {
ctx.request.query.name = ctx.request.query.name + "_query2";
await next();
ctx.response.body = ctx.response.body + "_query2";
});
// 最里层的中间件
app.use(async (ctx, next) => {
const query = ctx.request.query;
// console.log(query) => { name: 'zhangsan_query1_query2' }
ctx.response.body = "hello world";
});
// 请求参数如下:
// http://localhost:3001?name=zhangsan
// 返回结果如下:
// hello world_query2_query1
简单分析可以发现,我们以next函数为分界线,next函数的上面部分可以理解为request请求的流程(从外到内),next函数下面的部分可以理解为response响应的流程(从内到外)
从表现上来看,我觉得这和递归的模式还挺相似的,开始都是先一层层往里调用,直到调用到最后一层,开始执行,得到结果,返回给上一层,然后再从最后一层往回执行,直到回到第一层,得到最终的结果
中间件的使方式非常简单,只需要在 app.use(fn) 中添加中间件函数即可。
该函数接受两个参数:ctx——上下文、next——下一个中间件函数。
const Koa = require("Koa");
const app = new Koa();
const fn = async (ctx, next) => {
const start = Date.now();
await next();
const ms = Date.now() - start;
console.log(`${ctx.method} ${ctx.url} - ${ms}ms`);
};
app.use(fn);
中间件链错误
ctx.onerror = function {
this.app.emit('error', err, this);
};
listen(){
const fnMiddleware = compose(this.middleware);
if (!this.listenerCount('error')) this.on('error', this.onerror);
const onerror = err => ctx.onerror(err);
fnMiddleware(ctx).then(handleResponse).catch(onerror);
}
onerror(err) {
// 代码省略
// ...
}
中间件链错误会由ctx.onerror捕获,该函数中会调用this.app.emit('error', err, this)(因为koa继承自events模块,所以有'emit'和on等方法),可以使用app.on('error', (err) => {}),或者app.onerror = (err) => {}进行捕获
中间件使用举例
token 校验
module.exports = (options) => async (ctx, next) {
try {
// 获取 token
const token = ctx.header.authorization
if (token) {
try {
// verify 函数验证 token,并获取用户相关信息
await verify(token)
} catch (err) {
console.log(err)
}
}
// 进入下一个中间件
await next()
} catch (err) {
console.log(err)
}
}
日志模块
const fs = require("fs");
module.exports = (options) => async (ctx, next) => {
const startTime = Date.now();
const requestTime = new Date();
await next();
const ms = Date.now() - startTime;
let logout = `${ctx.request.ip} -- ${requestTime} -- ${ctx.method} -- ${ctx.url} -- ${ms}ms`;
// 输出日志文件
fs.appendFileSync("./log.txt", logout + "\n");
};
Koa存在很多第三方的中间件,如koa-bodyparser、koa-static等
下面再来看看它们的大体的简单实现:
koa-bodyparser
koa-bodyparser 中间件是将我们的 post 请求和表单提交的查询字符串转换成对象,并挂在 ctx.request.body 上,方便我们在其他中间件或接口处取值
// 文件:my-koa-bodyparser.js
const querystring = require("querystring");
module.exports = function bodyParser() {
return async (ctx, next) => {
await new Promise((resolve, reject) => {
// 存储数据的数组
let dataArr = [];
// 接收数据
ctx.req.on("data", (data) => dataArr.push(data));
// 整合数据并使用 Promise 成功
ctx.req.on("end", () => {
// 获取请求数据的类型 json 或表单
let contentType = ctx.get("Content-Type");
// 获取数据 Buffer 格式
let data = Buffer.concat(dataArr).toString();
if (contentType === "application/x-www-form-urlencoded") {
// 如果是表单提交,则将查询字符串转换成对象赋值给 ctx.request.body
ctx.request.body = querystring.parse(data);
} else if (contentType === "applaction/json") {
// 如果是 json,则将字符串格式的对象转换成对象赋值给 ctx.request.body
ctx.request.body = JSON.parse(data);
}
// 执行成功的回调
resolve();
});
});
// 继续向下执行
await next();
};
};
koa-static
koa-static 中间件的作用是在服务器接到请求时,帮我们处理静态文件
const fs = require("fs");
const path = require("path");
const mime = require("mime");
const { promisify } = require("util");
// 将 stat 和 access 转换成 Promise
const stat = promisify(fs.stat);
const access = promisify(fs.access);
module.exports = function (dir) {
return async (ctx, next) => {
// 将访问的路由处理成绝对路径,这里要使用 join 因为有可能是 /
let realPath = path.join(dir, ctx.path);
try {
// 获取 stat 对象
let statObj = await stat(realPath);
// 如果是文件,则设置文件类型并直接响应内容,否则当作文件夹寻找 index.html
if (statObj.isFile()) {
ctx.set("Content-Type", `${mime.getType()};charset=utf8`);
ctx.body = fs.createReadStream(realPath);
} else {
let filename = path.join(realPath, "index.html");
// 如果不存在该文件则执行 catch 中的 next 交给其他中间件处理
await access(filename);
// 存在设置文件类型并响应内容
ctx.set("Content-Type", "text/html;charset=utf8");
ctx.body = fs.createReadStream(filename);
}
} catch (e) {
await next();
}
};
};
3.Koa 的洋葱模型

Koa 中间件采用的是洋葱圈模型,每次执行下一个中间件传入两个参数 ctx 和 next,参数 ctx 是由 koa 传入的,封装了 request 和 response 对象,可以通过它访问 request 和 response,next 就是进入下一个要执行的中间件。
在洋葱模型中,每一层相当于一个中间件,用来处理特定的功能,比如错误处理、Session 处理等等。其处理顺序先是 next() 前请求(Request,从外层到内层)然后执行 next() 函数,最后是 next() 后响应(Response,从内层到外层),也就是说每一个中间件都有两次处理时机。
按照传统逻辑分析,一个中间件函数应该是自上而下的执行,执行结束后再执行下一个中间件,即从头到尾按顺序链式调用。
但是这样会产生一些问题,比如:
- 如果只链式执行一次,怎么能保证前面的中间件能使用之后的中间件所添加的东西呢?
- 如何正确划分请求前和请求后的关联逻辑?
简要说明:
问题一:如果不是next分层这种执行方式,对于普通的链式调用,在执行下一个中间件并对数据做了一些特殊处理之后,怎么做到让上一个中间件获取到该特殊数据后并且再次执行呢,以及如何避免对其他中间件的影响和整个应用的执行呢?
问题二:以对一个数据库的查询时间做计算来说明,中间件以next分层,上面为开始请求逻辑部分,标记开始的时间,然后执行next函数进入下一个中间件,调用数据库查询相关的中间件功能函数,执行结束后,来到了next函数的下面部分,这里为返回结果,标记结束请求的时间,两数相减即可,非常的简单,功能划分也是很清晰。对于中间件的各种添加、拓展等等,都可以很好集成进去,并做到功能的纯净。
可以发现使用洋葱模型可以很好(优雅)的解决这些问题。
洋葱模型是怎么实现?
app.use() 把中间件函数存储在middleware数组中,最终会调用koa-compose导出的函数compose返回一个promise,中间函数的第一个参数ctx是包含响应和请求的一个对象,会不断传递给下一个中间件。next是一个函数,返回的是一个promise
// 这样就可能更好理解了。
// simpleKoaCompose
const [fn1, fn2, fn3] = this.middleware;
const fnMiddleware = function(context){
return Promise.resolve(
fn1(context, function next(){
return Promise.resolve(
fn2(context, function next(){
return Promise.resolve(
fn3(context, function next(){
return Promise.resolve();
})
)
})
)
})
);
};
fnMiddleware(ctx).then(handleResponse).catch(onerror);
koa-compose是将app.use添加到middleware数组中的中间件(函数),通过使用Promise串联起来,next()返回的是一个promise。
koa-convert 判断app.use传入的函数是否是generator函数,如果是则用koa-convert来转换,最终还是调用的co来转换。
co源码实现原理:其实就是通过不断的调用generator函数的next()函数,来达到自动执行generator函数的效果(类似async、await函数的自动自行)。
koa框架总结:主要就是四个核心概念,洋葱模型(把中间件串联起来),http请求上下文(context)、http请求对象、http响应对象。
4.Koa 简单实现
koa2 的源码目录结构的 lib 文件夹,lib 文件夹下放着四个 koa2 的核心文件:application.js、context.js、request.js、response.js
application.js
application.js 是 koa 的入口文件,它向外导出了创建 class 实例的构造函数,它继承了 events,这样就会赋予框架事件监听和事件触发的能力。application 还暴露了一些常用的 api,比如 toJSON、listen、use 等等。
listen 的实现原理其实就是对 http.createServer 进行了一个封装,重点是这个函数中传入的 callback,它里面包含了中间件的合并,上下文的处理,对 res 的特殊处理。
use 是收集中间件,将多个中间件放入一个缓存队列中,然后通过 koa-compose 这个插件进行递归组合调用这一些列的中间件。
context.js
这部分就是 koa 的应用上下文 ctx,其实就一个简单的对象暴露,里面的重点在 delegate,这个就是代理,这个就是为了开发者方便而设计的,比如我们要访问 ctx.repsponse.status 但是我们通过 delegate,可以直接访问 ctx.status 访问到它。
request.js、response.js
这两部分就是对原生的 res、req 的一些操作了,大量使用 es6 的 get 和 set 的一些语法,去取 headers 或者设置 headers、还有设置 body 等等
实现 koa2 的四大模块
上文简述了 koa2 源码的大体框架结构,接下来我们来实现一个 koa2 的框架,笔者认为理解和实现一个 koa 框架需要实现四个大模块,分别是:
- 封装 node http server、创建 Koa 类构造函数
- 构造 request、response、context 对象
- 中间件机制和剥洋葱模型的实现
- 错误捕获和错误处理
下面我们就逐一分析和实现。
模块一:封装 node http server 和创建 Koa 类构造函数
阅读 koa2 的源码得知,实现 koa 的服务器应用和端口监听,其实就是基于 node 的原生代码进行了封装,如下图的代码就是通过 node 原生代码实现的服务器监听。
let http = require('http');
let server = http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world');
});
server.listen(3000, () => {
console.log('listenning on 3000');
});
我们需要将上面的 node 原生代码封装实现成 koa 的模式:
const http = require('http');
const Koa = require('koa');
const app = new Koa();
app.listen(3000);
实现 koa 的第一步就是对以上的这个过程进行封装,为此我们需要创建 application.js 实现一个 Application 类的构造函数:
let http = require("http");
class Application {
constructor() {
this.callbackFunc;
}
listen(port) {
let server = http.createServer(this.callback());
server.listen(port);
}
use(fn) {
this.callbackFunc = fn;
}
callback() {
return (req, res) => {
this.callbackFunc(req, res);
};
}
}
module.exports = Application;
然后创建 example.js,引入 application.js,运行服务器实例启动监听代码:
let Koa = require('./application');
let app = new Koa();
app.use((req, res) => {
res.writeHead(200);
res.end('hello world');
});
app.listen(3000, () => {
console.log('listening on 3000');
});
现在在浏览器输入 localhost:3000 即可看到浏览器里显示“hello world”。现在第一步我们已经完成了,对 http server 进行了简单的封装和创建了一个可以生成 koa 实例的类 class,这个类里还实现了 app.use 用来注册中间件和注册回调函数,app.listen 用来开启服务器实例并传入 callback 回调函数,第一模块主要是实现典型的 koa 风格和搭好了一个 koa 的简单的架子。接下来我们开始编写和讲解第二模块。
模块二:构造 request、response、context 对象
阅读 koa2 的源码得知,其中 context.js、request.js、response.js 三个文件分别是 request、response、context 三个模块的代码文件。context 就是我们平时写 koa 代码时的 ctx,它相当于一个全局的 koa 实例上下文 this,它连接了 request、response 两个功能模块,并且暴露给 koa 的实例和中间件等回调函数的参数中,起到承上启下的作用。
request、response 两个功能模块分别对 node 的原生 request、response进行了一个功能的封装,使用了 getter 和 setter 属性,基于 node 的对象 req/res 对象封装 koa 的 request/response 对象。我们基于这个原理简单实现一下 request.js、response.js,首先创建 request.js 文件,然后写入以下代码:
let url = require("url");
module.exports = {
get query() {
return url.parse(this.req.url, true).query;
},
};
这样当你在 koa 实例里使用 ctx.query 的时候,就会返回url.parse(this.req.url, true).query的值。看源码可知,基于 getter 和 setter,在request.js里还封装了 header、url、origin、path 等方法,都是对原生的 request 上用 getter 和 setter 进行了封装,笔者不再这里一一实现。
接下来我们实现 response.js 文件代码模块,它和 request 原理一样,也是基于 getter 和 setter 对原生 response 进行了封装,那我们接下来通过对常用的 ctx.body 和 ctx.status 这个两个语句当做例子简述一下如果实现 koa 的 response 的模块,我们首先创建好 response.js 文件,然后输入下面的代码:
module.exports = {
get body() {
return this._body;
},
set body(data) {
this._body = data;
},
get status() {
return this.res.statusCode;
},
set status(statusCode) {
if (typeof statusCode !== 'number') {
throw new Error('something wrong!');
}
this.res.statusCode = statusCode;
}
};
以上代码实现了对 koa 的 status 的读取和设置,读取的时候返回的是基于原生的 response 对象的 statusCode 属性,而 body 的读取则是对 this._body 进行读写和操作。这里对 body 进行操作并没有使用原生的 this.res.end,因为在我们编写 koa 代码的时候,会对 body 进行多次的读取和修改,所以真正返回浏览器信息的操作是在 application.js 里进行封装和操作。
现在我们已经实现了 request.js、response.js,获取到了 request、response 对象和他们的封装的方法,然后我们开始实现context.js,context 的作用就是将 request、response 对象挂载到 ctx 的上面,让 koa 实例和代码能方便的使用到 request、response 对象中的方法。现在我们创建 context.js 文件,输入如下代码:
let proto = {};
function delegateSet(property, name) {
proto.__defineSetter__(name, function (val) {
this[property][name] = val;
});
}
function delegateGet(property, name) {
proto.__defineGetter__(name, function () {
return this[property][name];
});
}
let requestSet = [];
let requestGet = ['query'];
let responseSet = ['body', 'status'];
let responseGet = responseSet;
requestSet.forEach(ele => {
delegateSet('request', ele);
});
requestGet.forEach(ele => {
delegateGet('request', ele);
});
responseSet.forEach(ele => {
delegateSet('response', ele);
});
responseGet.forEach(ele => {
delegateGet('response', ele);
});
module.exports = proto;
context.js 文件主要是对常用的 request 和 response 方法进行挂载和代理,通过context.query直接代理了 context.request.query,context.body 和 context.status 代理了 context.response.body 与 context.response.status。而context.request,context.response则会在 application.js 中挂载
本来可以用简单的 setter 和 getter 去设置每一个方法,但是由于 context 对象定义方法比较简单和规范,在 koa 源码里可以看到,koa 源码用的是defineSetter和defineSetter来代替 setter/getter 每一个属性的读取设置,这样做主要是方便拓展和精简了写法,当我们需要代理更多的res 和 req的方法的时候,可以向context.js文件里面的数组对象里面添加对应的方法名和属性名即可。
目前为止,我们已经得到了 request、response、context 三个模块对象了,接下来就是将 request、response 所有方法挂载到 context 下,让 context 实现它的承上启下的作用,修改 application.js 文件,添加如下代码:
let http = require('http');
let context = require('./context');
let request = require('./request');
let response = require('./response');
createContext(req, res) {
let ctx = Object.create(this.context);
ctx.request = Object.create(this.request);
ctx.response = Object.create(this.response);
ctx.req = ctx.request.req = req;
ctx.res = ctx.response.res = res;
return ctx;
}
可以看到,我们添加了createContext 这个方法,这个方法是关键,它通过 Object.create 创建了 ctx,并将 request 和 response 挂载到了 ctx 上面,将原生的 req 和 res 挂载到了 ctx 的子属性上,往回看一下 context/request/response.js 文件,就能知道当时使用的 this.res 或者 this.response 之类的是从哪里来的了,原来是在这个 createContext 方法中挂载到了对应的实例上,构建了运行时上下文 ctx 之后,我们的 app.use 回调函数参数就都基于 ctx 了。
模块三:中间件机制和剥洋葱模型的实现
目前为止我们已经成功实现了上下文 context 对象、 请求 request 对象和响应 response 对象模块,还差一个最重要的模块,就是 koa 的中间件模块,koa 的中间件机制是一个剥洋葱式的模型,多个中间件通过 use 放进一个数组队列然后从外层开始执行,遇到 next 后进入队列中的下一个中间件,所有中间件执行完后开始回帧,执行队列中之前中间件中未执行的代码部分,这就是剥洋葱模型,koa 的中间件机制。
koa 的剥洋葱模型在 koa1 中使用的是 generator + co.js 去实现的,koa2 则使用了 async/await + Promise 去实现的,接下来我们基于 async/await + Promise 去实现 koa2 中的中间件机制。首先,假设当 koa 的中间件机制已经做好了,那么它是能成功运行下面代码的:
let Koa = require('../src/application');
let app = new Koa();
app.use(async (ctx, next) => {
console.log(1);
await next();
console.log(6);
});
app.use(async (ctx, next) => {
console.log(2);
await next();
console.log(5);
});
app.use(async (ctx, next) => {
console.log(3);
ctx.body = "hello world";
console.log(4);
});
app.listen(3000, () => {
console.log('listenning on 3000');
});
运行成功后会在终端输出 123456,那就能验证我们的 koa 的剥洋葱模型是正确的。接下来我们开始实现,修改 application.js 文件,添加如下代码:
compose() {
return async ctx => {
function createNext(middleware, oldNext) {
return async () => {
await middleware(ctx, oldNext);
}
}
let len = this.middlewares.length;
let next = async () => {
return Promise.resolve();
};
for (let i = len - 1; i >= 0; i--) {
let currentMiddleware = this.middlewares[i];
next = createNext(currentMiddleware, next);
}
await next();
};
}
callback() {
return (req, res) => {
let ctx = this.createContext(req, res);
let respond = () => this.responseBody(ctx);
let onerror = (err) => this.onerror(err, ctx);
let fn = this.compose();
return fn(ctx);
};
}
koa 通过 use 函数,把所有的中间件push 到一个内部数组队列 this.middlewares 中,剥洋葱模型能让所有的中间件依次执行,每次执行完一个中间件,遇到next()就会将控制权传递到下一个中间件,下一个中间件的 next 参数,剥洋葱模型的最关键代码是 compose 这个函数:
compose() {
return async ctx => {
function createNext(middleware, oldNext) {
return async () => {
await middleware(ctx, oldNext);
}
}
let len = this.middlewares.length;
let next = async () => {
return Promise.resolve();
};
for (let i = len - 1; i >= 0; i--) {
let currentMiddleware = this.middlewares[i];
next = createNext(currentMiddleware, next);
}
await next();
};
}
createNext 函数的作用就是将上一个中间件的 next 当做参数传给下一个中间件,并且将上下文 ctx 绑定当前中间件,当中间件执行完,调用 next()的时候,其实就是去执行下一个中间件。
for (let i = len - 1; i >= 0; i--) {
let currentMiddleware = this.middlewares[i];
next = createNext(currentMiddleware, next);
}
上面这段代码其实就是一个链式反向递归模型的实现,i 是从最大数开始循环的,将中间件从最后一个开始封装,每一次都是将自己的执行函数封装成 next 当做上一个中间件的 next 参数,这样当循环到第一个中间件的时候,只需要执行一次 next(),就能链式的递归调用所有中间件,这个就是 koa 剥洋葱的核心代码机制。
到这里我们总结一下上面所有剥洋葱模型代码的流程,通过 use 传进来的中间件是一个回调函数,回调函数的参数是 ctx 上下文和 next,next 其实就是控制权的交接棒,next 的作用是停止运行当前中间件,将控制权交给下一个中间件,执行下一个中间件的 next()之前的代码,当下一个中间件运行的代码遇到了 next(),又会将代码执行权交给下下个中间件,当执行到最后一个中间件的时候,控制权发生反转,开始回头去执行之前所有中间件中剩下未执行的代码,这整个流程有点像一个伪递归,当最终所有中间件全部执行完后,会返回一个 Promise 对象,因为我们的 compose 函数返回的是一个 async 的函数,async 函数执行完后会返回一个 Promise,这样我们就能将所有的中间件异步执行同步化,通过 then 就可以执行响应函数和错误处理函数。
当中间件机制代码写好了以后,运行我们的上面的例子,已经能输出 123456 了,至此,我们的 koa 的基本框架已经基本做好了,不过一个框架不能只实现功能,为了框架和服务器实例的健壮,还需要加上错误处理机制。
模块四:错误捕获和错误处理
要实现一个基础框架,错误处理和捕获必不可少,一个健壮的框架,必须保证在发生错误的时候,能够捕获到错误和抛出的异常,并反馈出来,将错误信息发送到监控系统上进行反馈,目前我们实现的简易 koa 框架还没有能实现这一点,我们接下加上错误处理和捕获的机制。
throw new Error("oooops");
基于现在的框架,如果中间件代码中出现如上错误异常抛出,是捕获不到错误的,这时候我们看一下 application.js 中的 callback 函数的 return 返回代码,如下:
return fn(ctx).then(respond);
可以看到,fn 是中间件的执行函数,每一个中间件代码都是由 async 包裹着的,而且中间件的执行函数 compose 返回的也是一个 async 函数,我们根据 es7 的规范知道,async 返回的是一个 promise 的对象实例,我们如果想要捕获 promise 的错误,只需要使用 promise 的 catch 方法,就可以把所有的中间件的异常全部捕获到,修改后 callback 的返回代码如下:
return fn(ctx).then(respond).catch(onerror);
现在我们已经实现了中间件的错误异常捕获,但是我们还缺少框架层发生错误的捕获机制,我们希望我们的服务器实例能有错误事件的监听机制,通过 on 的监听函数就能订阅和监听框架层面上的错误,实现这个机制不难,使用 nodejs 原生 events 模块即可,events 模块给我们提供了事件监听 on 函数和事件触发 emit 行为函数,一个发射事件,一个负责接收事件,我们只需要将 koa 的构造函数继承 events 模块即可,构造后的伪代码如下:
let EventEmitter = require('events');
class Application extends EventEmitter {
}
继承了 events 模块后,当我们创建 koa 实例的时候,加上 on 监听函数,代码如下:
let app = new Koa();
app.on('error', err => {
console.log('error happends: ', err.stack);
}
);
这样我们就实现了框架层面上的错误的捕获和监听机制了。总结一下,错误处理和捕获,分中间件的错误处理捕获和框架层的错误处理捕获,中间件的错误处理用 promise 的 catch,框架层面的错误处理用 nodejs 的原生模块 events,这样我们就可以把一个服务器实例上的所有的错误异常全部捕获到了。至此,我们就完整实现了一个轻量版的 koa 框架了。
Egg
Egg 继承于 Koa
Koa 是一个非常优秀的框架,然而对于企业级应用来说,它还比较基础。 Egg 选择了 Koa 作为其基础框架,在它的模型基础上,进一步对它进行了一些增强。扩展和插件更为完善和便捷。
目录约定
上面创建的项目只是最小化结构,一个典型的 egg 项目有如下目录结构:
egg-project
├── package.json
├── app.js (可选)
├── agent.js (可选)
├── app/
| ├── router.js # 用于配置 URL 路由规则
│ ├── controller/ # 用于存放控制器(解析用户的输入、加工处理、返回结果)
│ ├── model/ (可选) # 用于存放数据库模型
│ ├── service/ (可选) # 用于编写业务逻辑层
│ ├── middleware/ (可选) # 用于编写中间件
│ ├── schedule/ (可选) # 用于设置定时任务
│ ├── public/ (可选) # 用于放置静态资源
│ ├── view/ (可选) # 用于放置模板文件
│ └── extend/ (可选) # 用于框架的扩展
│ ├── helper.js (可选)
│ ├── request.js (可选)
│ ├── response.js (可选)
│ ├── context.js (可选)
│ ├── application.js (可选)
│ └── agent.js (可选)
├── config/
| ├── plugin.js # 用于配置需要加载的插件
| ├── config.{env}.js # 用于编写配置文件(env 可以是 default,prod,test,local,unittest)
这是由 egg 框架或内置插件约定好的,是阿里总结出来的最佳实践,虽然框架也提供了让用户自定义目录结构的能力,但是依然建议大家采用阿里的这套方案。在接下来的篇章当中,会逐一讲解上述约定目录和文件的作用。
路由(Router)
路由定义了 请求路径(URL) 和 控制器(Controller) 之间的映射关系,即用户访问的网址应交由哪个控制器进行处理。我们打开 app/router.js 看一下:
module.exports = (app) => {
const { router, controller } = app;
router.get("/", controller.home.index);
};
可以看到,路由文件导出了一个函数,接收 app 对象作为参数,通过下面的语法定义映射关系:
router.verb("path-match", controllerAction);
其中 verb 一般是 HTTP 动词的小写,例如:
- HEAD -
router.head - OPTIONS -
router.options - GET -
router.get - PUT -
router.put - POST -
router.post - PATCH -
router.patch - DELETE -
router.delete或router.del
除此之外,还有一个特殊的动词 router.redirect 表示重定向。
而 controllerAction 则是通过点(·)语法指定 controller 目录下某个文件内的某个具体函数,例如:
controller.home.index; // 映射到 controller/home.js 文件的 index 方法
controller.v1.user.create; // controller/v1/user.js 文件的 create 方法
下面是一些示例及其解释:
module.exports = (app) => {
const { router, controller } = app;
// 当用户访问 news 会交由 controller/news.js 的 index 方法进行处理
router.get("/news", controller.news.index);
// 通过冒号 `:x` 来捕获 URL 中的命名参数 x,放入 ctx.params.x
router.get("/user/:id/:name", controller.user.info);
// 通过自定义正则来捕获 URL 中的分组参数,放入 ctx.params 中
router.get(/^\/package\/([\w-.]+\/[\w-.]+)$/, controller.package.detail);
};
除了使用动词的方式创建路由之外,egg 还提供了下面的语法快速生成 CRUD 路由:
// 对 posts 按照 RESTful 风格映射到控制器 controller/posts.js 中
router.resources("posts", "/posts", controller.posts);
会自动生成下面的路由:
| HTTP 方法 | 请求路径 | 路由名称 | 控制器函数 |
|---|---|---|---|
| GET | /posts | posts | app.controller.posts.index |
| GET | /posts/new | new_post | app.controller.posts.new |
| GET | /posts/:id | post | app.controller.posts.show |
| GET | /posts/:id/edit | edit_post | app.controller.posts.edit |
| POST | /posts | posts | app.controller.posts.create |
| PATCH | /posts/:id | post | app.controller.posts.update |
| DELETE | /posts/:id | post | app.controller.posts.destroy |
| 只需要到 controller 中实现对应的方法即可。 |
当项目越来越大之后,路由映射会越来越多,我们可能希望能够将路由映射按照文件进行拆分,这个时候有两种办法:
手动引入,即把路由文件写到
app/router目录下,然后再app/router.js中引入这些文件。示例代码:// app/router.js
module.exports = (app) => {
require("./router/news")(app);
require("./router/admin")(app);
};
// app/router/news.js
module.exports = (app) => {
app.router.get("/news/list", app.controller.news.list);
app.router.get("/news/detail", app.controller.news.detail);
};
// app/router/admin.js
module.exports = (app) => {
app.router.get("/admin/user", app.controller.admin.user);
app.router.get("/admin/log", app.controller.admin.log);
};使用 egg-router-plus 插件自动引入
app/router/**/*.js,并且提供了 namespace 功能:// app/router.js
module.exports = (app) => {
const subRouter = app.router.namespace("/sub");
subRouter.get("/test", app.controller.sub.test); // 最终路径为 /sub/test
};
除了 HTTP verb 之外,Router 还提供了一个 redirect 方法,用于内部重定向,例如:
module.exports = (app) => {
app.router.get("index", "/home/index", app.controller.home.index);
app.router.redirect("/", "/home/index", 302);
};
中间件(Middleware)
egg 约定一个中间件是一个放置在 app/middleware 目录下的单独文件,它需要导出一个普通的函数,该函数接受两个参数:
- options: 中间件的配置项,框架会将
app.config[${middlewareName}]传递进来。 - app: 当前应用 Application 的实例。
我们新建一个 middleware/slow.js 慢查询中间件,当请求时间超过我们指定的阈值,就打印日志,代码为:
module.exports = (options, app) => {
return async function (ctx, next) {
const startTime = Date.now();
await next();
const consume = Date.now() - startTime;
const { threshold = 0 } = options || {};
if (consume > threshold) {
console.log(`${ctx.url}请求耗时${consume}毫秒`);
}
};
};
然后在 config.default.js 中使用:
module.exports = {
// 配置需要的中间件,数组顺序即为中间件的加载顺序
middleware: ["slow"],
// slow 中间件的 options 参数
slow: {
enable: true,
},
};
这里配置的中间件是全局启用的,如果只是想在指定路由中使用中间件的话,例如只针对 /api 前缀开头的 url 请求使用某个中间件的话,有两种方式:
在
config.default.js配置中设置 match 或 ignore 属性:module.exports = {
middleware: ["slow"],
slow: {
threshold: 1,
match: "/api",
},
};在路由文件
router.js中引入module.exports = (app) => {
const { router, controller } = app;
// 在 controller 处理之前添加任意中间件
router.get(
"/api/home",
app.middleware.slow({ threshold: 1 }),
controller.home.index
);
};
egg 把中间件分成应用层定义的中间件(app.config.appMiddleware)和框架默认中间件(app.config.coreMiddleware),我们打印看一下:
module.exports = (app) => {
const { router, controller } = app;
console.log(app.config.appMiddleware);
console.log(app.config.coreMiddleware);
router.get(
"/api/home",
app.middleware.slow({ threshold: 1 }),
controller.home.index
);
};
结果是:
// appMiddleware
["slow"][
// coreMiddleware
("meta",
"siteFile",
"notfound",
"static",
"bodyParser",
"overrideMethod",
"session",
"securities",
"i18n",
"eggLoaderTrace")
];
其中那些 coreMiddleware 是 egg 帮我们内置的中间件,默认是开启的,如果不想用,可以通过配置的方式进行关闭:
module.exports = {
i18n: {
enable: false,
},
};
控制器(Controller)
Controller 负责解析用户的输入,处理后返回相应的结果,一个最简单的 helloworld 示例:
const { Controller } = require("egg");
class HomeController extends Controller {
async index() {
const { ctx } = this;
ctx.body = "hi, egg";
}
}
module.exports = HomeController;
当然,我们实际项目中的代码不会这么简单,通常情况下,在 Controller 中会做如下几件事情:
- 接收、校验、处理 HTTP 请求参数
- 向下调用服务(Service)处理业务
- 通过 HTTP 将结果响应给用户
一个真实的案例如下:
const { Controller } = require("egg");
class PostController extends Controller {
async create() {
const { ctx, service } = this;
const createRule = {
title: { type: "string" },
content: { type: "string" },
};
// 校验和组装参数
ctx.validate(createRule);
const data = Object.assign(ctx.request.body, {
author: ctx.session.userId,
});
// 调用 Service 进行业务处理
const res = await service.post.create(data);
// 响应客户端数据
ctx.body = { id: res.id };
ctx.status = 201;
}
}
module.exports = PostController;
由于 Controller 是类,因此可以通过自定义基类的方式封装常用方法,例如:
// app/core/base_controller.js
const { Controller } = require("egg");
class BaseController extends Controller {
get user() {
return this.ctx.session.user;
}
success(data) {
this.ctx.body = { success: true, data };
}
notFound(msg) {
this.ctx.throw(404, msg || "not found");
}
}
module.exports = BaseController;
然后让所有 Controller 继承这个自定义的 BaseController:
// app/controller/post.js
const Controller = require("../core/base_controller");
class PostController extends Controller {
async list() {
const posts = await this.service.listByUser(this.user);
this.success(posts);
}
}
在 Controller 中通过 this.ctx 可以获取上下文对象,方便获取和设置相关参数,例如:
ctx.query:URL 中的请求参数(忽略重复 key)ctx.quries:URL 中的请求参数(重复的 key 被放入数组中)ctx.params:Router 上的命名参数ctx.request.body:HTTP 请求体中的内容ctx.request.files:前端上传的文件对象ctx.getFileStream():获取上传的文件流ctx.multipart():获取multipart/form-data数据ctx.cookies:读取和设置 cookiectx.session:读取和设置 sessionctx.service.xxx:获取指定 service 对象的实例(懒加载)ctx.status:设置状态码ctx.body:设置响应体ctx.set:设置响应头ctx.redirect(url):重定向ctx.render(template):渲染模板
this.ctx 上下文对象是 egg 框架和 koa 框架中最重要的一个对象,我们要弄清楚该对象的作用,不过需要注意的是,有些属性并非直接挂在 app.ctx 对象上,而是代理了 request 或 response 对象的属性,我们可以用 Object.keys(ctx) 看一下:
[
"request",
"response",
"app",
"req",
"res",
"onerror",
"originalUrl",
"starttime",
"matched",
"_matchedRoute",
"_matchedRouteName",
"captures",
"params",
"routerName",
"routerPath",
];
服务(Service)
Service 是具体业务逻辑的实现,一个封装好的 Service 可供多个 Controller 调用,而一个 Controller 里面也可以调用多个 Service,虽然在 Controller 中也可以写业务逻辑,但是并不建议这么做,代码中应该保持 Controller 逻辑简洁,仅仅发挥「桥梁」作用。
Controller 可以调用任何一个 Service 上的任何方法,值得注意的是:Service 是懒加载的,即只有当访问到它的时候框架才会去实例化它。
通常情况下,在 Service 中会做如下几件事情:
- 处理复杂业务逻辑
- 调用数据库或第三方服务(例如 GitHub 信息获取等)
一个简单的 Service 示例,将数据库中的查询结果返回出去:
// app/service/user.js
const { Service } = require("egg").Service;
class UserService extends Service {
async find(uid) {
const user = await this.ctx.db.query(
"select * from user where uid = ?",
uid
);
return user;
}
}
module.exports = UserService;
在 Controller 中可以直接调用:
class UserController extends Controller {
async info() {
const { ctx } = this;
const userId = ctx.params.id;
const userInfo = await ctx.service.user.find(userId);
ctx.body = userInfo;
}
}
注意,Service 文件必须放在 app/service 目录,支持多级目录,访问的时候可以通过目录名级联访问:
app/service/biz/user.js => ctx.service.biz.user
app/service/sync_user.js => ctx.service.syncUser
app/service/HackerNews.js => ctx.service.hackerNews
Service 里面的函数,可以理解为某个具体业务逻辑的最小单元,Service 里面也可以调用其他 Service,值得注意的是:Service 不是单例,是 请求级别 的对象,框架在每次请求中首次访问 ctx.service.xx 时延迟实例化,所以 Service 中可以通过 this.ctx 获取到当前请求的上下文。
模板渲染
egg 框架内置了 egg-view 作为模板解决方案,并支持多种模板渲染,例如 ejs、handlebars、nunjunks 等模板引擎,每个模板引擎都以插件的方式引入,默认情况下,所有插件都会去找 app/view 目录下的文件,然后根据 config\config.default.js 中定义的后缀映射来选择不同的模板引擎:
config.view = {
defaultExtension: ".nj",
defaultViewEngine: "nunjucks",
mapping: {
".nj": "nunjucks",
".hbs": "handlebars",
".ejs": "ejs",
},
};
上面的配置表示,当文件:
- 后缀是
.nj时使用 nunjunks 模板引擎 - 后缀是
.hbs时使用 handlebars 模板引擎 - 后缀是
.ejs时使用 ejs 模板引擎 - 当未指定后缀时默认为
.html - 当未指定模板引擎时默认为 nunjunks
接下来我们安装模板引擎插件:
$ npm i egg-view-nunjucks egg-view-ejs egg-view-handlebars --save
# 或者 yarn add egg-view-nunjucks egg-view-ejs egg-view-handlebars
然后在 config/plugin.js 中启用该插件:
exports.nunjucks = {
enable: true,
package: "egg-view-nunjucks",
};
exports.handlebars = {
enable: true,
package: "egg-view-handlebars",
};
exports.ejs = {
enable: true,
package: "egg-view-ejs",
};
然后添加 app/view 目录,里面增加几个文件:
app/view
├── ejs.ejs
├── handlebars.hbs
└── nunjunks.nj
代码分别是:
<!-- ejs.ejs 文件代码 -->
<h1>ejs</h1>
<ul>
<% items.forEach(function(item){ %>
<li><%= item.title %></li>
<% }); %>
</ul>
<!-- handlebars.hbs 文件代码 -->
<h1>handlebars</h1>
{{#each items}}
<li>{{title}}</li>
{{~/each}}
<!-- nunjunks.nj 文件代码 -->
<h1>nunjunks</h1>
<ul>
{% for item in items %}
<li>{{ item.title }}</li>
{% endfor %}
</ul>
然后在 Router 中配置路由:
module.exports = (app) => {
const { router, controller } = app;
router.get("/ejs", controller.home.ejs);
router.get("/handlebars", controller.home.handlebars);
router.get("/nunjunks", controller.home.nunjunks);
};
接下来实现 Controller 的逻辑:
const Controller = require("egg").Controller;
class HomeController extends Controller {
async ejs() {
const { ctx } = this;
const items = await ctx.service.view.getItems();
await ctx.render("ejs.ejs", { items });
}
async handlebars() {
const { ctx } = this;
const items = await ctx.service.view.getItems();
await ctx.render("handlebars.hbs", { items });
}
async nunjunks() {
const { ctx } = this;
const items = await ctx.service.view.getItems();
await ctx.render("nunjunks.nj", { items });
}
}
module.exports = HomeController;
我们把数据放到了 Service 里面:
const { Service } = require("egg");
class ViewService extends Service {
getItems() {
return [
{ title: "foo", id: 1 },
{ title: "bar", id: 2 },
];
}
}
module.exports = ViewService;
访问下面的地址可以查看不同模板引擎渲染出的结果:
GET http://localhost:7001/nunjunks
GET http://localhost:7001/handlebars
GET http://localhost:7001/ejs
你可能会问,ctx.render 方法是哪来的呢?没错,是由 egg-view 对 context 进行扩展而提供的,为 ctx 上下文对象增加了 render、renderView 和 renderString 三个方法,代码如下:
const ContextView = require("../../lib/context_view");
const VIEW = Symbol("Context#view");
module.exports = {
render(...args) {
return this.renderView(...args).then((body) => {
this.body = body;
});
},
renderView(...args) {
return this.view.render(...args);
},
renderString(...args) {
return this.view.renderString(...args);
},
get view() {
if (this[VIEW]) return this[VIEW];
return (this[VIEW] = new ContextView(this));
},
};
它内部最终会把调用转发给 ContextView 实例上的 render 方法,ContextView 是一个能够根据配置里面定义的 mapping,帮助我们找到对应渲染引擎的类。
插件
上节课讲解模板渲染的时候,我们已经知道如何使用插件了,即只需要在应用或框架的 config/plugin.js 中声明:
exports.myPlugin = {
enable: true, // 是否开启
package: "egg-myPlugin", // 从 node_modules 中引入
path: path.join(__dirname, "../lib/plugin/egg-mysql"), // 从本地目录中引入
env: ["local", "unittest", "prod"], // 只有在指定运行环境才能开启
};
开启插件后,就可以使用插件提供的功能了:
app.myPlugin.xxx();
如果插件包含需要用户自定义的配置,可以在 config.default.js 进行指定,例如:
exports.myPlugin = {
hello: "world",
};
一个插件其实就是一个『迷你的应用』,包含了 Service、中间件、配置、框架扩展等,但是没有独立的 Router 和 Controller,也不能定义自己的 plugin.js。
在开发中必不可少要连接数据库,最实用的插件就是数据库集成的插件了。
集成 MongoDB
首先确保电脑中已安装并启动 MongoDB 数据库,如果是 Mac 电脑,可以用下面的命令快速安装和启动:
$ brew install mongodb-community
$ brew services start mongodb/brew/mongodb-community # 后台启动
# 或者使用 mongod --config /usr/local/etc/mongod.conf 前台启动
然后安装 egg-mongoose 插件:
$ npm i egg-mongoose
# 或者 yarn add egg-mongoose
在 config/plugin.js 中开启插件:
exports.mongoose = {
enable: true,
package: "egg-mongoose",
};
在 config/config.default.js 中定义连接参数:
config.mongoose = {
client: {
url: "mongodb://127.0.0.1/example",
options: {},
},
};
然后在 model/user.js 中定义模型:
module.exports = (app) => {
const mongoose = app.mongoose;
const UserSchema = new mongoose.Schema(
{
username: { type: String, required: true, unique: true }, // 用户名
password: { type: String, required: true }, // 密码
},
{ timestamps: true } // 自动生成 createdAt 和 updatedAt 时间戳
);
return mongoose.model("user", UserSchema);
};
在控制器中调用 mongoose 的方法:
const { Controller } = require("egg");
class UserController extends Controller {
// 用户列表 GET /users
async index() {
const { ctx } = this;
ctx.body = await ctx.model.User.find({});
}
// 用户详情 GET /users/:id
async show() {
const { ctx } = this;
ctx.body = await ctx.model.User.findById(ctx.params.id);
}
// 创建用户 POST /users
async create() {
const { ctx } = this;
ctx.body = await ctx.model.User.create(ctx.request.body);
}
// 更新用户 PUT /users/:id
async update() {
const { ctx } = this;
ctx.body = await ctx.model.User.findByIdAndUpdate(
ctx.params.id,
ctx.request.body
);
}
// 删除用户 DELETE /users/:id
async destroy() {
const { ctx } = this;
ctx.body = await ctx.model.User.findByIdAndRemove(ctx.params.id);
}
}
module.exports = UserController;
最后配置 RESTful 路由映射:
module.exports = (app) => {
const { router, controller } = app;
router.resources("users", "/users", controller.user);
};
集成 MySQL
首先确保电脑中已安装 MySQL 数据库,如果是 Mac 电脑,可通过下面的命令快速安装和启动:
$ brew install mysql
$ brew services start mysql # 后台启动
# 或者 mysql.server start 前台启动
$ mysql_secure_installation # 设置密码
官方有个 egg-mysql 插件,可以连接 MySQL 数据库,使用方法非常简单:
$ npm i egg-mysql
# 或者 yarn add egg-mysql
在 config/plugin.js 中开启插件:
exports.mysql = {
enable: true,
package: "egg-mysql",
};
在 config/config.default.js 中定义连接参数:
config.mysql = {
client: {
host: "localhost",
port: "3306",
user: "root",
password: "root",
database: "cms",
},
};
然后就能在 Controller 或 Service 的 app.mysql 中获取到 mysql 对象,例如:
class UserService extends Service {
async find(uid) {
const user = await this.app.mysql.get("users", { id: 11 });
return { user };
}
}
但是更好的集成 MySQL 的方式是借助 ORM 框架来帮助我们管理数据层的代码,sequelize 是当前最流行的 ORM 框架,它支持 MySQL、PostgreSQL、SQLite 和 MSSQL 等多个数据源,接下来我们使用 sequelize 来连接 MySQL 数据库,首先安装依赖:
npm install egg-sequelize mysql2 --save
yarn add egg-sequelize mysql2
然后在 config/plugin.js 中开启 egg-sequelize 插件:
exports.sequelize = {
enable: true,
package: "egg-sequelize",
};
同样要在 config/config.default.js 中编写 sequelize 配置
config.sequelize = {
dialect: "mysql",
host: "127.0.0.1",
port: 3306,
database: "example",
};
然后在 egg_example 库中创建 books 表:
CREATE TABLE `books` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'primary key',
`name` varchar(30) DEFAULT NULL COMMENT 'book name',
`created_at` datetime DEFAULT NULL COMMENT 'created time',
`updated_at` datetime DEFAULT NULL COMMENT 'updated time',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='book';
创建 model/book.js 文件,代码是:
module.exports = (app) => {
const { STRING, INTEGER } = app.Sequelize;
const Book = app.model.define("book", {
id: { type: INTEGER, primaryKey: true, autoIncrement: true },
name: STRING(30),
});
return Book;
};
添加 controller/book.js 控制器:
const Controller = require("egg").Controller;
class BookController extends Controller {
async index() {
const ctx = this.ctx;
ctx.body = await ctx.model.Book.findAll({});
}
async show() {
const ctx = this.ctx;
ctx.body = await ctx.model.Book.findByPk(+ctx.params.id);
}
async create() {
const ctx = this.ctx;
ctx.body = await ctx.model.Book.create(ctx.request.body);
}
async update() {
const ctx = this.ctx;
const book = await ctx.model.Book.findByPk(+ctx.params.id);
if (!book) return (ctx.status = 404);
await book.update(ctx.request.body);
ctx.body = book;
}
async destroy() {
const ctx = this.ctx;
const book = await ctx.model.Book.findByPk(+ctx.params.id);
if (!book) return (ctx.status = 404);
await book.destroy();
ctx.body = book;
}
}
module.exports = BookController;
最后配置 RESTful 路由映射:
module.exports = (app) => {
const { router, controller } = app;
router.resources("books", "/books", controller.book);
};
自定义插件
掌握了插件的使用,接下来就要讲讲如何自己写插件了,首先根据插件脚手架模板创建一个插件项目:
npm init egg --type=plugin
# 或者 yarn create egg --type=plugin
默认的目录结构为:
├── config
│ └── config.default.js
├── package.json
插件没有独立的 router 和 controller,并且需要在 package.json 中的 eggPlugin 节点指定插件特有的信息,例如:
{
"eggPlugin": {
"name": "myPlugin",
"dependencies": ["registry"],
"optionalDependencies": ["vip"],
"env": ["local", "test", "unittest", "prod"]
}
}
上述字段的含义为:
name- 插件名,配置依赖关系时会指定依赖插件的 name。dependencies- 当前插件强依赖的插件列表(如果依赖的插件没找到,应用启动失败)。optionalDependencies- 当前插件的可选依赖插件列表(如果依赖的插件未开启,只会 warning,不会影响应用启动)。env- 指定在某些运行环境才开启当前插件
定时任务
一个复杂的业务场景中,不可避免会有定时任务的需求,例如:
- 每天检查一下是否有用户过生日,自动发送生日祝福
- 每天备份一下数据库,防止操作不当导致数据丢失
- 每周删除一次临时文件,释放磁盘空间
- 定时从远程接口获取数据,更新本地缓存
egg 框架提供了定时任务功能,在 app/schedule 目录下,每一个文件都是一个独立的定时任务,可以配置定时任务的属性和要执行的方法,例如创建一个 update_cache.js 的更新缓存任务,每分钟执行一次:
const Subscription = require("egg").Subscription;
class UpdateCache extends Subscription {
// 通过 schedule 属性来设置定时任务的执行间隔等配置
static get schedule() {
return {
interval: "1m", // 1 分钟间隔
type: "all", // 指定所有的 worker 都需要执行
};
}
// subscribe 是真正定时任务执行时被运行的函数
async subscribe() {
const res = await this.ctx.curl("http://www.api.com/cache", {
dataType: "json",
});
this.ctx.app.cache = res.data;
}
}
module.exports = UpdateCache;
也就是说,egg 会从静态访问器属性 schedule 中获取定时任务的配置,然后按照配置来执行 subscribe 方法。执行任务的时机可以用 interval 或者 cron 两种方式来指定:
interval 可以使数字或字符串,如果是数字则表示毫秒数,例如
5000就是 5 秒,如果是字符类型,会通过 ms 这个包转换成毫秒数,例如 5 秒可以直接写成5s。cron 表达式则通过 cron-parser 进行解析,语法为:
* * * * * *
┬ ┬ ┬ ┬ ┬ ┬
│ │ │ │ │ |
│ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
│ │ │ │ └───── month (1 - 12)
│ │ │ └────────── day of month (1 - 31)
│ │ └─────────────── hour (0 - 23)
│ └──────────────────── minute (0 - 59)
└───────────────────────── second (0 - 59, optional)
执行任务的类型有两种:
worker类型:只有一个 worker 会执行这个定时任务(随机选择)all类型:每个 worker 都会执行这个定时任务
使用哪种类型要看具体的业务了,例如更新缓存的任务肯定是选择 all,而备份数据库的任务选择 worker 就够了,否则会重复备份。
有一些场景我们可能需要手动的执行定时任务,例如应用启动时的初始化任务,可以通过 app.runSchedule(schedulePath) 来运行。app.runSchedule 接受一个定时任务文件路径(app/schedule 目录下的相对路径或者完整的绝对路径),在 app.js 中代码为:
module.exports = (app) => {
app.beforeStart(async () => {
// 程序启动前确保缓存已更新
await app.runSchedule("update_cache");
});
};
生命周期
在 egg 启动的过程中,提供了下面几个生命周期钩子方便大家调用:
- 配置文件即将加载,这是最后动态修改配置的时机(
configWillLoad) - 配置文件加载完成(
configDidLoad) - 文件加载完成(
didLoad) - 插件启动完毕(
willReady) - worker 准备就绪(
didReady) - 应用启动完成(
serverDidReady) - 应用即将关闭(
beforeClose)
只要在项目根目录中创建 app.js,添加并导出一个类即可:
class AppBootHook {
constructor(app) {
this.app = app;
}
configWillLoad() {
// config 文件已经被读取并合并,但是还并未生效,这是应用层修改配置的最后时机
// 注意:此函数只支持同步调用
}
configDidLoad() {
// 所有的配置已经加载完毕,可以用来加载应用自定义的文件,启动自定义的服务
}
async didLoad() {
// 所有的配置已经加载完毕,可以用来加载应用自定义的文件,启动自定义的服务
}
async willReady() {
// 所有的插件都已启动完毕,但是应用整体还未 ready
// 可以做一些数据初始化等操作,这些操作成功才会启动应用
}
async didReady() {
// 应用已经启动完毕
}
async serverDidReady() {
// http / https server 已启动,开始接受外部请求
// 此时可以从 app.server 拿到 server 的实例
}
async beforeClose() {
// 应用即将关闭
}
}
module.exports = AppBootHook;
框架扩展
egg 框架提供了下面几个扩展点:
- Application: Koa 的全局应用对象(应用级别),全局只有一个,在应用启动时被创建
- Context:Koa 的请求上下文对象(请求级别),每次请求生成一个 Context 实例
- Request:Koa 的 Request 对象(请求级别),提供请求相关的属性和方法
- Response:Koa 的 Response 对象(请求级别),提供响应相关的属性和方法
- Helper:用来提供一些实用的 utility 函数
也就是说,开发者可以对上述框架内置对象进行任意扩展。扩展的写法为:
const BAR = Symbol("bar");
module.exports = {
foo(param) {}, // 扩展方法
get bar() {
// 扩展属性
if (!this[BAR]) {
this[BAR] = this.get("x-bar");
}
return this[BAR];
},
};
扩展点方法里面的 this 就指代扩展点对象自身,扩展的本质就是将用户自定义的对象合并到 Koa 扩展点对象的原型上面,即:
- 扩展 Application 就是把
app/extend/application.js中定义的对象与 Koa Application 的 prototype 对象进行合并,在应用启动时会基于扩展后的 prototype 生成app对象,可通过ctx.app.xxx来进行访问: - 扩展 Context 就是把
app/extend/context.js中定义的对象与 Koa Context 的 prototype 对象进行合并,在处理请求时会基于扩展后的 prototype 生成 ctx 对象。 - 扩展 Request/Response 就是把
app/extend/<request|response>.js中定义的对象与内置request或response的 prototype 对象进行合并,在处理请求时会基于扩展后的 prototype 生成request或response对象。 - 扩展 Helper 就是把
app/extend/helper.js中定义的对象与内置helper的 prototype 对象进行合并,在处理请求时会基于扩展后的 prototype 生成helper对象。
综合问题
Node.js 架构
nodejs 架构,下图所示:
如上图所示,nodejs 自上而下分为
- 用户代码 ( js 代码 )
用户代码即我们编写的应用程序代码、npm 包、nodejs 内置的 js 模块等,我们日常工作中的大部分时间都是编写这个层面的代码。
- binding 代码或者三方插件(js 或 C/C++ 代码)
胶水代码,能够让 js 调用 C/C++的代码。可以将其理解为一个桥,桥这头是 js,桥那头是 C/C++,通过这个桥可以让 js 调用 C/C++。 在 nodejs 里,胶水代码的主要作用是把 nodejs 底层实现的 C/C++库暴露给 js 环境。 三方插件是我们自己实现的 C/C++库,同时需要我们自己实现胶水代码,将 js 和 C/C++进行桥接。
- 底层库
nodejs 的依赖库,包括大名鼎鼎的 V8、libuv。 V8: 我们都知道,是 google 开发的一套高效 javascript 运行时,nodejs 能够高效执行 js 代码的很大原因主要在它。 libuv:是用 C 语言实现的一套异步功能库,nodejs 高效的异步编程模型很大程度上归功于 libuv 的实现,而 libuv 则是我们今天重点要分析的。 还有一些其他的依赖库 http-parser:负责解析 http 响应 openssl:加解密 c-ares:dns 解析 npm:nodejs 包管理器 ...
重点要分析的就是 libuv。
libuv 架构
我们知道,nodejs 实现异步机制的核心便是 libuv,libuv 承担着 nodejs 与文件、网络等异步任务的沟通桥梁,下面这张图让我们对 libuv 有个大概的印象:
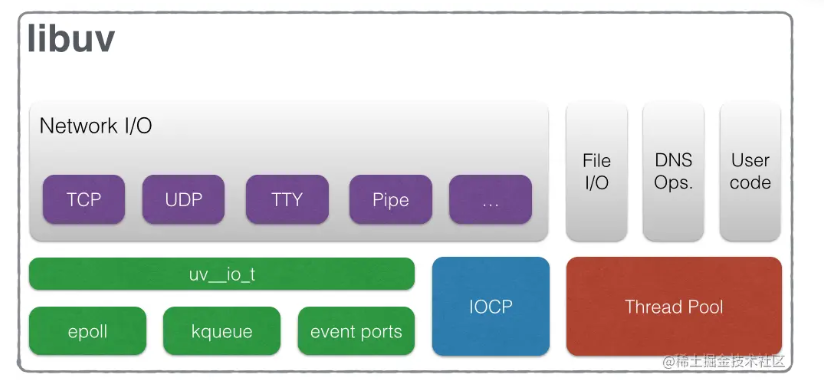
这是 libuv 官网的一张图,很明显,nodejs 的网络 I/O、文件 I/O、DNS 操作、还有一些用户代码都是在 libuv 工作的。 既然谈到了异步,那么我们首先归纳下 nodejs 里的异步事件:
- 非 I/O:
- 定时器(setTimeout,setInterval)
- microtask(promise)
- process.nextTick
- setImmediate
- DNS.lookup
- I/O:
- 网络 I/O
- 文件 I/O
- 一些 DNS 操作
网络 I/O
对于网络 I/O,各个平台的实现机制不一样,linux 是 epoll 模型,类 unix 是 kquene 、windows 下是高效的 IOCP 完成端口、SunOs 是 event ports,libuv 对这几种网络 I/O 模型进行了封装。
文件 I/O、异步 DNS 操作
libuv 内部还维护着一个默认 4 个线程的线程池,这些线程负责执行文件 I/O 操作、DNS 操作、用户异步代码。当 js 层传递给 libuv 一个操作任务时,libuv 会把这个任务加到队列中。之后分两种情况:
- 1、线程池中的线程都被占用的时候,队列中任务就要进行排队等待空闲线程。
- 2、线程池中有可用线程时,从队列中取出这个任务执行,执行完毕后,线程归还到线程池,等待下个任务。同时以事件的方式通知 event-loop,event-loop 接收到事件执行该事件注册的回调函数。
当然,如果觉得 4 个线程不够用,可以在 nodejs 启动时,设置环境变量UV_THREADPOOL_SIZE来调整,出于系统性能考虑,libuv 规定可设置线程数不能超过128个。
nodejs 源码
先简要介绍下 nodejs 的启动过程:
- 1、调用platformInit方法 ,初始化 nodejs 的运行环境。
- 2、调用 performance_node_start 方法,对 nodejs 进行性能统计。
- 3、openssl设置的判断。
- 4、调用v8_platform.Initialize,初始化 libuv 线程池。
- 5、调用 V8::Initialize,初始化 V8 环境。
- 6、创建一个nodejs运行实例。
- 7、启动上一步创建好的实例。
- 8、开始执行 js 文件,同步代码执行完毕后,进入事件循环。
- 9、在没有任何可监听的事件时,销毁 nodejs 实例,程序执行完毕。
事件循环原理
- node 的初始化
- 初始化 node 环境。
- 执行输入代码。
- 执行 process.nextTick 回调。
- 执行 microtasks。
- 进入 event-loop
- 进入 timers 阶段
- 检查 timer 队列是否有到期的 timer 回调,如果有,将到期的 timer 回调按照 timerId 升序执行。
- 检查是否有 process.nextTick 任务,如果有,全部执行。
- 检查是否有 microtask,如果有,全部执行。
- 退出该阶段。
- 进入 IO callbacks 阶段。
- 检查是否有 pending 的 I/O 回调。如果有,执行回调。如果没有,退出该阶段。
- 检查是否有 process.nextTick 任务,如果有,全部执行。
- 检查是否有 microtask,如果有,全部执行。
- 退出该阶段。
- 进入 idle,prepare 阶段:
- 这两个阶段与我们编程关系不大,暂且按下不表。
- 进入 poll 阶段
- 首先检查是否存在尚未完成的回调,如果存在,那么分两种情况。
- 第一种情况:
- 如果有可用回调(可用回调包含到期的定时器还有一些 IO 事件等),执行所有可用回调。
- 检查是否有 process.nextTick 回调,如果有,全部执行。
- 检查是否有 microtaks,如果有,全部执行。
- 退出该阶段。
- 第二种情况:
- 如果没有可用回调。
- 检查是否有 immediate 回调,如果有,退出 poll 阶段。如果没有,阻塞在此阶段,等待新的事件通知。
- 第一种情况:
- 如果不存在尚未完成的回调,退出 poll 阶段。
- 首先检查是否存在尚未完成的回调,如果存在,那么分两种情况。
- 进入 check 阶段。
- 如果有 immediate 回调,则执行所有 immediate 回调。
- 检查是否有 process.nextTick 回调,如果有,全部执行。
- 检查是否有 microtaks,如果有,全部执行。
- 退出 check 阶段
- 进入 closing 阶段。
- 如果有 immediate 回调,则执行所有 immediate 回调。
- 检查是否有 process.nextTick 回调,如果有,全部执行。
- 检查是否有 microtaks,如果有,全部执行。
- 退出 closing 阶段
- 检查是否有活跃的 handles(定时器、IO 等事件句柄)。
- 如果有,继续下一轮循环。
- 如果没有,结束事件循环,退出程序。
- 进入 timers 阶段
可以发现,在事件循环的每一个子阶段退出之前都会按顺序执行如下过程:
- 检查是否有 process.nextTick 回调,如果有,全部执行。
- 检查是否有 microtaks,如果有,全部执行。
- 退出当前阶段。
Node.js 的异步 IO
Node 事件循环的流程
在传统 web 服务中,大多都是使用多线程机制来解决并发的问题,原因是 I/O 事件会阻塞线程,而阻塞就意味着要等待。而 node 的设计是采用了单线程的机制,但它为什么还能承载高并发的请求呢?因为 node 的单线程仅针对主线程来说,即每个 node 进程只有一个主线程来执行程序代码,但 node 采用了事件驱动的机制,将耗时阻塞的 I/O 操作交给线程池中的某个线程去完成,主线程本身只负责不断地调度,并没有执行真正的 I/O 操作。也就是说 node 实现的是异步非阻塞式
- 在进程启动时,Node 便会创建一个类似于 while(true)的循环,每执行一次循环体的过程我们成为 Tick。
- 每个 Tick 的过程就是查看是否有事件待处理。如果有就取出事件及其相关的回调函数。然后进入下一个循环,如果不再有事件处理,就退出进程。
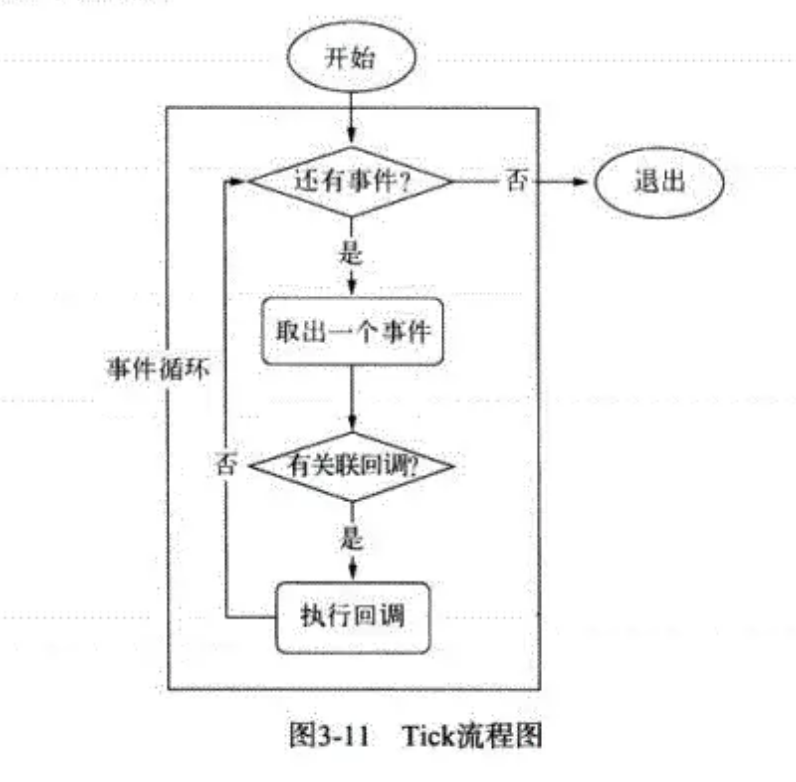
node 每次事件循环机制都包含了 6 个阶段:
- timers 阶段:这个阶段执行已经到期的 timer(setTimeout、setInterval)回调
- I/O callbacks 阶段:执行 I/O(例如文件、网络)的回调
- idle, prepare 阶段:node 内部使用
- poll 阶段:获取新的 I/O 事件, 适当的条件下 node 将阻塞在这里
- check 阶段:执行 setImmediate 回调
- close callbacks 阶段:执行 close 事件回调,比如 TCP 断开连接
node 和浏览器相比一个明显的不同就是 node 在每个阶段结束后会去执行所有 microtask 任务
相对于浏览器环境,node 环境下多出了 setImmediate 和 process.nextTick 这两种异步操作。setImmediate 的回调函数是被放在 check 阶段执行,即相当于事件循环的最后阶段了。而 process.nextTick 会被当做一种 microtask,前面提到每个阶段结束后都会执行所有 microtask 任务,所以 process.nextTick 有种类似于插队的作用
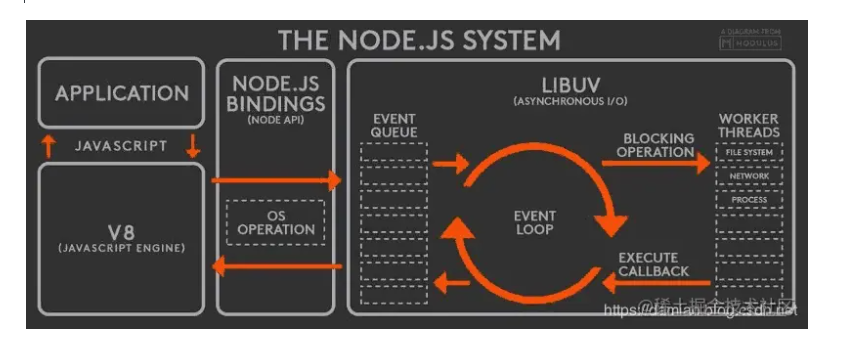
这个图是整个 Node.js 的运行原理,从左到右,从上到下,Node.js 被分为了四层,分别是 应用层、V8引擎层、Node API层 和 LIBUV层。
- 应用层: 即 JavaScript 交互层,常见的就是 Node.js 的模块,比如 http,fs
- V8 引擎层: 即利用 V8 引擎来解析 JavaScript 语法,进而和下层 API 交互
- NodeAPI 层: 为上层模块提供系统调用,一般是由 C 语言来实现,和操作系统进行交互 。
- LIBUV 层: 是跨平台的底层封装,实现了 事件循环、文件操作等,是 Node.js 实现异步的核心 。
在每个 tick 的过程中,如何判断是否有事件需要处理呢
- 每个事件循环中有一个或者多个观察者,而判断是否有事件需要处理的过程就是向这些观察者询问是否有要处理的事件。
- 在 Node 中,事件主要来源于网络请求、文件的 I/O 等,这些事件对应的观察者有文件 I/O 观察者,网络 I/O 的观察者。
- 事件循环是一个典型的生产者/消费者模型。异步 I/O,网络请求等则是事件的生产者,源源不断为 Node 提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
- 在 windows 下,这个循环基于 IOCP 创建,在*nix 下则基于多线程创建
描述一下整个异步 I/O 的流程
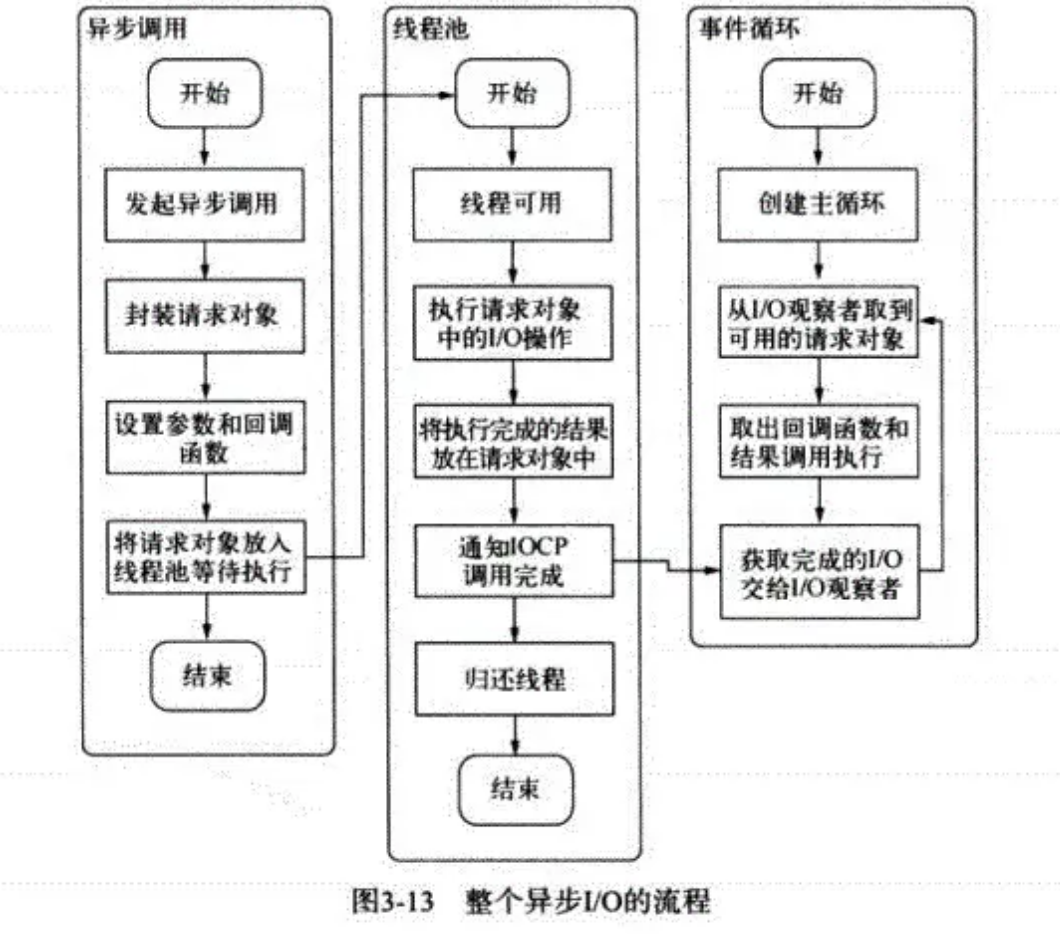
Node.js 中创建子进程的方法
众所周知,Node.js 是单线程、异步非阻塞的程序语言,那如何充分利用多核 CPU 的优势呢?这就需要用到 child_process 模块来创建子进程了,在 Node.js 中,有四种方法可以创建子进程:
execexecFilespawnfork
上面四个方法都会返回 ChildProcess 实例(继承自 EventEmitter),该实例拥有三个标准的 stdio 流:
child.stdinchild.stdoutchild.stderr
子进程生命周期内可以注册监听的事件有:
exit:子进程结束时触发,参数为 code 错误码和 signal 中断信号。
close:子进程结束并且 stdio 流被关闭时触发,参数同 exit 事件。
disconnect:父进程调用 child.disconnect() 或子进程调用 process.disconnect() 时触发。
error:子进程无法创建、或无法被杀掉、或发消息给子进程失败时触发。
message:子进程通过 process.send() 发送消息时触发。
spawn:子进程创建成功时触发(Node.js v15.1 版本才添加此事件)。
而 exec 和 execFile 方法还额外提供了一个回调函数,会在子进程终止的时候触发。接下来进行详细分析:
exec
exec 方法用于执行 bash 命令,它的参数是一个命令字符串。例如统计当前目录下的文件数量,用 exec 函数的写法为:
const { exec } = require("child_process")
exec("find . -type f | wc -l", (err, stdout, stderr) => {
if (err) return console.error(`exec error: ${err}`)
console.log(`Number of files ${stdout}`)
})
exec 会新建一个子进程,然后缓存它的运行结果,运行结束后调用回调函数。
可能你已经想到了,exec 命令是比较危险的,假如把用户提供的字符串作为 exec 函数的参数,会面临命令行注入的风险,例如:
find . -type f | wc -l; rm -rf /;
另外,由于 exec 会在内存中缓存全部的输出结果,当数据比较大的时候,spawn 会是更好的选择。
execFile
execFile 和 exec 的区别在于它并不会创建 shell,而是直接执行命令,所以会更高效一点,例如:
const { execFile } = require("child_process")
const child = execFile("node", ["--version"], (error, stdout, stderr) => {
if (error) throw error
console.log(stdout)
})
由于没有创建 shell,程序的参数作为数组传入,因此具有较高的安全性。
spawn
spawn 函数和 execFile 类似,默认不开启 shell,但区别在于 execFile 会缓存命令行的输出,然后把结果传入回调函数中,而 spawn 则是以流的方式输出,有了流,就能非常方便的对接输入和输出了,例如典型的 wc 命令:
const child = spawn("wc")
process.stdin.pipe(child.stdin)
child.stdout.on("data", data => {
console.log(`child stdout:\n${data}`)
})
此时就会从命令行 stdin 获取输入,当用户触发回车 + ctrl D 时就开始执行命令,并把结果从 stdout 输出。
wc 是 Word Count 的缩写,用于统计单词数,语法为:
wc [OPTION]... [FILE]...如果在终端上输入 wc 命令并回车,这时候统计的是从键盘输入终端中的字符,再次按回车键,然后按
Ctrl + D会输出统计的结果。
通过管道还可以组合复杂的命令,例如统计当前目录下的文件数量,在 Linux 命令行中会这么写:
find . -type f | wc -l
在 Node.js 中的写法和命令行一模一样:
const find = spawn("find", [".", "-type", "f"])
const wc = spawn("wc", ["-l"])
find.stdout.pipe(wc.stdin)
wc.stdout.on("data", (data) => {
console.log(`Number of files ${data}`)
})
spawn 有丰富的自定义配置,例如:
const child = spawn("find . -type f | wc -l", {
stdio: "inherit", // 继承父进程的输入输出流
shell: true, // 开启命令行模式
cwd: "/Users/keliq/code", // 指定执行目录
env: { ANSWER: 42 }, // 指定环境变量(默认是 process.env)
detached: true, // 作为独立进程存在
})
fork
fork 函数是 spawn 函数的变体,使用 fork 创建的子进程和父进程之间会自动创建一个通信通道,子进程的全局对象 process 上面会挂载 send 方法。例如父进程 parent.js 代码:
const { fork } = require("child_process")
const forked = fork("./child.js")
forked.on("message", msg => {
console.log("Message from child", msg);
})
forked.send({ hello: "world" })
子进程 child.js 代码:
process.on("message", msg => {
console.log("Message from parent:", msg)
})
let counter = 0
setInterval(() => {
process.send({ counter: counter++ })
}, 1000)
当调用 fork("child.js")的时候,实际上就是用 node 来执行该文件中的代码,相当于 spawn('node', ['./child.js'])。
fork 的一个典型的应用场景如下:假如现在用 Node.js 创建一个 http 服务,当路由为 compute 的时候,执行一个耗时的运算。
const http = require("http")
const server = http.createServer()
server.on("request", (req, res) => {
if (req.url === "/compute") {
const sum = longComputation()
return res.end(Sum is ${sum})
} else {
res.end("OK")
}
})
server.listen(3000);
可以用下面的代码来模拟该耗时的运算:
const longComputation = () => {
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i
}
return sum
}
那么在上线后,只要服务端收到了 compute 请求,由于 Node.js 是单线程的,耗时运算占用了 CPU,用户的其他请求都会阻塞在这里,表现出来的现象就是服务器无响应。
解决这个问题最简单的方法就是把耗时运算放到子进程中去处理,例如创建一个 compute.js 的文件,代码如下:
const longComputation = () => {
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
}
return sum
}
process.on("message", msg => {
const sum = longComputation()
process.send(sum)
})
再把服务端的代码稍作改造:
const http = require("http")
const { fork } = require("child_process")
const server = http.createServer()
server.on("request", (req, res) => {
if (req.url === "/compute") {
const compute = fork("compute.js")
compute.send("start")
compute.on("message", sum => {
res.end(Sum is ${sum})
})
} else {
res.end("OK")
}
})
server.listen(3000)
这样的话,主线程就不会阻塞,而是继续处理其他的请求,当耗时运算的结果返回后,再做出响应。其实更简单的处理方式是利用 cluster 模块,限于篇幅原因,后面再展开讲。
总结
掌握了上面四种创建子进程的方法之后,总结了以下三条规律:
- 创建 node 子进程用 fork,因为自带通道方便通信。
- 创建非 node 子进程用 execFile 或 spawn。如果输出内容较少用 execFile,会缓存结果并传给回调方便处理;如果输出内容多用 spawn,使用流的方式不会占用大量内存。
- 执行复杂的、固定的终端命令用 exec,写起来更方便。但一定要记住 exec 会创建 shell,效率不如 execFile 和 spawn,且存在命令行注入的风险。
Express 和 Koa 的区别
Koa
- 基于 node 的一个 web 开发框架,利用 co 作为底层运行框架,利用 Generator 的特性,实现“无回调”的异步处理;
- ES7;
- 更小、更富有表现力、更健壮的基石;
- 利用 async 函数、Koa 丢弃回调函数,增强错误处理;
- 很小的体积,因为没有捆绑任何中间件;
- 类似堆栈的方式组织和执行;
- 低级中间件层中提供高级“语法糖”,提高了互操性、稳健性;
Express
- Node 的基础框架,基础 Connect 中间件,自身封装了路由、视图处理等功能;
- 线性逻辑,路由和中间件完美融合,清晰明了;
- 弊端是 callback 回调方式,不可组合、异常不可捕获;
- ES5;
- connect 的执行流程: connect 的中间件模型是线性的,即一个一个往下执行;
egg.js 的特点
Egg
Egg的底层框架是基于Koa开发,在性能与开发体验上会比Express更优越。- 可选用
JS以及TS开发,两者都是基于Classify开发,对刚接触服务端开发的前端更友好。 - 约定优于配置,减少开发负担、学习以及协作成本。
- 高度可扩展的插件机制,可以方便定制插件。
- 内置集群:使用
Cluster,自带进程守护、多进程以及进程间通讯等功能。
怎么实现文件上传
一、是什么
文件上传在日常开发中应用很广泛,我们发微博、发微信朋友圈都会用到了图片上传功能
因为浏览器限制,浏览器不能直接操作文件系统的,需要通过浏览器所暴露出来的统一接口,由用户主动授权发起来访问文件动作,然后读取文件内容进指定内存里,最后执行提交请求操作,将内存里的文件内容数据上传到服务端,服务端解析前端传来的数据信息后存入文件里
对于文件上传,我们需要设置请求头为content-type:multipart/form-data
multipart 互联网上的混合资源,就是资源由多种元素组成,form-data 表示可以使用 HTML Forms 和 POST 方法上传文件
结构如下:
POST /t2/upload.do HTTP/1.1
User-Agent: SOHUWapRebot
Accept-Language: zh-cn,zh;q=0.5
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Content-Length: 60408
Content-Type:multipart/form-data; boundary=ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Host: w.sohu.com
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data; name="city"
Santa colo
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data;name="desc"
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
...
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data;name="pic"; filename="photo.jpg"
Content-Type: application/octet-stream
Content-Transfer-Encoding: binary
... binary data of the jpg ...
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC--
boundary表示分隔符,如果要上传多个表单项,就要使用boundary分割,每个表单项由———XXX开始,以———XXX结尾
而xxx是即时生成的字符串,用以确保整个分隔符不会在文件或表单项的内容中出现
每个表单项必须包含一个 Content-Disposition 头,其他的头信息则为可选项, 比如 Content-Type
Content-Disposition 包含了 type和 一个名字为name的 parameter,type 是 form-data,name参数的值则为表单控件(也即 field)的名字,如果是文件,那么还有一个 filename参数,值就是文件名
Content-Disposition: form-data; name="user"; filename="logo.png"
至于使用multipart/form-data,是因为文件是以二进制的形式存在,其作用是专门用于传输大型二进制数据,效率高
二、如何实现
关于文件的上传的上传,我们可以分成两步骤:
- 文件的上传
- 文件的解析
文件上传
传统前端文件上传的表单结构如下:
<form
action="http://localhost:8080/api/upload"
method="post"
enctype="multipart/form-data"
>
<input type="file" name="file" id="file" value="" multiple="multiple" />
<input type="submit" value="提交" />
</form>
action` 就是我们的提交到的接口,`enctype="multipart/form-data"` 就是指定上传文件格式,`input` 的 `name` 属性一定要等于`file
文件解析
在服务器中,这里采用koa2中间件的形式解析上传的文件数据,分别有下面两种形式:
- koa-body
- koa-multer
koa-body
安装依赖
npm install koa-body
引入koa-body中间件
const koaBody = require("koa-body");
app.use(
koaBody({
multipart: true,
formidable: {
maxFileSize: 200 * 1024 * 1024, // 设置上传文件大小最大限制,默认2M
},
})
);
获取上传的文件
const file = ctx.request.files.file; // 获取上传文件
获取文件数据后,可以通过fs模块将文件保存到指定目录
router.post("/uploadfile", async (ctx, next) => {
// 上传单个文件
const file = ctx.request.files.file; // 获取上传文件
// 创建可读流
const reader = fs.createReadStream(file.path);
let filePath = path.join(__dirname, "public/upload/") + `/${file.name}`;
// 创建可写流
const upStream = fs.createWriteStream(filePath);
// 可读流通过管道写入可写流
reader.pipe(upStream);
return (ctx.body = "上传成功!");
});
koa-multer
安装依赖:
npm install koa-multer
使用 multer 中间件实现文件上传
const storage = multer.diskStorage({
destination: (req, file, cb) => {
cb(null, "./upload/");
},
filename: (req, file, cb) => {
cb(null, Date.now() + path.extname(file.originalname));
},
});
const upload = multer({
storage,
});
const fileRouter = new Router();
fileRouter.post("/upload", upload.single("file"), (ctx, next) => {
console.log(ctx.req.file); // 获取文件
});
app.use(fileRouter.routes());
怎么进行大文件上传
NodeJS 实现 jwt 鉴权、文件上传、分页、性能监控和优化
不管怎样简单的需求,在量级达到一定层次时,都会变得异常复杂
文件上传简单,文件变大就复杂
上传大文件时,以下几个变量会影响我们的用户体验
- 服务器处理数据的能力
- 请求超时
- 网络波动
上传时间会变长,高频次文件上传失败,失败后又需要重新上传等等
为了解决上述问题,我们需要对大文件上传单独处理
这里涉及到分片上传及断点续传两个概念
http 断点续传
断点续传:指的是在上传/下载时,将任务(一个文件或压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传/下载,如果碰到网络故障,可以从已经上传/下载的部分开始继续上传/下载未完成的部分,而没有必要从头开始上传/下载。可以节省时间,提高速度。
它通过在 Header 里两个参数实现的,客户端发请求时对应的是 Range ,服务器端响应时对应的是 Content-Range。 Range
用于请求头中,指定第一个字节的位置和最后一个字节的位置,一般格式:
Range:(unit=first byte pos)-[last byte pos]
Range 头部的格式有以下几种情况:
Range: bytes=0-499 表示第 0-499 字节范围的内容 Range: bytes=500-999 表示第 500-999 字节范围的内容 Range: bytes=-500 表示最后 500 字节的内容 Range: bytes=500- 表示从第 500 字节开始到文件结束部分的内容 Range: bytes=0-0,-1 表示第一个和最后一个字节 Range: bytes=500-600,601-999 同时指定几个范围
Content-Range
用于响应头中,在发出带 Range 的请求后,服务器会在 Content-Range 头部返回当前接受的范围和文件总大小。一般格式:
Content-Range: bytes (unit first byte pos) - [last byte pos]/[entity legth]
例如:
Content-Range: bytes 0-499/22400
0-499 是指当前发送的数据的范围,而 22400 则是文件的总大小。
而在响应完成后,返回的响应头内容也不同:
HTTP/1.1 200 Ok(不使用断点续传方式) HTTP/1.1 206 Partial Content(使用断点续传方式)
断点续传流程 HTTP1.1 协议(RFC2616)中定义了断点续传相关的 HTTP 头 Range 和 Content-Range 字段,一个最简单的断点续传实现大概如下:
客户端下载一个 1024K 的文件,已经下载了其中 512K 网络中断,客户端请求续传,因此需要在 HTTP 头中申明本次需要续传的片段:Range:bytes=512000-,这个头通知服务端从文件的 512K 位置开始传输文件 服务端收到断点续传请求,从文件的 512K 位置开始传输,并且在 HTTP 头中增加:Content-Range:bytes 512000-/1024000,并且此时服务端返回的 HTTP 状态码应该是 206,而不是 200。
注意的问题
在实际场景中,会出现一种情况,即在终端发起续传请求时,URL 对应的文件内容在服务端已经发生变化,此时续传的数据肯定是错误的。如何解决这个问题了?显然此时我们需要有一个标识文件唯一性的方法。
在 RFC2616 中也有相应的定义,比如实现 Last-Modified 来标识文件的最后修改时间,这样即可判断出续传文件时是否已经发生过改动。同时 RFC2616 中还定义有一个 ETag 的头,可以使用 ETag 头来放置文件的唯一标识,比如文件的 MD5 值。
终端在发起续传请求时应该在 HTTP 头中申明 If-Match 或者 If-Modified-Since 字段,帮助服务端判别文件变化。
另外 RFC2616 中同时定义有一个 If-Range 头,终端如果在续传是使用 If-Range。If-Range 中的内容可以为最初收到的 ETag 头或者是 Last-Modfied 中的最后修改时候。服务端在收到续传请求时,通过 If-Range 中的内容进行校验,校验一致时返回 206 的续传回应,不一致时服务端则返回 200 回应,回应的内容为新的文件的全部数据。
分片上传
分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(Part)来进行分片上传
如下图
上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件
大致流程如下:
- 将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;
- 初始化一个分片上传任务,返回本次分片上传唯一标识;
- 按照一定的策略(串行或并行)发送各个分片数据块;
- 发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件
一、断点续传
断点续传指的是在下载或上传时,将下载或上传任务人为的划分为几个部分
每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传下载未完成的部分,而没有必要从头开始上传下载。用户可以节省时间,提高速度
一般实现方式有两种:
- 服务器端返回,告知从哪开始
- 浏览器端自行处理
上传过程中将文件在服务器写为临时文件,等全部写完了(文件上传完),将此临时文件重命名为正式文件即可
如果中途上传中断过,下次上传的时候根据当前临时文件大小,作为在客户端读取文件的偏移量,从此位置继续读取文件数据块,上传到服务器从此偏移量继续写入文件即可
二、实现思路
整体思路比较简单,拿到文件,保存文件唯一性标识,切割文件,分段上传,每次上传一段,根据唯一性标识判断文件上传进度,直到文件的全部片段上传完毕
下面的内容都是伪代码
读取文件内容:
const input = document.querySelector("input");
input.addEventListener("change", function () {
var file = this.files[0];
});
可以使用md5实现文件的唯一性
const md5code = md5(file);
然后开始对文件进行分割
var reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.addEventListener("load", function (e) {
//每10M切割一段,这里只做一个切割演示,实际切割需要循环切割,
var slice = e.target.result.slice(0, 10 * 1024 * 1024);
});
h5 上传一个(一片)
const formdata = new FormData();
formdata.append("0", slice);
//这里是有一个坑的,部分设备无法获取文件名称,和文件类型,这个在最后给出解决方案
formdata.append("filename", file.filename);
var xhr = new XMLHttpRequest();
xhr.addEventListener("load", function () {
//xhr.responseText
});
xhr.open("POST", "");
xhr.send(formdata);
xhr.addEventListener("progress", updateProgress);
xhr.upload.addEventListener("progress", updateProgress);
function updateProgress(event) {
if (event.lengthComputable) {
//进度条
}
}
这里给出常见的图片和视频的文件类型判断
function checkFileType(type, file, back) {
/**
* type png jpg mp4 ...
* file input.change=> this.files[0]
* back callback(boolean)
*/
var args = arguments;
if (args.length != 3) {
back(0);
}
var type = args[0]; // type = '(png|jpg)' , 'png'
var file = args[1];
var back = typeof args[2] == "function" ? args[2] : function () {};
if (file.type == "") {
// 如果系统无法获取文件类型,则读取二进制流,对二进制进行解析文件类型
var imgType = [
"ff d8 ff", //jpg
"89 50 4e", //png
"0 0 0 14 66 74 79 70 69 73 6F 6D", //mp4
"0 0 0 18 66 74 79 70 33 67 70 35", //mp4
"0 0 0 0 66 74 79 70 33 67 70 35", //mp4
"0 0 0 0 66 74 79 70 4D 53 4E 56", //mp4
"0 0 0 0 66 74 79 70 69 73 6F 6D", //mp4
"0 0 0 18 66 74 79 70 6D 70 34 32", //m4v
"0 0 0 0 66 74 79 70 6D 70 34 32", //m4v
"0 0 0 14 66 74 79 70 71 74 20 20", //mov
"0 0 0 0 66 74 79 70 71 74 20 20", //mov
"0 0 0 0 6D 6F 6F 76", //mov
"4F 67 67 53 0 02", //ogg
"1A 45 DF A3", //ogg
"52 49 46 46 x x x x 41 56 49 20", //avi (RIFF fileSize fileType LIST)(52 49 46 46,DC 6C 57 09,41 56 49 20,4C 49 53 54)
];
var typeName = [
"jpg",
"png",
"mp4",
"mp4",
"mp4",
"mp4",
"mp4",
"m4v",
"m4v",
"mov",
"mov",
"mov",
"ogg",
"ogg",
"avi",
];
var sliceSize = /png|jpg|jpeg/.test(type) ? 3 : 12;
var reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.addEventListener("load", function (e) {
var slice = e.target.result.slice(0, sliceSize);
reader = null;
if (slice && slice.byteLength == sliceSize) {
var view = new Uint8Array(slice);
var arr = [];
view.forEach(function (v) {
arr.push(v.toString(16));
});
view = null;
var idx = arr.join(" ").indexOf(imgType);
if (idx > -1) {
back(typeName[idx]);
} else {
arr = arr.map(function (v) {
if (i > 3 && i < 8) {
return "x";
}
return v;
});
var idx = arr.join(" ").indexOf(imgType);
if (idx > -1) {
back(typeName[idx]);
} else {
back(false);
}
}
} else {
back(false);
}
});
} else {
var type = file.name.match(/\.(\w+)$/)[1];
back(type);
}
}
调用方法如下
checkFileType("(mov|mp4|avi)", file, function (fileType) {
// fileType = mp4,
// 如果file的类型不在枚举之列,则返回false
});
上面上传文件的一步,可以改成:
formdata.append("filename", md5code + "." + fileType);
有了切割上传后,也就有了文件唯一标识信息,断点续传变成了后台的一个小小的逻辑判断
后端主要做的内容为:根据前端传给后台的md5值,到服务器磁盘查找是否有之前未完成的文件合并信息(也就是未完成的半成品文件切片),取到之后根据上传切片的数量,返回数据告诉前端开始从第几节上传
如果想要暂停切片的上传,可以使用XMLHttpRequest的 abort方法
三、使用场景
- 大文件加速上传:当文件大小超过预期大小时,使用分片上传可实现并行上传多个 Part, 以加快上传速度
- 网络环境较差:建议使用分片上传。当出现上传失败的时候,仅需重传失败的 Part
- 流式上传:可以在需要上传的文件大小还不确定的情况下开始上传。这种场景在视频监控等行业应用中比较常见
小结
当前的伪代码,只是提供一个简单的思路,想要把事情做到极致,我们还需要考虑到更多场景,比如
- 切片上传失败怎么办
- 上传过程中刷新页面怎么办
- 如何进行并行上传
- 切片什么时候按数量切,什么时候按大小切
- 如何结合 Web Worker 处理大文件上传
- 如何实现秒传
FormData 传输表单文件
multipart/form-data
在前端开发过程中,不可避免地会遇到表单,即 multipart/form-data,你是否知道:
- HTTP 如何传输
multipart/form-data - 服务端如何解析
multipart/form-data - 浏览器如何组装
multipart/form-data
我们来看一个简单的 form 表单:
<form action="/submit" method="POST" enctype="multipart/form-data">
<input type="text" name="username"><br>
<input type="text" name="password"><br>
<button>提交</button>
</form>
复制代码
当提交的时候,查看浏览器的网络请求:
请求头:
POST /submit HTTP/1.1
Host: localhost:3000
Accept-Encoding: gzip, deflate
Content-Type: multipart/form-data; boundary=---------------------------340073633417401055292887335273
Content-Length: 303
复制代码
请求体:
-----------------------------340073633417401055292887335273
Content-Disposition: form-data; name="username"
张三
-----------------------------340073633417401055292887335273
Content-Disposition: form-data; name="password"
123456
-----------------------------340073633417401055292887335273--
复制代码
这就是 multipart/form-data 的传输过程了,但是这里面有三个大坑:
请求头 Content-Type 里面的 boundary 分隔符比请求体用的分隔符少了两个杠(-)
从请求头中取分隔符之后,一定要在之前加两个 - 再对请求体进行分割
请求头 Content-Length 的换行用的是
\r\n而不是\n请求体的真实面目是下面的字符串: "-----------------------------340073633417401055292887335273\r\nContent-Disposition: form-data; name="username"\r\n\r\n 张三\r\n-----------------------------340073633417401055292887335273\r\nContent-Disposition: form-data; name="password"\r\n\r\n123456\r\n-----------------------------340073633417401055292887335273--\r\n"
请求头 Content-Length 的值表示字节的长度,而不是字符串的长度
因为字节的长度跟编码无关,而字符串的长度往往跟编码有关,举个例子,在 utf8 编码下:
console.log('a1'.length) // 2
console.log(Buffer.from('a1').length) // 2
console.log('张三'.length) // 2
console.log(Buffer.from('张三').length) // 6
复制代码
如果仅仅是基本的字符串类型,完全可以用 www-form-urlencoded 来进行传输,multipart/form-data 强大的地方是其能够传输二进制文件的能力,我们看一下如果包含二进制文件的话应该如何处理。我们增加一个 file 类型的 input,上传一张图片作为头像,发现请求体多出了一部分:
-----------------------------114007818631328932362459060915
Content-Disposition: form-data; name="avatar"; filename="1.jpg"
Content-Type: image/jpeg
xxxxxx文件的二进制数据xxxxx
可以发现,文件类型的 part 跟之前字符串的格式有所不同了,head 部分有两个头字段,多出一个 Content-Type 头,而且 Content-Disposition 头多出来 filename 字段,body 部分是文件的二进制数据。
了解这这些规律之后,接下来就可以在服务端对 multipart/form-data 进行解码了:
const http = require("http");
const fs = require("fs");
http
.createServer(function (req, res) {
// 获取 content-type 头,格式为: multipart/form-data; boundary=--------------------------754404743474233185974315
const contentType = req.headers["content-type"];
const headBoundary = contentType.slice(contentType.lastIndexOf("=") + 1); // 截取 header 里面的 boundary 部分
const bodyBoundary = "--" + headBoundary; // 前面加两个 - 才是 body 里面真实的分隔符
const arr = [],
obj = {};
req.on("data", (chunk) => arr.push(chunk));
req.on("end", function () {
const parts = Buffer.concat(arr).split(bodyBoundary).slice(1, -1); // 根据分隔符进行分割
for (let i = 0; i < parts.length; i++) {
const { key, value } = handlePart(parts[i]);
obj[key] = value;
}
res.end(JSON.stringify(obj));
});
})
.listen(3000);
其中关键的就是 handlePart 部分,即对分隔出来的每一部分单独处理,如果是二进制的就保存到文件,是字符串就返回键值对:
function handlePart(part) {
const [head, body] = part.split("\r\n\r\n"); // buffer 分割
const headStr = head.toString();
const key = headStr.match(/name="(.+?)"/)[1];
const match = headStr.match(/filename="(.+?)"/);
if (!match) {
const value = body.toString().slice(0, -2); // 把末尾的 \r\n 去掉
return { key, value };
}
const filename = match[1];
const content = part.slice(head.length + 4, -2); // 文件二进制部分是 head + \r\n\r\n 再去掉最后的 \r\n
fs.writeFileSync(filename, content);
return { key, value: filename };
}
复制代码;
这里面涉及到 buffer 的分割,nodejs 中并没有提供 split 方法,可根据 slice 方法自己实现:
Buffer.prototype.split = function (sep) {
let sepLength = sep.length, arr = [], offset = 0, currentIndex = 0
while ((currentIndex = this.indexOf(sep, offset)) !== -1) {
arr.push(this.slice(offset, currentIndex))
offset = currentIndex + sepLength
}
arr.push(this.slice(offset))
return arr
}
FormData 传输表单文件
在浏览器中,我们用 <form> 元素来提交表单中的文件,表单的编码类型由 enctype 属性决定,必须是以下三种之一:
application/x-www-form-urlencoded:表单默认的编码类型multipart/form-data:如果包含文件,只能选择这种类型text/plain:无需编码,直接发送
最重要的就是 multipart/form-data 这种类型了,因为可以传输文件,之前有写过专门的文章介绍过其底层原理。在 node.js 中我们一般用 form-data 这个包来模拟浏览器中的表单,使用方法如下:
var form = new FormData();
form.append("my_string", "my value");
form.append("my_integer", 1);
form.append("my_boolean", true);
form.append("my_buffer", Buffer.from("hello"));
form.append("my_file", fs.readFileSync("/foo/bar.jpg"));
form.append("my_file", fs.createReadStream("/foo/bar.jpg"));
用法很简单,不再赘述,对于文件类型,用 createReadStream 或者 readFileSync 两种方式来读取即可,这里主要强调一点:form-data 对这两种格式的处理稍有不同。请看下面两段代码:
createReadStreamvar media = new FormData();
media.append("contentType", "image/jpeg");
media.append("value", fs.createReadStream("/Users/keliq/Pictures/1.jpeg"));readFileSyncvar media = new FormData();
media.append("contentType", "image/jpeg");
media.append("value", fs.readFileSync("/Users/keliq/Pictures/1.jpeg"));
抓包得到的结果是:
createReadStream----------------------------015517802272525417891317
Content-Disposition: form-data; name="contentType"
image/jpeg
----------------------------015517802272525417891317
Content-Disposition: form-data; name="value"; filename="1.jpeg"
Content-Type: image/jpegreadFileSync----------------------------152374567568773937407488
Content-Disposition: form-data; name="contentType"
image/jpeg
----------------------------152374567568773937407488
Content-Disposition: form-data; name="value"
Content-Type: application/octet-stream
最后发现原因在这个 merge 里面,把 Content-Type 默认设置为 application/octet-stream 了,那如果想和 createReadStream 的格式一样,需要改成这样子:
var media = new FormData();
media.append("contentType", "image/jpeg");
media.append(
"value",
fs.readFileSync("/Users/keliq/Pictures/1.jpeg"),
"1.jpeg"
);
这是 form-data 库提供的 API:
// Set filename by providing a string for options
form.append("my_file", fs.createReadStream("/foo/bar.jpg"), "bar.jpg");
// provide an object.
form.append("my_file", fs.createReadStream("/foo/bar.jpg"), {
filename: "bar.jpg",
contentType: "image/jpeg",
knownLength: 19806,
});
查看了一下源码,原因是如果提供了文件名,就会用 mime-types 的 lookup 方法自动判断 Content-Type,例如:
mime.lookup("json"); // 'application/json'
mime.lookup(".md"); // 'text/markdown'
mime.lookup("file.html"); // 'text/html'
mime.lookup("folder/file.js"); // 'application/javascript'
这也是为什么当提供了 1.jpeg 参数之后,Content-Type 会从默认的 application/octet-stream 变成了 image/jpeg。
设计一个分页功能
一、是什么
在我们做数据查询的时候,如果数据量很大,比如几万条数据,放在一个页面显示的话显然不友好,这时候就需要采用分页显示的形式,如每次只显示 10 条数据

要实现分页功能,实际上就是从结果集中显示第 1~10 条记录作为第 1 页,显示第 11~20 条记录作为第 2 页,以此类推
因此,分页实际上就是从结果集中截取出第 M~N 条记录
二、如何实现
前端实现分页功能,需要后端返回必要的数据,如总的页数,总的数据量,当前页,当前的数据
{
"totalCount": 1836, // 总的条数
"totalPages": 92, // 总页数
"currentPage": 1 // 当前页数
"data": [ // 当前页的数据
{
...
}
]
后端采用mysql作为数据的持久性存储
前端向后端发送目标的页码page以及每页显示数据的数量pageSize,默认情况每次取 10 条数据,则每一条数据的起始位置start为:
const start = (page - 1) * pageSize;
当确定了limit和start的值后,就能够确定SQL语句:
const sql = `SELECT * FROM record limit ${pageSize} OFFSET ${start};`;
上诉SQL语句表达的意思为:截取从start到start+pageSize之间(左闭右开)的数据
关于查询数据总数的SQL语句为,record为表名:
SELECT COUNT(*) FROM record
因此后端的处理逻辑为:
- 获取用户参数页码数 page 和每页显示的数目 pageSize ,其中 page 是必须传递的参数,pageSize 为可选参数,默认为 10
- 编写 SQL 语句,利用 limit 和 OFFSET 关键字进行分页查询
- 查询数据库,返回总数据量、总页数、当前页、当前页数据给前端
代码如下所示:
router.all("/api", function (req, res, next) {
var param = "";
// 获取参数
if (req.method == "POST") {
param = req.body;
} else {
param = req.query || req.params;
}
if (param.page == "" || param.page == null || param.page == undefined) {
res.end(JSON.stringify({ msg: "请传入参数page", status: "102" }));
return;
}
const pageSize = param.pageSize || 10;
const start = (param.page - 1) * pageSize;
const sql = `SELECT * FROM record limit ${pageSize} OFFSET ${start};`;
pool.getConnection(function (err, connection) {
if (err) throw err;
connection.query(sql, function (err, results) {
connection.release();
if (err) {
throw err;
} else {
// 计算总页数
var allCount = results[0][0]["COUNT(*)"];
var allPage = parseInt(allCount) / 20;
var pageStr = allPage.toString();
// 不能被整除
if (pageStr.indexOf(".") > 0) {
allPage = parseInt(pageStr.split(".")[0]) + 1;
}
var list = results[1];
res.end(
JSON.stringify({
msg: "操作成功",
status: "200",
totalPages: allPage,
currentPage: param.page,
totalCount: allCount,
data: list,
})
);
}
});
});
});
三、总结
通过上面的分析,可以看到分页查询的关键在于,要首先确定每页显示的数量pageSize,然后根据当前页的索引pageIndex(从 1 开始),确定LIMIT和OFFSET应该设定的值:
- LIMIT 总是设定为 pageSize
- OFFSET 计算公式为 pageSize * (pageIndex - 1)
确定了这两个值,就能查询出第 N页的数据
Node.js 性能监控和优化
一、 是什么
Node作为一门服务端语言,性能方面尤为重要,其衡量指标一般有如下:
- CPU
- 内存
- I/O
- 网络
CPU
主要分成了两部分:
- CPU 负载:在某个时间段内,占用以及等待 CPU 的进程总数
- CPU 使用率:CPU 时间占用状况,等于 1 - 空闲 CPU 时间(idle time) / CPU 总时间
这两个指标都是用来评估系统当前 CPU 的繁忙程度的量化指标
Node应用一般不会消耗很多的CPU,如果CPU占用率高,则表明应用存在很多同步操作,导致异步任务回调被阻塞
内存指标
内存是一个非常容易量化的指标。 内存占用率是评判一个系统的内存瓶颈的常见指标。 对于 Node 来说,内部内存堆栈的使用状态也是一个可以量化的指标
// /app/lib/memory.js
const os = require("os");
// 获取当前Node内存堆栈情况
const { rss, heapUsed, heapTotal } = process.memoryUsage();
// 获取系统空闲内存
const sysFree = os.freemem();
// 获取系统总内存
const sysTotal = os.totalmem();
module.exports = {
memory: () => {
return {
sys: 1 - sysFree / sysTotal, // 系统内存占用率
heap: heapUsed / headTotal, // Node堆内存占用率
node: rss / sysTotal, // Node占用系统内存的比例
};
},
};
- rss:表示 node 进程占用的内存总量。
- heapTotal:表示堆内存的总量。
- heapUsed:实际堆内存的使用量。
- external :外部程序的内存使用量,包含 Node 核心的 C++程序的内存使用量
在Node中,一个进程的最大内存容量为 1.5GB。因此我们需要减少内存泄露
磁盘 I/O
硬盘的IO 开销是非常昂贵的,硬盘 IO 花费的 CPU 时钟周期是内存的 164000 倍
内存 IO比磁盘IO 快非常多,所以使用内存缓存数据是有效的优化方法。常用的工具如 redis、memcached等
并不是所有数据都需要缓存,访问频率高,生成代价比较高的才考虑是否缓存,也就是说影响你性能瓶颈的考虑去缓存,并且而且缓存还有缓存雪崩、缓存穿透等问题要解决
二、如何监控
关于性能方面的监控,一般情况都需要借助工具来实现
这里采用Easy-Monitor 2.0,其是轻量级的 Node.js 项目内核性能监控 + 分析工具,在默认模式下,只需要在项目入口文件 require 一次,无需改动任何业务代码即可开启内核级别的性能监控分析
使用方法如下:
在你的项目入口文件中按照如下方式引入,当然请传入你的项目名称:
const easyMonitor = require("easy-monitor");
easyMonitor("你的项目名称");
打开你的浏览器,访问 http://localhost:12333 ,即可看到进程界面
关于定制化开发、通用配置项以及如何动态更新配置项详见官方文档
三、如何优化
关于Node的性能优化的方式有:
- 使用最新版本 Node.js
- 正确使用流 Stream
- 代码层面优化
- 内存管理优化
使用最新版本 Node.js
每个版本的性能提升主要来自于两个方面:
- V8 的版本更新
- Node.js 内部代码的更新优化
正确使用流 Stream
在Node中,很多对象都实现了流,对于一个大文件可以通过流的形式发送,不需要将其完全读入内存
const http = require("http");
const fs = require("fs");
// bad
http.createServer(function (req, res) {
fs.readFile(__dirname + "/data.txt", function (err, data) {
res.end(data);
});
});
// good
http.createServer(function (req, res) {
const stream = fs.createReadStream(__dirname + "/data.txt");
stream.pipe(res);
});
代码层面优化
合并查询,将多次查询合并一次,减少数据库的查询次数
// bad
for user_id in userIds
let account = user_account.findOne(user_id)
// good
const user_account_map = {} // 注意这个对象将会消耗大量内存。
user_account.find(user_id in user_ids).forEach(account){
user_account_map[account.user_id] = account
}
for user_id in userIds
var account = user_account_map[user_id]
内存管理优化
在 V8 中,主要将内存分为新生代和老生代两代:
- 新生代:对象的存活时间较短。新生对象或只经过一次垃圾回收的对象
- 老生代:对象存活时间较长。经历过一次或多次垃圾回收的对象
若新生代内存空间不够,直接分配到老生代
通过减少内存占用,可以提高服务器的性能。如果有内存泄露,也会导致大量的对象存储到老生代中,服务器性能会大大降低
如下面情况:
const buffer = fs.readFileSync(__dirname + "/source/index.htm");
app.use(
mount("/", async (ctx) => {
ctx.status = 200;
ctx.type = "html";
ctx.body = buffer;
leak.push(fs.readFileSync(__dirname + "/source/index.htm"));
})
);
const leak = [];
leak的内存非常大,造成内存泄露,应当避免这样的操作,通过减少内存使用,是提高服务性能的手段之一
而节省内存最好的方式是使用池,其将频用、可复用对象存储起来,减少创建和销毁操作
例如有个图片请求接口,每次请求,都需要用到类。若每次都需要重新 new 这些类,并不是很合适,在大量请求时,频繁创建和销毁这些类,造成内存抖动
使用对象池的机制,对这种频繁需要创建和销毁的对象保存在一个对象池中。每次用到该对象时,就取对象池空闲的对象,并对它进行初始化操作,从而提高框架的性能
获取一个目录下面所有文件
const fs = require("fs");
const path = require("path");
function readDir(pathUrl) {
fs.readdir(pathUrl, (err, fileName) => {
if (err) {
console.log("文件夹读取错误", err);
} else {
for (let i = 0; i < fileName.length; i++) {
if (fs.statSync(`${pathUrl}/${fileName[i]}`).isFile() === true) {
let extent = fileName[i].split(".")[1];
if (extent == "json") {
fs.readFile(
`${pathUrl}/${fileName[i]}`,
"utf-8",
(err, content) => {
if (err) {
console.log("读取文件内容失败", err);
} else {
let copyJson = JSON.parse(JSON.stringify(content));
let copyObj = JSON.parse(copyJson);
let itemsArr = copyObj.items;
for (let i = 0; i < itemsArr.length; i++) {
let str = itemsArr[i].evaluate_text;
let reg = /[\u3002|\uff1f|\uff01|\uff1b]$/g; //判断是否为
if (reg.test(str)) {
itemsArr[i].category = "read_sentence";
}
}
copyObj.items = itemsArr;
let result = JSON.stringify(copyObj);
fs.writeFile(`${pathUrl}/${fileName[i]}`, result, (err) => {
if (!err) console.log("修改成功");
});
}
}
);
}
} else {
readDir(`${pathUrl}/${fileName[i]}`);
}
}
}
});
}
readDir("./classification");