Webpack
webpack 的作用是什么?
webpack 是一个模块打包工具
webpack的作用其实有以下几点:
- 模块打包。可以将不同模块的文件打包整合在一起,并且保证它们之间的引用正确,执行有序。利用打包我们就可以在开发的时候根据我们自己的业务自由划分文件模块,保证项目结构的清晰和可读性。
- 编译兼容。在前端的“上古时期”,手写一堆浏览器兼容代码一直是令前端工程师头皮发麻的事情,而在今天这个问题被大大的弱化了,通过
webpack的Loader机制,不仅仅可以帮助我们对代码做polyfill,还可以编译转换诸如.less, .vue, .jsx这类在浏览器无法识别的格式文件,让我们在开发的时候可以使用新特性和新语法做开发,提高开发效率。 - 能力扩展。通过
webpack的Plugin机制,我们在实现模块化打包和编译兼容的基础上,可以进一步实现诸如按需加载,代码压缩等一系列功能,帮助我们进一步提高自动化程度,工程效率以及打包输出的质量。
webpack 解决了什么问题?
回答这个问题,可以和还没有 Webpack、没有构建工具时对比一下,就能明显地感觉出来了。这里就来列举一下不使用构建工具时的痛点。
web 开发时调用后端接口跨域,需要其他工具代理或者其他方式规避。
改动代码后要手动刷新浏览器,如果做了缓存还需要清缓存刷新。
因为 js 和 css 的兼容性问题,很多新语法学习了却不能使用,无论是开发效率和个人成长都受影响。
打包问题。需要使用额外的平台如 jekins 打包,自己编写打包脚本,对各个环节如压缩图片,打包 js、打包 css 都要一一处理
常见打包工具
分类
如果把工具按类型分可以分为这三类:
- 基于任务运行的工具: Grunt、Gulp 它们会自动执行指定的任务,就像流水线,把资源放上去然后通过不同插件进行加工,它们包含活跃的社区,丰富的插件,能方便的打造各种工作流。
- 基于模块化打包的工具:
Browserify、Webpack、rollup.js
有过 Node.js 开发经历的应该对模块很熟悉,需要引用组件直接一个
require就 OK,这类工具就是这个模式,还可以实现按需加载、异步加载模块。 - 整合型工具: Yeoman、FIS、jdf、Athena、cooking、weflow 使用了多种技术栈实现的脚手架工具,好处是即开即用,缺点就是它们约束了技术选型,并且学习成本相对较高。
一. 后端语言打包阶段( -2009 年)
2009 年之前,前端刚发展,市面上没有一个为前端开发设计的打包工具。所以这个阶段问题,需求,解决办法:
- 问题:没有为前端开发的打包工具,手动打包费时费力
- 需求:需要自动打包的方法。
- 办法:用 PHP/Python/Java/Ruby/BashScript 写打包脚本,用 make 做构建工具
- 好处:解决了手动打包的困扰
- 痛点:前端必须学一门后端语言
每个阶段的痛点都为新一代打包工具产生提供了方向。
二. 文件打包阶段(2009 年-2014 年)
为什么这个阶段的开始节点是 2009 年?
因为,nodejs 诞生了,这也意味着前端不在学习需要后端语言就可以操作文件了!
这个阶段代表工具有:Grunt,Gulp 等
Grunt
Grunt 可以说是一个任务执行器,为什么这么说,看例子:
// Gruntfile.js
grunt.initConfig({
jshint: {...}, watch: {files, tasks: ['jshint']}
})
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-contrib-qunit);
grunt.loadNpmTasks('grunt-contrib-concat');
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.registerTask('default', ['jshint', 'qunit', 'concat', 'uglify']);
// 在命令行运行 grunt 命令,就会触发 default 任务
grunt 语句是由任务任务构成的,操作对象是文件。每个任务官方都定义好了。他有这些特点:
- 问题:之前打包需要学习后端语言。
- 需求:需要简单的打包方法。
- 办法:Grunt 通过配置任务,操作文件解决
- 好处:有了简单,配置性的打包办法。
- 痛点:Grunt 一次打包由多个任务组成,每个任务都要吞吐文件,多个任务存在重复吞吐文件的情况,性能非常拉胯
Gulp
Gulp 是另一个任务执行器,他主要针对 Grunt 问题做了改进:
// gulpfile.js
const clean = ()=> {...}
const css = ()=> gulp.src('scss/**/*.scss').pipe(sass())...
const jslint = ()=> gulp.src('js/**/*').pipe(...
const minify = ()=> gulp.src('js/**/*').pipe(...
const watch = ()=> {
gulp.watch("scss/**/*", css)
gulp.watch("js/**/*", gulp.series(jslint, minify))
}
const js = gulp.series(jslint, minify)
const build = gulp.series(clean, gulp.parallel(css, js))
exports.css = css
exports.js = js
exports.default = build
- 问题:Grunt 打包太慢了
- 需求:想要快速打包的方法
- 办法:Gulp 引入管道、流、并行、串行等概念,将操作放在内存,而不是硬盘。
- 好处:有了更快的打包办法。
- 痛点:只是对 Grunt 进行了优化,本质没有变。当前端开始向模块化发展,特别当 react,vue 出来,项目文件越来越多。基于文件的操作打包工具越来越吃力。
三. Webpack 阶段(2014 年-2019 年)
Webpack
2014 年 Webpack 发布,这是专门为前端设计开发的打包工具。它有这些特点:
- 问题:前端模块化,文件越来越多,基于文件打包的工具无法满足需求
- 需求:想要一种新的打包工具
- 办法:webpack 以打包 JS 为主要功能,不再是任务运行。loader 用于加载文件、plugin 用于扩展功能。提供 webpack-dev-server、热更新
- 好处:极大满足了前端的打包需求,不管多么复杂都能搞定
- 痛点:配置复杂,基本没人能不出错。随着项目变大,大家发现打包越来越慢了。
Rollup
Rollup 又一个前端打包器,有着这些特点:
- 问题:webpack 太慢了
- 需求:想要一种更快的打包工具
- 办法:面向 ES Modules 而不是 AMD / CommonJS,支 Tree-shaking。不提供 dev server,只做生产环境打包
- 好处:打包性能比 Webpack 好
- 痛点:功能不如 Webpack 全,支持生成环境
Parcel
Parcel 是一款“速度快、零配置的 web 应用程序打包器”。有以下这些特点:很快、捆绑项目的所有资产、没有配置代码拆分。
Parcel 是 2017 年发布的,出现的原因是因为当时的 Webpack 使用过于烦琐,文档也不是很清晰明了,
所以 Parcel 一经推出就迅速被推上风口浪尖。
其核心特点就是:
- 真正做到了完全零配置,对项目没有任何的侵入;
- 自动安装依赖,开发过程更专注;
- 构建速度更快,因为内部使用了多进程同时工作,能够充分发挥多核 CPU 的效率。
四. vite 阶段
vite 是面向下一代的前端构建工具,他有接下来的特点:
- 问题:webpack 太慢了,Rollup 只支持生成环境打包
- 需求:想要一种生产,开发环境,更简单更快的打包工具
- 办法:开发时,不打包,充分利用浏览器的 module 能力。发布时,用 Rollup 打包
- 好处:开发速度甩 Webpack 十八条街
- 痛点:插件不够多,但问题不大,自己写插件即可。热更新会失灵,但问题不大,自己点刷新即可
1.常用的 loader 和 plugin 有哪些
根据官网介绍,Webpack 是一个用于现代 JavaScript 应用程序的 静态模块打包工具。当 webpack 处理应用程序时,它会在内部从一个或多个入口点构建一个 依赖图(dependency graph),然后将你项目中所需的每一个模块组合成一个或多个 bundles,它们均为静态资源,用于展示你的内容。
Webpack 一些核心概念:
- Entry:入口,指示 Webpack 应该使用哪个模块,来作为构建其内部 依赖图(dependency graph) 的开始。
- Output:输出结果,告诉 Webpack 在哪里输出它所创建的 bundle,以及如何命名这些文件。
- Module:模块,在 Webpack 里一切皆模块,一个模块对应着一个文件。Webpack 会从配置的 Entry 开始递归找出所有依赖的模块。
- Chunk:代码块,一个 Chunk 由多个模块组合而成,用于代码合并与分割。
- Loader:模块代码转换器,让 webpack 能够去处理除了 JS、JSON 之外的其他类型的文件,并将它们转换为有效 模块,以供应用程序使用,以及被添加到依赖图中。
- Plugin:扩展插件。在 webpack 运行的生命周期中会广播出许多事件,plugin 可以监听这些事件,在合适的时机通过 webpack 提供的 api 改变输出结果。常见的有:打包优化,资源管理,注入环境变量。
- Mode:模式,告知 webpack 使用相应模式的内置优化
- Browser Compatibility:浏览器兼容性,Webpack 支持所有符合 ES5 标准 的浏览器(IE8 以上版本)
loader 特点
- loader 本质上是一个函数,output=loader(input) // input 可为工程源文件的字符串,也可是上一个 loader 转化后的结果;
- 第一个 loader 的传入参数只有一个:资源文件(resource file)的内容;
- loader 支持链式调用,webpack 打包时是按照数组从后往前的顺序将资源交给 loader 处理的。
- 支持同步或异步函数。
代码结构
代码结构通常如下:
// source:资源输入,对于第一个执行的 loader 为资源文件的内容;后续执行的 loader 则为前一个 loader 的执行结果
// sourceMap: 可选参数,代码的 sourcemap 结构
// data: 可选参数,其它需要在 Loader 链中传递的信息,比如 posthtml/posthtml-loader 就会通过这个参数传递参数的 AST 对象
const loaderUtils = require("loader-utils");
module.exports = function (source, sourceMap?, data?) {
// 获取到用户给当前 Loader 传入的 options
const options = loaderUtils.getOptions(this);
// TODO: 此处为转换source的逻辑
return source;
};
常用的 Loader
1. babel-loader
babel-loader 基于 babel,用于解析 JavaScript 文件。babel 有丰富的预设和插件,babel 的配置可以直接写到 options 里或者单独写道配置文件里。
Babel 是一个 Javscript 编译器,可以将高级语法(主要是 ECMAScript 2015+ )编译成浏览器支持的低版本语法,它可以帮助你用最新版本的 Javascript 写代码,提高开发效率。
webpack 通过 babel-loader 使用 Babel。
用法
# 环境要求:
webpack 4.x || 5.x | babel-loader 8.x | babel 7.x
# 安装依赖包:
npm install -D babel-loader @babel/core @babel/preset-env webpack
然后,我们需要建立一个 Babel 配置文件来指定编译的规则。
Babel 配置里的两大核心:插件数组(plugins) 和 预设数组(presets)。
Babel 的预设(preset)可以被看作是一组 Babel 插件的集合,由一系列插件组成。
常用预设:
- @babel/preset-env ES2015+ 语法
- @babel/preset-typescript TypeScript
- @babel/preset-react React
- @babel/preset-flow Flow
插件和预设的执行顺序:
- 插件比预设先执行
- 插件执行顺序是插件数组从前向后执行
- 预设执行顺序是预设数组从后向前执行
webpack 配置代码:
// webpack.config.js
module: {
rules: [
{
test: /\.m?js$/,
exclude: /node_modules/,
use: {
loader: "babel-loader",
options: {
presets: [["@babel/preset-env", { targets: "defaults" }]],
plugins: ["@babel/plugin-proposal-class-properties"],
// 缓存 loader 的执行结果到指定目录,默认为node_modules/.cache/babel-loader,之后的 webpack 构建,将会尝试读取缓存
cacheDirectory: true,
},
},
},
];
}
以上 options 参数也可单独写到配置文件里,许多其他工具都有类似的配置文件:ESLint (.eslintrc)、Prettier (.prettierrc)。
配置文件我们一般只需要配置 presets(预设数组) 和 plugins(插件数组) ,其他一般也用不到,代码示例如下:
// babel.config.js
module.exports = (api) => {
return {
presets: [
"@babel/preset-react",
[
"@babel/preset-env",
{
useBuiltIns: "usage",
corejs: "2",
targets: {
chrome: "58",
ie: "10",
},
},
],
],
plugins: [
"@babel/plugin-transform-react-jsx",
"@babel/plugin-proposal-class-properties",
],
};
};
推荐阅读:
2. ts-loader
为 webpack 提供的 TypeScript loader,打包编译 Typescript
安装依赖:
npm install ts-loader --save-dev
npm install typescript --dev
webpack 配置如下:
// webpack.config.json
module.exports = {
mode: "development",
devtool: "inline-source-map",
entry: "./app.ts",
output: {
filename: "bundle.js"
},
resolve: {
// Add `.ts` and `.tsx` as a resolvable extension.
extensions: [".ts", ".tsx", ".js"]
},
module: {
rules: [
// all files with a `.ts` or `.tsx` extension will be handled by `ts-loader`
{ test: /\.tsx?$/, loader: "ts-loader" }
]
}
};
还需要 typescript 编译器的配置文件 tsconfig.json:
{
"compilerOptions": {
// 目标语言的版本
"target": "esnext",
// 生成代码的模板标准
"module": "esnext",
"moduleResolution": "node",
// 允许编译器编译JS,JSX文件
"allowJS": true,
// 允许在JS文件中报错,通常与allowJS一起使用
"checkJs": true,
"noEmit": true,
// 是否生成source map文件
"sourceMap": true,
// 指定jsx模式
"jsx": "react"
},
// 编译需要编译的文件或目录
"include": ["src", "test"],
// 编译器需要排除的文件或文件夹
"exclude": ["node_modules", "**/*.spec.ts"]
}
3. markdown-loader
markdown 编译器和解析器
用法:
只需将 loader 添加到您的配置中,并设置 options。
js 代码里引入 markdown 文件:
// file.js
import md from "markdown-file.md";
console.log(md);
webpack 配置:
// wenpack.config.js
const marked = require("marked");
const renderer = new marked.Renderer();
module.exports = {
// ...
module: {
rules: [
{
test: /\.md$/,
use: [
{
loader: "html-loader",
},
{
loader: "markdown-loader",
options: {
pedantic: true,
renderer,
},
},
],
},
],
},
};
4. raw-loader
可将文件作为字符串导入
// app.js
import txt from "./file.txt";
// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.txt$/,
use: "raw-loader",
},
],
},
};
5. file-loader
用于处理文件类型资源,如 jpg,png 等图片。返回值为 publicPath 为准
// file.js
import img from "./webpack.png";
console.log(img); // 编译后:https://www.tencent.com/webpack_605dc7bf.png
// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.(png|jpe?g|gif)$/i,
loader: "file-loader",
options: {
name: "[name]_[hash:8].[ext]",
publicPath: "https://www.tencent.com",
},
},
],
},
};
css 文件里的图片路径变成如下:
/* index.less */
.tag {
background-color: red;
background-image: url(./webpack.png);
}
/* 编译后:*/
background-image: url(https://www.tencent.com/webpack_605dc7bf.png);
6. url-loader:
它与 file-loader 作用相似,也是处理图片的,只不过 url-loader 可以设置一个根据图片大小进行不同的操作,如果该图片大小大于指定的大小,则将图片进行打包资源,否则将图片转换为 base64 字符串合并到 js 文件里。
module.exports = {
module: {
rules: [
{
test: /\.(png|jpg|jpeg)$/,
use: [
{
loader: "url-loader",
options: {
name: "[name]_[hash:8].[ext]",
// 这里单位为(b) 10240 => 10kb
// 这里如果小于10kb则转换为base64打包进js文件,如果大于10kb则打包到对应目录
limit: 10240,
},
},
],
},
],
},
};
7. svg-sprite-loader
会把引用的 svg 文件 塞到一个个 symbol 中,合并成一个大的 SVG sprite,使用时则通过 SVG 的 <use> 传入图标 id 后渲染出图标。最后将这个大的 svg 放入 body 中。symbol 的 id 如果不特别指定,就是你的文件名。
该 loader 可以搭配 svgo-loader 一起使用,svgo-loader 是 svg 的优化器,它可以删除和修改 SVG 元素,折叠内容,移动属性等
用途:可以用来开发统一的图标管理库
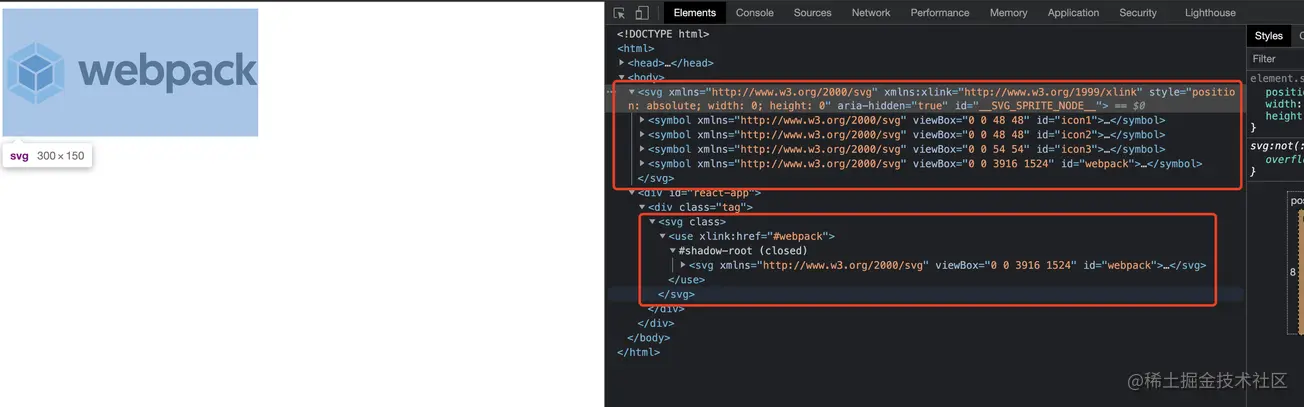
示例代码:
// js文件里用法
import webpack from "./webpack/webpack.svg";
const type = "webpack";
const svg = `<svg>
<use xlink:href="#${type}"/>
</svg>`;
const dom = `<div class="tag">
${svg}
</div>`;
document.getElementById("react-app").innerHTML = dom;
// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.(png|jpg|jpeg)$/,
use: [
{
test: /\.svg$/,
use: [
{
loader: "svg-sprite-loader",
},
"svgo-loader",
],
},
],
},
],
},
};
原理:利用 svg 的 symbol 元素,将每个 icon 包裹在 symbol 中,通过 use 使用该 symbol。
8. style-loader
style-loader 是通过注入style标签将 CSS 插入到 DOM 中
注意:
- 如果因为某些原因你需要将 CSS 提取为一个文件(即不要将 CSS 存储在 JS 模块中),此时你需要使用插件 mini-css-extract-plugin
- 对于 development 模式(包括 webpack-dev-server)你可以使用 style-loader,因为它是通过
style标签的方式引入 CSS 的,加载会更快; - 不要将 style-loader 和 mini-css-extract-plugin 针对同一个 CSS 模块一起使用!
9. css-loader
仅处理 css 的各种加载语法(@import 和 url()函数等),就像 js 解析 import/require() 一样
10. postcss-loader
PostCSS 是一个允许使用 JS 插件转换样式的工具。 这些插件可以检查(lint)你的 CSS,支持 CSS Variables 和 Mixins, 编译尚未被浏览器广泛支持的先进的 CSS 语法,内联图片,以及其它很多优秀的功能。
PostCSS 在业界被广泛地应用。PostCSS 的 **autoprefixer** 插件是最流行的 CSS 处理工具之一。
autoprefixer 添加了浏览器前缀,它使用 Can I Use 上面的数据。
安装
npm install postcss-loader autoprefixer --save-dev
代码示例:
// webpack.config.js
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
const isDev = process.NODE_ENV === "development";
module.exports = {
module: {
rules: [
{
test: /\.(css|less)$/,
exclude: /node_modules/,
use: [
isDev ? "style-loader" : MiniCssExtractPlugin.loader,
{
loader: "css-loader",
options: {
importLoaders: 1,
},
},
{
loader: "postcss-loader",
},
{
loader: "less-loader",
options: {
lessOptions: {
javascriptEnabled: true,
},
},
},
],
},
],
},
};
然后在项目根目录创建 postcss.config.js,并且设置支持哪些浏览器,必须设置支持的浏览器才会自动添加添加浏览器兼容
module.exports = {
plugins: [
require("precss"),
require("autoprefixer")({
browsers: [
"defaults",
"not ie < 11",
"last 2 versions",
"> 1%",
"iOS 7",
"last 3 iOS versions",
],
}),
],
};
11. less-loader
解析 less,转换为 css
12. vue-loader
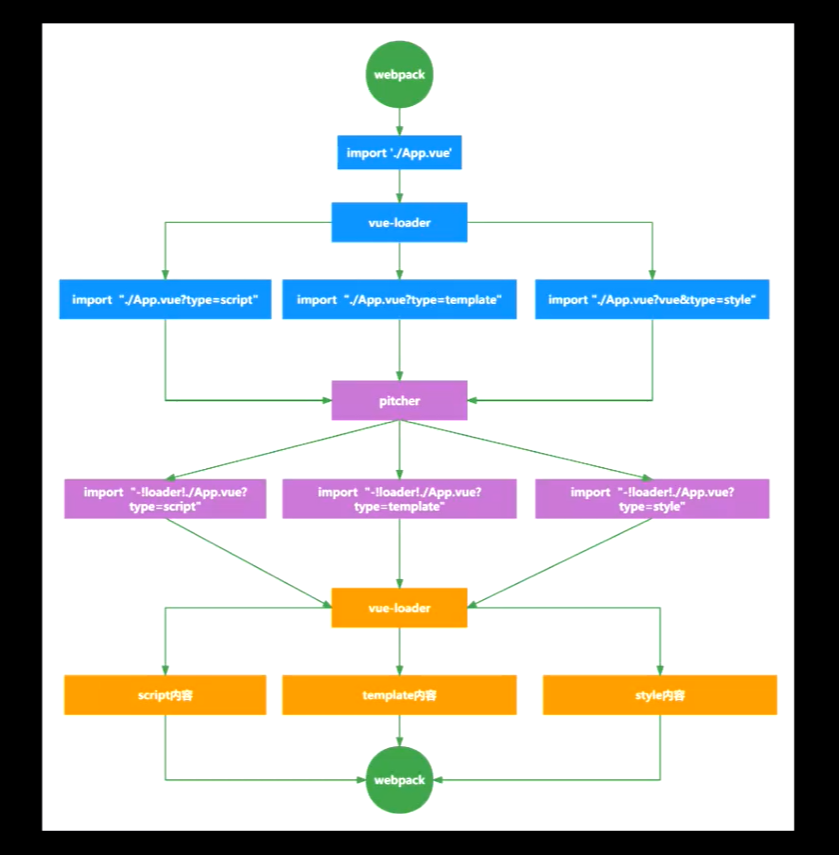
作为 webpack 中一个为解析 .vue 文件的 loader。主要的作用是是将单文件组件(SFC) 解析为 vue runtime是可识别的组件模块
对 .vue 文件转换大致分为三个阶段
第一个阶段:通过 vue-loader 将 .vue 文件转化为中间产物
vue-lodaer 现将读取的源文件,然后通过 @vue/component-compiler-utils(compiler-sfc)中的 parse 解析器将得到源文件的描述符。对每个 block 进行处理,生成对应的模块请求。由 normalizer 函数把每个 block 拼接到一起,形成一个 vue 组件
源文件描述符
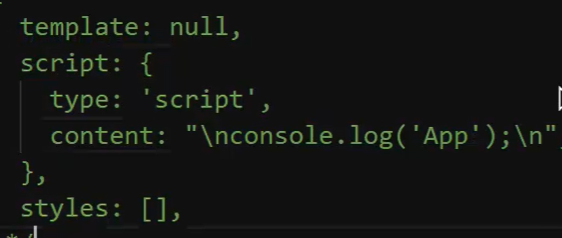
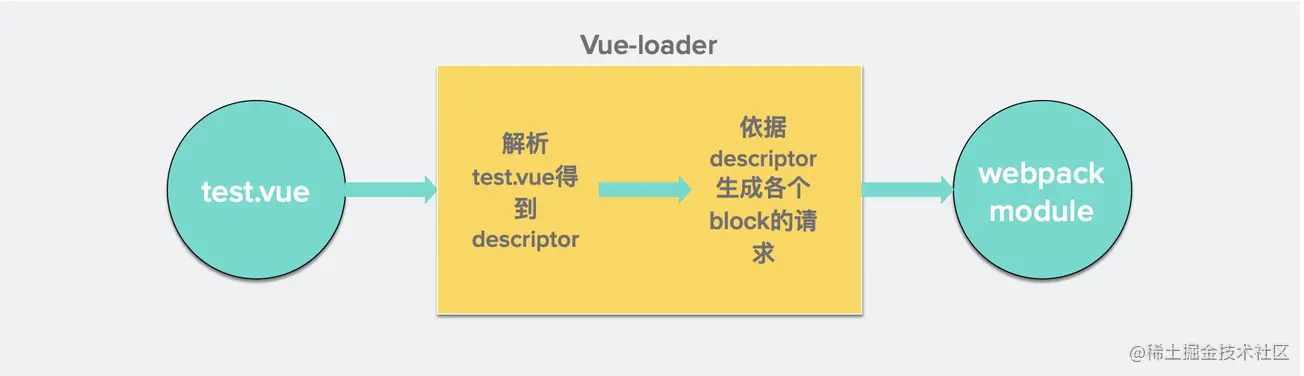
第二个阶段:通过 pitcher-loader(这个loader是通过 vueloaderplugin注入到webpack中的) 将第一阶段中间产物转化为另一阶段产物

通过 pitcher-loader(这个loader是通过 vueloaderplugin注入到webpack中的) 将第一阶段中间产物转化为另一阶段产物。 就以 import { render, staticRenderFns } from "./test.vue?vue&type=template&id=13429420&scoped=true&" 为例,会被转化为 -!./lib/vue-loader/loaders/templateLoader.js??vue-loader-options!./lib/vue-loader/index.js??vue-loader-options!./test.vue?vue&type=template&id=13429420&scoped=true&
在 webpack生成compiler之后,注入 pitcher-loader,我们主要这个loader的命中规则 resourceQuery。我们常用的是使用方式 test: /\.vue$/,在 webpack 内部会被 RuleSet 这个类标准化。所以上述 request 会先经由 pitcher-loader中的 pitch函数处理
这里面主要是要找到当前处理的 module 匹配中的 loaders,给他们排序,并在其中加入对应 block 块的处理 loader,比如这里的 templateLoader,然后通过 genRequest 生成我们最新的request, -!./lib/vue-loader/loaders/templateLoader.js??vue-loader-options!./lib/vue-loader/index.js??vue-loader-options!./test.vue?vue&type=template&id=13429420&scoped=true&
第三个阶段:第二阶段转化 request 请求,通过对应的 loader 进行处理
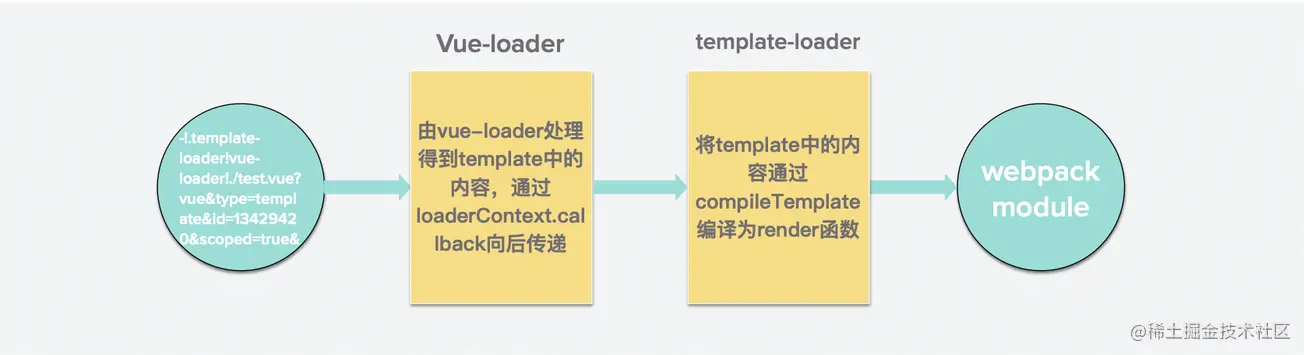
在得到上述的request 之后,webpack会先使用vue-loader处理,然后再使用template-loader来处理,然后得到最后模块
vue-loader的第二个出口,通过代码的注释我们知道,当 vue-loader在处理 .vue 文件中的一个 block 请求时,通过 qs.parse 序列化快请求参数 ?vue&type=template&id=13429420&scoped=true&,如果有 type 则返回 selectBlock 函数的执行结果
electBlock 依据传入的 query.type,将 descriptor 中对应的部分通过 loaderContext.callback 传递给下一个loader(这里是template-loader) 处理
template-loader 将 .vue 文件中的 template 部分通过自定义或者是内置 compileTemplate 编译为函数,其实就是 vue中 模块解析 的过程,这样可以提供 vue runtime 时的性能,毕竟模板解析是个耗性能的过程
render 函数的执行结果就是 vNode
生成的这个 render 函数就是对 template 模板解析的结果,render函数的执行结果就是其对应的 vNode,也就是 vue patch 阶段的入口参数。
13. px2rem-loader
利用 px2rem-loader 自动将 px 转成 rem 安装 npm i px2rem-loader -D 配置
modules: {
rules: [
{
test:/\.css$/,
use:[{
MiniCssExtractPlugin.loader,
'css-loader',
'postcss-loader',
{
loader:'px2rem-loader',
options:{
remUnit:75, // 根元素字体大小,也就是每 1rem 代表 75px
remPrecesion:8 // 精度,px 转 rem 的时候保留 8 位小树
}
}]
},
]
}
这里需要注意,px2rem-loader 是在 css-loader 之前的一个 loader,即:先处理好单位,再去走 css-loader
Plugin 特点
Webpack 就像一条生产线,要经过一系列处理流程后才能将源文件转换成输出结果。 这条生产线上的每个处理流程的职责都是单一的,多个流程之间有存在依赖关系,只有完成当前处理后才能交给下一个流程去处理。 插件就像是一个插入到生产线中的一个功能,在特定的时机对生产线上的资源做处理。
Webpack 通过 Tapable 来组织这条复杂的生产线。 Webpack 在运行过程中会广播事件,插件只需要监听它所关心的事件,就能加入到这条生产线中,去改变生产线的运作。 Webpack 的事件流机制保证了插件的有序性,使得整个系统扩展性很好。
与 Loader 用于转换特定类型的文件不同,插件(Plugin)可以贯穿 Webpack 打包的生命周期,执行不同的任务
常用 Plugin
1. copy-webpack-plugin
将已经存在的单个文件或整个目录复制到构建目录。
const CopyPlugin = require("copy-webpack-plugin");
module.exports = {
plugins: [
new CopyPlugin({
patterns: [
{
from: "./template/page.html",
to: `${__dirname}/output/cp/page.html`,
},
],
}),
],
};
2. html-webpack-plugin
基本作用是生成 html 文件
- 单页应用可以生成一个 html 入口,多页应用可以配置多个 html-webpack-plugin 实例来生成多个页面入口
- 为 html 引入外部资源如 script、link,将 entry 配置的相关入口 chunk 以及 mini-css-extract-plugin 抽取的 css 文件插入到基于该插件设置的 template 文件生成的 html 文件里面,具体的方式是 link 插入到 head 中,script 插入到 head 或 body 中。
const HtmlWebpackPlugin = require("html-webpack-plugin");
module.exports = {
entry: {
news: [path.resolve(__dirname, "../src/news/index.js")],
video: path.resolve(__dirname, "../src/video/index.js"),
},
plugins: [
new HtmlWebpackPlugin({
title: "news page",
// 生成的文件名称 相对于webpackConfig.output.path路径而言
filename: "pages/news.html",
// 生成filename的文件模板
template: path.resolve(__dirname, "../template/news/index.html"),
chunks: ["news"],
}),
new HtmlWebpackPlugin({
title: "video page",
// 生成的文件名称
filename: "pages/video.html",
// 生成filename的文件模板
template: path.resolve(__dirname, "../template/video/index.html"),
chunks: ["video"],
}),
],
};
3. clean-webpack-plugin
默认情况下,这个插件会删除 webpack 的 output.path 中的所有文件,以及每次成功重新构建后所有未使用的资源。
这个插件在生产环境用的频率非常高,因为生产环境经常会通过 hash 生成很多 bundle 文件,如果不进行清理的话每次都会生成新的,导致文件夹非常庞大。
const { CleanWebpackPlugin } = require("clean-webpack-plugin");
module.exports = {
plugins: [new CleanWebpackPlugin()],
};
4. mini-css-extract-plugin
本插件会将 CSS 提取到单独的文件中,为每个包含 CSS 的 JS 文件创建一个 CSS 文件。
// 建议 mini-css-extract-plugin 与 css-loader 一起使用
// 将 loader 与 plugin 添加到 webpack 配置文件中
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
module.exports = {
plugins: [new MiniCssExtractPlugin()],
module: {
rules: [
{
test: /\.css$/i,
use: [MiniCssExtractPlugin.loader, "css-loader"],
},
],
},
};
可以结合上文关于 style-loader 的介绍一起了解该插件。
5. webpack.HotModuleReplacementPlugin
模块热替换插件,除此之外还被称为 HMR。
该功能会在应用程序运行过程中,替换、添加或删除 模块,而无需重新加载整个页面。主要是通过以下几种方式,来显著加快开发速度:
- 保留在完全重新加载页面期间丢失的应用程序状态。
- 只更新变更内容,以节省宝贵的开发时间。
- 在源代码中 CSS/JS 产生修改时,会立刻在浏览器中进行更新,这几乎相当于在浏览器 devtools 直接更改样式。
启动方式有 2 种:
- 引入插件 webpack.HotModuleReplacementPlugin 并且设置 devServer.hot: true
- 命令行加 --hot 参数
package.json 配置:
{
"scripts": {
"start": "NODE_ENV=development webpack serve --progress --mode=development --config=scripts/dev.config.js --hot"
}
}
webpack 的配置如下:
// scripts/dev.config.js文件
const webpack = require("webpack");
const path = require("path");
const outputPath = path.resolve(__dirname, "./output/public");
module.exports = {
mode: "development",
entry: {
preview: [
"./node_modules/webpack-dev-server/client/index.js?path=http://localhost:9000",
path.resolve(__dirname, "../src/preview/index.js"),
],
},
output: {
filename: "static/js/[name]/index.js",
// 动态生成的chunk在输出时的文件名称
chunkFilename: "static/js/[name]/chunk_[chunkhash].js",
path: outputPath,
},
plugins: [
// 大多数情况下不需要任何配置
new webpack.HotModuleReplacementPlugin(),
],
devServer: {
// 仅在需要提供静态文件时才进行配置
contentBase: outputPath,
// publicPath: '', // 值默认为'/'
compress: true,
port: 9000,
watchContentBase: true,
hot: true,
// 在服务器启动后打开浏览器
open: true,
// 指定打开浏览器时要浏览的页面
openPage: ["pages/preview.html"],
// 将产生的文件写入硬盘。 写入位置为 output.path 配置的目录
writeToDisk: true,
},
};
注意:HMR 绝对不能被用在生产环境。
6. webpack.DefinePlugin
创建一个在编译时可以配置的全局常量。这会对开发模式和生产模式的构建允许不同的行为非常有用。
因为这个插件直接执行文本替换,给定的值必须包含字符串本身内的实际引号。
通常,有两种方式来达到这个效果,使用'"production"', 或者使用 JSON.stringify('production')
// webpack.config.js
const isProd = process.env.NODE_ENV === "production";
module.exports = {
plugins: [
new webpack.DefinePlugin({
PAGE_URL: JSON.stringify(
isProd
? "https://www.tencent.com/page"
: "http://testsite.tencent.com/page"
),
}),
],
};
// 代码里面直接使用
console.log(PAGE_URL);
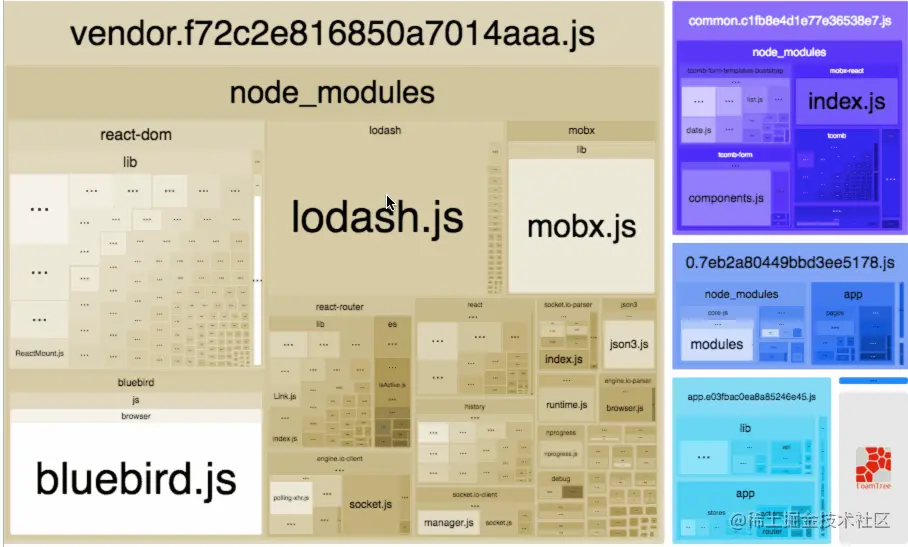
7. webpack-bundle-analyzer
可以看到项目各模块的大小,可以按需优化.一个 webpack 的 bundle 文件分析工具,将 bundle 文件以可交互缩放的 treemap 的形式展示。
const BundleAnalyzerPlugin =
require("webpack-bundle-analyzer").BundleAnalyzerPlugin;
module.exports = {
plugins: [new BundleAnalyzerPlugin()],
};
启动服务:
- 生产环境查看:NODE_ENV=production npm run build
- 开发环境查看:NODE_ENV=development npm run start
最终效果:
8. SplitChunksPlugin
代码分割。
const BundleAnalyzerPlugin =
require("webpack-bundle-analyzer").BundleAnalyzerPlugin;
module.exports = {
optimization: {
splitChunks: {
// 分隔符
// automaticNameDelimiter: '~',
// all, async, and initial
chunks: "all",
// 它可以继承/覆盖上面 splitChunks 中所有的参数值,除此之外还额外提供了三个配置,分别为:test, priority 和 reuseExistingChunk
cacheGroups: {
vendors: {
// 表示要过滤 modules,默认为所有的 modules,可匹配模块路径或 chunk 名字,当匹配的是 chunk 名字的时候,其里面的所有 modules 都会选中
test: /[\\/]node_modules\/antd\//,
// priority:表示抽取权重,数字越大表示优先级越高。因为一个 module 可能会满足多个 cacheGroups 的条件,那么抽取到哪个就由权重最高的说了算;
// priority: 3,
// reuseExistingChunk:表示是否使用已有的 chunk,如果为 true 则表示如果当前的 chunk 包含的模块已经被抽取出去了,那么将不会重新生成新的。
reuseExistingChunk: true,
name: "antd",
},
},
},
},
};
2.Webpack 构建流程
基本过程
- 初始化参数。获取用户在 webpack.config.js 文件配置的参数
- 开始编译。初始化 compiler 对象,注册所有的插件 plugins,插件开始监听webpack 构建过程的生命周期事件,不同环节会有相应的处理,然后开始执行编译。
- 确定入口。根据 webpack.config.js 文件的 entry 入口,从配置的 entry 入口,开始解析文件构建 AST 语法树,找出依赖,递归下去。
- 编译模块。递归过程中,根据文件类型和 loader 配置,调用相应的 loader 对不同的文件做转换处理,在找出该模块依赖的模块,递归本操作,直到项目中依赖的所有模块都经过了本操作的编译处理。
- 完成编译并输出。递归结束,得到每个文件结果,包含转换后的模块以及他们之前的依赖关系,根据 entry 以及 output 等配置生成代码块 chunk
- 打包完成。根据 output 输出所有的 chunk 到相应的文件目录
文件的解析与构建是一个比较复杂的过程,在webpack源码中主要依赖于compiler和compilation两个核心对象实现compiler对象是一个全局单例,他负责把控整个webpack打包的构建流程。 compilation对象是每一次构建的上下文对象,它包含了当次构建所需要的所有信息,每次热更新和重新构建,compiler都会重新生成一个新的compilation对象,负责此次更新的构建过程
而每个模块间的依赖关系,则依赖于AST语法树。每个模块文件在通过Loader解析完成之后,会通过acorn库生成模块代码的AST语法树,通过语法树就可以分析这个模块是否还有依赖的模块,进而继续循环执行下一个模块的编译解析。
Webpack打包出来的bundle文件是一个IIFE的执行函数
和webpack4相比,webpack5打包出来的 bundle 做了相当的精简。在上面的打包demo中,整个立即执行函数里边只有三个变量和一个函数方法,__webpack_modules__存放了编译后的各个文件模块的 JS 内容,__webpack_module_cache__ 用来做模块缓存,__webpack_require__是Webpack内部实现的一套依赖引入函数。最后一句则是代码运行的起点,从入口文件开始,启动整个项目。
__webpack_require__模块引入函数,我们在模块化开发的时候,通常会使用ES Module或者CommonJS规范导出/引入依赖模块,webpack打包编译的时候,会统一替换成自己的__webpack_require__来实现模块的引入和导出,从而实现模块缓存机制,以及抹平不同模块规范之间的一些差异性
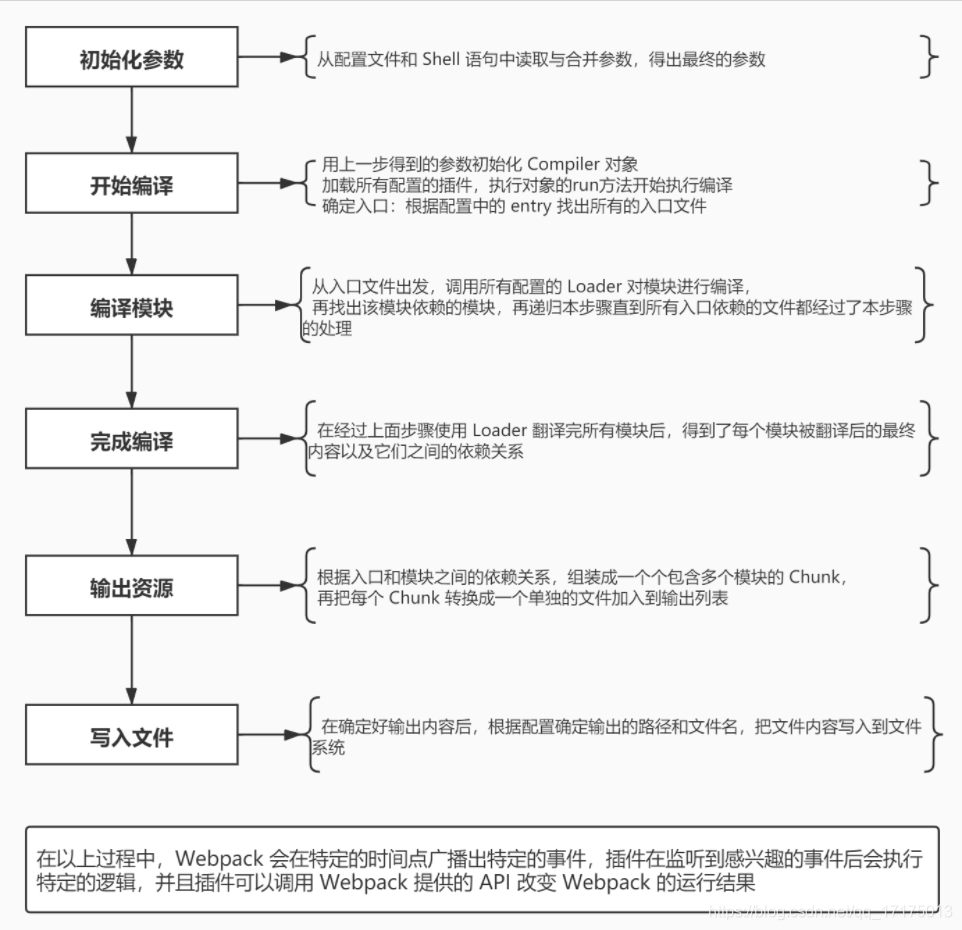
工作流程
- 初始化参数:从配置文件和 Shell 语句中读取并合并参数,得出最终的配置对象
- 用上一步得到的参数初始化 Compiler 对象
- 加载所有配置的插件
- 执行 Compiler 对象的 run 方法开始执行编译
- 根据配置中的 entry 找出入口文件
- 从入口文件触发,调用所有配置的 Loader 对模块进行编译
- 再找出该模块依赖的模块,再递归这个步骤,知道所有入口依赖的文件都经过了这个步骤的处理,得到入口与模块之间的依赖关系
- 根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk
- 再把每个 Chunk 转换成一个单独的文件加入到输出列表
- 在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统
- 以上过程中,webpack 会在特性的时间点广播出特定的事件,插件在监听到感兴趣的事件后执行特定的逻辑,并且插件可以调用 webpack 提供的 API 改变 webpack 的运行结果。
3.Webpack 打包后代码的结构
1、打包单一模块
webpack.config.js
module.exports = {
entry: "./chunk1.js",
output: {
path: __dirname + "/dist",
filename: "[name].js",
},
};
chunk1.js
var chunk1 = 1;
exports.chunk1 = chunk1;
打包后,main.js(webpack 生成的一些注释已经去掉)
(function (modules) {
// webpackBootstrap
// The module cache
var installedModules = {};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
if (installedModules[moduleId]) return installedModules[moduleId].exports;
// Create a new module (and put it into the cache)
var module = (installedModules[moduleId] = {
exports: {},
id: moduleId,
loaded: false,
});
// Execute the module function
modules[moduleId].call(
module.exports,
module,
module.exports,
__webpack_require__
);
// Flag the module as loaded
module.loaded = true;
// Return the exports of the module
return module.exports;
}
// expose the modules object (__webpack_modules__)
__webpack_require__.m = modules;
// expose the module cache
__webpack_require__.c = installedModules;
// __webpack_public_path__
__webpack_require__.p = "";
// Load entry module and return exports
return __webpack_require__(0);
})([
function (module, exports) {
var chunk1 = 1;
exports.chunk1 = chunk1;
},
]);
这其实就是一个立即执行函数,简化一下就是:
function(modules) { // webpackBootstrap
// modules就是一个数组,元素就是一个个函数体,就是我们声明的模块
var installedModules = {};
// The require function
function __webpack_require__(moduleId) {
...
}
// expose the modules object (__webpack_modules__)
__webpack_require__.m = modules;
// expose the module cache
__webpack_require__.c = installedModules;
// __webpack_public_path__
__webpack_require__.p = "";
// Load entry module and return exports
return __webpack_require__(0);
}
整个函数里就声明了一个变量 installedModules 和函数webpack_require,并在函数上添加了一个 m,c,p 属性,m 属性保存的是传入的模块数组,c 属性保存的是 installedModules 变量,P 是一个空字符串。最后执行webpack_require函数,参数为零,并将其执行结果返回。下面看一下webpack_require干了什么:
function __webpack_require__(moduleId) {
//moduleId就是调用是传入的0
// installedModules[0]是undefined,继续往下
if (installedModules[moduleId]) return installedModules[moduleId].exports;
// module就是{exports: {},id: 0,loaded: false}
var module = (installedModules[moduleId] = {
exports: {},
id: moduleId,
loaded: false,
});
// 下面接着分析这个
modules[moduleId].call(
module.exports,
module,
module.exports,
__webpack_require__
);
// 表明模块已经载入
module.loaded = true;
// 返回module.exports(注意modules[moduleId].call的时候module.exports会被修改)
return module.exports;
}
接着看一下 modules[moduleId].call(module.exports, module, module.exports, webpack_require),其实就是
modules[moduleId].call({}, module, module.exports, __webpack_require__);
对 call 不了解当然也可以认为是这样(但是并不是等价,call 能确保当模块中使用 this 的时候,this 是指向 module.exports 的):
function a(module, exports) {
var chunk1 = 1;
exports.chunk1 = chunk1;
}
a(module, exports, __webpack_require__);
传入的 module 就是{exports: {},id: 0,loaded: false},exports 就是{},webpack_require就是声明的webpack_require函数(传入这个函数有什么用呢,第二节将会介绍); 运行后 module.exports 就是{chunk1:1}。所以当我们使用 chunk1 这个模块的时候(比如 var chunk1=require(“chunk1”),得到的就是一个对象{chunk1:1})。如果模块里没有 exports.chunk1=chunk1 或者 module.exports=chunk1 得到的就是一个空对象{}
2、使用模块
上面我们已经分析了 webpack 是怎么打包一个模块的(入口文件就是一个模块),现在我们来看一下使用一个模块,然后使用模块的文件作为入口文件 webpack.config.js
module.exports = {
entry: "./main.js",
output: {
path: __dirname + "/dist",
filename: "[name].js",
},
};
main.js
var chunk1 = require("./chunk1");
console.log(chunk1);
打包后
(function (modules) {
// webpackBootstrap
// The module cache
var installedModules = {};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
if (installedModules[moduleId]) return installedModules[moduleId].exports;
// Create a new module (and put it into the cache)
var module = (installedModules[moduleId] = {
exports: {},
id: moduleId,
loaded: false,
});
// Execute the module function
modules[moduleId].call(
module.exports,
module,
module.exports,
__webpack_require__
);
// Flag the module as loaded
module.loaded = true;
// Return the exports of the module
return module.exports;
}
// expose the modules object (__webpack_modules__)
__webpack_require__.m = modules;
// expose the module cache
__webpack_require__.c = installedModules;
// __webpack_public_path__
__webpack_require__.p = "";
// Load entry module and return exports
return __webpack_require__(0);
})([
function (module, exports, __webpack_require__) {
var chunk1 = __webpack_require__(1);
console.log(chunk1);
},
function (module, exports) {
var chunk1 = 1;
exports.chunk1 = chunk1;
},
]);
不一样的地方就是自执行函数的参数由
[
function (module, exports) {
var chunk1 = 1;
exports.chunk1 = chunk1;
},
];
变为
[
function (module, exports, __webpack_require__) {
var chunk1 = __webpack_require__(1);
console.log(chunk1);
},
function (module, exports) {
var chunk1 = 1;
exports.chunk1 = chunk1;
},
];
其实就是多了一个 main 模块,不过这个模块没有导出项,而且这个模块依赖于 chunk1 模块。所以当运行webpack_require(0)的时候,main 模块缓存到 installedModules[0]上,modules[0].call(也就是调用 main 模块)的时候,chunk1 被缓存到 installedModules[1]上,并且导出对象{chunk1:1}给模块 main 使用
3、重复使用模块
webpack.config.js
module.exports = {
entry: "./main.js",
output: {
path: __dirname + "/dist",
filename: "[name].js",
},
};
main.js
var chunk1 = require("./chunk1");
var chunk2 = require(".chunlk2");
console.log(chunk1);
console.log(chunk2);
chunk1.js
var chunk2 = require("./chunk2");
var chunk1 = 1;
exports.chunk1 = chunk1;
chunk2.js
var chunk2 = 1;
exports.chunk2 = chunk2;
打包后
(function (modules) {
// webpackBootstrap
// The module cache
var installedModules = {};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
if (installedModules[moduleId]) return installedModules[moduleId].exports;
// Create a new module (and put it into the cache)
var module = (installedModules[moduleId] = {
exports: {},
id: moduleId,
loaded: false,
});
// Execute the module function
modules[moduleId].call(
module.exports,
module,
module.exports,
__webpack_require__
);
// Flag the module as loaded
module.loaded = true;
// Return the exports of the module
return module.exports;
}
// expose the modules object (__webpack_modules__)
__webpack_require__.m = modules;
// expose the module cache
__webpack_require__.c = installedModules;
// __webpack_public_path__
__webpack_require__.p = "";
// Load entry module and return exports
return __webpack_require__(0);
})([
function (module, exports, __webpack_require__) {
var chunk1 = __webpack_require__(1);
var chunk2 = __webpack_require__(2);
console.log(chunk1);
console.log(chunk2);
},
function (module, exports, __webpack_require__) {
__webpack_require__(2);
var chunk1 = 1;
exports.chunk1 = chunk1;
},
function (module, exports) {
var chunk2 = 1;
exports.chunk2 = chunk2;
},
]);
不难发现,当需要重复使用模块的时候,缓存变量 installedModules 就起作用了
4.HMR 热更新
热更新原理
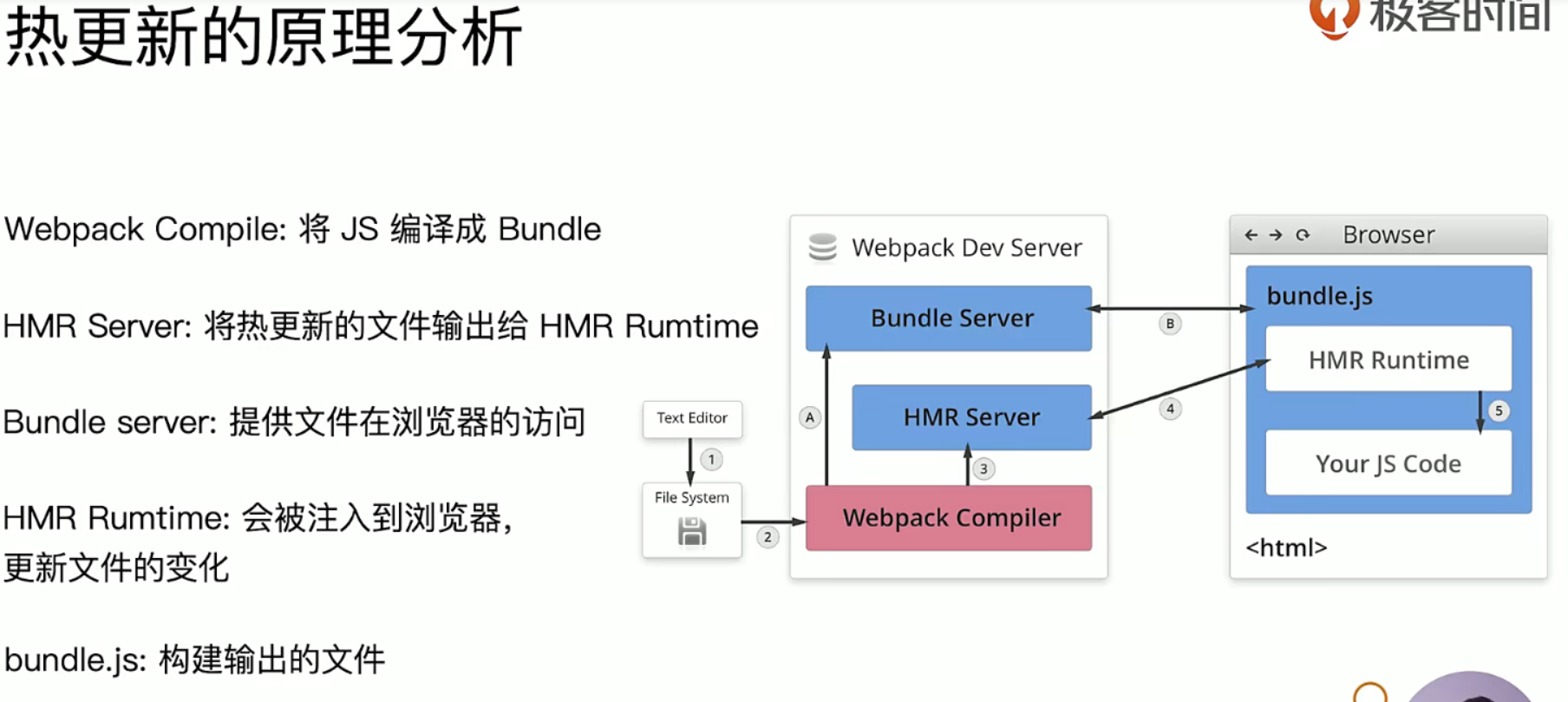
HMR即Hot Module Replacement是指当你对代码修改并保存后,webpack将会对代码进行重新打包,并将改动的模块发送到浏览器端,浏览器用新的模块替换掉旧的模块,去实现局部更新页面而非整体刷新页面。
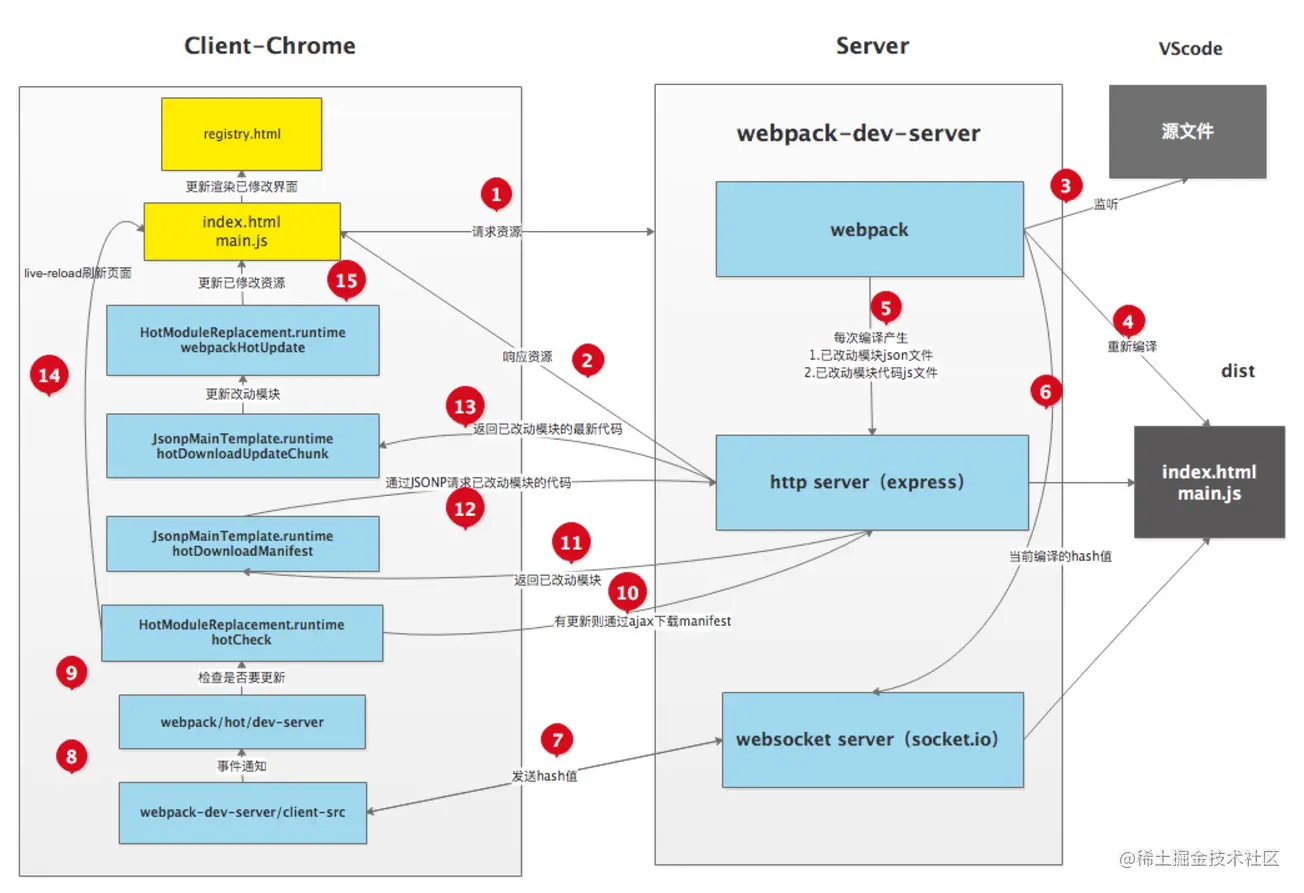
如上图所示,右侧Server端使用webpack-dev-server去启动本地服务,内部实现主要使用了webpack、express、websocket。
使用
express启动本地服务,当浏览器访问资源时对此做响应。服务端和客户端使用
websocket实现长连接 webpack监听源文件的变化,即当开发者保存文件时触发 webpack 的重新编译。
- 每次编译都会生成
hash值、已改动模块的json文件、已改动模块代码的js文件 - 编译完成后通过
socket向客户端推送当前编译的hash戳
- 每次编译都会生成
客户端的 websocket 监听到有文件改动推送过来的 hash 戳,会和上一次对比
- 一致则走缓存
- 不一致则通过
ajax和jsonp向服务端获取最新资源
使用
内存文件系统去替换有修改的内容实现局部刷新
webpack-dev-middleware
是一个中间件,它可以嵌入到现在的其他的 express 应用,提供打包功能,并且可以提供产出文件的访问服务
一个 express 服务
let express = require("express");
let app = express();
const webpack = require("webpack");
const webpackDevMiddleware = require("webpack-dev-middleware");
const webpackOptions = require("./webpack.config.js");
// compiler就是一个webpack实例,代表整个编译的任务,有个方法叫run,compiler.run()可以启动编译
const compiler = webpack(webpackOptions);
app.use(webpackDevMiddleware(compiler, {}));
app.listen(3003);
- 这样,你用 node 执行上面这个文件,在 3003 端口起一个服务,将项目根据 webpack 打包,并且可以访问编译完后的静态资源(内存中的)
- 所以,该中间件的作用就是:
- 会自动按配置文件的要求打包项目
- 会提供打包后的文件的访问服务
webpack-dev-server
webpack-dev-server 实际上相当于启用了一个 express 的 Http 服务器+调用 webpack-dev-middleware。它的作用主要是用来伺服资源文件。这个 Http 服务器和 client 使用了 websocket 通讯协议,原始文件作出改动后,webpack-dev-server 会用 webpack 实时的编译,再用 webpack-dev-middleware 将 webpack 编译后文件会输出到内存中。适合纯前端项目,很难编写后端服务,进行整合。
webpack-dev-middleware webpack-dev-middleware 输出的文件存在于内存中。你定义了 webpack.config,webpack 就能据此梳理出 entry 和 output 模块的关系脉络,而 webpack-dev-middleware 就在此基础上形成一个文件映射系统,每当应用程序请求一个文件,它匹配到了就把内存中缓存的对应结果以文件的格式返回给你,反之则进入到下一个中间件。
因为是内存型文件系统,所以重建速度非常快,很适合于开发阶段用作静态资源服务器;因为 webpack 可以把任何一种资源都当作是模块来处理,因此能向客户端反馈各种格式的资源,所以可以替代 HTTP 服务器。事实上,大多数 webpack 用户用过的 webpack-dev-server 就是一个 express + webpack-dev-middleware 的实现。二者的区别仅在于 webpack-dev-server 是封装好的,除了 webpack.config 和命令行参数之外,很难去做定制型开发。而 webpack-dev-middleware 是中间件,可以编写自己的后端服务然后把它整合进来,相对而言比较灵活自由。
webpack-hot-middleware 是一个结合 webpack-dev-middleware 使用的 middleware,它可以实现浏览器的无刷新更新(hot reload),这也是 webpack 文档里常说的 HMR(Hot Module Replacement)。HMR 和热加载的区别是:热加载是刷新整个页面。
5.devServe
解决跨域问题
devServer.proxy 可以代理开发环境中的 url
添了changeOrigin: true后才可跨域
从跨域的原理看来,浏览器就是通过判断请求头中的 origin 结合请求的 url 来判断是否跨域的,那是不是可以更改 origin 来骗过浏览器?不行的 报错:Refused to set unsafe header "Origin"
header 中的 origin 是浏览器设置的,无法自行更改它
设置了changeOrigin只是更改了 request 请求中的 host,并不是 origin
devServer 中的 proxy 就相当于 charles 进行 url 的代理,在sxx()执行后发送的请求是http://0.0.0.0:8080/robot/send?XXXXXXXX,我们是在 0.0.0.0:8080 下,当然不会限制这样的请求的发送,然后 devServer 的 proxy 通过配置将 host 更改为oapi.dingtalk.com,该请求就能正常进行
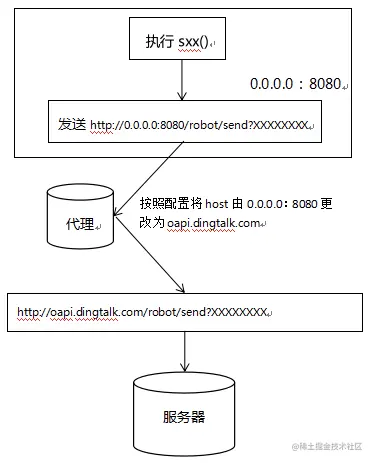
proxy: {
'/index':{ // 这个是你要替换的位置
/** 比如你要讲http://localhost:8080/index/xxx 替换成 http://10.20.30.120:8080/sth/xxx
* 那么就需要将 index 前面的值替换掉, 或者说是替换掉根地址,
*你可能发现了index也是需要替换的, 没错, 我会在后续操作中处理.
*/
target: 'http://10.20.30.120:8080'//这个是被替换的目标地址
changeOrigin: true // 默认是false,如果需要代理需要改成true
secure:false //不检查安全问题 可以接受https
pathRewrite:{
'^/index' : '/' //在这里 http://localhost:8080/index/xxx 已经被替换成 http://10.20.30.120:8080/
}}
}
// 然后在你发起请求的js文件中的地址需要忽略http://10.20.30.120:8080/
//比如 demo.js
axios.post({
url:'http://10.20.30.120:8080/sth/xxx'// 需要替换成下面的地址
url:'/sth/xxx'
}
)
proxy 工作原理上市利用 http-proxy-middleware 这个 http 代理中间件,实现请求转发给其他的服务器。如下:在开发阶段,本地地址是 Http://loaclhost:3000 , 该浏览器发送一个前缀带有 /api 标识的向服务器请求数据,但是这个服务器只是将这个请求转发给另一台服务器:
const express = require("express");
const proxy = require("http-proxy-middleware");
const app = express();
app.use(
"/api",
proxy({ target: "http://www.example.org", changeOrigin: true })
);
app.listen(3000);
// http://localhost:3000/api/foo/bar -> http://www.example.org/api/foo/bar
在开发阶段,webpack-dev-server 会自动启动一个本地开发服务器,所以我们的应用在开发阶段是独立运行在 localhost 的一个端口上的,而后端服务器又是运行在另一个地址上
所以在开发阶段中,由于浏览器的同源策略,当本地访问的时候就会出现跨域资源请求的问题,通过设置 webpack proxy 实现代理请求后,相当于浏览器和服务器之间添加了一个代理者。当本地发送请求的时候,中间服务器会接受这个情求,并将这个请求转发给目标服务器,目标服务器返回数据后,中间服务器又会将数据返回给浏览器,当中间服务器将数据返回给服务器的时候,它们两者是同源的,并不会存在跨域的问题。
服务器和服务器之间是不会存在跨域资源的问题的。
6.treeShaking 原理
Tree Shaking中文含义是摇树,在 webpack 中指的是打包时把无用的代码摇掉,以优化打包结果。
而webpack5已经自带了这个功能了,当打包环境为production时,默认开启tree-shaking功能。
把函数、不可能执行的代码、定义未用的变量通通都剔除了,这在一个项目中,能减少很多的代码量,进而减少打包后的文件体积。
有无副作用的判断,可以决定tree-shaking的优化程度,举个例子:
- 我现在引入
a.js但是我不用他的console函数,那么在优化阶段我完全可以不打包a.js这个文件。 - 我现在引入
b.js但是我不用他的console函数,但是我不可以不打包b.js这个文件,因为他有副作用,不能不打包。
sideEffects可以在package.json中设置:
// 所有文件都有副作用,全都不可 tree-shaking
{
"sideEffects": true
}
// 没有文件有副作用,全都可以 tree-shaking
{
"sideEffects": false
}
// 只有这些文件有副作用,
// 所有其他文件都可以 tree-shaking,
// 但会保留这些文件
{
"sideEffects": [
"./src/file1.js",
"./src/file2.js"
]
}
tree-shaking 的功能主要是有两点:
- 按需加载,即没有被引用的模块不会被打包进来;
- 把加载后未使用的模块干掉
- 把加载完毕的模块中的未使用的代码干掉
tree-shaking 实现原理:
- Tree-shaking = ES6odule(非 default) + UglifyJS
- 其中,es6module 通过对模块进行静态分析,找到未引入模块和引入但未使用模块; UglifyJS 实现对引入模块中未使用的代码进行干掉
在 Webpack 中,启动 Tree Shaking 功能必须同时满足三个条件:
- 使用 ESM 规范编写模块代码
- 配置
optimization.usedExports为true,启动标记功能 - 启动代码优化功能,可以通过如下方式实现:
- 配置
mode = production - 配置
optimization.minimize = true - 提供
optimization.minimizer数组
- 配置
在 CommonJs、AMD、CMD 等旧版本的 JavaScript 模块化方案中,导入导出行为是高度动态,难以预测的,例如:
if(process.env.NODE_ENV === 'development'){
require('./bar');
exports.foo = 'foo';
}
而 ESM 方案则从规范层面规避这一行为,它要求所有的导入导出语句只能出现在模块顶层,且导入导出的模块名必须为字符串常量,这意味着下述代码在 ESM 方案下是非法的:
if(process.env.NODE_ENV === 'development'){
import bar from 'bar';
export const foo = 'foo';
}
所以,ESM 下模块之间的依赖关系是高度确定的,与运行状态无关,编译工具只需要对 ESM 模块做静态分析,就可以从代码字面量中推断出哪些模块值未曾被其它模块使用,这是实现 Tree Shaking 技术的必要条件。
Webpack 中,Tree-shaking 的实现一是先标记出模块导出值中哪些没有被用过,二是使用 Terser 删掉这些没被用到的导出语句。标记过程大致可划分为三个步骤:
Make 阶段,收集模块导出变量并记录到模块依赖关系图 ModuleGraph 变量中
Seal 阶段,遍历 ModuleGraph 标记模块导出变量有没有被使用
生成产物时,若变量没有被其它模块使用则删除对应的导出语句
ES6的模块引入是静态分析的,所以在编译时能正确判断到底加载了哪些模块分析程序流,判断哪些变量未被使用、引用,进而删除此代码
特点:
- 在生产模式下它是默认开启的,但是由于经过
babel编译全部模块被封装成IIFE,它存在副作用无法被tree-shaking掉 - 可以在
package.json中配置sideEffects来指定哪些文件是有副作用的。它有两种值,一个是布尔类型,如果是false则表示所有文件都没有副作用;如果是一个数组的话,数组里的文件路径表示改文件有副作用 rollup和webpack中对tree-shaking的层度不同,例如对babel转译后的class,如果babel的转译是宽松模式下的话(也就是loose为true),webpack依旧会认为它有副作用不会tree-shaking掉,而rollup会。这是因为rollup有程序流分析的功能,可以更好的判断代码是否真正会产生副作用
原理
ES6 Module引入进行静态分析,故而编译的时候正确判断到底加载了那些模块- 静态分析程序流,判断那些模块和变量未被使用或者引用,进而删除对应代码
依赖于
import/export
通过导入所有的包后再进行条件获取
ES6 的 import 语法完美可以使用 tree shaking,因为可以在代码不运行的情况下就能分析出不需要的代码
CommonJS 的动态特性模块意味着 tree shaking 不适用。因为它是不可能确定哪些模块实际运行之前是需要的或者是不需要的。在 ES6 中,进入了完全静态的导入语法:import
7.webpack 中,module,chunk 和 bundle 的区别是什么?
ES6的模块引入是静态分析的,所以在编译时能正确判断到底加载了哪些模块- 分析程序流,判断哪些变量未被使用、引用,进而删除此代码
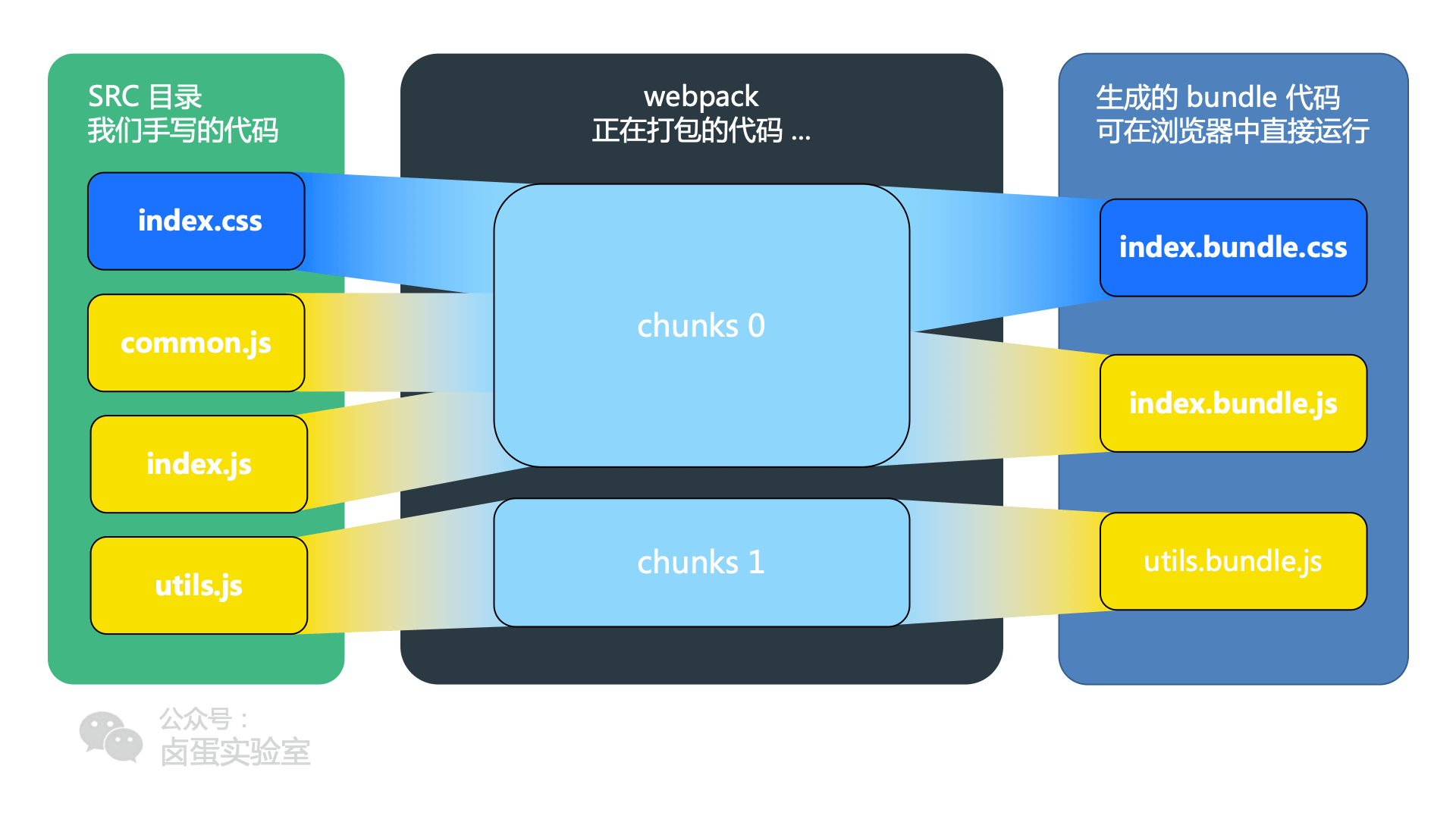
看这个图就很明白了:
- 对于一份同逻辑的代码,当我们手写下一个一个的文件,它们无论是 ESM 还是 commonJS 或是 AMD,他们都是 module ;
- 当我们写的 module 源文件传到 webpack 进行打包时,webpack 会根据文件引用关系生成 chunk 文件,webpack 会对这个 chunk 文件进行一些操作;
- webpack 处理好 chunk 文件后,最后会输出 bundle 文件,这个 bundle 文件包含了经过加载和编译的最终源文件,所以它可以直接在浏览器中运行。
一般来说一个 chunk 对应一个 bundle,比如上图中的 utils.js -> chunks 1 -> utils.bundle.js;但也有例外,比如说上图中,我就用 MiniCssExtractPlugin 从 chunks 0 中抽离出了 index.bundle.css 文件
module,chunk 和 bundle 其实就是同一份逻辑代码在不同转换场景下的取了三个名字:
我们直接写出来的是 module,webpack 处理时是 chunk,最后生成浏览器可以直接运行的 bundle。
8.sourceMap
sourceMap是一项将编译、打包、压缩后的代码映射回源代码的技术,由于打包压缩后的代码并没有阅读性可言,一旦在开发中报错或者遇到问题,直接在混淆代码中debug问题会带来非常糟糕的体验,sourceMap可以帮助我们快速定位到源代码的位置,提高我们的开发效率。sourceMap其实并不是Webpack特有的功能,而是Webpack支持sourceMap,像JQuery也支持souceMap
有一份映射的文件,来标记混淆代码里对应的源码的位置,通常这份映射文件以.map结尾,里边的数据结构大概长这样
{
"version" : 3, // Source Map版本
"file": "out.js", // 输出文件(可选)
"sourceRoot": "", // 源文件根目录(可选)
"sources": ["foo.js", "bar.js"], // 源文件列表
"sourcesContent": [null, null], // 源内容列表(可选,和源文件列表顺序一致)
"names": ["src", "maps", "are", "fun"], // mappings使用的符号名称列表
"mappings": "A,AAAB;;ABCDE;" // 带有编码映射数据的字符串
}
其中mappings数据有如下规则:
- 生成文件中的一行的每个组用“;”分隔;
- 每一段用“,”分隔;
- 每个段由 1、4 或 5 个可变长度字段组成;
在我们的压缩代码的最末端加上这句注释,即可让 sourceMap 生效:
//# sourceURL=/path/to/file.js.map
有了这段注释后,浏览器就会通过sourceURL去获取这份映射文件,通过解释器解析后,实现源码和混淆代码之间的映射。因此 sourceMap 其实也是一项需要浏览器支持的技术。
如果我们仔细查看 webpack 打包出来的 bundle 文件,就可以发现在默认的development开发模式下,每个_webpack_modules__文件模块的代码最末端,都会加上//# sourceURL=webpack://file-path?,从而实现对 sourceMap 的支持。
9.手写 loader
1.loader 接受的参数
content源文件的内容mapSourceMap 数据meta数据,可以是任何内容
this.callback方法则更灵活,因为它允许传递多个参数,而不仅仅是 content
传递 map,让 source-map 不中断
传递 meta,让下一个 loader 接收到其他参数
在配资文件中
// webpack.config.js
module.exports = {
// ...other config
module: {
rules: [
{
test: /^your-regExp$/,
use: [
{
loader: "loader-name-A",
},
{
loader: "loader-name-B",
},
],
},
],
},
};
通过配置可以看出,针对每个文件类型,loader是支持以数组的形式配置多个的,因此当Webpack在转换该文件类型的时候,会按顺序链式调用每一个loader,前一个loader返回的内容会作为下一个loader的入参。因此loader的开发需要遵循一些规范,比如返回值必须是标准的JS代码字符串,以保证下一个loader能够正常工作,同时在开发上需要严格遵循“单一职责”,只关心loader的输出以及对应的输出
loader函数中的this上下文由webpack提供,可以通过this对象提供的相关属性,获取当前loader需要的各种信息数据,事实上,这个this指向了一个叫loaderContext的loader-runner特有对象
2.loader 的类型
2.1 loader 分类
loader 一般分为四类:
- post(后置)
- inline(内联)
- normal(正常)
- pre(前置)
2.2 四类 loader 如何区分,如何配置?
除了 inline-loader 在业务代码内配置,也就是使用的时候配置。其余均在 webpack 配置文件中配置。
- require 内的是 inline-loader
- webpack 中通过 enforce 来配置是 normal(可以不写,默认值)还是 post 还是 pre
//定在require方法里的 inline Loader
let filecontent = require(`!!inline1-loader!inline2-loader!${filePath}`); //inline-loader是这么写的!!!
//不同的loader并不决定loader的类型属性,而是你在使用 的使用了什么样的enforce
let rules = [
{
test: /\.js$/,
use: ["normal1-loader", "normal2-loader"], //普通的loader
},
{
test: /\.js$/,
enforce: "post",
use: ["post1-loader", "post2-loader"], //post的loader 后置
},
{
test: /\.js$/,
enforce: "pre",
use: ["pre1-loader", "pre2-loader"], //pre的loader 前置
},
];
- 内联 loader 前面的符号
| 符号 | 变量 | 含义 |
|---|---|---|
-! | noPreAutoLoaders | 不要前置和普通 loader, 这个 require 的文件不会走前置和普通的 loader |
! | noAutoLoaders | 不要普通 loader, 这个 require 的文件不会走普通的 loader |
!! | noPrePostAutoLoaders | 不要前后置和普通 loader,只要内联 loader, 这个 require 的文件只会走内联的 loader |
loader 有特定的执行顺序,且是在所以 loader 开始执行前,先把 loader 的顺序整理好,然后一个个开始执行的。
3. loader 的执行顺序
在 webpack 开始正式编译的时候,会找到入口文件,然后调用 loader 对文件进行处理,处理的时候会按照一定顺序对 loader 进行组合,然后一个个执行 loader。执行完后会返回处理完的代码,是 Buffer 或 String 类型。然后 webpack 才开始真正的 ast 语法树解析。
一般来说 loader.pitch 是从左往右,normal 是从右往左。具体是这样的:
首先 loader 能够分成四类:post-loader(后置 loader)、inline-loader(内联 loader)、normal-loader(普通的 loader)和 pre-loader(前置 loader)
另外,一个 loader 由两部分组成,一个是普通的函数,一个数这个函数的 pitch 方法。那么我们姑且认为一个完整的 laoder 由 loader-pitch 方法和 loader-normal 方法组成。那么结合上面所说的四类来将,loader 的执行顺序是这样的:
首先执行 loader-pitch 方法,先是 post-loader 的 pitch,然后 inline-loader 的 pitch,然后是 normal-loader 的 pitch,然后是 pre-loader 的 pitch,pitch 走完,开始走 loader-normal 方法,先走 pre-loader 的方法,再走 normal-loader 的方法,再走 inline-loader 的方法,再走 post-loader 的方法。
如果是同类 loader,比如都是 normal-loader,有 loader1,loader2,loader3,那么就是先走 loader1 的 pitch,再走 loader2 的 pitch,再走 loader3 的 pitch,然后走 loader3 的 normal 函数,再走 loader2 的 normal 函数,最后走 loader1 的 normal 函数。这里最后走的 loader 的 normal 函数的顺序,其实就是我们常说的 laoder 的执行顺序,从右往左。但其实是要分 pitch 和 normal 两种的。
当然,pitch 方法如果有返回值,那么将忽略后面所有的 loader 以及本身这个 loader 对应的 normal 函数,然后相反顺序一次走前面的 loader 的 normal 函数
loader 有特定的执行顺序,且是在所以 loader 开始执行前,先把 loader 的顺序整理好,然后一个个开始执行的。所以本节 2.2 中的三个符号,可以过滤掉指定的 loader。
loader 的执行顺序是洋葱模型吗?
不是,洋葱模型是嵌套关系,而 loader 执行顺序是并列关系。
4. 常用 loader 的实现
1. babel-loader
babel-loader 的主要原理
(面试点)就是:调动@babel/core 这个包下面的 transform 方法,将源码通过 presets 预设来进行转换,然后生成新的代码、map 和 ast 语法树传给下一个 loader。这里的 presets,比如@babel/preset-env 这个预设其实就是各类插件的集合,基本上一个插件转换一个语法,比如箭头函数转换,有箭头函数转换的插件,这些插件集合就组成了预设。
const babel = require("@babel/core");
const path = require("path");
function loader(inputSource, map, ast) {
// 上一个loader的源码。映射,和抽象语法树
const options = {
presets: ["@babel/preset-env"], // 转换靠预设。预设是插件的集合
sourceMaps: true, // 如果这个参数不传,默认值为false,不会生成sourceMap
filename: path.basename(this.resourcePath), // 生成的文件名
};
// 返回有三个值,code转换后的es5代码,map转换后的代码到转换前的戴梦得映射,ast是转换后的抽象语法树
let transRes = babel.transform(inputSource, options);
// loader的返回值可以是一个值,也可以是多个值
// return inputSource; // 返回一个值,用return
return this.callback(null, transRes.code, transRes.map, transRes.ast); // 返回多个值, 必须调用this.callback(err, 后面的参数是传递给下一个loader的参数)。这个callback是loader-runner提供的一个方法,内置的。这个this默认是loader-runner内部的context,默认是空对象,但是在loader-runner执行的过程中会天机爱很多方法和属性,包括这个callback方法。
}
module.exports = loader;
2. file-loader 的实现
file-loader 的原理
(面试点)就是通过 laoder 的参数拿到文件的内容,然后解析出 file-loader 配置中的名字,解析名字其实就是替换[hash]、[ext]等,然后向输出目录里输出一个文件,这个文件的内容就是 loader 的参数,名字就是刚刚说的解析出的名字。但是,实际上,并不是在 loader 里输出文件的,loader 只是向 webpack 的 complication 的 assets 中,添加的文件 id 和内容,最终还是 webpack 将文件写进硬盘的。
const { getOptions, interpolateName } = require("loader-utils");
/*
content是上一个loader传给当前loader的内容,或者源文件内容,默认是字符串类型
如果你希望得到Buffer,不希望转成字符串,那么就给loader.row置为true。即loader.row若为默认值false则content是字符串,为true就是Buffer
*/
function loader(content) {
let options = getOptions(this) || {}; // 拿到参数
// 下面的参数 this是loaderContext, filename是文件名生成模板,即webpack配置中的[hash].[ext] content是文件内容
let url = interpolateName(this, options.filename || "[hash].[ext]", {
content,
}); // 转换名字
// 向输出目录里输出一个文件
// this.emitFile是loaderRunner提供的
this.emitFile(url, content); // 向输出目录里输出一个文件,其实本质就是webpack中的complication.assets[filename]=content,然后webpack会将assets写到目标目录下。所以不是loader去生成文件的。
return `module.exports = ${JSON.stringify(url)}`; // 这里的loader肯定要返回一个JS模块代码,即导出一个值,这个值将会成为次模块的导出结果
}
loader.raw = true; // loader的参数content会是buffer类型
module.exports = loader;
3.url-loader 的实现
(面试点)url-loader 是 file-loader 的升级版,内部包含了 file-loader。url-loader 配置的时候回配置一个 limit,这个配置的值代表小于 limit 的值的时候,转成 base64,大于的时候还是文件,比如说原本是图片,那大于 limit 就还是图片。所以,url-loader 主要就是先判断大小(内容的 buffer 的 lenth)是否大于 limit,大于就走 file-loader,否则就用
toStrng('base64')转成 base64。
const { getOptions, interpolateName } = require("loader-utils");
const mime = require("mime");
/*
content是上一个loader传给当前loader的内容,或者源文件内容,默认是字符串类型
如果你希望得到Buffer,不希望转成字符串,那么就给loader.row置为true。即loader.row若为默认值false则content是字符串,为true就是Buffer
*/
function loader(content) {
// console.log(content)
let options = getOptions(this) || {}; // 拿到参数
let { limit, fallback } = options;
if (limit) {
limit = parseInt(limit, 10);
}
const mimeType = mime.getType(this.resourcePath);
if (!limit || content.length < limit) {
let base64 = `data:${mimeType};base64,${content.toString("base64")}`;
return `module.exports = ${JSON.stringify(base64)}`;
} else {
// 这里不能用require('file-loader'),因为如果这样写的话,会去node_modules中找,而不是我们自己的file-loader了。源码是可以的,因为源码总file-loader就是装在node_modules中
return require(fallback).call(this, content);
}
}
loader.raw = true; // loader的参数content会是buffer类型
module.exports = loader;
4. 样式处理的 loader——style-loader、css-loader 和 less-loader
一般我们处理像是的 loader 配置为:
{
test:/\.less$/,
loaders: [
'style-loader',
'css-loader',
'less-loader',
]
}
1.less-loader 的实现
less-loader 的原理
(面试点):主要是借助 less 模块的 render 方法,将 less 语法进行转换成 css 语法,然后返回或者额调用 this.callback()传递给下一个 loader。但是由于 less-loader 原本设计的时候,是想让 less-loader 可以作为最后一个 loader 使用的,所谓的最后一个 loader,也就是说最后的返回值是一个 js 模块,也就是说 module.exports = xxx 这种,所以 less-loader 在返回结果的时候,将转换后的内容,外面套了一层 module.exports = 转换后的内容。那么这里变成了 module.exports 导出后,给到 css-loader,css-loader 只是处理了 import、url 等语法,将内容给到了 style-loader,style-loader 也就要跟着改变,因为 style-loader 的作用是创建一个 style 脚本,将 css 内容包裹在 style 标签中去,然后把 style 插入到 document.head 中。那么这里的关键就是拿到样式内容,这个内容刚才说了,被 module.exports 包裹了,那怎么拿到?直接 require 就可以了,因为 module.exports 本来就是 js 模块的导出格式,所以直接 require 就可以了。
实际上,在真正的 style-loader、css-loader 和 less-loader 的执行过程是这样的
(面试点):先执行 loader 的 pitch 函数,pitch 函数是从左往右的,从上到下的,也就是先执行 style-loader 的 pitch,这个函数主要是创建一个 script 脚本,这个脚本主要是创建一个 style 标签,style 标签的 innerHTML 就是 css 样式,然后将 style 标签插入 document.head 中,然后将这个 script 脚本返回。注意,这边是有返回值的。pitch-loader 一旦有返回值,那么后面的 css-loader 和 less-loader 都将不会直接,也不会执行当前 loader 的 normal-loader,既然都不会执行了,那么 style 标签的 css 内容哪里来呢?其实,他在创建 style 标签后,它又 require 了 css-loader 和 less-loader 这两个内联 loader,是走了内联 loader 才获取到的。内联 loader 从右往左,从下往上,也就是先执行 less-loader,然后执行 css-loader,最后将内容返给 stylel-loader,这样才得到了 css 内容,赋值给 style 标签的 innerHTML,然后插入到 document.head 中,这样才完成了整个样式的 loader 处理。
let less = require("less");
function loader(inputSource) {
// let css;
// less.render(inputSource, { filename: this.resource }, (err, output) => {
// css = output.css;
// })
// return css; // 虽然上面css赋值在回调中,但是本身render是同步的,所以可以在这里return。但是假如render是异步,那么就不能够这么写了,异步怎么写,看下面:
let callback = this.async(); // 这种写法就是即便render是异步,也可以在loader中返回callback的参数值。this.async()这个方法是loader-runner提供的,乳沟调用了async方法,可以把loader的执行变成异步
less.render(inputSource, { filename: this.resource }, (err, output) => {
// less-loader本来可以写成callback(err, output.css),但是作者为了能够使得less-loader放在最后一个,也就是返回的应该是一段JS脚本,所以就写成了下面的写法
callback(err, `module.exports = ${JSON.stringify(output.css)}`); // 这个callback的是this.async(),而this.async()里面的实现就是调用context.callback,而这里的this就是context,所以你不写let callback = this.async(),在回调中直接用this.callback(null, 内容)是一样的
});
}
module.exports = loader;
2.css-loader 的作用
其实 less-loader 已经转成 css 了,但是有些语法比如 import、url 还尚未处理,所以这个 css-loader 就是用来处理 import、url 等语法的,功能比较单一。
3.style-loader 的实现
见 less-loader 的笔记
(面试点)
const { Console } = require("console");
const loaderUtils = require("loader-utils");
function loader() {}
/*
参数:
remainingRequest 剩下的请求
previousRequest 前面的请求
data 数据
*/
loader.pitch = (remainingRequest, previousRequest, data) => {
console.log("remainingRequest", remainingRequest);
console.log("previousRequest", previousRequest);
console.log(
"data",
data,
loaderUtils.stringifyRequest(this, "!!" + remainingRequest)
);
let script = `
let style = document.createElement('style');
style.innerHTML = require(${loaderUtils.stringifyRequest(
this,
"!!" + remainingRequest
)}); // 依赖的值为!!C:/Users/yuhua7/Desktop/webpack/4.webpack-loader/loaders/less-loader.js!C:/Users/yuhua7/Desktop/webpack/4.webpack-loader/src/style.less
document.head.appendChild(style);
module.exports = '';
`;
// 这个返回的js脚本给了webpack了
// webpack会把这个js脚本转成AST抽象语法树,分析脚本中的依赖,也就是上面的require,加载依赖,依赖(require的参数)为!!C:/Users/yuhua7/Desktop/webpack/4.webpack-loader/loaders/less-loader.js!C:/Users/yuhua7/Desktop/webpack/4.webpack-loader/src/style.less,那么这个参数有两个感叹号!!,这代表只走行内,也就是说其实只需要一个内联loader去处理,所以会去走内联loader处理文件。
return script;
};
module.exports = loader;
css-loader 的功能很纯粹,就是处理 import 和 url 的
最后一个 loader 需要返回的是 js 模块,也就是module.exports = JSON.stringify(内容)
5.loader.pitch 的重要参数(面试点)
loader.pitch 方法中有三个参数,分别是remainingRequest、previousRequest和data
remainingRequest:剩余的请求previousRequest:前面的请求data:数据
下面解释下三个参数:
假设当前已经走到 laoder3.pitch 了,那么
remainingRequest剩余的请求就是当前 loader 后面(不含当前)的 loader 和 file 的路径用感叹号’!'拼接,类型是字符串。previousRequest前面的请求就是当前 loder 之前(不含当前)的 loader 的路径用感叹号’!'拼接,类型是字符串。data数据其实是一个空对象{},给 loader 内部存放数据使用的。上面除了
remainingRequest、previousRequest和request,其实还有一个currentRequest,这个currentRequest其实就是 loader3
10.手写 plugin
webpack基于发布订阅模式,在运行的生命周期中会广播出许多事件,插件通过监听这些事件,就可以在特定的阶段执行自己的插件任务,从而实现自己想要的功能
compiler和compilation是Webpack两个非常核心的对象,其中compiler暴露了和 Webpack整个生命周期相关的钩子(compiler-hooks),而compilation则暴露了与模块和依赖有关的粒度更小的事件钩子(Compilation Hooks)。
Plugin的开发和开发Loader一样,需要遵循一些开发上的规范和原则:
- 插件必须是一个函数或者是一个包含
apply方法的对象,这样才能访问compiler实例; - 传给每个插件的
compiler和compilation对象都是同一个引用,若在一个插件中修改了它们身上的属性,会影响后面的插件; - 异步的事件需要在插件处理完任务时调用回调函数通知
Webpack进入下一个流程,不然会卡住;
怎么开发的
- 一般来说,插件是一个类
- 类上有一个 apply 方法,一般我们插件的逻辑就写在这个 apply 方法内。因为 apply 方法在安装插件时,会被 webpack compiler 调用,并且将 compiler 传给 apply 方法,也就是参数参数是 compiler。
- 由于 webpack 的事件流是由 tapable 前后贯穿的,所以 webpack 在内部提供了很多钩子,我们在 apply 方法中去注册特定钩子的事件,那么 webpack 就会在特定的时机来调用这些钩子对应的事件函数。
- 比如:资源编译结束我需要将文件压缩存档,那么在 apply 方法中就可以写 compiler.hooks.done.tap(‘XXXPlugin’, 压缩存档的回调函数),这个代码的意思就是我在 done 的这个时机去注册一个事件,tap 方法就是注册事件,事件名是第一个参数’xxxPlugin’,事件执行的内容就是压缩存档的回调函数。其实这个 done 源码中对应的就是 tapable 的 AsyncSeriesHook 异步串行钩子,相当于在这个钩子上 tap 了一个事件。那么等 webpack 编译完成的时候,就会触发 tapable 的 callAsync 函数,这个函数的意思就是异步触发之前 done 的时候注册的钩子。那么也就是在编译完成的时候回执行压缩存档的回调函数。这就完成了一个插件开发了。
- 其实,tapable 就是一个订阅发布,tap 的时候注册一些事件,放到队列中,然后 call 的时候去一个个触发,只不过 tapable 在触发的时候根据不同的钩子类型改变了触发的顺序,比如 SyncBailHook 注册的钩子,触发的时候,一旦有返回值,就不继续执行下个事件函数了。当然源码中也不是直接循环调用这些事件函数的,而是 new 了一个 Function,通过对每个队列构造一个函数,去执行的。
- 另外,插件有两个重要的对象,一个是 compiler,另一个是 compilation:
- compiler,这个 webpack 编译过程就一个 compiler,代表了完整的 webpack 环境配置。这个对象在启动 webpack 时被一次性建立,并配置好所有可操作的设置,包括 options,loader 和 plugin。当在 webpack 环境中应用一个插件时,插件将收到此 compiler 对象的引用。可以使用它来访问 webpack 的主环境。
- compilation:每次资源构建都会有一个 compilation,所以它代表了一次资源版本构建。当运行 webpack 开发环境中间件时,每当检测到一个文件变化,就会创建一个新的 compilation,从而生成一组新的编译资源。一个 compilation 对象表现了当前的模块资源、编译生成资源、变化的文件、以及被跟踪依赖的状态信息。compilation 对象也提供了很多关键时机的回调,以供插件做自定义处理时选择使用。
- 最后,钩子的使用的话就很简单,在 webpack 配置文件中,new 一个插件这个类,然后传一些配置参数进去就可以了。webpack 会自动去调 apply 方法的。
例如实现 文件打包
const Jz = require("jszip");
const { RawSource } = require("webpack-sources");
class JsZip {
constructor(options) {
this.options = options; // filename是压缩完成后的压缩包的名字,不带后缀
}
apply(compiler) {
compiler.hooks.emit.tapAsync("JsPlugin", (compilation, callback) => {
console.log(compilation.assets);
var zip = new Jz();
for (let filename in compilation.assets) {
let source = compilation.assets[filename].source();
zip.file(filename, source);
}
zip.generateAsync({ type: "nodebuffer" }).then((content) => {
compilation.assets[this.options.filename + ".zip"] = new RawSource(
content
);
callback();
});
});
}
}
module.exports = JsZip;
11.Babel 使用和原理
Babel 的用途
转译 esnext、typescript、flow 等到目标环境支持的 js
这个是最常用的功能,用来把代码中的 esnext 的新的语法、typescript 和 flow 的语法转成基于目标环境支持的语法的实现。并且还可以把目标环境不支持的 api 进行 polyfill。
babel7 支持了 preset-env,可以指定 targets 来进行按需转换,转换更加的精准,产物更小。
一些特定用途的代码转换
babel 是一个转译器,暴露了很多 api,用这些 api 可以完成代码到 AST 的解析、转换、以及目标代码的生成。
开发者可以用它来来完成一些特定用途的转换,比如函数插桩(函数中自动插入一些代码,例如埋点代码)、自动国际化等。这些都是后面的实战案例。
现在比较流行的小程序转译工具 taro,就是基于 babel 的 api 来实现的。
代码的静态分析
对代码进行 parse 之后,能够进行转换,是因为通过 AST 的结构能够理解代码。理解了代码之后,除了进行转换然后生成目标代码之外,也同样可以用于分析代码的信息,进行一些检查。
- linter 工具就是分析 AST 的结构,对代码规范进行检查。
- api 文档自动生成工具,可以提取源码中的注释,然后生成文档。
- type checker 会根据从 AST 中提取的或者推导的类型信息,对 AST 进行类型是否一致的检查,从而减少运行时因类型导致的错误。
- 压缩混淆工具,这个也是分析代码结构,进行删除死代码、变量名混淆、常量折叠等各种编译优化,生成体积更小、性能更优的代码。
- js 解释器,除了对 AST 进行各种信息的提取和检查以外,我们还可以直接解释执行 AST。
常见plugin和Preset
Preset就是一些Plugin组成的合集,你可以将Preset理解称为就是一些的Plugin整合称为的一个包
babel-preset-env
@babel/preset-env是一个智能预设,它可以将我们的高版本JavaScript代码进行转译根据内置的规则转译成为低版本的javascript代码。
preset-env内部集成了绝大多数plugin(State > 3)的转译插件,它会根据对应的参数进行代码转译。
额外注意的是babel-preset-env仅仅针对语法阶段的转译,比如转译箭头函数,const/let语法。针对一些Api或者ES 6内置模块的polyfill,preset-env是无法进行转译的
babel-preset-react
通常我们在使用React中的jsx时,相信大家都明白实质上jsx最终会被编译称为React.createElement()方法。
babel-preset-react这个预设起到的就是将jsx进行转译的作用。
babel-preset-typescript
对于TypeScript代码,我们有两种方式去编译TypeScript代码成为JavaScript代码。
- 使用
tsc命令,结合cli命令行参数方式或者tsconfig配置文件进行编译ts代码。 - 使用
babel,通过babel-preset-typescript代码进行编译ts代码。
Babel 的相关配置
关于WebPack中我们日常使用的babel相关配置主要涉及以下三个相关插件:
babel-loaderbabel-corebabel-preset-env
webpack中loader的本质就是一个函数,接受我们的源代码作为入参同时返回新的内容
babel-loader的本质就是一个函数,我们匹配到对应的jsx?/tsx?的文件交给babel-loader
function babelLoader(sourceCode, options) {
// ..
return targetCode;
}
关于options,babel-loader支持直接通过loader的参数形式注入,同时也在loader函数内部通过读取.babelrc/babel.config.js/babel.config.json``等文件注入配置
babel-loader仅仅是识别匹配文件和接受对应参数的函数,那么babel在编译代码过程中核心的库就是@babel/core这个库
babel-core是babel最核心的一个编译库,他可以将我们的代码进行词法分析--语法分析--语义分析过程从而生成AST抽象语法树,从而对于“这棵树”的操作之后再通过编译称为新的代码
babel-core其实相当于@babel/parse和@babel/generator这两个包的合体,接触过js编译的同学可能有了解esprima和escodegen这两个库,你可以将babel-core的作用理解称为这两个库的合体。
babel-preset-env在这里充当的就是这个作用:告诉babel我需要以为什么样的规则进行代码转移
Babel 的编译流程
babel 是 source to source 的转换,整体编译流程分为三步:
- parse:通过 parser 把源码转成抽象语法树(AST)
- transform:遍历 AST,调用各种 transform 插件对 AST 进行增删改
- generate:把转换后的 AST 打印成目标代码,并生成 sourcemap

为什么 babel 的编译流程会分 parse、transform、generate 这 3 步呢?
源码是一串按照语法格式来组织的字符串,人能够认识,但是计算机并不认识,想让计算机认识就要转成一种数据结构,通过不同的对象来保存不同的数据,并且按照依赖关系组织起来,这种数据结构就是抽象语法树(abstract syntax tree)。之所以叫“抽象”语法树是因为数据结构中省略掉了一些无具体意义的分隔符比如 ; { } 等。
有了 AST,计算机就能理解源码字符串的意思,而理解是能够转换的前提,所以编译的第一步需要把源码 parse 成 AST。
转成 AST 之后就可以通过修改 AST 的方式来修改代码,这一步会遍历 AST 并进行各种增删改,这一步也是 babel 最核心的部分。
经过转换以后的 AST 就是符合要求的代码,就可以再转回字符串,转回字符串的过程中把之前删掉的一些分隔符再加回来。
简单总结一下就是:为了让计算机理解代码需要先对源码字符串进行 parse,生成 AST,把对代码的修改转为对 AST 的增删改,转换完 AST 之后再打印成目标代码字符串
这三步都做了什么?
parse
parse 阶段的目的是把源码字符串转换成机器能够理解的 AST,这个过程分为词法分析、语法分析。
比如 let name = 'guang'; 这样一段源码,我们要先把它分成一个个不能细分的单词(token),也就是 let, name, =, 'guang',这个过程是词法分析,按照单词的构成规则来拆分字符串成单词。
之后要把 token 进行递归的组装,生成 AST,这个过程是语法分析,按照不同的语法结构,来把一组单词组合成对象,比如声明语句、赋值表达式等都有对应的 AST 节点。
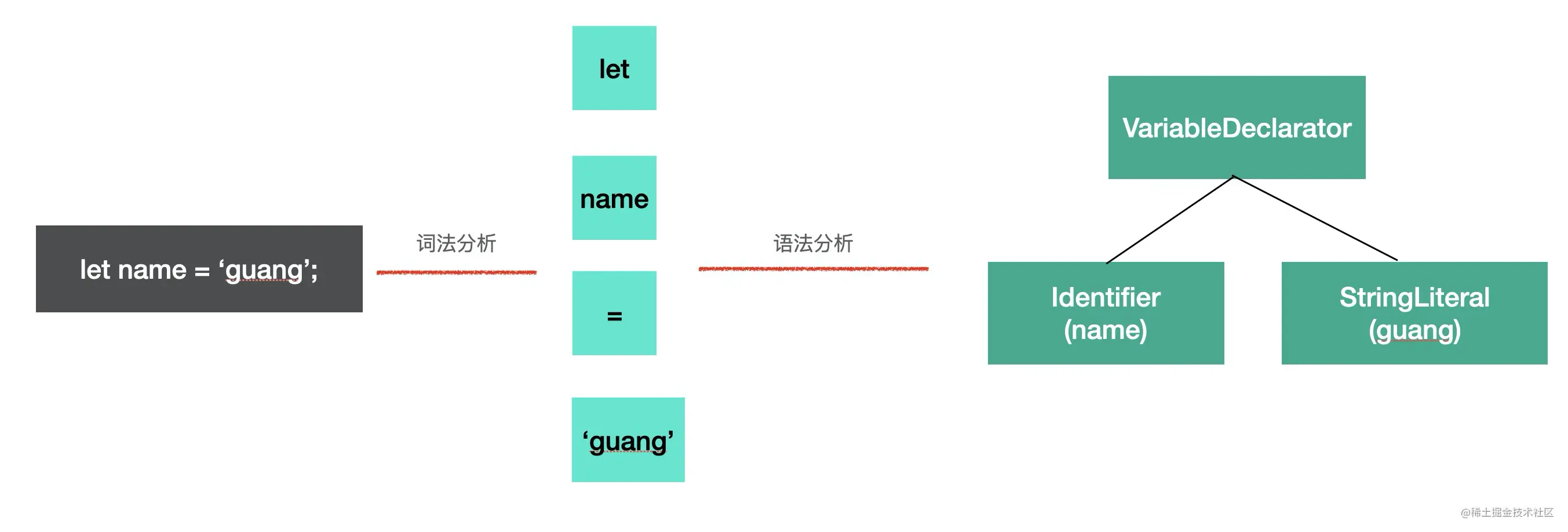
transform
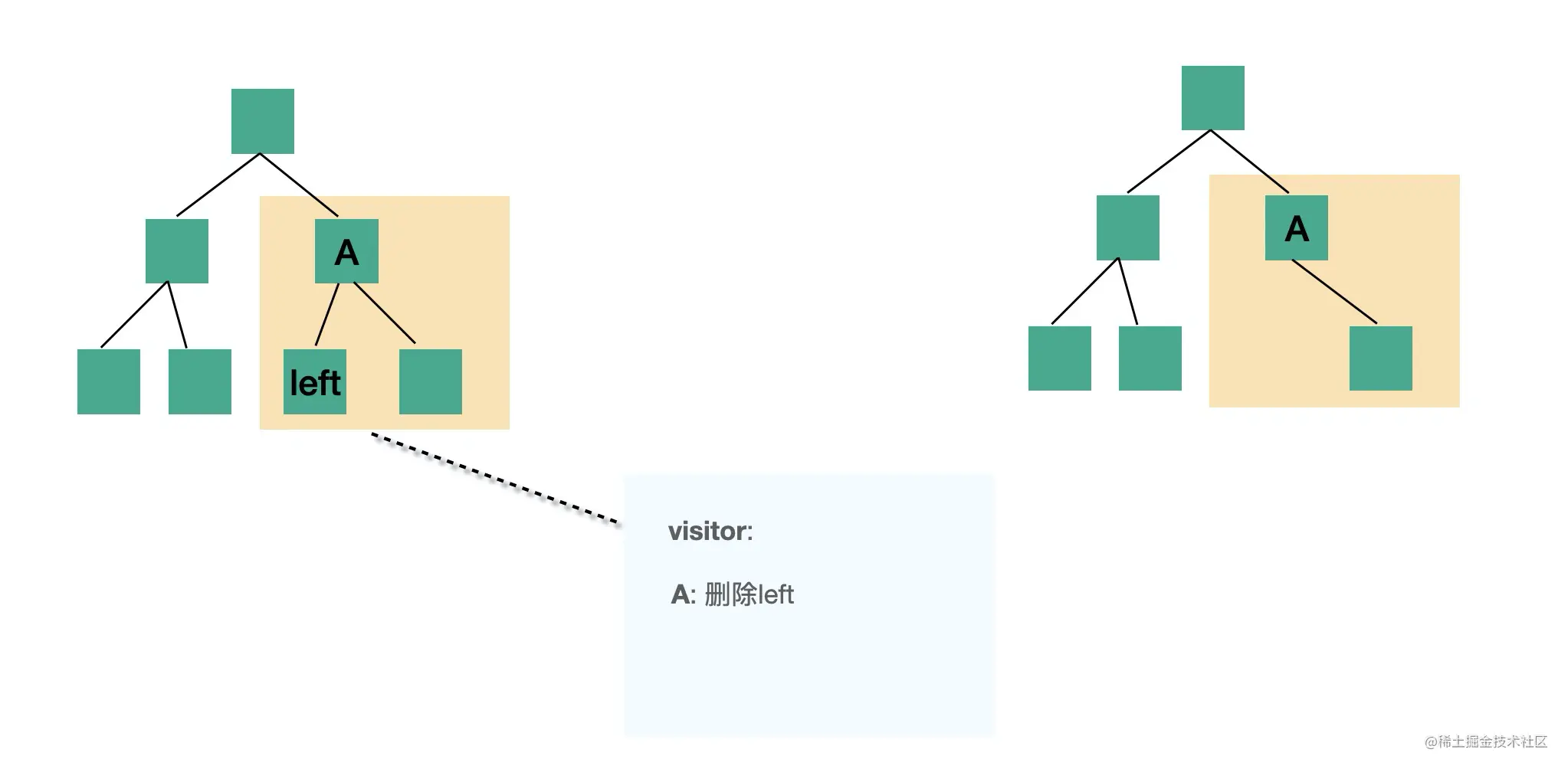
transform 阶段是对 parse 生成的 AST 的处理,会进行 AST 的遍历,遍历的过程中处理到不同的 AST 节点会调用注册的相应的 visitor 函数,visitor 函数里可以对 AST 节点进行增删改,返回新的 AST(可以指定是否继续遍历新生成的 AST)。这样遍历完一遍 AST 之后就完成了对代码的修改。
generate
generate 阶段会把 AST 打印成目标代码字符串,并且会生成 sourcemap。不同的 AST 对应的不同结构的字符串。比如 IfStatement 就可以打印成 if(test) {} 格式的代码。这样从 AST 根节点进行递归的字符串拼接,就可以生成目标代码的字符串。

sourcemap 记录了源码到目标代码的转换关系,通过它我们可以找到目标代码中每一个节点对应的源码位置,用于调试的时候把编译后的代码映射回源码,或者线上报错的时候把报错位置映射到源码。
Babel相关polyfill内容
关于polyfill,我们先来解释下何谓polyfill。
首先我们来理清楚这三个概念:
- 最新
ES语法,比如:箭头函数,let/const。 - 最新
ES Api,比如Promise - 最新
ES实例/静态方法,比如String.prototype.include
babel-prest-env仅仅只会转化最新的es语法,并不会转化对应的Api和实例方法,比如说ES 6中的Array.from静态方法。babel是不会转译这个方法的,如果想在低版本浏览器中识别并且运行Array.from方法达到我们的预期就需要额外引入polyfill进行在Array上添加实现这个方法
语法层面的转化preset-env完全可以胜任。但是一些内置方法模块,仅仅通过preset-env的语法转化是无法进行识别转化的,所以就需要一系列类似”垫片“的工具进行补充实现这部分内容的低版本代码实现。这就是所谓的polyfill的作用
针对于polyfill方法的内容,babel中涉及两个方面来解决:
@babel/polyfill@babel/runtime@babel/plugin-transform-runtime
@babel/polyfill
通过babelPolyfill通过往全局对象上添加属性以及直接修改内置对象的Prototype上添加方法实现polyfill。
比如说我们需要支持String.prototype.include,在引入babelPolyfill这个包之后,它会在全局String的原型对象上添加include方法从而支持我们的Js Api
我们说到这种方式本质上是往全局对象/内置对象上挂载属性,所以这种方式难免会造成全局污染
在babel-preset-env中存在一个useBuiltIns参数,这个参数决定了如何在preset-env中使用@babel/polyfill。
{
"presets": [
[
"@babel/preset-env",
{
"useBuiltIns": false
}
]
]
}
useBuiltIns--"usage"|"entry"|false
false
当我们使用preset-env传入useBuiltIns参数时候,默认为false。它表示仅仅会转化最新的ES语法,并不会转化任何Api和方法
entry
当传入entry时,需要我们在项目入口文件中手动引入一次core-js,它会根据我们配置的浏览器兼容性列表(browserList)然后全量引入不兼容的polyfill
在我们使用
useBuiltIns:entry/usage时,需要额外指定core-js这个参数。默认为使用core-js 2.0,所谓的core-js就是我们上文讲到的“垫片”的实现。它会实现一系列内置方法或者Promise等Api
usage
上边我们说到配置为entry时,perset-env会基于我们的浏览器兼容列表进行全量引入polyfill。所谓的全量引入比如说我们代码中仅仅使用了Array.from这个方法。但是polyfill并不仅仅会引入Array.from,同时也会引入Promise、Array.prototype.include等其他并未使用到的方法。这就会造成包中引入的体积太大了。
此时就引入出了我们的useBuintIns:usage配置。
当我们配置useBuintIns:usage时,会根据配置的浏览器兼容,以及代码中 使用到的Api 进行引入polyfill按需添加。
当使用usage时,我们不需要额外在项目入口中引入polyfill了,它会根据我们项目中使用到的进行按需引入。
@babel/runtime
上边我们讲到@babel/polyfill是存在污染全局变量的副作用,在实现polyfill时Babel还提供了另外一种方式去让我们实现这功能,那就是@babel/runtime。
简单来讲,@babel/runtime更像是一种按需加载的解决方案,比如哪里需要使用到Promise,@babel/runtime就会在他的文件顶部添加import promise from 'babel-runtime/core-js/promise'。
同时上边我们讲到对于preset-env的useBuintIns配置项,我们的polyfill是preset-env帮我们智能引入。
而babel-runtime则会将引入方式由智能完全交由我们自己,我们需要什么自己引入什么。
它的用法很简单,只要我们去安装npm install --save @babel/runtime后,在需要使用对应的polyfill的地方去单独引入就可以了
// a.js 中需要使用Promise 我们需要手动引入对应的运行时polyfill
import Promise from "babel-runtime/core-js/promise";
const promsies = new Promise();
babel/runtime你可以理解称为就是一个运行时“哪里需要引哪里”的工具库。
针对
babel/runtime绝大多数情况下我们都会配合@babel/plugin-transfrom-runtime进行使用达到智能化runtime的polyfill引入
@babel/plugin-transform-runtime
babel-runtime存在的问题
babel-runtime在我们手动引入一些polyfill的时候,它会给我们的代码中注入一些类似_extend(), classCallCheck()之类的工具函数,这些工具函数的代码会包含在编译后的每个文件中,比如:
class Circle {}
// babel-runtime 编译Class需要借助_classCallCheck这个工具函数
function _classCallCheck(instance, Constructor) { //... }
var Circle = function Circle() { _classCallCheck(this, Circle); };
如果我们项目中存在多个文件使用了class,那么无疑在每个文件中注入这样一段冗余重复的工具函数将是一种灾难。
所以针对上述提到的两个问题:
babel-runtime无法做到智能化分析,需要我们手动引入。babel-runtime编译过程中会重复生成冗余代码。
我们就要引入我们的主角@babel/plugin-transform-runtime。
@babel/plugin-transform-runtime作用
@babel/plugin-transform-runtime插件的作用恰恰就是为了解决上述我们提到的run-time存在的问题而提出的插件。
babel-runtime无法做到智能化分析,需要我们手动引入。
@babel/plugin-transform-runtime插件会智能化的分析我们的项目中所使用到需要转译的js代码,从而实现模块化从babel-runtime中引入所需的polyfill实现。
babel-runtime编译过程中会重复生成冗余代码。
@babel/plugin-transform-runtime插件提供了一个helpers参数。具体你可以在这里查阅它的所有配置参数。
这个helpers参数开启后可以将上边提到编译阶段重复的工具函数,比如classCallCheck, extends等代码转化称为require语句。此时,这些工具函数就不会重复的出现在使用中的模块中了。比如这样:
// @babel/plugin-transform-runtime会将工具函数转化为require语句进行引入
// 而非runtime那样直接将工具模块代码注入到模块中
var _classCallCheck = require("@babel/runtime/helpers/classCallCheck");
var Circle = function Circle() {
_classCallCheck(this, Circle);
};
{
"plugins": [
[
"@babel/plugin-transform-runtime",
{
"absoluteRuntime": false,
"corejs": false,
"helpers": true,
"regenerator": true,
"version": "7.0.0-beta.0"
}
]
]
}
在babel中实现polyfill主要有两种方式:
- 一种是通过
@babel/polyfill配合preset-env去使用,这种方式可能会存在污染全局作用域。 - 一种是通过
@babel/runtime配合@babel/plugin-transform-runtime去使用,这种方式并不会污染作用域。 - 全局引入会污染全局作用域,但是相对于局部引入来说。它会增加很多额外的引入语句,增加包体积
在开发类库时遵守不污染全局为首先使用@babel/plugin-transform-runtime而在业务开发中使用@babel/polyfill
babel-runtime 是为了减少重复代码而生的。 babel 生成的代码,可能会用到一些_extend(), classCallCheck() 之类的工具函数,默认情况下,这些工具函数的代码会包含在编译后的文件中。如果存在多个文件,那每个文件都有可能含有一份重复的代码。
babel-runtime 插件能够将这些工具函数的代码转换成 require 语句,指向为对 babel-runtime 的引用,如 require('babel-runtime/helpers/classCallCheck'). 这样, classCallCheck 的代码就不需要在每个文件中都存在了。
大多数 JavaScript Parser 遵循 estree 规范,Babel 最初基于 acorn 项目(轻量级现代 JavaScript 解析器) Babel 大概分为三大部分:
- 解析:将代码转换成 AST
- 词法分析:将代码(字符串)分割为 token 流,即语法单元成的数组
- 语法分析:分析 token 流(上面生成的数组)并生成 AST
- 转换:访问 AST 的节点进行变换操作生产新的 AST
- Taro 就是利用 babel 完成的小程序语法转换
- 生成:以新的 AST 为基础生成代码
shim 与 polyfill 的区别
针对es6-shim与es6-promise这两个库,认识下shim与polyfill的功能定义上有何不同。
shim
分析了下es6-shim的源码,现在把整体逻辑梳理为下面代码:
// UMD
(function (root, factory) {
if (typeof define === 'function' && define.amd) {
define(factory);
} else if (typeof exports === 'object') {
module.exports = factory();
} else {
// Browser globals (root is window)
root.returnExports = factory();
}
}(this, function () {
'use strict';
// 判断并获取全局对象
var getGlobal = function () {
if (typeof self !== 'undefined') { return self; }
if (typeof window !== 'undefined') { return window; }
if (typeof global !== 'undefined') { return global; }
throw new Error('unable to locate global object');
}
// 得到环境下的全局对象
var globals = getGlobal();
// es6 Map
globals.Map = ...
// es6 Set
globals.Set = ...
// es6 Symbol
globals.Symbol = ...
// 将全局对象返回,当es6-shim库被引入时,会自动在全局对象挂载API,也就是重新造了一个新环境。
return globals
}))
说明:当引入shim库时,它会影响全局对象。通过对全局对象增加 API,从而创建一个新的环境。shim不会判断 API 是否已经存在。
polyfill
es6-promise的polyfill代码逻辑:
import Promise from './promise';
export default function polyfill() {
let local;
// 这里同样是用的UMD
if (typeof global !== 'undefined') {
local = global;
} else if (typeof self !== 'undefined') {
local = self;
} else {
try {
local = Function('return this')();
} catch (e) {
throw new Error('polyfill failed because global object is unavailable in this environment');
}
}
let P = local.Promise;
// 这里判断了全局对象下是否有Promise这个属性。
if (P) {
var promiseToString = null;
try {
promiseToString = Object.prototype.toString.call(P.resolve());
} catch(e) {
...
}
if (promiseToString === '[object Promise]' && !P.cast){
// 如果已经有了Promise,就直接返回,不会再给全局对象增加Promise属性。
return;
}
}
// 代码执行到这里,给全局对象添加Promise的API
local.Promise = Promise;
}
说明:从上面的源码,可以看出,polyfill库与shim库大致逻辑基本一致。但是有所不同的是,polyfill会先判断当前环境是否已经有了目标 API,如果有了,会停止,没有时才会添加polyfill实现的 API。
总结
由上面的分析对比,可以知道的是,shim针对的是环境,polyfill针对的是 API。
在使用shim时,不会在意旧环境是否已经存在某 API,它会直接重新改变全局对象,为旧环境提供 API(它是一个垫片,为旧环境提供新功能,从而创建一个新环境)。
而在polyfill中,它会判断旧环境是否已经存在 API,不存在时才会添加新 API(它是腻子,抹平不同环境下的 API 差异)。
这二者的目的并不相同。
12.vite 和 webpack
如果应用过于复杂,使用 Webpack 的开发过程会出现以下问题
- Webpack Dev Server 冷启动时间会比较长
- Webpack HMR 热更新的反应速度比较慢
vite 的特点
- 轻量
- 按需打包
- HMR (热渲染依赖)
webpack dev server 在启动时需要先 build 一遍,而这个过程需要消耗很多时间
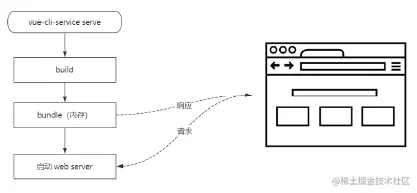
而 Vite 不同的是 执行 vite serve 时,内部直接启动了 web Server, 并不会先编译所有的代码文件。
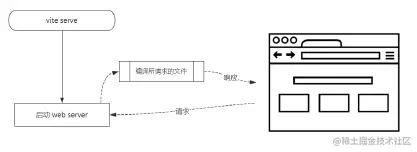
但是 webpack 这类工具的做法是将所有模块提前编译、打包进 bundle 里,换句话说,不管模块是否会被执行,都要被编译和打包到 bundle 里。随着项目越来越大,打包后的 bundle 也越来越大,打包的速度自然会越来越慢。
webpack 原理
webpack 打包过程
1.识别入口文件
2.通过逐层识别模块依赖。(Commonjs、amd 或者 es6 的 import,webpack 都会对其进行分析。来获取代码的依赖)
3.webpack 做的就是分析代码。转换代码,编译代码,输出代码
4.最终形成打包后的代码
webpack 打包原理
1.先逐级递归识别依赖,构建依赖图谱
2.将代码转化成 AST 抽象语法树
3.在 AST 阶段中去处理代码
4.把 AST 抽象语法树变成浏览器可以识别的代码, 然后输出
重点:这里需要递归识别依赖,构建依赖图谱。图谱对象就是类似下面这种
{ './app.js':
{ dependencies: { './test1.js': './test1.js' },
code:
'"use strict";\n\nvar _test = _interopRequireDefault(require("./test1.js"));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { "default": obj }; }\n\nconsole.log(test
1);' },
'./test1.js':
{ dependencies: { './test2.js': './test2.js' },
code:
'"use strict";\n\nvar _test = _interopRequireDefault(require("./test2.js"));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { "default": obj }; }\n\nconsole.log('th
is is test1.js ', _test["default"]);' },
'./test2.js':
{ dependencies: {},
code:
'"use strict";\n\nObject.defineProperty(exports, "__esModule", {\n value: true\n});\nexports["default"] = void 0;\n\nfunction test2() {\n console.log('this is test2 ');\n}\n\nvar _default = tes
t2;\nexports["default"] = _default;' } }
vite 原理
当声明一个 script 标签类型为 module 时
如:
浏览器就会像服务器发起一个GET
http://localhost:3000/src/main.js请求main.js文件:
// /src/main.js:
import { createApp } from 'vue'
import App from './App.vue'
createApp(App).mount('#app')
浏览器请求到了main.js文件,检测到内部含有import引入的包,又会对其内部的 import 引用发起 HTTP 请求获取模块的内容文件
如:GET http://localhost:3000/@modules/vue.js
如:GET http://localhost:3000/src/App.vue
Vite 的主要功能就是通过劫持浏览器的这些请求,并在后端进行相应的处理将项目中使用的文件通过简单的分解与整合,然后再返回给浏览器,Vite整个过程中没有对文件进行打包编译,所以其运行速度比原始的 webpack 开发编译速度快出许多!
webpack 缺点 1.缓慢的服务器启动
当冷启动开发服务器时,基于打包器的方式是在提供服务前去急切地抓取和构建你的整个应用。
vite 改进
Vite 通过在一开始将应用中的模块区分为 依赖 和 源码 两类,改进了开发服务器启动时间。依赖 大多为纯 JavaScript 并在开发时不会变动。一些较大的依赖(例如有上百个模块的组件库)处理的代价也很高。依赖也通常会以某些方式(例如 ESM 或者 CommonJS)被拆分到大量小模块中。Vite 将会使用 esbuild 预构建依赖。Esbuild 使用 Go 编写,并且比以 JavaScript 编写的打包器预构建依赖快 10-100 倍。
源码 通常包含一些并非直接是 JavaScript 的文件,需要转换(例如 JSX,CSS 或者 Vue/Svelte 组件),时常会被编辑。同时,并不是所有的源码都需要同时被加载。(例如基于路由拆分的代码模块)。Vite 以 原生 ESM 方式服务源码。这实际上是让浏览器接管了打包程序的部分工作:Vite 只需要在浏览器请求源码时进行转换并按需提供源码。根据情景动态导入的代码,即只在当前屏幕上实际使用时才会被处理。
webpack 缺点 2.使用的是 node.js 去实现
vite 改进
Vite 将会使用 esbuild 预构建依赖。Esbuild 使用 Go 编写,并且比以 Node.js 编写的打包器预构建依赖快 10-100 倍。
webpack 致命缺点 3.热更新效率低下
当基于打包器启动时,编辑文件后将重新构建文件本身。显然我们不应该重新构建整个包,因为这样更新速度会随着应用体积增长而直线下降。 一些打包器的开发服务器将构建内容存入内存,这样它们只需要在文件更改时使模块图的一部分失活[1],但它也仍需要整个重新构建并重载页面。这样代价很高,并且重新加载页面会消除应用的当前状态,所以打包器支持了动态模块热重载(HMR):允许一个模块 “热替换” 它自己,而对页面其余部分没有影响。这大大改进了开发体验 - 然而,在实践中我们发现,即使是 HMR 更新速度也会随着应用规模的增长而显著下降。
vite 改进
在 Vite 中,HMR 是在原生 ESM 上执行的。当编辑一个文件时,Vite 只需要精确地使已编辑的模块与其最近的 HMR 边界之间的链失效(大多数时候只需要模块本身),使 HMR 更新始终快速,无论应用的大小。Vite 同时利用 HTTP 头来加速整个页面的重新加载(再次让浏览器为我们做更多事情):源码模块的请求会根据 304 Not Modified 进行协商缓存,而依赖模块请求则会通过 Cache-Control: max-age=31536000,immutable 进行强缓存,因此一旦被缓存它们将不需要再次请求。
Vite 快速原因
Vite 这么快,是利用了 ES Modules 嘛?这只是其中的一部分。
Vite 在冷启动的时候,将代码分为依赖和源码两部分,源码部分通常会使用 ESModules 或者 CommonJS 拆分到大量小模块中,而对于依赖部分,Vite 使用 Esbuild 对依赖进行预构建。 而 Esbuild 有以下优势。
- 语言优势,Esbuild 使用 Go 语言开发,相对于 JavaScript,Go 语言是一种编译型语言,在编译阶段就已经将源码转译为机器码。
 2. 多线程,Rollup 和 webpack 都没有使用多线程的能力,而 Esbuild 在算法上进行了大量的优化,充分的利用了多 CPU 的优势。
2. 多线程,Rollup 和 webpack 都没有使用多线程的能力,而 Esbuild 在算法上进行了大量的优化,充分的利用了多 CPU 的优势。
以上这些原因,导致 Esbuild 构建模块的速度比 webpack 快到 10-100 倍。
其次,对于源码部分,Vite 省略了 webpack 遍历打包的时间,这部分工作让浏览器来执行,基本没有打包的时间,Vite 只是在浏览器发送对模块的请求时,拦截请求,对源码进行转换后提供给浏览器,实现了源码的动态导入。
以我们上面的读技术文章的例子来看,我们不关心 webpack,Rollup 和 Parcel 相关链接的内容是什么,这些内容不影响我们阅读当前的文章,只有当我们需要使用到相关链接内容的时候,我们才去点击链接查看对应的内容。
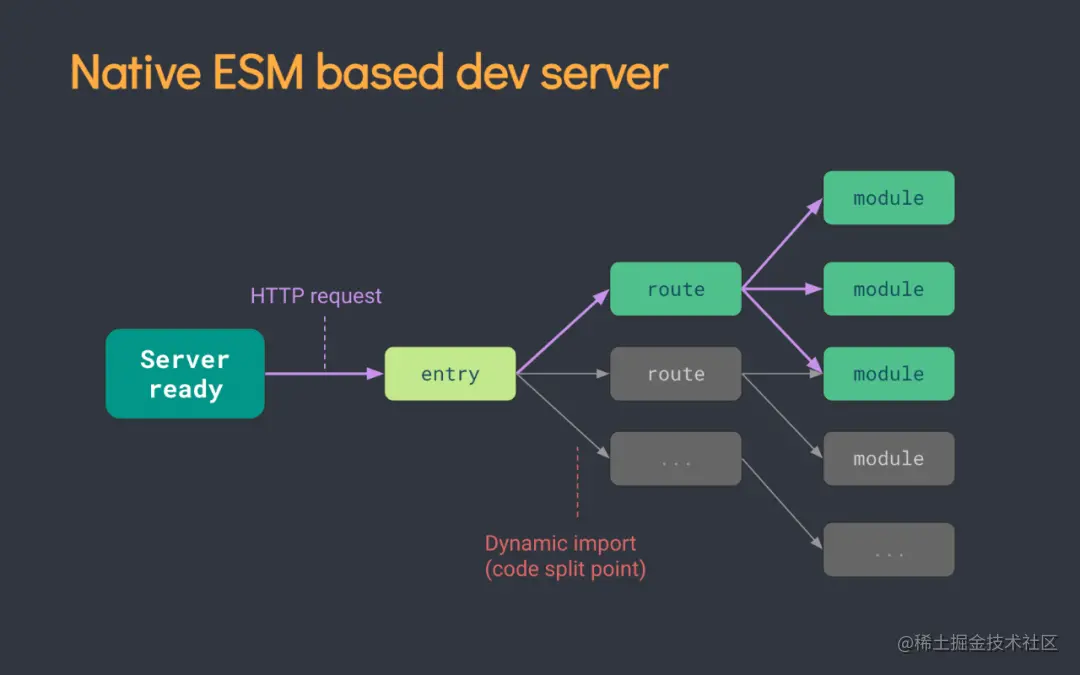
这两方面加起来,让 Vite 的冷启动快到不可思议。
而在热更新方面,基于已经启动的服务,我们不应该对所有的改动都完全重构打包项目,我们只需要对失活的模块进行热重载,而不影响页面的其他部分,但 webpack 依然会随着项目规模的扩大而变得更慢,因为 webpack 包含了完整的打包项目,对失活模块的替换和查找都会因为体积的增大而更加耗时。
相比之下,Vite 的热更新也是在原生的 ESM 上进行的,热更新的范围只在当前模块上,无论项目的规模多大,也只会加载当前使用到的模块,编辑一般也是在当前加载的模块上进行,控制住了体积,热更新的速度自然不受影响。
我们已经从冷启动,热更新,使用的语言方面,解释了 Vite 为什么会这么快,但是 Vite 也存在一些短板。
- Vite 的生态与 webpack 相差甚远,webpack 的 loader 和 plugin 已经非常丰富,而 Vite 在这方面还缺少积累。
- Vite 开发环境很快,但生产环境还达不到如此惊艳的程度,Vite 生产环境使用 Rollup 进行构建的,还是需要打包的,虽然在研发环境下,Vite 因为不需要打包,快得惊人,但相应的也增加了网络请求的次数,而在生产环境使用 ESM 效率仍然低下,综合考虑,在生产环境依然需要进行打包,而 Esbuild 对 css 的处理和代码分割并不友好,最终选择了 Rollup。
- Vite 作为新出来的构建工具,还没有经历过大量的项目考验,“实战经验”不够成熟,可能会存在没有发现的问题。
当我们开始构建越来越大型的应用时,需要处理的 JavaScript 代码量也呈指数级增长。包含数千个模块的大型项目相当普遍。我们开始遇到性能瓶颈 —— 使用 JavaScript 开发的工具通常需要很长时间(甚至是几分钟!)才能启动开发服务器,即使使用 HMR,文件修改后的效果也需要几秒钟才能在浏览器中反映出来。如此循环往复,迟钝的反馈会极大地影响开发者的开发效率和幸福感。
Vite 旨在利用生态系统中的新进展解决上述问题:浏览器开始原生支持 ES 模块,且越来越多 JavaScript 工具使用编译型语言编写。
13.如何进行 css 的抽离
直接引用样式文件,没有使用任何相关插件时,会出现css in js的情况,即打包到了一块
css 代码进行分割和压缩
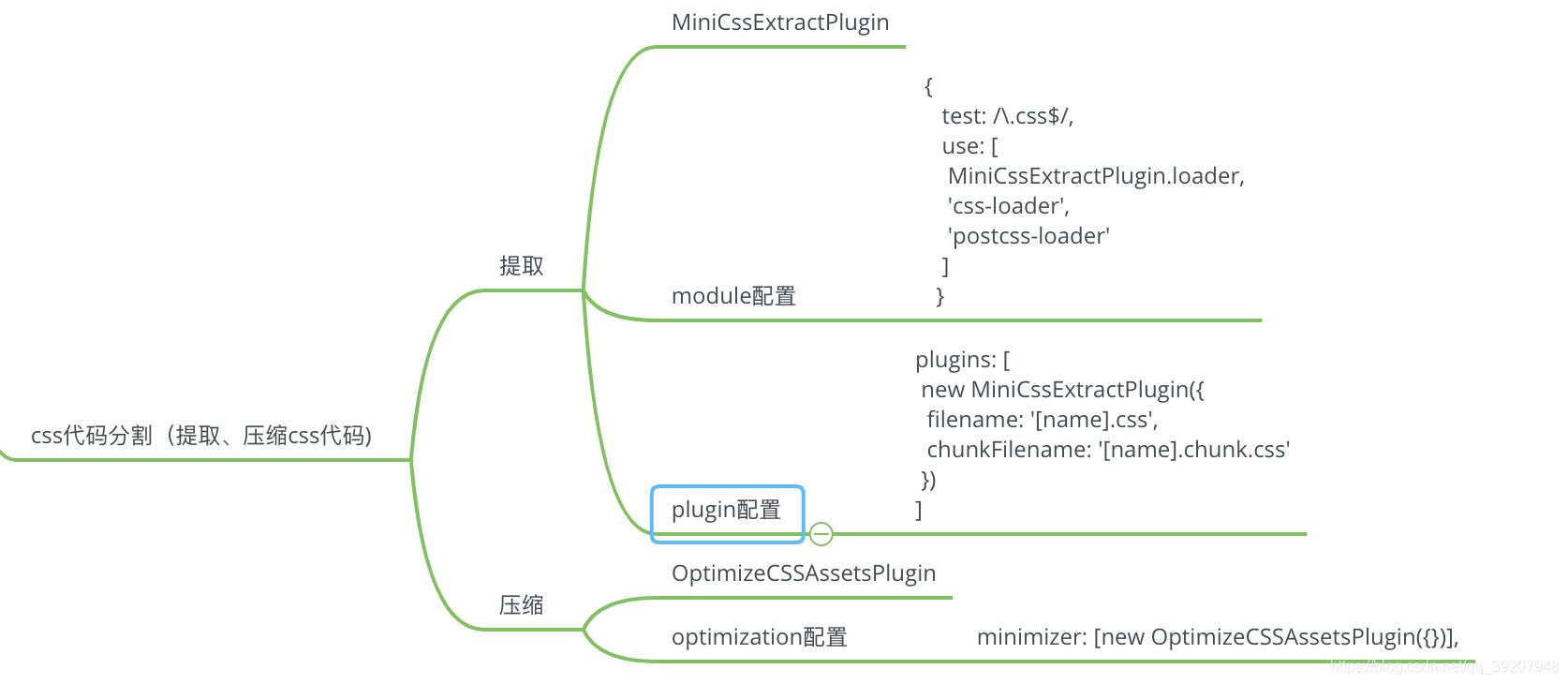
mini-css-extract-plugin:分割optimize-css-assets-webpack-plugin: 压缩
plugins:
// 抽离 css 文件
new MiniCssExtractPlugin({
filename: "css/main.[contentHash:8].css",
});
style-loader 的作用是将 css 挂载到页面上,而 MiniCssExtractPlugin.loader 是为了将 css 从页面上抽取出来作为文件。 注意 loader 的调用顺序: 从下往上,从右往左 注意 tree shaking 配置需要忽略掉.css 文件,否则有可能打包不到样式文件 “sideEffects”: [ “*.css” ],
// 抽离 css
{
test: /\.css$/,
loader: [
MiniCssExtractPlugin.loader, // 注意,这里不再用 style-loader
'css-loader',
'postcss-loader'
]
},
// 抽离 less --> css
{
test: /\.less$/,
loader: [
MiniCssExtractPlugin.loader, // 注意,这里不再用 style-loader
'css-loader',
'less-loader',
'postcss-loader'
]
}
optimize-css-assets-webpack-plugin可以对 css 进行压缩
optimization: {
// css样式的代码合并
minimizer: [new OptimizeCSSAssetsPlugin({})],
usedExports: true, // tree shaking
splitChunks: {
chunks: 'all'
}
},
14.如何实现多入口
设置 path.js 文件
const path = require("path");
const srcPath = path.join(__dirname, "..", "src");
const distPath = path.join(__dirname, "..", "dist");
module.exports = {
srcPath,
distPath,
};
设置多个 entry
entry: {
index: path.join(srcPath, 'index.js'),
other: path.join(srcPath, 'other.js')
},
// 多入口 - 生成 index.html
new HtmlWebpackPlugin({
template: path.join(srcPath, "index.html"),
filename: "index.html",
// chunks 表示该页面要引用哪些 chunk (即上面的 index 和 other),默认全部引用
chunks: ["index"], // 只引用 index.js
}),
// 多入口 - 生成 other.html
new HtmlWebpackPlugin({
template: path.join(srcPath, "other.html"),
filename: "other.html",
chunks: ["other"], // 只引用 other.js
});
chunks 表示该页面要引用哪些 chunk (即上面的 index 和 other),默认全部引用
chunks: ['index', 'vendor', 'common'] 要考虑代码分割
每个页面 css 抽离也可以
到了多页程序,因为存在多个入口文件以及对应的多个页面,每个页面都有自己的 css样式,所以需要为每个页面各自配置
plugins: [
new ExtractTextPlugin("index/[name].[contenthash].css"),
new ExtractTextPlugin("other/[name].[contenthash].css"),
];
15.加速打包速度
happyPack 开启多进程打包
// happyPack 开启多进程打包
new HappyPack({
// 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
id: 'babel',
// 如何处理 .js 文件,用法和 Loader 配置中一样
loaders: ['babel-loader?cacheDirectory']
}),
使用 ParallelUglifyPlugin 并行压缩输出的 JS 代码
// 使用 ParallelUglifyPlugin 并行压缩输出的 JS 代码
new ParallelUglifyPlugin({
// 传递给 UglifyJS 的参数
// (还是使用 UglifyJS 压缩,只不过帮助开启了多进程)
uglifyJS: {
output: {
beautify: false, // 最紧凑的输出
comments: false, // 删除所有的注释
},
compress: {
// 删除所有的 `console` 语句,可以兼容ie浏览器
drop_console: true,
// 内嵌定义了但是只用到一次的变量
collapse_vars: true,
// 提取出出现多次但是没有定义成变量去引用的静态值
reduce_vars: true,
},
},
});
IgnorePlugin避免引入无用模块
以时间处理库moment的使用为例进行学习和理解
默认会引入所有语言的 js 代码,代码会过大,只引入中文
在插件中使用webpack.IgnorePlugin匹配到moment下的locale语言包,进行忽略处理,即不引入所有的locale下的语言包。
在需要使用到具体的语言时,在代码中引入具体的语言包即可
noParse 的使用
一般使用.min.js结尾的文件,都是已经经过模块化处理的,那么这个时候就没必要在进行 loder 或者 webpack 分析了,noParer 的字面意思也是不再解析。
ignorePlugin 和 noParse 的对比
IgnorePlugin直接就将符合匹配条件的模块,不再进行引入,代码中没有。noParse该引入还是会引入,只是不参与 loader 或 webpack 的解析及打包
使用 DllPlugin

就是通过将引入的模块,打到一个 dll 文件下,生成模块包和整体包产物文件的对应关系,再次打包时,如果能在映射关系中找到该模块,便直接使用产物中的包,不在进行模块分割打包,以此来提高 Webpack 的打包速度。
开发环境使用 webpack-dev-server,不会生成 dist 目录,而是会把产物放到内存之中
优化打包构建速度 - 开发体验和效率
优化 babel-loader
在 babel-loader 后加一个?cacheDirectory,开启 babel-loader 的缓存。这样如果 es6 代码没有改,就不会再重新编译
还有就是通过 include 确定 babel 编译范围,通常为 src。(排除 node_modules)
IgnorePlugin
这个 plugin 作用是避免引入无用模块。比如我们通常会使用 moment.js,但默认会引入所有语言的 js 代码,代码过大。可能只需要引入中文和英文的模块,这个插件就可以帮助。
那么就可以在业务代码中手动引入中文和英文的语言包,然后再 webpack 配置中写入
new webpack.IgnorePlugin(/\.\/locale/, /moment/),
忽略掉 moment 里的 locale 语言包,这样就能减少无用的模块引入。
noParse
避免重复打包。社区中常有的 min.js 通常都是已经打包了的,因此没必要再次打包,在 module.noParse 中配置不需要打包的文件即可。只是 react.min.js 不能这么搞,这个没有采用模块化,还是需要打包的。
和 Ignore 的区别是,Ignore 直接不引入,代码中没有。但 noParse 会引入,但不打包。都能够提升构建速度,Ignore 还能够优化线上的性能。
happyPack 多进程打包
因为 js 是单线程的,所以 webpack 实际上也是进行的单线程打包。所以如果我们能够开启多进程进行打包,那么就能够大幅提高构建速度,happyPack 就能够做到这个
注:这是个 plugin
比如要将 babel 的解析放在新进程中,那么 module.rule 中对 js 的解析需要改成:
{
test: /\.js$/,
// 把对 .js 文件的处理转交给 id 为 babel 的 HappyPack 实例
use: ['happypack/loader?id=babel'],
include: srcPath,
// exclude: /node_modules/
},
然后需要在 plugin 中配置 babel 的 happyPack 实例:
new HappyPack({
// 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
id: 'babel',
// 如何处理 .js 文件,用法和 Loader 配置中一样
loaders: ['babel-loader?cacheDirectory']
}),
ParallelUglifyPlugin 多进程压缩 JS
webpack 本身内置了 uglify 压缩 JS,但压缩 JS 本身是比较高成本的,这里也可以进行多进程开启。 直接在 Plugin 中实例化就行。根据配置要求进行配置。
当然,关于开启多进程是否需要,并不是一定需要的。
如果项目较大,打包较慢,开启多进程能够提高速度;但开启多进程本身就需要成本和时间,小项目没必要配置,反而会造成打包时间增加。
热更新 HotModuleReplacementPlugin
自动刷新是速度比较慢,且状态会丢失。 热更新的话,则不会刷新,状态不丢失,且新代码能够立刻生效。
主要引入 HotModuleReplacementPlugin 即可。 首先 entry 需要修改:
entry: {
// index: path.join(srcPath, 'index.js'),
index: [
'webpack-dev-server/client?http://localhost:8080/',
'webpack/hot/dev-server',
path.join(srcPath, 'index.js')
],
other: path.join(srcPath, 'other.js')
},
Plugin 中实例化即可,并在 devServer 中设置 hot 为 true 即可。
最后,JS 代码需要还需要判断一下是否是热更新,注册监听范围
if (module.hot) {
module.hot.accept(['./math'), () => {});
}
所以热更新有成本,需要手动注册。
实际使用中没有遇见需要这样的,通常只用了 css 的逻辑(默认支持热更新)。
DllPlugin 动态链接库插件
前端框架通常会使用 vue、React,体积大,构建慢。但是比较稳定,开发情况下不会经常升级版本。
因此,这种内容同一个版本只需要构建一次就可以了,没必要每次都重新构建。
webpack 已经内置了 DllPlugin,主要包含两个插件:
DllPlugin:打包出 dll 文件,先进行一遍预打包,生成 dll 文件
DllReferencePlugin:在开发环境使用 dll 文件。
一般需要单独定义一个 dll.config.js
output: {
path: path.join(__dirname, '../build'), // 放在项目的/build目录下面
filename: '[name].dll.js', // 打包文件的名字
library: '[name]_library' // 可选 暴露出的全局变量名
// vendor.dll.js中暴露出的全局变量名。
// 主要是给DllPlugin中的name使用,
// 故这里需要和webpack.DllPlugin中的`name: '[name]_library',`保持一致。
},
plugin
new webpack.DllPlugin({
path: path.join(__dirname, '../build', '[name]_manifest.json'), // 生成上文说到清单文件,放在当前build文件下面,这个看你自己想放哪里了。
name: '[name]_library',
context: __dirname,
}),
然后定义 dll 的命令,进行 dll 打包
最后输出了 dll 和 manifest 文件。dll 文件就是所有打包的文件内容,而 manifest 的作用就是索引,负责引导实际对于 dll 里模块的引用。
实际应用的话,就是需要在 dev 的 html 中去进行 script 进行引用。这里就可以用 dllReferencePlugin 插件去引用 manifest 文件,用 AddAssetHtmlPlugin 引用 dll 文件即可
16.如何优化产出代码
核心:让代码体积更小、合理分包,不重复加载、速度更快,内存使用更少
小图片用 base64 的编码
使用 url-loader,对小于 xkb 的图片做 base64 格式进行产出,没有必要再做一次网络请求
bundle 需要加 hash
根据文件内容算 hash 值,客户端可以实现缓存管理使用。js 代码如果没有变化,那么即便再次上线也能复用没变的 bundle 块
懒加载
import() 使用时,webpack 会自动进行单独打包,生成 0.js 这样的打包文件。
提取公共代码
一些通用代码和第三方应该被抽离。在 optimization 里的 splitChunks 进行设置
IngorePlugin
减少打包代码内容
使用 cdn 加速
使用 cdn 加速,修改 output 里的 publicPath,能够修改所有静态文件 url 的前缀 当然需要在部署上线脚本里加上上传到 cdn 的操作
图片则在图片的 url-loader 里加上 publicPath 就行
使用 production
在 mode 中使用 production,会自动开启代码压缩,减少代码体积
Vue\React 等成熟的库会自动删掉调试代码比如开发环境的 warning
其次 production 还会开启 Tree Shaking:可以移除 JavaScript 上下文中的未引用代码,删掉用不着的代码,能够有效减少 JS 代码文件的大小。
假设我们不使用 production mode,而是用 development mode,那么我们需要在配置文件中新增:
module.exports = {
mode: "development",
//...
optimization: {
useExports: true, // 模块内未使用的部分不进行导出
},
};
必须用 ES6 module 才能让 tree shaking 生效,commonjs 不行
仅仅因为 Webpack 看不到一段正在使用的代码,并不意味着它可以安全地进行 tree-shaking。有些模块导入,只要被引入,就会对应用程序产生重要的影响。一个很好的例子就是全局样式表,或者设置全局配置的 JavaScript 文件。 Webpack 认为这样的文件有“副作用”。具有副作用的文件不应该做 tree-shaking,因为这将破坏整个应用程序。Webpack 的设计者清楚地认识到不知道哪些文件有副作用的情况下打包代码的风险,因此默认地将所有代码视为有副作用。这可以保护你免于删除必要的文件,但这意味着 Webpack 的默认行为实际上是不进行 tree-shaking。 幸运的是,我们可以配置我们的项目,告诉 Webpack 它是没有副作用的,可以进行 tree-shaking。
package.json 有一个特殊的属性 sideEffects,就是为此而存在的。它有三个可能的值: true 是默认值,如果不指定其他值的话。这意味着所有的文件都有副作用,也就是没有一个文件可以 tree-shaking。 false 告诉 Webpack 没有文件有副作用,所有文件都可以 tree-shaking。 第三个值 […] 是文件路径数组。它告诉 webpack,除了数组中包含的文件外,你的任何文件都没有副作用。因此,除了指定的文件之外,其他文件都可以安全地进行 tree-shaking。
使用 Scope Hosting
当存在多个文件时,实际上在 webpack 中会打包成多个函数。但文件越多,函数越多,函数越多占用内存越多(作用域)。 是否可以把打包后的函数进行合并?这就是 Scope Hosting 的作用:代码体积更小、创建函数作用域更少、代码可读性更少
引用 ModuleConcatenationPlugin 插件并使用,代价是必须要用 ES6 模块化组织代码才能用这个效果,所以针对 NPM 中的第三方模块优先采用 jsnext:main 中指向 ES6 模块化语法的文件
配置 resolve:
resolve: {
mainFields: ["jsnext:main", "browser", "main"];
}
对 js 压缩
压缩 js 用terser-webpack-plugin插件,可以优化和压缩 JS 资源
插件配置:
module.exports = {
...
optimization: {
minimize: true,
minimizer: [
new TerserPlugin(),
],
},
}
为什么不使用 uglifyjs-webpack-plugin?
不在使用 uglifyjs-webpack-plugin,因为前者支持 ES6,后者不支持,所以现在都使用前者
17.代码分割
拆分原则是:
- 业务代码和第三方库分离打包,实现代码分割;
- 业务代码中的公共业务模块提取打包到一个模块;
- 第三方库最好也不要全部打包到一个文件中,因为第三方库加起来通常会很大,我会把一些特别大的库分别独立打包,剩下的加起来如果还很大,就把它按照一定大小切割成若干模块
optimization.splitChunks
cacheGroups是splitChunks配置的核心,对代码的拆分规则全在cacheGroups缓存组里配置。缓存组的每一个属性都是一个配置规则,我这里给他的default属性进行了配置,属性名可以不叫 default 可以自己定name:提取出来的公共模块将会以这个来命名,可以不配置,如果不配置,就会生成默认的文件名,大致格式是
index~a.js这样的。chunks:指定哪些类型的 chunk 参与拆分,值可以是 string 可以是函数。如果是 string,可以是这个三个值之一:
all,async,initial,all代表所有模块,async代表只管异步加载的,initial代表初始化时就能获取的模块。如果是函数,则可以根据 chunk 参数的 name 等属性进行更细致的筛选。splitChunks是自带默认配置的,而缓存组默认会继承这些配置,其中有个minChunks属性:- 它控制的是每个模块什么时候被抽离出去:当模块被不同 entry 引用的次数大于等于这个配置值时,才会被抽离出去。
- 它的默认值是 1。也就是任何模块都会被抽离出去(入口模块其实也会被 webpack 引入一次)
我希望公共模块common.js中,业务代码和第三方模块 jquery 能够剥离开来。
我们需要再添加一个拆分规则。
//webpack.config.js
optimization: {
splitChunks: {
minSize: 30, //提取出的chunk的最小大小
cacheGroups: {
default: {
name: 'common',
chunks: 'initial',
minChunks: 2, //模块被引用2次以上的才抽离
priority: -20
},
vendors: { //拆分第三方库(通过npm|yarn安装的库)
test: /[\\/]node_modules[\\/]/,
name: 'vendor',
chunks: 'initial',
priority: -10
}
}
}
}
我给 cacheGroups 添加了一个 vendors 属性(属性名可以自己取,只要不跟缓存组下其他定义过的属性同名就行,否则后面的拆分规则会把前面的配置覆盖掉)
18.webpack 对 CommonJS 的实现
因为低版本的浏览器对于模块化是不支持的,所以在前端工程化的今天,我们需要通过一些工具来帮助我们转换我们的模块化代码,借此来运行在低版本的浏览器上(目前谷歌等一些高版本的浏览器已经支持了es6Module)。我们来看下webpack是如何实现CommonJS规范的。
首先,我们先执行如下命令,新起一个webpack-demo的项目。
mkdir webpack-demo && cd webpack-demo
npm init -y
npm install webpack webpack-cli --save-dev
然后在项目里创建一个src文件夹,里面新建一个index.js和module1.js两个文件:
index.js:
const module1 = require("./module1");
const num = module1.status + 12;
module.exports = {
num,
};
module1.js:
const status = 0;
module.exports = {
status,
};
然后我们再配置webpack,新创建一个webpack.config.js文件在根目录:
webpack.config.js
var path = require("path");
module.exports = {
entry: path.join(__dirname, "./src/index.js"),
output: {
path: path.join(__dirname, "dist"),
filename: "index.js",
},
mode: "development",
};
这里要注意配置mode: "development",因为我们需要查看打包后的具体的内容,不然webpack会帮我们压缩代码。
到目前为止一切准备就绪,我们在根目录执行webpack命令:
可以看到生成了一个dist文件夹,里面有一个index.js的文件,让我们来看看它究竟是什么。因为打包后的代码粗略的看上去,非常的凌乱,所以我这里把大部分注释先给去掉。我们将代码分为三部分来看:
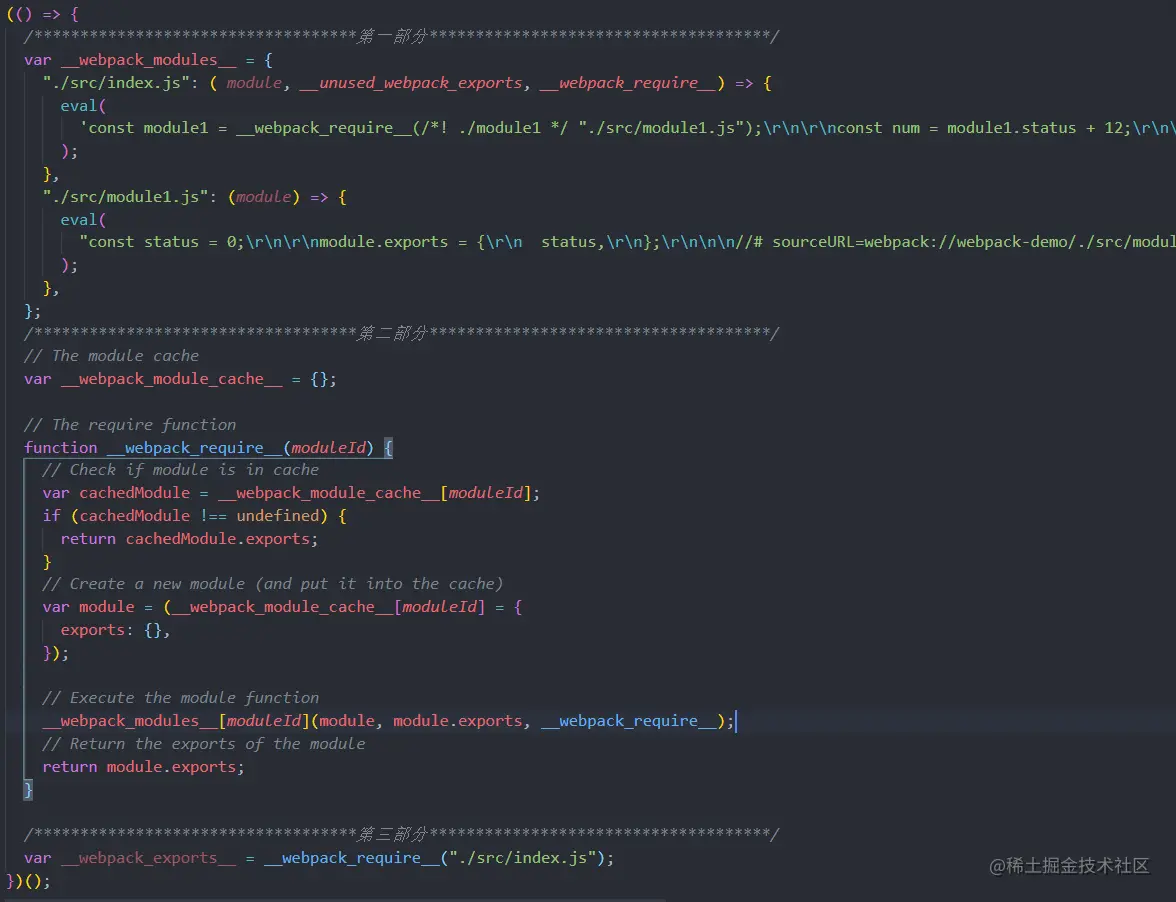
第一部分
/***********************************第一部分*************************************/
var __webpack_modules__ = {
"./src/index.js": (module, __unused_webpack_exports, __webpack_require__) => {
eval(
'const module1 = __webpack_require__(/*! ./module1 */ "./src/module1.js");\r\n\r\nconst num = module1.status + 12;\r\n\r\nmodule.exports = {\r\n num,\r\n};\r\n\n\n//# sourceURL=webpack://webpack-demo/./src/index.js?'
);
},
"./src/module1.js": (module) => {
eval(
"const status = 0;\r\n\r\nmodule.exports = {\r\n status,\r\n};\r\n\n\n//# sourceURL=webpack://webpack-demo/./src/module1.js?"
);
},
};
首先,我们可以看到它是一个自执行函数,能看到有一个__webpack_modules__的对象,他就是我们写的所有的模块(上面的index.js和module1.js)的一个集合。这个对象的键名是引用路径,值则是一个函数,这个函数有三个入参module、__unused_webpack_exports、__webpack_require__,函数体里面则是一个eval函数执行了我们写的代码。其实我们的 js 文件,被webpack加工打包了一层函数上去:
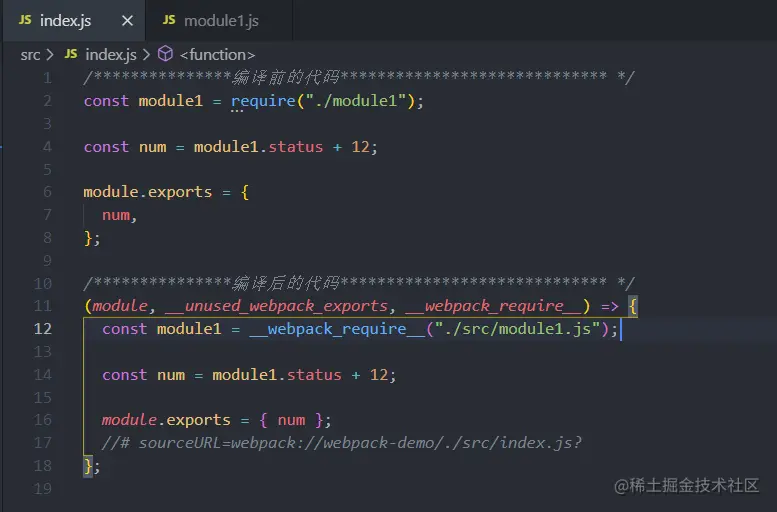
webpack会把我们写的所有的js 文件打包成一个函数,这样我们的 js 文件就是在一个函数作用域下面的,不会污染全局环境。再在打包之后,赋值给一个__webpack_modules__对象,把所有的模块引入。
第二部分
/***********************************第二部分*************************************/
// 缓存对象
var __webpack_module_cache__ = {};
// 导出函数 - 如果缓存对象中已经缓存过,则返回缓存对象中的模块。否则执行模块代码,存入缓存再返回
function __webpack_require__(moduleId) {
// 检查在缓存中是否存在该模块的缓存,如果有则直接返回
var cachedModule = __webpack_module_cache__[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// 创造一个新的module(并且存入缓存对象中)
var module = (__webpack_module_cache__[moduleId] = {
exports: {},
});
// 如果没有缓存则执行模块代码
__webpack_modules__[moduleId](module, module.exports, __webpack_require__);
// 返回模块
return module.exports;
}
复制代码
首先是一个__webpack_module_cache__,它是一个缓存对象,具体是干啥的下面再说,让我们继续往下看。
接下来就是一个__webpack_require__函数,这个就是上面的三个入参之一的require函数。它的具体作用就是:先检查缓存对象__webpack_module_cache__中是否存在被 require 的模块,如果存在就直接使用缓存,如果不存在则调用一遍第一部分的__webpack_modules__集合中的此模块,并存入一份到缓存中,最后返回被 require 的模块的导出。 而前两个参数则是缓存对象的引用地址,我们在模块最后的module.exports会赋值到该对象上,从而被缓存对象给记录下来。
我们现在知道了:我们写的所有的模块,如果被require给调用过,就会被复制一份存入缓存,之后一直会调用缓存中的该模块。值得注意的是,如果我们的模块没有被引用过,webpack则不会把这个模块给引入到__webpack_modules__这个集合中。
第三部分
/***********************************第三部分*************************************/
var __webpack_exports__ = __webpack_require__("./src/index.js");
最后的语句就是执行一遍require函数,调用我们在配置文件中配置的入口文件,从而执行整个代码逻辑。
webpack对于CommonJS的实现是基于函数作用域的,它把我们写的模块代码(js 文件)给包了一层函数,通过自己的__webpack_require__方法来实现CommonJS的 require。在模块被引用时,会把该模块的module.exports放入一个缓存对象中,下次再引用这个模块就直接从缓存中读取。而它一开始加载入口函数,在一开始就会把所有被用到的模块放入缓存中,这也正是webpack编译、打包时间慢的原因。因为webpack选择了一开始就把所有的模块进行加载,如果项目过大,加载的模块越多,时间也就越长。
CommonJS的实现我们已经知道了,他的require是在此模块加载完成后才会执行下面的语句,除非已经做过了缓存。所以它的导入是同步的,在浏览器环境里并不合适,所以一种异步加载的模块化规范来了
19.webpack 对 ES6Module 的实现
现在谷歌高版本的浏览器已经支持了此模块化方案,可以通过script标签加上type="module"来实现,但是还是有很多的浏览器不支持ES6的模块化方案,所以我们还是需要借助webpack等工具来实现。webpack支持多种模块化方案,可以把 ES6 的模块化代码转换成低版本浏览器兼容的模块化代码
具体实现
这边我们改变一下上面例子中的两个文件,把他们改成ES6Module的写法
index.js:
import module1 from "./module1";
module1.add(1, 2);
module1.js:
function add(a, b) {
return a + b;
}
export default {
add,
};
然后我们再执行webpack命令对其进行打包操作,可以看到dist又重新生成了一个index.js文件。我们会发现,跟CommonJS打包生成的index.js的组成部分来看,除了一二三部分,它额外多了一部分:
/* webpack/runtime/define property getters */
// 这是一个核心函数,给导出对象module.exports扩展属性用
(() => {
// define getter functions for harmony exports
__webpack_require__.d = (exports, definition) => {
for (var key in definition) {
if (
__webpack_require__.o(definition, key) &&
!__webpack_require__.o(exports, key)
) {
Object.defineProperty(exports, key, {
enumerable: true,
get: definition[key],
});
}
}
};
})();
/* webpack/runtime/hasOwnProperty shorthand */
// 此函数用于判断对象中是否存在某个属性
(() => {
__webpack_require__.o = (obj, prop) =>
Object.prototype.hasOwnProperty.call(obj, prop);
})();
/* webpack/runtime/make namespace object */
// 此函数用于向es6模块的导出对象module.exports标记一个 __esModule 属性
(() => {
// define __esModule on exports
__webpack_require__.r = (exports) => {
if (typeof Symbol !== "undefined" && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: "Module" });
}
Object.defineProperty(exports, "__esModule", { value: true });
};
})();
我们看多出来的部分,了解一下它的用法:
__webpack_require__.d:这是一个核心函数,给导出对象module.exports扩展属性用,说白了就是给导出对象赋值用的。__webpack_require__.o:此函数用于判断对象中是否存在某个属性。__webpack_require__.r:此函数用于向 es6 模块的导出对象 module.exports 标记一个__esModule属性。
让我们结合打包后的代码来看下,我们看下编译前后的index.js:
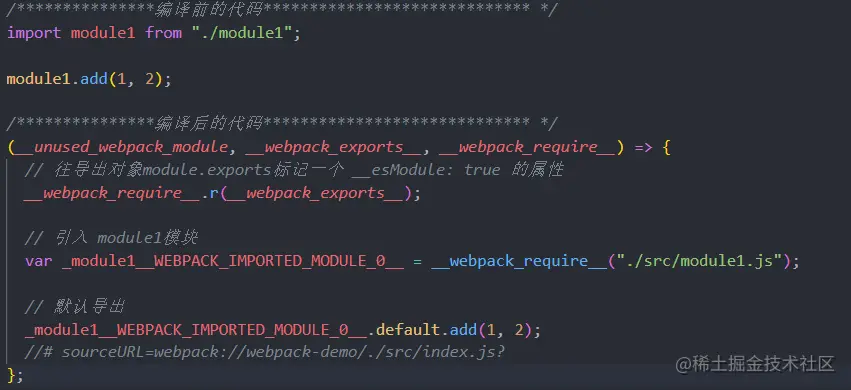
再看看编译前后的module1.js:
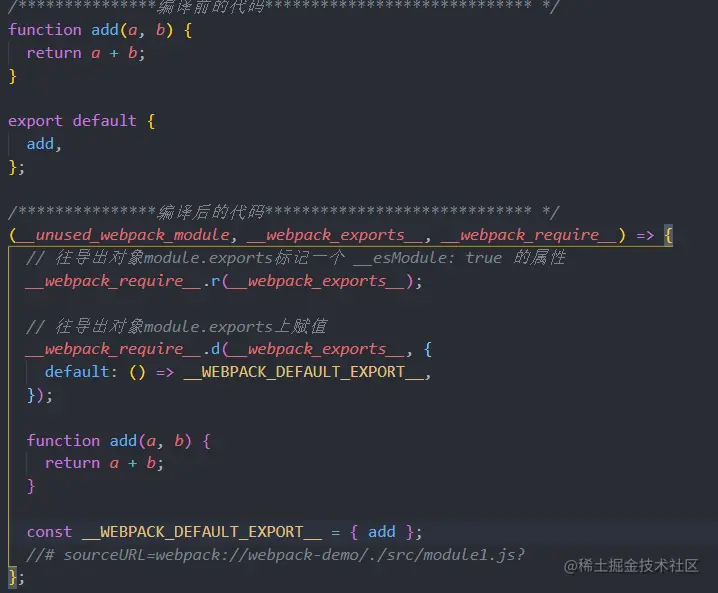
总结
这样我们就能很清楚的知道了,这一追加部分的作用了。而webpack对于ES6Module模块化的转换也是跟CommonJS差不多的。但是,在对于值的导出的部分,ES6Module跟CommonJS还是有所区别的。
在值的导出的部分,CommonJS使用的是赋值操作,也就是拷贝了导出对象的引用地址:

这样做会产生的影响是,其模块内部改变这个值,是影响不到导出结果的。因为导出的是这个值的拷贝,两个值不是同一个!
而ES6Module的导出,我们来看一个更为直观的栗子:
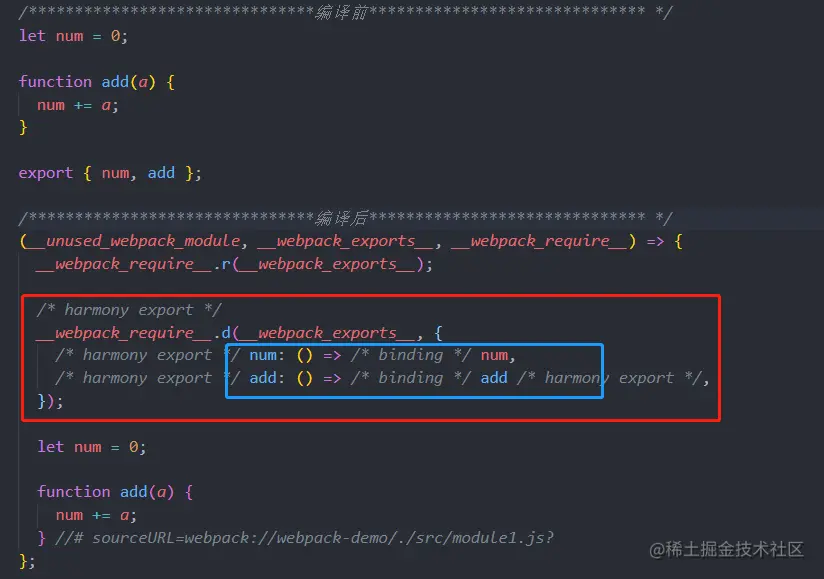
ES6Module的导出,并不是直接赋值,而是导出一个函数,这个函数引用的是模块内部值,这样就导致了模块内部改变其中一个值,导出模块的值也会发生改变,因为两个值都是同一个!
20.webpack 如何编译 commonjs 和 esModule
1.commonjs 加载 commonjs
引入是 commonjs,导出是 commonjs
- 引入文件
let title = require("./title");
console.log(title.name);
console.log(title.age);
- 导出文件
exports.name = "title_name";
exports.age = "title_age";
- webpack 编译结果及分析
(() => {
// 定义一个modules对象,key为moduleId,也就是文件相对于项目根目录的相对路径,value为一个函数,函数参数至少有一个module,函数体就是moduleId对应的文件的内容
var modules = {
"./src/title.js": (module) => {
module.exports = "title";
},
};
// 定义一个缓存
var cache = {};
// webpack自己实现一个require方法
// 为什么webpack需要自己实现一个require方法,而不是用node内置的require?
// 是因为node下的require是node环境使用的,如果我们webpack打包的结果需要去浏览器使用的话,就不能用node的require,所以需要自己写一个。
function require(moduleId) {
var cachedModule = cache[moduleId]; // 首先从缓存中读取key为moduleId的缓存,如果还有引用统一moduleId的文件的,那么就会是缓存存在,就直接将缓存返回了。如果不存在,继续往下走。所以可以看出,同一个路径的文件,多次引用,其实第二次开始都是返回缓存。
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// 如果缓存不存在,那就将对象赋值给缓存,同时赋值给新定义的module。
// 这里的对象有一个属性为exports,值为空对象
// 这里的module是需要传入到引用文件的执行函数中的。
var module = (cache[moduleId] = {
exports: {},
});
// 执行moduleId(引用文件)对应的函数,也就是去执行引用文件。这时,传入之前定义好的module,module.exports和require本身,因为引用文件中有可能还有require引用
modules[moduleId](module, module.exports, require); // 引用文件的内容最终应该有module.exports导出
return module.exports; // 返回导出的内容
}
var exports = {};
(() => {
// 这就是入口文件的内容
let title = require("./src/title.js");
console.log(title);
})();
})();
2.commonjs 加载 esModule
引入是 commonjs,导出是 esModule
- 引入文件
let title = require("./title");
console.log(title);
console.log(title.age);
- 导出文件
export default "title_name";
export const age = "title_age";
- webpack 编译结果及分析
(() => {
var modules = {
"./src/title.js": (__unused_webpack_module, exports, require) => {
"use strict";
require.renderEsModule(exports); // 作用就是使得exports.__esModule = true。 模块里出现了export或import的话,exports就会有一个__esModule属性,我们在运行的时候,可以通过__esModule来反推这是不是一个EsModule
require.defineProperties(exports, {
// 将default和age属性,挂在到exports上去
default: () => __WEBPACK_DEFAULT_EXPORT__,
age: () => age,
});
const __WEBPACK_DEFAULT_EXPORT__ = "title_name";
const age = "title_age";
},
};
var cache = {};
function require(moduleId) {
var cachedModule = cache[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
var module = (cache[moduleId] = {
exports: {},
});
modules[moduleId](module, module.exports, require);
return module.exports;
}
/*--------------以下是新增的三个函数--------------*/
require.defineProperties = (exports, definition) => {
for (var key in definition) {
if (require.o(definition, key) && !require.o(exports, key)) {
Object.defineProperty(exports, key, {
enumerable: true,
get: definition[key],
});
}
}
};
require.o = (obj, prop) => Object.prototype.hasOwnProperty.call(obj, prop);
require.renderEsModule = (exports) => {
if (typeof Symbol !== "undefined" && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: "Module" });
}
Object.defineProperty(exports, "__esModule", { value: true }); // 模块里出现了export或import的话,exports就会有一个__esModule属性,我们在运行的时候,可以通过__esModule来反推这是不是一个EsModule。只有esModule才有__esModule属性
};
/*--------------以上是新增的三个函数--------------*/
var exports = {};
(() => {
let title = require("./src/title.js");
console.log(title);
})();
})();
问题
webpack 如何判断是 esModule?
webpack 会把源码转成 AST 语法树,然后遍历语法树,找关键字 import/exports,找到就是 esModule
commonjs 加载 esModule,是怎么兼容的?
如果碰到模块中有 export 或 import,则认定为是 ESModule,这时候,会给 exports 对象加一个__esModule 为 true 的键值对。
然后再将引用模块中的 export 的属性挂在到 exports 对象上去
这个 exports 就是 module.exports。这样就将 esModule 转成了 commonjs
3.esModule 加载 esModule
导入是 esModule,导出是 esModule
- 导入文件
import name, { age } from "./title";
console.log(name);
console.log(age);
- 导出文件
export default name = "title_name";
export const age = "title_age";
- webpack 编译结果及分析
(() => {
var modules = {
"./src/title.js": (module) => {
// 引用的文件是commonjs,所以不需要做任何处理
module.exports = {
name: "title_name",
age: "title_age",
};
},
};
var cache = {};
function require(moduleId) {
var cachedModule = cache[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
var module = (cache[moduleId] = {
exports: {},
});
modules[moduleId](module, module.exports, require);
return module.exports;
}
require.n = (module) => {
// 最大的差别就在这里
// 判断module是否是一个esModule
var getter =
module && module.__esModule
? // 如果导入是一个es6 module的话,那么默认导出就会挂在导出对象exports.default上
() => module["default"] // 如果是esModule,则返回这个函数,函数返回module["default"]
: // 如果导入的是commonjs的话,那就取对象本身,exports对象就是默认导出对象
() => module; // 如果
require.defineProperties(getter, { a: getter }); // 相当于给getter添加了属性a,属性a的get是getter,即getter.a值是getter本身
return getter;
};
require.defineProperties = (exports, definition) => {
for (var key in definition) {
if (require.o(definition, key) && !require.o(exports, key)) {
Object.defineProperty(exports, key, {
enumerable: true,
get: definition[key],
});
}
}
};
require.o = (obj, prop) => Object.prototype.hasOwnProperty.call(obj, prop);
require.renderEsModule = (exports) => {
if (typeof Symbol !== "undefined" && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: "Module" });
}
Object.defineProperty(exports, "__esModule", { value: true });
};
var exports = {};
(() => {
// esModule加载commonjs的关键在于,default如何取
require.renderEsModule(exports); // exports.__esModule = true, esModule加载esModule 与 esModule加载commonjs,一样
var _title_0__ = require("./src/title.js"); // 虽然是esModule的import去引入模块,但是还是会转成require引入
var _title_0___default = /*#__PURE__*/ require.n(_title_0__);
console.log(_title_0___default());
console.log(_title_0__.age);
})();
})();
总结
esmodule 和 commonjs 相关转换的规律:
最终都是转成 commonjs
commonjs => 打包后不变
esModule => 打包后,首先会在 exports 上挂在一个__esModule 属性,值为 true,代表这是 esModule,然后将默认导出挂在 exports.default 上,其他属性挂在都 exports 上
21.webpack 异步加载原理
import()对于 webpack 来说,是一个天然的分割点,也就是说,webpack 碰到 import()会对 import()进行解析。怎么解析的,过程主要是:
首先,webpack 遇到 import 方法时,会将其当成一个代码分割点,也就是说碰到 import 方法了,那么就去解析 import 方法。
然后,import 引用的文件,webpack 会将其编译成一个 jsonp,也就是一个自执行函数,然后函数内部是引用的文件的内容,因为到时候是通过 jsonp 的方法去加载的。
具体就是,import 引用文件,会先调用 require.ensure 方法(打包的结果来看叫 require.e),这个方法主要是构造一个 promise,会将 resolve,reject 和 promise 放到一个数组中,将 promise 放到一个队列中。
然后,调用 require.load(打包结果来看叫 require.l)方法,这个方法主要是创建一个 jsonp,也就是创建一个 script 标签,标签的 url 就是文件加载地址,然后塞到 document.head 中,一塞进去,就会加载该文件了。
加载完,就去执行这段 jsonp,主要就是把 moduleId 和 module 内容存到 modules 数组中,然后再去走 webpack 内置的 require。
webpack 内置的 require,主要是先判断缓存,这个 moduleId 是否缓存过了,如果缓存过了,就直接返回。如果没有缓存,再继续往下走,也就是加载 module 内容,然后最终内容会挂在都 module,exports 上,返回 module.exports 就返回了引用文件的最终执行结果。
- 入口文件
import(/* webpackChunkName: "title"*/ "./title").then((result) => {
console.log(result);
});
- 依赖文件
module.exports = "title";
- webpack 编译结果及分析(缩减过后)
var modules = {};
var cache = {};
function require(moduleId) {
var cachedModule = cache[moduleId];
if (cachedModule) {
return cachedModule.exports; // 最终返回的都是module.exports
}
var module = (cache[moduleId] = {
exports: {},
});
modules[moduleId](module, module.exports, require);
return module.exports;
}
// 定义查找代码块的方法
require.find = {};
// 通过JSONP一部加载指定的代码块
require.ensure = (chunkId) => {
let promises = [];
require.find.jsonp(chunkId, promises); // 在jsonp中会创建一个promise,并且添加到promises数组中
return Promise.all(promises);
};
require.publicPath = ""; // 资源文件的访问路径,默认是空字符串,值从webpack.config.js的output的publicPath中去找
require.unionFileName = (chunkId) => {
// 统一文件名
return "" + chunkId + ".js"; // title.js
};
require.load = (url) => {
let script = document.createElement("script");
script.src = url;
document.head.appendChild(script); //一旦append之后,浏览器会立刻请求脚本
};
// 已经安装或者加载好的或者加载中的chunk
var installedChunks = {
main: 0, // key为“main”表示主入口文件,0表示ok,也就是已经加载就绪
// "title": [resolve, reject, promise]
};
require.find.jsonp = (chunkId, promises) => {
var installedChunkData;
let promise = new Promise((resolve, reject) => {
installedChunkData = installedChunks[chunkId] = [resolve, reject];
/*
这个相当于installedChunks值变成了
{
"main": 0,
"title": [resolve, reject, promise]
}
*/
});
installedChunkData[2] = promise;
promises.push(promise);
var url = require.publicPath + require.unionFileName(chunkId); //title.js
require.load(url); // 常见script,然后塞入document.head,然后会自动加载该文件
};
var webpackJsonpCallback = ([chunkIds, moreModules]) => {
var resolves = [];
for (let i = 0; i < chunkIds.length; i++) {
let chunkId = chunkIds[i];
resolves.push(installedChunks[chunkId][0]); //把chunk对应的promise的resolve方法添加到resolves数组里去
installedChunks[chunkId][0] = 0; // 表示已经添加完成
}
for (let moduleId in moreModules) {
modules[moduleId] = moreModules[moduleId];
}
while (resolves.length) {
resolves.shift()(); // 让promise的resolve执行,让promise成功
}
};
// 由于打包好了依赖文件title.js是被
var chunkLoadingGlobal = (self["webpackChunk_1_webpack_bundle"] =
self["webpackChunk_1_webpack_bundle"] || []);
// 重写数组的push方法
chunkLoadingGlobal.push = webpackJsonpCallback;
require
.ensure("title") // 先加载代码块,这里的参数"title"就是魔法字符串中的webpackChunkName的值title
.then(require.bind(require, "./src/title.js")) // require模块
.then((result) => {
// 获取结果
console.log(result);
});
22.webpack 打包性能优化
优化大纲
weibapck 性能优化主要可以考虑以下几方面
- 缩小查找范围,加快查找速度
- extensions
- alias
- modules
- mainFields
- mainFiles
- resolve
- resolveLoader
- noParse 不解析第三方库的第三方依赖
- DefinePlugin 创建编译时可以配置的全局变量,减少变量查找范围
- IgnorePlugin webpack 忽略某些模块,不把他们打包进去
- 净化 css,抽离 css
- thread-loader 代替 happypack,多进程处理
- cdn
- tree Shaking
- 代码分割
- 按需加载、提取公共代码
- scope Hosting 作用域提升
- 利用缓存
- babel-loader 开启缓存
- 使用 cache-loader
性能分析工具
- speed-measure-webpack-plugin 测试每个核心步骤耗费的事件
- webpack-bundle-analyzer 代码分析工具,生成代码体积等分析报告
1.缩小查找范围,加快查找速度
1.1 extensions
有了这个 extensions 后,在
require和import的时候不需要加文件扩展名,会一次添加扩展名进行匹配
resolve: {
extensions: [".js",".jsx",".json",".css"]
},
1.2 alias
配置别名可以加快 webpack 查找模块的速度
不需要从
node_modules文件夹中按模块的查找规则查找
const bootstrap = path.resolve(__dirname,'node_modules/_bootstrap@3.3.7@bootstrap/dist/css/bootstrap.css');
resolve: {
alias:{
"bootstrap":bootstrap
}
},
1.3 modules
modules字段指定第三方模块的查找目录
// 默认是查找node_modules,但是会类似Nodejs一样的路径进行搜索,一层一层网上找node_modules
resolve: {
modules: ['node_modules'],// 先当当前目录下的node_modules,找不到找上层目录的node_moudles,直到全局的node_modules
}
// 如果确定依赖模块在项目根目录下的node_modules中,那么可以写绝对路径确定查找范围
resolve: {
modules: [path.resolve(__dirname, 'node_modules')], // 确定查找目录就是项目下的node_modules,找不到不会往上层找
}
1.4 mainFilds 和 mainFiles
resolve: {
// 配置 target === "web" 或者 target === "webworker" 时 mainFields 默认值是:
mainFields: ['browser', 'module', 'main'],
// target 的值为其他时,mainFields 默认值为:
mainFields: ["module", "main"],
}
- 这里的 mainFileds 代表了一个包解析入口文件应该看的字段,按照上面代码的顺序查找
resolve: {
mainFiles: ['index'], // 你可以添加其他默认使用的文件名
},
- 这里的 mainFiles 代表入口文件,如果 mainFileds 对应的字段没有,那么就看 mainFiles 对应的入口文件,如果 mainFiles 也没有,那么就是 index
问:解析一个包或模块,如何找到入口文件面试点
- 先找到包/模块下对应的
package.json中的main字段,如果存在此字段,直接找到了,就直接返回。 - 如果没有这个字段,就找对应 mainFiles,默认就是 index.js
1.5 resolveLoader
用于配置解析 loader 时的 resolve,默认配置:
module.exports = {
resolveLoader: {
modules: ["node_modules"],
extensions: [".js", ".json"],
mainFields: ["loader", "main"],
},
};
resolve 与 resolveLoader 对象的 key 是一样的,后者是专门用于查找 loader 的
2.noParse 忽略对指定第三方模块的第三方依赖的解析
比如:
import jq from "jquery";
当解析 jq 的时候,会去解析 jq 这个库是否有依赖其他的包
但是,如果配置了
noParse,那么就不需要再去解析 jquery 中的依赖库了,这样能够增加打包速率。
module:{
noParse:/jquery/,//不去解析jquery中的依赖库
rules: [
...
]
}
3.DefinePlugin 定义全局变量
创建一些在编译时可以配置的全局变量,在编译的时候会直接替换掉,不需要再去查找
let webpack = require("webpack");
new webpack.DefinePlugin({
PRODUCTION: JSON.stringify(true),
VERSION: "1",
EXPRESSION: "1+2",
COPYRIGHT: {
AUTHOR: JSON.stringify("yh"),
},
});
console.log(PRODUCTION);
console.log(VERSION);
console.log(EXPRESSION);
console.log(COPYRIGHT);
- 如果配置的值是字符串,那么整个字符串会被当成代码片段来执行,其结果作为最终变量的值
- 如果配置的值不是字符串,也不是一个对象字面量,那么该值会被转为一个字符串,如 true,最后的结果是 ‘true’
- 如果配置的是一个对象字面量,那么该对象的所有 key 会以同样的方式去定义
- JSON.stringify(true) 的结果是 ‘true’
4.IgnorePlugin 忽略某些模块,不把他们打包进去
忽略第三方包的指定目录,让这些指定目录不要被打包进去。比如 moment 包,我只用中文的,那么可以用这个插件指定只打包中文的目录,其他语言就不需要打包了。加快了打包速度,减少了打包体积。
18、webpack 优化(3)——IgnorePlugin_俞华的博客-CSDN 博客_ignoreplugin
5.purgecss-webpack-plugin 净化 css,mini-css-extract-plugin 压缩并抽离 css
purgecss-webpack-plugin 净化 css,mini-css-extract-plugin 压缩并抽离 css,两者需要配合使用
- 使用:
const path = require("path");
+const glob = require("glob");
+const PurgecssPlugin = require("purgecss-webpack-plugin");
+const MiniCssExtractPlugin = require('mini-css-extract-plugin');
const PATHS = {
src: path.join(__dirname, 'src')
}
module.exports = {
mode: "development",
entry: "./src/index.js",
module: {
rules: [
{
test: /\.js/,
include: path.resolve(__dirname, "src"),
use: [
{
loader: "babel-loader",
options: {
presets: ["@babel/preset-env", "@babel/preset-react"],
},
},
],
},
+ {
+ test: /\.css$/,
+ include: path.resolve(__dirname, "src"),
+ exclude: /node_modules/,
+ use: [
+ {
+ loader: MiniCssExtractPlugin.loader,
+ },
+ "css-loader",
+ ],
+ },
],
},
plugins: [
+ new MiniCssExtractPlugin({
+ filename: "[name].css",
+ }),
+ new PurgecssPlugin({
+ paths: glob.sync(`${PATHS.src}/**/*`, { nodir: true }),
+ })
],
};
6.thread-loader 代替 happypack,多进程处理
把这个 loader 放置在其他 loader 之前, 放置在这个 loader 之后的 loader 就会在一个单独的 worker 池(worker pool)中运行
module.exports = {
mode: "development",
entry: "./src/index.js",
module: {
rules: [
{
test: /\.js/,
include: path.resolve(__dirname, "src"),
use: [
+ {
+ loader:'thread-loader',
+ options:{
+ workers:3
+ }
+ },
{
loader: "babel-loader",
options: {
presets: ["@babel/preset-env", "@babel/preset-react"],
},
},
],
},
{
test: /\.css$/,
include: path.resolve(__dirname, "src"),
exclude: /node_modules/,
use: [
{
loader: MiniCssExtractPlugin.loader,
},
"css-loader",
],
},
],
}
};
7.CDN 内容分发网络
CDN 又叫内容分发网络,通过把资源部署到世界各地,用户在访问时按照就近原则从离用户最近的服务器获取资源,从而加速资源的获取速度。
问:怎么使用 CDN 提高性能,加快访问速度?面试题
- 首先,我们一般将入口 html 文件不缓存,放在自己的服务器上,关闭自己服务器的缓存,静态资源的 url 变成指向 CDN 服务器的地址
- 这样做,是因为 cdn 服务一般会给资源开启很长时间,例如用户从 cdn 上获取了 index.html 后,即使之后发布操作把 index.html 覆盖了,但是用户在很长一段时间内,依旧使用的是之前运行的版本,这会导致新发布不能立即生效,所以我们将 index.html 不开启缓存放在自己服务器上
- 然后,很对静态的 js、css、图片等文件需要开启缓存,上传到 CDN 上去,并且给每个文件名带上由文件内容算出的 hash 值
- 开启缓存和上传到 CDN 是为了能够读取更快,加上 hash 是因为文件会随着内容而变化,只要文件内容变化,那么对应的 url 就会变化,那么就会重新下载,无论缓存时间有多长。这样能保证文件一更新,读取的就是最新的文件,文件不更新,读取的就是缓存。
- 启用 CDN 后,所有的相对路径都改成指向 CDN 服务器的绝对路径。通过 webpack 的 publicPath 可以设置。
{
output: {
path: path.resolve(__dirname, 'dist'),
+ filename: '[name]_[hash:8].js',
+ publicPath: 'http://img.aiqiyi.cn'
},
}
另外,会把不同的静态资源分散到不同的 CDN 服务上去,因为同一时候,针对同一域名的资源 并行请求是优先的。
但是,多个域名会增加域名解析时间,所以可以在 HTML 的 HEAD 标签中加入
link标签去与解析域名,以降低域名解析带来的延迟。link标签一般会有一个rel属性,值为dns-prefetch,代表 dns 预拉取,拉取的地址是href属性的值,比如:<link rel="dns-prefetch" href="http://img.aiqiyi.cn">
8.TreeShaking 只打包用到的 API
tree shaking 就是只把用到的方法打入 bundle,没用到的方法会
uglify阶段擦除掉
原理是利用 es6 模块的特点,只能作为模块顶层语句出现,import 的模块名只能是字符串常量,所以只能用在 esModule 中(
面试点)没有导入的 API 都不会被打包
代码不会被执行,不可到达的不会被打包
import a from 'a'if(false){console.log(a) // 不会达到,所以a不会打包进来}代码执行的结果不被用到,不会被打包
代码中只赋值,不使用的变量,不会被打包
9.代码分割
9.1 按入口点分割
多入口项目,入口 chunks 之间包含了重复的模块,那么这些重复的模块会被引入到各个 bundle 中,所以提取出重复的模块作为单独的 bundle,能够提升减少打包体积,提升打包效率
9.2 动态导入(懒加载,按需加载)
使用
import()函数配合魔法注释,代表按需加载,魔法注释一样的会打成一个包
import(/* webpackChunkName: "title" */ "./components/Title");
9.3 预先加载 preload 和预先拉取 prefetch
9.3.1 预先加载 preLoad
- preload-webpack-plugin 能够将资源加载通过 preload 的方式加载,也就是预先加载
- 举例如下:
- 现在需要 preload 的地方,添加魔法注释"/* webpackPreload: true*/"(图 1-1)
- 然后 webpack 配置插件(图 1-2)
- 然后会发现,原先按需加载的权重应该是 Low,但是现在变成了 Hight(图 1-3)
- 从 html 发现,还没点击按钮,已经插入了 link 标签,也就是资源已经被预先加载了(图 1-4)
- 举例如下:
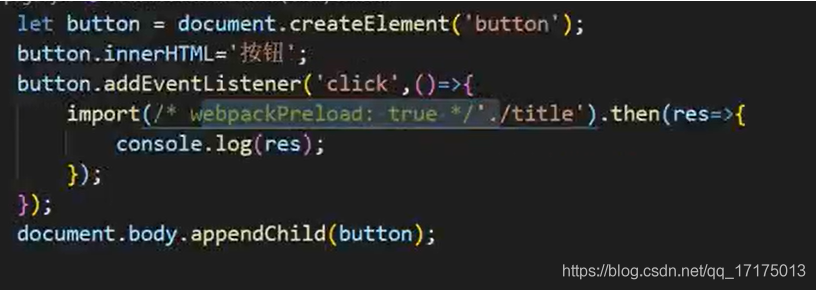
(图 1-1)
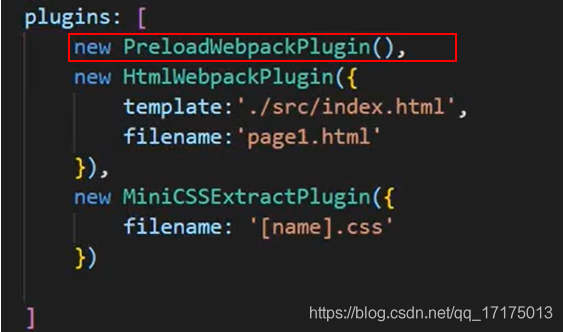
(图 1-2)
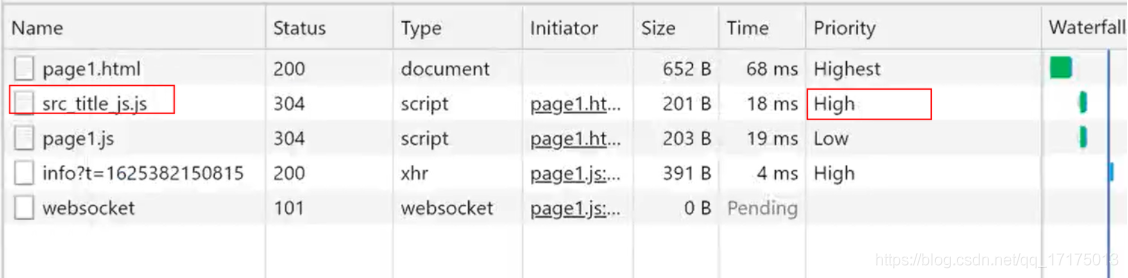
(图 1-3)
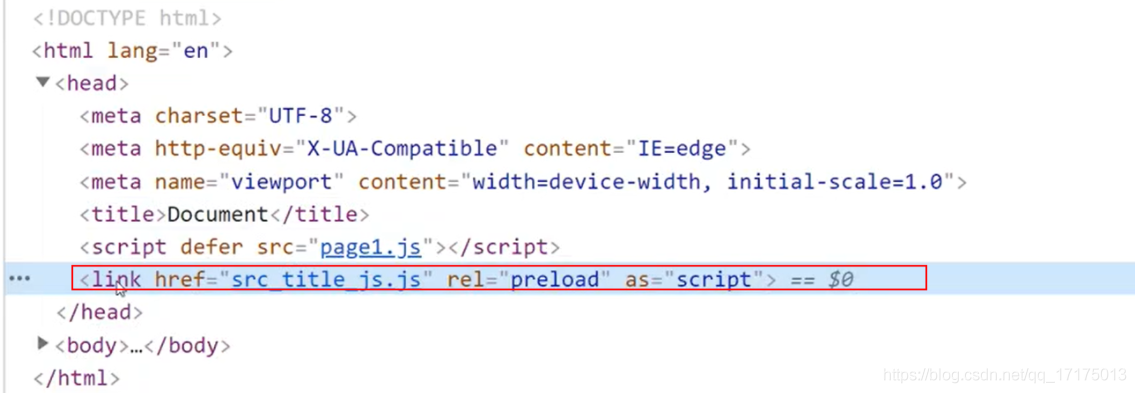
(图 1-4)
- 上面的 html 可以看出,link 标签不止可以引出 css,还可以引入 script,只要写一个 as=“script”,应该还可以引入其他类型。另外,上面的 rel="preload"表示预加载
9.3.2 预先拉取 prefetch
- prefetch 跟 preload 不同,它的作用是告诉浏览器未来可能会使用到的某个资源,浏览器就会在闲时去加载对应的资源,若能预测到用户的行为,比如懒加载,点击到其它页面等则相当于提前预加载了需要的资源
<link rel="prefetch" href="utils.js" as="script">
button.addEventListener('click', () => {
import(
`./utils.js`
/* webpackPrefetch: true */
/* webpackChunkName: "utils" */
).then(result => {
result.default.log('hello');
})
});
9.3.3 preload 与 prefetch 的区别
preload 告诉浏览器我马上要用到这个资源,请提高加载优先级为 high,预先加载
prefetch 告诉浏览器我未来可能会用到这个资源,请浏览器优先级设为 lowest,在浏览器空闲的时候加载
- preload 不要轻易用,因为会阻塞主要模块的加载,所以慎用。只有最关键最急需的资源才用。
9.4 提取公共代码
问:以下模块依赖图,由 page1、page2、page3 三个入口,实线代表依赖,比如 page1 依赖了 module1,虚线代表动态导入,比如 page1 动态导入 asyncModule1.js。请问:利用你觉得最佳的优化方案,会产出哪些文件?
思路:
提取第三方模块 jquery
会提取出一个 endorspage1page2~page3.chunk.js
提取公共模块 module1 module2 module3
会提取出 page1page2.chunk.js、page1page2~page3.chunk.js
提取动态加载的模块(import()),动态模块也按照 1 2 3 步骤提取
会提取出 asyncModule1.chunk.js,然后还会提取出动态加载的模块的第三方依赖 vendors~asyncModule.chunk.js,然后去提供公共模块,因为这里没有,所以么有产出
提取出入口文件
会提取出 page1.js、page2.js、page3.js
问:module3 在哪个产出文件中?
- 答:在 page3.js 中。因为如果一个模块被两个或两个以上引用,那么会单独打包出一个 bundle,如果只有被一个引用,那么就会打包到引用方的包中。
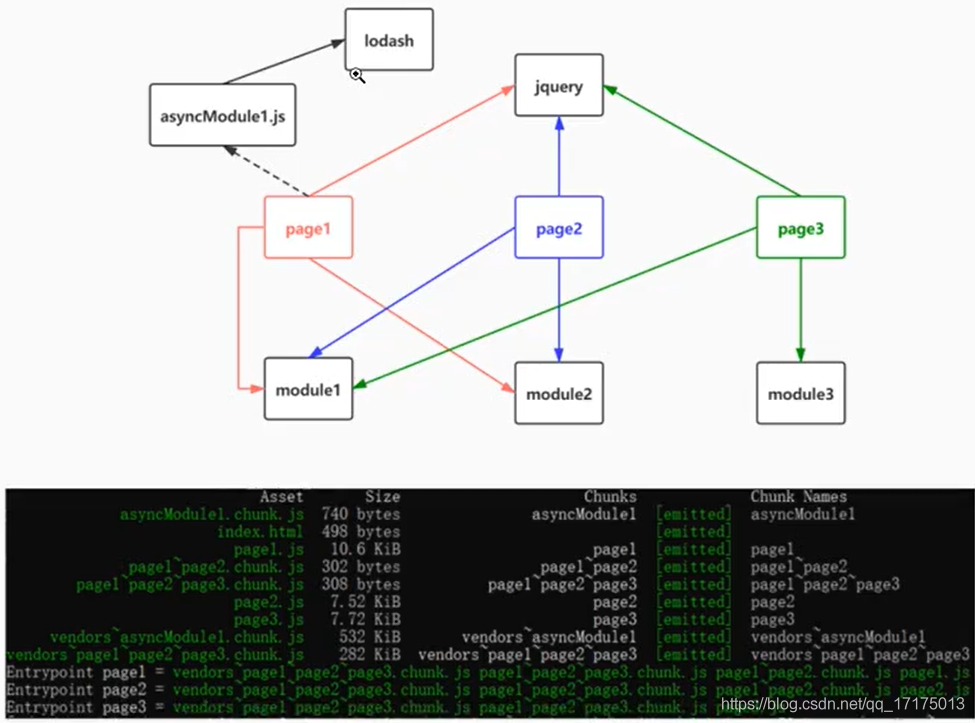
分包是什么意思?
分包就是提取多个入口之间的公共模块,一般用于 mpa 多页应用
那么单页应用如何分包?通过懒加载 import 实现分包
代码分割的配置应该怎么配?
应该在 webpack 配置文件的 optimization 属性的 splitChunks 属性中配置
module.exports = {
optimization: {
splitChunks: {
chunks: "all", //代码分割应用于哪些情况,默认作用于异步chunk,值为all(同步+异步)/initial(同步import a from './a')/async(异步import())
minSize: 0, //分割出去的代码块最小的尺寸多大,代码块的最小尺寸,小于这个尺寸的就没必要分割出来,太小了,默认值是30kb,0就是不限制
minChunks: 2, //被多少模块共享,在分割之前模块的被引用次数
maxAsyncRequests: 3, //限制异步模块内部的并行最大请求数的,说白了你可以理解为是每个import()它里面的最大并行请求数量
maxInitialRequests: 5, //限制入口的拆分数量
name: false, //打包后的名称,默认是chunk的名字通过分隔符(默认是~)分隔开,如vendor~,值可以是false、string或function,不能是true
automaticNameDelimiter: "~", //分隔符,默认webpack将会使用入口名和代码块的名称生成命名,比如 'vendors~main.js'
cacheGroups: {// 将多个chunk的缓存合并成一个组
//设置缓存组用来抽取满足不同规则的chunk,下面以生成common为例
vendors: {
chunks: "all",
test: /node_modules/, //条件,如果这个模块request路径(绝对路径)里面包含node_modules,那么就属于第三方模块
priority: -10, ///优先级,一个chunk很可能满足多个缓存组,会被抽取到优先级高的缓存组中,为了能够让自定义缓存组有更高的优先级(默认0),默认缓存组的priority属性为负值.
},
default: {
chunks: "all",
minSize: 0, //最小提取字节数
minChunks: 2, //最少被几个chunk引用
priority: -20,
reuseExistingChunk: false
}
// 有些模块,比如jquery,按照上面的配置,它会同时属于vendors和default两个缓存组,那么到底属于哪个缓存组呢,根据配置中的priority值大小来确定。
},
runtimeChunk:true // 运行时代码块单独打包成一个文件
},
}
上面的缓存组中,为什么 priority 要配置成负数?
- 答:因为 webpack 有默认缓存组,默认缓存组优先级为 0。
- 如果你想要优先级比默认的要高,用正数
- 比默认的要低,就用负数。(负数的话,就是不覆盖默认配置)
- 答:因为 webpack 有默认缓存组,默认缓存组优先级为 0。
多页应用 html 怎么配置?
- 根据下图配置,但是需要配置 chunks,代表 page1.html 引用对应自己的 chunks。
10.scope Hosting 作用域提升
Scope Hosting 作用于提升,可以让 Webpack 打包出来的代码体积更小、运行速度更快。这是 webpack3 退出的功能。
为什么 Scope Hosting 能够减少代码体积、加快运行速度?
答:举个例子说明下:
如果文件 a 导出了字符串 a,index.js 引入了 a,并且 console.log(字符串 a),那么如果没有开启
scope hosting,打包出来的结果是:在 modules 数组中,有一个对象元素,key 为 a 模块路径,value 为一个函数,函数内部包含了 a 模块的内容;然后还有一个 index.js 模块,根据引用关系去找到 modules 中的 a 模块,然后加载进来。相当于打包后,a 模块的内容都被打包进去了。
但其实,我只是在 index.js 中使用了一下 a 模块的导出结果,也就是字符串 a,那么我只要把 index.js 中用到 a 的地方替换成字符串’a’就可以了,没必要把整个 a 模块都打包进来。
scope hosting就是用来做到这一点的。
// a.js
export default 'a';
// index.js
import a from './a.js';
console.log(a);
// 不开启scope hosting打包出来的结果
"./src/index.js":
(function(module, __webpack_exports__, __webpack_require__) {
__webpack_require__.r(__webpack_exports__);
var a = ('a');
console.log(a);
})
// 开启scope hosting打包出来的结果
(() => {"use strict";console.log("a")})
11.利用缓存
webpack 利用缓存来优化一般有 2 种思路:
- babel-loader 开启缓存
- 使用 cache-loader
11.1 babel-loader
- Babel 在转义 js 文件过程中消耗性能较高(语法树解析啥的),将 babel-loader 执行的结果缓存起来,当重新打包构建时会尝试读取缓存,从而提高打包构建速度、降低消耗
{
test: /\.js$/,
exclude: /node_modules/,
use: [{
loader: "babel-loader",
options: {
cacheDirectory: true
}
}]
},
11.2 cache-loader
- 在一些性能开销较大的 loader 之前添加此 loader,以将结果缓存到磁盘里
- 存和读取这些缓存文件会有一些时间开销,所以请只对性能开销较大的 loader 使用此 loader
const loaders = ["babel-loader"];
module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: ["cache-loader", ...loaders],
include: path.resolve("src"),
},
],
},
};
12.oneOf
一般来说,一个类型的文件只对应一个 rule,但是 webpack 编译的时候,会对每个 rules 中的所有规则都遍历一遍,匹配 test 规则的整理出来,然后去执行 laoder。
但是,如果用了 oneOf,只要匹配 test,匹配到一个,那么后面的 loader 就不再处理了。
也正是一个只匹配一个,所以 oneOf 中不能两个配置处理同一种类型的文件。
module.exports = {
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
//优先执行
enforce: 'pre',
loader: 'eslint-loader',
options: {
fix: true
}
},
{
// 以下 loader 只会匹配一个
oneOf: [
...,
{test: /js/, ...}, // 匹配到一个,后面就不会再去匹配了
{test: /css/, ...}
]
}
]
}
}
13.性能分析工具
1.speed-measure-webpack-plugin 测试每个核心步骤耗费的时间
- 使用:在 module.exports 导出的内容外包一层 wrap 函数即可。
const SpeedMeasureWebpackPlugin = require("speed-measure-webpack-plugin");
const smw = new SpeedMeasureWebpackPlugin();
module.exports = smw.wrap({});
- 结果:可以看到每个步骤、每个 loader、plugin 等消耗的时间
2.webpack-bundle-analyzer
webpack-bundle-analyzer 是一个 webpack 的插件,需要配合 webpack 和 webpack-cli 一起使用。这个插件的功能是生成代码分析报告,帮助提升代码质量和网站性能
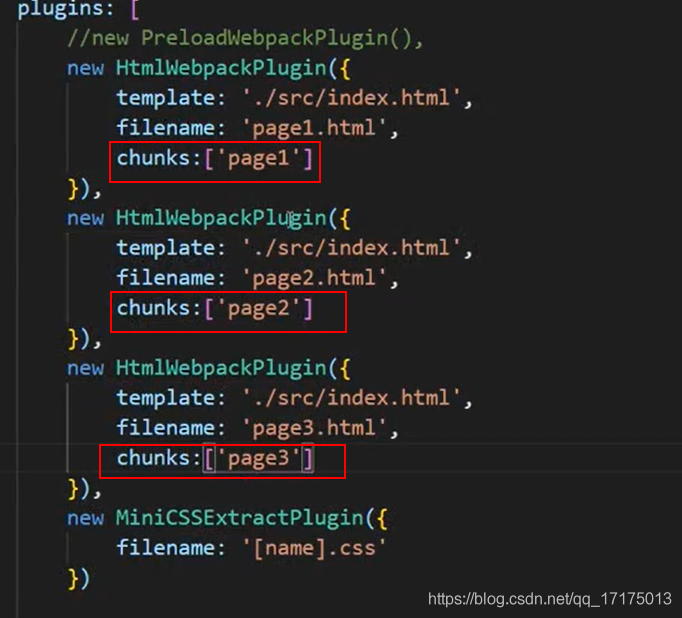
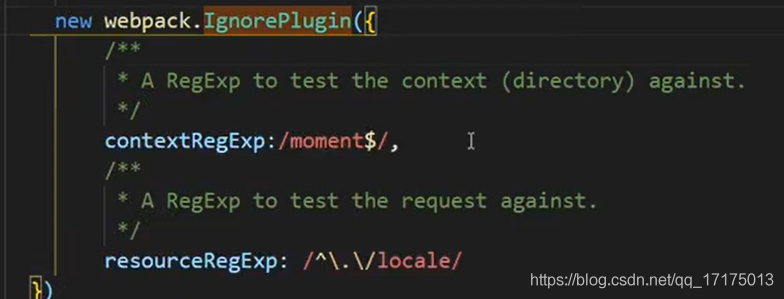
上面这个插件的用法改了
耗时分析
const SpeedMeasureWebpackPlugin = require('speed-measure-webpack-plugin');const smw = new SpeedMeasureWebpackPlugin();module.exports =smw.wrap({ ...});
- 可以看到每个步骤、每个 loader、plugin 等消耗的时间
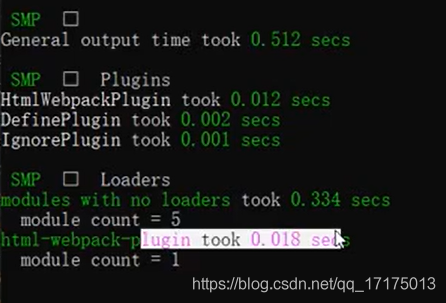
webpack 打包文件分析工具 webpack-bundle-analyzer
webpack-bundle-analyzer 是一个 webpack 的插件,需要配合 webpack 和 webpack-cli 一起使用。这个插件的功能是生成代码分析报告,帮助提升代码质量和网站性能
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin
module.exports={
plugins: [
new BundleAnalyzerPlugin() // 使用默认配置
// 默认配置的具体配置项
// new BundleAnalyzerPlugin({
// analyzerMode: 'server',
// analyzerHost: '127.0.0.1',
// analyzerPort: '8888',
// reportFilename: 'report.html',
// defaultSizes: 'parsed',
// openAnalyzer: true,
// generateStatsFile: false,
// statsFilename: 'stats.json',
// statsOptions: null,
// excludeAssets: null,
// logLevel: info
// })
]
}
// 配置脚本
{
"scripts": {
"generateAnalyzFile": "webpack --profile --json > stats.json", // 生成分析文件
"analyz": "webpack-bundle-analyzer --port 8888 ./dist/stats.json" // 启动展示打包报告的http服务器
}
}
23.tapable 的使用和原理
webpack 生命周期
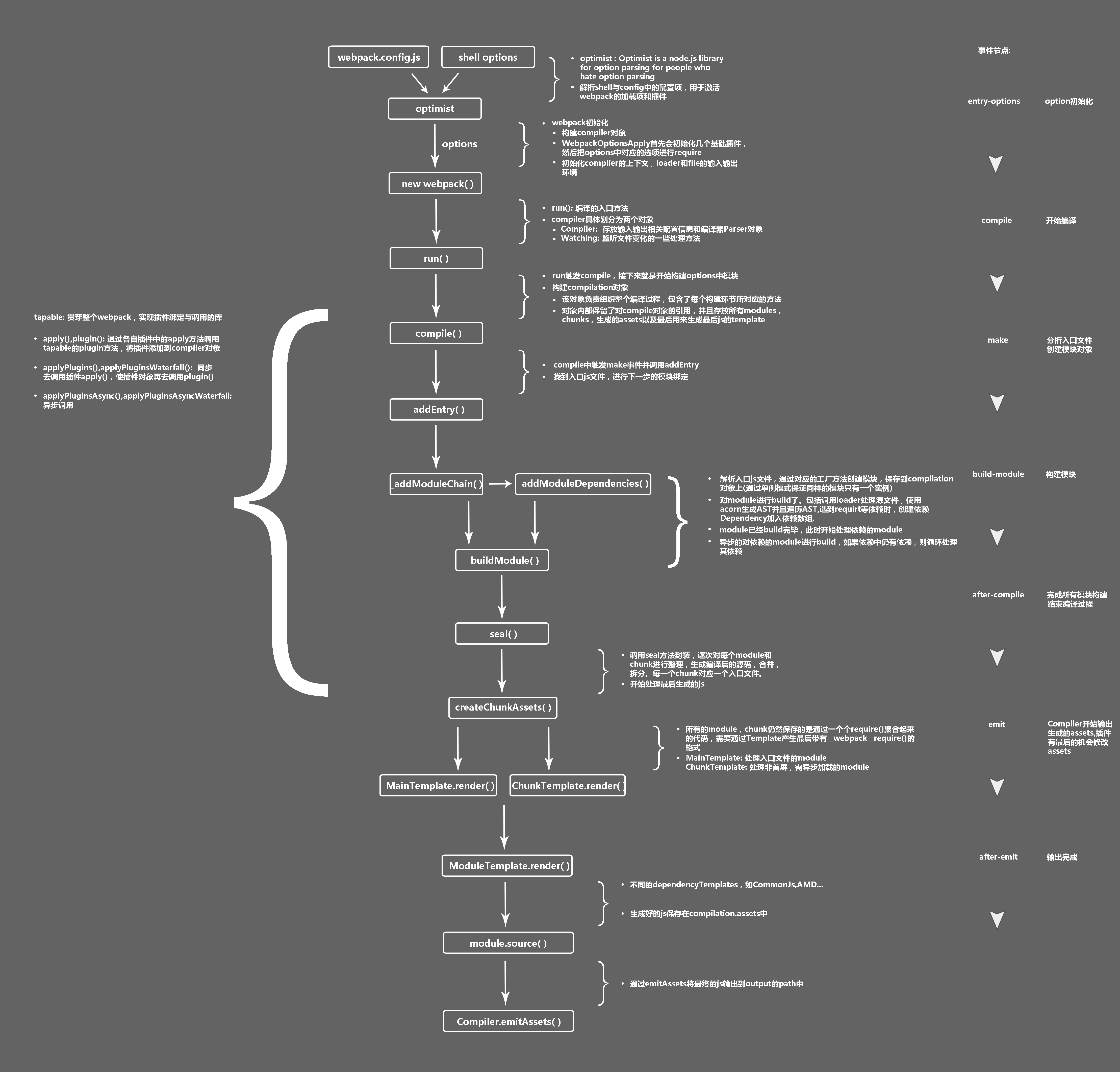
webpack 生命周期
概念:webpack 工作流中最核心的两个模块 Compiler Compilation 都扩展与 Tapable 类,用于实现工作流中的生命周期的划分,以便在不同的生命周期注册和调用插件,所以暴露出各个生命周期的节点称为 Hook。(俗称钩子函数)
webpack 插件
webpack 插件是一个包含 apply 方法的 js 类。这个 apply 方法 通常是注册 webpack 中某一个生命周期的 hook,并添加对应的处理函数。
Hook 的使用方式:
1.在 Compiler 构造函数中定义参数和类型,生成 hook 对象。
2.在插件中注册 hook,添加对应 Hook 触发时的执行函数。
3.生成插件实例,运行 apply 方法。
4.在运行到对应生命周期节点时调用 Hook,执行注册过的插件的回调函数。
Compiler Hooks
构建器实例的生命周期可以分为 3 个阶段:初始化阶段、构建过程阶段、产物生成阶段。
初始化阶段
environment、afterEnvironment:在创建完 compiler 实例且执行了配置内定义的插件的 apply 方法后触发。
entryOption、afterPlugins、afterResolvers:在 WebpackOptionsApply.js 中,这 3 个 Hooks 分别在执行 EntryOptions 插件和其他 Webpack 内置插件,以及解析了 resolver 配置后触发。
构建过程阶段
normalModuleFactory、contextModuleFactory:在两类模块工厂创建后触发。
beforeRun、run、watchRun、beforeCompile、compile、thisCompilation、compilation、make、afterCompile:在运行构建过程中触发。
产物生成阶段
shouldEmit、emit、assetEmitted、afterEmit:在构建完成后,处理产物的过程中触发。
failed、done:在达到最终结果状态时触发。
tapable 是一个类似于 Node.js 中的 EventEmitter 的库,但更专注于自定义事件的触发和处理 webpack 本质上是一种事件流的机制,它的工作流程就是将各个插件串联起来,而实现这一切的核心就是 Tapable。Tapable 其实就是一个用于事件发布订阅执行的插件架构。webpack 通过 tapable 将实现与流程解耦,所有具体实现通过插件的形式存在。 tapable 核心原理:发布订阅模式。
1.tapable 的使用
tapable 在 webpack 中被广泛应用,先来看看 tapable 是怎么使用的吧~
let { SyncHook } = require("tapable");
let syncHook = new SyncHook();
syncHook.tap("name1", (...args) => {
// 监听,类似events的on
console.log("name1", ...args);
});
syncHook.tap("name2", (...args) => {
console.log("name2", ...args);
});
syncHook.tap("name2", (...args) => {
console.log("name22", ...args);
});
syncHook.call("name2", "a", "b"); // 触发
/*
结果为
name1
name2
name22
*/
- 可见 tapable 这个库,监听用
tap,触发用call,且上面无论是箭头还是触发的第一个参数,也就是 name,是没有任何意义的
2.手写 tapable
module.exports = class SyncHook {
constructor() {
this.events = [];
}
tap(eventName, callback) {
this.events.push(callback);
}
call(eventName, ...args) {
this.events.forEach((fn) => fn(...args));
}
};
3.优化 tapable
优化 tapable,使得其能指定触发某一个事件
module.exports = class SyncHook {
constructor() {
this.events = {};
}
tap(eventName, callback) {
if (this.events[eventName]) {
this.events[eventName].push(callback);
} else {
this.events[eventName] = [callback];
}
}
call(eventName, ...args) {
if (eventName && this.events[eventName]) {
this.events[eventName].forEach((fn) => fn());
} else if (!eventName) {
Object.keys(this.events).forEach((e) => {
this.events[e].forEach((fn) => fn(...args));
});
}
}
};
4.关于 tapable 的钩子函数
const {
SyncHook,
SyncBailHook,
SyncWaterfallHook,
SyncLoopHook,
AsyncParallelHook,
AsyncParallelBailHook,
AsyncSeriesHook,
AsyncSeriesBailHook,
AsyncSeriesWaterfallHook,
} = require("tapable");
SyncHook
这是同步钩子,能够同步执行注册的监听函数
let { SyncHook } = require("tapable");
class Lesson {
constructor() {
this.hooks = {
arch: new SyncHook(["name"]),
};
}
tap() {
//注册监听函数
this.hooks.arch.tap("node", function (name) {
console.log("node", name);
});
this.hooks.arch.tap("react", function (name) {
console.log("react", name);
});
}
start() {
this.hooks.arch.call("yuhua");
}
}
let l = new Lesson();
l.tap(); //注册两个监听函数(时间)
l.start(); //启动钩子
SyncHook 原理实现
class SyncHook {
//钩子是同步的
constructor(args) {
//args => ['name']
this.tasks = [];
}
call(...args) {
this.tasks.forEach((task) => task(...args));
}
tap(name, task) {
this.tasks.push(task);
}
}
let hook = new SyncHook(["name"]);
hook.tap("react", function (name) {
console.log("react", name);
});
hook.tap("node", function (name) {
console.log("node", name);
});
hook.call("yuhua");
SyncBailHook
SyncBailHook 同步熔断保险钩子,即 return 一个非 undefined 的值,则不再继续执行后面的监听函数
let { SyncBailHook } = require("tapable"); //SyncBailHook同步熔断保险钩子,即return一个非undefined的值,则不再继续执行后面的监听函数
class Lesson {
constructor() {
this.hooks = {
arch: new SyncBailHook(["name"]),
};
}
tap() {
this.hooks.arch.tap("node", function (name) {
console.log("node", name);
// return undefined;
return "想停止学习"; //当返回的内容为非undefined的时候,会停止往下执行监听函数
});
this.hooks.arch.tap("react", function (name) {
console.log("react", name);
});
}
start() {
this.hooks.arch.call("yuhua");
}
}
let l = new Lesson();
l.tap();
l.start();
SyncBailHook 原理实现
class SyncBailHook {
//钩子是同步的
constructor(args) {
//args => ['name']
this.tasks = [];
}
call(...args) {
let ret; //ret代表当前函数的返回值
let index = 0; //index表示当前是第几个函数
do {
ret = this.tasks[index](...args);
index++;
} while (ret === undefined && this.tasks.length > index);
}
tap(name, task) {
this.tasks.push(task);
}
}
let hook = new SyncBailHook(["name"]);
hook.tap("react", function (name) {
console.log("react", name);
return "停止向下执行";
});
hook.tap("node", function (name) {
console.log("node", name);
});
hook.call("yuhua");
SyncWaterfallHook
SyncWaterfallHook,同步瀑布钩子,上一个监听函数的返回值会传递给下一个监听函数
let { SyncWaterfallHook } = require("tapable"); //SyncWaterfallHook,同步瀑布钩子,上一个监听函数的返回值会传递给下一个监听函数
class Lesson {
constructor() {
this.hooks = {
arch: new SyncWaterfallHook(["name"]),
};
}
tap() {
this.hooks.arch.tap("node", function (name) {
console.log("node", name);
return "node学的还不错";
});
this.hooks.arch.tap("react", function (data) {
console.log("react", data);
});
}
start() {
this.hooks.arch.call("yuhua");
}
}
let l = new Lesson();
l.tap();
l.start();
SyncWaterfallHook 原理实现
class SyncWaterfallHook {
//钩子是同步的
constructor(args) {
//args => ['name']
this.tasks = [];
}
call(...args) {
let [first, ...others] = this.tasks;
let ret = first(...args);
others.reduce((a, b) => {
return b(a);
}, ret);
}
tap(name, task) {
this.tasks.push(task);
}
}
let hook = new SyncWaterfallHook(["name"]);
hook.tap("react", function (name) {
console.log("react", name);
return "react ok";
});
hook.tap("node", function (data) {
console.log("node", data);
return "node ok";
});
hook.tap("webpack", function (data) {
console.log("node", data);
});
hook.call("yuhua");
SyncLoopHook
SyncLoopHook,同步遇到某个不返回 undefined 的监听函数,就重复执行
let { SyncLoopHook } = require("tapable"); //SyncLoopHook,同步遇到某个不返回undefined的监听函数,就重复执行
class Lesson {
constructor() {
this.index = 0;
this.hooks = {
arch: new SyncLoopHook(["name"]),
};
}
tap() {
this.hooks.arch.tap("node", (name) => {
console.log("node", name);
return ++this.index === 3 ? undefined : "继续学";
});
this.hooks.arch.tap("react", (data) => {
console.log("react", data);
});
}
start() {
this.hooks.arch.call("yuhua");
}
}
let l = new Lesson();
l.tap();
l.start();
SyncLoopHook 原理实现
class SyncLoopHook {
//钩子是同步的
constructor(args) {
//args => ['name']
this.tasks = [];
}
call(...args) {
this.tasks.forEach((task) => {
let ret;
do {
ret = task(...args);
} while (ret !== undefined);
});
}
tap(name, task) {
this.tasks.push(task);
}
}
let hook = new SyncLoopHook(["name"]);
let total = 0;
hook.tap("react", function (name) {
console.log("react", name);
return ++total === 3 ? undefined : "继续学";
});
hook.tap("node", function (name) {
console.log("node", name);
});
hook.tap("webpack", function (name) {
console.log("node", name);
});
hook.call("yuhua");
24.webpack 中文件 hash
1. 文件指纹
文件指纹指的是打包后输出的文件名和后缀
文件指纹可以由以下占位符组成:
| 占位符名称 | 含义 |
|---|---|
| ext | 资源后缀名 |
| name | 文件名称 |
| path | 文件的相对路径 |
| folder | 文件所在的文件夹 |
| hash | 每次 webpack 构建时生成一个唯一的 hash 值 |
| chunkhash | 根据 chunk 生成 hash 值,来源于同一个 chunk,则 hash 值就一样 |
| contenthash | 根据内容生成 hash 值,文件内容相同 hash 值就相同 |
2. hash、chunkhash 和 contenthash 的区别
hash:一整个项目,一次打包,只有一个 hash 值
chunkhash:
什么是 chunk?
- 从入口 entry 出发,到它的依赖,以及依赖的依赖,依赖的依赖的依赖,等等,一直下去,所打包构成的代码块(模块的集合)叫做一个 chunk,也就是说,入口文件和它的依赖的模块构成的一个代码块,被称为一个 chunk。
- 所以,一个入口对应一个 chunk,多个入口,就会产生多个 chunk
- 所以,单入口文件,打包后 chunkhash 和 hash 值是不同的,但是效果是一样的
什么是 chunkhash?
- 每个 chunk 打包后,会产生的哈希,叫做 chunkhash
举例:
- 错误示例:
// webpack.config.js
module.exports = {
entry: {
entry1: "./src/entry1.js",
entry2: "./src/entry2.js",
},
output: {
path: path.resolve(__dirname, "dist"),
filename: "bundle.[hash:8].js", // 这样是错误的,因为hash,整个项目只有一个,但是我们这边入口有两个,打包生成的文件肯定也是两个,这两个肯定是不一样的,所以如果用hash的话,两个文件名就一样的,这是不对的,所以,可以换成'bundle.[chunkhash:8].js'
},
};- 正确示例:
// webpack.config.js
module.exports = {
entry: {
entry1: "./src/entry1.js",
entry2: "./src/entry2.js",
},
output: {
path: path.resolve(__dirname, "dist"),
filename: "bundle.[chunkhash:8].js",
},
};
contenthash:
什么是 contenthash
这个哈希只跟内容有关系,内容不变,哈希值不变。
// a文件
require('./b')
console.log(1)
// b文件
console.log(2)
console.log(3)
// 那么其实内容就是下面三句代码,contenthash是对下面的内容进行哈希提取
console.log(2)
console.log(3)
console.log(1)
----------------------------------------------------------------------
// 那么其实,跟以下是一样的:
// a文件
require('./b')
console.log(3)
console.log(1)
// b文件
console.log(2)
// 那么这时候内容也是下面三句代码。contenthash也是对下面三句代码进行哈希提取
console.log(2)
console.log(3)
console.log(1)
3. 各类哈希是如何生成的?
hash 是如何生成的,这里指得是对某个文件生成一个 hash?
let crypto = require("crypto");
let content = fs.readFileSync("a.jpg"); // 读取文件
let hash = crypto.createHash("md5").update(content).digest("hex").slice(0, 10); // 生成10位hash
webpack 中的 hash 是如何生成的?
let crypto = require('crypto');
// 伪代码
let entry = {
entry1: 'entry1', // 值'entry1'代表entry1这个文件,伪代码
entry2: 'entry2', // 值'entry2'代表entry2这个文件,伪代码
}
let entry1 = ’require("./depModule1")'; // 代表entry1中引入了depModule1,伪代码
let entry2 = ’require("./depModule2")'; // 代表entry2中引入了depModule2,伪代码
let depModule1 = 'depModule1'; // 代表depModule1的内容是depModule1
let depModule2 = 'depModule2'; // 代表depModule2的内容是depModule2
let hash = crypto.createHash('md5')
.update(entry1)
.update(entry2)
.update(depModule1)
.update(depModule2)
.digest('hex');
// 这就说明,webpack的hash是对每个依赖模块进行update得到的,只要任意依赖的模块由改变,那么hash值就会改变
chunkhash 是如何生成的?
let crypto = require('crypto');
// 伪代码
let entry = {
entry1: 'entry1', // 值'entry1'代表entry1这个文件,伪代码
entry2: 'entry2', // 值'entry2'代表entry2这个文件,伪代码
}
let entry1 = ’require("./depModule1")'; // 代表entry1中引入了depModule1,伪代码
let entry2 = ’require("./depModule2")'; // 代表entry2中引入了depModule2,伪代码
let depModule1 = 'depModule1'; // 代表depModule1的内容是depModule1
let depModule2 = 'depModule2'; // 代表depModule2的内容是depModule2
let chunkhash_of_entry1 = crypto.createHash('md5')
.update(entry1)
.update(depModule1)
.digest('hex');
let chunkhash_of_entry2 = crypto.createHash('md5')
.update(entry2)
.update(depModule2)
.digest('hex');
// 这就说明,webpack的chunkhash是对每个入口自己的依赖模块进行update得到的,每个入口对应一个chunkhash,入口文件和依赖有所改变,那么这个入口对应的chunkhash就会改变
contenthash 是如何生成的?
let crypto = require('crypto');
// 伪代码
let entry = {
entry1: 'entry1', // 值'entry1'代表entry1这个文件,伪代码
entry2: 'entry2', // 值'entry2'代表entry2这个文件,伪代码
}
let entry1 = ’require("./depModule1")'; // 代表entry1中引入了depModule1,伪代码
let entry2 = ’require("./depModule2")'; // 代表entry2中引入了depModule2,伪代码
let depModule1 = 'depModule1'; // 代表depModule1的内容是depModule1
let depModule2 = 'depModule2'; // 代表depModule2的内容是depModule2
let entry1File = entry1 + depModule1;
let contenthash_of_entry1 = crypto.createHash('md5')
.update(entry1File)
.digest('hex');
4. 各类哈希的区别,或,各类哈希如何选择?
hash、chunkhash、contenthash,首先生成效率越来越低,成本越来越高,影响范围越来越小,精度越来越细。
hash 是一整个项目,一次打包,只有一个 hash 值,是项目级的
chunhash 是从入口 entry 出发,到它的依赖,以及依赖的依赖,依赖的依赖的依赖,等等,一直下去,所打包构成的代码块(模块的集合)叫做一个 chunk,也就是说,入口文件和它的依赖的模块构成的一个代码块,被称为一个 chunk。
contenthash 是哈希只跟内容有关系,内容不变,哈希值不变。与 chunkhash 的区别可以举上面 contenthash 的例子,同时可以说明 contenthash 跟内容有关,但是 chunkhash 会考虑很多因素,比如模块路径、模块名称、模块大小、模块 id 等等。
5. 各类哈希的应用
题目一:以下能否打包成功,如果不能,是什么原因?
答案:
不能,因为这是多入口文件打包,会生成多个文件,但是由于 hash 是根据项目生成的,一个项目对应一个 hash,所以会导致生成的文件同名,webpack 不允许这么做,所以不能打包成功。
module.exports = {
entry: {
main: "./src/index.js",
vendor: ["lodash"],
},
output: {
path: path.resolve(__dirname, "dist"),
filename: "[hash].js",
},
};题目二:以下能否打包成功,如果不能,是什么原因?
答案:
能,因为虽然是多入口文件打包,会生成多个文件,并且即便 hash 一样,由于 filename 是根据 name 和 hash 共同决定的,name 是 entry 的 key,key 不同,所以生成的文件不同,所以可以打包成功。
module.exports = {
entry: {
main: "./src/index.js",
vendor: ["lodash"],
},
output: {
path: path.resolve(__dirname, "dist"),
filename: "[name].[hash].js",
},
};题目三:上面的打包方式是否存在缺点,如果存在,则应该怎么优化?
答案:
存在缺陷。
首先,为什么我们需要使用哈希,主要是为了使用缓存,哈希不变,采取缓存的文件,哈希变了,采取新的文件,这样能够大大提高请求效率。
但是由于上面的配置是多入口文件打包,文件名使用 hash 的话,会导致其中一个入口文件有变化,项目的 hash 值就会变化,这样就使得没有变化的入口的 hash 也变了。那么没有变化的文件就无法读取缓存了。
所以,在这里使用 hash 是不合适的,可以采取 chunkhash,chunkhash 是根据入口文件和入口文件的依赖生成的,如果 main 发生变化,那么 main 对应的 chunkhash 会变化,而 vendor 不变的话,vendor 对应的 chunkhash 是不变的,这样对于不变的文件依旧可以读取缓存。
题目四:已知在
./src/index.js中import './a.css',那么请问下面的打包方式是否存在缺点,如果存在,则应该怎么优化?答案:
存在缺陷。
首先,output 中的 chunkhash 是没有问题的,问题在于 plugin 的 css 的 chunkhash。
这里 css 应该使用 contenthash。原因如下:
由于已知入口文件 main 引入了 a.css,那么插件 MiniCssExtractPlugin 会将 css 从入口文件 main 中抽离出来打包成单独的 css 文件,由于是从入口文件 main 中抽离出来的,所以 main 的 chunkhash 和 css 的 chunkhash 是一样的,因为 chunkhash 是根入口文件和入口文件的依赖相关。
这就存在了一个问题:当我 main 中的 js 代码发生了变化,那么这个 chunkhash 就变了,这样 css 的哈希也就跟着变了,但事实上,css 并没有做修改,所以不需要变化哈希值。
所以,这里的 css 的哈希就可以使用 contenthash,根据 css 的内容来变化,内容变了哈希就变,内容不变哈希就不变。
module.exports = {
entry: {
main: "./src/index.js", // 这里有引入a.css
vendor: ["lodash"],
},
output: {
path: path.resolve(__dirname, "dist"),
filename: "[name].[chunkhash].js",
},
plugin: [
new MiniCssExtractPlugin({
filename: "css/[chunkhash].css",
}),
],
};
6. 其他问题:
问题一:一个入口文件就只能生成一个文件吗?
答案:
不是的,
main 可以生成两个文件,比如 main.js 和 main.css,css 是用插件从 main.js 中抽离出来的
问题二:生成 hash 的时候,对同一个内容,多次 update,结果一样吗?
答案:
不一样。
.update(a).update(b)相当于.update(a+b)
let hash1 = crypto.createHash("md5").update(content).digest("hex");
let hash2 = crypto
.createHash("md5")
.update(content)
.update(content)
.digest("hex");
console.log(hash1 !== hash2); // true
let hashA = crypto.createHash("md5").update("123").digest("hex");
let hashB = crypto
.createHash("md5")
.update("1")
.update("2")
.update("3")
.digest("hex");
console.log(hashA === hashB); // true
25.webpack 如何挂在全局变量
1.直接引入
import _ from "lodash";
console.log(_.join(["a", "b", "c"], "@"));
2.插件引入
- 利用
webpack.ProvidePlugin插件,如下例:- 这个插件会先
require这个第三方库lodash,然后赋值给_,即:let _= require('lodash')。 - 然后自动向每个模块内注入
_变量 - 这是注入在模块内的,所以全局变量 window 上是拿不到
_的
- 这个插件会先
所以这样配置后:就不需要再去 require 或 import 这个库了
plugins: [
new webpack.ProvidePlugin({
_: "lodash",
}),
];
3.expose-loader
- 上面的
webpack.ProvodePlugin无法将第三方依赖放到全局对象上,而这个expose-loader可以做到,在调试的时候比较有用 - 注意点:
- 将
expose-loader添加到所有loader之前 - 会向全局变量
window上挂在globalName,也就是window._,如果window下已经有这个属性了,那么override为true就表示覆盖 - 必须要在使用的地方 require 或 import 了之后,才会挂在到全局变量上
- 将
// index.js
import _ from "lodash"; // 这里必须要引入,才会将_挂在到window上
console.log(_);
console.log(_.join(["a", "b", "c"], "@"));
// webpack.config.js
module: {
rules: [
{
test: require.resolve("lodash"), // 获取lodash的绝对路径
loader: "expose-loader",
options: {
// 会向全局变量window上挂在globalName,也就是window._,如果window下已经有这个属性了,那么override为true就表示覆盖
exposes: {
globalName: "_",
override: true,
},
},
},
];
}
4.externals
使用该属性,需要配合
script引用第三方库的脚本,如下:// html中
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.js"></script>
// webpack.config.js中
externals: {
jquery: '$',
},
// js代码中
import $ from 'jquery'
console.log($)这里需要注意几点:
- externals 代表的是外部依赖,需要用
script去加载外部的依赖 - 这种外部依赖是不会被 webpack 打包的
- external 中的’ ′ 和 j s 代 码 中 的 ′ '和 js 代码中的' ′和 js 代码中的′'不能随便取,得是 jquery 内置的
- 如此配置之后,window 上能够取到’$’
- externals 代表的是外部依赖,需要用
externals详解有一片文章,推荐阅读:webpack externals 详解
5.html-webpack-externals-plugin
上述 externals 配置,需要三步骤,其实比较麻烦,那么可以使用
html-webpack-externals-plugin插件一步到位,在webpack配置中配置即可
使用
// webpack的配置:
new HtmlWebpackExternalsPlugin({
externals: [
{
module: "jquery",
entry: "dist/jquery.min.js",
global: "jQuery",
},
],
});- 以上的 entry 可以先 cdn 地址,也可以写文件目录地址
- global 就是挂在到 window 上的变量名称
26.Webpack 打包后的代码是怎样的
webpack 会递归的构建依赖关系图,其中包含应用程序的每个模块,然后将这些模块打包成一个或者多个 bundle。
那么webpack 打包后的代码是怎样的呢?是怎么将各个 bundle连接在一起的?模块与模块之间的关系是怎么处理的?动态 import() 的时候又是怎样的呢?
创建一个文件,并初始化
mkdir learn-webpack-output
cd learn-webpack-output
npm init -y
yarn add webpack webpack-cli -D
根目录中新建一个文件 webpack.config.js,这个是 webpack 默认的配置文件
const path = require("path");
module.exports = {
mode: "development", // 可以设置为 production
// 执行的入口文件
entry: "./src/index.js",
output: {
// 输出的文件名
filename: "bundle.js",
// 输出文件都放在 dist
path: path.resolve(__dirname, "./dist"),
},
// 为了更加方便查看输出
devtool: "cheap-source-map",
};
然后我们回到 package.json 文件中,在 npm script 中添加启动 webpack 配置的命令
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "webpack"
}
新建一个 src文件夹,新增 index.js 文件和 sayHello 文件
// src/index.js
import sayHello from "./sayHello";
console.log(sayHello, sayHello("Gopal"));
// src/sayHello.js
function sayHello(name) {
return `Hello ${name}`;
}
export default sayHello;
一切准备完毕,执行 yarn build
分析主流程
看输出文件,这里不放具体的代码,有点占篇幅,可以点击这里查看
其实就是一个 IIFE
莫慌,我们一点点拆分开看,其实总体的文件就是一个 IIFE——立即执行函数。
(function (modules) {
// webpackBootstrap
// The module cache
var installedModules = {};
function __webpack_require__(moduleId) {
// ...省略细节
}
// 入口文件
return __webpack_require__((__webpack_require__.s = "./src/index.js"));
})({
"./src/index.js": function (
module,
__webpack_exports__,
__webpack_require__
) {},
"./src/sayHello.js": function (
module,
__webpack_exports__,
__webpack_require__
) {},
});
函数的入参 modules 是一个对象,对象的 key 就是每个 js 模块的相对路径,value 就是一个函数(我们下面称之为模块函数)。IIFE 会先 require 入口模块。即上面就是 ./src/index.js:
// 入口文件
return __webpack_require__((__webpack_require__.s = "./src/index.js"));
然后入口模块会在执行时 require 其他模块例如 ./src/sayHello.js" 以下为简化后的代码,从而不断的加载所依赖的模块,形成依赖树,比如如下的模块函数中就引用了其他的文件 sayHello.js
{
"./src/index.js": (function(module, __webpack_exports__, __webpack_require__) {
__webpack_require__.r(__webpack_exports__);
var _sayHello__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/sayHello.js");
console.log(_sayHello__WEBPACK_IMPORTED_MODULE_0__["default"],
Object(_sayHello__WEBPACK_IMPORTED_MODULE_0__["default"])('Gopal'));
})
}
重要的实现机制——__webpack_require__
这里去 require 其他模块的函数主要是 __webpack_require__ 。接下来主要介绍一下 __webpack_require__ 这个函数
// 缓存模块使用
var installedModules = {};
// The require function
// 模拟模块的加载,webpack 实现的 require
function __webpack_require__(moduleId) {
// Check if module is in cache
// 检查模块是否在缓存中,有则直接从缓存中获取
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// Create a new module (and put it into the cache)
// 没有则创建并放入缓存中,其中 key 值就是模块 Id,也就是上面所说的文件路径
var module = (installedModules[moduleId] = {
i: moduleId, // Module ID
l: false, // 是否已经执行
exports: {},
});
// Execute the module function
// 执行模块函数,挂载到 module.exports 上。this 指向 module.exports
modules[moduleId].call(
module.exports,
module,
module.exports,
__webpack_require__
);
// Flag the module as loaded
// 标记这个 module 已经被加载
module.l = true;
// Return the exports of the module
// module.exports通过在执行module的时候,作为参数存进去,然后会保存module中暴露给外界的接口,如函数、变量等
return module.exports;
}
第一步,webpack 这里做了一层优化,通过对象 installedModules 进行缓存,检查模块是否在缓存中,有则直接从缓存中获取,没有则创建并放入缓存中,其中 key 值就是模块 Id,也就是上面所说的文件路径
第二步,然后执行模块函数,将 module, module.exports, __webpack_require__ 作为参数传递,并把模块的函数调用对象指向 module.exports,保证模块中的 this 指向永远指向当前的模块。
第三步,最后返回加载的模块,调用方直接调用即可。
所以这个__webpack_require__就是来加载一个模块,并在最后返回模块 module.exports 变量
webpack 是如何支持 ESM 的
可能大家已经发现,我上面的写法是 ESM 的写法,对于模块化的一些方案的了解,可以看看我的另外一篇文章【面试说】Javascript 中的 CJS, AMD, UMD 和 ESM 是什么?
我们重新看回模块函数
{
"./src/index.js": (function(module, __webpack_exports__, __webpack_require__) {
__webpack_require__.r(__webpack_exports__);
var _sayHello__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/sayHello.js");
console.log(_sayHello__WEBPACK_IMPORTED_MODULE_0__["default"],
Object(_sayHello__WEBPACK_IMPORTED_MODULE_0__["default"])('Gopal'));
})
}
我们看看 __webpack_require__.r 函数
__webpack_require__.r = function (exports) {
object.defineProperty(exports, "__esModule", { value: true });
};
就是为 __webpack_exports__ 添加一个属性 __esModule,值为 true
再看一个 __webpack_require__.n 的实现
// getDefaultExport function for compatibility with non-harmony modules
__webpack_require__.n = function (module) {
var getter =
module && module.__esModule
? function getDefault() {
return module["default"];
}
: function getModuleExports() {
return module;
};
__webpack_require__.d(getter, "a", getter);
return getter;
};
__webpack_require__.n会判断 module 是否为 es 模块,当__esModule为 true 的时候,标识 module 为 es 模块,默认返回module.default,否则返回module。
最后看 __webpack_require__.d,主要的工作就是将上面的 getter 函数绑定到 exports 中的属性 a 的 getter 上
// define getter function for harmony exports
__webpack_require__.d = function (exports, name, getter) {
if (!__webpack_require__.o(exports, name)) {
Object.defineProperty(exports, name, {
configurable: false,
enumerable: true,
get: getter,
});
}
};
我们最后再看会 sayHello.js 打包后的模块函数,可以看到这里的导出是 __webpack_exports__["default"] ,实际上就是 __webpack_require__.n 做了一层包装来实现的,其实也可以看出,实际上 webpack 是可以支持 CommonJS 和 ES Module 一起混用的
"./src/sayHello.js":
/*! exports provided: default */
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
__webpack_require__.r(__webpack_exports__);
function sayHello(name) {
return `Hello ${name}`;
}
/* harmony default export */ __webpack_exports__["default"] = (sayHello);
})
目前为止,我们大致知道了 webpack 打包出来的文件是怎么作用的了,接下来我们分析下代码分离的一种特殊场景——动态导入
动态导入
代码分离是 webpack 中最引人注目的特性之一。此特性能够把代码分离到不同的 bundle 中,然后可以按需加载或并行加载这些文件。代码分离可以用于获取更小的 bundle,以及控制资源加载优先级,如果使用合理,会极大影响加载时间。
常见的代码分割有以下几种方法:
- 入口起点:使用
entry配置手动地分离代码。 - 防止重复:使用 Entry dependencies 或者
SplitChunksPlugin去重和分离 chunk。 - 动态导入:通过模块的内联函数调用来分离代码。
本文我们主要看看动态导入,我们在 src 下面新建一个文件 another.js
function Another() {
return "Hi, I am Another Module";
}
export { Another };
修改 index.js
import sayHello from "./sayHello";
console.log(sayHello, sayHello("Gopal"));
// 单纯为了演示,就是有条件的时候才去动态加载
if (true) {
import("./Another.js").then((res) => console.log(res));
}
我们来看下打包出来的内容,忽略 .map 文件,可以看到多出一个 0.bundle.js 文件,这个我们称它为动态加载的 chunk,bundle.js 我们称为主 chunk
输出的代码的话,主 chunk 看这里,动态加载的 chunk 看这里 ,下面是针对这两份代码的分析
主 chunk 分析
我们先来看看主 chunk
内容多了很多,我们来细看一下:
首先我们注意到,我们动态导入的地方编译后变成了以下,这是看起来就像是一个异步加载的函数
if (true) {
__webpack_require__
.e(/*! import() */ 0)
.then(
__webpack_require__.bind(null, /*! ./Another.js */ "./src/Another.js")
)
.then((res) => console.log(res));
}
所以我们来看 __webpack_require__.e 这个函数的实现
__webpack_require__.e ——使用 JSONP 动态加载
// 已加载的chunk缓存
var installedChunks = {
main: 0,
};
// ...
__webpack_require__.e = function requireEnsure(chunkId) {
// promises 队列,等待多个异步 chunk 都加载完成才执行回调
var promises = [];
// JSONP chunk loading for javascript
var installedChunkData = installedChunks[chunkId];
// 0 代表已经 installed
if (installedChunkData !== 0) {
// 0 means "already installed".
// a Promise means "currently loading".
// 目标chunk正在加载,则将 promise push到 promises 数组
if (installedChunkData) {
promises.push(installedChunkData[2]);
} else {
// setup Promise in chunk cache
// 利用Promise去异步加载目标chunk
var promise = new Promise(function (resolve, reject) {
// 设置 installedChunks[chunkId]
installedChunkData = installedChunks[chunkId] = [resolve, reject];
});
// i设置chunk加载的三种状态并缓存在 installedChunks 中,防止chunk重复加载
// nstalledChunks[chunkId] = [resolve, reject, promise]
promises.push((installedChunkData[2] = promise));
// start chunk loading
// 使用 JSONP
var head = document.getElementsByTagName("head")[0];
var script = document.createElement("script");
script.charset = "utf-8";
script.timeout = 120;
if (__webpack_require__.nc) {
script.setAttribute("nonce", __webpack_require__.nc);
}
// 获取目标chunk的地址,__webpack_require__.p 表示设置的publicPath,默认为空串
script.src = __webpack_require__.p + "" + chunkId + ".bundle.js";
// 请求超时的时候直接调用方法结束,时间为 120 s
var timeout = setTimeout(function () {
onScriptComplete({ type: "timeout", target: script });
}, 120000);
script.onerror = script.onload = onScriptComplete;
// 设置加载完成或者错误的回调
function onScriptComplete(event) {
// avoid mem leaks in IE.
// 防止 IE 内存泄露
script.onerror = script.onload = null;
clearTimeout(timeout);
var chunk = installedChunks[chunkId];
// 如果为 0 则表示已加载,主要逻辑看 webpackJsonpCallback 函数
if (chunk !== 0) {
if (chunk) {
var errorType =
event && (event.type === "load" ? "missing" : event.type);
var realSrc = event && event.target && event.target.src;
var error = new Error(
"Loading chunk " +
chunkId +
" failed.\n(" +
errorType +
": " +
realSrc +
")"
);
error.type = errorType;
error.request = realSrc;
chunk[1](error);
}
installedChunks[chunkId] = undefined;
}
}
head.appendChild(script);
}
}
return Promise.all(promises);
};
可以看出将
import()转换成模拟JSONP去加载动态加载的chunk文件设置
chunk加载的三种状态并缓存在installedChunks中,防止 chunk 重复加载。这些状态的改变会在webpackJsonpCallback中提到// 设置 installedChunks[chunkId]
installedChunkData = installedChunks[chunkId] = [resolve, reject];installedChunks[chunkId]为0,代表该chunk已经加载完毕installedChunks[chunkId]为undefined,代表该chunk加载失败、加载超时、从未加载过installedChunks[chunkId]为Promise对象,代表该chunk正在加载
看完__webpack_require__.e,我们知道的是,我们通过 JSONP 去动态引入 chunk 文件,并根据引入的结果状态进行处理,那么我们怎么知道引入之后的状态呢?我们来看异步加载的 chunk 是怎样的
异步 Chunk
// window["webpackJsonp"] 实际上是一个数组,向中添加一个元素。这个元素也是一个数组,其中数组的第一个元素是chunkId,第二个对象,跟传入到 IIFE 中的参数一样
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([
[0],
{
/***/ "./src/Another.js": /***/ function (
module,
__webpack_exports__,
__webpack_require__
) {
"use strict";
__webpack_require__.r(__webpack_exports__);
/* harmony export (binding) */ __webpack_require__.d(
__webpack_exports__,
"Another",
function () {
return Another;
}
);
function Another() {
return "Hi, I am Another Module";
}
/***/
},
},
]);
//# sourceMappingURL=0.bundle.js.map
主要做的事情就是往一个数组 window['webpackJsonp'] 中塞入一个元素,这个元素也是一个数组,其中数组的第一个元素是 chunkId,第二个对象,跟主 chunk 中 IIFE 传入的参数类似。关键是这个 window['webpackJsonp'] 在哪里会用到呢?我们回到主 chunk 中。在 return __webpack_require__(__webpack_require__.s = "./src/index.js"); 进入入口之前还有一段
var jsonpArray = (window["webpackJsonp"] = window["webpackJsonp"] || []);
// 保存原始的 Array.prototype.push 方法
var oldJsonpFunction = jsonpArray.push.bind(jsonpArray);
// 将 push 方法的实现修改为 webpackJsonpCallback
// 这样我们在异步 chunk 中执行的 window['webpackJsonp'].push 其实是 webpackJsonpCallback 函数。
jsonpArray.push = webpackJsonpCallback;
jsonpArray = jsonpArray.slice();
// 对已在数组中的元素依次执行webpackJsonpCallback方法
for (var i = 0; i < jsonpArray.length; i++) webpackJsonpCallback(jsonpArray[i]);
var parentJsonpFunction = oldJsonpFunction;
jsonpArray 就是 window["webpackJsonp"] ,重点看下面这一句代码,当执行 push 方法的时候,就会执行 webpackJsonpCallback,相当于做了一层劫持,也就是执行完 push 操作的时候就会调用这个函数
jsonpArray.push = webpackJsonpCallback;
webpackJsonpCallback ——加载完动态 chunk 之后的回调
我们再来看看 webpackJsonpCallback 函数,这里的入参就是动态加载的 chunk 的 window['webpackJsonp'] push 进去的参数。
var installedChunks = {
main: 0,
};
function webpackJsonpCallback(data) {
// window["webpackJsonp"] 中的第一个参数——即[0]
var chunkIds = data[0];
// 对应的模块详细信息,详见打包出来的 chunk 模块中的 push 进 window["webpackJsonp"] 中的第二个参数
var moreModules = data[1];
// add "moreModules" to the modules object,
// then flag all "chunkIds" as loaded and fire callback
var moduleId,
chunkId,
i = 0,
resolves = [];
for (; i < chunkIds.length; i++) {
chunkId = chunkIds[i];
// 所以此处是找到那些未加载完的chunk,他们的value还是[resolve, reject, promise]
// 这个可以看 __webpack_require__.e 中设置的状态
// 表示正在执行的chunk,加入到 resolves 数组中
if (installedChunks[chunkId]) {
resolves.push(installedChunks[chunkId][0]);
}
// 标记成已经执行完
installedChunks[chunkId] = 0;
}
// 挨个将异步 chunk 中的 module 加入主 chunk 的 modules 数组中
for (moduleId in moreModules) {
if (Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
// parentJsonpFunction: 原始的数组 push 方法,将 data 加入 window["webpackJsonp"] 数组。
if (parentJsonpFunction) parentJsonpFunction(data);
// 等到 while 循环结束后,__webpack_require__.e 的返回值 Promise 得到 resolve
// 执行 resolove
while (resolves.length) {
resolves.shift()();
}
}
当我们 JSONP 去加载异步 chunk 完成之后,就会去执行 window["webpackJsonp"] || []).push,也就是 webpackJsonpCallback。主要有以下几步
- 遍历要加载的 chunkIds,找到未执行完的 chunk,并加入到 resolves 中
for (; i < chunkIds.length; i++) {
chunkId = chunkIds[i];
// 所以此处是找到那些未加载完的chunk,他们的value还是[resolve, reject, promise]
// 这个可以看 __webpack_require__.e 中设置的状态
// 表示正在执行的chunk,加入到 resolves 数组中
if (installedChunks[chunkId]) {
resolves.push(installedChunks[chunkId][0]);
}
// 标记成已经执行完
installedChunks[chunkId] = 0;
}
这里未执行的是非 0 状态,执行完就设置为 0
installedChunks[chunkId][0]实际上就是 Promise 构造函数中的 resolve// __webpack_require__.e
var promise = new Promise(function (resolve, reject) {
installedChunkData = installedChunks[chunkId] = [resolve, reject];
});挨个将异步
chunk中的module加入主chunk的modules数组中原始的数组
push方法,将data加入window["webpackJsonp"]数组执行各个
resolves方法,告诉__webpack_require__.e中回调函数的状态
只有当这个方法执行完成的时候,我们才知道 JSONP 成功与否,也就是script.onload/onerror 会在 webpackJsonpCallback 之后执行。所以 onload/onerror 其实是用来检查 webpackJsonpCallback 的完成度:有没有将 installedChunks 中对应的 chunk 值设为 0
动态导入小结
大致的流程如下图所示
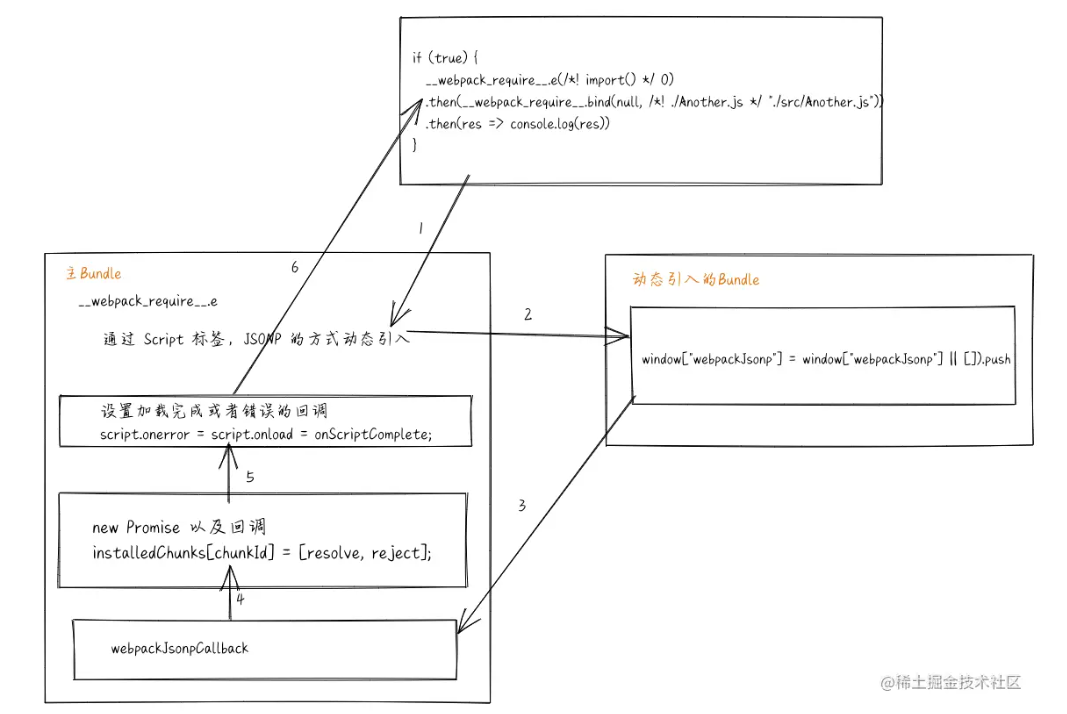
总结
本篇文章分析了 webpack 打包主流程以及和动态加载情况下输出代码,总结如下
- 总体的文件就是一个
IIFE——立即执行函数 webpack会对加载过的文件进行缓存,从而优化性能- 主要是通过
__webpack_require__来模拟import一个模块,并在最后返回模块export的变量 webpack是如何支持ES Module的- 动态加载
import()的实现主要是使用JSONP动态加载模块,并通过webpackJsonpCallback判断加载的结果
27.路由懒加载原理
Vue 的特点是 SPA - Single Page Application(单页面应用程序)。
像 vue 这种单页面应用,如果没有应用懒加载,运用 webpack 打包后,一般情况下,会放在一个单独的 js 文件中。但是,如果很多的页面都放在同一个 js 文件中,必然会造成这个页面非常大,造成进入首页时,需要加载的内容过多,时间过长,会出现长时间的白屏,即使做了 loading 也是不利于用户体验,而运用懒加载则可以将页面进行划分,需要的时候加载页面,可以有效的分担首页所承担的加载压力,减少首页加载用时。
路由懒加载有着诸如:“只有第一次会加载页面,以后的每次页面切换,只需要进行组件替换。减少了请求体积,加快页面的响应速度,降低了对服务器的压力”等等优点。
为了解决上面的问题,我们需要对 Vue 实现组件懒加载(按需加载)。
为什么要进行路由懒加载
1.当进行打包构建应用时,打包后的代码逻辑实现包可能会非常大。
2.当我们把不同的路由对应的组件分别打包,在路由被访问时再进行加载,就会更加高效。
路由懒加载所做的事情
1.将路由对应的组件加载成一个个对应的 js 包 。 2.路由被访问时才将对应的组件加载。
理解基本原理
webpack 打包的时候,碰到 import()这种函数,就会把里面对应的文件单独打包成 js,然后通过 script 异步加载这个 js,这样就实现了异步懒加载
异步加载利用了 promise 和定时器,在需要的时候异步再去加载
要实现懒加载,就得先将进行懒加载的子模块(子组件)分离出来。
懒加载实现的前提:ES6 的动态加载模块 - import()
调用 import()之处,被作为分离的模块起点,意思是,被请求的模块和它引用的所有子模块,会分离到一个单独的 chunk 中。
1:import 是解构过程并且是编译时执行 2:require 是赋值过程并且是运行时才执行,也就是异步加载 3:require 的性能相对于 import 稍低,因为 require 是在运行时才引入模块并且还赋值给某个变量
在 html 中
从上面我们可以看到,先用 link 定义 Home.js、app.js、chunk-vendors.js 这些资源和 web 客户端的关系。
ref=preload:告诉浏览器这个资源要给我提前加载。rel=prefetch:告诉浏览器这个资源空闲的时候给我加载一下。as=script:告诉浏览器这个资源是 script,提升加载的优先级。
然后在 body 里面加载了 chunk-vendors.js、app.js 这两个 js 资源。可以看出 web 客户端初始化时候就加载了这个两个 js 资源。
分析 chunk-vendors.js
chunk-vendors.js 可以称为项目公共模块集合,代码精简后如下所示,
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([["chunk-vendors"],{
"01f9":(function(module,exports,__webpack_require__){
...//省略
})
...//省略
}])
从代码中可以看出,执行 chunk-vendors.js,仅仅把下面这个数组push到window["webpackJsonp"]中,而数组第二项是个对象,对象的每个 value 值是一个函数表达式,不会执行。就这样结束了,当然不是,我们带着window["webpackJsonp"]去 app.js 中找找。
分析 app.js
app.js 可以称为项目的入口文件。
app.js 里面是一个自执行函数,通过搜索window["webpackJsonp"]可以找到如下相关代码。
(function (modules) {
//省略...
var jsonpArray = (window["webpackJsonp"] = window["webpackJsonp"] || []);
var oldJsonpFunction = jsonpArray.push.bind(jsonpArray);
jsonpArray.push = webpackJsonpCallback;
jsonpArray = jsonpArray.slice();
for (var i = 0; i < jsonpArray.length; i++)
webpackJsonpCallback(jsonpArray[i]);
var parentJsonpFunction = oldJsonpFunction;
//省略...
})({
0: function (module, exports, __webpack_require__) {
module.exports = __webpack_require__("56d7");
},
//省略...
});
- 先把
window["webpackJsonp"]赋值给jsonpArray。 - 把
jsonpArray的push方法赋值给oldJsonpFunction。 - 用
webpackJsonpCallback函数拦截jsopArray的push方法,也就是说调用window["webpackJsonp"]的push方法都会执行webpackJsonpCallback函数。 - 将
jsonpArray浅拷贝一下再赋值给jsonpArray。 - 因为执行 chunk-vendors.js 中的
window["webpackJsonp"].push时push方法还未被webpackJsonpCallback函数拦截,所以要循环jsonpArray,将每项作为参数传入webpackJsonpCallback函数并调用。 - 将
jsonpArray的push方法再赋值给parentJsonpFunction。
webpackJsonpCallback 函数
(function (modules) {
function webpackJsonpCallback(data) {
var chunkIds = data[0];
var moreModules = data[1];
var executeModules = data[2];
var moduleId,
chunkId,
i = 0,
resolves = [];
for (; i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if (
Object.prototype.hasOwnProperty.call(installedChunks, chunkId) &&
installedChunks[chunkId]
) {
resolves.push(installedChunks[chunkId][0]);
}
installedChunks[chunkId] = 0;
}
for (moduleId in moreModules) {
if (Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
if (parentJsonpFunction) parentJsonpFunction(data);
while (resolves.length) {
resolves.shift()();
}
deferredModules.push.apply(deferredModules, executeModules || []);
return checkDeferredModules();
}
var installedChunks = {
app: 0,
};
//省略...
})({
0: function (module, exports, __webpack_require__) {
module.exports = __webpack_require__("56d7");
},
//省略...
});
- module 是指任意的代码块,chunk 是 webpack 处理过程中被分组的 module 的合集。
modules缓存所有的 module(代码块),调用modules中的 module 就可以执行里面的代码。installedChunks缓存所有 chunk 的加载状态,如果installedChunks[chunk]为 0,代表 chunk 已经加载完毕。deferredModules中每项也是一个数组,例如[module,chunk1,chunk2,chunk3],其作用是如果要执行 module,必须在 chunk1、chunk2、chunk3 都加载完毕后才能执行。
if (parentJsonpFunction) parentJsonpFunction(data)这句代码在多入口项目中才有作用,在前面提到过jsonpArray的push方法被赋值给parentJsonpFunction,调用parentJsonpFunction是真正把 chunk 中 push 方法中的参数 push 到window["webpackJsonp"]这个数组中。
checkDeferredModules 函数
var deferredModules = [];
var installedChunks = {
app: 0,
};
function checkDeferredModules() {
var result;
for (var i = 0; i < deferredModules.length; i++) {
var deferredModule = deferredModules[i];
var fulfilled = true;
for (var j = 1; j < deferredModule.length; j++) {
var depId = deferredModule[j];
if (installedChunks[depId] !== 0) fulfilled = false;
}
if (fulfilled) {
deferredModules.splice(i--, 1);
result = __webpack_require__((__webpack_require__.s = deferredModule[0]));
}
}
return result;
}
- 循环
deferredModules,创建变量fulfilled表示deferredModule中的 chunk 加载情况,true表示全部加载完毕,false表示未全部加载完毕。 - 从
j=1开始循环deferredModule中的 chunk,因为deferredModule[0]是 module,如果installedChunks[chunk]!==0,则这个 chunk 未加载完毕,把变量fulfilled设置为false。循环结束后返回 result。 - 经循环
deferredModule中的 chunk 并判断 chunk 的加载状态后,fulfilled还是为 true,则调用__webpack_require__函数,将deferredModule[0](module)作为参数传入执行。 deferredModules.splice(i--, 1),删除满足条件的 deferredModule,并将 i 减一,其中i--是先使用 i,然后在减一。
因为在webpackJsonpCallback函数中deferredModules为[],所以回到主体函数继续往下看。
deferredModules.push([0, "chunk-vendors"]);
return checkDeferredModules();
按上面逻辑分析后,会执行__webpack_require__(0),那么来看一下__webpack_require__这个函数。
webpack_require函数
var installedModules = {};
function __webpack_require__(moduleId) {
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
var module = (installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {},
});
modules[moduleId].call(
module.exports,
module,
module.exports,
__webpack_require__
);
module.l = true;
return module.exports;
}
从代码可知__webpack_require__就是一个执行 module 的方法。
installedModules用来缓存 module 的执行状态。- 通过 moduleId 在 modules(在
webpackJsonpCallback函数中缓存所有 module 的集合)获取对应的 module 用 call 方法执行。 - 将执行结果赋值到 module.exports 并返回。
__webpack_require__.e方法是实现懒加载的核心,在这个方法里面处理了三件事情。
- 使用 JSONP 模式加载路由对应的 js 文件,也可以称为 chunk。
- 设置 chunk 加载的三种状态并缓存在
installedChunks中,防止 chunk 重复加载。 - 处理 chunk 加载超时和加载出错的场景。
chunk 加载的三种状态
installedChunks[chunkId]为0,代表该 chunk 已经加载完毕。installedChunks[chunkId]为undefined,代表该 chunk 加载失败、加载超时、从未加载过。installedChunks[chunkId]为Promise对象,代表该 chunk 正在加载。
简单实现 webpack
webpack.config.js配置文件
const path = require("path");
const RunPlugin = require("./myPlugins/run-plugin");
const DonePlugin = require("./myPlugins/done-plugin");
const EmitPlugin = require("./myPlugins/emmit-plugin");
module.exports = {
mode: "production",
devtool: false,
context: process.cwd(), // 上下文,如果想改变根目录,可以改这边。默认值就是当前命令执行的时候所在的目录(不是webpack.config.js的目录,是执行时的目录)
entry: {
entry1: "./src/entry1.js",
entry2: "./src/entry2.js",
},
output: {
path: path.join(__dirname, "dist"),
filename: "[name].js",
},
resolve: {
extensions: [".js", ".jsx", ".json"],
},
module: {
rules: [
{
test: /\.js$/,
use: [
path.resolve(__dirname, "loaders", "logger1-loader.js"),
path.resolve(__dirname, "loaders", "logger2-loader.js"),
],
},
],
},
plugins: [new RunPlugin(), new DonePlugin(), new EmitPlugin()],
};
然后开始手写 webpack
- 创建
webpack.run.js文件,该文件主要用于手动跑 webpack- webpack 一般会返回一个
compiler,这个compiler有一个 run 方法,调用该方法可以启动编译
- webpack 一般会返回一个
const webpack = require("./myWebpack/myWebpack");
const webpackOptions = require("./webpack.config");
// compiler代表整个编译过程
const compiler = webpack(webpackOptions);
// 调用run方法,可以启动编译
compiler.run((err, stats) => {
console.log(err);
console.log(stats.toJson());
});
- 然后编写我们自己的 webpack,也就是上面代码中引入的 myWebpack
- 这里主要做:
- 参数合并
- 加载插件
- 执行 compiler 的 run 方法
- 将 compiler 返回
- 这里主要做:
const Compiler = require("./Compiler");
function webpack(options) {
// 1. 初始化文件,从配置文件和Shell语句中读取并合并参数,得出最终的配置对象
// console.log(process.argv); // 获取命令参数,参数与webpack.config.js同名的时候,参数会覆盖配置文件,也就是说参数的优先级更高
let shellOptions = process.argv.slice(2).reduce((shellConfig, item) => {
let [key, value] = item.split("=");
shellConfig[key.slice(2)] = value;
return shellConfig;
}, {});
let finalConfig = { ...options, ...shellOptions };
// console.log(finalConfig)
// 2. 用上一步得到的参数初始化Compiler对象
let compiler = new Compiler(finalConfig);
// 3. 加载所有配置的插件
let { plugins } = finalConfig;
for (let plugin of plugins) {
plugin.apply(compiler);
// 注册所有插件的事件,是通过tapable的tap来注册的,然后就是等待着合适的时机去触发事件,也就是调用tapable的call函数
// 由于触发的时机是固定的,所以不同时机触发的插件,在注册的时候谁先谁后都无所谓,那么webpack的plugins中写的谁先谁后其实都无所谓。但是如果多个插件是统一时机触发的,那么就是谁先注册谁就先触发。
}
// 4. 执行compiler对象的run方法开始编译,调用run在外面,具体的run方法在Compiler类中
// 最后,需要将compiler对象返回
return compiler;
}
module.exports = webpack;
- 然后去实现
Compiler类,该类主要是run和compiler方法
let { SyncHook } = require("tapable");
let Complication = require("./complication");
let fs = require("fs");
class Complier {
constructor(options) {
this.options = options;
this.hooks = {
// 类似run的钩子有四五十个,下面几个是比较典型的
run: new SyncHook(), // 开始启动编译
emit: new SyncHook(["assets"]), // 会在将要写入文件的时候触发
done: new SyncHook(), // 会在完成编译的时候触发 全部完成
};
}
run(callback) {
// 开始编译
// 4. 执行compiler对象的run方法开始编译
/* 下面都是编译过程 */
// 首先是触发run钩子
this.hooks.run.call();
// 5. 根据配置中的entry找到入口文件
// 开启编译
this.compile(callback);
// 监听入口文件的变化, 如果文件变化了,重新再开始编译
Object.values(this.options.entry).forEach((entry) => {
// 考虑到多入口
fs.watchFile(entry, () => this.compile(callback));
});
// 最后是触发done钩子
this.hooks.done.call();
/* 上面都是编译过程 */
callback(null, {
toJson() {
return {
files: [], // 产出哪些文件
assets: [], // 生成哪些资源
chunk: [], // 生成哪些代码块
module: [], // 模块信息
entries: [], // 入口信息
};
},
});
}
compile(callback) {
let complication = new Complication(this.options, this.hooks);
complication.make(callback);
}
}
module.exports = Complier;
执行compier的时候,会调用Complication类
const path = require("path");
const fs = require("fs");
const types = require("babel-types");
const parser = require("@babel/parser"); // 编译
const traverse = require("@babel/traverse").default; // 转换
const generator = require("@babel/generator").default; // 生成 新源码
const baseDir = toUnitPath(process.cwd()); // process.cwd()表示当前文件所在绝对路径,toUnitPath(路径)将路径分隔符统一转成正斜杠/
class Complication {
// 一次编译会有一个complication,会存放所有入口
constructor(options, hooks) {
this.options = options;
this.hooks = hooks;
// 下面这些 webpack4中都是数组 但是webpack5中都换成了set,优化了下,防止重复的资源编译,当然数组也可以做到防止重复资源编译
this.entries = []; // 存放所有的入口
this.modules = []; // 存放所有的模块
this.chunks = []; // 存放所有的代码块
this.assets = {}; // 对象,key为文件名,value为文件编译后的源码,存放所有的产出的资源, this.assets就是文件输出列表
this.files = []; // 存放所有的产出的文件
}
make(callback) {
// 5. 根据配置中的entry找出入口文件
let entry = {};
if (typeof this.options.entry === "string") {
entry.main = this.options.entry;
} else {
entry = this.options.entry;
}
// entry = {entry1: "./src/entry1.js", entry2: './src/entry2.js'}
for (let entryName in entry) {
// 获取入口文件的绝对路径,这里的this.options.context默认是process.cwd(),这个默认值在这边没做处理
let entryFilePath = toUnitPath(
path.join(this.options.context, entry[entryName])
);
// 6.从入口文件出发,调用所有配置的Loader对模块进行编译,返回一个入口模块
let entryModule = this.buildModule(entryName, entryFilePath);
// // 把入口module也放到this.modules中去
// this.modules.push(entryModule);
// 8.根据入口和模块之间的依赖关系,组装成一个个包含多个模块的Chunk
let chunk = {
name: entryName,
entryModule,
modules: this.modules.filter((item) => item.name === entryName),
};
this.entries.push(chunk); // 代码块会放到entries和chunks中
this.chunks.push(chunk); // 代码块会放到entries和chunks中
// 9.再把每个Chunk转换成一个单独的文件加入到输出列表
this.chunks.forEach((chunk) => {
let filename = this.options.output.filename.replace(
"[name]",
chunk.name
);
// 这个this.assets就是文件输出列表, key为文件名,value为chunk的源码
this.assets[filename] = getSource(chunk); // assets中key为文件名,value为chunk的源码
});
// 10.在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统
this.files = Object.keys(this.assets);
this.hooks.emit.call(this.assets);
for (let fileName in this.assets) {
let filePath = path.join(this.options.output.path, fileName);
fs.writeFileSync(filePath, this.assets[fileName], "utf8");
}
// 最后调用callback,返回一个对象,对象内有toJSON方法
callback(null, {
toJson: () => {
return {
entries: this.entries,
chunks: this.chunks,
modules: this.modules,
files: this.files,
assets: this.assets,
};
},
});
}
}
buildModule(name, modulePath) {
// 参数第一个是代码块的名称,第二个是模块的绝对路径
// 6.从入口文件出发,调用所有配置的Loader对模块进行编译,返回一个入口模块
// 6.1 读取模块文件内容
let sourceCode = fs.readFileSync(modulePath, "utf-8");
let rules = this.options.module.rules;
let loaders = []; // 寻找匹配的loader
for (let i = 0; i < rules.length; i++) {
if (rules[i].test.test(modulePath)) {
// 如果当前文件路径能够匹配上loader的正则的,那么就调用这个loader去处理
loaders = [...loaders, ...rules[i].use];
}
}
// 用loader进行转换,从右往左,从下往上,在这里就是数组从右往左
for (let i = loaders.length - 1; i >= 0; i--) {
let loader = loaders[i];
sourceCode = require(loader)(sourceCode);
}
// 7. 再找出该模块依赖的模块,再递归这个步骤,知道所有入口依赖的文件都经过了这个步骤的处理,得到入口与模块之间的依赖关系
let moduleId = "./" + path.posix.relative(baseDir, modulePath); // 当前模块的id
let module = {
id: moduleId, // 模块id,也就是相对于项目根目录的相对路径
dependencies: [], // 模块依赖
name, // 模块名称
};
let ast = parser.parse(sourceCode, { sourceType: "module" }); // 生成语法树
traverse(ast, {
// CallExpression这个节点代表方法调用
CallExpression: ({ node }) => {
if (node.callee.name === "require") {
let moduleName = node.arguments[0].value; // 获取require函数的参数 './title',也就是模块的相对路径
let dirname = path.posix.dirname(modulePath); // 获取模块的所在目录(title文件的父文件夹) path.posix相当于把路径都转成/,不论是什么系统,都是正斜杠,如果不用posix的话,linux是正斜杠,windows是反斜杠
let depModulePath = path.posix.join(dirname, moduleName); // 模块的绝对路径,但是可能没有后缀,
let extensions = this.options.resolve.extensions; // 如果options中没有配置resolve,需要做判断,这边就暂时不写了
depModulePath = tryExtensions(depModulePath, extensions); // 生成依赖的模块绝对路径,已经包含了扩展名了
// 找到引用的模块的id,引用的模块的id的特点是:相对于根目录的路径
let depModuleId = "./" + path.posix.relative(baseDir, depModulePath);
node.arguments = [types.stringLiteral(depModulePath)]; // 这个就是参数这个节点要变,因为原来是require('./title'),现在要变成require('./src/title.js'),这个types.stringLiteral就是用来修改参数的
let alreadyImportedModuleIds = this.modules.map((item) => item.id); // 遍历出已有的modules的moduleId
// 把依赖模块的绝对路径放到依赖数组里面
// if (!alreadyImportedModuleIds.includes(dependency.depModuleId)) { // 如果不存在,才放进this.modules数组,这样防止已经编译过的模块重复放到this.modules中
module.dependencies.push({ depModuleId, depModulePath });
// }
}
},
});
let { code } = generator(ast);
console.log(code, toUnitPath(this.options.context));
module._source = code.replace(toUnitPath(this.options.context), "."); // 模块源代码指向语法树转换后的新生村的源代码
// 7. 再找出该模块依赖的模块,再递归这个步骤,知道所有入口依赖的文件都经过了这个步骤的处理,得到入口与模块之间的依赖关系 这时候需要开始递归了
module.dependencies.forEach((dependency) => {
let depModule = this.modules.find(
(item) => item.id === dependency.depModuleId
);
// 判断模块是否已经被编译过了,如果编译过了直接push,如果没有编译过,那么就先编译,编译完了再push
if (depModule) {
this.modules.push({ ...depModule, name }); // 重新改下名字
} else {
let dependencyModule = this.buildModule(name, dependency.depModulePath); // 这个name为啥是一样的??????
this.modules.push(dependencyModule);
}
});
return module;
}
}
function tryExtensions(modulePath, extensions) {
extensions.unshift(""); // 为什么要加一个空串,因为有可能用户写的路径是带后缀的,所以路径跟空串结合就是路径,如果不加空串,用户如果路径带了后缀,那判断就是title.js.js title.js.jsx title.js.json
for (let i = 0; i < extensions.length; i++) {
let filePath = modulePath + extensions[i];
if (fs.existsSync(filePath)) {
return filePath;
}
}
throw new Error("Module not found");
}
function toUnitPath(modulePath) {
return modulePath.replace(/\\/g, "/");
}
function getSource(chunk) {
return `
(() => {
var modules = ({
${chunk.modules
.map(
(module) => `
"${module.id}":(module,exports,require)=>{
${module._source}
}
`
)
.join(",")}
});
var cache = {};
function require(moduleId) {
var cachedModule = cache[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
var module = cache[moduleId] = {
exports: {}
};
modules[moduleId](module, module.exports, require);
return module.exports;
}
var exports = {};
(() => {
${chunk.entryModule._source}
})();
})()
;
`;
}
module.exports = Complication;
webpack 编译过程中有两个最重要的对象
- Compiler 生产产品的工厂,代表整个编译过程
- Compilation 代表一个生产过程,代表依次编译
const fs = require("fs");
const path = require("path");
// 代表具体的一次编译,代表一次生产过程
class Complication {
build() {
console.log("编译一次");
}
}
// 代表整个编译
class Compiler {
run() {
this.compile(); // 开始编译
fs.watchFile(path.resolve(__dirname, "./test.js"), () => {
this.compile(); // 监听文件变化,一旦变化,我就开始编译
});
}
compile() {
let complication = new Complication();
complication.build();
}
}
const compiler = new Compiler();
compiler.run();
webpack 插件,主要是调用 apply 方法,apply 方法是 webpack 会去调用的。
apply 方法参数为 compiler。
实现最简单的一个 emit-plugin
class EmitPlugin {
apply(compiler) {
compiler.hooks.emit.tap("emit", (assets) => {
assets["assets.md"] = Object.keys(assets).join("\n");
console.log("这是发射文件之前触发");
});
}
}
module.exports = EmitPlugin;
path.join('a', 'b', 'c')在 windows 结果是 a\b\c,在 linux 中是 a/b/c
path.posix.join('a', 'b', 'c')不管在哪个操作系统下,返回的都是 a/b/c(都是 linux 的结果, 一般我们都希望用这个)
path.win32.join('a', 'b', 'c')不管在哪个操作系统下,返回的都是 a\b\c(都是 windows 的结果)
process.cwd()表示当前文件所在绝对路径,路径分隔符是反斜杠\,一般来说我们需要手动转成 linux 下的正斜杠/,可以用正则 replace 替换
slash这个库,可以自动将反斜杠转成正斜杠